Messaging¶
1. Nombre del Patrón¶
- Nombre oficial: Messaging
- Categoría: Integration Styles (Estilos de Integración)
- Traducción contextual: Mensajería (Integración Basada en Mensajes)
2. Resumen Ejecutivo¶
Messaging es un estilo de integración en el cual las aplicaciones se comunican enviando y recibiendo mensajes a través de un intermediario conocido como message broker o messaging system. En lugar de invocar funcionalidad directamente entre sí o compartir datos a través de archivos o bases de datos, las aplicaciones depositan mensajes en canales lógicos (queues o topics) gestionados por una infraestructura de mensajería, y otras aplicaciones consumen esos mensajes de forma asíncrona e independiente.
Este patrón existe porque los otros tres estilos de integración (File Transfer, Shared Database, Remote Procedure Invocation) presentan limitaciones fundamentales en escenarios enterprise de alta escala: File Transfer impone latencia inaceptable para flujos en tiempo real, Shared Database crea acoplamiento estructural entre aplicaciones, y Remote Procedure Invocation introduce acoplamiento temporal que compromete la resiliencia. Messaging resuelve estas limitaciones al introducir un intermediario que desacopla a los participantes tanto en tiempo como en espacio, permitiendo comunicación asíncrona, confiable y escalable.
Messaging no es simplemente otro estilo de integración. Es el estilo de integración fundacional sobre el cual se construye la totalidad de los Enterprise Integration Patterns. Todos los patrones catalogados por Hohpe y Woolf -- Message Channel, Message, Pipes and Filters, Message Router, Message Translator, Message Endpoint -- presuponen una infraestructura de mensajería. Sin Messaging como estilo de integración, ninguno de los demás patrones EIP tiene sentido. Es, en la taxonomía de los patrones de integración, el principio generador.
3. Definición Detallada¶
Propósito¶
El propósito de Messaging es permitir que dos o más aplicaciones intercambien datos y coordinen comportamiento de forma asíncrona, confiable y desacoplada, mediante el envío de unidades discretas de información (mensajes) a través de un intermediario (broker o messaging system) que gestiona la entrega, el almacenamiento temporal y el routing de esos mensajes.
Lógica Arquitectónica¶
Messaging introduce una triple indirección entre productor y consumidor:
- Indirección temporal: el productor y el consumidor no necesitan estar disponibles simultáneamente. El broker almacena los mensajes hasta que el consumidor esté listo para procesarlos. Si el consumidor está caído, los mensajes se acumulan en el broker y se entregarán cuando el consumidor se recupere.
- Indirección espacial: el productor no necesita conocer la ubicación, dirección IP, endpoint ni identidad del consumidor. Solo necesita conocer el canal (queue o topic) donde depositar el mensaje. El broker se encarga de la entrega al consumidor correcto.
- Indirección de velocidad: el productor puede emitir mensajes a su propio ritmo sin esperar a que el consumidor los procese. El broker actúa como buffer, absorbiendo picos de carga y permitiendo que productor y consumidor operen a velocidades independientes.
Principio de Diseño Subyacente¶
El principio fundamental es desacoplamiento asíncrono a través de un intermediario. Este principio tiene raíces profundas en la ingeniería de sistemas: es análogo al concepto de buffer en hardware, al mailbox en sistemas operativos, al pipe en Unix, y al concepto de indirección que permea toda la ciencia de la computación ("todo problema en computación se puede resolver con un nivel adicional de indirección"). La innovación de Messaging no es la idea de intermediario en sí misma, sino su aplicación sistemática al problema de integración enterprise, con garantías de durabilidad, confiabilidad, ordering y routing que superan las capacidades de mecanismos más simples.
Problema Estructural que Resuelve¶
En arquitecturas enterprise, las aplicaciones que necesitan coordinar su comportamiento enfrentan un dilema fundamental: si se comunican directamente (invocación remota), cada una necesita conocer la ubicación y disponibilidad de las demás, creando una red de dependencias frágil que crece cuadráticamente con el número de sistemas; si comparten estado a través de una base de datos, acoplan sus modelos de datos internos a un esquema compartido que se convierte en un cuello de botella para la evolución independiente; si intercambian archivos, la latencia inherente impide la coordinación en tiempo real.
Messaging resuelve este dilema al introducir un intermediario que absorbe la complejidad de la comunicación. Los sistemas solo necesitan saber cómo enviar y recibir mensajes. El broker se encarga de todo lo demás: almacenamiento, entrega, routing, balanceo de carga, reintento, persistencia. El resultado es una topología donde N sistemas se integran a través de N conexiones al broker, en lugar de N*(N-1)/2 conexiones punto a punto.
Contexto en el que Emerge¶
Messaging emerge naturalmente en contextos donde:
- Múltiples sistemas necesitan coordinar su comportamiento sin acoplamiento directo.
- La disponibilidad de cada sistema no puede depender de la disponibilidad de los demás.
- El volumen de eventos o transacciones requiere procesamiento paralelo y escalable.
- Los flujos de negocio son inherentemente asíncronos (un pedido pasa por múltiples etapas no instantáneas).
- Se necesita routing dinámico basado en el contenido o tipo de mensaje.
- Los sistemas evolucionan de forma independiente y no pueden coordinarse para deployments simultáneos.
- Se requiere resiliencia ante fallos parciales: si un subsistema falla, los demás continúan operando.
Por Qué No Es Trivial¶
Aunque el concepto de "enviar un mensaje a través de un intermediario" parece simple, la implementación correcta de Messaging a escala enterprise implica resolver un conjunto de problemas no triviales que han ocupado décadas de investigación en sistemas distribuidos:
- Garantías de entrega: ¿el mensaje se entrega exactamente una vez (exactly-once), al menos una vez (at-least-once) o como máximo una vez (at-most-once)? Cada semántica tiene implicaciones profundas para el diseño del consumidor.
- Ordenamiento: ¿los mensajes se entregan en el orden en que fueron producidos? ¿A nivel global, por partición, o sin garantía de orden? El ordenamiento afecta fundamentalmente la correctitud de procesos que dependen de secuencia (e.g., debitar antes que acreditar).
- Idempotencia: dado que at-least-once es la semántica más práctica, ¿cómo garantiza el consumidor que procesar el mismo mensaje dos veces produce el mismo resultado que procesarlo una vez?
- Consistencia eventual: cuando múltiples sistemas se coordinan a través de mensajes, el estado global del sistema es eventualmente consistente, no inmediatamente consistente. Esto tiene implicaciones profundas para la experiencia del usuario, la lógica de negocio y el diseño de queries.
- Contrapresión (back-pressure): ¿qué ocurre cuando el productor emite mensajes más rápido de lo que el consumidor puede procesarlos? El broker actúa como buffer, pero todo buffer tiene un límite.
- Dead letters: ¿qué ocurre con mensajes que no pueden ser procesados? ¿Cómo se diagnostican? ¿Cómo se reenvían tras corrección?
- Schema evolution: cuando el formato del mensaje cambia, ¿cómo se garantiza compatibilidad entre productores y consumidores que se despliegan de forma independiente?
- Observabilidad: en un flujo donde un mensaje pasa por múltiples servicios y transformaciones, ¿cómo se traza el camino end-to-end para diagnosticar problemas?
Relación con Sistemas Distribuidos¶
Messaging es, en esencia, un sistema distribuido embebido dentro de una arquitectura de integración. Hereda todas las propiedades y desafíos de los sistemas distribuidos: el teorema CAP aplica al broker (¿prioriza consistencia o disponibilidad durante una partición de red?), el problema de los Two Generals aplica a la entrega de mensajes, y el consenso distribuido (Raft, Paxos, ZAB) subyace a la replicación de mensajes entre nodos del broker para alta disponibilidad.
Para un arquitecto, comprender Messaging requiere comprender sistemas distribuidos. No porque necesite implementar un broker desde cero, sino porque las decisiones de configuración del broker (replication factor, acknowledgment mode, retention policy, partition count) son decisiones de sistemas distribuidos que afectan directamente la correctitud, disponibilidad y rendimiento de la integración.
Relación con los Enterprise Integration Patterns¶
Messaging no es simplemente el cuarto estilo de integración. Es el estilo que habilita la existencia de todos los demás patrones EIP:
- Message Channel define cómo se nombran y tipifican los canales de Messaging.
- Message define la estructura de los datos que fluyen por esos canales.
- Pipes and Filters describe cómo encadenar procesadores de mensajes.
- Message Router describe cómo dirigir mensajes a diferentes canales basándose en contenido.
- Message Translator describe cómo transformar el formato de los mensajes.
- Message Endpoint describe cómo las aplicaciones se conectan al sistema de mensajería.
Sin Messaging como infraestructura, estos patrones serían abstracciones sin sustrato. Messaging es el fundamento sobre el cual se construye todo el catálogo de patrones de integración enterprise.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Messaging, las alternativas para coordinar el comportamiento de múltiples sistemas en tiempo real son:
- Invocación directa (RPC/API): cada sistema llama directamente a los demás cuando necesita que algo ocurra. Esto crea acoplamiento temporal (el llamador debe esperar respuesta), acoplamiento de disponibilidad (si el sistema llamado está caído, el llamador falla), y acoplamiento de velocidad (el llamador avanza a la velocidad del sistema más lento). A escala, una red de invocaciones directas entre N sistemas crea una malla frágil donde el fallo de un solo nodo puede desencadenar fallos en cascada.
- Base de datos compartida: los sistemas coordinan escribiendo y leyendo de una base de datos común. Esto acopla los modelos de datos internos de cada sistema a un esquema compartido, impide la evolución independiente, crea contención por locks en la base de datos, y el polling de la base de datos para detectar cambios es ineficiente y frágil.
- Transferencia de archivos: los sistemas intercambian datos mediante archivos. La latencia inherente (minutos a horas) impide la coordinación en tiempo real, y la ausencia de un mecanismo de notificación nativo obliga a polling o soluciones ad-hoc.
Síntomas del Problema¶
- Acoplamiento temporal: cuando el servicio de pagos se cae, el servicio de órdenes deja de funcionar porque está esperando una respuesta síncrona del servicio de pagos.
- Fallos en cascada: un timeout en el servicio de inventario causa timeouts en el servicio de órdenes, que causa timeouts en el gateway de API, que causa errores 500 en el frontend. Un fallo local se propaga como un dominó.
- Cuellos de botella de escalabilidad: el servicio de notificaciones no puede procesar el pico de emails del Black Friday porque está acoplado sincrónicamente a la velocidad de generación de órdenes.
- Deployment coordinado: no se puede actualizar el servicio de shipping sin actualizar simultáneamente el servicio de órdenes porque comparten una interfaz de invocación directa con contrato acoplado.
- Pérdida de datos en tránsito: una llamada HTTP que falla no tiene mecanismo nativo de retry durable. Si el caller no implementa retry con persistencia, el dato se pierde.
- Imposibilidad de replay: cuando se descubre un bug en el procesamiento, no hay forma de reprocesar los eventos pasados porque no fueron almacenados. La información se procesó y se perdió.
Impacto Operativo y Arquitectónico¶
Sin un sistema de mensajería:
- La resiliencia del sistema global es la del eslabón más débil: la disponibilidad es el producto de las disponibilidades individuales. Con 5 servicios al 99.5%, la disponibilidad combinada en invocación síncrona es 97.5%.
- La escalabilidad está limitada por el servicio más lento en la cadena síncrona. No se puede escalar el frontend sin escalar proporcionalmente todos los backends que llama sincrónicamente.
- El debugging de flujos que cruzan múltiples sistemas es extremadamente difícil sin trazabilidad centralizada.
- Los equipos no pueden evolucionar sus servicios de forma independiente porque cada cambio en una interfaz puede romper a los callers.
- Los procesos de negocio que son inherentemente asíncronos (un pedido tarda días en entregarse) se modelan con workarounds síncronos: polling de estado, callbacks frágiles, tablas de estado compartidas.
Riesgos Si No Se Implementa Correctamente¶
- Pérdida de mensajes: si el broker no está configurado con persistencia y replicación adecuadas, un fallo de infraestructura puede perder mensajes en tránsito.
- Procesamiento duplicado: sin idempotencia en el consumidor, la semántica at-least-once del broker causa que el mismo evento se procese múltiples veces (e.g., cobrar dos veces al cliente).
- Inconsistencia prolongada: si un consumidor deja de procesar mensajes (bug, crash, resource exhaustion), la ventana de inconsistencia entre sistemas crece indefinidamente.
- Complejidad de debugging: un flujo de negocio distribuido a través de mensajes asincrónicos es inherentemente más difícil de debuggear que una cadena de llamadas síncronas con un stack trace unificado.
- Mensajes envenenados (poison messages): un mensaje con formato inválido o contenido que causa un error en el consumidor puede bloquear el procesamiento de todos los mensajes posteriores en la queue si no se maneja correctamente.
Ejemplos Reales¶
- E-commerce: un marketplace global necesita que la creación de un pedido desencadene reserva de inventario, procesamiento de pago, asignación de envío, notificación al vendedor y notificación al comprador, todo de forma desacoplada para que el fallo de cualquier subsistema no impida la creación del pedido.
- Banca: un sistema de transferencias interbancarias necesita coordinar débito, acreditación, notificación regulatoria y registro contable de forma resiliente, garantizando que ninguna transferencia se pierda incluso si algún subsistema está temporalmente no disponible.
- Telecomunicaciones: un sistema de provisioning de líneas necesita orquestar la activación de SIM, asignación de número, configuración de plan, activación de roaming y envío de welcome kit, procesos que involucran sistemas heterogéneos con tiempos de respuesta que van de milisegundos a días.
- Logística: una cadena de suministro global necesita propagar eventos de tracking (recogido, en tránsito, en aduana, entregado) desde sensores IoT y sistemas de fulfillment hacia sistemas de visibilidad, facturación y servicio al cliente.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando múltiples sistemas necesitan coordinar comportamiento de forma asíncrona y desacoplada.
