Message Translator¶
1. Nombre del Patrón¶
- Nombre oficial: Message Translator
- Categoría: Messaging Systems (Sistemas de Mensajería — Transformación de Mensajes)
- Traducción contextual: Traductor de Mensajes
2. Resumen Ejecutivo¶
Message Translator es el patrón que encapsula la lógica de conversión entre formatos de mensaje heterogéneos dentro de un sistema de mensajería. Su propósito es permitir que aplicaciones que utilizan representaciones de datos incompatibles puedan comunicarse a través de una infraestructura de messaging común, sin que ninguna de ellas necesite modificar su modelo de datos interno ni conocer los formatos que las demás emplean.
El problema que resuelve es uno de los más ubicuos en la integración empresarial: las aplicaciones raramente comparten el mismo formato de datos. Un sistema legacy emite XML con namespaces propietarios; un microservicio moderno consume JSON con una estructura de campos completamente diferente; un sistema regulatorio requiere mensajes en formato EDI o HL7. Sin un mecanismo de traducción explícito y bien ubicado en la cadena de procesamiento, cada sistema necesitaría implementar conversores a todos los formatos de todos los sistemas con los que se comunica, produciendo una explosión combinatoria de adaptadores punto a punto.
Message Translator centraliza esta responsabilidad en un componente dedicado — posicionado entre el canal de entrada y el canal de salida — que recibe un mensaje en un formato, lo transforma, y emite el mensaje equivalente en el formato que el consumidor espera. Es el análogo arquitectónico de un intérprete humano entre dos hablantes de idiomas diferentes: ni el emisor ni el receptor necesitan aprender el idioma del otro; el intérprete media entre ambos.
Este patrón es un pilar de toda arquitectura de integración y aparece en cada implementación seria de Enterprise Service Bus, API Gateway, capa de integración de microservicios o pipeline de datos. Sin Message Translator, la integración empresarial a escala es simplemente inviable.
3. Definición Detallada¶
Propósito¶
Message Translator proporciona un mecanismo para convertir un mensaje de un formato a otro dentro de un flujo de mensajería. Su propósito es desacoplar el formato interno de datos de cada aplicación participante del formato que circula por la infraestructura de messaging, permitiendo que cada sistema mantenga su modelo de datos nativo mientras participa en un ecosistema de integración heterogéneo.
Lógica Arquitectónica¶
En un ecosistema de integración empresarial, cada aplicación tiene su propio modelo de datos. Este modelo refleja la historia, el dominio, la tecnología y las decisiones de diseño específicas de esa aplicación. Un sistema ERP representa un pedido como un objeto con campos VBELN, KUNNR, NETWR (terminología SAP); un sistema CRM representa el mismo concepto como OrderId, CustomerId, TotalAmount; un sistema de facturación electrónica lo representa como un documento XML UBL con namespaces y taxonomías propias.
Message Translator introduce un componente de mediación que conoce ambos formatos — el del emisor y el del receptor — y ejecuta la transformación necesaria. Esta transformación puede involucrar:
- Conversión de formato: de XML a JSON, de Avro a Protobuf, de CSV a Parquet.
- Conversión de esquema: renambramiento de campos, restructuración de jerarquías, aplanamiento o anidamiento de estructuras.
- Conversión de semántica: traducción de códigos (código de país ISO 3166 a código FIPS), conversión de unidades (libras a kilogramos), mapeo de enumeraciones (
ACTIVE/INACTIVEa1/0). - Conversión de protocolo implícita: cuando el formato está ligado a un protocolo (HL7v2 sobre MLLP a FHIR sobre REST), el translator puede mediar también en la representación ligada al transporte.
Principio de Diseño Subyacente¶
El principio es mediación de formato en un punto explícito de la cadena de procesamiento. En lugar de distribuir la lógica de conversión en múltiples sistemas (cada emisor convierte al formato de cada receptor, o cada receptor acepta múltiples formatos), Message Translator concentra la conversión en un componente dedicado cuya única responsabilidad es traducir. Esto sigue directamente el Single Responsibility Principle aplicado a la integración.
Un corolario importante de este principio es que Message Translator habilita el Open/Closed Principle a nivel de ecosistema: se pueden añadir nuevas aplicaciones al ecosistema sin modificar las existentes — solo se necesita crear un nuevo translator para cada nuevo formato.
Problema Estructural que Resuelve¶
Sin Message Translator, la integración entre N aplicaciones con formatos distintos requiere que cada aplicación implemente N-1 conversores (uno por cada otro sistema con el que se comunica). Esto produce O(N²) adaptadores en el caso general, una complejidad que crece cuadráticamente y que en la práctica se vuelve inmanejable a partir de un puñado de sistemas.
Además, la lógica de conversión queda distribuida y duplicada: si dos aplicaciones A y B ambas necesitan enviar datos a C, ambas implementan la conversión a formato C, con el riesgo de inconsistencias, bugs duplicados y esfuerzo de mantenimiento multiplicado.
Message Translator reduce esta complejidad a O(N) — un translator por aplicación — especialmente cuando se combina con Canonical Data Model, donde cada aplicación solo necesita un translator desde su formato nativo al formato canónico, y otro desde el canónico a su formato nativo.
Contexto en el que Emerge¶
Message Translator emerge tan pronto como dos sistemas que necesitan intercambiar mensajes utilizan formatos de datos diferentes — lo cual es, en la práctica, casi siempre. Los escenarios más comunes incluyen:
- Integración de sistemas legacy con sistemas modernos (COBOL copybooks a JSON).
- Integración con socios externos (formatos EDI, SWIFT, HL7).
- Migración incremental de monolito a microservicios donde coexisten formatos antiguos y nuevos.
- Ingesta de datos de múltiples fuentes en un data lake o data warehouse.
- Comunicación entre bounded contexts en una arquitectura DDD donde cada contexto tiene su propio modelo de dominio.
Por Qué No Es Trivial¶
La traducción de mensajes parece un simple mapeo de campos, pero en la realidad empresarial involucra complejidad significativa:
- Asimetrías semánticas: el modelo de datos del emisor puede contener información que el del receptor no necesita (y viceversa). El translator debe decidir qué hacer con campos sobrantes y cómo manejar campos faltantes.
- Transformaciones condicionales: el mapeo puede depender del contenido del mensaje. Un campo
addresspuede mapearse abillingAddressoshippingAddressdependiendo del tipo de pedido. - Enriquecimiento necesario: a veces la traducción requiere datos externos (lookups a bases de datos, resolución de códigos, validación contra catálogos). Esto cruza la frontera con Content Enricher y requiere decisiones de diseño sobre dónde termina la traducción y dónde empieza el enriquecimiento.
- Pérdida de información: no toda conversión es biunívoca. Convertir de un formato rico a uno pobre implica pérdida semántica. Convertir de un esquema con 50 campos a uno con 20 requiere decisiones sobre qué información descartar y cómo.
- Versionamiento: los formatos evolucionan. Un translator que funciona con la versión 2.1 del formato emisor y la versión 3.0 del formato receptor necesita actualizarse cuando cualquiera de los dos cambia. La gestión de esta evolución es un problema operativo no trivial.
- Rendimiento: en pipelines de alta volumetría (cientos de miles de mensajes por segundo), la transformación tiene un costo computacional que puede convertirse en el cuello de botella del sistema.
Relación con Sistemas Distribuidos y Mensajería¶
Message Translator es un componente stateless de procesamiento de mensajes que opera como un filtro en un pipeline de tipo Pipes and Filters. En términos de sistemas distribuidos, el translator es un procesador intermedio que consume de un canal de entrada, aplica una función de transformación pura (idealmente), y produce en un canal de salida.
La naturaleza stateless del translator tiene implicaciones importantes para la escalabilidad: múltiples instancias del translator pueden ejecutarse en paralelo, cada una procesando un subconjunto de mensajes, sin necesidad de coordinación entre ellas. Esto lo convierte en un candidato natural para escalado horizontal.
En el contexto de las garantías de entrega, el translator debe preservar las semánticas del sistema de messaging subyacente. Si el sistema garantiza exactly-once processing, el translator debe operar de forma idempotente. Si garantiza at-least-once, el translator debe producir la misma salida dada la misma entrada, para que un re-procesamiento no genere inconsistencias.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Message Translator, cuando una aplicación A necesita enviar datos a una aplicación B que usa un formato distinto, existen solo dos opciones, ambas insatisfactorias:
- Modificar A para que produzca en formato B: acopla A al modelo de datos de B. Si B cambia su formato, A debe cambiar. Si aparece C con otro formato, A debe implementar otro conversor. A acumula responsabilidades de conversión que no le corresponden.
- Modificar B para que acepte el formato A: acopla B al modelo de datos de A. Si A cambia su formato, B se rompe. Si D también envía datos a B en un formato diferente, B debe implementar múltiples parsers.
En la práctica empresarial, ambas opciones se combinan de forma caótica: algunos sistemas convierten antes de enviar, otros convierten al recibir, algunos lo hacen en ambos extremos produciendo doble conversión. La lógica de transformación queda dispersa, duplicada, inconsistente y sin visibilidad operativa.
Síntomas del Problema¶
- Código de conversión embebido en la lógica de negocio: clases de servicio que mezclan reglas de negocio con mapeos de campos JSON-a-XML, haciendo ambas responsabilidades más difíciles de mantener y testear.
- Adaptadores punto a punto proliferantes: cada nueva integración requiere escribir un nuevo adaptador desde cero, sin reutilizar lógica de conversión existente.
- Inconsistencias en la traducción: dos sistemas que convierten el mismo concepto (ej., código de moneda) lo hacen de forma diferente, produciendo discrepancias silenciosas en los datos.
- Fragilidad ante cambios de formato: cualquier cambio en el esquema de un sistema rompe múltiples integraciones, porque la lógica de conversión está acoplada y distribuida.
- Imposibilidad de testing aislado: la conversión no puede testearse de forma independiente porque está embebida en componentes más grandes.
- Latencia inexplicable: la serialización y deserialización repetida (convert-send-receive-convert-send-receive) añade latencia acumulativa no medible.
Impacto Operativo y Arquitectónico¶
Sin translators bien diseñados:
- Time-to-market degradado: integrar un nuevo sistema toma semanas o meses porque requiere desarrollar conversores ad-hoc en los sistemas existentes.
- Fragilidad sistémica: un cambio de esquema en un sistema upstream rompe en cascada todos los sistemas downstream que implementan su propia conversión.
- Deuda técnica acumulativa: cada integración punto a punto añade código de conversión que nadie entiende completamente, que no tiene tests, y que nadie se atreve a tocar.
- Imposibilidad de auditoría: no se puede verificar que la traducción es correcta porque no hay un componente aislado donde examinarla.
Riesgos Si No Se Implementa Correctamente¶
- Pérdida silenciosa de datos: campos que no se mapean correctamente y se descartan sin aviso, produciendo registros incompletos en el sistema destino.
- Corrupción semántica: campos que se mapean al campo incorrecto (el
taxIddel emisor se mapea alcustomerIddel receptor), introduciendo errores de datos difíciles de detectar. - Violaciones regulatorias: datos sensibles (PII, PHI) que se copian a campos no protegidos durante la traducción, violando GDPR, HIPAA u otras normativas.
- Degradación de performance: traducciones computacionalmente costosas (ej., transformaciones XSLT complejas sobre documentos XML grandes) que se convierten en el cuello de botella del pipeline.
Ejemplos Reales¶
- Banca: un banco que integra su core bancario (formato COBOL copybook) con una plataforma de pagos instantáneos (formato ISO 20022 XML) necesita un translator que convierta transacciones del formato plano del mainframe al formato XML regulatorio. Sin este translator, el banco no puede participar en redes de pagos modernos.
