Guaranteed Delivery¶
1. Nombre del Patrón¶
- Nombre oficial: Guaranteed Delivery
- Categoría: Messaging Channels (Canales de Mensajería)
- Traducción contextual: Entrega Garantizada
2. Resumen Ejecutivo¶
Guaranteed Delivery es el patrón que asegura que un mensaje enviado por un productor será entregado al consumidor incluso cuando componentes intermedios del sistema de mensajería fallen — brokers que se reinician, discos que fallan, redes que se interrumpen. El mecanismo fundamental es la persistencia: el mensaje se escribe en almacenamiento no volátil (disco) antes de confirmarse como recibido, y se mantiene allí hasta que el consumidor confirma su procesamiento exitoso.
El problema que resuelve es existencial para cualquier sistema de integración crítico: ¿qué ocurre con los mensajes que están en tránsito cuando un broker se cae? Sin Guaranteed Delivery, la respuesta es que se pierden irrecuperablemente. Con Guaranteed Delivery, la respuesta es que sobreviven al fallo y se entregan cuando el sistema se recupera.
Este patrón no es una feature aislada sino una propiedad emergente de varias decisiones de configuración coordinadas: persistencia en disco, replicación entre nodos, acknowledgments del productor, acknowledgments del consumidor y políticas de retención. En plataformas modernas como Apache Kafka con acks=all y replication factor 3, o Azure Service Bus Premium con geo-disaster recovery, Guaranteed Delivery se logra configurando correctamente la cadena completa de persistencia y confirmación.
3. Definición Detallada¶
Propósito¶
Guaranteed Delivery asegura que un mensaje depositado en un canal de mensajería no se perderá, independientemente de fallos de hardware, software o red que ocurran entre el momento de la producción y el momento del consumo. Su propósito es proporcionar una garantía de durabilidad que permita a los sistemas de integración tratar el canal como un intermediario confiable.
Lógica Arquitectónica¶
En una invocación síncrona (HTTP, gRPC), si el receptor falla durante la llamada, el emisor recibe un error y puede reintentar. Pero en messaging asíncrono, el productor envía y se desacopla — puede que no esté disponible para reintentar horas después cuando se descubra que el mensaje se perdió. Guaranteed Delivery introduce la idea de que el sistema de mensajería asume la responsabilidad de custodiar el mensaje hasta que el consumidor lo procese.
Esta garantía tiene implicaciones profundas:
- El broker se convierte en custodio: no es un simple relay que reenvía mensajes en memoria, sino un sistema de almacenamiento que persiste mensajes en disco y los protege contra fallos.
- La confirmación de recepción es un contrato: cuando el broker confirma al productor que aceptó el mensaje (
ack), está asumiendo la responsabilidad de entregarlo. - La cadena de custodia es completa: desde el productor hasta el consumidor, cada eslabón de la cadena confirma al anterior que el mensaje está seguro.
Principio de Diseño Subyacente¶
El principio es store-and-forward con durabilidad: el mensaje se almacena de forma durable en cada etapa antes de ser reenviado a la siguiente. Este principio es análogo al correo certificado: el sistema postal no solo transporta la carta, sino que registra cada punto de custodia y requiere firma de recepción. Si la carta se pierde en un punto, el sistema puede detectarlo y remediar la situación.
Problema Estructural que Resuelve¶
En un sistema distribuido, los componentes fallan inevitablemente: brokers se reinician por actualizaciones, discos fallan, redes se particionan, procesos se quedan sin memoria. Sin Guaranteed Delivery, cada uno de estos fallos puede causar pérdida silenciosa de mensajes — el productor cree que envió el mensaje, el consumidor nunca lo recibe, y nadie se entera hasta que un proceso de negocio falla horas o días después.
Contexto en el que Emerge¶
Guaranteed Delivery emerge cuando el contenido del mensaje tiene valor de negocio que no puede recrearse fácilmente. En un sistema de tracking IoT donde se pierden algunas ubicaciones GPS, el impacto es menor (la siguiente lectura corrige). Pero en un sistema bancario donde se pierde una instrucción de pago, el impacto es una transacción financiera perdida, con consecuencias regulatorias y de negocio.
Por Qué No Es Trivial¶
La garantía de entrega parece simple ("persiste el mensaje en disco"), pero la implementación completa requiere resolver varios problemas coordinados:
- Durabilidad del productor: ¿el productor espera confirmación del broker antes de considerar el mensaje enviado? ¿Qué hace si no recibe confirmación?
- Replicación del broker: si el disco del broker falla, ¿hay réplicas en otros nodos? ¿Cuántas réplicas deben confirmar antes de que el broker confirme al productor?
- Acknowledgment del consumidor: ¿cómo sabe el broker que el consumidor procesó el mensaje exitosamente? ¿Qué pasa si el consumidor falla antes de confirmar?
- Retención y limpieza: ¿cuándo es seguro eliminar un mensaje del almacenamiento persistente?
- Performance vs. durabilidad: cada escritura a disco, cada replicación, cada confirmación añade latencia. ¿Cuánta latencia es aceptable a cambio de la garantía?
Relación con Sistemas Distribuidos y Mensajería¶
Guaranteed Delivery está directamente relacionado con el concepto de durable writes y replication en sistemas distribuidos. En la teoría de consenso (Raft, Paxos), un dato se considera "committed" cuando una mayoría de réplicas lo ha persistido. Kafka usa exactamente este principio: un mensaje está "committed" cuando el número de réplicas en el ISR (In-Sync Replicas) que lo han escrito alcanza el min.insync.replicas. Este concepto de consenso aplicado a mensajería es lo que hace que Guaranteed Delivery sea robusto en plataformas modernas.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Guaranteed Delivery, un sistema de mensajería opera en modo "best-effort": el broker acepta mensajes en memoria, los reenvía a los consumidores conectados, y si cualquier componente falla antes de completar la entrega, el mensaje desaparece. Este modo es análogo a enviar un paquete por correo ordinario sin tracking ni confirmación de entrega.
Síntomas del Problema¶
- Mensajes que "desaparecen" sin dejar rastro cuando un broker se reinicia durante una ventana de mantenimiento.
- Procesos de negocio que fallan horas después de una interrupción del broker porque las instrucciones nunca llegaron al sistema destino.
- Inconsistencias entre sistemas que deberían estar sincronizados — por ejemplo, un pedido creado en el sistema de ventas que nunca llegó al sistema de fulfillment.
- Necesidad de procesos de reconciliación manuales periódicos para detectar y corregir mensajes perdidos.
- Desconfianza organizacional en la plataforma de messaging, llevando a equipos a implementar sus propios mecanismos de garantía sobre la plataforma.
Impacto Operativo y Arquitectónico¶
Sin entrega garantizada:
- Los equipos implementan mecanismos de retry ad-hoc en el productor, resultando en lógica duplicada, inconsistente y frágil distribuida por toda la organización.
- Se crean procesos de reconciliación batch que comparan datos entre sistemas origen y destino para detectar divergencias, añadiendo complejidad y latencia.
- La arquitectura event-driven pierde su premisa fundamental: que los eventos son la fuente de verdad y que todos los consumidores procesarán todos los eventos relevantes.
- Los SLAs de integración son imposibles de cumplir porque la plataforma no puede garantizar que los mensajes sobrevivirán a fallos.
Riesgos Si No Se Implementa Correctamente¶
- Falsa sensación de seguridad: configurar solo persistencia en disco sin replicación protege contra restart del proceso pero no contra fallo de disco.
- Acks insuficientes:
acks=1en Kafka (solo el leader confirma) protege contra pérdida del productor pero no contra fallo del leader antes de replicar. - Consumer sin commit: un consumidor que procesa mensajes sin confirmar (commit offset) recibirá los mismos mensajes de nuevo tras un restart, causando procesamiento duplicado.
