Message¶
1. Nombre del Patrón¶
- Nombre oficial: Message
- Categoría: Messaging Systems (Sistemas de Mensajería — Conceptos Fundacionales)
- Traducción contextual: Mensaje
2. Resumen Ejecutivo¶
Message es la unidad atómica de datos que viaja a través de un Message Channel entre un productor y un consumidor. Representa el paquete de información que una aplicación necesita transmitir a otra, encapsulado en una estructura que el sistema de mensajería puede transportar, almacenar, enrutar y entregar.
El patrón existe porque los sistemas que se integran mediante messaging no intercambian datos arbitrarios — intercambian mensajes con estructura definida. Un mensaje no es solo un payload; es una combinación de headers (metadatos que el sistema de mensajería necesita para transportar el mensaje) y body (los datos que la aplicación necesita comunicar). Comprender esta estructura es prerequisito para todos los patrones de construcción, routing, transformación y procesamiento de mensajes.
Aparece en toda interacción dentro de un sistema de mensajería. Cada evento publicado en Kafka, cada mensaje encolado en RabbitMQ, cada BrokeredMessage en Azure Service Bus es una instancia de este patrón.
3. Definición Detallada¶
Propósito¶
El propósito de Message es definir la estructura y semántica de la unidad de comunicación entre aplicaciones en un sistema de mensajería. Un mensaje es el "átomo" del messaging: la unidad indivisible de intercambio que el sistema transporta de forma integral. El broker no descompone un mensaje en partes ni fusiona mensajes — los transporta como unidades completas.
Lógica Arquitectónica¶
Message introduce una separación clara entre infraestructura de transporte y datos de negocio:
- Los headers son metadatos utilizados por el sistema de mensajería y por los patrones de routing/transformación: message ID, correlation ID, timestamp, content type, reply-to address, expiration, priority, routing key.
- El body (o payload) es el contenido de negocio que la aplicación productora quiere comunicar a la aplicación consumidora: un evento, un comando, un documento, una consulta.
Esta separación permite que los componentes de infraestructura (routers, translators, wire taps) operen sobre los headers sin necesidad de parsear el body, y que los consumidores procesen el body sin preocuparse por la mecánica de transporte.
Principio de Diseño Subyacente¶
El principio es encapsulación de datos de negocio en una envolvente de transporte. Del mismo modo que un sobre postal separa la dirección de entrega (metadata de transporte) del contenido de la carta (datos de negocio), un Message separa los headers del body. Esta separación es lo que permite que el sistema de mensajería transporte, almacene y enrute mensajes de forma genérica sin necesidad de comprender su contenido de negocio.
Problema Estructural que Resuelve¶
Sin una estructura de mensaje definida, la comunicación entre sistemas es un flujo de bytes sin semántica. El sistema de mensajería no podría:
- Enrutar: ¿según qué criterio dirige el mensaje a un destino u otro si no puede examinar headers o routing keys?
- Correlacionar: ¿cómo se vincula una respuesta con su petición sin un correlation ID?
- Expirar: ¿cómo se sabe si un mensaje es obsoleto sin un timestamp o TTL?
- Deduplicar: ¿cómo se detecta un mensaje duplicado sin un message ID?
- Trazar: ¿cómo se sigue el recorrido de un mensaje a través de múltiples componentes sin un trace ID?
Message resuelve todo esto al establecer una estructura que soporta tanto las necesidades del transporte como las del negocio.
Contexto en el que Emerge¶
Message emerge tan pronto como se decide usar messaging como estilo de integración. Es el concepto que hace posible hablar de "enviar algo" y "recibir algo" — sin una definición de qué es ese "algo", el messaging no tiene significado.
Por Qué No Es Trivial¶
Las decisiones de diseño alrededor del mensaje tienen consecuencias directas en toda la arquitectura:
- Tamaño del mensaje: mensajes grandes saturan el broker, incrementan latencia y requieren más storage. Mensajes muy pequeños incrementan overhead de headers y reduce efficiency. ¿Cuál es el tamaño adecuado?
- Formato de serialización: JSON (legible, verbose), Avro (compacto, schema evolution), Protobuf (compacto, tipado fuerte), XML (verboso, extensible). Cada formato tiene trade-offs de tamaño, velocidad de parsing, schema evolution y tooling.
- Schema evolution: ¿qué ocurre cuando el formato del mensaje cambia? ¿Los consumidores existentes pueden leer mensajes con el nuevo formato? ¿Y al revés?
- Contenido del header: ¿qué metadatos incluir? ¿Demasiado pocos headers dificultan routing y tracing? ¿Demasiados headers incrementan overhead?
- Semántica del body: ¿el mensaje es un comando (instrucción para hacer algo), un evento (notificación de algo que ocurrió), o un documento (datos para consulta)? La semántica afecta cómo se procesa.
- Granularidad: ¿cada mensaje representa una entidad individual (un pedido) o un batch (100 pedidos)? La granularidad afecta latencia, throughput y complejidad de procesamiento.
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, un mensaje corresponde a una unidad de comunicación en un protocolo de intercambio. Las propiedades del mensaje — como su ID (para deduplicación), su timestamp (para ordenamiento), su correlation ID (para causalidad) — son los mecanismos que permiten a las aplicaciones construir semánticas de comunicación confiable sobre un sistema de transporte distribuido.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin una estructura de mensaje definida, las aplicaciones intercambian datos como bytes sin estructura y sin metadatos. Esto produce:
- Incapacidad de routing: no hay forma de dirigir un mensaje a su destino sin examinar el contenido completo.
- Incapacidad de correlación: no hay forma de vincular mensajes relacionados (petición-respuesta, partes de una secuencia).
- Incapacidad de gestión temporal: no hay forma de saber si un mensaje es obsoleto, cuándo fue creado, ni cuánto tiempo debe retenerse.
- Incapacidad de deduplicación: no hay forma de detectar si un mensaje es duplicado.
- Incapacidad de trazabilidad: no hay forma de seguir un mensaje a través de la cadena de procesamiento.
Síntomas del Problema¶
- Consumidores que reciben mensajes que no entienden porque no hay indicación de tipo o formato.
- Imposibilidad de implementar request-reply porque no hay correlation ID.
- Procesamiento duplicado porque no hay message ID para deduplicar.
- Mensajes obsoletos procesados porque no hay timestamp ni TTL.
- Debugging imposible porque no hay trazabilidad del mensaje a través del sistema.
