Message Endpoint¶
1. Nombre del Patrón¶
- Nombre oficial: Message Endpoint
- Categoría: Messaging Systems (Sistemas de Mensajería — Conceptos Fundacionales)
- Traducción contextual: Punto de Conexión de Mensajería
2. Resumen Ejecutivo¶
Message Endpoint es el patrón que define el componente de software encargado de conectar una aplicación con el sistema de mensajería subyacente. Es la frontera arquitectónica donde la lógica de negocio de una aplicación se encuentra con la infraestructura de messaging: el código que produce mensajes, los consume, los serializa, gestiona conexiones al broker, maneja acknowledgments y traduce entre el modelo de dominio de la aplicación y el formato de los mensajes que viajan por los canales.
El problema que resuelve es fundamentalmente uno de separación de responsabilidades: ¿cómo se conecta una aplicación al sistema de mensajería sin que la lógica de negocio quede contaminada con detalles de protocolos, conexiones, serialización, reintentos y semántica de entrega? Message Endpoint responde a esta pregunta introduciendo una capa de abstracción explícita — un componente dedicado exclusivamente a la interacción con el messaging system — que encapsula toda la complejidad técnica de la comunicación asíncrona y expone una interfaz limpia a la lógica de aplicación.
Si Message Channel es la tubería por donde fluyen los mensajes y Message es el paquete que viaja por la tubería, Message Endpoint es el enchufe — el punto de conexión donde la aplicación se conecta a la tubería. Sin este enchufe bien diseñado, la aplicación y la infraestructura de messaging quedan soldadas en un acoplamiento que hace imposible evolucionar una sin afectar a la otra.
3. Definición Detallada¶
Propósito¶
Message Endpoint encapsula toda la lógica necesaria para que una aplicación interactúe con un sistema de mensajería. Su propósito es servir como intermediario entre el dominio de la aplicación (objetos de negocio, eventos de dominio, comandos) y el dominio de la infraestructura de messaging (conexiones TCP, protocolos AMQP/Kafka/JMS, serialización binaria, offsets, acknowledgments, particiones). El endpoint traduce intenciones de negocio ("publicar que se creó un pedido") en operaciones técnicas de messaging ("serializar el evento a Avro, enviarlo al topic orders.created con order_id como partition key, esperar ack del broker con timeout de 5 segundos").
Lógica Arquitectónica¶
El endpoint introduce una capa de indirección entre la aplicación y el messaging system que tiene consecuencias arquitectónicas de primer orden:
- Encapsulación de protocolo: la aplicación no necesita conocer si el broker subyacente es Kafka, RabbitMQ, Azure Service Bus o AWS SQS. El endpoint abstrae el protocolo específico detrás de una interfaz uniforme.
- Encapsulación de ciclo de vida de conexión: la gestión de conexiones (apertura, pooling, heartbeat, reconexión ante fallos) queda contenida en el endpoint, invisible para la lógica de negocio.
- Encapsulación de serialización: la conversión entre objetos de dominio y bytes (JSON, Avro, Protobuf, MessagePack) es responsabilidad exclusiva del endpoint.
- Encapsulación de semántica de entrega: la lógica de reintentos, acknowledgments, idempotencia y manejo de errores de comunicación reside en el endpoint.
Esta separación permite que la lógica de negocio evolucione independientemente de la infraestructura de messaging, y viceversa. Un cambio de broker (de RabbitMQ a Kafka, por ejemplo) afecta solo al endpoint, no a toda la aplicación. Un cambio en el modelo de dominio afecta solo la lógica de negocio y la capa de serialización del endpoint, no la lógica de conexión y entrega.
Principio de Diseño Subyacente¶
El principio fundamental es separación de concerns entre lógica de aplicación e infraestructura de comunicación. Es una aplicación del principio de inversión de dependencias (DIP): la lógica de negocio de alto nivel no debe depender de los detalles de bajo nivel de la comunicación con el broker. Ambos deben depender de abstracciones (interfaces del endpoint).
Este principio es análogo al patrón Repository en Domain-Driven Design: así como Repository encapsula el acceso a datos detrás de una interfaz de colección, Message Endpoint encapsula el acceso al messaging system detrás de una interfaz de producción/consumo de mensajes.
Problema Estructural que Resuelve¶
Sin Message Endpoint, el código de interacción con el broker se dispersa por toda la aplicación. Cada servicio, cada handler, cada componente que necesita enviar o recibir mensajes contiene código de conexión, serialización, manejo de errores y reintentos. Esta dispersión produce:
- Duplicación: la misma lógica de conexión y serialización replicada en decenas de clases.
- Inconsistencia: cada desarrollador implementa el manejo de errores de forma diferente; algunos reintentan, otros ignoran, otros propagan excepciones no manejadas.
- Fragilidad: un cambio en la configuración del broker (nuevo puerto, nuevo protocolo de autenticación) requiere modificar código en múltiples puntos.
- Imposibilidad de testing: la lógica de negocio no se puede probar sin un broker real porque está entrelazada con el código de messaging.
Message Endpoint centraliza toda esta lógica en un componente cohesivo, eliminando la duplicación, estableciendo un comportamiento uniforme, reduciendo la superficie de cambio ante evoluciones de infraestructura y habilitando el testing mediante la sustitución del endpoint por un mock o stub.
Contexto en el que Emerge¶
Message Endpoint emerge en cualquier aplicación que participe en un sistema de mensajería, ya sea como productora, consumidora o ambas. Es especialmente crítico en aplicaciones empresariales donde:
- Múltiples servicios producen y consumen mensajes en múltiples canales.
- Existen requisitos de observabilidad (métricas de producción y consumo, tracing distribuido).
- La infraestructura de messaging puede cambiar (migración de broker, upgrade de versión).
- Existen estándares organizacionales de serialización, naming, manejo de errores y seguridad que deben aplicarse uniformemente.
Por Qué No Es Trivial¶
Aunque conceptualmente simple ("un componente que envía y recibe mensajes"), las decisiones de diseño alrededor del Message Endpoint son sorprendentemente complejas:
- Threading model: ¿el endpoint usa un thread pool dedicado? ¿Cuántos threads para producción? ¿Cuántos para consumo? ¿El consumo es blocking (poll) o event-driven (push)?
- Batching: ¿el endpoint acumula mensajes y los envía en batch para mejorar throughput, o envía uno a uno para minimizar latencia?
- Backpressure: ¿qué hace el endpoint cuando el broker está saturado o el consumidor no puede procesar tan rápido como llegan los mensajes? ¿Bloquea al productor? ¿Descarta mensajes? ¿Aplica rate limiting?
- Error handling: ¿qué ocurre cuando un mensaje no puede ser procesado? ¿Se reintenta? ¿Cuántas veces? ¿Con qué backoff? ¿Se envía a un Dead Letter Channel? ¿Se loggea y se ignora?
- Transaction boundaries: ¿el endpoint participa en la transacción de la aplicación? ¿El send es transaccional? ¿El receive + process + ack es atómico?
- Serialization strategy: ¿JSON flexible pero sin validación de schema? ¿Avro con schema registry y evolución controlada? ¿Protobuf con contratos compilados? La elección afecta performance, interoperabilidad y governance.
- Security: ¿cómo se autentifica el endpoint ante el broker? ¿TLS mutual? ¿SASL? ¿OAuth tokens rotativos? ¿Cómo se gestionan los secretos de conexión?
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, Message Endpoint corresponde al concepto de proceso participante en un sistema de comunicación por paso de mensajes. Es el punto donde un proceso inyecta mensajes en el canal de comunicación (send) y donde extrae mensajes del canal (receive). Las propiedades del endpoint (síncrono vs. asíncrono, confirmado vs. fire-and-forget, transaccional vs. no transaccional) determinan directamente las garantías de entrega que el sistema puede ofrecer:
- Un endpoint que hace send sin esperar ack ofrece at-most-once delivery.
- Un endpoint que hace send con ack y reintento ofrece at-least-once delivery.
- Un endpoint que combina send transaccional con consumo idempotente ofrece effectively-once processing.
En la práctica, cada plataforma de mensajería proporciona sus propias implementaciones de Message Endpoint:
- En Kafka, los endpoints son el
KafkaProducery elKafkaConsumer(Java client), o equivalentes en otros lenguajes. El producer gestiona batching, partitioning y acks. El consumer gestiona polling, offset management y rebalancing. - En RabbitMQ, los endpoints son el
Channelcon operacionesbasicPublishybasicConsume. Gestionan confirmaciones (publisher confirms), acknowledgments del consumidor y prefetch count. - En Azure Service Bus, los endpoints son
ServiceBusSenderyServiceBusReceiver(oServiceBusProcessor). Gestionan AMQP sessions, message locking y auto-complete. - En AWS SQS/SNS, los endpoints son los clientes SDK (
SQSClient,SNSClient). Gestionan long polling, visibility timeout y message deletion.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin la abstracción de Message Endpoint, las aplicaciones que necesitan interactuar con un sistema de mensajería enfrentan una serie de problemas entrelazados:
- Acoplamiento directo al broker: cada componente de la aplicación que envía o recibe mensajes contiene código específico del broker (imports de librerías, configuración de conexión, protocolo de serialización). Cambiar de broker requiere reescribir código en toda la aplicación.
- Dispersión de responsabilidades: la lógica de conexión, serialización, manejo de errores y observabilidad está esparcida por decenas de clases y módulos, sin un punto central de control.
- Inconsistencia de comportamiento: sin un endpoint estandarizado, cada desarrollador implementa la interacción con el broker a su manera. Un servicio reintenta 3 veces con backoff exponencial; otro reintenta infinitamente; otro no reintenta nunca. Un servicio serializa a JSON con snake_case; otro a JSON con camelCase; otro a XML.
- Contaminación de la lógica de negocio: los handlers de lógica de negocio contienen bloques try-catch para errores de conexión al broker, código de serialización/deserialización, configuración de propiedades de mensaje (headers, TTL, priority). El código de negocio es inseparable del código de infraestructura.
- Imposibilidad de testing unitario: no se puede testear la lógica de negocio que procesa un mensaje sin levantar un broker real (o al menos un embedded broker), porque el código de recepción del mensaje está entrelazado con la lógica de procesamiento.
Síntomas del Problema¶
- Clases de servicio que importan directamente librerías de Kafka/RabbitMQ/SQS y mezclan llamadas al broker con lógica de dominio.
- Bloques de configuración de conexión al broker duplicados en múltiples puntos de la aplicación.
- Bugs de producción causados por manejo inconsistente de errores de messaging: un servicio swallows exceptions silenciosamente, causando pérdida de mensajes sin traza.
- Tiempos de migración de broker desproporcionados: lo que debería ser un cambio de infraestructura se convierte en un refactoring masivo de la aplicación.
- Tests de integración lentos y frágiles que requieren un broker real porque no hay seam para inyectar un mock.
- Falta de métricas consistentes: algunos endpoints reportan latencia de envío, otros no; algunos reportan mensajes fallidos, otros los ignoran.
Impacto Operativo y Arquitectónico¶
Sin endpoints bien diseñados:
- Observabilidad fragmentada: no hay forma uniforme de saber cuántos mensajes produce cada servicio, cuántos consume, cuántos fallan, cuánta latencia introduce el endpoint. Cada implementación ad-hoc tiene (o no tiene) su propio mecanismo de métricas.
- Incapacidad de aplicar políticas transversales: si la organización decide que todos los mensajes deben llevar un correlation ID para tracing distribuido, no hay un punto central donde inyectar este header. Hay que modificar cada punto donde se produce un mensaje.
- Fragilidad ante fallos del broker: sin una estrategia uniforme de reconexión y reintento, los fallos del broker se manifiestan de formas impredecibles: algunos servicios se recuperan automáticamente, otros quedan en un estado zombie sin producir ni consumir, otros crashean.
- Imposibilidad de evolución tecnológica: la decisión de migrar de un broker a otro (frecuente en organizaciones que maduran su plataforma de messaging) se convierte en un proyecto de riesgo extremo porque los detalles del broker están infiltrados en toda la base de código.
