Datatype Channel¶
1. Nombre del Patrón¶
- Nombre oficial: Datatype Channel
- Categoría: Messaging Channels (Canales de Mensajería)
- Traducción contextual: Canal Tipado por Tipo de Dato
2. Resumen Ejecutivo¶
Datatype Channel es el patrón que establece que cada canal de mensajería debe transportar exclusivamente un tipo de mensaje bien definido. En lugar de enviar mensajes heterogéneos por un canal genérico y obligar a cada consumidor a inspeccionar, filtrar y descartar los mensajes que no le corresponden, se crean canales dedicados donde cada uno garantiza que todos los mensajes que fluyen por él comparten la misma estructura semántica y el mismo esquema de datos.
El problema que resuelve es la ambigüedad y la ineficiencia que surgen cuando un canal transporta múltiples tipos de mensaje. Un consumidor conectado a un canal heterogéneo debe implementar lógica de dispatch: inspeccionar cada mensaje, determinar su tipo, decidir si lo procesa o lo ignora, y manejar los tipos desconocidos. Esta lógica es frágil, ineficiente y acopla al consumidor con el conocimiento de todos los tipos que pueden circular por el canal, incluso aquellos que no le interesan.
En las arquitecturas modernas, Datatype Channel es la práctica estándar. En Apache Kafka, la convención topic-per-event-type (un topic por tipo de evento) es la norma de la industria. En combinación con Schema Registry, cada topic tiene un esquema asociado que valida automáticamente que los mensajes producidos respetan el tipo esperado. Esta combinación de canal tipado + validación de esquema proporciona type safety a nivel de infraestructura de messaging.
3. Definición Detallada¶
Propósito¶
Datatype Channel establece una correspondencia uno-a-uno entre un canal de mensajería y un tipo de mensaje específico. Su propósito es que el consumidor, por el solo hecho de estar suscrito a un canal, ya sepa exactamente qué tipo de mensaje va a recibir, sin necesidad de inspeccionar el contenido para determinar el tipo.
Lógica Arquitectónica¶
El patrón introduce tipado estático a nivel de canal. Del mismo modo que en un lenguaje tipado una variable tiene un tipo declarado y el compilador garantiza que solo se asignan valores de ese tipo, un Datatype Channel tiene un tipo de mensaje declarado y el sistema de mensajería (idealmente con un Schema Registry) garantiza que solo se producen mensajes conformes a ese tipo.
Esta decisión tiene implicaciones profundas:
- Eliminación de dispatch en el consumidor: el consumidor no necesita lógica de tipo
if message.type == "X" then process_X() else if message.type == "Y" then process_Y(). Todos los mensajes en el canal son del tipo esperado. - Escalabilidad selectiva: cada canal se escala de forma independiente según el volumen de su tipo de mensaje. Un tipo de alta frecuencia obtiene más particiones; un tipo de baja frecuencia requiere menos recursos.
- Evolución independiente del esquema: el esquema de cada tipo de mensaje evoluciona independientemente. Agregar un campo a los mensajes de tipo A no afecta al canal de tipo B.
- Routing implícito: la selección de canal por parte del productor funciona como un router implícito. El productor decide a qué canal enviar según el tipo de dato, y cada consumidor se conecta solo a los canales que le interesan.
Principio de Diseño Subyacente¶
El principio es separación por tipo semántico. Cada canal tiene una identidad semántica clara: transporta un tipo de información de negocio, no una mezcla arbitraria. Esto es análogo al principio de Single Responsibility: cada canal tiene una responsabilidad (transportar un tipo de dato), y esa responsabilidad no se comparte con otros tipos.
Problema Estructural que Resuelve¶
En un sistema de integración sin Datatype Channel, los canales se convierten en conductos genéricos donde fluyen mensajes de tipos variados. Cada consumidor debe implementar:
- Deserialización especulativa: intentar deserializar el mensaje con múltiples esquemas hasta encontrar el correcto.
- Dispatch manual: lógica condicional para determinar qué hacer con cada tipo de mensaje.
- Manejo de tipos desconocidos: decidir qué hacer cuando llega un mensaje de un tipo que el consumidor no reconoce (¿ignorar? ¿enviar a error channel? ¿fallar?).
Esta lógica duplicada en cada consumidor es un anti-pattern que produce código frágil, difícil de mantener y propenso a errores.
Contexto en el que Emerge¶
Datatype Channel emerge naturalmente cuando una organización pasa de tener pocos tipos de mensaje a tener decenas o cientos. Con dos tipos de mensaje, un canal compartido es manejable. Con cincuenta tipos, un canal compartido se convierte en un problema operacional y de desarrollo.
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas de tipos, Datatype Channel introduce un sistema de tipos simple (nominal) a nivel de infraestructura de messaging. El nombre del canal funciona como un type tag que identifica unívocamente el tipo de payload. En combinación con un Schema Registry, este sistema de tipos se vuelve verificable: el broker (o un interceptor) puede rechazar mensajes que no conforman al esquema registrado para ese canal.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Datatype Channel, los canales transportan una mezcla de tipos de mensaje. Esto produce múltiples problemas:
- Consumidores "omniscientes": cada consumidor necesita conocer todos los tipos de mensaje que pueden aparecer en el canal, incluso aquellos que no procesa. Un cambio en un tipo que el consumidor ignora puede romper su lógica de deserialización.
- Procesamiento ineficiente: un consumidor que solo necesita el 10% de los mensajes del canal debe recibir, inspeccionar y descartar el 90% restante. Esto desperdicia bandwidth, CPU y memoria.
- Escalabilidad acoplada: si un tipo de mensaje tiene un pico de volumen, todos los consumidores del canal se ven afectados, incluso los que no procesan ese tipo.
- Evolución bloqueada: cambiar el esquema de un tipo de mensaje requiere coordinación con todos los consumidores del canal, no solo con los que procesan ese tipo.
Síntomas del Problema¶
- Consumidores con bloques switch/case o cadenas if/else que crecen con cada nuevo tipo de mensaje.
- Errores de deserialización cuando un productor introduce un nuevo tipo que los consumidores existentes no reconocen.
- Consumer lag desproporcionado: un consumidor que procesa un tipo minoritario tiene el mismo lag que un consumidor que procesa el tipo mayoritario porque ambos leen del mismo canal.
- Incapacidad de escalar un tipo de mensaje independientemente de otros.
Impacto Operativo y Arquitectónico¶
Sin canales tipados:
- Los equipos de desarrollo tienen dependencias cruzadas: el equipo que produce mensajes de tipo A debe coordinarse con todos los consumidores del canal, incluyendo los que solo procesan tipo B.
- Las pruebas se complican porque el consumidor debe manejar mensajes de tipos que no le interesan.
- El monitoreo pierde granularidad: las métricas del canal mezclan throughput de tipos diferentes, imposibilitando alertas específicas por tipo.
- Los incidentes se propagan: un productor que envía mensajes malformados de tipo C afecta a consumidores de tipo A y B que comparten el canal.
Riesgos Si No Se Implementa Correctamente¶
- Poison messages: un mensaje de tipo desconocido puede bloquear a un consumidor que no sabe cómo manejarlo, deteniendo el procesamiento de todos los tipos en ese canal.
- Schema conflicts: dos tipos de mensaje con campos del mismo nombre pero semántica diferente producen errores de deserialización sutiles.
- Blast radius amplificado: un problema en un tipo de mensaje afecta a todos los consumidores del canal compartido.
Ejemplos Reales¶
- Telecomunicaciones: una operadora envía CDRs (Call Detail Records) de voz, datos móviles, SMS y MMS por un único canal. El sistema de facturación que solo procesa CDRs de voz debe recibir y descartar millones de CDRs de datos y SMS, generando consumer lag injustificado y costos de procesamiento innecesarios.
