Dead Letter Channel¶
1. Nombre del Patrón¶
- Nombre oficial: Dead Letter Channel
- Categoría: Messaging Channels (Canales de Mensajería)
- Traducción contextual: Canal de Mensajes No Entregables (Dead Letter Queue / DLQ)
2. Resumen Ejecutivo¶
Dead Letter Channel es el patrón que define un canal especial donde el sistema de mensajería deposita los mensajes que no pueden ser entregados o procesados después de agotar todos los intentos de entrega. A diferencia de Invalid Message Channel — donde el consumidor rechaza activamente un mensaje porque no puede comprenderlo — Dead Letter Channel recibe mensajes que el sistema de mensajería o el consumidor no pueden procesar después de múltiples reintentos, típicamente por errores transitorios que se vuelven permanentes, por excepciones no capturadas en el consumidor, o por timeout de procesamiento.
El problema que resuelve es existencial para cualquier sistema de mensajería en producción: ¿qué ocurre con un mensaje que no puede ser procesado después de N intentos? Sin Dead Letter Channel, las opciones son catastróficas: reintentar infinitamente (bloqueando el canal), descartar silenciosamente (perdiendo datos), o detener el consumidor (deteniendo todo el procesamiento). Dead Letter Channel proporciona una válvula de escape controlada: después de agotar los reintentos, el mensaje se mueve automáticamente a un canal separado donde puede ser diagnosticado y reprocesado cuando el problema subyacente se resuelva.
Toda plataforma de mensajería moderna implementa Dead Letter Channel como funcionalidad nativa: Dead Letter Queue (DLQ) en Amazon SQS, dead-letter sub-queue en Azure Service Bus, Dead Letter Exchange (DLX) en RabbitMQ, y Dead Letter Topic (DLT) en frameworks de Kafka como Spring Kafka. No es un patrón opcional — es una necesidad operacional de todo sistema de producción. Un sistema de mensajería sin DLQ es un sistema que eventualmente se bloqueará o perderá datos cuando un mensaje problemático aparezca.
3. Definición Detallada¶
Propósito¶
Dead Letter Channel establece un destino automático para mensajes que el sistema de mensajería no puede entregar exitosamente. Su propósito es triple: (1) evitar que un mensaje no procesable bloquee indefinidamente el procesamiento de otros mensajes, (2) preservar el mensaje no entregado para diagnóstico y reprocesamiento futuro, y (3) proporcionar una señal operacional clara de que existe un problema que requiere atención.
Lógica Arquitectónica¶
El patrón introduce un ciclo de vida extendido para los mensajes. En un flujo sin Dead Letter Channel, un mensaje tiene dos estados terminales: procesado exitosamente o perdido. Con Dead Letter Channel, aparece un tercer estado terminal intermedio: dead-lettered. Un mensaje dead-lettered no se ha perdido (está preservado) pero tampoco se ha procesado (requiere intervención).
El mecanismo funciona así:
- Un mensaje se entrega al consumidor.
- El consumidor falla al procesarlo (excepción, timeout, crash).
- El sistema de mensajería reintenta la entrega según la política configurada (N reintentos con backoff exponencial).
- Si tras N reintentos el mensaje sigue sin procesarse, el sistema lo mueve automáticamente al Dead Letter Channel.
- El procesamiento del canal principal continúa con el siguiente mensaje.
Esta automatización es lo que distingue Dead Letter Channel de Invalid Message Channel: el routing al Dead Letter Channel lo realiza la infraestructura de mensajería (basándose en conteo de reintentos), no la lógica de aplicación del consumidor.
Principio de Diseño Subyacente¶
El principio es fault tolerance con aislamiento de fallos: cuando un componente no puede procesar un dato después de un esfuerzo razonable, el dato se aísla en un contenedor especial para que no afecte al procesamiento de otros datos. Es el equivalente en messaging de un circuit breaker a nivel de mensaje individual.
Problema Estructural que Resuelve¶
En un sistema de mensajería sin Dead Letter Channel, un mensaje que causa un error en el consumidor produce uno de estos escenarios:
- Poison pill: el mensaje se reintenta infinitamente. Si el broker reentrega el mensaje al mismo consumidor (o a otro del grupo), y el error es determinista, el mensaje bloquea la partición o la cola indefinidamente. Todos los mensajes posteriores quedan atrapados detrás del poison pill.
- Cascading retries: reintentos masivos consumen recursos del broker, del consumidor y de la red, degradando el throughput general del sistema.
- Consumer instability: si el error causa un crash del consumidor, el reinicio y rebalanceo constante del consumer group desestabiliza a todos los consumidores del grupo.
- Silent loss: si el consumidor hace acknowledge del mensaje a pesar del error (para no bloquearse), el mensaje se pierde silenciosamente.
Dead Letter Channel resuelve todos estos escenarios proporcionando un destino automático que aísla el mensaje problemático y permite que el procesamiento normal continúe.
Contexto en el que Emerge¶
Dead Letter Channel emerge cuando un sistema de mensajería entra en producción y enfrenta la realidad de fallos intermitentes, dependencias no disponibles, bugs en consumidores y mensajes que exponen edge cases no previstos. En un entorno de desarrollo, los mensajes siempre se procesan correctamente. En producción, un porcentaje inevitable de mensajes fallará por razones que no se anticiparon.
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, Dead Letter Channel implementa el principio de bounded retry. En lugar de reintentar una operación indefinidamente (lo cual viola las propiedades de liveness del sistema), se define un límite de reintentos después del cual se declara el fallo y se toma una acción alternativa (mover al DLQ). Este principio es fundamental para evitar que fallos parciales se conviertan en fallos totales.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Dead Letter Channel, los mensajes que fallan repetidamente producen situaciones operacionales graves:
- Partición bloqueada (Kafka): si un consumidor no puede hacer commit del offset porque el procesamiento del mensaje falla, ese offset no avanza. Todos los mensajes posteriores en esa partición quedan bloqueados. Con 64 particiones, un poison pill en cada una puede bloquear completamente el procesamiento.
- Queue poisoning (RabbitMQ/SQS): el mensaje que falla se reencola y se vuelve a entregar, consumiendo un slot en la cola. Con backpressure, la cola crece hasta que se llena y los productores empiezan a ser rechazados.
- Consumer group instability (Kafka): un consumidor que falla repetidamente causa rebalanceos del consumer group. Cada rebalanceo detiene temporalmente el procesamiento de todos los consumidores del grupo, no solo del que falla.
- Resource exhaustion: reintentos con backoff exponencial que se acumulan consumen memoria (mensajes en retry buffer), threads (workers bloqueados esperando retry) y conexiones (al broker y a dependencias downstream).
Síntomas del Problema¶
- Consumer lag que crece monotónicamente a pesar de que los consumidores están activos (indica que los mensajes se reintentan pero nunca se completan).
- Alertas de "consumer restarting" en bucle (crash loop por poison pill).
- Throughput que cae drásticamente sin razón aparente de volumen (los reintentos consumen la capacidad).
- Procesos de negocio que "se detienen" sin error visible (los mensajes están atrapados en retry loops).
- Costos de infraestructura que crecen por el uso excesivo de recursos en reintentos.
Impacto Operativo y Arquitectónico¶
Sin Dead Letter Channel:
- Blast radius total: un mensaje problemático puede bloquear un canal completo, afectando a todos los flujos de negocio que dependen de ese canal.
- Intervención manual obligatoria: un operador debe intervenir para "saltar" el mensaje problemático. Esto no escala y no es sostenible en 24/7.
- Pérdida de confianza en el sistema: si los procesos de negocio se detienen periódicamente por mensajes envenenados, los stakeholders pierden confianza en la arquitectura de mensajería.
- Incumplimiento de SLAs: mensajes atrapados en retry loops pueden representar transacciones financieras, pedidos o solicitudes de servicio que no se procesan dentro del SLA.
Riesgos Si No Se Implementa Correctamente¶
- DLQ sin monitoreo: tener una DLQ pero no monitorearla es casi tan malo como no tenerla. Los mensajes se acumulan sin atención.
- Reintentos insuficientes: mover al DLQ después de 1 reintento envía mensajes que habrían tenido éxito con un segundo intento (error transitorio genuino).
- Reintentos excesivos: reintentar 100 veces antes de mover al DLQ mantiene al sistema degradado durante demasiado tiempo.
- DLQ sin capacidad de reprocesamiento: si no hay mecanismo para mover mensajes del DLQ de vuelta al canal principal, los mensajes quedan permanentemente atrapados.
Ejemplos Reales¶
- Financial Services: un sistema de procesamiento de pagos recibe una instrucción de pago que referencia una cuenta que está temporalmente bloqueada por una investigación de fraude. El procesamiento del pago falla porque el servicio de cuentas rechaza operaciones sobre cuentas bloqueadas. Después de 5 reintentos con backoff exponencial, el mensaje se mueve al DLQ. Cuando la investigación de fraude concluye y la cuenta se desbloquea, un operador reprocesa los mensajes del DLQ y los pagos se ejecutan exitosamente.
