Correlation Identifier¶
1. Nombre del Patrón¶
- Nombre oficial: Correlation Identifier
- Categoría: Message Construction (Construcción de Mensajes)
- Traducción contextual: Identificador de Correlación
2. Resumen Ejecutivo¶
Correlation Identifier es el patrón que resuelve el problema de vincular un mensaje de respuesta con su mensaje de petición original en un sistema de mensajería asíncrono. El solicitante genera un identificador único, lo incluye en el mensaje de petición, y el destinatario lo copia en el mensaje de respuesta. Al recibir la respuesta, el solicitante usa el identificador para asociarla con la petición correcta.
El problema que resuelve es sutil pero crítico: en messaging asíncrono, las respuestas no llegan por el mismo canal que las peticiones, y pueden llegar en un orden diferente al que fueron solicitadas. Si un solicitante envía tres peticiones concurrentes y recibe tres respuestas, ¿cómo sabe cuál respuesta corresponde a cuál petición? Sin Correlation Identifier, es imposible determinarlo.
Más allá de Request-Reply, Correlation Identifier es el mecanismo fundamental que conecta mensajes relacionados en cualquier flujo distribuido: pasos de una saga, fases de un pipeline, eventos de un workflow, o spans de un trace. Es, en esencia, el "hilo" que une mensajes dispersos en un sistema distribuido en una conversación o proceso lógico coherente.
El patrón tiene una relevancia extraordinaria en las arquitecturas modernas: el correlation-id es un header estándar en prácticamente todos los protocolos de messaging, y conceptos como el trace_id de OpenTelemetry, el saga_id de un orquestador, y el conversation_id de un chatbot son variantes especializadas del mismo principio.
3. Definición Detallada¶
Propósito¶
Correlation Identifier proporciona un mecanismo para vincular mensajes que pertenecen a la misma conversación, transacción o flujo de procesamiento. Su propósito principal es permitir que un receptor identifique a qué contexto previo pertenece un mensaje recibido, sin depender del orden de llegada, del canal de origen, ni de la inspección del contenido del mensaje.
Lógica Arquitectónica¶
En una comunicación síncrona (HTTP, gRPC), la correlación es implícita: la respuesta llega por la misma conexión que la petición, así que no hay ambigüedad sobre a qué petición corresponde. En messaging asíncrono, esta correlación implícita desaparece porque:
- La petición y la respuesta viajan por canales diferentes.
- Puede haber múltiples peticiones en vuelo simultáneamente.
- Las respuestas pueden llegar en un orden diferente al de las peticiones (por diferencias en tiempo de procesamiento, routing, o prioridad).
- Múltiples requestors pueden compartir un canal de respuesta común.
Correlation Identifier resuelve todas estas ambigüedades introduciendo un identificador único que viaja con el mensaje a lo largo de todo su ciclo de vida:
- El requestor genera un identificador único (UUID, ULID, snowflake, etc.).
- Lo incluye en la petición como header
correlation_id. - El replier copia ese
correlation_iden la respuesta. - El requestor, al recibir la respuesta, busca el
correlation_iden su registro de peticiones pendientes y los vincula.
La Tríada de Identificadores: message_id, correlation_id, causation_id¶
En sistemas maduros, se distinguen tres identificadores complementarios en cada mensaje:
message_id: identificador único de este mensaje específico. Cada mensaje tiene unmessage_iddiferente. Sirve para deduplicación y auditoría.correlation_id: identificador de la conversación o flujo al que pertenece este mensaje. Múltiples mensajes comparten el mismocorrelation_idsi pertenecen al mismo flujo. Sirve para correlación y tracing.causation_id: identificador del mensaje que causó directamente este mensaje. Es elmessage_iddel mensaje anterior en la cadena. Sirve para reconstruir el grafo de causalidad.
Ejemplo de un flujo de tres pasos:
| Paso | message_id | correlation_id | causation_id | Descripción |
|---|---|---|---|---|
| 1 | msg-001 | corr-ABC | (null) | Petición inicial |
| 2 | msg-002 | corr-ABC | msg-001 | Respuesta a la petición |
| 3 | msg-003 | corr-ABC | msg-002 | Acción derivada de la respuesta |
Los tres mensajes comparten el mismo correlation_id (corr-ABC) porque pertenecen al mismo flujo. Pero cada uno tiene un message_id diferente y un causation_id que apunta al mensaje que lo originó.
Principio de Diseño Subyacente¶
El principio es identidad de conversación propagada: un identificador único se genera al inicio de un flujo y se propaga en todos los mensajes derivados de ese flujo, independientemente de cuántos servicios, canales o transformaciones intervengan. Este principio es la base del distributed tracing, la saga orchestration y la auditoría de flujos de negocio.
Problema Estructural que Resuelve¶
Sin Correlation Identifier, la única forma de vincular mensajes relacionados es por inspección de contenido: comparar campos del body de la petición con campos del body de la respuesta (por ejemplo, buscar el mismo customer_id). Este enfoque es:
- Frágil: depende de la estructura interna del mensaje, que puede cambiar.
- Ambiguo: si hay dos peticiones para el mismo
customer_id, la inspección de contenido no distingue cuál es cuál. - Ineficiente: requiere parsear el body de cada mensaje para buscar coincidencias.
- Insuficiente: no funciona para mensajes cuyo contenido no tiene campos naturales de correlación.
Correlation Identifier proporciona un mecanismo genérico, externo al contenido, y libre de ambigüedad para vincular mensajes relacionados.
Contexto en el que Emerge¶
Correlation Identifier emerge en cualquier escenario donde:
- Se implementa Request-Reply con peticiones concurrentes.
- Se orquesta una saga con múltiples pasos y participantes.
- Se necesita distributed tracing a través de múltiples servicios y canales.
- Se implementa un pipeline de procesamiento con múltiples etapas.
- Se necesita auditoría de un flujo de negocio de principio a fin.
Relación con Sistemas Distribuidos¶
En la teoría de sistemas distribuidos, Correlation Identifier implementa un mecanismo de logical clock compartido a nivel de conversación. Así como un vector clock permite ordenar eventos en un sistema distribuido, el Correlation Identifier permite agrupar eventos (mensajes) que pertenecen a la misma "historia causal". La combinación de correlation_id + causation_id reconstruye el grafo de causalidad completo de un flujo.