- E-commerce: un marketplace que agrega productos de múltiples vendedores, cada uno con su propio formato de catálogo (CSV, JSON, XML con schemas diferentes), necesita translators que normalicen todos los formatos al modelo de datos interno del marketplace.
- Salud: un hospital que implementa interoperabilidad entre su HIS (Hospital Information System) que emite mensajes HL7v2 y una plataforma de telemedicina que consume recursos FHIR R4 necesita un translator que convierta entre estos estándares, mapeando segmentos HL7v2 (PID, OBX, ORC) a recursos FHIR (Patient, Observation, ServiceRequest).
- Gobierno: una agencia gubernamental que integra múltiples sistemas de declaración tributaria (cada uno con su formato XML propietario) con un sistema central de recaudación necesita translators que unifiquen los formatos antes de la consolidación.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando dos o más sistemas que se comunican por messaging utilizan formatos de datos diferentes y ninguno puede (o debe) modificar su formato para acomodarse al otro.
- Cuando se desea aislar la lógica de transformación de la lógica de negocio y la lógica de transporte.
- Cuando se está construyendo una capa de integración que media entre sistemas heterogéneos.
- Cuando se implementa un Canonical Data Model y se necesitan translators que conviertan entre formatos nativos y el modelo canónico.
- Cuando se migra incrementalmente entre formatos (ej., de HL7v2 a FHIR) y se necesita una capa de compatibilidad.
- Cuando se integra con socios externos cuyo formato de datos está fuera de nuestro control (EDI, SWIFT, regulatorio).
Cuándo No Usarlo¶
- Cuando los sistemas comparten el mismo formato: si emisor y receptor ya usan el mismo esquema, introducir un translator es overhead innecesario.
- Cuando la transformación es trivial y estática: si la conversión se reduce a renombrar un campo, puede resolverse con una configuración de serialización sin un componente de mediación dedicado.
- Cuando el emisor puede producir directamente en el formato del receptor: si no hay otros consumidores y el acoplamiento es aceptable, modificar el emisor puede ser más simple.
- Cuando se requiere transformación con estado complejo: si la conversión requiere acumular datos de múltiples mensajes antes de producir la salida, el patrón adecuado es un Aggregator combinado con transformación, no un Message Translator simple.
Precondiciones¶
- Existe al menos un Message Channel de entrada y uno de salida (el translator opera entre canales).
- Los formatos de origen y destino están documentados o son inferibles.
- Las reglas de mapeo entre formatos son definibles y determinísticas (dado un mensaje de entrada, la salida es predecible).
- El sistema de messaging subyacente soporta componentes intermediarios de procesamiento (consumers que son a su vez producers).
Restricciones¶
- El translator debe preservar la semántica del mensaje: la información de negocio relevante debe ser equivalente antes y después de la traducción.
- El translator no debe alterar la semántica de entrega del sistema de messaging (si el mensaje original tiene un correlation ID, el mensaje traducido debe preservarlo).
- El translator debe ser stateless en la medida de lo posible; si necesita estado (caché de lookups, acumulación), ese estado debe ser explícitamente gestionado.
- El translator no debe producir efectos secundarios fuera de la producción del mensaje traducido (no debe escribir en bases de datos, llamar a APIs no relacionadas, etc.).
Dependencias¶
- Message Channel: el translator consume de un canal y produce en otro (o en el mismo, en algunos diseños inline).
- Message: el translator opera sobre mensajes con estructura definida (headers + body).
- Message Endpoint: el translator necesita endpoints para conectarse a los canales de entrada y salida.
- Pipes and Filters: conceptualmente, el translator es un filtro en un pipeline de procesamiento.
Supuestos¶
- Los formatos de origen y destino son conocidos en tiempo de diseño (o, en translators dinámicos, son descubribles en runtime a partir de metadata del mensaje).
- La función de traducción es determinística: el mismo mensaje de entrada siempre produce el mismo mensaje de salida.
- El overhead de transformación es aceptable para los requisitos de latencia y throughput del sistema.
- Los esquemas evolucionan de forma gestionada (con versionamiento y backward/forward compatibility).
6. Fuerzas Arquitectónicas¶
Desacoplamiento vs. Complejidad Operativa¶
Message Translator desacopla emisores de receptores en la dimensión del formato, lo cual es un beneficio arquitectónico significativo. Sin embargo, introduce un componente adicional que debe ser desplegado, monitoreado, versionado y mantenido. Cada translator es un punto potencial de fallo y un artefacto adicional en el pipeline de CI/CD.
Centralización vs. Distribución de la Lógica¶
Centralizar la transformación en un translator dedicado facilita el testing, la auditoría y el cambio. Pero puede crear un cuello de botella organizacional si todas las traducciones las gestiona un solo equipo. La fuerza opuesta es distribuir la responsabilidad a los equipos de cada sistema, lo cual puede producir inconsistencias.
Rendimiento vs. Flexibilidad¶
Un translator genérico y configurable (ej., basado en mapping tables o DSLs de transformación) es flexible pero puede ser más lento que un translator compilado y específico. Transformaciones XSLT son muy flexibles pero computacionalmente costosas; mapeos hard-coded en código son rápidos pero rígidos.
Fidelidad vs. Simplicidad¶
Una traducción de alta fidelidad preserva toda la información del mensaje original, pero puede requerir un formato destino más complejo. Una traducción simplificada es más fácil de implementar pero puede perder información relevante. El arquitecto debe decidir qué nivel de fidelidad es suficiente para cada caso de uso.
Reutilización vs. Especificidad¶
Los translators genéricos (basados en reglas configurables) son reutilizables pero requieren infraestructura de configuración. Los translators específicos (código ad-hoc para cada par de formatos) son simples de entender pero no se reutilizan.
Latencia vs. Corrección¶
Añadir un paso de traducción incrementa la latencia del pipeline. En algunos casos, se puede reducir la latencia usando traducciones parciales o lazy, pero a costa de complejidad y riesgo de errores.
Acoplamiento al Esquema vs. Evolución Independiente¶
El translator acopla su implementación a los esquemas de origen y destino. Cuando cualquiera de los dos evoluciona, el translator necesita actualizarse. Este acoplamiento es inherente e irreducible — alguien tiene que saber cómo mapear A a B — pero su impacto se puede mitigar con versionamiento de esquemas, backward compatibility y estrategias de migración incremental.
7. Estructura Conceptual¶
Actores¶
-
Productor (Source System): la aplicación que emite mensajes en su formato nativo. No conoce ni se acopla al formato del consumidor final. Solo sabe producir en su propio formato y depositar mensajes en el canal de entrada.
-
Message Translator: el componente de mediación que recibe mensajes del canal de entrada, aplica la función de transformación, y deposita el mensaje traducido en el canal de salida. Es el actor central del patrón.
-
Consumidor (Target System): la aplicación que consume mensajes del canal de salida, esperando recibirlos en su formato nativo. No conoce ni se acopla al formato del productor original.
-
Canal de Entrada (Input Channel): el Message Channel donde el productor deposita mensajes en formato origen.
-
Canal de Salida (Output Channel): el Message Channel donde el translator deposita mensajes en formato destino.
-
Mapping Definition: la definición de las reglas de mapeo entre formatos. Puede ser código compilado, una especificación declarativa (XSLT, DataWeave, JSONata), una tabla de mapeo en configuración, o un schema registry que define la correspondencia.
Flujo¶
- El productor crea un mensaje en su formato nativo y lo deposita en el canal de entrada.
- El translator consume el mensaje del canal de entrada.
- El translator deserializa el mensaje de entrada según el formato origen.
- El translator aplica las reglas de mapeo, transformando la estructura, los campos, los tipos y los valores según la mapping definition.
- El translator serializa el resultado según el formato destino.
- El translator deposita el mensaje traducido en el canal de salida, preservando los headers de transporte relevantes (correlation ID, message ID, trace context).
- El consumidor consume el mensaje del canal de salida y lo procesa en su formato esperado.
Responsabilidades¶
| Actor | Responsabilidad |
|---|---|
| Productor | Crear mensajes en formato nativo. Depositar en canal de entrada. No conoce el formato destino. |
| Message Translator | Consumir del canal de entrada. Deserializar formato origen. Aplicar mapeo. Serializar formato destino. Producir en canal de salida. Preservar metadatos de transporte. Reportar errores de traducción. |
| Consumidor | Consumir del canal de salida. Procesar en formato esperado. No conoce el formato origen. |
| Mapping Definition | Definir las reglas de correspondencia entre campos, tipos, valores y estructuras. Ser versionable e independientemente desplegable. |
Interacciones Clave¶
- Translator ↔ Canal de Entrada: relación consumer. El translator actúa como Message Endpoint consumer en el canal de entrada.
- Translator ↔ Canal de Salida: relación producer. El translator actúa como Message Endpoint producer en el canal de salida.
- Translator ↔ Mapping Definition: el translator consulta la definición de mapeo para ejecutar la transformación. En implementaciones estáticas, la definición está embebida en código; en implementaciones dinámicas, se carga de un repositorio externo.
- Translator ↔ Dead Letter Channel: cuando una traducción falla (formato inesperado, campo obligatorio ausente, error de conversión de tipos), el translator envía el mensaje fallido a un Dead Letter Channel para inspección posterior.
Contratos¶
- Contrato de entrada: el translator se compromete a aceptar mensajes en el formato origen documentado (versiones soportadas).
- Contrato de salida: el translator se compromete a producir mensajes que cumplan el esquema del formato destino documentado.
- Contrato de metadatos: el translator se compromete a preservar los headers de transporte definidos (correlation ID, trace context, message ID original como referencia).
- Contrato de errores: el translator se compromete a no descartar silenciosamente mensajes no traducibles, sino a enrutarlos a un Dead Letter Channel con metadata sobre el error.
Decisiones de Diseño Clave¶
-
Ubicación del translator: ¿inline en el pipeline (como un filtro en Pipes and Filters) o como un servicio independiente invocado mediante request-reply? Inline es más simple y de menor latencia; servicio independiente permite reutilización y escalado independiente.
-
Tecnología de mapeo: ¿código imperativo (Java, Python, C#), DSL declarativo (XSLT, DataWeave, JSONata), configuración basada en tablas, o modelo visual (mapper gráfico)? Cada opción tiene trade-offs de flexibilidad, performance, facilidad de mantenimiento y curva de aprendizaje.
-
Granularidad: ¿un translator por par de formatos, un translator genérico configurable, o un translator que convierte a/desde un formato canónico intermedio?
-
Handling de errores: ¿fallar el mensaje entero si un campo no puede traducirse, usar valores por defecto, o producir un mensaje parcial con indicadores de campos faltantes?
-
Versionamiento: ¿cómo manejar versiones diferentes del formato de entrada y salida? ¿Múltiples translators, un translator con branching interno, o una capa de normalización previa?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Healthcare — Transformación HL7v2 a FHIR para Integración Hospitalaria¶
Contexto Empresarial¶
El Hospital Regional Central (HRC) es un hospital de 800 camas que opera un ecosistema de sistemas clínicos heterogéneo, acumulado a lo largo de 20 años de adquisiciones y actualizaciones parciales. El HRC está embarcado en un programa de modernización clínica digital que incluye la implementación de una plataforma de telemedicina, un portal de pacientes, y la integración con una red de intercambio de información de salud (Health Information Exchange — HIE) regional.