- E-commerce: un canal
orders.eventsmezcla OrderCreated, OrderPaid, OrderShipped, OrderDelivered, OrderCancelled. El servicio de inventario solo necesita OrderCreated y OrderCancelled pero debe deserializar y descartar los demás tipos. - Banca: un canal
transactionsmezcla transferencias, pagos de servicios, compras con tarjeta y retiros ATM. Cada sistema downstream debe implementar filtrado y dispatch para tipos que no le interesan.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando existen múltiples tipos de mensaje semánticamente distintos que fluyen entre productores y consumidores.
- Cuando diferentes consumidores necesitan diferentes subconjuntos de tipos de mensaje.
- Cuando los tipos de mensaje tienen volúmenes significativamente diferentes y requieren escalabilidad independiente.
- Cuando los esquemas de los tipos de mensaje evolucionan a ritmos diferentes y por equipos diferentes.
- Cuando se desea type safety a nivel de infraestructura, especialmente con Schema Registry.
Cuándo No Usarlo¶
- Cuando hay muy pocos tipos de mensaje (2-3) y todos los consumidores los necesitan todos. En este caso, un canal compartido con un discriminador simple puede ser suficiente.
- Cuando la proliferación de canales supera la capacidad de gestión operacional. Cientos de canales requieren automatización de gobierno.
- Cuando el tipo de mensaje no es estable ni predecible (mensajes con estructura altamente variable). En este caso, un canal genérico con schema-on-read puede ser más práctico.
Precondiciones¶
- Existe una taxonomía clara de tipos de mensaje en el dominio.
- El productor puede determinar el tipo del mensaje antes de enviarlo (para seleccionar el canal correcto).
- Existe una convención de naming que vincule el nombre del canal con el tipo de dato.
- Idealmente, existe un Schema Registry que valide la conformidad de los mensajes con el tipo del canal.
Restricciones¶
- El número de tipos de mensaje determina el número de canales. Si hay 200 tipos de evento, se necesitan 200 canales (o una agrupación razonable).
- Cada canal adicional consume recursos del broker (metadata, particiones, réplicas).
- Los productores deben tener lógica de routing para enviar al canal correcto según el tipo de mensaje.
Dependencias¶
- Convención de naming de canales que refleje el tipo de dato.
- Schema Registry para validación (recomendado pero no obligatorio).
- Governance para crear, documentar y gestionar los canales tipados.
Supuestos Arquitectónicos¶
- Los tipos de mensaje son identificables en el momento de producción.
- Los tipos de mensaje son suficientemente estables para justificar un canal dedicado.
- La infraestructura de messaging soporta la cantidad de canales requeridos sin degradación.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Datatype Channel reduce el acoplamiento entre consumidores de diferentes tipos: el equipo que procesa CDRs de voz no necesita conocer ni coordinar con el equipo que procesa CDRs de datos. Cada equipo solo conoce el esquema de su canal. Sin embargo, introduce un acoplamiento implícito entre el productor y la convención de naming: el productor debe saber a qué canal enviar cada tipo de mensaje.
Simplicidad vs. Robustez¶
Un canal por tipo es conceptualmente simple (cada canal tiene un propósito claro) pero operacionalmente más complejo (más canales que gestionar). La robustez aumenta porque los fallos están aislados por tipo: un problema con mensajes de tipo A no afecta al procesamiento de tipo B.
Granularidad vs. Manejabilidad¶
La tensión principal del patrón. Granularidad extrema (un canal por subtipo de evento) produce máximo aislamiento pero proliferación de canales. Granularidad insuficiente (un canal por dominio con múltiples tipos) reduce el número de canales pero reintroduce los problemas del canal heterogéneo. El equilibrio depende del contexto organizacional y de la capacidad de automatización.
Consistencia vs. Evolución¶
Cada canal con su propio esquema evoluciona independientemente, lo que facilita la evolución. Pero mantener consistencia transversal (campos comunes como timestamps, correlation IDs, metadata) requiere gobierno: convenciones de esquema base que todos los tipos deben respetar.
Eficiencia vs. Overhead Operacional¶
Canales tipados son más eficientes para el consumidor (no hay filtrado ni dispatch) pero generan overhead operacional para la plataforma (más canales que monitorear, más esquemas que registrar, más ACLs que configurar).
Type Safety vs. Flexibilidad Dinámica¶
Un canal con esquema estricto rechaza mensajes no conformes, proporcionando type safety. Pero esto reduce la flexibilidad para enviar mensajes con estructura variable o experimental. La solución habitual es tener canales con esquema estricto para producción y canales más flexibles para desarrollo/experimentación.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: genera mensajes y los envía al canal correspondiente según su tipo de dato.
- Router/Dispatcher del Productor: lógica (puede ser explícita o implícita) que selecciona el canal destino basándose en el tipo de mensaje.
- Datatype Channel: canal dedicado a un tipo de mensaje específico, con esquema asociado.
- Schema Registry: servicio que almacena y valida esquemas por canal (componente opcional pero recomendado).
- Consumidor Tipado: consumidor que se suscribe a un canal específico y procesa solo ese tipo de mensaje.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Genera mensaje de tipo VoiceCDR]
B --> C{Determina canal según tipo}
C -->|cdr.voice| D[Serializa según esquema del canal]
D --> E[Schema Registry: Valida conformidad]
E --> F[(Broker: Almacena en canal tipado)]
F --> G[Consumidor Tipado: Recibe de cdr.voice]
G --> H[Deserializa con certeza de tipo]
H --> I([Procesa sin lógica de dispatch])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Clasificar el mensaje por tipo, seleccionar el canal correcto, serializar según el esquema del canal |
| Schema Registry | Almacenar esquemas por canal, validar conformidad, gestionar evolución de esquemas |
| Datatype Channel | Transportar exclusivamente mensajes de un tipo, aplicar políticas específicas de ese tipo |
| Consumidor Tipado | Suscribirse al canal de su tipo, deserializar con esquema conocido, procesar sin dispatch |
Interacciones¶
- Productor → Schema Registry: valida el mensaje contra el esquema registrado antes de producir (o el serializer lo hace automáticamente).
- Productor → Canal: envía el mensaje al canal tipado correspondiente.
- Canal → Consumidor: entrega mensajes garantizadamente del tipo esperado.
- Consumidor → Schema Registry: obtiene el esquema para deserialización (cached localmente para performance).
Decisiones de Diseño Clave¶
- Nivel de granularidad del tipo: ¿un canal por entidad (
cdr.voice,cdr.data,cdr.sms) o por entidad-acción (cdr.voice.created,cdr.voice.rated,cdr.voice.billed)? La granularidad por entidad-acción da máximo aislamiento pero multiplica los canales. - Convención de naming: debe reflejar el tipo de dato. Convenciones comunes:
{domain}.{entity}.{event},{team}.{service}.{type},{bounded-context}.{aggregate}.{event-type}. - Esquema obligatorio vs. opcional: ¿el broker rechaza mensajes sin esquema válido o lo permite con best-effort validation?
- Agrupación de subtipos: ¿los subtipos de un mismo aggregate (OrderCreated, OrderUpdated, OrderCancelled) van en canales separados o en un canal compartido con discriminador?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Telecomunicaciones — Procesamiento de CDRs¶
Contexto del Negocio¶
Una operadora de telecomunicaciones procesa 500 millones de CDRs (Call Detail Records) diarios generados por su red. Los CDRs provienen de cuatro fuentes de red y representan cuatro tipos de actividad:
- Voice CDR: llamadas de voz — contienen caller, callee, duración, celda de origen, celda de destino, calidad de señal.
- Data CDR: sesiones de datos móviles — contienen subscriber, APN, bytes transferidos, duración de sesión, tecnología (4G/5G).