- E-commerce: un servicio de procesamiento de pedidos recibe un evento OrderCreated que requiere consultar el servicio de inventario para verificar disponibilidad. El servicio de inventario está desplegando una actualización (rolling update, 2 minutos de downtime). El mensaje falla 3 veces en 90 segundos. El DLQ captura el mensaje. Cuando el servicio de inventario completa el despliegue, los mensajes del DLQ se reprocesan automáticamente con un scheduled job que ejecuta cada 5 minutos.
- Telecomunicaciones: un mediador de CDRs envía registros a un sistema de rating que calcula el costo de cada llamada/sesión consultando un catálogo de tarifas. Un CDR referencia un plan tarifario que acaba de ser discontinuado y no existe en el catálogo actual. El rating falla con "tariff plan not found". Después de 3 reintentos, el CDR va al DLQ. Un analista de negocio identifica el plan discontinuado, lo reactiva temporalmente en el catálogo, y reprocesa los CDRs del DLQ.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En todo sistema de mensajería en producción. Sin excepción. Dead Letter Channel es un requisito operacional, no una optimización opcional.
- Cuando los consumidores dependen de servicios externos que pueden no estar disponibles temporalmente (microservicios, APIs de terceros, bases de datos).
- Cuando los mensajes representan datos de negocio valiosos que no pueden perderse (transacciones financieras, pedidos, resultados clínicos).
- Cuando el sistema opera en modo 24/7 y la intervención manual para resolver poison pills no es una opción viable.
Cuándo No Usarlo¶
- En sistemas de telemetría o logging donde la pérdida de mensajes individuales es aceptable y el volumen es tan alto que un DLQ se llenaría rápidamente. Incluso aquí, un DLQ con retención muy corta o con sampling puede ser útil para detectar problemas sistémicos.
- En canales de comunicación efímera (WebSocket messages, real-time notifications) donde un mensaje no entregado pierde su relevancia temporal. Sin embargo, incluso estos pueden beneficiarse de un DLQ para alertas operacionales.
Precondiciones¶
- Existe un canal principal donde el consumidor recibe mensajes.
- El sistema de mensajería soporta una política de reintentos configurable.
- Existe un mecanismo (nativo o custom) para mover mensajes al DLQ después de agotar reintentos.
- Existe un proceso operacional para monitorear y actuar sobre los mensajes en el DLQ.
Restricciones¶
- La política de reintentos (número de intentos, backoff) debe calibrarse para cada canal según la naturaleza de los errores esperados.
- El DLQ consume storage adicional. Su retención debe dimensionarse según el SLA de resolución.
- Los mensajes en el DLQ pueden volverse obsoletos (un pedido dead-lettered hace una semana puede no tener sentido reprocesarlo si el cliente ya canceló).
- El reprocesamiento desde el DLQ puede causar mensajes duplicados si no hay idempotencia.
Dependencias¶
- Canal principal donde el consumidor recibe mensajes.
- Dead Letter Channel configurado en el broker o implementado en el framework.
- Política de reintentos configurable.
- Mecanismo de reprocesamiento (manual o automatizado) para mover mensajes del DLQ al canal principal.
- Monitoreo del DLQ con alertas.
Supuestos Arquitectónicos¶
- Los errores de procesamiento pueden ser transitorios (se resolverán con reintentos) o permanentes (nunca se resolverán con reintentos). El DLQ captura los permanentes después de que los reintentos fallen.
- Los mensajes en el DLQ tienen valor y merecen investigación. Si no tienen valor, la estrategia debería ser discard con logging, no DLQ.
- Existe un equipo o proceso responsable de los mensajes en el DLQ.
6. Fuerzas Arquitectónicas¶
Resiliencia vs. Latencia¶
Dead Letter Channel maximiza la resiliencia del sistema: ningún mensaje problemático bloquea el procesamiento. Pero los reintentos previos al DLQ añaden latencia al procesamiento del mensaje individual. La configuración del backoff (cuánto tiempo entre reintentos) determina cuánta latencia agrega antes de mover al DLQ.
Preservación de Datos vs. Costo¶
Preservar todos los mensajes fallidos en el DLQ asegura zero data loss para mensajes no procesados. Pero el storage del DLQ tiene costo. En sistemas de alto throughput con tasas de error significativas, el DLQ puede crecer rápidamente. La retención del DLQ debe equilibrar la necesidad de reprocesamiento con el costo de storage.
Automatización vs. Control Humano¶
Un DLQ con reprocesamiento automatizado (scheduled job que reintenta cada N minutos) minimiza la intervención humana pero puede reintentar mensajes que necesitan corrección manual (produciendo más fallos y movimientos circulares entre canal principal y DLQ). Un DLQ con reprocesamiento manual da máximo control pero no escala. El equilibrio es automatización con supervisión: reprocesamiento automático para categorías de error conocidas, alertas para categorías desconocidas.
Reintentos vs. Dead-lettering Temprano¶
Más reintentos antes del DLQ = mayor probabilidad de que un error transitorio se resuelva sin intervención. Pero más reintentos = más tiempo con el mensaje bloqueando recursos antes de admitir que es un caso permanente. La calibración del retry count es crítica: muy pocos reintentos desperdician oportunidades de auto-recuperación; demasiados reintentos desperdician recursos y retrasan el diagnóstico.
Orden vs. Throughput¶
En sistemas con orden garantizado (Kafka partitions, SQS FIFO), mover un mensaje al DLQ rompe el orden. Los mensajes posteriores se procesan antes que el mensaje dead-lettered. Si el orden es crítico (transacciones financieras en secuencia), esta ruptura de orden puede ser inaceptable. La alternativa es pausar el procesamiento de esa partición hasta resolver el mensaje, pero esto reintroduce el bloqueo que el DLQ pretende evitar.
Simplicidad vs. Observabilidad¶
Un DLQ básico (simple queue/topic sin metadata adicional) es fácil de configurar pero difícil de diagnosticar: ¿por qué falló este mensaje? ¿Cuántas veces se reintentó? ¿Cuál fue el error? Un DLQ con metadata enriquecida (razón del fallo, stack trace, número de reintentos, timestamps) es más complejo de implementar pero proporciona diagnóstico inmediato.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: envía mensajes al canal principal (no está involucrado en el DLQ).
- Canal Principal: canal donde el consumidor recibe mensajes para procesar.
- Consumidor: intenta procesar el mensaje y falla.
- Retry Mechanism: mecanismo que reintenta la entrega/procesamiento según la política configurada (puede ser del broker o del framework).
- Dead Letter Channel: canal que recibe mensajes después de agotar los reintentos.
- DLQ Monitor: sistema que monitorea el DLQ y genera alertas.
- Operador / Reprocessing System: persona o sistema que diagnostica y reprocesa mensajes del DLQ.
Flujo Lógico¶
flowchart TD
A([Productor]) -->|Envía mensaje| B[(Canal Principal)]
B --> C[Broker: Entrega al consumidor]
C --> D[Consumidor: Intenta procesar]
D --> E{Resultado}
E -->|Éxito| F[Procesamiento completado]
E -->|Fallo| G{Intentos < max_retries?}
G -->|Sí| H[Espera con backoff] --> C
G -->|No| I[Mueve a Dead Letter Channel<br>con metadata de fallo]
I --> J[(Dead Letter Queue)]
I --> K[Broker: Confirma en canal principal]
K --> L[Canal principal continúa con siguiente mensaje]
J --> M[DLQ Monitor: Genera alerta]
M --> N[Operador: Diagnostica causa raíz]
N --> O{Causa resuelta}
O -->|Reenvía al canal| B
O -->|Procesa desde DLQ| P[Procesamiento directo]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Canal Principal | Transportar mensajes hacia el consumidor |
| Consumidor | Intentar procesar el mensaje, reportar fallo si no puede |
| Retry Mechanism | Gestionar política de reintentos (count, backoff, max retries) |
| Dead Letter Channel | Almacenar mensajes que agotaron reintentos, con metadata de diagnóstico |
| DLQ Monitor | Monitorear volumen y antigüedad de mensajes en DLQ, alertar |
| Operador/System | Diagnosticar causa raíz, resolver problema, reprocesar mensajes |
Interacciones¶
- Canal Principal → Consumidor: entrega normal del mensaje.
- Consumidor → Retry Mechanism: señalización de fallo (excepción, nack, visibility timeout).
- Retry Mechanism → Canal Principal: re-entrega del mensaje para reintento.
- Retry Mechanism → Dead Letter Channel: movimiento del mensaje tras agotar reintentos.
- DLQ Monitor → Alerting: generación de alertas por nuevos mensajes en DLQ.
- Operador → Dead Letter Channel → Canal Principal: reprocesamiento de mensajes resueltos.