Riesgos Si No Se Implementa Correctamente¶
- Endpoint que oculta errores: un endpoint que catch-all y loggea sin propagar el error causa pérdida silenciosa de mensajes. La aplicación cree que el mensaje fue enviado/procesado, pero no fue así.
- Endpoint sin backpressure: un endpoint consumidor que procesa mensajes más rápido de lo que la lógica de negocio puede manejar (o más lento de lo que el broker entrega) causa acumulación de mensajes en memoria, potencialmente llevando a OutOfMemoryError.
- Endpoint con serialización frágil: un endpoint que serializa objetos directamente (sin un schema explícito) se rompe silenciosamente cuando el modelo de dominio evoluciona y los consumidores esperan el formato anterior.
- Endpoint sin idempotencia: un endpoint consumidor que no maneja la recepción duplicada de un mensaje (posible en escenarios at-least-once) puede ejecutar efectos colaterales duplicados (doble cobro, doble envío).
- Endpoint con transaction scope incorrecto: un endpoint que hace acknowledge del mensaje antes de completar el procesamiento puede perder el mensaje si el procesamiento falla después del ack.
Ejemplos Reales¶
- Retail: un sistema POS (Point of Sale) en tienda necesita reportar cada venta al sistema central de inventario. Sin un endpoint bien encapsulado, el código del POS contiene directamente llamadas a la API de Kafka Producer con configuración de conexión al cluster central. Cuando la empresa migra a Azure Service Bus, hay que reescribir el módulo de ventas completo — no solo la capa de comunicación.
- Banca: un core bancario necesita publicar eventos de transacciones para que sistemas downstream (anti-fraude, reporting, notificaciones) los consuman. Sin endpoints estandarizados, cada módulo del core bancario serializa los eventos de forma diferente, algunos omiten campos que downstream necesita, y no hay forma uniforme de trazabilidad.
- Healthcare: un sistema de información hospitalaria consume mensajes HL7 FHIR de múltiples fuentes (laboratorio, farmacia, radiología). Sin un endpoint que normalice la recepción, cada integración implementa su propia lógica de parsing, validación y error handling, produciendo comportamiento inconsistente ante mensajes malformados.
- Telecomunicaciones: un sistema de mediación consume CDRs (Call Detail Records) a razón de millones por hora. Sin un endpoint con batching y backpressure bien diseñados, picos de tráfico causan acumulación de mensajes que degrada progresivamente el rendimiento hasta que el sistema colapsa.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Siempre que una aplicación necesite enviar o recibir mensajes de un sistema de mensajería. Al igual que Message Channel es constitutivo de todo sistema de messaging, Message Endpoint es constitutivo de toda aplicación que participe en messaging.
- Cuando se necesita aislar la lógica de negocio de los detalles de infraestructura del broker.
- Cuando existen requisitos de portabilidad entre brokers (actual o futura).
- Cuando la organización requiere comportamiento uniforme en la interacción con el messaging system (logging, métricas, tracing, manejo de errores, serialización).
- Cuando se necesita testear la lógica de negocio de forma unitaria sin dependencia de un broker real.
- Cuando múltiples equipos producen y consumen mensajes y se necesita un contrato de comportamiento estandarizado.
Cuándo No Usarlo¶
- En prototipos o pruebas de concepto donde la velocidad de desarrollo prima sobre la mantenibilidad, puede ser aceptable interactuar directamente con el SDK del broker sin una capa de abstracción adicional. Sin embargo, esta deuda técnica debe pagarse antes de llegar a producción.
- Cuando la aplicación es un conector o adapter cuya única responsabilidad es mover mensajes entre dos sistemas (en este caso, el endpoint ES la aplicación, no una capa dentro de ella).
- Cuando se usa un framework que ya proporciona la abstracción del endpoint de forma transparente (por ejemplo, Spring Cloud Stream abstrae completamente el endpoint detrás de bindings declarativos). En este caso, el framework implementa el patrón; el desarrollador no necesita implementarlo explícitamente pero sí debe comprenderlo.
Precondiciones¶
- Existe un sistema de mensajería (broker) al que la aplicación necesita conectarse.
- Existe claridad sobre los canales (topics, queues) con los que el endpoint interactuará.
- Existe un acuerdo sobre el formato de serialización de los mensajes (JSON, Avro, Protobuf).
- Existen credenciales y permisos para que el endpoint se autentifique y autorice ante el broker.
- La infraestructura de red permite la conectividad entre la aplicación y el broker.
Restricciones¶
- El endpoint debe ser compatible con la versión del protocolo del broker (por ejemplo, versión del Kafka protocol, versión de AMQP).
- Los recursos computacionales del endpoint (threads, memoria para buffers, conexiones de red) están limitados por el entorno de ejecución (container limits, VM resources).
- Las políticas de seguridad de la organización pueden restringir los mecanismos de autenticación y encriptación que el endpoint puede usar.
- En entornos multi-tenant, el endpoint puede estar restringido a un subconjunto de canales y operaciones.
Dependencias¶
- SDK o librería cliente del broker (kafka-clients, amqp-client, azure-servicebus, aws-sdk).
- Librería de serialización (jackson, avro, protobuf, confluent-schema-registry-client).
- Infraestructura de observabilidad (micrometer, OpenTelemetry, Prometheus client) para instrumentar el endpoint.
- Gestor de configuración para propiedades de conexión (spring-config, consul, vault para secretos).
- Framework de inyección de dependencias para registrar el endpoint como componente gestionado.
Supuestos Arquitectónicos¶
- El broker está disponible y accesible desde el entorno de ejecución de la aplicación.
- El endpoint gestiona su propio ciclo de vida de conexión (apertura, reconnection, cierre graceful).
- La lógica de negocio interactúa con el endpoint a través de una interfaz estable que no expone detalles del broker subyacente.
- El endpoint es responsable de la serialización y deserialización, no la lógica de negocio.
- El endpoint es responsable de garantizar la semántica de entrega acordada (at-least-once, at-most-once).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Microservicios event-driven que producen y consumen eventos de dominio.
- Aplicaciones empresariales que se integran con sistemas legacy a través de messaging.
- Sistemas de procesamiento de eventos en tiempo real (streaming pipelines).
- Aplicaciones IoT que ingestan telemetría de dispositivos.
- Plataformas de e-commerce con flujos asíncronos (pedidos, pagos, envíos, notificaciones).
- Sistemas financieros con publicación de transacciones para compliance y auditoría.
6. Fuerzas Arquitectónicas¶
Abstracción vs. Performance¶
El endpoint introduce una capa de abstracción entre la aplicación y el broker. Esta capa permite portabilidad y testabilidad, pero puede añadir overhead: una llamada adicional en el stack, una conversión de formato extra, un nivel más de buffering. En sistemas de ultra-baja latencia (trading de alta frecuencia, real-time bidding), esta capa adicional puede ser inaceptable. En la gran mayoría de aplicaciones empresariales, el overhead es despreciable frente a la latencia de red y del broker.
Encapsulación vs. Flexibilidad¶
Un endpoint que abstrae completamente el broker ofrece portabilidad pero puede ocultar capacidades específicas de la plataforma. Por ejemplo, un endpoint genérico no puede exponer la capacidad de Kafka de leer desde un offset específico, o la capacidad de RabbitMQ de enrutar por headers. La tensión está en decidir cuánta funcionalidad específica del broker se expone a través del endpoint vs. cuánta se oculta detrás de una interfaz genérica. El diseño más pragmático suele ser una interfaz genérica con escape hatches para funcionalidad específica.
Simplicidad vs. Robustez¶
Un endpoint simple (send message, receive message) es fácil de usar pero frágil ante fallos. Un endpoint robusto (con reintentos, circuit breaker, dead letter handling, métricas, tracing) es resiliente pero complejo de configurar y entender. El equilibrio depende de la criticidad del flujo de mensajes: un endpoint para notificaciones de marketing puede ser simple; un endpoint para transacciones financieras debe ser extremadamente robusto.
Síncrono vs. Asíncrono en la Interfaz del Endpoint¶
El endpoint puede exponer una interfaz síncrona (send() bloquea hasta recibir ack del broker) o asíncrona (sendAsync() retorna un Future/Promise). La interfaz síncrona es más simple de programar pero puede bloquear threads de la aplicación. La interfaz asíncrona es más eficiente pero introduce complejidad de manejo de callbacks, errores asíncronos y ordering.
Transaccionalidad vs. Throughput¶
Un endpoint transaccional (que participa en la transacción de la base de datos de la aplicación — transactional outbox, Kafka transactions) garantiza consistencia entre el estado de la aplicación y los mensajes enviados, pero reduce throughput por el overhead transaccional. Un endpoint no transaccional es más rápido pero puede producir inconsistencias (mensaje enviado pero base de datos no actualizada, o viceversa).
Centralización vs. Especialización¶
¿Un endpoint genérico para toda la aplicación, o endpoints especializados por tipo de mensaje/canal? Un endpoint genérico reduce duplicación pero puede resultar en una interfaz sobrecargada con parámetros opcionales para todos los casos de uso. Endpoints especializados son más expresivos pero multiplican el código de infraestructura.
Governance vs. Autonomía de Equipos¶
Un endpoint estándar impuesto por la plataforma (un "starter" o librería interna) garantiza comportamiento uniforme pero limita la autonomía de los equipos para optimizar su interacción con el broker. Equipos con requisitos atípicos (ultra-alto throughput, latencia ultra-baja) pueden necesitar bypasear el endpoint estándar, creando excepciones que erosionan la consistencia.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Aplicación (Business Logic): el código de dominio que produce eventos de negocio o procesa eventos recibidos. No conoce al broker ni al protocolo de messaging.
- Message Endpoint (Productor): componente que recibe objetos de dominio de la aplicación, los serializa a mensajes, gestiona la conexión al broker y los envía al canal correcto con la semántica de entrega requerida.
- Message Endpoint (Consumidor): componente que se conecta al broker, recibe mensajes del canal, los deserializa a objetos de dominio, los entrega a la lógica de negocio y gestiona acknowledgments.
- Broker / Messaging System: infraestructura que gestiona canales, almacena mensajes y los entrega. El endpoint interactúa con el broker a través de su protocolo nativo.
- Schema Registry (opcional): servicio que almacena y valida schemas de mensajes. El endpoint lo consulta para serialización/deserialización con validación de compatibilidad.
- Configuración: fuente de propiedades de conexión (bootstrap servers, credenciales, timeouts, retry policies) que el endpoint consume al inicializarse.
Flujo Lógico — Producción¶
flowchart TD
A([Business Logic]) -->|send domainEvent| B[Endpoint: Valida contra schema]
B --> C[Serializa al formato wire]
C --> D[Determina canal destino y partition key]
D --> E[Inyecta headers estándar]
E --> F[Envía mensaje al broker]
F --> G{Respuesta del broker}
G -->|ACK| H[Retorna éxito a business logic]
G -->|NACK/Timeout| I{Retries disponibles?}
I -->|Sí| J[Retry con backoff exponencial] --> F
I -->|No| K[Propaga error o envía a DLQ]
H --> L[Registra métricas y trace span]
K --> LFlujo Lógico — Consumo¶
flowchart TD
A[Endpoint: Conecta y se suscribe al canal] --> B[Broker: Asigna particiones/mensajes]
B --> C[Endpoint: Recibe mensaje del broker]
C --> D[Deserializa payload a objeto de dominio]
D --> E[Valida mensaje: schema, campos, versión]
E --> F[Extrae headers: correlation-id, metadata]
F --> G[Invoca handler de business logic]
G --> H{Resultado del procesamiento}
H -->|Success| I[Confirma ACK al broker]
H -->|Failure| J{Error handling}
J -->|Retry| C
J -->|Dead Letter| K[(Dead Letter Queue)]
J -->|NACK + requeue| B
I --> L[Registra métricas y consumer lag]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Business Logic | Producir eventos de dominio, procesar eventos recibidos. No conoce al broker. |
| Endpoint Productor | Serializar, enrutar al canal correcto, enviar, reintentar, registrar métricas |
| Endpoint Consumidor | Recibir, deserializar, entregar a business logic, acknowledge, manejar errores |
| Broker | Almacenar y entregar mensajes según semántica del canal |
| Schema Registry | Almacenar schemas, validar compatibilidad, servir schemas para serialización |
| Configuración | Proveer propiedades de conexión, policies, feature flags |
Interacciones¶
- Business Logic --> Endpoint Productor: invocación síncrona o asíncrona con un objeto de dominio como parámetro. El endpoint retorna confirmación de envío o excepción/error.
