Remote Procedure Invocation¶
1. Nombre del Patrón¶
- Nombre oficial: Remote Procedure Invocation
- Categoría: Integration Styles (Estilos de Integración)
- Traducción contextual: Invocación Remota de Procedimientos
2. Resumen Ejecutivo¶
Remote Procedure Invocation (RPI) es un estilo de integración en el cual una aplicación invoca directamente una función, operación o servicio expuesto por otra aplicación a través de una interfaz remota, como si se tratase de una llamada local. El sistema invocante (cliente) envía una solicitud estructurada al sistema invocado (servidor), espera una respuesta y continúa su procesamiento con el resultado obtenido.
Este patrón existe porque las organizaciones necesitan que sus sistemas colaboren en tiempo real, ejecutando operaciones transaccionales que requieren confirmación inmediata. A diferencia de File Transfer o Messaging, donde la comunicación es diferida, Remote Procedure Invocation permite que un sistema delegue una responsabilidad concreta a otro y obtenga un resultado en el acto, habilitando flujos de negocio que exigen consistencia síncrona y latencias bajas.
Aparece en prácticamente toda arquitectura enterprise moderna: consultas de saldo en tiempo real, autorización de transacciones, validación de identidad, cotización de productos, procesamiento de pagos, orquestación de microservicios, y cualquier escenario donde un sistema necesita una respuesta inmediata de otro para continuar su procesamiento.
3. Definición Detallada¶
Propósito¶
El propósito de Remote Procedure Invocation es permitir que una aplicación ejecute una operación definida en otra aplicación remota de forma directa, síncrona y tipada, obteniendo un resultado que utiliza para continuar su propio flujo de procesamiento. El cliente conoce la interfaz del servidor (el contrato), construye una solicitud conforme a ese contrato, la envía a través de la red, y recibe una respuesta tipada que puede ser un resultado de negocio, una confirmación, o un error estructurado.
Lógica Arquitectónica¶
Remote Procedure Invocation introduce una dependencia temporal y contractual entre cliente y servidor:
- Acoplamiento temporal: el cliente y el servidor deben estar disponibles simultáneamente. El cliente se bloquea (o suspende en modelos async-await) hasta que el servidor responde o se alcanza un timeout.
- Acoplamiento contractual: ambos sistemas comparten un contrato explícito que define operaciones disponibles, tipos de datos de entrada y salida, códigos de error y semántica esperada. Este contrato puede materializarse como un OpenAPI spec, un archivo
.protode gRPC, un schema GraphQL, un WSDL, o un IDL de CORBA. - Desacoplamiento de implementación: aunque el contrato es compartido, la implementación interna de cada sistema es independiente. El cliente no conoce ni depende de cómo el servidor implementa la operación internamente.
Principio de Diseño Subyacente¶
El principio fundamental es encapsulación funcional con interfaz remota: un sistema expone capacidades de negocio como operaciones invocables a través de la red, ocultando su complejidad interna detrás de un contrato bien definido. El consumidor trata la operación remota como una abstracción de alto nivel, delegando la responsabilidad al sistema que posee los datos y la lógica de negocio correspondiente.
Este principio se alinea con el Information Expert pattern de GRASP: la operación debe ejecutarla el sistema que posee la información necesaria para hacerlo correctamente. Remote Procedure Invocation es el mecanismo que materializa esta delegación a través de los límites de la red.
Problema Estructural que Resuelve¶
En entornos enterprise, la funcionalidad de negocio está distribuida entre múltiples sistemas especializados: un sistema gestiona clientes, otro gestiona inventario, otro gestiona facturación, otro gestiona logística. Cuando un proceso de negocio requiere coordinar información o acciones de varios sistemas en una misma transacción lógica (por ejemplo, verificar el crédito de un cliente, reservar inventario y generar una factura como parte de un pedido), es necesario un mecanismo que permita la invocación directa entre sistemas con confirmación inmediata.
Sin Remote Procedure Invocation, las alternativas son:
- Duplicar datos y lógica en cada sistema que los necesita, violando el principio de single source of truth y generando inconsistencias inevitables.
- Usar integración batch (File Transfer), lo cual introduce latencia inaceptable para operaciones transaccionales.
- Compartir base de datos (Shared Database), lo cual acopla los sistemas a nivel de modelo de datos interno, haciendo imposible la evolución independiente.
Contexto en el que Emerge¶
Remote Procedure Invocation emerge naturalmente en contextos donde:
- El proceso de negocio requiere respuesta inmediata (autorización, validación, consulta en tiempo real).
- El dato o la lógica residen en un sistema diferente al que inicia el flujo.
- La consistencia entre sistemas es crítica dentro de una operación individual (no eventual, sino transaccional).
- Los sistemas involucrados están conectados por red de baja latencia y alta disponibilidad.
- Existe voluntad y capacidad de definir y mantener contratos de interfaz formales entre sistemas.
Por Qué No Es Trivial¶
Aunque conceptualmente simple ("llamar a una función en otro sistema"), Remote Procedure Invocation en un contexto enterprise involucra decisiones profundas:
- Fallacies of distributed computing: la red no es confiable, la latencia no es cero, el ancho de banda no es infinito. Una llamada remota puede fallar por timeout, error de red, sobrecarga del servidor, o error de negocio. El cliente debe manejar cada caso de forma diferente.
- Diseño de contratos: definir qué operaciones exponer, con qué granularidad, qué tipos de datos usar, cómo versionar, cómo manejar backward compatibility. Un contrato mal diseñado genera acoplamiento rígido entre equipos.
- Semántica de idempotencia: si una llamada falla y el cliente reintenta, ¿el servidor ejecuta la operación dos veces? Las operaciones no idempotentes (como "crear un pedido") requieren mecanismos de deduplicación.
- Cascading failures: si el sistema A depende síncronamente de B, que depende síncronamente de C, un fallo en C puede propagarse en cascada y tumbar todo el grafo de dependencias.
- Performance y escalabilidad: cada llamada remota consume un thread (o conexión) en el cliente y en el servidor. Sin gestión adecuada de pools de conexión, timeouts y backpressure, el sistema se degrada bajo carga.
- Observabilidad distribuida: cuando una operación de negocio involucra múltiples llamadas remotas entre sistemas, rastrear el flujo completo requiere distributed tracing (correlation IDs, trace propagation).
Relación con Sistemas Distribuidos y Mensajería¶
Remote Procedure Invocation se posiciona en el polo opuesto de Messaging en el espectro de acoplamiento temporal. Mientras Messaging desacopla temporalmente productor y consumidor mediante un broker intermediario, RPI acopla temporalmente cliente y servidor en una interacción request-reply directa.
Sin embargo, ambos estilos no son mutuamente excluyentes. En arquitecturas modernas, es extremadamente común que las interacciones externas (front-end a back-end, partner APIs) sean RPI mientras que las interacciones internas (entre microservicios) combinen RPI para queries y Messaging para commands y eventos. El patrón CQRS (Command Query Responsibility Segregation) frecuentemente utiliza RPI para el lado de lectura y Messaging para el lado de escritura.
Históricamente, RPI ha evolucionado desde RPC (Remote Procedure Call) en los años 80, pasando por CORBA e IDL en los 90, DCOM y RMI a finales de los 90, SOAP y Web Services en los 2000, REST sobre HTTP en los 2010, y gRPC y GraphQL en la segunda mitad de la década de 2010. Cada generación ha refinado el modelo de contrato, el mecanismo de serialización y la semántica de errores, pero el principio fundamental permanece idéntico: un sistema invoca una operación en otro y espera el resultado.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Remote Procedure Invocation, cuando un sistema necesita datos o funcionalidad que residen en otro sistema en tiempo real, las opciones son:
- Replicación de datos y lógica: cada sistema mantiene una copia local de los datos y la lógica que necesita de otros sistemas. Esto genera redundancia, inconsistencias entre copias, y la necesidad de sincronización periódica que siempre tiene ventanas de inconsistencia.
- Integración batch diferida: el sistema solicita los datos mediante un proceso batch (File Transfer) y los procesa horas después. Esto es inviable cuando la operación requiere respuesta en milisegundos (por ejemplo, autorización de pago en punto de venta).
- Intervención manual: un operador consulta el sistema remoto manualmente y transcribe la información. Esto no escala y es propenso a error humano.
- Base de datos compartida: ambos sistemas acceden directamente a la misma base de datos, lo cual acopla sus modelos internos, impide la evolución independiente y genera contención de recursos.
Síntomas del Problema¶
- Datos duplicados entre sistemas que frecuentemente divergen porque la sincronización batch no alcanza a reflejar cambios recientes.
- Procesos de negocio que no pueden completarse en tiempo real porque dependen de información que solo estará disponible en el siguiente ciclo batch.
- Operadores que deben consultar múltiples sistemas manualmente para completar una operación de negocio, introduciendo latencia y error humano.
- Sistemas que toman decisiones con datos obsoletos (saldo del cliente que no refleja una transacción de hace 2 horas, inventario que no refleja una reserva de hace 10 minutos).
- Incapacidad de ofrecer experiencias digitales en tiempo real (consulta de saldo instantánea, cotización en línea, rastreo de envío en vivo) porque los sistemas backend no se comunican entre sí de forma síncrona.
Impacto Operativo y Arquitectónico¶
Sin un mecanismo de invocación remota:
- La arquitectura se fragmenta en silos de datos que no pueden colaborar en tiempo real.
- Los procesos de negocio que cruzan múltiples sistemas se convierten en procesos manuales o semi-manuales con SLAs de horas o días.
- La consistencia de datos entre sistemas depende de procesos batch cuya ventana de inconsistencia es inherentemente amplia.
- La experiencia de usuario se degrada porque las interfaces no pueden obtener datos actualizados de múltiples sistemas en una sola operación.
- La innovación se frena porque cualquier nuevo flujo de negocio que requiera coordinar múltiples sistemas demanda intervención humana o desarrollo de procesos batch ad-hoc.
Riesgos Si No Se Implementa Correctamente¶
- Cascading failures: un servicio lento o caído puede propagar el fallo a todos los sistemas que dependen de él, generando un efecto dominó que puede tumbar una cadena completa de servicios.
- Distributed monolith: sistemas que se invocan mutuamente sin circuit breakers, timeouts ni fallbacks se comportan como un monolito distribuido que combina las desventajas de ambos mundos (complejidad distribuida + acoplamiento monolítico).
- Chatty interfaces: interfaces remotas con granularidad excesivamente fina generan un volumen elevado de llamadas de red, amplificando la latencia y la probabilidad de fallo.
- Contract drift: si los contratos entre sistemas no se versionan ni validan formalmente, los cambios en un lado rompen silenciosamente al otro.
- Security surface expansion: cada interfaz remota expuesta es una superficie de ataque que debe protegerse con autenticación, autorización, cifrado en tránsito y validación de entrada.
Ejemplos Reales¶
- Telecomunicaciones: el sistema de autoservicio web del operador invoca al sistema de billing en tiempo real para mostrar el saldo actual del cliente. Sin RPI, el saldo mostrado sería el del último ciclo batch (posiblemente de hace 12 horas).
- Banca: el sistema de punto de venta invoca al sistema autorizador para aprobar o rechazar una transacción con tarjeta de débito. La respuesta debe llegar en menos de 2 segundos.
- E-commerce: durante el checkout, el sistema de orders invoca al sistema de inventario (verificar stock), al sistema de pricing (calcular descuentos), al sistema de payments (procesar cobro) y al sistema de shipping (estimar entrega). Todas estas invocaciones deben completarse en la ventana de una sola interacción de usuario.
- Salud: el sistema de admisión hospitalaria invoca al sistema de la aseguradora para verificar la cobertura del paciente antes de autorizar un procedimiento.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el proceso de negocio requiere respuesta inmediata (latencia de milisegundos a pocos segundos).
- Cuando la operación es de tipo request-reply: el cliente necesita el resultado para continuar.
- Cuando la consistencia dentro de una operación individual es crítica (no se puede tomar una decisión con datos potencialmente obsoletos).
- Cuando los sistemas están conectados por red confiable y de baja latencia (mismo data center, misma región cloud, VPN dedicada).