- Cuando se necesita resiliencia ante fallos parciales: que un subsistema caído no detenga todo el flujo.
- Cuando los volúmenes de eventos o transacciones requieren escalabilidad horizontal mediante paralelismo.
- Cuando el flujo de negocio es inherentemente asíncrono y no requiere respuesta inmediata al caller.
- Cuando se necesita routing dinámico: dirigir mensajes a diferentes consumidores según su contenido o tipo.
- Cuando múltiples consumidores necesitan recibir el mismo evento (fan-out / publish-subscribe).
- Cuando se necesita buffering para absorber picos de carga sin sobrecargar los sistemas downstream.
- Cuando los sistemas se despliegan y evolucionan de forma independiente (microservicios, equipos autónomos).
- Cuando se necesita la capacidad de replay: reprocesar eventos históricos tras corregir un bug o añadir un nuevo consumidor.
- Cuando se requiere un registro auditable y durable del flujo de eventos entre sistemas.
Cuándo No Usarlo¶
- Consultas simples síncrona con respuesta inmediata: cuando una aplicación necesita obtener el precio actual de un producto y presentarlo al usuario en milisegundos, una llamada API síncrona (REST, gRPC) es más simple y apropiada que un request-reply sobre messaging.
- Requerimientos de latencia ultra-baja: para escenarios de trading de alta frecuencia o gaming en tiempo real donde cada microsegundo importa, el overhead del broker (serialización, persistencia, network hop adicional) puede ser inaceptable.
- Dos sistemas con integración trivial: si la integración es entre exactamente dos sistemas con un contrato simple y estable, y ambos siempre están disponibles, Messaging puede ser over-engineering. Una API directa puede ser suficiente.
- Transacciones distribuidas estrictas: cuando se requiere consistencia inmediata entre múltiples sistemas (e.g., reservar y cobrar deben ser atómicos o no ocurrir), Messaging introduce eventual consistency que puede no ser aceptable. En estos casos, un patrón de Saga o un coordinador transaccional puede ser más apropiado, aunque ambos frecuentemente se implementan sobre Messaging.
- Equipos sin experiencia operacional en mensajería: operar un cluster de Kafka o RabbitMQ requiere expertise específica. Si el equipo no tiene esta capacidad y el problema no lo justifica, introducir messaging puede crear más problemas de los que resuelve.
Precondiciones¶
- Existe infraestructura de mensajería disponible (broker, managed service, o capacidad para desplegarla).
- Las aplicaciones participantes pueden conectarse al broker (red, firewall, credenciales).
- Existe acuerdo sobre el formato de los mensajes (schema, serialización, versionado).
- El equipo tiene capacidad operacional para gestionar la infraestructura de mensajería o utiliza un servicio gestionado.
- Los flujos de negocio toleran eventual consistency (o se diseñan mecanismos para gestionarla).
Restricciones¶
- El broker se convierte en un componente crítico de infraestructura: si el broker falla, la comunicación se detiene. La alta disponibilidad del broker es un prerrequisito no negociable.
- Los mensajes tienen un tamaño máximo práctico (típicamente entre 1 MB y 10 MB dependiendo del broker). Para payloads grandes, se necesita el patrón Claim Check.
- El ordenamiento de mensajes puede ser difícil de garantizar a escala, especialmente con consumidores paralelos y múltiples particiones.
- La depuración de flujos asíncronos distribuidos requiere instrumentación (distributed tracing, correlation IDs) que no es trivial de implementar.
Dependencias¶
- Infraestructura de mensajería (broker cluster con alta disponibilidad).
- Red confiable entre aplicaciones y broker.
- Mecanismo de serialización/deserialización de mensajes (JSON, Avro, Protobuf).
- Sistema de observabilidad para tracing y monitoreo de flujos de mensajes.
- Opcional: schema registry para gobierno de formatos de mensajes.
Supuestos Arquitectónicos¶
- Los flujos de negocio toleran asincronía (el productor no necesita respuesta inmediata).
- Los consumidores son idempotentes o pueden hacerse idempotentes.
- El volumen de mensajes justifica la infraestructura de mensajería.
- El equipo acepta la complejidad operacional adicional a cambio de los beneficios de desacoplamiento, resiliencia y escalabilidad.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Arquitecturas de microservicios con comunicación event-driven.
- Plataformas de e-commerce con flujos de pedidos, pagos y envíos.
- Sistemas financieros con procesamiento de transacciones y conciliación.
- Plataformas IoT con ingestión de telemetría de sensores.
- Sistemas de logística y cadena de suministro con tracking de eventos.
- Plataformas de telecomunicaciones con provisioning y activación de servicios.
- Sistemas de salud con intercambio de eventos clínicos (HL7 FHIR, eventos de historia clínica).
- Plataformas de streaming de datos y analytics en tiempo real.
- Cualquier sistema que procese eventos de dominio entre bounded contexts.
6. Fuerzas Arquitectónicas¶
Messaging es el estilo de integración con el trade-off profile más rico. A diferencia de File Transfer (latencia alta, simplicidad alta), Shared Database (consistencia alta, acoplamiento alto) o Remote Procedure Invocation (latencia baja, acoplamiento temporal alto), Messaging ocupa una posición intermedia que ofrece el mejor balance para la mayoría de los escenarios enterprise, pero introduce su propia complejidad que debe gestionarse explícitamente.
Acoplamiento vs. Flexibilidad¶
Messaging ofrece el nivel de acoplamiento más bajo de todos los estilos de integración para comunicación en near-real-time. El productor no conoce al consumidor, el consumidor no conoce al productor. Ambos solo conocen el canal (queue o topic) y el formato del mensaje. Esto permite una flexibilidad extraordinaria: se pueden añadir nuevos consumidores sin modificar al productor, se pueden reemplazar implementaciones de servicios sin afectar a los demás, y se pueden introducir transformadores, routers y filtros intermedios de forma transparente.
Sin embargo, existe un acoplamiento semántico inevitable: productor y consumidor deben acordar el significado del mensaje. Si el productor cambia la semántica del evento OrderPlaced (por ejemplo, antes significaba "orden confirmada" y ahora significa "orden recibida pendiente de validación"), los consumidores pueden comportarse incorrectamente aunque el schema no cambie. Este acoplamiento semántico es el más difícil de gestionar y el más peligroso porque es invisible a nivel técnico.
Asincronía vs. Complejidad de Razonamiento¶
La asincronía es la mayor fortaleza de Messaging y su mayor fuente de complejidad cognitiva. En una cadena de llamadas síncronas, el flujo es determinístico y trazable con un stack trace. En un flujo asíncrono, el productor "dispara y olvida", el mensaje pasa por el broker, y uno o más consumidores lo procesan en un momento indeterminado. Razonar sobre el estado del sistema en un momento dado es inherentemente más difícil: ¿el mensaje ya fue procesado? ¿Está en la queue? ¿Fue rechazado? ¿Cuántos consumidores lo recibieron?
Esta complejidad de razonamiento se manifiesta en debugging (no hay stack trace end-to-end sin distributed tracing), en testing (las pruebas de integración deben manejar asincronía, timeouts y ordering no determinístico), y en la experiencia del usuario (el usuario que coloca una orden no puede saber inmediatamente si el pago fue aceptado, si el inventario estaba disponible, o si el envío fue programado).
Resiliencia vs. Consistencia¶
Messaging mejora dramáticamente la resiliencia: si el servicio de notificaciones está caído, las órdenes siguen procesándose y las notificaciones se enviarán cuando el servicio se recupere. Pero esta resiliencia se logra al precio de consistencia eventual. Durante la ventana en que los mensajes están en el broker pero aún no han sido procesados por todos los consumidores, el estado global del sistema es inconsistente. El servicio de órdenes dice "orden confirmada", pero el servicio de inventario aún no ha reservado el stock, y el servicio de pagos aún no ha cobrado.
Para un arquitecto, la pregunta no es si aceptar eventual consistency (es inevitable en Messaging), sino cómo gestionarla: ¿cuál es la ventana de inconsistencia tolerable? ¿Qué pasa si el usuario consulta el estado durante esa ventana? ¿Cómo se compensa si un paso downstream falla después de que pasos anteriores ya se ejecutaron (Saga pattern)?
Escalabilidad vs. Complejidad Operacional¶
Messaging escala horizontalmente de forma natural: se pueden añadir más consumidores para procesar mensajes en paralelo, se pueden añadir más particiones para distribuir carga, se pueden añadir más nodos al cluster del broker para aumentar throughput. Esta escalabilidad es una de las razones principales para adoptar Messaging.
Pero esta escalabilidad requiere complejidad operacional significativa: configurar particiones, gestionar consumer groups, monitorear consumer lag, balancear particiones cuando se añaden o eliminan consumidores, gestionar la retención de mensajes, monitorear el espacio en disco del broker, configurar replicación para alta disponibilidad, gestionar upgrades del broker sin downtime. Operar un cluster de Kafka en producción a escala no es trivial.
Durabilidad vs. Latencia¶
Los brokers modernos persisten los mensajes en disco para garantizar durabilidad (no perder mensajes si el broker se reinicia). Pero la persistencia en disco introduce latencia adicional comparada con comunicación puramente en memoria. Los brokers ofrecen configuraciones para balancear este trade-off: Kafka permite configurar el acknowledgment mode (acks=0 para mínima latencia sin garantía, acks=1 para balance, acks=all para máxima durabilidad con latencia adicional). Esta configuración no es un detalle operativo: es una decisión arquitectónica que afecta la correctitud del sistema.
Throughput vs. Ordering¶
Para maximizar throughput, los brokers distribuyen mensajes entre múltiples particiones y múltiples consumidores procesan en paralelo. Pero el paralelismo rompe el ordenamiento global de mensajes. Kafka garantiza ordenamiento solo dentro de una partición, no entre particiones. Si el orden de procesamiento importa (e.g., los eventos de un pedido deben procesarse en secuencia), el arquitecto debe diseñar la partition key de modo que todos los eventos de un mismo pedido vayan a la misma partición. Esto limita el paralelismo para ese pedido específico, creando un trade-off directo entre throughput y ordering.
Gobernanza Centralizada vs. Autonomía de Equipos¶
Messaging introduce un componente de infraestructura compartida (el broker) que puede gestionarse de forma centralizada o descentralizada. Un schema registry centralizado garantiza compatibilidad de formatos pero limita la velocidad de los equipos. Topics con naming conventions estandarizadas facilitan el discovery pero requieren coordinación. La decisión de cómo gobernar el messaging system es una decisión organizacional tanto como técnica.
Observabilidad vs. Overhead¶
Para tener visibilidad de flujos asíncronos distribuidos, es necesario instrumentar cada productor y consumidor con correlation IDs, distributed tracing (OpenTelemetry), métricas de latencia, conteos de mensajes y monitoreo de consumer lag. Esta instrumentación añade overhead de desarrollo (cada servicio debe propagar headers de tracing), overhead de infraestructura (se necesita un backend de tracing como Jaeger, Zipkin o Tempo), y overhead de procesamiento (cada mensaje lleva metadata adicional). Pero sin esta observabilidad, un sistema de mensajería en producción es una caja negra imposible de diagnosticar.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
-
Productor (Producer / Sender): la aplicación que crea y envía un mensaje a un canal del broker. El productor es responsable de construir el mensaje (headers + body), serializarlo y entregarlo al broker. El productor no conoce a los consumidores; solo conoce el canal destino.
-
Mensaje (Message): la unidad de datos que fluye por el sistema de mensajería. Un mensaje típicamente consiste en:
- Headers / Metadata: información sobre el mensaje (message ID, correlation ID, timestamp, content type, reply-to address, custom headers).
- Body / Payload: los datos de negocio (el evento, el comando, el documento).
-
El mensaje es inmutable una vez publicado.
-
Canal (Channel / Queue / Topic): la abstracción lógica a través de la cual fluyen los mensajes. Existen dos modelos fundamentales:
- Queue (Point-to-Point): cada mensaje es consumido por exactamente un consumidor. Si hay múltiples consumidores, el broker balancea la carga entre ellos (competing consumers).
-
Topic (Publish-Subscribe): cada mensaje es entregado a todos los suscriptores. Cada suscriptor recibe su propia copia del mensaje.
-
Broker (Message Broker / Messaging System): el intermediario que gestiona canales, almacena mensajes, garantiza entrega, balancea carga y proporciona las garantías configuradas de durabilidad, ordering y acknowledgment. El broker es el componente central y crítico de la infraestructura de mensajería.
-
Consumidor (Consumer / Receiver): la aplicación que recibe y procesa mensajes de un canal. El consumidor es responsable de leer el mensaje, deserializarlo, procesarlo y confirmar (acknowledge) su procesamiento al broker.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Construye mensaje: headers + body]
B --> C[Serializa mensaje]
C --> D[Envía al broker con canal destino]
D --> E[Broker: Recibe, valida y persiste]
E --> F[(Almacena en el canal)]
F --> G{Modo de entrega}
G -->|Push| H[Notifica a consumidores suscritos]
G -->|Pull| I[Espera consulta del consumidor]
H --> J([Consumidor])
I --> J
J --> K[Deserializa mensaje]
K --> L[Procesa lógica de negocio]
L --> M[Confirma procesamiento - ACK]
M --> N[Broker: Marca como procesado]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Construir mensajes correctos, serializar, entregar al broker, gestionar errores de envío |
| Mensaje | Portar datos de negocio e información de routing/correlación de forma inmutable |
| Canal | Definir la semántica de entrega (point-to-point vs. pub-sub), agrupar mensajes lógicamente |
| Broker | Almacenar, entregar, garantizar durabilidad, balancear carga, gestionar suscripciones |
| Consumidor | Recibir, deserializar, procesar, confirmar, gestionar errores de procesamiento, ser idempotente |
Modelos de Entrega¶
Point-to-Point (Queue):
Producer → [Queue] → Consumer A (solo uno recibe cada mensaje)
→ Consumer B (el broker balancea entre A y B)
Publish-Subscribe (Topic):
Consumer Groups (modelo Kafka):
Producer → [Topic con 4 particiones] → Consumer Group "payments" (un miembro por partición)
→ Consumer Group "analytics" (independiente)
Contratos del Sistema de Mensajería¶
- Formato del mensaje: schema del body (JSON schema, Avro schema, Protobuf definition), headers esperados, encoding.