Decisiones de Diseño Clave¶
- Política de reintentos: ¿cuántos reintentos? ¿Con qué backoff? ¿Exponencial, lineal, fijo? ¿Con jitter para evitar thundering herd?
- Granularidad del DLQ: ¿un DLQ por canal principal? ¿Un DLQ compartido para toda la aplicación? ¿Un DLQ por tipo de error?
- Metadata en el DLQ: ¿qué información adicional se incluye? (razón, reintentos, timestamps, stack trace, consumer ID).
- Estrategia de reprocesamiento: ¿manual? ¿Automático con schedule? ¿Automático con condición (cuando la dependencia vuelve)?
- Retención del DLQ: ¿cuánto tiempo se retienen los mensajes? ¿Se archivan después de la retención?
- Idempotencia en reprocesamiento: ¿el consumidor es idempotente para manejar el reprocesamiento sin efectos secundarios duplicados?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Financial Services — Procesamiento de Pagos¶
Contexto del Negocio¶
Un banco digital procesa 2 millones de transacciones de pago diarias a través de su plataforma de pagos. Las transacciones incluyen transferencias entre cuentas, pagos de servicios, pagos a comercios (QR), transferencias internacionales y débitos automáticos. El procesamiento de cada pago involucra múltiples pasos:
- Validación: verificar que la cuenta origen tiene fondos suficientes.
- Compliance: verificar que el pago no viola reglas anti-lavado (AML) ni sanciones.
- Ejecución: debitar la cuenta origen y acreditar la cuenta destino.
- Notificación: notificar al pagador y al beneficiario.
- Registro: registrar la transacción para reporting regulatorio.
Necesidad de Integración¶
Cada paso del procesamiento puede fallar por razones diferentes:
- Servicio de fondos no disponible: degradación temporal del core bancario durante ventanas de batch nocturno.
- Servicio de compliance con latencia alta: el motor de reglas AML tiene picos de latencia que exceden el timeout configurado.
- Error de ejecución: la cuenta destino fue cerrada entre el momento de validación y el momento de ejecución (race condition).
- Fallo de notificación: el servicio de push notifications está temporalmente down.
- Error inesperado: un edge case en el parser de IBAN para un formato de país no probado.
Sistemas Involucrados¶
- Payment Gateway: recibe solicitudes de pago y produce eventos de transacción.
- Kafka Cluster: plataforma de messaging para el flujo de pagos.
- Payment Processor: servicio que ejecuta los pasos de procesamiento del pago.
- Core Banking System: sistema central que gestiona cuentas y saldos.
- AML Engine: motor de reglas de anti-lavado.
- Notification Service: servicio de notificaciones push/email/SMS.
- Dead Letter Topic: canal que recibe pagos que no pudieron procesarse.
- DLQ Dashboard: interfaz para monitorear y reprocesar pagos dead-lettered.
Diseño de Canales¶
| Canal (Kafka Topic) | Propósito | Retención | Política de Reintentos |
|---|---|---|---|
payments.transactions.pending | Pagos pendientes de procesamiento | 7 días | N/A (canal principal) |
payments.transactions.completed | Pagos procesados exitosamente | 90 días | N/A |
payments.transactions.failed | Pagos que fallaron definitivamente (negocio) | 365 días | N/A |
payments.transactions.pending.dlt | Dead Letter Topic para pagos | 30 días | Después de 5 reintentos |
Decisiones Arquitectónicas¶
-
Política de reintentos con backoff exponencial y jitter: 5 reintentos con backoff exponencial (1s, 2s, 4s, 8s, 16s) más jitter aleatorio de hasta 1s. Total: un mensaje se reintenta durante ~31 segundos antes de ir al DLT. Este tiempo es suficiente para errores transitorios (deployment rolling, spike de latencia) sin ser excesivo.
-
DLT con naming convention
.dlt: el Dead Letter Topic se nombra como el topic original más el sufijo.dlt. Esto facilita la correlación entre el canal principal y su DLT. -
Metadata de error enriquecida: cada mensaje en el DLT incluye headers con la excepción original, el número de reintentos, el timestamp del primer intento, el timestamp del último intento, y el consumer instance ID.
-
Distinción entre failed y dead-lettered: un pago que falla por razones de negocio (fondos insuficientes confirmados) va al canal
payments.transactions.faileddirectamente — no al DLT. El DLT solo recibe mensajes que fallan por razones técnicas (servicio no disponible, timeout, error inesperado). -
Reprocesamiento semi-automático: un job programado cada 15 minutos consulta el DLT, verifica si las dependencias que causaron el fallo están disponibles (health check al core banking, AML engine), y si lo están, mueve los mensajes de vuelta al canal principal.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pago atrapado en DLT por horas | Alerta si mensaje en DLT > 30 minutos, escalación si > 2 horas |
| Reprocesamiento duplica el pago | Consumer es idempotente: verifica payment_id antes de ejecutar |
| DLT se llena durante outage prolongado de core banking | Alerta de volumen en DLT, escalación a infraestructura |
| Mensaje en DLT se vuelve obsoleto (pago cancelado por el usuario) | Job de reconciliación diario verifica estado del pago antes de reprocesar |
| Orden de pagos se rompe por DLT | Pagos que requieren orden (débitos automáticos secuenciales) usan partition key por cuenta |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción del Mensaje de Pago¶
Un cliente del banco digital inicia una transferencia de EUR 1,500 desde su cuenta (IBAN: ES76 2100 0813 6101 2345 6789) a un proveedor (IBAN: DE89 3704 0044 0532 0130 00). El Payment Gateway genera un evento:
{
"payment_id": "PAY-2026-04-07-1847291",
"type": "TRANSFER_INTERNATIONAL",
"amount": 1500.00,
"currency": "EUR",
"source_iban": "ES7621000813610123456789",
"destination_iban": "DE89370400440532013000",
"initiated_by": "CUSTOMER",
"initiated_at": "2026-04-07T14:32:15Z",
"reference": "Pago factura #INV-2026-392"
}
El Payment Gateway produce este evento en payments.transactions.pending.
Paso 2: Primer Intento de Procesamiento¶
El Payment Processor (consumer group: cg-payment-processor) consume el mensaje:
- Validación de fondos: llama al Core Banking System para verificar saldo. El Core Banking System está ejecutando su batch de cierre de mes y responde con HTTP 503 (Service Unavailable).
- El Payment Processor captura la excepción
ServiceUnavailableException. - El retry mechanism registra: intento 1 de 5, error transitorio, próximo reintento en 1s.
Paso 3: Reintentos con Backoff¶
El retry mechanism ejecuta reintentos:
- Intento 2 (t + 1.3s): Core Banking todavía en batch. HTTP 503. Próximo reintento en 2s.
- Intento 3 (t + 3.7s): Core Banking todavía en batch. HTTP 503. Próximo reintento en 4s.
- Intento 4 (t + 8.1s): Core Banking todavía en batch. HTTP 503. Próximo reintento en 8s.
- Intento 5 (t + 16.9s): Core Banking todavía en batch. HTTP 503.
5 intentos agotados. Total de tiempo en reintentos: ~17 segundos. El error persiste.
Paso 4: Movimiento al Dead Letter Topic¶
El retry mechanism ejecuta la acción de dead-lettering:
- Produce el mensaje original en
payments.transactions.pending.dltcon headers adicionales:
kafka_dlt-exception-fqcn: org.springframework.web.client.HttpServerErrorException$ServiceUnavailable
kafka_dlt-exception-message: 503 Service Unavailable from Core Banking (batch window)
kafka_dlt-original-topic: payments.transactions.pending
kafka_dlt-original-partition: 42
kafka_dlt-original-offset: 8291847
kafka_dlt-original-timestamp: 1744036335000
kafka_dlt-retry-count: 5
kafka_dlt-first-failure-at: 2026-04-07T14:32:16Z
kafka_dlt-last-failure-at: 2026-04-07T14:32:33Z
- Confirma el offset del mensaje en el canal principal (
payments.transactions.pending). - El procesamiento del canal principal continúa con el siguiente mensaje.
Paso 5: Alerta Operacional¶
El DLQ Monitor consume de payments.transactions.pending.dlt:
- Detecta un nuevo mensaje de pago dead-lettered.
- Clasifica la severidad como HIGH (transacción financiera internacional).
- Genera alerta en el DLQ Dashboard y en Slack (#payments-ops).
- El SLA de resolución para pagos internacionales dead-lettered es 30 minutos.
Paso 6: Diagnóstico¶
El equipo de operaciones de pagos ve la alerta:
- Consulta el DLQ Dashboard: ve que hay 847 mensajes de pago en el DLT, todos con el mismo error:
503 Service Unavailable from Core Banking. - Consulta el health check del Core Banking System: estado "Batch Processing - Expected completion 15:00 UTC".
- Diagnóstico: el Core Banking está en su ventana de batch de cierre de mes (programada, esperada). Completará a las 15:00 UTC.