- Cuando existe capacidad organizacional para definir, mantener y evolucionar contratos de interfaz entre equipos.
- Cuando el volumen de invocaciones es manejable con el capacity del sistema servidor (o se puede escalar horizontalmente).
Cuándo No Usarlo¶
- Cuando la operación no necesita respuesta inmediata y puede procesarse de forma asíncrona (envío de notificaciones, generación de reportes, procesamiento de eventos).
- Cuando el sistema destino tiene disponibilidad baja o intermitente y no se puede garantizar su presencia cuando el cliente lo necesita.
- Cuando la latencia de red entre cliente y servidor es alta o impredecible (integración entre regiones geográficas distantes sin infraestructura dedicada).
- Cuando el volumen de operaciones es extremadamente alto y el sistema destino no puede escalar para absorber la carga (en este caso, Messaging con backpressure es más apropiado).
- Cuando se necesita desacoplamiento temporal: el emisor debe poder enviar su solicitud y continuar sin esperar respuesta.
- Cuando las operaciones son fire-and-forget (commands que no requieren confirmación inmediata).
- Cuando el acoplamiento entre equipos que produce el contrato compartido es inaceptable en el contexto organizacional.
Precondiciones¶
- Existe conectividad de red entre los sistemas involucrados con latencia y disponibilidad adecuadas.
- Existe un contrato de interfaz acordado y documentado (OpenAPI, protobuf, GraphQL schema, WSDL).
- El sistema servidor expone una interfaz remota accesible (REST endpoint, gRPC service, GraphQL endpoint, SOAP endpoint).
- Existe un mecanismo de autenticación y autorización entre los sistemas.
- El sistema cliente tiene capacidad de manejar fallos de comunicación (timeouts, errores, retries).
Restricciones¶
- La disponibilidad del sistema compuesto es el producto de las disponibilidades individuales de todos los sistemas en la cadena de invocación. Si A invoca a B que invoca a C, la disponibilidad del flujo A→B→C es
disponibilidad(A) × disponibilidad(B) × disponibilidad(C). - La latencia del flujo compuesto es la suma de las latencias individuales más la latencia de red entre cada par.
- El sistema servidor debe dimensionarse para absorber la carga de todos sus clientes, no solo de su propia carga interna.
- Los cambios en el contrato requieren coordinación entre los equipos del cliente y del servidor, introduciendo una dependencia organizacional.
Dependencias¶
- Infraestructura de red confiable entre sistemas.
- Mecanismo de service discovery (DNS, service registry, service mesh).
- Infraestructura de seguridad (certificados TLS, OAuth2 server, API keys).
- Opcional pero frecuente: API Gateway para routing, rate limiting y observabilidad centralizada.
- Opcional pero frecuente: service mesh para gestión de tráfico, circuit breaking y mutual TLS.
Supuestos Arquitectónicos¶
- Los sistemas involucrados están disponibles simultáneamente durante las horas de operación.
- La latencia de red entre sistemas es predecible y aceptable para el SLA del proceso de negocio.
- Los equipos pueden coordinar cambios de contrato con un proceso de versionado gestionable.
- El sistema servidor puede escalar para absorber la demanda de sus clientes.
- Existe infraestructura de observabilidad para monitorear y diagnosticar problemas en las invocaciones remotas.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- APIs públicas y privadas de cualquier plataforma digital.
- Comunicación entre microservicios en arquitecturas cloud-native.
- Integración front-end a back-end (BFF, API composition).
- Integración con servicios SaaS (Salesforce, Stripe, Twilio, AWS services).
- Integración con sistemas core (billing, CRM, ERP) que exponen APIs.
- Orquestación de servicios en plataformas de integración (MuleSoft, Boomi, Azure APIM).
- Comunicación entre partners B2B mediante APIs (Open Banking, APIs de telecomunicaciones TM Forum).
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Remote Procedure Invocation introduce un acoplamiento contractual explícito entre cliente y servidor. El cliente conoce la interfaz del servidor (operaciones, tipos de datos, semántica de errores) y depende de que esa interfaz se mantenga estable. Este acoplamiento es más fuerte que en File Transfer (donde el contrato es solo el formato del archivo) o Messaging (donde el contrato es el formato del mensaje y el canal). Sin embargo, este acoplamiento está limitado a la interfaz, no a la implementación: el servidor puede cambiar su implementación interna libremente mientras mantenga el contrato. La flexibilidad se preserva mediante versionado de APIs (URL versioning, header versioning, content negotiation), contratos backward-compatible y estrategias de evolución como el Tolerant Reader pattern.
Simplicidad vs. Robustez¶
La simplicidad conceptual de RPI es engañosa. Una llamada HTTP a un endpoint REST parece trivial. Pero alcanzar robustez enterprise requiere capas adicionales significativas: circuit breakers para evitar cascading failures, retries con exponential backoff para manejar fallos transitorios, timeouts para evitar bloqueo indefinido, bulkheads para aislar fallos, fallbacks para degradación elegante, health checks para detectar servicios no disponibles, y distributed tracing para diagnosticar problemas en cadenas de invocación. Sin estas capas, una integración RPI es frágil y propensa a fallos catastróficos en producción.
Sincronía vs. Asincronía¶
RPI es fundamentalmente síncrono en su modelo mental: el cliente envía una solicitud y espera la respuesta. Sin embargo, las implementaciones modernas frecuentemente introducen asincronía a nivel técnico (async/await, reactive streams, completable futures) para no bloquear threads mientras se espera la respuesta. Además, es posible combinar RPI con patrones asíncronos: el cliente hace una llamada RPI que inicia un proceso y recibe un identificador, luego hace polling o recibe un callback cuando el proceso completa (asynchronous request-reply). Esta tensión entre sincronía lógica y asincronía técnica es una fuerza constante en el diseño de sistemas basados en RPI.
Latencia vs. Confiabilidad¶
RPI favorece la baja latencia sobre la confiabilidad inherente. La respuesta es inmediata (milisegundos a segundos), pero si el servidor no está disponible, la operación simplemente falla. No hay buffer intermedio que retenga la solicitud (como un broker de mensajería). La confiabilidad debe construirse explícitamente con retries, circuit breakers y fallbacks. Messaging, en contraste, ofrece confiabilidad inherente (el mensaje persiste en el broker) a costa de mayor latencia y complejidad. La elección entre RPI y Messaging frecuentemente se reduce a esta tensión fundamental.
Consistencia vs. Disponibilidad¶
En términos del teorema CAP, RPI tiende hacia la consistencia (el cliente obtiene el dato más reciente del servidor) a costa de la disponibilidad (si el servidor está caído, la operación falla). Messaging tiende hacia la disponibilidad (el emisor puede enviar aunque el receptor esté caído) a costa de la consistencia eventual. Para operaciones donde la consistencia es crítica (autorización de pago, consulta de saldo, verificación de identidad), RPI es la elección natural. Para operaciones donde la disponibilidad es más importante que la consistencia inmediata (notificaciones, actualizaciones de catálogo, procesamiento de eventos), Messaging es superior.
Costo Operativo vs. Capacidad de Evolución¶
El costo operativo de RPI incluye: gestión de APIs (versionado, deprecación, documentación), infraestructura de API gateway, monitoreo de latencia y disponibilidad de endpoints, gestión de certificados y credenciales, y la coordinación organizacional para evolucionar contratos. Sin embargo, la capacidad de evolución es alta si se implementan buenas prácticas: APIs bien versionadas permiten evolución gradual, contratos backward-compatible permiten despliegue independiente de cliente y servidor, y las herramientas modernas (OpenAPI, contract testing, API management platforms) hacen que esta evolución sea manejable.
Gobernanza vs. Autonomía de Equipos¶
RPI requiere un equilibrio delicado entre gobernanza centralizada y autonomía de equipos. La gobernanza es necesaria para: estándares de diseño de APIs (naming conventions, error handling, pagination), políticas de seguridad (autenticación, autorización), políticas de versionado, y observabilidad. Pero una gobernanza excesiva puede convertir el desarrollo de APIs en un proceso burocrático que frena la entrega. Las organizaciones maduras implementan gobernanza como guardrails automatizados (linters de OpenAPI, contract tests en CI/CD, políticas de API gateway) en lugar de procesos de aprobación manual, preservando la autonomía de los equipos dentro de los límites definidos.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Cliente (Consumer / Caller): la aplicación que inicia la invocación remota. Construye la solicitud, la envía al servidor y procesa la respuesta.
- Servidor (Provider / Callee): la aplicación que expone la interfaz remota, recibe la solicitud, ejecuta la operación y retorna la respuesta.
- Contrato de Interfaz (Contract / API Specification): la definición formal de las operaciones disponibles, tipos de datos, códigos de error y semántica. Materializado como OpenAPI spec, archivo
.proto, schema GraphQL, WSDL, etc. - Stub / Proxy del Cliente (Client Stub): componente generado o implementado en el lado del cliente que abstrae los detalles de serialización, transporte y deserialización, presentando la operación remota como una llamada local.
- Skeleton / Dispatcher del Servidor (Server Skeleton): componente en el lado del servidor que recibe la solicitud de red, la deserializa, la despacha a la implementación y serializa la respuesta.
- Canal de Transporte (Transport Channel): el protocolo y la infraestructura de red que transportan la solicitud y la respuesta (HTTP/HTTPS, HTTP/2, TCP).
- Intermediarios (Intermediaries): componentes opcionales pero frecuentes que se interponen en el flujo: API gateways, load balancers, service meshes, proxies reversos.
Flujo Lógico¶
flowchart TD
A([Cliente]) --> B[Construye solicitud con parámetros]
B --> C[Client Stub: Serializa solicitud]
C --> D[Envía por canal de transporte]
D --> E[Intermediarios: Autenticación, rate limiting, routing]
E --> F[Server Skeleton: Recibe y deserializa]
F --> G[Despacha a implementación]
G --> H[Servidor: Ejecuta lógica de negocio]
H --> I[Construye respuesta]
I --> J[Server Skeleton: Serializa respuesta]
J --> K[Envía respuesta por canal de transporte]
K --> L[Intermediarios: Logging, metrics, caching]
L --> M[Client Stub: Recibe y deserializa]
M --> N([Cliente: Procesa respuesta])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Cliente | Conocer qué operación invocar, con qué parámetros, y cómo interpretar el resultado |
| Client Stub | Abstraer serialización, transporte, deserialización. Manejar timeouts y retries |
| Contrato | Definir operaciones, tipos, errores. Ser la fuente de verdad compartida |
| Intermediarios | Autenticación, autorización, rate limiting, load balancing, observabilidad |
| Server Skeleton | Deserializar solicitud, despachar a implementación, serializar respuesta |
| Servidor | Ejecutar la lógica de negocio correctamente, retornar resultado o error semántico |
Interacciones¶
- Cliente → Servidor: solicitud síncrona (request) con parámetros de la operación.
- Servidor → Cliente: respuesta síncrona (response) con resultado de negocio o error.
- Cliente ↔ Intermediarios ↔ Servidor: la cadena de intermediarios es transparente para la semántica de la operación pero visible para aspectos transversales (seguridad, observabilidad, resiliencia).
Contratos Implícitos y Explícitos¶
- Explícitos: operaciones disponibles, tipos de datos de entrada y salida, códigos de error, formato de serialización, URLs/endpoints, métodos HTTP (en REST), headers requeridos.
- Implícitos: latencia esperada, disponibilidad del servidor, semántica de idempotencia, comportamiento ante timeouts, política de versionado, rate limits.
Los contratos implícitos son frecuentemente la fuente de los problemas más difíciles de diagnosticar. Un servidor que "funciona" pero responde en 30 segundos cuando el cliente espera 2 segundos es técnicamente un cumplimiento del contrato explícito pero una violación del contrato implícito.
Decisiones de Diseño Clave¶
- Protocolo de transporte: HTTP/1.1 (REST), HTTP/2 (gRPC), WebSocket, TCP puro. Impacta latencia, multiplexing, streaming y compatibilidad con intermediarios.
