Channel Adapter¶
1. Nombre del Patrón¶
- Nombre oficial: Channel Adapter
- Categoría: Messaging Channels (Canales de Mensajería)
- Traducción contextual: Adaptador de Canal
2. Resumen Ejecutivo¶
Channel Adapter es el patrón que conecta una aplicación que no fue diseñada para messaging con la infraestructura de mensajería. Actúa como un traductor bidireccional: en un sentido, convierte las operaciones nativas de la aplicación (llamadas HTTP, consultas a base de datos, eventos de filesystem, cambios en registros) en mensajes que se depositan en un canal; en el otro sentido, consume mensajes del canal y los traduce en operaciones nativas que la aplicación entiende.
El problema que resuelve es práctico y omnipresente: la mayoría de las aplicaciones empresariales — ERPs, CRMs, sistemas legacy, APIs REST, bases de datos — no hablan el protocolo del broker de mensajería. No producen ni consumen mensajes nativamente. Channel Adapter es el puente que les permite participar en la arquitectura de mensajería sin modificar su código fuente.
En el ecosistema moderno, este patrón está más vigente que nunca. Kafka Connect con sus cientos de conectores (JDBC, Debezium, Elasticsearch, S3), MuleSoft con sus Anypoint Connectors, Azure Logic Apps con sus 400+ conectores, y Apache Camel con sus 300+ componentes son todos implementaciones industrializadas del patrón Channel Adapter. La revolución del Change Data Capture (CDC) con herramientas como Debezium es, en esencia, un Channel Adapter que convierte cambios en bases de datos en eventos en Kafka sin modificar la aplicación que escribe en la base de datos.
3. Definición Detallada¶
Propósito¶
Channel Adapter permite que cualquier aplicación, independientemente de su tecnología, protocolo o antigüedad, participe como productor o consumidor en una arquitectura de mensajería. Su propósito es eliminar la barrera de entrada al messaging para sistemas que no tienen capacidad nativa de producir o consumir mensajes.
Lógica Arquitectónica¶
En una arquitectura de integración basada en messaging, todos los participantes deben poder enviar y recibir mensajes a través de canales. Pero la realidad es que la mayoría de los sistemas empresariales no fueron diseñados con messaging en mente:
- Un ERP (SAP, Oracle) expone interfaces BAPI, RFC, IDoc o tablas de base de datos — no topics de Kafka.
- Un sistema POS (Point of Sale) envía transacciones vía REST API o archivos batch — no mensajes AMQP.
- Una base de datos relacional almacena cambios en tablas — no produce eventos a un broker.
- Un sistema legacy COBOL procesa archivos planos o colas MQ Series — no habla el protocolo de Azure Service Bus.
Channel Adapter resuelve esta incompatibilidad insertándose entre la aplicación y la infraestructura de messaging:
- Inbound Adapter (aplicación → messaging): detecta eventos o datos en la aplicación fuente y los convierte en mensajes que deposita en un canal.
- Outbound Adapter (messaging → aplicación): consume mensajes de un canal y los convierte en operaciones que ejecuta contra la aplicación destino.
Principio de Diseño Subyacente¶
El principio es traducción de protocolo en el borde: en lugar de modificar la aplicación para hablar messaging, se coloca un adaptador en el borde que traduce entre el protocolo nativo de la aplicación y el protocolo del sistema de mensajería. Este principio es idéntico al patrón Adapter de GoF aplicado a integración enterprise: el adapter implementa la interfaz esperada por el messaging system mientras delega internamente al sistema adaptado.
Problema Estructural que Resuelve¶
Sin Channel Adapter, integrar una aplicación no-messaging en una arquitectura de mensajería requiere una de dos opciones:
- Modificar la aplicación: añadir código de producción/consumo de mensajes directamente en la aplicación. Esto es invasivo, costoso (especialmente en sistemas legacy), y mezcla la lógica de integración con la lógica de negocio.
- No integrar: dejar la aplicación fuera de la arquitectura de messaging y usar otros mecanismos (APIs, archivos, ETL). Esto fragmenta la arquitectura y pierde los beneficios del desacoplamiento asíncrono.
Channel Adapter ofrece una tercera opción: integrar sin modificar, colocando la lógica de traducción en un componente externo dedicado.
Contexto en el que Emerge¶
Channel Adapter emerge en prácticamente toda implementación de messaging enterprise, porque toda organización tiene sistemas que no hablan messaging nativamente. Es especialmente frecuente en:
- Integraciones con sistemas legacy (mainframes, aplicaciones on-premise).
- Integración de bases de datos como fuentes de eventos (CDC).
- Conexión de APIs REST/SOAP al mundo event-driven.
- Integración de sistemas SaaS (Salesforce, SAP, Workday) con plataformas internas de messaging.
Por Qué No Es Trivial¶
Un Channel Adapter parece simple ("leer de la API, escribir en Kafka"), pero los desafíos reales son significativos:
- Semántica de entrega: ¿cómo garantiza el adapter at-least-once delivery cuando traduce de REST (síncrono) a messaging (asíncrono)? Si el adapter lee un registro de la base de datos, lo envía a Kafka, y falla antes de marcar el registro como procesado, ¿se duplica?
- Transformación: la estructura de datos de la aplicación fuente raramente coincide con el formato esperado en el canal. El adapter debe transformar, enriquecer o filtrar los datos.
- Detección de cambios: en un adapter inbound que lee de una base de datos, ¿cómo detecta qué registros son nuevos o modificados? ¿Polling periódico? ¿Triggers? ¿CDC vía transaction log?
- Manejo de errores: si la aplicación destino rechaza una operación (outbound adapter), ¿qué hace con el mensaje? ¿Retry? ¿Dead letter? ¿Compensación?
- Estado del adapter: el adapter necesita mantener estado (último offset procesado, último timestamp consultado) para saber qué datos ya procesó. ¿Dónde se almacena este estado? ¿Es durable?
Relación con Sistemas Distribuidos y Mensajería¶
Channel Adapter es el punto de contacto entre el mundo de messaging y el mundo de aplicaciones que no participan nativamente. En la taxonomía de patrones de integración, es uno de los patrones de infraestructura más prácticos: sin adapters, la arquitectura de messaging queda limitada a las aplicaciones que tienen SDKs nativos del broker. Con adapters, toda aplicación empresarial puede participar.
En plataformas modernas, Channel Adapter se ha industrializado enormemente:
- Kafka Connect: framework dedicado a Channel Adapters, con source connectors (inbound) y sink connectors (outbound), gestión distribuida de workers, offset tracking automático y fault tolerance.
- Debezium: familia de adapters CDC que leen el transaction log de bases de datos (PostgreSQL WAL, MySQL binlog, Oracle LogMiner) y producen eventos en Kafka, sin modificar la aplicación que escribe en la base de datos.
- MuleSoft Anypoint: plataforma de integración con cientos de conectores pre-construidos para SaaS, databases, protocols y messaging systems.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Channel Adapter, las organizaciones enfrentan una barrera fundamental: los sistemas que más necesitan integrarse (ERPs, CRMs, bases de datos transaccionales, sistemas legacy) son los que menos capacidad tienen de hablar messaging nativamente. El resultado es una de estas situaciones:
- Integración punto-a-punto: cada par de sistemas tiene una integración custom (ETL, API call, archivo compartido) sin pasar por el messaging, creando una maraña de conexiones difícil de mantener.
- Modificación invasiva: se modifica el código de la aplicación para añadir lógica de messaging, mezclando concerns y creando dependencias del broker en aplicaciones que no deberían tenerlas.
- Exclusión: los sistemas que no pueden adaptarse quedan excluidos de la arquitectura event-driven, creando islas de datos desconectadas.
Síntomas del Problema¶
- Sistemas legacy con datos valiosos que no participan en la arquitectura event-driven porque "no hablan Kafka".
- Equipos que implementan polling manual contra bases de datos para detectar cambios, con lógica frágil de tracking de "último registro procesado".
- APIs REST que se llaman síncronamente para obtener datos que deberían fluir como eventos asíncronos.
- Procesos ETL batch que mueven datos cada hora/día cuando podrían fluir en near-real-time como eventos.
- Código de integración embebido en la lógica de negocio de las aplicaciones, acoplando la aplicación al broker específico.