- Retención insuficiente: si la retención del canal expira antes de que un consumidor procese los mensajes (por downtime prolongado), los mensajes se pierden a pesar de haber sido persistidos.
Ejemplos Reales¶
- Banca: instrucciones de pago SWIFT entre bancos corresponsales que deben sobrevivir a fallos del broker. Una instrucción perdida es una transferencia que no se ejecuta, con impacto financiero directo y posibles sanciones regulatorias.
- Salud: órdenes médicas (prescripciones, solicitudes de laboratorio) enviadas desde el EMR al sistema de farmacia o laboratorio. Una orden perdida es un paciente que no recibe su medicación o su análisis.
- Manufactura: órdenes de producción enviadas al sistema MES (Manufacturing Execution System). Una orden perdida es un lote que no se produce, afectando la cadena de suministro.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el mensaje representa una acción de negocio que no puede perderse (pago, orden, notificación legal).
- Cuando el productor no puede reenviar el mensaje si se pierde (no almacena el estado del mensaje, o el evento es irrecuperable).
- Cuando los sistemas consumidores pueden tener downtime programado o no programado, y los mensajes deben esperarles.
- Cuando existen requisitos regulatorios de auditoría que requieren trazabilidad completa del flujo de mensajes.
- Cuando la reconciliación manual post-fallo es costosa, lenta o propensa a errores.
Cuándo No Usarlo¶
- Cuando los mensajes son efímeros y reemplazables: telemetría de sensores donde la siguiente lectura corrige la anterior.
- Cuando la latencia es más crítica que la durabilidad: streaming de video en tiempo real, gaming.
- Cuando el volumen es tan alto y el valor individual tan bajo que la persistencia no justifica el costo: métricas de observabilidad de alta frecuencia donde perder el 0.1% es aceptable.
- Cuando el productor puede recrear el mensaje fácilmente: por ejemplo, un cache invalidation event que puede regenerarse desde la base de datos fuente.
Precondiciones¶
- El sistema de mensajería soporta persistencia en disco (no es un broker puramente in-memory).
- Existe capacidad de almacenamiento suficiente para retener mensajes durante el tiempo necesario.
- El productor está configurado para esperar confirmación del broker (no fire-and-forget).
- El consumidor está configurado para confirmar el procesamiento (explicit ack/commit).
Restricciones¶
- Guaranteed Delivery añade latencia en cada operación (write to disk, replication, ack round-trip).
- El throughput máximo está limitado por la velocidad de I/O del disco y la latencia de red de replicación.
- El almacenamiento requerido crece proporcionalmente al throughput y la retención.
- Guaranteed Delivery garantiza at-least-once delivery, no exactly-once. Los mensajes pueden duplicarse en escenarios de fallo y retry.
Dependencias¶
- Infraestructura de almacenamiento durable (discos SSD/NVMe para brokers, storage replicado).
- Red confiable entre réplicas del broker (baja latencia para replicación síncrona).
- Configuración coordinada de productor, broker y consumidor (no basta con configurar solo uno de los tres).
Supuestos Arquitectónicos¶
- Los fallos son transitorios: el sistema eventualmente se recupera y los mensajes pendientes se entregan.
- Los consumidores son capaces de manejar mensajes duplicados (idempotencia) dado que at-least-once implica posibles duplicados.
- El almacenamiento persistente es más confiable que la memoria volátil, pero no infalible — por eso se requiere replicación.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas financieros (pagos, transferencias, compensación interbancaria).
- Sistemas de salud (órdenes médicas, resultados de laboratorio).
- Sistemas de e-commerce (pedidos, pagos, envíos).
- Sistemas regulados (cumplimiento normativo, auditoría, trazabilidad).
- Cualquier integración donde la pérdida de un mensaje tiene impacto de negocio medible.
6. Fuerzas Arquitectónicas¶
Durabilidad vs. Latencia¶
La fuerza más fundamental. Cada capa de protección (write to disk, replicación síncrona, ack del broker) añade latencia. En Kafka con acks=all y replication factor 3, un mensaje puede tardar 5-15ms en ser confirmado frente a <1ms con acks=0. La decisión depende del valor del mensaje: para instrucciones de pago, 15ms de latencia es irrelevante; para señales de trading de alta frecuencia, puede ser inaceptable.
Consistencia vs. Disponibilidad¶
Un broker que requiere replicación síncrona a todas las réplicas antes de confirmar es más consistente pero menos disponible: si una réplica está caída, el productor se bloquea. Kafka resuelve esto con el concepto de ISR (In-Sync Replicas) y min.insync.replicas: solo las réplicas que están al día participan en el quórum, permitiendo tolerar fallos de réplicas rezagadas sin bloquear la producción.
Throughput vs. Garantía¶
La persistencia reduce el throughput máximo porque el disco es más lento que la memoria. Las plataformas modernas mitigan esto con escrituras secuenciales (Kafka append-only log), page cache del OS, y batching. Aun así, un broker en modo persistente tendrá menor throughput que uno en modo in-memory. La pregunta es si el throughput requerido es compatible con la garantía requerida.
Costo de Infraestructura vs. Nivel de Protección¶
Replication factor 3 requiere 3x el almacenamiento. Geo-replicación (para protección contra desastres regionales) requiere clusters en múltiples regiones con sus costos de red y compute. El nivel de protección debe calibrarse con el costo del mensaje perdido: si perder un mensaje cuesta $100K (una transacción financiera perdida), el costo de 3 réplicas en 2 regiones es trivial en comparación.
Simplicidad Operativa vs. Robustez¶
Un broker single-node sin replicación es simple de operar pero ofrece poca protección. Un cluster replicado multi-zona es robusto pero requiere expertise operacional significativo. Las plataformas managed (Azure Service Bus Premium, Amazon MSK, Confluent Cloud) transfieren esta complejidad operacional al proveedor, a cambio de costo financiero.
Exactitud vs. Duplicación¶
Guaranteed Delivery en su forma más común proporciona at-least-once delivery: el mensaje se entrega al menos una vez, pero puede duplicarse si el consumidor falla después de procesar pero antes de confirmar. Exactly-once delivery (Kafka transactions, idempotent producers) es más exacto pero más complejo y con mayor overhead.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): la aplicación que envía el mensaje y espera confirmación del broker.
- Broker (Store-and-Forward Engine): el sistema que persiste el mensaje en disco, lo replica a otros nodos, y confirma al productor.
- Réplicas (Follower Brokers): nodos adicionales que mantienen copias del mensaje para protección contra fallo del nodo primario.
- Canal Persistente (Durable Channel): el canal configurado con durabilidad, retención y replicación.
- Consumidor (Receiver): la aplicación que recibe el mensaje, lo procesa, y confirma al broker.
Flujo Lógico¶
flowchart TD
A([Productor]) -->|Envía mensaje + request ACK| B[Broker Leader: Escribe en disco]
B --> C[Replica a Follower Brokers]
C --> D[Followers: Escriben en disco y confirman]
D --> E{min.insync.replicas alcanzado?}
E -->|Sí| F[Leader: Envía ACK al productor]
F --> G[Productor: Mensaje garantizado]
G --> H[Consumidor: Solicita/recibe mensaje]
H --> I[Broker: Entrega desde disco o page cache]
I --> J[Consumidor: Procesa mensaje]
J --> K[Consumidor: Envía ACK/commit]
K --> L[Broker: Avanza offset del consumer group]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Enviar con acks habilitados, manejar retry si no recibe ack, implementar idempotencia |
| Broker Leader | Persistir en disco, coordinar replicación, confirmar al productor |
| Follower Brokers | Replicar datos del leader, estar disponibles para failover |
| Consumidor | Procesar mensaje, confirmar procesamiento, ser idempotente ante duplicados |
Interacciones¶
- Productor → Broker: envío con nivel de acknowledgment configurado (
acks=0,acks=1,acks=all). - Leader → Followers: replicación síncrona (el leader espera confirmación) o asíncrona (el leader no espera).
