Message Router¶
1. Nombre del Patrón¶
- Nombre oficial: Message Router
- Categoría: Messaging Systems (Sistemas de Mensajería — Conceptos Fundacionales)
- Traducción contextual: Enrutador de Mensajes
2. Resumen Ejecutivo¶
Message Router es el patrón que introduce la capacidad de decisión en el flujo de mensajes dentro de un sistema de mensajería. Mientras que un Message Channel transporta mensajes de forma pasiva entre un punto A y un punto B, un Message Router examina cada mensaje entrante y decide activamente a cuál de los múltiples canales de salida debe dirigirlo. Es el equivalente conceptual a un desvío ferroviario: los trenes (mensajes) llegan por una vía (canal de entrada) y el desvío (router) los redirige a la vía correcta (canal de salida) según criterios definidos.
El problema que resuelve es fundamental en cualquier arquitectura de integración con más de dos participantes: ¿cómo se determina el destino de un mensaje cuando existen múltiples consumidores potenciales con necesidades diferentes? Sin un Message Router, el productor tendría que conocer las reglas de distribución y enviar cada mensaje al canal correcto, lo cual acopla la lógica de enrutamiento a la lógica de producción. Message Router externaliza esa decisión en un componente independiente, preservando el desacoplamiento entre productores y consumidores.
Este patrón es la base conceptual de toda una familia de patrones de routing más especializados — Content-Based Router, Message Filter, Dynamic Router, Recipient List, Splitter — cada uno de los cuales es una variante de Message Router con una estrategia de decisión particular. Comprender Message Router en su forma genérica es prerequisito para comprender y aplicar correctamente estos patrones derivados.
3. Definición Detallada¶
Propósito¶
Message Router establece un componente intermediario en el flujo de mensajería cuya responsabilidad exclusiva es consumir mensajes de un canal de entrada, evaluar cada mensaje contra un conjunto de criterios, y producirlo en el canal de salida apropiado. Su propósito es desacoplar la decisión de enrutamiento tanto del productor (que no debe saber quién consume) como del consumidor (que no debe saber quién produce), centralizándola en un componente dedicado, gobernable y evolucionable.
Lógica Arquitectónica¶
En una arquitectura de mensajería sin routing explícito, la topología de canales debe resolver por sí misma la distribución de mensajes. Esto implica que el productor envía cada tipo de mensaje al canal correcto directamente, o que todos los consumidores reciben todos los mensajes y cada uno decide cuáles procesar. Ambas estrategias tienen problemas graves a escala:
- Routing en el productor: el productor necesita conocer la topología de canales de consumo y las reglas de distribución. Cada nuevo consumidor o cada cambio en las reglas de routing requiere modificar el productor. Esto viola el principio de responsabilidad única y crea acoplamiento directo.
- Filtrado en el consumidor: cada consumidor recibe todos los mensajes y descarta los que no le corresponden. Esto desperdicia ancho de banda, consume recursos de procesamiento innecesarios y hace que los consumidores dependan del formato de mensajes que no les conciernen.
Message Router resuelve ambos problemas introduciendo un nivel de indirección en la decisión de enrutamiento. El productor envía al canal de entrada sin preocuparse del destino final. El consumidor escucha en su canal dedicado sin preocuparse del origen. El router, posicionado entre ambos, aplica la lógica de decisión.
Esta indirección tiene consecuencias arquitectónicas profundas:
- Desacoplamiento lógico: la regla de enrutamiento es independiente del código del productor y del consumidor.
- Punto único de gobierno: las reglas de routing se definen, versionan, auditan y modifican en un solo lugar.
- Extensibilidad: añadir un nuevo destino solo requiere añadir una regla al router y un canal de salida, sin tocar productor ni consumidores existentes.
- Composición: múltiples routers pueden encadenarse en topologías complejas usando Pipes and Filters.
Principio de Diseño Subyacente¶
El principio es separación de la lógica de enrutamiento de la lógica de negocio. En lugar de que la decisión de "a dónde va este mensaje" esté embebida en el productor o dispersa en los consumidores, se externaliza a un componente cuya única responsabilidad es tomar esa decisión. Este principio es análogo al Single Responsibility Principle aplicado a la arquitectura de integración: cada componente hace una cosa bien. El productor produce. El consumidor consume. El router enruta.
Problema Estructural que Resuelve¶
En un sistema de integración con N productores y M consumidores donde diferentes tipos de mensajes deben llegar a diferentes subconjuntos de consumidores, sin routing explícito se produce una de dos situaciones:
- Topología de canales N×M: cada par productor-consumidor tiene su propio canal. Esto produce una explosión combinatoria de canales y requiere que cada productor conozca todos los canales de destino.
- Canal único sobrecargado: todos los mensajes fluyen por un solo canal y cada consumidor filtra los que le interesan, desperdiciando recursos y acoplando consumidores a formatos de mensajes irrelevantes.
Message Router colapsa esta complejidad: los productores envían a un canal de entrada (o a un número reducido de canales). El router distribuye los mensajes a los canales de salida apropiados según reglas definidas. La topología se simplifica de N×M a N+M, con el router como nodo central de decisión.
Contexto en el que Emerge¶
Message Router emerge cuando una arquitectura de mensajería supera la trivialidad de la comunicación punto-a-punto. En cuanto existen al menos tres participantes (un productor y dos consumidores con necesidades diferentes, o dos productores y un consumidor que necesita distinguir entre ellos), la necesidad de enrutamiento aparece naturalmente. El patrón se vuelve crítico en integraciones enterprise donde decenas o cientos de sistemas intercambian mensajes con reglas de distribución complejas y cambiantes.
Por Qué No Es Trivial¶
Aunque el concepto parece simple ("mirar el mensaje y enviarlo al canal correcto"), las decisiones de diseño alrededor del routing son complejas y tienen impacto duradero:
- Criterios de decisión: ¿basados en qué? ¿El contenido del mensaje (Content-Based Router)? ¿Un header (Header-Based Router)? ¿El tipo de mensaje? ¿Una tabla de routing externa (Dynamic Router)? ¿Una combinación de criterios? La elección del criterio determina el acoplamiento del router con el formato del mensaje.
- Mutabilidad de las reglas: ¿las reglas de routing son estáticas (compiladas) o dinámicas (configurables en runtime)? Las reglas estáticas son más predecibles pero menos flexibles. Las dinámicas permiten evolución sin redespliegue pero introducen riesgos de configuración incorrecta.
- Performance: el router es un componente en el hot path de cada mensaje. Si el criterio de decisión requiere parseo profundo del contenido, deserialización, o consultas externas, el router se convierte en un cuello de botella.
- Handling de mensajes no enrutables: ¿qué sucede con un mensaje que no coincide con ninguna regla? ¿Se descarta? ¿Se envía a un dead-letter channel? ¿Se redirige a un canal por defecto? Esta decisión tiene implicaciones de negocio directas.
- Orden: si el canal de entrada tiene orden garantizado, ¿el router preserva ese orden en cada canal de salida? ¿O el routing paralelo puede reordenar mensajes entre canales?
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, Message Router corresponde a un demultiplexor: un componente que recibe datos de un canal de entrada y los distribuye a múltiples canales de salida según una función de clasificación. En redes de comunicación, el análogo directo es un router IP que examina la dirección de destino de cada paquete y lo reenvía por la interfaz correcta según su tabla de routing.
En la taxonomía de Enterprise Integration Patterns, Message Router es uno de los seis conceptos fundacionales (junto con Message Channel, Message, Pipes and Filters, Message Translator y Message Endpoint). Es el patrón que introduce la noción de flujo condicional en la mensajería: la idea de que el camino de un mensaje no está predeterminado por el canal donde fue producido, sino que se determina dinámicamente en función de propiedades del mensaje o del estado del sistema.
En la práctica, cada plataforma de mensajería implementa Message Router de forma diferente:
- En Kafka, el routing se implementa con Kafka Streams (
branch,KStream.split()) o con consumidores que re-producen en diferentes topics. - En RabbitMQ, el exchange es un router nativo: los exchanges de tipo
topic,headersydirectimplementan diferentes estrategias de routing sin necesidad de código adicional. - En Azure Service Bus, las Topic Subscriptions con SQL Filters implementan routing declarativo basado en propiedades del mensaje.
- En AWS, EventBridge Rules son routers nativos que evalúan patrones de eventos y los dirigen a targets específicos.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin un Message Router explícito, las arquitecturas de integración enfrentan un dilema estructural cuando los mensajes de un flujo deben distribuirse a múltiples destinos con criterios diferentes:
- Distribución hardcodeada en el productor: el productor evalúa cada mensaje, determina a qué canal debe enviarlo, y lo produce directamente en ese canal. Esto implica que el productor conoce la topología de consumo, las reglas de routing, y potencialmente el formato esperado por cada consumidor. Cada cambio en las reglas, cada nuevo consumidor, cada reorganización de canales, requiere modificar, probar y redesplegar el productor.
- Fan-out total con filtrado en el consumidor: el productor envía todos los mensajes a un canal único (o mediante pub-sub a todos los consumidores). Cada consumidor recibe todos los mensajes y descarta los que no le interesan. Esto funciona a escala pequeña pero es insostenible cuando el volumen es alto o el ratio de mensajes relevantes por consumidor es bajo.
- Canales ad-hoc por pareja productor-consumidor: se crean canales específicos para cada relación de routing. Esto multiplica la cantidad de canales y la complejidad operativa, y convierte al productor en el responsable de routing porque debe seleccionar el canal correcto para cada mensaje.
Síntomas del Problema¶
- El productor contiene bloques
if/elseoswitchque determinan a qué canal enviar cada mensaje, mezclando lógica de negocio con lógica de routing. - Cada nuevo consumidor requiere una modificación en el código del productor (añadir una nueva rama del
switch), lo cual produce ciclos de deployment acoplados. - Los consumidores reciben y descartan un porcentaje significativo de los mensajes que reciben (indicador de filtrado ineficiente en el lado equivocado de la arquitectura).
- Las reglas de distribución están dispersas en múltiples productores, sin visibilidad centralizada ni gobierno unificado.
- Los cambios en las reglas de routing requieren coordinación entre equipos de productores y equipos de consumidores, generando fricción organizacional.
- Los flujos de mensajería son opacos: no hay forma de visualizar o auditar las reglas de distribución sin leer el código fuente de múltiples productores.
Impacto Operativo y Arquitectónico¶
Sin routing explícito y externalizado:
- Acoplamiento entre productores y consumidores: viola el principio fundamental de la mensajería (desacoplamiento). El productor se convierte en un punto de fallo de governance porque conoce demasiado sobre la topología de consumo.
- Rigidez ante el cambio: añadir, remover o reubicar consumidores se convierte en una operación costosa que requiere cambios en productores.
- Ineficiencia de recursos: consumidores procesando y descartando mensajes irrelevantes consumen CPU, memoria y ancho de banda innecesariamente.
- Imposibilidad de auditoría: las reglas de routing, distribuidas en código fuente de múltiples aplicaciones, no son auditables ni gobernables como un conjunto coherente.
- Escalabilidad heterogénea: si todos los consumidores reciben todos los mensajes vía pub-sub, los consumidores que solo necesitan un subconjunto pequeño deben escalar para manejar el volumen total.
Riesgos Si No Se Implementa Correctamente¶
- Router como cuello de botella: si el router es un componente single-threaded que procesa secuencialmente, se convierte en el bottleneck de todo el flujo.
