Publish-Subscribe Channel¶
1. Nombre del Patrón¶
- Nombre oficial: Publish-Subscribe Channel
- Categoría: Messaging Channels (Canales de Mensajería)
- Traducción contextual: Canal de Publicación-Suscripción
2. Resumen Ejecutivo¶
Publish-Subscribe Channel es el patrón de canal que garantiza que cada mensaje publicado sea entregado a todos los consumidores suscritos, no solo a uno. Mientras que un Point-to-Point Channel entrega cada mensaje a exactamente un consumidor (competencia), un Publish-Subscribe Channel distribuye cada mensaje a todos los suscriptores registrados, permitiendo que múltiples sistemas reaccionen de forma independiente al mismo evento.
El problema que resuelve es la distribución one-to-many de mensajes: un productor genera un evento (por ejemplo, "se creó una cuenta bancaria") y múltiples sistemas necesitan reaccionar a ese evento de forma independiente — el sistema de notificaciones envía un email de bienvenida, el sistema de compliance registra la apertura para reporting regulatorio, el sistema de analytics actualiza los dashboards, el sistema de fraude inicializa el perfil de riesgo. Sin Publish-Subscribe Channel, el productor debería conocer a todos los consumidores y enviar el mensaje a cada uno explícitamente, creando un acoplamiento directo que viola el principio fundamental de la mensajería.
Este patrón es el cimiento de las arquitecturas event-driven modernas. Cada topic de Kafka con múltiples consumer groups, cada SNS topic de AWS, cada Azure Service Bus Topic con múltiples subscriptions, cada Google Pub/Sub topic — todos son implementaciones de Publish-Subscribe Channel. Es uno de los patrones más utilizados y más críticos de toda la taxonomía de integración empresarial.
3. Definición Detallada¶
Propósito¶
Publish-Subscribe Channel establece un canal de comunicación en el que cada mensaje publicado es entregado a todos los suscriptores registrados de forma independiente. Su propósito es permitir la distribución fan-out de eventos sin que el productor tenga conocimiento de quiénes son los consumidores, cuántos hay, ni qué hacen con el mensaje.
Lógica Arquitectónica¶
El patrón introduce una semántica de entrega fundamentalmente distinta a la de Point-to-Point Channel. En un canal point-to-point, el broker gestiona una cola y entrega cada mensaje a exactamente un consumidor (competing consumers). En un canal publish-subscribe, el broker mantiene una copia lógica del mensaje para cada suscriptor, garantizando que todos reciban todos los mensajes.
Esta semántica produce consecuencias arquitectónicas profundas:
- Desacoplamiento total productor-consumidores: el productor publica en un topic sin saber quién escucha. Pueden haber cero, uno o cien suscriptores; el productor no lo sabe y no le importa.
- Independencia entre suscriptores: cada suscriptor recibe y procesa los mensajes de forma independiente. Si el suscriptor A falla, el suscriptor B no se ve afectado. Si el suscriptor C es lento, los suscriptores A y B no esperan.
- Extensibilidad sin modificación: añadir un nuevo consumidor no requiere tocar al productor ni a los consumidores existentes. El nuevo suscriptor simplemente se registra en el canal y comienza a recibir mensajes.
- Fan-out implícito: el broker gestiona la multiplicación del mensaje. El productor envía una vez; el broker distribuye a N suscriptores.
Principio de Diseño Subyacente¶
El principio es notificación sin destinatario explícito. El productor no dirige el mensaje a un receptor específico — lo publica en un canal temático, y el broker se encarga de distribuirlo a todos los interesados. Esto es análogo a una emisora de radio: la estación transmite contenido sin saber quién está escuchando; cada oyente sintoniza la frecuencia que le interesa y recibe la misma señal de forma independiente.
Problema Estructural que Resuelve¶
En un sistema donde un evento debe provocar reacciones en múltiples sistemas, sin Publish-Subscribe Channel hay tres alternativas, todas problemáticas:
-
El productor envía a cada consumidor directamente: el productor necesita conocer a todos los consumidores (acoplamiento fuerte). Añadir un consumidor requiere modificar el productor. Si un consumidor no está disponible, el productor debe manejar el reintento.
-
Se usa un canal point-to-point con reenvío: un consumidor intermediario recibe el mensaje y lo reenvía a los demás. Esto crea un single point of failure y un cuello de botella.
-
Se duplica el mensaje en múltiples canales point-to-point: el productor envía el mismo mensaje a N colas, una por consumidor. Esto produce proliferación de canales, duplicación de datos y acoplamiento del productor con cada consumidor.
Publish-Subscribe Channel elimina estas alternativas deficientes: el productor publica una vez en un solo canal, y el broker garantiza la entrega a todos los suscriptores.
Contexto en el que Emerge¶
Publish-Subscribe Channel emerge en cualquier escenario donde un evento es relevante para múltiples sistemas o procesos que deben reaccionar de forma independiente. Los escenarios más comunes incluyen:
- Event notification: un cambio de estado en un sistema (pedido creado, cuenta actualizada, pago recibido) debe notificarse a múltiples sistemas downstream.
- Event sourcing fan-out: un event store publica eventos y múltiples proyecciones los consumen para construir vistas materializadas.
- Data distribution: un sistema maestro publica datos actualizados que múltiples sistemas réplica deben recibir.
- Audit and compliance: cada operación debe ser recibida por el sistema operacional y simultáneamente por el sistema de auditoría.
Relación con el Concepto de Topic¶
En la terminología de mensajería moderna, Publish-Subscribe Channel se implementa como un topic (Kafka, Azure Service Bus, Google Pub/Sub, SNS) o como un fanout exchange (RabbitMQ). El término "topic" se ha convertido en el término estándar de la industria para referirse a un canal con semántica publish-subscribe. A lo largo de este capítulo, "topic" y "Publish-Subscribe Channel" se usan como sinónimos cuando el contexto lo permite.
Por Qué No Es Trivial¶
Aunque el concepto parece simple (enviar a todos), las decisiones de diseño y los problemas operacionales son complejos:
- Message amplification: si un topic tiene 50 suscriptores y recibe 10,000 mensajes/segundo, el broker debe gestionar efectivamente 500,000 entregas/segundo. El costo de fan-out no es lineal en la práctica por overhead de networking, serialización y acknowledgment.
- Slow subscriber problem: si un suscriptor es significativamente más lento que los demás, ¿qué ocurre? ¿Se acumulan mensajes? ¿Se descarta al suscriptor? ¿Se ralentiza el canal entero? La respuesta depende de la plataforma y configuración.
- Ordenamiento por suscriptor: ¿cada suscriptor ve los mensajes en el mismo orden? ¿El orden de procesamiento depende de la velocidad del suscriptor?
- Semántica de entrega: ¿at-least-once para todos los suscriptores? ¿Exactly-once? ¿Qué ocurre si un suscriptor no confirma?
- Durabilidad de suscripciones: ¿qué pasa si un suscriptor se desconecta temporalmente? ¿Pierde los mensajes publicados durante su ausencia, o el broker los retiene? (Esto lleva al patrón Durable Subscriber.)
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Publish-Subscribe Channel, cuando un evento debe provocar reacciones en múltiples sistemas, la arquitectura enfrenta un dilema fundamental: ¿quién es responsable de la distribución?
Si la responsabilidad recae en el productor, este debe mantener una lista de todos los consumidores, implementar lógica de envío a cada uno, manejar fallos individuales, gestionar reintentos y mantener el orden. El productor se convierte en un router complejo que viola el principio de responsabilidad única.
Si la responsabilidad recae en un consumidor intermediario que reenvía a los demás, se crea una cadena de dependencias donde el fallo del intermediario bloquea a todos los downstream.
Si se implementa duplicando colas, cada nuevo consumidor requiere crear una nueva cola y modificar el productor para que envíe a ella, eliminando el desacoplamiento que motivó el uso de mensajería.
Síntomas del Problema¶
- El productor tiene configuración hardcodeada con la lista de consumidores y debe redeployarse cada vez que se añade o elimina un consumidor.
- Añadir un nuevo consumidor de un evento requiere un cambio en el código del productor, una revisión y un deployment coordinado.
- Si un consumidor falla, el productor debe decidir si bloquear el envío a todos los demás o continuar sin garantía para el consumidor fallido.
- No hay una forma estándar de descubrir qué sistemas están interesados en un evento — la información está dispersa en la configuración de cada productor.
- Los equipos que necesitan datos de un evento existente deben solicitar cambios al equipo propietario del productor, creando dependencias organizacionales.
Impacto Operativo y Arquitectónico¶
Sin un mecanismo de distribución fan-out gestionado por el broker:
- La topología de integración se convierte en una malla de conexiones directas (N productores × M consumidores) imposible de visualizar y mantener.
- Los cambios en el ecosistema de consumidores provocan cambios en los productores, creando un ciclo de deployments coordinados que ralentiza la entrega de valor.
- Los fallos no se aíslan: un consumidor problemático puede impactar al productor y, por transitividad, a todos los demás consumidores.
- La observabilidad es fragmentada: no hay un punto central donde ver quién consume qué evento y con qué estado.
Riesgos Si No Se Implementa Correctamente¶
- Fan-out incontrolado: un topic con demasiados suscriptores y alto throughput puede saturar el broker. Es necesario dimensionar la infraestructura para el volumen total de entregas, no solo para el volumen de producción.
- Suscriptor fantasma: un suscriptor que se registra, deja de consumir, pero no se des-registra. El broker sigue reteniendo mensajes para él, consumiendo recursos indefinidamente.
- Inconsistencia eventual no gestionada: diferentes suscriptores procesan el mismo evento a velocidades diferentes, produciendo ventanas donde unos sistemas reflejan el cambio y otros no. Si esto no se modela explícitamente, se producen bugs de sincronización.
- Acoplamiento semántico: aunque el desacoplamiento físico es total, puede surgir un acoplamiento semántico donde los suscriptores dependen de detalles del formato del mensaje que el productor cambia sin coordinación.
Ejemplos Reales¶
- Banca: un evento
account.balance.changeden el core bancario debe ser consumido simultáneamente por: notificaciones (SMS/push al cliente), detección de fraude (analizar patrón), analytics (actualizar dashboards), reporting regulatorio (registrar movimiento). Sin pub-sub, el core bancario debería conocer y enviar a cada uno de estos sistemas. - E-commerce: un evento
order.placeddebe disparar: confirmación al cliente, reserva de inventario, inicio del proceso de pago, notificación al vendedor, actualización del sistema de recomendaciones. Cada sistema reacciona de forma independiente. - Healthcare: un evento
patient.admitteddebe notificar a: el sistema de camas (asignar recurso), el sistema de farmacia (preparar medicación), el sistema de enfermería (asignar personal), el sistema de facturación (iniciar cuenta), el sistema de cocina (planificar dieta).
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un evento o mensaje debe ser procesado por múltiples consumidores independientes que no compiten entre sí, sino que cada uno necesita recibir todos los mensajes.