Sistemas Involucrados¶
-
HIS Legacy (Epic circa 2012): el Hospital Information System central, que gestiona admisiones, altas, transferencias (ADT), órdenes clínicas y resultados de laboratorio. Emite mensajes en HL7 v2.5.1 sobre protocolo MLLP (Minimum Lower Layer Protocol). Formato: segmentos delimitados por pipes (
|) con estructura posicional heredada de los años 80. -
LIS (Laboratory Information System — Cerner PathNet): el sistema de laboratorio que procesa muestras y emite resultados. También emite en HL7 v2.5.1, pero con extensiones propietarias en segmentos Z (ZLB, ZRS) y variaciones en la codificación de OBX segments.
-
Plataforma de Telemedicina (Telehealth Platform — desarrollo propio): aplicación moderna basada en microservicios que consume y produce recursos FHIR R4 en formato JSON. Requiere recursos Patient, Encounter, Observation, DiagnosticReport y ServiceRequest conformes al perfil US Core.
-
Portal del Paciente (Patient Portal — vendor SaaS): requiere datos en FHIR R4 con extensiones específicas del portal para consentimientos y preferencias de comunicación.
-
HIE Regional: la red de intercambio de información de salud regional que requiere FHIR R4 Bundles firmados digitalmente, conformes al perfil IHE MHD (Mobile Access to Health Documents).
Problema¶
Los sistemas legacy (HIS y LIS) emiten decenas de miles de mensajes diarios en HL7v2, un formato diseñado en la era pre-internet con una estructura posicional, delimitada por pipes, con semántica codificada en tablas de lookup específicas (HL7 Table 0001 para sexo administrativo, Table 0004 para tipo de paciente, etc.). Los sistemas modernos (telemedicina, portal, HIE) requieren FHIR R4, un estándar RESTful basado en recursos JSON con referencias explícitas, terminología basada en sistemas de codificación estándar (SNOMED CT, LOINC, ICD-10), y una semántica radicalmente diferente.
La distancia semántica entre HL7v2 y FHIR R4 es enorme:
- Estructural: HL7v2 es posicional (PID.5.1 = apellido del paciente); FHIR es jerárquico (Patient.name[0].family).
- Tipado: HL7v2 usa strings con significado posicional; FHIR usa tipos complejos con restricciones (HumanName, CodeableConcept, Reference).
- Terminología: HL7v2 usa tablas numéricas propietarias (Table 0001: M/F/U); FHIR usa sistemas de codificación estándar (http://hl7.org/fhir/administrative-gender: male/female/unknown).
- Relaciones: HL7v2 embebe datos relacionados en un solo mensaje (el paciente, la visita y las observaciones van en un solo ORU); FHIR los separa en recursos independientes con referencias explícitas.
Solución: Message Translator como Capa de Transformación¶
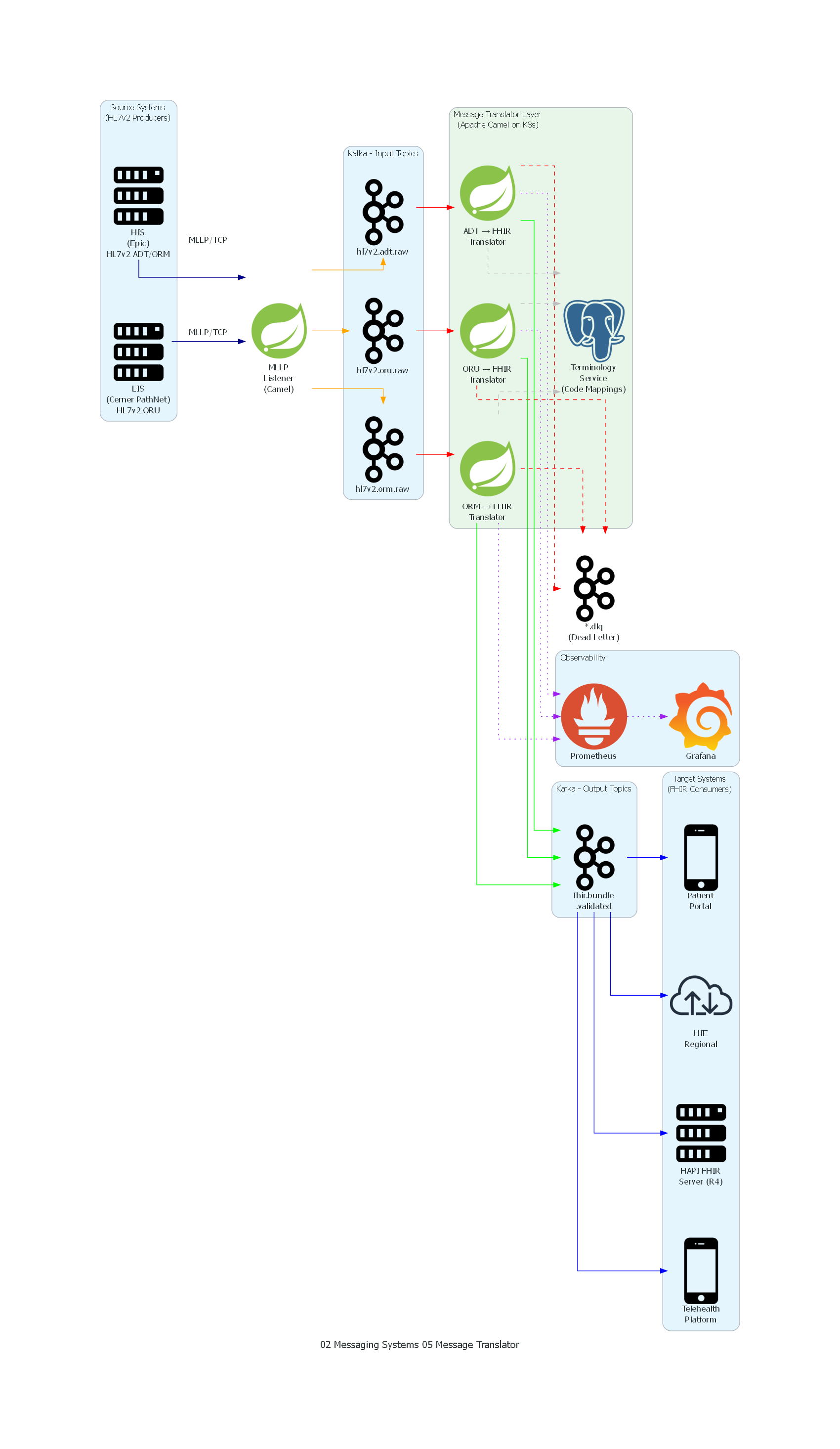
Se implementa una Integration Engine basada en Apache Camel desplegada en Kubernetes, con un conjunto de Message Translators especializados que convierten entre HL7v2 y FHIR R4. La arquitectura utiliza Kafka como backbone de messaging y un FHIR Server (HAPI FHIR) como repositorio de recursos transformados.
Los translators se organizan por tipo de mensaje HL7v2:
| Mensaje HL7v2 | Translator | Recursos FHIR Producidos |
|---|---|---|
| ADT^A01 (Admit) | ADT-to-Encounter Translator | Patient, Encounter, Condition, Coverage |
| ADT^A03 (Discharge) | ADT-to-Encounter Translator (modo update) | Encounter (status: finished), EpisodeOfCare |
| ORM^O01 (Order) | ORM-to-ServiceRequest Translator | ServiceRequest, Specimen, Practitioner |
| ORU^R01 (Result) | ORU-to-DiagnosticReport Translator | DiagnosticReport, Observation(s), Specimen |
| SIU^S12 (Schedule) | SIU-to-Appointment Translator | Appointment, Schedule, Slot |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción del Mensaje HL7v2¶
El HIS emite un mensaje HL7v2 ORU^R01 (resultado de laboratorio) cuando el LIS reporta un resultado. El mensaje viaja por MLLP al Integration Engine, donde un MLLP Listener lo recibe y lo deposita en un topic de Kafka (hl7v2.oru.raw).
Ejemplo de mensaje HL7v2 ORU^R01:
MSH|^~\&|LIS|HRC|INTEGRATION|HRC|20260407120000||ORU^R01^ORU_R01|MSG00001|P|2.5.1|||AL|NE
PID|1||PAT12345^^^HRC^MR||Garcia^Maria^Elena^^Sra.||19780315|F|||Av. Reforma 1234^^CDMX^^06600^MX||555-0123|||S|||RFC123456ABC
PV1|1|I|MED-3^301^A^^^HRC||||DOC789^Rodriguez^Carlos^^^Dr.|||MED||||ADM||DOC789^Rodriguez^Carlos^^^Dr.|IN|VIS98765|||||||||||||||||||HRC|||||20260405080000
ORC|RE|ORD456789|RES456789||CM||||20260407115500|||DOC789^Rodriguez^Carlos^^^Dr.
OBR|1|ORD456789|RES456789|24331-1^CBC^LN|||20260407100000||||||||DOC789^Rodriguez^Carlos^^^Dr.||||||||F
OBX|1|NM|718-7^Hemoglobin^LN||13.5|g/dL|12.0-16.0|N|||F
OBX|2|NM|4544-3^Hematocrit^LN||40.1|%|36.0-46.0|N|||F
OBX|3|NM|6690-2^WBC^LN||7.2|10*3/uL|4.5-11.0|N|||F
OBX|4|NM|789-8^RBC^LN||4.5|10*6/uL|4.0-5.5|N|||F
OBX|5|NM|32623-1^Platelet count^LN||245|10*3/uL|150-400|N|||F
Paso 2: Parsing y Validación del Mensaje HL7v2¶
El translator consume el mensaje de Kafka, lo parsea usando una librería HL7v2 (HAPI HL7v2 parser), y valida su estructura contra el perfil HL7v2.5.1 esperado. La validación verifica:
- Segmentos obligatorios presentes (MSH, PID, PV1, ORC, OBR, OBX).
- Campos obligatorios no vacíos (PID.3 = Patient ID, OBR.4 = Universal Service Identifier).
- Codificación de caracteres correcta (MSH.18).
- Versión del mensaje compatible (MSH.12 = 2.5.1).
Si la validación falla, el mensaje se enruta al Dead Letter Topic (hl7v2.oru.dlq) con metadata del error de validación.
Paso 3: Extracción de Datos del Mensaje HL7v2¶
El translator extrae los datos semánticos del mensaje posicional:
- De MSH: sending facility (HRC), timestamp (20260407120000), message control ID (MSG00001).
- De PID: patient ID (PAT12345), nombre (Garcia, Maria Elena), fecha nacimiento (19780315), sexo (F), dirección, teléfono.
- De PV1: tipo de paciente (inpatient), ubicación (MED-3, habitación 301), médico responsable (DOC789, Dr. Carlos Rodriguez), número de visita (VIS98765).
- De ORC: order control (RE = results), placer order (ORD456789), filler order (RES456789), order status (CM = completed).
- De OBR: universal service identifier (24331-1 = CBC = Complete Blood Count), specimen collection time, result status (F = final).
- De OBX (x5): cada observación con su código LOINC, valor numérico, unidad, rango de referencia y flag de interpretación.
Paso 4: Transformación Semántica¶
Esta es la fase core del Message Translator. Cada dato extraído del HL7v2 se mapea a la estructura FHIR correspondiente con transformación de tipos, terminología y relaciones.
