Message Channel¶
1. Nombre del Patrón¶
- Nombre oficial: Message Channel
- Categoría: Messaging Systems (Sistemas de Mensajería — Conceptos Fundacionales)
- Traducción contextual: Canal de Mensajes
2. Resumen Ejecutivo¶
Message Channel es la abstracción fundamental que representa el conducto lógico a través del cual fluyen los mensajes entre una aplicación productora y una aplicación consumidora. Es el equivalente conceptual a una tubería que conecta dos sistemas: el productor deposita mensajes en un extremo del canal, y el consumidor los recoge del otro extremo.
El problema que resuelve es aparentemente simple pero arquitectónicamente profundo: ¿cómo sabe el productor dónde enviar un mensaje, y cómo sabe el consumidor dónde buscarlo? Message Channel responde a esta pregunta introduciendo una dirección lógica compartida — un nombre o identificador de canal — que ambas partes conocen y que el sistema de mensajería gestiona como recurso.
Aparece en toda arquitectura basada en mensajería sin excepción. No existe sistema de messaging sin canales, del mismo modo que no existe red de comunicación sin conductos. Es el concepto más básico y más omnipresente de toda la taxonomía de patrones de integración.
3. Definición Detallada¶
Propósito¶
Message Channel establece una conexión virtual nombrada entre productores y consumidores de mensajes. Su propósito es proporcionar un destino conocido donde los productores pueden depositar mensajes y un origen conocido donde los consumidores pueden recogerlos, sin que productores y consumidores necesiten conocerse entre sí directamente.
Lógica Arquitectónica¶
El canal introduce un nivel de indirección fundamental en la comunicación entre sistemas. En una invocación directa (Remote Procedure Invocation), el llamador necesita conocer la dirección exacta del receptor (hostname, port, path). En messaging con canales, el productor solo necesita conocer el nombre del canal; el sistema de mensajería se encarga de entregar el mensaje a los consumidores registrados en ese canal.
Esta indirección tiene consecuencias arquitectónicas profundas:
- Desacoplamiento espacial: el productor no sabe (ni necesita saber) quién consume sus mensajes, ni cuántos consumidores hay, ni dónde están desplegados.
- Desacoplamiento temporal: el productor puede enviar mensajes aunque ningún consumidor esté disponible en ese instante (el canal almacena los mensajes hasta que un consumidor los recoja).
- Punto de control: el canal es un recurso gestionable donde se pueden aplicar políticas de seguridad, retención, monitoreo, throttling y priorización.
Principio de Diseño Subyacente¶
El principio es comunicación a través de un intermediario nombrado. En lugar de que los sistemas se hablen directamente (acoplamiento directo), se hablan a través de un recurso compartido identificado por un nombre lógico. Este principio es idéntico al de un buzón postal: el remitente deposita una carta en un buzón identificado por una dirección, y el destinatario la recoge de ese mismo buzón, sin que remitente y destinatario necesiten encontrarse en el mismo lugar al mismo tiempo.
Problema Estructural que Resuelve¶
En un sistema distribuido con múltiples productores y consumidores, sin canales la comunicación requiere que cada productor conozca la dirección de cada consumidor y mantenga una conexión activa con cada uno. Esto produce una topología de conexiones que crece cuadráticamente y que es imposible de gestionar a escala.
Message Channel colapsa esta complejidad: los productores envían a canales, los consumidores escuchan en canales. La gestión de la conectividad se delega al sistema de mensajería, que la optimiza internamente.
Contexto en el que Emerge¶
Message Channel emerge en cualquier escenario donde dos o más aplicaciones necesitan intercambiar mensajes de forma asíncrona. Es la primera decisión de diseño en un sistema de mensajería: ¿cuántos canales necesitamos, cómo los nombramos, qué semántica tiene cada uno, quién produce en cada canal, quién consume?
Por Qué No Es Trivial¶
Aunque el concepto parece simple (un "tubo" por donde pasan mensajes), las decisiones de diseño alrededor de los canales son complejas y tienen impacto duradero:
- Granularidad: ¿un canal por tipo de mensaje? ¿Un canal por dominio? ¿Un canal por consumidor? La granularidad del canal determina la granularidad del acoplamiento.
- Semántica de entrega: ¿el canal entrega cada mensaje a un solo consumidor (point-to-point) o a todos los consumidores (publish-subscribe)? Esta decisión afecta fundamentalmente el comportamiento del sistema.
- Retención: ¿el canal retiene mensajes después de entregarlos? ¿Por cuánto tiempo? Esto determina si los consumidores pueden "rebobinar" y reprocesar mensajes pasados.
- Ordenamiento: ¿el canal garantiza orden FIFO? ¿Dentro de una partición? ¿Globalmente? El ordenamiento tiene implicaciones directas en performance y correctitud.
- Capacidad y backpressure: ¿qué ocurre cuando el canal se llena porque los consumidores no pueden procesar tan rápido como los productores producen?
Relación con Sistemas Distribuidos y Mensajería¶
Message Channel es la abstracción central de todo sistema de mensajería. En la teoría de sistemas distribuidos, corresponde al concepto de un reliable ordered broadcast channel o un FIFO delivery channel, dependiendo de las garantías que ofrezca. Las propiedades del canal (durabilidad, orden, semántica de entrega) determinan directamente qué garantías de consistencia pueden alcanzar las aplicaciones que lo usan.
En la práctica, cada plataforma de mensajería implementa Message Channel con características diferentes:
- En Kafka, un canal es un Topic, subdividido en Partitions. El canal retiene mensajes por tiempo o tamaño, permite múltiples consumer groups, y garantiza orden dentro de cada partición.
- En RabbitMQ, un canal es una Queue (para point-to-point) o una combinación de Exchange + Queue bindings (para routing y pub-sub). Los mensajes se eliminan tras ser consumidos (por defecto).
- En Azure Service Bus, un canal es una Queue o un Topic con Subscriptions. Soporta sesiones para orden garantizado por partición lógica.
- En AWS SQS, un canal es una Queue estándar (best-effort ordering) o una FIFO Queue (orden estricto con limitaciones de throughput).
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin la abstracción de Message Channel, las aplicaciones que necesitan intercambiar mensajes deben resolver por sí mismas:
- Descubrimiento: ¿cómo encuentra el productor al consumidor? ¿Qué dirección IP, qué puerto, qué protocolo?
- Persistencia: ¿dónde se almacenan los mensajes mientras el consumidor no está disponible? Sin un canal, si el consumidor no está escuchando, el mensaje se pierde.
- Distribución: si hay múltiples consumidores, ¿cómo se decide quién recibe cada mensaje? ¿Todos? ¿Solo uno?
- Control de acceso: ¿quién tiene permiso para enviar y quién tiene permiso para recibir?
Cada aplicación resolviendo estos problemas de forma independiente produce implementaciones inconsistentes, frágiles y no interoperables.
Síntomas del Problema¶
- Productores con configuración hardcodeada de direcciones de consumidores que se rompe cuando un consumidor cambia de ubicación.
- Mensajes perdidos porque el consumidor estaba temporalmente no disponible y no había buffer intermedio.
- Imposibilidad de añadir un nuevo consumidor sin modificar el código del productor.
- Falta de visibilidad sobre qué mensajes están en tránsito, cuántos hay pendientes, cuáles fueron procesados.
- Incapacidad de aplicar políticas transversales (seguridad, retención, monitoreo) porque no hay punto de control centralizado.
Impacto Operativo y Arquitectónico¶
Sin canales bien diseñados:
- Las integraciones se convierten en una maraña de conexiones directas imposible de visualizar, monitorear y mantener.
- Los cambios en la topología (añadir consumidores, reubicar servicios) requieren cambios en los productores.