Paso 7: Reprocesamiento Automático¶
A las 15:02 UTC, el Core Banking System completa el batch y vuelve a estado "Available".
El job de reprocesamiento programado (ejecuta cada 15 minutos):
- Detecta mensajes en el DLT.
- Ejecuta health check al Core Banking: estado "Available".
- Inicia reprocesamiento: mueve mensajes del DLT de vuelta a
payments.transactions.pendingen batches de 100. - Los 847 pagos se reprocesan exitosamente en ~12 minutos.
- El DLT queda vacío.
- El DLQ Dashboard muestra: "847 messages reprocessed successfully".
Paso 8: Post-mortem y Mejora¶
El equipo de pagos revisa el incidente:
- La ventana de batch del Core Banking System es mensual y dura ~30 minutos.
- Durante esta ventana, el sistema de pagos no puede validar fondos.
- Mejora: implementar un circuit breaker que detecte cuando el Core Banking está en batch y pause el consumo del canal de pagos (en lugar de reintentar 5 veces por mensaje y saturar el DLT con cientos de mensajes que todos fallan por la misma razón).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
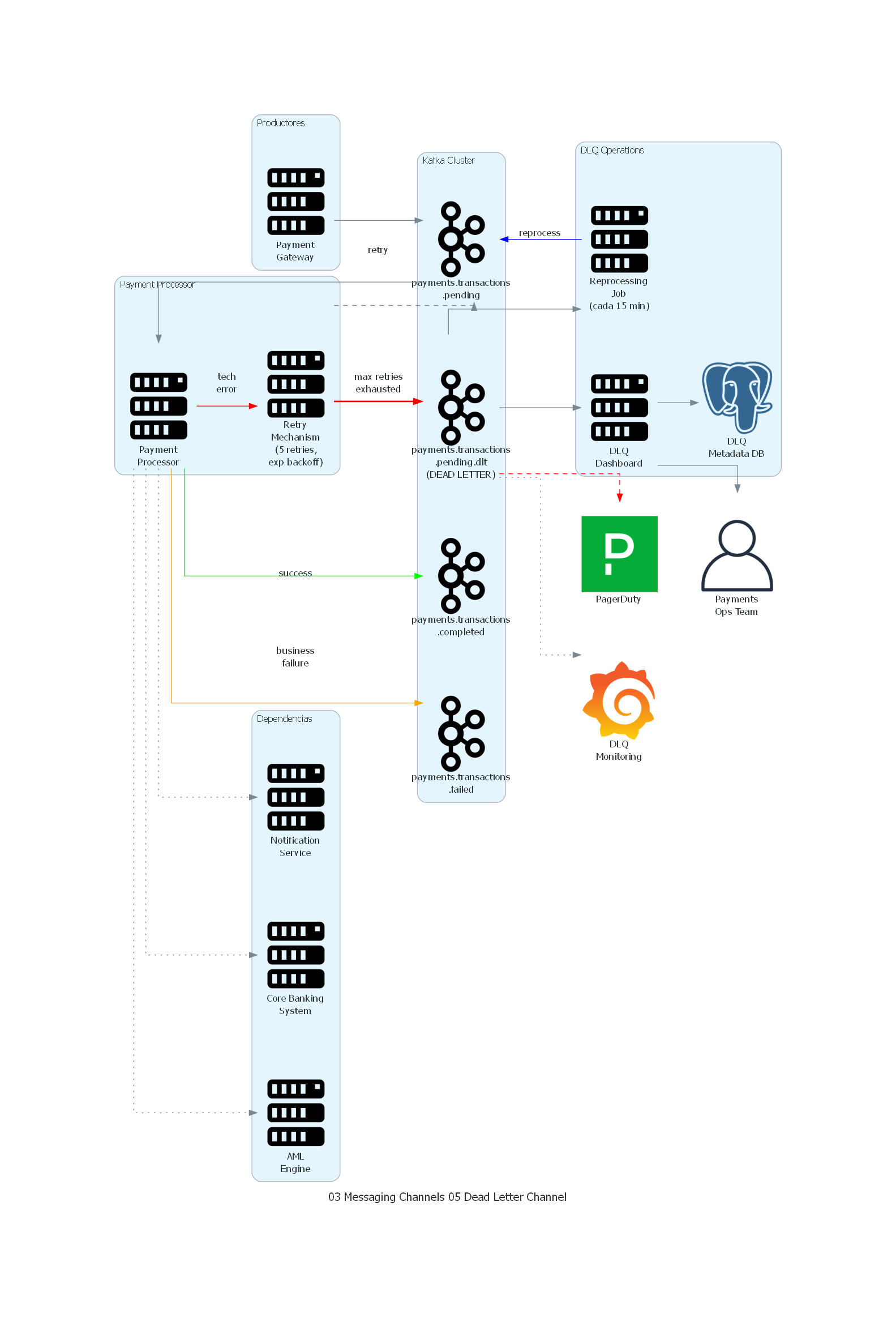
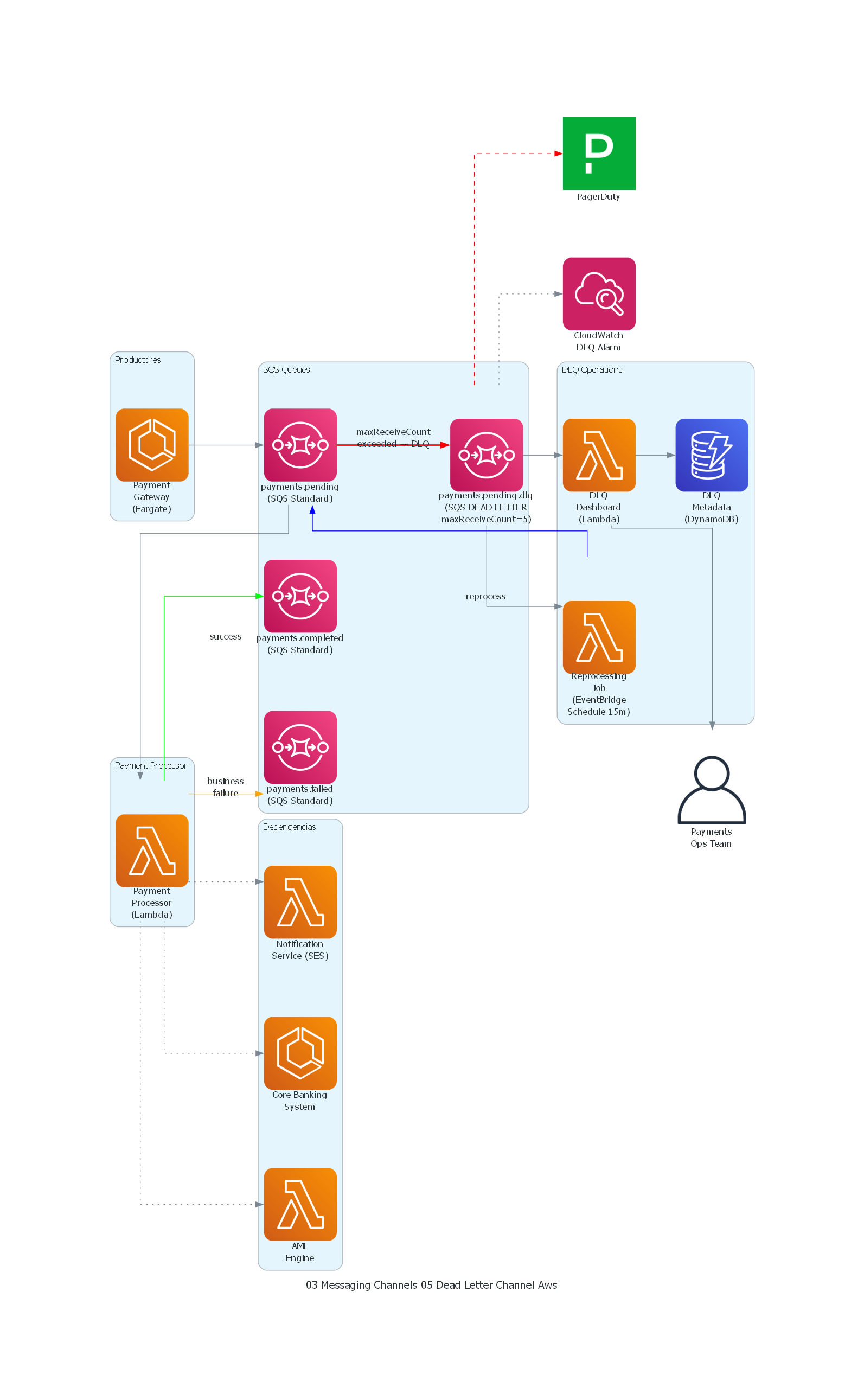
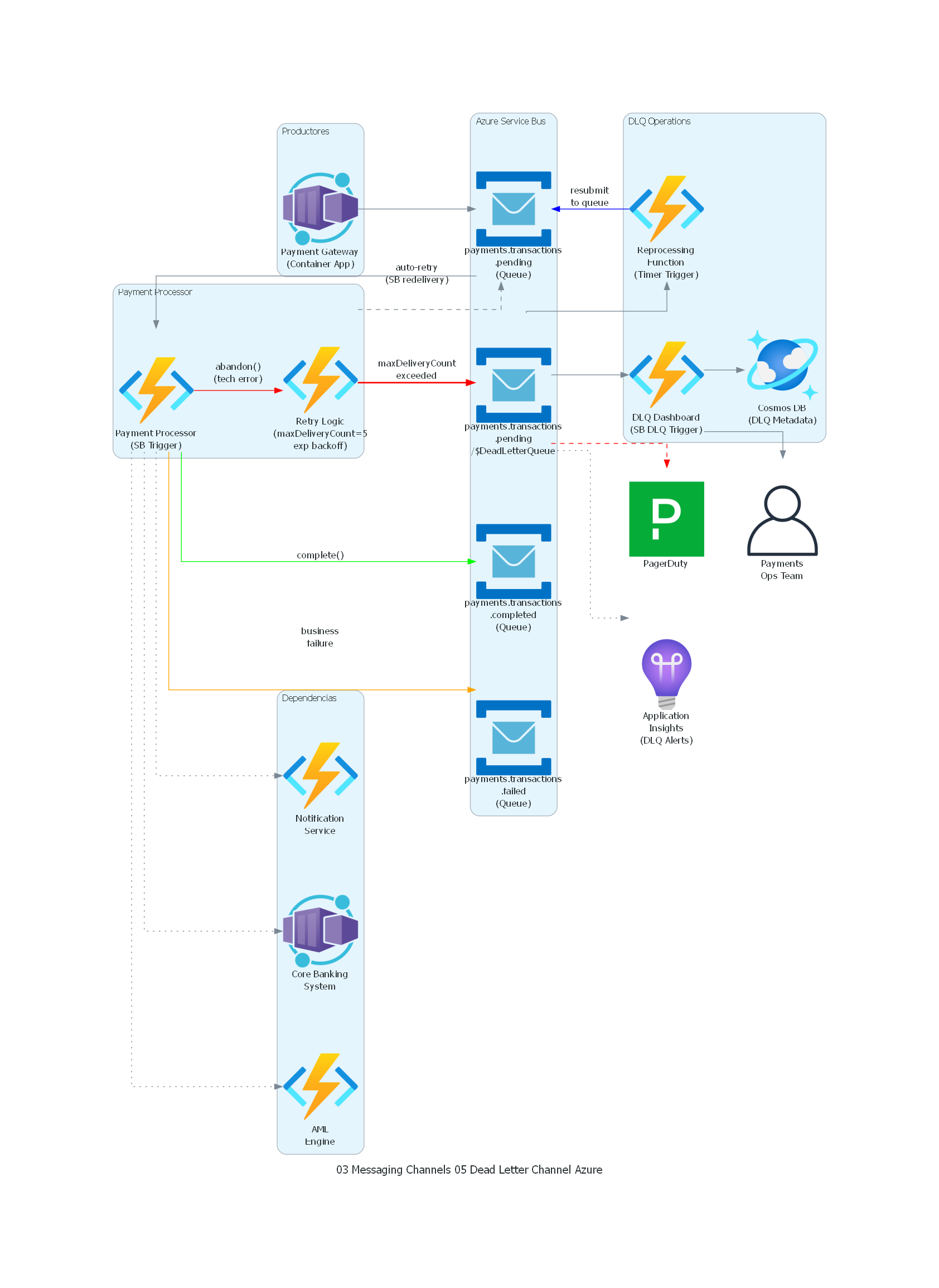
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.onprem.client import User
from diagrams.saas.alerting import Pagerduty
with Diagram("Dead Letter Channel - Payment Processing", show=False, direction="LR"):
with Cluster("Productores"):
gateway = Server("Payment\nGateway")
with Cluster("Kafka Cluster"):
pending = Kafka("payments.transactions\n.pending")
completed = Kafka("payments.transactions\n.completed")
failed = Kafka("payments.transactions\n.failed")
dlt = Kafka("payments.transactions\n.pending.dlt\n(DEAD LETTER)")
with Cluster("Payment Processor"):
processor = Server("Payment\nProcessor")
retry = Server("Retry\nMechanism\n(5 retries,\nexp backoff)")
with Cluster("Dependencias"):
core = Server("Core Banking\nSystem")
aml = Server("AML\nEngine")
notif = Server("Notification\nService")
with Cluster("DLQ Operations"):
dlq_dash = Server("DLQ\nDashboard")
reprocess = Server("Reprocessing\nJob\n(cada 15 min)")
dlq_db = PostgreSQL("DLQ\nMetadata DB")
operator = User("Payments\nOps Team")
pager = Pagerduty("PagerDuty")
monitoring = Grafana("DLQ\nMonitoring")
# Flujo principal
gateway >> pending
pending >> processor
# Procesamiento exitoso
processor >> Edge(color="green", label="success") >> completed
# Fallo de negocio (no DLQ)
processor >> Edge(color="orange", label="business\nfailure") >> failed
# Reintentos y DLQ
processor >> Edge(color="red", label="tech\nerror") >> retry
retry >> Edge(style="dashed", label="retry") >> pending
retry >> Edge(color="red", style="bold", label="max retries\nexhausted") >> dlt
# Dependencias
processor >> Edge(style="dotted") >> core
processor >> Edge(style="dotted") >> aml
processor >> Edge(style="dotted") >> notif
# DLQ Operations
dlt >> dlq_dash >> dlq_db
dlt >> Edge(style="dashed", color="red") >> pager
dlq_dash >> operator
dlt >> reprocess >> Edge(color="blue", label="reprocess") >> pending
dlt >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.saas.alerting import Pagerduty
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS
from diagrams.aws.management import Cloudwatch
with Diagram("Dead Letter Channel - Payment Processing (AWS)", show=False, direction="LR"):
with Cluster("Productores"):
gateway = ECS("Payment\nGateway\n(Fargate)")
with Cluster("SQS Queues"):
pending = SQS("payments.pending\n(SQS Standard)")
completed = SQS("payments.completed\n(SQS Standard)")
failed = SQS("payments.failed\n(SQS Standard)")
dlt = SQS("payments.pending.dlq\n(SQS DEAD LETTER\nmaxReceiveCount=5)")
with Cluster("Payment Processor"):
