File Transfer¶
1. Nombre del Patrón¶
- Nombre oficial: File Transfer
- Categoría: Integration Styles (Estilos de Integración)
- Traducción contextual: Transferencia de Archivos
2. Resumen Ejecutivo¶
File Transfer es un estilo de integración en el cual una aplicación produce un archivo que contiene datos que otra aplicación necesita, y lo deposita en una ubicación accesible para que la aplicación consumidora lo recoja, lo lea y lo procese. El intercambio de información se realiza a través del sistema de archivos como intermediario, no a través de una conexión directa entre las aplicaciones.
Este patrón existe porque es la forma más simple y universal de mover datos entre sistemas que no comparten tecnología, protocolo ni runtime. Cualquier sistema que pueda escribir un archivo y cualquier sistema que pueda leer un archivo pueden integrarse mediante File Transfer, sin necesidad de que compartan lenguaje de programación, plataforma, versión de API ni siquiera disponibilidad temporal simultánea.
Aparece en arquitecturas empresariales con enorme frecuencia en escenarios batch: cierres contables, conciliaciones bancarias, reportes regulatorios, cargas masivas de datos, sincronización nocturna entre sistemas legacy, alimentación de data warehouses y procesos ETL.
3. Definición Detallada¶
Propósito¶
El propósito de File Transfer es permitir que dos o más aplicaciones intercambien conjuntos de datos sin establecer una conexión directa en tiempo de ejecución. La aplicación productora serializa los datos en un formato de archivo acordado y los escribe en una ubicación accesible. La aplicación consumidora, en un momento posterior, lee el archivo, lo parsea y procesa los datos contenidos.
Lógica Arquitectónica¶
File Transfer introduce una indirección temporal y espacial entre productor y consumidor. El archivo actúa como un buffer persistente que desacopla ambos extremos:
- Desacoplamiento temporal: el productor y el consumidor no necesitan estar disponibles simultáneamente. El archivo persiste hasta que el consumidor lo procesa.
- Desacoplamiento tecnológico: el contrato entre ambos es el formato del archivo (CSV, XML, JSON, Parquet, fixed-width, etc.), no un protocolo de comunicación ni una API.
- Desacoplamiento de velocidad: el productor puede generar archivos a su propio ritmo, y el consumidor puede procesarlos al suyo.
Principio de Diseño Subyacente¶
El principio fundamental es simplicidad a través de un contrato mínimo. El único acuerdo necesario entre los sistemas es: qué formato tiene el archivo, dónde se deposita y con qué convención de nombres se identifica. No se requiere acuerdo sobre protocolos de red, esquemas de autenticación de servicio, versionado de APIs ni compatibilidad de runtime.
Problema Estructural que Resuelve¶
En entornos enterprise, es extremadamente común que los sistemas que necesitan intercambiar datos no compartan ninguna infraestructura de comunicación directa. Un mainframe COBOL de los años 90 y una aplicación cloud-native de 2025 pueden no tener ningún protocolo de comunicación en común. Pero ambos pueden leer y escribir archivos. File Transfer resuelve este problema de incompatibilidad fundamental al reducir el contrato de integración al mínimo común denominador: el sistema de archivos.
Contexto en el que Emerge¶
File Transfer emerge naturalmente en contextos donde:
- Los sistemas tienen ciclos de vida radicalmente diferentes y no pueden asumir disponibilidad mutua.
- Los volúmenes de datos son grandes y se procesan en batch (no transacción por transacción).
- Las restricciones regulatorias exigen evidencia física del intercambio (archivos como registro auditable).
- La infraestructura de red entre sistemas es limitada, intermitente o de alta latencia.
- Los sistemas involucrados son legacy y no exponen APIs ni interfaces de mensajería.
Por Qué No Es Trivial¶
Aunque File Transfer parece conceptualmente simple, su implementación correcta a escala enterprise involucra decisiones no triviales:
- Atomicidad de escritura: ¿cómo garantiza el productor que el archivo está completo antes de que el consumidor lo lea? Un archivo parcialmente escrito puede ser leído prematuramente.
- Detección de archivos nuevos: ¿cómo detecta el consumidor que hay un archivo nuevo disponible? Polling, file watchers, archivos de señal (.done, .trigger), timestamps.
- Manejo de errores: ¿qué ocurre si el archivo tiene un formato inválido? ¿Si faltan campos? ¿Si hay registros duplicados? ¿Quién se entera del fallo?
- Idempotencia: ¿qué ocurre si el consumidor procesa el mismo archivo dos veces? ¿El resultado es el mismo o se duplican registros?
- Orden de procesamiento: si se generan múltiples archivos, ¿importa el orden de procesamiento? ¿Cómo se garantiza?
- Limpieza: ¿quién elimina los archivos procesados? ¿Cuándo? ¿Se archivan?
- Seguridad: ¿cómo se protege el contenido en tránsito y en reposo? Cifrado, permisos de acceso, control de integridad.
Relación con Sistemas Distribuidos y Mensajería¶
File Transfer es el estilo de integración más distante de la mensajería. No hay broker, no hay canal, no hay garantía de entrega, no hay routing dinámico. Es, en esencia, el polo opuesto de la mensajería en el espectro de estilos de integración.
Sin embargo, en la práctica moderna, File Transfer frecuentemente se combina con mensajería: un evento notifica que un archivo está disponible, y el consumidor lo procesa en respuesta al evento. Esta combinación híbrida (event notification + file payload) es extremadamente común en integraciones cloud modernas.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin File Transfer, las opciones para mover datos entre sistemas incompatibles son:
- Intervención manual: un operador extrae datos de un sistema, los formatea manualmente y los carga en otro. Esto es lento, propenso a error y no escalable.
- Conexión directa: requiere que ambos sistemas soporten un protocolo común en tiempo real, lo cual frecuentemente no es posible con sistemas legacy.
- Duplicación de funcionalidad: cada sistema replica internamente la funcionalidad del otro para evitar la necesidad de integración, lo cual viola DRY a nivel de sistemas y diverge inevitablemente.
Síntomas del Problema¶
- Equipos copiando datos manualmente entre sistemas usando hojas de cálculo.
- Discrepancias frecuentes entre los datos de un sistema y otro porque la sincronización depende de procesos manuales.
- Incapacidad de procesar grandes volúmenes de datos entre sistemas porque la única alternativa es transacción por transacción a través de una interfaz lenta.
- Procesos de cierre contable, conciliación o reporting que dependen de que una persona ejecute scripts de extracción en horarios específicos.
Impacto Operativo y Arquitectónico¶
Sin un mecanismo de transferencia de archivos sistematizado:
- Los datos entre sistemas se desincronizan progresivamente.
- Los procesos batch se convierten en cuellos de botella operativos dependientes de intervención humana.
- La auditoría se dificulta porque no hay registro sistemático de qué datos se transfirieron, cuándo y con qué resultado.
- Los errores de integración se detectan tardíamente, a menudo cuando un proceso downstream falla porque recibió datos incompletos o desactualizados.
Riesgos Si No Se Implementa Correctamente¶
- Archivos parciales procesados: el consumidor lee un archivo que el productor aún no terminó de escribir, procesando datos incompletos.
- Archivos perdidos: un archivo se deposita pero nadie lo recoge porque el mecanismo de detección falló.
- Duplicación de procesamiento: el mismo archivo se procesa múltiples veces porque no hay mecanismo de tracking.
- Corrupción silenciosa: el formato del archivo cambia (el productor añade o elimina columnas) pero el consumidor no se adapta, procesando datos incorrectamente sin generar errores visibles.