- Los fallos se propagan sin contención: si un consumidor falla, el productor se bloquea o pierde mensajes.
- La observabilidad es nula: no hay forma de saber cuántos mensajes están en tránsito, cuántos se procesaron, cuántos fallaron.
Riesgos Si No Se Implementa Correctamente¶
- Canal sobrecargado: un canal que recibe mensajes de tipos muy diferentes se convierte en un cuello de botella y hace imposible el procesamiento selectivo.
- Proliferación de canales: crear un canal por cada par productor-consumidor produce una explosión combinatoria difícil de gestionar.
- Semántica incorrecta: usar un canal point-to-point cuando se necesita pub-sub (o viceversa) produce pérdida de mensajes o procesamiento duplicado.
- Falta de monitoreo: canales sin monitoreo acumulan mensajes sin ser procesados hasta que un proceso de negocio falla días después.
Ejemplos Reales¶
- Banca: un canal
transactions.clearingtransporta transacciones de compensación interbancaria entre el core bancario y el sistema de clearing. Si el canal no existe como abstracción gestionada, las transacciones se pierden durante ventanas de mantenimiento del sistema de clearing. - E-commerce: un canal
orders.createdtransporta eventos de creación de pedidos que deben ser consumidos por inventario, pagos, shipping y notificaciones. Sin un canal pub-sub, cada nuevo consumidor requiere modificar el productor. - Salud: un canal
lab.resultstransporta resultados de laboratorio desde el LIS (Laboratory Information System) al EMR (Electronic Medical Record). El canal debe garantizar que cada resultado se entrega exactamente a un sistema y no se pierde.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Siempre que dos o más aplicaciones necesiten intercambiar mensajes a través de un sistema de mensajería. Message Channel no es opcional — es constitutivo.
- Cuando se necesita desacoplar productores de consumidores en espacio y tiempo.
- Cuando se necesita un punto de control para aplicar políticas de seguridad, retención, monitoreo.
- Cuando la topología de productores y consumidores puede cambiar (nuevos consumidores, productores reubicados).
Cuándo No Usarlo¶
- Message Channel como concepto no tiene un "cuándo no usarlo" dentro del contexto de messaging — es inherente al estilo.
- Sin embargo, la decisión de cuántos canales usar y con qué granularidad sí tiene alternativas: un canal muy genérico vs. múltiples canales específicos.
Precondiciones¶
- Existe un sistema de mensajería (broker) que gestiona canales.
- Productores y consumidores comparten el conocimiento del nombre/identificador del canal.
- Existe acuerdo sobre la semántica del canal (point-to-point vs. pub-sub, ordenamiento, retención).
Restricciones¶
- El número de canales puede estar limitado por la plataforma (algunos brokers tienen límites prácticos de topics o queues).
- Las propiedades del canal (particionamiento, retención, throughput) están determinadas por la plataforma y su configuración.
- La evolución de la semántica de un canal en producción (por ejemplo, cambiar de point-to-point a pub-sub) puede ser disruptiva.
Dependencias¶
- Infraestructura de messaging (broker, cluster).
- Mecanismo de naming/discovery para que productores y consumidores resuelvan el nombre del canal a un recurso real.
- Políticas de gobierno que definan convenciones de nombres, propiedades por defecto y ownership de canales.
Supuestos Arquitectónicos¶
- El broker gestiona el almacenamiento y la entrega de mensajes en los canales.
- Los productores confían en que el canal aceptará y persistirá los mensajes (si el canal ofrece durabilidad).
- Los consumidores confían en que el canal entregará los mensajes según su semántica declarada.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Cualquier sistema basado en messaging: event-driven architectures, microservicios asíncronos, integraciones enterprise, streaming platforms, CQRS/ES.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Message Channel reduce drásticamente el acoplamiento entre productor y consumidor. El productor solo conoce el canal, no al consumidor. Esto permite añadir, remover o reemplazar consumidores sin tocar el productor. Sin embargo, el nombre del canal se convierte en un punto de acoplamiento implícito: si se renombra un canal, todos los productores y consumidores deben actualizarse.
Simplicidad vs. Robustez¶
Un diseño simple (pocos canales, uno por dominio) es fácil de entender pero puede resultar en canales sobrecargados con mensajes heterogéneos que dificultan el procesamiento selectivo. Un diseño robusto (muchos canales, uno por tipo de mensaje) permite procesamiento granular pero aumenta la complejidad de gestión. La tensión entre granularidad y manejabilidad es constante.
Sincronía vs. Asincronía¶
Message Channel es inherentemente asíncrono. El productor envía y continúa; el consumidor procesa cuando puede. Esto es una fortaleza para desacoplamiento temporal pero un desafío para escenarios que necesitan confirmación inmediata (para los cuales se usa Request-Reply sobre dos canales, lo cual añade complejidad).
Latencia vs. Confiabilidad¶
Un canal con garantía de entrega (persistent, durable) añade latencia por el write to disk. Un canal sin garantía (non-persistent, in-memory) es más rápido pero puede perder mensajes ante fallos. La elección depende del caso de uso: transacciones financieras exigen durabilidad; métricas de telemetría pueden tolerar pérdida.
Consistencia vs. Disponibilidad¶
Un canal replicado (para alta disponibilidad) puede introducir ventanas de inconsistencia entre réplicas. La configuración de acks (cuántas réplicas deben confirmar antes de considerar el mensaje "aceptado") determina el equilibrio entre consistencia y disponibilidad. En Kafka, acks=all maximiza consistencia; acks=1 maximiza throughput.
Costo Operativo vs. Capacidad de Evolución¶
Más canales = más flexibilidad para evolucionar la arquitectura (nuevos consumidores, nuevo routing) pero más costo operativo (más recursos para gestionar, monitorear, escalar). Menos canales = menos costo operativo pero menos capacidad de cambio sin impacto.
Gobernanza vs. Autonomía de Equipos¶
¿Quién crea canales? Si es un proceso centralizado, hay control pero fricción. Si cada equipo crea sus propios canales, hay agilidad pero riesgo de proliferación, inconsistencia y falta de visibilidad. Las organizaciones maduras definen convenciones de naming y procesos de registro, manteniendo autonomía con guardrails.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): la aplicación que envía mensajes al canal.
- Canal (Message Channel): el recurso lógico gestionado por el broker que almacena y transporta mensajes.
- Consumidor (Receiver): la aplicación que recibe mensajes del canal.
- Broker: el sistema de mensajería que gestiona los canales, almacena mensajes y los entrega a los consumidores.
- Administrador/Governance: el rol que crea, configura, monitorea y gestiona los canales.
Flujo Lógico¶
flowchart TD
A[Admin: Crea y configura el canal] --> B[Consumidor se suscribe al canal]
B --> C([Productor: Envía mensaje al canal])
C --> D[(Broker: Almacena mensaje)]
D --> E{Semántica del canal}
E -->|Point-to-Point| F[Entrega a UN consumidor]
E -->|Publish-Subscribe| G[Entrega a TODOS los suscritos]
F --> H[Consumidor: Procesa mensaje]
G --> H
H --> I[Consumidor: Envía ACK]
I --> J[Broker: Marca como consumido]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Serializar mensaje, enviarlo al canal correcto, manejar errores de envío |
| Canal/Broker | Almacenar mensaje, garantizar entrega según semántica, gestionar retención y orden |
| Consumidor | Suscribirse, recibir mensajes, procesarlos, confirmar procesamiento |
| Admin | Crear canal, definir propiedades, monitorear, gestionar capacidad |
Interacciones¶
- Productor → Canal: operación de envío (send, publish, produce). Puede ser síncrona (espera confirmación del broker) o asíncrona (fire-and-forget con callback).
