Shared Database¶
1. Nombre del Patrón¶
- Nombre oficial: Shared Database
- Categoría: Integration Styles (Estilos de Integración)
- Traducción contextual: Base de Datos Compartida
2. Resumen Ejecutivo¶
Shared Database es un estilo de integración en el cual múltiples aplicaciones comparten una base de datos común como mecanismo de intercambio de datos. En lugar de transferir datos explícitamente mediante archivos, mensajes o llamadas remotas, las aplicaciones leen y escriben directamente en tablas compartidas, utilizando la base de datos como medio de comunicación implícito.
Este patrón existe porque ofrece la forma más inmediata de compartir datos: si dos aplicaciones acceden a la misma base de datos, los datos que una escribe están instantáneamente disponibles para la otra, con consistencia transaccional garantizada por el motor de base de datos. No se necesita middleware, no se necesita transformación, no se necesita infraestructura de mensajería.
Aparece históricamente en arquitecturas enterprise donde múltiples módulos de un sistema (o sistemas independientes) fueron construidos contra la misma base de datos relacional. Sin embargo, en arquitecturas modernas basadas en microservicios, Shared Database es ampliamente reconocido como un anti-pattern que viola los principios de encapsulación, autonomía y bounded contexts.
3. Definición Detallada¶
Propósito¶
El propósito de Shared Database es permitir que múltiples aplicaciones accedan a los mismos datos sin necesidad de un mecanismo explícito de transferencia. Los datos se comparten "in situ": la base de datos es simultáneamente el almacenamiento de cada aplicación y el medio de integración entre ellas.
Lógica Arquitectónica¶
Shared Database elimina el problema de sincronización de datos al eliminar la copia: no hay datos duplicados porque hay una sola fuente. Cuando la aplicación A actualiza un registro, la aplicación B ve la actualización inmediatamente (o tan pronto como la transacción se confirme).
Esto proporciona:
- Consistencia inmediata: las aplicaciones ven los mismos datos en el mismo momento, con las garantías ACID del motor de base de datos.
- Cero latencia de integración: no hay delay entre que una aplicación escribe y otra lee.
- Cero infraestructura adicional: no se necesita broker, bus, API ni mecanismo de transferencia.
Principio de Diseño Subyacente¶
El principio es integración a través de datos compartidos en lugar de comunicación explícita. En lugar de que las aplicaciones se hablen entre sí (messaging, RPC), se hablan a través de los datos que ambas leen y escriben en un almacén común.
Problema Estructural que Resuelve¶
En su contexto original, Shared Database resuelve el problema de mantener datos consistentes entre múltiples aplicaciones sin necesidad de mecanismos de sincronización explícitos. Si el módulo de ventas y el módulo de inventario comparten la misma base de datos, la venta de un producto y la reducción del inventario pueden ocurrir en la misma transacción, garantizando consistencia sin necesidad de procesos de reconciliación.
Contexto en el que Emerge¶
Shared Database emerge naturalmente en contextos donde:
- Múltiples aplicaciones fueron desarrolladas como módulos de un mismo sistema.
- El equipo de base de datos es centralizado y gestiona un esquema compartido.
- La organización prioriza consistencia transaccional sobre autonomía de equipos.
- Las aplicaciones están co-locadas en el mismo data center con acceso directo al servidor de base de datos.
- El volumen de interacciones entre aplicaciones es alto y requiere baja latencia.
Por Qué No Es Trivial¶
Aunque parece la solución más simple, Shared Database introduce problemas profundos a medida que el sistema crece:
- Acoplamiento por esquema: todas las aplicaciones dependen del esquema de la base de datos. Un cambio en una tabla puede romper todas las aplicaciones que la leen.
- Contención por recursos: múltiples aplicaciones compiten por conexiones, locks, I/O y CPU del mismo servidor de base de datos.
- Escala limitada: la base de datos compartida se convierte en un cuello de botella que limita el crecimiento de todas las aplicaciones simultáneamente.
- Deployment acoplado: los cambios de esquema requieren coordinación entre todas las aplicaciones que usan las tablas afectadas.
- Falta de encapsulación: cualquier aplicación puede leer y modificar cualquier dato, sin control de acceso granular a nivel de lógica de negocio.
Relación con Sistemas Distribuidos y Mensajería¶
Shared Database es el estilo de integración que evita los problemas de sistemas distribuidos al no distribuir: todos los datos están en un solo lugar. Esto elimina los desafíos de consistencia eventual, orden de mensajes y exactly-once delivery, pero a cambio introduce un punto único de fallo, un cuello de botella de escalabilidad y un punto de acoplamiento máximo.
En la taxonomía de estilos de integración, Shared Database es el polo opuesto de Messaging en la dimensión de acoplamiento: Messaging maximiza el desacoplamiento; Shared Database maximiza el acoplamiento.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Shared Database (y sin otro estilo de integración), las aplicaciones que necesitan datos comunes cada una mantiene su propia copia, lo que produce:
- Inconsistencias entre copias (el nombre del cliente en el CRM difiere del nombre en el sistema de facturación).
- Procesos de reconciliación manuales o batch para detectar y corregir discrepancias.