- Acumulación sin control: archivos se acumulan en el directorio compartido sin ser procesados ni limpiados, consumiendo storage y dificultando la operación.
Ejemplos Reales¶
- Banca: el sistema core bancario genera un archivo diario con todas las transacciones del día para alimentar el sistema de prevención de lavado de dinero (AML). El archivo se deposita en un directorio SFTP seguro a las 23:00 y el sistema AML lo procesa a las 01:00.
- Retail: el sistema de punto de venta genera archivos de ventas diarias que se transfieren al ERP para actualización de inventario y contabilidad.
- Gobierno: las entidades reguladas envían archivos en formato específico (frecuentemente fixed-width o XML regulatorio) a las entidades supervisoras a través de canales seguros.
- Salud: los laboratorios clínicos generan archivos HL7 con resultados de exámenes que se transfieren a los sistemas de historia clínica electrónica.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando los datos se procesan en batch, no transacción por transacción.
- Cuando los sistemas involucrados tienen incompatibilidad tecnológica profunda (mainframe + cloud, por ejemplo).
- Cuando el volumen de datos por transferencia es alto (miles a millones de registros) y no justifica procesamiento unitario.
- Cuando existe un requisito regulatorio de conservar evidencia física del intercambio.
- Cuando la latencia tolerable es de horas o días, no segundos.
- Cuando la infraestructura de red entre sistemas es limitada o de alta latencia.
- Cuando los sistemas origen son legacy sin APIs ni interfaces de mensajería.
Cuándo No Usarlo¶
- Cuando se necesita integración en tiempo real o near-real-time (latencia de segundos o milisegundos).
- Cuando el volumen por evento es pequeño (un registro o un evento individual) — File Transfer introduce overhead desproporcionado.
- Cuando se requiere confirmación de procesamiento inmediata (request-reply).
- Cuando la frecuencia de intercambio es alta y continua (miles de eventos por segundo).
- Cuando los sistemas soportan mensajería nativa y la infraestructura de messaging está disponible.
- Cuando se necesita routing dinámico basado en contenido del mensaje.
Precondiciones¶
- Existe un sistema de archivos accesible por ambas aplicaciones (NFS, SMB, SFTP, S3, Azure Blob Storage, GCS).
- Existe acuerdo sobre el formato del archivo (esquema, delimitadores, encoding, convención de nombres).
- Existe un mecanismo de detección de archivos nuevos (polling, file watcher, señal de disponibilidad).
- Existe un mecanismo de manejo de archivos procesados (mover, renombrar, eliminar, archivar).
Restricciones¶
- La latencia mínima está determinada por la frecuencia de generación y la frecuencia de polling/detección.
- No hay mecanismo nativo de confirmación de entrega (el productor no sabe si el consumidor procesó correctamente).
- La granularidad del intercambio es el archivo completo, no el registro individual.
- La evolución del formato requiere coordinación bilateral entre productor y consumidor.
Dependencias¶
- Sistema de archivos compartido o mecanismo de transferencia (SFTP, S3, etc.).
- Scheduler o trigger para la generación y consumo de archivos.
- Opcional: sistema de notificación para avisar de la disponibilidad de archivos.
Supuestos Arquitectónicos¶
- El volumen de datos cabe razonablemente en un archivo (o un conjunto finito de archivos).
- La latencia de batch es aceptable para el caso de uso.
- Ambas aplicaciones pueden serializar/deserializar el formato acordado.
- El sistema de archivos intermedio tiene la capacidad, disponibilidad y seguridad adecuadas.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Integraciones con mainframes y sistemas legacy.
- Procesos ETL y alimentación de data warehouses.
- Reportes regulatorios y compliance.
- Conciliaciones bancarias y financieras.
- Intercambio de datos con socios externos (B2B).
- Carga masiva de datos en sistemas CRM, ERP, HCM.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
File Transfer ofrece un acoplamiento extremadamente bajo entre sistemas. El único punto de acoplamiento es el formato del archivo y la ubicación de depósito. Esto proporciona gran flexibilidad: cualquiera de los dos sistemas puede ser reemplazado sin afectar al otro, siempre que el nuevo sistema pueda producir o consumir archivos en el formato acordado. Sin embargo, esta flexibilidad tiene un costo: no hay contrato formal verificable en runtime (como un schema registry o un API contract), lo que puede derivar en errores silenciosos cuando el formato evoluciona.
Simplicidad vs. Robustez¶
La simplicidad de File Transfer es su mayor fortaleza y su mayor debilidad. Es simple de entender, simple de implementar inicialmente y simple de depurar (los archivos son inspectables). Pero alcanzar robustez enterprise requiere resolver manualmente problemas que otros estilos resuelven de forma nativa: detección de archivos, atomicidad, idempotencia, manejo de errores, tracking, limpieza y monitoreo.
Sincronía vs. Asincronía¶
File Transfer es inherentemente asíncrono. No hay handshake en tiempo real entre productor y consumidor. Esto es una ventaja para desacoplamiento temporal pero una desventaja para escenarios que requieren confirmación inmediata o retroalimentación.
Latencia vs. Confiabilidad¶
File Transfer favorece la confiabilidad sobre la latencia. Un archivo persistido en disco (o en object storage) sobrevive a reinicios de aplicaciones, fallos de red y paradas de mantenimiento. El dato no se pierde mientras el archivo exista. Pero la latencia es inherentemente alta: está determinada por la frecuencia de generación y la frecuencia de polling.
Consistencia vs. Disponibilidad¶
Los datos en un File Transfer son consistentes dentro del archivo (snapshot point-in-time), pero inevitablemente inconsistentes entre sistemas durante el intervalo entre transferencias. Si el sistema origen actualiza un registro después de generar el archivo pero antes de que el consumidor lo procese, hay una ventana de inconsistencia. Esta ventana puede ser de horas o días.
Costo Operativo vs. Capacidad de Evolución¶
El costo operativo inicial de File Transfer es bajo: no requiere infraestructura de mensajería, no requiere APIs, no requiere brokers. Pero el costo operativo a largo plazo puede ser alto: scripts de monitoreo ad-hoc, procesos de limpieza, manejo manual de errores, debugging de formatos rotos, y la dificultad de evolucionar el formato sin romper consumidores existentes.
Gobernanza vs. Autonomía de Equipos¶
File Transfer permite alta autonomía: cada equipo controla su propio proceso de generación o consumo sin depender de infraestructura centralizada. Pero esta misma autonomía dificulta la gobernanza: sin un registro central de qué archivos se intercambian, entre quién, con qué formato y con qué frecuencia, el landscape de integraciones por archivo se convierte en un "shadow integration" difícil de auditar y gobernar.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Aplicación Productora (Source): el sistema que genera los datos y los serializa en un archivo.
- Sistema de Archivos Compartido (Shared File System): el medio de almacenamiento intermedio donde se deposita el archivo. Puede ser un directorio local, NFS, SFTP, S3, Azure Blob, GCS, etc.
- Aplicación Consumidora (Target): el sistema que detecta, lee, parsea y procesa el archivo.
- Scheduler/Trigger (opcional): un mecanismo que controla cuándo se genera y cuándo se consume el archivo (cron jobs, schedulers, file watchers).
- Mecanismo de Señalización (opcional): un indicador de que el archivo está completo y disponible para consumo (archivo .done, rename atómico, evento de notificación).