- Canal → Consumidor: operación de entrega. Puede ser push (el broker envía al consumidor) o pull (el consumidor solicita al canal).
- Consumidor → Canal: operación de acknowledgment. Confirma que el mensaje fue procesado exitosamente.
Contratos Implícitos¶
- Nombre del canal: el productor y el consumidor deben usar el mismo nombre.
- Formato de mensajes: aunque el canal es agnóstico al contenido, existe un contrato implícito sobre qué tipo de mensajes circulan por cada canal.
- Semántica de entrega: ambas partes deben entender si el canal es point-to-point o pub-sub.
- Ordenamiento: si el procesamiento depende del orden, ambas partes deben entender las garantías de orden del canal.
Decisiones de Diseño Clave¶
- Point-to-Point vs. Publish-Subscribe: determina si cada mensaje va a un consumidor o a todos. Esta es la decisión más fundamental y se analiza en profundidad en los patrones Point-to-Point Channel y Publish-Subscribe Channel del capítulo 3.
- Durabilidad: mensajes persistidos en disco vs. solo en memoria.
- Particionamiento: dividir un canal lógico en particiones físicas para paralelismo (Kafka partitions, Service Bus partitions).
- Retención: cuánto tiempo se retienen los mensajes después de ser consumidos (o incluso antes).
- Naming convention: cómo se nombran los canales (
domain.entity.event,team.service.action, etc.).
8. Ejemplo Arquitectónico Detallado¶
Dominio: Logística — Tracking de Envíos en Tiempo Real¶
Contexto del Negocio¶
Una empresa de logística internacional opera una flota de 50,000 vehículos que realizan entregas en 15 países. Cada vehículo tiene un dispositivo IoT que reporta su ubicación GPS, estado de entrega y condiciones del paquete (temperatura, humedad para carga sensible) cada 30 segundos. Múltiples sistemas necesitan estos datos en tiempo real:
- Sistema de Tracking para Clientes: muestra la ubicación del envío en un mapa en tiempo real.
- Sistema de Optimización de Rutas: recalcula rutas basándose en ubicaciones actuales y condiciones de tráfico.
- Sistema de Alertas de SLA: detecta envíos que están en riesgo de incumplir su ventana de entrega.
- Sistema de Compliance de Cadena de Frío: monitorea condiciones de temperatura para carga perecedera.
- Data Lake Analítico: almacena todos los eventos para análisis histórico y modelos predictivos.
Necesidad de Integración¶
Los 50,000 dispositivos IoT generan aproximadamente 100,000 eventos por minuto. Estos eventos deben distribuirse a cinco sistemas consumidores con diferentes necesidades de latencia, filtrado y procesamiento. Ningún sistema consumidor debe depender directamente de los dispositivos ni de los otros consumidores.
Sistemas Involucrados¶
- IoT Gateway: recibe telemetría de los dispositivos y la normaliza.
- Kafka Cluster: plataforma de streaming que gestiona los canales.
- Customer Tracking Service: microservicio que alimenta la UI de tracking.
- Route Optimization Engine: servicio de ML que optimiza rutas.
- SLA Alert Service: servicio que evalúa riesgo de incumplimiento de SLA.
- Cold Chain Compliance Service: servicio que monitorea cadena de frío.
- Data Lake Ingestion: pipeline que almacena eventos en el data lake.
Restricciones Técnicas¶
- Latencia máxima aceptable para tracking de clientes: 5 segundos.
- Latencia aceptable para optimización de rutas: 30 segundos.
- Los eventos de cadena de frío deben procesarse en orden por vehículo (para detectar tendencias de temperatura).
- El data lake necesita todos los eventos sin excepción (zero data loss).
- Los dispositivos IoT no pueden reenviar datos si se pierden (memoria limitada a bordo).
Diseño de Canales¶
Se diseñan los siguientes Message Channels:
| Canal (Topic Kafka) | Productor | Semántica | Particionamiento | Retención |
|---|---|---|---|---|
fleet.telemetry.raw | IoT Gateway | Pub-Sub | Por vehicle_id | 7 días |
fleet.telemetry.location | Stream Processor | Pub-Sub | Por vehicle_id | 3 días |
fleet.telemetry.coldchain | Stream Processor | Pub-Sub | Por vehicle_id | 30 días |
fleet.alerts.sla | SLA Alert Service | Point-to-Point | Por shipment_id | 90 días |
Decisiones Arquitectónicas¶
-
Canal raw + canales derivados: en lugar de que cada consumidor filtre el canal raw (alto volumen, mensajes heterogéneos), un stream processor separa los datos en canales temáticos. Esto implementa un pattern Splitter + Content-Based Router sobre canales.
-
Particionamiento por vehicle_id: garantiza que todos los eventos de un mismo vehículo lleguen a la misma partición, preservando orden temporal por vehículo. Esto es crítico para el servicio de cadena de frío que necesita detectar tendencias.
-
Retención diferenciada: el canal raw retiene 7 días para reprocesamiento; el canal de cadena de frío retiene 30 días por requisitos de compliance; el canal de alertas retiene 90 días para auditoría.
-
Consumer groups independientes: cada sistema consumidor tiene su propio consumer group en Kafka, lo que permite que cada uno consuma a su propio ritmo sin afectar a los demás.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de telemetría | Canal raw con acks=all y replicación factor 3 |
| Consumidor lento bloquea a otros | Consumer groups independientes por servicio |
| Acumulación de lag en un consumidor | Alertas de consumer lag > umbral por servicio |
| Partición hotspot (un vehículo muy activo) | Distribución uniforme de vehicle_ids garantizada por hashing |
| Evolución del formato de telemetría | Schema Registry con Avro y compatibilidad BACKWARD |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción de Telemetría¶
Un vehículo de la flota (ID: VH-38291) entrega un paquete perecedero (vacunas, cadena de frío) en Madrid. Su dispositivo IoT genera un evento cada 30 segundos:
{
"vehicle_id": "VH-38291",
"timestamp": "2026-04-07T14:32:15Z",
"location": { "lat": 40.4168, "lon": -3.7038 },
"speed_kmh": 42,
"shipment_id": "SHP-2026-1847291",
"cargo_temp_celsius": 4.2,
"cargo_humidity_pct": 38,
"delivery_status": "in_transit"
}
El IoT Gateway recibe este evento vía MQTT, lo valida, le asigna un event_id único y lo publica en el canal fleet.telemetry.raw con vehicle_id como partition key.
Paso 2: Routing a Canales Temáticos¶
Un Kafka Streams application consume de fleet.telemetry.raw y ejecuta:
- Extrae campos de ubicación → publica en
fleet.telemetry.location(todos los consumidores de ubicación reciben un mensaje simplificado con solo location, speed y vehicle_id). - Filtra eventos con cargo_temp → publica en
fleet.telemetry.coldchain(solo los eventos que tienen datos de temperatura y humedad).
Esta separación permite que el servicio de tracking de clientes consuma solo datos de ubicación (menor volumen, menor parsing), y que el servicio de cadena de frío reciba solo datos relevantes de temperatura.
Paso 3: Consumo por Customer Tracking Service¶
El Customer Tracking Service (consumer group: cg-customer-tracking) consume de fleet.telemetry.location:
- Lee el mensaje con la ubicación del vehículo VH-38291.
- Actualiza la posición del envío SHP-2026-1847291 en una base de datos Redis (low-latency lookup).
- Publica la actualización vía WebSocket a los clientes que tienen abierta la página de tracking de ese envío.
- Confirma el mensaje (commit offset).
Latencia total desde evento IoT hasta actualización en UI: ~2 segundos.