- Broker → Consumidor: entrega del mensaje persistido.
- Consumidor → Broker: confirmación de procesamiento (ack/commit offset).
Contratos Implícitos¶
- Contrato de durabilidad: si el broker confirma (ack) al productor, el mensaje no se perderá mientras el cluster tenga al menos
min.insync.replicasnodos activos. - Contrato de entrega: el mensaje permanecerá disponible para el consumidor durante el período de retención configurado.
- Contrato de at-least-once: el mensaje se entregará al menos una vez; el consumidor debe tolerar duplicados.
Decisiones de Diseño Clave¶
- Nivel de acks:
acks=allpara máxima garantía;acks=1para equilibrio entre garantía y latencia. - Replication factor: típicamente 3 para producción (tolera fallo de 1 nodo sin pérdida de datos).
- min.insync.replicas: típicamente 2 (con RF=3, requiere que al menos 2 réplicas confirmen).
- Retención: suficiente para cubrir el downtime máximo esperado del consumidor más lento.
- Consumer offset commit: manual (after processing) vs. automático (periódico) — manual ofrece mayor garantía.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Instrucciones de Pago Interbancario¶
Contexto del Negocio¶
Un banco internacional procesa 2 millones de instrucciones de pago al día a través de su sistema de pagos core. Las instrucciones incluyen transferencias SWIFT, pagos SEPA, transferencias domésticas y liquidaciones interbancarias. Cada instrucción de pago tiene un valor promedio de €15,000 y un valor máximo de €500 millones para pagos corporativos.
La regulación bancaria (PSD2, regulación del Banco Central Europeo) exige que ninguna instrucción de pago se pierda durante el procesamiento. Una instrucción perdida requiere investigación formal, reporte al regulador y compensación al cliente. El costo estimado por instrucción perdida (investigación + multa potencial + daño reputacional) es de €50,000-€200,000.
Necesidad de Integración¶
El sistema de pagos core genera instrucciones que deben ser procesadas por múltiples sistemas downstream:
- Screening Engine: verifica la instrucción contra listas de sanciones (OFAC, EU, UN).
- Fraud Detection: evalúa el riesgo de fraude de la transacción.
- Liquidity Manager: verifica y reserva fondos en la cuenta del ordenante.
- SWIFT Gateway: envía la instrucción al sistema SWIFT para pagos internacionales.
- Reconciliation Engine: registra la instrucción para reconciliación contable.
- Regulatory Reporting: almacena datos para reportes regulatorios.
Si cualquier instrucción se pierde entre el sistema core y estos sistemas downstream, el pago no se ejecuta, o se ejecuta sin screening (riesgo de sanciones), o se ejecuta sin registro contable (riesgo de auditoría).
Sistemas Involucrados¶
- Payment Core: genera instrucciones de pago.
- Kafka Cluster: plataforma de mensajería con Guaranteed Delivery.
- Screening Service: consume instrucciones para compliance screening.
- Fraud Detection Service: consume instrucciones para análisis de fraude.
- Liquidity Service: consume instrucciones para gestión de fondos.
- SWIFT Adapter: consume instrucciones aprobadas para envío a SWIFT.
- Reconciliation Service: consume todas las instrucciones para conciliación.
- Regulatory Data Store: consume instrucciones para reporting regulatorio.
Restricciones Técnicas¶
- Zero message loss: ninguna instrucción de pago puede perderse bajo ninguna circunstancia operativa normal.
- RPO (Recovery Point Objective): 0 mensajes — no se tolera pérdida de datos.
- RTO (Recovery Time Objective): 5 minutos — el sistema debe recuperarse de un fallo de nodo en 5 minutos.
- Throughput: 2M instrucciones/día ≈ 25 instrucciones/segundo en promedio, con picos de 100/segundo.
- Latencia: la instrucción debe llegar al Screening Engine en <2 segundos.
- Retención: 90 días para cumplir requisitos de auditoría.
Configuración de Guaranteed Delivery¶
| Parámetro | Valor | Justificación |
|---|---|---|
| Replication Factor | 3 | Tolera fallo de 1 broker sin pérdida |
| min.insync.replicas | 2 | Requiere confirmación de 2 de 3 réplicas |
| acks | all | El productor espera confirmación de todas las réplicas ISR |
| Producer retries | 10 | Reintenta ante fallos transitorios de red |
| enable.idempotence | true | Evita duplicados por retries del productor |
| Consumer auto.commit | false | Commit manual después de procesamiento exitoso |
| Retention | 90 days | Cobertura de requisitos regulatorios |
| unclean.leader.election | false | Nunca promover una réplica no sincronizada |
Decisiones Arquitectónicas¶
-
acks=all+min.insync.replicas=2: esta combinación garantiza que cada instrucción está escrita en al menos 2 discos físicos antes de que el productor reciba confirmación. Si un broker falla, la instrucción sobrevive en las otras réplicas. -
unclean.leader.election=false: si el leader falla y ningún follower está sincronizado, el topic se vuelve no disponible en lugar de promover un follower desincronizado que podría perder mensajes. Se prefiere indisponibilidad temporal sobre pérdida de datos. -
Idempotent producer: el productor asigna un sequence number a cada mensaje. Si un retry resulta en un envío duplicado, el broker lo detecta y lo descarta. Esto garantiza exactly-once del productor al broker.
-
Manual consumer offset commit: el consumidor procesa la instrucción completamente (screening ejecutado, resultado almacenado) antes de hacer commit del offset. Si el consumidor falla antes del commit, recibirá la instrucción de nuevo tras el restart.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Fallo de 2 de 3 brokers simultáneamente | Brokers en 3 availability zones diferentes |
| Disco lleno en broker | Alertas de capacidad al 70%, auto-expansion de storage |
| Consumer offline >90 días | Alerta operacional al día 1 de offline, escalación automática |
| Mensajes duplicados por retry | Consumidores idempotentes (deduplicación por payment_id) |
| Corrupción de datos en disco | Checksums por segmento, verificación periódica |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción de una Instrucción de Pago¶
El Payment Core recibe una solicitud de transferencia internacional:
{
"payment_id": "PAY-2026-04-07-00847291",
"type": "SWIFT_MT103",
"ordering_bank": "BBVAESMMXXX",
"beneficiary_bank": "DEUTDEFFXXX",
"amount": 250000.00,
"currency": "EUR",
"ordering_customer": "Empresa Industrial S.A.",
"beneficiary": "Deutsche Maschinenbau GmbH",
"value_date": "2026-04-07",
"reference": "INV-2026-3847",
"timestamp": "2026-04-07T09:15:32.847Z"
}
El Payment Core serializa la instrucción en formato Avro (validado contra el Schema Registry), y la envía al topic payments.instructions.created con payment_id como partition key y acks=all.
Paso 2: Persistencia en el Broker Leader¶
El Kafka broker que es leader de la partición correspondiente (determinada por hash de PAY-2026-04-07-00847291):
- Recibe el mensaje del productor.
- Lo escribe en el segment file del log en disco (append operation, secuencial, muy eficiente).
- El filesystem flush ocurre según la configuración del OS (page cache) — Kafka confía en la replicación más que en fsync por cada mensaje.
Paso 3: Replicación a Followers¶
Simultáneamente, los 2 follower brokers:
- Hacen fetch del nuevo mensaje desde el leader (replicación pull-based).
- Lo escriben en sus propios segment files en disco.
- Confirman al leader que están sincronizados (avanzan su high-water mark).
