Document Message¶
1. Nombre del Patrón¶
- Nombre oficial: Document Message
- Categoría: Message Construction (Construcción de Mensajes)
- Traducción contextual: Mensaje de Documento
2. Resumen Ejecutivo¶
Document Message es un patrón de construcción de mensajes cuya semántica es informativa: el productor envía datos al consumidor sin prescribir qué debe hacer con ellos. El mensaje no ordena ni notifica — transfiere información. Es el equivalente asíncrono de un Data Transfer Object (DTO) enviado a través de un canal de mensajería: el productor empaqueta datos relevantes y los deposita en un canal; el consumidor los recibe y decide autónomamente cómo utilizarlos.
El problema que resuelve es sutil pero fundamental: en muchas integraciones, la intención del mensaje no es que el receptor ejecute una acción específica (eso sería un Command Message) ni que tome nota de un hecho ocurrido (eso sería un Event Message). La intención es simplemente transferir datos — un documento de póliza, un catálogo de productos, un reporte financiero, un perfil de cliente — para que el receptor los utilice según sus propias necesidades. Document Message formaliza esta semántica y sus consecuencias arquitectónicas.
Aunque a primera vista parece el menos "sofisticado" de los tres tipos de mensaje semántico (command, document, event), Document Message es extremadamente frecuente en la práctica. Los DTOs entre microservicios, los payloads de respuesta a queries, los bulk data transfers, los snapshots de estado y los mensajes de sincronización de datos son todos Document Messages. Comprender cuándo un mensaje es un documento — y no un comando ni un evento — evita errores de diseño que producen acoplamiento innecesario o semántica ambigua.
3. Definición Detallada¶
Propósito¶
Document Message establece un contrato semántico en el que el productor envía un mensaje que contiene datos estructurados sin imponer al consumidor ninguna acción o interpretación específica. El mensaje dice "aquí están los datos" — no "haz esto con ellos" ni "esto ocurrió". El propósito es transferir información de forma desacoplada, permitiendo que múltiples consumidores utilicen los mismos datos de maneras completamente diferentes.
Lógica Arquitectónica¶
La distinción clave de Document Message es la ausencia de prescripción. En un Command Message, el productor dicta la acción. En un Event Message, el productor declara un hecho. En un Document Message, el productor simplemente proporciona datos y el consumidor tiene autonomía total sobre cómo los utiliza:
- El consumidor decide la acción: un documento de póliza puede ser utilizado por un servicio para calcular primas, por otro para generar un PDF, por otro para actualizar un data warehouse y por otro para verificar compliance. El productor no sabe ni prescribe estos usos.
- El mensaje es data-centric, no action-centric: la estructura del mensaje refleja la estructura de los datos (campos de una póliza, atributos de un producto), no una instrucción (crear, actualizar, calcular).
- No tiene semántica temporal fuerte: a diferencia de un evento (que ocurrió en un momento específico), un documento representa el estado de los datos en un punto en el tiempo, pero su utilidad no depende del momento exacto de su producción.
Principio de Diseño Subyacente¶
El principio es transferencia de datos sin acoplamiento de intención. El productor no necesita conocer ni anticipar los posibles usos de los datos. Esto maximiza el desacoplamiento: el productor y el consumidor no comparten una semántica de acción — solo comparten un modelo de datos.
Problema Estructural que Resuelve¶
En un sistema distribuido, los servicios frecuentemente necesitan acceder a datos que residen en otro servicio. Las opciones son:
- Query síncrona: el servicio que necesita los datos los solicita en tiempo real al servicio que los posee. Acoplamiento temporal y de disponibilidad.
- Base de datos compartida: ambos servicios acceden a la misma base de datos. Acoplamiento fuerte a nivel de esquema y runtime.
- Document Message: el servicio que posee los datos los publica como un mensaje. Los servicios interesados los consumen y almacenan localmente. Desacoplamiento temporal, espacial y de esquema.
Contexto en el que Emerge¶
Document Message emerge en escenarios donde la transferencia de datos es el objetivo principal:
- Sincronización de datos entre servicios: un servicio de clientes publica el perfil actualizado de un cliente como document message; otros servicios mantienen una copia local.
- Respuestas a queries: en un patrón Request-Reply, la respuesta es típicamente un Document Message que contiene los datos solicitados.
- Bulk data transfer: migración o carga masiva de datos (catálogos, configuraciones, listas de referencia).
- Event-Carried State Transfer: un tipo específico de document message donde el evento incluye el estado completo de la entidad, no solo la notificación del cambio.
- Data feeds: publicación periódica de snapshots de datos (precios de mercado, tipos de cambio, inventario disponible).
Diferencia entre Document Message, Event Message y Command Message¶
| Aspecto | Document Message | Event Message | Command Message |
|---|---|---|---|
| Semántica | "Aquí están los datos" | "Esto ocurrió" | "Haz esto" |
| Intención | Transferir información | Notificar un hecho | Instruir una acción |
| Acción del receptor | Decide autónomamente | Reacciona al hecho | Ejecuta la instrucción |
| Temporalidad | Estado en un punto en el tiempo | Momento específico del hecho | Momento de ejecución futura |
| Ejemplo | PolicyDocument con datos completos | PolicyCreated (notificación) | CreatePolicy (instrucción) |
| Acoplamiento de intención | Bajo (no prescribe uso) | Medio (implica reactividad) | Alto (prescribe acción) |
Document Message vs. Event-Carried State Transfer¶
Una distinción sutil pero importante: cuando un evento incluye el estado completo de la entidad (PolicyUpdated con todos los campos de la póliza), está actuando parcialmente como Document Message. Martin Fowler distingue entre Event Notification (evento mínimo: "la póliza X cambió") y Event-Carried State Transfer (evento con datos completos: "la póliza X cambió y aquí está su nuevo estado"). El segundo caso es un híbrido entre Event Message y Document Message: tiene la semántica temporal del evento y el contenido de datos del documento.
Relación con Sistemas Distribuidos y Mensajería¶
Document Message es la implementación asíncrona del Data Transfer Object (DTO) de Martin Fowler. En sistemas distribuidos, corresponde al concepto de state transfer message — un mensaje que transporta una representación del estado de una entidad de un servicio a otro.
En la práctica, Document Message puede implementarse sobre cualquier tipo de canal:
- Point-to-Point: cuando un único consumidor necesita los datos (respuesta a una query).
- Publish-Subscribe: cuando múltiples consumidores necesitan los mismos datos (sincronización de datos).
- Kafka topic con compaction: para mantener el último estado de cada entidad como un documento.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Document Message como abstracción explícita, la transferencia de datos entre servicios se resuelve con mecanismos que introducen acoplamiento o ambigüedad:
- Queries síncronas (API calls): cada servicio que necesita datos de otro debe consultarlo en tiempo real. Esto produce acoplamiento temporal (si el servicio de datos no está disponible, el servicio que los necesita falla) y degradación de performance (latencia acumulada por múltiples llamadas).
- Base de datos compartida: todos los servicios acceden a los mismos datos directamente. Esto produce acoplamiento de esquema (un cambio en la tabla afecta a todos los servicios) y contención (múltiples servicios compiten por los mismos recursos de base de datos).
- Semántica ambigua: sin distinción explícita entre documentos, comandos y eventos, los desarrolladores envían mensajes con datos sin clarificar si el receptor debe hacer algo específico con ellos o si simplemente son datos para su uso libre.
Síntomas del Problema¶
- Servicios con alta latencia porque cada operación requiere múltiples llamadas síncronas a otros servicios para obtener datos.
- Fallos en cascada cuando un servicio de datos no está disponible y todos los servicios que dependen de él fallan simultáneamente.
- Base de datos central que es un cuello de botella de performance y un single point of failure.
- Mensajes que contienen datos pero se procesan como si fueran comandos (ejecutando acciones no intencionadas) porque la semántica no está clara.
- Servicios que duplican datos localmente de forma ad hoc, sin un mecanismo estandarizado de sincronización.
Impacto Operativo y Arquitectónico¶
Sin Document Message:
- Los servicios están temporalmente acoplados: si el proveedor de datos no está disponible, los consumidores de datos fallan.
- La performance del sistema está limitada por la latencia acumulada de las queries síncronas entre servicios.
- La evolución del esquema de datos es costosa porque afecta a todos los servicios que acceden directamente a los datos.
- No hay mecanismo estándar para que un servicio publique snapshots de sus datos para consumo de otros servicios.
Riesgos Si No Se Implementa Correctamente¶
- Documento desactualizado: si el mecanismo de publicación de documentos no es oportuno, los consumidores trabajan con datos obsoletos, produciendo decisiones incorrectas.
