Request-Reply¶
1. Nombre del Patrón¶
- Nombre oficial: Request-Reply
- Categoría: Message Construction (Construcción de Mensajes)
- Traducción contextual: Petición-Respuesta
2. Resumen Ejecutivo¶
Request-Reply es el patrón que permite establecer una conversación bidireccional sobre un sistema de mensajería asíncrono. El productor envía un mensaje de petición (request) a un canal y espera recibir un mensaje de respuesta (reply) en un segundo canal, logrando así una semántica de invocación síncrona sobre una infraestructura fundamentalmente asíncrona.
El problema que resuelve es central en toda arquitectura distribuida: ¿cómo puede un sistema obtener una respuesta a través de messaging cuando los mensajes fluyen en una sola dirección por cada canal? La respuesta de Request-Reply es directa pero con profundas implicaciones: se utilizan dos canales — uno para la petición y otro para la respuesta — coordinados mediante un identificador de correlación que permite al solicitante vincular la respuesta con su petición original.
Este patrón es omnipresente. Cada vez que un microservicio necesita consultar datos de otro servicio a través de un broker, cada vez que un API gateway traduce una llamada HTTP síncrona en messaging asíncrono, cada vez que un sistema de telecomunicaciones consulta el saldo en tiempo real de un cliente a través de una cola de mensajes — está aplicando Request-Reply. Es el puente entre el mundo síncrono que los usuarios y muchos protocolos esperan, y el mundo asíncrono que proporciona resiliencia, desacoplamiento y escalabilidad.
3. Definición Detallada¶
Propósito¶
Request-Reply establece un protocolo de comunicación bidireccional sobre messaging unidireccional. Su propósito es permitir que un solicitante (requestor) envíe una petición y reciba una respuesta del destinatario (replier), sin que ambos necesiten una conexión directa punto a punto, y manteniendo todas las ventajas del messaging asíncrono: desacoplamiento, resiliencia ante fallos temporales y capacidad de buffering.
Lógica Arquitectónica¶
En una invocación síncrona (REST, gRPC), la respuesta viaja de regreso por el mismo canal de comunicación que la petición — la conexión TCP/HTTP se mantiene abierta hasta que llega la respuesta. En messaging, cada canal es unidireccional: el productor deposita un mensaje y el consumidor lo recoge. No hay un "camino de vuelta" implícito.
Request-Reply resuelve esta asimetría introduciendo un segundo canal dedicado a las respuestas. El solicitante:
- Genera un identificador único para la petición.
- Incluye en el mensaje de petición la dirección del canal de respuesta (Return Address) y el identificador de correlación.
- Envía la petición al canal de request.
- Escucha en el canal de reply, filtrando por el identificador de correlación.
El destinatario:
- Consume la petición del canal de request.
- Procesa la petición y genera la respuesta.
- Envía la respuesta al canal indicado en la Return Address, incluyendo el identificador de correlación original.
Principio de Diseño Subyacente¶
El principio es conversación sobre canales unidireccionales. Así como un protocolo de red full-duplex se puede implementar sobre dos canales simplex, Request-Reply implementa interacción bidireccional sobre dos Message Channels unidireccionales. El identificador de correlación es el mecanismo que "une" los dos mensajes en una conversación lógica.
Problema Estructural que Resuelve¶
Sin Request-Reply, un sistema que necesita obtener una respuesta a través de messaging tiene dos opciones insatisfactorias:
- Polling: el solicitante envía la petición y luego consulta repetidamente un almacén de datos donde el destinatario deposita la respuesta. Ineficiente, genera carga innecesaria y tiene latencia impredecible.
- Callback directo: el solicitante expone un endpoint HTTP y el destinatario invoca ese endpoint cuando tiene la respuesta. Esto reintroduce acoplamiento directo y elimina las ventajas del messaging.
Request-Reply proporciona una solución nativa del paradigma de messaging: el solicitante escucha en un canal de respuesta, y el destinatario publica la respuesta en ese canal. No hay polling, no hay conexión directa.
Contexto en el que Emerge¶
Request-Reply emerge en cualquier escenario donde:
- Dos sistemas necesitan intercambiar información bidireccionalmente.
- Se desea mantener messaging como infraestructura de comunicación (por resiliencia, desacoplamiento, auditoría).
- El solicitante no puede continuar su procesamiento sin la respuesta.
- Se quiere abstraer múltiples backends detrás de un canal común de peticiones.
Relación con Sistemas Distribuidos¶
En la teoría de sistemas distribuidos, Request-Reply implementa un protocolo de comunicación tipo RPC (Remote Procedure Call) sobre un canal de mensajes. A diferencia de un RPC tradicional, donde el fallo del servidor resulta en un timeout del cliente, en Request-Reply con messaging la petición persiste en el canal hasta que el servidor esté disponible para procesarla. Esto proporciona una semántica de "RPC con durabilidad" que no existe en protocolos síncronos puros.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Request-Reply, los sistemas distribuidos que necesitan comunicación bidireccional sobre messaging enfrentan:
- Ausencia de mecanismo de respuesta: los canales de mensajería son unidireccionales por naturaleza. El productor envía un mensaje y no tiene forma nativa de recibir una respuesta del consumidor.
- Acoplamiento temporal en alternativas síncronas: si se recurre a HTTP/gRPC para las consultas, se pierde el desacoplamiento temporal que proporciona el messaging. Si el servidor no está disponible, la petición falla inmediatamente.
- Incapacidad de buffering de peticiones: sin messaging, si el servidor está sobrecargado, las peticiones se rechazan o se pierden. Con Request-Reply sobre messaging, las peticiones se acumulan en el canal y se procesan cuando el servidor tiene capacidad.
Síntomas del Problema¶
- Arquitecturas híbridas inconsistentes donde algunos flujos usan messaging y otros recurren a HTTP solo porque necesitan una respuesta, creando dos modelos de comunicación diferentes con diferentes modos de fallo.
- Sistemas que implementan polling artesanal: el solicitante escribe en una base de datos y el destinatario actualiza esa misma base de datos con la respuesta, con el solicitante consultando periódicamente.
- Pérdida de peticiones cuando el servidor receptor no está disponible y no hay buffer intermedio.
- Imposibilidad de aplicar políticas de priorización, throttling o auditoría a las peticiones porque no pasan por el middleware de messaging.
Impacto Operativo y Arquitectónico¶
Sin Request-Reply implementado correctamente:
- Las consultas críticas (saldo de cuenta, estado de envío, disponibilidad de inventario) fallan cuando el servicio backend tiene downtime, porque se usan llamadas síncronas directas.
- No hay visibilidad sobre las peticiones en tránsito: cuántas hay pendientes, cuál es la latencia promedio de respuesta, cuántas expiraron sin respuesta.
- No se puede aplicar backpressure: si llegan más peticiones de las que el backend puede procesar, no hay buffer.