- Cuando el productor no debe tener conocimiento de cuántos ni cuáles son los consumidores de sus eventos.
- Cuando se necesita extensibilidad sin modificación del productor: la capacidad de añadir nuevos consumidores sin tocar el sistema que genera los eventos.
- Cuando los consumidores tienen lógicas de procesamiento completamente distintas para el mismo evento (notificar, analizar, almacenar, auditar).
- Cuando se implementa una arquitectura event-driven donde los eventos son ciudadanos de primera clase y los sistemas reaccionan a ellos de forma autónoma.
Cuándo No Usarlo¶
- Cuando cada mensaje debe ser procesado por exactamente un consumidor (usar Point-to-Point Channel con Competing Consumers).
- Cuando se necesita balanceo de carga entre consumidores para procesamiento paralelo de una cola de trabajo (este es un escenario point-to-point).
- Cuando el costo de fan-out es prohibitivo: un mensaje de alto volumen con decenas de suscriptores donde la mayoría descarta el 90% de los mensajes puede ser ineficiente. En este caso, considerar filtrado en el broker (Message Filter) o canales más específicos (Datatype Channel).
- Cuando los consumidores son estrictamente homogéneos (misma lógica, múltiples instancias para escalabilidad): esto no es pub-sub sino competing consumers dentro de un mismo grupo.
Precondiciones¶
- Existe un sistema de mensajería que soporta semántica publish-subscribe (topics, fanout exchanges, SNS topics).
- Los consumidores son lógicamente independientes: cada uno tiene su propia razón de negocio para recibir el mensaje y su propia lógica de procesamiento.
- Existe acuerdo sobre el esquema del mensaje publicado en el canal (contrato de evento).
- La infraestructura puede soportar el volumen amplificado: throughput de producción × número de suscriptores.
Restricciones¶
- El throughput efectivo del broker es proporcional al número de suscriptores multiplicado por el throughput de producción. Esto debe dimensionarse.
- El ordenamiento de mensajes entre suscriptores no está garantizado: el suscriptor A puede procesar el mensaje 5 antes de que el suscriptor B procese el mensaje 3.
- La latencia de entrega puede variar entre suscriptores según su velocidad de procesamiento y la implementación del broker.
Dependencias¶
- Infraestructura de messaging con soporte pub-sub nativo o configurable.
- Schema Registry o contrato de evento compartido entre productor y suscriptores.
- Sistema de monitoreo capaz de medir consumer lag por suscriptor/grupo de consumo.
- Estrategia de dead-lettering por suscriptor (cada suscriptor necesita su propio Dead Letter Channel).
Supuestos Arquitectónicos¶
- Los suscriptores son tolerantes a mensajes duplicados (idempotencia) o la plataforma ofrece exactly-once delivery.
- Los suscriptores gestionan sus propios errores sin afectar al canal ni a otros suscriptores.
- El productor confía en que el broker distribuirá el mensaje a todos los suscriptores activos.
- La adición y eliminación de suscriptores es una operación que no requiere coordinación con el productor.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Event-driven architectures y microservicios reactivos.
- Sistemas CQRS/ES donde los eventos del write model se distribuyen a múltiples read models.
- Plataformas de notificación multicanal (email, SMS, push, in-app).
- Sistemas de auditoría y compliance donde cada operación debe ser registrada por múltiples sistemas.
- Pipelines de datos donde eventos operacionales alimentan simultáneamente sistemas analíticos y operacionales.
6. Fuerzas Arquitectónicas¶
Desacoplamiento vs. Visibilidad¶
Publish-Subscribe Channel maximiza el desacoplamiento entre productor y consumidores: el productor no tiene ninguna referencia a los suscriptores. Sin embargo, este desacoplamiento total puede reducir la visibilidad: ¿quién consume este evento? ¿Cuántos suscriptores hay? ¿Todos están procesando correctamente? Sin herramientas de gobierno y monitoreo, el flujo de datos se vuelve opaco. La paradoja es que cuanto mayor es el desacoplamiento, mayor es la necesidad de observabilidad para compensar la pérdida de visibilidad directa.
Extensibilidad vs. Complejidad Operacional¶
Cada nuevo suscriptor que se añade al canal incrementa la extensibilidad del sistema — más sistemas reaccionan al mismo evento sin cambios en el productor. Pero cada suscriptor adicional incrementa la complejidad operacional: más consumer groups que monitorear, más dead-letter queues que gestionar, más posibilidades de que un suscriptor lento degrade el rendimiento del broker. La extensibilidad es barata de implementar pero tiene un costo operacional acumulativo.
Fan-out vs. Rendimiento¶
El fan-out es la esencia del patrón: un mensaje se convierte en N entregas. Pero el rendimiento del broker no escala linealmente con el número de suscriptores. Cada suscriptor adicional implica: serialización adicional (o copia de referencia), entrega por red, espera de acknowledgment, gestión de reintentos. En escenarios de alto throughput con muchos suscriptores, el broker puede convertirse en cuello de botella.
Consistencia Eventual vs. Simplicidad¶
Cuando múltiples suscriptores procesan el mismo evento a velocidades diferentes, el sistema está en un estado de consistencia eventual donde algunos suscriptores reflejan el cambio y otros aún no. Esto es inherente al patrón y no es un defecto, pero requiere que la arquitectura lo modele explícitamente. Los equipos que asumen consistencia inmediata entre suscriptores producen bugs sutiles.
Durabilidad de Suscripción vs. Recursos¶
¿Debe el broker retener mensajes para un suscriptor que está temporalmente desconectado? Las suscripciones durables (Durable Subscriber) garantizan que ningún mensaje se pierda, pero consumen storage mientras el suscriptor está offline. Las suscripciones no durables liberan recursos pero pierden mensajes durante la desconexión. La elección depende de la criticidad del suscriptor.
Granularidad del Canal vs. Eficiencia del Fan-out¶
Un canal con eventos muy heterogéneos (por ejemplo, account.* que incluye creación, actualización, cierre, bloqueo) obliga a los suscriptores a filtrar mensajes irrelevantes. Esto desperdicia bandwidth y procesamiento en el suscriptor. Canales más granulares (account.created, account.blocked) reducen el filtrado pero multiplican el número de topics. La tensión entre granularidad y manejabilidad es constante.
Orden vs. Paralelismo¶
En un topic particionado, el orden está garantizado dentro de cada partición pero no entre particiones. Si un suscriptor necesita orden global, debe consumir de una sola partición (limitando el paralelismo) o implementar reordenamiento en su lógica. Los suscriptores que necesitan orden y los que necesitan paralelismo máximo tienen requisitos conflictivos sobre el mismo canal.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Publisher): la aplicación que publica mensajes en el canal. No tiene conocimiento de los suscriptores.
- Canal Publish-Subscribe (Topic): el recurso lógico gestionado por el broker que implementa la semántica de distribución fan-out.
- Suscriptor (Subscriber): cada aplicación que se registra en el canal para recibir todos los mensajes publicados. Cada suscriptor es independiente.
- Suscripción (Subscription): la relación registrada entre un suscriptor y un canal. Puede ser durable (persiste si el suscriptor se desconecta) o non-durable (se destruye al desconectarse).
- Broker: el sistema de mensajería que gestiona el canal, mantiene las suscripciones y ejecuta la distribución fan-out.
Flujo Lógico¶
flowchart TD
A[Admin: Crea topic con propiedades] --> B[Suscriptor A se suscribe]
A --> C[Suscriptor B se suscribe]
A --> D[Suscriptor C se suscribe]
E([Productor]) -->|Publica M1| F[(Canal / Topic)]
F -->|Copia de M1| G[Suscriptor A: Notificación]
F -->|Copia de M1| H[Suscriptor B: Analytics]
F -->|Copia de M1| I[Suscriptor C: Auditoría]
G -->|ACK| J[Broker: Gestiona retención]
H -->|ACK| J
I -->|ACK| JResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Serializar evento, publicar en el topic correcto, no asumir nada sobre los suscriptores |
| Canal/Topic | Almacenar mensaje, mantener registro de suscripciones, distribuir a todos los suscriptores |
| Suscriptor | Registrar suscripción, recibir mensajes, procesarlos con su lógica independiente, confirmar |
| Suscripción | Mantener el estado de consumo (offset, cursor) de cada suscriptor de forma independiente |
| Broker | Gestionar el fan-out, retener mensajes para suscriptores durables, manejar backpressure |
Interacciones¶
- Productor → Topic: operación de publicación (publish, send). El productor envía al topic sin especificar destinatarios. Es una operación one-way.
- Topic → Suscriptor (push): el broker envía proactivamente los mensajes a cada suscriptor conforme llegan. Modelo usado por RabbitMQ, Azure Service Bus, SNS.
- Suscriptor → Topic (pull): el suscriptor solicita mensajes al broker a su propio ritmo. Modelo usado por Kafka, Google Pub/Sub (pull mode). Esto da al suscriptor control sobre su velocidad de consumo.
- Suscriptor → Broker (ack): el suscriptor confirma el procesamiento exitoso. El significado del ack depende de la plataforma: en Kafka, es un commit de offset; en RabbitMQ, es un message ack; en SQS, es un delete message.
Contratos Implícitos¶
- Nombre del topic: productores y suscriptores deben usar el mismo nombre de canal.
- Esquema del mensaje: todos los suscriptores deben ser capaces de deserializar y comprender el formato del mensaje publicado.
- Semántica del evento: todos los participantes deben compartir la misma comprensión de lo que significa el evento (por ejemplo,
account.balance.changedincluye el saldo anterior y el nuevo, no solo el nuevo). - Garantía de entrega: todos deben entender si la entrega es at-most-once, at-least-once o exactly-once.
Diferencia Fundamental con Point-to-Point Channel¶
| Aspecto | Point-to-Point Channel | Publish-Subscribe Channel |
|---|---|---|
| Entrega | A exactamente un consumidor | A todos los suscriptores |
| Múltiples consumidores | Compiten por mensajes | Cada uno recibe todos |
| Metáfora | Cola de tickets: el siguiente disponible toma el ticket | Emisora de radio: todos los sintonizados reciben la señal |
| Caso de uso principal | Distribución de trabajo | Distribución de eventos |
| Añadir consumidor | No cambia el comportamiento (más competidores) | Nuevo destinatario recibe todos los mensajes |
| Implementación típica | Queue (SQS, RabbitMQ queue) | Topic (Kafka topic, SNS topic, Service Bus topic) |
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Distribución de Eventos de Cuenta¶
Contexto del Negocio¶
Un banco comercial opera un core bancario que gestiona 8 millones de cuentas de clientes (corrientes, ahorro, nómina, empresa). Cada operación sobre una cuenta — depósito, retiro, transferencia, cargo de comisión, actualización de datos — genera un evento que múltiples sistemas downstream necesitan recibir y procesar de forma independiente.
El banco tiene requisitos estrictos de regulación (PSD2, GDPR, normativa de prevención de blanqueo), de experiencia de cliente (notificaciones en tiempo real) y de operaciones (detección de fraude en sub-segundo). Todos estos requisitos convergen en un mismo punto: los eventos de cuenta deben distribuirse a múltiples consumidores con diferentes necesidades de latencia, granularidad y retención.