- Documento incompleto: un document message que omite campos relevantes obliga al consumidor a hacer queries adicionales, eliminando los beneficios del desacoplamiento.
- Documento como comando implícito: enviar un documento de póliza a un servicio que lo interpreta como "debes actualizar tu base de datos con estos datos" sin que esa instrucción sea explícita. Si la instrucción es intencional, debería ser un Command Message.
- Documento sin versionado: un document message cuyo schema evoluciona sin estrategia de compatibilidad produce errores de deserialización en los consumidores.
Ejemplos Reales¶
- Seguros: un servicio de pólizas publica el documento completo de una póliza (datos del asegurado, coberturas, primas, beneficiarios) en un topic. El servicio de facturación usa los datos para calcular cobros, el servicio de siniestros los usa para validar reclamaciones, el servicio de reaseguro los usa para calcular cesiones y el data warehouse los usa para reporting.
- Retail: un servicio de catálogo publica el documento completo de un producto (nombre, descripción, precios, imágenes, categorías, atributos). El servicio de búsqueda lo indexa, el servicio de recomendaciones lo incorpora a sus modelos, el servicio de pricing lo usa como base para promociones y el CMS lo usa para renderizar páginas.
- Finanzas: un servicio de mercados publica documentos de cotización (precio bid/ask, volumen, timestamp) de instrumentos financieros. Los servicios de trading, risk management, reporting y compliance los consumen para sus respectivos propósitos.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando la intención es transferir datos de un servicio a otro sin prescribir qué debe hacer el receptor con ellos.
- Cuando múltiples consumidores necesitan los mismos datos para propósitos diferentes.
- Cuando se quiere desacoplar al consumidor de datos del proveedor de datos, eliminando la dependencia de queries síncronas.
- Cuando se necesita que los servicios mantengan copias locales de datos que posee otro servicio (materializar read models).
- Cuando se responde a una query con los datos solicitados (la respuesta en Request-Reply es un Document Message).
- Cuando se publica un snapshot periódico del estado de una entidad o un dataset.
- Cuando se implementa Event-Carried State Transfer: eventos que incluyen el estado completo de la entidad para que los consumidores no necesiten consultar al productor.
Cuándo No Usarlo¶
- Cuando la intención es que el receptor ejecute una acción específica — usar Command Message.
- Cuando la intención es notificar que algo ocurrió — usar Event Message (al menos en su variante Event Notification).
- Cuando los datos son muy grandes y el messaging no es el mecanismo adecuado — usar Claim Check (referencia a datos almacenados externamente).
- Cuando los datos cambian con alta frecuencia y publicar un documento completo cada vez es ineficiente — considerar Event Notification (notificación de cambio) + query on demand.
Precondiciones¶
- El productor tiene los datos que necesita transferir y puede serializarlos en un formato estándar.
- Existe un canal (queue o topic) configurado para transportar los documentos.
- Los consumidores conocen el schema del documento y pueden deserializarlo.
- Si el documento reemplaza queries síncronas, los consumidores tienen almacenamiento local para materializar los datos.
Restricciones¶
- El tamaño del documento está limitado por el tamaño máximo de mensaje del broker (típicamente 1 MB en Kafka, 256 KB en SQS, 1 MB en Azure Service Bus). Documentos más grandes requieren Claim Check o Message Sequence.
- La frescura de los datos depende de la frecuencia de publicación. Los consumidores pueden trabajar con datos ligeramente desactualizados.
- La evolución del schema del documento requiere estrategias de compatibilidad (BACKWARD, FORWARD).
Dependencias¶
- Formato de serialización estándar (JSON, Avro, Protobuf) con schema definido.
- Canal de mensajería configurado (topic pub-sub si hay múltiples consumidores, queue si es punto a punto).
- Opcionalmente, Schema Registry para versionado y validación del schema del documento.
- Almacenamiento local en los consumidores si materializan los datos.
Supuestos Arquitectónicos¶
- Los consumidores son responsables de interpretar y utilizar los datos según sus necesidades.
- El productor no necesita saber cuántos ni cuáles consumidores reciben el documento.
- La latencia entre la producción del documento y su consumo es aceptable para los casos de uso del consumidor.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas de seguros (documentos de pólizas, siniestros, clientes).
- E-commerce (catálogos de productos, perfiles de clientes, inventario).
- Servicios financieros (cotizaciones, posiciones, estados de cuenta).
- Healthcare (historias clínicas, resultados de laboratorio, recetas).
- Sistemas de referencia de datos (master data management).
- Arquitecturas CQRS (read models materializados desde documentos).
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Autonomía¶
Document Message maximiza la autonomía del consumidor: recibe datos y decide qué hacer con ellos. Esto es menos acoplamiento que un Command Message (donde el productor dicta la acción) e incluso menos que un Event Message (donde la reactividad al evento es implícita). Sin embargo, existe acoplamiento al schema del documento — si el productor cambia la estructura de los datos, los consumidores se ven afectados.
Completitud vs. Tamaño¶
¿Cuántos datos debe incluir un Document Message? Un documento completo (todos los campos de la entidad) es más útil para los consumidores pero más grande y más costoso de transferir. Un documento parcial (solo los campos que cambiaron) es más pequeño pero puede requerir que el consumidor mantenga estado para reconstruir la entidad completa. La tensión entre completitud y eficiencia es constante.
Frescura vs. Eficiencia¶
Publicar un documento con cada cambio mínimo garantiza máxima frescura pero puede generar un volumen enorme de mensajes. Publicar documentos periódicamente (cada minuto, cada hora) es más eficiente pero introduce latencia. La frecuencia de publicación debe alinearse con los requisitos de frescura de los consumidores.
Duplicación de Datos vs. Desacoplamiento¶
Document Message implica que los consumidores almacenan copias locales de datos que el productor ya tiene. Esto es duplicación deliberada — el trade-off de mantener datos redundantes a cambio de desacoplamiento temporal y de disponibilidad. La alternativa (queries síncronas al productor) elimina la duplicación pero introduce acoplamiento.
Schema Evolution vs. Estabilidad¶
Los datos de un documento evolucionan (nuevos campos, campos deprecados, cambios de tipo). Cada evolución requiere que los consumidores se adapten. Un schema demasiado estable limita la evolución del productor; un schema que cambia frecuentemente es costoso para los consumidores. Las estrategias de compatibilidad (BACKWARD, FORWARD) mitigan esta tensión pero no la eliminan.
Granularidad del Documento vs. Flexibilidad¶
¿Un documento grande que representa una entidad completa (póliza con todos sus sub-objetos) o múltiples documentos pequeños por sub-entidad (datos del asegurado, coberturas, primas por separado)? Documentos grandes son más self-contained pero más difíciles de evolucionar; documentos pequeños son más flexibles pero requieren que el consumidor los ensamble.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Document Producer (Productor del Documento): el servicio que posee los datos y los publica como un mensaje.
- Document Channel (Canal del Documento): el canal (típicamente pub-sub) por donde viaja el documento.
- Document Consumer (Consumidor del Documento): uno o más servicios que reciben el documento y lo utilizan según sus necesidades.
- Local Store (Almacenamiento Local): la base de datos o cache donde el consumidor materializa los datos del documento.
- Schema Registry: opcionalmente, el registro que almacena y valida el schema del documento.
Flujo Lógico¶
flowchart TD
A([Document Producer]) --> B[Construir Document Message\ntipo + payload + metadata]
B --> C[(Document Channel)]
C --> D[Broker almacena y distribuye\na consumidores suscritos]
D --> E[Consumer A recibe documento]
D --> F[Consumer B recibe documento]
E --> G[Deserializar datos]
G --> H[(Local Store A)]
H --> I[Procesar según propósito A]
F --> J[Deserializar datos]
J --> K[(Local Store B)]
K --> L[Procesar según propósito B]
I --> M[Confirmar procesamiento - ack]
L --> M
M --> N([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Document Producer | Construir documento con datos completos y válidos, publicar en canal correcto |
| Document Channel | Distribuir el documento a todos los consumidores suscritos (pub-sub) |
| Document Consumer | Recibir documento, decidir cómo usarlo, almacenar localmente si necesario |
| Local Store | Almacenar la representación local de los datos recibidos |
| Schema Registry | Validar que el documento cumple con el schema esperado |
Interacciones¶
- Producer → Channel: publicación del documento (publish).
- Channel → Consumer: entrega del documento a cada suscriptor.
- Consumer → Local Store: materialización de los datos recibidos.
- Consumer → Channel: acknowledgment de procesamiento.