Riesgos Si No Se Implementa Correctamente¶
- Timeout inadecuado: el solicitante espera indefinidamente una respuesta que nunca llegará porque el mensaje se perdió o el consumidor falló.
- Canal de respuesta sobrecargado: si todos los solicitantes comparten un canal de respuesta sin filtrado eficiente, cada solicitante recibe y descarta mensajes que no le corresponden.
- Fuga de recursos: el solicitante crea recursos temporales (colas temporales, threads bloqueados) para esperar la respuesta y no los libera correctamente ante timeouts o errores.
- Correlación incorrecta: sin un Correlation Identifier robusto, las respuestas se vinculan a peticiones equivocadas, produciendo errores de datos difíciles de diagnosticar.
Ejemplos Reales¶
- Telecomunicaciones: un sistema de IVR (Interactive Voice Response) consulta el saldo del cliente en tiempo real. La consulta se envía vía messaging al core de billing, que responde con el saldo actual. El IVR necesita la respuesta en menos de 2 segundos para no degradar la experiencia del usuario.
- Banca: un servicio de autorización de transacciones envía la solicitud de autorización vía messaging al motor de riesgo, que responde con approve/decline. La petición debe persistir aunque el motor de riesgo esté temporalmente sobrecargado.
- E-commerce: el checkout consulta disponibilidad de inventario en un warehouse management system vía messaging. Si el WMS está procesando un batch de actualización, las consultas se encolan y se responden cuando el WMS tiene capacidad.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando se necesita comunicación bidireccional entre sistemas y se desea mantener messaging como infraestructura (por resiliencia, desacoplamiento, auditoría).
- Cuando el servicio backend puede tener períodos de indisponibilidad y las peticiones deben encolarse en lugar de perderse.
- Cuando se necesita aplicar políticas de priorización o throttling a las peticiones a nivel de middleware.
- Cuando múltiples solicitantes necesitan consultar un mismo servicio y se quiere un punto central de ingreso (canal de peticiones) para balanceo y monitoreo.
Cuándo No Usarlo¶
- Cuando la latencia de respuesta debe ser sub-milisegundo y el overhead de dos hops de messaging es inaceptable. En estos casos, una llamada directa gRPC/HTTP es más apropiada.
- Cuando no se necesita durabilidad de las peticiones: si una petición perdida se puede reintentar trivialmente, el overhead de messaging no se justifica.
- Cuando la comunicación es puramente fire-and-forget (el productor no necesita respuesta).
- Cuando ya existe una infraestructura de API gateway con circuit breakers y retries que proporciona resiliencia suficiente para llamadas síncronas.
Precondiciones¶
- Existe un sistema de mensajería (broker) con soporte para al menos dos canales.
- Existe un mecanismo para incluir metadata en los mensajes (headers para Return Address y Correlation Identifier).
- El solicitante puede actuar como consumidor (escuchar en un canal de respuesta), no solo como productor.
Restricciones¶
- La latencia mínima es al menos el doble de un single hop de messaging (ida + vuelta).
- Requiere gestión de timeouts: el solicitante debe definir cuánto tiempo espera la respuesta antes de considerar que falló.
- El canal de respuesta consume recursos del broker (storage, connections) que deben gestionarse.
Supuestos Arquitectónicos¶
- Ambos participantes (requestor y replier) están conectados al mismo sistema de mensajería o a sistemas federados.
- Los mensajes pueden transportar metadata (headers) además del payload.
- El solicitante tiene capacidad de bloquear o registrar un callback mientras espera la respuesta.
6. Fuerzas Arquitectónicas¶
Sincronía vs. Asincronía¶
La tensión fundamental de Request-Reply. El solicitante necesita un comportamiento "síncrono" (enviar y esperar respuesta), pero la infraestructura es asíncrona. Request-Reply reconcilia ambos mundos, pero el resultado es un patrón inherentemente más complejo que una llamada síncrona directa. La complejidad adicional (dos canales, correlación, timeouts) solo se justifica cuando las ventajas del messaging (durabilidad, desacoplamiento, buffering) son necesarias.
Latencia vs. Resiliencia¶
Una llamada HTTP directa tiene menor latencia (un round-trip de red) que Request-Reply sobre messaging (producir a canal + consumir del canal + procesar + producir respuesta + consumir respuesta). Sin embargo, Request-Reply es más resiliente: si el servidor está caído, la petición espera en el canal en lugar de fallar inmediatamente. El trade-off es latencia adicional a cambio de resiliencia ante fallos temporales.
Simplicidad vs. Observabilidad¶
Request-Reply introduce complejidad pero también un punto de observación valioso: los canales de petición y respuesta permiten medir el throughput de peticiones, la latencia de respuesta, la profundidad de la cola de peticiones pendientes y la tasa de timeouts. Esta observabilidad no existe en llamadas directas sin instrumentación adicional.
Acoplamiento vs. Flexibilidad¶
Con Request-Reply, el solicitante no necesita conocer la dirección del servicio backend — solo el nombre del canal de peticiones. Esto permite reemplazar, escalar o reubicar el backend sin cambiar el solicitante. Sin embargo, se introduce un acoplamiento implícito al formato del mensaje de petición y respuesta, y al nombre del canal.
Escalabilidad vs. Complejidad de Correlación¶
Si múltiples instancias del solicitante comparten un canal de respuesta, cada instancia debe filtrar las respuestas que le corresponden usando el Correlation Identifier. Si cada instancia crea su propio canal temporal de respuesta, se simplifica la correlación pero se aumenta la carga en el broker (creación/destrucción de canales). Esta tensión se manifiesta constantemente en implementaciones a escala.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Requestor (Solicitante): la aplicación que envía la petición y espera la respuesta.
- Replier (Respondedor): la aplicación que recibe la petición, la procesa y envía la respuesta.
- Request Channel: el canal por donde viaja la petición.
- Reply Channel: el canal por donde viaja la respuesta.
- Correlation Identifier: el identificador que vincula respuesta con petición.
- Broker: el sistema de mensajería que gestiona ambos canales.
Flujo Lógico¶
flowchart TD
A([Requestor]) --> B[Generar correlation_id\núnico - UUID]
B --> C[Construir mensaje de petición\nbody + reply_to + correlation_id]
C --> D[(Request Channel)]
A --> E[Iniciar timer de timeout]
A --> F[Escuchar en Reply Channel\nfiltrando por correlation_id]
D --> G([Replier])
G --> H[Consumir mensaje del\nRequest Channel]
H --> I[Procesar petición\nconsulta DB, lógica, etc.]