En el contexto de observabilidad, el correlation_id es funcionalmente equivalente al trace_id de OpenTelemetry: un identificador que agrupa todos los spans (operaciones) de una transacción distribuida. De hecho, muchos equipos usan el trace_id de OpenTelemetry como correlation_id de sus mensajes, unificando correlación de messaging con distributed tracing.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Correlation Identifier, un sistema que envía múltiples peticiones concurrentes y recibe respuestas en un canal compartido no puede determinar con certeza a qué petición corresponde cada respuesta:
Requestor envía:
Petición A (customer_id=100, query=balance) → Request Channel
Petición B (customer_id=200, query=balance) → Request Channel
Petición C (customer_id=100, query=last_payment) → Request Channel
Requestor recibe en Reply Channel:
Respuesta X: { balance: 5000 }
Respuesta Y: { balance: 12000 }
Respuesta Z: { last_payment: "2026-04-01" }
¿La respuesta X corresponde a la petición A o B? Ambas son consultas de balance. Sin un identificador de correlación, la única pista es el contenido, pero si el requestor no conoce los saldos de antemano, no puede distinguir cuál es cuál. La respuesta Z parece corresponder a la petición C por el tipo de dato, pero esto es frágil y no escala.
Síntomas del Problema¶
- Respuestas vinculadas a peticiones incorrectas, produciendo datos erróneos que se propagan silenciosamente.
- Implementaciones ad-hoc de correlación basadas en campos del body ("matching por customer_id + query_type") que son frágiles y no genéricas.
- Imposibilidad de tener peticiones concurrentes: el requestor se ve forzado a enviar una petición y esperar la respuesta antes de enviar la siguiente (serialización artificial).
- Imposibilidad de trazar un flujo de negocio de principio a fin: los mensajes relacionados no pueden vincularse porque no hay identificador común.
- Logs y métricas desconectados: los logs del requestor y del replier no pueden correlacionarse porque no hay identificador compartido.
Impacto Operativo y Arquitectónico¶
Sin Correlation Identifier:
- Debugging es una pesadilla: cuando un flujo falla, no hay forma de rastrear todos los mensajes relacionados a través de múltiples servicios y canales.
- Auditoría es imposible: los reguladores exigen poder reconstruir el flujo completo de una transacción (quién solicitó qué, quién respondió qué, en qué orden). Sin correlación, esto requiere minería de datos manual.
- Sagas son inviables: un saga orchestrator que envía comandos a múltiples servicios y espera confirmaciones no puede vincular las confirmaciones con los comandos sin correlación.
- Monitoreo de latencia es impreciso: no se puede medir la latencia end-to-end de un flujo si no se pueden vincular el primer y el último mensaje.
Riesgos Si No Se Implementa Correctamente¶
- Correlación duplicada: si el
correlation_idno es único (por colisión de IDs o reutilización), dos flujos diferentes se mezclan y las respuestas se vinculan a peticiones equivocadas. - Correlación perdida: si un intermediario (router, translator, aggregator) no propaga el
correlation_idde entrada en sus mensajes de salida, se rompe la cadena de correlación. - Correlación abusada: usar un solo
correlation_idpara todo el ciclo de vida de una entidad de negocio (ej. el ID del pedido como correlation_id) mezcla múltiples flujos independientes sobre la misma entidad.
Ejemplos Reales¶
- Seguros: un sistema de procesamiento de reclamos inicia una saga que involucra verificación de póliza, evaluación de daños, aprobación de gerencia y liquidación de pago. Cada paso es un mensaje asíncrono. El
correlation_id(=claim_id) vincula todos los mensajes de la saga para auditoría y monitoreo. - Telecomunicaciones: un sistema de portabilidad numérica envía solicitudes a múltiples operadores simultáneamente. Cada solicitud tiene un
correlation_idque permite vincular la respuesta de cada operador con la solicitud original, incluso cuando las respuestas llegan desordenadas. - E-commerce: un servicio de checkout envía concurrentemente una petición de validación de tarjeta, una consulta de inventario y una consulta de impuestos. Las tres respuestas llegan al mismo servicio, cada una con su
correlation_id, permitiendo completar el checkout correctamente.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En toda implementación de Request-Reply con peticiones concurrentes.
- En sagas (orchestration o choreography) para vincular todos los pasos del flujo.
- En pipelines de procesamiento multi-etapa para rastrear un item a través de todas las etapas.
- En distributed tracing para vincular spans de diferentes servicios.
- En auditoría de flujos de negocio para reconstruir la secuencia completa de eventos.
- En deduplicación: el
correlation_idcombinado con el paso del flujo permite detectar mensajes duplicados.
Cuándo No Usarlo¶
- En comunicación unidireccional fire-and-forget donde no hay respuesta ni flujo multi-paso.
- Cuando los mensajes son completamente independientes y no tienen relación causal entre sí (ej. eventos de telemetría de diferentes dispositivos).
- Cuando ya existe un identificador natural de correlación en el dominio de negocio que cumple los mismos requisitos (unicidad, propagación) — en este caso, se puede usar ese identificador como
correlation_idsin introducir uno nuevo.
Precondiciones¶
- El sistema de mensajería soporta headers/properties en los mensajes.
- Todos los participantes del flujo (requestors, repliers, intermediarios) implementan la lógica de leer y propagar el
correlation_id. - Existe una fuente de identificadores únicos (UUID generator, ULID, snowflake).
Restricciones¶
- El
correlation_iddebe ser único dentro del alcance temporal y funcional del sistema. Un UUID v4 tiene probabilidad de colisión despreciable; un identificador secuencial puede colisionar entre instancias. - Todos los intermediarios (routers, translators, enrichers) deben propagar el
correlation_id. Si un intermediario no lo hace, se rompe la cadena. - El
correlation_idno debe contener información sensible (PII, tokens) porque aparece en logs, traces y headers de messaging.
Supuestos Arquitectónicos¶
- Los mensajes pueden transportar metadata (headers) además del payload.
- Existe un acuerdo (contrato de integración) sobre el nombre del header que contiene el
correlation_id. - Los sistemas de logging y monitoring indexan por
correlation_idpara permitir búsquedas transversales.
6. Fuerzas Arquitectónicas¶
Simplicidad vs. Trazabilidad¶
Incluir un correlation_id en cada mensaje añade complejidad (generación del ID, propagación, logging). Pero sin él, la trazabilidad de flujos distribuidos es prácticamente inexistente. La fuerza gravitacional hacia la observabilidad en arquitecturas modernas hace que el costo de no tener correlación sea mucho mayor que el costo de implementarla.
Unicidad vs. Performance¶
Generar un UUID v4 para cada petición tiene un costo computacional mínimo pero no despreciable en sistemas de ultra-alto throughput (millones de mensajes por segundo). Alternativas como ULID (ordenable por tiempo) o snowflake (generación distribuida sin coordinación) ofrecen trade-offs diferentes entre unicidad, ordenamiento y performance.