Paso 4: Consumo por Cold Chain Compliance Service¶
El Cold Chain Compliance Service (consumer group: cg-cold-chain) consume de fleet.telemetry.coldchain:
- Lee el mensaje con temperatura 4.2°C para el vehículo VH-38291.
- Agrega el dato al histórico de temperatura del envío (almacenado en una time-series database, InfluxDB).
- Evalúa si la temperatura está dentro del rango aceptable (2-8°C para vacunas). 4.2°C es aceptable.
- Si la temperatura excediera el rango, generaría una alerta en el canal
fleet.alerts.sla. - Confirma el mensaje.
El orden por partición (garantizado porque vehicle_id es la partition key) asegura que las lecturas de temperatura se procesan en secuencia temporal, permitiendo detectar tendencias (temperatura subiendo gradualmente).
Paso 5: Consumo por Data Lake¶
El pipeline de ingesta al data lake (consumer group: cg-datalake) consume de fleet.telemetry.raw:
- Lee TODOS los eventos sin filtrar.
- Los acumula en micro-batches de 1 minuto.
- Escribe los batches en formato Parquet en Azure Data Lake Storage Gen2.
- Confirma los offsets después de la escritura exitosa.
Este consumidor puede tolerar mayor latencia (minutos) pero no puede perder ningún evento. La retención de 7 días en el canal raw permite que, si el pipeline falla, pueda retroceder sus offsets y reprocesar los eventos perdidos.
Paso 6: Monitoreo de Canales¶
Un dashboard de Grafana monitorea continuamente:
- Consumer lag de cada consumer group (diferencia entre el offset más reciente producido y el offset más reciente consumido).
- Throughput de producción y consumo en cada canal (mensajes/segundo).
- Tamaño de canal (bytes almacenados en cada topic).
- Errores de producción (rechazos del broker por canal lleno, timeout de acks).
Si el consumer lag del servicio de cadena de frío excede 5 minutos, se genera una alerta operacional porque los datos de temperatura están llegando con delay inaceptable.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.client import Client
from diagrams.onprem.compute import Server
from diagrams.onprem.database import InfluxDB
from diagrams.onprem.inmemory import Redis
from diagrams.azure.storage import DataLakeStorage
from diagrams.onprem.monitoring import Grafana
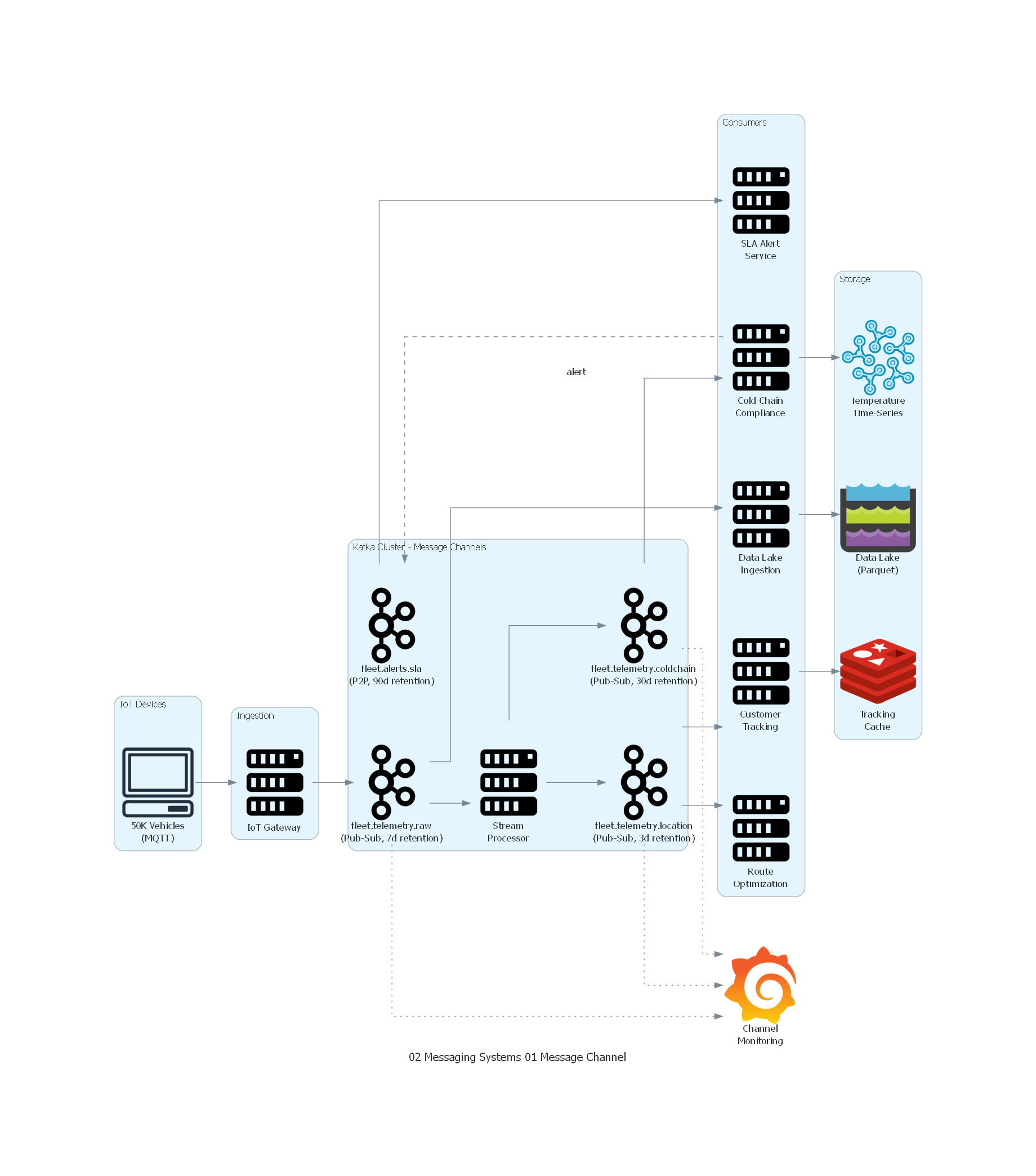
with Diagram("Message Channel - Fleet Telemetry", show=False, direction="LR"):
with Cluster("IoT Devices"):
devices = Client("50K Vehicles\n(MQTT)")
with Cluster("Ingestion"):
gateway = Server("IoT Gateway")
with Cluster("Kafka Cluster - Message Channels"):
raw_topic = Kafka("fleet.telemetry.raw\n(Pub-Sub, 7d retention)")
location_topic = Kafka("fleet.telemetry.location\n(Pub-Sub, 3d retention)")
coldchain_topic = Kafka("fleet.telemetry.coldchain\n(Pub-Sub, 30d retention)")
alerts_topic = Kafka("fleet.alerts.sla\n(P2P, 90d retention)")
stream_proc = Server("Stream\nProcessor")
with Cluster("Consumers"):
tracking = Server("Customer\nTracking")
route_opt = Server("Route\nOptimization")
cold_chain = Server("Cold Chain\nCompliance")
sla_alert = Server("SLA Alert\nService")
datalake = Server("Data Lake\nIngestion")
with Cluster("Storage"):
redis = Redis("Tracking\nCache")
influx = InfluxDB("Temperature\nTime-Series")
lake = DataLakeStorage("Data Lake\n(Parquet)")
monitoring = Grafana("Channel\nMonitoring")
# Flow
devices >> gateway >> raw_topic
raw_topic >> stream_proc
stream_proc >> location_topic
stream_proc >> coldchain_topic
location_topic >> tracking >> redis
location_topic >> route_opt
coldchain_topic >> cold_chain >> influx
cold_chain >> Edge(style="dashed", label="alert") >> alerts_topic