- Endpoint Productor --> Broker: comunicación de red con el protocolo nativo del broker. Incluye handshake, autenticación, envío de mensaje, recepción de ack.
- Broker --> Endpoint Consumidor: entrega de mensajes por push (RabbitMQ) o pull/poll (Kafka). Incluye asignación de particiones y gestión de offsets.
- Endpoint Consumidor --> Business Logic: invocación del handler de negocio con el objeto de dominio deserializado.
- Endpoint <--> Schema Registry: consulta de schema para serialización/deserialización. Cache local para evitar round trips en cada mensaje.
Contratos Implícitos¶
- Interfaz del endpoint hacia la business logic: un contrato de API que define cómo enviar y recibir mensajes sin exponer detalles del broker. Este contrato debe ser estable y versionado.
- Formato de serialización: acuerdo entre productor y consumidor sobre cómo se serializan los mensajes (JSON con cierto schema, Avro con schema ID, Protobuf con descriptores).
- Headers estándar: acuerdo sobre qué headers debe inyectar el endpoint (correlation-id, causation-id, message-type, schema-version, source-service, timestamp).
- Semántica de errores: cómo el endpoint reporta errores a la business logic (excepciones, error codes, callbacks de error) y qué errores son retriable vs. fatales.
- Ordering guarantee: si el endpoint garantiza orden de envío/recepción y bajo qué condiciones (mismo partition key, misma sesión).
Decisiones de Diseño Clave¶
- Granularidad: ¿un endpoint por canal? ¿Un endpoint por tipo de mensaje? ¿Un endpoint genérico para toda la aplicación? La granularidad afecta la cohesión, la configurabilidad y la superficie de testing.
- Interfaz síncrona vs. asíncrona: determina cómo la business logic interactúa con el endpoint y tiene implicaciones en threading y error handling.
- Estrategia de serialización: JSON (simple, legible, sin schema enforcement), Avro (compacto, schema-enforced, evolucionable), Protobuf (compacto, schema-enforced, compilado). La elección impacta performance, governance y acoplamiento.
- Estrategia de error handling: retry con backoff, dead letter queue, circuit breaker, fallback. Debe estar configurada externamente, no hardcodeada.
- Modelo de threading: threads dedicados para producción y consumo, pool compartido, event loop. Determina throughput, latencia y consumo de recursos.
- Observabilidad: qué métricas expone el endpoint (latency histograms, error rates, throughput, consumer lag), qué traces propaga, qué logs genera.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail — Sistema POS con Gestión de Inventario Event-Driven¶
Contexto del Negocio¶
Una cadena de retail con 850 tiendas físicas en 12 países opera un sistema Point of Sale (POS) que registra cada venta en el momento de la transacción. El inventario se gestiona mediante una arquitectura event-driven: cada venta genera un evento que debe propagarse en tiempo real al sistema central de inventario, al sistema de analytics, al motor de recomendaciones y al sistema de alertas de reposición. La cadena procesa un promedio de 2.3 millones de transacciones diarias, con picos de 15,000 transacciones por minuto durante campañas de descuento (Black Friday, rebajas de temporada).
Necesidad de Integración¶
El sistema POS de cada tienda debe reportar cada venta al ecosistema central sin bloquear la operación de caja. La latencia máxima aceptable entre el momento de la venta y la actualización del inventario es de 30 segundos. La pérdida de un evento de venta es crítica: produce discrepancia de inventario que se traduce en sobre-stock o rotura de stock, con impacto financiero directo.
El POS es una aplicación legacy escrita en Java que corre en terminales en tienda. El sistema de inventario es un microservicio Kotlin corriendo en Kubernetes. La comunicación se realiza a través de Apache Kafka desplegado en un cluster central con 12 brokers.
Sistemas Involucrados¶
- POS Terminal Application (Java 17, Spring Boot): aplicación desplegada en cada terminal de caja. Registra ventas, calcula totales, procesa pagos. Necesita un endpoint productor para publicar eventos de venta.
- Kafka Cluster (12 brokers, 3 datacenters): plataforma de streaming que gestiona los canales de eventos.
- Inventory Management Service (Kotlin, Spring Boot): microservicio que mantiene el inventario en tiempo real. Necesita un endpoint consumidor para recibir eventos de venta y decrementar stock.
- Analytics Pipeline (Kafka Streams + ClickHouse): pipeline que agrega datos de ventas para dashboards de negocio.
- Recommendation Engine (Python, consumidor Kafka): motor de ML que actualiza modelos de recomendación basándose en ventas recientes.
- Replenishment Alert Service (Go): servicio que genera alertas cuando el stock de un producto cae por debajo del umbral de reposición.
- Schema Registry (Confluent Schema Registry): almacena y valida schemas Avro de los eventos.
Restricciones Técnicas¶
- Los terminales POS tienen conectividad intermitente (WiFi de tienda, con cortes de minutos durante picos de carga de red).
- La venta NO debe bloquearse si el endpoint no puede conectar al broker. El POS debe seguir operando offline y sincronizar cuando recupere conectividad.
- El evento de venta debe contener toda la información necesaria para actualizar inventario (productos, cantidades, tienda, timestamp) sin necesidad de consultas adicionales.
- El inventario debe ser eventualmente consistente: no se requiere consistencia inmediata pero sí convergencia en menos de 30 segundos bajo operación normal.
- Existen 45,000 SKUs activos. El particionamiento debe garantizar que eventos del mismo producto se procesen en orden (para evitar race conditions en el decremento de stock).
- La serialización debe usar Avro con Schema Registry para garantizar evolución controlada del schema del evento.
Diseño de Endpoints¶
Endpoint Productor (POS Terminal)¶
El POS Terminal implementa un Message Endpoint productor con las siguientes características:
| Aspecto | Decisión de Diseño |
|---|---|
| Interfaz | SaleEventPublisher.publish(SaleCompletedEvent) — interfaz de dominio sin referencia a Kafka |
| Serialización | Avro con schema sale-completed-v2, registrado en Schema Registry |
| Canal destino | Topic retail.pos.sale-completed, 120 particiones |
| Partition key | store_id + product_sku (garantiza orden por producto por tienda) |
| Acks | acks=all (requiere confirmación de todas las réplicas ISR) |
| Reintentos | 5 reintentos con backoff exponencial (100ms, 200ms, 400ms, 800ms, 1600ms) |
| Buffering offline | Cola local persistente en SQLite para eventos no enviados durante desconexión |
| Métricas | Latencia de envío, tasa de error, mensajes en buffer offline, tamaño de batch |
| Headers | correlation-id, store-id, terminal-id, event-timestamp, schema-version |
Endpoint Consumidor (Inventory Management Service)¶
El Inventory Management Service implementa un Message Endpoint consumidor con las siguientes características:
| Aspecto | Decisión de Diseño |
|---|---|
| Interfaz | SaleEventHandler.handle(SaleCompletedEvent) — handler de dominio |
| Consumer Group | cg-inventory-mgmt |
| Deserialización | Avro con Schema Registry, backward compatible |
| Concurrencia | 12 consumer instances (una por partición asignada), max.poll.records=500 |
| Ack strategy | Manual commit después de procesamiento exitoso (at-least-once) |
| Idempotencia | Deduplicación por event_id con TTL de 24 horas en Redis |
| Error handling | 3 reintentos locales, luego dead letter topic retail.pos.sale-completed.dlq |
| Métricas | Consumer lag, latencia de procesamiento, tasa de error, mensajes en DLQ |
| Tracing | Propagación de correlation-id desde headers del mensaje al span de OpenTelemetry |
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de evento de venta por caída del POS | Buffer local en SQLite con flush al reconectar |
| Duplicación de eventos por retry del productor | Idempotent producer habilitado (Kafka enable.idempotence=true) |
| Procesamiento duplicado en el consumidor | Deduplicación por event_id en Redis antes del procesamiento |
| Schema evolution rompe consumidores | Avro con compatibilidad BACKWARD en Schema Registry; CI valida compatibilidad |
| Consumer lag excesivo por pico de ventas | Auto-scaling de consumer instances en Kubernetes basado en consumer lag metric |
| Desconexión prolongada del POS | Alertas si buffer offline supera 1000 eventos; escalamiento operacional |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Venta en el POS Terminal¶
Un cajero en la tienda de Madrid (store_id: ST-0342) registra una venta de 3 unidades del producto SKU ELEC-TV-55-SAM (televisor Samsung 55") y 1 unidad de SKU ACC-HDMI-2M (cable HDMI 2m) a las 14:32:15 UTC. El módulo de ventas del POS completa la transacción local (pago procesado, ticket emitido) y genera un evento de dominio:
{
"event_id": "evt-20260407-143215-ST0342-T04-00127",
"event_type": "SaleCompleted",
"event_timestamp": "2026-04-07T14:32:15.847Z",
"store_id": "ST-0342",
"terminal_id": "T04",
"transaction_id": "TXN-20260407-ST0342-T04-00127",
"items": [
{
"sku": "ELEC-TV-55-SAM",
"quantity": 3,
"unit_price_cents": 54999,
"total_price_cents": 164997
},
{
"sku": "ACC-HDMI-2M",
"quantity": 1,
"unit_price_cents": 1299,
"total_price_cents": 1299
}
],
"total_amount_cents": 166296,
"currency": "EUR",
"payment_method": "CARD",
"cashier_id": "EMP-28741"
}
La lógica de negocio invoca saleEventPublisher.publish(saleCompletedEvent) — una llamada simple a la interfaz del endpoint, sin ninguna referencia a Kafka, topics ni serialización.
Paso 2: El Endpoint Productor Procesa el Envío¶
El SaleEventPublisher (implementación del Message Endpoint productor) ejecuta la siguiente secuencia:
- Validación: verifica que el evento tiene todos los campos obligatorios (event_id, store_id, items no vacío).
- Serialización: consulta el schema
sale-completed-v2en la cache local del Schema Registry client. Serializa el evento a formato Avro binario (reduciendo el tamaño de ~450 bytes JSON a ~180 bytes Avro). - Headers: inyecta headers estándar de la organización:
X-Correlation-Id: genera un UUID nuevo (corr-a7f3e291-...) que permitirá trazar este evento a través de todo el ecosistema.X-Source-Service:pos-terminalX-Store-Id:ST-0342X-Event-Type:SaleCompletedX-Schema-Version:2- Partition key: genera la key como
ST-0342|ELEC-TV-55-SAMpara el primer item. Dado que un evento de venta puede contener múltiples SKUs, el endpoint produce un mensaje por item (split) con la misma correlation, para garantizar que eventos del mismo SKU en la misma tienda se procesan en orden. - Envío: invoca
kafkaProducer.send()con el topicretail.pos.sale-completed, la partition key calculada y el payload Avro. Espera elFuturede respuesta con timeout de 5 segundos. - Ack recibido: el broker confirma recepción (offset asignado: partition 47, offset 8,291,003). El endpoint registra la métrica
pos.sale.event.sentcon labelsstore=ST-0342,status=success,latency_ms=23. - Retorno: retorna éxito a la lógica de negocio.
Paso 3: Escenario de Desconexión¶
A las 15:10 UTC, la conexión WiFi de la tienda ST-0342 sufre una interrupción. El endpoint productor detecta que el send() falla con TimeoutException. Ejecuta la siguiente estrategia:
- Retry 1 (tras 100ms): falla de nuevo.
- Retry 2 (tras 200ms): falla de nuevo.
- El endpoint determina que la conectividad no se va a restaurar inmediatamente.
- Buffer offline: almacena el evento en una cola local SQLite (
pos_outboxtable) con estadoPENDING. - Retorno: retorna éxito a la lógica de negocio — la venta NO se bloquea por la desconexión.
- Un background thread monitorea la conectividad cada 5 segundos. Cuando la conexión se restaura (15:17 UTC), drena la cola SQLite en orden FIFO, reenviando cada evento a través del endpoint normal.