- Duplicación de esfuerzo en la captura y mantenimiento de datos.
Síntomas del Problema¶
- Diferentes sistemas muestran datos diferentes para la misma entidad (un cliente con dos direcciones diferentes según qué sistema se consulte).
- Procesos de negocio que fallan porque un sistema no tiene datos que otro sistema ya actualizó.
- Reports inconsistentes según la fuente de datos utilizada.
Impacto Operativo y Arquitectónico¶
- Sin una "fuente de verdad" compartida, la organización pierde confianza en la calidad de los datos.
- Los procesos de reconciliación consumen recursos significativos.
- Las decisiones de negocio se toman sobre datos potencialmente desactualizados o incorrectos.
Riesgos Si No Se Implementa Correctamente¶
- Deadlocks: múltiples aplicaciones intentando actualizar los mismos registros simultáneamente producen deadlocks que afectan a todas las aplicaciones.
- Schema coupling: un cambio en la estructura de una tabla (agregar columna NOT NULL, cambiar tipo de dato) puede romper múltiples aplicaciones simultáneamente.
- Performance degradation: queries no optimizadas de una aplicación pueden degradar el performance de todas las demás (un full table scan bloquea I/O para todos).
- Security breaches: sin aislamiento, una aplicación comprometida tiene acceso a todos los datos de todas las aplicaciones.
- Migration impossible: migrar una aplicación a otra tecnología requiere mantener compatibilidad con el esquema compartido.
Ejemplos Reales¶
- ERP clásico: múltiples módulos (ventas, inventario, finanzas, RRHH) comparten una base de datos Oracle/SAP con miles de tablas.
- Banca legacy: el core bancario, el módulo de tarjetas, el módulo de préstamos y el sistema de reporting comparten una base de datos DB2 en el mainframe.
- Universidad: el sistema de admisiones, el sistema académico y el sistema financiero comparten una base de datos PostgreSQL con datos de estudiantes.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En módulos de una misma aplicación (no diferentes aplicaciones) que comparten un bounded context.
- En prototipos y MVPs donde la velocidad de desarrollo supera la importancia de la arquitectura.
- En sistemas legacy donde la separación de bases de datos es prohibitivamente costosa.
- Cuando la consistencia transaccional fuerte es absolutamente mandatoria y no se pueden tolerar ventanas de inconsistencia eventual.
- En read replicas para reporting: una base de datos de lectura compartida alimentada desde fuentes autoritativas (esto es diferente de compartir la base de datos operacional).
Cuándo No Usarlo¶
- Entre microservicios: viola el principio de database-per-service que es fundamental en microservices architecture.
- Entre aplicaciones de diferentes equipos: produce acoplamiento organizacional además de técnico.
- Cuando las aplicaciones tienen diferentes requisitos de escalabilidad: la base de datos compartida limita a la aplicación más demandante.
- Cuando las aplicaciones usan diferentes modelos de datos: forzar un esquema compartido distorsiona el modelo de dominio de cada aplicación.
- Cuando se planea migrar o modernizar: la base de datos compartida es el obstáculo más grande para la modernización incremental.
Precondiciones¶
- Las aplicaciones están co-locadas o tienen acceso de baja latencia a la base de datos.
- Existe un equipo centralizado que gestiona el esquema.
- Todas las aplicaciones toleran el mismo motor de base de datos y la misma versión.
Restricciones¶
- La base de datos se convierte en el cuello de botella de escalabilidad de todo el sistema.
- Los cambios de esquema requieren coordinación entre todas las aplicaciones.
- El testing de cada aplicación requiere una instancia de la base de datos compartida con datos coherentes.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Shared Database representa el máximo acoplamiento entre aplicaciones: comparten esquema, conexiones, transacciones y el engine de la base de datos. Esto proporciona consistencia a costa de toda flexibilidad: cambiar una aplicación, un esquema o una tecnología de base de datos afecta a todas las demás.
Simplicidad vs. Robustez¶
Inicialmente simple (no se necesita infraestructura adicional), pero progresivamente frágil a medida que el número de aplicaciones y el volumen de datos crecen. Los problemas de contención, deadlocks y migration coupling hacen que la robustez a largo plazo sea difícil de mantener.
Consistencia vs. Disponibilidad¶
Shared Database maximiza la consistencia (ACID transaccional) a costa de la disponibilidad: un fallo de la base de datos afecta a todas las aplicaciones simultáneamente.
Costo Operativo vs. Capacidad de Evolución¶
Bajo costo operativo inicial (una sola base de datos para gestionar), pero la capacidad de evolución se degrada con cada aplicación adicional que depende del esquema compartido. Eventualmente, el costo de evolución es tan alto que el sistema se congela.
Gobernanza vs. Autonomía de Equipos¶
Shared Database impone gobernanza centralizada del esquema. Los equipos pierden autonomía para evolucionar su modelo de datos. Cada cambio de esquema es una negociación multi-equipo.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Aplicación A, B, ..., N: las aplicaciones que leen y escriben en la base de datos compartida.
- Base de Datos Compartida: el RDBMS (o NoSQL) que almacena los datos y proporciona acceso transaccional.