Granularidad vs. Utilidad¶
¿Qué alcance tiene el correlation_id? Si es demasiado amplio (ej. todos los mensajes de un pedido durante meses), acumula cientos de mensajes y pierde utilidad para debugging de un flujo específico. Si es demasiado estrecho (ej. solo la petición y su respuesta directa), no permite rastrear flujos multi-paso. La granularidad correcta es un flujo lógico de negocio: una consulta de saldo, un procesamiento de reclamo, un checkout completo.
Estandarización vs. Flexibilidad¶
¿Qué nombre tiene el header? correlation_id, correlationId, X-Correlation-ID, trace_id, request_id? Cada plataforma y cada equipo tiene su propia convención. La estandarización (un solo nombre en toda la organización) maximiza la interoperabilidad; la flexibilidad permite que cada equipo use su convención preferida. El W3C Trace Context define un estándar para traceparent, pero no todos los sistemas lo adoptan.
Propagación vs. Seguridad¶
El correlation_id se propaga a través de todos los servicios, logs, traces y posiblemente respuestas al cliente. Si el ID contiene información derivable (ej. un hash del customer_id), podría exponer información. Los correlation_id deben ser opacos (no derivables del contenido de negocio).
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Requestor: genera el
correlation_idy lo incluye en la petición. - Replier: lee el
correlation_idde la petición y lo copia en la respuesta. - Intermediarios (routers, translators, enrichers): propagan el
correlation_idde los mensajes de entrada a los mensajes de salida. - Sistema de logging/tracing: indexa logs y traces por
correlation_idpara búsquedas transversales.
Flujo Lógico¶
flowchart TD
A([Requestor]) --> B[Generar correlation_id\núnico - UUID v4]
B --> C[Incluir correlation_id\ncomo header del mensaje]
C --> D[(Request Channel)]
C --> E[(Mapa de pendientes\ncorrelation_id - petición)]
D --> F([Replier])
F --> G[Leer correlation_id\ndel header]
G --> H[Registrar en logs\npara trazabilidad]
H --> I[Procesar la petición]
I --> J[Construir respuesta con\nel mismo correlation_id]
J --> K[(Reply Channel)]
K --> L[Requestor recibe respuesta]
L --> M[Leer correlation_id\nde la respuesta]
M --> N[Buscar en mapa de\npeticiones pendientes]
N --> O[Vincular respuesta\ncon petición original]
O --> P[Eliminar del mapa\nde pendientes]
P --> Q([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Requestor | Generar correlation_id único, incluirlo en la petición, mantener mapa de peticiones pendientes, vincular respuesta con petición |
| Replier | Leer correlation_id de la petición, copiarlo en la respuesta |
| Intermediarios | Propagar correlation_id de mensajes de entrada a mensajes de salida |
| Logging/Tracing | Indexar por correlation_id para búsquedas transversales |
Decisiones de Diseño Clave¶
- Formato del identificador: UUID v4 (aleatorio, no ordenable), ULID (ordenable por tiempo), snowflake (distribuido, compacto), o identificador de negocio (claim_id, order_id).
- Quién genera el correlation_id: el requestor inicial (patrón estándar) o un servicio central de generación de IDs.
- Nombre del header:
correlation_id,correlationId,X-Correlation-ID, o alineado con OpenTelemetry (traceparent). - Alcance de la correlación: solo request-reply (dos mensajes) o todo un flujo de saga (N mensajes).
- Propagación automática vs. manual: ¿el framework propaga automáticamente el correlation_id o cada servicio debe hacerlo explícitamente?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Procesamiento de Reclamo con Correlación Multi-Servicio¶
Contexto del Negocio¶
Una compañía de seguros procesa reclamos de accidentes vehiculares. El procesamiento de un reclamo involucra múltiples servicios que operan asincrónicamente: verificación de póliza, evaluación de daños, detección de fraude, aprobación y liquidación. El flujo completo puede tardar entre minutos (caso simple) y días (caso con investigación de fraude).
Cada reclamo genera docenas de mensajes a través de múltiples servicios y canales. La compañía necesita:
- Poder rastrear todos los mensajes relacionados con un reclamo específico.
- Medir la latencia end-to-end del procesamiento de reclamos.
- Cumplir requisitos regulatorios de auditoría: reconstruir la secuencia completa de eventos de cualquier reclamo.
- Detectar reclamos "atascados" (donde un paso no avanzó).
Sistemas Involucrados¶
- Claims Portal: portal web donde el asegurado reporta el reclamo.
- Claims Orchestrator: saga orchestrator que coordina el flujo.
- Policy Service: verifica vigencia y cobertura de la póliza.
- Damage Assessment Service: evalúa el monto del daño (puede involucrar un perito).
- Fraud Detection Service: analiza el reclamo con modelos de ML para detectar fraude.
- Approval Service: gestiona la aprobación (automática o manual según monto).
- Payment Service: ejecuta la liquidación del pago al asegurado.
- Apache Kafka: plataforma de messaging.
Diseño de Correlación¶
Cada reclamo genera un flujo que produce múltiples mensajes. Se usa una jerarquía de identificadores:
| Identificador | Alcance | Ejemplo |
|---|---|---|
message_id | Único por mensaje | msg-8a7b6c5d-4e3f-2a1b-0c9d-8e7f6a5b4c3d |
correlation_id | Mismo para todo el flujo del reclamo | corr-claim-2026-04-07-001847 |
causation_id | message_id del mensaje que causó este | msg-1a2b3c4d-5e6f-7a8b-9c0d-1e2f3a4b5c6d |
Flujo de Mensajes con Correlación¶
| Paso | Mensaje | message_id | correlation_id | causation_id | Canal |
|---|---|---|---|---|---|
| 1 | Claim Submitted | msg-001 | corr-claim-001847 | — | claims.submitted |
| 2 | Verify Policy (cmd) | msg-002 | corr-claim-001847 | msg-001 | policy.verify.cmd |
| 3 | Policy Verified (reply) | msg-003 | corr-claim-001847 | msg-002 | claims.orchestrator.reply |
| 4 | Assess Damage (cmd) | msg-004 | corr-claim-001847 | msg-003 | damage.assess.cmd |
| 5 | Damage Assessed (reply) | msg-005 | corr-claim-001847 | msg-004 | claims.orchestrator.reply |
| 6 | Check Fraud (cmd) | msg-006 | corr-claim-001847 | msg-005 | fraud.check.cmd |
| 7 | Fraud Check Clear (reply) | msg-007 | corr-claim-001847 | msg-006 | claims.orchestrator.reply |
| 8 | Approve Claim (cmd) | msg-008 | corr-claim-001847 | msg-007 | approval.request.cmd |
| 9 | Claim Approved (reply) | msg-009 | corr-claim-001847 | msg-008 | claims.orchestrator.reply |
| 10 | Process Payment (cmd) | msg-010 | corr-claim-001847 | msg-009 | payment.process.cmd |
| 11 | Payment Completed (reply) | msg-011 | corr-claim-001847 | msg-010 | claims.orchestrator.reply |
| 12 | Claim Resolved (event) | msg-012 | corr-claim-001847 | msg-011 | claims.resolved |
Los 12 mensajes comparten el mismo correlation_id: corr-claim-001847. Buscando por este ID en los logs de cualquier servicio, se obtiene la historia completa del reclamo.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Un servicio no propaga el correlation_id | Validación automatizada: test de integración que verifica propagación; middleware que rechaza mensajes sin correlation_id |
| Colisión de correlation_id | Usar UUID v4 (probabilidad de colisión: 2^-122); o incluir un prefijo con timestamp (ULID) |
| Flujo "atascado" sin avanzar | Timer en el orchestrator por paso; alerta si un paso excede su SLA; dashboard de reclamos por estado |
| Auditoría requiere reconstruir el flujo | Todos los mensajes se indexan por correlation_id en un event store o data lake |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación del Correlation Identifier¶
El asegurado reporta un accidente en el Claims Portal. El portal genera la petición inicial:
{
"claimant": { "policy_number": "POL-2024-789456", "name": "María García" },
"incident": {
"date": "2026-04-05",
"type": "vehicle_collision",
"description": "Colisión lateral en intersección",
"estimated_damage_usd": 3500
},
"evidence": ["photo-001.jpg", "photo-002.jpg", "police-report-4521.pdf"]
}
Headers:
message_id: "msg-001-a1b2c3d4"
correlation_id: "corr-claim-2026-04-07-001847" ← GENERADO AQUÍ
causation_id: null ← es el primer mensaje
timestamp: "2026-04-07T10:30:15.847Z"
El correlation_id se genera en este momento y se propaga en todos los mensajes subsiguientes del flujo. Se elige un formato con prefijo semántico (corr-claim-) para facilitar la búsqueda en logs.