- Formato de serialización: JSON (legible, universal), Protocol Buffers (compacto, tipado, rápido), XML (verboso, extensible), Avro (schema evolution). Impacta performance, debugging y evolución.
- Estilo de interfaz: resource-oriented (REST), operation-oriented (gRPC, SOAP), query-oriented (GraphQL). Impacta granularidad, flexibilidad y complejidad del cliente.
- Granularidad de operaciones: operaciones finas (un campo por llamada) vs. operaciones gruesas (agregados completos por llamada). Impacta chattiness, latencia total y acoplamiento.
- Estrategia de manejo de errores: HTTP status codes + error body (REST), gRPC status codes + metadata, SOAP faults. El nivel de detalle del error impacta la capacidad de diagnóstico y la seguridad (no exponer detalles internos).
- Estrategia de versionado: URL path versioning (
/v1/,/v2/), header versioning (Accept-Version), content negotiation. Impacta la capacidad de evolución sin breaking changes. - Estrategia de resiliencia: circuit breakers, retries, timeouts, fallbacks, bulkheads. Cada decisión impacta el comportamiento del sistema bajo fallo.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Telecomunicaciones — Consulta de Saldo y Cobro en Tiempo Real vía API Gateway¶
Contexto del Negocio¶
Un operador de telecomunicaciones con 18 millones de suscriptores prepago necesita exponer la funcionalidad de consulta de saldo y cobro de servicios de valor agregado (VAS) a múltiples canales digitales: la aplicación móvil del operador, el portal web de autoservicio, la USSD gateway para terminales básicos, y plataformas de terceros (content providers) que ofrecen servicios de entretenimiento, streaming y gaming que se cobran directamente al saldo prepago del suscriptor.
Necesidad de Integración¶
El sistema de billing (OCS — Online Charging System) es el sistema autoritativo para el saldo de los suscriptores prepago. Todos los canales que necesitan consultar saldo o ejecutar cobros deben interactuar con el OCS en tiempo real. La operación de cobro es especialmente crítica: si se cobra el saldo al suscriptor, el content provider debe recibir confirmación inmediata para entregar el contenido, y si el cobro falla (saldo insuficiente, suscriptor bloqueado), el content provider no debe entregar el contenido.
Sistemas Involucrados¶
- OCS (Online Charging System): sistema core de billing que gestiona el saldo prepago de los 18 millones de suscriptores. Expone una interfaz Diameter (protocolo 3GPP) para charging y una interfaz REST interna para consultas. Desplegado on-premise en el data center del operador.
- API Gateway (Kong Enterprise): gateway centralizado que expone APIs REST hacia los canales externos, aplica políticas de seguridad, rate limiting y transformación de protocolos. Desplegado en Kubernetes on-premise.
- App Móvil / Portal Web: canales digitales del operador que consumen APIs REST para mostrar saldo y ejecutar compras.
- USSD Gateway: gateway de mensajería para terminales básicos que traduce sesiones USSD a invocaciones API REST.
- Partner Platform (Content Providers): plataformas de terceros (Spotify, Netflix, plataformas de gaming locales) que consumen APIs REST del operador para cobrar contenido al saldo prepago del suscriptor.
- Subscriber Management (CRM): sistema que gestiona datos del suscriptor (plan, estado, restricciones). Consultado durante el flujo de cobro para validar elegibilidad.
- Fraud Detection Engine: sistema que analiza patrones de cobro en tiempo real para detectar fraude. Consultado como parte del flujo de cobro.
Restricciones Técnicas¶
- El OCS soporta un máximo de 5,000 transacciones por segundo (TPS) para operaciones de cobro.
- La latencia end-to-end del flujo de cobro debe ser inferior a 3 segundos (SLA contractual con content providers).
- Las APIs expuestas a partners deben usar OAuth 2.0 client credentials flow para autenticación.
- Las APIs internas (app móvil, portal web) usan tokens JWT emitidos por el identity provider del operador.
- La comunicación con el OCS utiliza protocolo Diameter internamente, lo cual requiere una capa de traducción Diameter↔REST.
- Todos los cobros deben ser idempotentes: si un partner reintenta una solicitud con el mismo transaction ID, no debe cobrarse dos veces.
- Los content providers están distribuidos geográficamente y se conectan a través de Internet público.
- El operador debe poder aplicar rate limits diferenciados por partner (algunos partners tienen cuotas de 100 TPS, otros de 500 TPS).
Flujos de Datos¶
[App Móvil] → HTTPS/REST → [API Gateway] → HTTPS/REST → [OCS REST API] → Balance
[Partner Platform] → HTTPS/REST → [API Gateway] → OAuth2 validation
→ Rate limit check
→ [CRM] → Eligibility check
→ [Fraud Engine] → Fraud check
→ [OCS Adapter] → Diameter → [OCS] → Charge result
← HTTPS/REST ← [Partner Platform]
Eventos o Mensajes¶
Aunque el flujo principal es síncrono (RPI), se generan eventos asíncronos como efecto secundario:
- Cada cobro exitoso publica un evento
ChargeCompleteden Kafka para alimentar analytics, reconciliación y facturación a partners. - Cada intento de cobro fallido por fraude publica un evento
FraudAlertRaisedpara el equipo de seguridad. - Cada consulta de saldo genera una métrica en Prometheus para monitoreo de uso de API.
Decisiones Arquitectónicas¶
- API Gateway como punto de entrada único: todas las invocaciones de partners y canales digitales pasan por Kong API Gateway, centralizando autenticación, rate limiting, logging y transformación de protocolo.
- Adapter pattern para OCS: se implementa un microservicio adaptador (OCS Adapter) que traduce solicitudes REST a protocolo Diameter y viceversa, desacoplando los consumidores del protocolo propietario del OCS.
- Idempotencia por transaction ID: cada solicitud de cobro incluye un
transactionIdúnico generado por el caller. El OCS Adapter mantiene un cache de transacciones procesadas (Redis, TTL 24h) y rechaza duplicados. - Circuit breaker en el cliente: si el OCS no responde o responde con errores sistemáticos, el circuit breaker en el OCS Adapter se abre y retorna un error inmediato sin saturar al OCS.
- Rate limiting diferenciado: Kong aplica rate limits por consumer (partner), con cuotas configurables por contrato comercial.
- Orchestration pattern: el flujo de cobro es una orquestación secuencial (verificar elegibilidad → verificar fraude → ejecutar cobro) implementada en el OCS Adapter como lógica de orquestación.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| OCS alcanza límite de 5,000 TPS | Rate limiting en API Gateway distribuye carga; queue de solicitudes con backpressure |
| Timeout en comunicación con OCS | Timeout de 2 segundos en OCS Adapter; circuit breaker con fallback de error semántico |
| Partner reintenta cobro y genera doble cargo | Idempotencia por transactionId con cache Redis |
| Credenciales de partner comprometidas | OAuth2 con token rotation, IP whitelisting, alertas de anomalías de tráfico |
| Fallo del Fraud Engine bloquea cobros legítimos | Timeout de 500ms para Fraud Engine; si falla, el cobro procede (fail-open para no impactar revenue) |
| Latencia excesiva por cadena de invocaciones | Connection pooling, HTTP keep-alive, timeout estrictos; monitoreo de P99 latency |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Partner Inicia Solicitud de Cobro¶
Un content provider (por ejemplo, una plataforma de streaming) necesita cobrar $2.99 USD al suscriptor con MSISDN +573001234567 por la suscripción mensual a un paquete premium. El partner construye la solicitud:
POST /v1/charging/charges
Host: api.telecom-operator.com
Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9...
Content-Type: application/json
X-Request-ID: f47ac10b-58cc-4372-a567-0e02b2c3d479
X-Idempotency-Key: partner-tx-2026040700142
{
"subscriberId": "+573001234567",
"amount": 2.99,
"currency": "USD",
"serviceId": "streaming-premium-monthly",
"description": "Suscripción mensual Premium Streaming",
"partnerId": "PARTNER-STREAMING-001"
}
El X-Idempotency-Key es generado por el partner y garantiza que si la solicitud se reintenta (por timeout, error de red), no se produzca doble cobro.
Paso 2: API Gateway Recibe y Valida la Solicitud¶
Kong API Gateway recibe la solicitud HTTPS y ejecuta la cadena de plugins configurada:
- TLS Termination: termina la conexión TLS del partner. Verifica el certificado del servidor.
- OAuth2 Token Validation: valida el Bearer token contra el authorization server. Verifica que el token no está expirado, que el issuer es correcto, que el scope incluye
charging:execute, y que elclient_idcorresponde a un partner activo. - Rate Limiting: verifica que el partner PARTNER-STREAMING-001 no ha excedido su cuota de 200 TPS. Si la excede, retorna
429 Too Many Requestscon headerRetry-After. - Request Logging: registra la solicitud entrante con el
X-Request-IDpara trazabilidad. - Request Transformation: añade headers internos (
X-Consumer-Id,X-Authenticated-At,X-Gateway-Trace-Id) y enruta la solicitud al upstream service (OCS Adapter).
Paso 3: OCS Adapter Recibe la Solicitud¶
El microservicio OCS Adapter (desplegado como deployment en Kubernetes, 4 réplicas) recibe la solicitud del API Gateway:
- Idempotency Check: consulta Redis para verificar si el
X-Idempotency-Key(partner-tx-2026040700142) ya fue procesado. Si existe, retorna la respuesta almacenada sin ejecutar el cobro nuevamente. - Request Validation: valida el formato del MSISDN, que el amount es positivo, que el serviceId es conocido, que el partnerId coincide con el autenticado.
Paso 4: Verificación de Elegibilidad del Suscriptor¶
El OCS Adapter invoca al sistema CRM para verificar la elegibilidad del suscriptor:
GET /internal/v1/subscribers/+573001234567/eligibility?service=charging
Host: crm-service.internal.svc.cluster.local
X-Trace-Id: gateway-trace-abc123
El CRM verifica que: - El suscriptor existe y está activo (no suspendido, no cancelado). - El suscriptor no tiene bloqueo de cobros de terceros (parental control, solicitud del cliente). - El plan del suscriptor permite cobros de valor agregado.
Respuesta del CRM:
{
"subscriberId": "+573001234567",
"eligible": true,
"subscriberType": "PREPAID",
"restrictions": []
}
Timeout configurado: 500ms. Si el CRM no responde, el cobro se rechaza con error 503 Service Unavailable y motivo ELIGIBILITY_CHECK_FAILED.
Paso 5: Verificación de Fraude¶
El OCS Adapter invoca al Fraud Detection Engine:
POST /internal/v1/fraud/evaluate
Host: fraud-engine.internal.svc.cluster.local
X-Trace-Id: gateway-trace-abc123
{
"subscriberId": "+573001234567",
"amount": 2.99,
"partnerId": "PARTNER-STREAMING-001",
"serviceId": "streaming-premium-monthly"
}
El Fraud Engine evalúa reglas en tiempo real: - Frecuencia de cobros al suscriptor en la última hora (detectar cobros masivos automatizados). - Monto acumulado de cobros en las últimas 24 horas vs. umbral configurado. - Patrón de cobros del partner (volumen anómalo, nuevos subscribers inusuales).
Respuesta del Fraud Engine:
Timeout configurado: 500ms. Decisión ante timeout del Fraud Engine: fail-open (el cobro procede). Esta decisión de diseño prioriza el revenue y la experiencia de usuario sobre la detección de fraude en casos de fallo del motor. Se registra un evento de auditoría cuando el Fraud Engine no responde.
Paso 6: Ejecución del Cobro en el OCS¶
El OCS Adapter traduce la solicitud REST al protocolo Diameter (Credit-Control-Request, CCR) y la envía al OCS:
- Construye un mensaje Diameter CCR (Credit-Control-Request) con:
- Session-Id generado
- CC-Request-Type: EVENT_REQUEST
- Requested-Service-Unit: 2.99 USD
- Subscription-Id: MSISDN +573001234567
- Service-Identifier: streaming-premium-monthly
- Envía el CCR al OCS a través de una conexión Diameter persistente (connection pool de 50 conexiones).