- Esquema Compartido: la estructura de tablas, vistas, stored procedures y constraints que define el modelo de datos.
- DBA / Schema Owner: el rol que gestiona el esquema, los permisos y el performance.
Flujo Lógico¶
flowchart LR
A[App A] -->|INSERT/UPDATE| B[(Base de Datos Compartida)]
B -->|COMMIT| B
B -->|SELECT| C[App B]
C -->|Ve datos actualizados| CNo hay flujo explícito de integración: la "comunicación" es implícita a través de los datos compartidos.
Contratos Implícitos¶
- Esquema de tablas: las columnas, tipos, constraints y relaciones.
- Semántica de los datos: qué significa cada campo, qué valores son válidos, qué convenciones se usan.
- Patrones de acceso: qué tablas lee cada aplicación, qué tablas escribe, qué índices espera.
- Locking behavior: qué nivel de aislamiento transaccional usa cada aplicación.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Sistema de Pólizas y Reclamaciones¶
Contexto del Negocio¶
Una compañía de seguros mediana tiene tres sistemas que comparten una base de datos Oracle:
- Sistema de Emisión de Pólizas: crea y gestiona pólizas, coberturas, primas.
- Sistema de Reclamaciones: registra y procesa reclamaciones de siniestros.
- Sistema de Agentes: gestiona la red de agentes, comisiones y producción.
Los tres sistemas fueron desarrollados por el mismo equipo hace 15 años y comparten un esquema de 400 tablas en una instancia Oracle RAC.
Problemas que Emergen¶
-
Schema coupling: el equipo de reclamaciones necesita añadir un campo
fraud_scorea la tablaCLAIMS, pero el cambio requiere aprobación del equipo de pólizas (que lee esa tabla para mostrar el historial de reclamaciones) y del equipo de agentes (que lee la tabla para calcular comisiones). La aprobación tarda 3 semanas. -
Performance contention: el proceso nocturno de cálculo de comisiones ejecuta queries analíticas pesadas que degradan el performance del sistema de reclamaciones, que opera 24/7 porque los asegurados pueden reportar siniestros en cualquier momento.
-
Deployment coupling: una nueva versión del sistema de agentes requiere un cambio en la tabla
AGENTSque es incompatible con la versión actual del sistema de pólizas. Ambos sistemas deben desplegarse simultáneamente en una ventana de mantenimiento coordinada. -
Modernization blocked: el equipo de reclamaciones quiere migrar a microservicios en cloud, pero no puede separar su base de datos sin romper los queries del sistema de pólizas y del sistema de agentes que leen las tablas de reclamaciones.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Estado Inicial¶
Las tres aplicaciones comparten el esquema Oracle:
-- Tablas compartidas (simplificado)
POLICIES (policy_id, customer_id, agent_id, product_type, premium, status, ...)
CLAIMS (claim_id, policy_id, incident_date, amount, status, adjuster_id, ...)
AGENTS (agent_id, name, region, commission_rate, status, ...)
CUSTOMERS (customer_id, name, address, phone, email, ...)
Cada aplicación tiene acceso directo a todas las tablas. No hay vistas ni APIs intermedias.
Paso 2: El Problema del Schema Change¶
El equipo de reclamaciones necesita añadir:
Impacto: el sistema de pólizas ejecuta SELECT * FROM CLAIMS WHERE policy_id = ? — el cambio es compatible. Pero el sistema de agentes ejecuta un stored procedure que calcula comisiones basándose en un COUNT(*) de claims, y el DBA teme que el cambio afecte el plan de ejecución del procedure.
Se programa un comité de cambios. Tres semanas después, se aprueba. El cambio se ejecuta en una ventana de mantenimiento de domingo a las 03:00.
Paso 3: El Problema del Performance¶
El proceso de comisiones ejecuta cada noche:
SELECT a.agent_id, a.name, COUNT(c.claim_id), SUM(p.premium)
FROM AGENTS a
JOIN POLICIES p ON p.agent_id = a.agent_id
JOIN CLAIMS c ON c.policy_id = p.policy_id
WHERE p.status = 'ACTIVE'
GROUP BY a.agent_id, a.name;
Este query escanea millones de registros y consume I/O que compite con las transacciones operacionales del sistema de reclamaciones. Un asegurado que intenta reportar un siniestro a las 02:00 experimenta timeouts porque la base de datos está saturada por el batch de comisiones.
Paso 4: La Modernización Frustrada¶
El CTO decide migrar el sistema de reclamaciones a microservicios en Azure. El equipo inicia el diseño, pero descubre que:
- El sistema de pólizas ejecuta 47 queries directos contra tablas de CLAIMS.
- El sistema de agentes tiene 12 stored procedures que hacen JOIN entre AGENTS, POLICIES y CLAIMS.
- 8 reports de BI leen directamente de las tablas CLAIMS.
Separar la base de datos de reclamaciones requiere: 1. Crear APIs en el nuevo sistema de reclamaciones para cada query. 2. Modificar 47 queries en el sistema de pólizas para usar la API. 3. Reescribir 12 stored procedures. 4. Rediseñar 8 reports de BI.