Necesidad de Integración¶
El core bancario genera aproximadamente 150,000 eventos de cambio de saldo por hora en horario pico (lunes entre 9:00 y 14:00). Cada evento de cambio de saldo debe ser recibido simultáneamente por cinco sistemas independientes:
- Notification Service: envía notificaciones push/SMS al cliente cuando su saldo cambia (latencia objetivo: < 3 segundos).
- Fraud Detection Engine: analiza cada movimiento en tiempo real buscando patrones anómalos (latencia objetivo: < 500ms).
- Analytics Platform: actualiza dashboards ejecutivos y modelos predictivos (latencia tolerable: minutos).
- Regulatory Reporting Service: registra cada movimiento para informes regulatorios periódicos (latencia tolerable: horas, pero zero data loss).
- Account Ledger Reconciliation: verifica que el saldo calculado desde eventos coincide con el saldo del core (batch, ejecuta cada 4 horas).
Sistemas Involucrados¶
- Core Bancario (Producer): sistema legacy que ejecuta transacciones y genera eventos de cambio de saldo.
- Apache Kafka Cluster: plataforma de streaming que gestiona los Publish-Subscribe Channels.
- Notification Service: microservicio que orquesta notificaciones multicanal (push, SMS, email).
- Fraud Detection Engine: servicio de ML en tiempo real basado en Apache Flink que evalúa riesgo.
- Analytics Platform: pipeline de datos basado en Spark que alimenta un data warehouse.
- Regulatory Reporting Service: servicio batch que genera informes para el regulador.
- Account Ledger Reconciliation Service: proceso batch de reconciliación contable.
Restricciones Técnicas¶
- El core bancario solo puede producir eventos a un endpoint; no puede implementar fan-out nativo.
- El Fraud Detection Engine requiere latencia ultra-baja y orden por cuenta (para detectar patrones temporales como múltiples retiros rápidos).
- El Regulatory Reporting Service no puede perder ningún evento bajo ninguna circunstancia (zero data loss por requisito legal).
- El Notification Service necesita filtrabilidad: no todos los cambios de saldo generan notificación (por ejemplo, cargos de comisión menores a 1 EUR no se notifican según preferencias del cliente).
- La infraestructura debe soportar el pico de 150,000 eventos/hora sin degradación para ningún suscriptor.
Diseño del Publish-Subscribe Channel¶
Se diseña un Publish-Subscribe Channel principal implementado como un Kafka topic:
| Topic Kafka | Productor | Semántica | Particiones | Retención | Replicación |
|---|---|---|---|---|---|
banking.accounts.balance-changed | Core Bancario | Pub-Sub | 32 (por account_id) | 30 días | Factor 3, min.insync.replicas=2 |
Cada sistema consumidor se conecta como un consumer group independiente, que es la implementación de Kafka para Publish-Subscribe: cada consumer group recibe todos los mensajes del topic de forma independiente.
| Consumer Group | Servicio | Instancias | Latencia Target | Tolerancia a Pérdida |
|---|---|---|---|---|
cg-notifications | Notification Service | 4 | < 3s | Tolerable (best-effort) |
cg-fraud-detection | Fraud Detection Engine | 8 | < 500ms | Baja (near-zero) |
cg-analytics | Analytics Platform | 2 | < 5min | Media |
cg-regulatory | Regulatory Reporting | 2 | < 1h | Zero (ninguna) |
cg-reconciliation | Ledger Reconciliation | 1 | < 4h | Zero (ninguna) |
Decisiones Arquitectónicas¶
-
Un solo topic, múltiples consumer groups: en lugar de crear un topic por consumidor (lo cual sería point-to-point disfrazado), se usa un solo topic con la semántica nativa pub-sub de Kafka vía consumer groups. El core bancario produce una vez; Kafka distribuye a cinco consumer groups independientes.
-
Particionamiento por account_id: garantiza que todos los eventos de una misma cuenta llegan a la misma partición, preservando el orden temporal por cuenta. Esto es crítico para el Fraud Detection Engine que necesita ver la secuencia de operaciones en orden para detectar patrones (ejemplo: tres retiros en cajero en menos de 5 minutos).
-
32 particiones: dimensionadas para soportar el paralelismo máximo del Fraud Detection Engine (8 instancias, cada una procesando 4 particiones). Los consumer groups con menos instancias simplemente procesan más particiones por instancia.
-
Retención de 30 días: permite al Regulatory Reporting Service reprocesar eventos del mes completo si es necesario (por ejemplo, si un informe regulatorio necesita regenerarse). También permite al Reconciliation Service ejecutar reconciliación retrospectiva.
-
Replicación factor 3 con min.insync.replicas=2: garantiza que cada evento se persiste en al menos 2 brokers antes de confirmar al productor. Esto satisface el requisito de zero data loss del Regulatory Reporting.
Esquema del Evento¶
{
"event_id": "evt-2026-04-07-1847291",
"event_type": "account.balance.changed",
"timestamp": "2026-04-07T10:32:15.847Z",
"account_id": "ACC-00847291",
"account_type": "checking",
"customer_id": "CUS-00123456",
"transaction_id": "TXN-2026-04-07-9182736",
"transaction_type": "debit_transfer",
"amount": -1500.00,
"currency": "EUR",
"previous_balance": 12350.75,
"new_balance": 10850.75,
"channel": "mobile_app",
"counterparty_iban": "ES91 2100 0418 4502 0005 1332",
"description": "Transferencia a tercero",
"metadata": {
"ip_address": "83.47.192.15",
"device_id": "dev-iphone14-7291",
"geo_location": "Madrid, ES"
}
}
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de eventos regulatorios | acks=all, replicación factor 3, min.insync.replicas=2, retención 30 días |
| Fraud Detection demasiado lento | 8 instancias, prioridad en asignación de recursos, alertas si lag > 1s |
| Notification Service sobrecarga al cliente | Filtrado en el consumidor por preferencias de notificación del cliente |
| Analytics acumula lag excesivo | Monitoreo de lag, auto-scaling de instancias Spark |
| Suscriptor fantasma (consumer group abandonado) | Policy de TTL en consumer groups inactivos, revisión trimestral |
| Schema evolution rompe suscriptores | Schema Registry con Avro y política BACKWARD compatibility |
| Partición hotspot (cuenta corporativa con alto volumen) | Monitoreo de distribución por partición, re-keying si necesario |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción del Evento¶
Un cliente del banco (CUS-00123456) realiza una transferencia de 1,500 EUR desde su cuenta corriente (ACC-00847291) vía la app móvil a las 10:32 AM. El core bancario ejecuta la transacción, actualiza el saldo de la cuenta de 12,350.75 EUR a 10,850.75 EUR, y genera el evento account.balance.changed.
El Channel Adapter del core bancario (un componente CDC — Change Data Capture — que captura cambios en la base de datos transaccional) serializa el evento en formato Avro según el schema registrado en el Schema Registry y lo publica en el topic banking.accounts.balance-changed con account_id como partition key.
Kafka Produce:
Topic: banking.accounts.balance-changed
Key: ACC-00847291
Value: <Avro-encoded event>
Headers: {
"correlation-id": "corr-2026-04-07-91827",
"schema-id": "42",
"source-system": "core-banking"
}
Acks: all
El broker confirma la escritura tras replicar el mensaje a 2 de 3 brokers (min.insync.replicas=2). El partition key ACC-00847291 se hashea para determinar la partición destino (partición 17 de 32).
Paso 2: Fan-out a Todos los Consumer Groups¶
Una vez almacenado en la partición 17, el mensaje está disponible para todos los consumer groups suscritos. Kafka no "envía" el mensaje a cada grupo — cada consumer group tiene consumidores que hacen pull del topic a su propio ritmo. El fan-out se materializa porque cada consumer group mantiene su propio offset independiente en cada partición:
Partición 17, Offset 847291:
cg-fraud-detection → offset actual: 847290 → lee mensaje 847291 (lag: 1)
cg-notifications → offset actual: 847289 → lee mensaje 847290, 847291 (lag: 2)
cg-analytics → offset actual: 847100 → batch pendiente de 191 mensajes
cg-regulatory → offset actual: 847250 → procesando, lag: 41
cg-reconciliation → offset actual: 840000 → siguiente batch en 2 horas
Paso 3: Consumo por Fraud Detection Engine (Latencia < 500ms)¶
El Fraud Detection Engine (consumer group: cg-fraud-detection) es el consumidor más crítico en latencia. Sus 8 instancias hacen polling cada 50ms. La instancia asignada a la partición 17 recibe el mensaje de inmediato:
- Deserializa el evento Avro.
- Extrae: account_id, amount (-1,500 EUR), transaction_type (debit_transfer), channel (mobile_app), geo_location (Madrid), timestamp.
- Consulta el perfil de riesgo de ACC-00847291 en un feature store (Redis): el cliente normalmente opera desde Madrid, su monto promedio de transferencia es 800 EUR, frecuencia de transferencias: 2/semana.
- Evalúa el modelo de scoring: monto 1.87x superior al promedio, pero ubicación consistente, dispositivo conocido, horario habitual. Score de riesgo: 0.23 (bajo, umbral de alerta: 0.70).
- No genera alerta. Commit offset.
- Latencia total: 180ms desde la producción del evento.
Si el score hubiera sido > 0.70, el engine habría publicado un evento en un topic separado banking.fraud.alerts (otro Publish-Subscribe Channel) que el equipo de operaciones de fraude consume.
Paso 4: Consumo por Notification Service (Latencia < 3s)¶
El Notification Service (consumer group: cg-notifications) recibe el mismo mensaje:
- Deserializa el evento.
- Consulta las preferencias de notificación del cliente CUS-00123456 en su base de datos: el cliente tiene habilitadas notificaciones push para movimientos > 100 EUR.
- El monto es 1,500 EUR > 100 EUR → genera notificación.
- Construye el mensaje push: "Se ha realizado un cargo de 1.500,00 EUR en tu cuenta terminada en 7291. Nuevo saldo: 10.850,75 EUR."
- Envía la notificación push al dispositivo del cliente vía APNs/FCM.
- Registra la notificación enviada en su audit log.
- Commit offset.
- Latencia total: 1.2 segundos desde la producción del evento.
Nótese que el Notification Service aplica filtrado en el consumidor: no todos los eventos generan notificación. El filtrado es responsabilidad del suscriptor, no del canal. Esto mantiene el canal puro (todos los eventos de cambio de saldo) y permite que otros suscriptores que sí necesitan todos los eventos los reciban sin filtrar.
Paso 5: Consumo por Analytics Platform (Latencia < 5min)¶
El Analytics Platform (consumer group: cg-analytics) consume en micro-batches:
- Acumula eventos durante 60 segundos.
- Recibe un batch con ~2,500 eventos de cambio de saldo (incluyendo el de ACC-00847291).
- Transforma los eventos a formato Parquet columnar.
