Message Sequence¶
1. Nombre del Patrón¶
- Nombre oficial: Message Sequence
- Categoría: Message Construction (Construcción de Mensajes)
- Traducción contextual: Secuencia de Mensajes
2. Resumen Ejecutivo¶
Message Sequence es un patrón de construcción de mensajes que permite transmitir un conjunto de datos grande dividiéndolo en una serie ordenada y numerada de mensajes individuales que el consumidor puede reensamblar en el orden correcto para reconstruir el dataset original completo.
El patrón existe porque los sistemas de mensajería tienen límites de tamaño por mensaje (Kafka: 1 MB por defecto, SQS: 256 KB, Azure Service Bus Standard: 256 KB) y porque transmitir datasets masivos como un único mensaje genera problemas de latencia, consumo de memoria y riesgo de timeout. Dividir un dataset grande en una secuencia numerada de mensajes permite que el sistema de mensajería transporte los datos dentro de sus límites operacionales, que el productor libere recursos progresivamente y que el consumidor procese o acumule los fragmentos de forma controlada.
Aparece en escenarios donde los datos a transmitir exceden los límites razonables del broker o donde la naturaleza del dato es inherentemente secuencial y grande: imágenes médicas, archivos de audio/video, documentos regulatorios extensos, lotes de transacciones financieras, conjuntos de resultados de laboratorio y transferencias masivas de datos entre sistemas.
3. Definición Detallada¶
Propósito¶
El propósito de Message Sequence es permitir que un productor transmita un dataset que excede el tamaño práctico de un solo mensaje, dividiéndolo en fragmentos numerados que el consumidor puede reensamblar correctamente. Cada mensaje de la secuencia contiene metadatos que indican su posición dentro del conjunto y la identidad de la secuencia a la que pertenece.
Lógica Arquitectónica¶
Message Sequence introduce una fragmentación controlada del payload con metadatos de reensamblaje. Cada mensaje individual lleva:
- Sequence ID: identificador único que agrupa todos los mensajes pertenecientes a la misma secuencia.
- Sequence Position: número de orden del mensaje dentro de la secuencia (1 de N, 2 de N, ...).
- Sequence Size: número total de mensajes en la secuencia (N), o al menos un indicador de "último mensaje" (end-of-sequence flag).
- Payload Fragment: la porción de datos correspondiente a esta posición.
El consumidor utiliza estos metadatos para acumular fragmentos, detectar fragmentos faltantes, ordenarlos y reensamblar el dataset original.
Principio de Diseño Subyacente¶
El principio fundamental es descomposición de payload con preservación del orden. Del mismo modo que TCP fragmenta datos en segmentos numerados que se reensamblan en destino, Message Sequence fragmenta un dataset lógico en mensajes numerados que se reensamblan en el consumidor. La diferencia es que TCP opera a nivel de transporte con reensamblaje transparente, mientras que Message Sequence opera a nivel de aplicación y requiere que el consumidor implemente la lógica de reensamblaje explícitamente.
Problema Estructural que Resuelve¶
Sin Message Sequence, un productor que necesita transmitir un dataset de 50 MB a través de un broker con límite de 1 MB no tiene forma de hacerlo dentro del sistema de mensajería. Las alternativas son:
- Aumentar el límite del broker: técnicamente posible pero genera problemas de rendimiento para todos los demás productores y consumidores del ecosistema.
- Usar un mecanismo fuera de banda: transferir el dato fuera del broker (FTP, object storage) y enviar solo una referencia, lo cual es el patrón Claim Check.
- No transmitirlo: forzar al consumidor a consultar la fuente directamente, lo cual acopla los sistemas.
Message Sequence resuelve esto al permitir que el dato viaje por el mismo canal de mensajería que el resto de la comunicación, fragmentado y numerado.
Contexto en el que Emerge¶
Message Sequence emerge cuando:
- Los datos a transmitir exceden los límites de tamaño del broker.
- Se quiere mantener toda la comunicación dentro del mismo sistema de mensajería (no usar canales fuera de banda).
- Los datos tienen una estructura secuencial natural (frames de una imagen, registros de un batch, páginas de un documento).
- Se necesita que el consumidor pueda comenzar a procesar antes de recibir todos los fragmentos (streaming parcial).
Por Qué No Es Trivial¶
Implementar Message Sequence correctamente requiere resolver varios problemas no triviales:
- Reordenamiento: los mensajes pueden llegar fuera de orden, especialmente en sistemas con múltiples particiones o consumers. El consumidor debe poder reordenarlos.
- Fragmentos perdidos: si un mensaje de la secuencia se pierde, el consumidor debe detectar el hueco y decidir si espera, solicita retransmisión o descarta la secuencia completa.
- Timeout de secuencia: si el último mensaje nunca llega, el consumidor debe tener un mecanismo de timeout para no esperar indefinidamente, acumulando fragmentos parciales en memoria.
- Concurrencia de secuencias: múltiples secuencias pueden estar en tránsito simultáneamente. El consumidor debe mantener buffers independientes por Sequence ID.
- Consumo de recursos: acumular fragmentos en memoria hasta completar la secuencia puede requerir recursos significativos, especialmente si hay muchas secuencias concurrentes.
Relación con Sistemas Distribuidos y Mensajería¶
En sistemas distribuidos, la fragmentación y reensamblaje es un problema clásico resuelto a diferentes niveles del stack: IP fragmenta datagramas, TCP segmenta streams, HTTP/2 fragmenta frames. Message Sequence lleva este concepto al nivel de mensajería de aplicación, donde la semántica de los fragmentos tiene significado de negocio y el reensamblaje es responsabilidad del consumidor.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Message Sequence, cuando un sistema necesita transmitir un dataset grande a través de un sistema de mensajería con límites de tamaño:
- Transmisión imposible: el mensaje simplemente no cabe en el broker y el envío falla.