Transformaciones clave:
- PID → Patient Resource:
PID.3(CX datatype) →Patient.identifierconsystem=urn:oid:HRC-MRyvalue=PAT12345.PID.5(XPN datatype) →Patient.nameconfamily=Garcia,given=["Maria", "Elena"],prefix=["Sra."].PID.7(TS datatype) →Patient.birthDate=1978-03-15(conversión de formatoYYYYMMDDaYYYY-MM-DD).PID.8=F(HL7 Table 0001) →Patient.gender=female(FHIR administrative-gender ValueSet). Mapeo: M→male, F→female, U→unknown, O→other.-
PID.11(XAD datatype) →Patient.addressconline,city,postalCode,country. -
PV1 → Encounter Resource:
PV1.2=I(HL7 Table 0004) →Encounter.class=IMP(FHIR ActCode inpatient). Mapeo: I→IMP, O→AMB, E→EMER.PV1.3→Encounter.locationconreferenceal Location resource deMED-3/301/A.PV1.7→Encounter.participantconreferencea PractitionerDOC789.-
PV1.19→Encounter.identifiercon visit numberVIS98765. -
OBR + OBX → DiagnosticReport + Observation Resources:
OBR.4(CE datatype) →DiagnosticReport.codeconcoding.system=http://loinc.org,coding.code=24331-1,coding.display=CBC.OBR.25=F→DiagnosticReport.status=final. Mapeo: F→final, P→preliminary, C→corrected.-
Cada
OBX→ unObservationresource independiente:OBX.3(CE) →Observation.codecon sistema LOINC.OBX.5(NM) →Observation.valueQuantityconvalue,unit,system=http://unitsofmeasure.org.OBX.7→Observation.referenceRangeconlowyhigh.OBX.8=N→Observation.interpretation=N(normal). Mapeo según HL7 Table 0078 a FHIR ObservationInterpretation ValueSet.
-
Referencias cruzadas: el translator establece las references entre recursos FHIR:
DiagnosticReport.subject→Patient/PAT12345DiagnosticReport.encounter→Encounter/VIS98765DiagnosticReport.result[]→Observation/OBS-1,Observation/OBS-2, etc.Observation.subject→Patient/PAT12345- Cada recurso recibe un
meta.sourceindicando el sistema origen.
Paso 5: Serialización y Producción del Mensaje FHIR¶
El translator serializa el conjunto de recursos FHIR como un FHIR Bundle de tipo transaction, empaquetando todos los recursos producidos en una sola unidad atómica:
{
"resourceType": "Bundle",
"type": "transaction",
"meta": {
"source": "urn:oid:HRC-Integration-Engine",
"lastUpdated": "2026-04-07T12:00:30Z"
},
"entry": [
{
"resource": {
"resourceType": "Patient",
"identifier": [{"system": "urn:oid:HRC-MR", "value": "PAT12345"}],
"name": [{"family": "Garcia", "given": ["Maria", "Elena"], "prefix": ["Sra."]}],
"gender": "female",
"birthDate": "1978-03-15",
"address": [{"line": ["Av. Reforma 1234"], "city": "CDMX", "postalCode": "06600", "country": "MX"}],
"telecom": [{"system": "phone", "value": "555-0123"}]
},
"request": {"method": "PUT", "url": "Patient?identifier=urn:oid:HRC-MR|PAT12345"}
},
{
"resource": {
"resourceType": "DiagnosticReport",
"identifier": [{"system": "urn:oid:HRC-LIS", "value": "RES456789"}],
"status": "final",
"code": {
"coding": [{"system": "http://loinc.org", "code": "24331-1", "display": "Complete Blood Count"}]
},
"subject": {"reference": "Patient?identifier=urn:oid:HRC-MR|PAT12345"},
"encounter": {"reference": "Encounter?identifier=urn:oid:HRC-VIS|VIS98765"},
"effectiveDateTime": "2026-04-07T10:00:00Z",
"result": [
{"reference": "#obs-hemoglobin"},
{"reference": "#obs-hematocrit"},
{"reference": "#obs-wbc"},
{"reference": "#obs-rbc"},
{"reference": "#obs-platelets"}
]
},
"request": {"method": "PUT", "url": "DiagnosticReport?identifier=urn:oid:HRC-LIS|RES456789"}
},
{
"resource": {
"resourceType": "Observation",
"id": "obs-hemoglobin",
"status": "final",
"code": {
"coding": [{"system": "http://loinc.org", "code": "718-7", "display": "Hemoglobin"}]
},
"subject": {"reference": "Patient?identifier=urn:oid:HRC-MR|PAT12345"},
"valueQuantity": {"value": 13.5, "unit": "g/dL", "system": "http://unitsofmeasure.org", "code": "g/dL"},
"referenceRange": [{"low": {"value": 12.0, "unit": "g/dL"}, "high": {"value": 16.0, "unit": "g/dL"}}],
"interpretation": [{"coding": [{"system": "http://terminology.hl7.org/CodeSystem/v3-ObservationInterpretation", "code": "N", "display": "Normal"}]}]
},
"request": {"method": "POST", "url": "Observation"}
}
]
}
(El bundle completo contiene las 5 observaciones; se muestra una por brevedad.)
Paso 6: Publicación y Enrutamiento¶
El translator publica el FHIR Bundle en el topic de Kafka fhir.bundle.validated. Desde allí, tres consumidores downstream lo procesan:
- FHIR Server Writer: persiste los recursos en el HAPI FHIR Server mediante un POST del bundle transaccional.
- Telehealth Notifier: notifica a la plataforma de telemedicina si el paciente tiene una teleconsulta activa.
- HIE Publisher: si el paciente tiene consentimiento para compartir datos con la HIE regional, firma el bundle y lo envía al HIE endpoint.
Paso 7: Monitoreo y Observabilidad¶
Cada traducción genera métricas y trazas:
- Metrics: contador de mensajes traducidos (por tipo HL7v2), histograma de latencia de traducción, contador de errores por categoría (validation, mapping, serialization).
- Traces: cada mensaje lleva un trace ID (propagado desde el header MSH.10 del HL7v2) que permite trazar el recorrido completo desde el HIS hasta el FHIR Server.
- Logs estructurados: cada traducción genera un log con message ID, patient ID (ofuscado), tipo de mensaje, recursos producidos y duración.
- Alertas: si la tasa de errores supera el 1% o la latencia supera los 500ms p99, se dispara una alerta al equipo de integración.
10. Diagrama Técnico¶
Código Python con la librería diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.programming.framework import Spring
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Prometheus, Grafana
from diagrams.generic.device import Mobile
from diagrams.generic.storage import Storage
from diagrams.onprem.network import Internet
graph_attr = {
"fontsize": "20",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "1.0",
"ranksep": "1.2",
"splines": "ortho"
}
with Diagram(
"Message Translator - HL7v2 to FHIR Healthcare Integration",
show=False,
direction="LR",
filename="message_translator_healthcare",
graph_attr=graph_attr,
outformat="png"
):
# Source Systems
with Cluster("Source Systems\n(HL7v2 Producers)"):
his = Server("HIS\n(Epic)\nHL7v2 ADT/ORM")
lis = Server("LIS\n(Cerner PathNet)\nHL7v2 ORU")
# MLLP Listener
mllp = Spring("MLLP\nListener\n(Camel)")
# Kafka Input Topics
with Cluster("Kafka - Input Topics"):
hl7_adt = Kafka("hl7v2.adt.raw")
hl7_oru = Kafka("hl7v2.oru.raw")
hl7_orm = Kafka("hl7v2.orm.raw")
# Translation Layer
with Cluster("Message Translator Layer\n(Apache Camel on K8s)", graph_attr={"bgcolor": "#E8F5E9"}):
adt_translator = Spring("ADT → FHIR\nTranslator")
oru_translator = Spring("ORU → FHIR\nTranslator")
orm_translator = Spring("ORM → FHIR\nTranslator")
terminology = PostgreSQL("Terminology\nService\n(Code Mappings)")
# Dead Letter
dlq = Kafka("*.dlq\n(Dead Letter)")
# Kafka Output Topics
with Cluster("Kafka - Output Topics"):
fhir_bundle = Kafka("fhir.bundle\n.validated")
# Target Systems
with Cluster("Target Systems\n(FHIR Consumers)"):
fhir_server = Server("HAPI FHIR\nServer (R4)")
telehealth = Mobile("Telehealth\nPlatform")
portal = Mobile("Patient\nPortal")
hie = Internet("HIE\nRegional")
# Observability
with Cluster("Observability"):
prom = Prometheus("Prometheus")
graf = Grafana("Grafana")
# Connections - Source to MLLP
his >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
lis >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
# MLLP to Kafka Input
mllp >> Edge(color="orange") >> hl7_adt
mllp >> Edge(color="orange") >> hl7_oru
mllp >> Edge(color="orange") >> hl7_orm
# Kafka Input to Translators
hl7_adt >> Edge(color="red") >> adt_translator
hl7_oru >> Edge(color="red") >> oru_translator
hl7_orm >> Edge(color="red") >> orm_translator
# Translators use Terminology Service
adt_translator >> Edge(style="dashed", color="gray") >> terminology
oru_translator >> Edge(style="dashed", color="gray") >> terminology
orm_translator >> Edge(style="dashed", color="gray") >> terminology
# Translators to Output / DLQ
adt_translator >> Edge(color="green") >> fhir_bundle
oru_translator >> Edge(color="green") >> fhir_bundle
orm_translator >> Edge(color="green") >> fhir_bundle
adt_translator >> Edge(style="dashed", color="red") >> dlq
