Point-to-Point Channel¶
1. Nombre del Patrón¶
- Nombre oficial: Point-to-Point Channel
- Categoría: Messaging Channels (Canales de Mensajería — Variantes de Canal)
- Traducción contextual: Canal Punto a Punto
2. Resumen Ejecutivo¶
Point-to-Point Channel es el patrón de canal de mensajería que garantiza que cada mensaje enviado al canal es procesado por exactamente un consumidor. Cuando múltiples consumidores están conectados al mismo canal, el sistema de mensajería entrega cada mensaje a uno solo de ellos, creando una semántica de competencia en la que los consumidores "compiten" por los mensajes disponibles.
El problema que resuelve es fundamental: ¿cómo se asegura que una operación representada por un mensaje — un pedido que procesar, un pago que ejecutar, un email que enviar — se ejecuta una sola vez, sin duplicación, sin omisión, independientemente de cuántas instancias de consumidor existan? Point-to-Point Channel responde a esta pregunta introduciendo una semántica de entrega competitiva donde el broker actúa como árbitro, asignando cada mensaje a un único receptor.
Este patrón es omnipresente en la mensajería empresarial. Cada vez que un sistema necesita distribuir trabajo entre workers, procesar comandos de forma ordenada o garantizar que una tarea se ejecuta exactamente una vez, hay un Point-to-Point Channel involucrado. Es el modelo mental de la "cola de trabajo" (work queue) que todo desarrollador reconoce, formalizado como patrón arquitectónico con sus trade-offs, variantes y decisiones de diseño explícitas.
3. Definición Detallada¶
Propósito¶
Point-to-Point Channel establece un conducto de mensajes con semántica de entrega exclusiva: cada mensaje depositado en el canal es consumido por uno y solo un receptor. Su propósito es garantizar procesamiento singular — que el trabajo representado por cada mensaje se ejecuta una única vez — mientras permite que múltiples instancias de consumidor se conecten al canal para lograr procesamiento paralelo y alta disponibilidad.
Lógica Arquitectónica¶
La lógica fundamental del patrón reside en la distinción entre distribución y competencia. En un Publish-Subscribe Channel, cada mensaje se distribuye a todos los consumidores (fan-out). En un Point-to-Point Channel, cada mensaje se asigna a un solo consumidor (competing consumers). Esta diferencia tiene consecuencias arquitectónicas profundas:
- Semántica de comando: Point-to-Point Channel es el canal natural para mensajes que representan comandos o tareas: "procesar este pedido", "enviar este email", "generar este reporte". Estas operaciones deben ejecutarse una vez, no N veces.
- Balanceo de carga implícito: cuando múltiples consumidores escuchan en el mismo Point-to-Point Channel, el broker distribuye los mensajes entre ellos, creando un mecanismo de load balancing embebido en la infraestructura de mensajería.
- Elasticidad horizontal: para escalar el procesamiento, basta con añadir más consumidores al canal. Cada nuevo consumidor recibe una porción de los mensajes sin que se requiera ningún cambio en el productor ni en los consumidores existentes.
Principio de Diseño Subyacente¶
El principio es entrega competitiva con garantía de unicidad. El canal actúa como un punto de serialización donde los mensajes se encolan y se asignan a consumidores de forma mutuamente exclusiva. Una vez que un mensaje es asignado a un consumidor (entregado y acknowledged), ningún otro consumidor puede recibirlo. Este principio es análogo a una fila de clientes en un banco: cada cliente (mensaje) es atendido por exactamente un cajero (consumidor), y aunque haya cinco cajeros disponibles, un cliente no es atendido por dos cajeros simultáneamente.
Problema Estructural que Resuelve¶
En un sistema distribuido que necesita procesar trabajo en paralelo, sin Point-to-Point Channel existen dos alternativas subóptimas:
- Asignación estática: particionar el trabajo manualmente entre consumidores (consumidor A procesa mensajes A-M, consumidor B procesa N-Z). Esto es rígido, no tolera fallos de un consumidor y requiere reparticionamiento manual cuando se añaden o eliminan consumidores.
- Procesamiento duplicado: enviar cada mensaje a todos los consumidores (pub-sub) y confiar en que algún mecanismo de deduplicación evite procesamiento múltiple. Esto es frágil, ineficiente y propenso a errores de consistencia.
Point-to-Point Channel elimina ambos problemas: el broker gestiona la asignación dinámica de mensajes a consumidores, tolerando fallos (si un consumidor cae, sus mensajes se reasignan) y escalando automáticamente (si se añade un consumidor, recibe su parte de la carga).
Contexto en el que Emerge¶
Point-to-Point Channel emerge en cualquier escenario donde los mensajes representan trabajo que debe ejecutarse una vez:
- Procesamiento de pedidos de e-commerce.
- Ejecución de transacciones financieras.
- Envío de notificaciones (email, SMS, push).
- Generación de reportes o facturas.
- Sincronización de datos entre sistemas (cada cambio debe aplicarse una vez).
- Ejecución de jobs en un sistema de tareas distribuidas.
La señal clave es: si procesar el mismo mensaje dos veces produce un resultado incorrecto o una duplicación no deseada (cobrar dos veces, enviar dos emails, generar dos facturas), se necesita Point-to-Point Channel.
Por Qué No Es Trivial¶
Aunque la semántica parece simple ("cada mensaje a un consumidor"), las decisiones de diseño alrededor del patrón son complejas:
- Acknowledgment y redelivery: ¿qué ocurre si un consumidor recibe un mensaje pero falla antes de procesarlo completamente? El broker debe detectar esta situación y reasignar el mensaje a otro consumidor. Pero esto puede causar procesamiento duplicado si el consumidor original realmente procesó el mensaje y solo falló al enviar el acknowledgment. La semántica de "exactamente una vez" es notoriamente difícil de lograr en sistemas distribuidos.
- Orden de procesamiento: ¿el canal garantiza que los mensajes se procesan en el orden en que se encolaron (FIFO)? Con un solo consumidor, sí. Con múltiples consumidores compitiendo, el orden global se pierde porque diferentes consumidores procesan mensajes a diferentes velocidades. El orden por partición o por grupo requiere diseño explícito.
- Distribución equitativa: ¿cómo se distribuyen los mensajes entre consumidores? ¿Round-robin? ¿Al consumidor con menos carga? ¿Al consumidor que más rápido acknowledge? Las estrategias de dispatching afectan el rendimiento y la latencia.
- Visibility timeout y poison messages: ¿cuánto tiempo espera el broker antes de considerar que un consumidor falló y debe reasignar el mensaje? ¿Qué ocurre con mensajes que ningún consumidor puede procesar (poison messages)?
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, Point-to-Point Channel implementa el concepto de trabajo distribuido con exclusión mutua sobre unidades de trabajo. Cada mensaje es una unidad de trabajo, y el canal garantiza que solo un worker la adquiere. Esto es análogo al patrón de distributed lock, pero implementado a nivel de infraestructura de mensajería en lugar de a nivel de aplicación.
La semántica de Competing Consumers es central al patrón. Competing Consumers no es un patrón separado del Point-to-Point Channel; es su consecuencia natural cuando hay más de un consumidor conectado. El canal proporciona la semántica de entrega exclusiva; los competing consumers son el mecanismo por el cual esa semántica se traduce en procesamiento paralelo con balanceo de carga.
En la práctica, cada plataforma de mensajería implementa Point-to-Point Channel de forma diferente:
- En RabbitMQ, un Point-to-Point Channel es una Queue con múltiples consumidores. El broker despacha cada mensaje a exactamente un consumidor usando round-robin (por defecto) o prefetch-based dispatch.
- En AWS SQS, cada Queue es inherentemente Point-to-Point. Los consumidores compiten por los mensajes mediante polling con visibility timeout.
- En Azure Service Bus, una Queue es Point-to-Point. Los mensajes se bloquean (peek-lock) mientras un consumidor los procesa.
- En Kafka, un consumer group sobre un topic implementa semántica Point-to-Point: cada partición se asigna a exactamente un consumidor del grupo, garantizando que cada mensaje lo procesa un solo consumidor. Múltiples consumer groups sobre el mismo topic producen semántica Pub-Sub.
- En Apache ActiveMQ, una Queue implementa Point-to-Point Channel de forma nativa con message-level acknowledgment.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin la abstracción de Point-to-Point Channel, las aplicaciones que necesitan distribuir trabajo entre múltiples procesadores enfrentan dilemas difíciles:
- Distribución de trabajo: ¿quién decide qué worker procesa cada tarea? Sin un coordinador central (que introduce un single point of failure), los workers necesitan coordinarse entre sí, lo cual requiere consensus protocols complejos.
- Exclusividad de procesamiento: ¿cómo se garantiza que dos workers no procesan la misma tarea simultáneamente? Sin un mecanismo de lock distribuido (costoso y frágil), el procesamiento duplicado es inevitable.
- Tolerancia a fallos: ¿qué ocurre cuando un worker falla a mitad de una tarea? Sin un mecanismo de redelivery, la tarea queda sin ejecutar. Con redelivery ingenuo, la tarea se ejecuta dos veces.
- Escalabilidad elástica: ¿cómo se añaden o eliminan workers sin interrumpir el procesamiento? Sin un mecanismo de asignación dinámica, el reparticionamiento requiere parada y reinicio.
Síntomas del Problema¶
- Tareas ejecutadas múltiples veces: un cliente recibe dos emails de confirmación, un pedido se factura dos veces, una transferencia bancaria se ejecuta duplicada.
- Tareas perdidas: cuando un worker falla, las tareas que tenía asignadas se pierden porque nadie más las procesa.
- Distribución desigual de carga: unos workers están sobrecargados mientras otros están ociosos porque la asignación de trabajo es estática e inflexible.
- Imposibilidad de escalar: añadir más workers requiere cambios en configuración o código del distribuidor de trabajo.
- Cuellos de botella en coordinación: los workers gastan más tiempo coordinándose entre sí (quién procesa qué) que ejecutando trabajo real.
Impacto Operativo y Arquitectónico¶
Sin Point-to-Point Channel:
- Las operaciones de negocio sufren duplicación (dobles cobros, dobles envíos) o pérdida (pedidos que nunca se procesan), ambas con impacto directo en clientes y revenue.
- La escalabilidad horizontal requiere intervención manual: reconfigurar la distribución de trabajo cada vez que se añade o elimina un worker.
- Los fallos de un worker son catastróficos: las tareas que tenía asignadas se pierden o quedan en un estado inconsistente que requiere reconciliación manual.
- La observabilidad es limitada: sin un canal que sirva de buffer observable, no hay forma sencilla de saber cuántas tareas están pendientes, cuántas se completaron, cuántas fallaron.
Riesgos Si No Se Implementa Correctamente¶
- Procesamiento duplicado sin idempotencia: si el canal ofrece at-least-once delivery (la semántica más común) y los consumidores no son idempotentes, las reasignaciones de mensajes producen efectos duplicados.
- Starvation de mensajes: si un consumidor es mucho más lento que los demás y el dispatching no es equitativo, algunos mensajes esperan desproporcionadamente.