- Semántica de entrega: at-most-once, at-least-once, exactly-once (semántica transaccional).
- Naming convention de canales: cómo se nombran queues y topics (e.g.,
domain.entity.event,orders.order.placed). - Retención: cuánto tiempo permanecen los mensajes en el canal (indefinido en Kafka, hasta consumo en queues tradicionales).
- Tamaño máximo de mensaje: límite del broker (Kafka default 1MB, RabbitMQ configurable).
Decisiones de Diseño Clave¶
- Queue vs. Topic: ¿el mensaje debe ser procesado por un solo consumidor (command) o por múltiples suscriptores (event)? Esta decisión refleja la diferencia entre comandos y eventos en el dominio.
- Push vs. Pull: ¿el broker empuja mensajes al consumidor (RabbitMQ push model) o el consumidor solicita mensajes al broker (Kafka pull model)? Push es más simple; pull da más control al consumidor sobre su ritmo de procesamiento.
- Serialización: JSON (legible, flexible, sin schema enforcement), Avro (compacto, con schema evolution), Protobuf (compacto, con generación de código). Impacta performance, interoperabilidad y gobierno.
- Acknowledgment mode: auto-ack (mensajes se confirman al recibirlos, riesgo de pérdida si el consumidor falla), manual-ack (mensajes se confirman tras procesarlos, más seguro pero más complejo).
- Partition key: en brokers particionados (Kafka), la partition key determina qué mensajes van a la misma partición y por tanto comparten ordering guarantee. Elegir la key correcta es una decisión crítica.
- Retención vs. consumo destructivo: ¿los mensajes se eliminan tras ser consumidos (queues tradicionales) o se retienen independientemente del consumo (Kafka log)? La retención habilita replay; el consumo destructivo simplifica la gestión de storage.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail / E-commerce — Pipeline de Procesamiento de Pedidos¶
Contexto del Negocio¶
Una plataforma de e-commerce con presencia en múltiples países procesa aproximadamente 50,000 pedidos diarios en operación normal, con picos de hasta 500,000 pedidos durante eventos promocionales (Black Friday, Cyber Monday, campañas estacionales). El negocio opera con un catálogo de 2 millones de productos distribuidos en 15 categorías, fulfillment desde 8 centros de distribución, y soporte para múltiples métodos de pago y carriers de envío.
Necesidad de Integración¶
Cuando un cliente coloca un pedido, se desencadena una cadena de procesos que involucra múltiples sistemas independientes:
- Servicio de Órdenes: registra el pedido y sus line items.
- Servicio de Inventario: verifica disponibilidad y reserva stock.
- Servicio de Pagos: procesa el cobro al cliente.
- Servicio de Shipping: calcula opciones de envío, selecciona carrier, programa recolección.
- Servicio de Notificaciones: envía confirmación por email, push notification y SMS.
- Servicio de Analytics: registra métricas de conversión, revenue, basket size.
- Servicio de Fraud Detection: evalúa el riesgo de fraude de la transacción.
Cada uno de estos servicios es desarrollado y operado por un equipo diferente, desplegado de forma independiente, con tecnologías heterogéneas (Java, Go, Python, Node.js) y requisitos de escalabilidad diferentes (Analytics necesita procesar todos los eventos; Fraud Detection necesita baja latencia; Notificaciones tiene picos extremos).
Sistemas Involucrados¶
| Sistema | Tecnología | Rol | SLA de Disponibilidad |
|---|---|---|---|
| Order Service | Java / Spring Boot | Productor principal | 99.99% |
| Inventory Service | Go | Consumidor / Productor | 99.95% |
| Payment Service | Java / Micronaut | Consumidor / Productor | 99.99% |
| Shipping Service | Python / FastAPI | Consumidor | 99.9% |
| Notification Service | Node.js | Consumidor | 99.5% |
| Analytics Service | Python / Flink | Consumidor | 99.0% |
| Fraud Detection Service | Go | Consumidor / Productor | 99.99% |
| Message Broker | Apache Kafka (3 brokers) | Infraestructura | 99.99% |
Restricciones Técnicas¶
- El procesamiento de un pedido debe completarse en menos de 30 segundos en condiciones normales (excluyendo notificaciones).
- El servicio de pagos se integra con proveedores externos (Stripe, Adyen) que tienen su propia latencia (1-5 segundos).
- El inventario debe manejar concurrencia: múltiples pedidos simultáneos pueden competir por el mismo stock.
- Las notificaciones no deben bloquear el flujo principal: si el email falla, el pedido sigue siendo válido.
- El servicio de analytics no es crítico para el flujo de negocio pero debe recibir todos los eventos sin pérdida para reporting.
- El servicio de fraud detection debe evaluar el pedido antes de procesar el pago, pero su latencia no debe exceder 2 segundos.
Topics de Kafka¶
| Topic | Partition Key | Particiones | Productores | Consumidores |
|---|---|---|---|---|
orders.order.placed | order_id | 12 | Order Service | Inventory, Fraud Detection, Analytics |
orders.order.validated | order_id | 12 | Fraud Detection | Payment Service |
inventory.stock.reserved | order_id | 8 | Inventory Service | Payment Service |
payments.payment.completed | order_id | 8 | Payment Service | Shipping, Notification, Analytics |
payments.payment.failed | order_id | 8 | Payment Service | Order Service, Notification |
shipping.shipment.scheduled | order_id | 6 | Shipping Service | Notification, Analytics |
notifications.email.requested | customer_id | 4 | Notification Service (internal) | Email Worker |
Flujos de Datos¶
Cliente → [API Gateway] → Order Service → orders.order.placed
├─→ Fraud Detection → orders.order.validated
│ └─→ Payment Service
├─→ Inventory Service → inventory.stock.reserved
│ └─→ Payment Service
└─→ Analytics Service
Payment Service (espera validated + reserved) → payments.payment.completed
├─→ Shipping Service → shipping.shipment.scheduled
│ ├─→ Notification Service
│ └─→ Analytics Service
├─→ Notification Service
└─→ Analytics Service
Payment Service (si falla) → payments.payment.failed
├─→ Order Service (compensación)
└─→ Notification Service
Decisiones Arquitectónicas¶
- Kafka como broker: elegido por su capacidad de retención de eventos (7 días), replay, alto throughput (millones de mensajes/segundo), y consumer groups que permiten escalar consumidores independientemente.
- order_id como partition key: garantiza que todos los eventos de un mismo pedido se procesan en orden dentro de cada topic, lo cual es crítico para la correctitud del flujo.
- Avro como formato de serialización: con Confluent Schema Registry para gobierno de schemas y compatibilidad backward/forward entre versiones de productores y consumidores.
- Patrón Saga con coreografía: el flujo de negocio se orquesta a través de eventos entre servicios, sin un orquestador central. Cada servicio reacciona a eventos y produce nuevos eventos. Si un paso falla (e.g., pago rechazado), se publican eventos de compensación.
- Dead Letter Topics: cada consumer group tiene un DLT (e.g.,
orders.order.placed.dlq.payments) donde se depositan mensajes que no pudieron procesarse tras 3 intentos.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Cliente Coloca un Pedido¶
El cliente confirma su carrito en la aplicación web/mobile. La request llega al API Gateway, que la enruta al Order Service.
- El Order Service valida la request (campos requeridos, formatos, dirección de envío válida).
- Persiste el pedido en su base de datos PostgreSQL con estado
PENDING. - Construye un mensaje Avro
OrderPlacedcon:order_id,customer_id,items[](product_id, quantity, unit_price),shipping_address,payment_method,timestamp. - Publica el mensaje en el topic
orders.order.placedcon partition keyorder_id. - Retorna al cliente un HTTP 202 Accepted con el
order_idpara tracking.
El cliente no espera la confirmación del pago ni del inventario. La respuesta es inmediata. Todo el procesamiento posterior es asíncrono.
Paso 2: Evaluación de Fraude¶
El Fraud Detection Service es un consumer del topic orders.order.placed.
- Recibe el evento
OrderPlaced. - Evalúa el riesgo de fraude mediante un modelo ML que analiza: historial del cliente, monto del pedido, dirección de envío (nueva o conocida), velocidad de compra (múltiples pedidos en poco tiempo), dispositivo y geolocalización.
- Si el riesgo es bajo (score < 0.3), publica un evento
OrderValidatedenorders.order.validatedconfraud_scoreyvalidation_result: APPROVED. - Si el riesgo es alto (score >= 0.7), publica
OrderValidatedconvalidation_result: REJECTEDyrejection_reason. - Si el riesgo es medio (0.3 <= score < 0.7), publica
OrderValidatedconvalidation_result: MANUAL_REVIEWy encola una task para el equipo de fraude.
El Fraud Detection Service procesa cada mensaje en menos de 500ms. Si el servicio está caído, los mensajes se acumulan en la partición de Kafka y se procesarán cuando se recupere, sin perder ningún pedido.
Paso 3: Reserva de Inventario¶
El Inventory Service es otro consumer del topic orders.order.placed, operando en un consumer group independiente del Fraud Detection.
- Recibe el evento
OrderPlaced. - Para cada line item, verifica disponibilidad en la base de datos de inventario.
- Si hay stock suficiente para todos los items, ejecuta una reserva (decrementa stock disponible, incrementa stock reservado) de forma atómica en una transacción de base de datos.
- Publica un evento
StockReservedeninventory.stock.reservedcon los detalles de la reserva. - Si algún item no tiene stock, publica
StockReservationFailedcon los items faltantes. - La reserva tiene un TTL de 15 minutos: si el pago no se completa en ese tiempo, un proceso background libera la reserva.
La concurrencia se maneja mediante optimistic locking en la base de datos de inventario: si dos pedidos compiten por la última unidad, uno tendrá éxito y el otro recibirá un StockReservationFailed.
Paso 4: Procesamiento de Pago¶
El Payment Service consume de dos topics: orders.order.validated y inventory.stock.reserved. Solo procede cuando tiene ambos eventos para el mismo order_id.
- Implementa un patrón de agregación: almacena los eventos recibidos en una store local (keyed by order_id) y verifica si tiene el par completo.
- Una vez recibidos
OrderValidated(APPROVED)+StockReservedpara el mismo order_id: - Si el pedido fue rechazado por fraude, publica
PaymentFailedconreason: FRAUD_REJECTEDy no intenta cobrar. - Si fue aprobado, invoca al proveedor de pagos externo (Stripe/Adyen) con los datos del payment method del cliente.
- Si el cobro es exitoso, publica
PaymentCompletedenpayments.payment.completedconpayment_id,amount,payment_method,transaction_reference. - Si el cobro falla (tarjeta rechazada, fondos insuficientes, error del proveedor), publica
PaymentFailedenpayments.payment.failedconfailure_reason.
La comunicación con el proveedor de pagos es síncrona (HTTP/REST) porque requiere respuesta inmediata. Messaging se usa para la coordinación entre servicios internos; la interacción con el proveedor externo es RPC.
Paso 5: Compensación en Caso de Fallo¶
Si se publica PaymentFailed:
- El Order Service consume el evento y actualiza el estado del pedido a
FAILEDcon el motivo. - El Inventory Service consume el evento y libera la reserva de stock (compensación).
- El Notification Service consume el evento y envía un email al cliente informando que el pedido no pudo completarse, con el motivo (e.g., "tarjeta rechazada") y opciones para reintentar.
Este flujo de compensación es una implementación del patrón Saga con coreografía: cada servicio escucha los eventos de fallo y ejecuta su propia compensación sin necesidad de un orquestador central.
Paso 6: Programación de Envío¶
Si se publica PaymentCompleted:
- El Shipping Service consume el evento.
- Consulta las opciones de envío disponibles según la dirección de destino, peso/volumen de los productos y preferencia del cliente (estándar, express, next-day).
- Selecciona el carrier óptimo (costo vs. velocidad vs. disponibilidad).
- Crea un shipment en el sistema del carrier via API.
- Publica
ShipmentScheduledenshipping.shipment.scheduledconcarrier,tracking_number,estimated_delivery_date.
Paso 7: Notificaciones al Cliente¶
El Notification Service consume de múltiples topics: payments.payment.completed, payments.payment.failed, shipping.shipment.scheduled.
- Para
PaymentCompleted: envía email de confirmación de pedido con resumen, monto cobrado y detalles de la orden. - Para
ShipmentScheduled: envía email/push notification con tracking number y fecha estimada de entrega. - Para
PaymentFailed: envía email con motivo del fallo y enlace para reintentar.
Las notificaciones son fire-and-forget desde la perspectiva del flujo principal. Si el servicio de email externo (SendGrid, SES) está temporalmente no disponible, el Notification Service reintenta con backoff exponencial. Si falla tras 5 intentos, el mensaje va al DLT para investigación manual.
Paso 8: Registro de Analytics¶
El Analytics Service opera como un consumidor pasivo en consumer groups independientes de cada topic relevante.
- Consume
OrderPlaced,PaymentCompleted,PaymentFailed,ShipmentScheduled. - Enriquece los eventos con datos de sesión (de dónde vino el cliente, qué campaña, qué dispositivo).
- Materializa métricas en real-time: tasa de conversión, revenue por hora, tasa de rechazo de pagos, tiempo promedio de procesamiento.
- Alimenta dashboards de Grafana/Superset y alerta si las métricas se desvían de los umbrales esperados.
El Analytics Service puede estar horas detrás del flujo principal sin impactar la experiencia del usuario. Kafka retiene los mensajes 7 días, permitiendo replay completo si se necesita reprocesar por un bug en el pipeline de analytics.