- El OCS verifica el saldo del suscriptor:
- Saldo actual: $15.42 USD
- Monto a cobrar: $2.99 USD
- Saldo suficiente: sí
- El OCS debita el monto y responde con Credit-Control-Answer (CCA):
- Result-Code: DIAMETER_SUCCESS (2001)
- Granted-Service-Unit: 2.99 USD
- Remaining-Balance: $12.43 USD
Timeout configurado: 2 segundos. Si el OCS no responde dentro del timeout, el OCS Adapter retorna error al cliente. No se reintenta automáticamente la operación de cobro (operación no idempotente a nivel de protocolo Diameter; la idempotencia se gestiona a nivel de la capa REST).
Paso 7: Respuesta al Partner¶
El OCS Adapter construye la respuesta REST y la almacena en Redis (asociada al X-Idempotency-Key, TTL 24h) para garantizar idempotencia ante retries:
HTTP/1.1 201 Created
Content-Type: application/json
X-Request-ID: f47ac10b-58cc-4372-a567-0e02b2c3d479
X-Trace-Id: gateway-trace-abc123
{
"chargeId": "CHG-2026040700142-001",
"status": "COMPLETED",
"subscriberId": "+573001234567",
"amount": 2.99,
"currency": "USD",
"remainingBalance": 12.43,
"serviceId": "streaming-premium-monthly",
"timestamp": "2026-04-07T00:01:42.387Z"
}
Latencia total del flujo: ~180ms (CRM: 35ms, Fraud: 45ms, OCS Diameter: 68ms, overhead: 32ms).
Paso 8: Publicación de Evento Asíncrono¶
Como efecto secundario del cobro exitoso, el OCS Adapter publica un evento en Kafka (fire-and-forget, no afecta la latencia de la respuesta al partner):
{
"eventType": "ChargeCompleted",
"chargeId": "CHG-2026040700142-001",
"subscriberId": "+573001234567",
"amount": 2.99,
"currency": "USD",
"partnerId": "PARTNER-STREAMING-001",
"serviceId": "streaming-premium-monthly",
"timestamp": "2026-04-07T00:01:42.387Z",
"traceId": "gateway-trace-abc123"
}
Este evento es consumido por: - El sistema de analytics para dashboards de revenue en tiempo real. - El sistema de reconciliación para cuadre con los partners. - El sistema de facturación a partners para generar facturas mensuales.
Manejo de Errores¶
- Saldo insuficiente: el OCS retorna
DIAMETER_CREDIT_LIMIT_REACHED. El OCS Adapter traduce a402 Payment Requiredcon body{"error": "INSUFFICIENT_BALANCE", "remainingBalance": 1.50}. - Suscriptor no encontrado: el CRM retorna 404. El OCS Adapter traduce a
404 Not Foundcon body{"error": "SUBSCRIBER_NOT_FOUND"}. - Suscriptor bloqueado: el CRM retorna eligible=false. El OCS Adapter traduce a
403 Forbiddencon body{"error": "CHARGING_BLOCKED", "reason": "PARENTAL_CONTROL"}. - Fraude detectado: el Fraud Engine retorna
decision: DENY. El OCS Adapter traduce a403 Forbiddencon body{"error": "FRAUD_SUSPECTED"}. No se revela el riskScore al partner por seguridad. - Timeout del OCS:
504 Gateway Timeoutcon body{"error": "UPSTREAM_TIMEOUT", "message": "Charging system did not respond in time. Please retry with the same idempotency key."}.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
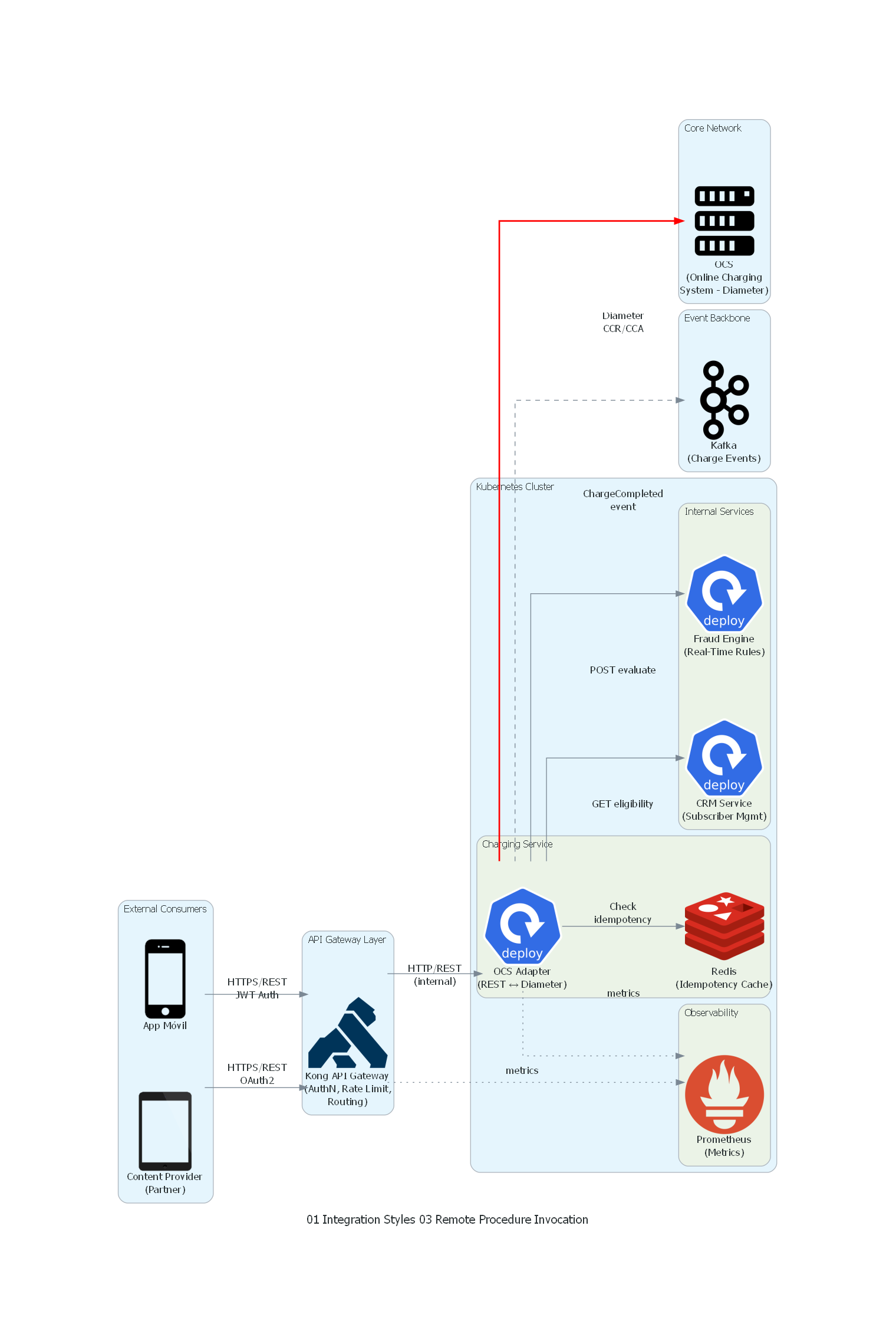
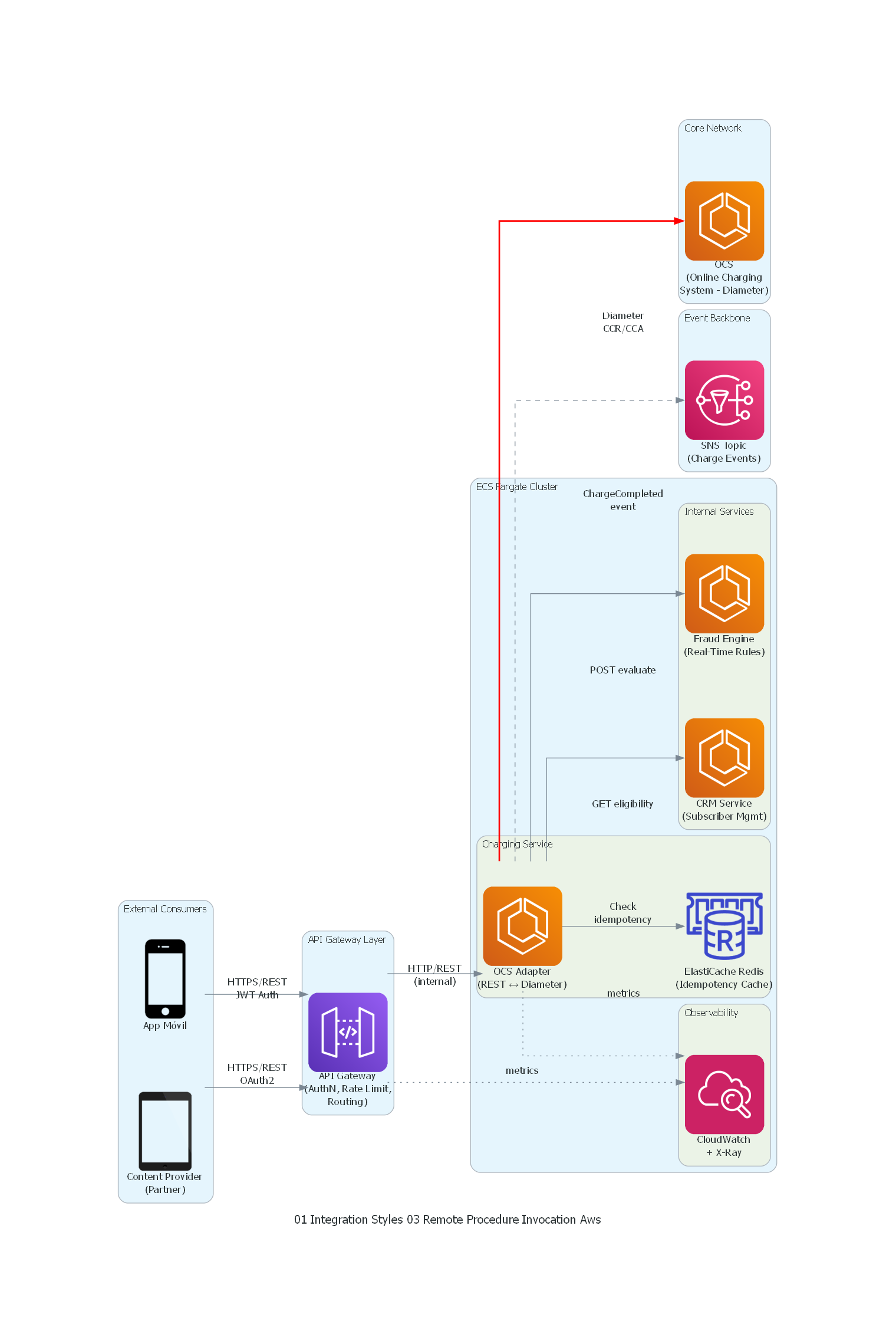
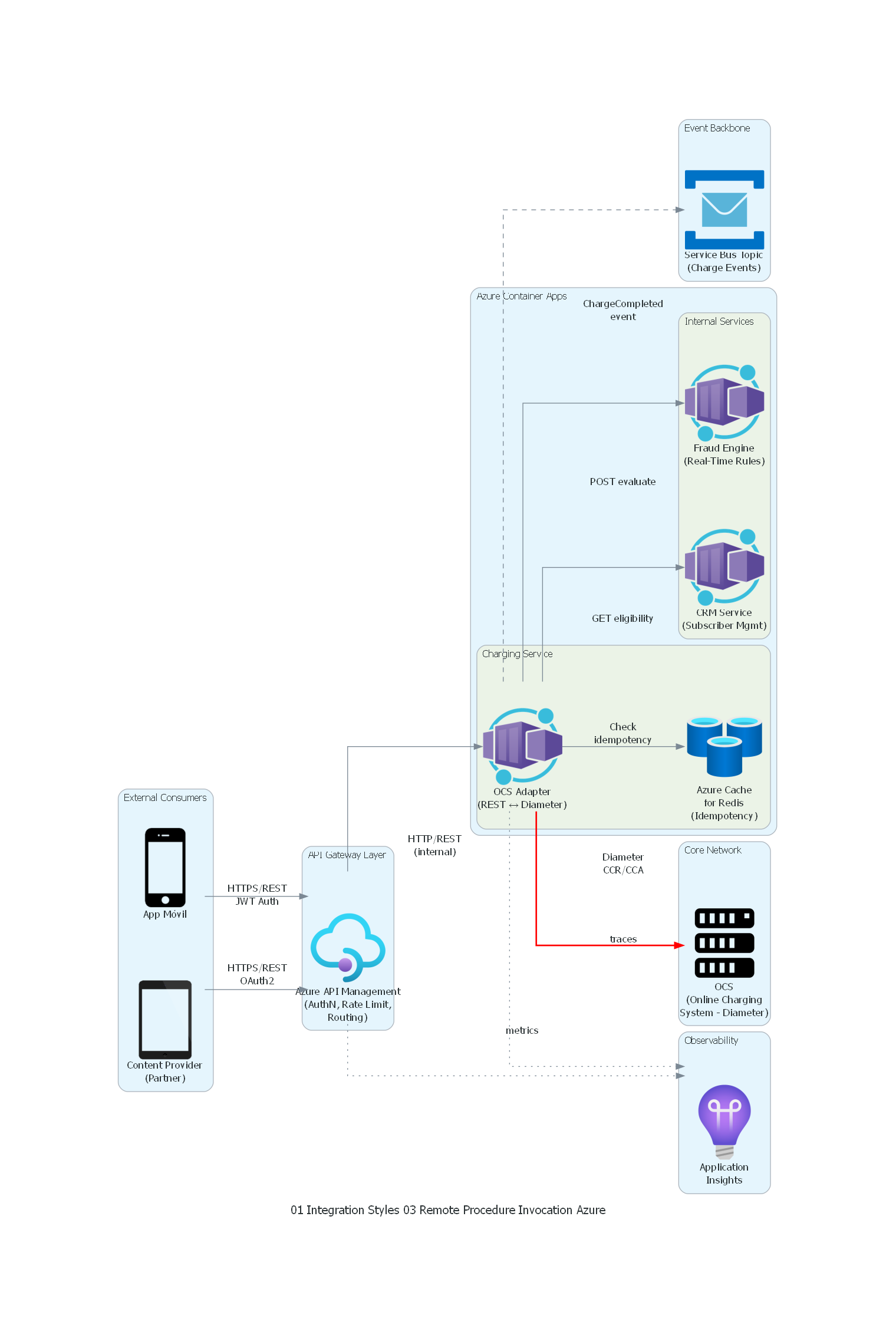
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.k8s.compute import Deployment, Pod
from diagrams.k8s.network import Service as K8sService
from diagrams.onprem.network import Kong
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.queue import Kafka
from diagrams.onprem.monitoring import Prometheus
from diagrams.onprem.compute import Server
from diagrams.generic.device import Mobile, Tablet
from diagrams.generic.compute import Rack
with Diagram(
"Remote Procedure Invocation - Telecom Real-Time Charging",
show=False,
direction="LR",
filename="rpi_telecom_charging"
):
with Cluster("External Consumers"):
mobile_app = Mobile("App Móvil")
partner = Tablet("Content Provider\n(Partner)")
with Cluster("API Gateway Layer"):
api_gw = Kong("Kong API Gateway\n(AuthN, Rate Limit,\nRouting)")
with Cluster("Kubernetes Cluster"):
with Cluster("Charging Service"):
ocs_adapter = Deployment("OCS Adapter\n(REST ↔ Diameter)")
idempotency_cache = Redis("Redis\n(Idempotency Cache)")
with Cluster("Internal Services"):
crm_svc = Deployment("CRM Service\n(Subscriber Mgmt)")
fraud_svc = Deployment("Fraud Engine\n(Real-Time Rules)")
with Cluster("Observability"):
prometheus = Prometheus("Prometheus\n(Metrics)")
with Cluster("Core Network"):
ocs = Server("OCS\n(Online Charging\nSystem - Diameter)")
with Cluster("Event Backbone"):
kafka = Kafka("Kafka\n(Charge Events)")
# External to Gateway
mobile_app >> Edge(label="HTTPS/REST\nJWT Auth") >> api_gw
partner >> Edge(label="HTTPS/REST\nOAuth2") >> api_gw
# Gateway to OCS Adapter
api_gw >> Edge(label="HTTP/REST\n(internal)") >> ocs_adapter
# OCS Adapter interactions
ocs_adapter >> Edge(label="Check\nidempotency") >> idempotency_cache
ocs_adapter >> Edge(label="GET eligibility") >> crm_svc
ocs_adapter >> Edge(label="POST evaluate") >> fraud_svc
ocs_adapter >> Edge(label="Diameter\nCCR/CCA", color="red", style="bold") >> ocs
# Async event publication
ocs_adapter >> Edge(label="ChargeCompleted\nevent", style="dashed") >> kafka
# Observability
ocs_adapter >> Edge(style="dotted", label="metrics") >> prometheus
api_gw >> Edge(style="dotted", label="metrics") >> prometheus
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.device import Mobile, Tablet
from diagrams.aws.compute import ECS
from diagrams.aws.database import ElasticacheForRedis
from diagrams.aws.integration import SNS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
with Diagram(
"Remote Procedure Invocation - Telecom Real-Time Charging",
show=False,
direction="LR",
filename="rpi_telecom_charging"
):
with Cluster("External Consumers"):
mobile_app = Mobile("App Móvil")
partner = Tablet("Content Provider\n(Partner)")
with Cluster("API Gateway Layer"):
api_gw = APIGateway("API Gateway\n(AuthN, Rate Limit,\nRouting)")
with Cluster("ECS Fargate Cluster"):