Impacto Operativo y Arquitectónico¶
Sin adapters bien diseñados:
- La arquitectura event-driven tiene "agujeros" — sistemas importantes que no participan, forzando workarounds.
- Los equipos de desarrollo gastan tiempo implementando lógica de integración ad-hoc en lugar de usar infraestructura declarativa.
- Los cambios en el sistema fuente (nueva tabla, nuevo campo, nueva API) requieren cambios en el código de integración embebido.
- La observabilidad de la integración es parcial: los adapters ad-hoc raramente tienen monitoreo, retry y dead-lettering estándar.
Riesgos Si No Se Implementa Correctamente¶
- Pérdida de eventos: un adapter que hace polling a una base de datos y no trackea correctamente el último registro procesado puede perder registros insertados entre intervalos de polling.
- Duplicados: un adapter que reenvía datos sin deduplicación produce duplicados en el canal de mensajería, contaminando a todos los consumidores downstream.
- Acoplamiento oculto: un adapter que expone la estructura interna de la base de datos fuente en los mensajes acopla a todos los consumidores al schema interno de la aplicación.
- Bottleneck: un adapter single-threaded que no puede manejar el throughput de la aplicación fuente se convierte en cuello de botella de toda la integración.
Ejemplos Reales¶
- Retail — POS a messaging: un sistema Point of Sale que registra ventas vía REST API necesita un adapter que convierta cada venta en un evento
sales.transaction.completeden Kafka, para que los sistemas de inventario, analytics, loyalty y contabilidad lo consuman. - Banca — Core bancario a eventos: un core bancario legacy (COBOL, mainframe) genera transacciones en tablas DB2. Un adapter CDC (Debezium for Db2) lee el transaction log y produce eventos en Kafka sin modificar el core.
- Salud — HL7 a messaging: un sistema HIS (Hospital Information System) envía mensajes HL7 v2 vía TCP/MLLP. Un adapter traduce estos mensajes a formato FHIR JSON y los deposita en un topic de Kafka para consumo por aplicaciones modernas.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando una aplicación necesita participar en la arquitectura de messaging pero no tiene SDK nativo del broker.
- Cuando se quiere evitar modificar el código fuente de la aplicación (especialmente en sistemas legacy, COTS o SaaS).
- Cuando se necesita convertir operaciones síncronas (REST API, database queries) en eventos asíncronos.
- Cuando se requiere Change Data Capture para convertir cambios en base de datos en eventos sin modificar la aplicación que escribe.
- Cuando se necesita conectar un sistema SaaS externo (Salesforce, SAP, Workday) con la plataforma interna de messaging.
Cuándo No Usarlo¶
- Cuando la aplicación ya tiene un SDK nativo del broker y puede producir/consumir directamente (por ejemplo, un microservicio con Kafka client library).
- Cuando la integración es puramente síncrona (request-response) y no se necesita desacoplamiento asíncrono — en este caso, un API Gateway es más apropiado.
- Cuando el volumen de datos es tan bajo y la frecuencia tan esporádica que un adapter permanente es over-engineering — una Lambda function trigger podría ser suficiente.
Precondiciones¶
- Existe una infraestructura de messaging (broker) donde depositar o consumir mensajes.
- La aplicación fuente tiene algún mecanismo accesible para extraer datos (API, base de datos, transaction log, archivos, webhooks).
- Existe un formato de mensaje definido (schema) para los eventos que el adapter debe producir o consumir.
- Se ha definido el canal (topic, queue) donde el adapter depositará o consumirá mensajes.
Restricciones¶
- El adapter está limitado por la capacidad de la interfaz del sistema adaptado (throughput de la API, velocidad de lectura del transaction log, frecuencia de archivos batch).
- La latencia del adapter depende del mecanismo de detección de cambios: CDC vía transaction log es near-real-time (~ms), polling es periódico (~seconds/minutes), archivos batch es por schedule.
- El adapter introduce un punto de fallo adicional entre la aplicación y el broker.
Dependencias¶
- Acceso a la interfaz del sistema adaptado (credentials de API, acceso a base de datos, permisos de lectura del transaction log).
- Infraestructura para ejecutar el adapter (Kafka Connect cluster, servidor de integración, contenedor).
- Schema Registry si se usa serialización con schema (Avro, Protobuf).
Supuestos Arquitectónicos¶
- El adapter es un componente de infraestructura, no de negocio. Su lógica debe limitarse a traducción y transporte, no a reglas de negocio.
- El adapter es operado por el equipo de plataforma o integración, no por el equipo de la aplicación adaptada.
- El adapter debe ser tan invisible como posible: la aplicación fuente no debería saber que tiene un adapter conectado (especialmente en CDC).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Integraciones con sistemas legacy (mainframes, ERPs on-premise).
- Integración de bases de datos como fuentes de eventos (CDC con Debezium).
- Conexión de sistemas SaaS con plataformas internas de messaging.
- Modernización de integraciones batch a near-real-time streaming.
- Arquitecturas de data mesh donde cada dominio expone sus datos como eventos.
6. Fuerzas Arquitectónicas¶
Invasividad vs. Funcionalidad¶
Modificar la aplicación fuente para producir mensajes directamente ofrece máxima funcionalidad (control total sobre qué eventos se producen, con qué formato, cuándo) pero es invasivo, costoso y a veces imposible (sistemas COTS, SaaS). Un Channel Adapter externo no requiere modificación pero está limitado por lo que la interfaz del sistema permite extraer. La tensión es entre el control que da la modificación y la no-invasividad que da el adapter.
Latencia vs. Impacto en el Sistema Fuente¶
Un adapter que lee el transaction log de la base de datos (CDC) ofrece latencia muy baja (<1 segundo) con impacto mínimo en la aplicación. Un adapter que hace polling vía API tiene latencia proporcional al intervalo de polling y genera carga en la API de la aplicación. Un adapter que lee archivos batch tiene la latencia más alta pero zero impacto en la aplicación durante su operación normal. El mecanismo de extracción determina el trade-off entre frescura de datos e impacto en el sistema fuente.
Acoplamiento al Schema Interno vs. Modelo Canónico¶
Un adapter puede producir mensajes que replican la estructura interna de la tabla o API fuente (máximo acoplamiento, mínimo esfuerzo de transformación) o puede transformar los datos a un modelo canónico del dominio (mínimo acoplamiento, máximo esfuerzo de transformación). La decisión afecta a todos los consumidores downstream.
Simplicidad vs. Resiliencia¶
Un adapter simple (leer de API, escribir en Kafka, sin gestión de estado ni retry) es fácil de construir pero frágil. Un adapter resiliente (con offset tracking durable, retry con backoff, dead-letter handling, checkpointing) es robusto pero complejo. Las plataformas como Kafka Connect proporcionan la resiliencia como infraestructura, simplificando el desarrollo del adapter individual.
Generalización vs. Especialización¶
Un adapter genérico (lee cualquier tabla, produce cualquier formato) es reutilizable pero requiere configuración compleja. Un adapter especializado (lee la tabla pos_transactions, produce eventos sales.transaction.completed con schema específico) es simple de configurar pero no reutilizable. Las plataformas de conectores (Kafka Connect, MuleSoft) ofrecen adapters genéricos con configuración declarativa, ofreciendo el equilibrio entre ambos extremos.
Throughput del Adapter vs. Throughput del Sistema Fuente¶
El adapter debe mantener el ritmo del sistema fuente. Si el POS genera 1,000 transacciones/segundo y el adapter solo puede procesar 100/segundo, se acumula un backlog creciente. El dimensionamiento del adapter debe considerar el throughput máximo de la fuente, no solo el promedio.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Aplicación No-Messaging: el sistema que no tiene capacidad nativa de messaging (ERP, base de datos, API REST, sistema legacy).
- Channel Adapter (Inbound / Source): componente que extrae datos/eventos de la aplicación y los produce como mensajes en un canal.
- Channel Adapter (Outbound / Sink): componente que consume mensajes de un canal y los traduce en operaciones contra la aplicación.
- Canal de Mensajería: el topic o queue donde el adapter deposita o consume mensajes.
- Offset/State Store: almacenamiento del estado del adapter (último registro procesado, último offset, checkpoint) para resiliencia.