Impacto Operativo y Arquitectónico¶
Sin mensajes bien estructurados:
- Todo el routing debe basarse en el canal (un canal por destino), lo cual es rígido e inflexible.
- La trazabilidad end-to-end es imposible, lo que convierte el debugging en producción en un ejercicio de adivinanza.
- La evolución del formato es un Big Bang: cualquier cambio rompe todos los consumidores simultáneamente.
- Los consumidores deben asumir y hardcodear el formato, lo que los acopla al productor.
Riesgos Si No Se Implementa Correctamente¶
- Mensajes sin ID: imposibilidad de deduplicar, tracear y auditar.
- Mensajes sin tipo/formato: consumidores que fallan al recibir un mensaje inesperado.
- Mensajes excesivamente grandes: brokers saturados, timeouts de transmisión, consumo excesivo de memoria en consumidores.
- Mensajes sin schema: evolución del formato imposible sin romper consumidores.
- Mensajes con datos sensibles no protegidos: PII, credentials o tokens viajando en texto plano.
Ejemplos Reales¶
- Banca: un mensaje de transferencia interbancaria debe contener no solo los datos de la transacción (body) sino también: message ID (deduplicación), correlation ID (vincular con la solicitud original), timestamp (auditoría), expiration (la transferencia tiene un deadline), priority (transacciones high-value tienen prioridad).
- E-commerce: un evento
OrderPlaceddebe contener el pedido completo (body) más metadatos: event ID, event timestamp, aggregate ID (order ID), schema version, source system. Sin estos headers, es imposible implementar event sourcing, CQRS o sagas correctamente. - Salud: un mensaje HL7 FHIR tiene una estructura rigurosa con bundle type, resource identifiers, timestamps, metadata y payload clínico. La estructura del mensaje es lo que permite interoperabilidad entre sistemas de diferentes vendors.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En toda interacción dentro de un sistema de mensajería. Message no es opcional — es constitutivo.
- Cuando se necesita transportar datos entre sistemas con metadatos de routing, correlación, temporalidad y trazabilidad.
Cuándo No Usarlo¶
- Como patrón aislado, Message no tiene un "cuándo no usarlo". La decisión relevante es qué tipo de mensaje usar (Command, Document, Event — patrones del Capítulo 4).
Precondiciones¶
- Existe un sistema de mensajería con soporte para mensajes estructurados (headers + body).
- Existe acuerdo sobre el formato de serialización del body (JSON, Avro, Protobuf, etc.).
- Existe política sobre qué headers son obligatorios (message ID, timestamp, content type como mínimo).
Restricciones¶
- Tamaño máximo del mensaje: cada broker tiene límites (Kafka default: 1MB, configurable; RabbitMQ: sin límite práctico pero recomendado <128MB; SQS: 256KB; Service Bus: 256KB standard, 100MB premium).
- Formato: algunos brokers son agnósticos (bytes); otros tienen soporte nativo para ciertos formatos.
Dependencias¶
- Librería de serialización/deserialización (Avro, Protobuf, JSON).
- Schema Registry si se usa schema evolution.
- Convenciones de headers compartidas entre todos los participantes del ecosistema.
Supuestos Arquitectónicos¶
- El broker trata el body como opaco (no lo interpreta ni modifica).
- Los headers son accesibles para el broker y para componentes intermedios (routers, translators).
- Los consumidores pueden deserializar el body usando la información de tipo/formato proporcionada en los headers.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Todo sistema basado en messaging, sin excepción.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
El formato del mensaje es el contrato entre productor y consumidor. Un formato rígido (Protobuf con tipos estrictos) reduce ambigüedad pero incrementa acoplamiento: cambiar un campo requiere regenerar código en ambos lados. Un formato flexible (JSON sin schema) reduce acoplamiento pero incrementa riesgo de errores: el consumidor puede recibir datos inesperados.
Simplicidad vs. Robustez¶
Un mensaje minimalista (solo body, sin headers) es simple pero carece de la metadata necesaria para routing, correlación y trazabilidad. Un mensaje con headers completos es más robusto pero más complejo de construir y parsear.
Tamaño vs. Completitud¶
Un mensaje debe contener suficiente información para ser procesado por el consumidor sin necesidad de queries adicionales (principio de autonomía del mensaje). Pero mensajes excesivamente grandes saturan el broker. La tensión entre contener "todo lo necesario" y "no demasiado" es constante.
Serialización: Velocidad vs. Legibilidad¶
JSON es legible por humanos y fácil de debuggear, pero es verbose y lento de parsear. Avro y Protobuf son compactos y rápidos, pero ilegibles sin herramientas de deserialización. La elección afecta debugging, storage, bandwidth y CPU.
Schema Evolution: Compatibilidad vs. Libertad¶
Estrategias de compatibilidad estrictas (FULL compatibility) garantizan que productores y consumidores con diferentes versiones del schema puedan coexistir, pero restringen qué cambios se pueden hacer al formato. Sin compatibilidad, la evolución del formato es libre pero coordinada manualmente (y propensa a errores).
Granularidad: Fino vs. Grueso¶
Mensajes de granularidad fina (un evento por cambio individual) proporcionan máxima flexibilidad al consumidor pero incrementan el volumen de mensajes. Mensajes de granularidad gruesa (un evento con múltiples cambios) reducen volumen pero dificultan el procesamiento selectivo.
Gobernanza vs. Autonomía de Equipos¶
¿Los equipos pueden definir libremente la estructura de sus mensajes, o deben seguir un schema corporativo? Libertad total produce fragmentación; schema corporativo produce burocracia. Las organizaciones exitosas definen un "envelope" estándar (headers obligatorios) y permiten libertad en el body.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: crea el mensaje, serializa el body, establece los headers y lo envía al canal.
- Mensaje: la unidad de datos con headers y body.
- Canal: transporta el mensaje.
- Componentes intermedios (routers, translators, wire taps): examinan y/o modifican headers y/o body durante el tránsito.
- Consumidor: recibe el mensaje, lee los headers, deserializa el body y procesa el contenido.
- Schema Registry (opcional pero recomendado): almacena y valida schemas de mensajes.