I --> J[Construir respuesta\ncon correlation_id copiado]
J --> K[(Reply Channel)]
K --> F
F --> L{correlation_id\ncoincide?}
L -- Sí --> M[Cancelar timer y\nprocesar respuesta]
M --> N([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Requestor | Generar correlation_id, incluir reply_to, enviar petición, escuchar respuesta, gestionar timeout |
| Replier | Consumir petición, procesar, enviar respuesta al reply_to con el correlation_id original |
| Request Channel | Almacenar y entregar peticiones al replier |
| Reply Channel | Almacenar y entregar respuestas al requestor |
| Broker | Gestionar ambos canales, garantizar entrega |
Decisiones de Diseño Clave¶
- Reply channel compartido vs. temporal: ¿todos los requestors comparten un reply channel (eficiente en recursos pero requiere filtrado) o cada requestor crea un canal temporal exclusivo (simple en correlación pero costoso en recursos)?
- Blocking vs. callback: ¿el requestor bloquea un thread esperando la respuesta o registra un callback/future que se invoca cuando la respuesta llega?
- Timeout handling: ¿qué ocurre cuando la respuesta no llega? ¿Se reintenta la petición? ¿Se escala a un sistema alternativo? ¿Se reporta error?
- Garantía de entrega: ¿la petición debe persistirse en el canal (durable) o puede ser in-memory (transient)?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Telecomunicaciones — Consulta de Saldo en Tiempo Real¶
Contexto del Negocio¶
Un operador de telecomunicaciones con 25 millones de clientes prepago opera un sistema de consulta de saldo que atiende múltiples canales de contacto: app móvil, USSD (#123#), IVR (llamada al 611), portal web y agentes de call center. Cada canal necesita consultar el saldo actual del cliente en tiempo real, con una latencia máxima aceptable de 2 segundos.
El core de billing que gestiona los saldos es un sistema legacy basado en Oracle que soporta un máximo de 500 consultas concurrentes. En horas pico (lunes a las 9:00 AM, primer día del mes), los canales de contacto generan hasta 3,000 consultas por segundo. Sin buffering, el core de billing colapsa.
Necesidad de Integración¶
Los canales de contacto necesitan consultar el saldo en tiempo real pero no pueden invocar directamente al core de billing porque:
- El core no soporta la carga directa de todos los canales simultáneamente.
- Si el core está en mantenimiento (ventana de 30 minutos cada noche), las peticiones deben encolarse, no fallar.
- Se necesita priorización: las consultas del IVR (cliente en llamada, experiencia real-time) tienen mayor prioridad que las del portal web.
- Se necesita auditoría centralizada de todas las consultas de saldo para compliance regulatorio.
Sistemas Involucrados¶
- Mobile App Backend: API REST que atiende la app móvil.
- USSD Gateway: gateway que procesa códigos USSD.
- IVR System: sistema de respuesta de voz interactiva.
- Web Portal Backend: API REST del portal web.
- Call Center CRM: aplicación de agentes de call center.
- Balance Query Service: microservicio que media entre los canales y el core de billing.
- Core Billing (Oracle): sistema legacy que gestiona saldos.
- RabbitMQ Cluster: broker de mensajería.
Diseño de Canales¶
| Canal (Queue RabbitMQ) | Dirección | Productor | Consumidor | Prioridad |
|---|---|---|---|---|
billing.balance.request.high | Request | IVR, USSD | Balance Query Service | Alta |
billing.balance.request.normal | Request | App, Web, CRM | Balance Query Service | Normal |
billing.balance.reply | Reply | Balance Query Service | Todos los solicitantes | N/A |
Decisiones Arquitectónicas¶
- Dos colas de request por prioridad: las consultas del IVR y USSD (usuario esperando en tiempo real) se enrutan a una cola de alta prioridad que el Balance Query Service consume primero.
- Cola de reply compartida con filtrado por correlation_id: todos los solicitantes escuchan en la misma cola de reply pero cada uno filtra por su correlation_id. RabbitMQ no soporta filtrado nativo por header en consumers, por lo que el Balance Query Service publica la respuesta en una cola temporal exclusiva del requestor (reply-to queue).
- Colas temporales exclusivas como reply channel: cada instancia del requestor crea una cola temporal (
amq.gen-*) al conectarse. Esta cola se usa como reply_to. Cuando la instancia se desconecta, la cola se elimina automáticamente. - Timeout de 2 segundos: si la respuesta no llega en 2 segundos, el requestor devuelve un mensaje genérico al canal de contacto ("Consulta temporalmente no disponible") y registra el timeout para monitoreo.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Core billing lento → timeouts masivos | Circuit breaker en Balance Query Service; cache de saldos recientes (TTL 30s) |
| Cola de request acumula miles de peticiones | Monitoring de queue depth + alertas; auto-scaling del Balance Query Service |
| Cola temporal del requestor se elimina antes de recibir la respuesta | TTL de respuesta en el mensaje (message expiration) |
| Respuesta llega después del timeout | El requestor descarta respuestas tardías; log para análisis de latencia |
| Pérdida de mensajes de petición | Colas durables con persistent delivery mode |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Petición desde el IVR¶
Un cliente llama al *611. El IVR le solicita su número de teléfono (MSISDN: +57-300-123-4567) y ofrece la opción "Consultar saldo". El IVR System genera la petición:
{
"msisdn": "+573001234567",
"query_type": "current_balance",
"channel": "ivr",
"timestamp": "2026-04-07T09:15:32.847Z"
}
Headers del mensaje:
message_id: "msg-a1b2c3d4-e5f6-7890-abcd-ef1234567890"
correlation_id: "corr-7f3e2a91-4b8c-4d2e-9a1f-8c5d3b6e7f90"
reply_to: "amq.gen-IVR-instance-42-reply"
priority: 8
content_type: "application/json"
expiration: "2000" (TTL: 2 segundos)
El IVR System publica este mensaje en la cola billing.balance.request.high (prioridad alta porque el cliente está en llamada).
Paso 2: Encolamiento y Priorización¶
RabbitMQ almacena el mensaje en billing.balance.request.high. El Balance Query Service consume de ambas colas de request, pero da preferencia a billing.balance.request.high usando un basic.consume con prefetch=1 y consumiendo primero de la cola de alta prioridad.
En este momento hay 47 peticiones en la cola normal y 3 en la cola de alta prioridad. El servicio procesa las 3 de alta prioridad primero.
Paso 3: Procesamiento por el Balance Query Service¶
El Balance Query Service consume la petición del IVR:
- Lee el
msisdndel body:+573001234567. - Consulta un cache Redis para verificar si hay un saldo reciente (TTL < 30s). No hay cache hit.
- Invoca el core de billing Oracle vía JDBC con la consulta de saldo.
- Oracle retorna: saldo = 15,420 COP, fecha último recargo = 2026-04-05.
- Almacena el resultado en Redis con TTL 30 segundos (para peticiones duplicadas en ventana corta).
- Construye el mensaje de respuesta.