Contratos Implícitos¶
- Schema del documento: la estructura de datos que el productor publica y los consumidores esperan.
- Frecuencia de publicación: ¿se publica con cada cambio? ¿Periódicamente? ¿Bajo demanda?
- Completitud: ¿el documento contiene todos los campos de la entidad o solo un subconjunto?
- Semántica de actualización: ¿el documento reemplaza el estado completo (snapshot) o es un delta (solo cambios)?
Decisiones de Diseño Clave¶
- Snapshot vs. Delta: ¿el documento contiene el estado completo (más simple para el consumidor) o solo los cambios (más eficiente en tamaño)?
- Frecuencia de publicación: en cada cambio, periódicamente, o bajo demanda.
- Granularidad: una entidad completa por documento o sub-entidades separadas.
- Canal type: pub-sub (múltiples consumidores) o point-to-point (un consumidor).
- Compaction: en Kafka, log compaction permite mantener solo la última versión de cada documento por key.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Documento de Póliza para Múltiples Consumidores¶
Contexto del Negocio¶
Una compañía aseguradora gestiona 2 millones de pólizas activas que cubren vida, hogar, auto y salud. Cuando una póliza se crea, modifica o renueva, múltiples departamentos y sistemas necesitan los datos actualizados de la póliza para sus operaciones:
- Facturación: necesita datos de primas, frecuencia de pago y método de cobro para generar recibos.
- Siniestros: necesita datos de coberturas, límites, deducibles y vigencia para validar reclamaciones.
- Reaseguro: necesita datos de sumas aseguradas, tipo de riesgo y condiciones para calcular cesiones.
- CRM: necesita datos del asegurado, agente y estado de la póliza para gestión comercial.
- Data Warehouse: necesita todos los datos para reporting actuarial, financiero y regulatorio.
- Portal del Cliente: necesita un subconjunto de datos para que el asegurado consulte su póliza online.
Necesidad de Integración¶
Cuando el servicio de pólizas (Policy Service) modifica una póliza, todos los sistemas anteriores necesitan los datos actualizados. Antes, cada sistema consultaba síncronamente al Policy Service mediante APIs REST. Esto producía:
- 6 llamadas síncronas por cada cambio de póliza (una por cada consumidor).
- Fallos en cascada cuando el Policy Service estaba sobrecargado o en mantenimiento.
- Inconsistencia temporal: los sistemas consultaban en diferentes momentos y podían tener versiones diferentes de la misma póliza.
- Performance degradada del Policy Service por la carga de queries concurrentes.
Sistemas Involucrados¶
- Policy Service: servicio que posee y gestiona los datos de las pólizas.
- Kafka Cluster: plataforma de streaming que transporta los documentos.
- Billing Service: calcula y emite recibos de primas.
- Claims Service: gestiona y valida siniestros.
- Reinsurance Service: calcula cesiones de reaseguro.
- CRM Service: gestión de relación con clientes y agentes.
- Data Warehouse: analytics y reporting.
- Customer Portal BFF: Backend-for-Frontend del portal del cliente.
Diseño del Document Message¶
{
"document_type": "PolicyDocument",
"document_id": "doc-pol-2026-04-07-c7a2f1",
"entity_id": "POL-2026-00182947",
"entity_version": 7,
"timestamp": "2026-04-07T14:32:15Z",
"schema_version": "3.1",
"payload": {
"policy_number": "POL-2026-00182947",
"product_type": "HOME_INSURANCE",
"status": "ACTIVE",
"effective_date": "2026-01-15",
"expiration_date": "2027-01-15",
"policyholder": {
"customer_id": "CUST-00482917",
"name": "María García López",
"tax_id": "12345678A",
"address": {
"street": "Calle Gran Vía 42, 3º A",
"city": "Madrid",
"postal_code": "28013",
"country": "ES"
}
},
"insured_property": {
"type": "APARTMENT",
"address": "Calle Gran Vía 42, 3º A, Madrid",
"built_area_sqm": 95,
"year_built": 1985,
"reconstruction_value": 185000.00
},
"coverages": [
{
"type": "BUILDING",
"sum_insured": 185000.00,
"deductible": 300.00,
"sublimits": {}
},
{
"type": "CONTENTS",
"sum_insured": 45000.00,
"deductible": 150.00,
"sublimits": {"jewelry": 3000.00, "electronics": 5000.00}
},
{
"type": "LIABILITY",
"sum_insured": 300000.00,
"deductible": 0,
"sublimits": {}
}
],
"premium": {
"annual_amount": 412.50,
"payment_frequency": "QUARTERLY",
"payment_method": "DIRECT_DEBIT",
"bank_account": "ES91 2100 0418 4502 0005 1332",
"next_payment_date": "2026-07-15"
},
"agent": {
"agent_id": "AGT-00291",
"name": "Corredor López & Asociados",
"commission_pct": 15.0
}
}
}
Decisiones Arquitectónicas¶
-
Documento completo (snapshot): cada publicación incluye todos los datos de la póliza, no solo los campos que cambiaron. Esto simplifica enormemente la lógica del consumidor: simplemente reemplaza la versión anterior con la nueva.
-
Entity version: el campo
entity_versiones un número monotónicamente creciente que permite al consumidor detectar si está recibiendo una versión más reciente o una más antigua (por reordenamiento de mensajes). Solo procesa si la versión es mayor que la que tiene almacenada. -
Kafka topic con log compaction: el topic
policy.documentsusa log compaction conentity_idcomo key. Esto garantiza que siempre hay al menos un mensaje por póliza, que contiene su último estado. Un nuevo consumidor puede leer desde el inicio del topic para materializar todas las pólizas. -
Pub-sub con consumer groups independientes: cada servicio consumidor tiene su propio consumer group y consume todos los documentos. Cada uno extrae los campos relevantes para su dominio.
-
Schema version explícita:
schema_version: "3.1"permite a los consumidores saber qué campos esperar y cómo deserializar.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Documento muy grande satura el broker | Monitoreo de tamaño promedio; Claim Check para pólizas con adjuntos |
| Consumidor procesa versión antigua | Entity version + lógica de "solo procesar si version > actual" |
| Schema incompatible rompe consumidores | Schema Registry con compatibilidad BACKWARD obligatoria |
| Datos sensibles (bank_account) expuestos | Cifrado de campos sensibles + ACLs en el topic |
| Consumidor lento acumula lag | Consumer lag alerting + escalado horizontal del consumer group |
| Pérdida de documento | Replication factor 3 + acks=all + log compaction como safety net |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Modificación de la Póliza¶
Un agente de seguros modifica la póliza POL-2026-00182947 a través del sistema de gestión de pólizas: añade una cobertura de responsabilidad civil con suma asegurada de 300,000 EUR y ajusta la prima anual de 380.00 a 412.50 EUR. El Policy Service:
- Valida la modificación contra las reglas de negocio del producto HOME_INSURANCE.
- Persiste los cambios en su base de datos, incrementando
entity_versionde 6 a 7. - Construye un Document Message
PolicyDocumentcon el estado completo de la póliza (incluyendo la nueva cobertura y la prima actualizada). - Publica el documento en el topic
policy.documentscon keyPOL-2026-00182947.
Paso 2: Distribución del Documento¶
El broker Kafka recibe el documento y lo almacena en la partición correspondiente al hash de POL-2026-00182947. Gracias a log compaction, el documento anterior (version 6) será eventualmente eliminado, manteniéndose solo la version 7 como el estado actual de la póliza.
Cinco consumer groups reciben el documento de forma independiente. Cada uno a su propio ritmo.
Paso 3: Consumo por el Billing Service¶
El Billing Service (consumer group: cg-billing) recibe el documento:
- Extrae los campos relevantes para facturación:
policy_number,premium.annual_amount,premium.payment_frequency,premium.payment_method,premium.bank_account,premium.next_payment_date. - Detecta que la prima cambió de 380.00 a 412.50 EUR (comparando con su registro local).
- Recalcula los próximos recibos trimestrales: 412.50 / 4 = 103.13 EUR.
- Actualiza su base de datos local con la nueva prima y los nuevos importes de recibos.
- Confirma el mensaje (commit offset).
El Billing Service ignora los campos de coberturas, propiedad asegurada y agente porque no son relevantes para su dominio. Esta es la esencia de Document Message: el consumidor usa solo lo que necesita.
Paso 4: Consumo por el Claims Service¶
El Claims Service (consumer group: cg-claims) recibe el mismo documento:
- Extrae los campos relevantes para validación de siniestros:
policy_number,status,effective_date,expiration_date,coverages(todos los tipos, sumas aseguradas, deducibles, sublímites). - Actualiza su local store con las coberturas actualizadas de la póliza.
