Pipes and Filters¶
1. Nombre del Patrón¶
- Nombre oficial: Pipes and Filters
- Categoría: Messaging Systems (Sistemas de Mensajería — Conceptos Fundacionales)
- Traducción contextual: Tuberías y Filtros
2. Resumen Ejecutivo¶
Pipes and Filters es un patrón arquitectónico que descompone una tarea de procesamiento compleja en una secuencia de etapas independientes (filtros), conectadas por canales (pipes). Cada filtro realiza una transformación o procesamiento específico sobre el mensaje que recibe, y produce un mensaje de salida que el siguiente filtro en la cadena puede consumir.
El problema que resuelve es la composición de procesamiento complejo. En lugar de construir un componente monolítico que realiza toda la lógica de procesamiento de un mensaje (validación, enriquecimiento, transformación, routing, persistencia), Pipes and Filters permite dividir esa lógica en etapas discretas, cada una con una responsabilidad única, que se pueden desarrollar, testear, escalar y desplegar de forma independiente.
Aparece en toda arquitectura de integración que procesa mensajes a través de múltiples etapas, desde pipelines ETL hasta stream processing topologies, desde workflows de Apache Camel hasta Azure Logic Apps.
3. Definición Detallada¶
Propósito¶
El propósito de Pipes and Filters es permitir la composición de procesamiento complejo mediante etapas simples e independientes. En lugar de un procesador monolítico, se construye un pipeline donde cada etapa tiene una responsabilidad única y está conectada a las etapas adyacentes mediante canales de mensajería.
Lógica Arquitectónica¶
La lógica es análoga a una cadena de montaje industrial: cada estación de trabajo realiza una operación específica sobre el producto en tránsito, y lo pasa a la siguiente estación. Ninguna estación necesita conocer qué ocurrió antes ni qué ocurrirá después — solo necesita saber qué operación realizar sobre el input que recibe y producir un output que cumpla el contrato esperado.
En términos de mensajería:
- Pipe (tubería): es un Message Channel que conecta dos filtros consecutivos.
- Filter (filtro): es un componente de procesamiento que consume un mensaje de un pipe de entrada, lo procesa y produce un mensaje en un pipe de salida.
La composición es inherentemente modular: los filtros se pueden reordenar, añadir, eliminar o reemplazar sin modificar los filtros adyacentes, siempre que se respete el contrato de entrada/salida.
Principio de Diseño Subyacente¶
El principio es Single Responsibility a nivel de componentes de integración. Cada filtro hace una cosa y la hace bien. La complejidad del procesamiento total emerge de la composición de filtros simples, no de la implementación de un filtro complejo.
Este principio tiene raíces profundas en la filosofía Unix de pipes y filtros (cat file.txt | grep "error" | sort | uniq -c | sort -rn), donde programas simples se componen mediante pipes para resolver problemas complejos.
Problema Estructural que Resuelve¶
Sin Pipes and Filters, el procesamiento de un mensaje típicamente se implementa como un componente monolítico que:
- Valida el mensaje
- Lo enriquece con datos de otras fuentes
- Lo transforma a otro formato
- Lo enruta al destino correcto
- Lo persiste para auditoría
- Lo retransmite a sistemas downstream
Este monolito de procesamiento tiene múltiples problemas: es difícil de testear (requiere mockear todas las dependencias), difícil de escalar (todas las etapas escalan juntas aunque solo una sea el cuello de botella), difícil de modificar (un cambio en una etapa puede afectar a las demás) y difícil de reutilizar (la lógica de validación no se puede reutilizar en otro flujo).
Contexto en el que Emerge¶
Pipes and Filters emerge cuando el procesamiento de mensajes involucra múltiples etapas con diferentes:
- Responsabilidades: validación, transformación, enriquecimiento, routing, persistencia.
- Complejidades: una etapa simple (validar formato) y otra compleja (consultar API externa para enriquecimiento).
- Requisitos de escalabilidad: una etapa CPU-intensive (transformación), otra I/O-intensive (consulta a base de datos).
- Frecuencias de cambio: una etapa estable (validación de formato) y otra que cambia frecuentemente (reglas de negocio).
- Ownership: una etapa mantenida por el equipo de integración, otra por el equipo de dominio.
Por Qué No Es Trivial¶
Las decisiones de diseño del pipeline son complejas:
- Granularidad de los filtros: ¿cuántas etapas? Filtros demasiado finos producen overhead de serialización/deserialización entre cada paso. Filtros demasiado gruesos pierden los beneficios de composición.
- Contrato entre filtros: ¿cada filtro produce y consume el mismo formato de mensaje? ¿O cada filtro puede transformar el formato? Si los formatos varían, los filtros pierden intercambiabilidad.
- Estado: ¿los filtros son stateless (procesan cada mensaje independientemente) o stateful (mantienen estado entre mensajes, como un Aggregator)? Los filtros stateful son más complejos de escalar y de hacer fault-tolerant.
- Error handling: ¿qué ocurre si un filtro falla? ¿Se descarta el mensaje? ¿Se reintenta? ¿Se envía a un dead-letter? ¿Se notifica al filtro anterior?
- Orden de los filtros: ¿el orden importa? Generalmente sí — validar antes de transformar, transformar antes de enrutar.
- Branching: ¿el pipeline es lineal o tiene bifurcaciones (un filtro que envía a múltiples pipes de salida según alguna condición)?
Relación con Sistemas Distribuidos y Mensajería¶
En sistemas distribuidos, Pipes and Filters es un patrón de composición de servicios. Cada filtro puede ser un servicio independiente, potencialmente desplegado en un nodo diferente. Los pipes son los canales de mensajería que conectan estos servicios. Esto introduce las complejidades clásicas de los sistemas distribuidos: latencia de red, fallos parciales, orden de mensajes y consistencia.
En stream processing, Pipes and Filters es el modelo de programación fundamental:
- En Kafka Streams, una topology es un grafo de procesadores (filtros) conectados por internal topics (pipes).
- En Apache Flink, un dataflow graph es una composición de operators (filtros) conectados por data streams (pipes).
- En Apache Camel, una route es una secuencia de processors (filtros) conectados por endpoints (pipes).
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Pipes and Filters, el procesamiento de mensajes se implementa como un componente monolítico:
MessageProcessor.process(message):
1. validate(message)
2. enrich(message, externalService)
3. transform(message, targetFormat)
4. checkFraud(message, mlModel)
5. route(message, destination)
6. persist(message, auditDB)
7. notify(message, downstream)
Este monolito:
- No se puede escalar selectivamente: si
checkFraudes el cuello de botella (CPU-intensive ML inference), no se puede escalar independientemente depersist(I/O-bound database write). - No se puede testear aisladamente: testear
transformrequiere mockearexternalService(deenrich),mlModel(decheckFraud) yauditDB(depersist). - No se puede reutilizar: si otro flujo necesita
validate+transformsin las demás etapas, hay que duplicar código o introducir flags condicionales. - No se puede evolucionar independientemente: añadir una nueva etapa (por ejemplo,
checkCompliance) requiere modificar, compilar, testear y desplegar todo el monolito.