Paso 4: Envío de la Respuesta¶
El Balance Query Service publica la respuesta en la cola indicada en reply_to (amq.gen-IVR-instance-42-reply):
{
"msisdn": "+573001234567",
"balance_cop": 15420,
"last_recharge": "2026-04-05T18:30:00Z",
"balance_expiry": "2026-05-05T23:59:59Z",
"query_status": "success"
}
Headers de la respuesta:
correlation_id: "corr-7f3e2a91-4b8c-4d2e-9a1f-8c5d3b6e7f90"
content_type: "application/json"
timestamp: "2026-04-07T09:15:33.124Z"
El correlation_id de la respuesta es idéntico al de la petición. Esto permite al IVR vincular la respuesta con la petición original.
Paso 5: Recepción por el IVR¶
El IVR System está escuchando en su cola temporal amq.gen-IVR-instance-42-reply. Recibe la respuesta, verifica que el correlation_id coincide con una petición pendiente, cancela el timer de timeout (solo habían transcurrido 277ms de los 2000ms permitidos) y reproduce al cliente: "Su saldo actual es quince mil cuatrocientos veinte pesos, válido hasta el cinco de mayo".
Paso 6: Escenario de Timeout¶
Simultáneamente, el portal web envió una consulta de saldo para otro cliente. La petición se encoló en billing.balance.request.normal. El core de billing estaba procesando un batch de reconciliación y la consulta tardó 3.2 segundos. El Web Portal Backend tenía un timeout de 2 segundos. Al expirar el timeout:
- El backend web devuelve al usuario: "No pudimos obtener tu saldo en este momento. Intenta de nuevo en unos segundos."
- Registra el timeout con el
correlation_idpara monitoreo. - Deja de escuchar en la cola temporal de reply.
- Cuando la respuesta finalmente llega (1.2 segundos después del timeout), la cola temporal ya fue eliminada y RabbitMQ descarta el mensaje (o lo envía a dead-letter si está configurado).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import RabbitMQ
from diagrams.onprem.compute import Server
from diagrams.onprem.database import Oracle
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.monitoring import Grafana
from diagrams.onprem.network import Nginx
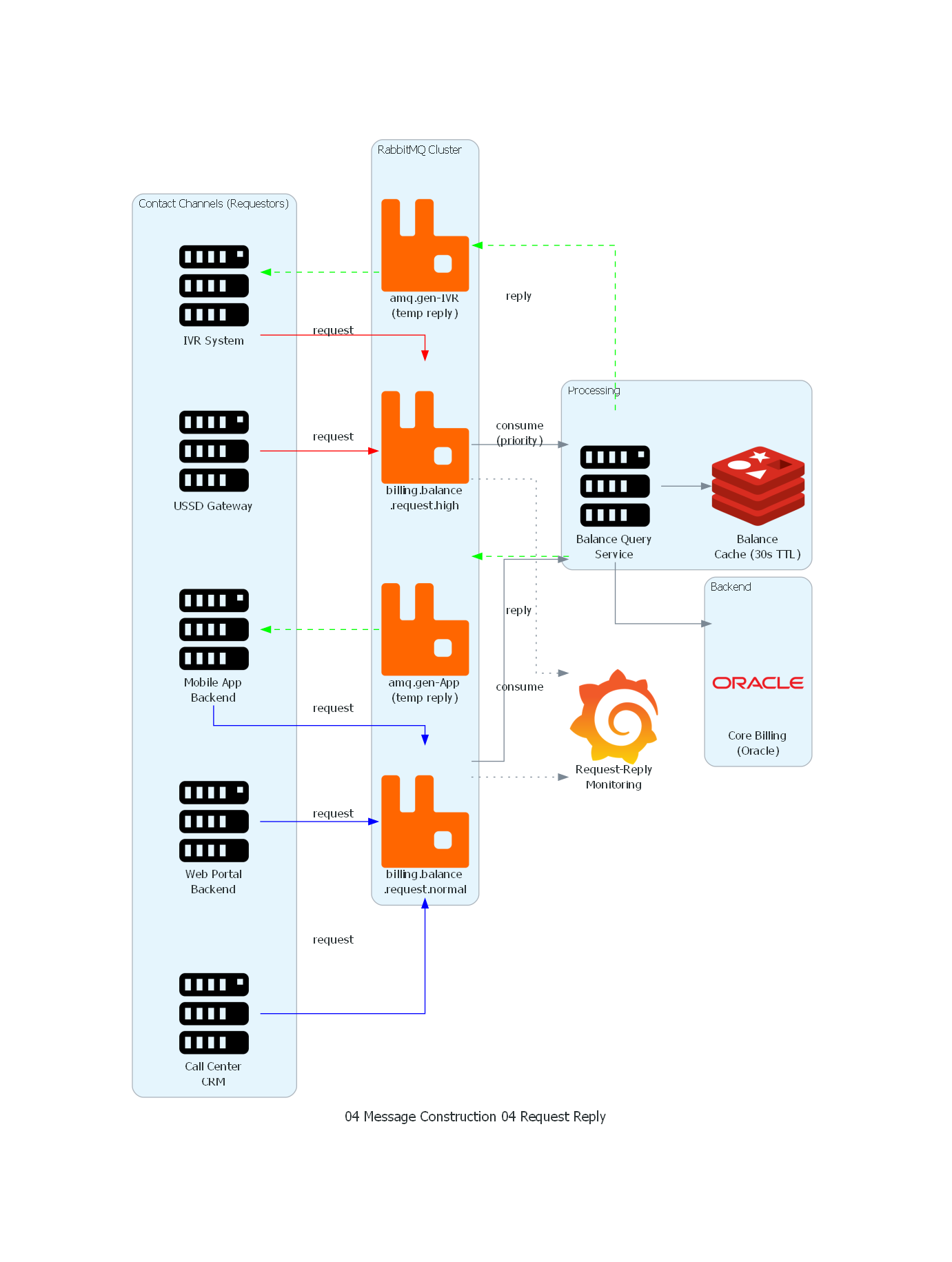
with Diagram("Request-Reply - Telecom Balance Query", show=False, direction="LR"):
with Cluster("Contact Channels (Requestors)"):
ivr = Server("IVR System")
ussd = Server("USSD Gateway")
app = Server("Mobile App\nBackend")
web = Server("Web Portal\nBackend")
crm = Server("Call Center\nCRM")
with Cluster("RabbitMQ Cluster"):
req_high = RabbitMQ("billing.balance\n.request.high")
req_normal = RabbitMQ("billing.balance\n.request.normal")
reply_ivr = RabbitMQ("amq.gen-IVR\n(temp reply)")
reply_app = RabbitMQ("amq.gen-App\n(temp reply)")
with Cluster("Processing"):
balance_svc = Server("Balance Query\nService")
cache = Redis("Balance\nCache (30s TTL)")
with Cluster("Backend"):
billing = Oracle("Core Billing\n(Oracle)")
monitoring = Grafana("Request-Reply\nMonitoring")
# Request flow (high priority)
ivr >> Edge(label="request", color="red") >> req_high
ussd >> Edge(label="request", color="red") >> req_high