- Degradación de rendimiento: si se fuerza el aumento del límite de tamaño, los mensajes grandes saturan el broker, incrementan latencia para todos los demás mensajes y pueden causar out-of-memory en el broker o en consumidores.
- Canal alternativo obligatorio: se fuerza el uso de un mecanismo fuera del sistema de mensajería (FTP, base de datos compartida), lo cual introduce complejidad operacional y rompe la uniformidad de la arquitectura de mensajería.
Síntomas del Problema¶
- Errores de "message too large" o "payload exceeds maximum size" en el broker.
- Configuración de límites de tamaño de mensaje excesivamente altos que afectan la estabilidad del broker.
- Mecanismos ad-hoc para transferir datos grandes fuera del sistema de mensajería, generando integraciones shadow que nadie gobierna.
- Consumidores que fallan con OutOfMemoryError al intentar deserializar mensajes excesivamente grandes.
- Latencia elevada en el broker porque mensajes muy grandes bloquean la transmisión de mensajes pequeños.
Impacto Operativo y Arquitectónico¶
Sin un mecanismo estándar de fragmentación:
- La arquitectura de mensajería tiene un límite práctico de tamaño de payload que no puede superarse sin comprometer estabilidad.
- Los equipos implementan soluciones ad-hoc para datos grandes (archivos compartidos, base de datos temporal), cada una con su propia mecánica, monitoreo y puntos de fallo.
- La consistencia de la arquitectura de integración se pierde: la misma información viaja por canales diferentes según su tamaño.
Riesgos Si No Se Implementa Correctamente¶
- Secuencias incompletas: fragmentos perdidos que resultan en datos parciales procesados como si fueran completos.
- Memory leaks: buffers de reensamblaje que nunca se liberan porque la secuencia nunca se completa.
- Datos corruptos: fragmentos reensamblados en orden incorrecto que producen un dataset inválido.
- Duplicación de fragmentos: retries del productor que generan fragmentos duplicados que corrompen el reensamblaje.
- Starvation: secuencias grandes que consumen todos los recursos del consumidor, impidiendo el procesamiento de otros mensajes.
Ejemplos Reales¶
- Salud: un estudio de resonancia magnética de 200 MB debe transmitirse entre el sistema PACS del hospital y un servicio de análisis de imagen por IA. El estudio se divide en una secuencia de mensajes de 1 MB cada uno, cada mensaje conteniendo un subconjunto de slices DICOM numerados.
- Finanzas: un cierre de mercado genera un archivo de 50,000 posiciones que deben distribuirse a múltiples consumidores downstream. Las posiciones se dividen en lotes de 500 registros, cada lote como un mensaje numerado de la secuencia.
- Telecomunicaciones: un CDR (Call Detail Record) dump de millones de registros se segmenta en mensajes de 10,000 registros para alimentar el sistema de billing a través de Kafka.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el payload excede el límite de tamaño del broker y no se puede o no se desea usar un canal fuera de banda.
- Cuando se quiere mantener toda la comunicación dentro del mismo sistema de mensajería por simplicidad operacional.
- Cuando los datos tienen estructura secuencial natural que facilita la fragmentación y el reensamblaje.
- Cuando el consumidor puede beneficiarse de recibir fragmentos progresivamente (procesamiento streaming).
- Cuando el escenario requiere que los datos transiten por los mismos canales de seguridad, auditoría y monitoreo que el resto de los mensajes.
Cuándo No Usarlo¶
- Cuando el dataset grande puede referenciarse en lugar de transmitirse (Claim Check es generalmente preferible para payloads muy grandes).
- Cuando el broker soporta nativamente mensajes del tamaño requerido sin degradación (por ejemplo, Kafka con
max.message.bytesconfigurado adecuadamente y producers/consumers dimensionados). - Cuando la complejidad del reensamblaje no se justifica (si el dato cabe en un solo mensaje, usarlo).
- Cuando el consumidor necesita el dataset completo antes de poder procesarlo y no puede procesar fragmentos parciales. En este caso, Claim Check es más simple.
- Cuando los requisitos de latencia son estrictos y el overhead de fragmentación/reensamblaje es inaceptable.
Precondiciones¶
- El sistema de mensajería preserva el orden de los mensajes dentro de un canal o partición (o el consumidor implementa reordenamiento).
- Existe acuerdo sobre el formato de los metadatos de secuencia (Sequence ID, Position, Size/End flag).
- El consumidor tiene capacidad de almacenamiento temporal para acumular fragmentos.
- Existe un mecanismo de timeout para secuencias incompletas.
Restricciones¶
- Cada fragmento debe caber dentro del límite de tamaño del broker.
- El consumidor debe recibir todos los fragmentos para reconstruir el dataset (a menos que se tolere pérdida parcial).
- El número de secuencias concurrentes está limitado por la memoria disponible en el consumidor.
Dependencias¶
- Sistema de mensajería con soporte para headers customizados (para los metadatos de secuencia).
- Buffer o almacenamiento temporal en el consumidor para acumulación de fragmentos.
- Mecanismo de timeout y limpieza de secuencias incompletas.
Supuestos Arquitectónicos¶
- Los mensajes dentro del canal se entregan al menos una vez (at-least-once delivery).
- El consumidor puede manejar mensajes duplicados (idempotencia a nivel de fragmento).
- El tamaño del dataset es finito y conocido a priori (o al menos se puede señalizar el final de la secuencia).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas de imagen médica (PACS, RIS, sistemas de IA diagnóstica).
- Sistemas de procesamiento de datos financieros en batch-near-real-time.
- Pipelines de datos que combinan messaging con procesamiento de archivos grandes.