- SMS CDR: mensajes de texto — contienen sender, receiver, timestamp, tipo (MT/MO), estado de entrega.
- MMS CDR: mensajes multimedia — contienen sender, receiver, tamaño del contenido, tipo de contenido, estado.
Necesidad de Integración¶
Cada tipo de CDR tiene consumidores diferentes con necesidades distintas:
- Sistema de Facturación (Billing): necesita Voice CDR y Data CDR para calcular cargos.
- Sistema de Fraude: necesita los cuatro tipos para detectar patrones anómalos, pero con diferentes modelos de detección por tipo.
- Sistema de Calidad de Red (QoS): necesita Voice CDR y Data CDR para métricas de calidad.
- Sistema de Reporting Regulatorio: necesita los cuatro tipos para reportes al regulador, pero con transformaciones diferentes por tipo.
- Data Lake Analítico: necesita todos los CDRs para análisis histórico y modelos predictivos.
Sistemas Involucrados¶
- Mediation Platform: recolecta CDRs crudos de los elementos de red y los normaliza.
- Kafka Cluster: plataforma de streaming con canales tipados.
- Confluent Schema Registry: registro de esquemas Avro por topic.
- Billing Engine: calcula cargos basados en CDRs de voz y datos.
- Fraud Detection System: aplica modelos de ML por tipo de CDR.
- QoS Monitoring: genera métricas de calidad de red.
- Regulatory Reporting: genera reportes para el regulador de telecomunicaciones.
- Data Lake: almacena todos los CDRs para analytics.
Diseño de Canales Tipados¶
| Canal (Kafka Topic) | Tipo de Dato | Esquema Avro | Particiones | Retención |
|---|---|---|---|---|
telecom.cdr.voice | VoiceCDR | com.telco.cdr.Voice v3 | 128 | 30 días |
telecom.cdr.data | DataCDR | com.telco.cdr.Data v5 | 256 | 30 días |
telecom.cdr.sms | SmsCDR | com.telco.cdr.Sms v2 | 64 | 15 días |
telecom.cdr.mms | MmsCDR | com.telco.cdr.Mms v2 | 32 | 15 días |
Decisiones Arquitectónicas¶
-
Un topic por tipo de CDR: cada tipo tiene estructura, volumen, consumidores y evolución de esquema diferentes. Separarlos en canales dedicados permite optimización independiente.
-
Particionamiento diferenciado: Voice CDR y Data CDR tienen volumen 10x mayor que SMS y MMS. Los topics de voz y datos tienen más particiones para mayor paralelismo de consumo.
-
Retención diferenciada: los CDRs de voz y datos se retienen 30 días (requisito regulatorio de reprocesamiento); SMS y MMS se retienen 15 días (menor requisito regulatorio).
-
Esquema Avro con Schema Registry: cada topic tiene un esquema Avro registrado con compatibilidad BACKWARD. El serializer del productor valida automáticamente que el CDR conforma al esquema antes de enviarlo al topic.
-
Consumer groups por servicio: Billing consume de
telecom.cdr.voiceytelecom.cdr.data; Fraud consume de los cuatro topics con consumer groups independientes; QoS consume de voice y data; Data Lake consume de los cuatro.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| CDR enviado al topic equivocado | Schema Registry rechaza mensajes con esquema no conforme |
| Evolución de esquema rompe consumidores | Compatibilidad BACKWARD + versionado semántico |
| Proliferación de topics por subtipos | Agrupación por tipo principal (voice, data, sms, mms), no por subtipo |
| Desbalance de particiones por subscriber_id | Uso de hash murmur2 sobre subscriber_id con particiones potencia de 2 |
| Consumidor subscrito al topic equivocado | ACLs de Kafka que restringen qué consumer groups pueden leer de qué topics |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación de CDRs en la Red¶
Un abonado (subscriber ID: SUB-9821347) realiza una llamada de voz de 4 minutos 32 segundos desde Madrid a Barcelona. El switch de voz genera un CDR crudo en formato ASN.1.
Simultáneamente, otro abonado (subscriber ID: SUB-5567210) está usando datos móviles 5G en Bilbao, generando una sesión de 250 MB. El packet gateway genera un CDR de datos.
Paso 2: Mediación y Normalización¶
La Mediation Platform recibe ambos CDRs crudos, los normaliza a formato JSON/Avro y los clasifica por tipo:
// Voice CDR
{
"cdr_id": "CDR-V-2026-04071432-9821347",
"type": "VOICE",
"subscriber_id": "SUB-9821347",
"caller": "+34611234567",
"callee": "+34932345678",
"start_time": "2026-04-07T14:32:15Z",
"duration_seconds": 272,
"origin_cell": "MAD-CENTRO-A3",
"dest_cell": "BCN-EIXAMPLE-B7",
"signal_quality": 0.92,
"codec": "AMR-WB"
}
// Data CDR
{
"cdr_id": "CDR-D-2026-04071433-5567210",
"type": "DATA",
"subscriber_id": "SUB-5567210",
"apn": "internet.telco.es",
"bytes_up": 25600000,
"bytes_down": 236800000,
"session_start": "2026-04-07T14:33:00Z",
"session_duration_seconds": 1800,
"technology": "5G-SA",
"cell_id": "BIL-ABANDO-5G-01"
}
Paso 3: Routing a Canales Tipados¶
La Mediation Platform inspecciona el campo type del CDR normalizado y selecciona el canal:
type == "VOICE"→ produce entelecom.cdr.voicecon partition key =subscriber_idtype == "DATA"→ produce entelecom.cdr.datacon partition key =subscriber_idtype == "SMS"→ produce entelecom.cdr.smscon partition key =subscriber_idtype == "MMS"→ produce entelecom.cdr.mmscon partition key =subscriber_id
El serializer Avro valida automáticamente que el Voice CDR conforma al esquema com.telco.cdr.Voice v3 antes de enviarlo. Si un CDR no conforma, el serializer lanza una excepción y el CDR se envía a un Invalid Message Channel para revisión.
Paso 4: Consumo por Billing Engine¶
El Billing Engine (consumer group: cg-billing) consume de telecom.cdr.voice y telecom.cdr.data:
- Del canal
telecom.cdr.voicerecibe el CDR de voz de SUB-9821347. - Deserializa con certeza de tipo — sabe que es VoiceCDR.
- Aplica la tarifa del plan del abonado: llamada nacional, 272 segundos, tarifa premium por codec AMR-WB.
- Calcula el cargo: EUR 0.45.
- Genera un registro de facturación y confirma el offset.
No necesita ninguna lógica de dispatch. No recibe CDRs de SMS ni de MMS. El consumidor es más simple, más rápido y más fácil de mantener.
Paso 5: Consumo por Fraud Detection¶
El Fraud Detection System tiene cuatro consumer groups independientes, uno por tipo de CDR:
cg-fraud-voiceconsume detelecom.cdr.voicey aplica el modelo de detección de fraude de voz (llamadas de larga duración a destinos internacionales premium).cg-fraud-dataconsume detelecom.cdr.datay aplica el modelo de detección de fraude de datos (sesiones masivas desde SIMs prepago recientes).cg-fraud-smsconsume detelecom.cdr.smsy aplica el modelo de detección de SMS spam/phishing.cg-fraud-mmsconsume detelecom.cdr.mmsy aplica el modelo de detección de MMS malicioso.
Cada modelo está optimizado para su tipo de CDR. La separación en canales tipados permite que cada modelo se despliegue, escale y actualice independientemente.
Paso 6: Monitoreo Diferenciado por Canal¶
El dashboard de operaciones monitorea cada canal tipado independientemente:
telecom.cdr.voice: throughput 2,800 msg/sec, consumer lag billing < 30 sec, lag fraud < 45 sec.telecom.cdr.data: throughput 3,200 msg/sec, consumer lag billing < 25 sec, lag fraud < 40 sec.telecom.cdr.sms: throughput 450 msg/sec, consumer lag fraud < 10 sec.telecom.cdr.mms: throughput 80 msg/sec, consumer lag fraud < 5 sec.