# Request flow (normal priority)
app >> Edge(label="request", color="blue") >> req_normal
web >> Edge(label="request", color="blue") >> req_normal
crm >> Edge(label="request", color="blue") >> req_normal
# Processing
req_high >> Edge(label="consume\n(priority)") >> balance_svc
req_normal >> Edge(label="consume") >> balance_svc
balance_svc >> cache
balance_svc >> billing
# Reply flow
balance_svc >> Edge(label="reply", style="dashed", color="green") >> reply_ivr
balance_svc >> Edge(label="reply", style="dashed", color="green") >> reply_app
reply_ivr >> Edge(style="dashed", color="green") >> ivr
reply_app >> Edge(style="dashed", color="green") >> app
# Monitoring
req_high >> Edge(style="dotted") >> monitoring
req_normal >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import ElasticacheForRedis, RDS
from diagrams.aws.integration import SQS
from diagrams.aws.management import Cloudwatch
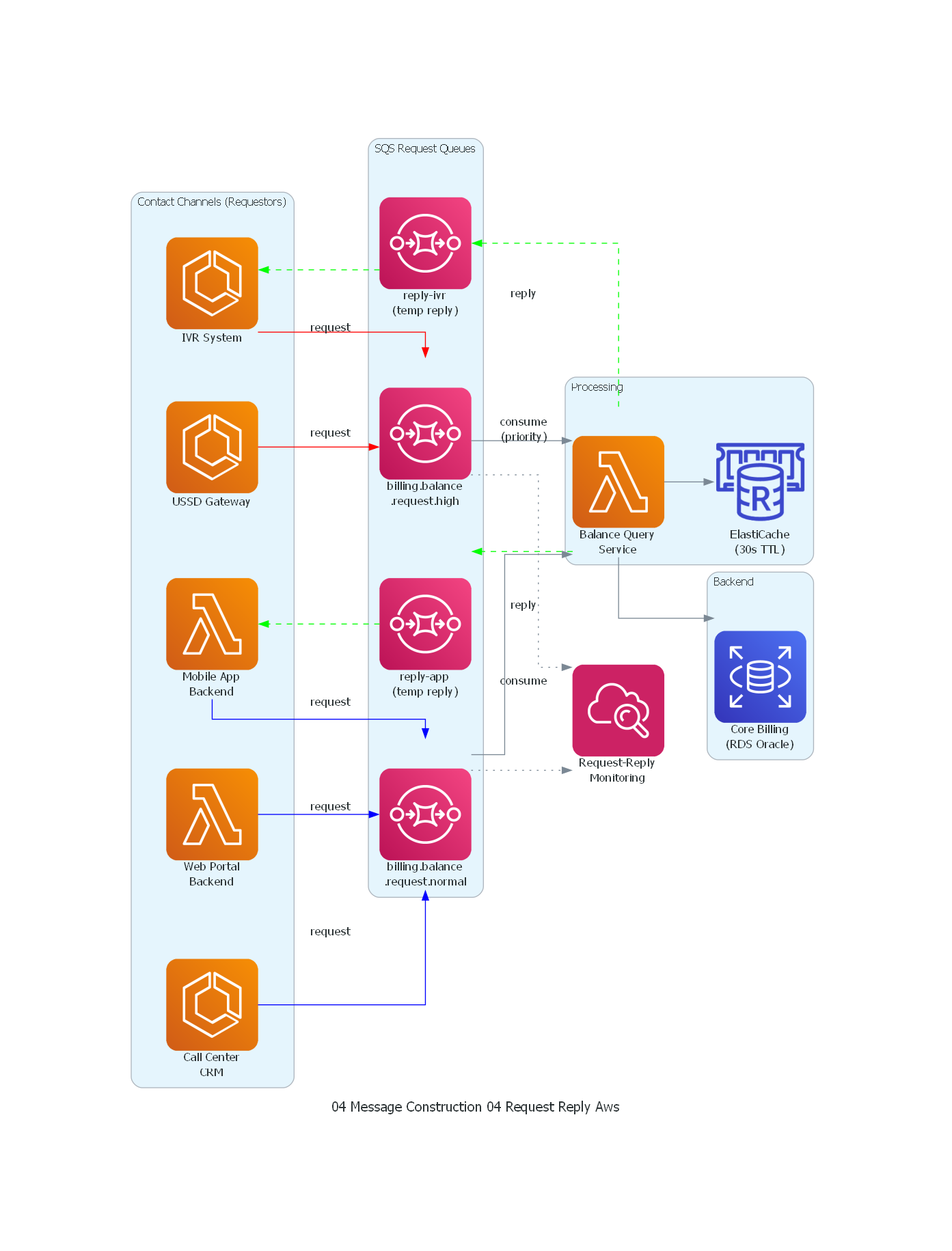
with Diagram("Request-Reply - Telecom Balance Query (AWS)", show=False, direction="LR"):
with Cluster("Contact Channels (Requestors)"):
ivr = ECS("IVR System")
ussd = ECS("USSD Gateway")
app = Lambda("Mobile App\nBackend")
web = Lambda("Web Portal\nBackend")
crm = ECS("Call Center\nCRM")
with Cluster("SQS Request Queues"):
req_high = SQS("billing.balance\n.request.high")
req_normal = SQS("billing.balance\n.request.normal")
reply_ivr = SQS("reply-ivr\n(temp reply)")
reply_app = SQS("reply-app\n(temp reply)")
with Cluster("Processing"):
balance_svc = Lambda("Balance Query\nService")
cache = ElasticacheForRedis("ElastiCache\n(30s TTL)")
with Cluster("Backend"):
billing = RDS("Core Billing\n(RDS Oracle)")
monitoring = Cloudwatch("Request-Reply\nMonitoring")
# Request flow (high priority)
ivr >> Edge(label="request", color="red") >> req_high
ussd >> Edge(label="request", color="red") >> req_high
# Request flow (normal priority)
app >> Edge(label="request", color="blue") >> req_normal
web >> Edge(label="request", color="blue") >> req_normal
crm >> Edge(label="request", color="blue") >> req_normal
# Processing
req_high >> Edge(label="consume\n(priority)") >> balance_svc
req_normal >> Edge(label="consume") >> balance_svc
balance_svc >> cache
balance_svc >> billing
# Reply flow
balance_svc >> Edge(label="reply", style="dashed", color="green") >> reply_ivr
balance_svc >> Edge(label="reply", style="dashed", color="green") >> reply_app
reply_ivr >> Edge(style="dashed", color="green") >> ivr
reply_app >> Edge(style="dashed", color="green") >> app
# Monitoring
req_high >> Edge(style="dotted") >> monitoring
req_normal >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis, SQLServers
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
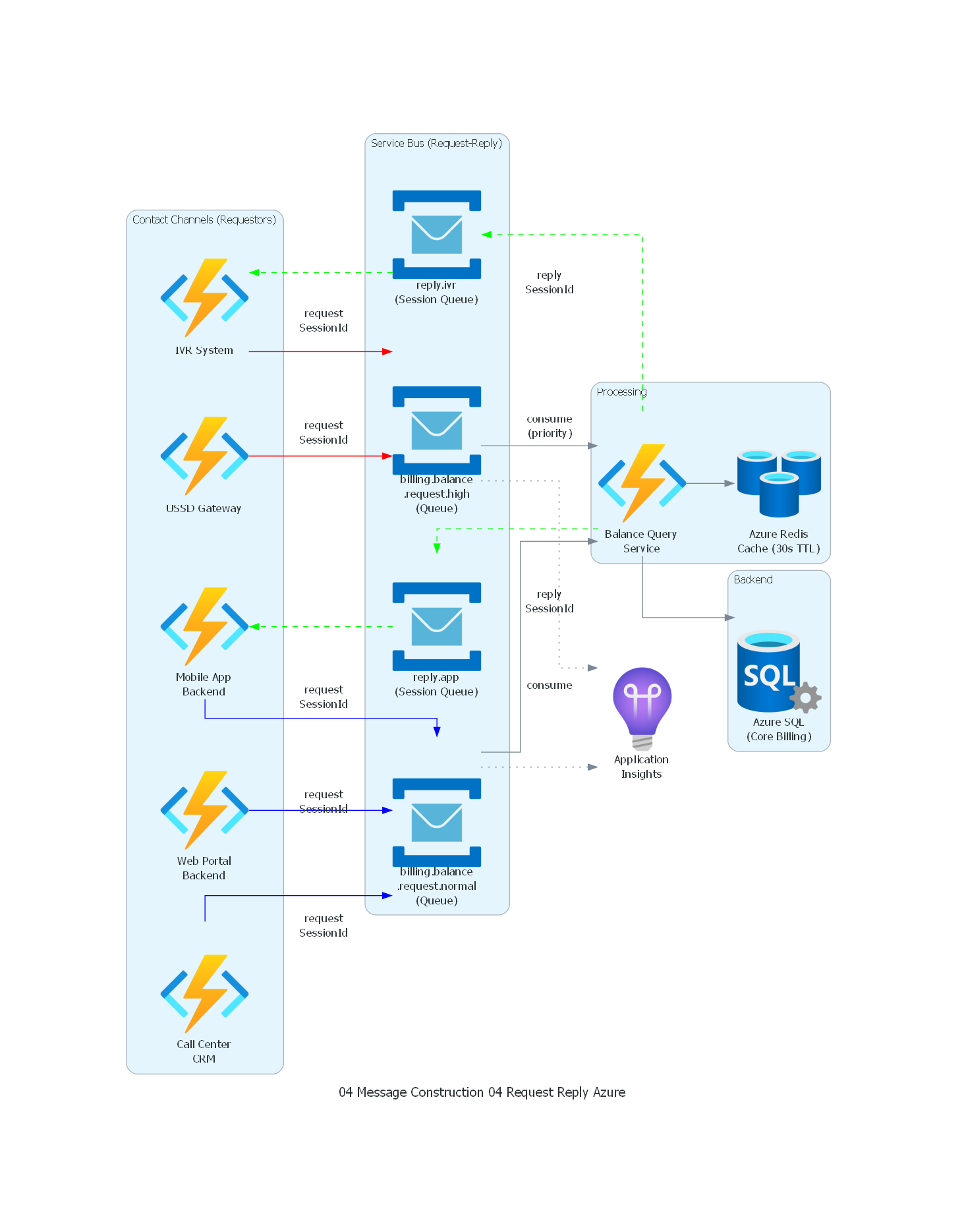
with Diagram("Request-Reply - Telecom Balance Query (Azure)", show=False, direction="LR"):
with Cluster("Contact Channels (Requestors)"):
ivr = FunctionApps("IVR System")
ussd = FunctionApps("USSD Gateway")
app = FunctionApps("Mobile App\nBackend")