Estructura del Mensaje¶
┌─────────────────────────────────────────┐
│ MESSAGE │
├─────────────────────────────────────────┤
│ HEADERS (Metadata) │
│ ├─ message_id: UUID │
│ ├─ correlation_id: UUID │
│ ├─ timestamp: ISO-8601 │
│ ├─ content_type: "application/avro" │
│ ├─ schema_version: "v3" │
│ ├─ source: "order-service" │
│ ├─ type: "OrderPlaced" │
│ ├─ reply_to: "responses.orders" │
│ ├─ expiration: "2026-04-07T15:00:00Z" │
│ ├─ priority: 5 │
│ ├─ trace_id: "abc123" │
│ └─ custom_headers: {...} │
├─────────────────────────────────────────┤
│ BODY (Payload) │
│ { │
│ "order_id": "ORD-2026-98712", │
│ "customer_id": "CUST-44821", │
│ "items": [...], │
│ "total_amount": 1547.80, │
│ "currency": "EUR", │
│ "shipping_address": {...} │
│ } │
└─────────────────────────────────────────┘
Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Construir mensaje con headers completos y body correctamente serializado |
| Headers | Proporcionar metadata para transporte, routing, correlación, temporalidad, trazabilidad |
| Body | Contener datos de negocio en formato acordado y versionado |
| Canal/Broker | Transportar el mensaje integralmente, sin modificar body ni headers (salvo headers de sistema) |
| Consumidor | Leer headers, deserializar body, procesar contenido, confirmar procesamiento |
Interacciones¶
- Productor → Mensaje: construcción (serialización del body, establecimiento de headers).
- Productor → Canal: envío del mensaje completo.
- Canal → Componentes intermedios: inspección de headers para routing, transformación, monitoreo.
- Canal → Consumidor: entrega del mensaje completo.
- Consumidor → Mensaje: lectura (deserialización del body usando información de headers).
Contratos Implícitos¶
- Format contract: productor y consumidor acuerdan el formato de serialización (JSON, Avro, Protobuf).
- Schema contract: la estructura del body sigue un schema versionado (explícito si hay schema registry, implícito si no).
- Header contract: los headers obligatorios están definidos y presentes en todo mensaje.
- Type contract: el header
typeindica qué tipo de mensaje es, lo que permite al consumidor elegir el handler apropiado.
Decisiones de Diseño Clave¶
- Formato de serialización: JSON vs. Avro vs. Protobuf vs. XML. Impacta tamaño, velocidad, schema evolution y tooling.
- Headers obligatorios vs. opcionales: definir un conjunto mínimo de headers que todo mensaje debe contener.
- Schema evolution strategy: BACKWARD, FORWARD, FULL, NONE. Determina cómo pueden cambiar los mensajes sin romper consumidores.
- Granularidad: un evento por cambio vs. un evento con múltiples cambios.
- Envelope vs. embedded metadata: ¿los metadatos van en headers del broker o dentro del body?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Procesamiento de Reclamaciones¶
Contexto del Negocio¶
Una compañía de seguros procesa 200,000 reclamaciones mensuales. Cuando un asegurado reporta un siniestro, se genera un mensaje que inicia un flujo de procesamiento que involucra:
- Validación de póliza activa
- Evaluación del monto de la reclamación
- Detección de fraude
- Aprobación o rechazo
- Notificación al asegurado
- Pago si procede
Cada etapa es un microservicio independiente que consume y produce mensajes.
Necesidad de Integración¶
Los mensajes que circulan en este sistema deben tener una estructura bien definida porque:
- El router de reclamaciones necesita headers para dirigir la reclamación al handler correcto (por tipo de póliza: auto, hogar, salud).
- El servicio de fraude necesita el body completo con detalles de la reclamación para su análisis.
- El servicio de auditoría necesita headers de trazabilidad para registrar cada paso del procesamiento.
- El servicio de notificaciones necesita metadata para correlacionar con la reclamación original y el asegurado.
Estructura del Mensaje¶
{
"headers": {
"message_id": "msg-2026-04-07-a8f3c291",
"correlation_id": "claim-2026-CLM-847291",
"causation_id": "msg-2026-04-07-b7e2d180",
"timestamp": "2026-04-07T10:15:32.847Z",
"source": "claims-intake-service",
"type": "ClaimSubmitted",
"schema_version": "v4",
"content_type": "application/avro",
"trace_id": "trace-x7k9m2p4",
"span_id": "span-a3b5c7d9",
"policy_type": "auto",
"priority": 3,
"ttl_seconds": 86400
},
"body": {
"claim_id": "CLM-847291",
"policy_id": "POL-2024-119284",
"policyholder_id": "PH-44821",
"incident_date": "2026-04-05",
"incident_type": "collision",
"incident_description": "Colisión frontal en intersección...",
"estimated_amount": 12500.00,
"currency": "EUR",
"vehicle": {
"make": "Toyota",
"model": "Corolla",
"year": 2023,
"vin": "JTDKN3DU5A0123456",
"license_plate": "1234-ABC"
},
"documents": [
{
"type": "police_report",
"reference": "doc-store://reports/PR-2026-98712"
},
{
"type": "photos",
"reference": "doc-store://photos/CLM-847291/"
}
],
"third_party": {
"involved": true,
"insurer": "Allianz",
"policy_number": "ALZ-2025-887412"
}
}
}
Decisiones Arquitectónicas¶
- message_id vs. correlation_id vs. causation_id: tres IDs diferentes con propósitos diferentes:
message_id: identifica este mensaje específico (para deduplicación).correlation_id: identifica la reclamación completa a lo largo de todo el flujo (para trazabilidad de negocio).-
causation_id: identifica el mensaje que causó este mensaje (para cadena causal). -
policy_type como header: el tipo de póliza está en los headers (no solo en el body) porque el Content-Based Router lo necesita para dirigir el mensaje sin parsear todo el body.
-
Documents como referencias: los documentos adjuntos (fotos, reportes policiales) no están embebidos en el mensaje sino referenciados vía URIs. Esto implementa el patrón Claim Check — el mensaje es pequeño pero referencia payloads pesados almacenados externamente.
-
Schema versioning:
schema_version: "v4"permite que consumidores con diferentes versiones del schema coexistan. El Schema Registry valida compatibilidad. -
TTL (Time-to-Live): la reclamación tiene un TTL de 24 horas. Si no se procesa en ese tiempo, el mensaje expira y se genera una alerta.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Creación del Mensaje¶
El claims-intake-service recibe la reclamación desde la UI del asegurado. El servicio:
- Valida los datos de entrada (campos obligatorios, formatos).
- Genera un
claim_idúnico. - Almacena los documentos adjuntos en el document store y obtiene las referencias URI.
- Construye el mensaje con:
- Headers: genera
message_id(UUID), establececorrelation_id=claim_id, establecesource,type,schema_version,timestamp,trace_id(del request entrante),policy_type(para routing). - Body: serializa los datos de la reclamación en formato Avro usando el schema v4 registrado en el Schema Registry.