Flujo Lógico¶
flowchart TD
A([Productor: Inicio]) --> B[Extrae datos del sistema origen]
B --> C[Serializa datos en formato acordado]
C --> D[Escribe archivo en ubicación temporal]
D --> E[Mueve/renombra a ubicación definitiva]
E --> F([Consumidor: Detecta archivo nuevo])
F --> G[Lee y parsea el archivo]
G --> H{Validación de formato y contenido}
H -->|Válido| I[Procesa registros]
H -->|Inválido| J[Registra error]
I --> K[Mueve archivo a procesados/archivados]
K --> L[Registra resultado]
J --> LResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Generar datos correctos, serializar en formato acordado, garantizar atomicidad de escritura |
| File System | Almacenar archivo de forma duradera, proporcionar acceso controlado |
| Consumidor | Detectar archivo, validar, procesar, manejar errores, registrar resultado |
| Scheduler | Orquestar timing de producción y consumo |
Interacciones¶
- Productor → File System: escritura del archivo (PUT, WRITE, UPLOAD).
- File System → Consumidor: lectura del archivo (GET, READ, DOWNLOAD). La interacción es pull-based por defecto (el consumidor busca archivos activamente).
- Señalización: puede ser implícita (la presencia del archivo es la señal) o explícita (archivo .done, evento, API call).
Contratos Implícitos¶
- Formato del archivo: delimitadores, encoding, headers, tipos de datos, orden de campos.
- Convención de nombres: cómo se nombran los archivos (típicamente incluye timestamp, tipo de dato, secuencia).
- Ubicación: directorio específico para depósito y detección.
- Frecuencia: cuándo se generan y cuándo se esperan archivos.
- Manejo post-procesamiento: qué ocurre con el archivo después de ser consumido.
Decisiones de Diseño Clave¶
- Formato de archivo: CSV, JSON, XML, Parquet, Avro, fixed-width. Impacta parseabilidad, tamaño, schema evolution y herramientas disponibles.
- Mecanismo de atomicidad: write-then-rename, archivo de señal, checksum. Evita lectura de archivos parciales.
- Mecanismo de detección: polling periódico, filesystem watcher (inotify, FSEvents), event notification. Impacta latencia y complejidad.
- Estrategia de manejo de errores: rechazar archivo completo, procesar registros válidos y reportar inválidos, dead-letter file.
- Estrategia de idempotencia: tracking de archivos procesados (por nombre, hash, sequence number) para evitar reprocesamiento.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Conciliación de Transacciones Interbancarias¶
Contexto del Negocio¶
Un banco comercial regional necesita conciliar diariamente sus transacciones interbancarias contra los registros de la cámara de compensación nacional. Cada día, el banco procesa aproximadamente 500,000 transacciones que pasan por la cámara de compensación. Al cierre del día, el banco debe verificar que sus registros internos coinciden con los registros de la cámara.
Necesidad de Integración¶
El sistema core bancario (un mainframe IBM z/OS con aplicaciones COBOL) debe comparar sus transacciones diarias con un archivo de liquidación que la cámara de compensación genera y deposita en un servidor SFTP seguro cada noche a las 22:00 UTC. El resultado de la conciliación debe cargarse en el sistema de reporting regulatorio del banco (una aplicación Java moderna desplegada en cloud).
Sistemas Involucrados¶
- Core Bancario (Mainframe z/OS): sistema legacy que registra todas las transacciones del banco. Genera archivos en formato fixed-width EBCDIC.
- Cámara de Compensación (Sistema Externo): entidad regulatoria que genera el archivo de liquidación diario en formato ISO 20022 XML.
- Motor de Conciliación: proceso batch que compara ambos conjuntos de datos y produce un reporte de discrepancias.
- Sistema de Reporting Regulatorio: aplicación cloud que almacena y presenta los resultados de conciliación para auditoría.
- SFTP Server: servidor seguro donde la cámara deposita el archivo de liquidación.
- Object Storage (Azure Blob): almacenamiento cloud donde se depositan archivos intermedios y resultados.
Restricciones Técnicas¶
- El mainframe solo puede generar archivos en formato fixed-width con encoding EBCDIC.
- La cámara de compensación genera archivos en ISO 20022 XML; el formato no es negociable.
- El archivo de la cámara solo está disponible después de las 22:00 UTC.
- El proceso de conciliación debe completarse antes de las 06:00 UTC del día siguiente.
- Todos los archivos deben conservarse durante 7 años por requisitos regulatorios.
- La comunicación con la cámara es exclusivamente vía SFTP con certificados mutuos (mTLS).
Flujos de Datos¶
Cámara de Compensación → [SFTP] → Archivo ISO 20022 XML
Core Bancario (Mainframe) → [FTP interno] → Archivo Fixed-Width EBCDIC
Ambos archivos → [Motor de Conciliación] → Archivo de Discrepancias (JSON)
Archivo de Discrepancias → [Azure Blob] → Sistema de Reporting Regulatorio
Eventos o Mensajes¶
En este escenario, no hay mensajería nativa. Sin embargo, se introduce una notificación event-based para optimizar el flujo:
- Cuando el archivo de la cámara llega al SFTP, un proceso watcher genera un evento en Azure Event Grid notificando la disponibilidad.
- Cuando el mainframe completa la generación de su archivo, un job scheduler (Control-M) dispara una notificación.
- Ambos eventos son condiciones de inicio para el motor de conciliación.
Decisiones Arquitectónicas¶
- Formato de conciliación intermedio: se transforma ambos archivos a un formato canónico JSON antes de comparar, para desacoplar el motor de conciliación de los formatos específicos de cada sistema.
- Atomicidad: el mainframe escribe el archivo con extensión
.tmpy lo renombra a.datal completar. El motor de conciliación solo procesa archivos.dat. - Idempotencia: cada archivo tiene un nombre que incluye la fecha de negocio (
TXNS_20260407.dat). El motor de conciliación registra qué fechas ya fueron conciliadas. - Archivado: tras procesamiento exitoso, los archivos se mueven a un directorio de archivado con retención de 7 años en Azure Blob Storage (tier Archive).
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Archivo de cámara no llega a tiempo | Alerta automática si no se detecta antes de las 23:30 UTC; proceso manual de escalación |
| Archivo del mainframe corrupto | Checksum MD5 generado por mainframe, verificado por motor de conciliación |
| Doble procesamiento del mismo archivo | Registro de archivos procesados por fecha de negocio en base de datos de control |
| Fallo del motor de conciliación a mitad de proceso | Proceso idempotente que puede re-ejecutarse sin duplicar resultados |
| Discrepancia no detectada | Validación cruzada de totales de control (número de transacciones, monto total) antes del matching detallado |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación del Archivo del Core Bancario¶
A las 21:30 UTC, un job programado en Control-M inicia un proceso batch en el mainframe. Este proceso:
- Ejecuta un programa COBOL que lee todas las transacciones interbancarias del día desde la base de datos DB2 del core.
- Serializa cada transacción en un registro de longitud fija (250 bytes) con encoding EBCDIC.
- Incluye un registro header con la fecha de negocio, número total de transacciones y monto total acumulado.
- Incluye un registro trailer con checksums de validación.
- Escribe el archivo como
TXNS_20260407.tmpen el directorio de salida del mainframe. - Al completar la escritura exitosamente, renombra el archivo a
TXNS_20260407.dat. - Un proceso FTP transfiere el archivo desde el mainframe a un directorio staging en Azure Blob Storage.
Paso 2: Recepción del Archivo de la Cámara de Compensación¶
A las 22:00 UTC, la cámara de compensación deposita el archivo CLEARING_20260407.xml en el servidor SFTP del banco. Un daemon watcher:
- Detecta la presencia del nuevo archivo mediante polling cada 60 segundos.
- Descarga el archivo al directorio de procesamiento.