Flujo Lógico — Inbound (Source) Adapter¶
flowchart TD
A[Adapter: Consulta state store] -->|Último punto procesado| B[Lee datos de la aplicación fuente]
B --> C[Transforma al formato del mensaje destino]
C --> D[Produce mensaje en el canal]
D --> E[Canal/Broker: Confirma recepción - ACK]
E --> F[(State Store: Actualiza punto procesado)]
F -->|Repite ciclo| BFlujo Lógico — Outbound (Sink) Adapter¶
flowchart TD
A[(Canal de Mensajería)] --> B[Adapter: Consume mensaje]
B --> C[Transforma al formato de la app destino]
C --> D[Ejecuta operación en destino]
D --> E[Aplicación: Confirma operación exitosa]
E --> F[Adapter: Commit offset al broker]
F -->|Repite ciclo| AResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Aplicación fuente | Exponer interfaz accesible (API, DB, log, archivo) |
| Inbound Adapter | Detectar cambios, extraer datos, transformar, producir mensajes, trackear progreso |
| Outbound Adapter | Consumir mensajes, transformar, ejecutar operación en destino, confirmar procesamiento |
| Canal | Almacenar y transportar mensajes entre adapters y otros participantes |
| State Store | Persistir el estado del adapter para recovery tras fallos |
Interacciones¶
- Aplicación → Inbound Adapter: lectura pasiva (la aplicación no sabe que el adapter existe, como en CDC) o activa (la aplicación envía datos al adapter vía webhook o push).
- Inbound Adapter → Canal: producción de mensajes con semántica at-least-once.
- Canal → Outbound Adapter: consumo de mensajes.
- Outbound Adapter → Aplicación: ejecución de operación (API call, DB write).
Contratos Implícitos¶
- Formato de mensaje: el adapter define la estructura del mensaje que produce o consume. Este es el contrato con el resto de la arquitectura de messaging.
- Semántica de entrega: typically at-least-once. El adapter garantiza que cada evento de la fuente se produce al menos una vez en el canal.
- Transformación: el adapter es responsable de la transformación entre el formato nativo del sistema y el formato del canal.
Decisiones de Diseño Clave¶
- Mecanismo de detección de cambios: CDC (transaction log), polling (query periódica), webhook (push del sistema), file watching. CDC es preferible cuando está disponible.
- Granularidad de transformación: raw (1:1 con la fuente) vs. transformado (modelo canónico). Transformar en el adapter simplifica los consumidores; raw en el adapter delega la transformación.
- Gestión de estado: dónde y cómo almacenar el progreso del adapter (Kafka Connect usa topics internos; custom adapters usan databases o archivos).
- Paralelismo: un adapter single-threaded vs. múltiples workers paralelos (Kafka Connect tasks).
- Manejo de errores: retry, dead-letter, circuit breaker, alerting.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail — Sistema POS a Arquitectura Event-Driven¶
Contexto del Negocio¶
Una cadena de retail con 500 tiendas en España y Portugal opera un sistema POS (Point of Sale) propietario que registra todas las transacciones de venta. El sistema POS fue desarrollado hace 12 años y expone una REST API para consulta de transacciones y un webhook para notificaciones de ventas en tiempo real. El POS no tiene capacidad nativa de producir mensajes a Kafka ni a ningún broker de mensajería.
La organización está implementando una arquitectura event-driven para modernizar sus operaciones. Múltiples sistemas necesitan recibir eventos de venta en near-real-time:
- Inventory Service: actualizar stock en tiempo real.
- Analytics Platform: dashboards de ventas en tiempo real para directivos.
- Loyalty Service: acumular puntos de fidelización.
- Fraud Detection: detectar patrones de fraude en transacciones.
- Accounting Service: registrar movimientos contables.
Necesidad de Integración¶
Las 500 tiendas generan aproximadamente 200,000 transacciones de venta al día (picos de 50 transacciones/segundo durante horas punta). Estas transacciones deben fluir desde el POS a Kafka para que los 5 servicios consumidores las procesen. El POS no puede modificarse (vendor lock-in del contrato de soporte), así que la integración debe ser no-invasiva.
Sistemas Involucrados¶
- POS System: 500 instancias (una por tienda) con REST API y webhooks.
- Channel Adapter (POS Adapter): servicio que recibe webhooks del POS y produce eventos en Kafka.
- Kafka Cluster: plataforma de mensajería central.
- Kafka Connect (JDBC Sink): sink adapter para alimentar el data warehouse.
- Schema Registry: validación de formato de mensajes.
- Inventory Service, Analytics, Loyalty, Fraud, Accounting: consumidores.
Restricciones Técnicas¶
- El POS no puede modificarse.
- La REST API del POS tiene rate limiting de 100 requests/segundo por tienda.
- El webhook del POS envía un POST HTTP con la transacción en formato JSON propietario.
- La latencia máxima aceptable desde venta hasta evento en Kafka: 5 segundos.
- El adapter debe ser resiliente: si Kafka está temporalmente no disponible, las transacciones no deben perderse.
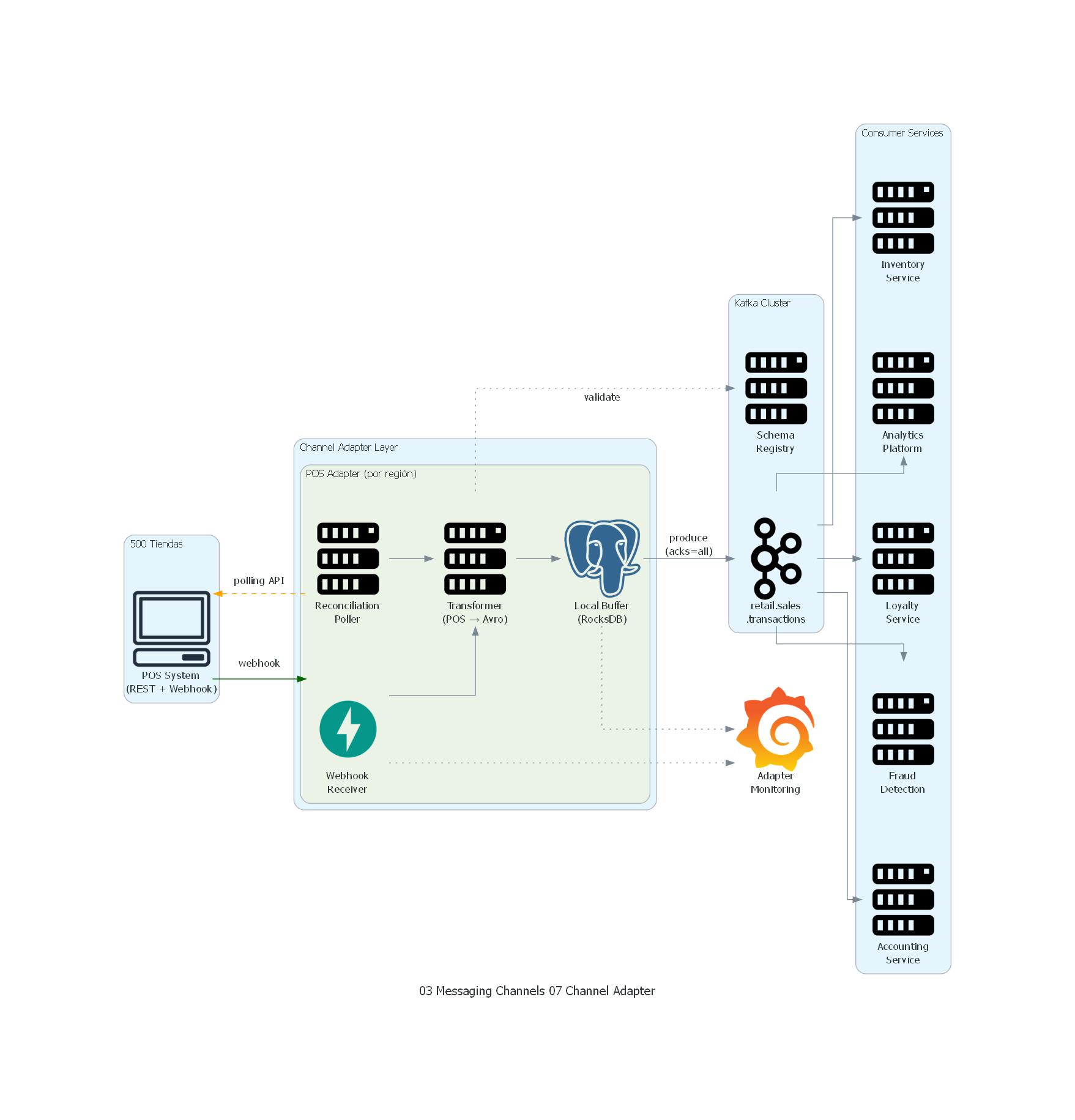
Diseño del Channel Adapter¶
Componentes del Adapter:
| Componente | Función |
|---|---|
| Webhook Receiver | Recibe POSTs del POS (endpoint HTTP) |
| Internal Buffer | Buffer en disco para resiliencia ante indisponibilidad de Kafka |
| Transformer | Convierte formato JSON propietario del POS a schema Avro canónico |
| Kafka Producer | Produce eventos al topic retail.sales.transactions |
| Reconciliation Poller | Polling periódico a la REST API del POS para detectar transacciones perdidas |
Decisiones Arquitectónicas¶
-
Webhook + Polling reconciliation: el webhook proporciona near-real-time (<1s), pero puede perder transacciones si el adapter está momentáneamente no disponible. El poller reconcilia cada 15 minutos, consultando transacciones de los últimos 30 minutos y verificando que todas están en Kafka (deduplicación por
transaction_id). -
Buffer local persistente: cuando Kafka no está disponible, el adapter almacena las transacciones en un buffer en disco local (embedded RocksDB). Cuando Kafka se recupera, el buffer se drena al topic. Esto desacopla la disponibilidad del POS de la disponibilidad de Kafka.