- Escribe el batch en el data warehouse (Snowflake/BigQuery).
- Actualiza las tablas de hechos
fact_account_movementsy las métricas agregadas. - Commit offsets de todo el batch.
- Latencia: 90 segundos promedio desde producción.
Este suscriptor opera a una velocidad completamente diferente al Fraud Detection Engine — y eso está bien. La independencia de consumer groups permite que cada suscriptor consuma a su ritmo óptimo.
Paso 6: Consumo por Regulatory Reporting Service¶
El Regulatory Reporting Service (consumer group: cg-regulatory) consume de forma continua pero con menor urgencia:
- Recibe el evento de cambio de saldo.
- Clasifica la transacción según la taxonomía regulatoria: transferencia doméstica SEPA, monto inferior a 10,000 EUR (no requiere reporte SAR inmediato).
- Almacena el evento en una base de datos de reporting con esquema conforme a la normativa PSD2.
- Marca el evento como disponible para el próximo informe regulatorio (trimestral).
- Commit offset.
Este suscriptor tiene un requisito no negociable de zero data loss. Si este servicio falla, no pierde mensajes porque su consumer group retiene el offset. Al reiniciar, reanuda desde el último offset confirmado. Si necesita reprocesar un período completo, puede retroceder el offset hasta 30 días gracias a la retención del topic.
Paso 7: Consumo por Reconciliation Service¶
El Account Ledger Reconciliation Service (consumer group: cg-reconciliation) opera en modo batch cada 4 horas:
- Se activa a las 12:00, 16:00, 20:00, 00:00, 04:00 y 08:00.
- Lee todos los eventos acumulados desde la última ejecución (aproximadamente 4 horas de eventos, ~150,000 mensajes).
- Para cada cuenta afectada, recalcula el saldo aplicando todos los movimientos en orden (garantizado por particionamiento por account_id).
- Compara el saldo calculado con el saldo actual en el core bancario.
- Genera un informe de discrepancias (si las hay).
- Commit offsets.
Este suscriptor demuestra un uso interesante de Publish-Subscribe Channel: el mismo evento que se procesa en sub-segundo (fraude) también se procesa horas después en batch (reconciliación), sin que ninguno afecte al otro.
Paso 8: Monitoreo del Canal¶
Un dashboard de Grafana monitorea el Publish-Subscribe Channel continuamente:
- Consumer lag por grupo: cg-fraud-detection debe tener lag < 100 mensajes (alerta si > 500). cg-regulatory debe tener lag < 100,000 mensajes (alerta si > 500,000).
- Throughput de producción: mensajes/segundo en el topic. Alerta si cae a cero (posible fallo del productor) o si excede 2x el promedio histórico (posible anomalía).
- Distribución por partición: verificar que no hay particiones hotspot con volumen desproporcionado.
- Error rates por consumer group: tasa de mensajes que van a dead-letter en cada suscriptor.
- End-to-end latency por consumer group: tiempo desde producción hasta commit del offset, por grupo.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
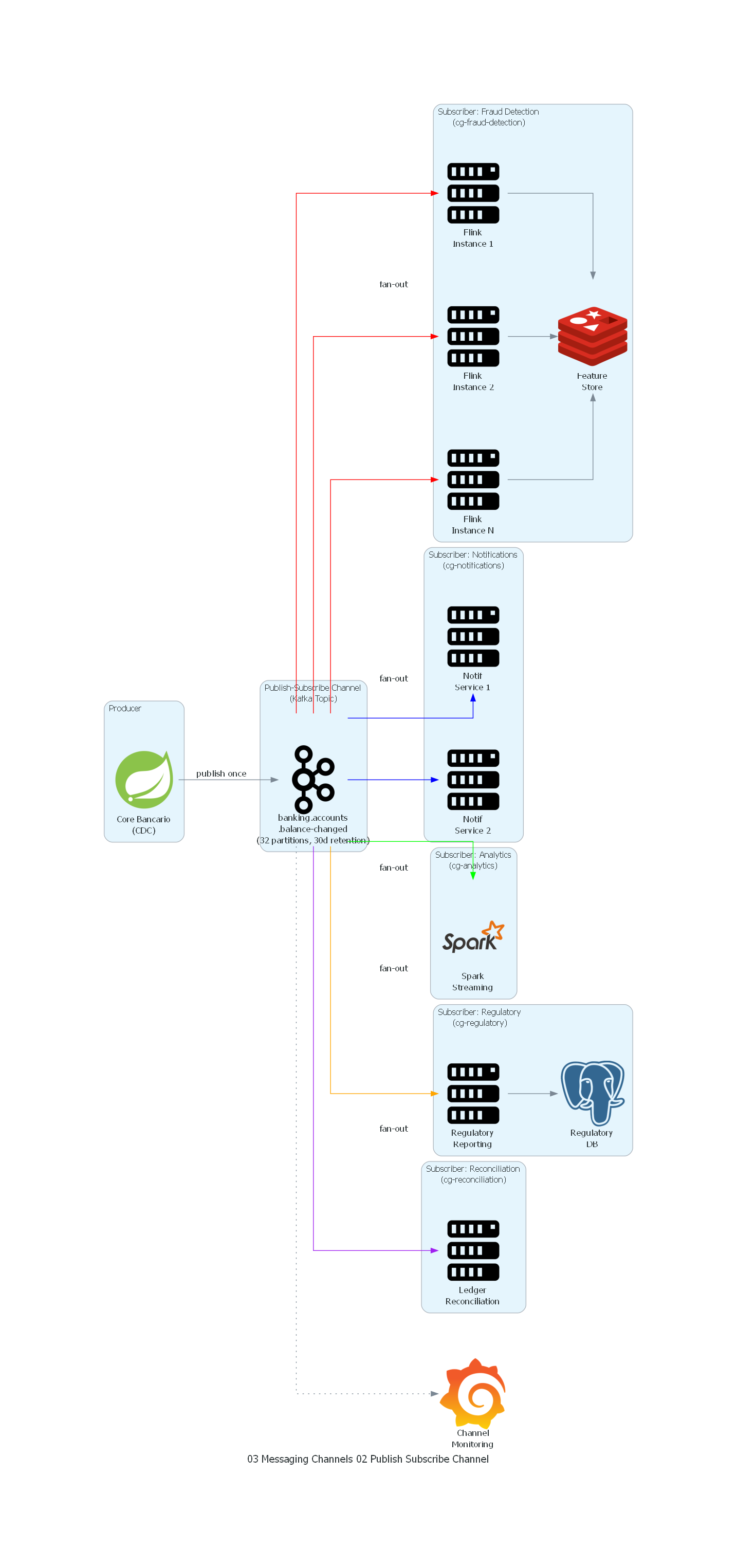
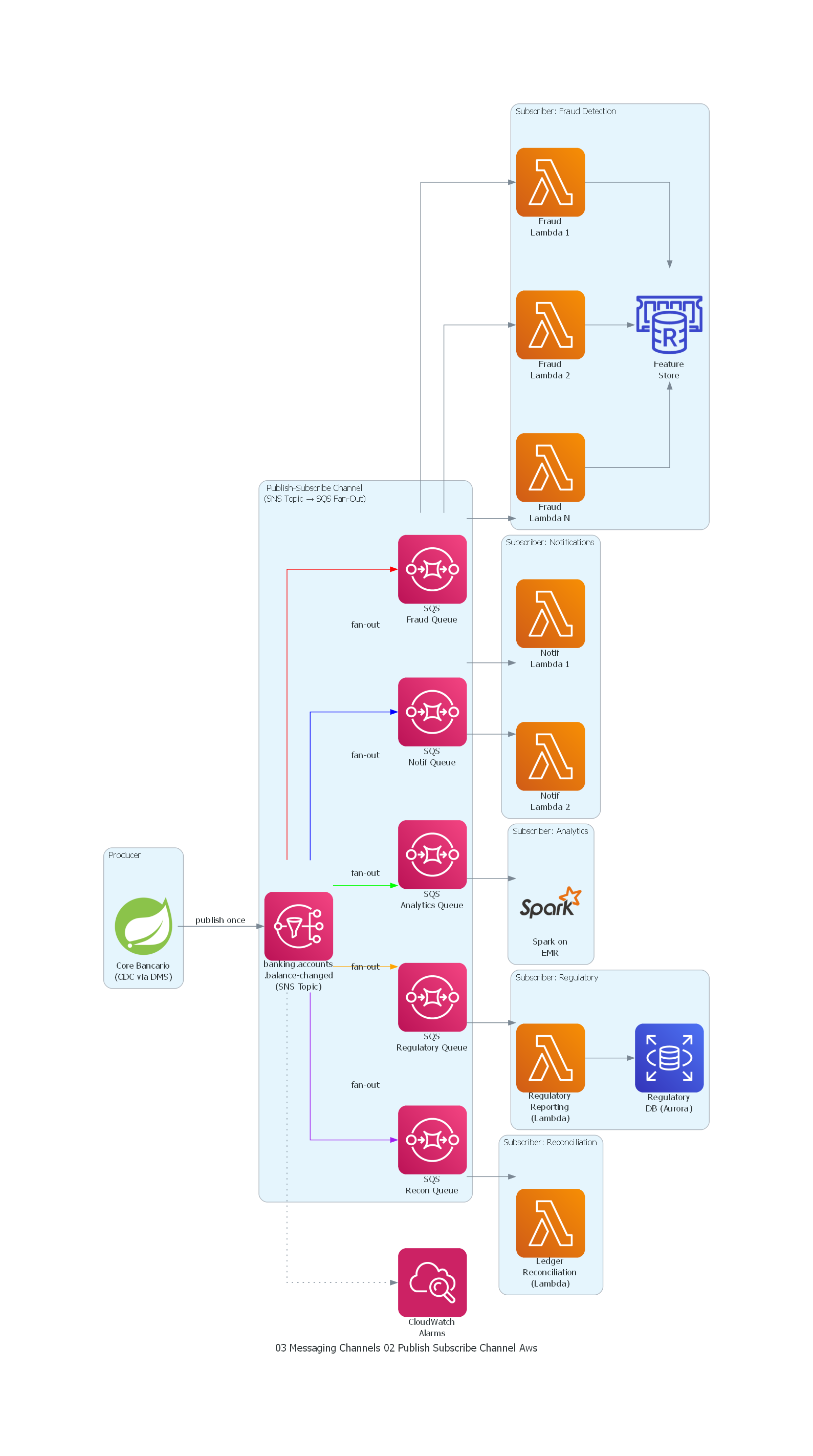
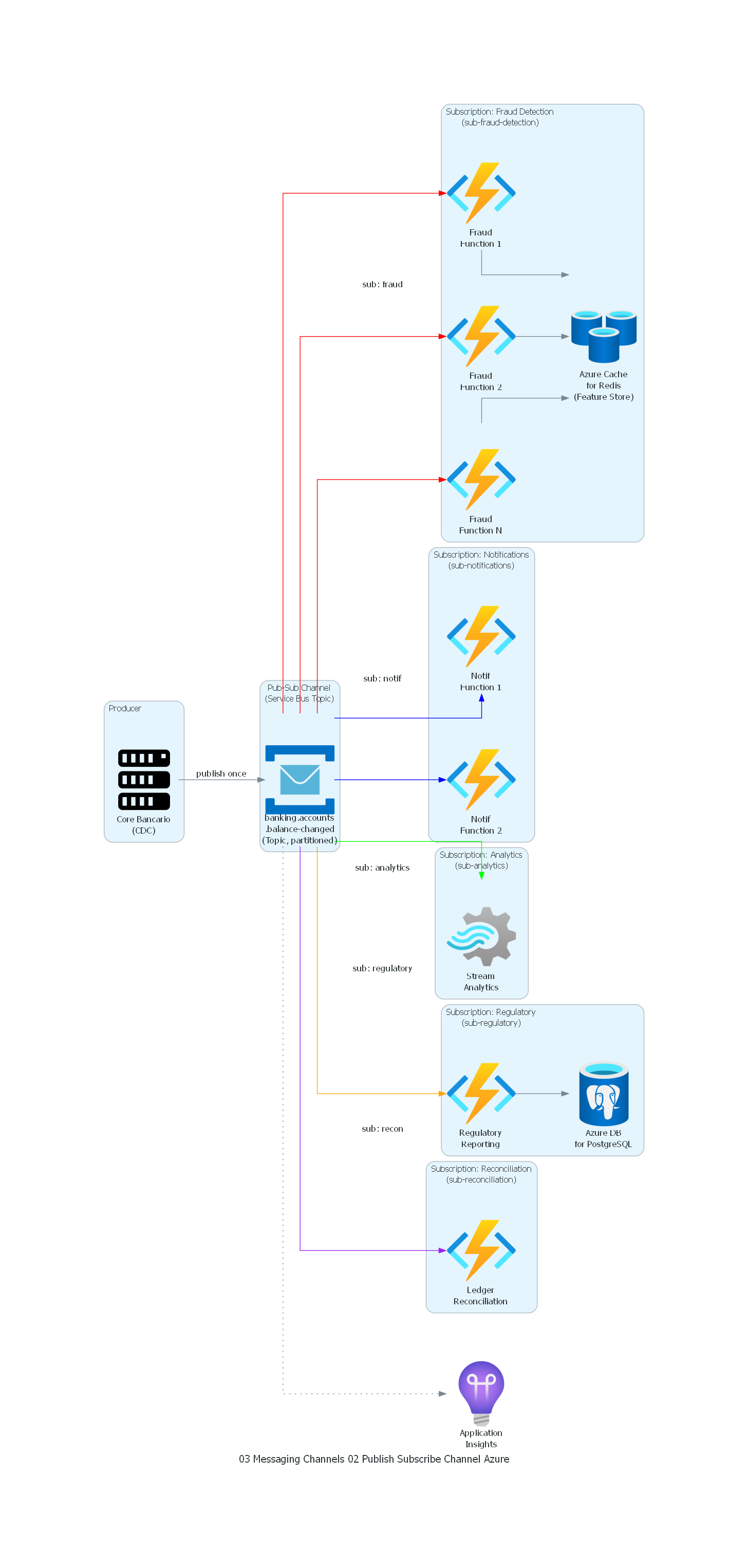
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.analytics import Spark
from diagrams.onprem.monitoring import Grafana
from diagrams.programming.framework import Spring
with Diagram(
"Publish-Subscribe Channel - Banking Account Events",
show=False,
direction="LR",
filename="publish_subscribe_channel"
):
with Cluster("Producer"):
core = Spring("Core Bancario\n(CDC)")
with Cluster("Publish-Subscribe Channel\n(Kafka Topic)"):
topic = Kafka(
"banking.accounts\n.balance-changed\n"
"(32 partitions, 30d retention)"
)
with Cluster("Subscriber: Fraud Detection\n(cg-fraud-detection)"):
fraud_1 = Server("Flink\nInstance 1")
fraud_2 = Server("Flink\nInstance 2")
fraud_n = Server("Flink\nInstance N")
fraud_store = Redis("Feature\nStore")
with Cluster("Subscriber: Notifications\n(cg-notifications)"):
notif_1 = Server("Notif\nService 1")
notif_2 = Server("Notif\nService 2")
with Cluster("Subscriber: Analytics\n(cg-analytics)"):
analytics = Spark("Spark\nStreaming")
with Cluster("Subscriber: Regulatory\n(cg-regulatory)"):
regulatory = Server("Regulatory\nReporting")
reg_db = PostgreSQL("Regulatory\nDB")
with Cluster("Subscriber: Reconciliation\n(cg-reconciliation)"):
reconciliation = Server("Ledger\nReconciliation")
monitoring = Grafana("Channel\nMonitoring")
# Producer -> Topic
core >> Edge(label="publish once") >> topic
# Topic -> All Subscribers (fan-out)
topic >> Edge(color="red", label="fan-out") >> fraud_1
topic >> Edge(color="red") >> fraud_2
topic >> Edge(color="red") >> fraud_n
fraud_1 >> fraud_store
fraud_2 >> fraud_store
fraud_n >> fraud_store
topic >> Edge(color="blue", label="fan-out") >> notif_1
topic >> Edge(color="blue") >> notif_2
topic >> Edge(color="green", label="fan-out") >> analytics
topic >> Edge(color="orange", label="fan-out") >> regulatory