- La nueva cobertura de responsabilidad civil (300,000 EUR, deducible 0) estará disponible para validar futuras reclamaciones de este tipo.
- Confirma el mensaje.
El Claims Service ignora los campos de facturación, datos bancarios y agente.
Paso 5: Consumo por el Reinsurance Service¶
El Reinsurance Service (consumer group: cg-reinsurance) recibe el documento:
- Extrae los campos relevantes para cesión de reaseguro:
product_type,coverages(sumas aseguradas),insured_property(tipo y valor de reconstrucción),premium.annual_amount. - Evalúa si la nueva suma asegurada total (185,000 + 45,000 + 300,000 = 530,000 EUR) excede el límite de retención propia de la aseguradora para este tipo de riesgo.
- Si excede, calcula la cesión de reaseguro y genera un registro de cesión.
- Confirma el mensaje.
Paso 6: Consumo por el Data Warehouse¶
El pipeline de ingesta del Data Warehouse (consumer group: cg-datalake) recibe el documento:
- Toma el documento completo sin filtrar campos.
- Lo transforma al formato del warehouse (desnormalización, conversión de tipos, adición de dimensiones).
- Lo carga en la tabla de hechos de pólizas, creando un nuevo registro con
entity_version = 7. - El registro anterior (version 6) permanece para análisis histórico (Slowly Changing Dimension Type 2).
- Confirma el mensaje.
Paso 7: Nuevo Consumidor Sin Cambio en el Productor¶
Tres meses después, el equipo de marketing necesita datos de pólizas para un modelo de propensión a renovación. Crean un nuevo servicio (ML Feature Service) que:
- Se registra como un nuevo consumer group (
cg-ml-features) en el topicpolicy.documents. - Lee desde el inicio del topic (offset 0). Gracias a log compaction, recibe el último documento de cada póliza activa.
- En pocas horas, materializa los datos de las 2 millones de pólizas en su feature store.
- A partir de ese momento, recibe actualizaciones incrementales como todos los demás consumidores.
No se modificó ni se reinició el Policy Service. El nuevo consumidor se conectó al topic existente y obtuvo los datos. Esta es la máxima expresión del desacoplamiento que ofrece Document Message.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
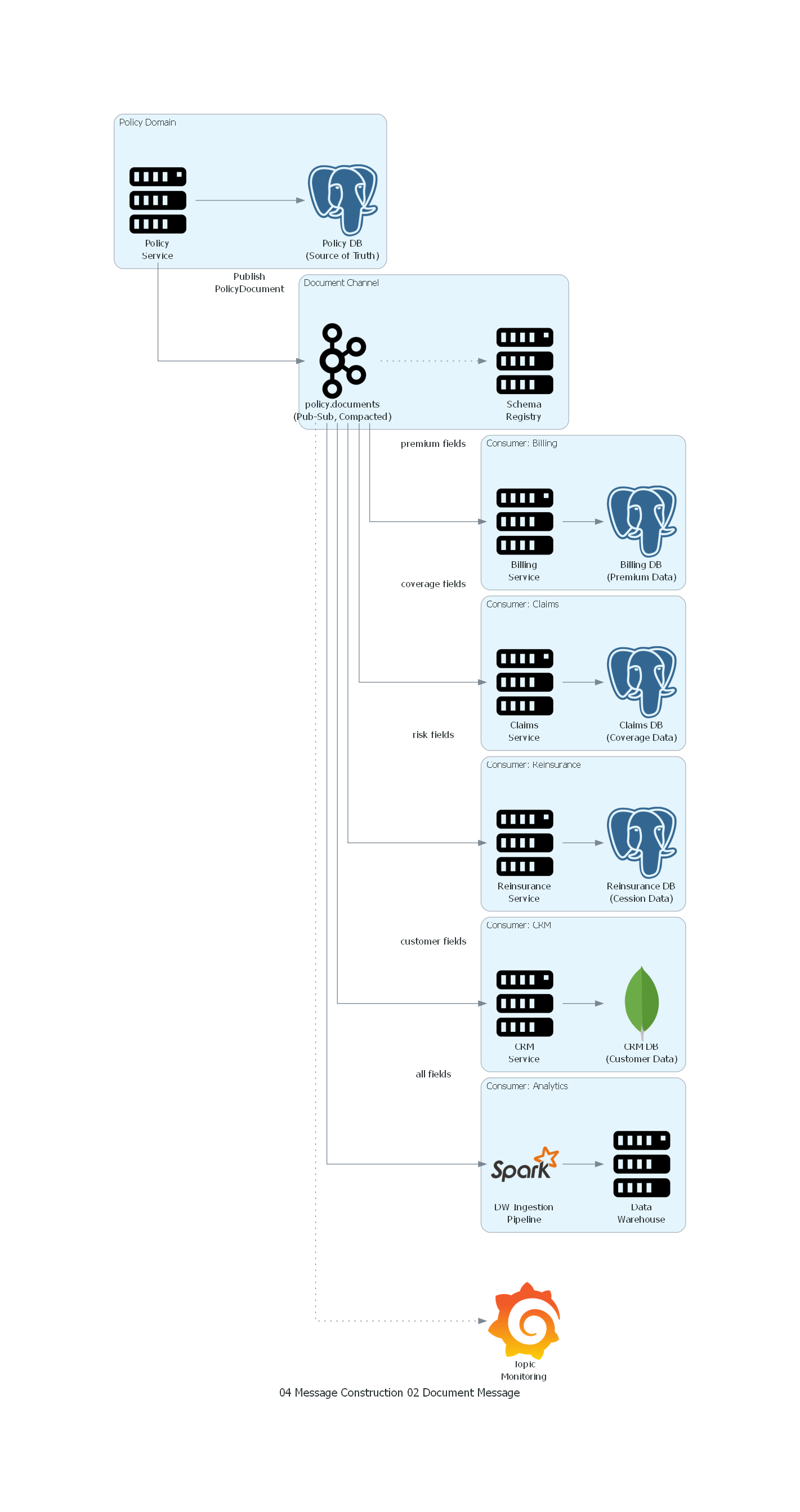
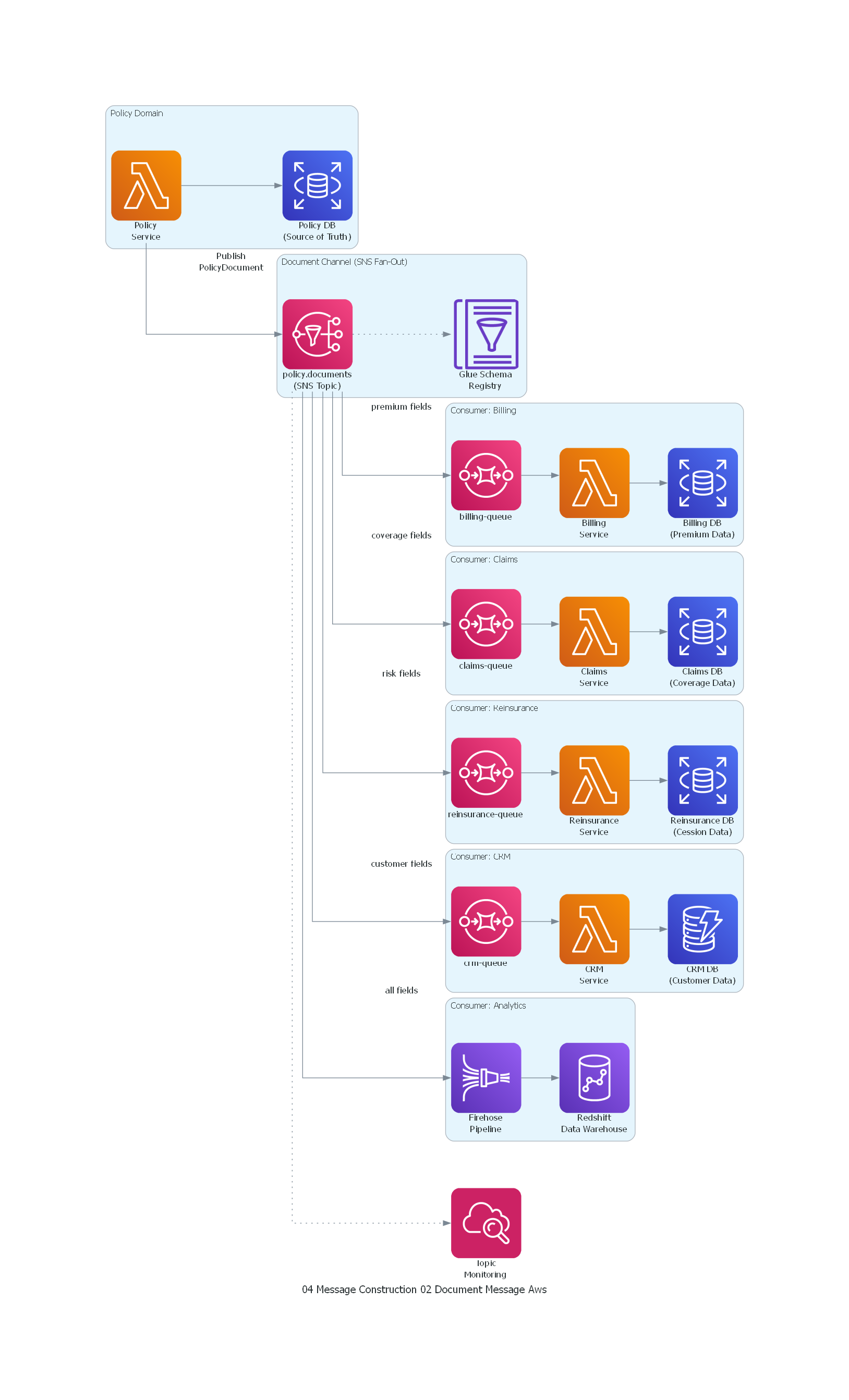
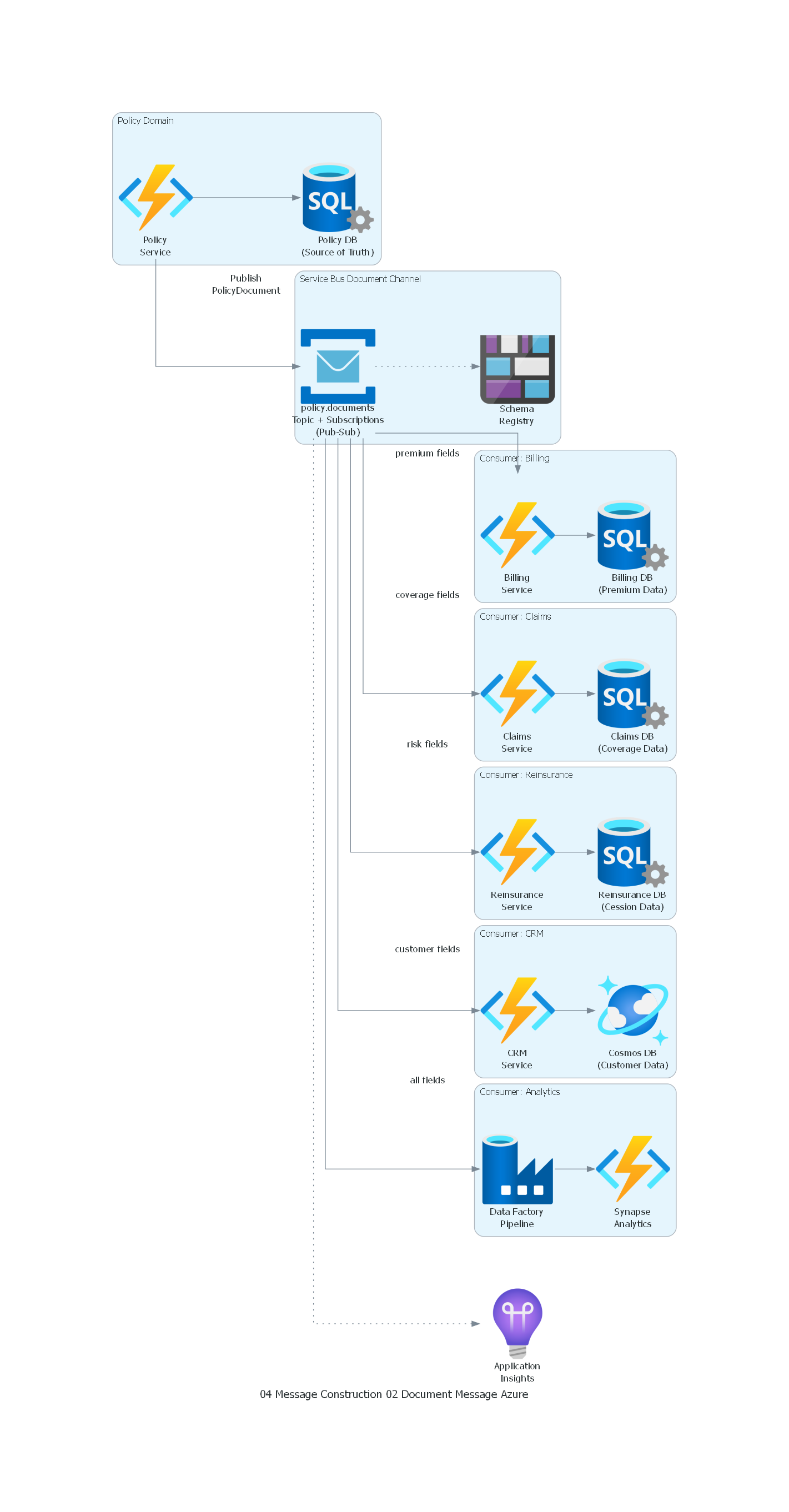
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL, MongoDB
from diagrams.onprem.analytics import Spark
from diagrams.onprem.monitoring import Grafana
with Diagram("Document Message - Insurance Policy Distribution", show=False, direction="LR"):
with Cluster("Policy Domain"):
policy_svc = Server("Policy\nService")
policy_db = PostgreSQL("Policy DB\n(Source of Truth)")
with Cluster("Document Channel"):
topic = Kafka("policy.documents\n(Pub-Sub, Compacted)")
schema_reg = Server("Schema\nRegistry")
with Cluster("Consumer: Billing"):
billing = Server("Billing\nService")
billing_db = PostgreSQL("Billing DB\n(Premium Data)")
with Cluster("Consumer: Claims"):
claims = Server("Claims\nService")
claims_db = PostgreSQL("Claims DB\n(Coverage Data)")
with Cluster("Consumer: Reinsurance"):
reinsurance = Server("Reinsurance\nService")
reins_db = PostgreSQL("Reinsurance DB\n(Cession Data)")
with Cluster("Consumer: CRM"):
crm = Server("CRM\nService")
crm_db = MongoDB("CRM DB\n(Customer Data)")
with Cluster("Consumer: Analytics"):
dw_pipeline = Spark("DW Ingestion\nPipeline")
dw = Server("Data\nWarehouse")
monitoring = Grafana("Topic\nMonitoring")
# Flow
policy_svc >> policy_db
policy_svc >> Edge(label="Publish\nPolicyDocument") >> topic
topic >> Edge(style="dotted") >> schema_reg
topic >> Edge(label="premium fields") >> billing >> billing_db
topic >> Edge(label="coverage fields") >> claims >> claims_db
topic >> Edge(label="risk fields") >> reinsurance >> reins_db
topic >> Edge(label="customer fields") >> crm >> crm_db
topic >> Edge(label="all fields") >> dw_pipeline >> dw
topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.analytics import KinesisDataFirehose, Redshift, GlueDataCatalog
from diagrams.aws.database import RDS, Dynamodb
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.management import Cloudwatch
with Diagram("Document Message - Insurance Policy Distribution (AWS)", show=False, direction="LR"):
with Cluster("Policy Domain"):
policy_svc = Lambda("Policy\nService")
policy_db = RDS("Policy DB\n(Source of Truth)")
with Cluster("Document Channel (SNS Fan-Out)"):
topic = SNS("policy.documents\n(SNS Topic)")
schema_reg = GlueDataCatalog("Glue Schema\nRegistry")
with Cluster("Consumer: Billing"):
billing_q = SQS("billing-queue")
billing = Lambda("Billing\nService")
billing_db = RDS("Billing DB\n(Premium Data)")
with Cluster("Consumer: Claims"):
claims_q = SQS("claims-queue")
claims = Lambda("Claims\nService")