-
Transformación a modelo canónico: el adapter transforma el JSON propietario del POS a un schema Avro canónico definido por el equipo de dominio. Los consumidores downstream reciben un formato estándar, independiente de la implementación del POS.
-
Despliegue distribuido: un adapter por región (10 regiones, 50 tiendas cada una) para distribuir la carga y limitar el blast radius de fallos.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Webhook perdido (adapter down) | Reconciliation poller cada 15 minutos |
| Kafka temporalmente no disponible | Buffer local en disco (RocksDB) |
| Transacción duplicada | Deduplicación por transaction_id en el adapter |
| Formato del POS cambia | Schema validation en el adapter con alertas si la transformación falla |
| Adapter single point of failure | Deploy en HA con 2 instancias por región (active-passive) |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Venta en Tienda¶
Un cliente compra 3 artículos en la tienda de Madrid Gran Vía (store_id: ES-MAD-001). El POS registra la venta y envía un webhook al adapter:
{
"pos_txn_id": "TXN-ES-MAD-001-20260407-093215-4821",
"store_code": "ES-MAD-001",
"register_id": "REG-03",
"cashier_id": "EMP-28471",
"timestamp": "2026-04-07T09:32:15.482Z",
"items": [
{"sku": "7501234567890", "desc": "Camiseta algodón L", "qty": 2, "unit_price": 19.99, "line_total": 39.98},
{"sku": "7509876543210", "desc": "Pantalón vaquero 32", "qty": 1, "unit_price": 49.99, "line_total": 49.99}
],
"subtotal": 89.97,
"tax_rate": 0.21,
"tax_amount": 18.89,
"total": 108.86,
"payment_method": "CARD",
"card_last4": "4821",
"currency": "EUR"
}
Paso 2: Recepción en el Webhook Receiver¶
El adapter (desplegado en la región Madrid) recibe el POST en su endpoint https://pos-adapter-mad.internal:8443/webhook/pos:
- Valida el payload (campos obligatorios presentes, tipos correctos).
- Valida la firma HMAC del webhook para autenticidad.
- Asigna un
event_idUUID para trazabilidad. - Envía el payload al Transformer.
Paso 3: Transformación a Modelo Canónico¶
El Transformer convierte el JSON propietario del POS al schema Avro canónico retail.sales.Transaction:
{
"event_id": "evt-a8f3c291-7e42-4b1a-9d5e-3f8a2c6e9b14",
"event_type": "sales.transaction.completed",
"event_time": "2026-04-07T09:32:15.482Z",
"source": "pos-adapter-mad",
"transaction_id": "TXN-ES-MAD-001-20260407-093215-4821",
"store_id": "ES-MAD-001",
"register_id": "REG-03",
"operator_id": "EMP-28471",
"line_items": [
{"product_id": "7501234567890", "description": "Camiseta algodón L", "quantity": 2, "unit_price_cents": 1999, "line_total_cents": 3998},
{"product_id": "7509876543210", "description": "Pantalón vaquero 32", "quantity": 1, "unit_price_cents": 4999, "line_total_cents": 4999}
],
"subtotal_cents": 8997,
"tax_percent": 21,
"tax_cents": 1889,
"total_cents": 10886,
"payment": {"method": "CARD", "card_last_four": "4821"},
"currency": "EUR"
}
Nótese las transformaciones: precios convertidos a céntimos (evitar floating point), campos renombrados al modelo canónico, metadata de evento añadida (event_id, event_type, source).
Paso 4: Producción en Kafka¶
El Kafka Producer serializa el evento con Avro (validado contra el Schema Registry) y lo produce al topic retail.sales.transactions con partition key store_id (para mantener orden por tienda):
- El producer envía con
acks=all. - El broker confirma la persistencia.
- El adapter registra el
event_idcomo producido exitosamente.
Paso 5: Consumo por Inventory Service¶
El Inventory Service (consumer group: cg-inventory) consume el evento:
- Lee la transacción de la tienda ES-MAD-001.
- Reduce el stock de SKU 7501234567890 en 2 unidades.
- Reduce el stock de SKU 7509876543210 en 1 unidad.
- Verifica si algún SKU queda por debajo del punto de reorden.
- Confirma el offset.
Paso 6: Reconciliación Periódica¶
Cada 15 minutos, el Reconciliation Poller del adapter:
- Consulta la REST API del POS para transacciones de los últimos 30 minutos.
- Compara cada
transaction_idcon su registro interno de transacciones ya producidas. - Si encuentra una transacción no producida (webhook perdido), la procesa como si fuera un webhook.