with Cluster("Charging Service"):
ocs_adapter = ECS("OCS Adapter\n(REST ↔ Diameter)")
idempotency_cache = ElasticacheForRedis("ElastiCache Redis\n(Idempotency Cache)")
with Cluster("Internal Services"):
crm_svc = ECS("CRM Service\n(Subscriber Mgmt)")
fraud_svc = ECS("Fraud Engine\n(Real-Time Rules)")
with Cluster("Observability"):
xray = Cloudwatch("CloudWatch\n+ X-Ray")
with Cluster("Core Network"):
ocs = ECS("OCS\n(Online Charging\nSystem - Diameter)")
with Cluster("Event Backbone"):
events = SNS("SNS Topic\n(Charge Events)")
# External to Gateway
mobile_app >> Edge(label="HTTPS/REST\nJWT Auth") >> api_gw
partner >> Edge(label="HTTPS/REST\nOAuth2") >> api_gw
# Gateway to OCS Adapter
api_gw >> Edge(label="HTTP/REST\n(internal)") >> ocs_adapter
# OCS Adapter interactions
ocs_adapter >> Edge(label="Check\nidempotency") >> idempotency_cache
ocs_adapter >> Edge(label="GET eligibility") >> crm_svc
ocs_adapter >> Edge(label="POST evaluate") >> fraud_svc
ocs_adapter >> Edge(label="Diameter\nCCR/CCA", color="red", style="bold") >> ocs
# Async event publication
ocs_adapter >> Edge(label="ChargeCompleted\nevent", style="dashed") >> events
# Observability
ocs_adapter >> Edge(style="dotted", label="metrics") >> xray
api_gw >> Edge(style="dotted", label="metrics") >> xray
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.device import Mobile, Tablet
from diagrams.azure.compute import ContainerApps
from diagrams.azure.database import CacheForRedis
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import APIManagement, ServiceBus
from diagrams.onprem.compute import Server
with Diagram(
"Remote Procedure Invocation - Telecom Real-Time Charging (Azure)",
show=False,
direction="LR",
filename="rpi_telecom_charging"
):
with Cluster("External Consumers"):
mobile_app = Mobile("App Móvil")
partner = Tablet("Content Provider\n(Partner)")
with Cluster("API Gateway Layer"):
api_gw = APIManagement("Azure API Management\n(AuthN, Rate Limit,\nRouting)")
with Cluster("Azure Container Apps"):
with Cluster("Charging Service"):
ocs_adapter = ContainerApps("OCS Adapter\n(REST ↔ Diameter)")
idempotency_cache = CacheForRedis("Azure Cache\nfor Redis\n(Idempotency)")
with Cluster("Internal Services"):
crm_svc = ContainerApps("CRM Service\n(Subscriber Mgmt)")
fraud_svc = ContainerApps("Fraud Engine\n(Real-Time Rules)")
with Cluster("Observability"):
app_insights = ApplicationInsights("Application\nInsights")
with Cluster("Core Network"):
ocs = Server("OCS\n(Online Charging\nSystem - Diameter)")
with Cluster("Event Backbone"):
service_bus = ServiceBus("Service Bus Topic\n(Charge Events)")
# External to Gateway
mobile_app >> Edge(label="HTTPS/REST\nJWT Auth") >> api_gw
partner >> Edge(label="HTTPS/REST\nOAuth2") >> api_gw
# Gateway to OCS Adapter
api_gw >> Edge(label="HTTP/REST\n(internal)") >> ocs_adapter
# OCS Adapter interactions
ocs_adapter >> Edge(label="Check\nidempotency") >> idempotency_cache
ocs_adapter >> Edge(label="GET eligibility") >> crm_svc
ocs_adapter >> Edge(label="POST evaluate") >> fraud_svc
ocs_adapter >> Edge(label="Diameter\nCCR/CCA", color="red", style="bold") >> ocs
# Async event publication
ocs_adapter >> Edge(label="ChargeCompleted\nevent", style="dashed") >> service_bus
# Observability
ocs_adapter >> Edge(style="dotted", label="traces") >> app_insights
api_gw >> Edge(style="dotted", label="metrics") >> app_insights
Explicación del Diagrama¶
El diagrama representa el flujo completo de Remote Procedure Invocation para el cobro en tiempo real en telecomunicaciones:
- External Consumers (izquierda): la app móvil del operador y los content providers (partners) inician solicitudes REST sobre HTTPS. La app usa JWT; los partners usan OAuth2 client credentials.
- API Gateway Layer: Kong API Gateway centraliza la autenticación, rate limiting, routing y logging. Es el punto de entrada único para todas las invocaciones externas.
- Charging Service: el OCS Adapter es el microservicio que orquesta el flujo de cobro. Consulta Redis para idempotencia, invoca al CRM para elegibilidad, al Fraud Engine para evaluación de riesgo, y al OCS para ejecutar el cobro (traduciendo REST a Diameter).
- Internal Services: CRM y Fraud Engine son servicios internos invocados síncronamente durante el flujo.
- Core Network: el OCS (Online Charging System) es el sistema legacy de billing que opera con protocolo Diameter. La línea roja indica la invocación crítica al sistema core.
- Event Backbone: Kafka recibe eventos asíncronos (línea punteada) como efecto secundario de cobros exitosos, para consumo por analytics, reconciliación y facturación.
- Observability: Prometheus recolecta métricas de latencia, TPS, error rates y circuit breaker status (líneas punteadas).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Cliente (Consumer) | App Móvil, Content Provider (Partner) |
| Contrato de Interfaz | OpenAPI spec de la Charging API (implícito en el flujo REST) |
| Intermediario | Kong API Gateway (AuthN, Rate Limiting, Routing) |
| Servidor (Provider) | OCS Adapter → OCS (cadena de invocación) |
| Stub del Cliente | HTTP client en la app/partner (serializa JSON, envía HTTPS) |
| Canal de Transporte | HTTPS/REST (externo), HTTP/REST (interno), Diameter (core) |
| Mecanismo de Idempotencia | Redis Idempotency Cache |
| Servicios internos invocados (RPI chain) | CRM Service, Fraud Engine |
| Efecto secundario asíncrono | Kafka (ChargeCompleted event) |
| Observabilidad | Prometheus (metrics) |
11. Beneficios¶
Impacto Técnico¶
- Baja latencia: RPI permite obtener respuestas en milisegundos a pocos segundos, habilitando flujos de negocio en tiempo real que son imposibles con integración batch. Una consulta de saldo, una autorización de pago o una verificación de identidad se resuelven en el acto.