Paso 4: Acknowledgment al Productor¶
Cuando al menos min.insync.replicas=2 réplicas (incluyendo el leader) han escrito el mensaje:
- El leader envía acknowledgment al productor.
- El productor recibe el ack y marca la instrucción como "enviada a messaging" en su base de datos.
- En este punto, la instrucción de €250,000 está segura en 2 discos físicos en 2 availability zones diferentes.
Paso 5: Consumo por el Screening Service¶
El Screening Service (consumer group: cg-compliance-screening):
- Hace poll al broker y recibe la instrucción de pago.
- La envía al motor de screening que verifica contra listas de sanciones OFAC, EU y UN.
- El screening toma ~200ms y retorna resultado "CLEAN" (no match).
- El servicio almacena el resultado del screening en su base de datos.
- Solo entonces ejecuta
consumer.commitSync()para confirmar el procesamiento del offset.
Si el Screening Service se cae entre el paso 2 y el paso 5, el offset no se ha committeado. Cuando el servicio reinicia, recibirá la misma instrucción de nuevo. El servicio verifica por payment_id si ya procesó esta instrucción (idempotencia) para evitar screening duplicado.
Paso 6: Escenario de Fallo — Broker Restart¶
A las 09:15:45 (13 segundos después del pago), el broker que es leader de la partición sufre un restart por actualización de parches de seguridad:
- El broker se cae. Los followers detectan la ausencia del leader.
- Kafka (vía ZooKeeper/KRaft) elige un nuevo leader entre los followers sincronizados.
- El nuevo leader asume en ~2 segundos. La instrucción de pago de €250,000 está intacta en el nuevo leader porque fue replicada antes del ack.
- Los consumidores reconectan automáticamente al nuevo leader y continúan consumiendo sin pérdida.
- El broker original reinicia, se une como follower, sincroniza los mensajes que perdió durante el downtime, y vuelve al ISR.
Sin Guaranteed Delivery (sin replicación, sin acks=all), la instrucción de €250,000 habría desaparecido con el restart del broker.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.onprem.network import Nginx
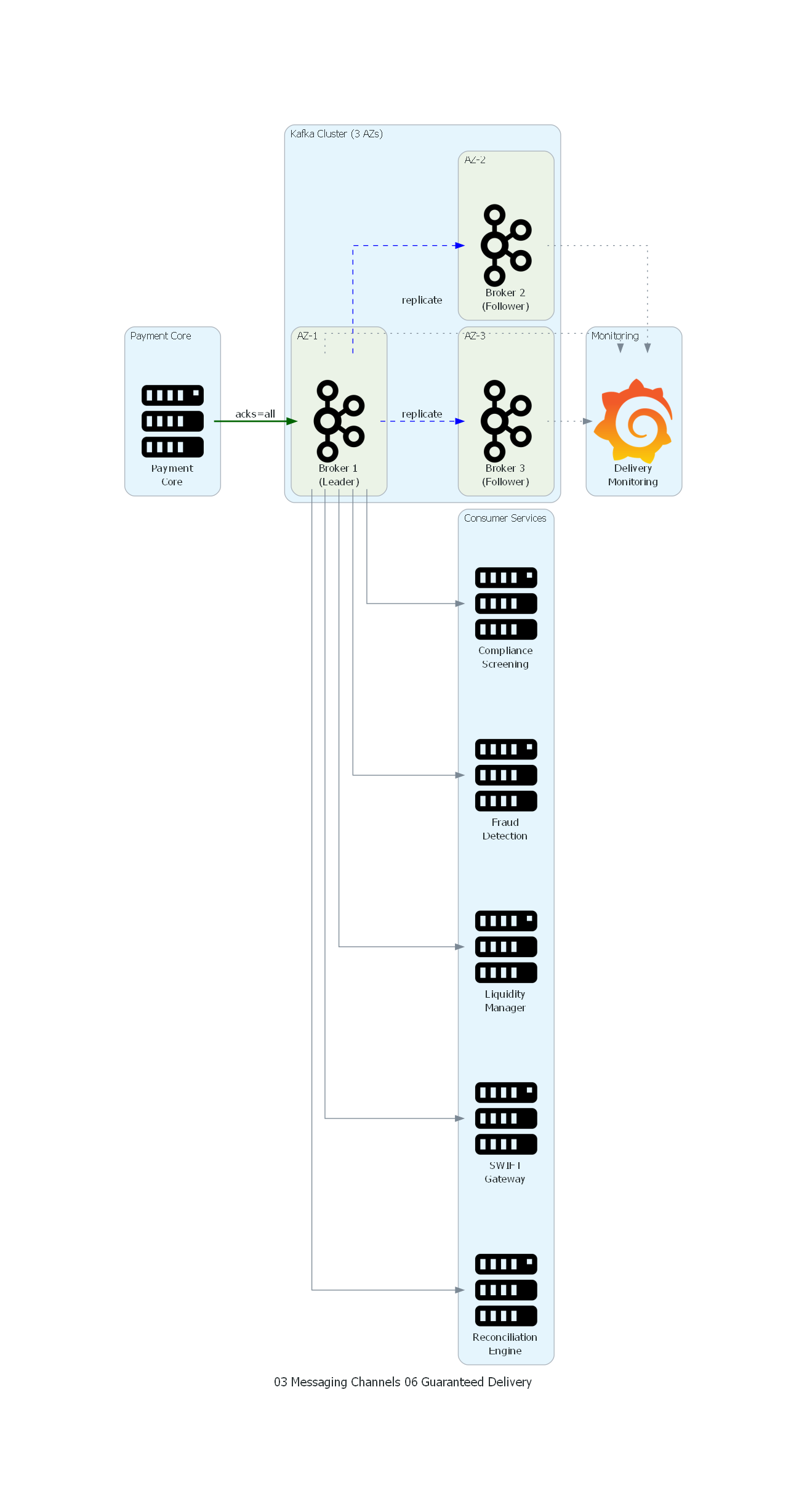
with Diagram("Guaranteed Delivery - Banking Payments", show=False, direction="LR"):
with Cluster("Payment Core"):
payment_core = Server("Payment\nCore")
with Cluster("Kafka Cluster (3 AZs)"):
with Cluster("AZ-1"):
broker1 = Kafka("Broker 1\n(Leader)")
with Cluster("AZ-2"):
broker2 = Kafka("Broker 2\n(Follower)")
with Cluster("AZ-3"):
broker3 = Kafka("Broker 3\n(Follower)")
with Cluster("Consumer Services"):
screening = Server("Compliance\nScreening")
fraud = Server("Fraud\nDetection")
liquidity = Server("Liquidity\nManager")
swift_gw = Server("SWIFT\nGateway")
recon = Server("Reconciliation\nEngine")
with Cluster("Monitoring"):
monitoring = Grafana("Delivery\nMonitoring")
# Producer → Leader with acks=all
payment_core >> Edge(label="acks=all", color="darkgreen", style="bold") >> broker1
# Replication
broker1 >> Edge(label="replicate", color="blue", style="dashed") >> broker2
broker1 >> Edge(label="replicate", color="blue", style="dashed") >> broker3
# Consumption
broker1 >> screening
broker1 >> fraud
broker1 >> liquidity
broker1 >> swift_gw
broker1 >> recon
# Monitoring
broker1 >> Edge(style="dotted") >> monitoring
broker2 >> Edge(style="dotted") >> monitoring
broker3 >> Edge(style="dotted") >> monitoring
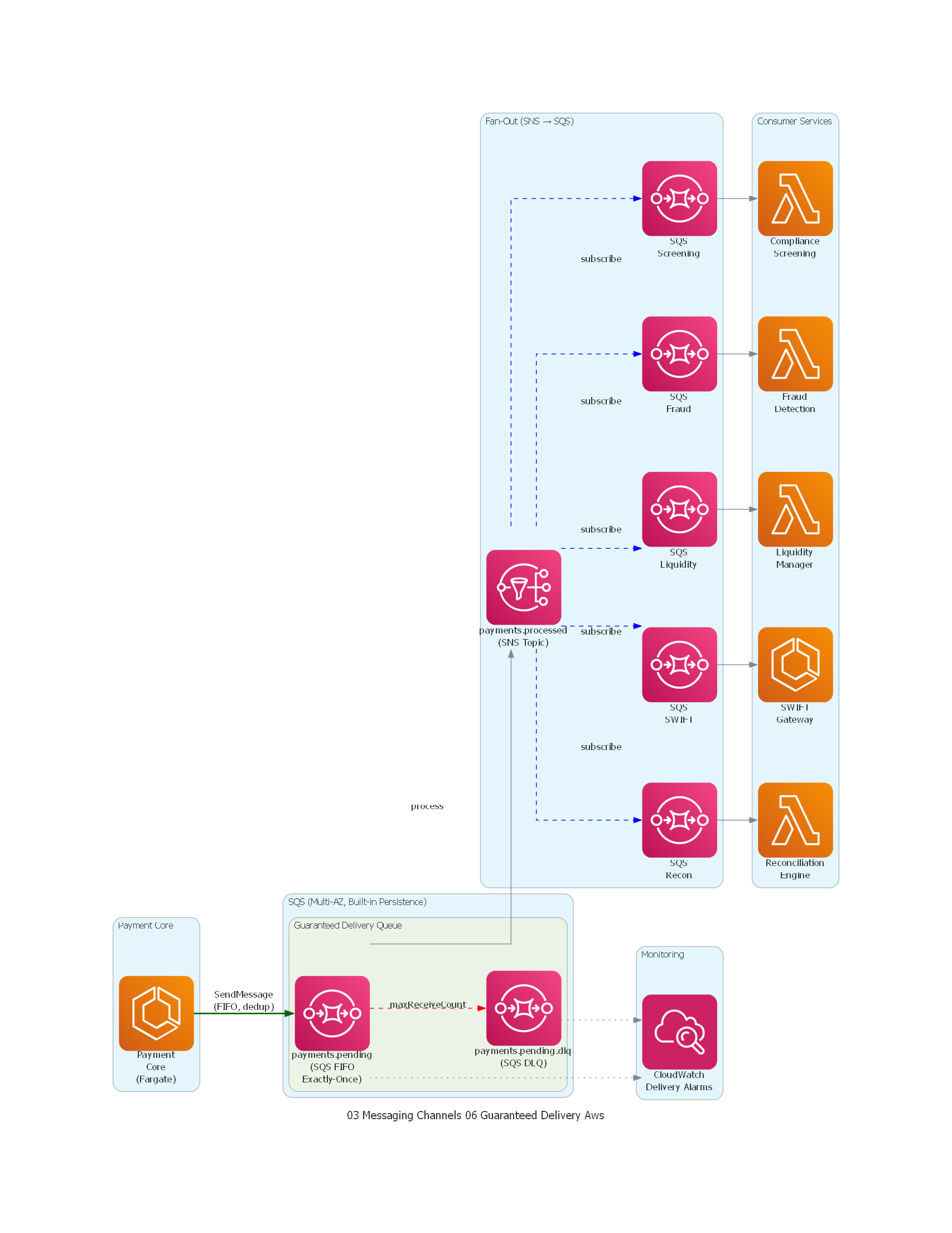
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.management import Cloudwatch
with Diagram("Guaranteed Delivery - Banking Payments (AWS)", show=False, direction="LR"):
with Cluster("Payment Core"):
payment_core = ECS("Payment\nCore\n(Fargate)")
with Cluster("SQS (Multi-AZ, Built-in Persistence)"):
with Cluster("Guaranteed Delivery Queue"):
queue = SQS("payments.pending\n(SQS FIFO\nExactly-Once)")
dlq = SQS("payments.pending.dlq\n(SQS DLQ)")