- Poison message loop: un mensaje que no puede procesarse (formato inválido, referencia a dato inexistente) se reasigna infinitamente entre consumidores si no hay un mecanismo de dead-lettering.
- Pérdida de orden: si la lógica de negocio requiere orden (procesar un pedido antes de su cancelación), el procesamiento paralelo por competing consumers puede violar este requisito.
Ejemplos Reales¶
- Banca: una cola
transactions.executecontiene transacciones financieras que deben ejecutarse exactamente una vez. Si se procesan en un Publish-Subscribe Channel por error, cada transacción se ejecuta N veces (una por cada consumidor suscrito), multiplicando los movimientos de dinero. - E-commerce: una cola
orders.processcontiene pedidos que deben prepararse para envío. Tres workers compiten por los pedidos. Si un worker falla procesando un pedido, el broker lo reasigna a otro worker. Sin Point-to-Point Channel, la coordinación entre workers requeriría un servicio de orquestación dedicado. - Telecomunicaciones: una cola
sms.sendcontiene mensajes SMS que deben enviarse a clientes. Cinco workers envían SMS en paralelo. Si un mensaje se envía dos veces porque se asignó a dos workers simultáneamente, el cliente recibe el SMS duplicado, lo cual degrada la experiencia y puede tener implicaciones regulatorias.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando cada mensaje representa un comando o tarea que debe ejecutarse exactamente una vez: "procesar pedido", "enviar notificación", "generar factura".
- Cuando se necesita distribuir trabajo entre múltiples workers para procesamiento paralelo con balanceo de carga.
- Cuando se necesita tolerancia a fallos en el procesamiento: si un worker falla, otro debe continuar el trabajo sin perder mensajes.
- Cuando la escalabilidad horizontal del procesamiento es un requisito: poder añadir o eliminar workers dinámicamente sin cambios en productores ni en la configuración de distribución.
- Cuando el procesamiento de un mensaje produce efectos secundarios (escritura en base de datos, envío de email, transferencia de dinero) que no deben duplicarse.
Cuándo No Usarlo¶
- Cuando cada mensaje debe ser recibido por todos los consumidores interesados (eventos que notifican a múltiples sistemas): para esto se usa Publish-Subscribe Channel.
- Cuando los consumidores representan funcionalidades diferentes (inventario, pagos, shipping) que necesitan recibir el mismo evento: esto es fan-out, no competencia.
- Cuando el objetivo es notificar en lugar de comandar: los eventos son naturalmente pub-sub; los comandos son naturalmente point-to-point.
Precondiciones¶
- Existe un sistema de mensajería (broker) capaz de gestionar colas con semántica de entrega exclusiva.
- Los consumidores son lógicamente equivalentes: cualquier consumidor puede procesar cualquier mensaje del canal. Si diferentes mensajes requieren consumidores diferentes, se necesitan múltiples canales o un Content-Based Router.
- Existe un mecanismo de acknowledgment que permite al consumidor confirmar el procesamiento exitoso de un mensaje.
- Los consumidores son idealmente idempotentes, capaces de procesar el mismo mensaje más de una vez sin efectos adversos (requerido para at-least-once delivery).
Restricciones¶
- El orden global FIFO se pierde cuando hay múltiples consumidores compitiendo, a menos que el canal ofrezca mecanismos de ordenamiento por partición o sesión.
- La latencia de procesamiento de un mensaje individual depende de la carga del canal y la disponibilidad de consumidores.
- El throughput máximo está limitado por el número de consumidores y la velocidad de dispatching del broker.
Dependencias¶
- Infraestructura de messaging (broker con soporte de queues o consumer groups).
- Mecanismo de acknowledgment (message-level ack, offset commit, visibility timeout).
- Estrategia de dead-lettering para mensajes que no pueden procesarse.
- Monitoreo de profundidad de cola (queue depth) y velocidad de procesamiento.
Supuestos Arquitectónicos¶
- Cada mensaje es una unidad de trabajo independiente que puede procesarse de forma aislada.
- Los consumidores tienen capacidad computacional suficiente para procesar mensajes a un ritmo que no permita acumulación indefinida.
- Los fallos de consumidores son transitorios: el consumidor se recupera o es reemplazado en un tiempo acotado.
- La semántica de entrega del broker es al menos at-least-once (el broker reentrega mensajes cuyo acknowledgment no recibe).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas de procesamiento de pedidos y transacciones.
- Sistemas de envío de notificaciones (email, SMS, push).
- Pipelines de procesamiento de datos con workers paralelos.
- Sistemas de tareas distribuidas (job queues, task queues).
- Arquitecturas de microservicios con comunicación asíncrona basada en comandos.
- Sistemas batch distribuidos (procesamiento de archivos, generación de reportes).
6. Fuerzas Arquitectónicas¶
Procesamiento Único vs. Alta Disponibilidad¶
La fuerza más fundamental del patrón: cada mensaje debe procesarse por un solo consumidor (unicidad), pero si hay un solo consumidor y falla, los mensajes dejan de procesarse (disponibilidad). Point-to-Point Channel resuelve esta tensión permitiendo múltiples consumidores donde el broker garantiza unicidad mientras mantiene disponibilidad: si un consumidor falla, los mensajes se despachan a los consumidores restantes.
Orden vs. Paralelismo¶
Con un solo consumidor, el orden FIFO está garantizado: los mensajes se procesan en la secuencia en que se encolaron. Con múltiples consumidores compitiendo, el paralelismo aumenta pero el orden global se pierde. Esta tensión es irresoluble en el caso general — es una manifestación del trade-off fundamental entre concurrencia y serialización. Las soluciones parciales incluyen:
- Ordenamiento por partición (Kafka consumer groups, Azure Service Bus sessions): los mensajes con la misma clave se procesan en orden, pero mensajes con claves diferentes se procesan en paralelo.
- Un solo consumidor por tipo de mensaje que requiere orden estricto.
- Reordenamiento en el consumidor (costoso y complejo).
Throughput vs. Latencia¶
Más consumidores compitiendo aumentan el throughput total (mensajes procesados por segundo) pero pueden aumentar la latencia individual de un mensaje si el mecanismo de dispatching tiene overhead por asignación. Además, técnicas como batching (acumular mensajes antes de entregarlos) aumentan throughput a costa de latencia.
Simplicidad vs. Exactitud Semántica¶
La implementación más simple de Point-to-Point es fire-and-forget: el broker despacha el mensaje y lo elimina. Pero si el consumidor falla, el mensaje se pierde. La implementación exacta requiere acknowledgment, redelivery, idempotencia y dead-lettering — cada capa añade complejidad. La mayoría de los sistemas necesitan al menos at-least-once delivery, lo cual requiere que los consumidores sean idempotentes.
Acoplamiento Temporal vs. Desacoplamiento¶
Point-to-Point Channel desacopla temporalmente al productor del consumidor: el productor puede enviar mensajes aunque todos los consumidores estén inactivos. Los mensajes se acumulan en la cola y se procesan cuando los consumidores se recuperan. Sin embargo, si la cola crece indefinidamente porque los consumidores no pueden mantener el ritmo, el sistema eventualmente falla (memoria, disco). El canal proporciona un buffer, no almacenamiento infinito.
Equidad de Distribución vs. Afinidad de Procesamiento¶
La distribución round-robin entre consumidores es equitativa pero ignora localidad de datos. Un consumidor que tiene en caché los datos del cliente X es más eficiente procesando mensajes del cliente X. Message affinity (dirigir mensajes relacionados al mismo consumidor) mejora eficiencia pero puede crear hotspots. La partición por clave es el compromiso habitual.
Costo Operativo vs. Resiliencia¶
Un Point-to-Point Channel con alta resiliencia (mensajes persistidos, replicados, con acknowledgment y dead-lettering) tiene mayor costo operativo que un canal in-memory sin garantías. La decisión depende de la criticidad del trabajo: transacciones financieras justifican el costo de máxima resiliencia; métricas operacionales pueden tolerar pérdida ocasional.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): la aplicación que genera mensajes representando trabajo a ejecutar y los deposita en el canal.
- Cola (Queue): el recurso gestionado por el broker que almacena mensajes en orden y los despacha a consumidores con semántica de entrega exclusiva.
- Consumidor (Receiver / Worker): una instancia de la aplicación que recibe mensajes del canal, los procesa y confirma el procesamiento.
- Broker: el sistema de mensajería que gestiona la cola, controla el dispatching de mensajes a consumidores, maneja acknowledgments y redelivery.
- Dead Letter Queue: canal auxiliar donde se depositan mensajes que no pueden procesarse después de N reintentos.
Flujo Lógico¶
flowchart TD
A([Productor]) -->|Enqueue| B[(Cola / Queue)]
B --> C[Broker: Selecciona siguiente mensaje]
C -->|Round-robin / least-busy| D[Despacha a UN consumidor]
D -->|Mensaje locked| E[Consumidor: Procesa mensaje]
E --> F{Resultado}
F -->|Éxito| G[Envía ACK]
G --> H[Broker: Elimina mensaje permanentemente]
F -->|Fallo| I[Envía NACK o timeout]
I --> J{delivery count > max_retries?}
J -->|No| K[Broker: Redelivery a la cola] --> C
J -->|Sí| L[(Dead Letter Queue)]Semántica de Competing Consumers¶
Cuando múltiples consumidores se conectan al mismo Point-to-Point Channel, se establece el patrón de Competing Consumers:
┌──────────────┐
│ Consumidor A │ ← recibe msg 1, 4, 7...
└──────────────┘
┌──────────┐ ┌──────────────┐
│ Productor│──→ Q ──│ Consumidor B │ ← recibe msg 2, 5, 8...
└──────────┘ └──────────────┘
┌──────────────┐
│ Consumidor C │ ← recibe msg 3, 6, 9...
└──────────────┘
Cada mensaje es despachado a exactamente un consumidor. La asignación es dinámica: si el Consumidor B falla, sus mensajes pendientes se redistribuyen entre A y C. Si se añade un Consumidor D, comienza a recibir su porción de mensajes sin que los demás se vean afectados.
Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Serializar mensaje, enviarlo a la cola correcta, manejar errores de envío (reintentos, circuit breaker) |
| Cola/Broker | Almacenar mensajes en orden, despachar cada mensaje a exactamente un consumidor, gestionar locks/visibility, manejar redelivery y dead-lettering |
| Consumidor | Conectarse a la cola, recibir mensajes, procesarlos, enviar ACK/NACK, ser idempotente ante redelivery |
| Dead Letter Queue | Almacenar mensajes problemáticos para inspección, alertar sobre mensajes que requieren intervención |
Interacciones¶
- Productor → Cola: operación de enqueue (send, produce, publish). Puede ser confirmada (el broker responde que aceptó el mensaje) o no confirmada (fire-and-forget).
- Cola → Consumidor: operación de dispatch. Puede ser push (el broker envía al consumidor cuando hay mensaje disponible) o pull (el consumidor solicita el siguiente mensaje).
- Consumidor → Cola: operación de acknowledgment (ACK si procesó correctamente, NACK o abandon si falló).