- Sistemas de telecomunicaciones con transmisión masiva de CDRs.
- Integraciones legacy donde se migran archivos grandes al mundo de mensajería.
6. Fuerzas Arquitectónicas¶
Tamaño del Mensaje vs. Límites del Broker¶
La tensión fundamental de Message Sequence es que el sistema de mensajería impone un límite de tamaño por mensaje, pero los datos de negocio no respetan ese límite. Message Sequence resuelve la tensión dividiendo los datos, pero introduce complejidad de reensamblaje.
Simplicidad vs. Complejidad de Reensamblaje¶
Un solo mensaje es simple de enviar y recibir. Una secuencia de mensajes que debe reensamblarse introduce complejidad significativa: buffering, reordenamiento, detección de huecos, timeouts, limpieza de secuencias incompletas. Esta complejidad es el costo del patrón.
Message Sequence vs. Claim Check¶
Este es el trade-off central para un arquitecto moderno. Message Sequence mantiene los datos dentro del sistema de mensajería, lo cual preserva la uniformidad de la arquitectura. Claim Check saca los datos a un almacenamiento externo (S3, Blob Storage) y envía solo una referencia, lo cual es más simple pero introduce una dependencia en un sistema externo y rompe la atomicidad del envío. La decisión depende de: tamaño del dataset (muy grande favorece Claim Check), necesidad de procesamiento streaming (favorece Message Sequence), infraestructura disponible (object storage listo favorece Claim Check) y requisitos de uniformidad de monitoreo (favorece Message Sequence).
Orden vs. Paralelismo¶
Si los mensajes de la secuencia deben procesarse en orden, el paralelismo se limita. Si pueden reensamblarse en cualquier orden, se gana paralelismo pero se necesita buffer y reordenamiento. La topología del sistema de mensajería (particiones de Kafka, colas de RabbitMQ) afecta esta tensión.
Throughput vs. Latencia¶
Fragmentar un dataset grande en muchos mensajes pequeños incrementa el throughput (los mensajes se transmiten en paralelo a través del broker) pero puede incrementar la latencia total de reensamblaje (el consumidor debe esperar a todos los fragmentos). Fragmentar en pocos mensajes grandes reduce el número de mensajes pero cada uno es más lento de transmitir.
Resiliencia vs. Recursos¶
Mantener buffers de reensamblaje para múltiples secuencias concurrentes consume memoria. Reducir los buffers ahorra recursos pero incrementa el riesgo de perder fragmentos si llegan fuera de orden o con retraso.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Splitter): divide el dataset original en fragmentos de tamaño adecuado y los envía como mensajes numerados con metadatos de secuencia.
- Canal de Mensajería: transporta los mensajes individuales de la secuencia. Puede o no preservar el orden.
- Consumidor (Aggregator/Reassembler): recibe los fragmentos, los acumula en un buffer indexado por Sequence ID, detecta completitud y reensambla el dataset original.
- Buffer de Reensamblaje: almacenamiento temporal (in-memory, Redis, base de datos) donde se acumulan fragmentos hasta completar la secuencia.
- Timer de Expiración: mecanismo que detecta secuencias incompletas que han excedido un timeout y libera los recursos asociados.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Dataset D de tamaño S]
B --> C[Calcular N fragmentos\nN = ceil S / max_size]
C --> D[Generar Sequence ID\núnico - UUID]
D --> E[Para cada fragmento i de 1..N\nextraer porción de datos]
E --> F[Construir mensaje\nSequenceId + Position=i + Size=N]
F --> G[(Canal de mensajería)]
G --> H[Consumidor recibe mensaje\nlee SequenceId]
H --> I[(Buffer\nSequenceId - Position)]
I --> J{Tiene todos\nlos N fragmentos?}
J -- Sí --> K[Reensamblar D\nen orden 1..N]
K --> L[Procesar y liberar buffer]
L --> M([Fin])
J -- No --> N{Timeout\nexpirado?}
N -- No --> H
N -- Sí --> O[Descartar secuencia\nincompleta y alertar]
O --> P[Liberar buffer]
P --> MResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Dividir datos, numerar fragmentos, garantizar que cada fragmento cabe en el broker |
| Canal | Transportar mensajes individuales con entrega garantizada |
| Consumidor | Acumular fragmentos, reordenar, detectar completitud, reensamblar, manejar timeouts |
| Buffer | Almacenar fragmentos parciales hasta completitud |
| Timer | Detectar y limpiar secuencias incompletas |
Interacciones¶
- Productor → Canal: envío de N mensajes, cada uno con headers de secuencia.
- Canal → Consumidor: entrega de mensajes (potencialmente desordenados o duplicados).
- Consumidor → Buffer: almacenamiento y consulta de fragmentos.
- Timer → Buffer: limpieza de secuencias expiradas.
Contratos Implícitos¶
- Formato de headers: nombres y tipos de los headers de secuencia (SequenceId: string, Position: int, Size: int).
- Tamaño máximo de fragmento: no debe exceder el límite del broker.
- Completitud: todos los fragmentos deben enviarse o la secuencia será incompleta.
- Unicidad de Sequence ID: cada secuencia tiene un ID único que no se reutiliza.
Decisiones de Diseño Clave¶
- Tamaño de fragmento: fijo (ej. 512 KB) o variable (ej. por registro lógico). Fijo es más simple; variable preserva la integridad de registros individuales.
- Indicador de fin: tamaño total en cada mensaje (Size=N) o flag de último mensaje (IsLast=true). Size requiere conocer N a priori; IsLast permite streaming donde N no se conoce de antemano.
- Almacenamiento del buffer: in-memory (rápido pero volátil), Redis (rápido y persistente), base de datos (lento pero durable). La elección depende del volumen de secuencias concurrentes y la tolerancia a pérdida.