Paso 2: Orquestación con Propagación de Correlación¶
El Claims Orchestrator consume el evento Claim Submitted y comienza la saga. Cada comando que envía a los servicios participantes copia el correlation_id y establece el causation_id:
Comando al Policy Service:
message_id: "msg-002-e5f6a7b8"
correlation_id: "corr-claim-2026-04-07-001847" ← COPIADO del mensaje original
causation_id: "msg-001-a1b2c3d4" ← message_id del mensaje que lo causó
El Policy Service verifica la póliza y responde:
message_id: "msg-003-c9d0e1f2"
correlation_id: "corr-claim-2026-04-07-001847" ← COPIADO del comando recibido
causation_id: "msg-002-e5f6a7b8" ← message_id del comando
Paso 3: Correlación en el Orchestrator¶
El Claims Orchestrator escucha en claims.orchestrator.reply. Recibe la respuesta del Policy Service. Para vincular la respuesta con el paso correcto de la saga:
- Lee el
correlation_id: "corr-claim-2026-04-07-001847". - Busca en su registro de sagas activas: encuentra la saga del reclamo 001847.
- Lee el
causation_id: "msg-002-e5f6a7b8"→ identifica que es la respuesta al comando de verificación de póliza. - Actualiza el estado de la saga: paso "policy verification" completado.
- Determina el siguiente paso: enviar comando de evaluación de daños.
Sin el correlation_id, el orchestrator no sabría a qué reclamo pertenece la respuesta. Sin el causation_id, no sabría a qué paso de la saga corresponde.
Paso 4: Detección de Fraude con Correlación¶
El Fraud Detection Service recibe el comando con correlation_id: "corr-claim-2026-04-07-001847". Su procesamiento involucra múltiples sub-pasos internos (consulta a bases externas, ejecución de modelo ML, scoring). Cada sub-paso registra logs con el correlation_id:
[2026-04-07T10:30:45.123Z] [correlation_id=corr-claim-2026-04-07-001847] Fraud check initiated
[2026-04-07T10:30:45.456Z] [correlation_id=corr-claim-2026-04-07-001847] External DB query: no prior claims
[2026-04-07T10:30:46.789Z] [correlation_id=corr-claim-2026-04-07-001847] ML model score: 0.12 (low risk)
[2026-04-07T10:30:46.890Z] [correlation_id=corr-claim-2026-04-07-001847] Fraud check result: CLEAR
Cuando un operador investiga el reclamo 001847, puede buscar correlation_id=corr-claim-2026-04-07-001847 en el sistema de logs centralizado y obtener todos los logs de todos los servicios involucrados, en orden cronológico.
Paso 5: Reclamo Atascado¶
Otro reclamo (corr-claim-2026-04-07-001523) envió un comando de evaluación de daños hace 48 horas y no ha recibido respuesta. El orchestrator tiene un timer por paso. El timer expira y genera una alerta:
[ALERT] Saga step timeout
correlation_id: corr-claim-2026-04-07-001523
step: damage_assessment
command_message_id: msg-047-x1y2z3
sent_at: 2026-04-05T14:22:10Z
timeout_after: 48h
action: escalate to supervisor
El supervisor busca el correlation_id en los logs y encuentra que el Damage Assessment Service recibió el comando pero el perito asignado no ha registrado su evaluación. El correlation_id permite vincular la alerta con el flujo completo del reclamo.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
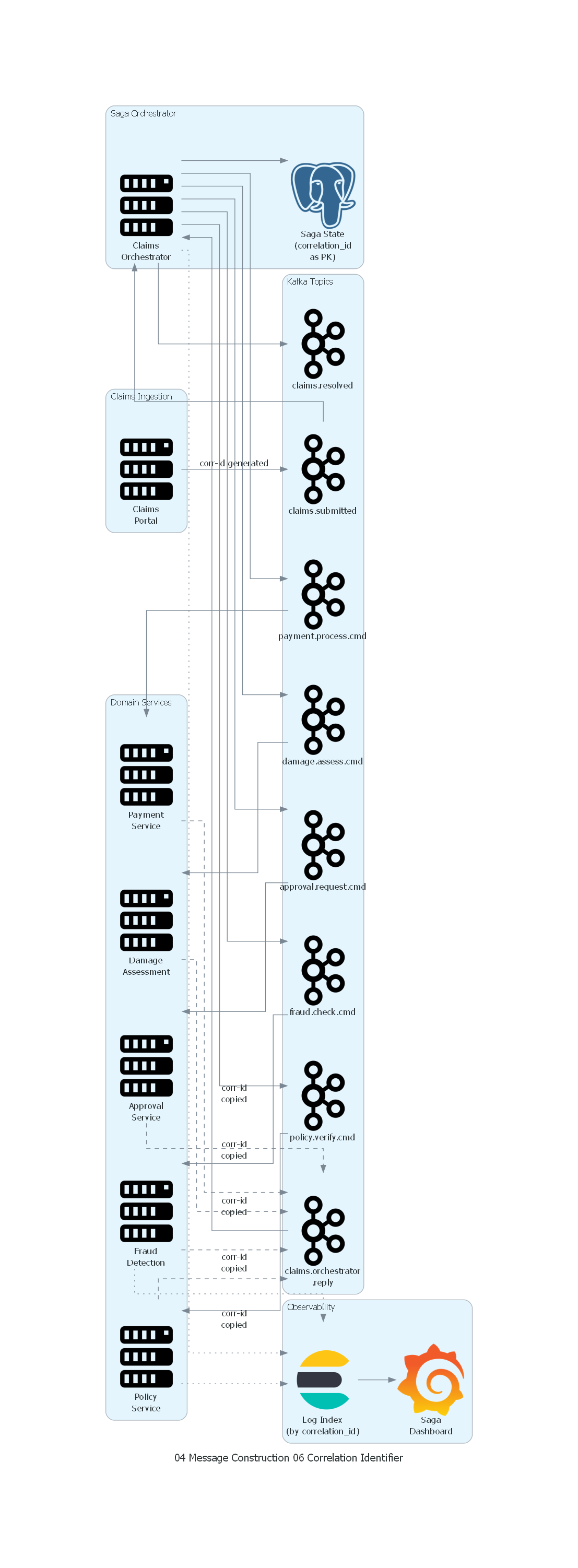
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.elastic.elasticsearch import Elasticsearch
with Diagram("Correlation Identifier - Insurance Claims Saga", show=False, direction="TB"):
with Cluster("Claims Ingestion"):
portal = Server("Claims\nPortal")
with Cluster("Kafka Topics"):
submitted = Kafka("claims.submitted")
policy_cmd = Kafka("policy.verify.cmd")
damage_cmd = Kafka("damage.assess.cmd")
fraud_cmd = Kafka("fraud.check.cmd")
approval_cmd = Kafka("approval.request.cmd")
payment_cmd = Kafka("payment.process.cmd")
orch_reply = Kafka("claims.orchestrator\n.reply")
resolved = Kafka("claims.resolved")
with Cluster("Saga Orchestrator"):
orchestrator = Server("Claims\nOrchestrator")
saga_db = PostgreSQL("Saga State\n(correlation_id\nas PK)")
with Cluster("Domain Services"):
policy_svc = Server("Policy\nService")
damage_svc = Server("Damage\nAssessment")
fraud_svc = Server("Fraud\nDetection")
approval_svc = Server("Approval\nService")
payment_svc = Server("Payment\nService")
with Cluster("Observability"):
elk = Elasticsearch("Log Index\n(by correlation_id)")
grafana = Grafana("Saga\nDashboard")
# Claim submission
portal >> Edge(label="corr-id generated") >> submitted
# Orchestrator consumes and produces
submitted >> orchestrator
orchestrator >> saga_db
orchestrator >> policy_cmd
orchestrator >> damage_cmd
orchestrator >> fraud_cmd
orchestrator >> approval_cmd
orchestrator >> payment_cmd
orchestrator >> resolved
# Services reply with same correlation_id
policy_cmd >> policy_svc
damage_cmd >> damage_svc
fraud_cmd >> fraud_svc
approval_cmd >> approval_svc
payment_cmd >> payment_svc
policy_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
damage_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