- Reglas de routing inconsistentes: reglas contradictorias, solapadas o incompletas pueden causar que mensajes se envíen a destinos incorrectos, se dupliquen en múltiples destinos inesperados, o se pierdan.
- Mensajes no enrutables sin manejo: mensajes que no coinciden con ninguna regla se pierden silenciosamente si no hay un canal por defecto o dead-letter.
- Pérdida de orden: un router que procesa mensajes en paralelo puede alterar el orden relativo de mensajes que deben procesarse secuencialmente.
- Falta de observabilidad: sin métricas sobre la distribución (cuántos mensajes van a cada destino, cuántos no son enrutables, latencia de routing), los problemas son invisibles hasta que afectan al negocio.
Ejemplos Reales¶
- Gobierno electrónico: una plataforma de declaración de impuestos recibe declaraciones de personas físicas, empresas nacionales y operaciones internacionales. Cada tipo requiere validación, procesamiento y workflow diferentes. Sin un Message Router, el sistema de recepción tendría que conocer la lógica de clasificación y los destinos de cada tipo, acoplándose a los subsistemas de procesamiento.
- Banca: un sistema de procesamiento de transacciones recibe operaciones de débito, crédito, transferencias nacionales e internacionales. Cada tipo tiene reglas de validación, límites y sistemas de liquidación diferentes. Un router clasifica y dirige cada transacción al pipeline correcto.
- Telecomunicaciones: un sistema de gestión de incidentes recibe tickets de diferentes severidades y tipos de servicio. Un router dirige cada ticket al equipo de resolución apropiado según severidad, tipo de servicio y SLA contractual.
- Salud: un sistema de interoperabilidad hospitalaria recibe mensajes HL7/FHIR de diferentes tipos (admisiones, resultados de laboratorio, prescripciones, informes de radiología). Un router dirige cada tipo al subsistema clínico correspondiente.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un flujo de mensajes debe dividirse en múltiples destinos según criterios definidos (tipo, contenido, prioridad, origen, destino lógico).
- Cuando la lógica de distribución no debe residir en el productor ni en el consumidor, sino en un componente dedicado y gobernable.
- Cuando se necesita modificar las reglas de routing sin redesplegar productores ni consumidores.
- Cuando diferentes consumidores tienen diferentes requisitos de procesamiento para diferentes subconjuntos de mensajes del mismo flujo.
- Cuando se busca una topología de integración donde la adición de nuevos consumidores no requiere cambios en componentes existentes.
Cuándo No Usarlo¶
- Cuando el flujo de mensajes tiene un solo destino posible y no se anticipa que tendrá más. En ese caso, un Message Channel directo es suficiente.
- Cuando la distribución es puramente fan-out (todos los consumidores reciben todos los mensajes). En ese caso, Publish-Subscribe Channel es la solución correcta sin necesidad de routing.
- Cuando la decisión de qué consumidor procesa cada mensaje debe basarse en disponibilidad o carga (load balancing), no en contenido o tipo. En ese caso, Competing Consumers es más apropiado.
- Cuando la overhead de un componente intermedio de routing no es aceptable (escenarios de latencia ultra-baja donde cada microsegundo cuenta). En estos casos excepcionales, el routing puede integrarse en el productor aceptando el acoplamiento.
Precondiciones¶
- Existe una infraestructura de mensajería (broker) con capacidad de múltiples canales.
- Los mensajes tienen alguna propiedad inspectable (tipo, header, campo en el payload) que permite la clasificación.
- Existe una definición clara de los canales de salida y de los criterios de clasificación.
- Existe gobierno sobre las reglas de routing: quién las define, quién las aprueba, cómo se versionan.
Restricciones¶
- El router introduce latencia adicional (consume, evalúa, produce). Esta latencia debe ser aceptable para el caso de uso.
- El router es un componente adicional que requiere despliegue, monitoreo y mantenimiento.
- Las reglas de routing deben ser determinísticas y completas: para cualquier mensaje de entrada, debe existir una regla que lo clasifique (incluyendo una regla default).
- El formato de los mensajes debe ser suficientemente estable como para que los criterios de routing sean confiables. Si el formato cambia frecuentemente, los criterios pueden dejar de funcionar.
Dependencias¶
- Infraestructura de messaging con capacidad de múltiples canales (topics, queues).
- Mecanismo de deserialización o inspección de mensajes (Schema Registry, parser de headers).
- Opcionalmente, un sistema de configuración para reglas dinámicas (config server, database de reglas).
- Opcionalmente, un schema registry para validar que los mensajes contienen los campos necesarios para el routing.
Supuestos Arquitectónicos¶
- Los mensajes entrantes contienen información suficiente para determinar su destino. Si la información de routing depende de datos externos (por ejemplo, una base de datos que mapea cliente a región), el router necesita acceso a esa fuente externa, lo que introduce acoplamiento y latencia adicional.
- Los canales de salida existen y están configurados antes de que el router comience a operar.
- Los consumidores en los canales de salida están preparados para procesar los mensajes que recibirán (formato, semántica, volumen).
- El throughput del router es suficiente para manejar el volumen del canal de entrada sin generar lag significativo.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Plataformas de gobierno electrónico con múltiples tipos de trámites.
- Sistemas bancarios con diferentes tipos de transacciones y canales de liquidación.
- Plataformas de e-commerce con flujos diferenciados por tipo de orden, región o prioridad.
- Sistemas de salud con mensajes clínicos de diferentes tipos (HL7, FHIR).
- Arquitecturas event-driven con múltiples microservicios que procesan diferentes subconjuntos de eventos.
- Plataformas IoT donde diferentes tipos de telemetría requieren diferentes pipelines de procesamiento.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Message Router reduce el acoplamiento entre productor y consumidores al centralizar la lógica de routing en un componente independiente. El productor solo conoce el canal de entrada; los consumidores solo conocen sus canales de salida. Sin embargo, el router introduce un nuevo punto de acoplamiento: las reglas de routing dependen del formato del mensaje (al menos de los campos usados para clasificación). Si el formato cambia, las reglas deben actualizarse. La flexibilidad ganada en la topología de canales se paga con un acoplamiento entre router y schema del mensaje.
Simplicidad vs. Robustez¶
Un router simple con reglas estáticas (if-else compilado) es fácil de entender, rápido de ejecutar y predecible. Un router dinámico con reglas configurables en runtime es más robusto ante el cambio pero más complejo de operar: requiere validación de reglas, versioning, rollback, y testing de nuevas configuraciones antes de activarlas. La tensión entre simplicidad operativa y capacidad de evolución sin redespliegue es constante.
Latencia vs. Desacoplamiento¶
Cada router en el flujo añade latencia: consume del canal de entrada, evalúa criterios, produce en el canal de salida. En un pipeline con múltiples routers encadenados (routing jerárquico), la latencia acumulada puede ser significativa. La alternativa — routing en el productor — elimina la latencia intermedia pero sacrifica el desacoplamiento. La decisión depende de los SLA de latencia del caso de uso.
Centralización vs. Distribución del Routing¶
Centralizar todo el routing en un solo componente proporciona visibilidad, governance y consistencia. Pero un router centralizado es un single point of failure y un potencial cuello de botella. Distribuir el routing entre múltiples componentes mejora la resiliencia y la escalabilidad pero dificulta la visibilidad global y la governance de las reglas. Las organizaciones maduras combinan ambas aproximaciones: routing descentralizado en la ejecución pero gobernado centralmente mediante políticas y configuración compartida.
Performance vs. Granularidad de Criterios¶
Criterios de routing simples (evaluar un header, un campo de tipo) son extremadamente rápidos. Criterios complejos (evaluar contenido del payload con expresiones XPath/JSONPath, consultar una base de datos externa, aplicar reglas de negocio complejas) pueden ser órdenes de magnitud más lentos. La granularidad de los criterios de routing debe equilibrarse con los requisitos de performance.
Consistencia de Reglas vs. Autonomía de Equipos¶
¿Quién define las reglas de routing? Si es un equipo central de arquitectura, hay consistencia pero posible fricción con los equipos de producto. Si cada equipo define las reglas que afectan a sus mensajes, hay agilidad pero riesgo de inconsistencia, solapamiento o conflicto entre reglas. Los modelos maduros definen un framework de reglas (formato, validación, testing) que los equipos populan con autonomía dentro de guardrails definidos.
Observabilidad vs. Overhead¶
Instrumentar el router con métricas detalladas (mensajes por destino, latencia de evaluación, mensajes no enrutables, distribución por criterio) es valioso para governance y debugging pero añade overhead por mensaje. La granularidad de la instrumentación debe ser proporcional a la criticidad del flujo.
Costo Operativo vs. Capacidad de Evolución¶
Un router es un componente adicional en la arquitectura: requiere despliegue, monitoreo, escalamiento, mantenimiento, y un equipo que entienda sus reglas. Este costo operativo se justifica cuando la frecuencia de cambio en las reglas de routing es significativa o cuando la cantidad de destinos es suficientemente alta como para que el acoplamiento directo sea inmanejable.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): la aplicación que envía mensajes al canal de entrada del router. El productor no conoce ni le importa el destino final del mensaje.
- Canal de Entrada (Input Channel): el Message Channel del cual el router consume mensajes.
- Message Router: el componente que consume mensajes del canal de entrada, evalúa cada uno contra un conjunto de criterios, y los produce en el canal de salida correspondiente.
- Criterios de Routing (Routing Rules): el conjunto de reglas que determinan a qué canal de salida va cada mensaje. Pueden ser estáticas (compiladas) o dinámicas (configurables en runtime).
- Canales de Salida (Output Channels): los Message Channels a los que el router envía los mensajes clasificados. Cada canal de salida corresponde a un destino o grupo de destinos.
- Consumidores (Receivers): las aplicaciones que escuchan en los canales de salida y procesan los mensajes enrutados.
- Canal por Defecto / Dead-Letter (Default/DLQ Channel): canal para mensajes que no coinciden con ninguna regla. Su existencia es una decisión de diseño crítica.
Flujo Lógico¶
flowchart TD
A([Productor]) -->|Envía mensaje M| B[(Canal de Entrada)]
B --> C[Router: Consume e inspecciona M]
C --> D{Evalúa reglas de routing}
D -->|Condición 1| E[(Canal Salida S1)]
D -->|Condición 2| F[(Canal Salida S2)]
D -->|Condición 3| G[(Canal Salida S3)]
D -->|Ninguna condición| H[(Canal Default / DLQ)]
E --> I([Consumidor S1])
F --> J([Consumidor S2])
G --> K([Consumidor S3])
C -->|ACK/Commit| BResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Producir mensajes con información suficiente para routing (tipo, headers, campos clasificatorios) |
| Canal de Entrada | Almacenar y entregar mensajes al router |
| Router | Consumir, evaluar, clasificar y producir en el canal correcto. No transformar el mensaje. |
| Reglas de Routing | Definir los criterios de clasificación de forma completa, consistente y sin ambigüedades |
| Canales de Salida | Almacenar y entregar mensajes clasificados a los consumidores apropiados |
| Consumidores | Procesar los mensajes del canal asignado |
| Canal Default/DLQ | Capturar mensajes no clasificables para análisis y resolución |
Interacciones¶
- Productor → Canal de Entrada: operación estándar de produce/send. El productor no sabe que hay un router downstream.
- Canal de Entrada → Router: operación de consume/receive. El router actúa como consumidor del canal de entrada.