alerts_topic >> sla_alert
raw_topic >> datalake >> lake
raw_topic >> Edge(style="dotted") >> monitoring
location_topic >> Edge(style="dotted") >> monitoring
coldchain_topic >> Edge(style="dotted") >> monitoring
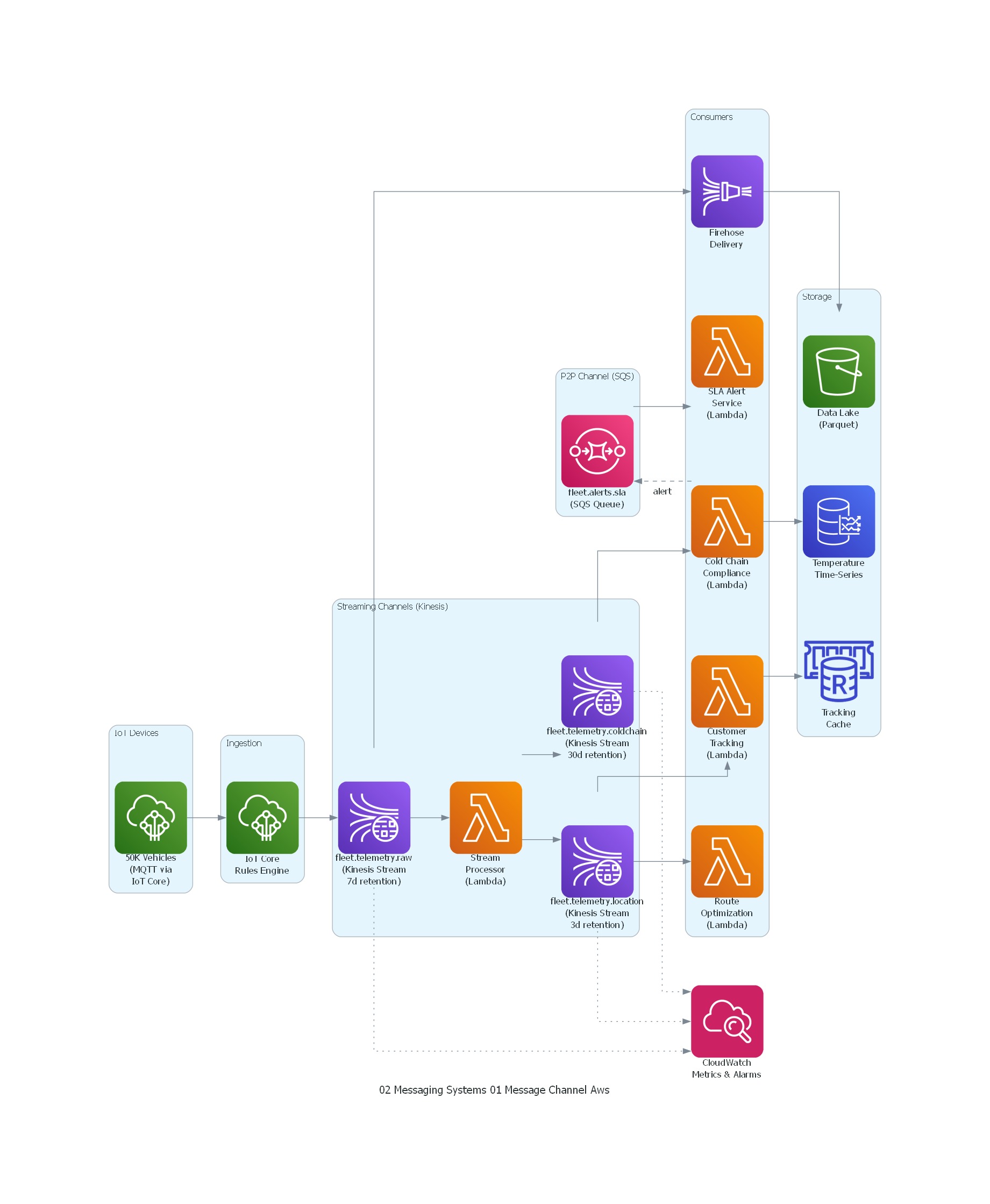
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.analytics import KinesisDataStreams, KinesisDataFirehose
from diagrams.aws.compute import Lambda
from diagrams.aws.database import ElasticacheForRedis, Timestream
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.iot import IotCore
from diagrams.aws.management import Cloudwatch
from diagrams.aws.storage import S3
with Diagram("Message Channel - Fleet Telemetry (AWS)", show=False, direction="LR"):
with Cluster("IoT Devices"):
devices = IotCore("50K Vehicles\n(MQTT via\nIoT Core)")
with Cluster("Ingestion"):
gateway = IotCore("IoT Core\nRules Engine")
with Cluster("Streaming Channels (Kinesis)"):
raw_stream = KinesisDataStreams("fleet.telemetry.raw\n(Kinesis Stream\n7d retention)")
location_stream = KinesisDataStreams("fleet.telemetry.location\n(Kinesis Stream\n3d retention)")
coldchain_stream = KinesisDataStreams("fleet.telemetry.coldchain\n(Kinesis Stream\n30d retention)")
stream_proc = Lambda("Stream\nProcessor\n(Lambda)")
with Cluster("P2P Channel (SQS)"):
alerts_queue = SQS("fleet.alerts.sla\n(SQS Queue)")
with Cluster("Consumers"):
tracking = Lambda("Customer\nTracking\n(Lambda)")
route_opt = Lambda("Route\nOptimization\n(Lambda)")
cold_chain = Lambda("Cold Chain\nCompliance\n(Lambda)")
sla_alert = Lambda("SLA Alert\nService\n(Lambda)")
firehose = KinesisDataFirehose("Firehose\nDelivery")
with Cluster("Storage"):
redis = ElasticacheForRedis("Tracking\nCache")
influx = Timestream("Temperature\nTime-Series")
lake = S3("Data Lake\n(Parquet)")
monitoring = Cloudwatch("CloudWatch\nMetrics & Alarms")
# Flow
devices >> gateway >> raw_stream
raw_stream >> stream_proc
stream_proc >> location_stream
stream_proc >> coldchain_stream
location_stream >> tracking >> redis
location_stream >> route_opt
coldchain_stream >> cold_chain >> influx
cold_chain >> Edge(style="dashed", label="alert") >> alerts_queue
alerts_queue >> sla_alert
raw_stream >> firehose >> lake
raw_stream >> Edge(style="dotted") >> monitoring
location_stream >> Edge(style="dotted") >> monitoring
coldchain_stream >> Edge(style="dotted") >> monitoring
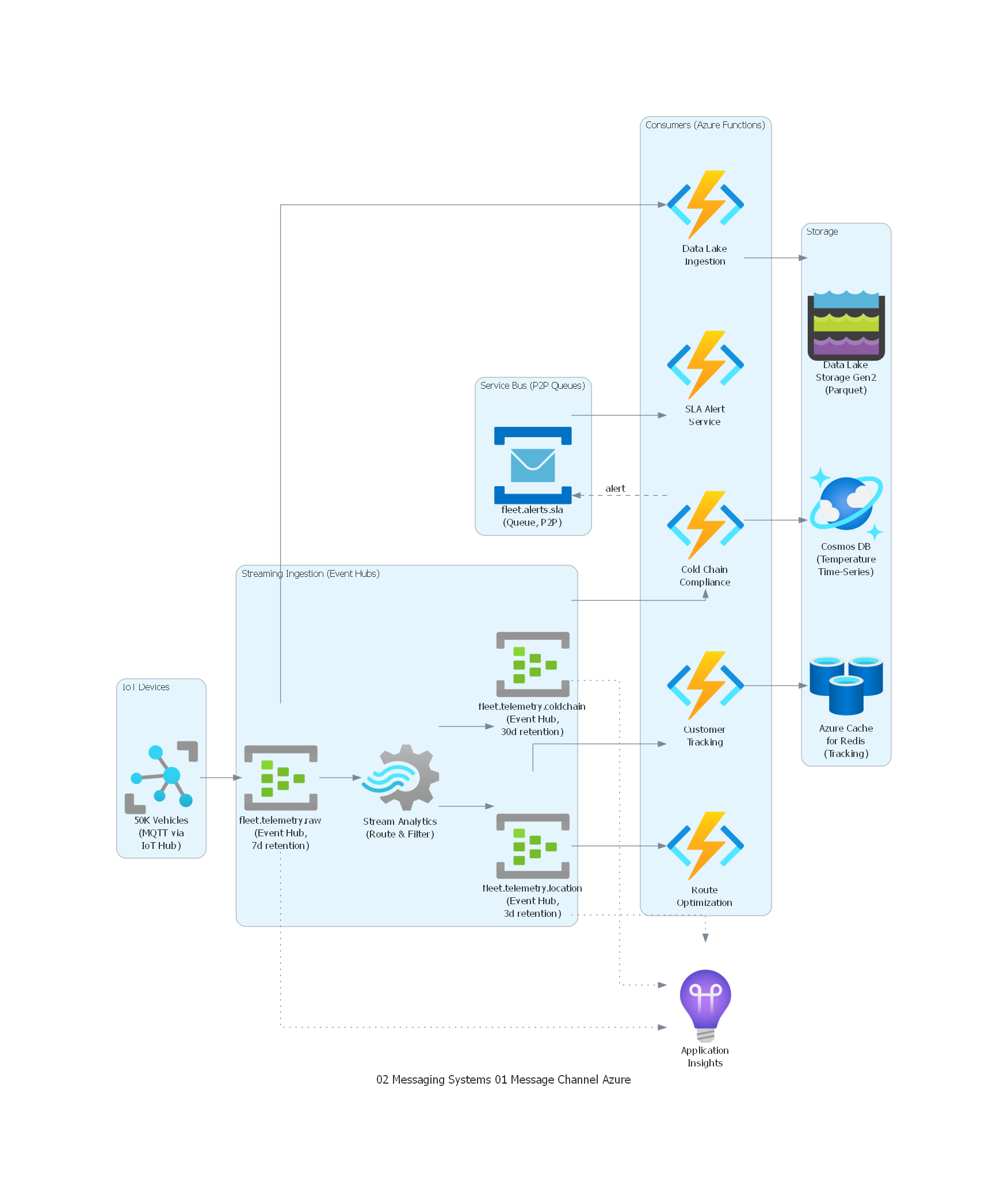
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis, CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.analytics import EventHubs
from diagrams.azure.iot import IotHub
from diagrams.azure.storage import DataLakeStorage
from diagrams.azure.analytics import StreamAnalyticsJobs
with Diagram("Message Channel - Fleet Telemetry (Azure)", show=False, direction="LR"):
with Cluster("IoT Devices"):
devices = IotHub("50K Vehicles\n(MQTT via\nIoT Hub)")
with Cluster("Streaming Ingestion (Event Hubs)"):
raw_stream = EventHubs("fleet.telemetry.raw\n(Event Hub,\n7d retention)")
location_stream = EventHubs("fleet.telemetry.location\n(Event Hub,\n3d retention)")
coldchain_stream = EventHubs("fleet.telemetry.coldchain\n(Event Hub,\n30d retention)")
stream_proc = StreamAnalyticsJobs("Stream Analytics\n(Route & Filter)")
with Cluster("Service Bus (P2P Queues)"):
alerts_queue = ServiceBus("fleet.alerts.sla\n(Queue, P2P)")
with Cluster("Consumers (Azure Functions)"):
tracking = FunctionApps("Customer\nTracking")
route_opt = FunctionApps("Route\nOptimization")
cold_chain = FunctionApps("Cold Chain\nCompliance")
sla_alert = FunctionApps("SLA Alert\nService")