- Registra métrica
pos.sale.event.bufferedypos.sale.event.buffer.drained.
Paso 4: El Endpoint Consumidor Recibe el Evento¶
El Inventory Management Service tiene 12 instancias corriendo en Kubernetes, cada una con un endpoint consumidor que participa en el consumer group cg-inventory-mgmt. El broker ha asignado 10 particiones a cada instancia.
La instancia #7 recibe el mensaje de la partición 47 (correspondiente al key ST-0342|ELEC-TV-55-SAM):
- Polling: el endpoint ejecuta
consumer.poll(Duration.ofMillis(100))y recibe un batch de 23 mensajes, incluyendo el evento de venta. - Deserialización: el endpoint consulta el Schema Registry para obtener el schema correspondiente al schema ID embebido en el mensaje Avro. Deserializa el payload binario al objeto
SaleCompletedEvent. - Validación: verifica que el evento deserializado es structuralmente válido.
- Deduplicación: consulta Redis con key
dedup:evt-20260407-143215-ST0342-T04-00127. No existe — el evento no es duplicado. Inserta la key con TTL de 24 horas. - Header extraction: extrae
X-Correlation-Idy lo propaga al contexto de OpenTelemetry para tracing distribuido. - Invocación del handler: invoca
saleEventHandler.handle(saleCompletedEvent). El handler de negocio: - Consulta el stock actual del SKU
ELEC-TV-55-SAMen la tiendaST-0342: 8 unidades. - Decrementa en 3: nuevo stock = 5 unidades.
- Persiste el nuevo stock en PostgreSQL.
- Si el stock cae por debajo del umbral de reposición (10 unidades), genera un evento
ReplenishmentNeeded. - Acknowledge: tras el retorno exitoso del handler, el endpoint ejecuta
consumer.commitSync()para confirmar el offset procesado. - Métricas: registra
inventory.sale.event.processedcon labelsstore=ST-0342,sku=ELEC-TV-55-SAM,status=success,processing_time_ms=12.
Paso 5: Error Handling en el Consumidor¶
Un mensaje posterior contiene un SKU desconocido (ELEC-TV-65-LGX) que no existe en el catálogo de inventario. El handler de negocio lanza UnknownSkuException:
- Retry 1: el endpoint reintenta la invocación del handler (por si el catálogo se estaba actualizando). Falla de nuevo.
- Retry 2: falla de nuevo.
- Retry 3: falla de nuevo.
- Dead Letter: el endpoint publica el mensaje original en el topic
retail.pos.sale-completed.dlqcon headers adicionales: X-DLQ-Reason:UnknownSkuException: SKU ELEC-TV-65-LGX not found in catalogX-DLQ-Retry-Count:3X-DLQ-Original-Topic:retail.pos.sale-completedX-DLQ-Original-Partition:47X-DLQ-Original-Offset:8291047X-DLQ-Timestamp:2026-04-07T14:35:02.103Z- Acknowledge: confirma el offset del mensaje original (para no bloquear la partición).
- Alerta: la métrica
inventory.sale.event.dlqse incrementa, disparando una alerta en PagerDuty para que el equipo de inventario investigue.
Paso 6: Observabilidad End-to-End¶
El correlation-id corr-a7f3e291-... permite trazar el flujo completo:
- Jaeger/Tempo: muestra un trace con spans desde el POS terminal (producción), pasando por Kafka (broker), hasta el Inventory Service (consumo y procesamiento). Latencia total: 847ms.
- Grafana dashboards: muestran métricas del endpoint productor (events/sec por tienda, latencia p99 de envío, tasa de buffer offline) y del endpoint consumidor (consumer lag por partición, latencia p99 de procesamiento, tasa de DLQ).
- Alertas: si el consumer lag de
cg-inventory-mgmtsupera 60 segundos, se dispara alerta de "inventory sync delayed".
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
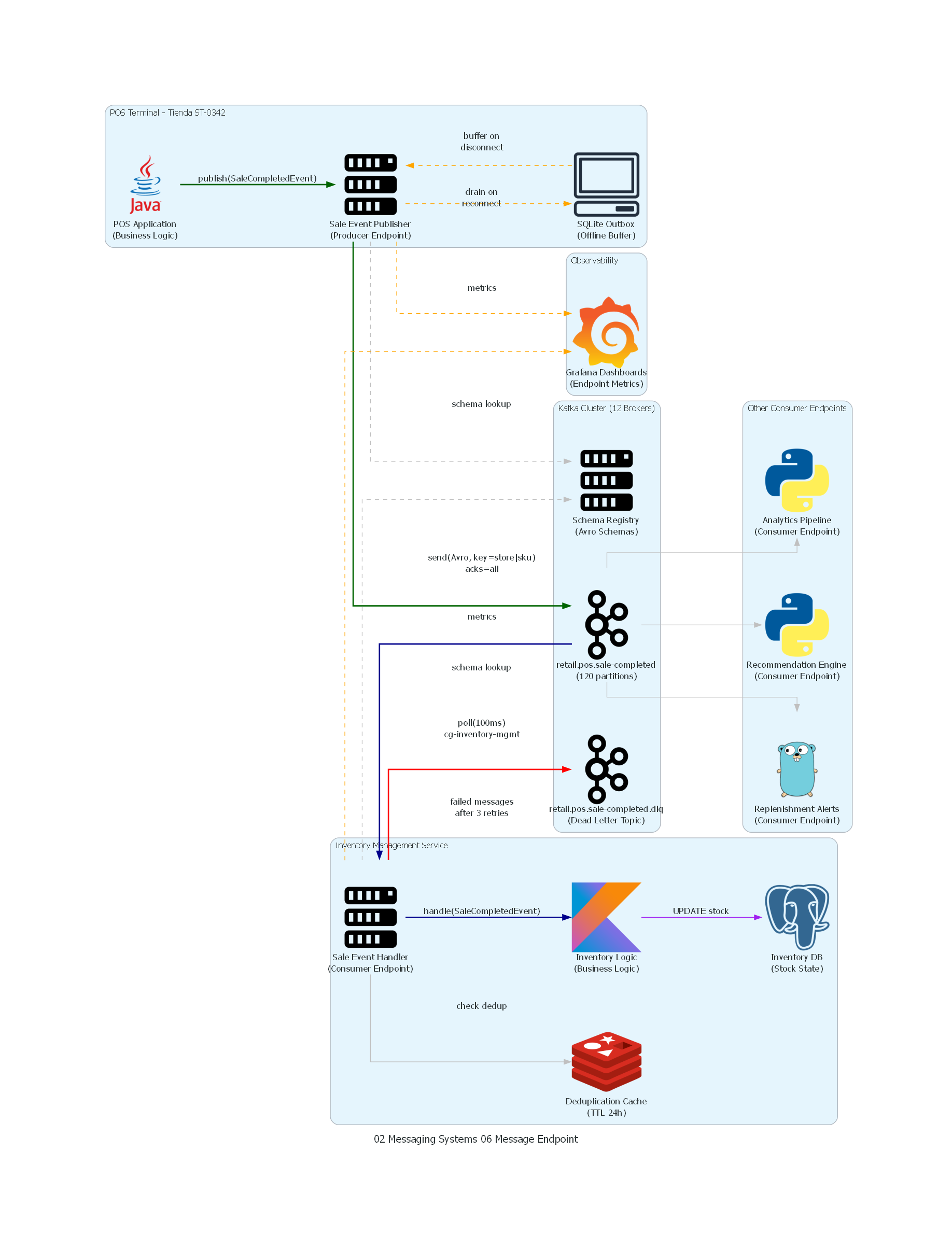
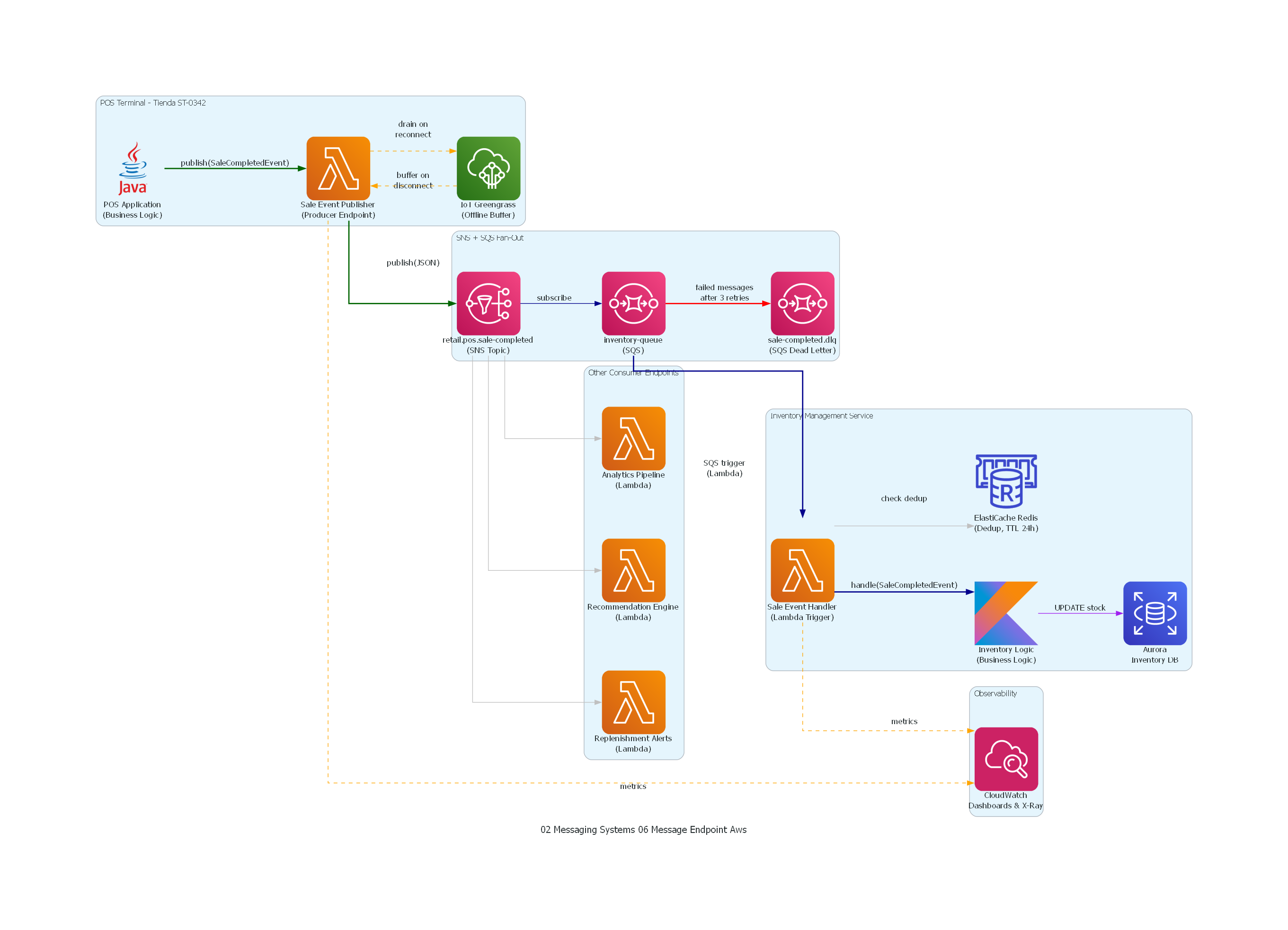
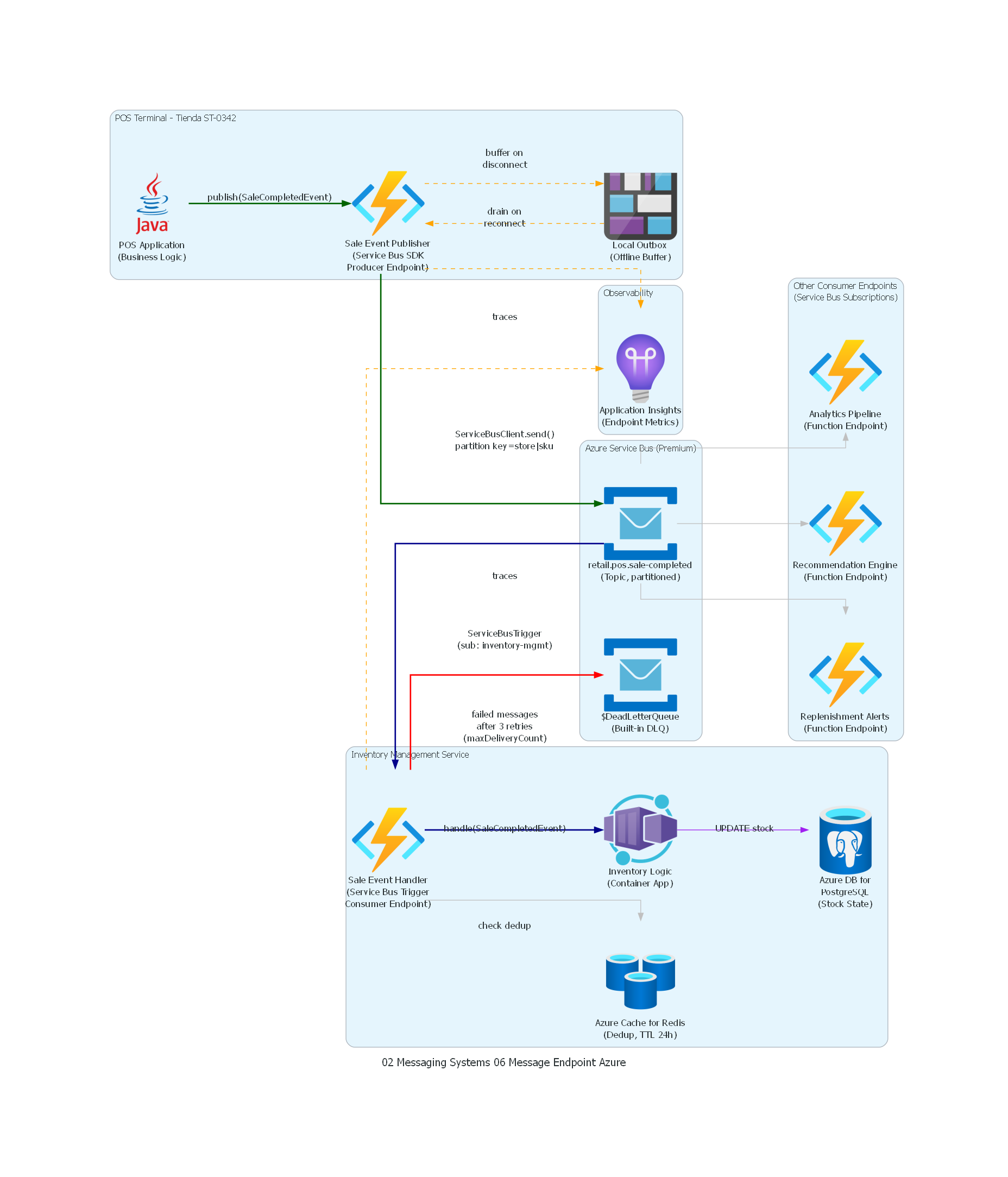
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.monitoring import Grafana
from diagrams.programming.language import Java, Kotlin, Go, Python
from diagrams.onprem.client import Client
with Diagram(
"Message Endpoint - Retail POS to Inventory",
show=False,
direction="LR",
graph_attr={"fontsize": "14", "pad": "0.5"}
):
# === POS TERMINAL (PRODUCER ENDPOINT) ===
with Cluster("POS Terminal - Tienda ST-0342"):
pos_app = Java("POS Application\n(Business Logic)")
producer_endpoint = Server("Sale Event Publisher\n(Producer Endpoint)")
local_buffer = Client("SQLite Outbox\n(Offline Buffer)")
pos_app >> Edge(
label="publish(SaleCompletedEvent)",
color="darkgreen",
style="bold"
) >> producer_endpoint
producer_endpoint >> Edge(
label="buffer on\ndisconnect",
color="orange",
style="dashed"
) >> local_buffer
local_buffer >> Edge(
label="drain on\nreconnect",
color="orange",
style="dashed"
) >> producer_endpoint
# === KAFKA CLUSTER ===
with Cluster("Kafka Cluster (12 Brokers)"):
schema_registry = Server("Schema Registry\n(Avro Schemas)")
sale_topic = Kafka("retail.pos.sale-completed\n(120 partitions)")
dlq_topic = Kafka("retail.pos.sale-completed.dlq\n(Dead Letter Topic)")
# === INVENTORY SERVICE (CONSUMER ENDPOINT) ===
with Cluster("Inventory Management Service"):
consumer_endpoint = Server("Sale Event Handler\n(Consumer Endpoint)")
inventory_logic = Kotlin("Inventory Logic\n(Business Logic)")
dedup_cache = Redis("Deduplication Cache\n(TTL 24h)")
inventory_db = PostgreSQL("Inventory DB\n(Stock State)")
consumer_endpoint >> Edge(
label="handle(SaleCompletedEvent)",
color="darkblue",
style="bold"
) >> inventory_logic
consumer_endpoint >> Edge(
label="check dedup",
color="gray"
) >> dedup_cache
inventory_logic >> Edge(
label="UPDATE stock",
color="purple"
) >> inventory_db
# === OTHER CONSUMERS ===
with Cluster("Other Consumer Endpoints"):
analytics = Python("Analytics Pipeline\n(Consumer Endpoint)")
recommendations = Python("Recommendation Engine\n(Consumer Endpoint)")
replenishment = Go("Replenishment Alerts\n(Consumer Endpoint)")
# === OBSERVABILITY ===
with Cluster("Observability"):
monitoring = Grafana("Grafana Dashboards\n(Endpoint Metrics)")
# === CONNECTIONS ===
# Producer to Kafka
producer_endpoint >> Edge(
label="send(Avro, key=store|sku)\nacks=all",
color="darkgreen",
style="bold"
) >> sale_topic
producer_endpoint >> Edge(
label="schema lookup",
color="gray",
style="dashed"
) >> schema_registry
# Kafka to Consumer
sale_topic >> Edge(
label="poll(100ms)\ncg-inventory-mgmt",
color="darkblue",
style="bold"
) >> consumer_endpoint
consumer_endpoint >> Edge(
label="schema lookup",
color="gray",
style="dashed"
) >> schema_registry
# Dead Letter
consumer_endpoint >> Edge(
label="failed messages\nafter 3 retries",
color="red",
style="bold"
) >> dlq_topic
# Other consumers from same topic
sale_topic >> Edge(color="gray") >> analytics
sale_topic >> Edge(color="gray") >> recommendations
sale_topic >> Edge(color="gray") >> replenishment
# Monitoring
producer_endpoint >> Edge(
label="metrics",
color="orange",
style="dashed"
) >> monitoring
consumer_endpoint >> Edge(
label="metrics",
color="orange",
style="dashed"
) >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.language import Java, Kotlin, Go, Python
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb, ElasticacheForRedis, RDS
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.iot import IotCore