- Estrategia de timeout: tiempo fijo desde el primer fragmento, o sliding window desde el último fragmento recibido.
- Manejo de duplicados: el consumidor debe poder recibir el mismo fragmento múltiples veces sin corromper el reensamblaje (idempotencia por Position).
8. Ejemplo Arquitectónico Detallado¶
Dominio: Salud — Transmisión de Estudios de Imagen Médica¶
Contexto del Negocio¶
Un hospital universitario con 800 camas opera un sistema de imagen médica (PACS) que almacena estudios de resonancia magnética (MRI), tomografía computarizada (CT), radiografía digital y ultrasonido. El hospital ha implementado un servicio de inteligencia artificial para asistencia diagnóstica que analiza estudios de imagen y genera reportes preliminares de hallazgos para los radiólogos.
Necesidad de Integración¶
Cuando un técnico completa un estudio de imagen, este debe transmitirse desde el PACS al servicio de IA para análisis. Un estudio de MRI cerebral típico contiene entre 200 y 2,000 slices DICOM, con un tamaño total de 50 MB a 500 MB. El sistema de mensajería del hospital (RabbitMQ) tiene un límite práctico de 128 MB por mensaje, pero enviar mensajes de cientos de megabytes genera problemas de rendimiento que afectan a los demás flujos de mensajería clínica (órdenes médicas, resultados de laboratorio, alertas).
Sistemas Involucrados¶
- PACS (Philips IntelliSpace): sistema de archivo y comunicación de imágenes que almacena estudios DICOM.
- PACS Router: componente que detecta estudios completados y los envía al sistema de mensajería.
- RabbitMQ Cluster: broker de mensajería del hospital, compartido por múltiples flujos clínicos.
- AI Analysis Service: servicio de IA que recibe estudios, ejecuta modelos de detección y genera reportes de hallazgos.
- Redis Cluster: almacenamiento temporal para el buffer de reensamblaje de secuencias.
- RIS (Radiology Information System): sistema que recibe el reporte de hallazgos de la IA y lo presenta al radiólogo.
Restricciones Técnicas¶
- RabbitMQ está configurado con
max-message-size=16MBpara proteger la estabilidad del cluster (compartido con flujos críticos de órdenes y alertas). - Los estudios de MRI varían entre 50 MB y 500 MB, muy por encima del límite de 16 MB.
- El servicio de IA necesita todos los slices del estudio para ejecutar el análisis (no puede operar con datos parciales).
- La latencia aceptable entre la finalización del estudio y la disponibilidad del reporte de IA es de 15 minutos.
- Los datos de imagen son PHI (Protected Health Information) regulados por normativas de privacidad de datos de salud.
Flujos de Datos¶
PACS → [PACS Router] → Divide estudio en fragmentos de 8 MB
→ [RabbitMQ: queue "imaging.ai.intake"] → N mensajes secuenciados
→ [AI Analysis Service] → Reensambla estudio desde Redis buffer
→ Ejecuta modelo de IA
→ [RabbitMQ: queue "imaging.ai.results"] → Reporte de hallazgos
→ [RIS] → Presenta al radiólogo
Eventos o Mensajes¶
Cada mensaje de la secuencia tiene los siguientes headers:
| Header | Tipo | Ejemplo |
|---|---|---|
x-sequence-id | String (UUID) | a1b2c3d4-e5f6-7890-abcd-ef1234567890 |
x-sequence-position | Integer | 3 |
x-sequence-size | Integer | 25 |
x-study-id | String | 1.2.840.113619.2.55.3.12345 |
x-patient-id | String (pseudonymized) | PAT-2026-00789 |
x-modality | String | MR |
x-body-part | String | BRAIN |
content-type | String | application/dicom |
El body contiene los bytes crudos de un subconjunto de archivos DICOM del estudio.
Decisiones Arquitectónicas¶
- Tamaño de fragmento: 8 MB (mitad del límite de RabbitMQ de 16 MB, dejando margen para headers y overhead).
- Fragmentación por archivo DICOM: cada fragmento contiene uno o más archivos DICOM completos (no se cortan archivos a la mitad). Si un archivo DICOM individual excede 8 MB (raro pero posible en ultrasonido 3D), se comprime antes de fragmentar.
- Buffer en Redis: los fragmentos se almacenan en Redis con TTL de 20 minutos. Si la secuencia no se completa en ese tiempo, Redis expira automáticamente los fragmentos.
- Orden de fragmentos: los fragmentos se envían al mismo queue con
x-sequence-idcomo routing key. RabbitMQ preserva FIFO dentro del queue, pero el consumidor no asume orden y usa Position para reensamblar. - Encriptación: los datos DICOM se cifran en tránsito (TLS en RabbitMQ) y en el buffer de Redis (Redis TLS + encryption at rest).
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Fragmento perdido por fallo de RabbitMQ | Queue durable con publisher confirms; dead-letter queue para mensajes no procesados |
| Buffer de Redis alcanza límite de memoria | Configuración de maxmemory con eviction policy volatile-ttl; alerta al 80% de capacidad |
| Estudio nunca se completa en el servicio de IA | Timeout de 20 minutos en Redis; alerta al equipo de soporte de imaging |
| Fragmentos duplicados por retry del productor | Idempotencia por (SequenceId, Position): si el fragmento ya existe en Redis, se ignora |
| Concurrencia de múltiples estudios simultáneos | Cada estudio tiene su propio SequenceId; los buffers son independientes |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Detección de Estudio Completado¶
El PACS Router detecta que un estudio de MRI cerebral ha sido completado (todos los slices adquiridos y archivados). El estudio tiene el ID 1.2.840.113619.2.55.3.12345, contiene 350 archivos DICOM y ocupa 180 MB en total.