claims_db = RDS("Claims DB\n(Coverage Data)")
with Cluster("Consumer: Reinsurance"):
reins_q = SQS("reinsurance-queue")
reinsurance = Lambda("Reinsurance\nService")
reins_db = RDS("Reinsurance DB\n(Cession Data)")
with Cluster("Consumer: CRM"):
crm_q = SQS("crm-queue")
crm = Lambda("CRM\nService")
crm_db = Dynamodb("CRM DB\n(Customer Data)")
with Cluster("Consumer: Analytics"):
dw_pipeline = KinesisDataFirehose("Firehose\nPipeline")
dw = Redshift("Redshift\nData Warehouse")
monitoring = Cloudwatch("Topic\nMonitoring")
# Flow
policy_svc >> policy_db
policy_svc >> Edge(label="Publish\nPolicyDocument") >> topic
topic >> Edge(style="dotted") >> schema_reg
topic >> Edge(label="premium fields") >> billing_q >> billing >> billing_db
topic >> Edge(label="coverage fields") >> claims_q >> claims >> claims_db
topic >> Edge(label="risk fields") >> reins_q >> reinsurance >> reins_db
topic >> Edge(label="customer fields") >> crm_q >> crm >> crm_db
topic >> Edge(label="all fields") >> dw_pipeline >> dw
topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import SQLServers, CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.integration import DataFactories
from diagrams.azure.storage import BlobStorage
with Diagram("Document Message - Insurance Policy Distribution (Azure)", show=False, direction="LR"):
with Cluster("Policy Domain"):
policy_svc = FunctionApps("Policy\nService")
policy_db = SQLServers("Policy DB\n(Source of Truth)")
with Cluster("Service Bus Document Channel"):
topic = ServiceBus("policy.documents\nTopic + Subscriptions\n(Pub-Sub)")
schema_reg = BlobStorage("Schema\nRegistry")
with Cluster("Consumer: Billing"):
billing = FunctionApps("Billing\nService")
billing_db = SQLServers("Billing DB\n(Premium Data)")
with Cluster("Consumer: Claims"):
claims = FunctionApps("Claims\nService")
claims_db = SQLServers("Claims DB\n(Coverage Data)")
with Cluster("Consumer: Reinsurance"):
reinsurance = FunctionApps("Reinsurance\nService")
reins_db = SQLServers("Reinsurance DB\n(Cession Data)")
with Cluster("Consumer: CRM"):
crm = FunctionApps("CRM\nService")
crm_db = CosmosDb("Cosmos DB\n(Customer Data)")
with Cluster("Consumer: Analytics"):
dw_pipeline = DataFactories("Data Factory\nPipeline")
dw = FunctionApps("Synapse\nAnalytics")
monitoring = ApplicationInsights("Application\nInsights")
# Flow
policy_svc >> policy_db
policy_svc >> Edge(label="Publish\nPolicyDocument") >> topic
topic >> Edge(style="dotted") >> schema_reg
topic >> Edge(label="premium fields") >> billing >> billing_db
topic >> Edge(label="coverage fields") >> claims >> claims_db
topic >> Edge(label="risk fields") >> reinsurance >> reins_db
topic >> Edge(label="customer fields") >> crm >> crm_db
topic >> Edge(label="all fields") >> dw_pipeline >> dw
topic >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la distribución de un Document Message de póliza desde el servicio productor hacia múltiples consumidores:
- El Policy Service modifica una póliza en su base de datos y publica el documento completo en el topic policy.documents (compactado, pub-sub).
- El Schema Registry valida que el documento cumple con el schema registrado.
- Cinco consumidores independientes reciben el mismo documento:
- Billing extrae campos de primas y facturación.
- Claims extrae campos de coberturas y vigencia.
- Reinsurance extrae campos de sumas aseguradas y riesgo.
- CRM extrae campos del asegurado y agente.
- DW Pipeline consume el documento completo para analytics.
- Cada consumidor materializa en su Local Store solo los campos relevantes para su dominio.
- Grafana monitorea el estado del topic (lag por consumer group, throughput).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Document Producer | Policy Service |
| Document Message | PolicyDocument JSON publicado en Kafka |
| Document Channel (Pub-Sub) | policy.documents topic (compacted) |
| Document Consumer | Billing, Claims, Reinsurance, CRM, DW Pipeline |
| Local Store | Cada base de datos de consumidor (Billing DB, Claims DB, etc.) |
| Schema Registry | Schema Registry (validación de formato) |
| Autonomía del consumidor | Cada consumidor extrae campos diferentes del mismo documento |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento temporal: los consumidores no necesitan que el Policy Service esté disponible para acceder a los datos de pólizas. Tienen copias locales materializadas desde los documentos.
- Performance localizada: cada consumidor consulta su propia base de datos en lugar de hacer queries remotos al Policy Service. La latencia de lectura es local, no de red.
- Escalabilidad del productor: el Policy Service publica una vez en el topic; el broker se encarga de distribuir a todos los consumidores. El productor no escala con el número de consumidores.