with Cluster("Fan-Out (SNS → SQS)"):
topic = SNS("payments.processed\n(SNS Topic)")
sqs_screening = SQS("SQS\nScreening")
sqs_fraud = SQS("SQS\nFraud")
sqs_liquidity = SQS("SQS\nLiquidity")
sqs_swift = SQS("SQS\nSWIFT")
sqs_recon = SQS("SQS\nRecon")
with Cluster("Consumer Services"):
screening = Lambda("Compliance\nScreening")
fraud = Lambda("Fraud\nDetection")
liquidity = Lambda("Liquidity\nManager")
swift_gw = ECS("SWIFT\nGateway")
recon = Lambda("Reconciliation\nEngine")
with Cluster("Monitoring"):
monitoring = Cloudwatch("CloudWatch\nDelivery Alarms")
# Producer → SQS FIFO (guaranteed delivery)
payment_core >> Edge(label="SendMessage\n(FIFO, dedup)", color="darkgreen", style="bold") >> queue
# DLQ for failed processing
queue >> Edge(label="maxReceiveCount", color="red", style="dashed") >> dlq
# Processed → SNS fan-out
queue >> Edge(label="process") >> topic
topic >> Edge(label="subscribe", color="blue", style="dashed") >> sqs_screening
topic >> Edge(label="subscribe", color="blue", style="dashed") >> sqs_fraud
topic >> Edge(label="subscribe", color="blue", style="dashed") >> sqs_liquidity
topic >> Edge(label="subscribe", color="blue", style="dashed") >> sqs_swift
topic >> Edge(label="subscribe", color="blue", style="dashed") >> sqs_recon
# SQS → Consumer services
sqs_screening >> screening
sqs_fraud >> fraud
sqs_liquidity >> liquidity
sqs_swift >> swift_gw
sqs_recon >> recon
# Monitoring
queue >> Edge(style="dotted") >> monitoring
dlq >> Edge(style="dotted") >> monitoring
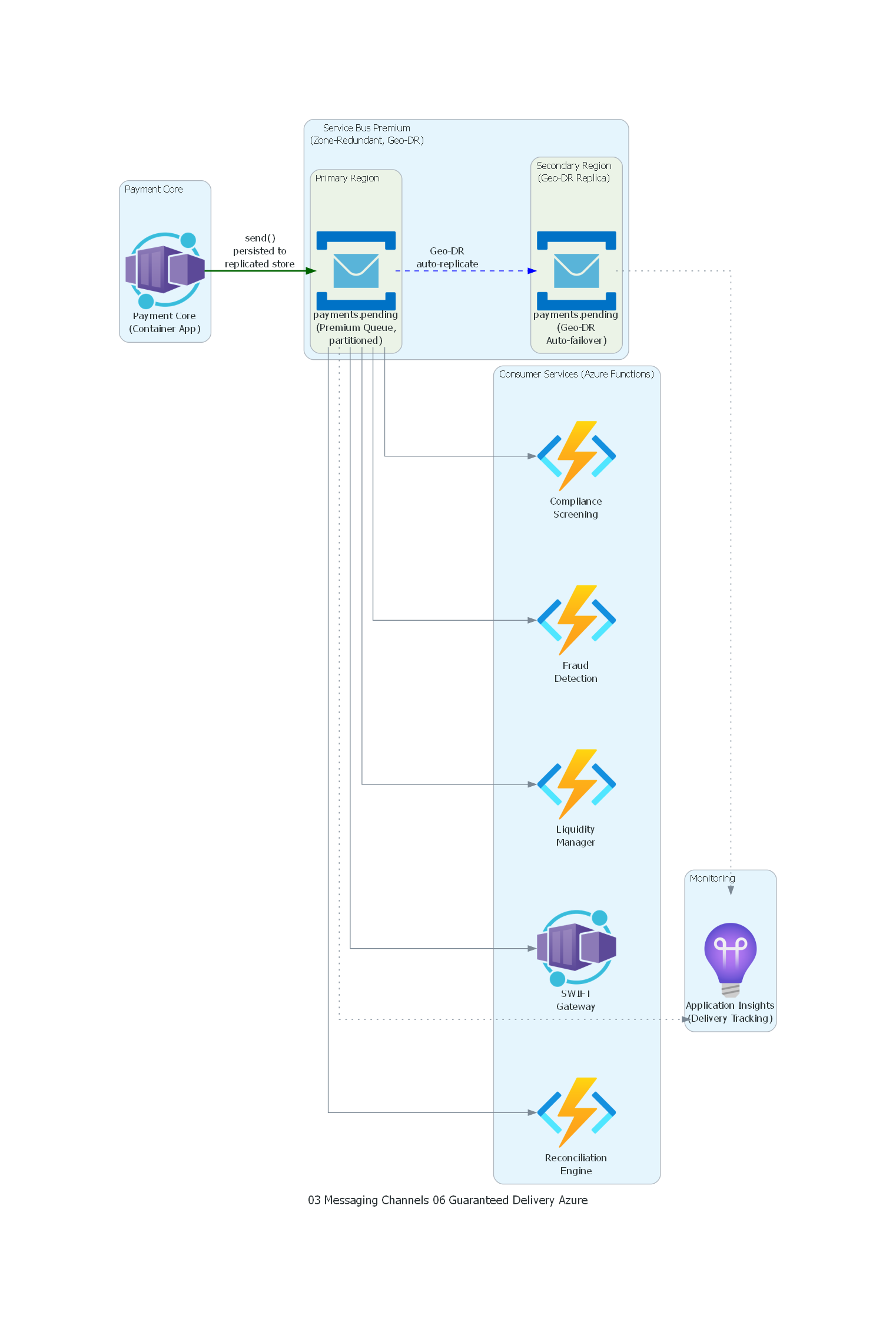
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Guaranteed Delivery - Banking Payments (Azure)", show=False, direction="LR"):
with Cluster("Payment Core"):
payment_core = ContainerApps("Payment Core\n(Container App)")
with Cluster("Service Bus Premium\n(Zone-Redundant, Geo-DR)"):
with Cluster("Primary Region"):
sb_primary = ServiceBus("payments.pending\n(Premium Queue,\npartitioned)")
with Cluster("Secondary Region\n(Geo-DR Replica)"):
sb_secondary = ServiceBus("payments.pending\n(Geo-DR\nAuto-failover)")
with Cluster("Consumer Services (Azure Functions)"):
screening = FunctionApps("Compliance\nScreening")
fraud = FunctionApps("Fraud\nDetection")
liquidity = FunctionApps("Liquidity\nManager")
swift_gw = ContainerApps("SWIFT\nGateway")
recon = FunctionApps("Reconciliation\nEngine")
with Cluster("Monitoring"):
monitoring = ApplicationInsights("Application Insights\n(Delivery Tracking)")
# Producer → Service Bus Premium (guaranteed persistence)
payment_core >> Edge(label="send()\npersisted to\nreplicated store", color="darkgreen", style="bold") >> sb_primary
# Geo-DR Replication
sb_primary >> Edge(label="Geo-DR\nauto-replicate", color="blue", style="dashed") >> sb_secondary
# Consumption (Service Bus guarantees at-least-once via peek-lock)
sb_primary >> screening
sb_primary >> fraud
sb_primary >> liquidity
sb_primary >> swift_gw
sb_primary >> recon
# Monitoring
sb_primary >> Edge(style="dotted") >> monitoring
sb_secondary >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de Guaranteed Delivery para el sistema de pagos bancarios:
- Payment Core envía instrucciones de pago al broker leader con
acks=all, asegurando que el productor no considera el mensaje como enviado hasta que esté replicado. - Broker 1 (Leader) persiste el mensaje en disco y lo replica a Broker 2 y Broker 3 en availability zones diferentes.
- Solo cuando al menos 2 brokers han confirmado la persistencia, el leader envía acknowledgment al Payment Core.
- Los Consumer Services consumen del topic con commit manual de offsets, asegurando que solo se confirma el procesamiento después de completar la lógica de negocio.
- Grafana monitorea el estado de replicación, consumer lag y health de los 3 brokers.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor con acks | Payment Core con acks=all |