- Envía el mensaje al canal
claims.submitted.
Paso 2: Routing por Tipo de Póliza¶
Un Content-Based Router consume de claims.submitted y examina el header policy_type:
auto→ publica enclaims.auto.pendinghome→ publica enclaims.home.pendinghealth→ publica enclaims.health.pending
El router copia TODOS los headers originales y añade un header routed_at con el timestamp de routing. No modifica el body.
Paso 3: Validación de Póliza¶
El servicio de validación de pólizas consume de claims.auto.pending:
- Lee el header
correlation_idpara identificar la reclamación. - Deserializa el body para obtener
policy_id. - Consulta el servicio de pólizas para verificar que la póliza está activa y cubre el tipo de siniestro.
- Produce un nuevo mensaje en
claims.auto.validatedcon: - Nuevo
message_id. - Mismo
correlation_id(la reclamación sigue siendo la misma). causation_id=message_iddel mensaje que consumió.- Body enriquecido con datos de la póliza (coverage limits, deductible).
Paso 4: Detección de Fraude¶
El servicio de detección de fraude consume de claims.auto.validated:
- Lee el body completo (datos de la reclamación + datos de la póliza).
- Ejecuta reglas de negocio y modelos de ML para evaluar riesgo de fraude.
- Produce un mensaje en
claims.auto.assessedcon unfraud_scoreañadido al body.
Paso 5: Auditoría Transversal¶
Un Wire Tap en el canal claims.auto.validated copia cada mensaje al canal audit.claims. El servicio de auditoría:
- Consume de
audit.claims. - Extrae
correlation_id,message_id,causation_id,timestampysourcede los headers. - Persiste un registro de auditoría con estos datos sin procesar el body (no necesita los datos de negocio, solo los metadatos de trazabilidad).
La cadena de causation_id permite reconstruir el flujo completo de procesamiento de una reclamación específica en orden causal.
Paso 6: Notificación¶
El servicio de notificaciones consume de claims.auto.assessed:
- Lee
correlation_idpara vincular con la reclamación original. - Lee
policyholder_iddel body para obtener datos de contacto. - Genera una notificación (email, SMS, push) informando al asegurado del estado de su reclamación.
- Produce un mensaje de confirmación en
notifications.sentconcorrelation_idpreservado.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.generic.storage import Storage
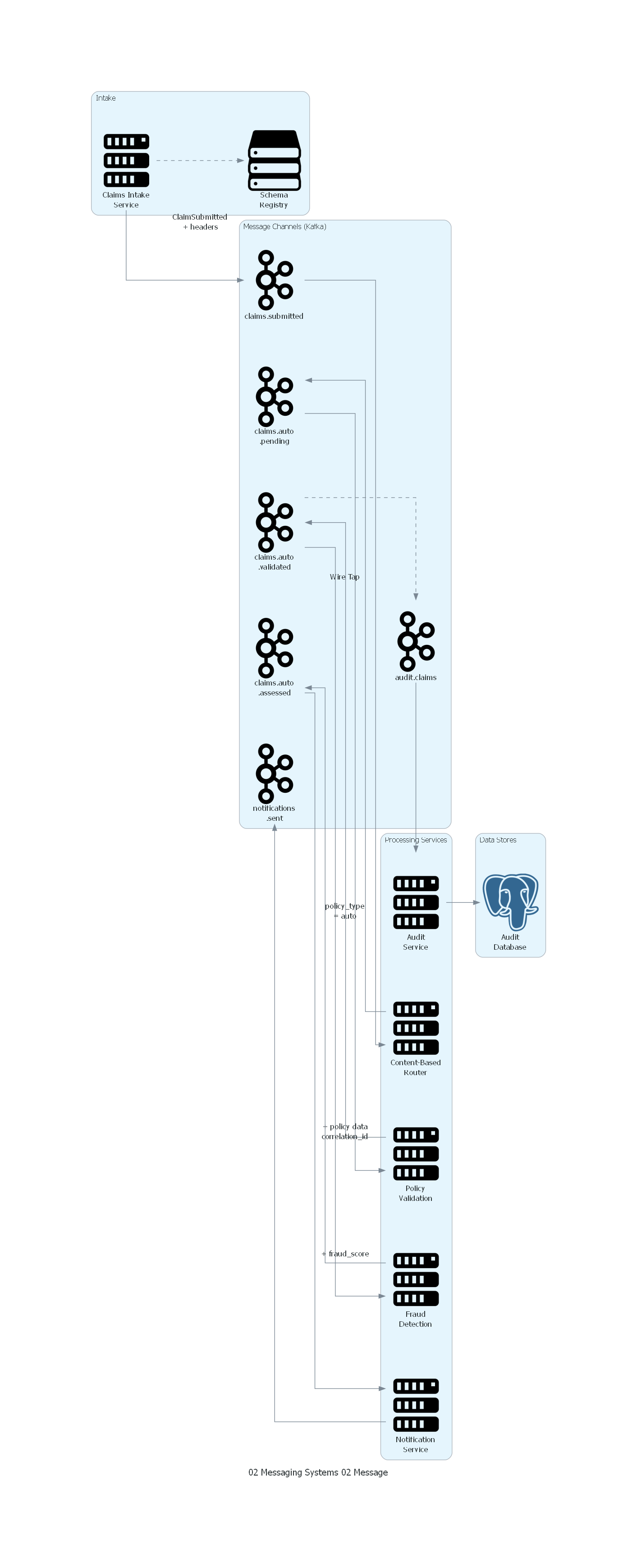
with Diagram("Message Pattern - Insurance Claims Processing", show=False, direction="LR"):
with Cluster("Intake"):
intake = Server("Claims Intake\nService")
schema_reg = Storage("Schema\nRegistry")
with Cluster("Message Channels (Kafka)"):
submitted = Kafka("claims.submitted")
auto_pending = Kafka("claims.auto\n.pending")
auto_validated = Kafka("claims.auto\n.validated")
auto_assessed = Kafka("claims.auto\n.assessed")
audit_ch = Kafka("audit.claims")