- Verifica la firma digital del archivo (la cámara firma con su certificado).
- Calcula el hash SHA-256 del archivo y lo registra.
- Deposita el archivo en Azure Blob Storage en el contenedor
incoming/clearing/. - Publica un evento en Azure Event Grid:
ClearingFileReceived { date: "2026-04-07", path: "incoming/clearing/CLEARING_20260407.xml" }.
Paso 3: Transformación a Formato Canónico¶
Un proceso de transformación (Azure Function triggered por Event Grid) ejecuta dos transformaciones:
- Archivo del mainframe (fixed-width EBCDIC → JSON):
- Convierte encoding EBCDIC a UTF-8.
- Parsea registros de longitud fija según la especificación de campos.
- Genera un archivo JSON con un array de transacciones normalizadas.
-
Cada transacción tiene:
transaction_id,amount,currency,debtor_bank,creditor_bank,value_date,status. -
Archivo de la cámara (ISO 20022 XML → JSON):
- Parsea la estructura XML ISO 20022.
- Extrae las transacciones del bloque
<FIToFIPmtSts>. - Genera un archivo JSON con la misma estructura normalizada.
Ambos archivos transformados se depositan en processing/canonical/.
Paso 4: Proceso de Conciliación¶
El motor de conciliación (un servicio Java desplegado como container en Azure Container Apps):
- Lee ambos archivos canónicos JSON.
- Construye un índice en memoria por
transaction_iddel archivo del core bancario. - Itera sobre las transacciones del archivo de la cámara y busca coincidencias.
- Clasifica cada transacción como:
- Matched: presente en ambos archivos con datos coincidentes.
- Amount Mismatch: presente en ambos pero con diferencia en monto.
- Missing in Core: presente en cámara pero no en core (transacción no registrada por el banco).
- Missing in Clearing: presente en core pero no en cámara (transacción no procesada por la cámara).
- Genera un archivo de resultado:
RECON_20260407.jsoncon todas las discrepancias. - Genera totales de control: transacciones matched, mismatched, missing, montos totales.
Paso 5: Carga en Sistema de Reporting¶
El archivo RECON_20260407.json se deposita en results/reconciliation/ en Azure Blob Storage. Un evento dispara la ingesta en el sistema de reporting:
- El sistema de reporting lee el archivo JSON.
- Persiste las discrepancias en una base de datos PostgreSQL.
- Actualiza dashboards de conciliación.
- Si el porcentaje de discrepancias supera un umbral (>0.1%), genera una alerta al equipo de operaciones.
Paso 6: Archivado y Limpieza¶
Al completar el proceso exitosamente:
- Todos los archivos originales y transformados se mueven al contenedor
archive/2026/04/07/. - Se aplica una política de retención de 7 años (Azure Blob Lifecycle Management, tier Archive).
- Se registra en la base de datos de control: fecha procesada, archivos involucrados, hashes, resultado, timestamp.
- Los directorios de staging y processing se limpian.
Manejo de Errores¶
- Error de parsing: si algún archivo no puede parsearse, el proceso se detiene, se genera una alerta y el archivo se mueve a un directorio
error/para inspección manual. - Error de transformación: si la transformación a formato canónico falla, se registra el error y se reintenta una vez. Si falla nuevamente, se escala.
- Error de conciliación: si el motor de conciliación falla a mitad de proceso, puede re-ejecutarse porque el resultado depende exclusivamente de los archivos de entrada (idempotencia).
- SLA breach: si el proceso no completa antes de las 05:00 UTC, se genera una alerta de alta prioridad.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
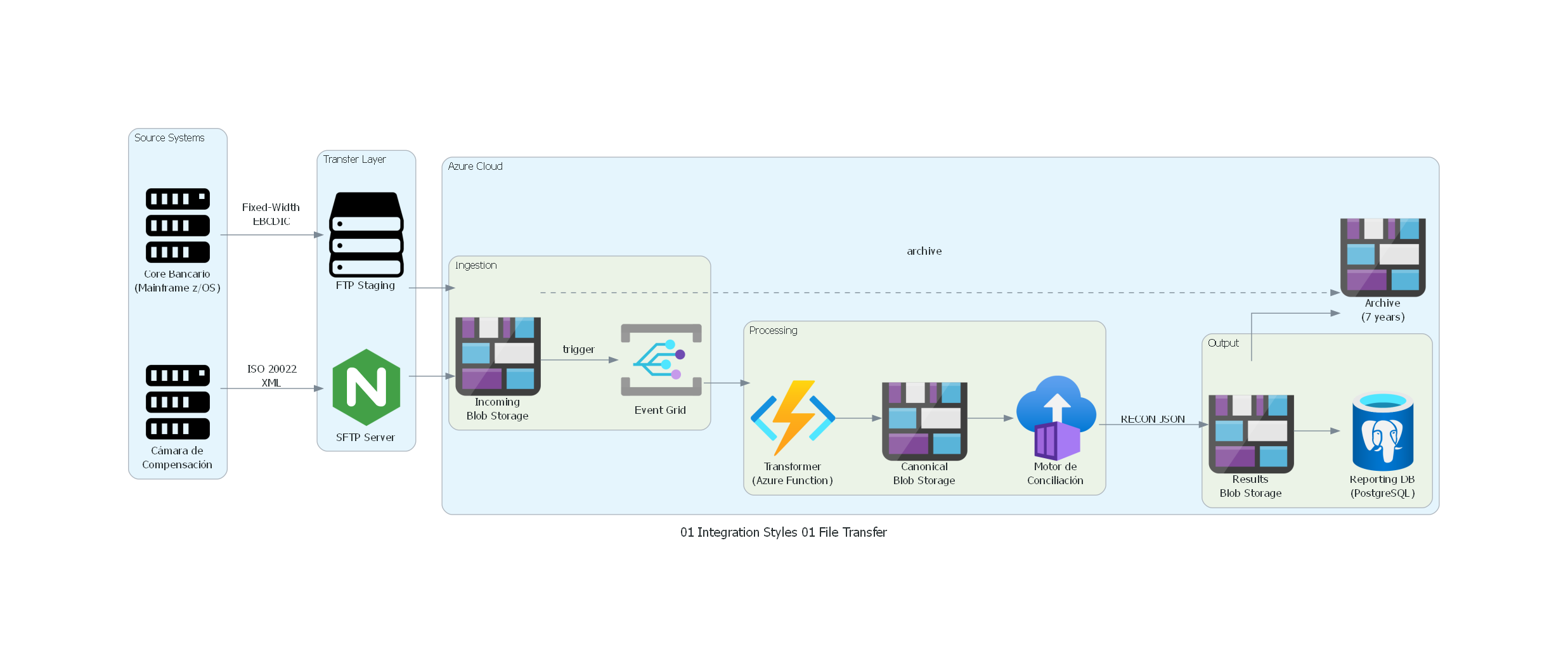
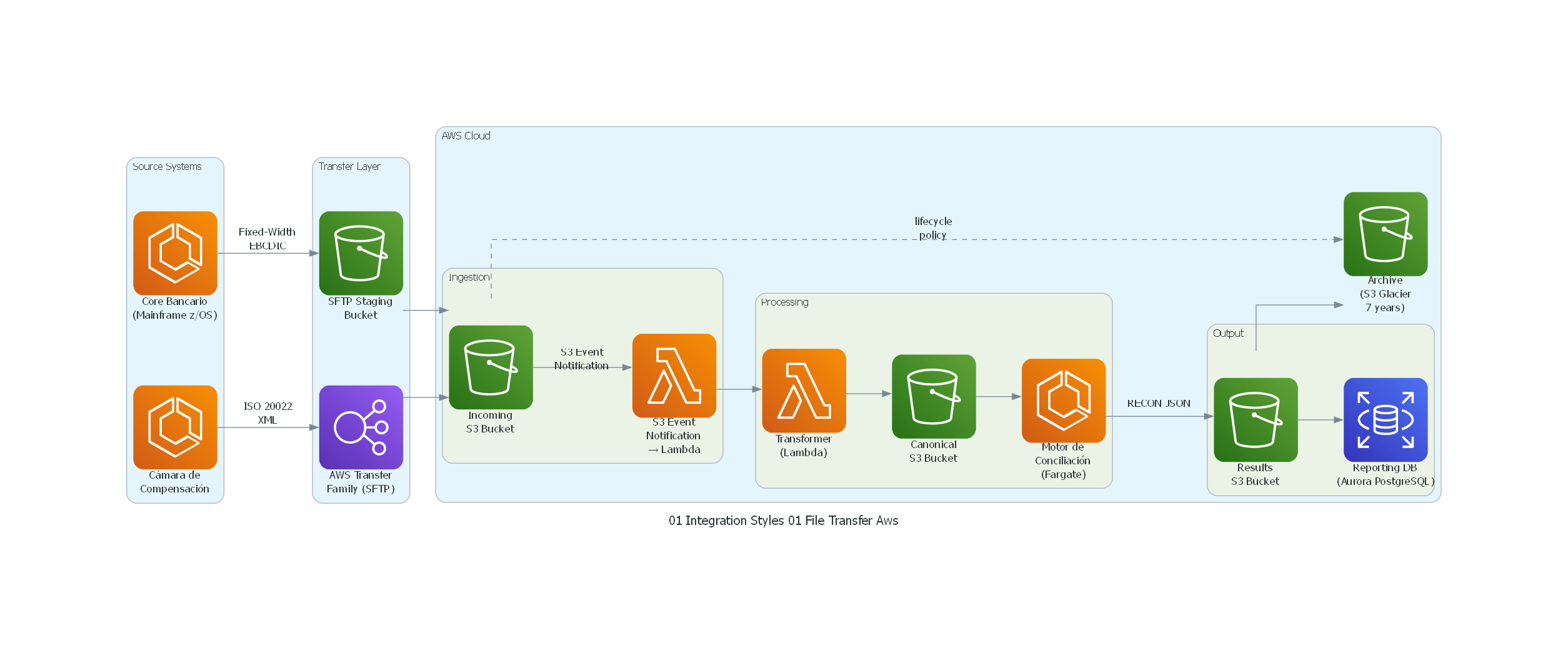
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.storage import BlobStorage
from diagrams.azure.compute import FunctionApps, ContainerInstances
from diagrams.azure.integration import EventGridDomains
from diagrams.azure.database import DatabaseForPostgresqlServers
from diagrams.onprem.compute import Server
from diagrams.onprem.network import Nginx
from diagrams.generic.storage import Storage
with Diagram("File Transfer - Bank Reconciliation", show=False, direction="LR"):
with Cluster("Source Systems"):
mainframe = Server("Core Bancario\n(Mainframe z/OS)")
clearing = Server("Cámara de\nCompensación")
with Cluster("Transfer Layer"):
sftp = Nginx("SFTP Server")
ftp_staging = Storage("FTP Staging")
with Cluster("Azure Cloud"):
with Cluster("Ingestion"):
blob_incoming = BlobStorage("Incoming\nBlob Storage")
event_grid = EventGridDomains("Event Grid")