Estimación: 18 meses. El proyecto se pospone indefinidamente.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
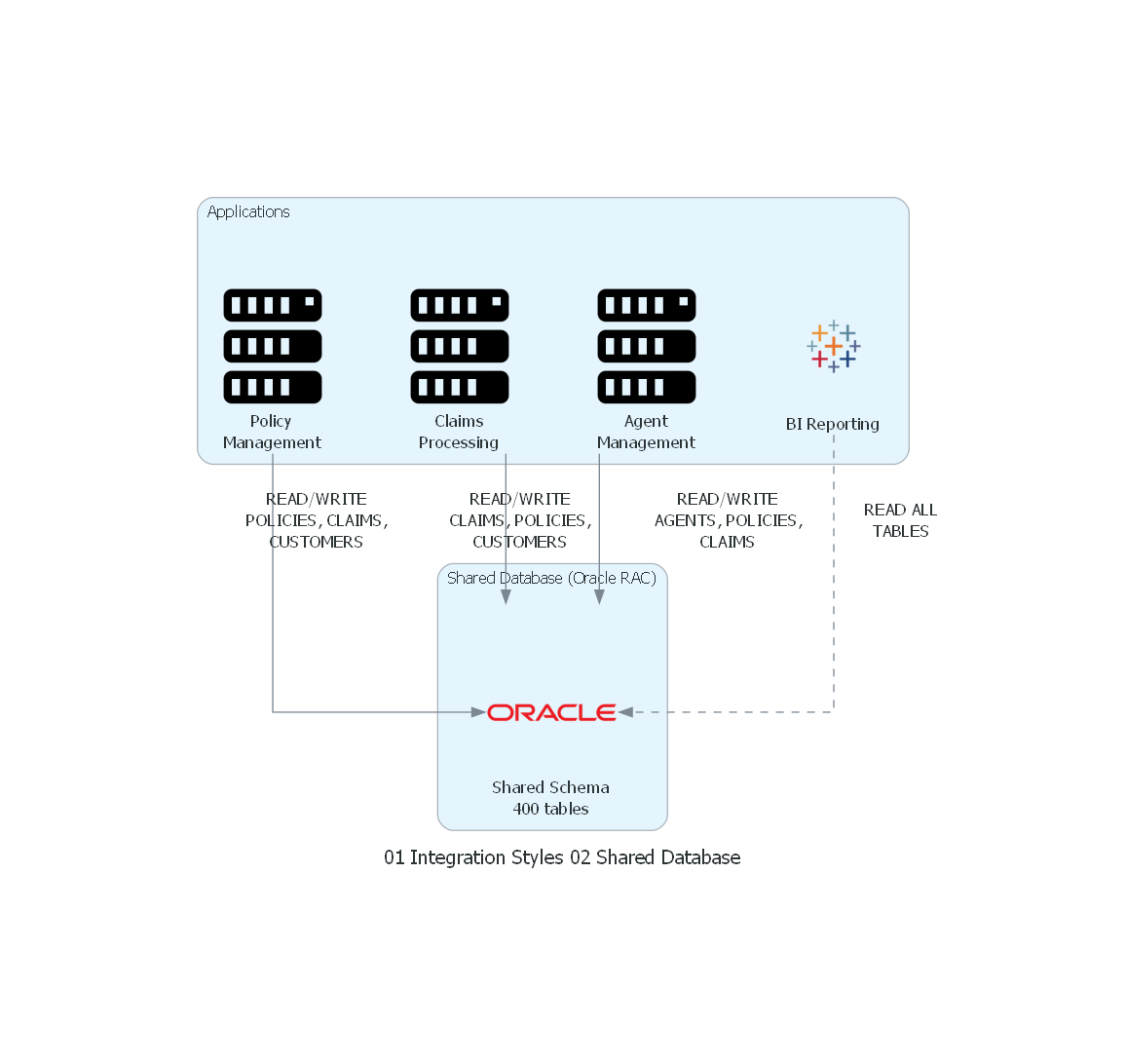
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.database import Oracle
from diagrams.onprem.compute import Server
from diagrams.onprem.analytics import Tableau
with Diagram("Shared Database - Insurance Systems", show=False, direction="TB"):
with Cluster("Applications"):
policies = Server("Policy\nManagement")
claims = Server("Claims\nProcessing")
agents = Server("Agent\nManagement")
reports = Tableau("BI Reporting")
with Cluster("Shared Database (Oracle RAC)"):
db = Oracle("Shared Schema\n400 tables")
# All applications directly access the shared database
policies >> Edge(label="READ/WRITE\nPOLICIES, CLAIMS,\nCUSTOMERS") >> db
claims >> Edge(label="READ/WRITE\nCLAIMS, POLICIES,\nCUSTOMERS") >> db
agents >> Edge(label="READ/WRITE\nAGENTS, POLICIES,\nCLAIMS") >> db
reports >> Edge(label="READ ALL\nTABLES", style="dashed") >> db
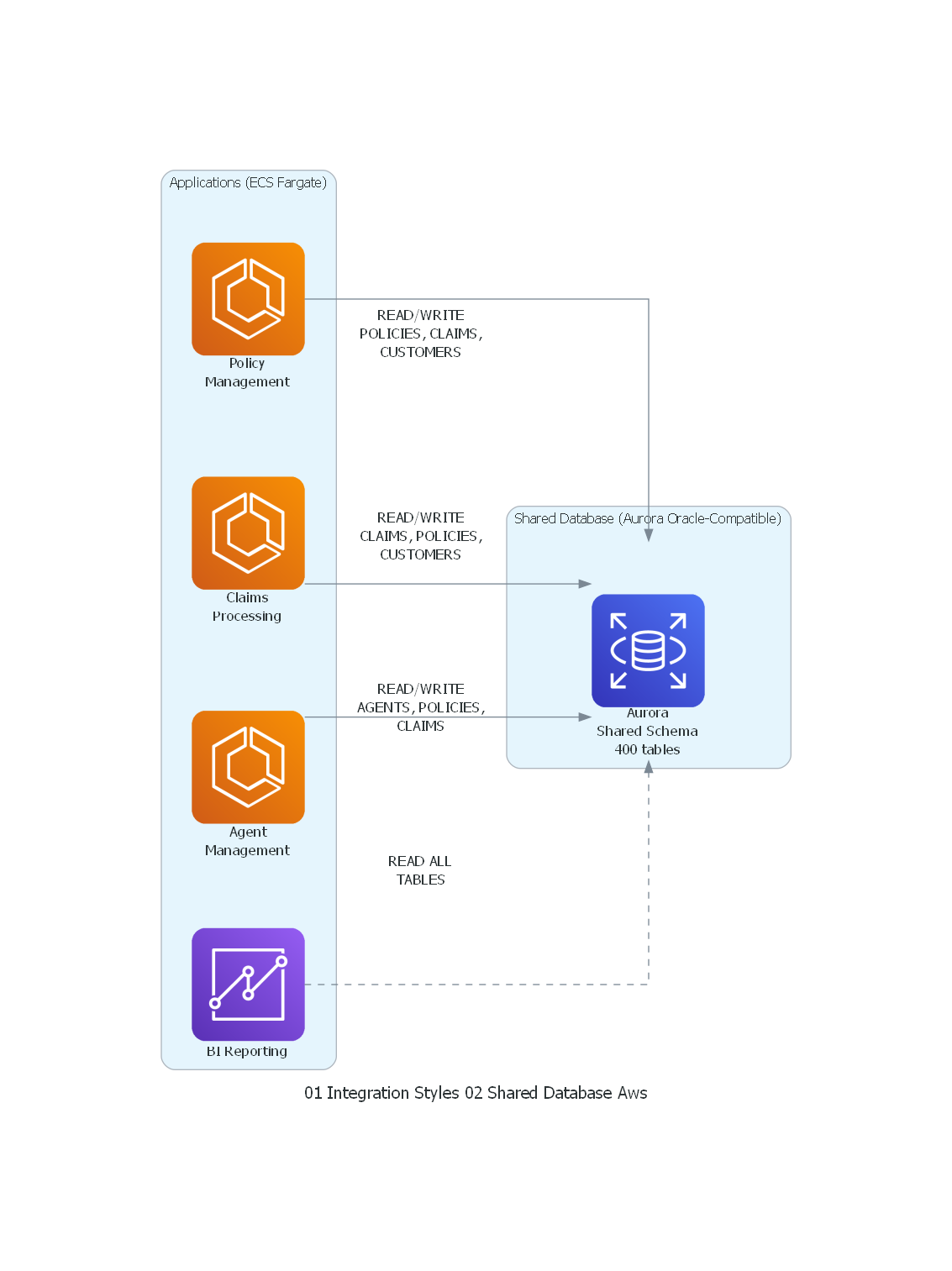
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.analytics import Quicksight
from diagrams.aws.compute import ECS
from diagrams.aws.database import RDS
with Diagram("Shared Database - Insurance Systems (AWS)", show=False, direction="TB"):
with Cluster("Applications (ECS Fargate)"):
policies = ECS("Policy\nManagement")
claims = ECS("Claims\nProcessing")
agents = ECS("Agent\nManagement")