- Router → Reglas de Routing: evaluación interna. Puede ser in-memory (reglas compiladas), lookup en configuración, o consulta a un servicio externo (Dynamic Router).
- Router → Canal de Salida: operación de produce/send al canal determinado por la regla. El router actúa como productor en los canales de salida.
- Canal de Salida → Consumidor: operación estándar de consume/receive. El consumidor no sabe que los mensajes fueron enrutados.
Contratos Implícitos¶
- Formato inspectable: el mensaje debe contener información suficiente para que el router pueda evaluarlo. Si las reglas se basan en un campo
type, ese campo debe existir y estar poblado en todos los mensajes. - Completitud de reglas: para cualquier mensaje válido que entre al router, debe existir una regla que lo clasifique. El canal default debe capturar mensajes no clasificados, pero un volumen alto de mensajes en el canal default indica reglas incompletas.
- Invarianza del mensaje: el router no debe modificar el contenido del mensaje (esa es la responsabilidad de un Message Translator). El mensaje que sale del router debe ser idéntico al que entró, posiblemente con headers de routing adicionales.
- Exclusividad de destino: en el caso base, cada mensaje va a exactamente un canal de salida. Si un mensaje debe ir a múltiples destinos, el patrón es Recipient List, no Message Router.
Decisiones de Diseño Clave¶
- Criterio de routing: ¿basado en headers (bajo costo, no requiere deserialización del payload)? ¿Basado en el contenido del payload (más flexible pero más costoso)? ¿Basado en tipo de mensaje (simple pero requiere tipado explícito)?
- Reglas estáticas vs. dinámicas: ¿las reglas se definen en código (máxima performance, requiere redespliegue) o en configuración externa (modificables en runtime, riesgo de configuración incorrecta)?
- Handling de mensajes no enrutables: ¿canal default, dead-letter, excepción, descarte silencioso? La elección tiene implicaciones de negocio directas.
- Garantía de entrega: ¿el router confirma el mensaje de entrada antes o después de producirlo en la salida? "Antes" arriesga pérdida si el router falla entre ack y produce. "Después" arriesga duplicados si el router falla entre produce y ack. La solución ideal es transaccionalidad (produce + ack atómicos).
- Paralelismo: ¿el router procesa mensajes secuencialmente (preserva orden) o en paralelo (mayor throughput pero posible reordenamiento)?
- Idempotencia: ¿qué sucede si el router procesa el mismo mensaje dos veces? El diseño debe garantizar que un re-routing no produzca duplicados en los canales de salida, o que los consumidores sean idempotentes.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Gobierno — Routing de Declaraciones de Impuestos¶
Contexto del Negocio¶
La Agencia Tributaria Nacional (ATN) de un país gestiona la recepción y procesamiento de declaraciones de impuestos de tres tipos fundamentalmente diferentes:
- Declaraciones de Personas Físicas (IRPF): declaraciones individuales de renta de ciudadanos. Volumen alto (millones durante el período de declaración), complejidad media, procesamiento mayoritariamente automatizado con validación contra datos de empleadores y entidades financieras.
- Declaraciones Corporativas (Impuesto de Sociedades): declaraciones de empresas nacionales. Volumen medio (cientos de miles), alta complejidad contable, requieren cruce con información de múltiples fuentes (facturación electrónica, nóminas, inversiones, amortizaciones).
- Declaraciones Internacionales (Operaciones Transfronterizas): declaraciones que involucran operaciones entre jurisdicciones fiscales (precios de transferencia, establecimientos permanentes, tratados de doble imposición). Volumen bajo (miles), complejidad muy alta, requieren intervención de especialistas y coordinación con agencias tributarias de otros países.
Necesidad de Integración¶
Todos los tipos de declaraciones ingresan al sistema a través de un portal unificado de presentación electrónica. El portal genera un mensaje por cada declaración presentada y lo deposita en un canal de entrada único. Cada tipo de declaración requiere un pipeline de procesamiento radicalmente diferente:
- IRPF: validación automática contra datos precargados → cálculo de resultado (a pagar/a devolver) → notificación al contribuyente. Pipeline altamente automatizado, tiempo de respuesta objetivo: 48 horas.
- Corporativas: validación formal → cruce con facturación electrónica → verificación contable automatizada → asignación a inspector fiscal si hay discrepancias → resolución. Pipeline semi-automatizado, tiempo de procesamiento: 30 días.
- Internacionales: validación formal → clasificación por tratado aplicable → análisis de precios de transferencia → coordinación con agencia extranjera → resolución por comité especializado. Pipeline mayoritariamente manual con soporte de sistemas, tiempo de procesamiento: 6-12 meses.
Sistemas Involucrados¶
- Portal de Presentación Electrónica: aplicación web/móvil donde los contribuyentes presentan sus declaraciones. Produce mensajes en el canal de entrada.
- Message Router (Motor de Enrutamiento Tributario): componente que clasifica cada declaración y la dirige al pipeline correcto.
- Pipeline IRPF: conjunto de microservicios que procesan declaraciones de personas físicas (validación, cálculo, notificación).
- Pipeline Corporativo: conjunto de microservicios que procesan declaraciones de empresas (validación, cruce contable, asignación de inspectores).
- Pipeline Internacional: sistema de workflow que gestiona declaraciones internacionales (análisis, coordinación interagencias, comité especializado).
- Sistema de Auditoría: registra todas las decisiones de routing para trazabilidad regulatoria.
- Sistema de Monitoreo: dashboard que muestra volúmenes, distribución y anomalías del routing en tiempo real.
- Dead-Letter Queue: canal para declaraciones que no pueden clasificarse automáticamente (formato incorrecto, tipo desconocido, datos insuficientes).
Restricciones Técnicas¶
- Período pico: durante los 2 meses de campaña de renta, el portal recibe hasta 50,000 declaraciones por hora en períodos pico, con el 85% siendo IRPF.
- Zero data loss: ninguna declaración puede perderse. Cada declaración presentada debe ser procesada o explícitamente marcada como no procesable.
- Trazabilidad regulatoria: cada decisión de routing debe ser auditable: qué declaración, qué tipo se determinó, a qué pipeline se envió, cuándo, por qué regla.
- Disponibilidad: el sistema de routing debe estar disponible 24/7 durante el período de declaración con un SLA de 99.95%.
- Latencia de routing: la clasificación y enrutamiento de cada declaración debe completarse en menos de 500ms.
- Inmutabilidad: el router no debe modificar el contenido de la declaración. Solo la clasifica y reenvía.
Diseño de Canales¶
| Canal | Productor | Consumidor | Semántica | Retención |
|---|---|---|---|---|
tributario.declaraciones.entrada | Portal de Presentación | Message Router | Point-to-Point | 30 días |
tributario.declaraciones.irpf | Message Router | Pipeline IRPF | Point-to-Point | 90 días |
tributario.declaraciones.corporativas | Message Router | Pipeline Corporativo | Point-to-Point | 365 días |
tributario.declaraciones.internacionales | Message Router | Pipeline Internacional | Point-to-Point | 730 días |
tributario.declaraciones.no-clasificables | Message Router | Equipo de Soporte | Point-to-Point | 365 días |
tributario.routing.audit-log | Message Router | Sistema de Auditoría | Pub-Sub | 2555 días (7 años) |
Decisiones Arquitectónicas¶
-
Criterio de routing basado en campo
tipo_declaracion: cada declaración incluye un campo explícito que indica su tipo (IRPF,ISpara Impuesto de Sociedades,INTpara Internacional). El router evalúa este campo como criterio primario. Se eligió este criterio sobre análisis de contenido porque es determinístico, rápido y no requiere deserialización profunda del payload. -
Routing secundario por sub-tipo: dentro del tipo
INT(Internacional), existe un routing secundario por tratado aplicable que se realiza en un segundo router dentro del Pipeline Internacional. Este diseño jerárquico evita sobrecargar el router principal con reglas de granularidad excesiva. -
Transaccionalidad del routing: el router utiliza transacciones Kafka para garantizar que el consume del canal de entrada y el produce en el canal de salida son atómicos. Si el router falla entre ambas operaciones, la transacción se revierte y el mensaje se re-procesa.
-
Audit log como subproducto del routing: cada decisión de routing produce un evento en el canal de auditoría con la información de clasificación. Esto satisface el requisito regulatorio de trazabilidad sin impactar la latencia del routing principal (produce asíncrono).
-
Canal de no-clasificables con alertas: los mensajes que no coinciden con ninguna regla se envían al canal
tributario.declaraciones.no-clasificablesy generan una alerta inmediata al equipo de soporte. Un volumen anómalo de mensajes no-clasificables indica un problema en el portal (formato incorrecto) o en las reglas del router (regla faltante).
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de declaraciones durante routing | Transacciones Kafka (produce + ack atómicos) |
| Router como single point of failure | Múltiples instancias con consumer group y failover automático |
| Reglas de routing incorrectas en producción | Reglas versionadas con pipeline de testing; canary deployment |
| Pico de carga durante campaña de renta | Auto-scaling del router con pre-provisioning para el pico estimado |
| Declaración con tipo desconocido | Canal de no-clasificables + alerta inmediata + procesamiento manual |
| Pérdida de trazabilidad de auditoría | Canal de audit-log con retención de 7 años y backup a almacenamiento frío |
| Latencia de routing excesiva | Criterio de routing basado en header (no requiere deserialización del payload completo) |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Presentación de la Declaración¶
Un contribuyente persona física (NIF: 12345678A) presenta su declaración de IRPF del ejercicio 2025 a través del Portal de Presentación Electrónica. El portal genera un mensaje con la declaración y lo publica en el canal de entrada:
{
"mensaje_id": "DECL-2026-00847291",
"timestamp": "2026-04-07T10:15:32Z",
"tipo_declaracion": "IRPF",
"ejercicio": 2025,
"contribuyente": {
"nif": "12345678A",
"tipo_contribuyente": "persona_fisica",
"jurisdiccion": "ES"
},
"declaracion": {
"rendimientos_trabajo": 45200.00,
"rendimientos_capital": 1850.00,
"deducciones": [
{ "tipo": "vivienda_habitual", "importe": 3200.00 },
{ "tipo": "donaciones", "importe": 450.00 }
],
"resultado_autoliquidacion": -1247.50
},
"metadata": {
"canal_presentacion": "web",
"ip_origen": "83.47.xxx.xxx",
"certificado_digital": "FNMT-12345678A-2025",
"hash_declaracion": "sha256:a1b2c3d4..."
}
}
El mensaje se publica en tributario.declaraciones.entrada con la partition key 12345678A (NIF del contribuyente) para garantizar que todas las declaraciones del mismo contribuyente se procesan en orden.
Paso 2: Consumo por el Message Router¶
El Motor de Enrutamiento Tributario (consumer group: cg-routing-tributario) consume el mensaje del canal de entrada. El router opera con 8 instancias en paralelo, cada una procesando un subconjunto de particiones del canal de entrada.
La instancia que procesa la partición correspondiente al NIF 12345678A recibe el mensaje y comienza la evaluación.