regulatory >> reg_db
topic >> Edge(color="purple", label="fan-out") >> reconciliation
# Monitoring
topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.analytics import Spark
from diagrams.programming.framework import Spring
from diagrams.aws.compute import Lambda
from diagrams.aws.database import ElasticacheForRedis, RDS
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.management import Cloudwatch
with Diagram(
"Publish-Subscribe Channel - Banking Account Events",
show=False,
direction="LR",
filename="publish_subscribe_channel"
):
with Cluster("Producer"):
core = Spring("Core Bancario\n(CDC via DMS)")
with Cluster("Publish-Subscribe Channel\n(SNS Topic → SQS Fan-Out)"):
topic = SNS(
"banking.accounts\n.balance-changed\n"
"(SNS Topic)"
)
sqs_fraud = SQS("SQS\nFraud Queue")
sqs_notif = SQS("SQS\nNotif Queue")
sqs_analytics = SQS("SQS\nAnalytics Queue")
sqs_regulatory = SQS("SQS\nRegulatory Queue")
sqs_recon = SQS("SQS\nRecon Queue")
with Cluster("Subscriber: Fraud Detection"):
fraud_1 = Lambda("Fraud\nLambda 1")
fraud_2 = Lambda("Fraud\nLambda 2")
fraud_n = Lambda("Fraud\nLambda N")
fraud_store = ElasticacheForRedis("Feature\nStore")
with Cluster("Subscriber: Notifications"):
notif_1 = Lambda("Notif\nLambda 1")
notif_2 = Lambda("Notif\nLambda 2")
with Cluster("Subscriber: Analytics"):
analytics = Spark("Spark on\nEMR")
with Cluster("Subscriber: Regulatory"):
regulatory = Lambda("Regulatory\nReporting\n(Lambda)")
reg_db = RDS("Regulatory\nDB (Aurora)")
with Cluster("Subscriber: Reconciliation"):
reconciliation = Lambda("Ledger\nReconciliation\n(Lambda)")
monitoring = Cloudwatch("CloudWatch\nAlarms")
# Producer -> SNS Topic
core >> Edge(label="publish once") >> topic
# SNS → SQS fan-out (each subscriber gets its own queue)
topic >> Edge(color="red", label="fan-out") >> sqs_fraud
topic >> Edge(color="blue", label="fan-out") >> sqs_notif
topic >> Edge(color="green", label="fan-out") >> sqs_analytics
topic >> Edge(color="orange", label="fan-out") >> sqs_regulatory
topic >> Edge(color="purple", label="fan-out") >> sqs_recon
# SQS → Lambda consumers
sqs_fraud >> fraud_1
sqs_fraud >> fraud_2
sqs_fraud >> fraud_n
fraud_1 >> fraud_store
fraud_2 >> fraud_store
fraud_n >> fraud_store
sqs_notif >> notif_1
sqs_notif >> notif_2
sqs_analytics >> analytics
sqs_regulatory >> regulatory
regulatory >> reg_db
sqs_recon >> reconciliation
# Monitoring
topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.analytics import StreamAnalyticsJobs
from diagrams.onprem.compute import Server
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis, DatabaseForPostgresqlServers
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram(
"Publish-Subscribe Channel - Banking Account Events (Azure)",
show=False,
direction="LR",
filename="publish_subscribe_channel"
):
with Cluster("Producer"):
core = Server("Core Bancario\n(CDC)")
with Cluster("Pub-Sub Channel\n(Service Bus Topic)"):
topic = ServiceBus(
"banking.accounts\n.balance-changed\n"
"(Topic, partitioned)"
)
with Cluster("Subscription: Fraud Detection\n(sub-fraud-detection)"):
fraud_1 = FunctionApps("Fraud\nFunction 1")
fraud_2 = FunctionApps("Fraud\nFunction 2")
fraud_n = FunctionApps("Fraud\nFunction N")
fraud_store = CacheForRedis("Azure Cache\nfor Redis\n(Feature Store)")
with Cluster("Subscription: Notifications\n(sub-notifications)"):
notif_1 = FunctionApps("Notif\nFunction 1")
notif_2 = FunctionApps("Notif\nFunction 2")
with Cluster("Subscription: Analytics\n(sub-analytics)"):
analytics = StreamAnalyticsJobs("Stream\nAnalytics")
with Cluster("Subscription: Regulatory\n(sub-regulatory)"):
regulatory = FunctionApps("Regulatory\nReporting")
reg_db = DatabaseForPostgresqlServers("Azure DB\nfor PostgreSQL")
with Cluster("Subscription: Reconciliation\n(sub-reconciliation)"):
reconciliation = FunctionApps("Ledger\nReconciliation")
monitoring = ApplicationInsights("Application\nInsights")
# Producer -> Topic (publish once)
core >> Edge(label="publish once") >> topic
# Topic -> Subscriptions (each subscription = independent copy)
topic >> Edge(color="red", label="sub: fraud") >> fraud_1
topic >> Edge(color="red") >> fraud_2
topic >> Edge(color="red") >> fraud_n
fraud_1 >> fraud_store
fraud_2 >> fraud_store
fraud_n >> fraud_store
topic >> Edge(color="blue", label="sub: notif") >> notif_1
topic >> Edge(color="blue") >> notif_2
topic >> Edge(color="green", label="sub: analytics") >> analytics
topic >> Edge(color="orange", label="sub: regulatory") >> regulatory
regulatory >> reg_db
topic >> Edge(color="purple", label="sub: recon") >> reconciliation
# Monitoring
topic >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de Publish-Subscribe Channel para distribución de eventos de cuenta bancaria:
-
Core Bancario (Producer) publica eventos de cambio de saldo en un solo topic de Kafka. El productor envía cada mensaje una sola vez.