- Cola → Dead Letter Queue: operación automática cuando un mensaje excede el número máximo de intentos de entrega.
Contratos Implícitos¶
- Equivalencia de consumidores: todos los consumidores conectados al canal deben ser capaces de procesar cualquier mensaje del canal. El broker no discrimina qué consumidor recibe qué mensaje.
- Idempotencia: dado que el broker puede reenviar mensajes (por timeout, fallo de ACK, partición de red), los consumidores deben tolerar procesamiento duplicado.
- Tiempo de procesamiento acotado: el consumidor debe procesar y confirmar el mensaje dentro del visibility timeout o lock duration; de lo contrario, el broker asume que el consumidor falló y reasigna el mensaje.
Decisiones de Diseño Clave¶
- Push vs. Pull: ¿el broker empuja mensajes a los consumidores (RabbitMQ), o los consumidores solicitan mensajes (SQS)?
- Prefetch count: ¿cuántos mensajes puede recibir un consumidor antes de confirmar los anteriores? Un prefetch alto aumenta throughput pero reduce equidad.
- Visibility timeout / Lock duration: ¿cuánto tiempo se considera "en procesamiento" un mensaje antes de reasignarlo? Muy corto causa redelivery innecesario; muy largo retrasa la recuperación ante fallos.
- Max delivery count: ¿cuántos reintentos antes de enviar a dead letter? Muy bajo causa dead-lettering prematuro; muy alto causa loops.
- FIFO vs. Standard: ¿se requiere orden estricto (con limitaciones de throughput) o se acepta best-effort ordering (con mayor throughput)?
8. Ejemplo Arquitectónico Detallado¶
Dominio: E-commerce — Cola de Procesamiento de Pedidos con Competing Consumers¶
Contexto del Negocio¶
Una plataforma de e-commerce que opera en seis países latinoamericanos procesa un promedio de 15,000 pedidos por hora, con picos de hasta 80,000 pedidos/hora durante eventos de venta especial (Black Friday, Hot Sale, Cyber Monday). Cada pedido, una vez confirmado el pago, debe pasar por un pipeline de procesamiento que incluye:
- Validación de inventario: verificar que todos los productos del pedido están disponibles en el warehouse asignado.
- Reserva de stock: apartar las unidades del inventario para evitar overselling.
- Cálculo de logística: determinar el warehouse óptimo, el carrier de envío y la fecha estimada de entrega.
- Generación de documentos: crear la orden de despacho, la guía de envío y la factura electrónica.
- Notificación al cliente: enviar confirmación por email y push notification con el tracking number.
Este pipeline debe ejecutarse una sola vez por pedido. Si un pedido se procesa dos veces, el stock se reserva doblemente (produciendo inventory discrepancies), se generan dos facturas (problema fiscal y contable) y el cliente recibe notificaciones duplicadas.
Necesidad de Integración¶
El sistema de checkout (productor) genera un mensaje por cada pedido confirmado. Este mensaje debe ser consumido por el Order Processing Service, que ejecuta el pipeline completo. Durante operaciones normales, un solo worker del Order Processing Service puede manejar la carga. Pero durante picos de 80,000 pedidos/hora, se necesitan múltiples workers procesando en paralelo sin que ningún pedido se procese más de una vez ni se quede sin procesar.
Sistemas Involucrados¶
- Checkout Service: microservicio que confirma el pago y produce el mensaje de pedido.
- Message Broker (RabbitMQ): gestiona la cola Point-to-Point de pedidos.
- Order Processing Workers (x N): instancias del servicio que consumen mensajes de la cola y ejecutan el pipeline.
- Inventory Service: API que gestiona stock y reservas.
- Logistics Service: API que calcula opciones de envío.
- Document Service: genera facturas electrónicas y guías de envío.
- Notification Service: envía emails y push notifications.
- Dead Letter Queue: almacena pedidos que no pudieron procesarse.
- Monitoring Stack (Prometheus + Grafana): observabilidad del sistema.
Restricciones Técnicas¶
- Latencia máxima aceptable desde confirmación de pago hasta notificación al cliente: 5 minutos en operación normal, 15 minutos en picos.
- Cada worker puede procesar un pedido en ~2 segundos en promedio (incluye llamadas a Inventory, Logistics, Document y Notification services).
- El stock debe reservarse antes de generar documentos; si la reserva falla (producto agotado), el pedido debe enviarse a un flujo de compensación, no a dead letter.
- Los mensajes que fallan por errores transitorios (timeout de un servicio downstream) deben reintentarse hasta 5 veces con backoff exponencial.
- Los mensajes que fallan por errores permanentes (producto inexistente, datos inválidos) deben ir a dead letter después de 1 intento.
Diseño de la Cola¶
Queue: orders.process
Type: Classic (durable)
Delivery mode: persistent
Acknowledgment: manual (per-message)
Prefetch count: 1 (per consumer)
Max delivery count: 5
Dead Letter Exchange: orders.dlx
Dead Letter Queue: orders.process.dlq
TTL: ninguno (los pedidos no expiran)
Max length: sin límite (backpressure gestionada por autoscaling)
Dimensionamiento de Workers¶
| Escenario | Pedidos/hora | Pedidos/seg | Tiempo por pedido | Workers necesarios |
|---|---|---|---|---|
| Normal | 15,000 | ~4.2 | 2 seg | 9 (con margen: 12) |
| Pico moderado | 40,000 | ~11.1 | 2 seg | 23 (con margen: 28) |
| Pico extremo (Black Friday) | 80,000 | ~22.2 | 2 seg | 45 (con margen: 55) |
Los workers se despliegan en Kubernetes con Horizontal Pod Autoscaler (HPA) basado en la métrica de queue depth (profundidad de cola). Cuando la cola supera los 500 mensajes pendientes, HPA escala horizontalmente.
Decisiones Arquitectónicas¶
-
Prefetch count = 1: cada worker recibe un mensaje a la vez. Esto maximiza la equidad de distribución (ningún worker acapara mensajes) a costa de un ligero overhead de dispatching. Con prefetch > 1, un worker rápido podría acumular mensajes mientras otro está ocioso.
-
Manual acknowledgment: el worker confirma el mensaje solo después de completar todo el pipeline (reserva + documentos + notificación). Si el worker falla a mitad del pipeline, el mensaje se reencola y otro worker lo reintenta. Los servicios downstream (Inventory, Document) son idempotentes por diseño.
-
Dead Letter después de 5 intentos: los errores transitorios (timeouts, rate limits) se resuelven típicamente en 2-3 reintentos. Si un mensaje falla 5 veces, el problema es probablemente permanente y requiere intervención humana.
-
Cola única (no particionada): RabbitMQ no tiene concepto nativo de particiones. Todos los workers consumen de la misma cola. Esto simplifica la arquitectura pero implica que el orden de procesamiento entre pedidos no está garantizado. Para este caso de uso, el orden global no es necesario — cada pedido es independiente.
-
Idempotencia en el pipeline: el Inventory Service usa idempotency keys basados en el order_id. Si una reserva se solicita dos veces con el mismo order_id, la segunda solicitud es un no-op. El Document Service verifica si la factura ya existe antes de generarla. Esta idempotencia protege contra los efectos del redelivery.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Procesamiento duplicado por redelivery | Idempotency keys en todos los servicios downstream |
| Worker lento acumula mensajes | Prefetch = 1, monitoreo de procesamiento time per message |
| Cola crece sin control en picos | Autoscaling de workers basado en queue depth |
| Dead letter no atendido | Alertas en Slack/PagerDuty cuando DLQ depth > 0 |
| Fallo del broker (RabbitMQ) | Cluster de 3 nodos con quorum queues, mensajes persistidos |
| Pedidos de productos agotados | Flujo de compensación separado (no dead letter), notificación al cliente |
| Latencia alta por servicios downstream lentos | Circuit breaker en llamadas a Inventory/Logistics/Document/Notification |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción del Mensaje de Pedido¶
Un cliente en Ciudad de Mexico confirma la compra de un pedido (ID: ORD-2026-0407-58291) que contiene 3 productos. El Checkout Service confirma el pago con el payment gateway y produce un mensaje en la cola orders.process:
{
"order_id": "ORD-2026-0407-58291",
"timestamp": "2026-04-07T14:32:15Z",
"customer_id": "CUST-MX-482917",
"payment_id": "PAY-2026-8291746",
"shipping_address": {
"country": "MX",
"city": "Ciudad de Mexico",
"zip": "06600",
"line1": "Av. Paseo de la Reforma 222"
},
"items": [
{ "sku": "ELEC-LAPTOP-001", "qty": 1, "warehouse_hint": "WH-MX-CDMX" },
{ "sku": "ACC-MOUSE-042", "qty": 1, "warehouse_hint": "WH-MX-CDMX" },
{ "sku": "ACC-HDMI-007", "qty": 2, "warehouse_hint": "WH-MX-CDMX" }
],
"total_amount": { "value": 28500.00, "currency": "MXN" },
"idempotency_key": "ORD-2026-0407-58291-v1"
}
El Checkout Service publica el mensaje con delivery_mode=2 (persistent) y espera la confirmación del broker (publisher confirms). Solo después de recibir la confirmación, el Checkout Service marca la transacción como "enviada a procesamiento" en su base de datos. Si la confirmación no llega (timeout), reintenta el envío.
Paso 2: Dispatching por el Broker¶
RabbitMQ recibe el mensaje y lo almacena en la cola orders.process de forma persistida en disco. En este momento, hay 12 workers conectados a la cola como consumidores. RabbitMQ selecciona el Worker 7 (siguiente en round-robin) y le despacha el mensaje.
El mensaje queda marcado como "unacknowledged" en el broker. Si el Worker 7 no envía un ACK dentro de 30 minutos (el consumer timeout configurado), RabbitMQ lo considerará fallido y redespachará el mensaje a otro worker.
Paso 3: Validación de Inventario¶
El Worker 7 recibe el mensaje y comienza el pipeline. Primero, llama al Inventory Service para verificar disponibilidad de cada producto:
GET /inventory/check
Body: { "sku": "ELEC-LAPTOP-001", "qty": 1, "warehouse": "WH-MX-CDMX" }
Response: { "available": true, "reserved_until": null }
GET /inventory/check
Body: { "sku": "ACC-MOUSE-042", "qty": 1, "warehouse": "WH-MX-CDMX" }
Response: { "available": true, "reserved_until": null }
GET /inventory/check
Body: { "sku": "ACC-HDMI-007", "qty": 2, "warehouse": "WH-MX-CDMX" }
Response: { "available": true, "reserved_until": null }
Todos los productos están disponibles. Si alguno no estuviera disponible, el worker enviaría el pedido a una cola de compensación (orders.compensation) y haría ACK del mensaje original (el mensaje se retira de la cola principal porque la compensación es un flujo diferente, no un error de procesamiento).