oru_translator >> Edge(style="dashed", color="red") >> dlq
orm_translator >> Edge(style="dashed", color="red") >> dlq
# Output to Target Systems
fhir_bundle >> Edge(color="blue") >> fhir_server
fhir_bundle >> Edge(color="blue") >> telehealth
fhir_bundle >> Edge(color="blue") >> portal
fhir_bundle >> Edge(color="blue") >> hie
# Observability
adt_translator >> Edge(style="dotted", color="purple") >> prom
oru_translator >> Edge(style="dotted", color="purple") >> prom
orm_translator >> Edge(style="dotted", color="purple") >> prom
prom >> Edge(style="dotted", color="purple") >> graf
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.device import Mobile
from diagrams.onprem.network import Internet
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import NLB
graph_attr = {
"fontsize": "20",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "1.0",
"ranksep": "1.2",
"splines": "ortho"
}
with Diagram(
"Message Translator - HL7v2 to FHIR Healthcare Integration",
show=False,
direction="LR",
filename="message_translator_healthcare",
graph_attr=graph_attr,
outformat="png"
):
# Source Systems
with Cluster("Source Systems\n(HL7v2 Producers)"):
his = ECS("HIS\n(Epic)\nHL7v2 ADT/ORM")
lis = ECS("LIS\n(Cerner PathNet)\nHL7v2 ORU")
# MLLP Listener
mllp = NLB("NLB\nMLLP Listener")
# Input Queues
with Cluster("Input Queues (SQS)"):
hl7_adt = SQS("hl7v2.adt.raw")
hl7_oru = SQS("hl7v2.oru.raw")
hl7_orm = SQS("hl7v2.orm.raw")
# Translation Layer
with Cluster("Message Translator Layer\n(Lambda Functions)", graph_attr={"bgcolor": "#E8F5E9"}):
adt_translator = Lambda("ADT → FHIR\nTranslator")
oru_translator = Lambda("ORU → FHIR\nTranslator")
orm_translator = Lambda("ORM → FHIR\nTranslator")
terminology = Dynamodb("Terminology\nService\n(DynamoDB)")
# Dead Letter
dlq = SQS("*.dlq\n(SQS Dead Letter)")
# Output Queue
with Cluster("Output Queue (SQS)"):
fhir_bundle = SQS("fhir.bundle\n.validated")
# Target Systems
with Cluster("Target Systems\n(FHIR Consumers)"):
fhir_server = ECS("HAPI FHIR\nServer (R4)\n(Fargate)")
telehealth = Mobile("Telehealth\nPlatform")
portal = Mobile("Patient\nPortal")
hie = Internet("HIE\nRegional")
# Observability
with Cluster("Observability"):
cw = Cloudwatch("CloudWatch\nMetrics")
xray = Cloudwatch("X-Ray\nTracing")
# Connections - Source to MLLP
his >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
lis >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
# MLLP to SQS Input
mllp >> Edge(color="orange") >> hl7_adt
mllp >> Edge(color="orange") >> hl7_oru
mllp >> Edge(color="orange") >> hl7_orm
# SQS triggers Lambda Translators
hl7_adt >> Edge(color="red") >> adt_translator
hl7_oru >> Edge(color="red") >> oru_translator
hl7_orm >> Edge(color="red") >> orm_translator
# Translators use Terminology Service
adt_translator >> Edge(style="dashed", color="gray") >> terminology
oru_translator >> Edge(style="dashed", color="gray") >> terminology
orm_translator >> Edge(style="dashed", color="gray") >> terminology
# Translators to Output / DLQ
adt_translator >> Edge(color="green") >> fhir_bundle
oru_translator >> Edge(color="green") >> fhir_bundle
orm_translator >> Edge(color="green") >> fhir_bundle
adt_translator >> Edge(style="dashed", color="red") >> dlq
oru_translator >> Edge(style="dashed", color="red") >> dlq
orm_translator >> Edge(style="dashed", color="red") >> dlq
# Output to Target Systems
fhir_bundle >> Edge(color="blue") >> fhir_server
fhir_bundle >> Edge(color="blue") >> telehealth
fhir_bundle >> Edge(color="blue") >> portal
fhir_bundle >> Edge(color="blue") >> hie
# Observability
adt_translator >> Edge(style="dotted", color="purple") >> cw
oru_translator >> Edge(style="dotted", color="purple") >> cw
orm_translator >> Edge(style="dotted", color="purple") >> cw
cw >> Edge(style="dotted", color="purple") >> xray
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.device import Mobile
from diagrams.onprem.network import Internet
from diagrams.onprem.compute import Server
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus, LogicApps
graph_attr = {
"fontsize": "20",
"bgcolor": "white",
"pad": "0.5",
"nodesep": "1.0",
"ranksep": "1.2",
"splines": "ortho"
}
with Diagram(
"Message Translator - HL7v2 to FHIR Healthcare Integration (Azure)",
show=False,
direction="LR",
filename="message_translator_healthcare",
graph_attr=graph_attr,
outformat="png"
):
# Source Systems
with Cluster("Source Systems\n(HL7v2 Producers)"):
his = Server("HIS\n(Epic)\nHL7v2 ADT/ORM")
lis = Server("LIS\n(Cerner PathNet)\nHL7v2 ORU")
# MLLP Listener (Logic App with HL7 connector)
mllp = LogicApps("Logic App\nMLLP Listener\n(HL7 Connector)")
# Service Bus Input Queues
with Cluster("Service Bus - Input Queues"):
hl7_adt = ServiceBus("hl7v2.adt.raw\n(Queue)")
hl7_oru = ServiceBus("hl7v2.oru.raw\n(Queue)")
hl7_orm = ServiceBus("hl7v2.orm.raw\n(Queue)")
# Translation Layer (Azure Functions)
with Cluster("Message Translator Layer\n(Azure Functions)", graph_attr={"bgcolor": "#E8F5E9"}):
adt_translator = FunctionApps("ADT → FHIR\nTranslator")
oru_translator = FunctionApps("ORU → FHIR\nTranslator")
orm_translator = FunctionApps("ORM → FHIR\nTranslator")
terminology = CosmosDb("Cosmos DB\nTerminology\n(Code Mappings)")
# Dead Letter (Service Bus built-in)
dlq = ServiceBus("$DeadLetterQueue\n(Built-in DLQ)")
# Service Bus Output Topic
with Cluster("Service Bus - Output Topic"):
fhir_bundle = ServiceBus("fhir.bundle.validated\n(Topic)")
# Target Systems
with Cluster("Target Systems\n(FHIR Consumers)"):
fhir_server = ContainerApps("FHIR Server\n(Container App)")
telehealth = Mobile("Telehealth\nPlatform")
portal = Mobile("Patient\nPortal")
hie = Internet("HIE\nRegional")
# Observability
with Cluster("Observability"):
app_insights = ApplicationInsights("Application\nInsights")
# Connections - Source to MLLP
his >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
lis >> Edge(label="MLLP/TCP", color="darkblue") >> mllp
# Logic App to Service Bus Input
mllp >> Edge(color="orange") >> hl7_adt
mllp >> Edge(color="orange") >> hl7_oru
mllp >> Edge(color="orange") >> hl7_orm
# Service Bus triggers Azure Functions
hl7_adt >> Edge(color="red") >> adt_translator
hl7_oru >> Edge(color="red") >> oru_translator
hl7_orm >> Edge(color="red") >> orm_translator
# Translators use Terminology Service
adt_translator >> Edge(style="dashed", color="gray") >> terminology
oru_translator >> Edge(style="dashed", color="gray") >> terminology
orm_translator >> Edge(style="dashed", color="gray") >> terminology
# Translators to Output / DLQ
adt_translator >> Edge(color="green") >> fhir_bundle
oru_translator >> Edge(color="green") >> fhir_bundle
orm_translator >> Edge(color="green") >> fhir_bundle
adt_translator >> Edge(style="dashed", color="red") >> dlq
oru_translator >> Edge(style="dashed", color="red") >> dlq
orm_translator >> Edge(style="dashed", color="red") >> dlq
# Output to Target Systems (via subscriptions)
fhir_bundle >> Edge(color="blue") >> fhir_server
fhir_bundle >> Edge(color="blue") >> telehealth
fhir_bundle >> Edge(color="blue") >> portal
fhir_bundle >> Edge(color="blue") >> hie
# Observability
adt_translator >> Edge(style="dotted", color="purple") >> app_insights
oru_translator >> Edge(style="dotted", color="purple") >> app_insights
orm_translator >> Edge(style="dotted", color="purple") >> app_insights
Explicación del Diagrama¶
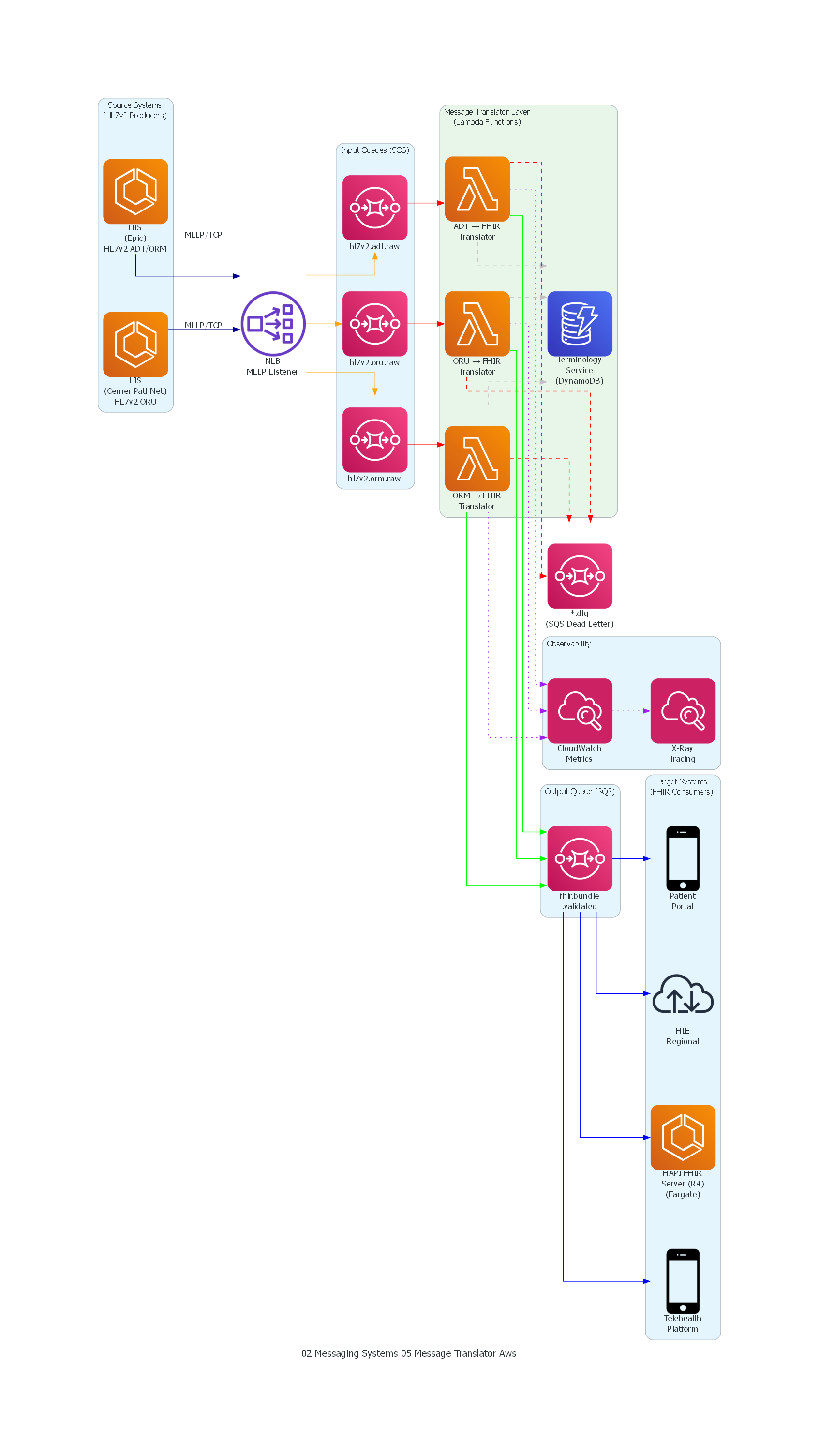
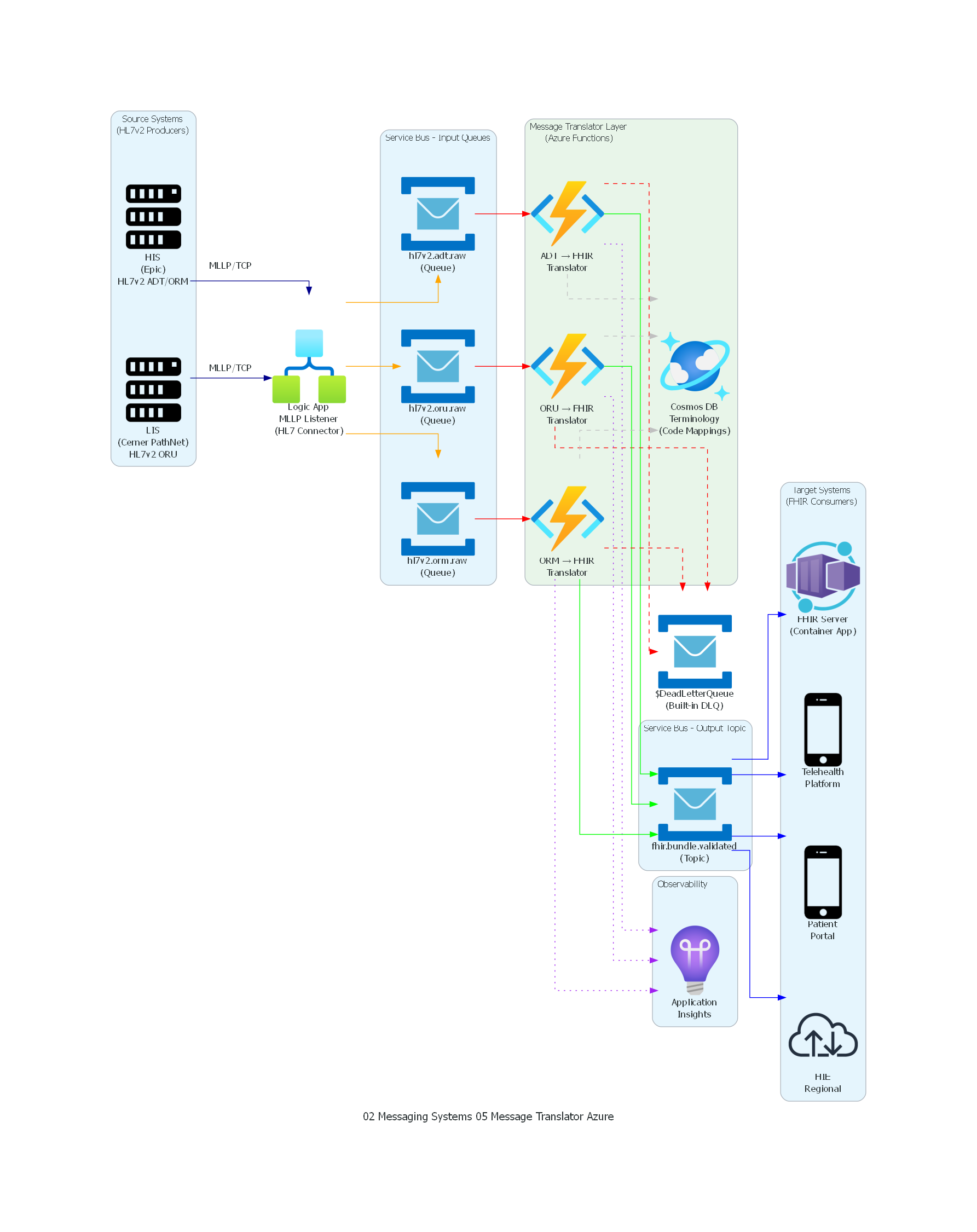
El diagrama muestra el flujo completo de transformación HL7v2-a-FHIR en la arquitectura del Hospital Regional Central. Los sistemas legacy (HIS, LIS) emiten mensajes HL7v2 via MLLP al listener de Apache Camel, que los clasifica y deposita en topics de Kafka segregados por tipo de mensaje. La capa de Message Translators — el componente central del patrón — consume de los topics de entrada, ejecuta la transformación semántica con apoyo de un servicio de terminología, y produce FHIR Bundles en el topic de salida. Los mensajes no traducibles se desvían al Dead Letter Queue. Finalmente, los consumidores FHIR (servidor, telemedicina, portal, HIE) consumen del topic de salida.