fraud_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
approval_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
payment_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
orch_reply >> orchestrator
# Observability indexed by correlation_id
orchestrator >> Edge(style="dotted") >> elk
policy_svc >> Edge(style="dotted") >> elk
fraud_svc >> Edge(style="dotted") >> elk
elk >> grafana
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS, StepFunctions
from diagrams.aws.management import Cloudwatch
from diagrams.aws.devtools import XRay
with Diagram("Correlation Identifier - Insurance Claims Saga (AWS)", show=False, direction="TB"):
with Cluster("Claims Ingestion"):
portal = Lambda("Claims\nPortal")
with Cluster("SQS Command Queues"):
submitted = SQS("claims.submitted")
policy_cmd = SQS("policy.verify.cmd")
damage_cmd = SQS("damage.assess.cmd")
fraud_cmd = SQS("fraud.check.cmd")
approval_cmd = SQS("approval.request.cmd")
payment_cmd = SQS("payment.process.cmd")
orch_reply = SQS("claims.orchestrator\n.reply")
resolved = SQS("claims.resolved")
with Cluster("Saga Orchestrator"):
orchestrator = StepFunctions("Claims\nOrchestrator\n(Step Functions)")
saga_db = Dynamodb("Dynamodb\n(correlation_id\nas PK)")
with Cluster("Domain Services"):
policy_svc = Lambda("Policy\nService")
damage_svc = Lambda("Damage\nAssessment")
fraud_svc = Lambda("Fraud\nDetection")
approval_svc = Lambda("Approval\nService")
payment_svc = Lambda("Payment\nService")
with Cluster("Observability"):
xray = XRay("X-Ray Traces\n(by correlation_id)")
cw_dash = Cloudwatch("CloudWatch\nSaga Dashboard")
# Claim submission
portal >> Edge(label="corr-id generated") >> submitted
# Orchestrator consumes and produces
submitted >> orchestrator
orchestrator >> saga_db
orchestrator >> policy_cmd
orchestrator >> damage_cmd
orchestrator >> fraud_cmd
orchestrator >> approval_cmd
orchestrator >> payment_cmd
orchestrator >> resolved
# Services reply with same correlation_id
policy_cmd >> policy_svc
damage_cmd >> damage_svc
fraud_cmd >> fraud_svc
approval_cmd >> approval_svc
payment_cmd >> payment_svc
policy_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
damage_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
fraud_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
approval_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
payment_svc >> Edge(style="dashed", label="corr-id\ncopied") >> orch_reply
orch_reply >> orchestrator
# Observability indexed by correlation_id
orchestrator >> Edge(style="dotted") >> xray
policy_svc >> Edge(style="dotted") >> xray
fraud_svc >> Edge(style="dotted") >> xray
xray >> cw_dash
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.analytics import LogAnalyticsWorkspaces
with Diagram("Correlation Identifier - Insurance Claims Saga (Azure)", show=False, direction="TB"):
with Cluster("Claims Ingestion"):
portal = FunctionApps("Claims\nPortal")
with Cluster("Service Bus Queues (CorrelationId)"):
submitted = ServiceBus("claims.submitted\n(Queue)")
policy_cmd = ServiceBus("policy.verify.cmd\n(Queue)")
damage_cmd = ServiceBus("damage.assess.cmd\n(Queue)")
fraud_cmd = ServiceBus("fraud.check.cmd\n(Queue)")
approval_cmd = ServiceBus("approval.request.cmd\n(Queue)")
payment_cmd = ServiceBus("payment.process.cmd\n(Queue)")
orch_reply = ServiceBus("claims.orchestrator\n.reply (Queue)")
resolved = ServiceBus("claims.resolved\n(Queue)")
with Cluster("Durable Functions Orchestrator"):
orchestrator = FunctionApps("Claims\nOrchestrator\n(Durable Functions)")
saga_db = CosmosDb("Saga State\n(CorrelationId\nas PK)")
with Cluster("Domain Services"):
policy_svc = FunctionApps("Policy\nService")
damage_svc = FunctionApps("Damage\nAssessment")
fraud_svc = FunctionApps("Fraud\nDetection")
approval_svc = FunctionApps("Approval\nService")
payment_svc = FunctionApps("Payment\nService")
with Cluster("Observability"):
app_insights = ApplicationInsights("Application Insights\n(by CorrelationId)")
log_analytics = LogAnalyticsWorkspaces("Log Analytics\nWorkspace")
# Claim submission
portal >> Edge(label="CorrelationId\ngenerated") >> submitted
# Orchestrator consumes and produces
submitted >> orchestrator
orchestrator >> saga_db
orchestrator >> policy_cmd
orchestrator >> damage_cmd
orchestrator >> fraud_cmd
orchestrator >> approval_cmd
orchestrator >> payment_cmd
orchestrator >> resolved
# Services reply with same CorrelationId
policy_cmd >> policy_svc
damage_cmd >> damage_svc
fraud_cmd >> fraud_svc
approval_cmd >> approval_svc
payment_cmd >> payment_svc
policy_svc >> Edge(style="dashed", label="CorrelationId\ncopied") >> orch_reply
damage_svc >> Edge(style="dashed", label="CorrelationId\ncopied") >> orch_reply
fraud_svc >> Edge(style="dashed", label="CorrelationId\ncopied") >> orch_reply
approval_svc >> Edge(style="dashed", label="CorrelationId\ncopied") >> orch_reply