reports = Quicksight("BI Reporting")
with Cluster("Shared Database (Aurora Oracle-Compatible)"):
db = RDS("Aurora\nShared Schema\n400 tables")
# All applications directly access the shared database
policies >> Edge(label="READ/WRITE\nPOLICIES, CLAIMS,\nCUSTOMERS") >> db
claims >> Edge(label="READ/WRITE\nCLAIMS, POLICIES,\nCUSTOMERS") >> db
agents >> Edge(label="READ/WRITE\nAGENTS, POLICIES,\nCLAIMS") >> db
reports >> Edge(label="READ ALL\nTABLES", style="dashed") >> db
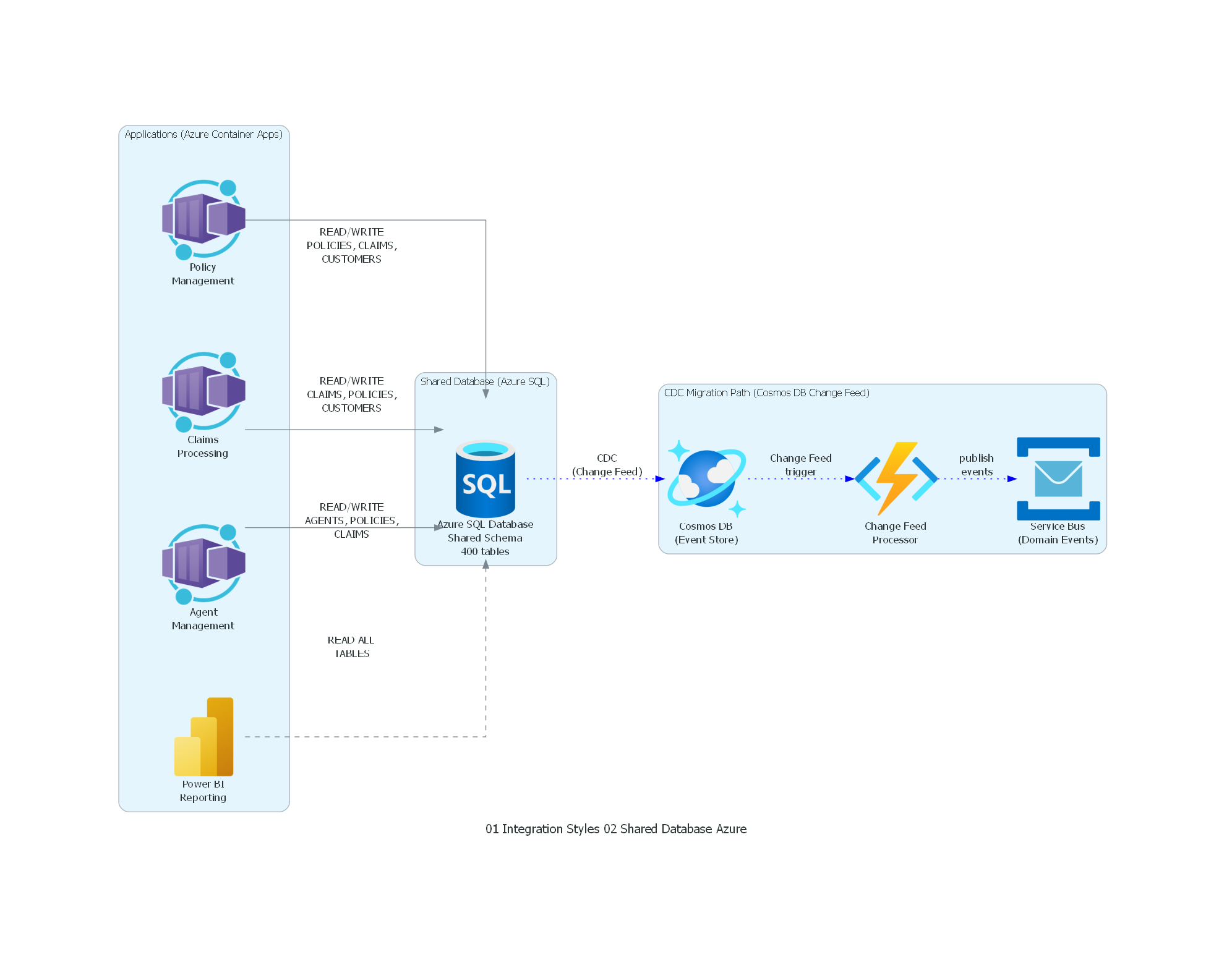
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.analytics import PowerBiEmbedded
from diagrams.azure.compute import ContainerApps, FunctionApps
from diagrams.azure.database import SQLDatabases, CosmosDb
from diagrams.azure.integration import ServiceBus
with Diagram("Shared Database - Insurance Systems (Azure)", show=False, direction="TB"):
with Cluster("Applications (Azure Container Apps)"):
policies = ContainerApps("Policy\nManagement")
claims = ContainerApps("Claims\nProcessing")
agents = ContainerApps("Agent\nManagement")
reports = PowerBiEmbedded("Power BI\nReporting")
with Cluster("Shared Database (Azure SQL)"):
db = SQLDatabases("Azure SQL Database\nShared Schema\n400 tables")
# All applications directly access the shared database
policies >> Edge(label="READ/WRITE\nPOLICIES, CLAIMS,\nCUSTOMERS") >> db
claims >> Edge(label="READ/WRITE\nCLAIMS, POLICIES,\nCUSTOMERS") >> db
agents >> Edge(label="READ/WRITE\nAGENTS, POLICIES,\nCLAIMS") >> db