Paso 3: Evaluación de Reglas de Routing¶
El router extrae el campo tipo_declaracion del mensaje (sin deserializar el payload completo de la declaración, ya que el campo está en el nivel superior del JSON). La evaluación sigue esta secuencia:
Regla 1: tipo_declaracion == "IRPF" → Canal: tributario.declaraciones.irpf ✓ MATCH
Regla 2: tipo_declaracion == "IS" → Canal: tributario.declaraciones.corporativas
Regla 3: tipo_declaracion == "INT" → Canal: tributario.declaraciones.internacionales
Default: ninguna regla coincide → Canal: tributario.declaraciones.no-clasificables
El mensaje coincide con la Regla 1. El destino es tributario.declaraciones.irpf.
Paso 4: Producción en el Canal de Salida¶
El router produce el mensaje sin modificarlo en el canal tributario.declaraciones.irpf. La operación se ejecuta dentro de una transacción Kafka que incluye:
- Producción del mensaje en
tributario.declaraciones.irpfcon la misma partition key (12345678A). - Producción del evento de auditoría en
tributario.routing.audit-log:
{
"audit_id": "AUD-2026-RT-00384712",
"timestamp": "2026-04-07T10:15:32.127Z",
"mensaje_origen_id": "DECL-2026-00847291",
"canal_entrada": "tributario.declaraciones.entrada",
"canal_salida": "tributario.declaraciones.irpf",
"regla_aplicada": "R1-IRPF",
"campo_evaluado": "tipo_declaracion",
"valor_evaluado": "IRPF",
"latencia_routing_ms": 12,
"instancia_router": "router-tributario-03"
}
- Commit del offset en el canal de entrada (confirmación de procesamiento).
Las tres operaciones son atómicas. Si cualquiera falla, la transacción se revierte y el mensaje se reintenta.
Paso 5: Procesamiento por el Pipeline IRPF¶
El Pipeline IRPF (consumer group: cg-pipeline-irpf) consume el mensaje del canal tributario.declaraciones.irpf. El pipeline ejecuta:
- Validación formal: verifica que todos los campos obligatorios están presentes y son válidos.
- Cruce con datos precargados: compara los rendimientos declarados contra los datos de empleadores (modelo 190) y entidades financieras (modelo 196) precargados en el sistema.
- Cálculo del resultado: verifica que el resultado de autoliquidación (-1,247.50 EUR, a devolver) es correcto según la normativa vigente.
- Resolución: si no hay discrepancias, marca la declaración como "conforme" y programa la devolución.
- Notificación: envía notificación al contribuyente confirmando la recepción y el resultado.
Paso 6: Escenario Alternativo — Declaración Corporativa¶
Simultáneamente, una empresa (NIF: B12345678) presenta su declaración de Impuesto de Sociedades. El mensaje tiene tipo_declaracion: "IS". El router evalúa:
Regla 1: tipo_declaracion == "IRPF" → No coincide
Regla 2: tipo_declaracion == "IS" → Canal: tributario.declaraciones.corporativas ✓ MATCH
El mensaje se envía a tributario.declaraciones.corporativas donde el Pipeline Corporativo lo procesa con su workflow específico (más largo, más complejo, con posible asignación a inspector).
Paso 7: Escenario de Error — Declaración No Clasificable¶
Una declaración llega con tipo_declaracion: "IVA_TRIMESTRAL" — un tipo que no está en las reglas del router (las declaraciones de IVA se presentan por otro canal y no deberían llegar a este flujo):
Regla 1: tipo_declaracion == "IRPF" → No coincide
Regla 2: tipo_declaracion == "IS" → No coincide
Regla 3: tipo_declaracion == "INT" → No coincide
Default: → Canal: tributario.declaraciones.no-clasificables ✓ DEFAULT
El mensaje se envía al canal de no-clasificables. El evento de auditoría registra la aplicación de la regla Default. Una alerta se genera al equipo de soporte para investigar por qué una declaración de IVA llegó al canal de entrada de renta/sociedades.
Paso 8: Monitoreo en Tiempo Real¶
El dashboard de monitoreo muestra en tiempo real:
- Volumen de routing: 847 declaraciones/minuto (período pico de campaña de renta).
- Distribución por tipo: IRPF 86%, IS 12%, INT 1%, No-clasificables 1%.
- Latencia de routing: p50 = 8ms, p95 = 23ms, p99 = 87ms (bien dentro del SLA de 500ms).
- Consumer lag del router: 0 (el router procesa en tiempo real sin acumulación).
- Mensajes en canal de no-clasificables: 8 en la última hora (bajo, pero se investiga).
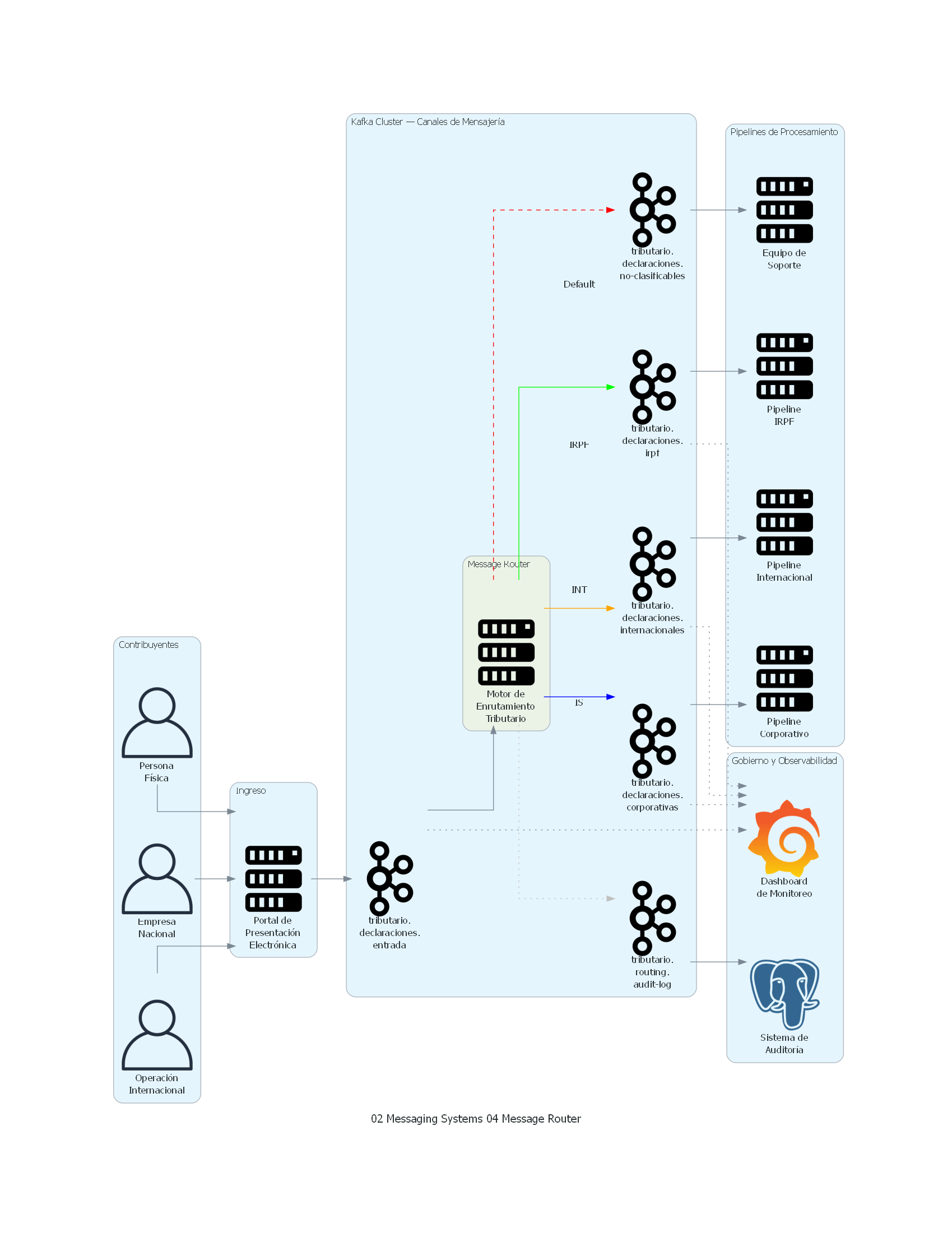
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.client import User
from diagrams.onprem.monitoring import Grafana
from diagrams.onprem.database import PostgreSQL
with Diagram("Message Router - Tax Return Routing", show=False, direction="LR"):
with Cluster("Contribuyentes"):
persona = User("Persona\nFísica")
empresa = User("Empresa\nNacional")
multinacional = User("Operación\nInternacional")
with Cluster("Ingreso"):
portal = Server("Portal de\nPresentación\nElectrónica")
with Cluster("Kafka Cluster — Canales de Mensajería"):
canal_entrada = Kafka("tributario.\ndeclaraciones.\nentrada")
with Cluster("Message Router"):
router = Server("Motor de\nEnrutamiento\nTributario")
canal_irpf = Kafka("tributario.\ndeclaraciones.\nirpf")
canal_corp = Kafka("tributario.\ndeclaraciones.\ncorporativas")
canal_int = Kafka("tributario.\ndeclaraciones.\ninternacionales")
canal_dlq = Kafka("tributario.\ndeclaraciones.\nno-clasificables")
canal_audit = Kafka("tributario.\nrouting.\naudit-log")
with Cluster("Pipelines de Procesamiento"):
pipeline_irpf = Server("Pipeline\nIRPF")
pipeline_corp = Server("Pipeline\nCorporativo")
pipeline_int = Server("Pipeline\nInternacional")
soporte = Server("Equipo de\nSoporte")
with Cluster("Gobierno y Observabilidad"):
auditoria = PostgreSQL("Sistema de\nAuditoría")
monitoring = Grafana("Dashboard\nde Monitoreo")
# Flujo de contribuyentes al portal
persona >> portal
empresa >> portal
multinacional >> portal
# Portal produce en canal de entrada
portal >> canal_entrada