- Produce métricas:
pos.adapter.reconciliation.recovered_count=0(indicando que no hubo pérdidas, o el número de transacciones recuperadas).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.client import Client
from diagrams.onprem.monitoring import Grafana
from diagrams.programming.framework import FastAPI
with Diagram("Channel Adapter - Retail POS Integration", show=False, direction="LR"):
with Cluster("500 Tiendas"):
pos = Client("POS System\n(REST + Webhook)")
with Cluster("Channel Adapter Layer"):
with Cluster("POS Adapter (por región)"):
webhook = FastAPI("Webhook\nReceiver")
transformer = Server("Transformer\n(POS → Avro)")
buffer = PostgreSQL("Local Buffer\n(RocksDB)")
poller = Server("Reconciliation\nPoller")
with Cluster("Kafka Cluster"):
topic = Kafka("retail.sales\n.transactions")
schema_reg = Server("Schema\nRegistry")
with Cluster("Consumer Services"):
inventory = Server("Inventory\nService")
analytics = Server("Analytics\nPlatform")
loyalty = Server("Loyalty\nService")
fraud = Server("Fraud\nDetection")
accounting = Server("Accounting\nService")
monitoring = Grafana("Adapter\nMonitoring")
# POS → Adapter
pos >> Edge(label="webhook", color="darkgreen") >> webhook
pos << Edge(label="polling API", color="orange", style="dashed") << poller
# Adapter internal
webhook >> transformer
poller >> transformer
transformer >> buffer
buffer >> Edge(label="produce\n(acks=all)") >> topic
transformer >> Edge(style="dotted", label="validate") >> schema_reg
# Consumption
topic >> inventory
topic >> analytics
topic >> loyalty
topic >> fraud
topic >> accounting
# Monitoring
webhook >> Edge(style="dotted") >> monitoring
buffer >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import Eventbridge, SNS, SQS
from diagrams.aws.iot import IotCore
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
with Diagram("Channel Adapter - Retail POS Integration (AWS)", show=False, direction="LR"):
with Cluster("500 Tiendas"):
pos = IotCore("POS System\n(IoT Core)")
with Cluster("Channel Adapter Layer"):
with Cluster("POS Adapter (EventBridge Pipes)"):
webhook = APIGateway("API Gateway\nWebhook")
transformer = Lambda("Transformer\n(Lambda)")
buffer = Dynamodb("Outbox Buffer\n(DynamoDB)")
poller = Lambda("Reconciliation\nPoller\n(EventBridge\nSchedule)")
with Cluster("SNS Fan-Out"):
topic = SNS("retail.sales\n.transactions\n(SNS Topic)")
with Cluster("Consumer Services (SQS → Lambda)"):
inventory = Lambda("Inventory\nService")
analytics = Lambda("Analytics\nPlatform")
loyalty = Lambda("Loyalty\nService")
fraud = Lambda("Fraud\nDetection")
accounting = Lambda("Accounting\nService")
monitoring = Cloudwatch("CloudWatch\nAdapter Metrics")
# POS → Adapter
pos >> Edge(label="webhook", color="darkgreen") >> webhook
pos << Edge(label="polling API", color="orange", style="dashed") << poller
# Adapter internal
webhook >> transformer
poller >> transformer
transformer >> buffer
buffer >> Edge(label="DynamoDB Streams\n→ Lambda → SNS") >> topic
# SNS → SQS → Lambda consumption
topic >> inventory
topic >> analytics
topic >> loyalty
topic >> fraud
topic >> accounting
# Monitoring
webhook >> Edge(style="dotted") >> monitoring
buffer >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import Client
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus, LogicApps, EventGridTopics
with Diagram("Channel Adapter - Retail POS Integration (Azure)", show=False, direction="LR"):
with Cluster("500 Tiendas"):
pos = Client("POS System\n(REST + Webhook)")
with Cluster("Channel Adapter Layer\n(Logic Apps = Connectors)"):
with Cluster("POS Adapter (per region)"):
webhook = FunctionApps("Webhook Receiver\n(HTTP Trigger)")
adapter = LogicApps("Logic App\nPOS Adapter\n(Transform + Route)")
poller = LogicApps("Logic App\nReconciliation\nPoller")
with Cluster("Azure Service Bus"):
topic = ServiceBus("retail.sales\n.transactions\n(Topic)")
with Cluster("Consumer Services (Azure Functions)"):
inventory = FunctionApps("Inventory\nService")
analytics = FunctionApps("Analytics\nPlatform")
loyalty = FunctionApps("Loyalty\nService")
fraud = FunctionApps("Fraud\nDetection")
accounting = FunctionApps("Accounting\nService")
monitoring = ApplicationInsights("Application Insights\n(Adapter Monitoring)")
# POS → Adapter
pos >> Edge(label="webhook", color="darkgreen") >> webhook
pos << Edge(label="polling API", color="orange", style="dashed") << poller
# Adapter internal (Logic App transforms and routes)
webhook >> adapter
poller >> adapter
adapter >> Edge(label="send to\nService Bus") >> topic
# Consumption (via subscriptions)
topic >> inventory
topic >> analytics
topic >> loyalty
topic >> fraud
topic >> accounting
# Monitoring
webhook >> Edge(style="dotted") >> monitoring
adapter >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
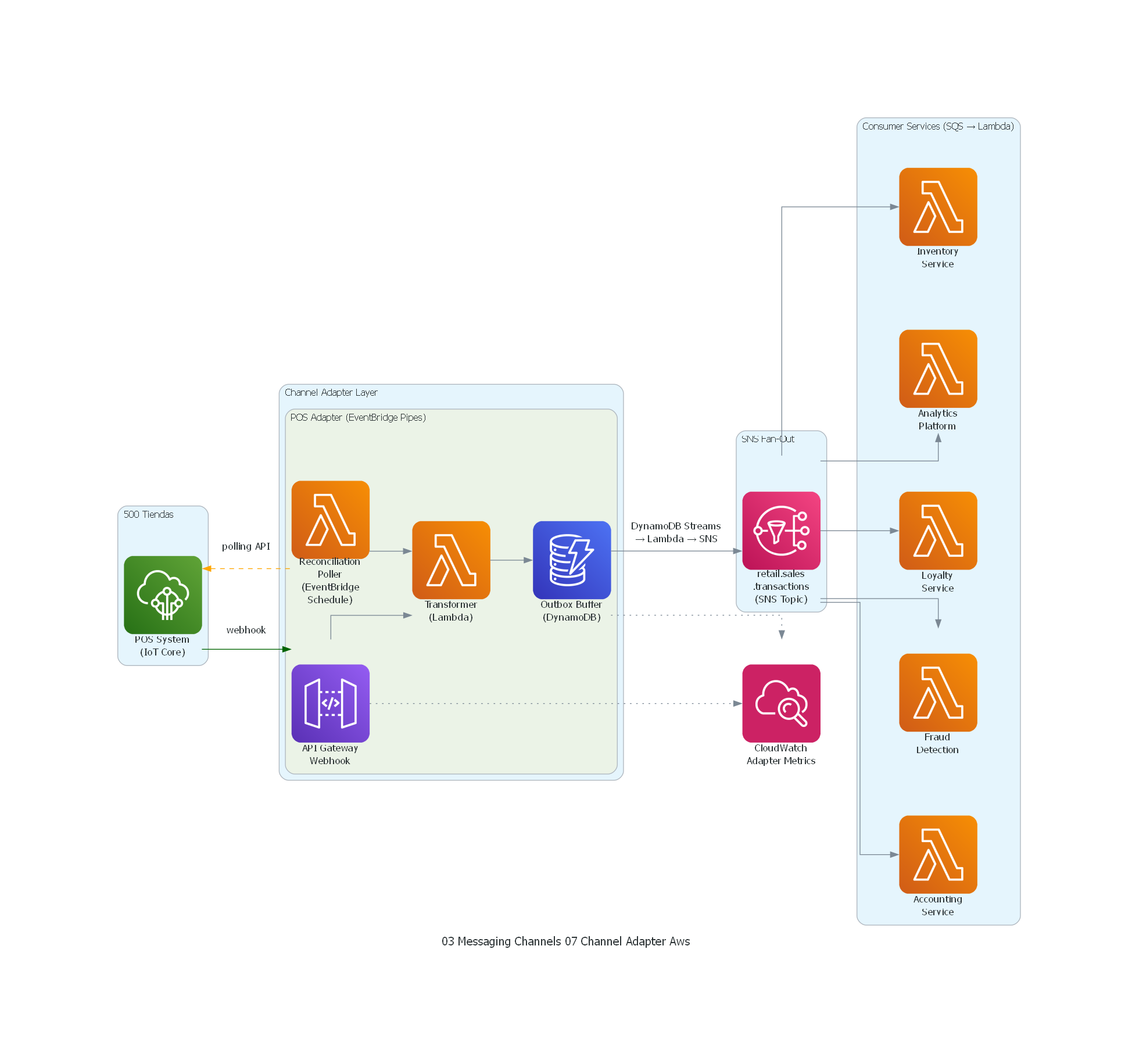
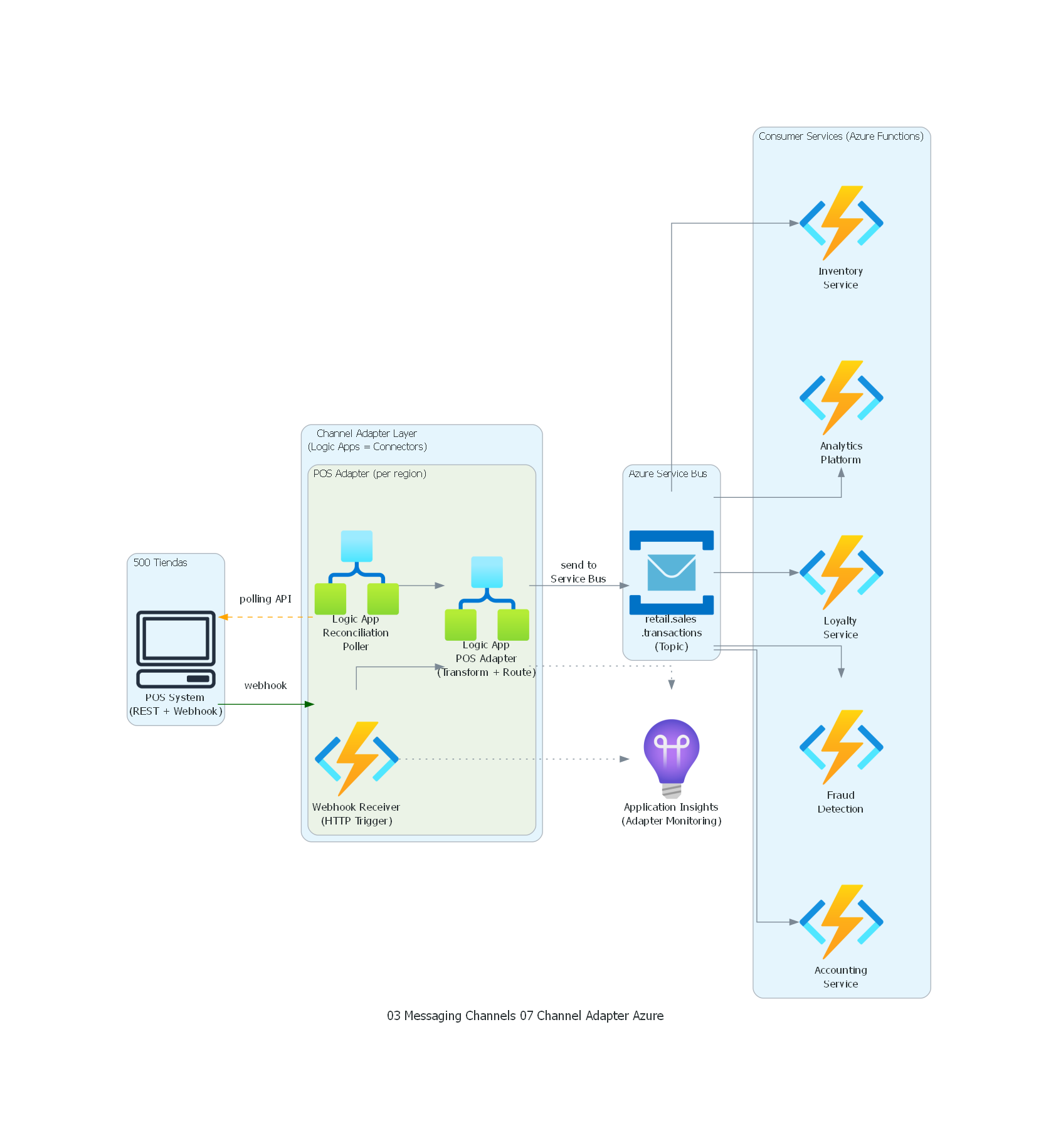
El diagrama muestra la arquitectura del Channel Adapter para integración del POS:
- POS System (500 tiendas) envía transacciones vía webhook al adapter y expone REST API para reconciliación.
- Webhook Receiver recibe notificaciones push en near-real-time.
- Reconciliation Poller consulta periódicamente la API para detectar transacciones perdidas.
- Transformer convierte el formato propietario del POS al modelo canónico Avro, validando contra el Schema Registry.
- Local Buffer almacena transacciones en disco cuando Kafka no está disponible.
- Los mensajes se producen al topic retail.sales.transactions con