reports >> Edge(label="READ ALL\nTABLES", style="dashed") >> db
# Modern CDC migration path
with Cluster("CDC Migration Path (Cosmos DB Change Feed)"):
cdc_store = CosmosDb("Cosmos DB\n(Event Store)")
cdc_func = FunctionApps("Change Feed\nProcessor")
bus = ServiceBus("Service Bus\n(Domain Events)")
db >> Edge(label="CDC\n(Change Feed)", style="dotted", color="blue") >> cdc_store
cdc_store >> Edge(label="Change Feed\ntrigger", style="dotted", color="blue") >> cdc_func
cdc_func >> Edge(label="publish\nevents", style="dotted", color="blue") >> bus
Explicación del Diagrama¶
El diagrama muestra la arquitectura Shared Database: tres aplicaciones y un sistema de reporting acceden directamente a la misma base de datos Oracle. Las flechas indican qué tablas lee y escribe cada aplicación. La sobreposición de acceso (todas leen POLICIES, dos leen CLAIMS) es la fuente del acoplamiento.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Aplicaciones integradas | Policy Management, Claims Processing, Agent Management |
| Base de datos compartida | Oracle RAC (Shared Schema) |
| Esquema compartido | 400 tables accedidas por múltiples apps |
| Acoplamiento implícito | Flechas cruzadas (todas acceden a las mismas tablas) |
| Consumidor read-only | BI Reporting |
11. Beneficios¶
Impacto Técnico¶
- Consistencia inmediata: las transacciones ACID garantizan que los datos son consistentes en todo momento.