# Router consume del canal de entrada
canal_entrada >> router
# Router produce en canales de salida según tipo
router >> Edge(label="IRPF", color="green") >> canal_irpf
router >> Edge(label="IS", color="blue") >> canal_corp
router >> Edge(label="INT", color="orange") >> canal_int
router >> Edge(label="Default", color="red", style="dashed") >> canal_dlq
router >> Edge(style="dotted", color="gray") >> canal_audit
# Consumidores de cada canal
canal_irpf >> pipeline_irpf
canal_corp >> pipeline_corp
canal_int >> pipeline_int
canal_dlq >> soporte
# Auditoría y monitoreo
canal_audit >> auditoria
canal_entrada >> Edge(style="dotted") >> monitoring
canal_irpf >> Edge(style="dotted") >> monitoring
canal_corp >> Edge(style="dotted") >> monitoring
canal_int >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import Eventbridge, SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
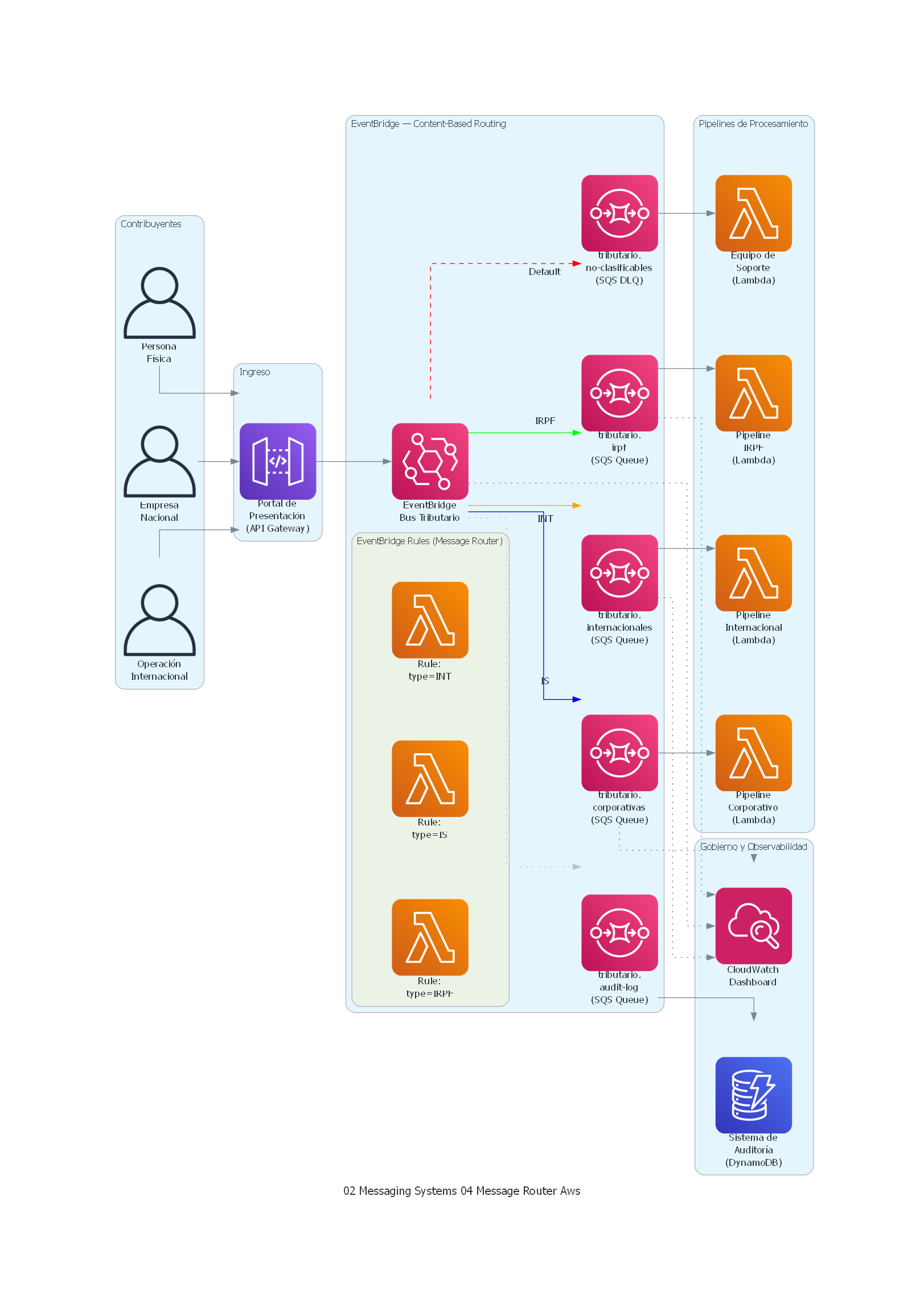
with Diagram("Message Router - Tax Return Routing (AWS)", show=False, direction="LR"):
with Cluster("Contribuyentes"):
persona = User("Persona\nFísica")
empresa = User("Empresa\nNacional")
multinacional = User("Operación\nInternacional")
with Cluster("Ingreso"):
portal = APIGateway("Portal de\nPresentación\n(API Gateway)")
with Cluster("EventBridge — Content-Based Routing"):
event_bus = Eventbridge("EventBridge\nBus Tributario")
with Cluster("EventBridge Rules (Message Router)"):
rule_irpf = Lambda("Rule:\ntype=IRPF")
rule_corp = Lambda("Rule:\ntype=IS")
rule_int = Lambda("Rule:\ntype=INT")
canal_irpf = SQS("tributario.\nirpf\n(SQS Queue)")
canal_corp = SQS("tributario.\ncorporativas\n(SQS Queue)")
canal_int = SQS("tributario.\ninternacionales\n(SQS Queue)")
canal_dlq = SQS("tributario.\nno-clasificables\n(SQS DLQ)")
canal_audit = SQS("tributario.\naudit-log\n(SQS Queue)")
with Cluster("Pipelines de Procesamiento"):
pipeline_irpf = Lambda("Pipeline\nIRPF\n(Lambda)")
pipeline_corp = Lambda("Pipeline\nCorporativo\n(Lambda)")
pipeline_int = Lambda("Pipeline\nInternacional\n(Lambda)")
soporte = Lambda("Equipo de\nSoporte\n(Lambda)")
with Cluster("Gobierno y Observabilidad"):
auditoria = Dynamodb("Sistema de\nAuditoría\n(DynamoDB)")
monitoring = Cloudwatch("CloudWatch\nDashboard")
# Flujo de contribuyentes al portal
persona >> portal
empresa >> portal
multinacional >> portal
# Portal publica en EventBridge
portal >> event_bus
# EventBridge rules route by content
event_bus >> Edge(label="IRPF", color="green") >> canal_irpf
event_bus >> Edge(label="IS", color="blue") >> canal_corp
event_bus >> Edge(label="INT", color="orange") >> canal_int
event_bus >> Edge(label="Default", color="red", style="dashed") >> canal_dlq
event_bus >> Edge(style="dotted", color="gray") >> canal_audit
# SQS triggers Lambda consumers
canal_irpf >> pipeline_irpf
canal_corp >> pipeline_corp
canal_int >> pipeline_int
canal_dlq >> soporte
# Auditoría y monitoreo
canal_audit >> auditoria
event_bus >> Edge(style="dotted") >> monitoring
canal_irpf >> Edge(style="dotted") >> monitoring
canal_corp >> Edge(style="dotted") >> monitoring
canal_int >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
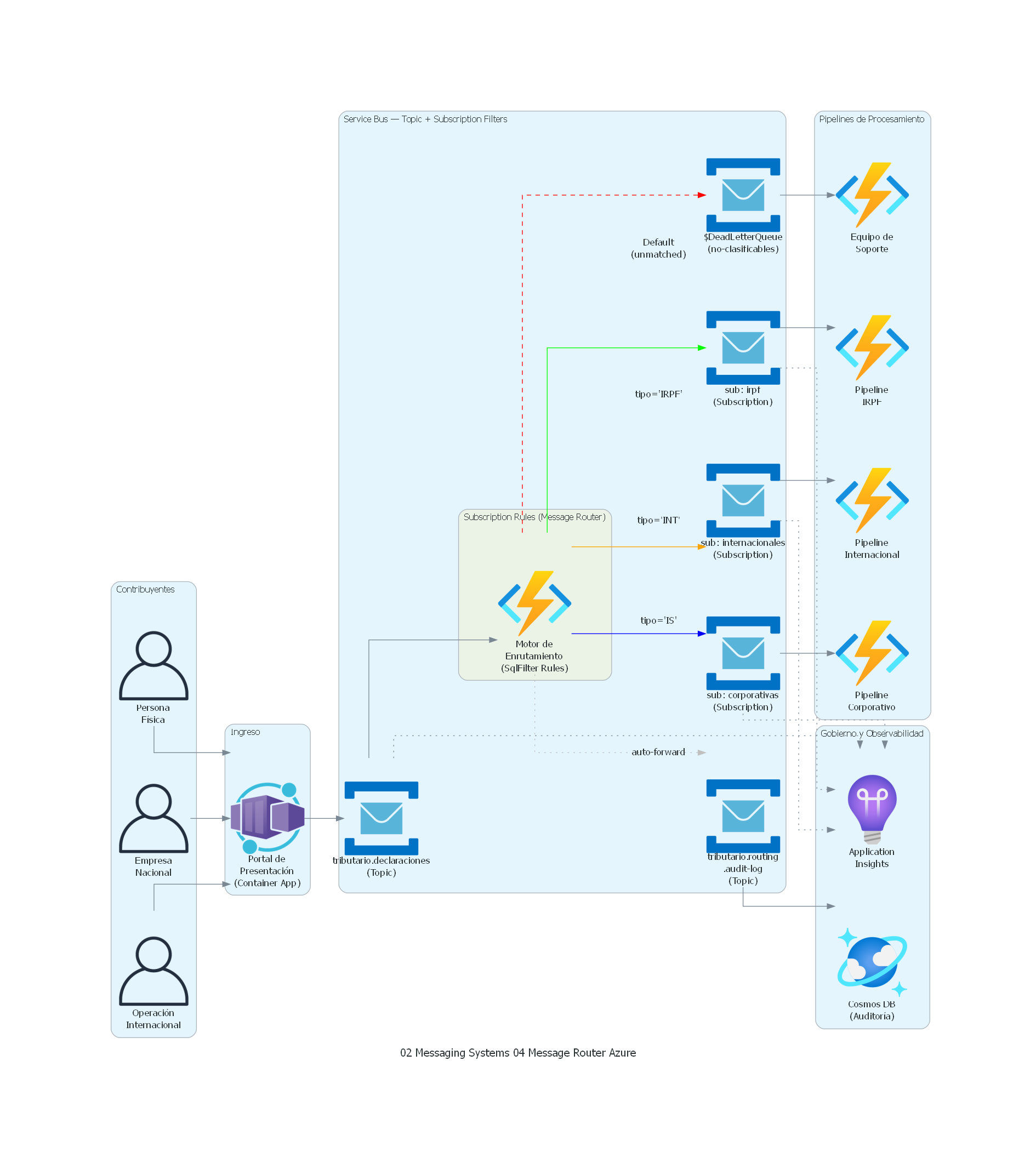
with Diagram("Message Router - Tax Return Routing (Azure)", show=False, direction="LR"):
with Cluster("Contribuyentes"):
persona = User("Persona\nFísica")
empresa = User("Empresa\nNacional")
multinacional = User("Operación\nInternacional")
with Cluster("Ingreso"):
portal = ContainerApps("Portal de\nPresentación\n(Container App)")
with Cluster("Service Bus — Topic + Subscription Filters"):
canal_entrada = ServiceBus("tributario.declaraciones\n(Topic)")
with Cluster("Subscription Rules (Message Router)"):
router = FunctionApps("Motor de\nEnrutamiento\n(SqlFilter Rules)")
canal_irpf = ServiceBus("sub: irpf\n(Subscription)")
canal_corp = ServiceBus("sub: corporativas\n(Subscription)")
canal_int = ServiceBus("sub: internacionales\n(Subscription)")
canal_dlq = ServiceBus("$DeadLetterQueue\n(no-clasificables)")
canal_audit = ServiceBus("tributario.routing\n.audit-log\n(Topic)")
with Cluster("Pipelines de Procesamiento"):
pipeline_irpf = FunctionApps("Pipeline\nIRPF")
pipeline_corp = FunctionApps("Pipeline\nCorporativo")
pipeline_int = FunctionApps("Pipeline\nInternacional")
soporte = FunctionApps("Equipo de\nSoporte")
with Cluster("Gobierno y Observabilidad"):
auditoria = CosmosDb("Cosmos DB\n(Auditoría)")
monitoring = ApplicationInsights("Application\nInsights")
# Flujo de contribuyentes al portal
persona >> portal
empresa >> portal
multinacional >> portal
# Portal produce en topic de entrada
portal >> canal_entrada
# Router filtra por subscription rules
canal_entrada >> router
# Subscriptions filtran por tipo de declaración
router >> Edge(label="tipo='IRPF'", color="green") >> canal_irpf
router >> Edge(label="tipo='IS'", color="blue") >> canal_corp
router >> Edge(label="tipo='INT'", color="orange") >> canal_int
router >> Edge(label="Default\n(unmatched)", color="red", style="dashed") >> canal_dlq
router >> Edge(style="dotted", color="gray", label="auto-forward") >> canal_audit
# Consumidores (Azure Functions triggered by subscription)
canal_irpf >> pipeline_irpf
canal_corp >> pipeline_corp
canal_int >> pipeline_int
canal_dlq >> soporte
# Auditoría y monitoreo
canal_audit >> auditoria
canal_entrada >> Edge(style="dotted") >> monitoring
canal_irpf >> Edge(style="dotted") >> monitoring
canal_corp >> Edge(style="dotted") >> monitoring
canal_int >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura completa de routing de declaraciones de impuestos:
- Contribuyentes de tres tipos (personas físicas, empresas, multinacionales) presentan sus declaraciones a través del Portal de Presentación Electrónica unificado.