Esta granularidad de monitoreo sería imposible si todos los CDRs fluyeran por un canal único. Un pico en CDRs de datos (por ejemplo, durante un evento deportivo con streaming masivo) se visualiza inmediatamente en el canal telecom.cdr.data sin afectar las métricas de los demás canales.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.network import Nginx
from diagrams.onprem.monitoring import Grafana
from diagrams.programming.framework import Spring
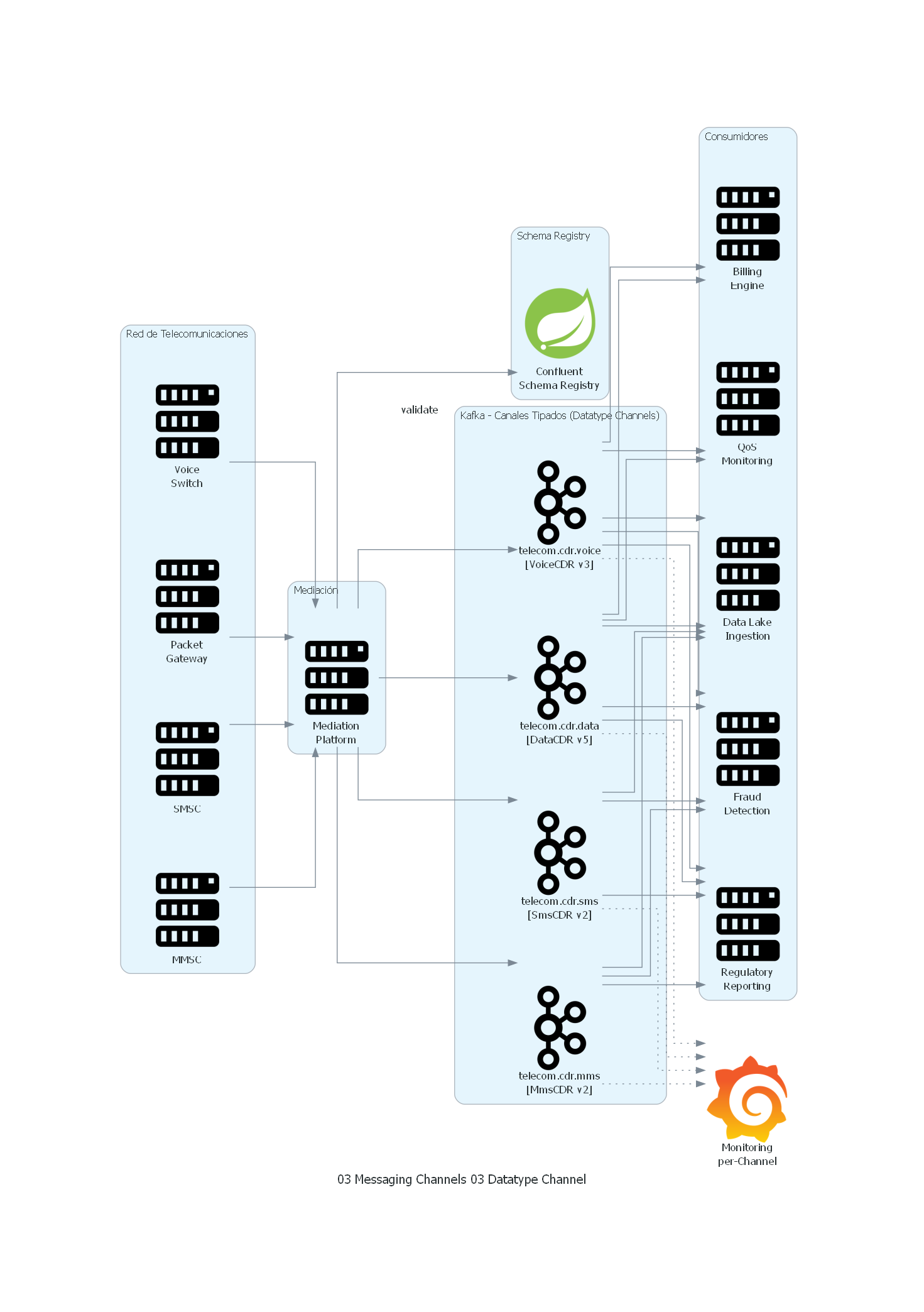
with Diagram("Datatype Channel - Telecom CDR Processing", show=False, direction="LR"):
with Cluster("Red de Telecomunicaciones"):
voice_switch = Server("Voice\nSwitch")
packet_gw = Server("Packet\nGateway")
smsc = Server("SMSC")
mmsc = Server("MMSC")
with Cluster("Mediación"):
mediation = Server("Mediation\nPlatform")
with Cluster("Schema Registry"):
registry = Spring("Confluent\nSchema Registry")
with Cluster("Kafka - Canales Tipados (Datatype Channels)"):
voice_topic = Kafka("telecom.cdr.voice\n[VoiceCDR v3]")
data_topic = Kafka("telecom.cdr.data\n[DataCDR v5]")
sms_topic = Kafka("telecom.cdr.sms\n[SmsCDR v2]")
mms_topic = Kafka("telecom.cdr.mms\n[MmsCDR v2]")
with Cluster("Consumidores"):
billing = Server("Billing\nEngine")
fraud = Server("Fraud\nDetection")
qos = Server("QoS\nMonitoring")
regulatory = Server("Regulatory\nReporting")
datalake = Server("Data Lake\nIngestion")
monitoring = Grafana("Monitoring\nper-Channel")
# Fuentes de red a mediación
voice_switch >> mediation
packet_gw >> mediation
smsc >> mediation
mmsc >> mediation
# Mediación valida esquema y produce a canales tipados
mediation >> Edge(label="validate") >> registry
mediation >> voice_topic
mediation >> data_topic
mediation >> sms_topic
mediation >> mms_topic
# Consumidores suscritos a canales específicos
voice_topic >> billing
data_topic >> billing
voice_topic >> fraud
data_topic >> fraud
sms_topic >> fraud
mms_topic >> fraud
voice_topic >> qos
data_topic >> qos
voice_topic >> regulatory
data_topic >> regulatory
sms_topic >> regulatory
mms_topic >> regulatory
voice_topic >> datalake
data_topic >> datalake
sms_topic >> datalake
mms_topic >> datalake
# Monitoreo por canal
voice_topic >> Edge(style="dotted") >> monitoring
data_topic >> Edge(style="dotted") >> monitoring
sms_topic >> Edge(style="dotted") >> monitoring
mms_topic >> Edge(style="dotted") >> monitoring
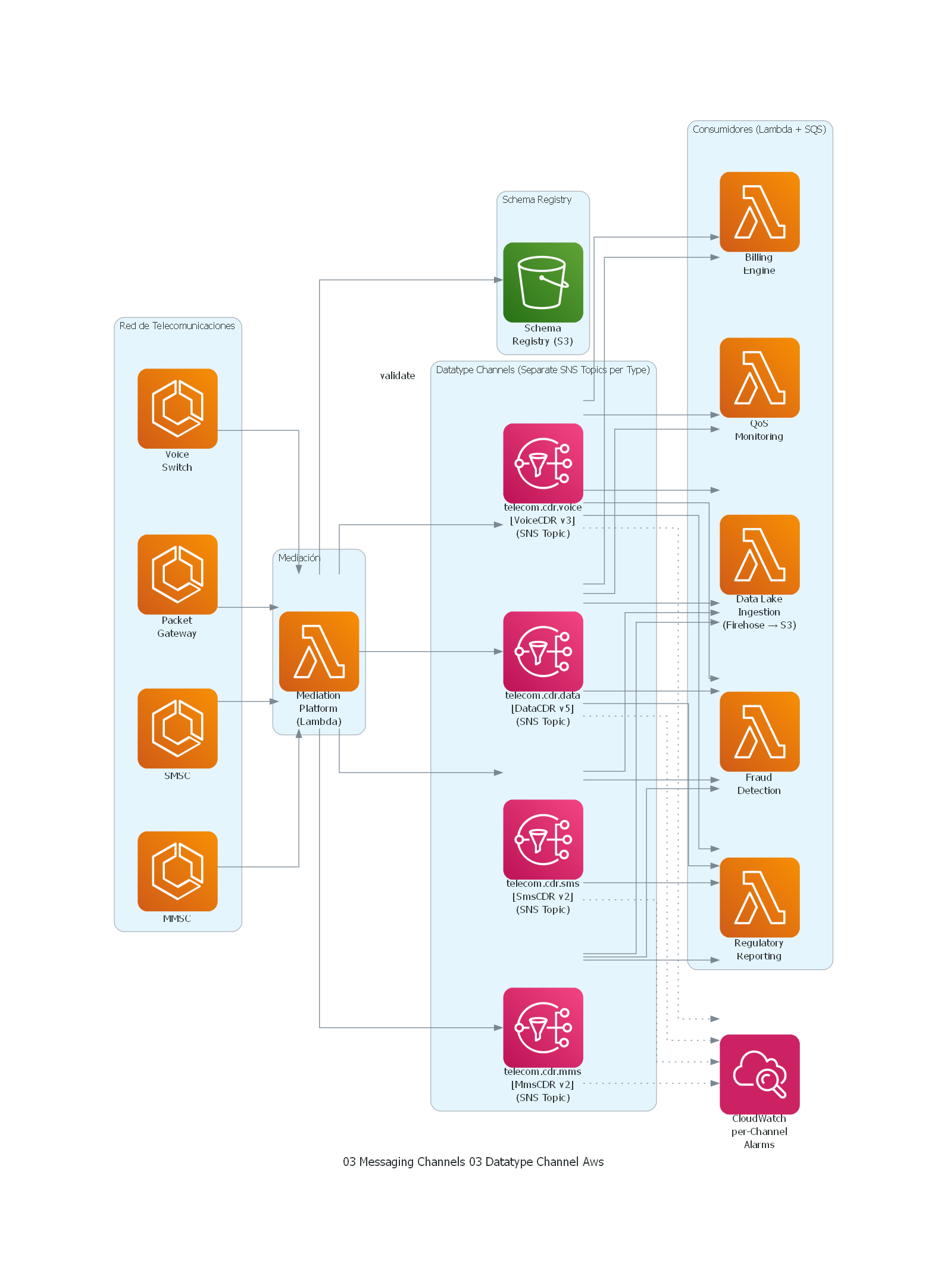
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.integration import Eventbridge, SNS, SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.storage import S3
with Diagram("Datatype Channel - Telecom CDR Processing (AWS)", show=False, direction="LR"):
with Cluster("Red de Telecomunicaciones"):
voice_switch = ECS("Voice\nSwitch")
packet_gw = ECS("Packet\nGateway")
smsc = ECS("SMSC")
mmsc = ECS("MMSC")
with Cluster("Mediación"):
mediation = Lambda("Mediation\nPlatform\n(Lambda)")
with Cluster("Schema Registry"):
registry = S3("Schema\nRegistry (S3)")
with Cluster("Datatype Channels (Separate SNS Topics per Type)"):
voice_topic = SNS("telecom.cdr.voice\n[VoiceCDR v3]\n(SNS Topic)")
data_topic = SNS("telecom.cdr.data\n[DataCDR v5]\n(SNS Topic)")
sms_topic = SNS("telecom.cdr.sms\n[SmsCDR v2]\n(SNS Topic)")
mms_topic = SNS("telecom.cdr.mms\n[MmsCDR v2]\n(SNS Topic)")
with Cluster("Consumidores (Lambda + SQS)"):
billing = Lambda("Billing\nEngine")
fraud = Lambda("Fraud\nDetection")
qos = Lambda("QoS\nMonitoring")
regulatory = Lambda("Regulatory\nReporting")