Síntomas del Problema¶
- Componentes de procesamiento con centenares o miles de líneas de código que realizan múltiples responsabilidades.
- Testing que requiere fixtures complejos con múltiples mocks y stubs.
- Imposibilidad de escalar una etapa sin escalar todas las demás.
- Cambios frecuentes que introducen regresiones porque una modificación en una etapa afecta a las demás.
- Duplicación de lógica entre diferentes flujos de procesamiento que comparten algunas etapas pero no todas.
Impacto Operativo y Arquitectónico¶
- Performance desbalanceado: todo el pipeline está limitado por la etapa más lenta, y no hay forma de optimizar esa etapa sin modificar todo el componente.
- Blast radius de fallos: un error en cualquier etapa colapsa todo el procesamiento, no solo la etapa fallida.
- Deployment monolítico: cualquier cambio en cualquier etapa requiere redesplegar todo el componente.
- Visibilidad limitada: no se puede medir el performance ni la tasa de error de cada etapa individualmente.
Riesgos Si No Se Implementa Correctamente¶
- Pipeline demasiado largo: cada pipe introduce latencia y overhead de serialización. Un pipeline de 20 etapas con pipes persistentes entre cada una puede tener latencia inaceptable.
- Filtros acoplados: si los filtros comparten estado o asumen el orden exacto de las etapas anteriores, se pierde la modularidad que el patrón promete.
- Error handling inconsistente: si cada filtro maneja errores de forma diferente, el comportamiento del pipeline ante fallos es impredecible.
Ejemplos Reales¶
- Telecom: procesamiento de CDRs (Call Detail Records). Cada CDR pasa por: parsing → validación de formato → normalización de números → rating (cálculo de costo) → correlación con plan de tarifa → persistencia → facturación. Cada etapa es un filtro independiente.
- Banca: procesamiento de transacciones SWIFT: parsing ISO 20022 → validación de campos → screening AML → verificación de fondos → routing a sistema de compensación → auditoría. Cada etapa tiene requisitos de performance y compliance diferentes.
- E-commerce: procesamiento de pedidos: validación → reserva de inventario → procesamiento de pago → generación de shipping label → notificación → actualización de CRM.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el procesamiento de mensajes involucra múltiples etapas con responsabilidades distintas.
- Cuando diferentes etapas tienen diferentes requisitos de escalabilidad, performance o frecuencia de cambio.
- Cuando se desea reutilizar etapas de procesamiento en diferentes flujos.
- Cuando se necesita visibilidad granular (métricas, logs, tracing) de cada etapa individualmente.
- Cuando el processing pipeline evoluciona frecuentemente (se añaden, modifican o eliminan etapas).
Cuándo No Usarlo¶
- Cuando el procesamiento es trivial (una o dos operaciones simples) y la descomposición en pipeline añade complejidad sin beneficio.
- Cuando la latencia es crítica y cada pipe adicional introduce overhead inaceptable.
- Cuando las etapas están tan estrechamente acopladas que no pueden operar independientemente (comparten estado mutable, por ejemplo).
- Cuando el volumen de mensajes es bajo y la escalabilidad independiente de etapas no aporta valor.
Precondiciones¶
- Existe infraestructura de messaging (broker) para implementar los pipes.
- Las etapas de procesamiento pueden descomponerse en responsabilidades independientes.
- El formato de los mensajes entre etapas puede estandarizarse o al menos definirse como contrato.
Restricciones¶
- Cada pipe introduce latencia (serialización, transmisión, deserialización).
- Los filtros stateful son más complejos de implementar, escalar y hacer fault-tolerant.
- El debugging end-to-end del pipeline requiere distributed tracing.
Dependencias¶
- Message Channels (pipes) entre cada par de filtros consecutivos.
- Infraestructura de monitoreo para visibilidad de cada etapa.
- Mecanismo de error handling (dead-letter, retry) en cada pipe.
Supuestos Arquitectónicos¶
- Los filtros son idealmente stateless y pueden procesarse en paralelo (múltiples instancias del mismo filtro).
- Los pipes son reliable (los mensajes no se pierden entre filtros).
- El formato de los mensajes en cada pipe está definido (implícita o explícitamente).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Stream processing (Kafka Streams, Flink, Spark Streaming).
- Integration platforms (Apache Camel, MuleSoft, Spring Integration).
- Workflow engines (Azure Logic Apps, AWS Step Functions, Temporal).
- ETL/ELT pipelines (Apache NiFi, Azure Data Factory, dbt).
- API gateways (request processing pipeline).
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Pipes and Filters reduce el acoplamiento entre etapas de procesamiento. Cada filtro solo conoce su formato de entrada y su formato de salida, no los filtros adyacentes. Esto permite reordenar, añadir o eliminar filtros. Sin embargo, el formato de los mensajes en los pipes se convierte en un punto de acoplamiento implícito: si cambia el formato de salida de un filtro, el siguiente filtro debe adaptarse.
Simplicidad vs. Robustez¶
Un pipeline con filtros simples es más fácil de entender, testear y mantener que un procesador monolítico. Pero la infraestructura del pipeline (pipes, error handling, monitoring, retry policies) añade complejidad operacional. La robustez se gana a cambio de complejidad infrastructural.
Latencia vs. Modularidad¶
Cada pipe entre filtros añade latencia (serialización + transmisión + deserialización). Un pipeline de 10 filtros con pipes persistentes puede tener una latencia significativamente mayor que un procesador monolítico que ejecuta las mismas 10 operaciones en memoria. La modularidad tiene un costo en latencia.
Throughput vs. Granularidad¶
Filtros de granularidad fina (cada uno hace una operación mínima) maximizan la reutilización y la composición pero incrementan el overhead por mensaje. Filtros de granularidad gruesa (cada uno hace varias operaciones) reducen overhead pero pierden modularidad. La granularidad óptima depende del trade-off entre overhead y flexibilidad.
Consistencia vs. Disponibilidad¶
En un pipeline distribuido, la consistencia end-to-end (garantizar que un mensaje que entró al pipeline sea procesado completamente o no sea procesado en absoluto) requiere mecanismos como transacciones distribuidas o sagas. Sin estos mecanismos, un fallo en el filtro 5 de 10 deja el mensaje parcialmente procesado.
Costo Operativo vs. Capacidad de Evolución¶
Un pipeline con pipes explícitos (canales de mensajería entre cada filtro) es operacionalmente más costoso que un procesador en memoria. Pero permite evolución: añadir un filtro es crear un consumidor y un canal, no modificar código existente. El costo operacional compra capacidad de cambio.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Source (Fuente): el productor original que introduce mensajes en el pipeline.