from diagrams.aws.management import Cloudwatch
with Diagram(
"Message Endpoint - Retail POS to Inventory",
show=False,
direction="LR",
graph_attr={"fontsize": "14", "pad": "0.5"}
):
# === POS TERMINAL (PRODUCER ENDPOINT) ===
with Cluster("POS Terminal - Tienda ST-0342"):
pos_app = Java("POS Application\n(Business Logic)")
producer_endpoint = Lambda("Sale Event Publisher\n(Producer Endpoint)")
local_buffer = IotCore("IoT Greengrass\n(Offline Buffer)")
pos_app >> Edge(
label="publish(SaleCompletedEvent)",
color="darkgreen",
style="bold"
) >> producer_endpoint
producer_endpoint >> Edge(
label="buffer on\ndisconnect",
color="orange",
style="dashed"
) >> local_buffer
local_buffer >> Edge(
label="drain on\nreconnect",
color="orange",
style="dashed"
) >> producer_endpoint
# === SNS + SQS FAN-OUT ===
with Cluster("SNS + SQS Fan-Out"):
sale_topic = SNS("retail.pos.sale-completed\n(SNS Topic)")
sale_queue = SQS("inventory-queue\n(SQS)")
dlq = SQS("sale-completed.dlq\n(SQS Dead Letter)")
# === INVENTORY SERVICE (CONSUMER ENDPOINT) ===
with Cluster("Inventory Management Service"):
consumer_endpoint = Lambda("Sale Event Handler\n(Lambda Trigger)")
inventory_logic = Kotlin("Inventory Logic\n(Business Logic)")
dedup_cache = ElasticacheForRedis("ElastiCache Redis\n(Dedup, TTL 24h)")
inventory_db = RDS("Aurora\nInventory DB")
consumer_endpoint >> Edge(
label="handle(SaleCompletedEvent)",
color="darkblue",
style="bold"
) >> inventory_logic
consumer_endpoint >> Edge(
label="check dedup",
color="gray"
) >> dedup_cache
inventory_logic >> Edge(
label="UPDATE stock",
color="purple"
) >> inventory_db
# === OTHER CONSUMERS (SQS Subscriptions) ===
with Cluster("Other Consumer Endpoints"):
analytics = Lambda("Analytics Pipeline\n(Lambda)")
recommendations = Lambda("Recommendation Engine\n(Lambda)")
replenishment = Lambda("Replenishment Alerts\n(Lambda)")
# === OBSERVABILITY ===
with Cluster("Observability"):
monitoring = Cloudwatch("CloudWatch\nDashboards & X-Ray")
# === CONNECTIONS ===
# Producer to SNS
producer_endpoint >> Edge(
label="publish(JSON)",
color="darkgreen",
style="bold"
) >> sale_topic
# SNS fan-out to SQS queues
sale_topic >> Edge(
label="subscribe",
color="darkblue"
) >> sale_queue
# SQS triggers Lambda consumer
sale_queue >> Edge(
label="SQS trigger\n(Lambda)",
color="darkblue",
style="bold"
) >> consumer_endpoint
# Dead Letter (SQS DLQ)
sale_queue >> Edge(
label="failed messages\nafter 3 retries",
color="red",
style="bold"
) >> dlq
# Other consumers from same SNS topic (fan-out)
sale_topic >> Edge(color="gray") >> analytics
sale_topic >> Edge(color="gray") >> recommendations
sale_topic >> Edge(color="gray") >> replenishment
# Monitoring
producer_endpoint >> Edge(
label="metrics",
color="orange",
style="dashed"
) >> monitoring
consumer_endpoint >> Edge(
label="metrics",
color="orange",
style="dashed"
) >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.language import Java
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CacheForRedis, DatabaseForPostgresqlServers
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.storage import BlobStorage
with Diagram(
"Message Endpoint - Retail POS to Inventory (Azure)",
show=False,
direction="LR",
graph_attr={"fontsize": "14", "pad": "0.5"}
):
# === POS TERMINAL (PRODUCER ENDPOINT) ===
with Cluster("POS Terminal - Tienda ST-0342"):
pos_app = Java("POS Application\n(Business Logic)")
producer_endpoint = FunctionApps("Sale Event Publisher\n(Service Bus SDK\nProducer Endpoint)")
local_buffer = BlobStorage("Local Outbox\n(Offline Buffer)")
pos_app >> Edge(
label="publish(SaleCompletedEvent)",
color="darkgreen",
style="bold"
) >> producer_endpoint
producer_endpoint >> Edge(
label="buffer on\ndisconnect",
color="orange",
style="dashed"
) >> local_buffer
local_buffer >> Edge(
label="drain on\nreconnect",
color="orange",
style="dashed"
) >> producer_endpoint
# === SERVICE BUS ===
with Cluster("Azure Service Bus (Premium)"):
sale_topic = ServiceBus("retail.pos.sale-completed\n(Topic, partitioned)")
dlq_topic = ServiceBus("$DeadLetterQueue\n(Built-in DLQ)")
# === INVENTORY SERVICE (CONSUMER ENDPOINT) ===
with Cluster("Inventory Management Service"):
consumer_endpoint = FunctionApps("Sale Event Handler\n(Service Bus Trigger\nConsumer Endpoint)")
inventory_logic = ContainerApps("Inventory Logic\n(Container App)")
dedup_cache = CacheForRedis("Azure Cache for Redis\n(Dedup, TTL 24h)")
inventory_db = DatabaseForPostgresqlServers("Azure DB for\nPostgreSQL\n(Stock State)")
consumer_endpoint >> Edge(
label="handle(SaleCompletedEvent)",
color="darkblue",
style="bold"
) >> inventory_logic
consumer_endpoint >> Edge(
label="check dedup",
color="gray"
) >> dedup_cache
inventory_logic >> Edge(
label="UPDATE stock",
color="purple"
) >> inventory_db
# === OTHER CONSUMERS (Subscriptions) ===
with Cluster("Other Consumer Endpoints\n(Service Bus Subscriptions)"):
analytics = FunctionApps("Analytics Pipeline\n(Function Endpoint)")
recommendations = FunctionApps("Recommendation Engine\n(Function Endpoint)")
replenishment = FunctionApps("Replenishment Alerts\n(Function Endpoint)")
# === OBSERVABILITY ===
with Cluster("Observability"):
monitoring = ApplicationInsights("Application Insights\n(Endpoint Metrics)")
# === CONNECTIONS ===
# Producer to Service Bus
producer_endpoint >> Edge(
label="ServiceBusClient.send()\npartition key=store|sku",
color="darkgreen",
style="bold"
) >> sale_topic
# Service Bus triggers Consumer Function
sale_topic >> Edge(
label="ServiceBusTrigger\n(sub: inventory-mgmt)",
color="darkblue",
style="bold"
) >> consumer_endpoint
# Dead Letter (built-in)
consumer_endpoint >> Edge(
label="failed messages\nafter 3 retries\n(maxDeliveryCount)",
color="red",
style="bold"
) >> dlq_topic
# Other consumers via subscriptions
sale_topic >> Edge(color="gray") >> analytics
sale_topic >> Edge(color="gray") >> recommendations
sale_topic >> Edge(color="gray") >> replenishment
# Monitoring
producer_endpoint >> Edge(
label="traces",
color="orange",
style="dashed"
) >> monitoring
consumer_endpoint >> Edge(
label="traces",
color="orange",
style="dashed"
) >> monitoring
Explicación del Diagrama¶
El diagrama representa la arquitectura completa del flujo de ventas desde el POS terminal hasta el sistema de inventario, enfatizando los dos Message Endpoints como componentes centrales de la integración. A la izquierda, el POS Terminal contiene la lógica de negocio (que solo conoce la interfaz publish(SaleCompletedEvent)) y el endpoint productor (que gestiona serialización Avro, conexión al cluster Kafka, acks, retries y buffering offline). A la derecha, el Inventory Management Service contiene el endpoint consumidor (que gestiona polling, deserialización, deduplicación y acknowledgment) y la lógica de negocio de inventario (que solo recibe un objeto de dominio tipado). El flujo de dead letter muestra cómo el endpoint consumidor maneja errores irrecuperables sin bloquear el procesamiento de otros mensajes.