notif_ch = Kafka("notifications\n.sent")
with Cluster("Processing Services"):
router = Server("Content-Based\nRouter")
validator = Server("Policy\nValidation")
fraud = Server("Fraud\nDetection")
notifier = Server("Notification\nService")
auditor = Server("Audit\nService")
with Cluster("Data Stores"):
audit_db = PostgreSQL("Audit\nDatabase")
# Message flow
intake >> Edge(label="ClaimSubmitted\n+ headers") >> submitted
intake >> Edge(style="dashed") >> schema_reg
submitted >> router
router >> Edge(label="policy_type\n= auto") >> auto_pending
auto_pending >> validator
validator >> Edge(label="+ policy data\ncorrelation_id") >> auto_validated
auto_validated >> fraud
auto_validated >> Edge(style="dashed", label="Wire Tap") >> audit_ch
fraud >> Edge(label="+ fraud_score") >> auto_assessed
auto_assessed >> notifier >> notif_ch
audit_ch >> auditor >> audit_db
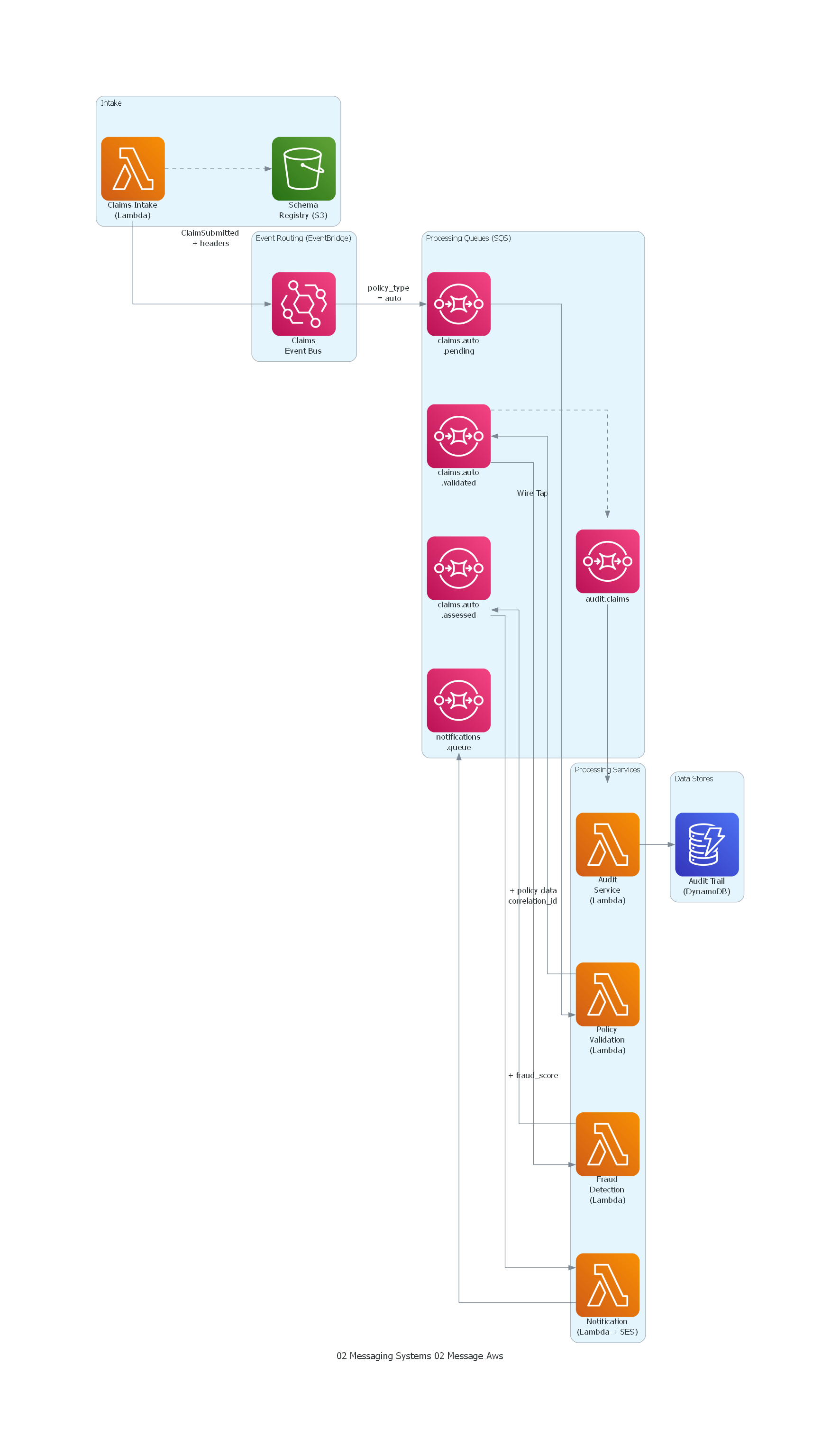
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb, RDS
from diagrams.aws.integration import Eventbridge, SNS, SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.storage import S3
with Diagram("Message Pattern - Insurance Claims Processing (AWS)", show=False, direction="LR"):
with Cluster("Intake"):
intake = Lambda("Claims Intake\n(Lambda)")
schema_reg = S3("Schema\nRegistry (S3)")
with Cluster("Event Routing (EventBridge)"):
event_bus = Eventbridge("Claims\nEvent Bus")
with Cluster("Processing Queues (SQS)"):
auto_pending = SQS("claims.auto\n.pending")
auto_validated = SQS("claims.auto\n.validated")
auto_assessed = SQS("claims.auto\n.assessed")
audit_queue = SQS("audit.claims")
notif_queue = SQS("notifications\n.queue")
with Cluster("Processing Services"):
validator = Lambda("Policy\nValidation\n(Lambda)")
fraud = Lambda("Fraud\nDetection\n(Lambda)")
notifier = Lambda("Notification\n(Lambda + SES)")
auditor = Lambda("Audit\nService\n(Lambda)")
with Cluster("Data Stores"):
audit_db = Dynamodb("Audit Trail\n(DynamoDB)")
# Message flow
intake >> Edge(label="ClaimSubmitted\n+ headers") >> event_bus
intake >> Edge(style="dashed") >> schema_reg
event_bus >> Edge(label="policy_type\n= auto") >> auto_pending
auto_pending >> validator
validator >> Edge(label="+ policy data\ncorrelation_id") >> auto_validated
auto_validated >> fraud
auto_validated >> Edge(style="dashed", label="Wire Tap") >> audit_queue
fraud >> Edge(label="+ fraud_score") >> auto_assessed
auto_assessed >> notifier >> notif_queue
audit_queue >> auditor >> audit_db
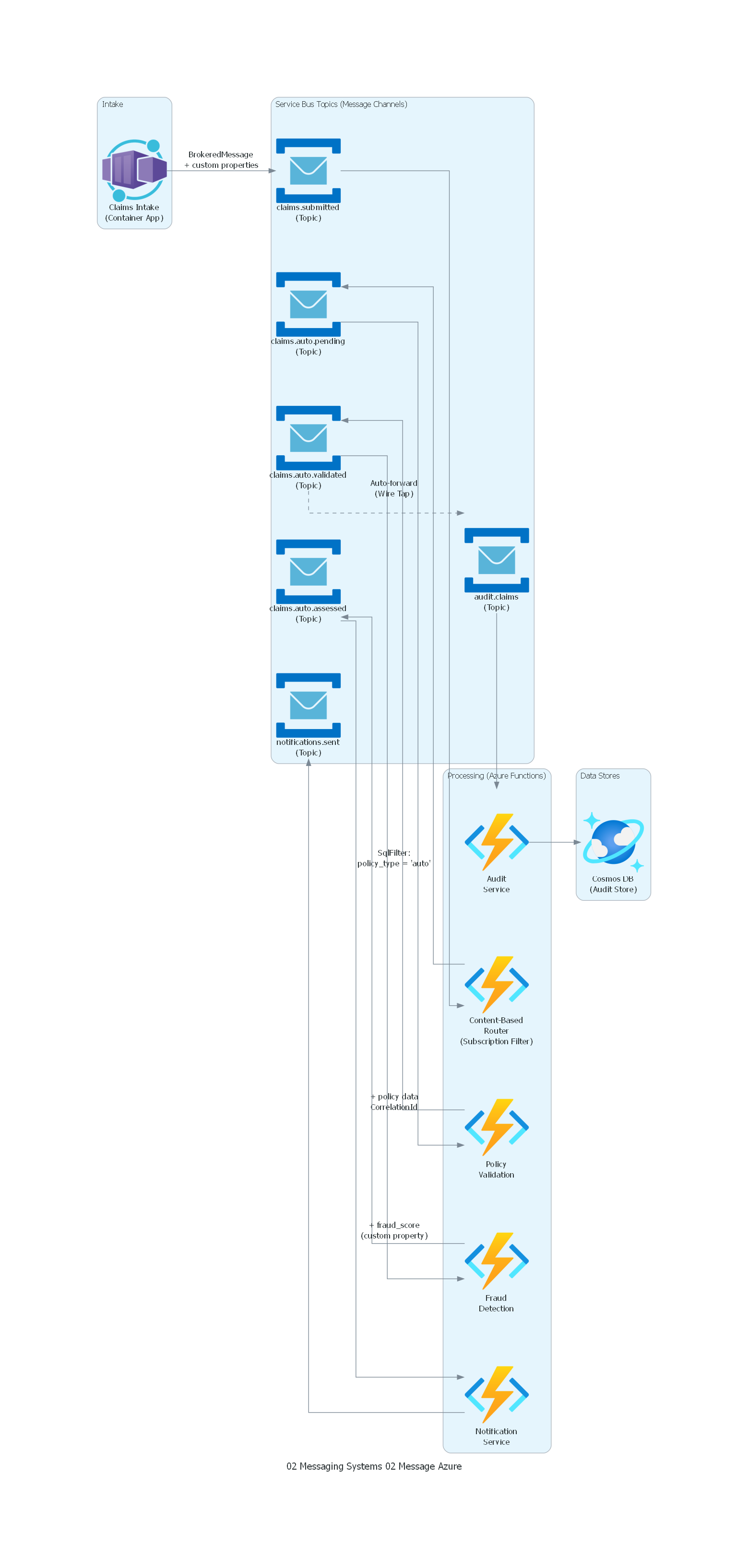
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
with Diagram("Message Pattern - Insurance Claims Processing (Azure)", show=False, direction="LR"):
with Cluster("Intake"):
intake = ContainerApps("Claims Intake\n(Container App)")
with Cluster("Service Bus Topics (Message Channels)"):