| Persistent Store (Leader) | Broker 1 en AZ-1 |
| Réplicas | Broker 2 (AZ-2), Broker 3 (AZ-3) |
| Canal Durable | Topic payments.instructions.created (implícito) |
| Consumidor con ack manual | Screening, Fraud, Liquidity, SWIFT, Reconciliation |
| Monitoreo de delivery | Grafana dashboard |
11. Beneficios¶
Impacto Técnico¶
- Zero message loss bajo fallos de un nodo: con replication factor 3 y
min.insync.replicas=2, el sistema tolera la pérdida completa de un broker (hardware failure, no solo restart) sin perder ningún mensaje. - Recuperación automática: cuando el broker fallido vuelve, se sincroniza automáticamente con el leader y reanuda la replicación. No se requiere intervención manual.
- Reprocesamiento garantizado: la combinación de persistencia + retención de 90 días permite que cualquier consumidor retroceda offsets y reprocese instrucciones pasadas para correcciones o auditorías.
- Cadena de custodia completa: desde el productor (ack) hasta el consumidor (commit), cada eslabón de la cadena confirma la custodia del mensaje.
Impacto Organizacional¶
- Confianza en la plataforma: los equipos de negocio y regulatorio confían en que la plataforma de messaging no perderá instrucciones, eliminando la necesidad de mecanismos de reconciliación paralelos.
- Simplificación de la lógica de negocio: los desarrolladores no necesitan implementar retry logic complejo en el productor ni mecanismos de detección de pérdida en el consumidor — la plataforma gestiona la garantía.
- Cumplimiento regulatorio: la capacidad de demostrar ante auditores que la plataforma ofrece guaranteed delivery simplifica las auditorías de sistemas de pago.
Impacto Operacional¶
- Mantenimiento sin pérdida: los brokers pueden reiniciarse para actualizaciones (rolling restart) sin pérdida de mensajes gracias a la replicación.
- Monitoreo proactivo: métricas de replicación lag, ISR count y under-replicated partitions permiten detectar riesgos antes de que se materialicen.
- Disaster recovery: con geo-replicación, incluso un desastre de data center no resulta en pérdida de mensajes.
Beneficios de Mantenibilidad y Evolución¶
- Cambio de consumidores sin riesgo: un consumidor puede reemplazarse o actualizarse con confidence de que los mensajes no procesados durante el cambio serán entregados al nuevo consumidor.
- Adición de consumidores retroactiva: un nuevo consumidor puede "rebobinar" al inicio de la retención y procesar mensajes históricos, gracias a la persistencia.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Configuración coordinada: la garantía depende de la configuración correcta y coordinada de producer (acks), broker (replication, min.insync.replicas, unclean.leader.election) y consumer (auto.commit). Un error en cualquier eslabón rompe la cadena.
- Infraestructura más robusta: un cluster de 3+ brokers en 3 availability zones es significativamente más costoso y complejo que un broker single-node.
- Idempotencia obligatoria: dado que at-least-once delivery puede producir duplicados, todos los consumidores deben implementar idempotencia, lo cual añade complejidad a la lógica de procesamiento.
Riesgos de Mal Uso¶
- Configuración parcial: configurar
acks=allen el productor pero dejarunclean.leader.election=trueen el broker permite promover un follower desincronizado como leader, perdiendo mensajes que el productor creía garantizados. - Auto-commit de offsets: dejar
enable.auto.commit=trueen el consumidor hace commit periódicamente independientemente de si el procesamiento completó, creando ventanas de pérdida si el consumidor falla entre el auto-commit y el procesamiento. - Retención insuficiente: configurar retención de 24 horas cuando un consumidor puede estar offline por 48 horas resulta en pérdida de mensajes a pesar de la persistencia.