datalake = Lambda("Data Lake\nIngestion\n(Firehose → S3)")
monitoring = Cloudwatch("CloudWatch\nper-Channel\nAlarms")
# Fuentes de red a mediación
voice_switch >> mediation
packet_gw >> mediation
smsc >> mediation
mmsc >> mediation
# Mediación valida esquema y produce a canales tipados
mediation >> Edge(label="validate") >> registry
mediation >> voice_topic
mediation >> data_topic
mediation >> sms_topic
mediation >> mms_topic
# Consumidores suscritos a canales específicos (SNS → SQS → Lambda)
voice_topic >> billing
data_topic >> billing
voice_topic >> fraud
data_topic >> fraud
sms_topic >> fraud
mms_topic >> fraud
voice_topic >> qos
data_topic >> qos
voice_topic >> regulatory
data_topic >> regulatory
sms_topic >> regulatory
mms_topic >> regulatory
voice_topic >> datalake
data_topic >> datalake
sms_topic >> datalake
mms_topic >> datalake
# Monitoreo por canal
voice_topic >> Edge(style="dotted") >> monitoring
data_topic >> Edge(style="dotted") >> monitoring
sms_topic >> Edge(style="dotted") >> monitoring
mms_topic >> Edge(style="dotted") >> monitoring
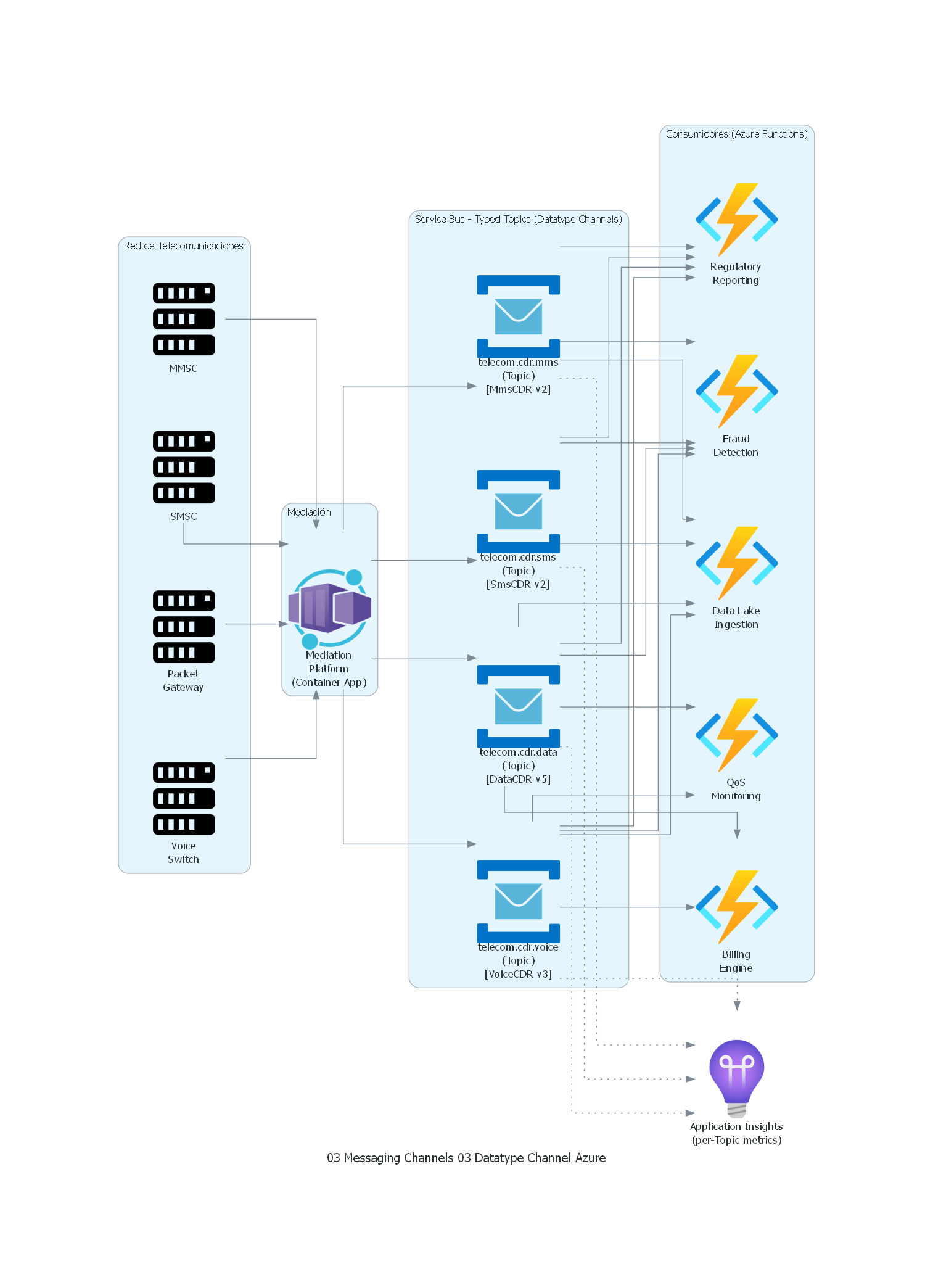
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.compute import Server
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Datatype Channel - Telecom CDR Processing (Azure)", show=False, direction="LR"):
with Cluster("Red de Telecomunicaciones"):
voice_switch = Server("Voice\nSwitch")
packet_gw = Server("Packet\nGateway")
smsc = Server("SMSC")
mmsc = Server("MMSC")
with Cluster("Mediación"):
mediation = ContainerApps("Mediation\nPlatform\n(Container App)")
with Cluster("Service Bus - Typed Topics (Datatype Channels)"):
voice_topic = ServiceBus("telecom.cdr.voice\n(Topic)\n[VoiceCDR v3]")
data_topic = ServiceBus("telecom.cdr.data\n(Topic)\n[DataCDR v5]")
sms_topic = ServiceBus("telecom.cdr.sms\n(Topic)\n[SmsCDR v2]")
mms_topic = ServiceBus("telecom.cdr.mms\n(Topic)\n[MmsCDR v2]")
with Cluster("Consumidores (Azure Functions)"):
billing = FunctionApps("Billing\nEngine")
fraud = FunctionApps("Fraud\nDetection")
qos = FunctionApps("QoS\nMonitoring")
regulatory = FunctionApps("Regulatory\nReporting")
datalake = FunctionApps("Data Lake\nIngestion")
monitoring = ApplicationInsights("Application Insights\n(per-Topic metrics)")
# Fuentes de red a mediación
voice_switch >> mediation
packet_gw >> mediation
smsc >> mediation
mmsc >> mediation
# Mediación produce a topics tipados (one topic per data type)
mediation >> voice_topic
mediation >> data_topic
mediation >> sms_topic
mediation >> mms_topic
# Consumidores suscritos a topics específicos via subscriptions
voice_topic >> billing
data_topic >> billing
voice_topic >> fraud
data_topic >> fraud
sms_topic >> fraud
mms_topic >> fraud
voice_topic >> qos
data_topic >> qos
voice_topic >> regulatory
data_topic >> regulatory
sms_topic >> regulatory
mms_topic >> regulatory
voice_topic >> datalake
data_topic >> datalake
sms_topic >> datalake
mms_topic >> datalake
# Monitoreo por canal
voice_topic >> Edge(style="dotted") >> monitoring
data_topic >> Edge(style="dotted") >> monitoring
sms_topic >> Edge(style="dotted") >> monitoring
mms_topic >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de Datatype Channel para el procesamiento de CDRs en una operadora de telecomunicaciones:
- Fuentes de red (Voice Switch, Packet Gateway, SMSC, MMSC) envían CDRs crudos a la Mediation Platform.
- La Mediation Platform normaliza los CDRs, valida su esquema contra Schema Registry y los produce en el canal tipado correspondiente.