-
El Topic
banking.accounts.balance-changedes el Publish-Subscribe Channel central. Sus 32 particiones permiten paralelismo y orden por account_id. La retención de 30 días soporta reprocesamiento. -
Cinco consumer groups independientes reciben todos los mensajes del topic de forma independiente:
- Fraud Detection (rojo): 8 instancias Flink para procesamiento de latencia ultra-baja, consultando un feature store Redis.
- Notifications (azul): 4 instancias que filtran y envían notificaciones push/SMS.
- Analytics (verde): pipeline Spark que procesa en micro-batches.
- Regulatory Reporting (naranja): servicio que almacena para informes regulatorios.
-
Reconciliation (morado): proceso batch de reconciliación contable.
-
Grafana monitorea el estado del topic y el lag de cada consumer group.
Correspondencia Patrón-Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Publisher | Core Bancario (CDC) |
| Publish-Subscribe Channel | Topic Kafka banking.accounts.balance-changed |
| Subscriber (independiente) | Cada consumer group (fraud, notifications, analytics, regulatory, reconciliation) |
| Fan-out | Las cinco flechas que salen del topic hacia los cinco grupos |
| Independencia de suscriptores | Cada grupo consume a su propio ritmo con su propio offset |
| Durabilidad | 30 días de retención + replicación factor 3 |
| Monitoring | Grafana dashboard |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento total del productor: el core bancario no conoce ni referencia a ninguno de los cinco sistemas downstream. Si mañana se añade un sexto suscriptor (por ejemplo, un sistema de scoring crediticio), no se toca ni una línea del core bancario.
- Fan-out sin costo para el productor: el productor envía una vez; el broker gestiona la distribución a N suscriptores. El productor no paga el costo de fan-out en su throughput ni en su complejidad.
- Aislamiento total de fallos entre suscriptores: si el Fraud Detection Engine falla, el Notification Service sigue operando. Si el Analytics Pipeline acumula lag, el Regulatory Reporting no se ve afectado. Cada suscriptor es un universo independiente.
- Escalabilidad independiente por suscriptor: el Fraud Detection necesita 8 instancias; el Reconciliation necesita 1. Cada consumer group escala sus instancias según su propia necesidad sin afectar a los demás.
- Reprocesamiento sin impacto: cualquier suscriptor puede retroceder su offset y reprocesar eventos pasados (hasta 30 días) sin que el productor ni los demás suscriptores se enteren.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de fraude, el equipo de notificaciones, el equipo de analytics y el equipo de compliance operan de forma completamente independiente. El contrato compartido es el esquema del evento en el Schema Registry, no una API del core bancario.
- Time-to-market para nuevos consumidores: cuando el negocio pide un nuevo sistema que reaccione a cambios de saldo (por ejemplo, alertas de ahorro automático), el equipo responsable crea un nuevo consumer group y se conecta al topic existente. No hay dependency en otro equipo.
- Ownership claro: el equipo del core bancario es owner del evento y del topic; cada equipo downstream es owner de su consumer group y su lógica de procesamiento. Las responsabilidades son claras y no se solapan.
Impacto en Event-Driven Architecture¶
- Eventos como ciudadanos de primera clase: el Publish-Subscribe Channel establece que los eventos son recursos compartidos de la organización, no mensajes punto a punto entre dos sistemas. Esto habilita la evolución de la arquitectura.
- Composición de flujos: los suscriptores pueden a su vez ser productores de nuevos eventos (el Fraud Detection Engine publica en
banking.fraud.alerts), creando cadenas de procesamiento event-driven sin acoplamiento directo. - Base para CQRS/ES: el topic actúa como un event log inmutable del que múltiples read models (analytics, reporting, reconciliación) se materializan de forma independiente.
Beneficios de Mantenibilidad y Evolución¶
- Extensibilidad aditiva: el sistema se extiende añadiendo suscriptores, nunca modificando el productor ni los suscriptores existentes. Esto cumple el Open/Closed Principle a nivel arquitectónico.
- Migración no disruptiva: un suscriptor puede reemplazarse conectando la nueva versión como un nuevo consumer group, verificando que procesa correctamente, y luego apagando el consumer group antiguo.
- Evolución de schema: con un Schema Registry con compatibilidad BACKWARD, el productor puede añadir campos al evento sin romper suscriptores existentes que no los usan.
12. Desventajas y Riesgos¶
Message Amplification¶
El riesgo más significativo del patrón. Si el topic recibe T mensajes/segundo y tiene S suscriptores, el broker debe gestionar T x S entregas/segundo. Con 150,000 eventos/hora y 5 suscriptores, el fan-out produce 750,000 entregas/hora. Con 20 suscriptores (posible en organizaciones grandes), serían 3,000,000 entregas/hora desde un solo topic. El dimensionamiento del cluster de Kafka debe considerar el throughput total de fan-out, no solo el throughput de producción.
Slow Subscriber Problem¶
El suscriptor más lento de un Publish-Subscribe Channel puede causar problemas operacionales significativos. Si el Reconciliation Service (batch cada 4 horas) consume del mismo topic que el Fraud Detection Engine (latencia < 500ms), el broker debe retener mensajes por horas para el suscriptor lento. En plataformas con retención basada en acknowledgment (RabbitMQ sin lazy queues), esto puede consumir memoria del broker. En Kafka, con retención basada en tiempo, el problema es menor, pero el consumer lag del suscriptor lento sigue requiriendo monitoreo.
En plataformas donde un suscriptor lento puede bloquear al broker (modelos push sin backpressure), un solo suscriptor lento puede degradar la entrega a todos los demás suscriptores.
Complejidad Operacional Acumulativa¶
Cada suscriptor añadido al topic incrementa la superficie de monitoreo:
- Un consumer group más que vigilar por lag, errores y throughput.
- Un Dead Letter Channel más que gestionar.
- Un pipeline más que puede fallar silenciosamente.
- Un equipo más que puede cambiar su patrón de consumo sin avisar.
Con 10+ suscriptores, la operación del Publish-Subscribe Channel requiere dashboards sofisticados y alertas granulares por consumer group.
Acoplamiento Semántico Oculto¶
Aunque el desacoplamiento físico es total (el productor no referencia a los suscriptores), existe un acoplamiento semántico a través del esquema del evento. Si el productor cambia el formato del evento (renombra un campo, cambia el tipo de un valor, elimina un campo), todos los suscriptores se ven afectados simultáneamente. Este acoplamiento es más peligroso que el acoplamiento directo porque es invisible: el productor no sabe a quién rompe.
La mitigación es un Schema Registry con políticas de compatibilidad estrictas, pero requiere disciplina organizacional.
Consistencia Eventual No Gestionada¶
Cuando el Fraud Detection Engine ha procesado el evento (200ms) pero el Notification Service aún no (1.5s), hay una ventana de 1.3 segundos donde el motor de fraude refleja la transacción pero el cliente aún no ha sido notificado. Con suscriptores batch (analytics, reconciliación), esta ventana puede ser de horas. Si los sistemas tienen interacciones cruzadas (por ejemplo, un agente de soporte consulta analytics y notificaciones simultáneamente), puede ver datos inconsistentes.
Mensajes No Filtrados¶
En un Publish-Subscribe Channel puro, todos los suscriptores reciben todos los mensajes. Si el Notification Service solo necesita notificar sobre transferencias > 100 EUR, sigue recibiendo los eventos de transferencias < 100 EUR que descarta. Esto es bandwidth y procesamiento desperdiciado. En alto volumen, puede ser significativo. Las mitigaciones incluyen:
- Filtrado en el broker (Azure Service Bus subscription filters, SNS filter policies).
- Canales más granulares (un topic por tipo de operación).
- Aceptar el overhead si el filtrado en el consumidor es suficientemente barato.
Costos de Operación¶
- Storage: la retención del topic multiplicada por el throughput. Un topic con 150K eventos/hora, 30 días de retención y mensajes de 2KB promedio requiere ~216 GB de storage (antes de replicación; con factor 3, ~648 GB).
- Networking: cada consumer group genera tráfico de red proporcional al throughput total del topic. Con 5 consumer groups, el tráfico de salida del broker es 5x el tráfico de entrada.
- Compute: el broker necesita CPU y memoria proporcionales al número de consumer groups activos y su frecuencia de polling.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
-
Point-to-Point Channel (este capítulo): el complemento directo. Mientras Publish-Subscribe Channel distribuye a todos, Point-to-Point Channel entrega a uno. La primera decisión en el diseño de un canal es: ¿pub-sub o point-to-point? En la práctica, muchas plataformas combinan ambos: un topic Kafka con múltiples consumer groups (pub-sub entre grupos, point-to-point dentro de cada grupo vía competing consumers).
-
Durable Subscriber (patrón relacionado): resuelve el problema de qué ocurre cuando un suscriptor se desconecta temporalmente de un Publish-Subscribe Channel. Sin Durable Subscriber, los mensajes publicados durante la ausencia se pierden. Con Durable Subscriber, el broker retiene los mensajes hasta que el suscriptor se reconecte. En Kafka, todas las suscripciones son durables por defecto (los offsets se retienen). En RabbitMQ, una queue durable con binding al exchange mantiene la suscripción activa durante la desconexión.
-
Message Filter (Capítulo de Message Routing): cuando los suscriptores solo necesitan un subconjunto de los mensajes del canal, un Message Filter puede aplicarse en el broker (subscription filter) o en el consumidor para descartar mensajes irrelevantes. Esto es particularmente útil en Publish-Subscribe Channels con eventos heterogéneos.
-
Dead Letter Channel (este capítulo): cada suscriptor de un Publish-Subscribe Channel necesita su propio Dead Letter Channel. Si el Notification Service no puede procesar un mensaje después de N reintentos, ese mensaje va al DLQ del Notification Service, no a un DLQ compartido. La independencia de suscriptores se extiende al manejo de errores.
-
Guaranteed Delivery (este capítulo): un Publish-Subscribe Channel con Guaranteed Delivery asegura que los mensajes se persisten y no se pierden ante fallos del broker. En el ejemplo bancario,
acks=all+ replicación factor 3 implementan Guaranteed Delivery para satisfacer el requisito de zero data loss del Regulatory Reporting.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Channel (concepto abstracto) — Publish-Subscribe Channel es una especialización de Message Channel con semántica de entrega fan-out.
- Antes: Channel Adapter — si el productor (core bancario legacy) no habla el protocolo del broker, un Channel Adapter (CDC connector) adapta los cambios de base de datos a mensajes en el topic.
- Después: Content-Based Router — un suscriptor puede actuar como router que consume del Publish-Subscribe Channel y redirige mensajes a canales más específicos según su contenido.
- Después: Competing Consumers — dentro de cada consumer group, múltiples instancias compiten por los mensajes de las particiones asignadas, combinando pub-sub (entre grupos) con point-to-point (dentro del grupo).