- Consistencia fuerte: el cliente obtiene el estado más reciente del servidor al momento de la invocación. No hay ventana de inconsistencia como en File Transfer o eventual consistency como en Messaging. Esto es crítico para operaciones financieras, de seguridad o regulatorias.
- Contrato explícito y verificable: la interfaz remota está formalmente definida (OpenAPI, protobuf, GraphQL schema), lo cual permite validación automática, generación de código, documentación automática y contract testing. El contrato es la fuente de verdad compartida.
- Composición de servicios: RPI permite componer servicios complejos a partir de servicios simples. Un servicio de orden de compra puede orquestar invocaciones a servicios de inventario, pricing, payment y shipping, cada uno independiente y especializado.
- Tipado fuerte: con protocolos como gRPC (Protocol Buffers) o GraphQL, los tipos de datos están definidos formalmente, lo cual permite detección temprana de errores en compilación, autocompletado en IDEs y documentación automática.
Impacto Organizacional¶
- Ownership claro: cada API tiene un equipo dueño que es responsable de su contrato, implementación, disponibilidad y evolución. Esto alinea la arquitectura técnica con la estructura organizacional (Ley de Conway como ventaja).
- Autonomía con contrato: los equipos pueden evolucionar la implementación interna de sus servicios de forma independiente, siempre que mantengan el contrato de interfaz. Esto permite despliegue independiente y cadencia de release independiente.
- Ecosistema de partners: las APIs REST/gRPC permiten construir ecosistemas de partners y desarrolladores externos que consumen la funcionalidad de la organización, generando nuevas fuentes de revenue (API-as-a-product, Open Banking, TM Forum APIs).
- Onboarding acelerado: una API bien documentada (con OpenAPI spec, ejemplos, sandbox) permite que nuevos consumidores se integren sin necesidad de coordinación directa con el equipo proveedor.
Impacto Operacional¶
- Feedback inmediato: cuando una invocación falla, el error se manifiesta inmediatamente (HTTP 500, timeout, error de negocio). No hay fallos silenciosos diferidos como en File Transfer donde un archivo corrupto puede pasar desapercibido durante horas.
- Observabilidad nativa: cada invocación genera métricas (latencia, status code, TPS), logs y traces que alimentan dashboards operacionales. Las herramientas modernas (Prometheus, Grafana, Jaeger, Zipkin) están diseñadas para monitorear invocaciones HTTP/gRPC.
- Escalabilidad horizontal: los servicios que exponen APIs pueden escalarse horizontalmente (más réplicas) detrás de un load balancer, distribuyendo la carga de invocaciones entrantes.
Beneficios de Mantenibilidad y Evolución¶
- Versionado de APIs: las APIs pueden versionarse formalmente (v1, v2) permitiendo evolución gradual sin romper consumidores existentes. Los consumidores migran al nuevo version a su propio ritmo.
- Contract testing: herramientas como Pact o Spring Cloud Contract permiten verificar automáticamente que el proveedor cumple el contrato esperado por los consumidores, detectando breaking changes antes del despliegue.
- Generación de código: los contratos formales (OpenAPI, protobuf) permiten generar automáticamente clients, stubs, documentación y tests, reduciendo el esfuerzo manual y los errores.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Acoplamiento temporal: el cliente depende de que el servidor esté disponible y responda a tiempo. Esto introduce una fragilidad que no existe en File Transfer ni Messaging. Si el servidor está caído, el cliente no puede completar su operación.
- Fallacies of distributed computing: cada invocación remota está sujeta a fallos de red, latencia variable, timeouts, DNS failures, TLS handshake failures, connection resets. El código del cliente debe manejar todos estos escenarios, lo cual añade complejidad significativa.
- Infraestructura de soporte: para que RPI funcione de forma robusta en producción, se necesita infraestructura adicional: API gateways, service meshes, circuit breakers, load balancers, service registries, distributed tracing, certificate management. Esta infraestructura tiene su propio costo operacional.
- Coordinación de contratos: evolucionar una API que tiene múltiples consumidores requiere un proceso de versionado disciplinado. Los breaking changes deben gestionarse con periodos de deprecación, comunicación a consumidores y soporte temporal de múltiples versiones.
Riesgos de Mal Uso¶
- Distributed monolith: cuando múltiples servicios se invocan síncronamente en cadena sin circuit breakers ni fallbacks, el resultado es un monolito distribuido que combina la complejidad de los sistemas distribuidos con el acoplamiento de un monolito. Un servicio lento puede paralizar toda la cadena.
- Chatty APIs: diseñar APIs con granularidad excesivamente fina resulta en múltiples round-trips de red para completar una operación de negocio. En lugar de una llamada que retorna el agregado completo, se hacen 15 llamadas para obtener cada campo individual. La latencia se multiplica y la probabilidad de fallo crece exponencialmente.
- God APIs: el polo opuesto de chatty — APIs que intentan hacer todo en una sola operación, con payloads enormes y lógica compleja. Son difíciles de entender, difíciles de mantener y difíciles de evolucionar.
- Ignorar idempotencia: no diseñar operaciones de mutación como idempotentes significa que un retry puede causar efectos duplicados (doble cobro, doble creación). Este es uno de los errores más costosos en producción.
- Timeout sin strategy: no configurar timeouts o configurarlos demasiado altos resulta en threads bloqueados indefinidamente, agotamiento de connection pools y cascading failures.
Sobreingeniería¶
- API Gateway para un solo servicio: desplegar y operar un API Gateway full-featured (Kong, Apigee) cuando solo hay un servicio y un consumidor es overhead innecesario.
- Service mesh prematuro: implementar Istio o Linkerd antes de tener más de 5-10 servicios puede ser más costoso (en complejidad operacional) que los problemas que resuelve.
- Contract-first extremo: invertir semanas en perfeccionar un schema OpenAPI antes de implementar cualquier funcionalidad puede ser contraproducente en las etapas iniciales de un producto. El diseño iterativo (contract-first para APIs estables, code-first para APIs en exploración) es más pragmático.
- gRPC everywhere: usar gRPC para APIs públicas consumidas por navegadores web es una sobreingeniería cuando REST sobre HTTP es perfectamente adecuado y universalmente compatible. gRPC brilla en comunicación service-to-service de alto rendimiento.
Costos de Operación¶
- Gestión de APIs: documentación, versionado, deprecación, comunicación de cambios, soporte a consumidores, API portal.
- Gestión de certificados y credenciales: TLS certificates, OAuth2 secrets, API keys, certificate rotation.
- Monitoreo y alerting: dashboards de latencia P50/P95/P99, error rates, availability, circuit breaker status, saturation.
- Capacity planning: cada nuevo consumidor de una API añade carga al proveedor. Sin capacity planning, un nuevo partner con alto volumen puede degradar el servicio para todos.
Errores Frecuentes de Implementación¶
- No implementar timeouts en el cliente, resultando en threads bloqueados indefinidamente.
- No implementar circuit breakers, permitiendo que un servicio caído reciba miles de solicitudes que todas fallan.
- Exponer detalles internos de implementación en las respuestas de error (stack traces, nombres de tablas, queries SQL).
- No validar la entrada del cliente en el servidor, confiando en que el cliente envía datos correctos.
- Retornar HTTP 200 para todos los casos (éxito y error) con un campo
statusen el body, violando las convenciones HTTP y rompiendo intermediarios.
Anti-Patterns Relacionados¶
- Remote Facade Gone Wrong: exponer directamente el modelo de dominio interno como API sin una capa de presentación, lo cual acopla los consumidores al modelo interno y hace imposible su evolución.
- Synchronous Everything: usar RPI síncrono para todas las integraciones, incluyendo aquellas que serían mejor servidas por Messaging asíncrono (notificaciones, procesamiento batch, event propagation).
- Leaky Abstraction: la interfaz remota expone detalles de implementación (IDs de base de datos, nombres de tablas, estructura de microservicios internos) que deberían estar ocultos.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Messaging: RPI y Messaging se complementan frecuentemente. RPI se usa para queries (consultas en tiempo real) y operaciones que requieren respuesta inmediata. Messaging se usa para commands asíncronos, propagación de eventos y procesos que no requieren respuesta inmediata. El patrón CQRS formaliza esta separación.
- Service Activator: un Message Endpoint que recibe un mensaje y lo convierte en una invocación local al servicio. Es el puente entre el mundo de Messaging y el mundo de RPI.
- Request-Reply (Messaging): cuando se necesita la semántica de request-reply pero con desacoplamiento temporal, se puede implementar request-reply sobre Messaging (solicitud en una cola, respuesta en otra). Esto combina la semántica de RPI con las propiedades de Messaging.
- API Gateway: patrón arquitectónico que centraliza las invocaciones entrantes, aplicando cross-cutting concerns (autenticación, rate limiting, transformación) de forma uniforme. Es complementario a RPI como mecanismo de entrada.
Patrones que Suelen Aparecer Antes o Después¶
- Circuit Breaker: aparece como protección del cliente contra fallos del servidor. Cuando las invocaciones fallan consecutivamente, el circuit breaker se abre y retorna un error inmediato sin intentar la invocación.
- Retry con Backoff: aparece cuando una invocación falla por error transitorio (timeout, 503). El cliente reintenta con espera exponencial.
- Bulkhead: aparece para aislar las invocaciones a diferentes servicios en pools separados, evitando que el fallo de un servicio consuma todos los recursos del cliente.
- Message Translator / Anti-Corruption Layer: aparece cuando el contrato del servidor no coincide con el modelo del cliente. Una capa de traducción adapta los tipos de datos, convenciones y semántica entre ambos.
- Claim Check: cuando el payload es demasiado grande para transportar en la invocación remota, se almacena externamente y solo se transporta una referencia.
Combinaciones Comunes¶
- RPI + Circuit Breaker + Retry: la combinación estándar para invocaciones resilientes. El cliente reintenta ante fallos transitorios, pero el circuit breaker previene la saturación del servidor cuando los fallos son persistentes.
- RPI + API Gateway + Service Mesh: la combinación estándar para arquitecturas de microservicios. El API Gateway maneja tráfico externo, el service mesh maneja tráfico interno, y RPI es el estilo de comunicación para ambos.
- RPI + CQRS + Messaging: RPI para el lado de lectura (queries con baja latencia), Messaging para el lado de escritura (commands con desacoplamiento temporal y reliability).
- RPI + Saga: para transacciones distribuidas que involucran múltiples servicios, el patrón Saga coordina una secuencia de invocaciones RPI con compensaciones en caso de fallo.
Diferencias con Patrones Similares¶
- vs. File Transfer: RPI es síncrono, de baja latencia, transacción por transacción; File Transfer es asíncrono, batch, de alta latencia. RPI acopla temporalmente; File Transfer desacopla temporalmente.
- vs. Shared Database: RPI preserva la encapsulación de datos (cada sistema controla su propio storage); Shared Database expone los datos internos. RPI permite evolución independiente del modelo de datos; Shared Database la impide.
- vs. Messaging: RPI es request-reply síncrono; Messaging es fire-and-forget asíncrono (por defecto). RPI ofrece consistencia fuerte; Messaging ofrece consistencia eventual. RPI falla si el servidor está caído; Messaging bufferiza en el broker.
Encaje en un Flujo Mayor de Integración¶
Remote Procedure Invocation típicamente aparece en el centro de la arquitectura de integración: como mecanismo de comunicación entre el front-end y el back-end, entre microservicios que necesitan coordinarse en tiempo real, y como interfaz expuesta a partners externos. En los bordes de la arquitectura (integración con mainframes legacy, sistemas batch, data pipelines), File Transfer y Messaging pueden ser más apropiados. En una arquitectura enterprise madura, RPI coexiste con Messaging: RPI para el plano de control y queries, Messaging para el plano de datos y eventos.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Remote Procedure Invocation es, sin discusión, el estilo de integración dominante en las arquitecturas modernas. Su relevancia no solo se ha mantenido sino que ha crecido exponencialmente con la adopción masiva de microservicios, APIs REST, gRPC, GraphQL, API management platforms y service meshes. La economía digital actual se construye sobre APIs, y cada API es una manifestación de Remote Procedure Invocation.