- Cada Kafka topic transporta exclusivamente un tipo de CDR, con su esquema Avro asociado.
- Los consumidores se suscriben solo a los canales que necesitan: Billing consume voice y data; Fraud consume los cuatro; QoS consume voice y data; Data Lake consume todos.
- Grafana monitorea cada canal independientemente con métricas específicas.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor con routing por tipo | Mediation Platform (clasifica CDRs por tipo) |
| Datatype Channel | Cada topic Kafka (voice, data, sms, mms) |
| Tipo de dato / Esquema | Esquema Avro registrado en Schema Registry |
| Validación de tipo | Schema Registry valida antes de producir |
| Consumidor tipado | Billing, Fraud, QoS, Regulatory (suscritos a canales específicos) |
| Monitoreo por tipo | Grafana con dashboards por canal |
11. Beneficios¶
Impacto Técnico¶
- Eliminación de dispatch en consumidores: cada consumidor recibe solo el tipo de mensaje que espera. No hay lógica condicional de tipo, no hay deserialización especulativa, no hay manejo de tipos desconocidos.
- Type safety a nivel de infraestructura: con Schema Registry, el broker rechaza mensajes que no conforman al esquema del canal, detectando errores de producción antes de que lleguen al consumidor.
- Escalabilidad granular: cada canal se escala según el volumen de su tipo de dato. Los CDRs de datos (alto volumen) tienen 256 particiones; los CDRs de MMS (bajo volumen) tienen 32.
- Aislamiento de fallos por tipo: un problema con la deserialización de CDRs de voz no afecta al procesamiento de CDRs de datos. Los blast radius están contenidos por tipo.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de Billing evoluciona el esquema de VoiceCDR sin coordinar con el equipo de QoS que procesa DataCDR. Cada tipo tiene su propio ciclo de vida de esquema.
- Ownership claro: cada canal tipado tiene un owner (el equipo productor) y consumidores registrados. La responsabilidad es inequívoca.
- Onboarding simplificado: un nuevo consumidor entiende inmediatamente qué datos recibe al conectarse a un canal con nombre semántico (
telecom.cdr.voice) y esquema documentado en Schema Registry.
Impacto Operacional¶
- Monitoreo diferenciado: métricas de throughput, lag y errores por tipo de dato, no mezcladas en un canal genérico. Esto permite alertas precisas y diagnóstico rápido.
- Capacity planning por tipo: se puede proyectar el crecimiento de cada tipo independientemente (el volumen de CDRs de datos crece 40% anual; el de SMS decrece 15%).
- Debugging focalizado: cuando hay un error, el canal afectado identifica inmediatamente el tipo de dato problemático.
Beneficios de Mantenibilidad y Evolución¶
- Evolución de esquema independiente: agregar un campo a VoiceCDR (por ejemplo,
volte_indicator) se hace en el esquema del canal de voz sin impactar ningún otro canal. - Migración gradual: un nuevo sistema de billing puede conectarse primero al canal de voz, validar, y luego conectarse al canal de datos, sin big-bang.
- Testing aislado: los tests del consumidor de voz no necesitan fixtures de CDRs de datos, SMS ni MMS.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Proliferación de canales: si la taxonomía de tipos es amplia, el número de canales crece proporcionalmente. Una organización con 50 tipos de evento tiene 50 canales que gestionar.
- Lógica de routing en el productor: el productor debe implementar la selección de canal según el tipo. Esto puede ser trivial (un mapa tipo→canal) o complejo si los tipos no son mutuamente excluyentes.