processor = Lambda("Payment\nProcessor\n(Lambda)")
with Cluster("Dependencias"):
core = ECS("Core Banking\nSystem")
aml = Lambda("AML\nEngine")
notif = Lambda("Notification\nService (SES)")
with Cluster("DLQ Operations"):
dlq_dash = Lambda("DLQ\nDashboard\n(Lambda)")
reprocess = Lambda("Reprocessing\nJob\n(EventBridge\nSchedule 15m)")
dlq_db = Dynamodb("DLQ\nMetadata\n(DynamoDB)")
operator = User("Payments\nOps Team")
pager = Pagerduty("PagerDuty")
monitoring = Cloudwatch("CloudWatch\nDLQ Alarm")
# Flujo principal
gateway >> pending
pending >> processor
# Procesamiento exitoso
processor >> Edge(color="green", label="success") >> completed
# Fallo de negocio (no DLQ)
processor >> Edge(color="orange", label="business\nfailure") >> failed
# SQS DLQ (automatic after maxReceiveCount)
pending >> Edge(color="red", style="bold", label="maxReceiveCount\nexceeded → DLQ") >> dlt
# Dependencias
processor >> Edge(style="dotted") >> core
processor >> Edge(style="dotted") >> aml
processor >> Edge(style="dotted") >> notif
# DLQ Operations
dlt >> dlq_dash >> dlq_db
dlt >> Edge(style="dashed", color="red") >> pager
dlq_dash >> operator
dlt >> reprocess >> Edge(color="blue", label="reprocess") >> pending
dlt >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.saas.alerting import Pagerduty
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Dead Letter Channel - Payment Processing (Azure)", show=False, direction="LR"):
with Cluster("Productores"):
gateway = ContainerApps("Payment Gateway\n(Container App)")
with Cluster("Azure Service Bus"):
pending = ServiceBus("payments.transactions\n.pending\n(Queue)")
completed = ServiceBus("payments.transactions\n.completed\n(Queue)")
failed = ServiceBus("payments.transactions\n.failed\n(Queue)")
dlt = ServiceBus("payments.transactions\n.pending\n/$DeadLetterQueue")
with Cluster("Payment Processor"):
processor = FunctionApps("Payment Processor\n(SB Trigger)")
retry = FunctionApps("Retry Logic\n(maxDeliveryCount=5\nexp backoff)")
with Cluster("Dependencias"):
core = ContainerApps("Core Banking\nSystem")
aml = FunctionApps("AML\nEngine")
notif = FunctionApps("Notification\nService")
with Cluster("DLQ Operations"):
dlq_dash = FunctionApps("DLQ Dashboard\n(SB DLQ Trigger)")
reprocess = FunctionApps("Reprocessing\nFunction\n(Timer Trigger)")
dlq_db = CosmosDb("Cosmos DB\n(DLQ Metadata)")
operator = User("Payments\nOps Team")
pager = Pagerduty("PagerDuty")
monitoring = ApplicationInsights("Application\nInsights\n(DLQ Alerts)")
# Flujo principal
gateway >> pending
pending >> processor
# Procesamiento exitoso
processor >> Edge(color="green", label="complete()") >> completed
# Fallo de negocio (no DLQ)
processor >> Edge(color="orange", label="business\nfailure") >> failed
# Reintentos y DLQ (Service Bus built-in)
processor >> Edge(color="red", label="abandon()\n(tech error)") >> retry
retry >> Edge(style="dashed", label="auto-retry\n(SB redelivery)") >> pending
retry >> Edge(color="red", style="bold", label="maxDeliveryCount\nexceeded") >> dlt
# Dependencias
processor >> Edge(style="dotted") >> core
processor >> Edge(style="dotted") >> aml
processor >> Edge(style="dotted") >> notif
# DLQ Operations
dlt >> dlq_dash >> dlq_db
dlt >> Edge(style="dashed", color="red") >> pager
dlq_dash >> operator
dlt >> reprocess >> Edge(color="blue", label="resubmit\nto queue") >> pending
dlt >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de Dead Letter Channel para el procesamiento de pagos:
- El Payment Gateway produce eventos de pago en el canal
payments.transactions.pending. - El Payment Processor consume del canal principal e intenta procesar cada pago consultando Core Banking, AML Engine y Notification Service.