- Cero latencia de integración: los datos están disponibles instantáneamente para todas las aplicaciones.
- Sin infraestructura adicional: no se necesita broker, bus, API ni mecanismo de sincronización.
- Queries cruzados: las aplicaciones pueden hacer JOINs entre datos de diferentes dominios con la eficiencia nativa del motor SQL.
Impacto Organizacional¶
- Simplicidad conceptual: todos entienden que los datos están "en la base de datos". No hay conceptos de messaging, eventos ni canales que aprender.
- Un solo punto de verdad: no hay copias divergentes de los datos.
Impacto Operacional¶
- Una sola infraestructura: un solo servidor de base de datos para operar, monitorear, backupear y escalar.
- Herramientas maduras: los RDBMS tienen décadas de herramientas de monitoring, tuning, backup y recovery.
12. Desventajas y Riesgos¶
Complejidad Añadida (a largo plazo)¶
- Schema evolution: cada cambio de esquema es un evento coordinado multi-equipo.
- Performance tuning: optimizar queries de una aplicación puede degradar el performance de otra (cambios de índices, por ejemplo).
- Testing: testear una aplicación requiere una instancia completa de la base de datos con datos coherentes de todas las aplicaciones.
Riesgos de Mal Uso¶
- Bypass de lógica de negocio: una aplicación puede modificar directamente datos que deberían pasar por validaciones de otra aplicación (incrementar el saldo de una cuenta sin pasar por la lógica de transacciones, por ejemplo).
- Tight coupling invisible: el acoplamiento no es visible en el código de la aplicación sino en la base de datos. Los arquitectos pueden no ser conscientes de todas las dependencias.
Anti-Patterns Derivados¶
- Database as Integration Bus: usar triggers, stored procedures o change data capture en la base de datos compartida como mecanismo de integración event-driven. Esto oculta la lógica de integración en la capa de datos.
- Schema as API: tratar el esquema de la base de datos como el contrato de integración. El esquema no fue diseñado para este propósito y no tiene el versionado, la documentación ni la governance de una API.
- Shared Database in Microservices: descomponer una aplicación en microservicios pero mantener una base de datos compartida, lo cual anula los beneficios de la descomposición.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Change Data Capture (CDC): la evolución moderna de Shared Database. En lugar de que múltiples aplicaciones lean directamente, un CDC connector (Debezium, Oracle GoldenGate) captura los cambios en la base de datos y los publica como eventos en un canal de mensajería. Esto desacopla a los consumidores sin modificar la aplicación productora.
Patrones que Lo Reemplazan¶
- Messaging: para comunicación entre aplicaciones desacopladas.
- Remote Procedure Invocation: para consultas síncronas entre aplicaciones.
- Channel Adapter + CDC: para migración gradual de Shared Database a event-driven.
Diferencias con Patrones Similares¶
- vs. File Transfer: File Transfer mueve snapshots; Shared Database comparte datos en vivo.
- vs. Messaging: Messaging desacopla; Shared Database acopla. Messaging es eventual; Shared Database es inmediato.
- vs. Remote Procedure Invocation: RPI encapsula acceso tras una interfaz; Shared Database expone directamente.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Baja¶
Argumentación¶
Shared Database es ampliamente reconocido como un anti-pattern en las arquitecturas modernas basadas en microservicios:
- Viola el principio de database-per-service (cada servicio posee y gestiona su propia base de datos).
- Viola el principio de bounded contexts de DDD (cada contexto tiene su propio modelo de datos).
- Impide la autonomía de equipos (cada cambio requiere coordinación multi-equipo).
- Impide la escalabilidad independiente (la base de datos compartida es el cuello de botella).
- Impide la modernización incremental (no se puede migrar una aplicación sin afectar a las demás).
Contextos Donde Aún Se Encuentra¶
- Sistemas legacy: ERPs, core bancarios y sistemas legacy que fueron diseñados con base de datos compartida y no han sido modernizados.
- Read replicas para BI: una réplica de lectura compartida para reporting y analytics es aceptable si la fuente autoritativa está bien definida.