acks=all. - Los 5 Consumer Services consumen del topic de forma independiente.
- Grafana monitorea el health del adapter (webhooks recibidos, buffer size, producción exitosa).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Aplicación No-Messaging | POS System (REST + Webhook) |
| Inbound Channel Adapter | Webhook Receiver + Transformer + Buffer |
| Mecanismo de detección (push) | Webhook |
| Mecanismo de detección (pull) | Reconciliation Poller |
| Transformación | Transformer (POS JSON → Avro canónico) |
| Canal de Mensajería | Topic retail.sales.transactions |
| State Store | Local Buffer (RocksDB) |
| Consumidores | Inventory, Analytics, Loyalty, Fraud, Accounting |
11. Beneficios¶
Impacto Técnico¶
- Integración sin modificación: el POS no requiere ninguna modificación. El adapter se conecta a sus interfaces existentes (webhook, REST API) sin impactar su funcionamiento.
- Near-real-time: las transacciones de venta fluyen en <2 segundos desde el POS hasta Kafka, habilitando casos de uso que antes requerían horas con procesos batch.
- Desacoplamiento del POS: los 5 consumidores no dependen directamente del POS. Si el POS se reemplaza por otro sistema, solo el adapter necesita modificarse — los consumidores siguen consumiendo del mismo topic con el mismo schema.
- Resiliencia: el buffer local permite que el adapter continúe aceptando webhooks incluso cuando Kafka tiene downtime. Las transacciones no se pierden.
Impacto Organizacional¶
- Separación de responsabilidades: el equipo de POS/tiendas gestiona el POS; el equipo de plataforma gestiona el adapter; los equipos de dominio (inventario, loyalty, etc.) gestionan sus consumidores. Cada equipo evoluciona independientemente.
- Reutilización: el adapter produce un evento canónico que cualquier equipo puede consumir sin coordinación con el equipo de POS.
- Velocidad de integración: añadir un sexto consumidor (por ejemplo, marketing campaigns) solo requiere crear un nuevo consumer group — no requiere cambios en el POS ni en el adapter.
Impacto Operacional¶
- Monitoreo centralizado: el adapter produce métricas estándar (webhooks recibidos/segundo, transformations/segundo, buffer size, production success rate) que se integran en el dashboard general de la plataforma.
- Reconciliación automática: el poller detecta y recupera transacciones perdidas sin intervención manual.
- Evolución del POS transparente: si el POS cambia su formato de webhook, solo el Transformer del adapter necesita actualizarse.
Beneficios de Mantenibilidad y Evolución¶
- Migración de POS: si la organización reemplaza el POS propietario por otro sistema, solo necesita desarrollar un nuevo adapter. Los 5 consumidores no se enteran.
- Evolución del schema: el adapter puede evolucionar el schema Avro (con compatibilidad backward en el Schema Registry) para incluir nuevos campos del POS sin impactar consumidores existentes.
- Extensibilidad: el adapter puede enriquecerse con nuevas funciones (filtrado, enriquecimiento con datos de catálogo) sin modificar el POS ni los consumidores.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente adicional: el adapter es un servicio más que desplegar, monitorear, mantener y escalar. En una organización con decenas de sistemas fuente, la cantidad de adapters puede ser significativa.
- Lógica de detección de cambios: implementar correctamente el tracking de "qué datos ya procesé" es complejo, especialmente con mecanismos de polling. CDC vía transaction log simplifica esto pero requiere acceso privilegiado a la base de datos.
- Transformación compleja: si la transformación del formato propietario al canónico es compleja (joins entre múltiples tablas, enriquecimiento con datos externos), el adapter se convierte en un componente sofisticado que requiere testing exhaustivo.
Riesgos de Mal Uso¶
- Adapter como ETL: sobrecargar el adapter con lógica de negocio compleja (validaciones, cálculos, aggregaciones) lo convierte en un ETL disfrazado. El adapter debe traducir y transportar, no procesar.
- Acoplamiento al schema interno: producir mensajes que replican exactamente la estructura de la tabla fuente acopla a todos los consumidores al modelo de datos interno del POS. La transformación a un modelo canónico es esencial.
- Adapter sin monitoreo: un adapter sin métricas ni alertas puede fallar silenciosamente, dejando de producir eventos sin que nadie lo note hasta que los consumidores reportan datos faltantes.
Sobreingeniería¶
- Adapter custom cuando existe conector estándar: implementar un adapter JDBC custom cuando Kafka Connect tiene un JDBC Source Connector configurable desperdicia esfuerzo.
- Buffer excesivo: implementar un buffer local sofisticado cuando la plataforma de messaging tiene alta disponibilidad y el adapter puede simplemente reintentar.
- Reconciliación over-engineered: implementar reconciliación compleja con comparación de checksums cuando la deduplicación por ID es suficiente.
Costos de Operación¶
- Infraestructura del adapter: compute, storage, networking para el adapter. En organizaciones con muchos adapters, el costo agregado es significativo.
- Mantenimiento ante cambios: cuando el sistema fuente cambia su API o formato, el adapter debe actualizarse. Esto crea una dependencia de mantenimiento continuo.
- Testing: el adapter necesita tests de integración con el sistema fuente y con el broker, lo cual es más complejo que unit tests aislados.