- Filter (Filtro): componente de procesamiento con una responsabilidad específica. Consume de un pipe de entrada, procesa y produce en un pipe de salida.
- Pipe (Tubería): un Message Channel que conecta dos filtros consecutivos.
- Sink (Destino): el consumidor final que recibe el mensaje completamente procesado.
Flujo Lógico¶
flowchart LR
A([Source]) -->|Pipe A| B[Filter 1: Validación]
B -->|Pipe B| C[Filter 2: Enriquecimiento]
C -->|Pipe C| D[Filter 3: Routing]
D -->|Pipe D| E([Sink])
F([Order API]) -->|orders.raw| G[Validator]
G -->|orders.valid| H[Enricher]
H -->|orders.enriched| I[Router]
I -->|orders.domestic| J([Processor Doméstico])
I -->|orders.international| K([Processor Internacional])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Source | Producir mensajes de entrada al pipeline |
| Filter | Realizar UNA responsabilidad de procesamiento (validar, transformar, enriquecer, filtrar, enrutar) |
| Pipe | Transportar mensajes entre filtros de forma confiable |
| Sink | Consumir el resultado final del pipeline |
Interacciones¶
- Source → Pipe A: producción del mensaje inicial.
- Pipe → Filter: el filtro consume del pipe (pull) o el pipe entrega al filtro (push).
- Filter → Pipe: el filtro produce el mensaje procesado al siguiente pipe.
- Filter → Dead Letter: si el filtro no puede procesar el mensaje, lo envía a un canal de error.
Contratos Implícitos¶
- Formato de entrada/salida de cada filtro: cada filtro espera un formato específico de entrada y produce un formato específico de salida.
- Idempotencia de filtros: idealmente, cada filtro es idempotente (procesar el mismo mensaje dos veces produce el mismo resultado), lo que facilita retries.
- Orden de procesamiento: el pipeline asume un orden específico de filtros que tiene significado semántico.
Decisiones de Diseño Clave¶
-
Pipes persistentes vs. in-memory: pipes persistentes (Kafka topics, queues) proporcionan durabilidad y desacoplamiento temporal pero añaden latencia. Pipes in-memory (internal channels en Kafka Streams, Spring Integration channels) minimizan latencia pero acoplan los filtros en el mismo proceso.
-
Filtros como procesos independientes vs. in-process: filtros como microservicios separados maximizan la independencia de despliegue y escalabilidad. Filtros como componentes in-process (processors en Kafka Streams, beans en Camel) minimizan latencia.
-
Error handling strategy: fail-fast (detener el pipeline al primer error), skip-and-log (continuar con el siguiente mensaje), dead-letter (enviar mensajes fallidos a un canal de error), retry (reintentar con backoff).
-
Pipeline lineal vs. DAG: un pipeline lineal es una secuencia simple. Un DAG (directed acyclic graph) permite bifurcaciones (un filtro envía a múltiples pipes), merge (un filtro consume de múltiples pipes) y paralelismo.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Pipeline de Procesamiento de Pagos Internacionales¶
Contexto del Negocio¶
Un banco multinacional procesa 2 millones de órdenes de pago internacional diarias (transferencias SWIFT). Cada orden de pago debe pasar por una serie de verificaciones, transformaciones y enrutamientos antes de ser enviada al sistema de compensación correspondiente. Las etapas varían en complejidad, performance y requisitos regulatorios.
Necesidad de Integración¶
El pipeline de procesamiento debe:
- Parsear mensajes SWIFT (MT103) desde la red SWIFT.
- Validar campos obligatorios según el estándar ISO 20022.
- Hacer screening de sanciones (verificar que emisor y receptor no están en listas de sanciones OFAC, EU, ONU).
- Verificar disponibilidad de fondos en la cuenta del ordenante.
- Calcular comisiones según el tipo de transferencia, moneda y corredor.
- Transformar al formato del sistema de compensación destino (SEPA, Fedwire, TARGET2, CHAPS según el corredor).
- Enrutar al sistema de compensación correcto.
- Generar registro de auditoría regulatoria.
Cada etapa tiene características diferentes:
| Etapa | Complejidad | Latencia | Dependencias Externas | Criticidad |
|---|---|---|---|---|
| Parsing | Baja | <1ms | Ninguna | Alta |
| Validación | Media | <5ms | Schema catalog | Alta |
| Sanctions Screening | Alta | 50-200ms | Sanctions API (externo) | Crítica (regulatoria) |
| Verificación de fondos | Media | 10-50ms | Core bancario | Alta |
| Cálculo de comisiones | Media | <5ms | Tabla de tarifas | Media |
| Transformación | Media | <10ms | Schemas destino | Alta |
| Routing | Baja | <1ms | Tabla de routing | Alta |
| Auditoría | Baja | async | Base de datos de auditoría | Alta (regulatoria) |
Sistemas Involucrados¶
- SWIFT Gateway: recibe mensajes MT103 de la red SWIFT.
- Kafka Cluster: plataforma de streaming que implementa los pipes.
- Sanctions API: servicio externo de screening de sanciones (Dow Jones, World-Check).
- Core Banking System: sistema que gestiona cuentas y saldos.
- Compensation Systems: SEPA, Fedwire, TARGET2, CHAPS.
- Audit Database: base de datos de auditoría regulatoria.
Diseño del Pipeline¶
SWIFT GW → [payments.raw] → Parser → [payments.parsed] → Validator → [payments.valid]
→ SanctionsFilter → [payments.screened] → FundsChecker → [payments.funded]
→ FeeCalculator → [payments.rated] → Transformer → [payments.transformed]
→ Router → [payments.sepa / payments.fedwire / payments.target2 / payments.chaps]
→ Compensation Adapters
En paralelo: Wire Tap en cada pipe → [audit.payments] → AuditWriter
Decisiones Arquitectónicas¶
-
Pipes persistentes (Kafka topics) entre cada filtro para durabilidad. Si el banco sufre un outage, los mensajes no se pierden y el pipeline se reanuda donde quedó.
-
Sanctions screening como filtro independiente porque tiene la latencia más alta (50-200ms por llamada al API externo) y es el cuello de botella del pipeline. Puede escalarse independientemente (más instancias del filtro consumiendo del mismo topic con consumer group).
-
Wire Tap en cada pipe para copiar todos los mensajes a un canal de auditoría. Esto proporciona trazabilidad completa del estado del pago en cada etapa, sin añadir lógica de auditoría a ningún filtro.