web = FunctionApps("Web Portal\nBackend")
crm = FunctionApps("Call Center\nCRM")
with Cluster("Service Bus (Request-Reply)"):
req_high = ServiceBus("billing.balance\n.request.high\n(Queue)")
req_normal = ServiceBus("billing.balance\n.request.normal\n(Queue)")
reply_ivr = ServiceBus("reply.ivr\n(Session Queue)")
reply_app = ServiceBus("reply.app\n(Session Queue)")
with Cluster("Processing"):
balance_svc = FunctionApps("Balance Query\nService")
cache = CacheForRedis("Azure Redis\nCache (30s TTL)")
with Cluster("Backend"):
billing = SQLServers("Azure SQL\n(Core Billing)")
monitoring = ApplicationInsights("Application\nInsights")
# Request flow (high priority)
ivr >> Edge(label="request\nSessionId", color="red") >> req_high
ussd >> Edge(label="request\nSessionId", color="red") >> req_high
# Request flow (normal priority)
app >> Edge(label="request\nSessionId", color="blue") >> req_normal
web >> Edge(label="request\nSessionId", color="blue") >> req_normal
crm >> Edge(label="request\nSessionId", color="blue") >> req_normal
# Processing
req_high >> Edge(label="consume\n(priority)") >> balance_svc
req_normal >> Edge(label="consume") >> balance_svc
balance_svc >> cache
balance_svc >> billing
# Reply flow
balance_svc >> Edge(label="reply\nSessionId", style="dashed", color="green") >> reply_ivr
balance_svc >> Edge(label="reply\nSessionId", style="dashed", color="green") >> reply_app
reply_ivr >> Edge(style="dashed", color="green") >> ivr
reply_app >> Edge(style="dashed", color="green") >> app
# Monitoring
req_high >> Edge(style="dotted") >> monitoring
req_normal >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama ilustra la arquitectura de Request-Reply para consultas de saldo en telecomunicaciones:
- Contact Channels actúan como requestors: envían peticiones de saldo a las colas de request.
- Dos colas de request separadas por prioridad:
billing.balance.request.high(IVR, USSD) ybilling.balance.request.normal(App, Web, CRM). - El Balance Query Service consume de ambas colas, priorizando la cola high.
- El servicio consulta un cache Redis y, si no hay hit, invoca al Core Billing Oracle.
- Las respuestas se envían a las colas temporales de reply de cada requestor (indicadas en el header
reply_to). - Cada requestor recibe su respuesta de su cola temporal exclusiva.
- Grafana monitorea queue depth, latencia y timeouts.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Requestor | IVR, USSD, App, Web, CRM |
| Replier | Balance Query Service |
| Request Channel | billing.balance.request.high/normal |
| Reply Channel | amq.gen-* (colas temporales por requestor) |
| Correlation Identifier | Header correlation_id en request y reply |
| Return Address | Header reply_to apuntando a la cola temporal |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento: los canales de contacto no conocen la dirección del core de billing ni del Balance Query Service. Solo conocen el nombre de la cola de request y su propia cola de reply.