Sobreingeniería¶
- Aplicar a todos los canales: no todos los canales necesitan guaranteed delivery. Aplicar
acks=ally RF=3 a canales de métricas o logs de baja criticidad desperdicia recursos. - Geo-replicación innecesaria: para la mayoría de los sistemas, replicación dentro de una región es suficiente. Geo-replicación entre regiones añade latencia y complejidad significativas.
Costos de Operación¶
- Storage: RF=3 multiplica el almacenamiento por 3. Con retención de 90 días y 2M mensajes/día, el storage total puede ser significativo.
- Latencia:
acks=allañade la latencia de replicación a cada producción. En clusters distribuidos geográficamente, esto puede ser decenas de milisegundos. - Complejidad de troubleshooting: diagnosticar problemas de replicación (ISR shrinking, under-replicated partitions) requiere expertise específico de la plataforma.
Anti-Patterns Relacionados¶
- Guaranteed Delivery sin idempotencia: garantizar la entrega pero no manejar duplicados resulta en procesamiento duplicado — doble cobro de un pago, doble envío de un pedido.
- Guaranteed Delivery como excusa para no monitorear: confiar en que "Kafka no pierde mensajes" sin monitorear ISR, consumer lag y under-replicated partitions es peligroso.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): Guaranteed Delivery es una propiedad de un Message Channel. Define la dimensión de durabilidad del canal.
- Dead Letter Channel (Capítulo 3): cuando un mensaje no puede procesarse después de múltiples intentos, Guaranteed Delivery asegura que llegue al Dead Letter Channel en lugar de perderse.
- Idempotent Receiver (Capítulo 7): patrón necesario del lado del consumidor para manejar los duplicados que at-least-once delivery puede producir.
- Message Store: complementa Guaranteed Delivery almacenando mensajes en un store externo (base de datos) además del broker, para auditoría y reprocesamiento a largo plazo.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: la decisión de usar Messaging (estilo de integración) y la definición de Message Channels preceden a la configuración de Guaranteed Delivery.
- Después: Competing Consumers, Content-Based Router y otros patrones de procesamiento operan sobre mensajes cuya entrega ya está garantizada.
Combinaciones Comunes¶
- Guaranteed Delivery + Transactional Client: el productor usa transacciones (Kafka Transactions) para garantizar que un grupo de mensajes se produce atómicamente o no se produce.
- Guaranteed Delivery + Channel Adapter: el adapter que conecta un sistema legacy al messaging debe participar en la cadena de custodia, esperando el ack del broker antes de confirmar al sistema origen.
- Guaranteed Delivery + Message Bridge: al hacer bridge entre dos sistemas de mensajería, ambos extremos deben ofrecer guaranteed delivery para que la cadena no se rompa.
Diferencias con Patrones Similares¶
- vs. Durable Subscriber: Durable Subscriber asegura que un consumidor recibe mensajes publicados mientras estaba offline. Guaranteed Delivery asegura que el mensaje no se pierde en el broker. Son complementarios.
- vs. Message Store: Message Store persiste mensajes en un almacén externo para consulta. Guaranteed Delivery persiste mensajes en el broker para entrega. Diferentes propósitos de persistencia.
Encaje en un Flujo Mayor de Integración¶
Guaranteed Delivery es la capa de confiabilidad sobre la cual se construye toda la integración. Sin esta garantía, patrones como Content-Based Router, Splitter y Aggregator no pueden operar de forma confiable porque podrían perder mensajes en tránsito.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Guaranteed Delivery es más relevante que nunca porque las arquitecturas modernas dependen de messaging como columna vertebral:
- Event-driven architectures: si los eventos son la fuente de verdad (Event Sourcing), perder un evento es perder un hecho de negocio. Guaranteed Delivery es existencial.
- Microservicios: la comunicación asíncrona entre microservicios depende de que los mensajes no se pierdan para mantener la consistencia eventual.
- Streaming platforms: Kafka se usa como log de commits de datos (CDC, Event Sourcing), donde cada mensaje es un cambio de estado que no puede perderse.
- Regulación: normativas como PSD2 (pagos), HIPAA (salud), SOX (contabilidad) exigen trazabilidad completa que requiere guaranteed delivery.
Cómo Se Implementa Hoy¶
| Plataforma | Mecanismo de Guaranteed Delivery | Nivel de garantía |
|---|---|---|
| Kafka | acks=all + RF=3 + min.insync.replicas=2 | At-least-once (exactly-once con transactions) |
| Azure Service Bus Premium | Storage replicado + geo-DR | At-least-once (exactly-once con sessions) |
| AWS SQS | Redundancia multi-AZ automática | At-least-once (exactly-once en FIFO) |
| RabbitMQ | Durable queues + publisher confirms + mirroring | At-least-once |
| Google Pub/Sub | Replicación multi-zona automática | At-least-once (exactly-once delivery) |
| Apache Pulsar | BookKeeper (write quorum + ack quorum) | At-least-once (exactly-once con transactions) |
Qué Parte Sigue Siendo Esencial¶
- El principio de store-and-forward con durabilidad: independientemente de la plataforma, persistir antes de confirmar es el mecanismo universal.
- La configuración de la cadena completa: producer acks + broker replication + consumer acks sigue siendo la cadena de custodia que debe configurarse correctamente.
- La tensión durabilidad vs. performance: sigue siendo la fuerza arquitectónica fundamental que los arquitectos deben resolver caso por caso.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
Broker Configuration:
default.replication.factor=3
min.insync.replicas=2
unclean.leader.election.enable=false
log.flush.interval.messages=10000
log.flush.interval.ms=1000
Producer Configuration:
acks=all
retries=2147483647
enable.idempotence=true
max.in.flight.requests.per.connection=5
delivery.timeout.ms=120000
Consumer Configuration:
enable.auto.commit=false
isolation.level=read_committed
auto.offset.reset=earliest
Kafka implementa Guaranteed Delivery mediante un log replicado y particionado. El productor idempotente con acks=all garantiza que cada mensaje se persiste en al menos min.insync.replicas nodos antes de confirmarse. El consumidor con commit manual garantiza que solo se confirman offsets de mensajes procesados exitosamente.
Azure Service Bus Premium¶
Namespace Tier: Premium (dedicated resources)
Queue Properties:
EnablePartitioning: true
RequiresDuplicateDetection: true
DuplicateDetectionHistoryTimeWindow: PT10M
MaxDeliveryCount: 10
DeadLetteringOnMessageExpiration: true
LockDuration: PT5M
Geo-Disaster Recovery:
PrimaryNamespace: sb-payments-westeurope
SecondaryNamespace: sb-payments-northeurope
Alias: sb-payments
Azure Service Bus Premium ofrece Guaranteed Delivery con storage replicado automáticamente, duplicate detection nativo, dead-letter queue automática y geo-disaster recovery que replica metadata y mensajes entre regiones.
AWS SQS¶
Queue Configuration:
QueueType: Standard (or FIFO for ordering)
VisibilityTimeout: 300 seconds
MessageRetentionPeriod: 1209600 (14 days)
RedrivePolicy:
deadLetterTargetArn: arn:aws:sqs:eu-west-1:123456789:payments-dlq
maxReceiveCount: 5
SQS ofrece Guaranteed Delivery de forma nativa: los mensajes se almacenan redundantemente en múltiples availability zones automáticamente. No hay configuración de replicación — AWS gestiona la durabilidad internamente.