Tabla de Correspondencia¶
| Elemento del Diagrama | Componente Arquitectónico | Rol en el Patrón |
|---|---|---|
| HIS (Epic) | Source System | Productor de mensajes HL7v2 ADT/ORM |
| LIS (Cerner PathNet) | Source System | Productor de mensajes HL7v2 ORU |
| MLLP Listener (Camel) | Protocol Adapter / Channel Adapter | Recibe MLLP, produce en Kafka |
| hl7v2.adt.raw / oru / orm | Kafka Topics | Input Channels por tipo de mensaje |
| ADT/ORU/ORM → FHIR Translators | Message Translator | Componente central del patrón |
| Terminology Service | Mapping Definition Store | Tablas de mapeo de códigos HL7↔FHIR |
| *.dlq (Dead Letter) | Dead Letter Channel | Destino de mensajes no traducibles |
| fhir.bundle.validated | Kafka Topic | Output Channel con FHIR Bundles |
| HAPI FHIR Server | Target System | Persistencia de recursos FHIR |
| Telehealth Platform | Target System | Consumidor FHIR para telemedicina |
| Patient Portal | Target System | Consumidor FHIR para portal paciente |
| HIE Regional | Target System | Consumidor FHIR para intercambio regional |
| Prometheus / Grafana | Observability Stack | Monitoreo de métricas de traducción |
11. Beneficios¶
Desacoplamiento de Formatos¶
Message Translator elimina la dependencia directa entre el formato de datos del productor y el del consumidor. Cada sistema puede evolucionar su modelo de datos de forma independiente; solo el translator necesita actualizarse cuando un formato cambia. Esto es especialmente valioso en ecosistemas con múltiples sistemas de múltiples vendors.
Reutilización y Composición¶
Los translators se componen en pipelines de Pipes and Filters. Un translator que convierte HL7v2 a un modelo canónico interno puede reutilizarse para alimentar múltiples consumidores, sin necesidad de implementar la conversión HL7v2 → formato específico de cada consumidor.
Testing Aislado¶
Al ser un componente con responsabilidad única (entrada definida → salida definida), el translator es altamente testeable. Se pueden escribir suites de tests exhaustivas con inputs conocidos y outputs esperados, sin necesidad de levantar la infraestructura de messaging completa.
Transparencia y Auditabilidad¶
Al centralizar la transformación en un componente explícito, se puede auditar exactamente qué transformaciones se aplican, cuándo se aplicaron, y qué versión de las reglas de mapeo se usó. Esto es crítico en dominios regulados (banca, salud, gobierno).
Escalabilidad Horizontal¶
Los translators stateless se escalan horizontalmente de forma trivial: se añaden más instancias del translator (más pods en Kubernetes, más consumers en un consumer group de Kafka) y el throughput crece linealmente.
Habilitación de Canonical Data Model¶
Message Translator es el mecanismo de implementación del patrón Canonical Data Model. Sin translators, un modelo canónico es una especificación sin implementación. Los translators son los que materializan la conversión entre formatos nativos y el modelo canónico.
Reducción del Time-to-Integration¶
Una vez que existen translators para el formato canónico, integrar un nuevo sistema requiere solo implementar dos translators (nativo → canónico y canónico → nativo) en lugar de N adaptadores punto a punto.
12. Desventajas y Riesgos¶
Latencia Adicional¶
Cada paso de traducción añade latencia al pipeline. La deserialización, transformación y re-serialización tienen un costo computacional que, en pipelines de alta frecuencia (trading, IoT en tiempo real), puede ser inaceptable. En el ejemplo hospitalario, la traducción HL7v2→FHIR típicamente añade 5-50ms por mensaje dependiendo de la complejidad.
Punto de Fallo Adicional¶
El translator es un componente adicional que puede fallar. Un bug en la lógica de mapeo, un error en la deserialización, o un crash del proceso translator puede detener todo el flujo de integración. La mitigación requiere redundancia, Dead Letter Queues y monitoreo proactivo.
Complejidad de Mantenimiento de Mapeos¶
Las reglas de mapeo deben mantenerse sincronizadas con la evolución de los formatos de origen y destino. Cuando un sistema upstream cambia su esquema (añade campos, renombra atributos, cambia codificaciones), todos los translators que consumen ese formato deben actualizarse. Esta carga de mantenimiento crece con el número de formatos y translators.
Pérdida de Información¶
No toda traducción preserva toda la información. Convertir de un formato rico a uno más pobre implica necesariamente pérdida semántica. En el ejemplo HL7v2→FHIR, ciertos segmentos Z propietarios del LIS pueden no tener equivalente en FHIR estándar. El arquitecto debe documentar explícitamente qué información se pierde y confirmar que es aceptable para el negocio.
Riesgo de Over-Engineering¶
Implementar translators genéricos con frameworks de mapping sofisticados cuando la transformación es simple puede introducir complejidad accidental significativa. No toda integración necesita un motor de reglas configurable; a veces un método con mapeos explícitos es la solución más adecuada.
Proliferación de Translators¶
En un ecosistema con M formatos de origen y N formatos de destino, sin un modelo canónico se necesitan M×N translators. Incluso con modelo canónico, se necesitan M+N translators más el mantenimiento del modelo canónico mismo. La proliferación de translators puede convertirse en una carga operativa significativa.
Dificultad de Debugging¶
Cuando un dato aparece incorrecto en el sistema destino, diagnosticar si el error está en el origen, en el translator, o en el consumidor puede ser difícil. Se requiere trazabilidad end-to-end y capacidad de inspeccionar el mensaje antes y después de la traducción.
13. Relación con Otros Patrones¶
Canonical Data Model¶
Relación: complemento esencial. Canonical Data Model define un formato intermedio universal al que todos los sistemas se convierten. Message Translator es el mecanismo de implementación que ejecuta la conversión entre cada formato nativo y el modelo canónico. Sin Canonical Data Model, los translators operan punto a punto (formato A → formato B); con Canonical Data Model, operan hub-and-spoke (formato A → canónico → formato B). En el ejemplo hospitalario, el modelo canónico sería FHIR R4: todos los sistemas legacy convierten a FHIR (vía translators), y todos los sistemas modernos consumen FHIR directamente.
Normalizer¶
Relación: caso especializado. Normalizer es un Message Router que inspecciona el formato del mensaje entrante y lo enruta al Message Translator correspondiente, produciendo una salida en formato uniforme independientemente del formato de entrada. El Normalizer orquesta múltiples translators, cada uno especializado en un formato de entrada diferente. En el ejemplo hospitalario, el MLLP Listener actúa parcialmente como Normalizer al clasificar mensajes HL7v2 por tipo (ADT, ORU, ORM) y enrutarlos al translator correspondiente.
Content Enricher¶
Relación: complemento frecuente. La línea entre traducción y enriquecimiento es a veces difusa. Message Translator convierte formato y estructura; Content Enricher añade datos que no están en el mensaje original (consultando fuentes externas). En la práctica, muchas traducciones requieren enriquecimiento: al convertir HL7v2→FHIR, el translator puede necesitar consultar un servicio de terminología para resolver códigos LOINC a sus descripciones completas, o un Master Patient Index para obtener el identificador nacional del paciente. El diseño debe decidir si esta lógica reside en el translator o en un Content Enricher separado en el pipeline.
Envelope Wrapper¶
Relación: patrón adyacente. Envelope Wrapper añade o remueve headers y metadata de transporte sin modificar el body del mensaje. Message Translator modifica el body (contenido de negocio) del mensaje. En un pipeline completo, Envelope Wrapper puede preparar el mensaje para que el translator lo procese (removiendo headers propietarios del protocolo de transporte) y luego empaquetar el resultado del translator con los headers necesarios para el canal de salida. En el ejemplo hospitalario, el MLLP Listener hace un unwrapping (remueve los bytes de framing MLLP) antes de entregar el mensaje HL7v2 al translator.
Relaciones Adicionales Relevantes¶
- Pipes and Filters: Message Translator es un filtro en un pipeline. Se compone con otros filtros (validators, enrichers, routers) para formar cadenas de procesamiento complejas.
- Message Router (Content-Based Router): a menudo precede al translator, decidiendo qué translator aplicar según el tipo de mensaje entrante.
- Dead Letter Channel: destino de mensajes que el translator no puede procesar, preservándolos para inspección y reprocesamiento manual.
- Wire Tap: puede capturar una copia del mensaje antes y después de la traducción para auditoría y debugging.
- Claim Check: cuando el mensaje es muy grande para traducir in-memory, Claim Check puede almacenar el payload externamente y el translator opera sobre una referencia.