datalake = FunctionApps("Data Lake\nIngestion")
with Cluster("Storage"):
redis = CacheForRedis("Azure Cache\nfor Redis\n(Tracking)")
cosmos = CosmosDb("Cosmos DB\n(Temperature\nTime-Series)")
lake = DataLakeStorage("Data Lake\nStorage Gen2\n(Parquet)")
monitoring = ApplicationInsights("Application\nInsights")
# Flow
devices >> raw_stream
raw_stream >> stream_proc
stream_proc >> location_stream
stream_proc >> coldchain_stream
location_stream >> tracking >> redis
location_stream >> route_opt
coldchain_stream >> cold_chain >> cosmos
cold_chain >> Edge(style="dashed", label="alert") >> alerts_queue
alerts_queue >> sla_alert
raw_stream >> datalake >> lake
raw_stream >> Edge(style="dotted") >> monitoring
location_stream >> Edge(style="dotted") >> monitoring
coldchain_stream >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de canales para el sistema de tracking logístico:
- IoT Devices envían telemetría al IoT Gateway que la normaliza.
- El gateway produce al canal fleet.telemetry.raw (el canal primario con todos los eventos).
- Un Stream Processor consume del canal raw y produce en dos canales derivados: fleet.telemetry.location (datos de ubicación simplificados) y fleet.telemetry.coldchain (datos de temperatura filtrados).
- Cada servicio consumidor tiene su propio consumer group y consume del canal relevante.
- El Cold Chain Compliance service puede producir alertas en el canal fleet.alerts.sla si detecta excursiones de temperatura.
- El Data Lake Ingestion consume directamente del canal raw para almacenar todos los eventos.
- Grafana monitorea el estado de todos los canales (lag, throughput, errores).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor | IoT Gateway, Stream Processor, Cold Chain Compliance |
| Message Channel | Cada topic de Kafka (raw, location, coldchain, alerts) |
| Consumidor | Customer Tracking, Route Optimization, Cold Chain, SLA Alert, Data Lake |
| Broker | Kafka Cluster |
| Semántica Pub-Sub | Topics raw, location, coldchain (múltiples consumer groups) |
| Semántica Point-to-Point | Topic alerts (un solo consumer group) |
| Monitoring | Grafana dashboard |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento productor-consumidor: el IoT Gateway no sabe ni necesita saber cuántos servicios consumen la telemetría. Se pueden añadir nuevos consumidores sin modificar el gateway.
- Escalabilidad independiente: cada canal se escala (particiones) según su carga. El canal raw necesita más particiones que el canal de alertas.
- Aislamiento de fallos: si el servicio de cadena de frío falla, no afecta al tracking de clientes ni al data lake. Cada consumidor tiene su propio offset y consumer group.
- Reprocesamiento: gracias a la retención del canal, cualquier consumidor puede retroceder sus offsets y reprocesar eventos pasados sin necesidad de que el productor los reenvíe.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de tracking, el equipo de compliance y el equipo de data pueden desarrollar, desplegar y escalar sus servicios de forma independiente. El canal es el contrato compartido.
- Descubrimiento: los nombres de los canales (
fleet.telemetry.raw,fleet.alerts.sla) documentan implícitamente qué datos fluyen por la arquitectura. - Onboarding: un nuevo equipo que necesita datos de telemetría puede conectarse al canal relevante sin coordinación con el productor.
Impacto Operacional¶
- Monitoreo centralizado: los canales proporcionan un punto de observación donde se puede medir throughput, lag, errores y health de toda la arquitectura de integración.