Manejo de Errores Transversales¶
- Mensaje envenenado (poison message): si un consumidor falla repetidamente al procesar un mensaje específico (e.g., JSON malformado, campo requerido ausente), el mensaje se envía al Dead Letter Topic tras 3 intentos. Un proceso de monitoreo alerta al equipo responsable.
- Timeout de reserva de inventario: si el Payment Service no procesa el pedido en 15 minutos (e.g., por un bug, un restart, o un pico de carga), el Inventory Service libera la reserva automáticamente. El Payment Service debe verificar que la reserva sigue activa antes de cobrar.
- Duplicados: dado que Kafka usa at-least-once delivery por defecto, cada consumidor implementa idempotencia: el Payment Service verifica si ya cobró ese order_id antes de llamar al proveedor; el Inventory Service verifica si ya reservó ese order_id antes de decrementar stock.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.client import Users
from diagrams.generic.compute import Rack
from diagrams.onprem.compute import Server
from diagrams.onprem.analytics import Flink
from diagrams.onprem.monitoring import Grafana
graph_attr = {
"fontsize": "14",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "0.8",
"ranksep": "1.2"
}
with Diagram(
"Messaging - E-commerce Order Processing Pipeline",
show=False,
direction="LR",
graph_attr=graph_attr,
filename="messaging_ecommerce_pipeline"
):
client = Users("Cliente")
with Cluster("API Layer"):
api_gw = Server("API Gateway")
with Cluster("Order Domain"):
order_svc = Server("Order\nService")
with Cluster("Message Broker - Apache Kafka"):
topic_placed = Kafka("orders.order\n.placed")
topic_validated = Kafka("orders.order\n.validated")
topic_reserved = Kafka("inventory.stock\n.reserved")
topic_paid = Kafka("payments.payment\n.completed")
topic_failed = Kafka("payments.payment\n.failed")
topic_shipped = Kafka("shipping.shipment\n.scheduled")
topic_dlq = Kafka("*.dlq\n(Dead Letter)")
with Cluster("Processing Services"):
fraud_svc = Server("Fraud Detection\nService")
inventory_svc = Server("Inventory\nService")
payment_svc = Server("Payment\nService")
with Cluster("Downstream Services"):
shipping_svc = Server("Shipping\nService")
notification_svc = Server("Notification\nService")
analytics_svc = Flink("Analytics\nService")
monitoring = Grafana("Observability\n(Grafana)")
# Client flow
client >> Edge(label="HTTP POST\n/orders") >> api_gw
api_gw >> order_svc
# Order publishes event
order_svc >> Edge(label="OrderPlaced", color="darkgreen") >> topic_placed
# Fan-out from OrderPlaced
topic_placed >> Edge(color="blue") >> fraud_svc
topic_placed >> Edge(color="blue") >> inventory_svc
topic_placed >> Edge(color="gray", style="dashed") >> analytics_svc
# Fraud produces validated
fraud_svc >> Edge(label="OrderValidated", color="darkgreen") >> topic_validated
# Inventory produces reserved
inventory_svc >> Edge(label="StockReserved", color="darkgreen") >> topic_reserved
# Payment consumes both, produces result
topic_validated >> Edge(color="blue") >> payment_svc
topic_reserved >> Edge(color="blue") >> payment_svc
payment_svc >> Edge(label="PaymentCompleted", color="darkgreen") >> topic_paid
payment_svc >> Edge(label="PaymentFailed", color="red") >> topic_failed
# Downstream from payment completed
topic_paid >> Edge(color="blue") >> shipping_svc
topic_paid >> Edge(color="blue") >> notification_svc
topic_paid >> Edge(color="gray", style="dashed") >> analytics_svc
# Shipping produces scheduled
shipping_svc >> Edge(label="ShipmentScheduled", color="darkgreen") >> topic_shipped
topic_shipped >> Edge(color="blue") >> notification_svc
topic_shipped >> Edge(color="gray", style="dashed") >> analytics_svc
# Failure flow
topic_failed >> Edge(color="red") >> order_svc
topic_failed >> Edge(color="red") >> notification_svc
# DLQ (conceptual)
fraud_svc >> Edge(style="dotted", color="orange") >> topic_dlq
inventory_svc >> Edge(style="dotted", color="orange") >> topic_dlq
payment_svc >> Edge(style="dotted", color="orange") >> topic_dlq
# Monitoring
topic_dlq >> Edge(style="dashed", color="orange") >> monitoring
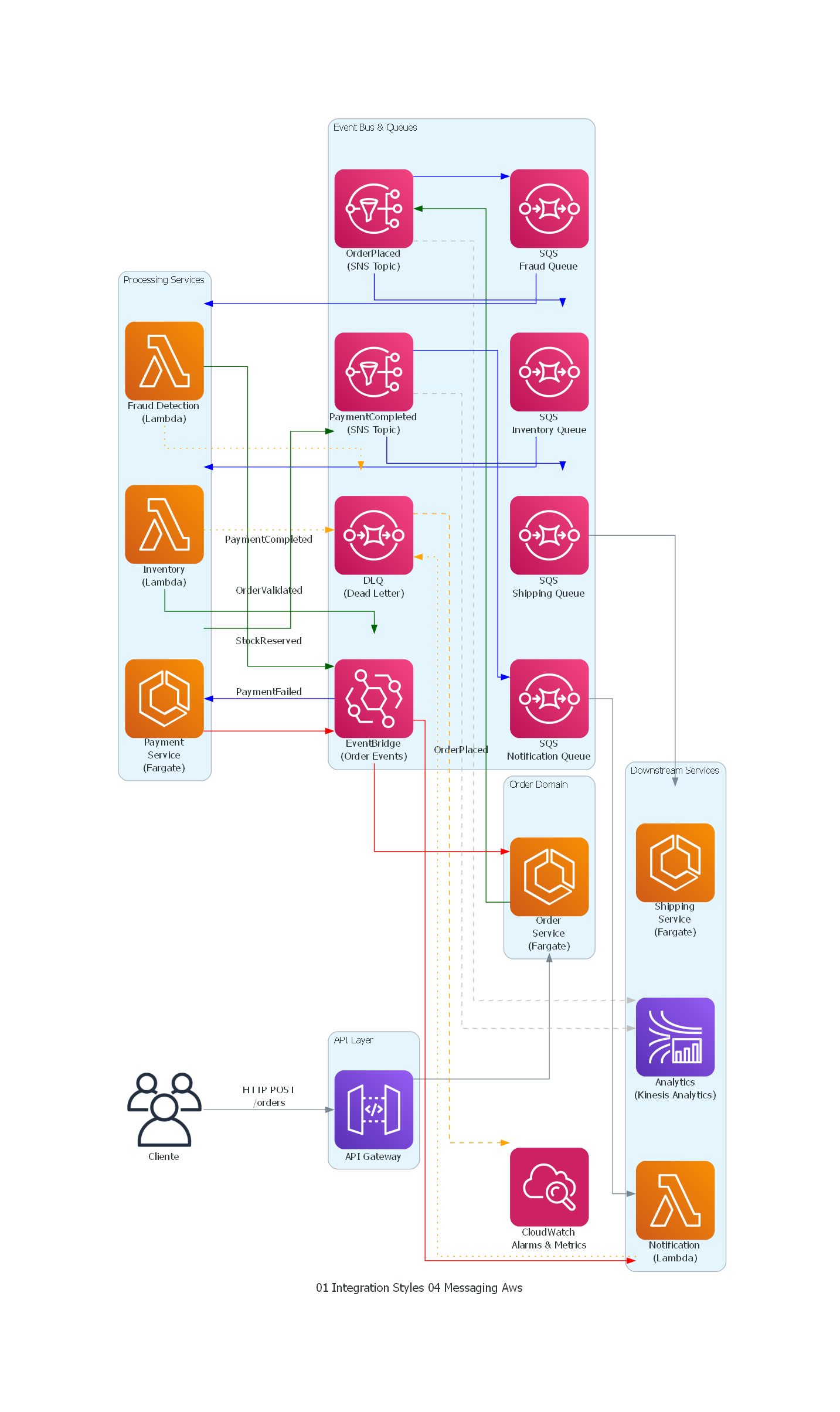
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import Users
from diagrams.aws.analytics import KinesisDataAnalytics
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.integration import SNS, SQS, Eventbridge
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
graph_attr = {
"fontsize": "14",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "0.8",
"ranksep": "1.2"
}
with Diagram(
"Messaging - E-commerce Order Processing Pipeline",
show=False,
direction="LR",
graph_attr=graph_attr,
filename="messaging_ecommerce_pipeline"
):
client = Users("Cliente")
with Cluster("API Layer"):
api_gw = APIGateway("API Gateway")
with Cluster("Order Domain"):
order_svc = ECS("Order\nService\n(Fargate)")
with Cluster("Event Bus & Queues"):
topic_placed = SNS("OrderPlaced\n(SNS Topic)")
sqs_fraud = SQS("SQS\nFraud Queue")
sqs_inventory = SQS("SQS\nInventory Queue")
event_bus = Eventbridge("EventBridge\n(Order Events)")
topic_paid = SNS("PaymentCompleted\n(SNS Topic)")
sqs_shipping = SQS("SQS\nShipping Queue")
sqs_notif = SQS("SQS\nNotification Queue")
dlq = SQS("DLQ\n(Dead Letter)")
with Cluster("Processing Services"):
fraud_svc = Lambda("Fraud Detection\n(Lambda)")
inventory_svc = Lambda("Inventory\n(Lambda)")
payment_svc = ECS("Payment\nService\n(Fargate)")
with Cluster("Downstream Services"):
shipping_svc = ECS("Shipping\nService\n(Fargate)")
notification_svc = Lambda("Notification\n(Lambda)")
analytics_svc = KinesisDataAnalytics("Analytics\n(Kinesis Analytics)")
monitoring = Cloudwatch("CloudWatch\nAlarms & Metrics")
# Client flow
client >> Edge(label="HTTP POST\n/orders") >> api_gw
api_gw >> order_svc
# Order publishes event (SNS fan-out)
order_svc >> Edge(label="OrderPlaced", color="darkgreen") >> topic_placed
# SNS fan-out to SQS subscribers
topic_placed >> Edge(color="blue") >> sqs_fraud
topic_placed >> Edge(color="blue") >> sqs_inventory
topic_placed >> Edge(color="gray", style="dashed") >> analytics_svc
# SQS triggers Lambda consumers
sqs_fraud >> Edge(color="blue") >> fraud_svc
sqs_inventory >> Edge(color="blue") >> inventory_svc
# Processing results routed through EventBridge
fraud_svc >> Edge(label="OrderValidated", color="darkgreen") >> event_bus
inventory_svc >> Edge(label="StockReserved", color="darkgreen") >> event_bus
# EventBridge routes to Payment service
event_bus >> Edge(color="blue") >> payment_svc
payment_svc >> Edge(label="PaymentCompleted", color="darkgreen") >> topic_paid
payment_svc >> Edge(label="PaymentFailed", color="red") >> event_bus
# SNS fan-out from payment completed
topic_paid >> Edge(color="blue") >> sqs_shipping
topic_paid >> Edge(color="blue") >> sqs_notif
topic_paid >> Edge(color="gray", style="dashed") >> analytics_svc
sqs_shipping >> shipping_svc
sqs_notif >> notification_svc
# Failure flow via EventBridge
event_bus >> Edge(color="red") >> order_svc
event_bus >> Edge(color="red") >> notification_svc
# DLQ for failed Lambda invocations
fraud_svc >> Edge(style="dotted", color="orange") >> dlq
inventory_svc >> Edge(style="dotted", color="orange") >> dlq
notification_svc >> Edge(style="dotted", color="orange") >> dlq
# Monitoring
dlq >> Edge(style="dashed", color="orange") >> monitoring
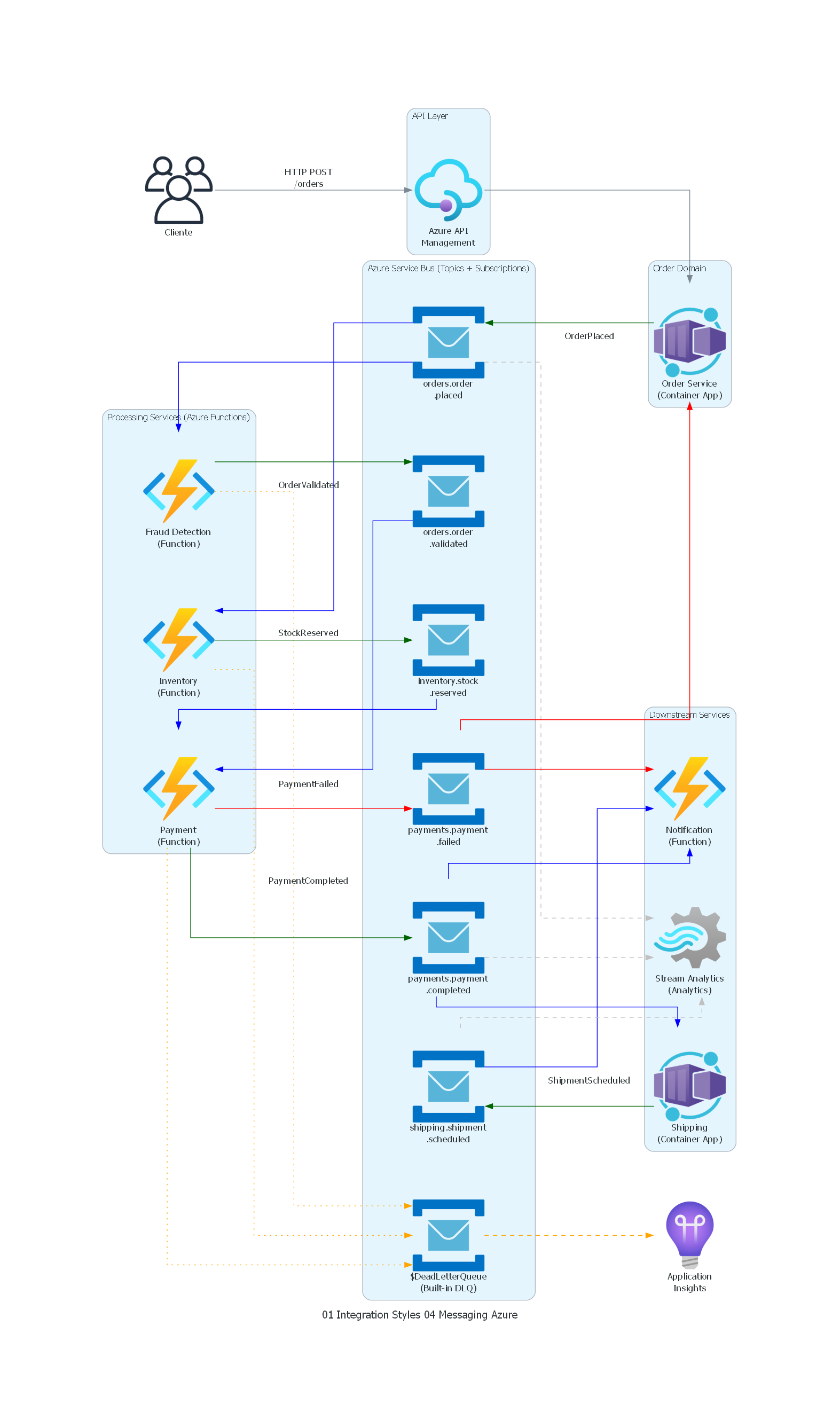
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import Users
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.analytics import StreamAnalyticsJobs
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import APIManagement, ServiceBus, EventGridTopics
graph_attr = {
"fontsize": "14",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "0.8",
"ranksep": "1.2"
}
with Diagram(
"Messaging - E-commerce Order Processing Pipeline (Azure)",
show=False,
direction="LR",
graph_attr=graph_attr,