14. Relevancia Actual¶
Nivel de relevancia: ALTA
Message Translator es uno de los patrones de integración con mayor relevancia en la arquitectura moderna, y su importancia continúa creciendo. Las razones son múltiples:
Proliferación de Formatos en el Ecosistema Moderno¶
El ecosistema tecnológico actual es más heterogéneo que nunca. Una organización típica opera sistemas en JSON (microservicios REST), Protobuf (gRPC services), Avro (Kafka streams), GraphQL (frontend APIs), XML (legacy/regulatorio), CSV/Parquet (data pipelines), y formatos propietarios de SaaS. La necesidad de traducir entre estos formatos es ubicua.
Microservicios y Bounded Contexts¶
En arquitecturas de microservicios inspiradas en DDD, cada bounded context mantiene su propio modelo de dominio. La comunicación entre contexts requiere traducción (lo que DDD llama Anti-Corruption Layer, que es conceptualmente un Message Translator). Esta necesidad se multiplica con cada nuevo servicio.
Data Mesh y Data Products¶
El paradigma de Data Mesh promueve que cada dominio publique sus datos como productos con contratos bien definidos. Los consumidores de estos data products frecuentemente necesitan adaptar los datos a su modelo interno, lo cual es una instancia directa de Message Translator.
Cloud-Native Integration¶
Las plataformas cloud ofrecen servicios nativos de transformación que son instancias del patrón: Azure Logic Apps Built-in Transforms, AWS EventBridge Input Transformers, Google Cloud Dataflow transformations. Entender el patrón subyacente permite usar estas herramientas de forma efectiva.
APIs y API Gateways¶
Los API Gateways modernos (Kong, Apigee, AWS API Gateway) incluyen capacidades de transformación de request/response que son Message Translators en el contexto de comunicación síncrona. La traducción de formatos en API facades es una aplicación directa del patrón.
Interoperabilidad Regulatoria¶
Las regulaciones de interoperabilidad (ONC Cures Act en salud, PSD2 en banca, Open Banking) exigen que los sistemas expongan datos en formatos estándar. Esto requiere translators desde los formatos internos a los formatos regulatorios.
Event-Driven Architecture y Event Sourcing¶
En arquitecturas event-driven, los eventos publicados por un servicio pueden necesitar traducción antes de ser consumidos por otro servicio que espera un esquema diferente. Schema evolution (manejada por Schema Registry con Avro/Protobuf) es una forma de traducción automática, pero las transformaciones semánticas siguen requiriendo translators explícitos.
AI y Transformaciones Inteligentes¶
Un área emergente es el uso de modelos de lenguaje (LLMs) para asistir en la generación automática de reglas de mapeo entre esquemas complejos. Herramientas como las propuestas por vendors de integración permiten describir el mapeo en lenguaje natural y generar la transformación. Esto no elimina el patrón, sino que facilita su implementación.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka Connect — Single Message Transforms (SMTs)¶
Kafka Connect SMTs son la implementación más nativa del patrón Message Translator en el ecosistema Kafka. Las SMTs son funciones de transformación que se aplican a cada mensaje individualmente dentro de un connector, sin necesidad de un servicio de procesamiento separado.
Características: - Se configuran declarativamente en el JSON de configuración del connector. - Se aplican en cadena (múltiples SMTs forman un pipeline de transformación). - Operan sobre el record Kafka (key, value, headers, topic, partition, offset). - Son stateless por diseño.
SMTs built-in relevantes: ReplaceField (renombrar/eliminar campos), MaskField (ofuscar datos sensibles), InsertField (añadir campos estáticos), ValueToKey (extraer campos del value al key), HoistField (envolver el record en un campo), Flatten (aplanar estructuras anidadas), Cast (conversión de tipos), TimestampConverter, RegexRouter, HeaderFrom.
Limitaciones: las SMTs built-in solo cubren transformaciones simples. Para transformaciones semánticas complejas (como HL7v2→FHIR), se necesitan SMTs custom implementadas en Java, o bien un Kafka Streams application dedicada que actúe como translator.
# Ejemplo: SMT chain para normalizar un evento de pedido
transforms=renameFields,addTimestamp,maskPII
transforms.renameFields.type=org.apache.kafka.connect.transforms.ReplaceField$Value
transforms.renameFields.renames=order_id:orderId,cust_id:customerId,total_amt:totalAmount
transforms.addTimestamp.type=org.apache.kafka.connect.transforms.InsertField$Value
transforms.addTimestamp.timestamp.field=processedAt
transforms.maskPII.type=org.apache.kafka.connect.transforms.MaskField$Value
transforms.maskPII.fields=ssn,creditCardNumber
transforms.maskPII.replacement=****
Azure Logic Apps¶
Azure Logic Apps implementa Message Translator mediante acciones de transformación declarativas dentro de workflows:
- Liquid Templates: motor de templates para transformaciones JSON-a-JSON, JSON-a-texto, o XML-a-texto. Se definen templates Liquid que mapean la estructura de entrada a la estructura de salida con expresiones y filtros.
- XSLT Maps: para transformaciones XML-a-XML o XML-a-JSON. Se suben mapas XSLT al Integration Account y se referencian desde la acción Transform XML.
- Integration Account Maps: artefactos reutilizables de transformación que se comparten entre múltiples Logic Apps.
- Inline Expressions: para transformaciones simples, las expresiones del Workflow Definition Language permiten mapeos directos sin artefactos externos.
Ventajas: visual designer para construir transformaciones, managed service sin infraestructura, integración nativa con Azure Service Bus, Event Grid y Event Hubs.
Limitaciones: performance limitado para alto volumen (throttling en plan Consumption), costos elevados en plan Standard para transformaciones masivas, debugging de transformaciones complejas es difícil en el designer visual.
AWS Step Functions con Lambda¶
En AWS, el patrón se implementa típicamente combinando Step Functions para orquestación con Lambda functions para la lógica de transformación:
- EventBridge Input Transformers: para transformaciones simples de eventos, EventBridge permite definir input templates que re-mapean campos del evento antes de entregarlo al target. Limitado a transformaciones de campos y expresiones simples.
- Lambda Functions: para transformaciones complejas, una Lambda function actúa como translator. Consume el evento, aplica la transformación, y produce el resultado. Se puede integrar con SQS, SNS, Kinesis o EventBridge.
- Step Functions: orquestan pipelines de transformación multi-paso donde cada paso es una Lambda translator con una responsabilidad específica (validate → enrich → transform → serialize).
- AWS Glue: para transformaciones en batch sobre datos en S3, Glue ETL jobs actúan como Message Translators a escala de datos.
# Lambda como Message Translator: HL7v2 segment to FHIR Patient
import json
from hl7apy.parser import parse_message
def lambda_handler(event, context):
hl7_raw = event['Records'][0]['body']
msg = parse_message(hl7_raw)
pid = msg.pid
fhir_patient = {
"resourceType": "Patient",
"identifier": [{"system": "urn:oid:hospital", "value": str(pid.pid_3.pid_3_1)}],
"name": [{"family": str(pid.pid_5.pid_5_1), "given": [str(pid.pid_5.pid_5_2)]}],
"gender": map_gender(str(pid.pid_8)),
"birthDate": format_date(str(pid.pid_7))
}
return {"statusCode": 200, "body": json.dumps(fhir_patient)}
MuleSoft DataWeave¶
DataWeave es el lenguaje de transformación nativo de MuleSoft Anypoint Platform y representa una de las implementaciones más sofisticadas del patrón Message Translator. Es un lenguaje funcional y declarativo diseñado específicamente para transformación de datos.
Características: - Tipado con inferencia automática basada en metadata de conectores. - Soporta múltiples formatos nativamente: JSON, XML, CSV, Avro, Protobuf, fixed-width, COBOL copybook, Excel, YAML. - Pattern matching, recursión, funciones de orden superior. - Streaming para documentos grandes. - Módulos reutilizables para lógica de mapeo compartida.
%dw 2.0
output application/json
---
{
resourceType: "Patient",
identifier: [{
system: "urn:oid:hospital-mr",
value: payload.PID."PID.3"."PID.3.1"
}],
name: [{
family: payload.PID."PID.5"."PID.5.1",
given: [payload.PID."PID.5"."PID.5.2"],
prefix: [payload.PID."PID.5"."PID.5.5"]
}],
gender: payload.PID."PID.8" match {
case "M" -> "male"
case "F" -> "female"
case "U" -> "unknown"
else -> "other"
},
birthDate: payload.PID."PID.7" as Date {format: "yyyyMMdd"} as String {format: "yyyy-MM-dd"}
}
Apache Camel¶
Apache Camel es el framework open-source de integración que implementa directamente los Enterprise Integration Patterns, incluido Message Translator.
Mecanismos de traducción en Camel: - Processor: implementación imperativa en Java/Kotlin donde se programa la transformación completa. - Bean: delegación a un POJO que recibe el mensaje de entrada y devuelve el transformado. - Type Converters: sistema extensible de conversión automática entre tipos Java. - Data Formats: marshallers/unmarshallers para JSON (Jackson), XML (JAXB), Avro, Protobuf, HL7, FHIR, CSV, etc. - Transform DSL: expresiones inline en la ruta Camel usando Simple language, OGNL o SpEL. - XSLT Component: transformaciones XML basadas en hojas de estilo XSLT. - JSONata / JQ Components: transformaciones JSON declarativas.
from("kafka:hl7v2.oru.raw")
.unmarshal().hl7() // Deserialize HL7v2
.process(new Hl7v2Validator()) // Validate structure
.bean(OruToFhirTranslator.class, "translate") // Core translation
.marshal().fhirJson("R4") // Serialize FHIR JSON
.to("kafka:fhir.bundle.validated")
.onException(TranslationException.class)
.handled(true)
.to("kafka:hl7v2.oru.dlq"); // Dead Letter on failure
Spring Integration¶
Spring Integration implementa Message Translator directamente como un @Transformer component dentro de su modelo de programación basado en canales y endpoints.
Mecanismos: - @Transformer: anotación que marca un método como translator. El método recibe un Message o su payload y devuelve el objeto transformado. - MessageTransformingHandler: handler que aplica una función de transformación a cada mensaje. - HeaderEnricher / HeaderFilter: para transformaciones enfocadas en headers. - Integration con Jackson, JAXB y otros serializers para conversión de formatos.
@Component
public class HL7ToFhirTranslator {
@Transformer(inputChannel = "hl7v2InChannel", outputChannel = "fhirOutChannel")
public Bundle translateToFhir(Message<String> hl7Message) {
HapiContext ctx = new DefaultHapiContext();
Parser parser = ctx.getPipeParser();
ca.uhn.hl7v2.model.Message parsed = parser.parse(hl7Message.getPayload());
Bundle bundle = new Bundle();
bundle.setType(Bundle.BundleType.TRANSACTION);
// Extract PID -> Patient
Patient patient = extractPatient(parsed);
bundle.addEntry()
.setResource(patient)
.getRequest().setMethod(Bundle.HTTPVerb.PUT)
.setUrl("Patient?identifier=" + patient.getIdentifierFirstRep().getValue());
// Extract OBX -> Observations
List<Observation> observations = extractObservations(parsed);
observations.forEach(obs ->
bundle.addEntry().setResource(obs).getRequest()
.setMethod(Bundle.HTTPVerb.POST).setUrl("Observation"));
return bundle;
}
}
16. Consideraciones de Gobierno y Operación¶
Registro y Catálogo de Translators¶
Cada translator en la organización debe estar registrado en un catálogo que documente: formato de entrada (con versión), formato de salida (con versión), reglas de mapeo, owner del translator, SLA (latencia máxima, throughput garantizado), y procedimiento de actualización. Sin este catálogo, la proliferación de translators se vuelve ingobernable.