- Backpressure natural: si un consumidor es más lento que el productor, los mensajes se acumulan en el canal (visible como consumer lag) en lugar de causar errores o pérdida de datos.
- Debugging: los mensajes en el canal pueden inspeccionarse directamente (kafka-console-consumer, Azure Service Bus Explorer) para diagnosticar problemas.
Beneficios de Mantenibilidad y Evolución¶
- Extensibilidad: añadir un sexto consumidor (por ejemplo, un sistema de facturación basado en kilómetros recorridos) solo requiere crear un nuevo consumer group y conectarlo al canal relevante.
- Migración: un sistema consumidor puede reemplazarse sin afectar a los demás: el nuevo sistema se conecta al mismo canal con el mismo consumer group.
- Evolución del formato: con un Schema Registry, el formato de los mensajes puede evolucionar de forma compatible sin interrumpir a los consumidores existentes.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Infraestructura de messaging: un cluster de Kafka o un Azure Service Bus no es trivial de operar. Requiere expertise en configuración, monitoreo, tuning y recovery.
- Diseño de canales: decidir la granularidad, semántica, particionamiento y retención de los canales requiere análisis y experiencia. Un mal diseño de canales es costoso de cambiar.
- Indirección: la abstracción del canal hace que el flujo de datos sea menos visible que en una conexión directa. El debugging end-to-end requiere herramientas de tracing.
Riesgos de Mal Uso¶
- Canal como database: usar la retención del canal como storage primario, leyendo mensajes repetidamente como si fueran registros de una tabla, en lugar de materializar los datos en un store apropiado.
- Canal comodín: crear un solo canal para todos los tipos de mensaje ("catch-all topic"), lo que impide el procesamiento selectivo y la escalabilidad independiente.
- Semántica incorrecta: no comprender la diferencia entre point-to-point y pub-sub y diseñar los canales con la semántica equivocada.
Sobreingeniería¶
- Demasiados canales: crear un canal por cada combinación de entidad, acción y contexto produce una explosión de canales difícil de gestionar. Regla general: los canales deben alinearse con dominios y tipos de mensaje, no con consumidores individuales.
- Sobre-particionamiento: crear más particiones de las necesarias incrementa overhead sin beneficio si no hay suficientes consumidores para el paralelismo.
Costos de Operación¶
- Storage: los canales con retención alta consumen storage significativo, especialmente con alto throughput.
- Networking: la replicación entre nodos del cluster consume bandwidth.
- Monitoreo: cada canal requiere monitoreo independiente (lag, throughput, errors, size).
Errores Frecuentes de Implementación¶
- No definir convenciones de naming desde el inicio, resultando en nombres inconsistentes (
OrderCreated,order-created,orders.created,ORDERS_CREATED). - No configurar retención adecuada, resultando en pérdida de mensajes (retención muy corta) o consumo excesivo de storage (retención muy larga).
- No monitorear consumer lag, perdiendo visibilidad sobre consumidores que se atrasan.
- No configurar dead-letter handling, resultando en mensajes que se reintentan infinitamente.
Anti-Patterns Relacionados¶
- God Channel: un canal único por donde fluyen todos los mensajes de la organización. Imposible de escalar, monitorear o evolucionar.
- Ephemeral Channel Abuse: crear y destruir canales dinámicamente para cada request (emulando RPC sobre messaging), lo cual es ineficiente y frágil.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Point-to-Point Channel y Publish-Subscribe Channel (Capítulo 3): son las dos variantes fundamentales de Message Channel. Todo canal es una u otra (o una combinación en plataformas modernas).
- Guaranteed Delivery (Capítulo 3): define cómo el canal asegura que los mensajes no se pierdan ante fallos.
- Dead Letter Channel (Capítulo 3): define un canal especial para mensajes que no pueden ser procesados.
- Message (este capítulo): define qué viaja por el canal.
- Message Endpoint (este capítulo): define cómo las aplicaciones se conectan al canal.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Messaging (estilo de integración) — la decisión de usar messaging precede a la creación de canales.
- Después: todos los demás patrones operan sobre canales ya definidos.
Combinaciones Comunes¶
- Message Channel + Content-Based Router: un router consume de un canal y redirige mensajes a otros canales según su contenido.
- Message Channel + Competing Consumers: múltiples instancias de un mismo consumidor compiten por mensajes en un canal point-to-point para procesamiento paralelo.
- Message Channel + Wire Tap: un canal se "intercepta" para copiar mensajes a un canal auxiliar de monitoreo o logging.
Diferencias con Patrones Similares¶
- vs. Pipes and Filters: un canal es un conducto pasivo; un pipeline (Pipes and Filters) es una composición activa de procesamiento conectado por canales.
- vs. Message Bus: un bus es una infraestructura de messaging completa con canales, routing y transformación; un canal es un componente individual del bus.
Encaje en un Flujo Mayor de Integración¶
Message Channel es el tejido conectivo de toda la arquitectura de integración. Todos los demás patrones — routers, translators, splitters, aggregators, endpoints — operan enviando y recibiendo mensajes a través de canales. El diseño de los canales define la topología de la integración.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Message Channel no solo sigue vigente — es más importante que nunca. En las arquitecturas modernas:
- Cada topic de Kafka es un Message Channel.
- Cada queue o topic de Azure Service Bus es un Message Channel.
- Cada SQS queue o SNS topic de AWS es un Message Channel.
- Cada Pub/Sub topic de Google Cloud es un Message Channel.
- Cada exchange + queue de RabbitMQ implementa Message Channel.
El concepto es idéntico; la implementación varía. Comprender Message Channel permite:
- Diseñar topologías de canales correctas desde el inicio.
- Configurar propiedades (retención, particionamiento, replicación) con criterio.
- Diagnosticar problemas (consumer lag, mensajes perdidos, hot partitions) con vocabulario preciso.
- Evaluar trade-offs entre plataformas (Kafka topics vs. SQS queues vs. Azure Service Bus topics) con criterio fundamentado.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación de Message Channel | Características distintivas |
|---|---|---|
| Kafka | Topic + Partitions | Retención por tiempo, consumer groups, offset-based |
| RabbitMQ | Exchange + Queue | Routing flexible, message-level ack, transient + durable |
| Azure Service Bus | Queue / Topic + Subscription | Sessions, dead-lettering nativo, scheduled messages |
| AWS SQS | Standard Queue / FIFO Queue | Serverless, pay-per-message, visibility timeout |
| AWS SNS | Topic | Fan-out pub-sub, integración con SQS/Lambda/HTTP |
| Google Pub/Sub | Topic + Subscription | Serverless, seek (rewind), exactly-once |
| NATS | Subject | Ultra-low latency, JetStream para persistencia |
| Apache Pulsar | Topic + Subscription | Multi-tenancy, tiered storage, unified queuing+streaming |
Qué Parte Sigue Siendo Esencial¶
- El concepto de canal nombrado como contrato de integración: independientemente de la plataforma, el nombre del canal es el punto de encuentro entre productores y consumidores.
- La semántica de entrega: point-to-point vs. pub-sub sigue siendo la decisión fundamental.
- El particionamiento como mecanismo de paralelismo y orden: la noción de partición dentro de un canal es universal en plataformas de alto throughput.
- El monitoreo de canales como indicador de salud del sistema: consumer lag, throughput y error rates en canales son las métricas más reveladoras de una arquitectura event-driven.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
Topic: fleet.telemetry.raw
Partitions: 64 (por vehicle_id hash)
Replication Factor: 3
Retention: 7 days
Cleanup Policy: delete
Min ISR: 2
Kafka implementa Message Channel como un append-only log particionado y replicado. Los consumidores mantienen su propio offset, lo que permite múltiples consumer groups independientes y reprocesamiento por rebobinado de offset.