-
Dead-letter per filter: cada filtro tiene su propio dead-letter topic (
payments.screened.dlq,payments.funded.dlq, etc.) para que los operadores puedan identificar en qué etapa falló un mensaje y por qué. -
Filtros stateless: todos los filtros son stateless excepto FundsChecker (que necesita consultar saldos). Esto permite escalar horizontalmente sin preocuparse por afinidad de partición.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Sanctions API no disponible | Circuit breaker + fallback a caché local de sanciones (actualizada daily) |
| Pipeline latency > SLA | Monitoring de latencia por etapa + autoscaling del cuello de botella |
| Mensaje perdido entre filtros | Kafka con acks=all + replication factor 3 |
| Procesamiento duplicado tras retry | Idempotency key (payment_id) en cada filtro |
| Formato inválido de mensaje | Validator como primer filtro con dead-letter para mensajes inválidos |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción y Parsing¶
El SWIFT Gateway recibe un mensaje MT103 y lo publica en el topic payments.raw:
:20:TXNREF123456
:23B:CRED
:32A:260407EUR12500,00
:50K:/DE89370400440532013000
JOHN DOE
MAIN STREET 123
:59:/ES9121000418450200051332
MARIA GARCIA
CALLE MAYOR 45
:71A:SHA
El filtro Parser consume este mensaje, lo parsea según la especificación MT103 y produce un mensaje JSON estructurado en payments.parsed:
{
"payment_id": "TXNREF123456",
"value_date": "2026-04-07",
"currency": "EUR",
"amount": 12500.00,
"debtor": {
"account": "DE89370400440532013000",
"name": "JOHN DOE"
},
"creditor": {
"account": "ES9121000418450200051332",
"name": "MARIA GARCIA"
},
"charge_bearer": "SHA"
}
Paso 2: Validación¶
El filtro Validator consume de payments.parsed:
- Verifica campos obligatorios presentes (payment_id, amount, currency, debtor, creditor).
- Valida formato de IBAN (DE y ES son válidos).
- Valida que el monto es positivo.
- Valida que la fecha de valor no es pasada.
Si la validación es exitosa, produce el mensaje (sin modificar) en payments.valid. Si falla, envía a payments.valid.dlq con el motivo de rechazo.
Paso 3: Sanctions Screening¶
El filtro SanctionsFilter consume de payments.valid:
- Extrae nombres y jurisdicciones de debtor y creditor.
- Consulta el Sanctions API (Dow Jones Factiva) con ambos nombres.
- El API responde en 120ms: no hay match.
- Produce el mensaje en
payments.screenedcon un headersanctions_status: CLEAR.
Si hubiera match, el pago se detiene (no se produce en payments.screened), se envía a payments.screened.dlq y se genera una alerta al equipo de compliance.
Paso 4: Verificación de Fondos¶
El filtro FundsChecker consume de payments.screened:
- Consulta el core bancario por el saldo de la cuenta
DE89370400440532013000. - Verifica que el saldo disponible ≥ 12,500 EUR.
- Realiza un bloqueo temporal del monto (soft hold).
- Produce en
payments.fundedconfunds_status: HELD, hold_reference: HOLD-847291.
Paso 5: Cálculo de Comisiones¶
El filtro FeeCalculator consume de payments.funded:
- Determina tipo de transferencia (SEPA intra-EU, DE→ES).
- Consulta tabla de tarifas: SEPA credit transfer, charge_bearer SHA = EUR 1.50 para ordenante.
- Produce en
payments.ratedconfee: { debtor_fee: 1.50, creditor_fee: 0, currency: "EUR" }.
Paso 6: Transformación a Formato Destino¶
El filtro Transformer consume de payments.rated:
- Determina que DE→ES es una transferencia SEPA.
- Transforma el mensaje JSON al formato ISO 20022 pacs.008 (SEPA Credit Transfer).
- Produce el XML ISO 20022 en
payments.transformed.
Paso 7: Routing¶
El filtro Router consume de payments.transformed:
- Examina el corredor de destino (SEPA).
- Produce en
payments.sepa.
Si fuera una transferencia a USA, produciría en payments.fedwire. Si fuera intra-UK, en payments.chaps.
Paso 8: Auditoría Transversal¶
El Wire Tap en cada pipe copia todos los mensajes al topic audit.payments. El filtro AuditWriter consume y persiste un registro por cada etapa:
payment_id=TXNREF123456, stage=parsed, timestamp=...
payment_id=TXNREF123456, stage=validated, timestamp=...
payment_id=TXNREF123456, stage=screened, sanctions_status=CLEAR, timestamp=...
payment_id=TXNREF123456, stage=funded, hold_ref=HOLD-847291, timestamp=...
payment_id=TXNREF123456, stage=rated, fee=1.50, timestamp=...
payment_id=TXNREF123456, stage=transformed, format=pacs.008, timestamp=...
payment_id=TXNREF123456, stage=routed, destination=SEPA, timestamp=...
Esta trazabilidad permite reconstruir el estado exacto de cualquier pago en cualquier etapa del pipeline, requisito regulatorio en banca.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶

Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.network import Nginx
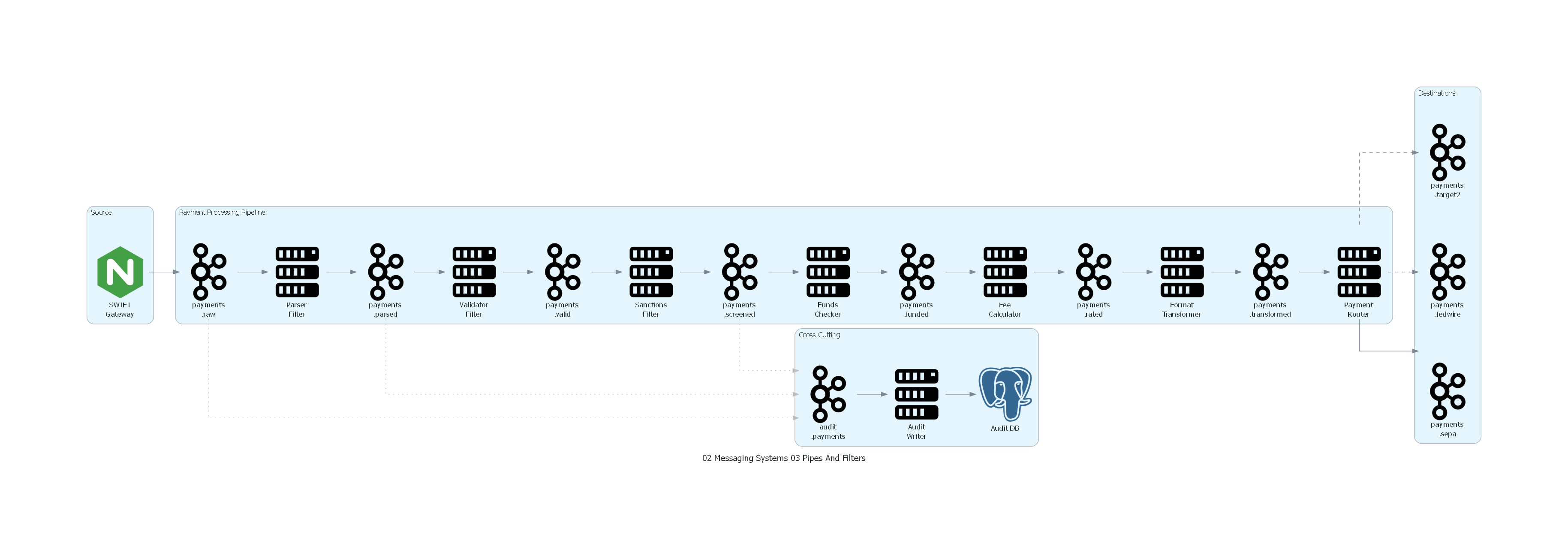
with Diagram("Pipes and Filters - International Payments Pipeline", show=False, direction="LR"):
with Cluster("Source"):
swift_gw = Nginx("SWIFT\nGateway")
with Cluster("Payment Processing Pipeline"):
# Pipes (Kafka Topics)
raw = Kafka("payments\n.raw")
parsed = Kafka("payments\n.parsed")
valid = Kafka("payments\n.valid")
screened = Kafka("payments\n.screened")
funded = Kafka("payments\n.funded")
rated = Kafka("payments\n.rated")
transformed = Kafka("payments\n.transformed")
# Filters
parser = Server("Parser\nFilter")
validator = Server("Validator\nFilter")
sanctions = Server("Sanctions\nFilter")
funds = Server("Funds\nChecker")
fees = Server("Fee\nCalculator")
transformer = Server("Format\nTransformer")
router = Server("Payment\nRouter")
with Cluster("Destinations"):
sepa = Kafka("payments\n.sepa")
fedwire = Kafka("payments\n.fedwire")
target2 = Kafka("payments\n.target2")
with Cluster("Cross-Cutting"):
audit_topic = Kafka("audit\n.payments")
audit_writer = Server("Audit\nWriter")
audit_db = PostgreSQL("Audit DB")
# Pipeline flow
swift_gw >> raw >> parser >> parsed >> validator >> valid
valid >> sanctions >> screened >> funds >> funded
funded >> fees >> rated >> transformer >> transformed >> router
# Routing destinations
router >> sepa
router >> Edge(style="dashed") >> fedwire
router >> Edge(style="dashed") >> target2
# Audit (Wire Tap)
raw >> Edge(style="dotted", color="gray") >> audit_topic
parsed >> Edge(style="dotted", color="gray") >> audit_topic
screened >> Edge(style="dotted", color="gray") >> audit_topic
audit_topic >> audit_writer >> audit_db
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS, StepFunctions
from diagrams.aws.network import ELB
with Diagram("Pipes and Filters - International Payments Pipeline (AWS)", show=False, direction="LR"):
with Cluster("Source"):
swift_gw = ELB("SWIFT\nGateway (NLB)")
with Cluster("Payment Processing Pipeline (Step Functions + SQS)"):
# Pipes (SQS Queues between filters)
raw = SQS("payments\n.raw")
parsed = SQS("payments\n.parsed")
valid = SQS("payments\n.valid")
screened = SQS("payments\n.screened")
funded = SQS("payments\n.funded")
rated = SQS("payments\n.rated")
transformed = SQS("payments\n.transformed")
# Filters (Lambda functions)
parser = Lambda("Parser\nFilter")
validator = Lambda("Validator\nFilter")
sanctions = Lambda("Sanctions\nFilter")
funds = Lambda("Funds\nChecker")
fees = Lambda("Fee\nCalculator")
transformer = Lambda("Format\nTransformer")
router = Lambda("Payment\nRouter")
with Cluster("Destinations"):
sepa = SQS("payments\n.sepa")
fedwire = SQS("payments\n.fedwire")
target2 = SQS("payments\n.target2")
with Cluster("Cross-Cutting"):
audit_queue = SQS("audit\n.payments")
audit_writer = Lambda("Audit\nWriter")
audit_db = Dynamodb("Audit DB\n(DynamoDB)")
# Pipeline flow (SQS → Lambda → SQS chain)
swift_gw >> raw >> parser >> parsed >> validator >> valid
valid >> sanctions >> screened >> funds >> funded
funded >> fees >> rated >> transformer >> transformed >> router
# Routing destinations
router >> sepa
router >> Edge(style="dashed") >> fedwire
router >> Edge(style="dashed") >> target2
# Audit (Wire Tap via SQS)
raw >> Edge(style="dotted", color="gray") >> audit_queue
parsed >> Edge(style="dotted", color="gray") >> audit_queue
screened >> Edge(style="dotted", color="gray") >> audit_queue
audit_queue >> audit_writer >> audit_db
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
from diagrams.onprem.network import Nginx
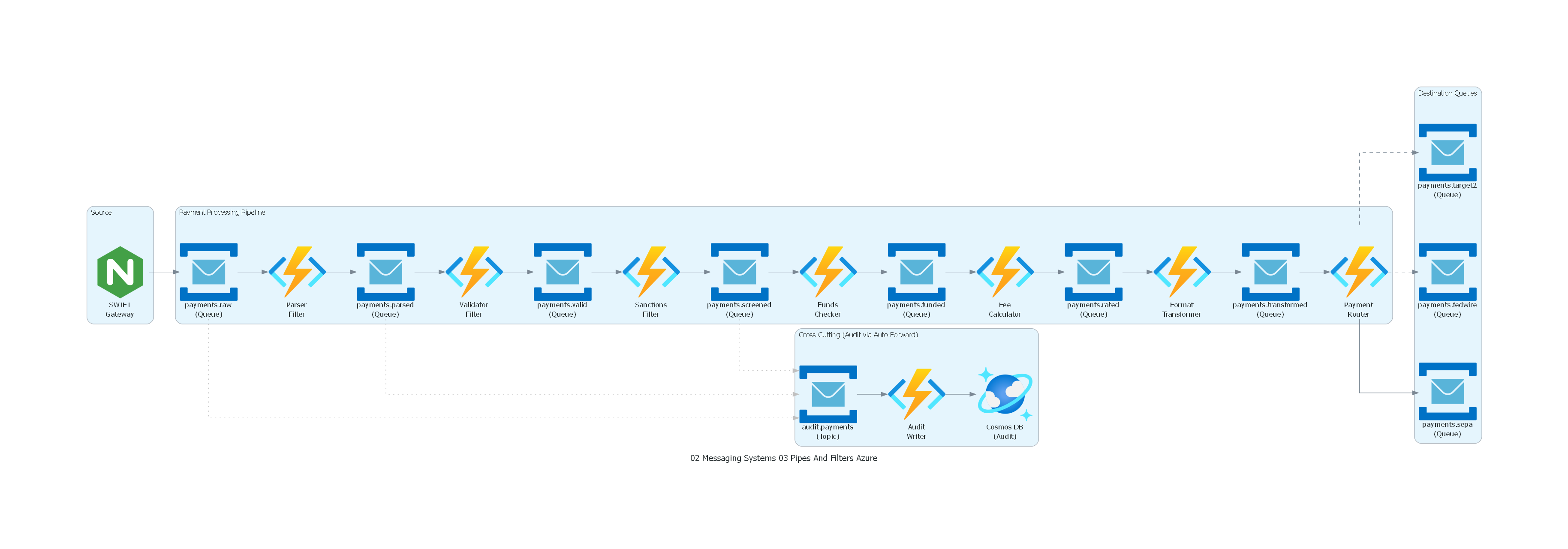
with Diagram("Pipes and Filters - International Payments Pipeline (Azure)", show=False, direction="LR"):
with Cluster("Source"):
swift_gw = Nginx("SWIFT\nGateway")
with Cluster("Payment Processing Pipeline"):
# Pipes (Service Bus Queues - sequential P2P)
raw = ServiceBus("payments.raw\n(Queue)")
parsed = ServiceBus("payments.parsed\n(Queue)")
valid = ServiceBus("payments.valid\n(Queue)")
screened = ServiceBus("payments.screened\n(Queue)")
funded = ServiceBus("payments.funded\n(Queue)")
rated = ServiceBus("payments.rated\n(Queue)")
transformed = ServiceBus("payments.transformed\n(Queue)")
# Filters (Azure Functions chained via Service Bus triggers)
parser = FunctionApps("Parser\nFilter")
validator = FunctionApps("Validator\nFilter")
sanctions = FunctionApps("Sanctions\nFilter")
funds = FunctionApps("Funds\nChecker")
fees = FunctionApps("Fee\nCalculator")
transformer = FunctionApps("Format\nTransformer")