Combinaciones Comunes¶
- Publish-Subscribe Channel + Competing Consumers: la combinación más frecuente en Kafka. Múltiples consumer groups (pub-sub) donde cada grupo tiene múltiples instancias (competing consumers). Esto permite fan-out + escalabilidad de procesamiento.
- Publish-Subscribe Channel + Message Filter: el suscriptor aplica filtros para procesar solo los mensajes relevantes. En Azure Service Bus y SNS, los filtros pueden aplicarse a nivel de suscripción en el broker.
- Publish-Subscribe Channel + Wire Tap: se añade un suscriptor de "espionaje" que copia todos los mensajes a un canal de auditoría o logging sin afectar el flujo principal.
- Publish-Subscribe Channel + Content-Based Router: un suscriptor consume del topic genérico y distribuye a topics más específicos según el contenido del mensaje (pattern de "derivación de canales" visto en el ejemplo anterior).
Diferencias con Patrones Similares¶
- vs. Point-to-Point Channel: en P2P, el mensaje se entrega a exactamente un consumidor; en Pub-Sub, a todos los suscriptores. P2P es para distribución de trabajo; Pub-Sub es para distribución de eventos.
- vs. Message Bus: un Message Bus es una infraestructura completa de integración con canales, routing, transformación y governance. Un Publish-Subscribe Channel es un componente individual que puede ser parte de un Message Bus.
- vs. Observer Pattern (GoF): el Observer Pattern es un patrón de diseño a nivel de proceso (in-memory); Publish-Subscribe Channel es un patrón de integración a nivel de sistema distribuido (cross-process, cross-network). La semántica es similar (subject notifica a observers), pero la implementación y los desafíos son fundamentalmente diferentes (latencia de red, fallos parciales, durabilidad, ordenamiento).
Encaje en un Flujo Mayor de Integración¶
Publish-Subscribe Channel es el mecanismo de distribución de eventos en una arquitectura event-driven. Es el "hub" donde los eventos se publican y desde donde los sistemas reaccionan. En una arquitectura completa, los Publish-Subscribe Channels forman la columna vertebral del flujo de datos, conectando productores de eventos con consumidores de eventos sin acoplamiento directo. Cada topic es un punto de extensión donde nuevos sistemas pueden conectarse sin modificar los existentes.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Publish-Subscribe Channel es el patrón central de las arquitecturas event-driven modernas, que son el estilo dominante en sistemas distribuidos de escala. Su relevancia no solo se ha mantenido desde su formulación original por Hohpe y Woolf en 2003 — ha aumentado significativamente.
En 2003, el pub-sub era una capacidad del middleware enterprise (JMS Topics, TIBCO, IBM MQ). En 2026, es un primitivo fundamental de toda plataforma cloud, todo framework de microservicios y toda arquitectura de datos en streaming:
- Cada organización con microservicios usa Publish-Subscribe Channels para comunicación event-driven entre servicios.
- Cada data platform usa topics de streaming para distribuir eventos a múltiples pipelines analíticos.
- Cada sistema IoT usa pub-sub para distribuir telemetría a múltiples consumidores.
- Cada implementación de CQRS/ES usa un event log (que es un Publish-Subscribe Channel con retención) para alimentar read models.
La adopción masiva de Apache Kafka (utilizado por más del 80% de Fortune 100) ha convertido al Publish-Subscribe Channel de un patrón de diseño en un commodity de infraestructura.
Evolución del Patrón en la Era Cloud-Native¶
El patrón ha evolucionado en aspectos importantes:
-
De topics efímeros a event logs durables: en JMS clásico, los topics no retenían mensajes — si un suscriptor no estaba conectado, perdía el mensaje. Kafka introdujo topics con retención (días, semanas, indefinida), convirtiendo el Publish-Subscribe Channel en un event log del que los suscriptores pueden leer histórico.
-
De push a pull: los systems legacy (JMS, TIBCO) usaban push (el broker envía al suscriptor). Kafka popularizó pull (el suscriptor pide al broker), dando al suscriptor control sobre su velocidad de consumo y eliminando el slow subscriber problem a nivel de broker.
-
De filtrado en cliente a filtrado en broker: plataformas modernas (Azure Service Bus, SNS, Google Pub/Sub) soportan filtros a nivel de suscripción, reduciendo el tráfico innecesario a suscriptores que solo necesitan un subconjunto de mensajes.
-
Consumer groups como pub-sub + competing consumers: Kafka fusionó los conceptos de pub-sub y competing consumers en un solo primitivo (consumer groups), permitiendo fan-out entre grupos y balanceo de carga dentro de cada grupo.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación de Pub-Sub | Características Distintivas |
|---|---|---|
| Apache Kafka | Topic + Consumer Groups | Log durable, pull-based, retención configurable, exactly-once con transactions |
| AWS SNS + SQS | SNS Topic → SQS Queues | Serverless fan-out, filter policies en SNS, SQS como buffer durable por suscriptor |
| Azure Service Bus | Topic + Subscriptions | SQL-like filters por subscription, sessions para orden, dead-lettering nativo |
| Google Pub/Sub | Topic + Subscriptions | Serverless, exactly-once, seek (rewind), filtering, push y pull |
| RabbitMQ | Fanout Exchange + Queues | Cada queue bound al exchange recibe todos los mensajes, routing flexible con topic exchanges |
| Apache Pulsar | Topic + Subscriptions | Shared/exclusive/failover subscription modes, tiered storage, multi-tenancy |
| NATS JetStream | Subject + Consumers | Ultra-low latency, work queue y fan-out modes, key-value y object stores integrados |
| Redpanda | Topic + Consumer Groups | Compatible con Kafka API, sin JVM, menor latencia y costo operacional |
15. Implementación en Arquitecturas Modernas¶
Apache Kafka (Topics + Consumer Groups)¶
Topic: banking.accounts.balance-changed
Partitions: 32 (key: account_id)
Replication Factor: 3
Min ISR: 2
Retention: 30 days
Cleanup Policy: delete
Compression: lz4
Consumer Groups (cada uno recibe TODOS los mensajes):
cg-fraud-detection → 8 consumers, max.poll.records=100
cg-notifications → 4 consumers, max.poll.records=500
cg-analytics → 2 consumers, max.poll.records=10000
cg-regulatory → 2 consumers, max.poll.records=1000
cg-reconciliation → 1 consumer, max.poll.records=50000
Kafka implementa Publish-Subscribe Channel a través de consumer groups: cada consumer group mantiene su propio offset en cada partición del topic, lo que garantiza que cada grupo reciba todos los mensajes independientemente. Dentro de cada grupo, las particiones se distribuyen entre los consumers del grupo (competing consumers), proporcionando paralelismo de procesamiento.
La retención de 30 días convierte al topic en un event log durable del que cualquier suscriptor puede "rebobinar" para reprocesar eventos. Esto elimina la necesidad de Durable Subscriber como patrón separado — en Kafka, toda suscripción es durable por defecto.
AWS SNS + SQS (Fan-out Serverless)¶
SNS Topic: banking-accounts-balance-changed
Subscriptions:
→ SQS Queue: fraud-detection-queue
Filter: (none - all messages)
→ SQS Queue: notifications-queue
Filter: {"amount": [{"numeric": [">", 100]}]}
→ SQS Queue: analytics-queue
Filter: (none - all messages)
→ SQS Queue: regulatory-queue
Filter: (none - all messages)
→ Lambda: reconciliation-trigger
Filter: (none - batch trigger)
AWS implementa Publish-Subscribe Channel como la combinación SNS (fan-out) + SQS (buffer durable por suscriptor). El productor publica en un SNS topic; SNS distribuye a todas las SQS queues suscritas. Cada SQS queue actúa como un buffer independiente donde el suscriptor consume a su ritmo.
La ventaja principal es el modelo serverless: no hay cluster que gestionar, escala automáticamente y se paga por mensaje. La desventaja es que el ordenamiento dentro de cada SQS queue es best-effort (a menos que se use SQS FIFO, que tiene limitaciones de throughput a 300 msg/s por grupo).
SNS filter policies permiten filtrado en el broker, eliminando la necesidad de que el suscriptor procese y descarte mensajes irrelevantes.
Azure Service Bus (Topics + Subscriptions)¶
Service Bus Namespace: banking-events
Topic: accounts-balance-changed
Subscription: fraud-detection
Filter: 1=1 (all messages)
Max Delivery Count: 3
Dead Letter: enabled
Subscription: notifications
Filter: amount > 100 OR transaction_type = 'high_risk'
Max Delivery Count: 5
Dead Letter: enabled
Subscription: analytics
Filter: 1=1
Max Delivery Count: 10
Subscription: regulatory
Filter: 1=1
Forward Dead Letter To: regulatory-dlq
Subscription: reconciliation
Filter: 1=1
Sessions: enabled (by account_id)
Azure Service Bus implementa Publish-Subscribe Channel con Topics y Subscriptions. Cada subscription es un "virtual queue" con su propio filtro SQL-like, su propio dead-letter queue y su propia configuración de retry. El filtrado a nivel de subscription es uno de los features más potentes: el broker evalúa la condición y solo entrega el mensaje a la subscription si la condición es verdadera.
Las sessions de Service Bus proporcionan orden garantizado por session ID (equivalente a order-by-key), útil para el reconciliation service que necesita procesar eventos de una misma cuenta en orden.
Google Pub/Sub (Serverless con Seek)¶
Project: banking-platform
Topic: accounts-balance-changed
Schema: AccountBalanceChanged (Avro, revision 3)
Subscription: fraud-detection-sub
Type: Pull
Ack Deadline: 10s
Retry Policy: exponential backoff, max 600s
Dead Letter Topic: fraud-detection-dlq
Subscription: notifications-sub
Type: Pull
Filter: attributes.amount_eur > 100
Ack Deadline: 30s
Subscription: analytics-sub
Type: Pull
Ack Deadline: 600s
Enable Exactly Once: true
Subscription: regulatory-sub
Type: Pull
Retain Acked Messages: 7 days
Enable Exactly Once: true
Subscription: reconciliation-sub
Type: Pull
Ack Deadline: 600s
Google Pub/Sub es fully serverless con soporte nativo de schema validation, exactly-once delivery, message filtering y seek (rebobinado a un timestamp o snapshot). El feature de "retain acked messages" permite al regulatory service rebobinar a un punto en el tiempo para reprocesar, similar a Kafka pero sin gestionar offsets manualmente.
RabbitMQ (Fanout Exchange + Queues)¶
Exchange: banking.accounts.balance-changed
Type: fanout
Durable: true
Bindings:
→ Queue: fraud-detection.balance-changed (durable, lazy)
→ Queue: notifications.balance-changed (durable)
→ Queue: analytics.balance-changed (durable, lazy)
→ Queue: regulatory.balance-changed (durable, lazy)
→ Queue: reconciliation.balance-changed (durable, lazy)
RabbitMQ implementa Publish-Subscribe Channel como un fanout exchange que copia cada mensaje a todas las queues bound al exchange. Cada queue es independiente con su propio estado de consumo. Las queues marcadas como "lazy" almacenan mensajes en disco en lugar de memoria, soportando suscriptores lentos sin presionar la memoria del broker.