- Si el procesamiento tiene éxito, el pago va al canal
payments.transactions.completed(verde). - Si el procesamiento falla por razón de negocio (fondos insuficientes confirmados), el pago va a
payments.transactions.failed(naranja) — no al DLQ. - Si el procesamiento falla por error técnico, el Retry Mechanism reintenta hasta 5 veces con backoff exponencial (rojo).
- Si los 5 reintentos se agotan, el mensaje se mueve al Dead Letter Topic (rojo bold).
- El DLQ Dashboard consume del DLT, almacena metadata y alerta al equipo de operaciones vía PagerDuty.
- El Reprocessing Job (ejecuta cada 15 minutos) verifica el estado de las dependencias y reprocesa mensajes del DLT de vuelta al canal principal (azul).
- Grafana monitorea el volumen y antigüedad de mensajes en el DLT.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Canal Principal | payments.transactions.pending |
| Consumidor que falla | Payment Processor |
| Retry Mechanism | Retry Mechanism (5 retries, exp backoff) |
| Dead Letter Channel | payments.transactions.pending.dlt |
| Metadata de error | Headers en DLT (exception, retry count, timestamps) |
| Monitoreo del DLQ | Grafana + PagerDuty |
| Reprocesamiento | Reprocessing Job → canal principal |
| Diagnóstico humano | DLQ Dashboard → Payments Ops Team |
11. Beneficios¶
Impacto Técnico¶
- Eliminación de poison pills: un mensaje que causa errores repetidos nunca bloquea el canal principal. Después de N reintentos, se aísla automáticamente en el DLQ y el procesamiento continúa.
- Resiliencia ante fallos transitorios: la combinación de reintentos + DLQ maneja automáticamente el espectro completo de fallos: los transitorios se resuelven con reintentos; los permanentes se aíslan en el DLQ.
- Preservación de datos: ningún mensaje se pierde. Los mensajes que no se pudieron procesar están preservados en el DLQ con toda su metadata para reprocesamiento futuro.
- Recuperación automatizable: el reprocesamiento desde el DLQ puede automatizarse con jobs que detectan cuando la causa del fallo se resuelve.
Impacto Organizacional¶
- Operaciones predecibles: el equipo de operaciones tiene un procedimiento claro para fallos de procesamiento: revisar DLQ, diagnosticar, resolver causa raíz, reprocesar. No hay incertidumbre sobre "dónde están los mensajes perdidos".
- SLAs definibles: con el DLQ como punto de observación, se pueden definir SLAs de resolución: "un mensaje en el DLQ de pagos debe resolverse en 30 minutos".
- Métricas de confiabilidad: la tasa de dead-lettering (mensajes al DLQ / mensajes totales) es un KPI de confiabilidad del sistema. Una tasa decreciente indica mejora continua.
Impacto Operacional¶
- Alertas tempranas: la aparición de mensajes en el DLQ señala problemas antes de que el impacto de negocio sea visible. Un pico de dead-lettering indica degradación de una dependencia.
- Diagnóstico contextualizado: la metadata en el DLQ (excepción, reintentos, timestamps) proporciona contexto inmediato para el diagnóstico, sin necesidad de buscar en logs.
- Capacidad de reprocesamiento: cuando la causa se resuelve (dependencia restaurada, bug corregido), los mensajes del DLQ se reprocesan sin pérdida de datos.
Beneficios de Mantenibilidad y Evolución¶
- Testing de resiliencia: el DLQ permite probar escenarios de fallo de forma controlada: simular la caída de una dependencia, verificar que los mensajes van al DLQ, restaurar la dependencia, verificar que el reprocesamiento funciona.
- Evolución de consumidores: cuando se despliega una nueva versión del consumidor con un bug, los mensajes que fallan van al DLQ. El rollback del consumidor + reprocesamiento del DLQ restaura el sistema sin pérdida de datos.
- Capacidad de análisis: los patrones de errores en el DLQ revelan debilidades de la arquitectura que pueden corregirse proactivamente.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Configuración de retry policy: determinar el número óptimo de reintentos, el tipo de backoff y el jitter requiere análisis y tuning por canal.
- Mecanismo de reprocesamiento: implementar un sistema de reprocesamiento desde el DLQ que sea correcto (idempotente, ordenado si es necesario, con rate limiting) no es trivial.
- Infraestructura adicional: el DLQ, el dashboard, el monitoring, el job de reprocesamiento y las alertas son componentes adicionales que desarrollar y mantener.
Riesgos de Mal Uso¶
- DLQ como alfombra: enviar mensajes al DLQ y olvidarse de ellos. El DLQ se llena de mensajes que nadie revisa, proporcionando una falsa sensación de manejo de errores. Es el anti-pattern más peligroso y más común.
- Reintentos insuficientes: configurar max_retries = 1 envía al DLQ mensajes que se habrían resuelto con un segundo intento. El resultado es un DLQ artificialmente grande y reprocesamiento innecesario.
- Reprocesamiento sin verificación: mover mensajes del DLQ al canal principal automáticamente sin verificar que la causa raíz se resolvió produce un ciclo de ping-pong entre canal principal y DLQ.
- No distinguir errores transitorios de permanentes: reintentar 5 veces un mensaje con formato corrupto (error permanente) desperdicia recursos. Estos deberían ir al Invalid Message Channel directamente, no al DLQ.
Sobreingeniería¶
- DLQ por cada tipo de error: crear un DLQ separado para cada tipo de excepción (timeout DLQ, connection error DLQ, parsing error DLQ) produce proliferación de canales sin beneficio proporcional. Un DLQ por canal principal con metadata del tipo de error es suficiente en la mayoría de casos.
- Reprocesamiento complejo: sistemas de reprocesamiento con reglas condicionales complejas (reprocesar si es martes, si el error fue timeout, si la dependencia X está healthy, si han pasado más de 10 minutos) añaden fragilidad.
Costos de Operación¶
- Storage del DLQ: en un outage prolongado de una dependencia, el DLQ puede acumular miles o millones de mensajes.
- Costo de reprocesamiento: reprocesar un DLQ grande genera un spike de carga en el canal principal y en las dependencias.
- Tiempo de operador: diagnosticar causas raíz de mensajes dead-lettered consume tiempo del equipo de operaciones.
Anti-Patterns Relacionados¶
- Infinite Retry: no tener DLQ y reintentar indefinidamente. El sistema nunca se recupera de un mensaje problemático.
- Silent Discard: descartar mensajes que fallan sin registro ni DLQ. Datos perdidos sin posibilidad de recuperación.
- DLQ Ping-Pong: reprocesar automáticamente desde el DLQ sin resolver la causa raíz. Los mensajes viajan entre canal principal y DLQ indefinidamente.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Invalid Message Channel (Capítulo 3): patrón complementario para mensajes que el consumidor rechaza por contenido inválido. Invalid Message Channel maneja errores de contenido; Dead Letter Channel maneja errores de procesamiento/entrega.
- Guaranteed Delivery (Capítulo 3): Dead Letter Channel complementa Guaranteed Delivery. Guaranteed Delivery asegura que el mensaje llega al canal; Dead Letter Channel asegura que si no puede procesarse, se preserva.