Paso 4: Reserva de Stock¶
Con la disponibilidad confirmada, el worker solicita la reserva atómica de todos los productos:
POST /inventory/reserve
Body: {
"idempotency_key": "ORD-2026-0407-58291-v1",
"items": [
{ "sku": "ELEC-LAPTOP-001", "qty": 1, "warehouse": "WH-MX-CDMX" },
{ "sku": "ACC-MOUSE-042", "qty": 1, "warehouse": "WH-MX-CDMX" },
{ "sku": "ACC-HDMI-007", "qty": 2, "warehouse": "WH-MX-CDMX" }
],
"reservation_ttl_minutes": 60
}
Response: { "reservation_id": "RSV-2026-4821", "status": "confirmed" }
El idempotency_key garantiza que si este paso se ejecuta dos veces (por redelivery del mensaje), la segunda reserva es un no-op que retorna la misma reservation_id.
Paso 5: Cálculo de Logística¶
El worker consulta al Logistics Service para determinar el carrier y la fecha estimada:
POST /logistics/calculate
Body: {
"origin_warehouse": "WH-MX-CDMX",
"destination": { "country": "MX", "city": "Ciudad de Mexico", "zip": "06600" },
"items": [ { "sku": "ELEC-LAPTOP-001", "weight_kg": 2.3 }, ... ],
"priority": "standard"
}
Response: {
"carrier": "FedEx Mexico",
"service": "Express",
"estimated_delivery": "2026-04-09",
"tracking_prefix": "FMX",
"shipping_cost": { "value": 189.00, "currency": "MXN" }
}
Paso 6: Generación de Documentos¶
El worker solicita al Document Service la generación de factura y guía de envío:
POST /documents/generate
Body: {
"order_id": "ORD-2026-0407-58291",
"idempotency_key": "ORD-2026-0407-58291-v1",
"type": "invoice_and_shipping_label",
"reservation_id": "RSV-2026-4821",
"carrier": "FedEx Mexico",
"tracking_number": "FMX-2026-938271"
}
Response: {
"invoice_url": "https://docs.store.mx/inv/ORD-2026-0407-58291.pdf",
"shipping_label_url": "https://docs.store.mx/ship/FMX-2026-938271.pdf",
"cfdi_uuid": "a1b2c3d4-e5f6-7890-abcd-ef1234567890"
}
Paso 7: Notificación al Cliente¶
El worker solicita al Notification Service el envío de confirmación:
POST /notifications/send
Body: {
"customer_id": "CUST-MX-482917",
"template": "order_confirmed",
"channels": ["email", "push"],
"data": {
"order_id": "ORD-2026-0407-58291",
"estimated_delivery": "2026-04-09",
"tracking_number": "FMX-2026-938271",
"invoice_url": "https://docs.store.mx/inv/ORD-2026-0407-58291.pdf"
}
}
Response: { "notification_id": "NOTIF-2026-192837", "status": "queued" }
Paso 8: Acknowledgment¶
El Worker 7 ha completado todo el pipeline exitosamente. Envía un ACK al broker:
RabbitMQ recibe el ACK y elimina permanentemente el mensaje de la cola orders.process. El mensaje no puede ser recibido por ningún otro worker. El pedido está procesado.
Tiempo total: 2.1 segundos desde la recepción del mensaje hasta el ACK.
Paso 9: Escenario de Fallo y Redelivery¶
Supongamos que durante el procesamiento de otro pedido (ORD-2026-0407-58305), el Worker 3 falla (OOMKilled por Kubernetes) después de reservar stock pero antes de generar documentos. El proceso:
- RabbitMQ detecta que la conexión del Worker 3 se cerró sin ACK.
- El mensaje del pedido
ORD-2026-0407-58305se reasigna al Worker 9 (siguiente disponible). - El Worker 9 ejecuta el pipeline desde el inicio.
- Al intentar reservar stock, el Inventory Service detecta el
idempotency_keyduplicado y retorna la reserva existente (RSV-2026-4825) sin crear una nueva. - El Worker 9 continúa con generación de documentos y notificación.
- El Worker 9 envía ACK. El pedido se procesa exactamente una vez a nivel de efecto de negocio, aunque fue despachado dos veces a nivel de broker.
Paso 10: Monitoreo y Observabilidad¶
Grafana muestra en tiempo real:
- Queue depth de
orders.process: 23 mensajes pendientes (normal para la hora actual). - Processing rate: 4.1 mensajes/segundo (dentro del rango esperado).
- DLQ depth de
orders.process.dlq: 0 mensajes (saludable). - Consumer count: 12 workers conectados.
- Avg processing time: 2.1 segundos por mensaje.
- Redelivery rate: 0.02% (2 de cada 10,000 mensajes se reasignan).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
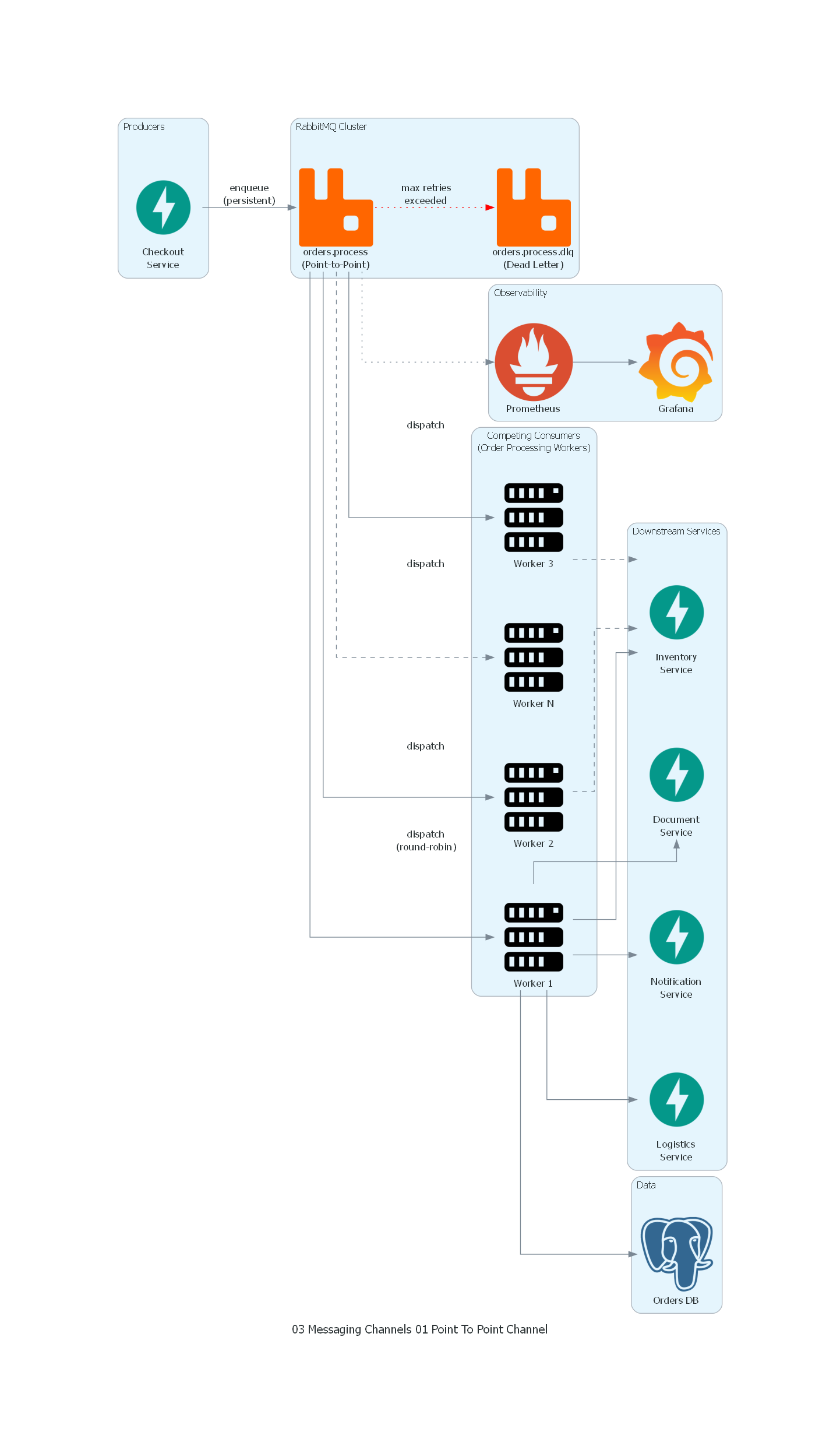
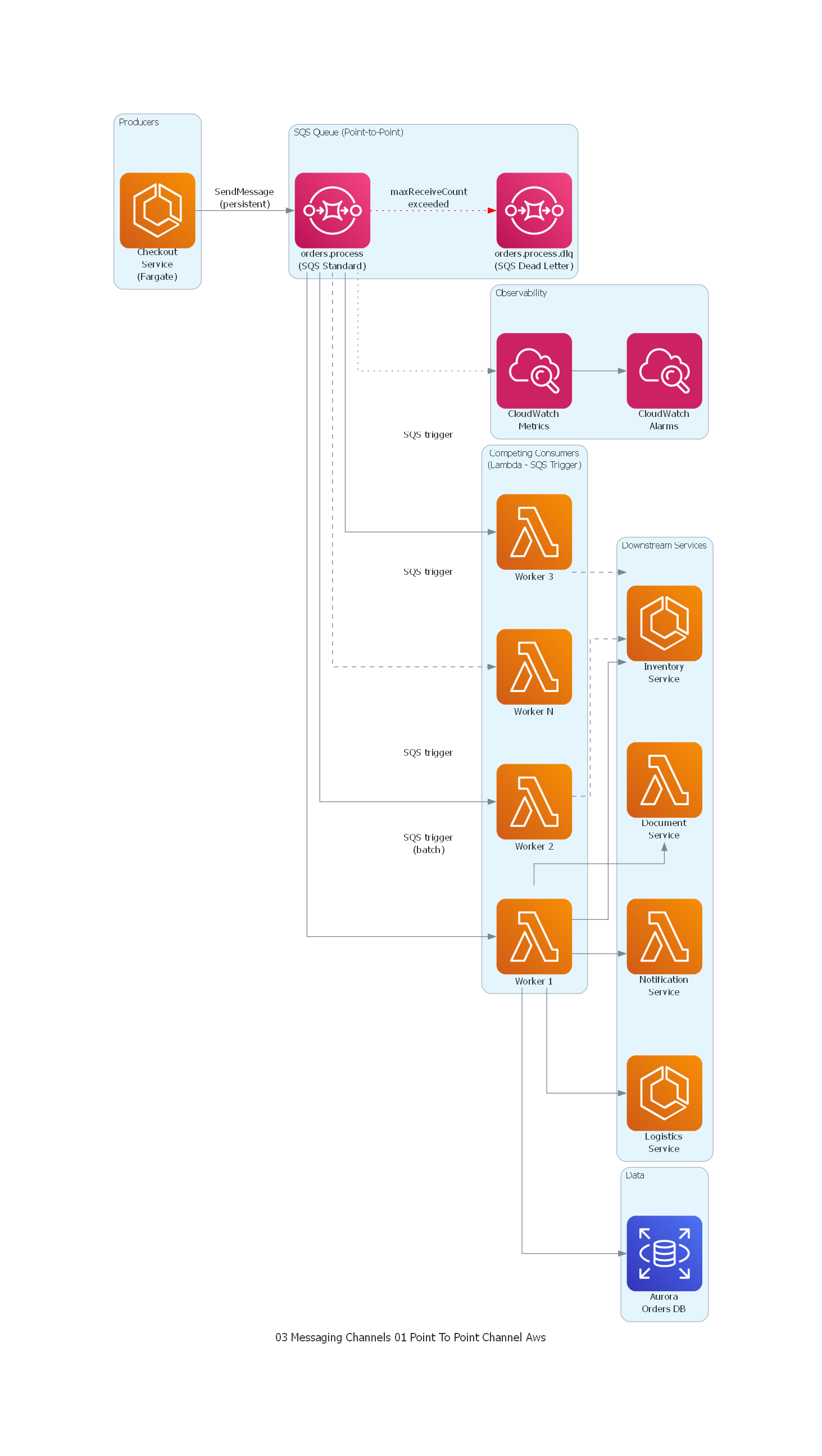
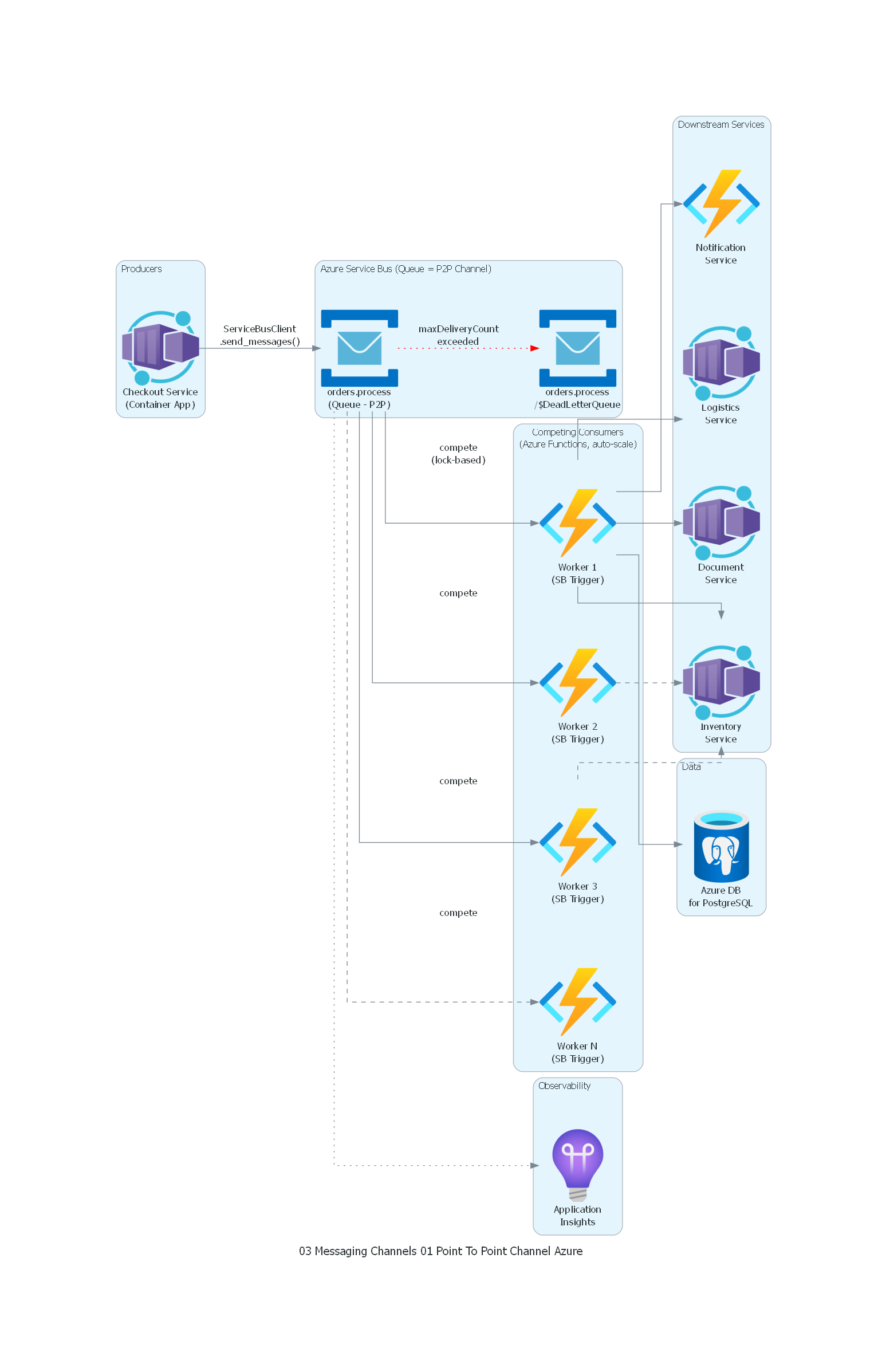
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import RabbitMQ
from diagrams.onprem.compute import Server
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.network import Nginx
from diagrams.programming.framework import FastAPI
with Diagram("Point-to-Point Channel - Order Processing", show=False, direction="LR"):
with Cluster("Producers"):
checkout = FastAPI("Checkout\nService")
with Cluster("RabbitMQ Cluster"):
queue = RabbitMQ("orders.process\n(Point-to-Point)")
dlq = RabbitMQ("orders.process.dlq\n(Dead Letter)")
with Cluster("Competing Consumers\n(Order Processing Workers)"):
worker1 = Server("Worker 1")
worker2 = Server("Worker 2")
worker3 = Server("Worker 3")
worker_n = Server("Worker N")
with Cluster("Downstream Services"):
inventory = FastAPI("Inventory\nService")
logistics = FastAPI("Logistics\nService")
documents = FastAPI("Document\nService")
notifications = FastAPI("Notification\nService")
with Cluster("Data"):