- Buffering de peticiones: durante picos de carga, las peticiones se encolan en lugar de rechazarse. El core de billing procesa a su capacidad máxima (500 concurrentes) sin recibir más carga de la que puede manejar.
- Priorización: las colas separadas permiten que las peticiones del IVR (cliente en llamada) se procesen antes que las del portal web (cliente puede esperar o reintentar).
- Resiliencia: si el Balance Query Service se reinicia, las peticiones pendientes siguen en la cola y se procesan cuando el servicio vuelve.
Impacto Organizacional¶
- El equipo de IVR, el equipo de la app móvil y el equipo del portal web pueden evolucionar sus sistemas independientemente. El contrato compartido es el formato del mensaje de petición y respuesta.
- El equipo de billing puede reemplazar el core Oracle por un nuevo sistema sin afectar a los canales de contacto — solo el Balance Query Service se actualiza.
Impacto Operacional¶
- Observabilidad de extremo a extremo: la profundidad de las colas de request indica la carga actual sobre billing; la latencia entre envío de request y recepción de reply mide la experiencia del usuario; la tasa de timeouts indica degradación del backend.
- Capacity planning: el histórico de queue depth permite predecir cuándo se necesita escalar el Balance Query Service.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Dos canales en lugar de uno: cada interacción Request-Reply requiere gestionar un canal de petición y un canal de respuesta (o N canales de respuesta si se usan colas temporales).
- Gestión de timeouts: el solicitante debe implementar lógica de timeout, cancelación y manejo de respuestas tardías. Esto es significativamente más complejo que un HTTP call con timeout nativo.
- Correlación: se debe implementar correctamente el mecanismo de Correlation Identifier para vincular respuestas con peticiones.
Riesgos de Mal Uso¶
- Request-Reply donde no se necesita: usar Request-Reply para operaciones que pueden ser fire-and-forget añade complejidad sin beneficio.
- Síncrono disfrazado: implementar Request-Reply con un thread bloqueado esperando la respuesta es, funcionalmente, una llamada síncrona con mayor latencia y complejidad. Si no se aprovecha la asincronía (non-blocking wait, futures), se obtiene lo peor de ambos mundos.
- Ignorar respuestas tardías: no implementar limpieza de respuestas que llegan después del timeout produce memory leaks o colas que crecen indefinidamente.
Costos de Operación¶
- Recursos del broker: colas temporales de reply consumen recursos del broker (memoria, file descriptors, connections).
- Complejidad de monitoreo: se deben monitorear las colas de request y las colas de reply por separado, más las métricas de correlación (latencia, timeout rate).
Anti-Patterns¶
- Request-Reply sin timeout: esperar indefinidamente una respuesta que puede no llegar nunca. Todo Request-Reply debe tener un timeout explícito.
- Shared reply queue sin correlación: múltiples requestors compartiendo una cola de reply sin Correlation Identifier, resultando en respuestas entregadas al requestor equivocado.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Return Address (este capítulo): define el mecanismo específico por el cual el requestor indica dónde enviar la respuesta. Return Address es un componente esencial de Request-Reply.
- Correlation Identifier (este capítulo): define el mecanismo para vincular la respuesta con la petición original. Sin Correlation Identifier, Request-Reply no puede funcionar cuando hay múltiples peticiones concurrentes.
- Message Expiration (este capítulo): define el TTL del mensaje de petición y/o respuesta, implementando el timeout del Request-Reply a nivel de infraestructura.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Command Message o Document Message — la petición es típicamente un Command ("consulta el saldo") o un Document ("aquí están los datos para la consulta").
- Después: Content-Based Router o Message Translator — la respuesta puede necesitar routing o transformación antes de llegar al solicitante final.
Combinaciones Comunes¶
- Request-Reply + Competing Consumers: múltiples instancias del replier consumen peticiones del canal de request en paralelo. Cada instancia procesa una petición y envía la respuesta.
- Request-Reply + Dead Letter Channel: peticiones que no se pueden procesar se envían a dead-letter para análisis posterior, en lugar de descartarse silenciosamente.
- Request-Reply + Wire Tap: las peticiones y respuestas se interceptan para auditoría o logging sin afectar el flujo principal.
Diferencias con Patrones Similares¶
- vs. RPC síncrono: Request-Reply añade durabilidad (la petición persiste en el canal) y desacoplamiento (el requestor no conoce la dirección del replier), a cambio de mayor latencia y complejidad.
- vs. Event Message + eventual query: en lugar de request-reply, algunos diseños emiten un evento y el interesado consulta un read model. Esto elimina la bidireccionalidad pero introduce eventual consistency.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Request-Reply sigue siendo uno de los patrones más utilizados en arquitecturas modernas porque la necesidad de comunicación bidireccional es inherente a la mayoría de los sistemas distribuidos. Aunque las arquitecturas event-driven y reactive reducen la necesidad de request-reply en favor de eventos y proyecciones, hay escenarios donde una respuesta directa es imprescindible:
- Consultas en tiempo real: saldos, estados, disponibilidad — el usuario espera una respuesta inmediata.
- Validaciones: verificación de identidad, autorización de transacciones — el flujo no puede continuar sin la respuesta.
- Orquestación de sagas: el orquestador envía comandos a los participantes y espera confirmaciones.
Cómo Se Implementa Hoy¶
| Plataforma | Mecanismo de Request-Reply |
|---|---|
| RabbitMQ | reply_to header + temporary exclusive queue (amq.gen-*) |
| Kafka | Reply topic con consumer filtering por correlation_id; KafkaReplyingTemplate en Spring |
| Azure Service Bus | ReplyTo + ReplyToSessionId para correlación basada en sesiones |
| AWS SQS | Reply queue separada + correlation_id en message attributes |
| gRPC sobre messaging | Request como Command Message, reply como Event/Document en reply channel |
| NATS | Request-Reply nativo con nats.Request() y inbox subjects |
Qué Parte Sigue Siendo Esencial¶
- El concepto de dos canales coordinados (request + reply) es universal.
- El Correlation Identifier como mecanismo de vinculación es esencial en toda implementación.
- La gestión de timeouts sigue siendo el aspecto más crítico y más frecuentemente mal implementado.
15. Implementación en Arquitecturas Modernas¶
RabbitMQ (AMQP 0-9-1)¶
Request:
Exchange: "" (default)
Routing Key: "billing.balance.request"
Properties:
reply_to: "amq.gen-Xa1b2c3d4" (auto-generated exclusive queue)
correlation_id: "corr-7f3e2a91"
expiration: "2000"
Reply:
Exchange: "" (default)
Routing Key: "amq.gen-Xa1b2c3d4" (el valor de reply_to)
Properties:
correlation_id: "corr-7f3e2a91" (copiado de la petición)
RabbitMQ tiene soporte nativo para Request-Reply con colas temporales exclusivas. El requestor crea una cola anónima (amq.gen-*), la incluye en reply_to, y el replier envía la respuesta a esa cola. La cola se destruye automáticamente cuando el requestor se desconecta.