router = FunctionApps("Payment\nRouter")
with Cluster("Destination Queues"):
sepa = ServiceBus("payments.sepa\n(Queue)")
fedwire = ServiceBus("payments.fedwire\n(Queue)")
target2 = ServiceBus("payments.target2\n(Queue)")
with Cluster("Cross-Cutting (Audit via Auto-Forward)"):
audit_topic = ServiceBus("audit.payments\n(Topic)")
audit_writer = FunctionApps("Audit\nWriter")
audit_db = CosmosDb("Cosmos DB\n(Audit)")
# Pipeline flow (Functions triggered by Service Bus Queue)
swift_gw >> raw >> parser >> parsed >> validator >> valid
valid >> sanctions >> screened >> funds >> funded
funded >> fees >> rated >> transformer >> transformed >> router
# Routing destinations
router >> sepa
router >> Edge(style="dashed") >> fedwire
router >> Edge(style="dashed") >> target2
# Audit (Service Bus auto-forward / Wire Tap)
raw >> Edge(style="dotted", color="gray") >> audit_topic
parsed >> Edge(style="dotted", color="gray") >> audit_topic
screened >> Edge(style="dotted", color="gray") >> audit_topic
audit_topic >> audit_writer >> audit_db
Explicación del Diagrama¶
El diagrama muestra el pipeline lineal de procesamiento de pagos internacionales:
- El SWIFT Gateway introduce mensajes MT103 en el primer pipe (
payments.raw). - Cada filtro consume de un pipe, procesa y produce en el siguiente pipe.
- El pipeline es lineal hasta el Router, que bifurca hacia diferentes destinos (SEPA, Fedwire, TARGET2).
- Los Wire Taps (líneas punteadas grises) copian mensajes de varios pipes al canal de auditoría.
- El Audit Writer persiste la trazabilidad completa en la base de datos de auditoría.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Source | SWIFT Gateway |
| Pipe | Cada Kafka topic (payments.raw, .parsed, .valid, etc.) |
| Filter | Cada Server (Parser, Validator, Sanctions, Funds, Fees, Transformer, Router) |
| Sink | Destination topics (payments.sepa, .fedwire, .target2) |
| Cross-cutting concern | Wire Tap → audit.payments → Audit Writer → Audit DB |
| Branching | Router → múltiples destination pipes |
11. Beneficios¶
Impacto Técnico¶
- Escalabilidad independiente: el filtro de Sanctions (cuello de botella con 50-200ms/mensaje) puede escalarse a 20 instancias mientras el Parser se mantiene con 3 instancias. Cada etapa se escala según su carga real.
- Aislamiento de fallos: si el Sanctions API falla, solo el filtro de Sanctions se detiene. Los mensajes se acumulan en
payments.validsin afectar al Parser ni al Validator. Cuando el API se recupera, el filtro reanuda el procesamiento. - Testabilidad: cada filtro se testea aisladamente con mensajes de entrada y verificación de salida. No se necesita mockear el pipeline completo.
- Performance profiling: el monitoreo por etapa permite identificar exactamente cuál filtro es el cuello de botella y optimizarlo específicamente.
Impacto Organizacional¶
- Ownership por etapa: el equipo de compliance puede mantener el filtro de Sanctions, el equipo de core el de Funds, y el equipo de integración el Router, sin interferirse.
- Deployment independiente: un cambio en las reglas de comisiones solo requiere redesplegar el FeeCalculator, sin tocar el resto del pipeline.
- Reutilización: el Parser y el Validator pueden reutilizarse en otros flujos (por ejemplo, procesamiento de pagos domésticos) sin modificación.
Impacto Operacional¶
- Visibilidad granular: métricas por etapa (throughput, latency, error rate) proporcionan visibilidad total del estado del pipeline.
- Debugging dirigido: si un pago no llegó a su destino, el trail de auditoría muestra exactamente en qué etapa se detuvo y por qué.
- Recovery parcial: si el pipeline se detiene por un fallo, solo es necesario reprocesar desde la etapa fallida, no desde el inicio.
Beneficios de Mantenibilidad y Evolución¶
- Inserción de etapas: añadir una nueva verificación (por ejemplo, compliance PSD2) consiste en crear un nuevo filtro y conectarlo entre dos pipes existentes.
- Reordenamiento: si se descubre que verificar fondos antes de screening reduce costos (no se gasta en API calls para pagos sin fondos), se reordena sin modificar ningún filtro.
- Eliminación de etapas: si una regulación se deroga, se elimina el filtro correspondiente sin afectar al resto.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Infraestructura de pipes: cada pipe es un Kafka topic (o equivalente) que requiere creación, configuración, monitoreo y mantenimiento.
- Latencia acumulada: con 7 filtros y pipes persistentes, la latencia total puede ser significativa (100ms+ por pipe × 7 = 700ms+ solo de overhead de infraestructura).