payment_svc >> Edge(style="dashed", label="CorrelationId\ncopied") >> orch_reply
orch_reply >> orchestrator
# Observability indexed by CorrelationId
orchestrator >> Edge(style="dotted") >> app_insights
policy_svc >> Edge(style="dotted") >> app_insights
fraud_svc >> Edge(style="dotted") >> app_insights
app_insights >> log_analytics
Explicación del Diagrama¶
El diagrama muestra cómo el Correlation Identifier (corr-id) fluye a través de toda la saga de procesamiento de reclamos:
- El Claims Portal genera el
correlation_idal crear el reclamo y lo incluye en el primer mensaje (claims.submitted). - El Claims Orchestrator consume el evento, almacena el estado de la saga indexado por
correlation_id, y envía comandos a cada servicio con el mismocorrelation_id. - Cada Domain Service recibe el comando, procesa y responde al canal
claims.orchestrator.replycopiando elcorrelation_id. - El Orchestrator recibe las respuestas, las vincula con la saga correcta usando el
correlation_id, y avanza al siguiente paso. - Todos los servicios envían sus logs a Elasticsearch indexados por
correlation_id, permitiendo búsquedas transversales. - Grafana muestra dashboards de sagas en progreso, latencia por paso y reclamos atascados.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Correlation Identifier | Header correlation_id presente en todos los mensajes de la saga |
| Generación del ID | Claims Portal (primer mensaje) |
| Propagación del ID | Cada servicio copia el correlation_id de entrada en su respuesta |
| Vinculación por ID | Claims Orchestrator busca por correlation_id en su saga state |
| Trazabilidad por ID | Elasticsearch indexa logs por correlation_id |
11. Beneficios¶
Impacto Técnico¶
- Correlación determinista: cada respuesta se vincula con su petición original sin ambigüedad, independientemente del orden de llegada o la concurrencia.
- Distributed tracing: el
correlation_idpermite rastrear un flujo a través de múltiples servicios, canales y bases de datos. Una búsqueda porcorrelation_iden los logs centralizados devuelve la historia completa del flujo. - Saga management: el orchestrator puede gestionar miles de sagas concurrentes, cada una identificada por su
correlation_id, sin confundir pasos de diferentes sagas. - Deduplicación: la combinación de
correlation_id+ paso de la saga permite detectar mensajes duplicados (ej. dos respuestas del mismo servicio para el mismo paso de la misma saga).
Impacto Organizacional¶
- Debugging cross-team: cuando un flujo falla, el equipo de soporte comparte el
correlation_idcon los equipos de cada servicio involucrado. Cada equipo busca el ID en sus logs y contribuye su perspectiva. El ID es el lenguaje común de troubleshooting. - SLA measurement: la latencia de cada reclamo (desde
Claim SubmittedhastaClaim Resolved) se mide vinculando el primer y último mensaje porcorrelation_id.
Impacto Operacional¶
- Alertas contextuales: cuando se detecta un reclamo atascado, la alerta incluye el
correlation_id, que permite al operador acceder inmediatamente al contexto completo. - Auditoría automatizada: los auditores pueden solicitar el registro completo de un reclamo proporcionando el
correlation_id. El sistema genera automáticamente un timeline con todos los mensajes, decisiones y respuestas. - Monitoreo de flujo: dashboards que muestran flujos por estado (in-progress, completed, stuck, failed) agrupados por
correlation_id.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Propagación obligatoria: todos los servicios del flujo deben leer y propagar el
correlation_id. Si un servicio no lo hace (por bug, oversight o incompatibilidad), se rompe la cadena de correlación para todos los mensajes posteriores. - Infraestructura de logging: para que el
correlation_idsea útil, los logs de todos los servicios deben centralizarse e indexarse por este campo. Sin logging centralizado, el beneficio se reduce drásticamente. - Complejidad en intermediarios: routers, translators, splitters y aggregators deben propagar el
correlation_idde los mensajes de entrada a los de salida. En splitters, ¿todos los fragments comparten el mismocorrelation_id? En aggregators, ¿quécorrelation_idtiene el mensaje agregado?
Riesgos de Mal Uso¶
- Confundir message_id con correlation_id: usar el
message_idde la petición comocorrelation_idde la respuesta funciona para request-reply simple, pero no para flujos multi-paso (porque cada mensaje del flujo tendría uncorrelation_iddiferente). - Reutilizar correlation_id entre flujos: asignar el mismo
correlation_ida dos flujos independientes (ej. usando un ID secuencial que se reinicia) mezcla sus mensajes en logs y traces. - Correlation_id demasiado amplio: usar un ID de entidad de negocio (customer_id, order_id) como
correlation_idagrupa todos los flujos de esa entidad bajo el mismo ID, dificultando aislar un flujo específico.