Paso 2: Planificación de la Secuencia¶
El PACS Router:
- Genera un Sequence ID:
a1b2c3d4-e5f6-7890-abcd-ef1234567890. - Ordena los 350 archivos DICOM por Instance Number (orden de adquisición).
- Agrupa los archivos en fragmentos de hasta 8 MB: los primeros 15 archivos (7.8 MB), los siguientes 16 archivos (7.5 MB), etc.
- Calcula el total de fragmentos: 23.
- Registra en base de datos local: SequenceId, StudyId, total de fragmentos, timestamp de inicio.
Paso 3: Envío de Fragmentos¶
Para cada fragmento i (1 a 23):
- Serializa los archivos DICOM del fragmento en un blob binario (los archivos DICOM ya están en formato binario nativo).
- Construye el mensaje con headers:
x-sequence-id=a1b2...,x-sequence-position=i,x-sequence-size=23, más los metadatos del estudio. - Publica el mensaje en el queue
imaging.ai.intakede RabbitMQ conpublisher-confirmshabilitado. - Espera confirmación del broker antes de enviar el siguiente fragmento.
- Si el broker no confirma en 5 segundos, reintenta hasta 3 veces con backoff exponencial.
El envío de los 23 fragmentos toma aproximadamente 12 segundos (180 MB / ~15 MB/s de throughput de red).
Paso 4: Recepción y Buffering¶
El AI Analysis Service tiene un consumer escuchando el queue imaging.ai.intake. Para cada mensaje recibido:
- Lee el header
x-sequence-idyx-sequence-position. - Almacena el body del mensaje en Redis con la key
seq:{SequenceId}:frag:{Position}y TTL de 20 minutos. - Incrementa un contador atómico en Redis:
seq:{SequenceId}:count. - Compara el contador con
x-sequence-size. - Si
count == size, la secuencia está completa. Publica un mensaje internoSequenceComplete:{SequenceId}. - Hace ACK del mensaje en RabbitMQ.
Paso 5: Reensamblaje¶
Cuando el servicio recibe SequenceComplete:
- Lee todos los fragmentos de Redis en orden:
seq:{SequenceId}:frag:1,seq:{SequenceId}:frag:2, ...,seq:{SequenceId}:frag:23. - Concatena los blobs binarios en orden.
- Deserializa los archivos DICOM del blob combinado.
- Verifica integridad: el número de archivos DICOM coincide con lo esperado, cada archivo DICOM es parseable.
- Almacena los archivos DICOM en el sistema de archivos local del servicio de IA para procesamiento.
- Limpia las keys de Redis para esta secuencia.
Paso 6: Procesamiento y Resultado¶
El servicio de IA:
- Ejecuta el modelo de detección de anomalías sobre los 350 slices DICOM.
- Genera un reporte de hallazgos en formato FHIR DiagnosticReport.
- Publica el reporte como un único mensaje (típicamente <100 KB) en el queue
imaging.ai.results. - El RIS recibe el reporte y lo presenta al radiólogo junto con el estudio original del PACS.