db = PostgreSQL("Orders DB")
with Cluster("Observability"):
prometheus = Prometheus("Prometheus")
grafana = Grafana("Grafana")
# Producer to Queue
checkout >> Edge(label="enqueue\n(persistent)") >> queue
# Queue to Competing Consumers (each message to ONE worker)
queue >> Edge(label="dispatch\n(round-robin)") >> worker1
queue >> Edge(label="dispatch") >> worker2
queue >> Edge(label="dispatch") >> worker3
queue >> Edge(style="dashed", label="dispatch") >> worker_n
# Dead Letter
queue >> Edge(style="dotted", color="red", label="max retries\nexceeded") >> dlq
# Workers to Downstream (each worker calls all services)
worker1 >> inventory
worker1 >> logistics
worker1 >> documents
worker1 >> notifications
worker1 >> db
worker2 >> Edge(style="dashed") >> inventory
worker3 >> Edge(style="dashed") >> inventory
# Monitoring
queue >> Edge(style="dotted") >> prometheus
prometheus >> grafana
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.database import RDS
from diagrams.aws.integration import SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
with Diagram("Point-to-Point Channel - Order Processing (AWS)", show=False, direction="LR"):
with Cluster("Producers"):
checkout = ECS("Checkout\nService\n(Fargate)")
with Cluster("SQS Queue (Point-to-Point)"):
queue = SQS("orders.process\n(SQS Standard)")
dlq = SQS("orders.process.dlq\n(SQS Dead Letter)")
with Cluster("Competing Consumers\n(Lambda - SQS Trigger)"):
worker1 = Lambda("Worker 1")
worker2 = Lambda("Worker 2")
worker3 = Lambda("Worker 3")
worker_n = Lambda("Worker N")
with Cluster("Downstream Services"):
inventory = ECS("Inventory\nService")
logistics = ECS("Logistics\nService")
documents = Lambda("Document\nService")
notifications = Lambda("Notification\nService")
with Cluster("Data"):
db = RDS("Aurora\nOrders DB")
with Cluster("Observability"):
cw_metrics = Cloudwatch("CloudWatch\nMetrics")
cw_alarms = Cloudwatch("CloudWatch\nAlarms")
# Producer to Queue
checkout >> Edge(label="SendMessage\n(persistent)") >> queue
# Queue to Competing Consumers (each message to ONE Lambda)
queue >> Edge(label="SQS trigger\n(batch)") >> worker1
queue >> Edge(label="SQS trigger") >> worker2
queue >> Edge(label="SQS trigger") >> worker3
queue >> Edge(style="dashed", label="SQS trigger") >> worker_n
# Dead Letter
queue >> Edge(style="dotted", color="red", label="maxReceiveCount\nexceeded") >> dlq
# Workers to Downstream (each worker calls all services)
worker1 >> inventory
worker1 >> logistics
worker1 >> documents
worker1 >> notifications
worker1 >> db
worker2 >> Edge(style="dashed") >> inventory
worker3 >> Edge(style="dashed") >> inventory
# Monitoring
queue >> Edge(style="dotted") >> cw_metrics
cw_metrics >> cw_alarms
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import DatabaseForPostgresqlServers
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Point-to-Point Channel - Order Processing (Azure)", show=False, direction="LR"):
with Cluster("Producers"):
checkout = ContainerApps("Checkout Service\n(Container App)")
with Cluster("Azure Service Bus (Queue = P2P Channel)"):
queue = ServiceBus("orders.process\n(Queue - P2P)")
dlq = ServiceBus("orders.process\n/$DeadLetterQueue")
with Cluster("Competing Consumers\n(Azure Functions, auto-scale)"):
worker1 = FunctionApps("Worker 1\n(SB Trigger)")
worker2 = FunctionApps("Worker 2\n(SB Trigger)")
worker3 = FunctionApps("Worker 3\n(SB Trigger)")
worker_n = FunctionApps("Worker N\n(SB Trigger)")
with Cluster("Downstream Services"):
inventory = ContainerApps("Inventory\nService")
logistics = ContainerApps("Logistics\nService")
documents = ContainerApps("Document\nService")
notifications = FunctionApps("Notification\nService")
with Cluster("Data"):
db = DatabaseForPostgresqlServers("Azure DB\nfor PostgreSQL")
with Cluster("Observability"):
app_insights = ApplicationInsights("Application\nInsights")
# Producer to Queue (Service Bus Queue = Point-to-Point)
checkout >> Edge(label="ServiceBusClient\n.send_messages()") >> queue
# Queue to Competing Consumers (each message to ONE worker)
queue >> Edge(label="compete\n(lock-based)") >> worker1
queue >> Edge(label="compete") >> worker2
queue >> Edge(label="compete") >> worker3
queue >> Edge(style="dashed", label="compete") >> worker_n
# Dead Letter (built-in maxDeliveryCount)
queue >> Edge(style="dotted", color="red", label="maxDeliveryCount\nexceeded") >> dlq
# Workers to Downstream (each worker calls all services)
worker1 >> inventory
worker1 >> logistics
worker1 >> documents
worker1 >> notifications
worker1 >> db
worker2 >> Edge(style="dashed") >> inventory
worker3 >> Edge(style="dashed") >> inventory
# Monitoring
queue >> Edge(style="dotted") >> app_insights
Explicación del Diagrama¶
El diagrama ilustra la arquitectura completa del Point-to-Point Channel para procesamiento de pedidos:
- Checkout Service (productor) envía mensajes a la cola
orders.processcon persistencia habilitada. - RabbitMQ gestiona la cola y despacha cada mensaje a exactamente un worker usando round-robin.