Versionamiento de Reglas de Mapeo¶
Las reglas de mapeo deben versionarse con el mismo rigor que el código fuente. Cada cambio en una regla de mapeo debe pasar por code review, tener tests automatizados que cubran los casos de borde, y ser desplegable de forma independiente del translator engine. Se recomienda almacenar las reglas de mapeo en un repositorio de artefactos (Maven Central, npm registry, OCI registry) versionado semánticamente.
Compatibilidad con Schema Evolution¶
Cuando el formato de entrada evoluciona (v1 → v2), el translator debe seguir soportando v1 durante un período de transición, mientras los productores migran. Esto requiere:
- Backward compatibility: el translator acepta mensajes en formato v1 y v2.
- Multi-version routing: un router previo al translator inspecciona la versión del mensaje y lo envía al translator correspondiente, o un solo translator con lógica de branching interno.
- Deprecation policy: documentar cuándo se dejará de soportar cada versión antigua.
Monitoreo y Alerting¶
Métricas esenciales para cada translator:
- Throughput: mensajes traducidos por segundo (por tipo).
- Latency: percentiles p50, p95, p99 de tiempo de traducción.
- Error rate: porcentaje de mensajes que fallan la traducción.
- DLQ depth: número de mensajes en el Dead Letter Queue (indica problemas acumulados).
- Schema validation failures: mensajes que no pasan validación de esquema (indica cambios no anunciados en upstream).
Alertas recomendadas: error rate > 1%, p99 latency > SLA, DLQ depth > threshold, throughput drop > 50% (indica que el productor dejó de emitir o el translator dejó de consumir).
Testing y Validación¶
Los translators deben tener suites de tests que cubran:
- Happy path: mensajes completos y bien formados producen la salida esperada.
- Campos opcionales ausentes: el translator maneja gracefully la ausencia de campos opcionales.
- Valores de borde: campos vacíos, valores nulos, strings muy largos, caracteres especiales, encodings no estándar.
- Versiones de esquema: mensajes en cada versión soportada producen salida correcta.
- Regression tests: cada bug reportado en producción se convierte en un test case.
- Contract tests: validación de que la salida del translator cumple el schema del consumidor.
Data Quality y Validación¶
El translator debe validar tanto la entrada como la salida:
- Validación de entrada: rechazar mensajes que no cumplen el esquema de entrada documentado, enrutándolos al DLQ.
- Validación de salida: verificar que el mensaje producido cumple el esquema de salida antes de publicarlo. Esto previene que errores en la lógica de mapeo propaguen datos inválidos downstream.
- Data quality metrics: tracking de campos que consistentemente llegan vacíos, valores fuera de rango, o codificaciones no reconocidas.
Seguridad y Compliance¶
- Datos sensibles: el translator puede ser un punto donde datos sensibles (PII, PHI, PCI) se copian o transforman. Debe asegurarse que los datos sensibles se manejan según la normativa aplicable (encriptación en tránsito y en reposo, ofuscación en logs, control de acceso al translator).
- Auditoría: en dominios regulados, cada traducción debe ser auditable. Esto implica logging inmutable de quién ejecutó la traducción, cuándo, con qué versión de las reglas, y cuál fue el resultado.
- Data residency: si los datos no pueden salir de una región geográfica, el translator debe estar desplegado en esa región.
Gestión de Capacidad¶
Los translators deben dimensionarse para el throughput esperado con margen para picos:
- Baseline sizing: medir el throughput de un pod/instancia del translator bajo carga sostenida.
- Scaling policy: definir reglas de auto-scaling basadas en lag del consumer group (Kafka), profundidad de cola (RabbitMQ/SQS), o CPU/memoria.
- Capacity planning: proyectar el crecimiento del throughput basado en el roadmap de integraciones y planificar la capacidad con anticipación.
17. Errores Comunes¶
Error 1: Embeber la Transformación en el Productor o el Consumidor¶
Manifestación: el equipo del sistema emisor añade lógica de conversión al formato del consumidor directamente en su código de negocio, o el equipo del consumidor parsea directamente el formato del emisor.
Por qué es un error: acopla ambos sistemas en la dimensión del formato. Cuando el formato cambia, los equipos deben coordinarse. La lógica de transformación no puede testearse, versionarse ni desplegarse independientemente.
Corrección: extraer la lógica de transformación a un componente Message Translator independiente, desplegable y versionable de forma autónoma.
Error 2: Translator Monolítico para Todos los Formatos¶
Manifestación: un único componente translator que maneja todas las conversiones de la organización, con una masiva estructura switch/case que crece con cada nueva integración.
Por qué es un error: viola Single Responsibility, se convierte en un cuello de botella organizacional (un solo equipo es owner), un despliegue para un formato afecta a todos los demás, y el testing es exponencialmente complejo.
Corrección: un translator por par de formatos (o por tipo de mensaje), desplegable independientemente, con su propio ciclo de vida.
Error 3: Ignorar la Pérdida de Información¶
Manifestación: el translator descarta silenciosamente campos que no tienen equivalente en el formato destino, sin documentar ni alertar sobre la pérdida.
Por qué es un error: los consumidores asumen que reciben información completa y toman decisiones de negocio basadas en datos incompletos. En el dominio healthcare, perder un campo OBX con un resultado anormal puede tener consecuencias clínicas.
Corrección: documentar explícitamente qué campos se mapean, cuáles se descartan, y cuáles se transforman con pérdida semántica. Incluir un campo de metadata en el mensaje traducido indicando completeness. Alertar cuando un campo esperado no está presente en la entrada.
Error 4: No Manejar Errores de Traducción¶
Manifestación: cuando un mensaje no puede traducirse (campo obligatorio ausente, valor fuera de rango, formato inesperado), el translator swallows la excepción, logea un warning, y sigue adelante. El mensaje desaparece silenciosamente.
Por qué es un error: violación del principio de no perder mensajes. El productor cree que el mensaje fue enviado; el consumidor nunca lo recibe; nadie se entera hasta que un proceso de negocio falla días después.
Corrección: enviar todo mensaje no traducible al Dead Letter Channel con metadata completa sobre el error. Monitorear la profundidad del DLQ. Implementar un proceso de review y reprocesamiento de mensajes en DLQ.
Error 5: Hardcodear Tablas de Mapeo de Códigos¶
Manifestación: los mapeos de códigos (ej., HL7 Table 0001 a FHIR administrative-gender) están hardcodeados en el código del translator como constantes o diccionarios estáticos.
Por qué es un error: cuando las tablas de mapeo cambian (se añade un nuevo código, se depreca uno existente), se requiere un cambio de código, un rebuild y un redeploy del translator. En entornos regulados con ciclos de release lentos, esto puede tardar semanas.
Corrección: externalizar las tablas de mapeo a un servicio de terminología (ej., un Terminology Server FHIR, una base de datos de mapeos, o un configuration service). El translator consulta las tablas en runtime (con caching adecuado).
Error 6: No Versionar el Translator con los Esquemas¶
Manifestación: el translator se despliega sin versión explícita, y cuando el formato de entrada o salida cambia, se actualiza "in place" sin rollback posible.
Por qué es un error: si la nueva versión tiene un bug, no hay forma de volver a la versión anterior. Si productores y consumidores migran a diferentes velocidades, no hay forma de mantener translators compatibles con ambas versiones.
Corrección: versionar el translator semánticamente (MAJOR.MINOR.PATCH), alinear las versiones del translator con las versiones de los esquemas que soporta, y mantener múltiples versiones en producción durante períodos de transición.
Error 7: No Considerar el Rendimiento¶
Manifestación: el translator usa parsing DOM completo para documentos XML de 10MB, o XSLT recursivas sobre mensajes grandes, o reflexión Java extensiva para mapeos genéricos, resultando en tiempos de traducción de segundos por mensaje.
Por qué es un error: en un pipeline con miles de mensajes por segundo, un translator lento se convierte en el cuello de botella del sistema completo. El backpressure se propaga upstream causando timeouts y pérdida de mensajes.
Corrección: perfilar el translator con cargas representativas. Usar parsing streaming (SAX, StAX) para documentos grandes. Pre-compilar expresiones de mapeo. Usar serialización binaria (Avro, Protobuf) cuando la legibilidad no es necesaria. Implementar caching de lookups frecuentes.
Error 8: Transformar Headers de Transporte¶
Manifestación: el translator modifica o descarta headers de transporte del mensaje (correlation ID, trace context, message ID) como parte de la traducción.
Por qué es un error: rompe la trazabilidad end-to-end, impide la correlación request-reply, y puede causar reprocesamiento duplicado si se pierde el message ID.
Corrección: el translator debe preservar todos los headers de transporte del mensaje original. La traducción opera sobre el body (contenido de negocio), no sobre los headers de infraestructura.
18. Conclusión Técnica¶
Message Translator es un patrón estructural de integración que resuelve uno de los problemas más fundamentales y persistentes en la arquitectura empresarial: la heterogeneidad de formatos de datos entre sistemas. Su importancia no ha disminuido con la modernización tecnológica; al contrario, la proliferación de microservicios, APIs, formatos de serialización, estándares regulatorios y plataformas cloud ha multiplicado la necesidad de traducciones bien diseñadas, explícitamente ubicadas y rigurosamente gestionadas.
Desde la perspectiva del arquitecto senior, las decisiones clave alrededor de Message Translator no son sobre la implementación de la transformación (que es esencialmente un ejercicio de programación), sino sobre su ubicación en la arquitectura (inline vs. servicio independiente), su granularidad (un translator por par de formatos vs. hub canónico), su tecnología de mapeo (imperativa vs. declarativa), su gobernanza (versionamiento, ownership, testing) y su operación (monitoreo, escalabilidad, gestión de errores).
El ejemplo de healthcare presentado — la transformación HL7v2 a FHIR en un hospital — ilustra la complejidad real que enfrentan los translators en producción: no es solo renombrar campos, sino convertir entre paradigmas de modelado radicalmente diferentes, traducir terminologías, establecer relaciones entre recursos, y manejar la pérdida semántica inherente a toda traducción entre modelos de diferente riqueza expresiva.
La combinación de Message Translator con Canonical Data Model sigue siendo la estrategia más escalable para ecosistemas con múltiples formatos: reduce la complejidad de O(N²) a O(N), proporciona un punto de referencia semántico compartido, y facilita la incorporación de nuevos sistemas. Sin embargo, requiere la disciplina organizativa de mantener el modelo canónico actualizado y los translators sincronizados con las evoluciones de los formatos nativos.
En el contexto tecnológico actual, el patrón se implementa de formas diversas — desde SMTs de Kafka Connect para transformaciones simples, pasando por DataWeave de MuleSoft o rutas Apache Camel para transformaciones complejas, hasta pipelines de Step Functions con Lambda para orquestaciones multi-paso en cloud. La elección de la tecnología de implementación debe responder a los requisitos de volumen, latencia, complejidad de la transformación, y capacidades del equipo, no a preferencias de vendor.
El arquitecto debe resistir la tentación de trivializar Message Translator como "solo un mapeo de campos" y reconocerlo como un componente arquitectónico de primera clase que requiere diseño intencional, testing exhaustivo, monitoreo proactivo y gobierno disciplinado. Los errores en la traducción de mensajes son particularmente insidiosos porque pueden producir datos incorrectos que se propagan silenciosamente por todo el ecosistema, causando problemas de negocio que solo se descubren semanas o meses después de la traducción errónea.
Message Translator, correctamente diseñado y operado, es el habilitador silencioso de la interoperabilidad empresarial — el componente que permite que sistemas diseñados por diferentes equipos, en diferentes épocas, con diferentes tecnologías y diferentes modelos de datos, colaboren de forma fluida en un ecosistema integrado.