submitted = ServiceBus("claims.submitted\n(Topic)")
auto_pending = ServiceBus("claims.auto.pending\n(Topic)")
auto_validated = ServiceBus("claims.auto.validated\n(Topic)")
auto_assessed = ServiceBus("claims.auto.assessed\n(Topic)")
audit_ch = ServiceBus("audit.claims\n(Topic)")
notif_ch = ServiceBus("notifications.sent\n(Topic)")
with Cluster("Processing (Azure Functions)"):
router = FunctionApps("Content-Based\nRouter\n(Subscription Filter)")
validator = FunctionApps("Policy\nValidation")
fraud = FunctionApps("Fraud\nDetection")
notifier = FunctionApps("Notification\nService")
auditor = FunctionApps("Audit\nService")
with Cluster("Data Stores"):
audit_db = CosmosDb("Cosmos DB\n(Audit Store)")
# Message flow (Service Bus BrokeredMessage with headers + body)
intake >> Edge(label="BrokeredMessage\n+ custom properties") >> submitted
submitted >> router
router >> Edge(label="SqlFilter:\npolicy_type = 'auto'") >> auto_pending
auto_pending >> validator
validator >> Edge(label="+ policy data\nCorrelationId") >> auto_validated
auto_validated >> fraud
auto_validated >> Edge(style="dashed", label="Auto-forward\n(Wire Tap)") >> audit_ch
fraud >> Edge(label="+ fraud_score\n(custom property)") >> auto_assessed
auto_assessed >> notifier >> notif_ch
audit_ch >> auditor >> audit_db
Explicación del Diagrama¶
El diagrama muestra cómo un mensaje (ClaimSubmitted) fluye a través del sistema de procesamiento de reclamaciones:
- El Claims Intake Service crea el mensaje con headers completos y body serializado según el schema registrado.
- El mensaje viaja por el canal claims.submitted hasta un Content-Based Router que lo dirige según el header
policy_type. - Cada servicio en la cadena (Policy Validation, Fraud Detection) consume el mensaje, procesa el body, produce un nuevo mensaje con el mismo
correlation_idy body enriquecido. - Un Wire Tap copia mensajes al canal de auditoría donde el servicio de auditoría extrae solo los headers para su registro.
- El Notification Service usa los headers y body para notificar al asegurado.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Message (estructura completa) | Los objetos que fluyen entre servicios con headers + body |
| Headers (routing) | policy_type usado por Content-Based Router |
| Headers (correlación) | correlation_id preservado a lo largo de todo el flujo |
| Headers (trazabilidad) | message_id, causation_id, trace_id usados por Audit Service |
| Body (payload) | Datos de la reclamación, enriquecidos en cada etapa |
| Schema Registry | Validación del formato del body en producción |
| Message Channel | Cada topic de Kafka |
11. Beneficios¶
Impacto Técnico¶
- Routing sin parsing de body: los headers permiten que routers y filtros tomen decisiones sin deserializar el body completo, mejorando performance.