- Consistencia eventual gestionable: todos los consumidores eventualmente tendrán la misma versión del documento. El entity_version permite detectar y resolver inconsistencias temporales.
- Replay y catch-up: un nuevo consumidor puede leer el topic desde el inicio y materializar todos los documentos. Log compaction garantiza que al menos la última versión de cada póliza está disponible.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de facturación, el equipo de siniestros y el equipo de analytics trabajan de forma independiente. El contrato compartido es el schema del documento, no el código ni la API del Policy Service.
- Extensibilidad sin coordinación: un nuevo equipo que necesita datos de pólizas puede conectarse al topic existente sin coordinación con el equipo de pólizas. Este es un beneficio transformador para organizaciones grandes.
- Propiedad de datos clara: el Policy Service es el dueño y la fuente de verdad de los datos de pólizas. Los consumidores tienen copias locales para lectura, no para modificación.
Impacto Operacional¶
- Resiliencia: si el Policy Service tiene downtime, los consumidores siguen operando con los últimos datos que materializaron. El sistema es tolerante a fallos parciales.
- Debugging: el documento completo en el topic es inspeccionable. Si un consumidor tiene datos incorrectos, se puede verificar qué documento recibió y cuándo.
- Auditoría de datos: el topic (con retención suficiente) sirve como audit trail de cómo evolucionaron los datos de cada póliza.
Beneficios de Mantenibilidad y Evolución¶
- Evolución del consumidor: un consumidor puede cambiar completamente cómo utiliza los datos del documento sin afectar al productor ni a los demás consumidores.
- Migración de sistemas: un consumidor legacy puede reemplazarse por un nuevo sistema que se conecta al mismo topic y materializa los datos en su propio formato.
- Schema evolution: con compatibilidad BACKWARD, el productor puede añadir nuevos campos al documento sin romper los consumidores existentes (que simplemente ignoran los campos desconocidos).
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Duplicación de datos: cada consumidor almacena una copia (parcial o completa) de los datos del documento. Esto consume storage y requiere gestión de la consistencia entre copias.
- Consistencia eventual: los consumidores pueden tener versiones diferentes del mismo documento durante ventanas de tiempo. Esto puede producir inconsistencias visibles para el usuario (la factura muestra una prima diferente a la que ve el agente en el CRM).
- Schema management: mantener un schema del documento que satisfaga las necesidades de todos los consumidores sin ser excesivamente grande o inestable requiere governance activo.
- Tamaño del documento: documentos completos (snapshots) pueden ser significativamente más grandes que mensajes de evento o delta, consumiendo más bandwidth y storage.
Riesgos de Mal Uso¶
- Documento como comando implícito: enviar un document message y esperar que el consumidor ejecute una acción específica al recibirlo. Si la intención es que el consumidor haga algo concreto, debe ser un Command Message explícito.
- Documento como fuente de verdad: que los consumidores consideren su copia local como la fuente de verdad en lugar del servicio productor. La fuente de verdad es siempre el productor; las copias locales son read replicas.
- Documento sin versionado: publicar documentos cuyo schema evoluciona sin mecanismos de versionado ni compatibilidad. Los consumidores fallan al deserializar.
- Sobre-publicación: publicar un documento completo con cada cambio mínimo (actualización de un solo campo) cuando un Event Notification sería más eficiente.
Sobreingeniería¶
- Document Message para datos triviales: implementar un pipeline completo de document messaging para transferir 3 campos entre 2 servicios cuando una API REST sería suficiente.
- Schema demasiado genérico: diseñar un schema de documento tan genérico que pierde utilidad (un campo
data: anyque puede contener cualquier cosa). - Materialización prematura: hacer que todos los servicios materialicen todos los documentos "por si acaso" cuando solo 2 de 5 servicios realmente los necesitan activamente.
Costos de Operación¶
- Storage: el topic con compaction retiene al menos un documento por cada entidad. Con 2 millones de pólizas y documentos de ~5 KB, son ~10 GB solo en el topic.
- Consumer lag monitoring: cada consumer group necesita monitoreo independiente de lag.
- Schema Registry operation: mantener y operar un Schema Registry añade complejidad a la infraestructura.
Anti-Patterns Relacionados¶
- God Document: un documento único que intenta representar todas las entidades del dominio. Demasiado grande, demasiado inestable, imposible de evolucionar.