Para filtrado, se puede usar un topic exchange en lugar de fanout, donde cada queue se subscribe con un routing key pattern (por ejemplo, balance.changed.high_value.*).
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por suscriptor: consumer lag (mensajes pendientes por consumer group), throughput de consumo (msg/s), error rate (mensajes a DLQ), processing latency (p50, p95, p99 desde publicación hasta ack).
- Métricas del canal: throughput de producción (msg/s), total de suscriptores activos, storage utilizado, tasa de crecimiento.
- Distributed tracing: propagar correlation-id en headers del mensaje para trazar el fan-out: cómo un solo evento publicado genera procesamiento en cinco suscriptores. Herramientas como Jaeger o OpenTelemetry deben mostrar el "árbol" de procesamiento de un evento.
- Consumer group health: estado de cada consumer group (active, rebalancing, dead), asignación de particiones, instancias activas.
Monitoreo¶
- Consumer lag por grupo — la métrica más crítica:
cg-fraud-detectionlag > 500 mensajes → alerta P1 (latencia de detección de fraude degradada).cg-regulatorylag > 500,000 mensajes → alerta P2 (posible incumplimiento de reporting).cg-reconciliationlag > esperado para 4h → alerta P3 (reconciliación se atrasará).- Dead-letter queue depth por suscriptor: si la DLQ del Notification Service crece, hay clientes que no reciben notificaciones.
- Throughput anomaly detection: caída repentina de throughput de producción puede indicar fallo del CDC del core bancario.
- Partition skew: si una partición tiene significativamente más mensajes que las demás, hay un desequilibrio que puede causar hotspots.
Versionado del Esquema¶
- Schema Registry centralizado (Confluent, Apicurio, AWS Glue) con el schema Avro/Protobuf del evento registrado y versionado.
- Política de compatibilidad BACKWARD: el productor puede añadir campos opcionales o eliminar campos con default sin romper suscriptores existentes.
- Contrato de evento documentado: cada topic tiene un "contract" publicado que describe el esquema, la semántica de cada campo, las garantías de entrega y las reglas de evolución.
- Testing de compatibilidad: antes de publicar una nueva versión del schema, validar automáticamente que es compatible con la versión anterior según la política definida.
Seguridad¶
- ACLs por consumer group: cada consumer group tiene permisos explícitos de lectura en el topic. No hay acceso implícito.
- ACL del productor: solo el CDC del core bancario tiene permiso de escritura en el topic.
- Encryption in transit: TLS entre todos los clientes y el broker.
- Encryption at rest: los datos del topic cifrados con KMS (AWS KMS, Azure Key Vault, GCP KMS).
- Datos sensibles: los campos
ip_address,device_idygeo_locationdel evento pueden requerir pseudonimización según GDPR. Considerar campos cifrados selectivamente o un pattern de "claim check" donde los datos sensibles se almacenan aparte.
Gestión del Ciclo de Vida de Suscriptores¶
- Registro: todo nuevo consumer group debe registrarse en un catálogo de suscriptores con: equipo owner, propósito, SLA de consumo, persona de contacto.
- Health checks: verificar periódicamente que todos los consumer groups registrados están activos y consumiendo. Un consumer group inactivo que sigue registrado consume recursos (retención de offsets).
- Decomisión: cuando un suscriptor se retira, su consumer group debe eliminarse del broker y del catálogo. Offsets retenidos para consumer groups inactivos se limpian según política (Kafka
offsets.retention.minutes).
Idempotencia y Exactly-Once¶
- El Publish-Subscribe Channel con semántica at-least-once (la más común) puede entregar mensajes duplicados a los suscriptores (por ejemplo, tras un rebalanceo de consumer group). Los suscriptores deben ser idempotentes.
- Para suscriptores que no pueden ser idempotentes, usar exactly-once delivery si la plataforma lo soporta (Kafka transactions, Google Pub/Sub exactly-once) o implementar deduplicación en el consumidor usando el
event_idcomo clave de deduplicación.
Performance y Capacity Planning¶
- Throughput total del broker: producción × suscriptores. Con 5 suscriptores, el broker debe soportar 5x el throughput de producción en entregas.
- Batch size por consumer group: ajustar
max.poll.records(Kafka) o equivalente por suscriptor. El Fraud Detection Engine usa batches pequeños (100) para baja latencia; el Analytics Pipeline usa batches grandes (10,000) para throughput. - Compresión: lz4 o zstd para reducir bandwidth y storage. El overhead de compresión/descompresión es mínimo comparado con el ahorro en I/O.
- Particiones: el número de particiones determina el paralelismo máximo por consumer group. Dimensionar para el consumer group que necesite más paralelismo (en el ejemplo, Fraud Detection con 8 instancias requiere al menos 8 particiones).
17. Errores Comunes¶
Usar Publish-Subscribe Cuando Se Necesita Point-to-Point¶
Un error frecuente es diseñar un Publish-Subscribe Channel para un escenario donde cada mensaje debe procesarse exactamente una vez por un pool de workers. Si el objetivo es balanceo de carga entre instancias del mismo servicio, se necesita Point-to-Point Channel (una queue con competing consumers), no un topic. En Kafka, este error se manifiesta como crear un consumer group diferente para cada instancia del mismo servicio, provocando que cada instancia procese todos los mensajes en lugar de repartírselos.
No Dimensionar para el Fan-out¶
Diseñar la infraestructura para el throughput de producción sin considerar el multiplicador de suscriptores. Si el topic recibe 1,000 msg/s y hay 10 suscriptores, el broker debe sostener 10,000 msg/s de entregas. El networking, el I/O de disco y la memoria del broker deben dimensionarse para el throughput amplificado.
Suscriptor Fantasma¶
Un consumer group que fue creado para pruebas o para un servicio que se retiró, y que nunca fue eliminado. El broker retiene offsets y, en algunas configuraciones, retiene mensajes para ese consumer group. Esto desperdicia recursos y contamina el monitoreo con falsos positivos de "consumer group con lag infinito". Solución: política de lifecycle que requiera des-registro explícito y limpieza periódica de consumer groups inactivos.
Acoplar el Productor al Número de Suscriptores¶
Diseñar la lógica del productor considerando cuántos o cuáles son los suscriptores destruye el beneficio principal del patrón. Si el productor incluye lógica como "si el tipo de transacción es X, también publicar en el topic Y para el suscriptor Z", se ha recreado el acoplamiento directo con una capa de indirección. El productor debe publicar en un topic con la semántica del evento, no del consumidor.
Topic Demasiado Genérico¶
Un topic como banking.events que contiene creaciones de cuenta, cambios de saldo, bloqueos, actualizaciones de datos y cierres de cuenta. Cada suscriptor debe parsear y descartar la gran mayoría de mensajes que no le interesan. Esto desperdicia bandwidth y procesamiento. La solución es crear topics con granularidad de dominio y tipo de evento: banking.accounts.balance-changed, banking.accounts.created, banking.accounts.blocked.
Topic Demasiado Específico¶
El extremo opuesto: un topic por cada combinación de evento y consumidor (balance-changed-for-notifications, balance-changed-for-fraud). Esto elimina el fan-out del broker y recrea el acoplamiento directo. Los topics deben alinearse con eventos de negocio, no con relaciones productor-consumidor.
Ignorar la Consistencia Eventual Entre Suscriptores¶
Asumir que cuando el Notification Service ha procesado el evento, el Analytics Platform también lo ha procesado. Esto lleva a bugs como: un agente de soporte recibe la llamada del cliente que vio la notificación, consulta el dashboard de analytics y no ve la transacción aún porque analytics tiene 2 minutos de lag. La solución es diseñar las interfaces de usuario y los procesos de negocio asumiendo explícitamente que diferentes sistemas pueden tener diferentes visiones temporales de los datos.
No Implementar Dead-Lettering por Suscriptor¶
Usar un solo Dead Letter Channel compartido para todos los suscriptores del topic. Cuando un mensaje falla en el Notification Service y en el Analytics Platform, ambos envían a la misma DLQ, mezclando errores de naturaleza completamente diferente. Cada consumer group necesita su propia DLQ con su propia política de retry y su propio proceso de resolución.
No Planificar la Evolución del Schema¶
Publicar eventos sin schema registry ni política de compatibilidad. Cuando el productor necesita añadir un campo o cambiar un tipo, rompe a suscriptores de forma silenciosa. La primera versión del evento se define con prisa y se convierte en un contrato implícito que no se puede evolucionar sin coordinación manual con todos los suscriptores.
18. Conclusión Técnica¶
Publish-Subscribe Channel es el patrón de canal más potente y más utilizado en las arquitecturas de integración modernas. Su contribución fundamental es la distribución fan-out de eventos desacoplada: un productor publica un evento una vez, y N suscriptores lo reciben y procesan de forma completamente independiente, sin que el productor sepa ni le importe quiénes son los suscriptores, cuántos hay, ni a qué velocidad procesan.
Cuándo aporta valor: siempre que un evento de negocio sea relevante para múltiples sistemas independientes. Es el patrón correcto para distribución de eventos en event-driven architectures, notificación multicanal, alimentación de read models en CQRS/ES, auditoría y compliance, y distribución de datos a pipelines analíticos. Cuantos más sistemas necesiten reaccionar al mismo evento, mayor es el valor del patrón.
Cuándo evita problemas importantes: un diseño correcto de Publish-Subscribe Channels desde el inicio evita los tres problemas más costosos de las integraciones enterprise: (1) acoplamiento del productor con cada consumidor, que convierte cada nuevo consumidor en un proyecto de modificación del productor; (2) fragilidad en cascada, donde el fallo de un consumidor impacta a todos los demás; (3) imposibilidad de extensión, donde añadir un nuevo sistema que reaccione a un evento existente requiere semanas de coordinación.
Cuándo no conviene adoptarlo: cuando el escenario es genuinamente point-to-point (un solo consumidor, o múltiples instancias del mismo consumidor para balanceo de carga); cuando el costo de fan-out es prohibitivo y los suscriptores descartan la mayoría de los mensajes (considerar canales más específicos o filtrado en broker); cuando la organización no tiene la madurez operacional para gestionar múltiples consumer groups con monitoreo, dead-lettering y governance por suscriptor.
Recomendación para arquitectos: trate cada Publish-Subscribe Channel como un contrato de evento público de la organización. El nombre del topic, el esquema del mensaje, la semántica de entrega y la política de retención son decisiones de diseño con impacto duradero. Defina un Schema Registry con política de compatibilidad antes de publicar el primer mensaje. Implemente monitoreo de consumer lag desde el día uno — es la métrica que revela si el sistema está sano. Planifique el ciclo de vida de suscriptores con registro, health-check y decomisión. Y diseñe la granularidad de los topics alineada con eventos de negocio, no con relaciones entre sistemas: un buen Publish-Subscribe Channel sobrevive a la evolución de los suscriptores porque el evento de negocio es estable, aunque los sistemas que lo consumen cambien.