RabbitMQ¶
Queue Declaration:
durable: true
arguments:
x-queue-type: quorum (replicated queue)
x-delivery-limit: 10
Publisher:
confirm_delivery: true
mandatory: true
persistent: true (delivery_mode=2)
Consumer:
prefetch_count: 10
auto_ack: false
RabbitMQ implementa Guaranteed Delivery mediante quorum queues (replicadas vía Raft), publisher confirms (el broker confirma al productor que el mensaje está persistido), y manual ack del consumidor.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Under-replicated partitions: la métrica más crítica. Si una partición tiene menos réplicas ISR que
min.insync.replicas, la producción se bloquea (prefiriendo indisponibilidad sobre pérdida de datos). - ISR shrink/expand events: indican que réplicas están cayendo o recuperándose. Shrinks frecuentes sugieren problemas de infraestructura.
- Producer ack latency: el tiempo entre envío y confirmación. Aumentos indican problemas de replicación o disco.
- Consumer lag: si crece, el consumidor no puede mantener el ritmo, y mensajes antiguos podrían expirar antes de ser consumidos.
Monitoreo¶
- Alertas de ISR: alerta inmediata si
ISR count < replication.factorpara cualquier partición. Alerta crítica siISR count < min.insync.replicas. - Alertas de consumer lag: alerta si el lag excede un umbral configurado por consumer group.
- Alertas de disk space: alerta al 70% de capacidad del broker para prevenir pérdida de mensajes por disco lleno.
- End-to-end latency monitoring: producir mensajes de prueba periódicamente y medir el tiempo hasta que son consumidos.
Versionado¶
- Schema Registry: los mensajes persistidos deben tener schema versionado para que consumidores futuros puedan deserializarlos correctamente, especialmente con retención larga (90 días).
- Compatibilidad backward: un consumidor actualizado debe poder leer mensajes producidos con versiones anteriores del schema que aún están en retención.
Seguridad¶
- Encryption at rest: los mensajes persistidos en disco deben estar cifrados (LUKS, Azure SSE, AWS KMS).
- Encryption in transit: TLS entre productores, brokers y consumidores.
- ACLs estrictos: en canales de pagos, solo el Payment Core puede producir y solo los servicios autorizados pueden consumir.
Manejo de Errores y Dead-Lettering¶
- Mensajes que fallan procesamiento después de N intentos deben enviarse a Dead Letter Channel con metadata de error para diagnóstico.
- El Dead Letter Channel de pagos debe tener su propia Guaranteed Delivery (RF=3, retención extendida).
- Proceso de revisión manual de dead-letters con SLA de resolución (por ejemplo, 4 horas para pagos de alto valor).
Idempotencia¶
- Cada consumidor debe implementar deduplicación basada en
payment_id(omessage_id). - El store de deduplicación debe retener IDs por al menos el período de retención del canal + margen de seguridad.
- Kafka Transactions (
isolation.level=read_committed) pueden evitar lectura de mensajes de transacciones abortadas.
Auditoría¶
- Registrar every ack del productor con timestamp, partition, offset para trazabilidad.
- Registrar every commit del consumidor con timestamp, partition, offset, consumer group.
- Correlacionar acks y commits para verificar que cada mensaje producido fue consumido.
Performance¶
- Batching del productor: batch.size=65536, linger.ms=5 para amortizar overhead de acks.
- Compression: lz4 o zstd para reducir I/O de disco y network sin impacto significativo en latencia.
- Page cache: dimensionar la RAM del broker para que el working set quepa en page cache, evitando lecturas de disco.
Escalabilidad¶
- Más particiones para más paralelismo de consumo (pero no más de lo que los consumidores pueden manejar).
- Brokers con discos NVMe para maximizar throughput de I/O con persistencia.
- Clusters managed (Confluent Cloud, Amazon MSK) para escalar sin gestionar infraestructura.
17. Errores Comunes¶
Configurar acks Solo en el Productor¶
Configurar acks=all en el productor pero dejar min.insync.replicas=1 en el broker significa que el "all" se satisface con solo el leader. No hay replicación real protegiendo el mensaje. La configuración debe coordinarse: acks=all en el productor Y min.insync.replicas=2 (o más) en el broker.
Dejar Auto-Commit Habilitado en Consumidores Críticos¶
El auto-commit de offsets (habilitado por defecto en muchos clientes Kafka) hace commit periódicamente sin relación con el procesamiento. Si el consumidor procesa un mensaje durante 10 segundos y el auto-commit ocurre cada 5 segundos, puede hacer commit de un offset que aún no se procesó. Si el consumidor falla antes de completar, el mensaje se pierde efectivamente.
Ignorar el Escenario de Disco Lleno¶
Si el disco del broker se llena, el broker no puede persistir nuevos mensajes y la producción falla. Muchos equipos configuran replicación y acks correctamente pero no monitorean el espacio en disco, resultando en indisponibilidad cuando la retención alta llena los discos.
No Probar Escenarios de Fallo¶
Configurar Guaranteed Delivery sin probar que realmente funciona ante fallos es peligroso. Los equipos deben ejecutar pruebas de caos (kill broker, fill disk, partition network) en entornos de pre-producción para verificar que los mensajes sobreviven.
Confundir Guaranteed Delivery con Exactly-Once Processing¶
Guaranteed Delivery garantiza que el mensaje no se pierde, pero no garantiza que se procese exactamente una vez. El consumidor puede recibir el mismo mensaje múltiples veces. Sin idempotencia en el consumidor, esto resulta en procesamiento duplicado — el patrón garantiza la entrega, no la unicidad del procesamiento.
Retención Corta en Canales Críticos¶
Configurar retención de 24 horas en un canal de pagos cuando el consumidor de reconciliación tiene ventanas de mantenimiento de 48 horas resulta en pérdida de mensajes a pesar de la persistencia. La retención debe cubrir el downtime máximo esperado de todos los consumidores con margen de seguridad.
18. Conclusión Técnica¶
Guaranteed Delivery es el patrón que transforma un sistema de mensajería de un mecanismo best-effort a una infraestructura de confianza para procesos de negocio críticos. No es un toggle que se activa con un solo parámetro — es una propiedad emergente de la configuración coordinada de toda la cadena: productor (acks, retries, idempotencia), broker (replicación, min.insync.replicas, unclean.leader.election) y consumidor (manual commit, idempotencia).
Cuándo aporta valor: siempre que el mensaje tenga valor de negocio que excede el costo de la infraestructura de garantía. En sistemas financieros, de salud, regulatorios y de e-commerce, el costo de perder un mensaje (investigación, multa, pérdida de negocio, daño reputacional) supera ampliamente el costo de replicación y almacenamiento.
Cuándo evita problemas importantes: un sistema de pagos sin guaranteed delivery eventualmente perderá instrucciones de pago durante un fallo operativo — no es cuestión de si ocurrirá sino de cuándo. La combinación de acks=all, RF=3, min.insync.replicas=2 y unclean.leader.election=false en Kafka, o el storage replicado con geo-DR en Azure Service Bus Premium, convierte el "cuándo" en "nunca bajo condiciones operativas normales".
Cuándo no conviene adoptarlo: para canales de baja criticidad donde la pérdida ocasional es aceptable (métricas, telemetría de baja resolución, notificaciones no críticas), la sobrecarga de replicación y acks no se justifica. En estos casos, acks=1 o incluso acks=0 con replicación asíncrona puede ser apropiado.
Recomendación para arquitectos: clasifique los canales de su arquitectura por criticidad de negocio. Para canales críticos (pagos, órdenes, datos regulatorios), configure la cadena completa de Guaranteed Delivery sin compromisos. Para canales operacionales (métricas, logs, heartbeats), aplique un nivel de garantía proporcional a su importancia. Y en todos los casos, pruebe los escenarios de fallo en pre-producción — la configuración sin validación es solo teoría.