RabbitMQ¶
Exchange: fleet.telemetry (type: topic)
Binding: *.location → Queue: tracking.location
Binding: *.coldchain → Queue: compliance.coldchain
Binding: # → Queue: datalake.all
RabbitMQ implementa Message Channel como una combinación de Exchange (routing) y Queue (almacenamiento). El exchange dirige mensajes a queues según routing keys y bindings.
Azure Service Bus¶
Topic: fleet-telemetry
Subscription: tracking (filter: type = 'location')
Subscription: cold-chain (filter: type = 'coldchain')
Subscription: datalake (no filter)
Azure Service Bus implementa Message Channel como Topics con Subscriptions que tienen filtros SQL-like. Cada subscription es un canal virtual con su propia semántica de entrega.
AWS¶
SNS Topic: fleet-telemetry (fan-out)
→ SQS Queue: tracking-queue (filtered)
→ SQS Queue: coldchain-queue (filtered)
→ SQS Queue: datalake-queue (no filter)
AWS implementa pub-sub como SNS Topics que fan-out a SQS Queues, combinando distribución (SNS) con almacenamiento y procesamiento confiable (SQS).
Google Pub/Sub¶
Topic: fleet-telemetry
Subscription: tracking-sub (pull, filter)
Subscription: coldchain-sub (pull, filter)
Subscription: datalake-sub (pull, no filter)
Google Pub/Sub es serverless con subscriptions pull o push, seek para reprocesamiento y exactly-once delivery.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por canal: messages-in/sec, messages-out/sec, consumer lag (por consumer group), storage size, oldest unprocessed message age.
- Distributed tracing: propagar trace ID y span ID en headers del mensaje para trazabilidad end-to-end a través de múltiples canales.
- Structured logging: cada operación en un canal (produce, consume, ack, nack, expire) debe generar un log estructurado con channel name, message ID, consumer group, timestamp, outcome.
Monitoreo¶
- Consumer lag: la métrica más importante. Si el lag crece, los consumidores no pueden mantener el ritmo.
- Error rates: tasa de mensajes que van a dead-letter o que son rechazados por el consumidor.
- Throughput anomalies: caídas o picos inusuales en el throughput de un canal indican problemas en productor o consumidor.
- Storage: crecimiento del storage de canales con retención alta.
Versionado¶
- Schema Registry: usar un schema registry (Confluent Schema Registry, Apicurio, Azure Schema Registry) para versionar el formato de los mensajes en cada canal.
- Compatibilidad: definir la estrategia de compatibilidad (BACKWARD, FORWARD, FULL) y validarla automáticamente en cada producción.
- Canal versionado: en lugar de versionar mensajes dentro del canal, a veces es preferible crear un canal nuevo (
v2.fleet.telemetry) y migrar productores y consumidores gradualmente.
Seguridad¶
- Authentication: productores y consumidores deben autenticarse ante el broker (SASL/SCRAM, mTLS, OAuth2).
- Authorization: ACLs por canal que definan quién puede producir, quién puede consumir, quién puede administrar.
- Encryption in transit: TLS entre clientes y broker.
- Encryption at rest: cifrado de los datos almacenados en el canal (SSE, CMEK).
Manejo de Errores y Dead-Lettering¶
- Mensajes que no pueden procesarse después de N reintentos deben enviarse a un Dead Letter Channel dedicado.
- El Dead Letter Channel debe monitorearse con alertas: un mensaje en dead-letter es un problema de negocio que requiere atención.
Idempotencia¶
- El canal puede entregar mensajes duplicados (at-least-once semantics). Los consumidores deben ser idempotentes.
- Algunas plataformas ofrecen exactly-once (Kafka transactions, Google Pub/Sub exactly-once) pero con trade-offs de performance.
Auditoría¶
- Registrar quién creó cada canal, cuándo, con qué configuración.
- Registrar quién tiene permisos de producción y consumo.
- Registrar cambios de configuración (retención, particiones, ACLs).
Performance¶
- Batch producing: enviar mensajes en lotes para amortizar overhead de red.
- Compression: comprimir mensajes (Snappy, LZ4, Zstandard) para reducir bandwidth y storage.
- Partition count: más particiones = más paralelismo de consumo, pero más overhead de broker.
Escalabilidad¶
- Horizontal: añadir particiones (Kafka), shards (Kinesis) o workers (SQS) para escalar throughput.
- Los canales cloud-native (SQS, Pub/Sub) escalan automáticamente.
- Los canales auto-gestionados (Kafka, RabbitMQ) requieren planificación de capacidad.
17. Errores Comunes¶
Diseñar Canales Sin Convención de Naming¶
Sin una convención clara desde el inicio, los nombres de canales se vuelven inconsistentes y confusos. Recomendación: definir una convención ({domain}.{entity}.{action}) y aplicarla con validación automatizada o PR reviews.
Usar Un Solo Canal Para Todo¶
El "God Channel" donde fluyen todos los mensajes de la organización es uno de los anti-patterns más destructivos. Impide escalabilidad independiente, procesamiento selectivo y evolución de la semántica.
No Dimensionar Retención Correctamente¶
Retención demasiado corta: los consumidores que tienen downtime pierden mensajes irrecuperablemente. Retención demasiado larga: costos de storage crecen sin control. La retención debe definirse por canal según los SLAs de los consumidores y requisitos de reprocesamiento.
Ignorar el Consumer Lag¶
No monitorear el consumer lag de cada consumer group es como conducir sin velocímetro. Cuando un consumidor se atrasa, los síntomas (datos desactualizados, procesamiento tardío) aparecen mucho después de que el problema comenzó.
Confundir Orden Local con Orden Global¶
En un canal particionado, el orden está garantizado dentro de cada partición, no entre particiones. Asumir orden global cuando solo hay orden por partición produce bugs sutiles y difíciles de diagnosticar.
Proliferación Descontrolada de Canales¶
El extremo opuesto al "God Channel": crear un canal para cada interacción específica. Esto produce miles de canales difíciles de gobernar, monitorear y mantener. Los canales deben alinearse con dominios y tipos de evento, no con relaciones específicas productor-consumidor.
18. Conclusión Técnica¶
Message Channel es el patrón más fundamental de toda la taxonomía de patrones de integración empresarial. No es un patrón que se "decide aplicar" — es un patrón que existe implícitamente en todo sistema de mensajería. La decisión real no es si usar canales, sino cómo diseñarlos: cuántos, con qué nombres, con qué semántica, con qué garantías, con qué retención, con qué particionamiento.
Cuándo aporta valor: siempre que se use messaging como estilo de integración. El valor del canal está en la indirección que proporciona: desacoplar productores de consumidores, permitir escalabilidad independiente y proporcionar un punto de observación y control.
Cuándo evita problemas importantes: un diseño deliberado de canales desde el inicio — con naming conventions, governance, monitoreo y dimensionamiento de retención — evita los problemas más costosos de las arquitecturas event-driven: canales sobrecargados, mensajes perdidos, consumidores silenciosamente atrasados y evolución imposible.
Cuándo no conviene adoptarlo: si no se está usando messaging como estilo de integración (por ejemplo, en integraciones puramente síncronas API-to-API), el concepto de canal no aplica. Pero esto es menos una decisión sobre el patrón y más una decisión sobre el estilo de integración.
Recomendación para arquitectos: trate el diseño de canales con la misma seriedad que el diseño de APIs. Los canales son contratos de integración. Defina naming conventions, documente la semántica de cada canal, establezca ownership, configure monitoreo desde el día uno y planifique la evolución del esquema de mensajes. Un canal bien diseñado es invisible; un canal mal diseñado es el origen de la mayoría de los problemas operacionales en una arquitectura event-driven.