filename="messaging_ecommerce_pipeline"
):
client = Users("Cliente")
with Cluster("API Layer"):
api_gw = APIManagement("Azure API\nManagement")
with Cluster("Order Domain"):
order_svc = ContainerApps("Order Service\n(Container App)")
with Cluster("Azure Service Bus (Topics + Subscriptions)"):
topic_placed = ServiceBus("orders.order\n.placed")
topic_validated = ServiceBus("orders.order\n.validated")
topic_reserved = ServiceBus("inventory.stock\n.reserved")
topic_paid = ServiceBus("payments.payment\n.completed")
topic_failed = ServiceBus("payments.payment\n.failed")
topic_shipped = ServiceBus("shipping.shipment\n.scheduled")
topic_dlq = ServiceBus("$DeadLetterQueue\n(Built-in DLQ)")
with Cluster("Processing Services (Azure Functions)"):
fraud_svc = FunctionApps("Fraud Detection\n(Function)")
inventory_svc = FunctionApps("Inventory\n(Function)")
payment_svc = FunctionApps("Payment\n(Function)")
with Cluster("Downstream Services"):
shipping_svc = ContainerApps("Shipping\n(Container App)")
notification_svc = FunctionApps("Notification\n(Function)")
analytics_svc = StreamAnalyticsJobs("Stream Analytics\n(Analytics)")
monitoring = ApplicationInsights("Application\nInsights")
# Client flow
client >> Edge(label="HTTP POST\n/orders") >> api_gw
api_gw >> order_svc
# Order publishes event
order_svc >> Edge(label="OrderPlaced", color="darkgreen") >> topic_placed
# Fan-out from OrderPlaced (Service Bus subscriptions)
topic_placed >> Edge(color="blue") >> fraud_svc
topic_placed >> Edge(color="blue") >> inventory_svc
topic_placed >> Edge(color="gray", style="dashed") >> analytics_svc
# Fraud produces validated
fraud_svc >> Edge(label="OrderValidated", color="darkgreen") >> topic_validated
# Inventory produces reserved
inventory_svc >> Edge(label="StockReserved", color="darkgreen") >> topic_reserved
# Payment consumes both, produces result
topic_validated >> Edge(color="blue") >> payment_svc
topic_reserved >> Edge(color="blue") >> payment_svc
payment_svc >> Edge(label="PaymentCompleted", color="darkgreen") >> topic_paid
payment_svc >> Edge(label="PaymentFailed", color="red") >> topic_failed
# Downstream from payment completed
topic_paid >> Edge(color="blue") >> shipping_svc
topic_paid >> Edge(color="blue") >> notification_svc
topic_paid >> Edge(color="gray", style="dashed") >> analytics_svc
# Shipping produces scheduled
shipping_svc >> Edge(label="ShipmentScheduled", color="darkgreen") >> topic_shipped
topic_shipped >> Edge(color="blue") >> notification_svc
topic_shipped >> Edge(color="gray", style="dashed") >> analytics_svc
# Failure flow
topic_failed >> Edge(color="red") >> order_svc
topic_failed >> Edge(color="red") >> notification_svc
# DLQ (Service Bus built-in dead-letter)
fraud_svc >> Edge(style="dotted", color="orange") >> topic_dlq
inventory_svc >> Edge(style="dotted", color="orange") >> topic_dlq
payment_svc >> Edge(style="dotted", color="orange") >> topic_dlq
# Monitoring
topic_dlq >> Edge(style="dashed", color="orange") >> monitoring
Explicación del Diagrama¶
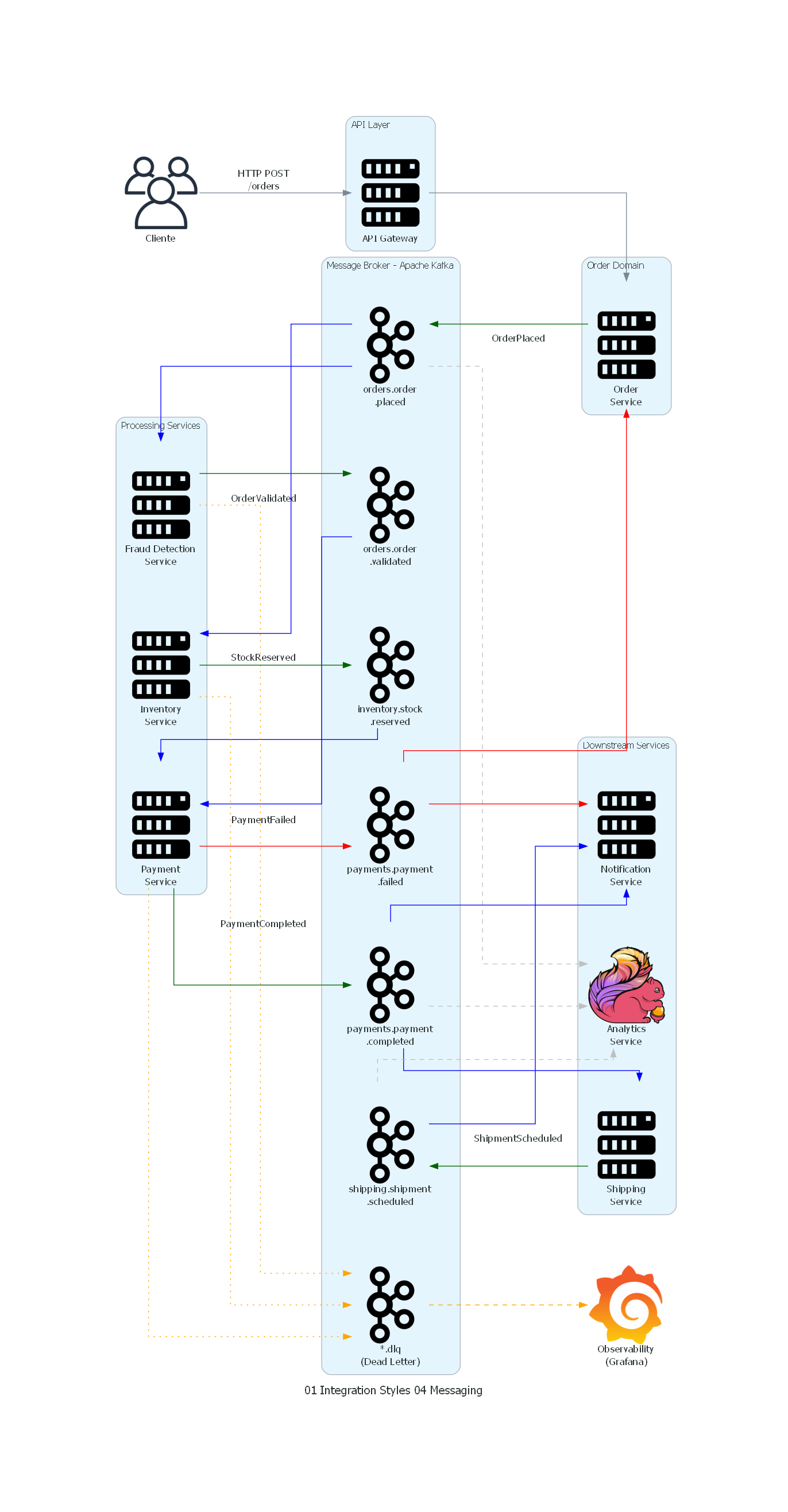
El diagrama representa el pipeline completo de procesamiento de pedidos en una plataforma de e-commerce, con Apache Kafka como message broker central:
-
API Layer (izquierda): el cliente interactúa sincrónicamente con el API Gateway, que enruta la request al Order Service.
-
Order Domain: el Order Service es el punto de entrada al flujo asíncrono. Tras persistir el pedido, publica el evento
OrderPlaceden Kafka. -
Message Broker (centro): Kafka contiene los topics que representan los canales de comunicación entre servicios. Cada topic es un log inmutable particionado por
order_id. El diagrama muestra los topics principales del flujo, incluyendo los Dead Letter Topics para mensajes que no pudieron procesarse. -
Processing Services: Fraud Detection e Inventory Service consumen de
orders.order.placeden paralelo (fan-out). El Payment Service agrega resultados de ambos antes de procesar el cobro. -
Downstream Services: Shipping, Notification y Analytics consumen de los topics de resultado. Los flujos en gris punteado representan consumidores no críticos (analytics).
-
Flujo de error (rojo): cuando el pago falla, el evento
PaymentFailedse propaga al Order Service (compensación) y al Notification Service (informar al cliente). -
Dead Letter / Observability (naranja punteado): los mensajes que no pueden procesarse tras reintentos se envían a los DLT. Grafana monitorea la profundidad de los DLT y alerta cuando hay mensajes estancados.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor (Producer) | Order Service, Fraud Detection, Inventory, Payment, Shipping |
| Mensaje (Message) | OrderPlaced, OrderValidated, StockReserved, PaymentCompleted, etc. |
| Canal (Channel / Topic) | Kafka Topics: orders.order.placed, payments.payment.completed, etc. |
| Broker (Messaging System) | Apache Kafka cluster (3 brokers) |
| Consumidor (Consumer) | Cada servicio que lee de un topic |
| Point-to-Point (Queue semántica) | Consumer groups: solo un miembro del grupo procesa cada mensaje |
| Publish-Subscribe | Múltiples consumer groups en el mismo topic (e.g., Analytics + Notification) |
| Dead Letter Channel | *.dlq topics |
| Fan-out | OrderPlaced consumido por Fraud, Inventory y Analytics simultáneamente |
| Aggregator | Payment Service esperando OrderValidated + StockReserved |
| Saga (Compensación) | PaymentFailed → Order Service (rollback estado) + Inventory (liberar reserva) |
11. Beneficios¶
Impacto Técnico¶
-
Desacoplamiento temporal: el productor y el consumidor no necesitan estar disponibles simultáneamente. El Order Service puede publicar miles de pedidos incluso si el Payment Service está temporalmente caído. Kafka almacena los mensajes hasta que el consumidor se recupere, sin pérdida de datos. Esto cambia la ecuación de disponibilidad de multiplicativa (99.9% × 99.9% × 99.9% = 99.7%) a individual: cada servicio mantiene su propia disponibilidad independiente.
-
Escalabilidad horizontal nativa: cada consumidor puede escalarse de forma independiente añadiendo más instancias al consumer group. Si durante Black Friday el Notification Service se satura, se escalan 10 instancias adicionales sin modificar ningún otro servicio. Las particiones de Kafka distribuyen la carga automáticamente entre los miembros del consumer group.
-
Resiliencia ante fallos parciales: si el Shipping Service tiene un outage de 2 horas, los mensajes de
PaymentCompletedse acumulan en Kafka. Cuando el servicio se recupera, procesa el backlog sin intervención manual. Ningún pedido se pierde, ningún otro servicio se ve afectado. -
Absorción de picos de carga (buffering): el broker actúa como amortiguador entre productores rápidos y consumidores lentos. Si el Order Service recibe un pico de 10,000 pedidos/minuto pero el Payment Service solo puede procesar 5,000/minuto, Kafka absorbe el exceso sin rechazar pedidos. El Payment Service procesa a su ritmo máximo y eventualmente converge.
-
Capacidad de replay: Kafka retiene los mensajes durante el período configurado (7 días, 30 días, indefinido). Si se descubre un bug en el Analytics Service que produjo métricas incorrectas, se puede resetear el offset del consumer group y reprocesar todos los eventos desde el punto deseado. Esta capacidad es imposible con RPC síncrono.
-
Evolución independiente de servicios: como los servicios se comunican a través de mensajes con schemas versionados, un equipo puede actualizar su servicio sin coordinarse con los demás, siempre que respete la compatibilidad del schema (backward/forward compatibility).
Impacto Organizacional¶
-
Autonomía de equipos: cada equipo es dueño de sus consumers y puede desplegarlos, escalarlos y evolucionar su lógica de forma independiente. El contrato entre equipos es el schema del mensaje, no una interfaz de invocación directa.