- Document as Database: tratar el topic de documentos como una base de datos consultable, haciendo seeks y reads arbitrarios en lugar de materializar los datos localmente.
- Chatty Documents: publicar un documento completo por cada cambio mínimo, generando un volumen de mensajes desproporcionado.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Event Message (este capítulo): frecuentemente, un evento notifica que algo cambió y un document message proporciona los datos actualizados. La combinación "Event Notification + Document Message on demand" es un patrón de integración muy común. Alternativamente, Event-Carried State Transfer combina ambos en un solo mensaje.
- Command Message (este capítulo): un command message puede producir un document message como efecto secundario. El comando
UpdatePolicymodifica la póliza, y el Policy Service publica el documento actualizado. - Claim Check (Chapter 6): cuando el documento es demasiado grande para el canal de mensajería, Claim Check almacena los datos externamente y el mensaje contiene solo una referencia.
- Message Sequence (este capítulo): cuando el documento excede el tamaño máximo de mensaje, Message Sequence lo fragmenta en múltiples mensajes.
- Format Indicator (este capítulo): el
schema_versionen el documento es una implementación de Format Indicator.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Event Message — un evento como
PolicyUpdateddispara la publicación del documento de póliza. - Antes: Command Message — un comando como
UpdatePolicymodifica los datos que luego se publican como documento. - Complementario: Content-Based Router — un router puede dirigir documentos a diferentes consumidores según su contenido (por ejemplo, documentos de pólizas de auto a un consumidor, pólizas de hogar a otro).
- Complementario: Message Filter — un consumidor puede filtrar documentos que no le interesan basándose en campos del documento.
Combinaciones Comunes¶
- Document Message + Log Compaction: Kafka log compaction mantiene el último documento por key, proporcionando un "snapshot store" consultable.
- Document Message + Schema Registry: validación y evolución controlada del schema del documento.
- Document Message + Materializer: un consumidor que materializa documentos en un read model optimizado para queries.
Diferencias con Patrones Similares¶
- vs. Event Message: el evento tiene semántica temporal ("algo ocurrió en un momento"); el documento tiene semántica de estado ("así están los datos ahora"). Un evento puede no contener datos (solo la notificación); un documento siempre contiene datos.
- vs. Command Message: el comando prescribe una acción; el documento proporciona datos sin prescribir uso. El comando tiene un único handler; el documento puede tener múltiples consumidores.
- vs. Claim Check: Claim Check es una técnica para transportar documentos grandes sin saturar el canal. El documento sigue existiendo, pero el mensaje solo contiene una referencia.
Encaje en un Flujo Mayor de Integración¶
Document Message es el mecanismo principal para sincronizar datos entre bounded contexts en una arquitectura de microservicios. Cada bounded context es dueño de sus datos y los publica como documentos. Los demás bounded contexts consumen estos documentos y mantienen sus propias representaciones locales. Este patrón es fundamental para implementar el principio de "cada servicio tiene su propia base de datos".
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Document Message es omnipresente en las arquitecturas modernas, aunque frecuentemente no se lo llame por su nombre:
- DTOs en APIs: cada response body de una API REST es, conceptualmente, un Document Message síncrono. La versión asíncrona sobre messaging es el mismo concepto desacoplado temporalmente.
- Event-Carried State Transfer: el patrón descrito por Martin Fowler donde los eventos incluyen el estado completo de la entidad es, en esencia, un híbrido Event + Document. Es la forma más común de sincronizar datos entre microservicios sin queries síncronas.
- Kafka compacted topics: usar Kafka topics con log compaction como un "table" de datos (similar a KTable en Kafka Streams) es una implementación moderna de Document Message.
- Change Data Capture (CDC): herramientas como Debezium capturan cambios en la base de datos y los publican como documentos (el estado completo de la fila después del cambio). Esto es Document Message automatizado.
- GraphQL Subscriptions: una subscription que envía el estado actualizado de una entidad cuando cambia es un Document Message en tiempo real.
- CQRS Read Models: los read models se materializan consumiendo documentos (o eventos con estado) del write side.
Cómo Se Implementa Hoy¶
| Plataforma / Técnica | Implementación de Document Message |
|---|---|
| Kafka + Compaction | Topic compactado: último documento por entity key |
| Debezium (CDC) | Captura de cambios en DB → documento completo en Kafka |
| Kafka Streams KTable | Materialización de documentos como tabla de estado |
| gRPC server streaming | Stream de documentos actualizados al consumidor |
| GraphQL Subscriptions | Push de documentos actualizados al cliente |
| Azure Cosmos DB Change Feed | Stream de documentos modificados |
| AWS Dynamodb Streams | Stream de cambios en items como documentos |
| Firebase Realtime Database | Sincronización de documentos en tiempo real |
Qué Parte Sigue Siendo Esencial¶
- La semántica de "datos sin prescripción": la distinción entre transferir datos (document) y ordenar acciones (command) sigue siendo fundamental para el diseño correcto de mensajes.
- El desacoplamiento de queries: reemplazar queries síncronas por documentos materializados localmente es una de las técnicas más efectivas para mejorar resiliencia y performance en microservicios.
- Log compaction como snapshot store: la combinación de Document Message + Kafka compaction proporciona una primitiva poderosa para sincronización de estado entre servicios.
15. Implementación en Arquitecturas Modernas¶
Kafka con Log Compaction¶
Topic: policy.documents
Partitions: 32 (por hash de policy_number)
Replication Factor: 3
Cleanup Policy: compact
Min Compaction Lag: 1 hour
Retention: infinite (compacted)
Log compaction garantiza que el topic retiene al menos el último mensaje por key (policy_number). Un nuevo consumidor puede leer el topic completo para materializar el estado actual de todas las pólizas.
Debezium (Change Data Capture)¶
{
"name": "policy-cdc-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "policy-db.internal",
"database.dbname": "policies",
"table.include.list": "public.policies",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter"
}
}
Debezium captura automáticamente cada cambio en la tabla policies y publica el nuevo estado completo de la fila como un Document Message en Kafka. Esto automatiza la publicación de documentos sin modificar el Policy Service.
Python Consumer (Materializer)¶
from confluent_kafka import Consumer, KafkaError
import json
class PolicyMaterializer:
"""Materializes policy documents into local read store."""
def __init__(self, local_store, consumer_config):
self.store = local_store
self.consumer = Consumer(consumer_config)
self.consumer.subscribe(["policy.documents"])
def run(self):
while True:
msg = self.consumer.poll(1.0)
if msg is None:
continue
if msg.error():
self.handle_error(msg.error())
continue
document = json.loads(msg.value())
entity_id = document["entity_id"]
entity_version = document["entity_version"]
# Only process if newer than what we have
current_version = self.store.get_version(entity_id)
if current_version and entity_version <= current_version:
continue # Stale document, skip
# Extract domain-relevant fields
local_record = self.transform(document["payload"])
local_record["_entity_version"] = entity_version
local_record["_received_at"] = datetime.utcnow()
# Materialize
self.store.upsert(entity_id, local_record)
def transform(self, payload):
"""Override in subclass to extract domain-relevant fields."""
raise NotImplementedError
Azure Cosmos DB Change Feed¶
var changeFeedProcessor = container
.GetChangeFeedProcessorBuilder<PolicyDocument>(
"billingProcessor",
async (changes, ct) =>
{
foreach (var document in changes)
{
// Materialize premium data in billing store
await billingStore.UpsertPremiumData(
document.PolicyNumber,
document.Premium.AnnualAmount,
document.Premium.PaymentFrequency,
document.EntityVersion
);
}
})
.WithInstanceName("billing-instance-01")
.WithLeaseContainer(leaseContainer)
.WithStartTime(DateTime.MinValue.ToUniversalTime())
.Build();
Cosmos DB Change Feed es un mecanismo nativo de Document Message: cada cambio en un documento de Cosmos DB se propaga como un Document Message a los procesadores registrados.
Schema Registry (Avro)¶
{
"type": "record",
"name": "PolicyDocument",
"namespace": "com.insurance.policy",
"fields": [
{"name": "policy_number", "type": "string"},
{"name": "product_type", "type": {"type": "enum", "name": "ProductType",
"symbols": ["HOME_INSURANCE", "AUTO_INSURANCE", "LIFE_INSURANCE", "HEALTH_INSURANCE"]}},
{"name": "status", "type": "string"},
{"name": "effective_date", "type": "string"},
{"name": "expiration_date", "type": "string"},
{"name": "policyholder", "type": "Policyholder"},
{"name": "coverages", "type": {"type": "array", "items": "Coverage"}},
{"name": "premium", "type": "Premium"},
{"name": "agent", "type": ["null", "Agent"], "default": null}
]
}
El schema Avro registrado con compatibilidad BACKWARD permite que el productor añada nuevos campos (con defaults) sin romper los consumidores existentes.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por topic de documentos: documents-published/sec, documents-consumed/sec (por consumer group), consumer lag, average document size, schema validation errors.