Evidencia de vigencia:
- Prácticamente toda plataforma digital expone APIs REST/gRPC como mecanismo primario de integración.
- Los cloud providers (AWS, Azure, GCP) exponen toda su funcionalidad como APIs REST. Interactuar con cualquier servicio cloud es una forma de RPI.
- Los estándares de industria modernos (Open Banking, TM Forum APIs, FHIR para salud, PSD2) están definidos como APIs REST/gRPC.
- El ecosistema de herramientas alrededor de RPI es enormemente maduro: OpenAPI, Swagger, Postman, gRPC, GraphQL, API gateways, contract testing, API management platforms.
- Los service meshes (Istio, Linkerd, Consul Connect) están diseñados específicamente para gestionar las complejidades de RPI en arquitecturas de microservicios.
Manifestaciones Modernas de RPI¶
REST APIs sobre HTTP: la manifestación más ubicua de RPI. APIs resource-oriented que usan HTTP methods (GET, POST, PUT, DELETE, PATCH) con JSON como formato de serialización. Fortalezas: universalidad, simplicidad, herramientas maduras, cacheable (GET). Debilidades: no es tipado fuertemente, JSON es verbose, HTTP/1.1 tiene limitaciones de multiplexing.
gRPC sobre HTTP/2: la manifestación de alto rendimiento de RPI. APIs operation-oriented definidas con Protocol Buffers, transportadas sobre HTTP/2 con multiplexing, streaming bidireccional y serialización binaria compacta. Fortalezas: rendimiento superior (10x más rápido que REST/JSON en algunos benchmarks), tipado fuerte, code generation, streaming. Debilidades: no legible por humanos, soporte limitado en navegadores (requiere gRPC-Web o proxy), menos herramientas de debugging.
GraphQL: la manifestación query-oriented de RPI. El cliente define exactamente qué datos necesita en una query tipada. Fortalezas: elimina over-fetching y under-fetching, un solo endpoint para múltiples recursos, tipado fuerte con schema introspectable. Debilidades: complejidad del servidor (resolvers, N+1 queries), caching más difícil (POST para todo), seguridad (queries arbitrariamente complejas).
Service Meshes como Infraestructura de RPI¶
Los service meshes (Istio, Linkerd, Consul Connect) representan la evolución de la infraestructura que soporta RPI en arquitecturas de microservicios. Un service mesh proporciona, de forma transparente para la aplicación:
- Mutual TLS (mTLS): cifrado y autenticación bidireccional entre servicios sin cambios en el código de la aplicación.
- Traffic management: load balancing inteligente, canary deployments, traffic splitting, retries automáticos.
- Circuit breaking: protección automática contra servicios degradados.
- Observabilidad: distributed tracing, métricas de latencia y error rates, sin instrumentación manual.
- Access control: políticas de autorización service-to-service basadas en identidad.
API Gateways como Punto de Entrada de RPI¶
Los API gateways (Kong, Apigee, Azure API Management, AWS API Gateway, MuleSoft Anypoint) han madurado como la capa estándar para gestionar invocaciones remotas entrantes. Proporcionan:
- Autenticación y autorización centralizadas (OAuth2, JWT, API keys).
- Rate limiting y throttling por consumidor.
- Request/response transformation.
- Caching de respuestas.
- Analytics y reporting de uso de API.
- Developer portal para documentación y onboarding de consumidores.
Contract Testing como Práctica de Calidad¶
El contract testing (Pact, Spring Cloud Contract) ha emergido como la práctica clave para gestionar la calidad de las invocaciones remotas. En lugar de tests de integración end-to-end (lentos, frágiles, costosos), el contract testing verifica que:
- El consumidor envía solicitudes conformes al contrato esperado.
- El proveedor retorna respuestas conformes al contrato publicado.
- Los cambios en el proveedor no rompen los contratos existentes de los consumidores.
Esto permite despliegue independiente con confianza, uno de los beneficios fundamentales de RPI bien implementado.
15. Implementación en Arquitecturas Modernas¶
REST sobre HTTP (Spring Boot, Express, FastAPI)¶
La implementación más común de RPI. Un servicio expone endpoints HTTP con recursos tipados. Frameworks como Spring Boot (Java), Express (Node.js), FastAPI (Python) y ASP.NET Core (.NET) proporcionan abstracciones maduras para definir controllers, serialización JSON automática, validación de entrada, manejo de errores y generación de OpenAPI spec.
# Ejemplo conceptual de un endpoint REST:
GET /v1/subscribers/{msisdn}/balance → { balance: 15.42, currency: "USD" }
POST /v1/charging/charges → { chargeId: "CHG-001", status: "COMPLETED" }
Consideraciones: - Versionado: URL path versioning (/v1/) es lo más simple y explícito. - Pagination: cursor-based pagination para colecciones grandes. - HATEOAS: útil para APIs explorables, pero rara vez implementado completamente en la práctica. - Compression: gzip/brotli para responses grandes. - Connection pooling: HTTP keep-alive para reutilizar conexiones TCP.
gRPC (Protocol Buffers)¶
Implementación de alto rendimiento de RPI. Ideal para comunicación service-to-service dentro de un cluster donde la legibilidad humana es menos importante que el rendimiento. Los archivos .proto definen el contrato:
service ChargingService {
rpc ExecuteCharge (ChargeRequest) returns (ChargeResponse);
rpc GetBalance (BalanceRequest) returns (BalanceResponse);
}
Consideraciones: - Requiere generación de código (protoc) para cada lenguaje. - HTTP/2 nativo: multiplexing, header compression, bidirectional streaming. - Streaming: server streaming (push de actualizaciones), client streaming (carga de datos), bidirectional streaming (chat, telemetry). - Dead-letter en caso de desconexión: no nativo, debe implementarse externamente. - Load balancing: L7 load balancing necesario (envoy, Istio) porque HTTP/2 multiplexing puede concentrar todas las requests en una conexión.
GraphQL (Apollo, Hasura, Relay)¶
Implementación query-oriented de RPI. Especialmente útil como capa de agregación (BFF - Backend For Frontend) que compone datos de múltiples servicios backend en una sola query del front-end.
query SubscriberDashboard($msisdn: String!) {
subscriber(msisdn: $msisdn) {
name
balance { amount currency }
recentCharges(limit: 5) { chargeId amount date }
plan { name dataRemaining }
}
}
Consideraciones: - El servidor GraphQL actúa como un agregador que invoca múltiples servicios backend (cada campo puede resolver desde un servicio diferente). - Query complexity limits: limitar la profundidad y complejidad de queries para prevenir abuso. - DataLoader pattern: batching y caching de resolvers para evitar N+1 queries. - Subscriptions: GraphQL subscriptions sobre WebSocket para datos en tiempo real.
API Gateways¶
Kong Enterprise: API gateway open-source (core) y enterprise con plugins para autenticación, rate limiting, transformación, logging. Desplegable en Kubernetes, VM o cloud. Soporta OpenID Connect, OAuth2, JWT, mTLS. Plugin ecosystem extenso (Lua, Go).
Apigee (Google Cloud): plataforma de API management full lifecycle. Incluye developer portal, analytics, monetización. Adecuado para programas de APIs externas (partner APIs, public APIs). Soporte para mediation, transformation y orchestration.
Azure API Management (APIM): API management nativo de Azure. Integración profunda con Azure AD, Azure Functions, Logic Apps. Policies engine para transformación, caching, rate limiting. Developer portal auto-generado desde OpenAPI specs.
AWS API Gateway: API gateway serverless de AWS. Integración nativa con Lambda, DynamoDB, Step Functions. REST APIs y HTTP APIs (más simples y baratas). WebSocket APIs para comunicación bidireccional.
Service Meshes¶
Istio: service mesh basado en Envoy proxy. Proporciona mTLS automático, traffic management (canary, blue-green, fault injection), observabilidad (integración con Jaeger, Prometheus, Kiali) y authorization policies. Complejidad operacional significativa; recomendado para organizaciones con madurez en Kubernetes.
Linkerd: service mesh ultraligero. Menor footprint y complejidad que Istio. Proporciona mTLS, load balancing, retries, timeouts y observabilidad con bajo overhead. Excelente opción para organizaciones que necesitan las ventajas de un service mesh sin la complejidad de Istio.
Spring Cloud¶
Spring Cloud proporciona un conjunto integrado de herramientas para implementar RPI en el ecosistema Java/Spring:
- Spring Cloud OpenFeign: clientes HTTP declarativos con circuit breaker integrado (Resilience4j).
- Spring Cloud Gateway: API gateway reactivo para routing, filtering y rate limiting.
- Spring Cloud Circuit Breaker: abstracción sobre Resilience4j para circuit breakers, retries, bulkheads.
- Spring Cloud Contract: contract testing consumer-driven.
- Spring Cloud Sleuth / Micrometer Tracing: distributed tracing con propagación automática de trace IDs.
MuleSoft Anypoint Platform¶
MuleSoft implementa RPI a través de su plataforma de integración:
- API Designer: diseño contract-first con RAML u OpenAPI.
- Mule Runtime: engine de integración que expone y consume APIs REST/SOAP.
- Anypoint API Manager: governance, rate limiting, analytics.
- Anypoint Exchange: catálogo de APIs reutilizables.
- DataWeave: lenguaje de transformación para mapeo de datos entre contratos.
MuleSoft es particularmente relevante en contextos enterprise donde se necesita mediar entre sistemas legacy (SOAP, JMS, ficheros) y consumidores modernos (REST, GraphQL), actuando como capa de traducción que expone las capacidades legacy como APIs modernas.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave (RED method): Rate (solicitudes por segundo), Errors (tasa de errores), Duration (latencia P50, P95, P99). Estas métricas deben estar disponibles por endpoint, por consumidor y por versión de API.
- Métricas de saturación: utilización de connection pools, threads activos, cola de solicitudes pendientes, utilización de CPU y memoria del servicio.
- Health checks: liveness probe (el servicio está corriendo), readiness probe (el servicio puede recibir tráfico), dependency health (los servicios de los que depende están disponibles).
- Alertas: latencia P99 excede SLA, error rate supera umbral, circuit breaker abierto, rate limit alcanzado, certificado próximo a expirar.
Tracing¶
- Distributed tracing: cada invocación remota debe propagar un trace ID (W3C Trace Context, B3 propagation) que permite reconstruir el flujo completo de una operación de negocio a través de múltiples servicios.
- Herramientas: Jaeger, Zipkin, AWS X-Ray, Azure Application Insights, Google Cloud Trace, Datadog APM.
- Span metadata: cada span debe incluir el servicio origen, servicio destino, operación, status code, duración, y atributos relevantes de negocio.
- Sampling: en entornos de alto tráfico, el tracing al 100% es prohibitivo. Se implementa sampling (1%, 10%) con excepción de traces con errores (always sample errors).
Monitoreo¶
- Dashboard operacional: disponibilidad de cada API endpoint (uptime), latencia actual vs. SLA, top errores, top consumidores por volumen, circuit breaker status.
- Dependency map: visualización del grafo de dependencias entre servicios (qué servicio invoca a qué otro servicio, con qué volumen y qué latencia). Herramientas: Kiali (Istio), Jaeger dependency graph, ServiceNow CMDB.
- SLA monitoring: tracking automatizado de cumplimiento de SLAs por API y por consumidor.
- Capacity monitoring: proyección de cuándo se alcanzará el límite de capacidad del servicio basado en tendencias de tráfico.
Versionado¶
- Estrategia de versionado: URL path versioning (
/v1/,/v2/) es la más común y explícita. Header versioning (Accept-Version: 2) es más limpio pero menos visible. Content negotiation (Accept: application/vnd.api.v2+json) es más RESTful pero más complejo. - Backward compatibility: los cambios que no rompen consumidores (añadir campos opcionales, añadir endpoints) no requieren nueva versión. Los cambios que rompen consumidores (eliminar campos, cambiar tipos, eliminar endpoints) requieren nueva versión.
- Deprecation policy: las versiones antiguas deben tener un periodo de deprecación anunciado (6-12 meses es típico) durante el cual siguen funcionando pero se comunica a los consumidores la necesidad de migrar.