Tiempo total desde finalización del estudio hasta disponibilidad del reporte de IA: aproximadamente 4 minutos (12 segundos de transmisión + 3.5 minutos de análisis de IA + overhead).
Manejo de Errores¶
- Fragmento perdido: si el contador en Redis no alcanza
x-sequence-sizeen 20 minutos, el timer de Redis expira los fragmentos. El servicio de IA detecta la expiración y genera una alerta. El PACS Router puede reenviar la secuencia completa. - Fragmento duplicado: si el productor reenvía un fragmento (por timeout de confirmación), el consumidor verifica si la key
seq:{SequenceId}:frag:{Position}ya existe en Redis. Si existe, ignora el duplicado y no incrementa el contador. - Error de reensamblaje: si la verificación de integridad falla (archivo DICOM corrupto), se descarta la secuencia, se alerta y se solicita reenvío.
- Redis no disponible: el consumer hace NACK del mensaje en RabbitMQ para que vuelva al queue. Cuando Redis se recupera, el procesamiento se reanuda.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import RabbitMQ
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.storage import Storage
from diagrams.programming.flowchart import Document
with Diagram("Message Sequence - Medical Imaging Study", show=False, direction="LR"):
with Cluster("Source - PACS"):
pacs = Server("PACS\n(Philips)")
router = Server("PACS Router\n(Splitter)")
pacs >> Edge(label="Study\n350 DICOM files\n180 MB") >> router
with Cluster("Messaging Layer"):
rmq = RabbitMQ("RabbitMQ\nQueue: imaging.ai.intake")
router >> Edge(label="23 messages\n8 MB each\nSequenceId + Position") >> rmq
with Cluster("AI Analysis Service"):
consumer = Server("Consumer\n(Reassembler)")
redis_buffer = Redis("Redis Buffer\nTTL: 20 min")
ai_engine = Server("AI Engine\n(Detection Model)")
rmq >> consumer
consumer >> Edge(label="store\nfragments") >> redis_buffer
redis_buffer >> Edge(label="reassemble\nin order") >> consumer
consumer >> Edge(label="complete\nstudy") >> ai_engine
with Cluster("Output"):
rmq_results = RabbitMQ("RabbitMQ\nQueue: imaging.ai.results")
ris = Server("RIS\n(Radiology IS)")
ai_engine >> Edge(label="FHIR\nDiagnosticReport") >> rmq_results
rmq_results >> ris
from diagrams import Diagram, Cluster, Edge
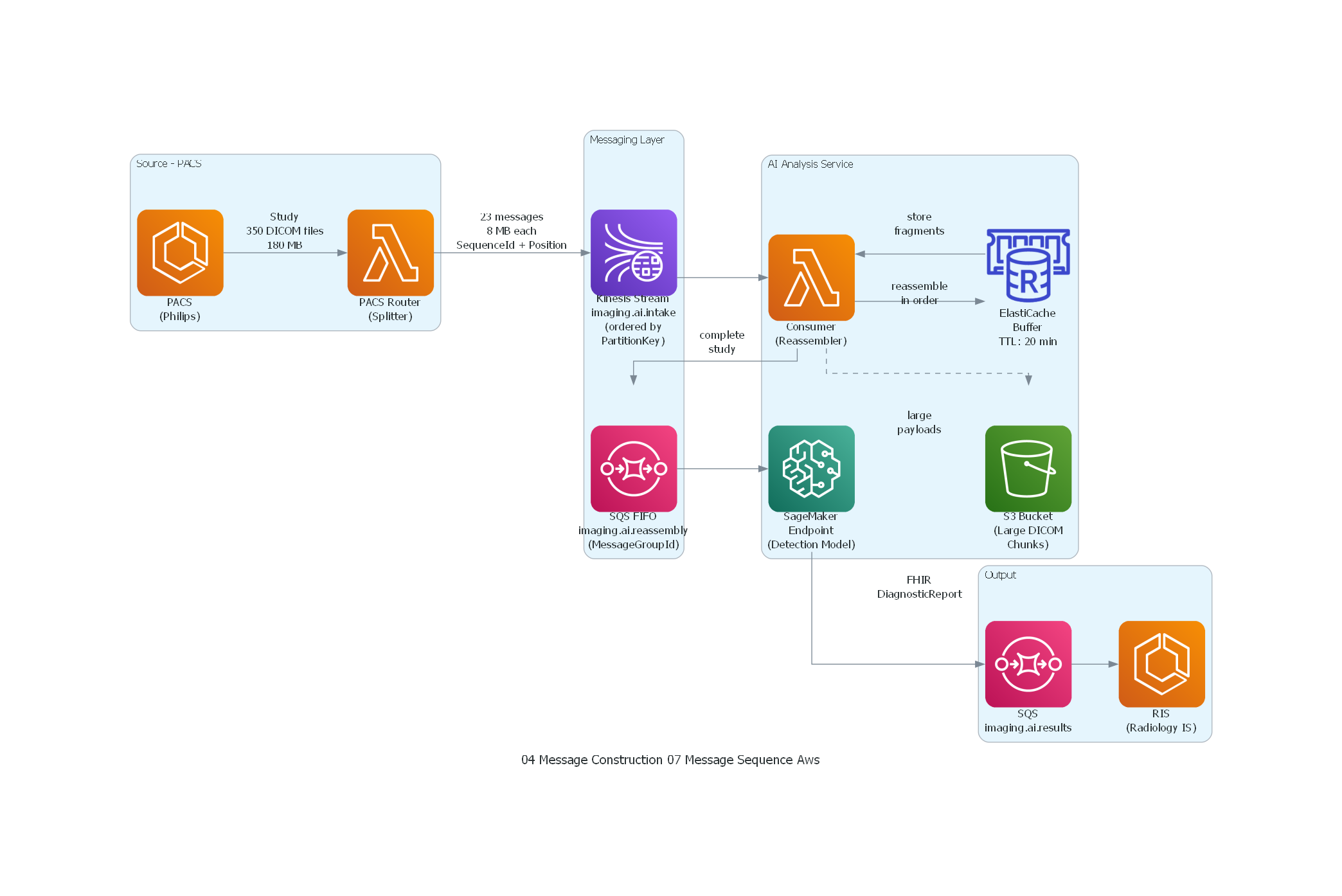
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import ElasticacheForRedis
from diagrams.aws.analytics import KinesisDataStreams
from diagrams.aws.integration import SQS
from diagrams.aws.ml import Sagemaker
from diagrams.aws.storage import S3
with Diagram("Message Sequence - Medical Imaging Study (AWS)", show=False, direction="LR"):