-
Habilitación de nuevos consumidores: añadir un nuevo servicio que necesite reaccionar a eventos existentes es trivial: solo necesita suscribirse al topic correspondiente. No requiere cambios en el productor ni en los consumidores existentes. Esto reduce drásticamente el time-to-market para nuevas funcionalidades.
-
Reducción de coordinación inter-equipos: los equipos no necesitan coordinarse para deployments simultáneos. El productor y el consumidor pueden desplegarse en momentos diferentes, siempre que los schemas sean compatibles.
Impacto Operacional¶
-
Recuperación automática: tras un fallo, los consumidores retoman el procesamiento desde el último offset confirmado sin intervención humana. El backlog se procesa automáticamente.
-
Visibilidad del estado del sistema: el consumer lag (diferencia entre el último mensaje producido y el último consumido) proporciona una métrica inmediata de la salud de cada consumidor. Un lag creciente indica que el consumidor no puede mantener el ritmo.
-
Debugging con mensaje almacenados: los mensajes en Kafka son inspeccionables. Si un pedido tiene un problema, se puede buscar el evento
OrderPlacedoriginal en el topic y trazar todo su procesamiento a través de los topics subsecuentes.
Beneficios de Mantenibilidad y Evolución¶
-
Schema evolution controlada: con un schema registry (Confluent, Apicurio, AWS Glue), los schemas de mensajes evolucionan con reglas de compatibilidad (backward, forward, full). Un campo nuevo puede añadirse sin romper consumidores existentes.
-
Testing con mensajes reales: los mensajes pueden capturarse de producción (con datos anonimizados) y usarse como fixtures para pruebas de integración, proporcionando escenarios realistas que son difíciles de fabricar manualmente.
-
Migración incremental: migrar de un servicio legacy a uno nuevo es simple con Messaging: el nuevo servicio se suscribe al mismo topic, procesa en paralelo durante un período de validación, y cuando se confirma su correctitud, el servicio legacy se retira.
12. Desventajas y Riesgos¶
Complejidad de Consistencia Eventual¶
La desventaja más significativa de Messaging es la introducción de consistencia eventual como modelo por defecto. Cuando el Order Service retorna HTTP 202 al cliente, el pedido existe en el Order Service pero aún no ha sido validado por Fraud Detection, no tiene stock reservado, y no ha sido cobrado. Si el cliente consulta el estado inmediatamente, puede ver un pedido "en proceso" cuyos detalles son incompletos. Peor aún, el pedido podría ser rechazado 5 segundos después por falta de stock o fraude detectado, contradiciendo la confirmación inicial.
Gestionar esta inconsistencia temporal requiere: - UX que comunique claramente el estado asíncrono ("Pedido recibido, confirmación en breve"). - APIs de consulta que muestren el estado real del procesamiento. - Compensación robusta cuando un paso falla después de que pasos anteriores ya se ejecutaron.
Dificultad de Debugging y Troubleshooting¶
Debuggear un flujo asíncrono distribuido es cualitativamente más difícil que debuggear una cadena de llamadas síncronas. No existe un stack trace unificado. El flujo cruza múltiples procesos, múltiples máquinas, múltiples puntos temporales. Sin distributed tracing (OpenTelemetry, Jaeger, Zipkin), diagnosticar por qué un pedido específico no se procesó correctamente requiere correlacionar logs de múltiples servicios usando el order_id como clave, lo cual es tedioso y error-prone.
Complejidad del Ordenamiento de Mensajes¶
El ordenamiento es un problema sutil pero crítico. Kafka garantiza ordenamiento dentro de una partición, pero no entre particiones. Si un pedido se modifica después de ser creado (cambio de dirección, cancelación), los eventos OrderPlaced y OrderModified deben procesarse en orden. Si ambos van a la misma partición (porque comparten order_id como partition key), el orden se preserva. Pero si un consumidor tiene lógica que depende de eventos de diferentes entidades (e.g., el cliente y el pedido), el ordering cross-entity no está garantizado.
Infraestructura y Costo Operacional¶
Operar un cluster de Kafka (o cualquier broker distribuido) en producción requiere: - Planificación de capacidad: número de brokers, particiones, disco, memoria, network bandwidth. - Gestión de replicación: replication factor, min.insync.replicas, unclean leader election. - Monitoreo continuo: under-replicated partitions, consumer lag, disk usage, GC pauses. - Upgrades sin downtime: rolling upgrades de brokers, compatibilidad de protocol version. - Gestión de retención: balancear retención (para replay) con costo de storage.
Para organizaciones que no tienen expertise en Kafka, los managed services (Confluent Cloud, Amazon MSK, Azure Event Hubs, Google Managed Kafka) reducen esta carga pero introducen dependencia del proveedor y costo financiero significativo a escala.
Riesgo de Complejidad Accidental¶
Es tentador usar Messaging para todo una vez adoptado. Pero no todo requiere Messaging: una consulta síncrona de precio de producto, una validación de formato de email, una lectura de configuración no necesitan pasar por un broker. El over-use de messaging (chatty messaging) introduce latencia innecesaria, complejidad de debugging y carga en el broker para operaciones que serían triviales con una llamada directa.
Message Ordering vs. Exactly-Once¶
Lograr procesamiento exactly-once en un sistema distribuido es teóricamente imposible en el caso general (resultado del problema de los Two Generals). Las aproximaciones prácticas (transactional producers en Kafka, idempotent consumers) son complejas de implementar correctamente y añaden overhead. La mayoría de los sistemas implementan at-least-once + idempotencia en el consumidor, lo cual requiere que cada consumidor mantenga estado sobre qué mensajes ya procesó.
Dead Letter Management¶
Los Dead Letter Topics/Queues son la red de seguridad para mensajes que no pueden procesarse. Pero si no se monitorean y gestionan activamente, se convierten en un cementerio de mensajes que nadie revisa. Establecer procesos operacionales para revisar, diagnosticar y reenviar mensajes de DLT requiere herramientas y disciplina operacional.
13. Relación con Otros Patrones¶
Messaging como Patrón Habilitador¶
Messaging no es simplemente un patrón más en el catálogo de Enterprise Integration Patterns. Es el patrón que habilita la existencia de todos los demás. Los patrones EIP asumen que existe una infraestructura de Messaging operativa y construyen abstracciones sobre ella:
Patrones de Infraestructura de Mensajería (construidos directamente sobre Messaging)¶
- Message Channel: define los canales (queues, topics) por donde fluyen los mensajes. Sin Messaging, no hay canales.
- Message: define la estructura del dato que fluye. Sin Messaging, no hay mensajes.
- Pipes and Filters: describe cómo encadenar procesadores de mensajes. Cada filtro consume de un canal y produce en otro. Sin Messaging, no hay pipes.
- Message Router: dirige mensajes a diferentes canales según criterios. Sin canales de Messaging, no hay routing posible.
- Message Translator: transforma el formato de los mensajes entre productor y consumidor. Sin mensajes en tránsito, no hay nada que transformar.
- Message Endpoint: define cómo las aplicaciones se conectan al sistema de mensajería. Es la interfaz entre la aplicación y la infraestructura de Messaging.
Patrones de Routing (que operan sobre canales de Messaging)¶
- Content-Based Router: lee el contenido del mensaje y lo enruta al canal apropiado.
- Message Filter: descarta mensajes que no cumplen un criterio.
- Recipient List: envía un mensaje a una lista de destinatarios determinada dinámicamente.
- Splitter: divide un mensaje en múltiples mensajes más pequeños.
- Aggregator: combina múltiples mensajes relacionados en uno solo.
- Resequencer: reordena mensajes que llegaron fuera de orden.
Todos estos patrones presuponen que los mensajes fluyen por canales gestionados por un broker. Sin Messaging, no existen.
Patrones de Transformación (que operan sobre mensajes)¶
- Envelope Wrapper: envuelve un mensaje en una estructura adicional para transport.
- Content Enricher: añade información al mensaje consultando fuentes externas.
- Content Filter: elimina campos innecesarios del mensaje.
- Claim Check: almacena un payload grande externamente y lo reemplaza por una referencia en el mensaje.
- Normalizer: convierte mensajes de diferentes formatos a un formato canónico.
Patrones de Endpoint (que conectan aplicaciones con Messaging)¶
- Polling Consumer / Event-Driven Consumer: define cómo el consumidor obtiene mensajes (pull vs. push).
- Competing Consumers: múltiples instancias de un consumidor comparten la carga de una queue.
- Message Dispatcher: distribuye mensajes a handlers según su tipo.
- Idempotent Receiver: garantiza que procesar el mismo mensaje dos veces produce el mismo efecto.
- Transactional Client: envuelve el procesamiento de mensajes en una transacción.
Patrones de Gestión del Sistema (que monitorizan Messaging)¶
- Control Bus: canal de control para gestionar el sistema de mensajería.
- Dead Letter Channel: canal donde se depositan mensajes que no pudieron procesarse.
- Wire Tap: intercepta mensajes para inspección sin alterar el flujo.
- Message Store: almacena mensajes para auditoría o replay.
Relación con los Otros Estilos de Integración¶
- vs. File Transfer: Messaging opera con mensajes individuales en near-real-time; File Transfer opera con archivos batch. Messaging proporciona routing, acknowledgment y pub-sub nativos; File Transfer no. Sin embargo, ambos se combinan frecuentemente (Claim Check: un evento referencia un archivo).
- vs. Shared Database: Messaging desacopla completamente los modelos de datos de cada sistema; Shared Database los acopla. Messaging es eventualmente consistente; Shared Database puede ser inmediatamente consistente. Change Data Capture (CDC) es un puente entre ambos: captura cambios en una base de datos y los publica como mensajes.
- vs. Remote Procedure Invocation: Messaging desacopla temporalmente; RPI acopla temporalmente. Messaging es fire-and-forget; RPI es request-response. Ambos coexisten en la mayoría de las arquitecturas: RPI para queries síncronas, Messaging para eventos y comandos asíncronos.
Combinaciones Comunes con Otros Patrones EIP¶
- Messaging + Saga: los flujos de negocio distribuidos se implementan como Sagas (con coreografía o orquestación) sobre Messaging.
- Messaging + CQRS: los comandos se envían como mensajes a un servicio de escritura, y los eventos resultantes actualizan modelos de lectura optimizados.
- Messaging + Event Sourcing: los eventos de dominio se almacenan como log inmutable (Kafka) y se proyectan a diferentes vistas materializadas.
- Messaging + Circuit Breaker: los consumidores implementan circuit breakers para dejar de procesar mensajes cuando un servicio downstream está fallando repetidamente.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Muy Alta (la más alta de todos los estilos de integración)¶
Argumentación¶
Messaging no solo sigue siendo relevante en la arquitectura enterprise moderna: se ha convertido en el paradigma dominante para integración entre sistemas. Las razones son múltiples y convergentes:
Messaging como backbone de microservicios:
La adopción masiva de arquitecturas de microservicios ha hecho que Messaging sea la forma predeterminada de comunicación entre servicios para flujos asíncronos. Mientras que REST/gRPC dominan las queries síncronas, Messaging domina los flujos de negocio, la propagación de eventos de dominio, y la coordinación entre bounded contexts. Prácticamente toda organización con una arquitectura de microservicios tiene un message broker como pieza central de infraestructura.
Event-Driven Architecture (EDA) como paradigma dominante:
La arquitectura event-driven, que es una evolución natural de Messaging, se ha consolidado como el paradigma preferido para sistemas reactivos, resilientes y escalables. Event storming como técnica de diseño, event sourcing como patrón de persistencia, CQRS como patrón de lectura/escritura: todos presuponen una infraestructura de Messaging. La tendencia hacia EDA sigue acelerándose.
Streaming como evolución de Messaging:
Apache Kafka, lanzado en 2011, transformó Messaging al introducir el concepto de log inmutable con retención configurable, convirtiendo el broker no solo en un mecanismo de transporte sino en un sistema de almacenamiento de eventos. Esto habilitó nuevos patrones (replay, event sourcing, stream processing) que no eran prácticos con brokers tradicionales. Kafka y sus sucesores (Redpanda, Apache Pulsar) se han convertido en infraestructura fundamental para la mayoría de las organizaciones technology-forward.
Cloud-native Messaging:
Los proveedores cloud ofrecen servicios de mensajería gestionados que eliminan la complejidad operacional de operar brokers: - AWS: SQS, SNS, EventBridge, Kinesis, Amazon MSK - Azure: Service Bus, Event Hubs, Event Grid - GCP: Pub/Sub, Managed Kafka
Esto ha democratizado el acceso a Messaging: organizaciones que antes no tenían el expertise para operar un cluster de RabbitMQ o Kafka ahora pueden adoptar Messaging a través de servicios gestionados con configuración mínima.
Data streaming y real-time analytics:
La demanda de analytics en tiempo real (detección de fraude, personalización, monitoreo operacional) ha convertido a Messaging (especialmente Kafka y sus equivalentes) en el pipeline estándar para flujos de datos en tiempo real. Las arquitecturas Lambda y Kappa se construyen sobre Messaging como capa de transporte.
IoT y edge computing:
Los millones de dispositivos IoT que generan telemetría necesitan una infraestructura de ingestión que absorba volúmenes masivos de eventos. Messaging (MQTT + broker, Kafka, Event Hubs) es la respuesta estándar. Protocolos como MQTT están diseñados específicamente para Messaging en contextos IoT.
Tendencias Actuales que Refuerzan la Relevancia¶
- Event Mesh: la evolución de un broker centralizado a una malla de brokers distribuidos geográficamente (Solace, Confluent Cluster Linking) para organizaciones globales.
- Schema-First Design: el diseño de integraciones partiendo del schema del evento (AsyncAPI, CloudEvents) como contrato fundamental.