with Cluster("Processing"):
transformer = FunctionApps("Transformer\n(Azure Function)")
blob_canonical = BlobStorage("Canonical\nBlob Storage")
recon_engine = ContainerInstances("Motor de\nConciliación")
with Cluster("Output"):
blob_results = BlobStorage("Results\nBlob Storage")
reporting_db = DatabaseForPostgresqlServers("Reporting DB\n(PostgreSQL)")
blob_archive = BlobStorage("Archive\n(7 years)")
# Flows
mainframe >> Edge(label="Fixed-Width\nEBCDIC") >> ftp_staging
clearing >> Edge(label="ISO 20022\nXML") >> sftp
ftp_staging >> blob_incoming
sftp >> blob_incoming
blob_incoming >> Edge(label="trigger") >> event_grid
event_grid >> transformer
transformer >> blob_canonical
blob_canonical >> recon_engine
recon_engine >> Edge(label="RECON JSON") >> blob_results
blob_results >> reporting_db
blob_results >> blob_archive
blob_incoming >> Edge(style="dashed", label="archive") >> blob_archive
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.database import RDS
from diagrams.aws.network import ELB
from diagrams.aws.storage import S3
with Diagram("File Transfer - Bank Reconciliation (AWS)", show=False, direction="LR"):
with Cluster("Source Systems"):
mainframe = ECS("Core Bancario\n(Mainframe z/OS)")
clearing = ECS("Cámara de\nCompensación")
with Cluster("Transfer Layer"):
sftp = ELB("AWS Transfer\nFamily (SFTP)")
ftp_staging = S3("SFTP Staging\nBucket")
with Cluster("AWS Cloud"):
with Cluster("Ingestion"):
s3_incoming = S3("Incoming\nS3 Bucket")
s3_notification = Lambda("S3 Event\nNotification\n→ Lambda")
with Cluster("Processing"):
transformer = Lambda("Transformer\n(Lambda)")
s3_canonical = S3("Canonical\nS3 Bucket")
recon_engine = ECS("Motor de\nConciliación\n(Fargate)")
with Cluster("Output"):
s3_results = S3("Results\nS3 Bucket")
reporting_db = RDS("Reporting DB\n(Aurora PostgreSQL)")
s3_archive = S3("Archive\n(S3 Glacier\n7 years)")
# Flows
mainframe >> Edge(label="Fixed-Width\nEBCDIC") >> ftp_staging
clearing >> Edge(label="ISO 20022\nXML") >> sftp
ftp_staging >> s3_incoming
sftp >> s3_incoming
s3_incoming >> Edge(label="S3 Event\nNotification") >> s3_notification
s3_notification >> transformer
transformer >> s3_canonical
s3_canonical >> recon_engine
recon_engine >> Edge(label="RECON JSON") >> s3_results
s3_results >> reporting_db
s3_results >> s3_archive
s3_incoming >> Edge(style="dashed", label="lifecycle\npolicy") >> s3_archive
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.storage import BlobStorage
from diagrams.azure.compute import FunctionApps, ContainerInstances
from diagrams.azure.integration import EventGridTopics
from diagrams.azure.database import DatabaseForPostgresqlServers
from diagrams.azure.network import ApplicationGateway
from diagrams.onprem.compute import Server
with Diagram("File Transfer - Bank Reconciliation (Azure)", show=False, direction="LR"):
with Cluster("Source Systems"):
mainframe = Server("Core Bancario\n(Mainframe z/OS)")
clearing = Server("Cámara de\nCompensación")
with Cluster("Transfer Layer"):
sftp = ApplicationGateway("Azure SFTP\n(Blob SFTP endpoint)")
with Cluster("Azure Cloud"):
with Cluster("Ingestion"):
blob_incoming = BlobStorage("Incoming\nBlob Container")
event_grid = EventGridTopics("Event Grid Topic\n(BlobCreated)")
with Cluster("Processing"):
transformer = FunctionApps("Transformer\n(Azure Function)")
blob_canonical = BlobStorage("Canonical\nBlob Container")
recon_engine = ContainerInstances("Motor de\nConciliación\n(Container Instance)")
with Cluster("Output"):
blob_results = BlobStorage("Results\nBlob Container")
reporting_db = DatabaseForPostgresqlServers("Azure DB\nfor PostgreSQL")
blob_archive = BlobStorage("Archive Storage\n(Cool Tier, 7 years)")
# Flows
mainframe >> Edge(label="Fixed-Width\nEBCDIC") >> sftp
clearing >> Edge(label="ISO 20022\nXML") >> sftp
sftp >> blob_incoming
blob_incoming >> Edge(label="BlobCreated\nevent") >> event_grid
event_grid >> Edge(label="trigger") >> transformer
transformer >> blob_canonical
blob_canonical >> recon_engine
recon_engine >> Edge(label="RECON JSON") >> blob_results
blob_results >> reporting_db
blob_results >> blob_archive
blob_incoming >> Edge(style="dashed", label="lifecycle\npolicy") >> blob_archive
Explicación del Diagrama¶
El diagrama representa el flujo completo de File Transfer para la conciliación bancaria:
- Source Systems (izquierda): el mainframe del core bancario genera archivos fixed-width EBCDIC, y la cámara de compensación genera archivos ISO 20022 XML.