- Workers 1-N (Competing Consumers) compiten por los mensajes. Cada mensaje lo recibe un solo worker. El diagrama muestra N workers para representar la escalabilidad horizontal.
- Cada worker llama a los Downstream Services (Inventory, Logistics, Document, Notification) para ejecutar el pipeline completo del pedido.
- Los mensajes que exceden el número máximo de reintentos se desvían a la Dead Letter Queue (
orders.process.dlq) representada con flecha roja. - Prometheus recolecta métricas de la cola (depth, consumer count, delivery rate) y Grafana las visualiza.
Correspondencia Patron ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor | Checkout Service |
| Point-to-Point Channel | Cola orders.process en RabbitMQ |
| Competing Consumers | Workers 1-N (cada mensaje a exactamente uno) |
| Semántica de entrega exclusiva | Flechas "dispatch" — cada flecha representa que UN mensaje va a UN worker |
| Redelivery / Fault tolerance | Implícito: si un worker falla, el mensaje se redespacha a otro |
| Dead Letter Channel | Cola orders.process.dlq |
| Load Balancing | Round-robin dispatch entre workers |
| Observability | Prometheus + Grafana monitoreando la cola |
11. Beneficios¶
Impacto Técnico¶
- Balanceo de carga automático: el broker distribuye mensajes entre consumidores de forma equitativa, sin necesidad de un load balancer explícito. Añadir un consumidor inmediatamente reduce la carga de los existentes; eliminar uno redistribuye su carga automáticamente.
- Escalabilidad horizontal lineal: duplicar el número de workers aproximadamente duplica el throughput de procesamiento, hasta el límite del broker. No se requieren cambios en el productor, en la configuración del canal ni en los consumidores existentes.
- Tolerancia a fallos transparente: si un worker falla, los mensajes que tenía pendientes se reasignan automáticamente. El productor no se entera del fallo; los demás workers no se ven afectados. La recuperación es automática y sin intervención humana.
- Buffer natural contra picos: la cola absorbe picos de producción sin que los workers necesiten escalar instantáneamente. Los mensajes se acumulan en la cola y se procesan a medida que los workers tienen capacidad. Esto desacopla la velocidad del productor de la velocidad de los consumidores.
- Procesamiento garantizado: cada mensaje se procesa o se envía a dead letter. No hay mensajes que "desaparezcan" silenciosamente. La combinación de acknowledgment + redelivery + dead-lettering garantiza que todo mensaje tiene una resolución.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de checkout solo necesita conocer la cola y el formato del mensaje. No necesita coordinar con el equipo de order processing sobre cuántos workers hay, dónde están desplegados ni cómo se distribuye la carga.
- Escalabilidad operacional: durante eventos de alto tráfico, el equipo de operaciones puede escalar workers sin coordinar con el equipo de desarrollo. El único knob es el número de instancias.
- Debugging simplificado: los mensajes en la cola son inspeccionables. Si un pedido no se procesa, el equipo puede buscar el mensaje en la cola, en la dead letter queue o en los logs del worker que lo procesó. La trazabilidad es directa.
Impacto Operacional¶
- Observabilidad centralizada: la profundidad de la cola es la métrica central que indica la salud del sistema. Si crece, los consumidores no dan abasto. Si está en cero, el sistema tiene capacidad sobrante. Una única métrica resume el estado de toda la pipeline.
- Backpressure sin pérdida: cuando los consumidores no pueden mantener el ritmo, los mensajes se acumulan en la cola en lugar de perderse o causar errores en el productor. El productor continúa operando normalmente.
- Deployment sin downtime: los workers pueden desplegarse con rolling updates. Durante el despliegue, los workers que se apagan devuelven sus mensajes no-acknowledged a la cola, y los nuevos workers los toman. No hay pérdida de mensajes ni ventana de inactividad.
Beneficios de Mantenibilidad y Evolución¶
- Refactoring transparente: la lógica interna del worker puede refactorizarse completamente (cambiar de lenguaje, framework, base de datos) sin afectar al productor ni a la cola. El contrato es el formato del mensaje.
- Testing aislado: los workers pueden testearse de forma aislada consumiendo mensajes de una cola de test. No se necesita el productor real para probar el procesamiento.
- Migración de broker: la semántica de Point-to-Point Channel es universal. Migrar de RabbitMQ a SQS o Azure Service Bus requiere cambiar el adapter de conexión, no la lógica de negocio.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Acknowledgment management: la gestión correcta de ACK/NACK añade complejidad al código del consumidor. Un ACK prematuro (antes de completar el procesamiento) causa pérdida de mensajes ante fallo. Un ACK tardío o ausente causa redelivery innecesario. El punto exacto donde hacer ACK requiere diseño cuidadoso.
- Idempotencia obligatoria: dado que el redelivery es un escenario esperado (no excepcional), cada consumidor y cada servicio downstream deben implementar idempotencia. Esto añade complejidad significativa a todo el stack, requiriendo idempotency keys, deduplication stores o diseño inherentemente idempotente.
- Infraestructura de broker: operar un cluster de RabbitMQ, gestionar quorum queues, configurar mirroring y monitorear la salud del broker no es trivial. Incluso con servicios managed (Amazon MQ, CloudAMQP), el dimensionamiento y la configuración requieren expertise.
Riesgos de Mal Uso¶
- Point-to-Point donde se necesita Pub-Sub: usar una cola Point-to-Point para mensajes que deberían distribuirse a múltiples sistemas independientes. Si el pedido confirmado debe notificar a inventario, a pagos y a shipping como sistemas separados, cada uno necesita su propia copia del mensaje (Pub-Sub), no competir por una sola copia.
- Cola como base de datos: consultar la cola para "ver qué pedidos están pendientes" en lugar de usar un store dedicado. Las colas no están diseñadas para queries; están diseñadas para FIFO dispatch.
- Procesamiento parcial sin compensación: si el worker falla después de ejecutar algunos pasos del pipeline pero antes de completar todos, el redelivery causa que los pasos ya ejecutados se repitan. Sin idempotencia en cada paso, esto produce inconsistencias.
Pérdida de Orden¶
- Con un solo consumidor, el orden FIFO está garantizado. Con N consumidores compitiendo, el orden global se pierde irrecuperablemente. Si el pedido A entra antes que el pedido B, pero el Worker 1 (procesando A) es más lento que el Worker 2 (procesando B), B se completa antes que A. Para la mayoría de use cases de work queues esto no es problema (cada pedido es independiente), pero para escenarios que requieren orden estricto (procesamiento de transacciones de una misma cuenta), Point-to-Point con competing consumers no es suficiente sin mecanismos adicionales (particionamiento por clave, single consumer per partition).
Sobreingeniería¶
- Demasiados workers para poca carga: desplegar 20 workers para una cola que recibe 10 mensajes por hora desperdicia recursos y añade complejidad de monitoreo sin beneficio real.
- Visibility timeout excesivamente conservador: configurar un timeout de 1 hora "por si acaso" retrasa la recuperación ante fallos reales durante 1 hora.
Costos de Operación¶
- Storage de la cola: en picos extremos, la cola puede acumular millones de mensajes que consumen storage significativo.
- Networking entre workers y servicios downstream: N workers haciendo llamadas HTTP a los mismos servicios downstream pueden saturarlos si no hay rate limiting o circuit breaking.
- Monitoreo per-queue: cada cola requiere alertas configuradas (queue depth, DLQ depth, consumer count, redelivery rate).
Anti-Patterns Relacionados¶
- Competing Consumers sin idempotencia: el anti-pattern más peligroso. Se asume que cada mensaje se procesa exactamente una vez, cuando la realidad es at-least-once. Sin idempotencia, los redeliveries causan duplicación de efectos (doble cobro, doble envío).
- Infinite Retry Loop: no configurar max delivery count ni dead-lettering, causando que un poison message se reasigne infinitamente entre consumidores, consumiendo capacidad de procesamiento sin resultado.
- Acknowledgment Before Processing: hacer ACK del mensaje al recibirlo (antes de procesarlo) para "mejorar throughput". Si el worker falla después del ACK pero antes de completar el procesamiento, el mensaje se pierde permanentemente.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): Point-to-Point Channel es una especialización de Message Channel. Todo Point-to-Point Channel es un Message Channel con semántica de entrega exclusiva.
- Dead Letter Channel (este capítulo): toda cola Point-to-Point necesita un Dead Letter Channel para mensajes que no pueden procesarse después de N reintentos.
- Guaranteed Delivery (este capítulo): Point-to-Point Channel típicamente se combina con Guaranteed Delivery para asegurar que los mensajes no se pierden ante fallos del broker.
- Invalid Message Channel (este capítulo): complementa al Dead Letter Channel. Los mensajes que el consumidor no puede entender (formato inválido, versión desconocida) se envían a un canal de mensajes inválidos.
- Competing Consumers: no es un patrón separado de Point-to-Point Channel — es la consecuencia natural de conectar múltiples consumidores a un canal con semántica de entrega exclusiva. Competing Consumers es Point-to-Point Channel con N>1 consumidores.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: un Message Router o Content-Based Router puede dirigir mensajes a diferentes Point-to-Point Channels según su contenido (por ejemplo, pedidos nacionales a una cola, pedidos internacionales a otra).
- Después: el consumidor de un Point-to-Point Channel puede producir mensajes en otro canal (por ejemplo, después de procesar un pedido, produce un evento
order.processeden un Publish-Subscribe Channel para notificar a otros sistemas).
Combinaciones Comunes¶
- Point-to-Point Channel + Message Dispatcher: un único consumidor recibe todos los mensajes del canal y los distribuye internamente a handlers especializados según el tipo de mensaje. Útil cuando el dispatching no es por competencia sino por tipo.
- Point-to-Point Channel + Content-Based Router: mensajes de diferentes tipos se enrutan a diferentes colas Point-to-Point, cada una con sus propios workers especializados.
- Point-to-Point Channel + Wire Tap: se intercepta la cola para copiar mensajes a un canal de auditoría o logging sin afectar el procesamiento principal.
- Point-to-Point Channel + Message Filter: antes de la cola, un filtro descarta mensajes que no cumplen criterios de validación, evitando que mensajes inválidos ocupen capacidad de la cola y de los workers.
Diferencias con Patrones Similares¶
- vs. Publish-Subscribe Channel: la diferencia fundamental. En Point-to-Point, cada mensaje es consumido por exactamente un receptor. En Pub-Sub, cada mensaje es consumido por todos los receptores suscritos. Point-to-Point es para comandos y tareas; Pub-Sub es para eventos y notificaciones. Point-to-Point implica competencia; Pub-Sub implica distribución.