- Debugging end-to-end: seguir un mensaje a través de 7 filtros y 8 pipes requiere distributed tracing configurado correctamente.
Riesgos de Mal Uso¶
- Pipeline como excusa para no diseñar: descomponer arbitrariamente sin criterio de responsabilidad produce filtros sin cohesión que no aportan modularidad real.
- Filtros que comparten estado: si dos filtros acceden a la misma base de datos para leer y escribir el mismo registro, están acoplados a pesar de estar en filtros "independientes".
- Pipeline lineal para procesamiento no lineal: forzar un flujo que naturalmente es un grafo (con bifurcaciones, joins y loops) en un pipeline estrictamente lineal produce contorsiones innecesarias.
Sobreingeniería¶
- Un filtro por línea de código: descomponer en filtros excesivamente finos (un filtro que solo añade un header, otro que solo cambia un campo) produce overhead desproporcionado.
- Pipes persistentes para todo: entre filtros que siempre se ejecutan en el mismo proceso (como en Kafka Streams), usar pipes persistentes en lugar de internal topics añade latencia sin beneficio.
Costos de Operación¶
- Multiplicación de recursos: N filtros × M instancias × K topics = muchos recursos para monitorear, escalar y mantener.
- Coordinación de deploys: aunque cada filtro se despliega independientemente, cambios en el formato del pipe requieren coordinación entre los filtros adyacentes.
Anti-Patterns Relacionados¶
- Spaghetti Pipeline: un pipeline que bifurca, merge, loops y se entrecruza de formas incomprensibles. Si el pipeline no se puede dibujar como un flujo legible, probablemente necesita rediseño.
- Filter God: un filtro que hace demasiado (validación + transformación + routing + persistencia), anulando el propósito del patrón.
- Pipe as Database: usar la retención del pipe como storage permanente en lugar de persistir los datos en un store apropiado.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel: los pipes son Message Channels. Todo pipe es una instancia de Message Channel.
- Message Router: un router es un filtro especializado en dirigir mensajes a diferentes pipes de salida.
- Message Translator: un translator es un filtro especializado en transformar el formato del mensaje.
- Content Enricher: un enricher es un filtro que consulta fuentes externas para añadir datos al mensaje.
- Content Filter: un content filter es un filtro que elimina campos innecesarios del mensaje.
- Wire Tap: un wire tap es un pipe especial que copia mensajes a un canal auxiliar sin alterar el flujo principal.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Channel y Message (el pipeline opera sobre mensajes que viajan por canales).
- Después: todos los patrones de routing y transformación son especializaciones de filtros dentro de un pipeline.
Combinaciones Comunes¶
- Pipes and Filters + Competing Consumers: cada filtro se escala horizontalmente con múltiples instancias que compiten por mensajes en el pipe de entrada.
- Pipes and Filters + Dead Letter Channel: cada pipe tiene un DLQ asociado para mensajes que su filtro no puede procesar.
- Pipes and Filters + Wire Tap: wire taps en los pipes copian mensajes a canales de auditoría, monitoring o analytics.
- Pipes and Filters + Content-Based Router: el último filtro del pipeline es frecuentemente un router que dirige mensajes a diferentes destinos.
Diferencias con Patrones Similares¶
- vs. Process Manager: un pipeline es una secuencia predefinida; un Process Manager es un orquestador dinámico que decide los pasos en runtime basándose en estado.
- vs. Routing Slip: un pipeline tiene un flujo fijo; un Routing Slip lleva la lista de etapas dentro del propio mensaje, permitiendo flujos dinámicos por mensaje.
Encaje en un Flujo Mayor de Integración¶
Pipes and Filters es el modelo de composición más común para el procesamiento de mensajes. La mayoría de los flujos de integración — desde simples transformaciones hasta complejos workflows multi-etapa — se pueden modelar como pipelines. Es el "esqueleto" sobre el cual se instancian los demás patrones (routers, translators, enrichers, etc.) como filtros.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Pipes and Filters no solo sigue vigente — es el modelo de programación dominante en múltiples dominios modernos:
- Stream processing: Kafka Streams, Apache Flink, Apache Beam definen su procesamiento como topologías de filtros conectados por streams (pipes).
- Integration platforms: Apache Camel routes, MuleSoft flows, Spring Integration chains son instancias directas de Pipes and Filters.
- Serverless workflows: AWS Step Functions, Azure Durable Functions, Google Workflows componen funciones (filtros) conectadas por paso de estado (pipes).
- API gateways: el request processing pipeline de API gateways (auth → rate limit → transform → route → log) es Pipes and Filters.
- CI/CD pipelines: GitHub Actions, GitLab CI, Azure DevOps Pipelines son Pipes and Filters a nivel de build y deployment.
- Data engineering: Apache NiFi, dbt, Azure Data Factory construyen pipelines de procesamiento de datos como Pipes and Filters.
Cómo Se Implementa Hoy¶
| Plataforma | Pipe | Filter | Composición |
|---|---|---|---|
| Kafka Streams | Internal/External Topics | Processor/Transformer | Topology builder API |
| Apache Camel | Direct/SEDA/JMS/Kafka endpoints | Processor/Bean/Transform | RouteBuilder DSL |
| Spring Integration | MessageChannel | MessageHandler | IntegrationFlow DSL |
| MuleSoft | Connectors | Processors/Transformers | Flow designer |
| Azure Logic Apps | Triggers/Connectors | Actions | Visual workflow |
| AWS Step Functions | State transitions | Lambda/Activity | State machine JSON |
| Apache NiFi | Connections | Processors | Visual canvas |
Qué Parte Sigue Siendo Esencial¶
- Composición de procesamiento mediante etapas simples: el principio de descomposición es universal.
- Escalabilidad independiente por etapa: sigue siendo el mecanismo principal para optimizar throughput en pipelines.
- Aislamiento de fallos: la contención de errores en filtros individuales sigue siendo crítica.
- Trazabilidad por etapa: la visibilidad granular es lo que permite operar pipelines complejos en producción.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka (Kafka Streams)¶
StreamsBuilder builder = new StreamsBuilder();
KStream<String, Payment> raw = builder.stream("payments.raw");
raw.mapValues(Parser::parse) // Filter: Parser
.filter(Validator::isValid) // Filter: Validator
.mapValues(Sanctions::screen) // Filter: Sanctions
.mapValues(FundsChecker::verify) // Filter: Funds
.mapValues(FeeCalculator::calculate) // Filter: Fees
.mapValues(Transformer::toISO20022) // Filter: Transformer
.to((key, value, ctx) -> // Filter: Router
routeByDestination(value));
Kafka Streams implementa pipes internamente como changelog topics para filtros stateful y como pass-through para filtros stateless. La topología se optimiza automáticamente.