Costos de Operación¶
- Storage de logs indexados: indexar logs por
correlation_idrequiere un campo adicional en cada log entry y un índice adicional en el sistema de logging (Elasticsearch, CloudWatch, etc.). - Overhead de headers: cada mensaje transporta headers adicionales (
correlation_id,causation_id,message_id), incrementando el tamaño de los mensajes (generalmente unos pocos bytes, despreciable en la mayoría de casos).
Anti-Patterns¶
- Correlation without logging: incluir
correlation_iden los mensajes pero no en los logs. El ID viaja por el sistema pero no se registra en ningún lugar consultable, anulando su utilidad para debugging. - Manual correlation: depender de que cada desarrollador recuerde incluir el
correlation_iden cada mensaje, en lugar de implementarlo como middleware automático.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Request-Reply (este capítulo): Correlation Identifier es un componente esencial de Request-Reply. Sin él, las respuestas no pueden vincularse con las peticiones.
- Return Address (este capítulo): Return Address indica dónde enviar la respuesta; Correlation Identifier indica a qué petición corresponde la respuesta. Ambos son necesarios para Request-Reply completo.
- Message Expiration (este capítulo): cuando una petición tiene un
correlation_idy un TTL, las peticiones expiradas pueden limpiarse del mapa de peticiones pendientes del requestor.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Command Message — los comandos de una saga incluyen
correlation_idpara vincular las respuestas. - Después: Aggregator — un aggregator que recolecta múltiples mensajes para producir un resultado combinado usa el
correlation_idpara agrupar los mensajes que deben agregarse.
Combinaciones Comunes¶
- Correlation Identifier + Saga Orchestrator: el orchestrator usa el
correlation_idcomo clave primaria del estado de la saga. - Correlation Identifier + Distributed Tracing (OpenTelemetry): el
correlation_idse mapea altrace_idde OpenTelemetry, unificando correlación de messaging con distributed tracing. - Correlation Identifier + Dead Letter Channel: los mensajes en dead-letter incluyen el
correlation_id, permitiendo vincularlos con el flujo original que falló. - Correlation Identifier + Wire Tap: los mensajes interceptados por wire tap incluyen el
correlation_id, permitiendo auditoría sin afectar el flujo.
Diferencias con Patrones Similares¶
- vs. Message Sequence: Message Sequence numera los fragmentos de un mensaje grande (sequence number); Correlation Identifier vincula mensajes de un mismo flujo lógico. Pueden combinarse: los fragmentos de un mismo flujo comparten
correlation_idy cada uno tiene susequence_number. - vs. Claim Check: Claim Check usa un identificador para recuperar datos de un store externo; Correlation Identifier usa un identificador para vincular mensajes relacionados. Diferentes propósitos para un mecanismo superficialmente similar.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Correlation Identifier no solo sigue vigente — su importancia ha crecido exponencialmente con la adopción de microservicios, event-driven architectures y observability-first design. En la era monolítica, la correlación era implícita (todo ocurría en el mismo proceso). En arquitecturas distribuidas, la correlación explícita es un requisito de supervivencia operacional.
Cómo Se Implementa Hoy¶
| Plataforma / Estándar | Implementación |
|---|---|
| JMS | JMSCorrelationID — header estándar de la especificación |
| AMQP 0-9-1 (RabbitMQ) | correlation_id — propiedad del mensaje |
| Azure Service Bus | CorrelationId — propiedad del sistema |
| Apache Kafka | kafka_correlationId — header por convención (Spring Kafka) |
| AWS SQS/SNS | CorrelationId — message attribute por convención |
| OpenTelemetry | trace_id + span_id — estándar W3C Trace Context |
| HTTP | X-Correlation-ID o X-Request-ID — header por convención |
| gRPC | x-correlation-id — metadata por convención |
Convergencia con OpenTelemetry¶
La tendencia moderna es unificar el correlation_id de messaging con el trace_id de OpenTelemetry:
Mensaje Kafka Header:
traceparent: "00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01"
correlation_id: "4bf92f3577b34da6a3ce929d0e0e4736" (= trace_id)
Esto permite que los traces de OpenTelemetry (visibles en Jaeger, Zipkin, Azure Monitor) y los logs de messaging (visibles en Elasticsearch, Splunk) se vinculen automáticamente.
Qué Parte Sigue Siendo Esencial¶
- El concepto de un identificador único que viaja con el mensaje a través de todo el flujo.
- La tríada message_id / correlation_id / causation_id como modelo de identidad de mensajes.
- La propagación automática del correlation_id por middleware y frameworks.
- La indexación de logs y traces por correlation_id para observabilidad transversal.
15. Implementación en Arquitecturas Modernas¶
Spring Boot + Kafka (Java)¶
// Middleware que propaga correlation_id automáticamente
@Component
public class CorrelationInterceptor implements ProducerInterceptor<String, String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String correlationId = CorrelationContext.getCurrentCorrelationId();
if (correlationId != null) {
record.headers().add("correlation_id", correlationId.getBytes());
}
return record;
}
}
Spring Kafka y Spring Cloud Stream propagan el correlation_id automáticamente si se configura correctamente, eliminando la necesidad de propagación manual en cada servicio.
Azure Service Bus (.NET)¶
// Procesamiento con propagación automática de CorrelationId
[ServiceBusAccount("claims")]
public class ClaimProcessor {
public async Task ProcessClaim(
[ServiceBusTrigger("policy.verify.cmd")] ServiceBusReceivedMessage message,
[ServiceBus("claims.orchestrator.reply")] IAsyncCollector<ServiceBusMessage> replies
) {
var result = await VerifyPolicy(message.Body);
var reply = new ServiceBusMessage(result) {
CorrelationId = message.CorrelationId, // PROPAGACIÓN
ApplicationProperties = {
["causation_id"] = message.MessageId
}
};
await replies.AddAsync(reply);
}
}
OpenTelemetry Integration¶
# Crear span con correlation_id como trace context
from opentelemetry import trace
from opentelemetry.context import attach, set_value
tracer = trace.get_tracer("claims-service")
def process_message(message):
correlation_id = message.headers.get("correlation_id")
# Crear span vinculado al trace del correlation_id
with tracer.start_as_current_span(
"process_claim",
attributes={
"correlation_id": correlation_id,
"message_id": message.headers.get("message_id"),
"causation_id": message.headers.get("causation_id"),
}
) as span:
# Toda la lógica dentro de este span se vincula al trace
result = verify_policy(message.body)
return result
Saga State Management¶
-- Estado de saga indexado por correlation_id
CREATE TABLE saga_state (
correlation_id VARCHAR(64) PRIMARY KEY,
saga_type VARCHAR(50) NOT NULL,
current_step VARCHAR(50) NOT NULL,
status VARCHAR(20) NOT NULL, -- ACTIVE, COMPLETED, COMPENSATING, FAILED
payload JSONB,
created_at TIMESTAMPTZ NOT NULL,
updated_at TIMESTAMPTZ NOT NULL,
timeout_at TIMESTAMPTZ
);
CREATE INDEX idx_saga_status ON saga_state(status, timeout_at);
-- Permite encontrar sagas atascadas: WHERE status='ACTIVE' AND timeout_at < NOW()
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Indexación obligatoria: todos los logs de todos los servicios deben incluir el
correlation_idcomo campo estructurado (no embebido en el texto). Esto permite búsquedas eficientes. - Cross-service timeline: herramientas como Jaeger o Zipkin visualizan el flujo completo de una transacción vinculando spans por
trace_id(que puede ser elcorrelation_id). - Métricas por correlation_id: latencia end-to-end del flujo, número de pasos completados, número de reintentos.