Tabla de Correspondencia¶
| Elemento del Diagrama | Componente del Patrón | Tecnología Concreta |
|---|---|---|
| POS Application | Business Logic (Productor) | Java 17, Spring Boot |
| Sale Event Publisher | Message Endpoint (Productor) | KafkaProducer API, Avro Serializer |
| SQLite Outbox | Transactional Outbox / Offline Buffer | SQLite local en terminal |
| retail.pos.sale-completed | Message Channel | Kafka Topic, 120 particiones |
| Schema Registry | Schema Governance | Confluent Schema Registry |
| Sale Event Handler | Message Endpoint (Consumidor) | KafkaConsumer API, Avro Deserializer |
| Inventory Logic | Business Logic (Consumidor) | Kotlin, Spring Boot |
| Deduplication Cache | Idempotency mechanism | Redis con TTL 24h |
| Inventory DB | State Store | PostgreSQL |
| retail.pos.sale-completed.dlq | Dead Letter Channel | Kafka Topic |
| Analytics / Recommendations / Replenishment | Otros Message Endpoints Consumidores | Python, Go, consumer groups independientes |
| Grafana Dashboards | Observabilidad de Endpoints | Prometheus + Grafana |
11. Beneficios¶
Separación Clara de Responsabilidades¶
El beneficio más fundamental de Message Endpoint es la separación explícita entre lógica de negocio e infraestructura de messaging. Los desarrolladores de dominio escriben código de negocio que opera con objetos de dominio tipados; los ingenieros de plataforma configuran el endpoint para interactuar con el broker de forma óptima. Ninguno necesita invadir el territorio del otro.
Portabilidad entre Plataformas de Messaging¶
Un endpoint bien diseñado con una interfaz genérica permite cambiar de broker con impacto mínimo. Solo la implementación del endpoint cambia; la lógica de negocio permanece intacta. Esto es particularmente valioso en organizaciones que migran entre plataformas (de RabbitMQ a Kafka, de on-premise a cloud) o que operan en entornos multi-cloud con diferentes servicios de messaging.
Testabilidad¶
Con la lógica de negocio desacoplada del broker a través de una interfaz de endpoint, los tests unitarios pueden inyectar un mock o stub del endpoint. Esto permite testear lógica de procesamiento de mensajes sin infraestructura, con ejecución rápida y determinista. Los tests de integración se reservan para validar el endpoint real contra un broker embebido o de test.
Comportamiento Uniforme y Predecible¶
Un endpoint estandarizado garantiza que todos los servicios de la organización interactúan con el messaging system de la misma manera: misma estrategia de reintentos, misma serialización, mismos headers, mismas métricas, mismo manejo de errores. Esto reduce los bugs de integración y facilita la operación.
Observabilidad Centralizada¶
El endpoint es el punto natural para instrumentar la interacción con el messaging system. Métricas de producción (throughput, latencia, errores), métricas de consumo (consumer lag, processing time, error rate), traces distribuidos y logs estructurados se generan en un solo componente, con formato y semántica consistentes.
Resiliencia y Tolerancia a Fallos¶
Un endpoint bien implementado gestiona fallos de forma autónoma: reconecta al broker tras desconexiones, reintenta envíos fallidos con backoff, redirige mensajes irrecuperables a dead letter queues, aplica circuit breaker cuando el broker está degradado. La lógica de negocio no necesita implementar ninguna de estas estrategias.
Evolución Controlada de Schemas¶
El endpoint, al centralizar la serialización/deserialización, es el punto donde se aplica la gobernanza de schemas. La validación contra Schema Registry, la detección de incompatibilidades y la evolución controlada del formato de mensajes se gestionan en el endpoint sin afectar a la lógica de negocio.
12. Desventajas y Riesgos¶
Complejidad Adicional¶
El endpoint introduce una capa de abstracción que, si no se diseña con cuidado, puede convertirse en un over-engineering. En aplicaciones simples con un solo canal y un solo broker, el overhead de mantener una abstracción de endpoint puede no justificarse frente a la simplicidad de usar el SDK del broker directamente.
Leaky Abstraction¶
Es difícil crear un endpoint que abstraiga completamente las diferencias entre brokers. Las semánticas de Kafka (offset-based, partitioned, log-structured) son fundamentalmente diferentes de las de RabbitMQ (queue-based, exchange routing, message acknowledgment). Un endpoint que intente unificar ambas tras una interfaz común inevitablemente pierde funcionalidad específica de cada plataforma o expone una abstracción que no mapea naturalmente a ninguna de las dos.
Falsa Sensación de Portabilidad¶
El hecho de que la interfaz del endpoint sea genérica no garantiza que la migración de broker sea trivial. Las diferencias en garantías de entrega, ordenamiento, particionamiento y retención entre brokers pueden requerir cambios arquitectónicos que van más allá del endpoint.
Overhead de Performance¶
Cada capa de abstracción añade overhead: una indirección de método, una conversión de formato, una copia de buffer. En escenarios de ultra-alta performance (millones de mensajes por segundo, latencia sub-milisegundo), este overhead puede ser significativo. En la práctica, para la mayoría de aplicaciones empresariales el overhead es despreciable (microsegundos) comparado con la latencia de red y del broker (milisegundos).
Riesgo de God Endpoint¶
Un endpoint que acumula demasiada responsabilidad (serialización, validación, routing, transformación, enriquecimiento, logging, métricas, tracing, autenticación, encriptación) se convierte en un componente monolítico difícil de entender, mantener y testear. Es necesario mantener la cohesión del endpoint y delegar responsabilidades a colaboradores especializados (Messaging Mapper para serialización, Channel Adapter para adaptación de protocolo).
Debugging Más Complejo¶
Cuando un mensaje no llega a su destino, la capa de abstracción del endpoint puede dificultar el debugging. ¿El problema está en la serialización del endpoint productor? ¿En el routing del broker? ¿En la deserialización del endpoint consumidor? ¿En la lógica de negocio? La indirección del endpoint añade un nodo más en la cadena de diagnóstico.
Acoplamiento a la Abstracción¶
Si la interfaz del endpoint se diseña mal (demasiado genérica, demasiado específica, sin considerar la evolución), toda la aplicación queda acoplada a esa interfaz. Cambiarla requiere modificar todos los clientes del endpoint, lo cual puede ser tan disruptivo como cambiar de broker.
13. Relación con Otros Patrones¶
Messaging Gateway¶
Messaging Gateway es el patrón que introduce una fachada que encapsula el acceso al messaging system detrás de una API de dominio. La relación con Message Endpoint es de complementariedad directa: Message Endpoint es el componente de bajo nivel que interactúa con el broker; Messaging Gateway es la interfaz de alto nivel que la aplicación usa para producir y consumir mensajes. En la práctica, el Gateway es la interfaz pública y el Endpoint es la implementación interna. El Gateway expone métodos con semántica de dominio (publishOrderCreated(order)) que internamente delegan en el Endpoint para la mecánica de envío (endpoint.send(channel, serialize(event), headers)). La separación permite que la lógica de dominio use la Gateway sin conocer el Endpoint, y que el Endpoint se reemplace sin modificar la Gateway.
Messaging Mapper¶
Messaging Mapper es el patrón responsable de la conversión entre objetos de dominio y mensajes del sistema de mensajería. Es uno de los colaboradores más importantes del Message Endpoint. Mientras el Endpoint gestiona la conexión, el envío y la recepción, el Mapper gestiona la transformación: serializar un SaleCompletedEvent (objeto Java/Kotlin) a un ProducerRecord (mensaje Kafka con bytes Avro), y deserializar un ConsumerRecord de vuelta a un SaleCompletedEvent. La separación Endpoint-Mapper sigue el Single Responsibility Principle: el Endpoint se encarga de la comunicación; el Mapper se encarga de la representación. Esto permite evolucionar la estrategia de serialización (cambiar de JSON a Avro, por ejemplo) sin modificar la lógica de conexión y entrega del Endpoint.
Channel Adapter¶
Channel Adapter es el patrón que conecta una aplicación que no fue diseñada para messaging con un sistema de mensajería. La relación con Message Endpoint es de especialización: Channel Adapter es un Message Endpoint diseñado para adaptar un sistema legacy o no-messaging al mundo de messaging. Por ejemplo, un Channel Adapter puede escuchar cambios en una tabla de base de datos (CDC — Change Data Capture) y publicar cada cambio como un mensaje en un topic de Kafka. En este caso, el Channel Adapter es un Message Endpoint productor cuyo "lado de aplicación" no es una invocación explícita sino un trigger automático. La distinción clave es que un Message Endpoint genérico asume que la aplicación invoca activamente al endpoint; un Channel Adapter asume que la aplicación no sabe que existe messaging y el adapter lo hace transparente.
Service Activator¶
Service Activator es el patrón que conecta un servicio de aplicación (que expone una interfaz de request-response síncrona) con un Message Channel, permitiendo que el servicio sea invocado asíncronamente a través de messaging. Es un tipo especializado de Message Endpoint consumidor que, además de recibir y deserializar el mensaje, invoca un servicio existente como si fuera una llamada síncrona y opcionalmente publica la respuesta en un canal de respuesta. La relación con Message Endpoint es que Service Activator construye sobre el endpoint consumidor añadiendo la semántica de invocación de servicio y opcionalmente la producción de respuesta. Es el puente entre el mundo asíncrono del messaging y el mundo síncrono de los servicios de aplicación.