with Cluster("Source - PACS"):
pacs = ECS("PACS\n(Philips)")
router = Lambda("PACS Router\n(Splitter)")
pacs >> Edge(label="Study\n350 DICOM files\n180 MB") >> router
with Cluster("Messaging Layer"):
kinesis = KinesisDataStreams("Kinesis Stream\nimaging.ai.intake\n(ordered by\nPartitionKey)")
sqs_fifo = SQS("SQS FIFO\nimaging.ai.reassembly\n(MessageGroupId)")
router >> Edge(label="23 messages\n8 MB each\nSequenceId + Position") >> kinesis
with Cluster("AI Analysis Service"):
consumer = Lambda("Consumer\n(Reassembler)")
redis_buffer = ElasticacheForRedis("ElastiCache\nBuffer\nTTL: 20 min")
large_store = S3("S3 Bucket\n(Large DICOM\nChunks)")
ai_engine = Sagemaker("SageMaker\nEndpoint\n(Detection Model)")
kinesis >> consumer
consumer >> Edge(label="store\nfragments") >> redis_buffer
consumer >> Edge(label="large\npayloads", style="dashed") >> large_store
redis_buffer >> Edge(label="reassemble\nin order") >> consumer
consumer >> Edge(label="complete\nstudy") >> sqs_fifo
sqs_fifo >> ai_engine
with Cluster("Output"):
sqs_results = SQS("SQS\nimaging.ai.results")
ris = ECS("RIS\n(Radiology IS)")
ai_engine >> Edge(label="FHIR\nDiagnosticReport") >> sqs_results
sqs_results >> ris
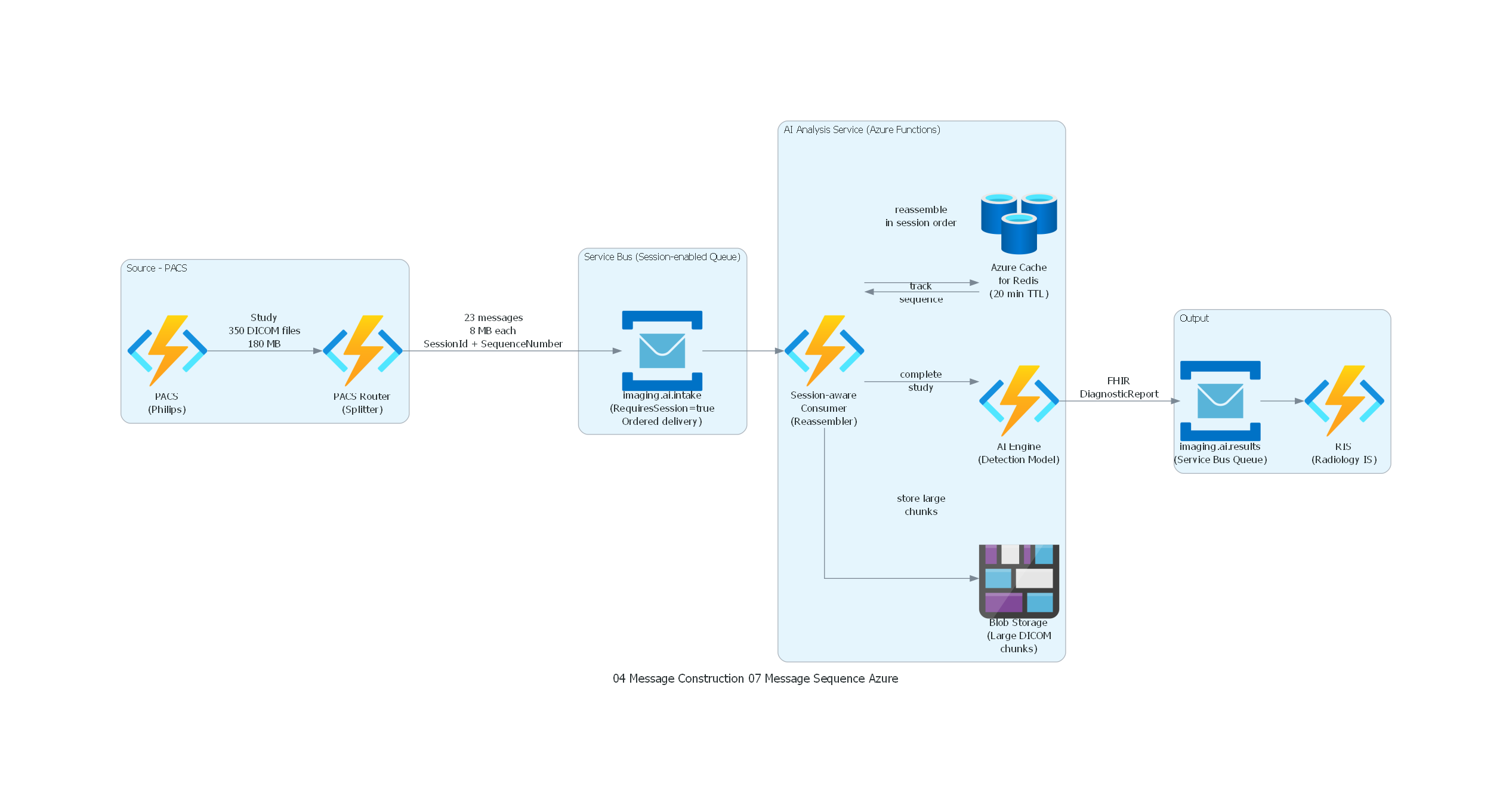
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.flowchart import Document
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis
from diagrams.azure.integration import ServiceBus
from diagrams.azure.storage import BlobStorage
with Diagram("Message Sequence - Medical Imaging Study (Azure)", show=False, direction="LR"):
with Cluster("Source - PACS"):
pacs = FunctionApps("PACS\n(Philips)")
router = FunctionApps("PACS Router\n(Splitter)")
pacs >> Edge(label="Study\n350 DICOM files\n180 MB") >> router
with Cluster("Service Bus (Session-enabled Queue)"):
sb_queue = ServiceBus("imaging.ai.intake\n(RequiresSession=true\nOrdered delivery)")
router >> Edge(label="23 messages\n8 MB each\nSessionId + SequenceNumber") >> sb_queue
with Cluster("AI Analysis Service (Azure Functions)"):
consumer = FunctionApps("Session-aware\nConsumer\n(Reassembler)")
redis_buffer = CacheForRedis("Azure Cache\nfor Redis\n(20 min TTL)")
blob_chunks = BlobStorage("Blob Storage\n(Large DICOM\nchunks)")
ai_engine = FunctionApps("AI Engine\n(Detection Model)")
sb_queue >> consumer
consumer >> Edge(label="store large\nchunks") >> blob_chunks
consumer >> Edge(label="track\nsequence") >> redis_buffer
redis_buffer >> Edge(label="reassemble\nin session order") >> consumer
consumer >> Edge(label="complete\nstudy") >> ai_engine
with Cluster("Output"):