Anti-Patterns Relacionados¶
- Adapter Monolith: un solo adapter gigante que conecta 50 sistemas fuente a Kafka. Imposible de mantener, escalar y depurar. Cada sistema fuente debe tener su propio adapter.
- Bidirectional Adapter Without Care: un adapter que es simultáneamente source y sink para el mismo sistema sin gestión cuidadosa de loops puede causar ciclos infinitos de eventos.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): el adapter produce mensajes en un canal o consume de uno. El canal es la infraestructura sobre la cual opera el adapter.
- Message Translator (Capítulo 5): la transformación que realiza el adapter es una instancia de Message Translator. La diferencia es que en Channel Adapter la traducción está integrada en el componente de conectividad.
- Guaranteed Delivery (este capítulo): el adapter debe participar en la cadena de Guaranteed Delivery, esperando acks del broker antes de confirmar el procesamiento.
- Messaging Bridge (este capítulo): si el adapter conecta dos sistemas de messaging (en lugar de un sistema non-messaging), es un Messaging Bridge.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: la decisión de integrar un sistema no-messaging en la arquitectura event-driven precede al diseño del adapter.
- Después: Content-Based Router, Splitter, Aggregator y otros patrones de procesamiento operan sobre los mensajes que el adapter produce.
Combinaciones Comunes¶
- Channel Adapter + Content-Based Router: el adapter produce todos los eventos de la fuente en un canal; un router los distribuye a canales específicos según el tipo de evento.
- Channel Adapter + Dead Letter Channel: cuando el adapter (outbound) no puede ejecutar la operación en el destino, envía el mensaje a un dead letter channel.
- Channel Adapter + Idempotent Receiver: el adapter outbound debe ser idempotente porque puede recibir el mismo mensaje múltiples veces (at-least-once).
Diferencias con Patrones Similares¶
- vs. Messaging Bridge: Channel Adapter conecta un sistema non-messaging al messaging. Messaging Bridge conecta dos sistemas de messaging entre sí.
- vs. Message Endpoint: Message Endpoint es la abstracción general de cómo una aplicación se conecta al messaging. Channel Adapter es un tipo específico de endpoint para aplicaciones que no pueden conectarse directamente.
- vs. Service Activator: Service Activator invoca un servicio cuando llega un mensaje. Channel Adapter es más amplio: puede producir mensajes (no solo consumir) y puede usar mecanismos no invocativos (CDC, file watching).
Encaje en un Flujo Mayor de Integración¶
Channel Adapter está en los extremos del flujo de integración: es el primer patrón que se aplica para incorporar sistemas al mundo messaging y el último que se aplica para llevar resultados de vuelta a sistemas no-messaging. Entre los adapters, todos los demás patrones (routers, filters, transformers, aggregators) operan sobre mensajes ya dentro de la infraestructura de messaging.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Channel Adapter es posiblemente el patrón más implementado en las plataformas modernas de integración:
- Kafka Connect: es literalmente un framework de Channel Adapters. Cada source connector es un inbound adapter; cada sink connector es un outbound adapter. Con cientos de conectores disponibles (JDBC, MongoDB, Elasticsearch, S3, Salesforce, SAP, etc.), Kafka Connect ha industrializado la construcción de adapters.
- Debezium: es un Channel Adapter especializado en CDC. Lee transaction logs de PostgreSQL (WAL), MySQL (binlog), Oracle (LogMiner), SQL Server (CDC), MongoDB (change streams) y produce eventos en Kafka. Es la implementación más sofisticada y exitosa de un inbound adapter.
- MuleSoft Anypoint Connectors: 400+ conectores pre-construidos que son Channel Adapters para sistemas SaaS, databases, protocols y APIs.
- Azure Logic Apps: 600+ conectores que permiten integrar sistemas sin código, cada uno un Channel Adapter visual.
- Apache Camel: 300+ componentes que implementan adapters para protocolos, APIs y sistemas.
Cómo Se Implementa Hoy¶
| Plataforma | Tipo de Channel Adapter | Ejemplo concreto |
|---|---|---|
| Kafka Connect | Source/Sink configurable | JDBC Source, S3 Sink, Elasticsearch Sink |
| Debezium | CDC Source | PostgreSQL, MySQL, Oracle, MongoDB connectors |
| MuleSoft | Bidirectional connector | Salesforce, SAP, Workday connectors |
| Azure Logic Apps | Trigger/Action connector | Dynamics 365, SharePoint, SQL connectors |
| Apache Camel | Component | file, ftp, http, jms, kafka components |
| AWS EventBridge | Event source | SaaS partner integrations |
| Apache NiFi | Processor | GetFile, PutKafka, QueryDatabaseTable |
Qué Parte Sigue Siendo Esencial¶
- El concepto de adapter como puente entre mundos: independientemente de la tecnología, la necesidad de conectar sistemas non-messaging a la infraestructura de messaging es permanente.
- CDC como mecanismo preferido: la lectura del transaction log (en lugar de polling o triggers) se ha consolidado como la forma más eficiente y menos invasiva de detectar cambios en bases de datos.
- Adapter como infraestructura, no como código de aplicación: la tendencia es hacia adapters declarativos (configuración, no código) gestionados como infraestructura de plataforma.
15. Implementación en Arquitecturas Modernas¶
Kafka Connect — JDBC Source Connector¶
{
"name": "pos-transactions-source",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:postgresql://pos-db:5432/pos",
"connection.user": "kafka_connect",
"connection.password": "${secretsManager:pos-db-password}",
"table.whitelist": "pos_transactions",
"mode": "timestamp+incrementing",
"timestamp.column.name": "updated_at",
"incrementing.column.name": "txn_id",
"topic.prefix": "retail.pos.",
"transforms": "extractKey,setSchema",
"transforms.extractKey.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractKey.field": "txn_id",
"poll.interval.ms": 1000,
"batch.max.rows": 500
}
}
Kafka Connect gestiona automáticamente el offset tracking (qué registros ya se procesaron), la distribución de trabajo entre workers, la tolerancia a fallos (si un worker muere, otro asume su trabajo), y la serialización/deserialización con Schema Registry.
Debezium — CDC para PostgreSQL¶
{
"name": "pos-cdc-source",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "pos-db",
"database.port": "5432",
"database.user": "debezium",
"database.password": "${secretsManager:pos-db-password}",
"database.dbname": "pos",
"database.server.name": "pos",
"table.include.list": "public.pos_transactions",
"plugin.name": "pgoutput",
"slot.name": "debezium_pos",
"topic.prefix": "cdc.pos",
"transforms": "route",
"transforms.route.type": "io.debezium.transforms.ByLogicalTableRouter",
"transforms.route.topic.regex": "cdc\\.pos\\.public\\.(.*)",
"transforms.route.topic.replacement": "retail.pos.$1"
}
}
Debezium lee el PostgreSQL WAL (Write-Ahead Log) directamente, capturando inserts, updates y deletes en near-real-time (<100ms de latencia) sin ningún impacto en la aplicación POS. Cada cambio en la tabla pos_transactions se convierte en un evento en el topic retail.pos.pos_transactions.
MuleSoft — Salesforce to Kafka Adapter¶
<flow name="salesforce-to-kafka">
<salesforce:subscribe-topic config-ref="Salesforce_Config"
topic="/data/OpportunityChangeEvent" />
<ee:transform>
<ee:message>
<ee:set-payload><![CDATA[%dw 2.0
output application/json
---
{
event_type: "crm.opportunity.changed",
opportunity_id: payload.ChangeEventHeader.recordIds[0],
change_type: payload.ChangeEventHeader.changeType,
fields: payload.ChangeEventHeader.changedFields
}]]></ee:set-payload>
</ee:message>
</ee:transform>
<kafka:publish config-ref="Kafka_Config"
topic="crm.opportunities.changes">
<kafka:key>#[payload.opportunity_id]</kafka:key>
</kafka:publish>
</flow>
MuleSoft actúa como Channel Adapter suscribiéndose a Change Data Capture events de Salesforce, transformándolos a un formato canónico y produciéndolos en Kafka.