- Sunset header:
Sunset: Sat, 01 Jan 2027 00:00:00 GMTindica cuándo una API dejará de funcionar.
Seguridad¶
- Transport security: TLS 1.2+ obligatorio para todas las invocaciones. mTLS (mutual TLS) para comunicación service-to-service en entornos de alta seguridad.
- Autenticación: OAuth 2.0 (client credentials para service-to-service, authorization code para usuarios), JWT (validación local sin round-trip al auth server), API keys (para APIs de baja seguridad).
- Autorización: RBAC (Role-Based Access Control), ABAC (Attribute-Based Access Control), scope-based authorization (OAuth2 scopes). Implementada en el API Gateway y/o en el servicio.
- Input validation: toda entrada del cliente debe validarse en el servidor. Nunca confiar en la validación del lado del cliente. Validar tipos, rangos, formatos, longitudes, y rechazar caracteres o patrones peligrosos (SQL injection, XSS).
- Rate limiting: proteger contra abuso y DDoS. Implementar rate limiting por consumidor, por IP, por endpoint. Retornar
429 Too Many Requestscon headerRetry-After. - CORS: para APIs consumidas desde navegadores, configurar CORS policies restrictivas (solo orígenes permitidos, solo métodos necesarios).
Manejo de Errores¶
- Error responses estructuradas: utilizar un formato consistente para todas las respuestas de error. RFC 7807 (Problem Details for HTTP APIs) es el estándar recomendado:
- HTTP status codes semánticos: 400 (bad request), 401 (not authenticated), 403 (not authorized), 404 (not found), 409 (conflict), 422 (validation error), 429 (rate limited), 500 (internal error), 502 (bad gateway), 503 (service unavailable), 504 (gateway timeout).
- No exponer detalles internos: las respuestas de error nunca deben incluir stack traces, nombres de tablas de base de datos, queries SQL, IPs internas u otra información que pueda ser explotada por un atacante.
Retries¶
- Retry con exponential backoff: ante errores transitorios (503, 504, connection reset), reintentar con espera exponencial (1s, 2s, 4s, 8s...) con jitter aleatorio para evitar thundering herd.
- Retry budget: limitar el número total de retries para evitar amplificación de carga. Si el servicio está caído, 1000 clientes retransmitiendo 3 veces cada uno generan 3000 solicitudes adicionales que empeoran la situación.
- Idempotency keys: para operaciones de mutación, el cliente debe enviar un idempotency key que permita al servidor detectar y deduplicar retries.
Circuit Breakers¶
- Estados: Closed (flujo normal), Open (invocaciones rechazadas inmediatamente), Half-Open (se permite una solicitud de prueba para verificar si el servicio se recuperó).
- Umbrales: configurar umbral de apertura (e.g., 50% de error en los últimos 10 segundos), duración de estado Open (e.g., 30 segundos), número de solicitudes de prueba en Half-Open.
- Fallbacks: cuando el circuit breaker está abierto, el cliente puede: retornar un valor por defecto (cached), retornar un error inmediato, invocar un servicio alternativo, o degradar la funcionalidad (mostrar datos parciales).
- Herramientas: Resilience4j (Java), Polly (.NET), Hystrix (Java, deprecated), Istio circuit breaking (infraestructura).
Rate Limiting¶
- Algoritmos: Token bucket (permite ráfagas), Sliding window (más preciso), Fixed window (más simple). Token bucket es el más utilizado en API gateways.
- Granularidad: por consumidor (API key, client ID), por IP, por endpoint, por plan comercial.
- Headers de respuesta:
X-RateLimit-Limit,X-RateLimit-Remaining,X-RateLimit-Resetinforman al consumidor su cuota y uso. - Distributed rate limiting: en entornos multi-instancia, el rate limiting debe ser distribuido (Redis como backend de contadores) para ser preciso.
Autenticación y Autorización¶
- OAuth 2.0 flows: Client Credentials (service-to-service), Authorization Code + PKCE (usuarios), Resource Owner Password (legacy, no recomendado). Token introspection para validación centralizada; JWT validation para validación local (sin round-trip al auth server, pero sin revocación inmediata).
- API Keys: simples de implementar, útiles para rate limiting y analytics. No proporcionan la seguridad de OAuth2. Deben transmitirse solo en headers (no en URLs, que se loguean).
- Scopes y permissions: los tokens OAuth2 deben tener scopes que limiten las operaciones permitidas. Un token con scope
balance:readno debe poder ejecutar cobros. La autorización granular se implementa en el servicio o en el API gateway.
17. Errores Comunes¶
Construir un Distributed Monolith¶
El error más grave y más frecuente al adoptar RPI en una arquitectura de microservicios es construir un distributed monolith: servicios que se invocan síncronamente en cadenas largas, sin circuit breakers, sin timeouts adecuados, sin fallbacks, donde el fallo de cualquier servicio en la cadena tumba toda la operación. El resultado tiene la complejidad de un sistema distribuido y el acoplamiento de un monolito. La solución requiere disciplina arquitectónica: minimizar las cadenas de invocación síncrona, implementar circuit breakers en cada invocación, definir fallbacks para cada dependencia, y evaluar si algunas interacciones deberían ser asíncronas (Messaging) en lugar de síncronas (RPI).
Diseñar APIs Chatty (Charlatanas)¶
APIs con granularidad excesivamente fina que requieren múltiples round-trips para completar una operación de negocio. Ejemplo: para mostrar el dashboard de un suscriptor, el front-end hace 12 llamadas HTTP independientes (perfil, saldo, plan, historial de consumo, ofertas, notificaciones, configuración, contactos frecuentes...). La latencia total es la suma de las latencias individuales más el overhead de cada conexión. La solución: diseñar APIs con granularidad adecuada al caso de uso (aggregate endpoints, BFF pattern, GraphQL), agrupando los datos que el consumidor necesita en conjunto.
No Implementar Circuit Breakers¶
Omitir circuit breakers es el equivalente a no tener fusibles en una instalación eléctrica. Cuando un servicio downstream falla o se degrada, sin circuit breaker el cliente sigue enviando solicitudes que todas fallan, consumiendo threads, conexiones y tiempo. Peor aún, el servidor degradado recibe más carga de la que puede manejar, profundizando su degradación. El circuit breaker corta el flujo de solicitudes hacia el servicio fallido, permite que se recupere, y retorna errores inmediatos al cliente, liberando recursos.
Acoplamiento a Través de Modelos Compartidos¶
Cuando múltiples servicios comparten las mismas clases de modelo de datos (por ejemplo, una librería common-models.jar con la clase Customer usada por 15 servicios), cualquier cambio en el modelo obliga a recompilar y redesplegar todos los consumidores. Esto es acoplamiento de compilación a través de modelos compartidos. La solución: cada servicio define su propia representación interna de los datos y traduce desde/hacia el contrato de la API. Los servicios no comparten código de modelo; comparten el contrato (OpenAPI spec, protobuf file) y cada uno genera o implementa su propia representación.
Ignorar la Evolución de Contratos¶
Desplegar un cambio breaking en una API sin versionar, sin comunicar a los consumidores, y sin periodo de transición es un error que genera fallos en cascada en producción. Ejemplo: renombrar un campo de customerId a subscriberId en la respuesta rompe todos los consumidores que parsean customerId. La solución: todo cambio breaking requiere nueva versión de API, periodo de deprecación de la versión anterior, comunicación formal a consumidores, y coexistencia temporal de ambas versiones.
Timeouts Ausentes o Mal Configurados¶
No configurar timeouts es una bomba de tiempo. Cuando el servicio destino se cuelga (no responde, no cierra la conexión, responde infinitamente lento), el cliente se bloquea indefinidamente, agotando su pool de threads o conexiones. Timeouts demasiado altos (60 segundos) tienen un efecto similar. Timeouts demasiado bajos generan falsos positivos. La configuración correcta requiere conocer la latencia P99 del servicio destino y configurar el timeout con un margen razonable (e.g., P99 * 2 o P99 + 1 segundo). Además, los timeouts deben incluir connection timeout (tiempo para establecer la conexión TCP) y read timeout (tiempo para recibir la respuesta).
Logging Insuficiente o Excesivo¶
Logging insuficiente: no registrar el request/response de invocaciones remotas hace imposible diagnosticar problemas en producción. Logging excesivo: registrar el body completo de todas las solicitudes y respuestas en producción genera volúmenes de logs inmanejables, costos de storage elevados, y potenciales violaciones de privacidad (PII en logs). La solución es un balance: loguear siempre request ID, endpoint, status code, latencia y error message. Loguear body solo en nivel DEBUG, con sanitización de datos sensibles, y solo habilitarlo temporalmente para diagnóstico.
No Medir la Latencia End-to-End¶
Medir la latencia de cada servicio individual no es suficiente si no se mide la latencia end-to-end experimentada por el cliente. Un flujo que invoca 5 servicios, cada uno con 100ms de latencia, tiene 500ms de latencia total mínima (sin contar overhead de red). Si el SLA del cliente es 1 segundo, el budget de latencia por servicio es muy limitado. El distributed tracing proporciona esta visibilidad end-to-end.
18. Conclusión Técnica¶
Remote Procedure Invocation es el estilo de integración que ha definido la era de las plataformas digitales. Desde las primeras implementaciones de RPC y CORBA hasta las APIs REST, gRPC y GraphQL de hoy, el principio permanece invariable: un sistema invoca una operación en otro y obtiene un resultado en tiempo real. Este principio simple es la base sobre la cual se construyen experiencias digitales interactivas, ecosistemas de partners, arquitecturas de microservicios y plataformas API-first.
Para un arquitecto senior, las claves de una implementación exitosa de RPI son:
- Diseño de contratos como producto: las APIs no son un detalle de implementación sino un producto que tiene consumidores, un ciclo de vida, un contrato de calidad (SLA) y un proceso de evolución. El diseño de APIs requiere la misma disciplina que el diseño de cualquier otro producto de software: usabilidad, consistencia, extensibilidad y documentación.
- Resiliencia como requisito, no como optimización: circuit breakers, timeouts, retries, fallbacks y bulkheads no son mejoras opcionales. Son requisitos de primera clase para cualquier sistema que depende de invocaciones remotas en producción. Sin ellos, el sistema falla de formas catastróficas e impredecibles.
- Observabilidad como habilitador, no como overhead: distributed tracing, métricas RED, health checks y dashboards operacionales no son "nice to have". Son la herramienta fundamental para diagnosticar problemas en un sistema distribuido donde el flujo de una operación cruza múltiples servicios, redes y equipos.
- Gobierno pragmático: estándares de diseño de APIs, políticas de versionado, revisión de contratos y contract testing deben implementarse como guardrails automatizados en CI/CD, no como procesos de aprobación manual que frenan la entrega. El objetivo es permitir que los equipos se muevan rápido dentro de límites seguros.
- Evaluación honesta de sincronía vs. asincronía: no toda interacción entre sistemas debe ser síncrona. Un arquitecto maduro evalúa si cada interacción realmente necesita respuesta inmediata (RPI) o si puede beneficiarse del desacoplamiento temporal de Messaging. La respuesta correcta frecuentemente es una combinación de ambos estilos dentro de la misma arquitectura: RPI para queries y operaciones transaccionales, Messaging para eventos, commands asíncronos y procesamiento diferido.
Recomendación para arquitectos: Remote Procedure Invocation es probablemente el estilo de integración que más utilizará en su carrera. Invierta en dominarlo profundamente: no solo la mecánica de hacer una llamada HTTP, sino el diseño de contratos evolutivos, la gestión de fallos distribuidos, la observabilidad end-to-end, la seguridad de APIs, y las decisiones de cuándo usar REST vs. gRPC vs. GraphQL vs. Messaging. La diferencia entre una arquitectura basada en APIs que funciona en producción y una que se convierte en un distributed monolith frágil no está en la tecnología elegida, sino en la disciplina con la que se aplican los patrones de resiliencia, el rigor con el que se diseñan los contratos y la honestidad con la que se evalúan los trade-offs entre sincronía y asincronía.