- El portal produce todas las declaraciones en un canal de entrada único (
tributario.declaraciones.entrada), sin distinguir tipos. - El Motor de Enrutamiento Tributario (Message Router) consume cada declaración del canal de entrada.
- El router evalúa el campo
tipo_declaraciony produce el mensaje en el canal de salida correspondiente: IRPF (verde), Corporativas (azul), Internacionales (naranja), o No-clasificables (rojo, dashed) si no coincide con ninguna regla. - Simultáneamente, el router produce un evento de auditoría (línea gris punteada) en el canal
tributario.routing.audit-log. - Cada pipeline de procesamiento consume de su canal dedicado y procesa las declaraciones según su workflow específico.
- El Sistema de Auditoría persiste los eventos de routing para trazabilidad regulatoria.
- El Dashboard de Monitoreo (Grafana) observa todos los canales para detectar anomalías en volumen, distribución y latencia.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor | Portal de Presentación Electrónica |
| Canal de Entrada (Input Channel) | tributario.declaraciones.entrada |
| Message Router | Motor de Enrutamiento Tributario |
| Reglas de Routing | Evaluación de tipo_declaracion (IRPF, IS, INT, Default) |
| Canales de Salida (Output Channels) | tributario.declaraciones.irpf, .corporativas, .internacionales |
| Canal Default / Dead-Letter | tributario.declaraciones.no-clasificables |
| Consumidores | Pipeline IRPF, Pipeline Corporativo, Pipeline Internacional, Equipo de Soporte |
| Audit Trail | tributario.routing.audit-log → Sistema de Auditoría |
| Observabilidad | Dashboard de Monitoreo (Grafana) |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento productor-destino: el Portal de Presentación no sabe ni necesita saber que existen tres pipelines diferentes. Solo produce en un canal de entrada. Esto permite modificar, reemplazar o añadir pipelines sin tocar el portal.
- Escalabilidad independiente por pipeline: el Pipeline IRPF (85% del volumen) puede escalar a 20 instancias mientras el Pipeline Internacional (1%) opera con 2 instancias. Sin routing, todos recibirían el volumen total.
- Extensibilidad: si la ATN introduce un nuevo tipo de declaración (por ejemplo, declaraciones de patrimonio), solo se requiere añadir una nueva regla al router y crear el canal y pipeline correspondientes. Ningún componente existente se modifica.
- Resiliencia por aislamiento: si el Pipeline Corporativo falla, las declaraciones corporativas se acumulan en su canal sin afectar el procesamiento de IRPF ni Internacional. El router sigue operando normalmente.
- Transaccionalidad: el uso de transacciones Kafka garantiza que ninguna declaración se pierde ni se duplica durante el routing.
Impacto Organizacional¶
- Autonomía de equipos: el equipo del Pipeline IRPF, el equipo del Pipeline Corporativo y el equipo del Pipeline Internacional desarrollan, despliegan y escalan sus sistemas de forma completamente independiente. El contrato compartido es el formato del mensaje y el nombre del canal.
- Governance centralizada: las reglas de routing están definidas en un solo lugar, son versionadas, auditables y modificables sin impacto en productores ni consumidores.
- Trazabilidad regulatoria: el audit log del router satisface los requisitos de auditoría de la administración tributaria: cada declaración tiene un registro inmutable de cuándo fue clasificada, por qué regla, a qué destino.
- Visibilidad operativa: el dashboard de monitoreo proporciona visibilidad en tiempo real sobre la distribución de declaraciones por tipo, detectando anomalías (por ejemplo, un pico inusual de declaraciones internacionales que podría indicar un error en el portal).
Impacto Operacional¶
- Monitoreo granular: métricas por canal de salida permiten detectar problemas específicos de cada pipeline (lag en corporativas, error rate en internacionales) sin ruido de los otros flujos.
- Manejo explícito de excepciones: el canal de no-clasificables con alertas asegura que ninguna declaración anómala pasa desapercibida.
- Debugging simplificado: cuando un contribuyente reporta un problema, el audit log permite trazar exactamente qué ruta siguió su declaración y en qué punto del pipeline se encuentra.
Beneficios de Mantenibilidad y Evolución¶
- Cambio de reglas sin redespliegue: si las reglas de routing se externalizan en configuración, un cambio normativo (por ejemplo, reclasificar ciertos contribuyentes) se implementa con un cambio de configuración sin redesplegar ningún componente.
- Testing independiente: cada pipeline se testea de forma aislada con mensajes de su tipo, sin interferencia de otros tipos.
- Migración gradual: si se reescribe el Pipeline IRPF con nueva tecnología, se puede hacer un canary deployment dirigiendo un porcentaje del tráfico al nuevo pipeline mediante reglas de routing condicionales.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente adicional: el router es un componente que requiere despliegue, monitoreo, escalamiento y mantenimiento. En arquitecturas simples con pocos destinos estables, esta complejidad puede no justificarse.
- Transaccionalidad: garantizar atomicidad entre consume y produce requiere transacciones distribuidas (Kafka transactions, XA transactions) que añaden complejidad operativa y pueden reducir throughput.
- Configuración de reglas: las reglas de routing, especialmente cuando son dinámicas, requieren un sistema de configuración con versionado, validación, testing y rollback. Este meta-sistema puede ser más complejo que el router mismo.
Riesgos de Mal Uso¶
- Router como transformation engine: usar el router para modificar mensajes además de enrutarlos. Esto viola la separación de responsabilidades y produce un componente con demasiadas razones para cambiar. La transformación debe delegarse a un Message Translator separado.
- Reglas excesivamente complejas: reglas de routing que evalúan múltiples campos, realizan cálculos, consultan bases de datos y aplican lógica de negocio compleja. Esto convierte al router en un motor de reglas de negocio disfrazado, con problemas de performance, testing y mantenibilidad.
- Routing sin canal default: no implementar un destino para mensajes no clasificables. Esto produce pérdida silenciosa de mensajes o excepciones no manejadas que detienen el router.
- Acoplamiento al payload: reglas de routing basadas en campos profundamente anidados del payload (
declaracion.deducciones[0].tipo == "vivienda_habitual") acoplan el router al schema interno del mensaje, haciendo que cualquier cambio en la estructura del payload rompa el routing.
Sobreingeniería¶
- Dynamic Router cuando las reglas son estables: implementar un sistema de reglas dinámicas con configuración en runtime cuando las reglas cambian una vez al año. El overhead operativo del sistema de reglas dinámicas no se justifica si las reglas son estables.
- Routing jerárquico excesivo: crear cadenas de routers donde un segundo router sub-clasifica lo que un primer router clasificó, y un tercero sub-sub-clasifica, produciendo una topología de routing compleja y difícil de razonar. Cada nivel de routing añade latencia y complejidad operativa.
- Canales de salida excesivos: crear un canal de salida por cada variante menor del tipo de mensaje, produciendo decenas de canales con volúmenes muy bajos y overhead operativo desproporcionado.
Costos de Operación¶
- Infraestructura: N canales de salida adicionales, cada uno con su configuración de retención, particionamiento y replicación.
- Monitoreo: el router y cada canal de salida requieren métricas, alertas y dashboards independientes.
- Capacidad: el router debe dimensionarse para el throughput pico del canal de entrada, no para el throughput promedio.
- Incidentes: un fallo en el router detiene el routing de todos los tipos de mensajes simultáneamente (single point of failure mitigable con múltiples instancias).
Errores Frecuentes de Implementación¶
- No implementar retries con backoff en el router cuando la producción en el canal de salida falla transitoriamente.
- No monitorear la distribución de mensajes por destino, lo que impide detectar cuando una regla incorrecta envía mensajes al destino equivocado.
- Confirmar el mensaje de entrada antes de producirlo exitosamente en el canal de salida, arriesgando pérdida de mensajes.
- No versionar las reglas de routing, haciendo imposible determinar qué reglas estaban activas cuando un mensaje específico fue enrutado.
Anti-Patterns Relacionados¶
- God Router: un router con cientos de reglas que clasifica todos los mensajes de toda la organización. Imposible de mantener, testear y evolucionar. Mejor distribuir en múltiples routers por dominio.
- Routing Spaghetti: múltiples routers que se invocan mutuamente en ciclos o cadenas no lineales, produciendo una topología de routing incomprensible.
- Routing como Orquestación: usar el router para implementar lógica de flujo (si es tipo A, envía a B, espera respuesta, luego envía a C). El routing es una decisión puntual; la orquestación es un Process Manager.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Content-Based Router (Capítulo de Routing): es la especialización más directa de Message Router. Mientras Message Router define el concepto genérico de routing, Content-Based Router especifica que la decisión se basa en el contenido del mensaje (payload o headers). En la práctica, la mayoría de los Message Routers son Content-Based Routers.
- Message Filter (Capítulo de Routing): un caso especial de Message Router con solo dos destinos: "pasa" (canal de salida) o "no pasa" (descarte o dead-letter). Es un router binario.
- Dynamic Router (Capítulo de Routing): una variante donde las reglas de routing se obtienen de una fuente externa en runtime, permitiendo cambiar el comportamiento del router sin redespliegue.
- Recipient List (Capítulo de Routing): una variante donde un mensaje puede ir a múltiples destinos simultáneamente, a diferencia del Message Router básico que envía a exactamente un destino.
- Splitter (Capítulo de Routing): un patrón complementario que descompone un mensaje en múltiples sub-mensajes que luego pueden ser enrutados individualmente.
- Message Channel (este capítulo): Message Router opera sobre Message Channels. Sin canales, no hay routing. El router consume de un canal y produce en otros canales.
- Pipes and Filters (este capítulo): el router es un "filtro" en el sentido de Pipes and Filters: un componente de procesamiento que consume de un pipe (canal) y produce en otro pipe (canal). Múltiples routers, translators y otros procesadores se componen en pipelines usando este principio.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Channel (el canal de entrada debe existir antes de que el router pueda consumir), Message (los mensajes deben tener una estructura inspectable para que el routing sea posible).
- Después: Message Translator (frecuentemente después del routing, cada canal de salida tiene un translator que adapta el formato al consumidor específico), Message Endpoint (los consumidores se conectan a los canales de salida mediante endpoints).
Combinaciones Comunes¶
- Message Router + Message Translator: el router clasifica y envía al canal correcto; un translator en cada canal de salida adapta el formato al consumidor. Esta combinación es extremadamente frecuente y se conoce coloquialmente como "route and transform".