- Dentro de un bounded context: múltiples componentes dentro del mismo microservicio pueden compartir base de datos legítimamente porque pertenecen al mismo contexto.
La Evolución: De Shared Database a Event-Driven¶
La migración típica de Shared Database a arquitecturas modernas sigue estos pasos:
- Strangler Fig: crear servicios nuevos que encapsulan acceso a las tablas compartidas.
- CDC (Debezium): capturar cambios en las tablas compartidas y publicarlos como eventos.
- Reverse proxy: los consumidores migran de leer la base de datos a consumir eventos.
- Database split: cuando todos los consumidores directos han migrado, cada servicio puede tener su propia base de datos.
15. Implementación en Arquitecturas Modernas¶
Change Data Capture como Puente¶
La tecnología que permite migrar de Shared Database a event-driven sin reescribir las aplicaciones legacy es Change Data Capture (CDC):
- Debezium: captura cambios en PostgreSQL, MySQL, Oracle, SQL Server, MongoDB y los publica en Kafka topics. Cada INSERT, UPDATE, DELETE se convierte en un evento.
- Oracle GoldenGate: replicación y CDC para Oracle databases.
- AWS DMS: Database Migration Service con CDC para streaming de cambios.
- Azure Change Feed: CDC nativo para Cosmos DB.
Patrón Moderno: Database per Service + CDC¶
En lugar de Shared Database, la arquitectura moderna usa:
- Cada servicio tiene su propia base de datos (PostgreSQL, DynamoDB, Cosmos DB).
- Cada servicio publica eventos cuando sus datos cambian (Event Message).
- Los servicios que necesitan datos de otro servicio consumen eventos y mantienen su propia vista materializada.
- CDC se usa como bridge para servicios legacy que no pueden publicar eventos nativamente.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Query performance: monitoreo de slow queries por aplicación.
- Connection pools: cuántas conexiones usa cada aplicación.
- Lock contention: deadlocks, lock waits, bloqueos por aplicación.
- Space usage: crecimiento de tablas por dominio.
Seguridad¶
- Schema-level permissions: limitar qué tablas puede acceder cada aplicación (aunque en la práctica esto raramente se implementa bien).
- Row-level security: en algunas bases de datos, se puede limitar qué filas ve cada aplicación.
- Audit trail: registrar qué aplicación modificó qué datos.
Manejo de Schema Changes¶
- Backward-compatible changes: añadir columnas nullable, crear nuevas tablas. No rompen aplicaciones existentes.
- Breaking changes: renombrar columnas, cambiar tipos, eliminar columnas. Requieren coordinación con todas las aplicaciones.
- Migration strategy: usar herramientas como Liquibase o Flyway con aprobación multi-equipo.
17. Errores Comunes¶
Tratar la Base de Datos como una API¶
El esquema de la base de datos no fue diseñado para ser un contrato de integración. No tiene versionado, no tiene documentación, no tiene tests de contrato, no tiene backward compatibility garantizada. Tratar las tablas como APIs produce fragilidad.
No Monitorear por Aplicación¶
Sin monitoreo granular por aplicación (qué queries ejecuta cada una, cuántas conexiones consume), es imposible diagnosticar problemas de performance ni identificar qué aplicación está degradando la experiencia de las demás.
Asumir que Shared Database Escala¶
Un RDBMS compartido tiene límites de escalabilidad vertical (más CPU, más RAM) pero no escala horizontalmente de forma transparente. A partir de cierto volumen, el rendimiento se degrada para todos.
No Planificar la Migración¶
Mantener Shared Database como "solución temporal" que dura décadas es un patrón recurrente en organizaciones enterprise. Si la organización planea modernizar eventualmente, la Shared Database será el obstáculo más grande. Planifique la migración desde ahora, aunque la ejecución sea gradual.
18. Conclusión Técnica¶
Shared Database fue un estilo de integración pragmático en la era de aplicaciones monolíticas co-locadas. Su mayor virtud — consistencia transaccional inmediata sin infraestructura adicional — fue suficiente para justificar su uso en contextos donde la autonomía de equipos y la escalabilidad independiente no eran prioridades.
En las arquitecturas modernas, Shared Database es un anti-pattern que debe evitarse en nuevos diseños y migrarse gradualmente en sistemas legacy.
Cuándo aporta valor: dentro de un bounded context, donde múltiples componentes de un mismo servicio comparten legítimamente una base de datos. No como mecanismo de integración entre servicios.
Cuándo evita problemas: nunca, a largo plazo. Los beneficios iniciales (consistencia, simplicidad) se pagan con creces en acoplamiento, contención, deployment coupling y modernization lock-in.
Cuándo no conviene adoptarlo: en cualquier diseño nuevo con múltiples equipos, múltiples servicios o aspiraciones de escalabilidad independiente.
Recomendación para arquitectos: si hereda un sistema con Shared Database, comience a planificar la separación usando CDC (Debezium) como bridge. Si está diseñando un sistema nuevo, use database-per-service con eventos como mecanismo de integración. La consistencia eventual es un precio pequeño comparado con el costo de acoplamiento que Shared Database impone a largo plazo.