Visión de Conjunto¶
┌──────────────────────────────────┐
│ Application Layer │
│ │
│ ┌─────────────────────────────┐ │
│ │ Messaging Gateway │ │ ← Interfaz de dominio
│ │ (API de alto nivel) │ │
│ └─────────┬───────────────────┘ │
│ │ │
│ ┌─────────▼───────────────────┐ │
│ │ Message Endpoint │ │ ← Conexión + envío/recepción
│ │ (Conexión al broker) │ │
│ │ │ │
│ │ ┌──────────────────────┐ │ │
│ │ │ Messaging Mapper │ │ │ ← Serialización/deserialización
│ │ │ (Transformación) │ │ │
│ │ └──────────────────────┘ │ │
│ └─────────┬───────────────────┘ │
│ │ │
└────────────┼───────────────────────┘
│
┌────────────▼───────────────────────┐
│ Messaging System (Broker) │
│ Message Channels │
└────────────────────────────────────┘
Channel Adapter y Service Activator son variantes especializadas que se ubican en la posición del Message Endpoint cuando el contexto lo requiere: Channel Adapter cuando la aplicación no fue diseñada para messaging; Service Activator cuando se necesita invocar un servicio síncrono desde un canal asíncrono.
14. Relevancia Actual¶
Relevancia: ALTA
Message Endpoint es uno de los patrones con mayor relevancia en la arquitectura de software moderna. Su importancia ha crecido significativamente con la adopción masiva de arquitecturas event-driven, microservicios y plataformas de streaming. Lejos de ser un concepto teórico, es una decisión de diseño que todo equipo que trabaje con messaging enfrenta diariamente.
SDKs y Librerías de Consumidor Modernas¶
Las plataformas de messaging modernas proporcionan SDKs que son, en esencia, implementaciones listas para usar de Message Endpoint:
- Apache Kafka:
kafka-clients(Java),confluent-kafka-python,node-rdkafka,Sarama(Go). Estos clientes implementan endpoints productor y consumidor con configuración granular de batching, compression, acks, partitioning, offset management y rebalancing. - RabbitMQ:
amqp-client(Java),pika(Python),amqplib(Node.js). Proporcionan endpoints con publisher confirms, consumer acknowledgments, prefetch control y connection recovery. - Azure Service Bus:
@azure/service-bus(Node.js),azure-servicebus(Python),Azure.Messaging.ServiceBus(.NET). Ofrecen endpoints con message locking, session management, scheduled delivery y dead letter support nativo. - AWS SQS/SNS/EventBridge: AWS SDK v2/v3 en todos los lenguajes. Proporcionan endpoints con long polling, visibility timeout, message deduplication y FIFO support.
- Google Cloud Pub/Sub:
google-cloud-pubsubcon endpoints que gestionan message ordering, exactly-once delivery, dead letter topics y flow control.
Producer APIs en Plataformas Modernas¶
Los producer endpoints modernos han evolucionado significativamente respecto a los clientes de primera generación:
- Batching inteligente: los producers acumulan mensajes y los envían en batches optimizados por tamaño o latencia (Kafka
linger.ms,batch.size). - Compresión transparente: el endpoint comprime batches (LZ4, Snappy, Zstd) antes de enviarlos, reduciendo uso de red y almacenamiento.
- Idempotencia nativa: Kafka producer con
enable.idempotence=truegarantiza que retries no producen mensajes duplicados. - Transacciones: Kafka transactional producer permite enviar mensajes a múltiples topics atómicamente, habilitando patrones de exactly-once.
- Interceptors: hooks que permiten inyectar lógica transversal (métricas, tracing, header injection) sin modificar el código de producción.
Consumer Libraries y Frameworks¶
Los consumer endpoints modernos gestionan complejidad significativa:
- Consumer group management: rebalanceo automático de particiones entre instancias del consumer group (Kafka) o competición justa de mensajes (RabbitMQ).
- Offset/checkpoint management: commit automático o manual de progreso, con garantías de at-least-once o exactly-once.
- Concurrency models: single-threaded per partition (Kafka), multi-threaded con prefetch (RabbitMQ), async/event-driven (Azure Service Bus processor).
- Error handling integrado: retry policies configurables, dead letter queue routing automático, nack con requeue selectivo.
- Flow control/backpressure: mecanismos para limitar la tasa de consumo cuando el procesamiento es más lento que la entrega (RabbitMQ prefetch, Kafka
max.poll.records, Azure Service BusmaxConcurrentCalls).
Relevancia en el Ecosistema Cloud-Native¶
En arquitecturas cloud-native, Message Endpoint toma formas adicionales:
- Serverless endpoints: AWS Lambda con SQS trigger, Azure Functions con Service Bus trigger, Google Cloud Functions con Pub/Sub trigger. El cloud provider gestiona el endpoint consumidor; el desarrollador solo implementa la lógica de procesamiento. Sin embargo, es crucial entender el patrón subyacente para configurar correctamente batch size, timeout, retry policies y dead letter.
- Kubernetes operators: Strimzi (Kafka on K8s) y KEDA (event-driven autoscaling) gestionan el ciclo de vida de los endpoints y auto-escalan basándose en métricas de consumer lag.
- Service mesh integration: Dapr (Distributed Application Runtime) ofrece building blocks de pub/sub que abstraen completamente el endpoint detrás de una API HTTP, permitiendo cambiar de broker con solo un cambio de configuración YAML.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka — Producer y Consumer API¶
Producer Endpoint: la clase KafkaProducer es la implementación canónica del Message Endpoint productor en Kafka. Se configura con bootstrap.servers, key.serializer, value.serializer, y parámetros de comportamiento como acks, retries, linger.ms, batch.size, compression.type y enable.idempotence. El producer gestiona internamente un buffer de envío, un thread sender dedicado, partitioning, batching y retry. La interfaz es send(ProducerRecord) que retorna un Future<RecordMetadata>.
Consumer Endpoint: la clase KafkaConsumer implementa el endpoint consumidor. Se configura con bootstrap.servers, group.id, key.deserializer, value.deserializer, auto.offset.reset, enable.auto.commit y max.poll.records. El consumer gestiona group membership, partition assignment, offset tracking y rebalancing. La interfaz es un loop de poll(Duration) que retorna ConsumerRecords.
Patrón recomendado en producción: envolver KafkaProducer y KafkaConsumer en componentes de aplicación que implementen la interfaz del endpoint de dominio, inyectando serialización (Messaging Mapper), headers estándar, métricas e interceptors. Frameworks como Spring Kafka proporcionan KafkaTemplate (producer endpoint) y @KafkaListener (consumer endpoint) que aplican este envolvimiento.
RabbitMQ — Client Libraries¶
Producer Endpoint: en RabbitMQ, el producer endpoint se implementa usando un Channel con basicPublish(). Para garantía de entrega, se habilitan publisher confirms (confirmSelect()), donde el broker confirma la persistencia de cada mensaje. El producer gestiona connection recovery (AutoRecoveringConnection) y channel pooling.
Consumer Endpoint: el consumer endpoint usa basicConsume() con un DeliveryCallback. El prefetch count (basicQos()) controla cuántos mensajes el broker envía al consumidor antes de recibir acknowledgment, implementando backpressure. El acknowledgment es explícito (basicAck() / basicNack() con opción de requeue).
Patrón recomendado: Spring AMQP proporciona RabbitTemplate (producer endpoint con retry y confirmaciones) y @RabbitListener (consumer endpoint con auto-deserialization, retry configurable y dead letter support).
Azure Service Bus — SDK¶
Producer Endpoint: ServiceBusSender envía mensajes a una Queue o Topic. Soporta envío individual, batch (ServiceBusMessageBatch), scheduled messages y transacciones (ServiceBusTransactionContext). La autenticación se gestiona mediante Azure Identity (Managed Identity, DefaultAzureCredential).
Consumer Endpoint: dos modelos: ServiceBusReceiver (pull-based, para control explícito) y ServiceBusProcessor (push-based, event-driven, recomendado para la mayoría de escenarios). El Processor gestiona concurrencia (maxConcurrentCalls), auto-complete, auto-renew lock y error handling con callback configurables. Dead letter se gestiona nativamente con deadLetterMessage().
Patrón recomendado: usar ServiceBusProcessor para consumidores de larga duración. Envolver ServiceBusSender en un componente de dominio que gestione serialización y headers. Aprovechar sessions para procesamiento ordenado por entidad.
AWS SQS/SNS/EventBridge — SDK¶
Producer Endpoint: SqsClient.sendMessage() o SnsClient.publish() para producción. EventBridgeClient.putEvents() para eventos de dominio con routing basado en reglas. El SDK gestiona retry con exponential backoff, autenticación IAM y request signing.
Consumer Endpoint: SqsClient.receiveMessage() con long polling (WaitTimeSeconds=20). El consumer gestiona visibility timeout (tiempo durante el cual un mensaje recibido es invisible para otros consumers) y deleteMessage() como acknowledgment explícito. Para FIFO queues, el consumer procesa mensajes en orden dentro de cada message group.
Patrón serverless: AWS Lambda como consumer endpoint nativo. El event source mapping gestiona polling, batching, error handling y retry. Configuración de batchSize, maxBatchingWindowInSeconds, functionResponseTypes (para partial batch failure) y dead letter queue.
Spring Kafka / Spring JMS¶
Spring Kafka: proporciona la capa de abstracción más madura sobre Kafka: - KafkaTemplate: endpoint productor con send(), sendDefault(), callback de resultado, métricas Micrometer integradas y soporte transaccional. - @KafkaListener: endpoint consumidor declarativo. Anotación en un método que recibe el objeto de dominio ya deserializado. Spring gestiona el consumer loop, la deserialización, el error handling (DefaultErrorHandler con retry configurable y dead letter publishing), y el offset commit. - ConcurrentKafkaListenerContainerFactory: permite configurar concurrencia (número de consumer threads), ack mode, batch listening y container lifecycle.
Spring JMS: para brokers JMS (ActiveMQ, IBM MQ, TIBCO EMS): - JmsTemplate: endpoint productor con convertAndSend() que integra message conversion. - @JmsListener: endpoint consumidor declarativo, análogo a @KafkaListener. - DefaultJmsListenerContainerFactory: gestiona concurrencia, acknowledgment y transacciones.
MuleSoft Connectors¶
En MuleSoft Anypoint Platform, los Message Endpoints se implementan como Connectors: - Kafka Connector: proporciona operaciones Publish (producer endpoint) y Consumer (consumer endpoint source) con configuración visual en Anypoint Studio. Gestiona serialización, partitioning, offset management y error handling. - AMQP Connector: produce y consume mensajes de brokers AMQP (RabbitMQ) con publisher confirms y consumer acknowledgments. - JMS Connector: conecta con cualquier broker JMS. - Azure Service Bus Connector: operaciones de send y receive con soporte de sessions y dead letter. - Amazon SQS/SNS Connector: operaciones de send, receive y delete con long polling y visibility timeout.
Cada connector de MuleSoft es un Message Endpoint preempaquetado que abstrae los detalles del protocolo y expone una interfaz uniforme dentro del flujo de integración. La configuración del endpoint (credenciales, serialización, retry, error handling) se gestiona declarativamente en el flujo de MuleSoft.
16. Consideraciones de Gobierno y Operación¶
Estandarización de Endpoints¶
La organización debe definir un estándar de endpoint que establezca:
- Serialización: formato obligatorio (por ejemplo, Avro para eventos de dominio, JSON para logs, Protobuf para comunicación intra-servicio).
- Headers obligatorios: lista de headers que todo endpoint debe inyectar (correlation-id, source-service, event-type, schema-version, timestamp). Estos headers habilitan tracing distribuido, auditoría y debugging.
- Naming conventions: cómo se nombran los endpoints en logs, métricas y configuración.