- Correlación end-to-end: el
correlation_idpermite seguir una reclamación a través de todos los servicios sin que estos se conozcan entre sí. - Deduplicación: el
message_idpermite detectar y descartar mensajes duplicados (idempotent receiver). - Temporalidad: timestamps y TTL permiten manejar expiración y ordenamiento temporal.
- Schema evolution: el versionado del schema en los headers permite que productores y consumidores con diferentes versiones coexistan.
Impacto Organizacional¶
- Vocabulario compartido: la estructura del mensaje es un contrato visible que facilita la comunicación entre equipos.
- Independencia de equipos: cada equipo puede evolucionar su procesamiento siempre que respete el contrato del mensaje.
- Documentación viva: el Schema Registry actúa como documentación siempre actualizada del formato de los mensajes.
Impacto Operacional¶
- Debugging: los headers proporcionan contexto para diagnosticar problemas (¿cuándo se creó? ¿de dónde vino? ¿con qué correlación?).
- Auditoría: los metadatos del mensaje son lo que hace posible la auditoría automatizada del flujo de procesamiento.
- Monitoreo: los headers permiten métricas por tipo de mensaje, por source, por priority.
Beneficios de Mantenibilidad y Evolución¶
- Backward compatibility: con schema evolution, se pueden añadir campos opcionales sin romper consumidores existentes.
- Forward compatibility: consumidores nuevos pueden ignorar campos que no entienden.
- Versionado explícito:
schema_versionen headers permite transiciones graduales entre formatos.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Overhead de serialización: construir un mensaje con headers y body serializado requiere más código y más CPU que simplemente enviar bytes.
- Schema management: mantener un Schema Registry, definir reglas de compatibilidad y validar schemas en producción añade complejidad operacional.
- Header proliferation: sin disciplina, los headers crecen sin control hasta convertirse en un "metadata soup" difícil de mantener.
Riesgos de Mal Uso¶
- Mensajes gigantes: incluir demasiada información en el body (imágenes, PDFs, datasets completos) produce mensajes que saturan el broker. Usar Claim Check para payloads pesados.
- Headers como business logic: incluir datos de negocio en los headers (que deberían estar en el body) rompe la separación de concerns.
- Schema sin governance: dejar que cada equipo defina sus schemas sin coordinación produce formatos incompatibles y duplicación semántica.
Sobreingeniería¶
- Demasiados headers obligatorios: requerir 20 headers en cada mensaje cuando la mayoría no se usa produce overhead y fricción.
- Schema demasiado estricto: un schema que no permite ningún campo opcional ni evolución produce rigidez que frena el desarrollo.
- Mensajes auto-descriptivos excesivos: incluir el schema completo dentro de cada mensaje (en lugar de una referencia al Schema Registry) multiplica el tamaño sin necesidad.
Costos de Operación¶
- Schema Registry: es un servicio adicional que requiere disponibilidad, backup y monitoreo.
- Serialización/Deserialización: Avro y Protobuf requieren generación de código y gestión de artefactos compilados.
- Migración de schemas: cuando se necesita un cambio incompatible, la migración coordinada de productores y consumidores puede ser compleja.
Anti-Patterns Relacionados¶
- Envelope Anti-Pattern: meter un mensaje dentro de otro mensaje (JSON dentro de un string dentro de otro JSON), destruyendo la estructura y dificultando el routing.
- Opaque Message: un mensaje sin headers y con body en formato propietario ilegible. Solo puede ser procesado por un consumidor específico, anulando toda flexibilidad.
- Fat Message: un mensaje que contiene todos los datos posibles "por si acaso", en lugar de contener solo lo necesario para el caso de uso.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Command Message, Document Message, Event Message (Capítulo 4): especializan la semántica del body. Message define la estructura; los patrones del Capítulo 4 definen el propósito.
- Correlation Identifier (Capítulo 4): formaliza el uso de
correlation_iden headers. - Return Address (Capítulo 4): formaliza el uso de
reply_toen headers. - Message Expiration (Capítulo 4): formaliza el uso de TTL en headers.
- Format Indicator (Capítulo 4): formaliza el uso de
content_typeyschema_versionen headers.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Channel — el mensaje necesita un canal por donde viajar.
- Después: todos los patrones de routing (usan headers), transformación (modifican body) y endpoint (producen y consumen mensajes).
Combinaciones Comunes¶
- Message + Content-Based Router: el router inspecciona headers del mensaje para decidir el destino.
- Message + Message Translator: el translator transforma el body de un formato a otro, preservando headers.
- Message + Wire Tap: el tap copia el mensaje completo a un canal auxiliar para monitoring.
Diferencias con Patrones Similares¶
- vs. Message Channel: el canal es el conducto; el mensaje es lo que viaja por el conducto.
- vs. Command/Document/Event Message: Message es la estructura genérica; Command/Document/Event son especializaciones semánticas.
Encaje en un Flujo Mayor de Integración¶
Message es la "moneda" de todo flujo de integración basado en messaging. Cada componente — producer, router, translator, filter, aggregator, consumer — opera produciendo, transformando o consumiendo mensajes.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Message como concepto es absolutamente universal en las arquitecturas modernas:
- Cada Record en Kafka es un Message (key + headers + value).
- Cada Message en RabbitMQ es un Message (properties + body).
- Cada BrokeredMessage en Azure Service Bus es un Message (system properties + user properties + body).
- Cada SQS Message es un Message (message attributes + body).
- Cada CloudEvent es una estandarización del concepto de Message (context attributes + data).
La estandarización CloudEvents (CNCF) es particularmente relevante como evolución moderna del patrón: define un formato estándar para headers de eventos que permite interoperabilidad entre plataformas y vendors.
Cómo Se Implementa Hoy¶
La implementación moderna de Message se centra en:
- Schema Registry: Confluent Schema Registry, Apicurio Registry, Azure Schema Registry para gestionar schemas de mensajes.
- Serialización binaria: Avro y Protobuf como formatos dominantes para alto throughput; JSON para debugging y casos de bajo volumen.
- CloudEvents: estándar CNCF para headers de eventos que proporciona interoperabilidad.
- AsyncAPI: especificación para documentar la estructura de mensajes en arquitecturas event-driven (análogo a OpenAPI para REST).