- Message Router + Dead Letter Channel: el canal default del router es frecuentemente un Dead Letter Channel gestionado con políticas de retención, alertas y procesamiento manual.
- Message Router + Wire Tap: interceptar el flujo del router para enviar copias de los mensajes (o de las decisiones de routing) a un canal de monitoreo o auditoría.
- Splitter + Message Router: un mensaje compuesto se descompone en sub-mensajes (Splitter) que luego se enrutan individualmente a diferentes destinos (Router).
- Message Router + Competing Consumers: en cada canal de salida, múltiples instancias de consumidor compiten por mensajes para procesamiento paralelo.
Diferencias con Patrones Similares¶
- vs. Content-Based Router: Message Router es el concepto genérico; Content-Based Router es una implementación específica donde la decisión se basa en el contenido del mensaje. La relación es de generalización/especialización.
- vs. Publish-Subscribe Channel: en pub-sub, todos los suscriptores reciben todos los mensajes. En routing, cada mensaje va a un destino específico según criterios. Pub-sub es fan-out incondicional; routing es fan-out condicional.
- vs. Recipient List: en Message Router, cada mensaje va a exactamente un destino. En Recipient List, cada mensaje puede ir a múltiples destinos. La diferencia es cardinalidad de destino: 1 vs. N.
- vs. Process Manager: el router toma una decisión puntual (a dónde va este mensaje) sin mantener estado. El Process Manager orquesta un flujo multi-paso con estado persistente.
- vs. Message Dispatcher: el dispatcher envía mensajes a consumidores dentro del mismo proceso basándose en el tipo de mensaje. El router envía mensajes a canales externos. La diferencia es el scope: intra-proceso vs. inter-proceso.
Encaje en un Flujo Mayor de Integración¶
Message Router es típicamente el primer componente después del canal de entrada en un flujo de integración multi-destino. El patrón se compone con otros patrones para formar topologías complejas:
[Productor] → [Canal Entrada] → [Router] → [Canal A] → [Translator A] → [Consumidor A]
→ [Canal B] → [Translator B] → [Consumidor B]
→ [Canal C] → [Splitter] → [Router 2] → ...
→ [DLQ] → [Alert + Manual Processing]
En arquitecturas enterprise maduras, los routers se organizan jerárquicamente: un router de primer nivel clasifica por dominio, routers de segundo nivel clasifican por tipo de operación dentro de cada dominio, y así sucesivamente. Esta jerarquía mantiene cada router simple y gobernable.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Message Router no solo sigue vigente — su relevancia ha aumentado con la adopción masiva de arquitecturas event-driven, microservicios y plataformas de streaming. En las arquitecturas modernas, el routing de eventos es una necesidad omnipresente:
- Cada EventBridge Rule de AWS es un Message Router que evalúa patrones de eventos y los dirige a targets específicos (Lambda, SQS, Step Functions, API Gateway).
- Cada Exchange de RabbitMQ (direct, topic, headers) es un Message Router nativo integrado en el broker.
- Cada Topic Subscription con SQL Filter de Azure Service Bus es un Message Router declarativo.
- Cada
KStream.split()/branch()de Kafka Streams es un Message Router implementado en código. - Cada Rule de Google Cloud Pub/Sub es un Message Router que filtra y dirige mensajes a subscriptions específicas.
- Cada Route de Apache Camel o cada Choice Router de MuleSoft es una implementación explícita de Message Router.
Evolución del Patrón en el Contexto Moderno¶
El concepto de Message Router ha evolucionado significativamente en las plataformas modernas:
-
De código a configuración: en los frameworks clásicos (Camel, Spring Integration), el routing se definía en código. En las plataformas modernas (EventBridge, Service Bus), el routing se define declarativamente como reglas o filtros JSON/SQL, haciendo el routing gobernable sin código.
-
De componente a capacidad nativa del broker: en la mensajería clásica, el router era un componente de aplicación separado que consumía y re-producía. En brokers modernos (RabbitMQ exchanges, Service Bus subscriptions, EventBridge rules), el routing es una capacidad nativa del broker, eliminando la necesidad de código intermediario.
-
De estático a event-driven dinámico: las plataformas de event mesh (Solace, Confluent, Azure Event Grid) permiten routing dinámico basado en metadatos del evento, contexto del productor y estado del sistema, sin redespliegue.
-
De punto-a-punto a event mesh: en arquitecturas modernas de event mesh, el routing no es una decisión puntual de un componente, sino una propiedad emergente de la topología de suscripciones y filtros distribuidos en el mesh.
Qué Parte Sigue Siendo Esencial¶
- El principio de separar routing de producción y consumo: independientemente de si el routing se implementa como código, configuración o capacidad del broker, el principio de externalizar la decisión de routing sigue siendo la base del diseño.
- La completitud de reglas con handling de excepciones: la necesidad de definir un destino para cada posible tipo de mensaje, incluyendo mensajes no esperados, es tan relevante hoy como lo era en 2003.
- La trazabilidad del routing: en arquitecturas reguladas (finanzas, gobierno, salud), la auditoría de decisiones de routing es un requisito legal creciente.
- El gobierno centralizado de reglas: en organizaciones con decenas de microservicios y cientos de tipos de eventos, la governance de las reglas de routing es un desafío organizacional de primer orden.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka (Kafka Streams)¶
// Kafka Streams - Message Router para declaraciones tributarias
StreamsBuilder builder = new StreamsBuilder();
KStream<String, TaxDeclaration> input = builder.stream("tributario.declaraciones.entrada");
Map<String, KStream<String, TaxDeclaration>> branches = input
.split(Named.as("route-"))
.branch((key, value) -> "IRPF".equals(value.getTipoDeclaracion()),
Branched.as("irpf"))
.branch((key, value) -> "IS".equals(value.getTipoDeclaracion()),
Branched.as("corporativas"))
.branch((key, value) -> "INT".equals(value.getTipoDeclaracion()),
Branched.as("internacionales"))
.defaultBranch(Branched.as("no-clasificables"));
branches.get("route-irpf").to("tributario.declaraciones.irpf");
branches.get("route-corporativas").to("tributario.declaraciones.corporativas");
branches.get("route-internacionales").to("tributario.declaraciones.internacionales");
branches.get("route-no-clasificables").to("tributario.declaraciones.no-clasificables");
Kafka Streams implementa Message Router con la API split()/branch(), que evalúa predicados sobre cada mensaje y lo dirige al sub-stream correspondiente. El routing se ejecuta dentro de la topología de Kafka Streams, beneficiándose de las garantías exactly-once de Kafka transactions, fault-tolerance por state store replication, y escalamiento horizontal por reparticionamiento.
RabbitMQ (Exchanges)¶
# Declaración del exchange y queues con routing nativo
exchange: tributario.declaraciones (type: direct)
binding: routing_key="IRPF" → queue: tributario.declaraciones.irpf
binding: routing_key="IS" → queue: tributario.declaraciones.corporativas
binding: routing_key="INT" → queue: tributario.declaraciones.internacionales
# Alternate exchange para mensajes no enrutables
exchange: tributario.declaraciones
alternate-exchange: tributario.declaraciones.no-clasificables
RabbitMQ implementa Message Router de forma nativa en el broker mediante exchanges. Un exchange de tipo direct dirige mensajes según la routing key exacta. Un exchange de tipo topic permite patrones con wildcards. Un exchange de tipo headers permite routing basado en múltiples headers. El alternate-exchange implementa el canal default para mensajes que no coinciden con ningún binding, eliminando el riesgo de pérdida silenciosa.
Azure Service Bus (Topic Subscriptions con SQL Filters)¶
Topic: tributario-declaraciones-entrada
Subscription: irpf
SQL Filter: tipo_declaracion = 'IRPF'
Action: SET sys.label = 'routed-irpf'
→ Forward to: queue/tributario-declaraciones-irpf
Subscription: corporativas
SQL Filter: tipo_declaracion = 'IS'
Action: SET sys.label = 'routed-corporativas'
→ Forward to: queue/tributario-declaraciones-corporativas
Subscription: internacionales
SQL Filter: tipo_declaracion = 'INT'
Action: SET sys.label = 'routed-internacionales'
→ Forward to: queue/tributario-declaraciones-internacionales
Subscription: no-clasificables
SQL Filter: tipo_declaracion NOT IN ('IRPF', 'IS', 'INT')
→ Forward to: queue/tributario-declaraciones-no-clasificables
Azure Service Bus implementa Message Router mediante Topic Subscriptions con SQL Filters. Las subscriptions evalúan expresiones SQL-like sobre las propiedades del mensaje (custom properties, system properties). El routing es completamente declarativo, configurable en runtime mediante ARM templates, Bicep, o la API de gestión. Soporta acciones (Actions) que pueden añadir o modificar propiedades del mensaje como parte del routing.
AWS EventBridge¶
{
"Rule": "route-declaraciones-irpf",
"EventPattern": {
"source": ["gov.tributario.portal"],
"detail-type": ["DeclaracionPresentada"],
"detail": {
"tipo_declaracion": ["IRPF"]
}
},
"Targets": [
{
"Arn": "arn:aws:sqs:eu-west-1:123456:tributario-declaraciones-irpf",
"Id": "target-irpf"
}
]
}
AWS EventBridge implementa Message Router como Rules que evalúan Event Patterns contra eventos entrantes. Cada Rule es independiente y puede tener múltiples targets (lo que lo acerca a Recipient List). EventBridge es serverless: no requiere provisioning de infraestructura, escala automáticamente y cobra por evento evaluado. Soporta content filtering con patrones complejos (prefix, suffix, numeric ranges, exists/not-exists).
MuleSoft (Anypoint Platform)¶
<flow name="routing-declaraciones">
<jms:inbound-endpoint queue="tributario.declaraciones.entrada"/>
<choice doc:name="Route by tipo_declaracion">
<when expression="#[payload.tipo_declaracion == 'IRPF']">
<jms:outbound-endpoint queue="tributario.declaraciones.irpf"/>
</when>
<when expression="#[payload.tipo_declaracion == 'IS']">
<jms:outbound-endpoint queue="tributario.declaraciones.corporativas"/>
</when>
<when expression="#[payload.tipo_declaracion == 'INT']">
<jms:outbound-endpoint queue="tributario.declaraciones.internacionales"/>
</when>
<otherwise>
<jms:outbound-endpoint queue="tributario.declaraciones.no-clasificables"/>
</otherwise>
</choice>
</flow>
MuleSoft implementa Message Router mediante el componente <choice> que evalúa expresiones DataWeave o MEL sobre el payload del mensaje. El routing se define visualmente en Anypoint Studio o en XML/YAML. MuleSoft añade capacidades enterprise como retry policies, circuit breaker, transaction management y observabilidad integrada.
Apache Camel¶
from("kafka:tributario.declaraciones.entrada")
.routeId("routing-declaraciones-tributarias")
.choice()
.when(jsonpath("$.tipo_declaracion").isEqualTo("IRPF"))
.to("kafka:tributario.declaraciones.irpf")
.when(jsonpath("$.tipo_declaracion").isEqualTo("IS"))
.to("kafka:tributario.declaraciones.corporativas")
.when(jsonpath("$.tipo_declaracion").isEqualTo("INT"))
.to("kafka:tributario.declaraciones.internacionales")
.otherwise()
.to("kafka:tributario.declaraciones.no-clasificables")
.end();
Apache Camel implementa Message Router con la API fluida .choice()/.when()/.otherwise(). Camel es el framework de integración que más directamente refleja la taxonomía de Enterprise Integration Patterns, con implementaciones nombradas para cada patrón (Content Based Router, Dynamic Router, Recipient List, etc.). Soporta más de 300 conectores y expresiones en múltiples lenguajes (Simple, JSONPath, XPath, JavaScript).