- Error handling policy: retry count, backoff strategy, dead letter topic naming convention (
{original-topic}.dlq). - Métricas obligatorias: qué métricas debe exponer todo endpoint (producción: latency, throughput, error_rate; consumo: lag, processing_time, dlq_rate).
- Health checks: todo endpoint debe reportar su estado de salud (connected, degraded, disconnected) para que el orquestador (Kubernetes, etc.) pueda tomar decisiones de lifecycle.
Librería de Endpoint Interna¶
Muchas organizaciones maduras proporcionan una librería interna (a menudo llamada "starter" o "SDK interno") que implementa el Message Endpoint con todos los estándares preconfigurados. Los equipos de desarrollo la usan como dependencia, obteniendo automáticamente:
- Serialización Avro con Schema Registry configurado.
- Headers estándar inyectados automáticamente.
- Métricas Micrometer/OpenTelemetry exportadas al sistema de observabilidad corporativo.
- Tracing distribuido con propagación de contexto.
- Error handling con dead letter y alertas.
- Configuración externalizada (bootstrap servers, credenciales vía Vault).
Esta librería es el vehículo para aplicar políticas de gobierno sin requerir que cada equipo las implemente manualmente.
Gestión del Ciclo de Vida del Endpoint¶
- Startup: el endpoint debe conectarse al broker y validar que los canales destino existen antes de que la aplicación acepte tráfico. Si la conexión falla, el endpoint debe reportar unhealthy para que el health check de Kubernetes no envíe tráfico.
- Runtime: monitoreo continuo de la salud de la conexión, consumer lag, tasa de errores. Alertas automáticas ante degradación.
- Shutdown: graceful shutdown que completa los mensajes en proceso, flush los buffers de producción, commit los offsets pendientes y cierra las conexiones limpiamente. En Kubernetes, esto se gestiona con el
preStophook y unterminationGracePeriodSecondssuficiente.
Auditoría y Compliance¶
En industrias reguladas (banca, salud, telecomunicaciones), el endpoint debe soportar:
- Registro de todos los mensajes enviados y recibidos (o al menos metadata: timestamp, channel, message-id, correlation-id, resultado).
- No repudio: garantía de que un mensaje enviado no puede ser negado por el productor. Esto puede requerir firma digital del mensaje en el endpoint.
- Data residency: garantía de que los mensajes no cruzan fronteras geográficas no autorizadas. El endpoint debe validar que el broker destino está en la región correcta.
- Encryption in transit: TLS obligatorio entre endpoint y broker, con validación de certificados.
- Encryption at rest: si los mensajes contienen datos sensibles, el endpoint puede aplicar encriptación a nivel de payload antes del envío.
Gestión de Secretos¶
Las credenciales de conexión del endpoint (contraseñas, API keys, certificados TLS, tokens SASL) son datos sensibles que deben gestionarse con rigor:
- Nunca hardcodeadas en el código ni en archivos de configuración versionados.
- Almacenadas en un gestor de secretos (HashiCorp Vault, AWS Secrets Manager, Azure Key Vault).
- Rotadas periódicamente sin requerir redespliegue del endpoint (dynamic secrets).
- El endpoint debe soportar renovación de credenciales en runtime sin interrupción de servicio.
Capacity Planning¶
El dimensionamiento del endpoint requiere considerar:
- Producer throughput: cuántos mensajes/segundo produce el endpoint, tamaño promedio de mensaje, tamaño de batch, compresión.
- Consumer throughput: cuántos mensajes/segundo puede procesar la lógica de negocio downstream, número de consumer instances, max.poll.records.
- Memory: buffer de producción (
buffer.memoryen Kafka producer), batches en flight, objetos deserializados en proceso. - Network: ancho de banda entre endpoint y broker, número de conexiones TCP, latencia de red.
- Threads: thread pool del producer sender, threads del consumer poll loop, threads del procesamiento de negocio.
17. Errores Comunes¶
Error 1: Mezclar Lógica de Negocio con Lógica de Endpoint¶
Síntoma: clases de servicio que contienen directamente kafkaTemplate.send() entremezclado con cálculos de dominio, validaciones de negocio y acceso a base de datos.
Consecuencia: imposibilidad de testear la lógica de negocio sin Kafka, cambiar de broker requiere tocar código de dominio, las métricas de messaging están dispersas por toda la aplicación.
Corrección: extraer toda la interacción con el broker a un componente endpoint dedicado con una interfaz de dominio (OrderEventPublisher, SaleEventHandler). La business logic solo conoce esta interfaz.
Error 2: Acknowledge Antes de Procesar¶
Síntoma: el endpoint consumidor confirma (commit offset / ack) el mensaje inmediatamente al recibirlo, antes de que la lógica de negocio complete el procesamiento.
Consecuencia: si el procesamiento falla después del ack (excepción, crash, timeout), el mensaje se pierde irrecuperablemente. El broker cree que fue procesado; la aplicación nunca lo procesó.
Corrección: configurar manual acknowledge y confirmar solo después del procesamiento exitoso. En Kafka: enable.auto.commit=false con commitSync() después del procesamiento. En RabbitMQ: autoAck=false con basicAck() explícito.
Error 3: Ignorar la Idempotencia del Consumidor¶
Síntoma: el endpoint consumidor procesa cada mensaje asumiendo que será recibido exactamente una vez. No hay mecanismo de deduplicación.
Consecuencia: en escenarios at-least-once (que es lo más común), el redelivery de un mensaje produce efectos duplicados: doble cobro, doble decremento de stock, doble envío de notificación.
Corrección: implementar deduplicación en el endpoint consumidor. Opciones: almacenar el message-id en un cache (Redis) con TTL, usar una columna processed_event_id en la base de datos con constraint unique, o diseñar la lógica de negocio para que sea inherentemente idempotente (operaciones SET en vez de INCREMENT).
Error 4: No Implementar Dead Letter Queue¶
Síntoma: cuando un mensaje no puede ser procesado (formato inválido, datos inconsistentes, error no retriable), el endpoint reintenta indefinidamente o descarta el mensaje silenciosamente.
Consecuencia: reintentos infinitos bloquean la partición, impidiendo el procesamiento de mensajes posteriores (head-of-line blocking). Descarte silencioso causa pérdida de datos sin traza ni alerta.
Corrección: configurar una Dead Letter Queue (DLQ) y una política de retry limitada. Tras N reintentos, el endpoint redirige el mensaje a la DLQ con metadata de diagnóstico (razón del fallo, retry count, timestamp). Un proceso separado monitorea la DLQ y alerta al equipo.
Error 5: Hardcodear Configuración del Broker¶
Síntoma: bootstrap.servers=kafka-prod-01.internal:9092 directamente en el código fuente o en un archivo de properties versionado en git.
Consecuencia: cualquier cambio de infraestructura (nuevo broker, nueva dirección, nuevo puerto, cambio de cluster) requiere modificar código y redesplegar. En entornos multi-ambiente (dev, staging, prod), se copian y pegan configuraciones con errores.
Corrección: externalizar toda la configuración del endpoint: bootstrap servers, credenciales, topics, timeouts, retry policies. Usar variables de entorno, ConfigMaps de Kubernetes, Spring Cloud Config, o un servicio de configuración centralizado. Las credenciales deben estar en un gestor de secretos (Vault, AWS Secrets Manager).
Error 6: No Monitorear el Consumer Lag¶
Síntoma: los consumer endpoints funcionan pero nadie monitorea la diferencia entre el offset más reciente producido y el offset más reciente consumido.
Consecuencia: un consumidor que se degrada gradualmente (por memory leak, GC pauses, o downstream lento) acumula lag sin que nadie lo detecte. Cuando el lag alcanza horas o días, el negocio detecta el problema por síntomas downstream (inventario desactualizado, notificaciones tardías) en vez de por métricas de infraestructura.
Corrección: exportar la métrica de consumer lag desde el endpoint (Kafka proporciona records-lag-max en el consumer), configurar alertas en el sistema de monitoreo (consumer lag > umbral durante > N minutos), y visualizar en dashboards operacionales.
Error 7: Graceful Shutdown Inexistente¶
Síntoma: cuando el contenedor/pod se detiene, el endpoint se termina abruptamente sin flush de buffers ni commit de offsets.
Consecuencia: mensajes en el buffer del producer se pierden. Mensajes procesados pero no committed se reprocesan cuando la instancia se reinicia (duplicación). Rebalance de particiones innecesariamente largo (Kafka session timeout en lugar de graceful leave-group).
Corrección: implementar shutdown hook que: (1) deja de aceptar nuevos mensajes, (2) flush el buffer del producer, (3) completa el procesamiento de mensajes en curso, (4) commit offsets pendientes, (5) cierra la conexión al broker con consumer.close() que ejecuta leave-group. Configurar terminationGracePeriodSeconds en Kubernetes para dar tiempo suficiente.
Error 8: Un Endpoint para Todo¶
Síntoma: un único componente endpoint genérico que produce y consume mensajes de todos los topics de la aplicación, con lógica de routing interna para distribuir mensajes al handler correcto.
Consecuencia: el endpoint se convierte en un God Object con decenas de dependencias, difícil de entender, testear y mantener. Un cambio en la configuración de un topic afecta potencialmente a todos los flujos.
Corrección: diseñar endpoints con cohesión por bounded context o por flujo de negocio. Un endpoint por tipo de evento o por canal es más mantenible que un mega-endpoint. Compartir configuración común (conexión al broker, serialización) a través de una factory o builder, no a través de herencia.
18. Conclusión Técnica¶
Message Endpoint es el patrón que define la frontera entre el mundo de la lógica de negocio y el mundo de la infraestructura de mensajería. Es el punto de contacto — el enchufe — donde una aplicación se conecta al sistema de messaging para producir y consumir mensajes. Su correcta implementación es la diferencia entre una integración robusta, observable y evolucionable, y una integración frágil, opaca y rígida.
El patrón aborda un problema arquitectónico fundamental: la separación de concerns entre lo que la aplicación hace (lógica de dominio) y cómo comunica lo que hace (infraestructura de messaging). Sin esta separación, la lógica de negocio y la mecánica de comunicación se entrelazan de formas que hacen imposible evolucionar una sin impactar a la otra. Con un endpoint bien diseñado, la aplicación puede cambiar de broker, de formato de serialización, de estrategia de entrega o de plataforma de observabilidad sin tocar una sola línea de código de dominio.
En el ecosistema moderno, Message Endpoint se materializa en los SDKs de productores y consumidores de cada plataforma (Kafka Producer/Consumer, RabbitMQ Channel, Azure Service Bus Sender/Processor, AWS SQS Client), en los frameworks que los envuelven (Spring Kafka, Spring AMQP, MuleSoft Connectors) y en los abstractions de nivel superior (Dapr pub/sub, Spring Cloud Stream bindings, serverless event triggers). Comprender el patrón subyacente es lo que permite usar estas herramientas de forma efectiva: configurar correctamente acks, retries, offsets, serialización, dead letters y métricas; diagnosticar problemas cuando el flujo de mensajes falla; y tomar decisiones de diseño cuando las abstracciones del framework no cubren el caso de uso exacto.
Las decisiones de diseño críticas del endpoint — threading model, batching strategy, error handling policy, serialization format, transaction boundaries, observability instrumentation — no son detalles de implementación menores. Son decisiones arquitectónicas que determinan las garantías de entrega, la performance, la resiliencia y la operabilidad de todo el sistema de messaging. Un endpoint que hace acknowledge antes de procesar pierde mensajes. Un endpoint sin dead letter bloquea particiones. Un endpoint sin métricas es un punto ciego operacional. Un endpoint con configuración hardcodeada es una bomba de tiempo de mantenimiento.
Para el arquitecto senior, la recomendación es clara: tratar el Message Endpoint como un componente arquitectónico de primer nivel, no como un detalle de implementación delegado al framework. Definir estándares organizacionales de endpoint (serialización, headers, error handling, métricas). Proporcionar librerías internas que implementen estos estándares. Monitorear los endpoints con la misma rigurosidad que se monitorean los servicios. Y, sobre todo, nunca permitir que la lógica de negocio se mezcle con la mecánica de messaging — esa frontera, materializada en el Message Endpoint, es la que mantiene la arquitectura flexible y la operación predecible.