- Serverless Event Processing: Azure Functions, AWS Lambda, Google Cloud Functions triggered por eventos de Messaging, permitiendo procesamiento event-driven sin gestionar servidores.
- Change Data Capture (CDC): herramientas como Debezium convierten cambios en bases de datos en eventos de Messaging, cerrando el gap entre sistemas que usan base de datos y los que usan Messaging.
Qué Parte Sigue Siendo Esencial¶
Independientemente de la evolución tecnológica, los principios fundamentales de Messaging permanecen: - Desacoplamiento a través de un intermediario sigue siendo la forma más robusta de integrar sistemas distribuidos. - La semántica de entrega (at-least-once, exactly-once) sigue siendo una decisión arquitectónica crítica. - La idempotencia del consumidor sigue siendo un requisito ineludible. - El ordenamiento de mensajes sigue siendo un problema que requiere diseño explícito. - El monitoreo del consumer lag sigue siendo la métrica más importante para la salud de un sistema de mensajería.
15. Implementación en Arquitecturas Modernas¶
Categorización de Tecnologías¶
Antes de detallar cada tecnología, es fundamental distinguir tres categorías de infraestructura de Messaging, ya que cada una tiene propiedades arquitectónicas diferentes:
| Categoría | Modelo | Retención | Replay | Ejemplos |
|---|---|---|---|---|
| Message Queue | Point-to-Point | Hasta consumo | No (destrucción tras ACK) | RabbitMQ, ActiveMQ, SQS |
| Event Broker / Pub-Sub | Publish-Subscribe | Configurable | Limitado | Azure Service Bus, Google Pub/Sub, SNS |
| Event Streaming Platform | Log-based Pub-Sub | Configurable (días a indefinido) | Sí (reset de offset) | Kafka, Redpanda, Pulsar, Event Hubs, Kinesis |
Apache Kafka¶
Kafka es la implementación de referencia de Messaging como log distribuido. Su modelo se basa en un log inmutable particionado donde los mensajes se retienen independientemente del consumo. Los consumers son responsables de su offset (posición en el log), lo que habilita replay, rebobinado y procesamiento paralelo. Kafka es la opción predeterminada para event streaming a escala, event sourcing, y como backbone de arquitecturas event-driven.
- Modelo: log distribuido con particiones. Ordering garantizado dentro de partición.
- Entrega: at-least-once por defecto; exactly-once con transactional producers/consumers.
- Retención: configurable por tiempo o tamaño. Compaction disponible para topics de estado.
- Throughput: millones de mensajes/segundo en clusters adecuadamente dimensionados.
- Ecosistema: Kafka Connect (conectores), Kafka Streams (stream processing), ksqlDB (SQL sobre streams), Schema Registry.
- Managed: Confluent Cloud, Amazon MSK, Azure HDInsight Kafka, Aiven, Redpanda Cloud.
RabbitMQ¶
RabbitMQ es el broker de mensajería más maduro y flexible para patrones de routing complejos. Implementa AMQP 0.9.1 y soporta exchanges (direct, fanout, topic, headers) que permiten routing sofisticado sin lógica custom. Es ideal para workloads donde el routing dinámico, la priorización de mensajes y el modelo request-reply son importantes.
- Modelo: queues con exchanges para routing. Messages se eliminan tras ACK (no log-based).
- Entrega: at-least-once con publisher confirms y consumer acknowledgments.
- Routing: exchanges direct (por routing key), fanout (broadcast), topic (pattern matching), headers (por headers del mensaje).
- Características especiales: message priority, TTL, delayed messages, dead letter exchanges, quorum queues para HA.
- Managed: CloudAMQP, Amazon MQ, Azure (no nativo, disponible como container).
Apache ActiveMQ / Artemis¶
ActiveMQ (y su sucesor Artemis) es un broker JMS compliant ampliamente utilizado en el ecosistema Java enterprise. Soporta múltiples protocolos (AMQP, STOMP, MQTT, OpenWire) y es una opción sólida para organizaciones con inversión significativa en JMS.
- Modelo: queues y topics con soporte JMS nativo.
- Protocolos: AMQP 1.0, STOMP, MQTT, OpenWire.
- Características: message groups, virtual topics, network of brokers para federation.
- Managed: Amazon MQ (ActiveMQ y Artemis).
Azure Service Bus¶
Azure Service Bus es el servicio de mensajería enterprise de Microsoft Azure. Soporta queues (point-to-point) y topics con subscriptions (pub-sub), con características enterprise como sessions (para ordering garantizado), dead-lettering, scheduled delivery, y transacciones.
- Modelo: queues y topics con subscriptions. Mensajes se eliminan tras ACK.
- Entrega: at-least-once; peek-lock para procesamiento seguro.
- Características: sessions (ordering por session ID), duplicate detection, auto-forwarding, message deferral, scheduled enqueue.
- Integración Azure: nativa con Azure Functions, Logic Apps, Event Grid, Azure Monitor.
- Tier Premium: aislamiento de recursos, throughput garantizado, VNET integration.
Azure Event Hubs¶
Azure Event Hubs es la plataforma de event streaming de Azure, compatible con el protocolo de Apache Kafka. Diseñado para ingestión masiva de eventos (millones/segundo) con retención configurable y consumer groups.
- Modelo: log particionado similar a Kafka. Compatible con Kafka client libraries.
- Retención: 1-90 días (Standard), indefinida con Capture a Blob/ADLS.
- Throughput: medido en Throughput Units (1 TU = 1 MB/s ingress, 2 MB/s egress).
- Capture: archivado automático a Azure Blob Storage o Azure Data Lake en formato Avro.
- Schema Registry: integrado, con soporte Avro.
AWS SQS (Simple Queue Service)¶
SQS es el servicio de queues gestionado de AWS. Ofrece dos variantes: Standard (throughput ilimitado, ordering best-effort, at-least-once delivery) y FIFO (ordering estricto, exactly-once processing, throughput limitado).
- Standard Queue: throughput prácticamente ilimitado, at-least-once delivery, best-effort ordering.
- FIFO Queue: ordering estricto por message group ID, exactly-once processing, 3,000 msg/s con batching.
- Características: dead-letter queues, visibility timeout, long polling, message delay, server-side encryption.
- Integración: nativa con Lambda (event source mapping), SNS, EventBridge, Step Functions.
AWS SNS (Simple Notification Service)¶
SNS es el servicio de pub-sub gestionado de AWS. Permite publicar un mensaje y distribuirlo a múltiples suscriptores (SQS queues, Lambda functions, HTTP endpoints, email, SMS).
- Modelo: topic-based pub-sub. Fan-out nativo.
- Suscriptores: SQS, Lambda, HTTP/HTTPS, email, SMS, Kinesis Data Firehose.
- Filtering: message filtering por attributes en las subscriptions (sin lógica custom).
- FIFO Topics: ordering y deduplication para suscriptores SQS FIFO.
- Patrón común: SNS + SQS (fanout to queues) para combinar pub-sub con competing consumers.
AWS EventBridge¶
EventBridge es el event bus serverless de AWS. Diseñado para event-driven architectures con routing basado en reglas, schema discovery, y integración nativa con servicios AWS y SaaS partners.
- Modelo: event bus con rules engine para routing content-based.
- Schema Registry: integrado, con schema discovery automático y code generation.
- Targets: Lambda, SQS, SNS, Step Functions, Kinesis, API Gateway, ECS tasks, y más de 20 targets nativos.
- SaaS Integration: eventos de Shopify, Datadog, PagerDuty, Zendesk directamente en EventBridge.
- Archive & Replay: archivado de eventos con capacidad de replay.
Google Cloud Pub/Sub¶
Google Pub/Sub es el servicio de mensajería global de GCP. Ofrece pub-sub gestionado con delivery guarantees, dead-lettering, ordering y exactly-once delivery.
- Modelo: topics y subscriptions. Pull y push delivery.
- Entrega: at-least-once por defecto; exactly-once con ordering keys.
- Ordering: ordering garantizado por ordering key (análogo a partition key de Kafka).
- Dead-lettering: nativo con conteo de delivery attempts.
- Integración: Dataflow (stream processing), Cloud Functions, Cloud Run, BigQuery subscriptions (escritura directa a BigQuery).
NATS¶
NATS es un sistema de mensajería ultra-ligero de alto rendimiento diseñado para cloud-native applications. NATS JetStream añade persistencia y streaming capabilities.
- Core NATS: pub-sub y request-reply at-most-once sin persistencia. Latencia de microsegundos.
- JetStream: persistencia, replay, consumer groups, exactly-once delivery.
- Uso típico: service mesh communication, IoT, edge computing, sistemas con requisitos de latencia ultra-baja.
Apache Pulsar¶
Pulsar es una plataforma de messaging y streaming que separa compute (brokers) de storage (BookKeeper). Soporta multi-tenancy nativo, geo-replication, y combina características de queues (consumer groups exclusivos) y topics (pub-sub).
- Modelo: topics con subscriptions (exclusive, shared, failover, key_shared).
- Almacenamiento: separación de compute y storage via BookKeeper.
- Multi-tenancy: tenants, namespaces, y políticas de retención por namespace.
- Geo-replication: replicación nativa entre clusters en diferentes regiones.
- Managed: StreamNative.
MuleSoft Anypoint Platform¶
MuleSoft proporciona Messaging como parte de su plataforma de integración. Anypoint MQ es un servicio de queues gestionado, y los Mule flows pueden actuar como productores/consumidores de Kafka, RabbitMQ, JMS, y otros brokers.
- Anypoint MQ: queues y exchanges gestionados, integrados con Mule runtime.
- Conectores: Kafka, RabbitMQ, JMS, AMQP, MQTT, Azure Service Bus, SQS/SNS.
- DataWeave: lenguaje de transformación para message translation inline.
Apache Camel¶
Camel es el framework de integración más completo para implementar Enterprise Integration Patterns. Soporta más de 300 componentes, incluyendo Kafka, RabbitMQ, ActiveMQ, AMQP, MQTT, SQS, SNS, Azure Service Bus, Google Pub/Sub.
- DSL: Java, XML, YAML para definir rutas de integración.
- EIP nativos: todos los patrones EIP están implementados como procesadores de Camel.
- Runtime: Spring Boot (Camel Spring Boot), Quarkus (Camel Quarkus), standalone.
Spring Integration¶
Spring Integration implementa los Enterprise Integration Patterns dentro del ecosistema Spring. Proporciona abstractions sobre Kafka, RabbitMQ, JMS, AMQP, y otros.
- Channel abstraction: MessageChannel como abstracción sobre cualquier transporte.
- Adapters: inbound/outbound adapters para Kafka, RabbitMQ, JMS, MQTT, AMQP.
- Spring Cloud Stream: abstracción aún más alta que permite cambiar el binder (Kafka, RabbitMQ, etc.) sin cambiar código de aplicación.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
Distributed Tracing con Correlation IDs¶
En un flujo de Messaging, un evento puede pasar por 5-10 servicios antes de completar un proceso de negocio. Sin distributed tracing, diagnosticar un problema específico ("¿por qué el pedido X no fue enviado?") requiere correlacionar manualmente logs de múltiples servicios.
La solución estándar es:
-
Correlation ID: el primer servicio que genera el evento (Order Service) crea un
correlation_idúnico (UUID) que se propaga como header en todos los mensajes subsecuentes del flujo. Cada servicio lee elcorrelation_iddel mensaje entrante y lo incluye en el mensaje que produce. Los logs de cada servicio incluyen elcorrelation_id, permitiendo buscar toda la traza con una sola query. -
OpenTelemetry: el estándar de facto para distributed tracing. Cada servicio instrumentado crea spans que se propagan a través de los headers del mensaje (W3C Trace Context). Backends como Jaeger, Zipkin, Tempo, o Datadog visualizan la traza completa del flujo, mostrando la latencia de cada paso y las relaciones causales entre eventos.
-
Context Propagation: los headers de tracing (trace_id, span_id, trace_flags) deben propagarse del mensaje entrante al mensaje saliente en cada servicio. Los frameworks modernos (Spring Cloud Sleuth, Micrometer Tracing, OpenTelemetry SDK) automatizan esta propagación.
Métricas Fundamentales¶
- Producer metrics: messages produced/sec, produce latency (p50, p95, p99), produce errors/sec, batch size.
- Consumer metrics: messages consumed/sec, processing latency (p50, p95, p99), processing errors/sec, rebalance count.
- Broker metrics: bytes in/out per second, request rate, request latency, disk usage, active connections, under-replicated partitions (Kafka).
Monitoreo¶
Queue Depth / Consumer Lag¶
El consumer lag es la métrica más importante de un sistema de Messaging. Representa la diferencia entre el último mensaje producido y el último mensaje consumido. Un lag creciente indica que el consumidor no puede mantener el ritmo del productor, lo cual eventualmente resultará en: - Incremento de la latencia end-to-end del flujo. - Acumulación de mensajes en el broker que consume storage. - Si la retención es limitada, pérdida de mensajes no consumidos.
El monitoreo del consumer lag debe incluir: - Alertas de umbral: alerta cuando el lag excede un umbral configurable (e.g., 10,000 mensajes o 5 minutos). - Alertas de tendencia: alerta cuando el lag está creciendo sostenidamente (incluso si aún no alcanzó el umbral). - Dashboards por consumer group: visualización del lag por partición y por consumer group.
Herramientas: Burrow (Kafka consumer lag monitoring), Kafka Lag Exporter (Prometheus), Confluent Control Center, Grafana dashboards con métricas de broker.
Dead Letter Queue Monitoring¶
Los DLQ/DLT deben monitorearse activamente: - Alerta cuando un DLQ recibe un mensaje: cualquier mensaje en DLQ indica un problema que requiere investigación. - Dashboard de DLQ: número de mensajes por DLQ, timestamp del mensaje más antiguo, distribución por tipo de error. - Proceso de revisión: procedimiento operacional definido para revisar mensajes en DLQ, diagnosticar la causa, corregir el problema, y reenviar los mensajes al topic original.