- Transfer Layer: los archivos se transfieren mediante FTP (mainframe) y SFTP (cámara) a una capa de staging.
- Ingestion (Azure): los archivos llegan a Blob Storage y disparan eventos en Event Grid.
- Processing: una Azure Function transforma los archivos a formato canónico JSON, y el motor de conciliación (Container Instance) compara ambos conjuntos.
- Output: los resultados se depositan en Blob Storage y se cargan en PostgreSQL para el sistema de reporting.
- Archive: todos los archivos se archivan con retención de 7 años.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Aplicación Productora | Core Bancario (Mainframe), Cámara de Compensación |
| Archivo producido | Fixed-Width EBCDIC file, ISO 20022 XML file |
| Sistema de Archivos Compartido | SFTP Server, FTP Staging, Azure Blob Storage |
| Mecanismo de Señalización | Azure Event Grid (trigger) |
| Aplicación Consumidora | Transformer (Azure Function), Motor de Conciliación |
| Resultado del procesamiento | RECON JSON en Results Blob Storage, Reporting DB |
| Archivado | Archive Blob Storage (7 years) |
11. Beneficios¶
Impacto Técnico¶
- Universalidad: cualquier sistema que pueda leer/escribir archivos puede participar, independientemente de su tecnología, antigüedad o plataforma. Esto es especialmente valioso para integrar sistemas legacy que no exponen APIs.
- Inspectabilidad: los archivos son artefactos físicos que pueden inspeccionarse, copiarse, compararse y depurarse con herramientas estándar. No se necesita instrumentación especial para ver qué datos se intercambiaron.
- Resiliencia ante fallos de red: una vez el archivo está depositado, sobrevive a fallos de red, reinicios de aplicaciones y paradas de mantenimiento. El dato no se pierde.
- Procesamiento batch eficiente: para grandes volúmenes de datos que se procesan en conjunto, File Transfer es más eficiente que procesamiento unitario porque amortiza el overhead de conexión y setup.
Impacto Organizacional¶
- Baja barrera de entrada: los equipos no necesitan infraestructura de mensajería ni expertise en APIs para implementar una integración por archivo.
- Independencia de equipos: productor y consumidor pueden desarrollar y desplegar de forma completamente independiente. El único acuerdo necesario es el formato del archivo.
- Evidencia auditable: los archivos son evidencia tangible del intercambio de datos, lo cual facilita auditoría, compliance y resolución de disputas.
Impacto Operacional¶
- Reprocesabilidad: si algo falla, el archivo original sigue disponible y puede reprocesarse. No se pierde información.
- Simplicidad de monitoreo básico: verificar si un archivo existe en un directorio es un health check trivial.
- Compatibilidad con procesos existentes: muchos procesos operacionales enterprise ya están diseñados alrededor de archivos (schedulers, FTP, archivado). File Transfer encaja naturalmente.
Beneficios de Mantenibilidad y Evolución¶
- Reemplazabilidad de componentes: cambiar el sistema productor o consumidor no requiere cambiar la integración, solo mantener el formato del archivo.
- Testing independiente: el consumidor puede testearse con archivos de prueba sin necesidad del productor, y viceversa.
- Versionado de datos: los archivos pueden versionarse en su nombre o estructura, permitiendo evolución gradual del formato.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Gestión del ciclo de vida de archivos: producción, transferencia, detección, procesamiento, archivado y limpieza requieren orquestación que frecuentemente se implementa con scripts ad-hoc difíciles de mantener.
- Transformación de formatos: cada par productor-consumidor puede requerir transformaciones de formato que se multiplican combinatoriamente.
- Monitoreo y alerting: detectar que un archivo no llegó, llegó incompleto, o no fue procesado requiere instrumentación custom.
Riesgos de Mal Uso¶
- Usar File Transfer para integración en tiempo real: intentar reducir el intervalo de polling a segundos para simular near-real-time es un anti-pattern que resulta en alto consumo de I/O, complejidad operacional y fragilidad.
- Ignorar la atomicidad: leer archivos parcialmente escritos es uno de los errores más comunes y más difíciles de diagnosticar.
- Archivos como integración oculta: cuando las integraciones por archivo no se documentan ni gobiernan, se convierten en "shadow integration" invisible para los arquitectos pero crítica para el negocio.
Sobreingeniería¶
- Construir un framework de transferencia de archivos propio cuando existen herramientas maduras (Apache NiFi, Azure Data Factory, AWS Transfer Family, MuleSoft) que resuelven los problemas comunes de forma estandarizada.
- Implementar routing dinámico y transformación compleja sobre archivos cuando el escenario realmente requiere un sistema de mensajería.
Costos de Operación¶
- Storage: archivos grandes acumulados durante años consumen storage significativo.
- Coordinación temporal: schedulers, dependencias entre jobs, ventanas de procesamiento, y la gestión de excepciones cuando un job falla o se atrasa.
- Soporte operativo: diagnosticar problemas en integraciones por archivo frecuentemente requiere inspección manual de archivos, directorios, logs de transfer y registros de procesamiento.
Errores Frecuentes de Implementación¶
- No verificar completitud del archivo antes de procesarlo.
- No manejar archivos con cero registros (archivos vacíos legítimos vs. indicadores de error).
- No registrar qué archivos se procesaron, lo que impide detectar y evitar reprocesamiento.
- Hardcodear paths, formatos y convenciones de nombres en lugar de configurarlos.
- No implementar alertas cuando un archivo esperado no llega.
Anti-Patterns Relacionados¶
- Fire and Forget File: el productor genera el archivo pero nunca verifica si fue consumido. El archivo puede acumularse indefinidamente sin procesamiento.
- Polling Storm: reducir el intervalo de polling a intervalos muy cortos para reducir latencia, generando carga innecesaria en el sistema de archivos.
- Formato Tácito: no documentar formalmente el formato del archivo, confiando en que "los que saben" lo conocen. Esto falla inevitablemente cuando cambian las personas.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Messaging: frecuentemente se combina con File Transfer en un patrón híbrido donde un evento notifica la disponibilidad de un archivo y el consumidor lo procesa en respuesta al evento. Esto resuelve el problema de polling y reduce latencia.
- Claim Check: es conceptualmente similar — un mensaje ligero referencia un payload pesado almacenado externamente. File Transfer con notificación de evento es una forma de Claim Check.