Azure Logic Apps — Dynamics 365 to Service Bus¶
{
"definition": {
"triggers": {
"When_a_record_is_created": {
"type": "ApiConnection",
"inputs": {
"host": { "connection": { "name": "@parameters('$connections')['dynamicscrm']['connectionId']" } },
"method": "get",
"path": "/datasets/@{encodeURIComponent(encodeURIComponent('org'))}/tables/@{encodeURIComponent(encodeURIComponent('salesorders'))}/onnewitems"
},
"recurrence": { "frequency": "Minute", "interval": 1 }
}
},
"actions": {
"Send_message_to_Service_Bus": {
"type": "ApiConnection",
"inputs": {
"body": { "ContentData": "@{base64(triggerBody())}" },
"host": { "connection": { "name": "@parameters('$connections')['servicebus']['connectionId']" } },
"method": "post",
"path": "/messages/send"
}
}
}
}
}
Azure Logic Apps proporciona un Channel Adapter visual (low-code) que conecta Dynamics 365 con Azure Service Bus. El trigger detecta nuevos registros y la acción los envía como mensajes.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por adapter: events_received/sec (from source), events_produced/sec (to channel), transform_errors/sec, buffer_size, production_failures/sec.
- Latencia end-to-end: tiempo desde que el evento ocurre en la fuente hasta que está disponible en el canal. Para CDC, debería ser <1s; para polling, depende del intervalo.
- Reconciliation metrics: eventos recuperados por reconciliación (idealmente 0; cualquier valor >0 indica gaps en el mecanismo primario).
Monitoreo¶
- Adapter health: heartbeat y liveness del adapter. Si el adapter muere, los eventos dejan de fluir silenciosamente.
- Source connectivity: el adapter debe monitorear la conectividad con el sistema fuente (¿la API responde? ¿el replication slot está activo?).
- Lag: diferencia entre el timestamp del último evento producido y el timestamp actual. Si crece, el adapter no puede mantener el ritmo.
- Buffer drain rate: si se usa buffer local, monitorear que se drena correctamente cuando Kafka está disponible.
Versionado¶
- Schema evolution: cuando el sistema fuente añade campos, el adapter debe producir mensajes con el nuevo schema (compatible backward). El Schema Registry valida la compatibilidad.
- Adapter versioning: tratar el adapter como software versionado con releases, changelog y rollback capability.
- Source API versioning: si el sistema fuente evoluciona su API, el adapter debe adaptarse. Mantener compatibilidad con múltiples versiones de la API fuente si es necesario.
Seguridad¶
- Credentials management: el adapter necesita credenciales del sistema fuente (API key, database password) y del broker (SASL, mTLS). Usar secrets management (Vault, AWS Secrets Manager) — nunca hardcodear.
- Least privilege: el adapter debe tener los permisos mínimos necesarios en el sistema fuente (read-only para inbound adapters).
- Data masking: si los datos fuente contienen PII (nombres, direcciones, tarjetas de crédito), el adapter puede aplicar masking o tokenización durante la transformación.
Manejo de Errores y Dead-Lettering¶
- Eventos que el adapter no puede transformar (formato inesperado) deben enviarse a un dead letter topic con el payload original y metadata de error.
- Errores de producción (Kafka no disponible) deben activar el buffer local y alertas operacionales.
- Errores de conectividad con la fuente deben activar retry con backoff exponencial y alertas si exceden un umbral.
Idempotencia¶
- El adapter debe ser idempotente: si se reinicia y reprocesa eventos ya enviados, los duplicados deben manejarse (deduplicación por ID del evento fuente o idempotent producer de Kafka).
- En CDC con Debezium, el LSN (Log Sequence Number) del transaction log proporciona un punto de reanudación exacto, minimizando duplicados.
Auditoría¶
- Registrar cada evento procesado por el adapter con source_id, event_id, timestamp, outcome (success/error/dead-letter).
- Mantener un registro de la configuración del adapter (qué tablas/APIs se monitorean, qué transformaciones se aplican).
Performance¶
- Batching: producir mensajes en lotes para maximizar throughput (Kafka Connect lo gestiona automáticamente).
- Paralelismo: en Kafka Connect, configurar múltiples tasks por connector para paralelizar la extracción (por ejemplo, un task por tabla o por rango de IDs).
- Compression: comprimir mensajes producidos (lz4, zstd) para reducir overhead de red.
Escalabilidad¶
- Kafka Connect distributed mode: múltiples workers que se distribuyen automáticamente los connectors y tasks, con rebalanceo automático ante fallos.
- Horizontal scaling: añadir workers para manejar más connectors o mayor throughput.
- Throttling del adapter: si la fuente tiene rate limits, el adapter debe respetar los límites para no sobrecargar la aplicación fuente.
17. Errores Comunes¶
Implementar un Adapter Custom Cuando Existe un Conector Estándar¶
Muchos equipos implementan adapters custom en Java o Python cuando existe un conector de Kafka Connect, MuleSoft o Debezium que cubre su caso de uso. Los conectores estándar incluyen gestión de offsets, retry, distribución, monitoreo y tolerancia a fallos que un adapter custom tarda meses en implementar correctamente.
No Trackear el Progreso del Adapter¶
Un adapter que no persiste su punto de progreso (último offset, último timestamp procesado) pierde la capacidad de reanudación. Tras un restart, puede reprocesar todos los datos desde el inicio (generando masivos duplicados) o empezar desde "ahora" (perdiendo datos del período de downtime).
Exponer el Schema Interno del Sistema Fuente¶
Producir mensajes que replican exactamente las columnas de la tabla fuente (con nombres internos, IDs técnicos, campos deprecated) acopla a todos los consumidores al modelo interno. El adapter debe transformar los datos a un modelo canónico orientado al dominio.
Ignorar la Reconciliación¶
Confiar exclusivamente en el mecanismo primario (webhook, CDC) sin un mecanismo de reconciliación periódico es arriesgado. Cualquier gap en la captura primaria (replication slot borrado, webhook endpoint temporalmente no disponible) resulta en eventos perdidos sin posibilidad de recuperación.
No Monitorear el Adapter como Componente Crítico¶
El adapter es un componente silencioso: si falla, no hay error visible para el usuario. Los consumidores simplemente dejan de recibir eventos nuevos, y pueden pasar horas hasta que alguien note que los dashboards no se actualizan. Monitoreo con alertas de "zero events in last N minutes" es esencial.
Adapter con Lógica de Negocio Compleja¶
Un adapter que implementa reglas de negocio complejas (validación, cálculos, decisiones de routing) se convierte en un componente frágil, difícil de testar y propenso a errores. La lógica de negocio debe residir en servicios consumidores, no en el adapter.
18. Conclusión Técnica¶
Channel Adapter es el patrón que hace posible la realización práctica de una arquitectura de mensajería en una organización real, donde la mayoría de los sistemas no fueron diseñados para messaging. Sin adapters, la arquitectura event-driven queda limitada a los microservicios nuevos que incorporan SDKs de Kafka o AMQP; con adapters, toda la empresa puede participar.
Cuándo aporta valor: siempre que un sistema que no habla messaging nativamente necesita participar en la arquitectura event-driven, ya sea como fuente de eventos (inbound adapter) o como destino de eventos (outbound adapter). El valor es doble: integración sin modificación del sistema fuente y desacoplamiento de los consumidores respecto al sistema fuente.
Cuándo evita problemas importantes: cuando se usan plataformas industrializadas de adapters (Kafka Connect, Debezium, MuleSoft), se evitan los problemas más comunes de las integraciones custom: gestión de estado frágil, falta de tolerancia a fallos, ausencia de monitoreo, y duplicación de esfuerzo entre equipos. Debezium, en particular, ha revolucionado la integración de bases de datos al hacer CDC accesible sin modificar las aplicaciones que escriben en la base de datos.
Cuándo no conviene adoptarlo: si la aplicación ya tiene un SDK nativo del broker y puede producir/consumir directamente, un adapter externo añade complejidad innecesaria. También, si la integración es puramente síncrona y request-response, un API Gateway es más apropiado que un adapter a messaging.
Recomendación para arquitectos: antes de implementar un adapter custom, busque un conector estándar en el ecosistema de su plataforma (Kafka Connect Hub tiene 200+ conectores, Debezium cubre las bases de datos más comunes). Si debe implementar un adapter custom, use Kafka Connect como framework en lugar de construir desde cero — el framework proporciona offset tracking, distribución, tolerancia a fallos y monitoreo que tardaría meses en reimplementar. Y en todos los casos, transforme los datos al modelo canónico del dominio en el adapter — no propague el schema interno del sistema fuente a toda la organización.