Apache Camel¶
from("kafka:payments.raw")
.bean(Parser.class)
.bean(Validator.class)
.bean(SanctionsScreener.class)
.bean(FundsChecker.class)
.bean(FeeCalculator.class)
.bean(Transformer.class)
.choice()
.when(header("destination").isEqualTo("SEPA"))
.to("kafka:payments.sepa")
.when(header("destination").isEqualTo("FEDWIRE"))
.to("kafka:payments.fedwire");
Spring Integration¶
@Bean
IntegrationFlow paymentPipeline() {
return IntegrationFlow
.from(Kafka.messageDrivenChannelAdapter(...))
.transform(parser)
.filter(validator)
.handle(sanctionsScreener)
.handle(fundsChecker)
.transform(feeCalculator)
.transform(formatTransformer)
.route(paymentRouter)
.get();
}
Azure Logic Apps / AWS Step Functions¶
Ambas plataformas permiten componer filtros como pasos en un workflow visual, donde cada paso es una Azure Function / Lambda y las conexiones son gestionadas por la plataforma.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Distributed tracing: propagar trace context (OpenTelemetry) entre cada filtro para trazabilidad end-to-end del pipeline.
- Métricas por filtro: throughput (msg/s), latency (p50, p95, p99), error rate, processing time.
- Métricas por pipe: queue depth/consumer lag, message age (tiempo desde que el mensaje fue producido hasta que fue consumido).
- Pipeline health: latencia total source-to-sink, throughput total, tasa de mensajes que llegan al final vs. descartados.
Monitoreo¶
- Bottleneck detection: identificar el filtro con mayor latencia o menor throughput.
- Backpressure: consumer lag creciente en un pipe indica que el siguiente filtro no puede mantener el ritmo.
- Dead-letter rates: tasa de mensajes en DLQ por filtro.
- SLA compliance: % de mensajes procesados dentro del SLA de latencia total.
Versionado¶
- Los cambios en el formato de los mensajes en un pipe deben coordinarse con los filtros que producen y consumen de ese pipe.
- Estrategia recomendada: usar Schema Registry con compatibilidad BACKWARD para que los filtros consumidores puedan procesar tanto el formato viejo como el nuevo durante la transición.
Seguridad¶
- Principle of least privilege: cada filtro solo tiene acceso a los pipes que necesita (ACLs en Kafka, IAM policies en AWS).
- Datos sensibles: si un filtro procesa datos sensibles (PII, financieros), debe estar en un entorno seguro con acceso auditado.
- Encryption: mensajes con datos sensibles deben estar cifrados en tránsito y en reposo en los pipes.
Error Handling¶
- Per-filter DLQ: cada filtro tiene su propio dead-letter topic para diagnóstico granular.
- Retry con backoff: reintentos con exponential backoff antes de enviar a DLQ.
- Compensation: si un filtro tardío falla (después de que un filtro anterior hizo un side-effect como bloquear fondos), puede necesitarse una compensación (liberar el bloqueo).
- Circuit breaker: para filtros que dependen de servicios externos (Sanctions API), usar circuit breaker para evitar cascading failures.
Performance¶
- Pipeline parallelism: múltiples instancias de cada filtro consumiendo del mismo pipe (Competing Consumers).
- Batch processing: procesar mensajes en micro-batches dentro de cada filtro para amortizar overhead.
- In-process pipes: para filtros que siempre se ejecutan juntos, usar pipes in-memory en lugar de topics persistentes.
Escalabilidad¶
- Horizontal: añadir instancias de los filtros bottleneck.
- Partitioning: particionar los pipes para paralelismo de datos.
- Auto-scaling: configurar auto-scaling basado en consumer lag o queue depth.
17. Errores Comunes¶
Filtros Demasiado Finos¶
Descomponer en filtros que hacen operaciones triviales (un filtro que añade un timestamp, otro que valida un campo, otro que convierte un tipo de dato) produce overhead de serialización/deserialización desproporcionado. Regla general: un filtro debe tener una responsabilidad cohesiva, no una responsabilidad atómica.
Filtros Demasiado Gruesos¶
Un filtro que hace validación + enriquecimiento + transformación anula el propósito del patrón. Si no se puede explicar la responsabilidad del filtro en una frase, probablemente debería dividirse.
No Implementar Error Handling Consistente¶
Cada filtro maneja errores de forma diferente: uno loguea y continúa, otro lanza excepción, otro descarta silenciosamente. El comportamiento del pipeline ante fallos se vuelve impredecible. Definir una estrategia de error handling uniforme (DLQ + alerting) desde el inicio.
Asumir Orden de Procesamiento Determinista¶
En un pipeline con consumer groups y múltiples instancias por filtro, el orden de procesamiento de mensajes individuales no está garantizado (a menos que se particione explícitamente). Asumir orden cuando no está garantizado produce bugs sutiles.
No Monitorear Latencia por Etapa¶
Monitorear solo la latencia total del pipeline oculta el cuello de botella. Si la latencia total crece, ¿es el Parser? ¿El Sanctions API? ¿El FundsChecker? Sin métricas por etapa, el diagnóstico es a ciegas.
Crear Dependencias Ocultas Entre Filtros¶
Un filtro que asume que un campo fue añadido por un filtro anterior crea una dependencia implícita que se rompe si se reordena el pipeline. Los filtros deben validar la presencia de los datos que necesitan, no asumir que están presentes.
18. Conclusión Técnica¶
Pipes and Filters es uno de los patrones arquitectónicos más poderosos y duraderos, no solo en integración sino en el diseño de software en general. Su capacidad de descomponer procesamiento complejo en etapas simples, independientes y componibles es la base de los stream processing frameworks, las integration platforms, los workflow engines y los data pipelines modernos.
Cuándo aporta valor: cuando el procesamiento de mensajes es multi-etapa, cuando las etapas tienen diferentes requisitos de performance o frecuencia de cambio, cuando se necesita visibilidad granular del procesamiento, cuando se desea escalar selectivamente.
Cuándo evita problemas importantes: un pipeline bien diseñado evita los problemas clásicos del procesador monolítico: acoplamiento, falta de escalabilidad, blast radius de fallos, dificultad de testing y deployment monolítico.
Cuándo no conviene adoptarlo: cuando el procesamiento es trivial (1-2 pasos simples), cuando la latencia es tan crítica que el overhead de pipes es inaceptable, cuando las etapas están tan acopladas que la descomposición es artificial.
Recomendación para arquitectos: diseñe el pipeline con criterio de cohesión por etapa, no de descomposición mecánica. Cada filtro debe tener una responsabilidad que un arquitecto pueda nombrar en una frase ("validates payment format", "screens for sanctions", "calculates fees"). Implemente distributed tracing y métricas por etapa desde el día uno. Y evalúe conscientemente el trade-off entre pipes persistentes (durabilidad, desacoplamiento) e in-process (latencia, simplicidad): no todos los pipes de un pipeline necesitan la misma semántica.