- vs. Message Dispatcher: Message Dispatcher es un patrón de consumidor (cómo un consumidor distribuye mensajes internamente a handlers), no un patrón de canal. Un Message Dispatcher puede consumir de un Point-to-Point Channel.
- vs. Request-Reply: Request-Reply usa dos Point-to-Point Channels (uno para el request, otro para el reply) para simular comunicación síncrona sobre messaging asíncrono. Point-to-Point Channel es un componente de Request-Reply, no una alternativa.
- vs. Claim Check: cuando los mensajes son demasiado grandes para la cola, Claim Check almacena el payload en un store externo y el mensaje en la cola solo contiene una referencia. Son complementarios, no alternativos.
Encaje en un Flujo Mayor de Integración¶
En una arquitectura event-driven típica, Point-to-Point Channel y Publish-Subscribe Channel coexisten y se complementan:
- Un evento de negocio (ej: "pedido creado") se publica en un Publish-Subscribe Channel para que múltiples sistemas lo reciban.
- Cada sistema receptor tiene su propio Point-to-Point Channel (cola de trabajo) donde los mensajes se procesan por sus workers.
- El resultado del procesamiento puede generar nuevos eventos en otro Publish-Subscribe Channel.
Este patrón de "pub-sub para distribución, point-to-point para procesamiento" es la combinación más común en arquitecturas de microservicios basadas en eventos.
14. Relevancia Actual del Patrón¶
Evaluacion: Relevancia Alta¶
Argumentacion¶
Point-to-Point Channel es uno de los patrones de mayor relevancia en la arquitectura moderna. Las colas de trabajo son ubicuas en todo sistema distribuido contemporáneo:
- Cada SQS queue de AWS es un Point-to-Point Channel. AWS procesa cientos de miles de millones de mensajes SQS diariamente.
- Cada queue de RabbitMQ con múltiples consumidores es un Point-to-Point Channel. RabbitMQ es el broker más desplegado del mundo para work queues.
- Cada consumer group sobre un topic de Kafka implementa semántica Point-to-Point: cada partición se asigna a un solo consumidor del grupo.
- Cada queue de Azure Service Bus es Point-to-Point por defecto.
- Cada task queue de Celery, Sidekiq, Bull o cualquier sistema de tareas distribuidas es un Point-to-Point Channel.
- Cada subscription con un solo consumidor de Google Cloud Pub/Sub funciona como Point-to-Point.
El patrón no solo persiste — ha proliferado. Los sistemas modernos tienen más colas que nunca porque la arquitectura de microservicios genera más comunicación asíncrona que la arquitectura monolítica. Donde antes había una llamada a método dentro del monolito, ahora hay un mensaje en una cola entre dos microservicios.
Evolución del Patrón¶
El concepto fundamental no ha cambiado: cada mensaje a un consumidor. Lo que ha evolucionado es:
- Serverless queues: SQS, Google Pub/Sub y Azure Storage Queues eliminan la necesidad de gestionar infraestructura de broker. La cola es un servicio managed que escala automáticamente.
- Lambda/Functions triggers: las colas modernas se integran nativamente con funciones serverless. Cada mensaje trigger una ejecución de Lambda/Function, convirtiendo la cola en un mecanismo de invocación elástica.
- Exactly-once processing: plataformas como Kafka (con transactional consumers) y Google Pub/Sub (con exactly-once delivery) reducen la necesidad de idempotencia explícita en los consumidores, aunque con trade-offs de performance.
- Autoscaling basado en queue depth: KEDA (Kubernetes Event-Driven Autoscaling) y equivalentes escalan workers automáticamente basándose en la profundidad de la cola, automatizando la decisión de cuántos competing consumers desplegar.
Que Parte Sigue Siendo Esencial¶
- La semántica de entrega exclusiva: la necesidad de que cada tarea se ejecute una sola vez es permanente. Mientras existan operaciones con efectos secundarios (cobrar dinero, enviar paquetes, generar facturas), existirá la necesidad de Point-to-Point Channel.
- Competing Consumers para escalabilidad horizontal: la mecánica de "más workers = más throughput" sin cambios en el productor es fundamental para elasticidad en la nube.
- El acknowledgment como contrato de procesamiento: la noción de que un mensaje no se elimina hasta que el consumidor confirma su procesamiento es la base de la confiabilidad en messaging.
- Dead-lettering como safety net: la necesidad de un destino para mensajes que no pueden procesarse es permanente.
15. Implementación en Arquitecturas Modernas¶
Amazon SQS (Standard Queue)¶
Queue: orders-process-queue
Type: Standard
Visibility Timeout: 300 seconds (5 minutes)
Message Retention: 4 days
Max Receive Count: 5
Dead Letter Queue: orders-process-dlq
Receive Wait Time: 20 seconds (long polling)
Encryption: SSE-SQS
SQS implementa Point-to-Point Channel como un servicio fully managed. Los consumidores hacen polling con ReceiveMessage, procesan el mensaje y llaman DeleteMessage como acknowledgment. Si no se elimina antes del visibility timeout, el mensaje se vuelve visible para otros consumidores (redelivery). SQS es la implementación más simple y escalable de Point-to-Point Channel: no hay brokers que gestionar, no hay particiones que configurar, no hay consumer groups que coordinar. Escala automáticamente hasta cientos de miles de mensajes por segundo.
Integración con Lambda: SQS puede trigger funciones Lambda automáticamente. Cada mensaje invoca una ejecución de Lambda, convirtiendo la cola en un sistema de procesamiento elástico serverless donde los "competing consumers" son invocaciones efímeras de funciones.
Amazon SQS (FIFO Queue)¶
Queue: orders-process-queue.fifo
Type: FIFO
Content-Based Deduplication: enabled
Message Group ID: order_id
Visibility Timeout: 300 seconds
Throughput: High Throughput mode (up to 70,000 msg/sec)
Dead Letter Queue: orders-process-dlq.fifo
Para escenarios que requieren orden estricto, SQS FIFO garantiza procesamiento en orden dentro de cada Message Group. Los mensajes con el mismo MessageGroupId se procesan en el orden exacto en que fueron enviados. Mensajes con diferentes MessageGroupId se procesan en paralelo. El MessageGroupId funciona como partition key, permitiendo paralelismo con orden por grupo.
RabbitMQ¶
Queue: orders.process
Type: Quorum (replicated, fault-tolerant)
Durable: true
Arguments:
x-delivery-limit: 5
x-dead-letter-exchange: orders.dlx
x-dead-letter-routing-key: orders.process.dlq
x-queue-type: quorum
Consumer:
Prefetch count: 1
Acknowledgment: manual
RabbitMQ implementa Point-to-Point Channel como una Queue con múltiples consumidores. El dispatch es round-robin por defecto, con prefetch count controlando cuántos mensajes pre-asigna a cada consumidor. Quorum queues proporcionan replicación y tolerancia a fallos del broker. El x-delivery-limit configura cuántos reintentos se permiten antes de dead-lettering.
Ventaja diferencial: RabbitMQ soporta priority queues nativas (mensajes con mayor prioridad se despachan primero) y consumer priorities (algunos consumidores tienen preferencia para recibir mensajes). Esto permite implementar esquemas de procesamiento preferencial imposibles en SQS o Kafka.
Azure Service Bus Queue¶
Queue: orders-process
Lock Duration: 5 minutes
Max Delivery Count: 5
Dead-Lettering on Expiration: true
Sessions: disabled (or enabled for ordered processing)
Duplicate Detection: enabled (10-minute window)
Max Size: 5 GB
Partitioning: enabled
Azure Service Bus implementa Point-to-Point Channel con un modelo de peek-lock: el consumidor "bloquea" el mensaje mientras lo procesa. Si completa el procesamiento, llama Complete() (ACK). Si falla, puede llamar Abandon() (NACK, devuelve a la cola) o dejar que el lock expire (redelivery automático). Soporta Sessions para orden garantizado por sesión (equivalente a particiones lógicas).
Ventaja diferencial: duplicate detection nativo elimina mensajes duplicados en la ventana de detección sin lógica de aplicación. Scheduled messages permiten encolar mensajes que se harán visibles en un momento futuro.
Apache Kafka (Consumer Groups)¶
Topic: orders.process
Partitions: 12
Replication Factor: 3
Retention: 7 days
Cleanup Policy: delete
Consumer Group: order-processing-workers
Group Members: 12 (one per partition)
Auto Offset Reset: earliest
Enable Auto Commit: false (manual commit after processing)
Session Timeout: 30 seconds
Max Poll Interval: 5 minutes
Kafka implementa Point-to-Point Channel de forma diferente: un consumer group sobre un topic asigna cada partición a exactamente un consumidor del grupo. Cada mensaje es procesado por un solo consumidor, logrando semántica Point-to-Point. El número de consumidores activos no puede exceder el número de particiones (consumidores extra quedan idle).
Diferencia fundamental con colas tradicionales: en Kafka, el mensaje no se elimina después del procesamiento; se retiene según la política de retención. Esto permite reprocesamiento por rebobinado de offsets, pero también significa que la "cola" nunca se "vacía" en el sentido tradicional. El consumer lag (diferencia entre el offset producido y el offset consumido) es la métrica equivalente a queue depth.
Ventaja para order processing: al asignar pedidos del mismo cliente a la misma partición (usando customer_id como partition key), Kafka garantiza que los pedidos de un cliente se procesan en orden, mientras los pedidos de diferentes clientes se procesan en paralelo por diferentes consumidores.
Comparativa de Implementaciones¶
| Característica | SQS Standard | RabbitMQ Queue | Azure SB Queue | Kafka CG |
|---|---|---|---|---|
| Modelo de entrega | Pull (polling) | Push (dispatch) | Pull (peek-lock) | Pull (poll) |
| Orden | Best-effort | FIFO (single consumer) | FIFO / Sessions | Per-partition |
| Acknowledgment | DeleteMessage | basic_ack | Complete() | Offset commit |
| Redelivery | Visibility timeout | Requeue on NACK/timeout | Lock expiration | Offset not committed |
| Dead-lettering | Nativo (redrive policy) | Via DLX | Nativo | Requiere implementación |
| Escalabilidad | Automática, ilimitada | Manual, limited by node | Automática, partitioned | Por particiones |
| Retención post-ACK | No (mensaje eliminado) | No (mensaje eliminado) | No (mensaje eliminado) | Si (retention-based) |
| Managed/Serverless | Fully managed | Self-managed o managed | Fully managed | Self-managed o managed |
| Exactly-once | No (at-least-once) | No (at-least-once) | Duplicate detection | Transactional consumers |
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Queue depth / Consumer lag: la métrica principal. Debe monitorearse continuamente y generar alertas cuando excede umbrales definidos por SLA. Un queue depth creciente indica que los consumidores no pueden mantener el ritmo del productor.
- Processing rate: mensajes procesados por segundo (throughput del consumo). Debe ser igual o mayor que el production rate en estado estable.
- Dead letter queue depth: debe ser cero en operación normal. Cualquier mensaje en DLQ requiere investigación y resolución. Alertas inmediatas cuando DLQ depth > 0.