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas del router: mensajes enrutados por segundo (total y por destino), latencia de evaluación de reglas (p50, p95, p99), mensajes enviados al canal default/DLQ, tasa de errores de producción en canales de salida.
- Distribución de routing: porcentaje de mensajes enviados a cada destino. Cambios significativos en la distribución (por ejemplo, el porcentaje de IRPF baja del 85% al 60%) indican un problema en el productor o en las reglas.
- Distributed tracing: propagar trace ID y span ID a través del router para que el tracing end-to-end conecte la producción del mensaje con su routing y su procesamiento final.
- Structured logging: cada decisión de routing debe generar un log estructurado con:
message_id,input_channel,output_channel,rule_applied,evaluation_time_ms,router_instance.
Monitoreo¶
- Consumer lag del router: si el router acumula lag en el canal de entrada, los mensajes se procesan con delay creciente. Alerta cuando el lag excede un umbral definido por el SLA.
- Mensajes en el canal default/DLQ: volumen creciente indica reglas incompletas o cambios en el formato de los mensajes. Alerta inmediata cuando excede un umbral.
- Distribución anómala: desviación significativa de la distribución esperada de mensajes por destino.
- Latencia de routing: incremento en la latencia de evaluación puede indicar reglas mal optimizadas, contención de recursos o degradación de dependencias externas (en caso de Dynamic Router).
- Error rate: tasa de errores de producción en canales de salida (broker no disponible, canal lleno, timeout).
Versionado de Reglas¶
- Reglas como configuración versionada: las reglas de routing deben tratarse como código: versionadas en un repositorio, revisadas mediante pull request, testeadas automáticamente, desplegadas con pipeline CI/CD.
- Historial de reglas: mantener un registro histórico de todas las versiones de las reglas con timestamps de activación. Esto permite auditar qué reglas estaban activas cuando un mensaje específico fue enrutado.
- Rollback: capacidad de revertir a una versión anterior de las reglas en caso de error, sin necesidad de redesplegar el router.
- Testing de reglas: pipeline de testing que ejecuta las reglas contra un corpus de mensajes de prueba (representativos de todos los tipos) y verifica que la distribución es correcta.
Seguridad¶
- Authentication y authorization: el router debe autenticarse ante el broker y tener permisos de consumo en el canal de entrada y producción en todos los canales de salida.
- Principio de mínimo privilegio: el router solo debe tener permisos en los canales que usa, no acceso administrativo al broker.
- Encriptación: TLS en tránsito entre router y broker. Si los mensajes contienen datos sensibles (declaraciones de impuestos con datos personales), considerar cifrado a nivel de mensaje además de cifrado en tránsito.
- Audit trail inmutable: el canal de audit-log debe ser append-only con retención prolongada (7 años en el ejemplo tributario) y acceso restringido.
Manejo de Errores y Dead-Lettering¶
- Error de producción en canal de salida: retry con exponential backoff. Si persiste después de N reintentos, enviar al DLQ con metadatos de error.
- Error de deserialización: si el mensaje no puede parsearse para evaluar las reglas, enviarlo directamente al DLQ con la excepción original.
- Error de regla: si la evaluación de la regla lanza una excepción (por ejemplo, campo esperado no existe), enviar al DLQ en lugar de detener el router.
- Poison message: un mensaje que causa errores repetidos debe ser enviado al DLQ después de un número máximo de reintentos para evitar que bloquee el procesamiento de mensajes subsiguientes.
Idempotencia¶
- El router puede procesar el mismo mensaje más de una vez (at-least-once delivery). La producción idempotente de Kafka (idempotent producer) previene duplicados en el canal de salida. En brokers sin producción idempotente, los consumidores downstream deben ser idempotentes.
Auditoría¶
- Registrar cada decisión de routing con: mensaje ID, timestamp, regla aplicada, canal de entrada, canal de salida, instancia del router.
- Registrar cada cambio en las reglas de routing con: quién cambió, qué cambió, cuándo, versión anterior, versión nueva.
- Retener los registros de auditoría según la normativa aplicable (GDPR, SOX, regulaciones tributarias).
Performance¶
- Optimización de reglas: evaluar las reglas más frecuentes primero. Si el 85% de los mensajes son IRPF, la regla IRPF debe evaluarse antes que la regla INT (1%).
- Evaluación de headers vs. payload: si es posible, basar el routing en headers o campos de nivel superior (sin deserialización profunda) para minimizar la latencia de evaluación.
- Batch processing: algunos frameworks (Kafka Streams) procesan mensajes en micro-batches, amortizando el overhead de commit por mensaje.
- Pre-compilación de reglas: si las reglas usan expresiones (regex, JSONPath), pre-compilarlas al iniciar el router en lugar de compilarlas por mensaje.
Escalabilidad¶
- Horizontal: aumentar el número de instancias del router (miembros del consumer group). Cada instancia procesa un subconjunto de particiones del canal de entrada.
- Límite de paralelismo: el número máximo de instancias del router está limitado por el número de particiones del canal de entrada. Con 64 particiones, máximo 64 instancias.
- Auto-scaling: en plataformas cloud, configurar auto-scaling basado en consumer lag: cuando el lag crece, escalar horizontalmente; cuando baja, reducir instancias.
17. Errores Comunes¶
Implementar Routing en el Productor¶
El error más frecuente y más dañino. El productor contiene una lógica switch/case que decide a qué canal enviar cada mensaje. Esto acopla el productor a la topología de consumo, viola el principio de desacoplamiento de la mensajería y hace que cada cambio en las reglas de routing requiera modificar y redesplegar el productor. La solución es externalizar el routing a un componente dedicado.
No Implementar Canal Default¶
Asumir que las reglas cubren todos los casos posibles. Invariablemente, aparecerá un mensaje con un tipo no anticipado (por error en el productor, por evolución del formato, por nuevo tipo no contemplado). Sin un canal default, ese mensaje se pierde silenciosamente, genera una excepción que detiene el router, o entra en un ciclo infinito de reintentos. Siempre implementar un canal default con monitoreo y alertas.
Routing Basado en Lógica de Negocio Compleja¶
Transformar el router en un motor de reglas de negocio con condiciones que evalúan múltiples campos, realizan cálculos aritméticos, consultan bases de datos y aplican reglas fiscales. Esto produce un componente imposible de mantener, testear y evolucionar. Las reglas de routing deben ser simples y determinísticas. La lógica de negocio compleja pertenece a los consumidores, no al router.
No Monitorear la Distribución de Mensajes¶
Operar el router sin métricas sobre la distribución de mensajes por destino. Sin esta visibilidad, una regla incorrecta que envía el 100% de los mensajes al canal equivocado pasa desapercibida hasta que un proceso de negocio falla. La distribución esperada debe documentarse y compararse automáticamente con la distribución real.
Modificar el Mensaje Durante el Routing¶
El router no debe transformar el mensaje. Si los consumidores necesitan formatos diferentes, usar Message Translators dedicados en cada canal de salida. Cuando el router transforma, se mezclan dos responsabilidades: la decisión de "a dónde va" y la transformación de "en qué formato". Esto produce un componente con demasiadas razones para cambiar y dificulta el debugging cuando el formato resultante es incorrecto.
Confirmar el Mensaje Antes de Producirlo¶
Hacer commit del offset en el canal de entrada antes de confirmar la producción exitosa en el canal de salida. Si el router falla entre el commit y la producción, el mensaje se pierde irrecuperablemente. La operación correcta es: producir en el canal de salida, confirmar la producción, luego confirmar el consume del canal de entrada — o, idealmente, usar transacciones atómicas.
No Versionar las Reglas de Routing¶
Modificar las reglas de routing directamente en producción sin versionado ni registro de cambios. Cuando un problema de routing aparece, es imposible determinar qué reglas estaban activas en el momento del incidente. Las reglas deben ser código versionado con historial, aprobación y capacidad de rollback.
Escalar Verticalmente en Lugar de Horizontalmente¶
Ante un cuello de botella de throughput, aumentar el tamaño de la máquina del router (más CPU, más memoria) en lugar de añadir instancias al consumer group. El escalamiento vertical tiene límites estrictos y un solo punto de fallo. El escalamiento horizontal (más instancias, más particiones) proporciona tanto throughput como resiliencia.
No Planificar para Mensajes Poison¶
No considerar el escenario de un mensaje que causa un error repetido en el router (formato corrupto, tamaño excesivo, encoding incorrecto). Sin un límite de reintentos y un destino para mensajes poison (DLQ), un solo mensaje corrupto puede bloquear el procesamiento de todos los mensajes subsiguientes en la misma partición.
18. Conclusión Técnica¶
Message Router es el patrón que introduce capacidad de decisión en la mensajería. Sin él, los mensajes fluyen de punto A a punto B de forma pasiva, o se distribuyen por fan-out a todos los receptores. Con él, cada mensaje es evaluado individualmente y dirigido al destino apropiado según criterios definidos, gobernables y auditables.
Cuándo aporta valor: cuando un flujo de mensajes debe dividirse en múltiples destinos con criterios diferentes, y la decisión de routing no debe residir en el productor ni dispersarse en los consumidores. Esto ocurre en prácticamente toda arquitectura de integración enterprise con más de dos participantes: sistemas tributarios con diferentes tipos de declaraciones, sistemas bancarios con diferentes tipos de transacciones, plataformas de e-commerce con diferentes flujos por tipo de orden, sistemas de salud con diferentes tipos de mensajes clínicos.
Cuándo evita problemas importantes: un routing bien diseñado — con reglas completas, canal default, monitoreo de distribución, audit trail y transaccionalidad — evita los problemas más costosos de las arquitecturas de integración: mensajes perdidos silenciosamente, mensajes enviados al destino equivocado, productores acoplados a la topología de consumo, imposibilidad de auditoría regulatoria, y rigidez ante el cambio (cada nuevo consumidor requiere modificar componentes existentes).
Cuándo no conviene adoptarlo: cuando el flujo de mensajes tiene un solo destino (no hay decisión de routing), cuando la distribución es fan-out incondicional a todos los consumidores (Publish-Subscribe Channel es suficiente), o cuando el overhead de un componente intermedio no es aceptable para el SLA de latencia. En estos casos excepcionales, el routing en el productor puede ser aceptable si se documenta el trade-off de acoplamiento.
Recomendación para arquitectos: trate el Message Router como un componente de primera clase en la arquitectura, no como un detalle de implementación. Diseñe las reglas de routing con la misma rigurosidad que el schema de los mensajes: completas, determinísticas, versionadas, testeadas y monitoreadas. Implemente siempre un canal default con alertas. Instrumente el router con métricas de distribución, latencia y error rate. Externalice las reglas en configuración cuando la frecuencia de cambio lo justifique. Y recuerde que el router es un componente en el hot path de cada mensaje: su performance, resiliencia y correctitud afectan directamente a todos los flujos downstream. Un Message Router bien diseñado es invisible — los mensajes simplemente llegan al destino correcto. Un Message Router mal diseñado es la causa raíz de los incidentes más difíciles de diagnosticar en una arquitectura de integración.