- Channel Adapter: la capa que conecta un sistema legacy con File Transfer (el daemon SFTP, el proceso FTP del mainframe) funciona como un Channel Adapter.
Patrones que Suelen Aparecer Antes o Después¶
- Message Translator / Normalizer: los archivos producidos por diferentes sistemas raramente comparten formato. La transformación a un formato canónico antes del procesamiento es casi siempre necesaria.
- Content Enricher: a veces el archivo del productor contiene datos parciales que deben enriquecerse con datos de otros sistemas antes del procesamiento.
Combinaciones Comunes¶
- File Transfer + Event Notification: el productor deposita un archivo y publica un evento. El consumidor reacciona al evento en lugar de hacer polling. Reduce latencia y elimina polling innecesario.
- File Transfer + Content-Based Router: un proceso intermedio lee el archivo y, según su contenido, lo dirige a diferentes consumidores.
- File Transfer + Splitter: un archivo grande se divide en archivos más pequeños para procesamiento paralelo.
Diferencias con Patrones Similares¶
- vs. Shared Database: File Transfer mueve snapshots de datos; Shared Database comparte datos en vivo. File Transfer desacopla temporalmente; Shared Database acopla en tiempo real.
- vs. Messaging: File Transfer opera en batch con archivos completos; Messaging opera con mensajes individuales en flujo continuo. File Transfer tiene latencia inherentemente alta; Messaging puede tener latencia de milisegundos.
Encaje en un Flujo Mayor de Integración¶
File Transfer típicamente aparece en los extremos de una arquitectura de integración: como punto de entrada de datos desde sistemas legacy o externos, y como punto de salida para reportes, archivado o alimentación de sistemas analíticos. En el centro de una arquitectura moderna, la integración suele ser event-driven o API-based, pero en los bordes, File Transfer persiste.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
File Transfer sigue siendo ampliamente utilizado en la práctica enterprise, pero su relevancia como patrón de diseño para nuevas integraciones ha disminuido significativamente. Las razones son:
A favor de la vigencia:
- Los sistemas legacy que solo pueden interactuar mediante archivos siguen existiendo en abundancia, especialmente en banca, seguros, gobierno y salud.
- Los procesos batch regulatorios frecuentemente requieren intercambio de archivos en formatos específicos definidos por entidades supervisoras.
- Los data pipelines modernos (data lakes, lakehouses) operan fundamentalmente con archivos (Parquet, Avro, Delta Lake) almacenados en object storage.
- La simplicidad de File Transfer sigue siendo valiosa para integraciones con socios externos (B2B) donde no es viable establecer conectividad API o mensajería.
En contra de la vigencia:
- Para integraciones entre sistemas modernos (microservicios, SaaS, cloud-native), File Transfer es generalmente inferior a mensajería o APIs.
- Las herramientas modernas de integración (iPaaS, event brokers) hacen que implementar messaging sea tan simple como implementar file transfer.
- La latencia inherente de File Transfer es inaceptable para la mayoría de los casos de uso modernos que requieren near-real-time.
- La dificultad de gobernar integraciones por archivo a escala (cientos de archivos entre decenas de sistemas) hace que este estilo sea operacionalmente costoso.
Contexto Moderno Donde Sigue Siendo Útil¶
- Integración con mainframes y sistemas legacy que no exponen APIs.
- Procesos regulatorios con formatos de archivo mandatorios.
- Carga masiva de datos en data warehouses y data lakes.
- Intercambio B2B con socios que solo soportan SFTP/FTP.
- Migración de datos entre sistemas durante proyectos de modernización.
Cómo Se Implementa Hoy¶
La implementación moderna de File Transfer difiere significativamente de la clásica:
- Object storage (S3, Azure Blob, GCS) reemplaza a directorios SFTP como medio de almacenamiento.
- Event notifications (S3 Events, Azure Event Grid, GCS Pub/Sub) reemplazan al polling como mecanismo de detección.
- Managed transfer services (AWS Transfer Family, Azure Data Factory, Google Cloud Storage Transfer) reemplazan a scripts FTP custom.
- Data formats han evolucionado de CSV y fixed-width a Parquet, Avro y JSON Lines.
- Data quality frameworks (Great Expectations, Deequ) proporcionan validación automatizada.
Qué Herramientas Modernas Lo Abstraen¶
- Apache NiFi: orquestación de flujos de datos basados en archivos con UI visual.
- Azure Data Factory / AWS Glue: pipelines ETL gestionados que abstraen la mecánica de transferencia.
- Managed SFTP: AWS Transfer Family, Azure Blob SFTP endpoint.
- Apache Airflow: orquestación de procesos batch que incluyen transferencia de archivos.
- MuleSoft / Boomi: iPaaS que encapsulan File Transfer como conectores.
Qué Parte Sigue Siendo Esencial¶
Independientemente de la tecnología, los principios de File Transfer que permanecen esenciales son:
- Atomicidad de escritura: garantizar que el consumidor solo vea archivos completos.
- Idempotencia de procesamiento: poder reprocesar sin duplicar efectos.
- Tracking y auditoría: registrar qué se transfirió, cuándo y con qué resultado.
- Manejo de errores: definir qué ocurre cuando un archivo es inválido, incompleto o duplicado.
Estos principios aplican tanto si el archivo está en un directorio FTP como si está en un bucket S3.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka (indirecta)¶
Kafka no implementa File Transfer directamente, pero Kafka Connect incluye conectores de archivo (FileStreamSource, FileStreamSink) que permiten ingestar archivos como mensajes en topics y materializar topics como archivos. En la práctica, esto convierte File Transfer en un bridge hacia el mundo de streaming.
Azure Integration¶
- Azure Blob Storage: almacenamiento de archivos con event triggers nativos.
- Azure Event Grid: notificación de eventos cuando un archivo se crea en Blob Storage.
- Azure Data Factory: pipelines de copia y transformación de archivos entre fuentes heterogéneas.
- Azure Logic Apps: workflows que reaccionan a la llegada de archivos y orquestan procesamiento.
- Azure Functions: procesamiento serverless triggered por eventos de Blob Storage.
AWS Integration¶
- Amazon S3: almacenamiento de archivos con S3 Event Notifications.
- AWS Transfer Family: SFTP/FTPS/FTP gestionado con backend S3.
- AWS Lambda: procesamiento serverless triggered por S3 events.
- AWS Glue: ETL serverless para transformación de archivos.
- AWS Step Functions: orquestación de pipelines de procesamiento de archivos.
Google Cloud¶
- Google Cloud Storage: almacenamiento con Pub/Sub notifications.
- Cloud Functions: procesamiento triggered por eventos de GCS.
- Dataflow: procesamiento batch y streaming de archivos.
MuleSoft¶
MuleSoft proporciona conectores nativos para File, FTP, SFTP y cloud storage, con capacidades de polling, file locking, watermarking y manejo de errores integrados. El File Connector de MuleSoft abstrae la mayoría de los problemas operacionales de File Transfer.
Apache Camel¶
Camel tiene componentes file:, ftp:, sftp:, aws-s3:, azure-storage-blob: que implementan File Transfer como source y sink de rutas de integración, con soporte nativo para idempotencia, filtering, sorting y move-after-process.
Spring Integration¶
Spring Integration ofrece FileReadingMessageSource, FileWritingMessageHandler y adaptadores FTP/SFTP que convierten archivos en mensajes Spring Integration, permitiendo combinar File Transfer con el resto del framework de messaging.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: archivos producidos/hora, archivos consumidos/hora, archivos pendientes, tamaño promedio de archivos, latencia entre producción y consumo.