- Redelivery rate: porcentaje de mensajes que se reasignan (por timeout, NACK o fallo de consumidor). Una tasa alta indica problemas en los consumidores.
- Processing time per message: latencia del procesamiento individual. Crecimiento en esta métrica puede indicar degradación en servicios downstream.
- Consumer count: número de consumidores activos conectados a la cola. Un descenso inesperado indica fallos de workers.
- Age of oldest message: tiempo que lleva el mensaje más antiguo sin procesar. Debe mantenerse dentro del SLA de procesamiento.
- Distributed tracing: propagar correlation IDs y trace IDs en los headers del mensaje para trazabilidad end-to-end desde el productor hasta el último servicio downstream.
Monitoreo¶
- Dashboard operacional: una vista unificada con queue depth, consumer count, processing rate, DLQ depth y age of oldest message para cada cola Point-to-Point del sistema.
- Alertas escalonadas:
- Warning: queue depth > umbral normal durante 5 minutos (posible necesidad de escalar).
- Critical: queue depth > umbral alto durante 15 minutos (consumidores no pueden mantener ritmo).
- Emergency: DLQ depth > 0 (mensajes que no pueden procesarse, posible impacto en negocio).
- Informational: consumer count cambia (workers añadidos o eliminados).
Autoscaling¶
- KEDA (Kubernetes): escala workers basándose en queue depth. Cuando la cola supera N mensajes, KEDA añade workers. Cuando la cola se vacía, KEDA reduce workers a un mínimo.
- AWS Auto Scaling + SQS: CloudWatch alarms basados en
ApproximateNumberOfMessagesVisiblepueden trigger ASG scaling policies o Lambda concurrency adjustments. - Azure VMSS + Service Bus: métricas de queue length pueden trigger autoscaling de VM Scale Sets o Azure Functions scaling.
Seguridad¶
- Principio de least privilege: los productores solo tienen permiso de enviar (
SendMessage); los consumidores solo tienen permiso de recibir y eliminar (ReceiveMessage,DeleteMessage). Nadie excepto administradores puede purgar la cola. - Encryption in transit: TLS entre clientes y broker.
- Encryption at rest: mensajes cifrados en disco (SSE en SQS, TDE en Azure Service Bus, disk encryption en RabbitMQ).
- Network isolation: la cola accesible solo desde la VPC/VNET interna, no desde internet público.
Versionado y Evolución¶
- Schema evolution: el formato de los mensajes evoluciona con el tiempo (nuevos campos, campos deprecados). Usar un Schema Registry con compatibilidad BACKWARD permite que consumidores antiguos procesen mensajes nuevos sin romperse.
- Parallel queues para migración: para cambios breaking en el formato, crear una cola nueva (
orders.process.v2), migrar consumidores primero (dual reading), luego migrar productores, finalmente retirar la cola antigua. - Feature flags en consumidores: cuando se añade nueva lógica de procesamiento (por ejemplo, validación adicional), usar feature flags permite activarla gradualmente.
Capacity Planning¶
- Dimensionamiento de workers:
workers_needed = (messages_per_second * avg_processing_time) / utilization_target. Con margen de 30% para absorber variabilidad. - Storage del broker:
storage = messages_per_day * avg_message_size * retention_days * replication_factor. - Load testing: antes de eventos de alto tráfico, ejecutar load tests con el volumen esperado para validar que workers, broker y servicios downstream soportan la carga.
Idempotencia y Deduplicación¶
- Idempotency key en el mensaje: cada mensaje incluye un identificador único (ej:
order_id+version) que los consumidores usan para detectar procesamiento duplicado. - Deduplication store: un store rápido (Redis, DynamoDB) donde los consumidores registran los IDs de mensajes procesados. Antes de procesar, verifican si el ID ya fue procesado.
- Deduplicación nativa del broker: SQS FIFO y Azure Service Bus ofrecen deduplicación por
MessageDeduplicationIdoMessageIden una ventana de tiempo.
Auditoría¶
- Registrar quién creó cada cola, con qué configuración y cuándo.
- Registrar cambios de configuración (visibility timeout, max delivery count, DLQ association).
- Mantener un inventario de todas las colas Point-to-Point del sistema con su propósito, productor, consumidores y SLAs.
17. Errores Comunes¶
Confundir Point-to-Point con Publish-Subscribe¶
El error más frecuente y más costoso. Un equipo crea una cola Point-to-Point para un evento de negocio (ej: "pedido creado") porque solo hay un consumidor inicialmente. Cuando un segundo sistema necesita el mismo evento, se conecta a la misma cola como competing consumer. Ahora ambos sistemas compiten por los mensajes: el primer sistema recibe el 50% de los pedidos y el segundo sistema recibe el otro 50%. Ninguno recibe todos los pedidos. La solución correcta es Publish-Subscribe Channel (topic/exchange con múltiples subscriptions).
Regla heurística: si los consumidores hacen cosas diferentes con el mensaje (inventario vs. notificaciones vs. analytics), se necesita Pub-Sub. Si los consumidores hacen lo mismo con el mensaje (N instancias del mismo servicio procesando en paralelo), se necesita Point-to-Point.
No Implementar Idempotencia¶
Asumir que "cada mensaje se procesa una vez" porque el canal es Point-to-Point. En la práctica, la semántica es at-least-once: el mismo mensaje puede ser entregado dos o más veces por timeouts, fallos de red o rebalanceo de consumidores. Sin idempotencia, los redeliveries causan efectos duplicados. Este error es especialmente peligroso en operaciones financieras donde un redelivery puede causar un doble cobro.
Acknowledgment Prematuro¶
Hacer ACK del mensaje al recibirlo (antes de procesarlo) para "mejorar throughput" o por desconocimiento de la semántica de ACK. Si el consumidor falla después del ACK, el mensaje se pierde permanentemente porque el broker ya lo eliminó. La regla es: hacer ACK solo después de que todo el procesamiento se ha completado exitosamente, incluyendo la persistencia de resultados.
No Configurar Dead-Lettering¶
Operar una cola sin Dead Letter Queue. Un mensaje que ningún consumidor puede procesar (formato corrupto, referencia a dato inexistente, bug en el consumidor) se reintenta infinitamente. Cada reintento consume capacidad de procesamiento y genera logs de error. La cola se "contamina" con poison messages que ocupan espacio y roban ciclos a mensajes válidos. Siempre configurar max delivery count + DLQ.
Visibility Timeout Inadecuado¶
Configurar un visibility timeout demasiado corto. Si el procesamiento de un mensaje tarda 60 segundos pero el visibility timeout es 30 segundos, el mensaje se vuelve visible (y se reasigna a otro consumidor) mientras el primer consumidor aún lo está procesando. Esto causa procesamiento duplicado garantizado. El visibility timeout debe ser mayor que el processing time máximo esperado, con margen.
Ignorar Queue Depth como Métrica Operacional¶
No monitorear la profundidad de la cola. La cola crece silenciosamente porque un servicio downstream está degradado, los workers no escalan o hay un aumento de tráfico no anticipado. Cuando alguien se da cuenta, hay horas de procesamiento atrasado. El queue depth debe monitorearse con alertas que escalen según la severidad.
Demasiados Workers para el Throughput¶
Desplegar un número excesivo de workers "por seguridad". Cada worker mantiene una conexión al broker, consume memoria y CPU, y genera logs. Con SQS, demasiados pollers causan empty receives que incrementan costos. Con RabbitMQ, demasiados consumidores añaden overhead de dispatching. Dimensionar los workers según la carga real y usar autoscaling para ajustar dinámicamente.
No Planificar Backpressure¶
Asumir que los consumidores siempre pueden mantener el ritmo del productor. En picos de tráfico, la cola crece. Sin un plan de backpressure (autoscaling de workers, rate limiting del productor si la cola excede un umbral máximo, alertas operacionales), la cola puede crecer hasta agotar el storage del broker o exceder los límites de retención, causando pérdida de mensajes.
Usar Competing Consumers con Requerimiento de Orden Global¶
Desplegar múltiples workers en una cola que requiere procesamiento en orden estricto. Los competing consumers rompen el orden global porque diferentes workers procesan mensajes a diferentes velocidades. Si el orden es un requisito, las opciones son: un solo consumidor (sacrifica paralelismo), particionamiento por clave con un consumidor por partición (orden dentro de cada partición), o SQS FIFO con Message Groups / Azure Service Bus Sessions.
18. Conclusión Técnica¶
Point-to-Point Channel es el patrón fundamental para la distribución de trabajo en sistemas de mensajería. Su semántica de entrega exclusiva — cada mensaje procesado por exactamente un consumidor — lo convierte en la primitiva correcta para comandos, tareas y operaciones que producen efectos secundarios que no deben duplicarse. Combinado con Competing Consumers, proporciona escalabilidad horizontal, balanceo de carga y tolerancia a fallos sin coordinación explícita entre workers.
Cuándo aporta valor: siempre que un mensaje represente trabajo que debe ejecutarse una vez. Procesamiento de pedidos, envío de notificaciones, ejecución de transacciones, generación de documentos, sincronización de datos — todos estos escenarios requieren la garantía de unicidad que Point-to-Point Channel proporciona. Su valor se amplifica con Competing Consumers: la capacidad de escalar el procesamiento añadiendo workers sin cambiar productores ni configuración es una de las mecánicas de escalabilidad más poderosas de las arquitecturas modernas.
Cuándo evita problemas importantes: un diseño correcto de Point-to-Point Channel con acknowledgment manual, idempotencia en consumidores, dead-lettering configurado y monitoreo de queue depth evita los problemas más costosos de los sistemas de procesamiento distribuido: tareas perdidas, procesamiento duplicado, poison message loops y acumulación silenciosa de backlog. Cada uno de estos problemas tiene impacto directo en el negocio (pedidos no procesados, cobros duplicados, degradación progresiva).
Cuándo no conviene adoptarlo: cuando el objetivo es distribuir un evento a múltiples sistemas que necesitan su propia copia del mensaje (diferentes funcionalidades consumiendo el mismo evento), Point-to-Point Channel es incorrecto y Publish-Subscribe Channel es la elección correcta. La distinción es fundamental: si los consumidores compiten por el trabajo (son instancias equivalentes del mismo servicio), es Point-to-Point; si los consumidores cooperan recibiendo cada uno su copia (son servicios diferentes), es Pub-Sub.
Recomendación para arquitectos: trate Point-to-Point Channel como un contrato de procesamiento. Defina explícitamente el formato del mensaje, el SLA de procesamiento (latencia máxima desde enqueue hasta completion), la estrategia de idempotencia, el max delivery count, la DLQ y las métricas de monitoreo. Configure autoscaling de workers basado en queue depth. Diseñe los consumidores como unidades stateless e idempotentes que pueden arrancarse, detenerse y replicarse libremente. Y recuerde la distinción fundamental: si mañana un segundo equipo necesita los mismos mensajes para una funcionalidad diferente, la cola Point-to-Point que tiene hoy necesita evolucionar a un esquema Pub-Sub con colas separadas por consumidor lógico. Anticipe esa evolución desde el diseño inicial.