Versionado y Schema Evolution¶
Schema Registry¶
Un Schema Registry es un componente central para gobernar los formatos de mensajes en un sistema de Messaging a escala. Almacena las versiones de cada schema y valida que las nuevas versiones sean compatibles con las anteriores.
- Confluent Schema Registry: soporta Avro, JSON Schema, Protobuf. Modos de compatibilidad: BACKWARD (consumidores nuevos pueden leer mensajes viejos), FORWARD (consumidores viejos pueden leer mensajes nuevos), FULL (ambos), NONE (sin validación).
- AWS Glue Schema Registry: integrado con MSK, Kinesis, Lambda.
- Azure Schema Registry: integrado con Event Hubs.
- Apicurio Registry: open-source, soporta múltiples formatos.
Reglas de Compatibilidad¶
- Backward compatibility: se pueden añadir campos con default values; no se pueden eliminar campos requeridos. Los consumidores nuevos pueden leer mensajes producidos por productores viejos.
- Forward compatibility: se pueden eliminar campos; no se pueden añadir campos requeridos sin default. Los consumidores viejos pueden leer mensajes producidos por productores nuevos.
- Full compatibility: la intersección de backward y forward. Los cambios seguros son: añadir campos opcionales con default, eliminar campos opcionales.
Seguridad¶
Encryption¶
- En tránsito: TLS entre productores/consumidores y el broker. Kafka soporta SASL_SSL; RabbitMQ soporta TLS nativo; los managed services usan TLS por defecto.
- En reposo: server-side encryption del storage del broker. Kafka soporta encryption de log segments vía plugins; managed services (MSK, Event Hubs, Confluent Cloud) ofrecen encryption por defecto.
- End-to-end encryption: para datos altamente sensibles, el productor cifra el payload del mensaje con una key que solo los consumidores autorizados poseen. El broker almacena el mensaje cifrado sin poder leerlo.
Authentication y Authorization¶
- Authentication (AuthN): SASL/PLAIN, SASL/SCRAM, SASL/OAUTHBEARER, mTLS (certificados de cliente). Los managed services usan IAM roles o API keys.
- Authorization (AuthZ): ACLs por topic, por operación (produce, consume, create, delete), por principal. Kafka soporta ACLs nativas y pluggable authorizers (OPA, RBAC de Confluent). Los managed services usan IAM policies.
- Multi-tenancy: en organizaciones grandes, namespaces o prefijos de topics por equipo/dominio, con ACLs que restringen acceso entre equipos.
Error Handling¶
Dead Letter Queue / Dead Letter Topic¶
Cuando un consumidor no puede procesar un mensaje tras N intentos (configurable), el mensaje se envía a un DLQ/DLT en lugar de ser descartado o bloquear el procesamiento.
Implementación: - RabbitMQ: dead letter exchanges nativos configurables por queue. - Kafka: no tiene DLT nativo; se implementa en el consumidor (Spring Kafka DefaultErrorHandler con DeadLetterPublishingRecoverer). - SQS: RedrivePolicy nativo que envía a DLQ tras maxReceiveCount intentos. - Azure Service Bus: dead-lettering nativo con razón de dead-letter.
Retry Policies¶
- Immediate retry: reintentar inmediatamente (útil para errores transitorios de red).
- Exponential backoff: reintentar con delays crecientes (1s, 2s, 4s, 8s...) para evitar sobrecargar un servicio downstream que está fallando.
- Retry topics (Kafka pattern): en lugar de reintentar inmediatamente, publicar en un topic de retry con delay (e.g.,
orders.retry.1m,orders.retry.5m,orders.retry.30m). Cada topic tiene un consumidor que espera el delay y reenvía al topic original.
Idempotencia¶
Dado que at-least-once es la semántica de entrega más práctica, cada consumidor debe ser idempotente. Estrategias:
- Natural idempotency: operaciones que son naturalmente idempotentes (PUT de un recurso con el mismo estado).
- Deduplication store: almacenar los message_id procesados en una base de datos o cache (Redis, tabla SQL). Antes de procesar, verificar si el message_id ya fue procesado.
- Conditional writes: usar operaciones condicionales en la base de datos (INSERT IF NOT EXISTS, UPDATE WHERE version = expected).
- Transactional outbox: en combinación con la base de datos de la aplicación, garantizar que la publicación del mensaje de respuesta y la actualización del estado ocurren atómicamente.
Garantías de Ordering¶
El ordering de mensajes es una propiedad que debe diseñarse explícitamente:
- Kafka: ordering garantizado dentro de una partición. Se elige la partition key cuidadosamente (e.g.,
order_idpara que todos los eventos de un pedido estén en la misma partición). - SQS FIFO: ordering por message group ID.
- Azure Service Bus: ordering por session ID.
- RabbitMQ: ordering dentro de una queue single-consumer; pierde ordering con competing consumers.
Exactly-Once vs. At-Least-Once¶
- At-least-once: el broker garantiza que el mensaje se entrega al menos una vez. Si el ACK del consumidor se pierde, el broker reenvía. El consumidor puede recibir duplicados. Esta es la semántica por defecto de la mayoría de los brokers y la más práctica.
- Exactly-once: el broker garantiza que el mensaje se procesa exactamente una vez. Kafka implementa esto con transactional producers y consumers (idempotent produce + read-process-write transactionality). Azure Service Bus con peek-lock y duplicate detection. Esta semántica tiene overhead de performance y complejidad.
- Recomendación: para la mayoría de los casos, at-least-once + idempotencia en el consumidor es la opción más práctica y robusta. Exactly-once semántico (del broker) debe reservarse para casos donde la idempotencia en el consumidor es impráctica.
Performance y Tuning¶
- Batching: los productores deben batch-ear mensajes para reducir network round trips. Kafka
linger.msybatch.sizecontrolan el batching. - Compression: comprimir mensajes reduce network bandwidth y storage. Kafka soporta gzip, snappy, lz4, zstd.
- Partitioning: más particiones permiten más paralelismo, pero incrementan overhead de rebalanceo y metadata.
- Consumer concurrency: el número de consumers en un group debe ser <= número de particiones para máximo paralelismo.
- Prefetch / Fetch size: controlar cuántos mensajes el consumidor lee en cada fetch para balancear latencia y throughput.
17. Errores Comunes¶
No Comprender las Semánticas de Entrega¶
El error más peligroso es asumir que el broker entrega cada mensaje exactamente una vez sin esfuerzo adicional. La realidad es que: - At-most-once (auto-ack antes de procesar): si el consumidor falla después del ACK pero antes de completar el procesamiento, el mensaje se pierde. - At-least-once (ACK después de procesar): si el consumidor procesa pero el ACK se pierde, el broker reenvía y el mensaje se procesa dos veces. - Exactly-once: requiere coordinación transaccional entre el broker y el consumidor, con overhead significativo.
Un arquitecto que no comprende estas semánticas diseñará un sistema que pierde datos (at-most-once accidental) o que procesa duplicados sin detectarlos (at-least-once sin idempotencia).
Ignorar el Ordering Cuando Importa¶
Es común asumir que los mensajes se procesan en el orden en que se producen. En un broker particionado como Kafka, esto solo es cierto dentro de una partición. Si se usa una partition key incorrecta (o random), eventos que deben procesarse en orden (e.g., OrderPlaced antes de OrderCancelled) pueden llegar desordenados a diferentes consumers. El resultado es un consumidor que intenta cancelar un pedido que aún no existe en su estado local, o que procesa un pago para un pedido ya cancelado.
Poner Lógica de Negocio en el Broker¶
El broker debe ser un componente de infraestructura agnóstico al negocio. Patrones como "si el monto es mayor a $1000 y el cliente es nuevo, enviar al topic de revisión manual" no deben implementarse como reglas del broker sino como lógica en un servicio dedicado (Content-Based Router pattern). Poner lógica de negocio en la configuración del broker (exchanges de RabbitMQ con reglas complejas, rules de EventBridge con transformaciones) crea un acoplamiento oculto entre la infraestructura y el negocio que es difícil de versionar, testear y evolucionar.
No Implementar Dead Letter Queue¶
Sin DLQ, un mensaje que no puede procesarse tiene dos destinos posibles: se descarta silenciosamente (pérdida de datos) o bloquea indefinidamente al consumidor (si el consumidor reintenta infinitamente). Ambos son inaceptables. Todo consumer en producción debe tener un DLQ configurado con monitoreo activo.
Chatty Messaging (Mensajería Excesivamente Granular)¶
Publicar un evento por cada cambio mínimo ("campo X actualizado", "campo Y actualizado") en lugar de eventos significativos de dominio ("OrderPlaced", "PaymentCompleted") genera un volumen excesivo de mensajes que saturan el broker, dificultan el procesamiento en el consumidor (que debe reconstruir el estado a partir de decenas de micro-eventos), y crean ruido que dificulta el monitoreo. Los eventos deben representar hechos de negocio significativos, no cambios de campo.
Usar Messaging Cuando Sync Es Más Simple¶
No todo requiere Messaging. Una consulta síncrona ("¿cuál es el precio de este producto?") que necesita respuesta inmediata es más simple y eficiente con una llamada REST/gRPC directa. Forzar una interacción request-reply sobre Messaging (crear correlation ID, publicar request, esperar response con timeout, manejar que la response no llegue) añade complejidad innecesaria para un problema que una llamada HTTP resuelve trivialmente.
No Planificar la Capacidad del Broker¶
Un broker undersized se satura durante picos de carga: las latencias se disparan, los consumers no pueden mantener el ritmo, los mensajes se acumulan, y en el peor caso el broker se queda sin disco y pierde datos. La planificación de capacidad debe considerar: throughput pico (no promedio), retención requerida, replication factor, y un margen de seguridad de al menos 2x para absorber picos imprevistos.
No Gestionar el Schema Evolution¶
Cambiar el formato de un mensaje sin coordinación (añadir un campo requerido, eliminar un campo que los consumidores usan, cambiar el tipo de un campo) rompe a los consumidores. Sin un Schema Registry que valide compatibilidad, estos errores se descubren en producción cuando un consumidor empieza a fallar por deserialization errors. La gobernanza del schema es tan importante como la gobernanza de una API REST.
Ignorar el Patrón Outbox para Consistencia¶
Un error sutil pero devastador es publicar un mensaje y actualizar la base de datos como dos operaciones independientes. Si el servicio falla entre ambas operaciones, se produce inconsistencia: la base de datos se actualizó pero el mensaje no se publicó (o viceversa). El patrón Transactional Outbox resuelve esto: el servicio escribe el mensaje en una tabla outbox dentro de la misma transacción de base de datos, y un proceso separado (relay) lee la tabla outbox y publica los mensajes al broker. Esto garantiza atomicidad entre el estado de la base de datos y los mensajes publicados.
18. Conclusión Técnica¶
Messaging es, sin ambigüedad, el estilo de integración más importante y más influyente en la arquitectura enterprise moderna. No es simplemente una alternativa a File Transfer, Shared Database o Remote Procedure Invocation: es el estilo que, al introducir un intermediario asíncrono entre aplicaciones, habilita un universo entero de patrones de integración que no existen sin él. Message Channel, Message Router, Pipes and Filters, Aggregator, Saga, Event Sourcing, CQRS: todos presuponen Messaging como infraestructura fundamental.
Para un arquitecto senior, la decisión de adoptar Messaging no es la decisión difícil. La dificultad real reside en las decisiones que siguen:
Elección de tecnología: ¿Kafka (log inmutable, retención, replay) vs. RabbitMQ (routing flexible, request-reply nativo) vs. servicio gestionado (simplicidad operacional, vendor lock-in)? La respuesta depende de si el caso de uso principal es event streaming, task queuing, o integración enterprise con routing complejo.
Diseño de eventos: ¿Eventos gruesos (contienen todo el estado) vs. eventos finos (contienen solo el delta)? ¿Eventos de dominio (OrderPlaced) vs. eventos de integración (OrderPlacedForShipping)? ¿Convención de naming? ¿Schema evolution strategy? Estas decisiones definen el contrato entre equipos y la evolución a largo plazo del sistema.
Semántica de entrega: ¿At-least-once + idempotencia (la opción por defecto) o exactly-once transaccional (para casos que lo justifiquen)? Esta decisión impacta el diseño de cada consumidor y la complejidad del sistema.
Gobierno: ¿Schema Registry centralizado o libertad por equipo? ¿Naming conventions impuestas o sugeridas? ¿Ownership de topics por equipo productor o por plataforma? El gobierno del sistema de mensajería es un reflejo de la estructura organizacional (Conway's Law).
Observabilidad: sin distributed tracing, correlation IDs y monitoreo de consumer lag, un sistema de Messaging en producción es una caja negra. La inversión en observabilidad no es opcional: es un prerequisito para operar Messaging a escala.
Resiliencia y compensación: Messaging introduce consistencia eventual por definición. El arquitecto debe diseñar explícitamente las estrategias de compensación (Sagas), los mecanismos de idempotencia, y los procesos de dead-letter management. No diseñarlos no evita los problemas: solo los hace invisibles hasta que se manifiestan en producción.
La recomendación final para un arquitecto que enfrenta Messaging es esta: tratarlo como infraestructura crítica de primera clase, no como un detalle de implementación. Un sistema de mensajería mal diseñado, mal operado o mal gobernado genera más problemas de los que resuelve. Pero un sistema de mensajería bien diseñado -- con schemas gobernados, consumers idempotentes, DLQ monitoreados, tracing end-to-end y capacidad de replay -- es la base más sólida sobre la cual se puede construir una arquitectura enterprise que sea simultáneamente resiliente, escalable y evolucionable.
Messaging no es un patrón que se implementa una vez y se olvida. Es una disciplina arquitectónica que requiere diseño continuo, operación rigurosa y gobierno activo. El retorno de esta inversión es una arquitectura de integración que puede crecer, adaptarse y sobrevivir a los cambios inevitables del negocio y la tecnología durante años.