- Message Channel (Capítulo 2): Dead Letter Channel es un Message Channel con un propósito especial (recibir mensajes no procesados).
Distinción Crítica: Dead Letter Channel vs. Invalid Message Channel¶
| Aspecto | Dead Letter Channel | Invalid Message Channel |
|---|---|---|
| Causa | Error de procesamiento o entrega | Contenido del mensaje inválido |
| Quién decide | Infraestructura/broker después de N reintentos | Consumidor activamente en lógica de validación |
| Error determinista? | Puede ser transitorio o permanente | Siempre determinista (contenido no cambia) |
| Reintentos previos | Sí, N reintentos antes del DLQ | No, rechazo inmediato sin reintentos |
| Acción correctiva | Resolver dependencia/bug, reprocesar | Corregir contenido del mensaje o el productor |
| Ejemplo | Core Banking unavailable → 5 retries → DLQ | HL7 con campo obligatorio vacío → invalid channel |
Patrones que Suelen Aparecer Antes o Después¶
- Antes: la configuración de reintentos (retry policy) precede al DLQ. Sin reintentos, todo iría directamente al DLQ.
- Después: Reprocessing/Replay patterns: mecanismos para mover mensajes del DLQ de vuelta al canal principal.
- Asociado: Wire Tap puede copiar mensajes del DLQ a un sistema de analytics para análisis de patrones de fallos.
Combinaciones Comunes¶
- Dead Letter Channel + Invalid Message Channel: el consumidor primero valida el mensaje (si inválido → Invalid Message Channel). Si el mensaje es válido pero el procesamiento falla → reintentos → Dead Letter Channel. Dos canales de error, dos causas diferentes, dos procesos de resolución.
- Dead Letter Channel + Circuit Breaker: un circuit breaker detecta que una dependencia está down y abre el circuito, evitando enviar mensajes al DLQ masivamente. Cuando el circuito se cierra, el procesamiento se reanuda. Esto reduce el volumen del DLQ durante outages de dependencias.
- Dead Letter Channel + Competing Consumers: múltiples instancias del consumidor comparten un DLQ. El reprocessing job debe coordinar para no reprocesar el mismo mensaje desde múltiples instancias.
Encaje en un Flujo Mayor de Integración¶
Dead Letter Channel es un componente obligatorio de toda arquitectura de mensajería en producción. Junto con Invalid Message Channel, forma la estrategia completa de error handling. Todo canal principal debe tener un DLQ asociado, con política de reintentos calibrada, monitoreo activo y mecanismo de reprocesamiento.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Dead Letter Channel es uno de los patrones de integración con mayor soporte nativo en plataformas modernas. Toda plataforma de mensajería de producción lo implementa:
- Amazon SQS: Dead Letter Queue es una funcionalidad nativa. Se configura con
maxReceiveCount(número de reintentos) ydeadLetterTargetArn(ARN de la DLQ). Es una de las primeras configuraciones recomendadas en toda SQS queue. - Azure Service Bus: Dead-letter sub-queue es nativa en cada queue y subscription. Se activa automáticamente para mensajes que exceden
maxDeliveryCount, mensajes expirados (TTL), y mensajes que el consumidor dead-letters explícitamente. - RabbitMQ: Dead Letter Exchange (DLX) se configura por queue con
x-dead-letter-exchangeyx-dead-letter-routing-key. Los mensajes rejected, expired o que exceden la longitud de la queue se redirigen al DLX. - Apache Kafka: no tiene DLQ nativo a nivel de broker, pero los frameworks lo implementan. Spring Kafka proporciona
DeadLetterPublishingRecoverer. Kafka Connect tieneerrors.deadletterqueue.topic.name. Es la primera configuración de error handling en todo consumer Kafka. - Google Cloud Pub/Sub: Dead-letter topic es nativo. Se configura con
max_delivery_attemptspor subscription.
Cómo Se Implementa Hoy¶
| Plataforma | DLQ Nativa | Configuración Clave | Reprocesamiento |
|---|---|---|---|
| AWS SQS | Sí | maxReceiveCount, deadLetterTargetArn | Mover mensajes de DLQ a queue principal con CLI/SDK |
| Azure Service Bus | Sí | maxDeliveryCount, dead-letter sub-queue automática | ServiceBusReceiver con SubQueue.DeadLetter |
| RabbitMQ | Sí (DLX) | x-dead-letter-exchange, x-dead-letter-routing-key | Consumer en DLX queue, republish a queue principal |
| Kafka (Spring) | Framework | DeadLetterPublishingRecoverer, retry topic | Custom reprocessor, Spring Kafka non-blocking retry |
| Google Pub/Sub | Sí | dead_letter_policy.dead_letter_topic, max_delivery_attempts | Pull subscription en DLT, republish |
Qué Parte Sigue Siendo Esencial¶
- Aislamiento automático de poison pills: la funcionalidad core del DLQ — que ningún mensaje bloquee el procesamiento — es universalmente necesaria.
- Preservación para reprocesamiento: los mensajes dead-lettered tienen valor y deben poder reprocesarse cuando la causa se resuelve.
- Observabilidad del DLQ: el DLQ es la señal operacional más clara de que algo está mal. La monitorización del DLQ es un pilar de la operación de cualquier sistema de mensajería.
15. Implementación en Arquitecturas Modernas¶
Amazon SQS con Dead Letter Queue¶
// Configuración de DLQ en SQS via CloudFormation
{
"PaymentQueue": {
"Type": "AWS::SQS::Queue",
"Properties": {
"QueueName": "payments-transactions-pending",
"VisibilityTimeout": 30,
"RedrivePolicy": {
"deadLetterTargetArn": {"Fn::GetAtt": ["PaymentDLQ", "Arn"]},
"maxReceiveCount": 5
}
}
},
"PaymentDLQ": {
"Type": "AWS::SQS::Queue",
"Properties": {
"QueueName": "payments-transactions-pending-dlq",
"MessageRetentionPeriod": 1209600
}
}
}
Reprocesamiento con AWS CLI:
# Start DLQ redrive (mover mensajes de DLQ a queue principal)
aws sqs start-message-move-task \
--source-arn arn:aws:sqs:eu-west-1:123456:payments-transactions-pending-dlq \
--destination-arn arn:aws:sqs:eu-west-1:123456:payments-transactions-pending \
--max-number-of-messages-per-second 10
Azure Service Bus con Dead-Letter Sub-Queue¶
// Configuración del processor con max delivery count
var processor = client.CreateProcessor(
"payments-transactions-pending",
new ServiceBusProcessorOptions {
MaxConcurrentCalls = 10,
AutoCompleteMessages = false
});
// Consumir del dead-letter sub-queue
var dlqReceiver = client.CreateReceiver(
"payments-transactions-pending",
new ServiceBusReceiverOptions {
SubQueue = SubQueue.DeadLetter
});
// Reprocesar un mensaje del DLQ
var dlqMessage = await dlqReceiver.ReceiveMessageAsync();
if (dlqMessage != null) {
// Verificar que la causa se resolvió antes de reprocesar
if (await IsDependencyHealthy()) {
var sender = client.CreateSender("payments-transactions-pending");
await sender.SendMessageAsync(
new ServiceBusMessage(dlqMessage.Body));
await dlqReceiver.CompleteMessageAsync(dlqMessage);
}
}
Apache Kafka con Spring Kafka¶
// Configuración de retry con Dead Letter Topic
@Configuration
public class KafkaConfig {
@Bean
public RetryTopicConfiguration retryTopicConfig(KafkaTemplate<String, String> template) {
return RetryTopicConfigurationBuilder
.newInstance()
.exponentialBackoff(1000, 2, 16000) // 1s, 2s, 4s, 8s, 16s
.maxAttempts(5)
.retryTopicSuffix(".retry")
.dltSuffix(".dlt")
.setTopicSuffixingStrategy(TopicSuffixingStrategy.SUFFIX_WITH_INDEX_VALUE)
.create(template);
}
// Non-blocking retry: mensajes van a topics intermedios de retry
// antes del DLT, sin bloquear el topic principal
// Topics creados automáticamente:
// payments.transactions.pending.retry-0
// payments.transactions.pending.retry-1
// payments.transactions.pending.retry-2
// payments.transactions.pending.dlt
}
RabbitMQ con Dead Letter Exchange¶
// Declaración de queue con DLX
{
"queue": "payments-transactions-pending",
"durable": true,
"arguments": {
"x-dead-letter-exchange": "payments-dlx",
"x-dead-letter-routing-key": "payments.transactions.dead",
"x-message-ttl": 30000
}
}
// DLX exchange y queue
{
"exchange": "payments-dlx",
"type": "direct"
}
{
"queue": "payments-transactions-dlq",
"durable": true,
"bindings": [
{"exchange": "payments-dlx", "routing_key": "payments.transactions.dead"}
]
}
Google Cloud Pub/Sub con Dead Letter Topic¶
# Crear dead letter topic
gcloud pubsub topics create payments-transactions-pending-dlt
# Configurar subscription con dead lettering
gcloud pubsub subscriptions create payment-processor-sub \
--topic=payments-transactions-pending \
--dead-letter-topic=payments-transactions-pending-dlt \
--max-delivery-attempts=5 \
--ack-deadline=30
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Volumen del DLQ: número de mensajes en el DLQ en cualquier momento. Debe ser cercano a cero en operación normal. Un número creciente indica problema activo.