Monitoreo¶
- Sagas atascadas: consultar periódicamente la tabla de saga state para detectar sagas con status
ACTIVEcuyotimeout_atha pasado. - Propagation gaps: detectar mensajes que no tienen
correlation_id(indica un servicio que no lo propaga). Alertar cuando se detecten mensajes sin correlación en canales que deberían tenerla. - Correlation cardinality: monitorear el número de
correlation_idúnicos activos para dimensionar el saga state store y los índices de logs.
Estandarización¶
- Definir en la organización un único nombre para el header:
correlation_id(o alineado con W3C:traceparent). - Definir el formato del identificador: UUID v4, ULID, o formato custom con prefijo semántico.
- Definir qué servicio genera el
correlation_id(el primer servicio del flujo, el API gateway, el portal). - Documentar la política de propagación: todo intermediario debe copiar el
correlation_idde entrada en sus mensajes de salida.
Seguridad¶
- El
correlation_idno debe contener PII ni información sensible derivable. - El
correlation_idpuede usarse para auditoría regulatoria: conservar la asociación entrecorrelation_idy entidad de negocio (claim_id, order_id) en un store seguro. - En entornos multi-tenant, el
correlation_iddebe incluir un discriminador de tenant o validarse contra el tenant del mensaje.
Lifecycle Management¶
- Los
correlation_idde flujos completados pueden archivarse después de un período de retención. - Los logs indexados por
correlation_idtienen retención definida por política (30, 60, 90 días según el regulador). - La tabla de saga state debe tener un proceso de limpieza para sagas completadas, conservando un resumen para auditoría.
17. Errores Comunes¶
No Propagar el Correlation Identifier en Intermediarios¶
El error más frecuente y más dañino. Un servicio intermedio (router, translator, enricher) consume un mensaje con correlation_id, produce un nuevo mensaje, y no copia el correlation_id. El resultado: se rompe la cadena de correlación, y todos los mensajes posteriores no pueden vincularse con el flujo original. Prevención: implementar la propagación como middleware automático (interceptor, filter), no como código manual en cada servicio.
Confundir message_id con correlation_id¶
Usar el message_id de la petición como correlation_id de todo el flujo. Esto funciona para request-reply simple (dos mensajes), pero falla en flujos multi-paso: cada paso tiene un message_id diferente, así que si se usa message_id como clave de correlación, cada paso tendría una clave diferente. Solución: el correlation_id se genera una vez al inicio del flujo y se propaga sin cambios en todos los mensajes. El message_id es único por mensaje; el correlation_id es compartido por el flujo.
Correlation Identifier Demasiado Amplio¶
Usar un identificador de entidad de negocio duradero (customer_id, policy_number) como correlation_id. El resultado: todos los flujos relacionados con esa entidad (múltiples reclamos del mismo cliente, múltiples consultas sobre la misma póliza) se agrupan bajo el mismo correlation_id, haciendo imposible aislar un flujo específico. El correlation_id debe identificar un flujo, no una entidad.
No Incluir correlation_id en los Logs¶
El correlation_id viaja en los headers de los mensajes pero no se registra en los logs de los servicios. Esto anula el beneficio de trazabilidad: los mensajes están correlacionados, pero los logs no. Cada log entry debe incluir el correlation_id como campo estructurado para que las búsquedas transversales funcionen.
Generación de correlation_id con Colisiones¶
Usar un generador de IDs que produce colisiones (ej. timestamp truncado, contador por instancia sin discriminador). Dos flujos diferentes reciben el mismo correlation_id, y sus mensajes se mezclan en logs, traces y saga state. Solución: usar UUID v4 o ULID, cuya probabilidad de colisión es estadísticamente despreciable.
No Definir la Distinción correlation_id vs. causation_id¶
Usar solo correlation_id sin causation_id. Esto permite agrupar mensajes del mismo flujo pero no reconstruir el orden causal (qué mensaje causó qué otro mensaje). Para sagas complejas con bifurcaciones (pasos paralelos), el causation_id es necesario para reconstruir el grafo de causalidad.
18. Conclusión Técnica¶
Correlation Identifier es el patrón que convierte una colección de mensajes dispersos en un flujo coherente y rastreable. Sin correlación, los mensajes de un sistema distribuido son hojas sueltas; con correlación, son páginas de un mismo libro.
Cuándo aporta valor: en todo flujo que involucra más de un mensaje relacionado — Request-Reply, sagas, pipelines, workflows. El valor crece exponencialmente con el número de servicios y mensajes involucrados: en un flujo de 2 mensajes, la correlación es útil; en un flujo de 12 mensajes a través de 6 servicios (como la saga de reclamos del ejemplo), es absolutamente indispensable.
Cuándo evita problemas importantes: cuando se necesita diagnosticar un problema en un flujo distribuido. Sin correlation_id, el equipo de soporte debe reconstruir manualmente el flujo buscando coincidencias de timestamps, payloads y secuencias — un proceso que puede tomar horas. Con correlation_id, una búsqueda en los logs centralizados devuelve la historia completa en segundos.
Cuándo no conviene adoptarlo: en mensajes completamente independientes sin relación causal (ej. eventos de telemetría de dispositivos diferentes). Incluso en estos casos, un message_id es útil para deduplicación, pero el correlation_id no tiene propósito si no hay mensajes relacionados.
Recomendación para arquitectos: implemente la tríada completa — message_id, correlation_id, causation_id — como headers obligatorios en todos los mensajes del sistema. Implemente la propagación como middleware automático, no como código manual en cada servicio. Alinee el correlation_id con el trace_id de OpenTelemetry para unificar correlación de messaging con distributed tracing. Indexe todos los logs por correlation_id y construya dashboards que muestren flujos en progreso, completados, atascados y fallidos. El Correlation Identifier es la columna vertebral de la observabilidad en una arquitectura event-driven: sin él, se opera a ciegas.