- Overhead de Schema Registry: cada canal tiene un esquema registrado que debe gestionarse, versionarse y validarse. Esto añade una dependencia de infraestructura.
Riesgos de Mal Uso¶
- Sobre-fragmentación: crear canales para subtipos insignificantes (por ejemplo,
cdr.voice.national.mobile,cdr.voice.national.landline,cdr.voice.international.mobile) produce fragmentación excesiva sin beneficio proporcional. - Agrupación insuficiente: agrupar tipos demasiado diferentes en un canal "por conveniencia" reintroduce los problemas del canal heterogéneo.
- Esquema demasiado estricto: un esquema que rechaza cualquier variación impide la experimentación. Es necesario un balance entre strictness y flexibilidad.
Sobreingeniería¶
- Canales vacíos: crear canales anticipando tipos de mensaje que nunca se materializan consume recursos sin beneficio.
- Jerarquías complejas de naming: convenciones de naming con 5+ niveles de jerarquía (
org.division.team.service.entity.action.version) son difíciles de recordar y propensas a errores.
Costos de Operación¶
- Metadata overhead: cada canal consume recursos de metadata en el broker (Kafka controller, ZooKeeper/KRaft).
- Replicación multiplicada: si cada canal se replica 3x, más canales significa más replicación.
- Monitoreo multiplicado: más canales significa más dashboards, más alertas, más configuración de monitoreo.
Anti-Patterns Relacionados¶
- God Channel: el extremo opuesto a Datatype Channel. Un canal único con todos los tipos mezclados.
- Micro-Channel: un canal para cada instancia de un tipo (por ejemplo, un canal por subscriber) en lugar de un canal por tipo de dato. Produce miles de canales efímeros imposibles de gestionar.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): Datatype Channel es una especialización de Message Channel que añade la restricción de un tipo de dato por canal.
- Content-Based Router (Capítulo 5): si el productor genera mensajes heterogéneos, un Content-Based Router puede inspeccionar cada mensaje y dirigirlo al Datatype Channel correcto.
- Schema Registry / Canonical Data Model (Capítulo 6): el esquema registrado para cada canal actúa como contrato canónico del tipo de dato.
- Invalid Message Channel (Capítulo 3): cuando un mensaje no conforma al esquema del canal, se envía a un Invalid Message Channel para revisión.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: la decisión de usar messaging (Messaging pattern) y la definición de los tipos de mensaje (Message pattern) preceden a la creación de Datatype Channels.
- Después: Point-to-Point Channel o Publish-Subscribe Channel definen la semántica de entrega de cada Datatype Channel. Dead Letter Channel y Invalid Message Channel manejan los mensajes problemáticos.
Combinaciones Comunes¶
- Datatype Channel + Schema Registry: la combinación más poderosa. El canal transporta un tipo; el Schema Registry valida la conformidad. Esto proporciona type safety a nivel de infraestructura.
- Datatype Channel + Competing Consumers: múltiples instancias de un consumidor compiten por mensajes en un canal tipado para procesamiento paralelo del mismo tipo.
- Datatype Channel + Content-Based Router: un router consume de una fuente mixta y distribuye a canales tipados. El router es el punto de clasificación; los canales son los destinos tipados.
Diferencias con Patrones Similares¶
- vs. Publish-Subscribe Channel: Pub-Sub define la semántica de entrega (uno-a-muchos). Datatype Channel define la restricción de tipo. Un canal puede ser simultáneamente Datatype Channel y Publish-Subscribe Channel.
- vs. Message Filter: un Message Filter descarta mensajes que no cumplen un criterio. Datatype Channel evita que mensajes de tipo incorrecto lleguen al canal en primer lugar. Es prevención vs. filtrado.
- vs. Content-Based Router: el router dirige mensajes a diferentes canales según su contenido. Los canales destino suelen ser Datatype Channels. El router es el mecanismo; el Datatype Channel es el destino.
Encaje en un Flujo Mayor de Integración¶
Datatype Channel es una decisión de diseño de canales que se aplica transversalmente. Cuando un arquitecto diseña la topología de canales de un sistema de integración, la pregunta "¿este canal transporta un solo tipo o múltiples tipos?" es una de las primeras decisiones. La respuesta determina la complejidad de los consumidores, la granularidad del monitoreo y la capacidad de evolución independiente.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Datatype Channel no solo sigue vigente — se ha convertido en best practice de la industria. La convención topic-per-event-type es la norma en toda arquitectura event-driven moderna:
- En Apache Kafka, la recomendación oficial es un topic por tipo de evento. Los topics se nombran según el tipo de dato que transportan (
orders.created,payments.processed,shipments.dispatched). Confluent Schema Registry asocia un esquema a cada topic, proporcionando type safety. - En Azure Event Hubs / Service Bus, cada event hub o topic corresponde a un tipo de evento o entidad de negocio.
- En AWS EventBridge, las event buses tienen rules que filtran por tipo de evento (event source + detail-type) y los dirigen a targets específicos. Esto implementa Datatype Channel + Content-Based Router.
- En Domain-Driven Design y Event Sourcing, cada tipo de domain event tiene su propio stream/canal en el event store.
- En AsyncAPI (el equivalente de OpenAPI para APIs asíncronas), cada canal se define con un tipo de mensaje específico.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación de Datatype Channel | Schema Enforcement |
|---|---|---|
| Kafka + Schema Registry | Un topic por tipo de evento con esquema Avro/Protobuf/JSON Schema | Validación automática por serializer |
| Azure Service Bus | Un topic por tipo de evento con Azure Schema Registry | Validación en productor |
| AWS SNS + EventBridge | Event type → rule → target queue | Schema Registry de EventBridge |
| Google Pub/Sub | Un topic por tipo de evento con schema validation | Proto schemas en Pub/Sub |
| RabbitMQ | Un exchange + queue por tipo, con routing keys tipados | Plugin de schema validation |
Qué Parte Sigue Siendo Esencial¶
- Un canal = un tipo de dato: la correspondencia entre canal y tipo de dato es el principio más importante.
- Schema como contrato: el esquema asociado al canal documenta y valida el contrato de datos.
- Naming que refleja el tipo: el nombre del canal debe ser semánticamente claro sobre qué tipo de dato transporta.
- Monitoreo por tipo: las métricas por canal proporcionan visibilidad por tipo de dato, esencial para operaciones.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka con Confluent Schema Registry¶
# Topic creation con naming convention
kafka-topics --create --topic telecom.cdr.voice \
--partitions 128 --replication-factor 3
kafka-topics --create --topic telecom.cdr.data \
--partitions 256 --replication-factor 3
# Schema registration (Avro)
# Subject naming strategy: TopicNameStrategy (default)
# Subject: telecom.cdr.voice-value
curl -X POST http://schema-registry:8081/subjects/telecom.cdr.voice-value/versions \
-H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"schema": "{\"type\":\"record\",\"name\":\"VoiceCDR\",\"namespace\":\"com.telco.cdr\",\"fields\":[{\"name\":\"cdr_id\",\"type\":\"string\"},{\"name\":\"subscriber_id\",\"type\":\"string\"},{\"name\":\"caller\",\"type\":\"string\"},{\"name\":\"callee\",\"type\":\"string\"},{\"name\":\"duration_seconds\",\"type\":\"int\"},{\"name\":\"origin_cell\",\"type\":\"string\"},{\"name\":\"dest_cell\",\"type\":\"string\"}]}"}'
# Compatibility mode per subject
curl -X PUT http://schema-registry:8081/config/telecom.cdr.voice-value \
-H "Content-Type: application/vnd.schemaregistry.v1+json" \
-d '{"compatibility": "BACKWARD"}'
Con TopicNameStrategy, el Schema Registry asocia automáticamente el esquema al topic basándose en el nombre. El serializer valida que cada mensaje producido conforma al esquema registrado para ese topic.