- Antigüedad del mensaje más viejo: el mensaje más antiguo en el DLQ indica cuánto tiempo lleva sin resolverse el problema. Una antigüedad creciente indica que nadie está atendiendo el DLQ.
- Tasa de dead-lettering: mensajes al DLQ / mensajes totales procesados. Una tasa > 0.1% en un sistema estable merece investigación.
- Distribución de errores: ¿los mensajes en el DLQ fallan por la misma razón (outage de una dependencia) o por razones diversas (múltiples bugs)?
- Tiempo medio de resolución: desde que un mensaje llega al DLQ hasta que se reprocesa exitosamente.
Monitoreo¶
- Alerta por primer mensaje: cuando el DLQ recibe su primer mensaje después de estar vacío, alerta inmediata. Indica inicio de un problema.
- Alerta por volumen: si el DLQ acumula más de N mensajes en M minutos, escalación. Indica outage de dependencia.
- Alerta por antigüedad: si hay mensajes en el DLQ con más de X horas sin resolver, escalación.
- Dashboard: vista consolidada con gráficos de volumen del DLQ, tasa de dead-lettering, distribución de errores y estado de dependencias.
Versionado¶
- Política de reintentos versionada: la configuración de reintentos (count, backoff, timeout) debe estar versionada como infrastructure-as-code para reproducibilidad y auditabilidad.
- Formato de metadata del DLQ: el formato de los headers de error en el DLQ debe estar documentado y versionado para que las herramientas de reprocesamiento lo interpreten correctamente.
Seguridad¶
- Datos sensibles en DLQ: los mensajes en el DLQ contienen los mismos datos que el canal principal (transacciones financieras, datos personales). El DLQ debe tener las mismas políticas de cifrado y acceso.
- Acceso al reprocesamiento: el reprocesamiento de mensajes del DLQ debe estar restringido a operadores autorizados con audit trail.
Retención¶
- Retención del DLQ: debe ser suficiente para permitir la resolución del problema (outages prolongados, bugs que requieren deployment de fix). Típicamente 14-30 días.
- Archivado: mensajes del DLQ que no se resolvieron dentro de la retención deben archivarse a storage de bajo costo antes de expirar, con un registro de que no se procesaron.
Calibración de Retry Policy¶
- Errores transitorios (network timeout, 503, connection refused): benefician de reintentos con backoff exponencial. 3-5 reintentos suelen ser suficientes.
- Errores permanentes (400 Bad Request, formato corrupto): reintentos no resuelven el problema. Estos deberían ir al Invalid Message Channel directamente. La distinción se hace inspeccionando el tipo de excepción.
- Backoff exponencial con jitter: backoff exponencial evita thundering herd. Jitter (aleatorización) evita que múltiples consumidores reintentan simultáneamente después de un outage.
Performance¶
- Impacto de reintentos en throughput: durante un outage de dependencia, los reintentos consumen capacidad del consumidor. Un circuit breaker que detecta la dependencia down puede pausar el consumo, evitando reintentos inútiles y saturación del DLQ.
- Reprocesamiento con rate limiting: cuando se reprocesa un DLQ grande, el spike de carga puede sobrecargar las dependencias recién recuperadas. El reprocesamiento debe hacerse con rate limiting.
- Non-blocking retry (Kafka): Spring Kafka ofrece non-blocking retry que usa topics intermedios de retry, evitando bloquear el topic principal durante los reintentos.
17. Errores Comunes¶
No Configurar DLQ¶
El error más básico y más peligroso: operar un sistema de mensajería en producción sin DLQ. El primer poison pill bloquea el procesamiento indefinidamente. Solución: configurar DLQ como parte del setup inicial de toda queue/topic, no como algo que "se añadirá después".
DLQ Sin Monitoreo ("La Alfombra")¶
Configurar el DLQ pero no monitorear su contenido. Los mensajes se acumulan durante semanas o meses sin que nadie los revise. El DLQ da la falsa tranquilidad de que "los errores están manejados". Solución: alertas por primer mensaje, por volumen y por antigüedad desde el día uno.
No Distinguir Errores Transitorios de Permanentes¶
Reintentar 5 veces un mensaje con formato corrupto desperdicia recursos y tiempo. Un mensaje con formato corrupto fallará siempre — debería ir al Invalid Message Channel inmediatamente, no al DLQ después de 5 reintentos inútiles. Solución: inspeccionar el tipo de excepción. ServiceUnavailableException → reintentar. DeserializationException → Invalid Message Channel sin reintentos.
Reprocesamiento Sin Verificar Causa Raíz¶
Mover mensajes del DLQ al canal principal automáticamente sin verificar que el problema se resolvió produce un ciclo de ping-pong: mensaje → canal → fallo → DLQ → reprocesamiento → canal → fallo → DLQ. Solución: el job de reprocesamiento debe verificar el estado de la dependencia o la condición que causó el fallo antes de reprocesar.
Retry Policy No Calibrada¶
Usar la misma política de reintentos para todos los canales sin considerar la naturaleza de las dependencias. Un canal cuyo consumidor consulta un servicio con SLA de 99.9% (downtime < 9 horas/año) necesita pocos reintentos. Un canal cuyo consumidor consulta un servicio legacy con mantenimientos frecuentes necesita más reintentos y backoff más largo. Solución: calibrar retry policy por canal según la naturaleza de las dependencias.
No Considerar Idempotencia en Reprocesamiento¶
Reprocesar mensajes del DLQ puede producir duplicados si el consumidor parcialmente procesó el mensaje antes de fallar (por ejemplo, debitó la cuenta origen pero falló al acreditar la cuenta destino). Si el consumidor no es idempotente, el reprocesamiento debita la cuenta origen por segunda vez. Solución: diseñar consumidores idempotentes usando deduplication keys (payment_id, transaction_id) que verifican si la operación ya se ejecutó antes de ejecutarla.
No Planificar Reprocesamiento Masivo¶
Cuando una dependencia tiene un outage de 2 horas y el DLQ acumula 50,000 mensajes, el reprocesamiento masivo puede generar un spike de carga que vuelve a tumbar la dependencia recién recuperada. Solución: reprocesar con rate limiting (por ejemplo, 100 mensajes/segundo) y monitorear la salud de la dependencia durante el reprocesamiento.
18. Conclusión Técnica¶
Dead Letter Channel es el patrón que convierte los fallos de procesamiento de mensajes de un problema catastrófico (bloqueo, pérdida de datos, intervención manual) en un problema gestionable (aislamiento, preservación, diagnóstico, reprocesamiento). Es un requisito operacional de todo sistema de mensajería en producción, no una optimización optional.
Cuándo aporta valor: siempre que un sistema de mensajería opere en producción con dependencias que pueden fallar (es decir, siempre). El DLQ es la red de seguridad que asegura que ningún fallo de procesamiento produce bloqueo del canal principal ni pérdida de datos.
Cuándo evita problemas importantes: durante outages de dependencias (un escenario inevitable en sistemas distribuidos), el DLQ preserva automáticamente los mensajes afectados y permite su reprocesamiento cuando el servicio se restaura. Sin DLQ, un outage de 30 minutos puede resultar en miles de mensajes perdidos o un canal bloqueado durante horas.
Cuándo no conviene adoptarlo: en sistemas donde la pérdida de mensajes individuales es explícitamente aceptable y el costo operacional del DLQ no se justifica (telemetría de alta frecuencia con redundancia, logs efímeros). Incluso en estos casos, un DLQ con retención mínima y monitoreo básico es una buena práctica para detectar problemas sistémicos.
Recomendación para arquitectos: configure Dead Letter Channel para todo canal de mensajería desde el día uno, no como algo que "se añadirá cuando lo necesitemos". Calibre la política de reintentos por canal: 3-5 reintentos con backoff exponencial y jitter es un buen default. Distinga claramente entre Dead Letter Channel (errores de procesamiento/entrega, con reintentos previos) e Invalid Message Channel (errores de contenido, sin reintentos). Monitoree el DLQ con la misma seriedad que el canal principal: alerta por primer mensaje, por volumen y por antigüedad. Implemente reprocesamiento con rate limiting y verificación de dependencias. Y sobre todo, nunca trate el DLQ como una alfombra donde esconder problemas — un mensaje en el DLQ es un dato de negocio que merece atención, diagnóstico y resolución.