Apache Kafka¶
Request Topic: billing.balance.request
Headers:
kafka_replyTopic: "billing.balance.reply"
kafka_replyPartition: 2
kafka_correlationId: "corr-7f3e2a91"
Reply Topic: billing.balance.reply
Partition: 2
Headers:
kafka_correlationId: "corr-7f3e2a91"
En Kafka, Request-Reply es menos natural porque Kafka no soporta colas temporales. Spring Kafka proporciona ReplyingKafkaTemplate que automatiza el patrón: crea un consumer en el reply topic, filtra por correlation_id, y resuelve un Future cuando llega la respuesta.
Azure Service Bus¶
Request Queue: billing-balance-request
Properties:
ReplyTo: "billing-balance-reply"
CorrelationId: "corr-7f3e2a91"
ReplyToSessionId: "session-requestor-42"
TimeToLive: 00:00:02
Reply Queue: billing-balance-reply (session-enabled)
Session: "session-requestor-42"
Properties:
CorrelationId: "corr-7f3e2a91"
Azure Service Bus soporta Request-Reply con sessions: el requestor usa ReplyToSessionId para que sus respuestas se agrupen en una session específica, permitiendo correlación eficiente sin escanear todos los mensajes de la cola de reply.
NATS¶
NATS tiene Request-Reply como primitiva de primera clase. Request() crea automáticamente un inbox subject, lo incluye como reply_to, envía el mensaje y espera la respuesta con timeout integrado.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: request rate (peticiones/segundo), reply rate, timeout rate, latencia de round-trip (tiempo entre envío de request y recepción de reply), queue depth de colas de request.
- Distributed tracing: propagar el trace_id de OpenTelemetry en los headers del mensaje para trazar la petición completa a través del request channel, el processing y el reply channel.
- Alertas: timeout rate > 5% indica degradación del backend; queue depth > umbral indica saturación; reply rate < request rate indica pérdida de respuestas.
Monitoreo¶
- Consumer lag en colas de request: indica cuántas peticiones están pendientes de procesamiento.
- Edad del mensaje más antiguo en la cola de request: indica el tiempo de espera máximo actual.
- Colas temporales de reply: monitorear el número de colas temporales activas para detectar leaks (colas que no se destruyen).
Timeout Policy¶
- Definir timeouts por tipo de operación: consultas simples (2s), operaciones complejas (10s), reportes (60s).
- Implementar timeout tanto en el requestor (timer local) como en el mensaje (TTL/expiration) para que mensajes expirados no se procesen innecesariamente.
- Registrar todos los timeouts con el correlation_id para análisis de causas.
Seguridad¶
- Autenticación y autorización en ambos canales (request y reply).
- Validar que el requestor tiene permiso para enviar peticiones al request channel.
- Considerar cifrado end-to-end del payload si los datos son sensibles (ej. saldos financieros).
Idempotencia¶
- El replier debe ser idempotente: si la misma petición llega dos veces (por retry del requestor), debe retornar la misma respuesta sin efectos secundarios duplicados.
- Usar el
message_idocorrelation_idcomo clave de deduplicación.
17. Errores Comunes¶
No Implementar Timeout¶
El error más peligroso. Un requestor sin timeout puede quedar bloqueado indefinidamente esperando una respuesta que nunca llegará (porque el replier falló, el mensaje se perdió, o la cola de reply fue eliminada). Todo Request-Reply debe tener un timeout explícito, tanto a nivel de código (timer) como a nivel de mensaje (TTL).
Usar Request-Reply Para Todo¶
No toda interacción requiere una respuesta. Operaciones como "registrar evento", "enviar notificación" o "actualizar cache" son fire-and-forget por naturaleza. Forzar Request-Reply donde no se necesita duplica la complejidad sin beneficio.
Shared Reply Queue Sin Correlación Eficiente¶
Si múltiples requestors comparten una cola de reply y cada uno debe escanear todos los mensajes para encontrar los suyos, el overhead crece linealmente con el número de requestors. Solución: usar colas temporales exclusivas (RabbitMQ), sessions (Azure Service Bus) o particiones asignadas (Kafka).
No Limpiar Recursos de Reply¶
Colas temporales, consumers, timers y futures asociados a un Request-Reply deben limpiarse tanto en el caso de éxito como en el caso de timeout o error. La falta de limpieza produce leaks que degradan el broker y la aplicación gradualmente.
Confundir Latencia de Messaging con Latencia de API¶
Request-Reply sobre messaging siempre será más lento que una llamada HTTP directa. Si la latencia sub-milisegundo es crítica y no se necesitan las ventajas del messaging (buffering, durabilidad, desacoplamiento), una llamada directa es más apropiada.
No Manejar Respuestas Tardías¶
Después de un timeout, la respuesta puede llegar eventualmente. Si el requestor ya liberó los recursos (destruyó la cola temporal, canceló el future), no hay problema. Pero si la cola de reply persiste y acumula respuestas tardías sin consumirlas, se genera un leak de mensajes.
18. Conclusión Técnica¶
Request-Reply es el patrón que reconcilia la necesidad de comunicación bidireccional con las ventajas del messaging asíncrono. Su implementación requiere coordinar dos canales, un mecanismo de correlación y una política de timeout — más complejidad que una llamada síncrona directa, pero a cambio proporciona durabilidad de peticiones, desacoplamiento de sistemas, buffering ante picos de carga y un punto de observación centralizado.
Cuándo aporta valor: cuando la interacción requiere una respuesta y se necesitan las ventajas del messaging — durabilidad (peticiones que sobreviven caídas del servidor), desacoplamiento (el requestor no conoce la dirección del replier), buffering (peticiones encoladas durante picos) o auditoría (todas las peticiones y respuestas pasan por el broker).
Cuándo evita problemas importantes: en sistemas donde el backend tiene capacidad limitada (como el core de billing del ejemplo), Request-Reply con messaging previene la saturación directa del backend al actuar como buffer y control de flujo. Las peticiones se encolan y se procesan al ritmo que el backend puede manejar.
Cuándo no conviene adoptarlo: cuando la latencia mínima es crítica y no se necesitan las garantías del messaging. Una consulta que debe responder en microsegundos (cache lookup, in-memory computation) no se beneficia de Request-Reply sobre messaging. Tampoco conviene cuando la interacción es puramente unidireccional.
Recomendación para arquitectos: implemente Request-Reply solo cuando las ventajas del messaging superen el costo de la complejidad adicional. Cuando lo implemente, trate los tres componentes — Return Address, Correlation Identifier y Timeout — como requisitos no negociables, no como opciones. Monitoree la tasa de timeouts como indicador primario de salud del sistema y diseñe el reply channel considerando la escala de requestors concurrentes (colas temporales para escala moderada, particiones o sessions para escala alta).