Azure Service Bus con Azure Schema Registry¶
# Topic per data type
az servicebus topic create --name telecom-cdr-voice \
--namespace-name telco-messaging --resource-group telco-integration
az servicebus topic create --name telecom-cdr-data \
--namespace-name telco-messaging --resource-group telco-integration
# Subscriptions per consumer
az servicebus topic subscription create --name billing-sub \
--topic-name telecom-cdr-voice --namespace-name telco-messaging
# Schema registration in Azure Schema Registry
az eventhubs schema-registry schema create \
--group-name telco-cdr-schemas \
--name com.telco.cdr.VoiceCDR \
--schema-type Avro \
--content @voice-cdr-schema.avsc
AWS con EventBridge y Schema Registry¶
// EventBridge rule for datatype channel pattern
{
"Source": ["com.telco.mediation"],
"DetailType": ["VoiceCDR"],
"Detail": {}
}
// Routes VoiceCDR events to voice-specific SQS queue
// Different rule for DataCDR routes to data-specific queue
Google Cloud Pub/Sub con Schema Validation¶
# Topic per data type with schema
gcloud pubsub schemas create voice-cdr-schema \
--type=AVRO --definition-file=voice-cdr.avsc
gcloud pubsub topics create telecom-cdr-voice \
--schema=voice-cdr-schema \
--message-encoding=JSON
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por canal tipado: throughput, consumer lag, error rate y storage por cada canal. La granularidad por tipo de dato permite detectar anomalías específicas (pico de CDRs de datos durante un evento masivo).
- Schema evolution tracking: registrar cada cambio de versión de esquema en cada canal, quién lo hizo, cuándo y qué cambió.
- Cross-channel correlation: usar correlation IDs en headers para trazar un flujo de negocio que atraviesa múltiples canales tipados.
Monitoreo¶
- Per-type throughput: alerta si el throughput de un canal cae por debajo del mínimo esperado (puede indicar fallo en el productor de ese tipo).
- Schema validation failures: alerta si el Schema Registry rechaza mensajes (indica bug en el productor o incompatibilidad de esquema).
- Consumer lag per type: un consumidor puede estar al día en un tipo pero atrasado en otro. El monitoreo por canal revela esto.
Versionado¶
- Esquema por canal: cada canal tiene su propio esquema con su propia versión. La compatibilidad (BACKWARD, FORWARD, FULL) se configura por canal.
- Naming con versión opcional: algunas organizaciones incluyen la versión major en el nombre del canal (
telecom.cdr.voice.v3) para migraciones breaking. Otras prefieren versionado in-band (el esquema evoluciona con compatibilidad backward en el mismo canal).
Seguridad¶
- ACLs por canal tipado: restringir quién puede producir en cada canal (solo la Mediation Platform puede producir en
telecom.cdr.voice) y quién puede consumir (solo servicios autorizados). - Data classification por tipo: los canales que transportan datos sensibles (CDRs con información de localización) pueden tener políticas de cifrado y retención más estrictas.
Naming Convention¶
La convención de naming es crítica para Datatype Channel. Recomendaciones:
- Formato:
{domain}.{entity}.{event-type}o{domain}.{entity-type}para datos master. - Casing: kebab-case o dot-separated lowercase.
- Ejemplos:
telecom.cdr.voice,payments.transaction.completed,inventory.stock.adjusted. - Validación: scripts de CI/CD que validen que los nombres de nuevos topics conforman a la convención antes de crearlos.
Performance¶
- Particiones por tipo: dimensionar las particiones de cada canal según el volumen de su tipo de dato, no con un número uniforme para todos los canales.
- Compresión por tipo: tipos de mensaje con payloads grandes (MMS CDRs con metadata de contenido multimedia) se benefician más de compresión que tipos con payloads pequeños (SMS CDRs).
- Batch size por tipo: los productores pueden configurar batch size diferente por canal según las características del tipo de dato.
17. Errores Comunes¶
Crear un Canal "Catch-All" con Múltiples Tipos¶
El error más frecuente: un canal llamado events o messages donde fluyen todos los tipos de mensaje. Los consumidores deben filtrar por tipo, desperdiciando recursos. Solución: un canal por tipo desde el inicio, con naming convention clara.
No Usar Schema Registry¶
Un canal tipado sin validación de esquema es una promesa sin enforcement. Cualquier productor puede enviar un mensaje con estructura incorrecta, y el error solo se descubre cuando el consumidor falla al deserializar. Solución: Schema Registry con validación en el serializer del productor.
Granularidad Incorrecta del Tipo¶
Demasiado granular: un canal por cada subtipo menor (order.created.domestic.standard, order.created.domestic.express, order.created.international.standard). Esto multiplica canales sin beneficio proporcional. Demasiado grueso: un canal para todos los eventos de un dominio (order.events) que mezcla creación, pago, envío y cancelación. La granularidad correcta agrupa por tipo semántico principal que tiene consumidores y evolución de esquema distintos.
Naming Inconsistente entre Canales¶
Sin convención de naming enforced, se obtienen canales como orderCreated, payment-processed, SHIPMENT_DISPATCHED, inventory.stock.adjusted. La inconsistencia dificulta el descubrimiento, el monitoreo automatizado y la governance. Solución: definir y validar la convención antes de crear el primer canal.
No Planificar la Evolución del Esquema¶
Crear un canal con un esquema v1 sin definir la estrategia de compatibilidad. Cuando llega v2 con un campo nuevo obligatorio, todos los consumidores existentes se rompen. Solución: definir compatibilidad BACKWARD desde el inicio y agregar campos nuevos como opcionales con defaults.
Confundir Datatype Channel con Topic-per-Consumer¶
Datatype Channel separa por tipo de dato, no por consumidor. Crear un canal cdr-for-billing y otro cdr-for-fraud con el mismo tipo de dato es incorrecto: duplica datos y acopla canales con consumidores. La separación correcta es por tipo (cdr.voice, cdr.data) con múltiples consumer groups por canal.
18. Conclusión Técnica¶
Datatype Channel es el patrón que introduce type safety a nivel de infraestructura de mensajería. Su principio es simple pero poderoso: cada canal transporta un solo tipo de mensaje, y el nombre del canal identifica ese tipo. Esta restricción elimina la lógica de dispatch en los consumidores, permite escalabilidad y monitoreo por tipo, y habilita evolución independiente de esquemas.
Cuándo aporta valor: siempre que existan múltiples tipos de mensaje con consumidores, volúmenes o ciclos de evolución diferentes. En la práctica, esto aplica a la mayoría de las arquitecturas event-driven con más de tres tipos de evento.
Cuándo evita problemas importantes: cuando la organización crece y el número de tipos de evento aumenta, canales no tipados se convierten en cuellos de botella que afectan a todos los consumidores. Datatype Channel previene este problema desde el diseño.
Cuándo no conviene adoptarlo: en prototipos tempranos con 2-3 tipos de mensaje y un solo consumidor que los procesa todos, la separación en canales tipados puede ser prematura. Pero la migración posterior de un canal genérico a canales tipados es costosa, por lo que la recomendación es adoptar el patrón desde el inicio si se anticipa crecimiento.
Recomendación para arquitectos: establezca la convención topic-per-event-type como estándar organizacional. Combine cada canal tipado con un esquema en Schema Registry y compatibilidad BACKWARD. Defina una naming convention clara ({domain}.{entity}.{event-type}) y valídela automáticamente. Monitoree cada canal independientemente. Trate los canales tipados como contratos de datos: documentados, versionados, con ownership definido y evolución gobernada. Un canal bien tipado es el fundamento de una arquitectura event-driven que puede escalar, evolucionar y operarse a escala enterprise.