- Health checks: verificar que los directorios de entrada/salida son accesibles, que el espacio en disco es suficiente, que los procesos de producción y consumo están corriendo.
- Alertas: archivo esperado no llegó en la ventana esperada, archivo con tamaño anormalmente grande o pequeño, acumulación de archivos sin procesar.
Tracing¶
- Cada archivo debe tener un identificador único (típicamente incluido en el nombre del archivo o en un header dentro del archivo).
- El identificador debe propagarse a los registros de procesamiento para permitir trazabilidad end-to-end.
- En implementaciones híbridas (File Transfer + Event Notification), el trace ID del evento debe corresponder al identificador del archivo.
Monitoreo¶
- Dashboard operacional: estado de los últimos N archivos (recibidos, procesados, con error), tiempos de procesamiento, SLA compliance.
- Monitoreo de storage: espacio disponible, archivos acumulados, política de retención activa.
- Monitoreo de scheduler: jobs ejecutados, fallos, retrasos.
Versionado¶
- Los cambios de formato deben versionarse explícitamente (en el nombre del archivo, en un header, o en metadata).
- Los consumidores deben poder manejar múltiples versiones de formato durante períodos de transición.
- La documentación del formato (data dictionary) debe versionarse junto con el código que lo produce y consume.
Seguridad¶
- En tránsito: SFTP (SSH), FTPS (TLS), o HTTPS para transferencia.
- En reposo: cifrado de storage (SSE-S3, Azure Storage Encryption, CMEK).
- Control de acceso: permisos granulares sobre directorios y archivos (RBAC, IAM policies).
- Integridad: checksums (MD5, SHA-256) para verificar que el archivo no fue alterado.
- Datos sensibles: masking o tokenización de PII/PHI dentro de los archivos cuando sea necesario.
Manejo de Errores¶
- Archivo inválido: mover a directorio de error, generar alerta, notificar al productor si es posible.
- Procesamiento parcial: decidir si rechazar el archivo completo o procesar los registros válidos y reportar los inválidos.
- Timeout: si un archivo no se procesa en la ventana esperada, escalar.
Retries¶
- El procesamiento de archivos es naturalmente idempotente si se diseña correctamente (el resultado depende solo del contenido del archivo).
- Un retry consiste en reprocesar el archivo original, que debe conservarse hasta confirmar procesamiento exitoso.
Dead-Lettering¶
- Los archivos que no pueden procesarse después de N intentos deben moverse a un directorio de "dead letter" para inspección manual.
- Debe registrarse el motivo del fallo y el número de intentos.
Idempotencia¶
- Cada archivo debe tener un identificador natural (fecha de negocio, sequence number) que permita detectar reprocesamiento.
- El consumidor debe verificar si el archivo ya fue procesado antes de procesarlo.
- Si se reprocesa, el resultado debe ser idéntico (upsert en lugar de insert, por ejemplo).
Auditoría¶
- Registro completo de: qué archivo se produjo, cuándo, por quién, cuándo se recibió, cuándo se procesó, resultado, quién lo procesó.
- Los archivos originales deben conservarse según política de retención para verificación posterior.
Performance¶
- Tamaño de archivo: archivos muy grandes pueden exceder la memoria disponible del consumidor. Considerar streaming o procesamiento por chunks.
- Compresión: archivos grandes deben comprimirse (gzip, zstd) para reducir tiempos de transferencia y costos de storage.
- Paralelismo: archivos independientes pueden procesarse en paralelo. Un archivo grande puede dividirse (Splitter pattern) para procesamiento paralelo.
Escalabilidad¶
- File Transfer escala horizontalmente dividiendo la carga en múltiples archivos independientes que se procesan en paralelo.
- El cuello de botella suele ser el I/O del sistema de archivos o el throughput de la red de transferencia.
- Object storage cloud (S3, Blob, GCS) escala virtualmente sin límite.
17. Errores Comunes¶
Usar File Transfer para Integración en Tiempo Real¶
Intentar convertir File Transfer en un mecanismo near-real-time reduciendo archivos a un solo registro y polling a intervalos de segundos es un anti-pattern. El resultado es un sistema de mensajería improvisado y deficiente. Si se necesita integración en tiempo real, hay que usar Messaging o Remote Procedure Invocation.
Ignorar la Atomicidad de Escritura¶
El error más frecuente y destructivo es que el consumidor lea un archivo que el productor aún no terminó de escribir. Esto produce procesamiento de datos incompletos que pueden ser difíciles de detectar. La solución estándar es write-to-temp-then-rename o usar archivos de señal.
No Definir Formalmente el Contrato del Archivo¶
Confiar en que "todos saben" cómo es el formato del archivo lleva inevitablemente a fallos cuando el productor cambia el formato (añade una columna, cambia un delimitador, modifica encoding) sin notificar al consumidor. El contrato del archivo debe documentarse como cualquier otro API contract.
Acumular Archivos Sin Control¶
No implementar limpieza automática de archivos procesados resulta en directorios con miles de archivos que ralentizan el listing, consumen storage y dificultan la operación. Debe existir una política clara de archivado y purga.
No Monitorear la No-Llegada¶
Monitorear errores es fácil; monitorear la ausencia de actividad es más difícil pero igualmente importante. Si el archivo esperado a las 22:00 no llega, debe generarse una alerta. Muchos equipos solo descubren la ausencia del archivo cuando un proceso downstream falla horas después.
Mezclar Datos de Diferentes Entidades en un Solo Archivo¶
Incluir registros heterogéneos en un solo archivo (órdenes, clientes, productos) dificulta el procesamiento, la validación y la evolución del formato. Cada tipo de entidad debería tener su propio archivo o al menos estar claramente delimitado.
No Implementar Totales de Control¶
Un archivo puede parecer válido pero tener registros faltantes. Incluir un registro trailer con el conteo de registros y sumas de control permite al consumidor verificar completitud antes de procesar.
18. Conclusión Técnica¶
File Transfer es el estilo de integración más antiguo y más simple conceptualmente. Su fortaleza reside en su universalidad: cualquier sistema que pueda escribir un archivo puede ser productor, y cualquier sistema que pueda leer un archivo puede ser consumidor. Esta propiedad lo hace irremplazable para ciertos escenarios: integración con mainframes, procesos regulatorios, intercambio B2B y carga masiva de datos.
Sin embargo, para un arquitecto moderno, File Transfer debe evaluarse con cautela:
- Cuándo aporta valor: cuando los sistemas involucrados no pueden comunicarse de otra forma, cuando los volúmenes son grandes y el procesamiento es batch, cuando la latencia de horas es aceptable, cuando existen requisitos de auditoría que demandan evidencia física del intercambio.
- Cuándo evita problemas importantes: cuando se implementa con atomicidad, idempotencia, monitoreo y gobierno adecuados, evita los clásicos problemas de sincronización batch: datos incompletos, duplicaciones, procesamiento silencioso de errores.
- Cuándo no conviene adoptarlo: cuando se necesita integración en tiempo real, cuando los volúmenes son pequeños y frecuentes, cuando los sistemas soportan mensajería nativa, cuando se requiere routing dinámico o transformación compleja.
Recomendación para arquitectos: antes de diseñar una integración basada en File Transfer, verifique que no existe una alternativa superior (API, messaging, CDC). Si File Transfer es la opción correcta, invierta en la infraestructura operacional: atomicidad, idempotencia, monitoreo de no-llegada, gobierno de formatos y políticas de retención. La simplicidad aparente de File Transfer es engañosa: las integraciones por archivo que funcionan bien en producción son aquellas que trataron los archivos con el mismo rigor que cualquier otro contrato de integración.