Qué Parte Sigue Siendo Esencial¶
- La separación headers/body: es universal e imprescindible.
- El message ID: deduplicación e idempotencia siguen siendo críticas.
- El correlation ID: trazabilidad de negocio sigue siendo mandatoria.
- El schema versioning: la evolución del formato sigue siendo uno de los desafíos más difíciles.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
Un Kafka Record tiene: key (para particionamiento), headers (metadata), value (body), timestamp (implícito). El Schema Registry integrado permite validar schemas Avro/Protobuf/JSON Schema en producción y consumo.
RabbitMQ¶
Un AMQP Message tiene: properties (headers estándar como content-type, correlation-id, reply-to, expiration, message-id, timestamp) + headers exchange custom + body.
Azure Service Bus¶
Un BrokeredMessage tiene: system properties (MessageId, CorrelationId, To, ReplyTo, TimeToLive, ContentType, ScheduledEnqueueTimeUtc) + user properties (custom headers) + body.
AWS SQS/SNS¶
SQS Message: message attributes (key-value metadata) + body (string, max 256KB). SNS Message: message attributes + subject + message body.
CloudEvents (Estándar CNCF)¶
CloudEvents define atributos estándar: id, source, specversion, type, datacontenttype, dataschema, subject, time, + extension attributes + data (body). Adoptado por Azure Event Grid, Google Eventarc, Knative Eventing.
AsyncAPI¶
AsyncAPI proporciona una especificación para documentar la estructura de mensajes, canales y operaciones en arquitecturas event-driven. Permite generar documentación, código y validadores a partir de la especificación.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Trace propagation: propagación de trace_id y span_id en headers para distributed tracing (OpenTelemetry, Jaeger, Zipkin).
- Métricas por tipo: métricas separadas por
typeheader (throughput, latency, error rate por tipo de mensaje). - Message inspection: capacidad de examinar mensajes individuales en canales para debugging.
Monitoreo¶
- Schema validation failures: tasa de mensajes que fallan validación de schema en producción.
- Message size distribution: distribución de tamaños para detectar mensajes anómalamente grandes.
- Deserialization errors: tasa de errores de deserialización en consumidores (indica mismatch de formato).
Versionado¶
- Schema Registry: registro centralizado de schemas con validación de compatibilidad.
- Version in header:
schema_versiono referencia a schema ID en headers de cada mensaje. - Compatibility rules: BACKWARD (consumidores nuevos leen mensajes viejos), FORWARD (consumidores viejos leen mensajes nuevos), FULL (ambos), NONE (sin garantía).
Seguridad¶
- Encryption: cifrado del body para datos sensibles (payload encryption), independiente del cifrado de transporte (TLS).
- Data masking: masking de PII en mensajes que van a canales de auditoría o analytics.
- Access control: quién puede producir mensajes de cada tipo, quién puede consumirlos.
Idempotencia¶
- Deduplicación por message_id: el consumidor mantiene un registro de message_ids procesados y descarta duplicados.
- Exactamente una vez: Kafka transactions (produce + consume atómico), Azure Service Bus (duplicate detection window).
Auditoría¶
- Immutable log: Kafka topics con retención larga actúan como log inmutable auditable de todos los mensajes.
- Audit trail: la cadena correlation_id → causation_id permite reconstruir el flujo completo de procesamiento.
Performance¶
- Serialización: Avro y Protobuf son 5-10x más rápidos que JSON para serializar y 2-5x más compactos.
- Compression: compresión del body (Snappy, LZ4) para reducir bandwidth, especialmente efectiva con JSON.
- Batch: producción y consumo en batches para amortizar overhead de red.
17. Errores Comunes¶
No Definir Headers Obligatorios¶
Sin un estándar organizacional de headers mínimos, cada equipo incluye headers diferentes (o ninguno), haciendo imposible la trazabilidad, deduplicación y routing consistentes.
Incluir Datos Sensibles Sin Protección¶
PII, tokens, credentials o datos financieros en el body sin cifrado viajan en texto plano a través del broker y pueden ser leídos por cualquier consumidor con acceso al canal.
Mensajes Excesivamente Grandes¶
Incluir payloads binarios (imágenes, documentos) directamente en el body en lugar de usar referencias (Claim Check). Esto satura el broker y degrada performance.
No Versionar el Schema¶
Cambiar la estructura del body sin versionado explícito produce errores de deserialización en consumidores que no se han actualizado. La consecuencia típica es un despliegue coordinado "big bang" de todos los servicios.
Confundir Message ID con Correlation ID¶
Usar el message_id como correlation_id produce trazabilidad rota, porque cada servicio genera un nuevo message_id para sus mensajes de salida. El correlation_id debe propagarse intacto a lo largo de todo el flujo.
Abusar de Headers para Business Logic¶
Poner datos de negocio en headers (para "optimizar" el routing) rompe la separación de concerns y acopla la infraestructura de routing a la lógica de negocio.
18. Conclusión Técnica¶
Message es el concepto más fundamental y ubicuo de toda la arquitectura de integración basada en messaging. Cada interacción, cada evento, cada comando, cada query asíncrona se materializa como un mensaje con headers y body. Dominar el diseño de mensajes es prerequisito para diseñar correctamente routing, transformación, correlación, trazabilidad e idempotencia.
Cuándo aporta valor: siempre que se use messaging. Un diseño deliberado de la estructura del mensaje — con headers obligatorios, formato de serialización apropiado, schema versionado y tamaño controlado — aporta valor desde el primer día en trazabilidad, debugging, deduplicación y capacidad de evolución.
Cuándo evita problemas importantes: un estándar organizacional de mensajes (headers mínimos + schema registry + naming conventions para tipos) evita los problemas más costosos de las arquitecturas event-driven: mensajes irrastreables, formatos incompatibles, duplicación silenciosa y evolución imposible del formato.
Cuándo no conviene adoptarlo: no hay escenario dentro de messaging donde no se necesite un concepto de mensaje. La pregunta no es si usar mensajes estructurados, sino cuánta estructura es apropiada para el contexto.
Recomendación para arquitectos: defina un "message envelope" organizacional con headers mínimos obligatorios (message_id, correlation_id, timestamp, type, source, schema_version). Use un Schema Registry desde el día uno — no es un lujo, es infraestructura esencial. Adopte CloudEvents como estándar de headers si busca interoperabilidad entre plataformas. Y aplique la regla: si un header no es útil para al menos un componente intermediario (router, translator, auditor, monitor), probablemente debería estar en el body.