- Freshness tracking: medir el tiempo entre la modificación de la entidad en el productor y la materialización en cada consumidor. Si la frescura excede el SLA, alertar.
- Version tracking: monitorear la entity_version máxima en el productor y en cada consumidor para detectar consumidores que están procesando versiones antiguas.
Monitoreo¶
- Consumer lag por consumer group: la métrica más importante. Si el Billing Service tiene lag creciente, las facturas pueden emitirse con datos desactualizados.
- Document size distribution: documentos inusualmente grandes pueden indicar un problema (por ejemplo, una póliza con miles de coberturas por un bug).
- Schema validation failure rate: un incremento indica que el productor está publicando documentos que no cumplen el schema registrado.
- Compaction lag: en Kafka con log compaction, el lag de compaction indica cuánto almacenamiento extra se está usando por documentos obsoletos no compactados.
Versionado¶
- Schema Registry con BACKWARD compatibility: los consumidores existentes pueden deserializar documentos producidos con schemas más nuevos (que pueden tener campos adicionales con defaults).
- Entity version: cada documento incluye un número de versión de la entidad para que los consumidores puedan detectar y resolver conflictos de orden.
- Schema version: cada documento indica su schema version para que los consumidores puedan adaptar su deserialización.
Seguridad¶
- Field-level encryption: para documentos que contienen datos sensibles (números de cuenta, datos personales), considerar cifrado a nivel de campo. El consumidor autorizado puede descifrar los campos que necesita; los campos que no necesita permanecen cifrados.
- Topic ACLs: restringir quién puede publicar en el topic (solo el servicio dueño de los datos) y quién puede consumir (solo los servicios autorizados).
- Data masking: para consumidores que no necesitan ciertos datos sensibles (por ejemplo, analytics no necesita el nombre real del asegurado), implementar data masking en un stream processor intermedio.
Manejo de Errores¶
- Deserialización fallida: si un consumidor no puede deserializar un documento (schema incompatible), el mensaje debe ir a una dead-letter queue, no descartarse silenciosamente.
- Materialización fallida: si un consumidor no puede almacenar el documento en su local store (error de base de datos), debe reintentar con backoff.
- Version conflict: si un consumidor recibe un documento con entity_version menor que el que ya tiene, debe ignorarlo sin error.
Idempotencia¶
- Natural por entity_version: la materialización de documentos es naturalmente idempotente si se usa entity_version. Recibir el mismo documento dos veces y aplicar "solo si version > actual" produce el mismo resultado.
- Upsert semántico: la operación del consumidor es un upsert (insert or update), no un append. Esto hace que la re-entrega de documentos sea segura.
Auditoría¶
- Registrar qué documentos se publicaron, cuándo y con qué versión.
- Registrar qué consumidores materializaron cada documento y en qué momento.
- Mantener un historial de versiones del schema del documento.
Performance¶
- Compression: comprimir documentos grandes (Snappy, LZ4, Zstd) para reducir bandwidth y storage.
- Selective deserialization: en Avro, los consumidores pueden deserializar solo los campos que necesitan, ignorando el resto sin parsearlo.
- Batch materialization: acumular documentos y materializar en batch en lugar de uno a uno, para amortizar overhead de escritura.
Escalabilidad¶
- Más particiones: para topics con alto volumen de documentos, más particiones permiten mayor paralelismo de consumo.
- Consumer group scaling: añadir instancias a un consumer group para consumir más rápido.
- Tiered storage: para topics con retención larga (compacted + infinite retention), usar tiered storage para mover segmentos antiguos a almacenamiento más barato.
17. Errores Comunes¶
Confundir Document con Command¶
Enviar un documento de póliza y esperar que el consumidor ejecute una acción específica (por ejemplo, "cuando recibas el documento de la póliza, genera la factura") sin que esa instrucción sea explícita. Si la intención es que el consumidor ejecute una acción, debe ser un Command Message (GenerateInvoiceForPolicy). Si la intención es que el consumidor tenga los datos disponibles y los use como necesite, es un Document Message.
Documentos Sin Entity Version¶
Publicar documentos sin un número de versión de la entidad impide que los consumidores detecten mensajes desordenados. En un sistema distribuido, el consumidor puede recibir la versión 5 después de la versión 6. Sin entity_version, no tiene forma de saber cuál es más reciente y puede sobrescribir datos más nuevos con datos más antiguos.
Documentos Incompletos que Requieren Queries Adicionales¶
Un documento de póliza que incluye policyholder_id: "CUST-00482917" pero no los datos del asegurado obliga al consumidor a consultar el servicio de clientes para obtener el nombre y la dirección. Esto reintroduce el acoplamiento síncrono que Document Message pretende eliminar. Si el consumidor necesita los datos del asegurado, el documento debe incluirlos (denormalizados).
Sobre-publicación de Documentos¶
Publicar el documento completo de la póliza cada vez que cambia cualquier campo (incluso campos irrelevantes para la mayoría de consumidores) genera un volumen de mensajes desproporcionado. Considerar Event Notification para cambios menores y Document Message para cambios significativos, o usar filtrado a nivel de topic.
No Configurar Log Compaction¶
Sin log compaction en Kafka, un nuevo consumidor que lee desde el inicio del topic recibe todo el historial de documentos (versiones 1, 2, 3, ... N de cada póliza), cuando solo necesita la versión más reciente. Esto produce un catch-up innecesariamente largo y costoso.
Tratar la Copia Local como Fuente de Verdad¶
Cuando un consumidor materializa datos de un documento, su copia local es una read replica, no la fuente de verdad. Si necesita modificar los datos, debe enviar un Command Message al servicio dueño de los datos, no modificar su copia local directamente. Modificar la copia local produce inconsistencias imposibles de resolver.
Schema Evolution Sin Estrategia¶
Añadir, eliminar o cambiar campos del documento sin una estrategia de compatibilidad produce roturas en los consumidores. La estrategia recomendada es BACKWARD compatibility: los consumidores existentes pueden manejar documentos con nuevos schemas (ignoran campos desconocidos, usan defaults para campos ausentes). Los cambios incompatibles requieren una nueva versión del tipo de documento y una migración coordinada.
18. Conclusión Técnica¶
Document Message es el patrón que establece cómo transferir datos entre servicios sin imponer intención de acción. Su semántica — "aquí están los datos, úsalos como necesites" — lo diferencia del Command Message ("haz esto con los datos") y del Event Message ("algo ocurrió, estos son los datos del hecho"). Esta distinción es prácticamente relevante porque determina la responsabilidad del consumidor: en un Document Message, el consumidor tiene autonomía total sobre cómo utiliza los datos.
Cuándo aporta valor: siempre que un servicio necesite que otros servicios tengan acceso a sus datos sin crear acoplamiento temporal (queries síncronas) o de implementación (base de datos compartida). Los escenarios más frecuentes son sincronización de datos entre bounded contexts, materialización de read models en CQRS, data feeds para analytics y replicación de datos de referencia.
Cuándo evita problemas importantes: Document Message evita el "query cascade" donde cada servicio llama síncronamente a otros servicios para obtener datos, produciendo latencia acumulada y fallos en cascada. También evita la base de datos compartida como mecanismo de integración, que acopla los servicios a nivel de esquema de datos.
Cuándo no conviene adoptarlo: cuando el volumen de datos es bajo y la latencia de una query síncrona es aceptable, la complejidad del messaging no se justifica. Cuando los datos cambian con alta frecuencia y publicar el documento completo cada vez es ineficiente, Event Notification + query on demand puede ser más apropiado. Cuando la semántica no es realmente de transferencia de datos sino de instrucción o notificación, Command Message o Event Message son más correctos.
Recomendación para arquitectos: trate los Document Messages como contratos de datos versionados. Defina schemas explícitos con Schema Registry, establezca compatibilidad BACKWARD como default, incluya entity_version para manejar desordenamiento, y diseñe los documentos como snapshots completos cuando sea viable (más simple para los consumidores). La disciplina de separar "aquí están los datos" (document) de "haz algo" (command) y "algo ocurrió" (event) es esencial para mantener la claridad semántica en una arquitectura de messaging, especialmente a medida que el número de servicios y los volúmenes de mensajes crecen.