sb_results = ServiceBus("imaging.ai.results\n(Service Bus Queue)")
ris = FunctionApps("RIS\n(Radiology IS)")
ai_engine >> Edge(label="FHIR\nDiagnosticReport") >> sb_results
sb_results >> ris
Explicación del Diagrama¶
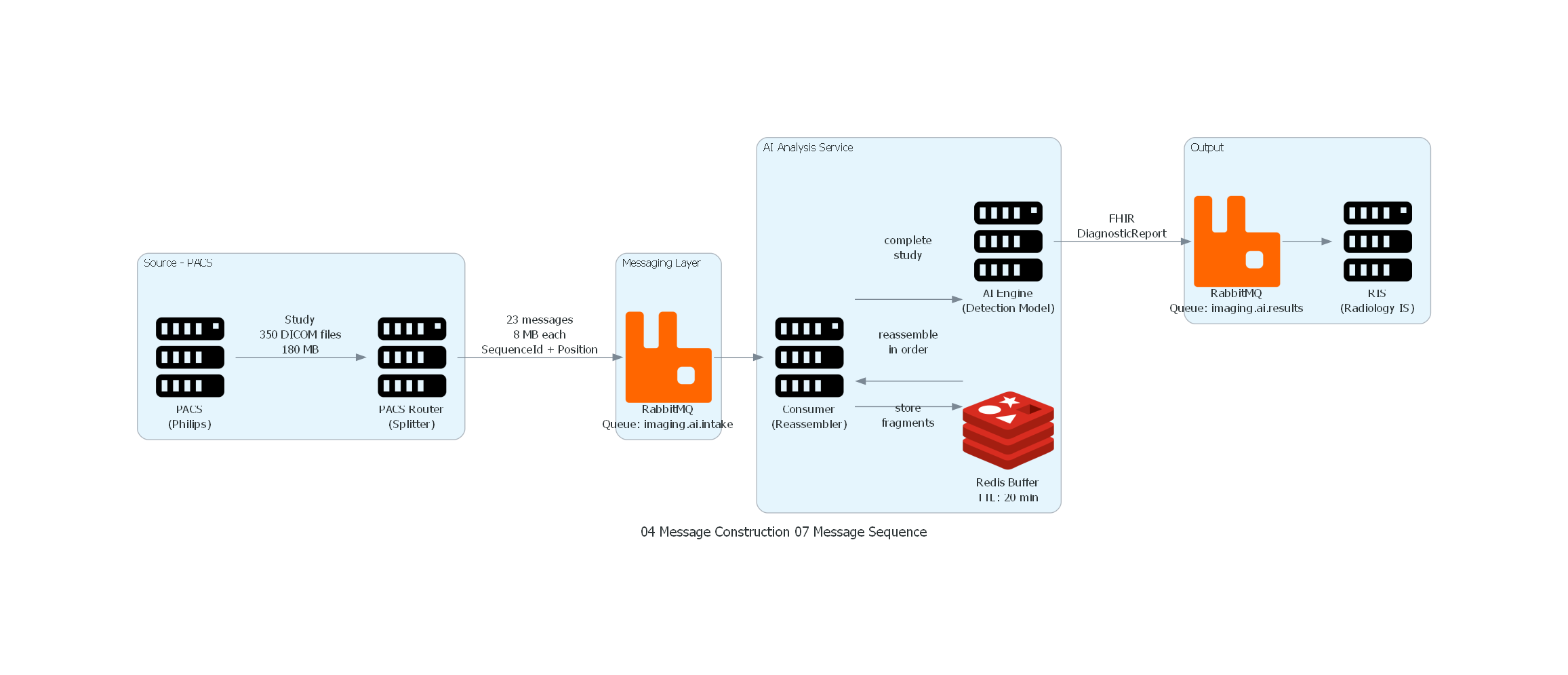
El diagrama representa el flujo completo de Message Sequence para la transmisión de un estudio de imagen médica:
- Source - PACS (izquierda): el sistema PACS contiene el estudio original (350 archivos DICOM, 180 MB). El PACS Router actúa como Splitter, dividiendo el estudio en 23 fragmentos de 8 MB.
- Messaging Layer: RabbitMQ transporta los 23 mensajes secuenciados, cada uno con headers de SequenceId y Position.
- AI Analysis Service: el Consumer recibe los fragmentos y los almacena en Redis. Cuando todos los fragmentos están presentes, los reensambla en orden y entrega el estudio completo al AI Engine.
- Output: el AI Engine genera un reporte FHIR que se publica como un mensaje normal en el queue de resultados, y el RIS lo recibe para presentación al radiólogo.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Dataset original | Study: 350 DICOM files, 180 MB |
| Productor (Splitter) | PACS Router |
| Mensajes de la secuencia | 23 messages, 8 MB each |
| Canal de mensajería | RabbitMQ Queue: imaging.ai.intake |
| Consumidor (Reassembler) | Consumer |
| Buffer de reensamblaje | Redis Buffer (TTL: 20 min) |
| Dataset reensamblado | Complete study entregado al AI Engine |
| Resultado del procesamiento | FHIR DiagnosticReport |
11. Beneficios¶
Impacto Técnico¶
- Superación de límites de tamaño: permite transmitir datasets de cualquier tamaño a través de un sistema de mensajería con límites de tamaño por mensaje, sin necesidad de canales fuera de banda.
- Protección del broker: al dividir datos grandes en mensajes de tamaño controlado, se evita que un payload masivo degrade el rendimiento del broker para todos los demás flujos.
- Uniformidad de arquitectura: toda la comunicación fluye por el mismo sistema de mensajería, lo cual simplifica monitoreo, auditoría y seguridad.
- Procesamiento streaming parcial: el consumidor puede comenzar a procesar fragmentos antes de recibir la secuencia completa (si la lógica de negocio lo permite).
Impacto Organizacional¶
- Estándar de comunicación: los equipos no necesitan implementar mecanismos ad-hoc para datos grandes; usan el mismo sistema de mensajería con una convención de headers de secuencia.
- Reutilización de infraestructura: no se necesita infraestructura adicional (FTP, file shares) para transmitir datos grandes.
Impacto Operacional¶
- Monitoreo unificado: los mensajes de secuencia se monitorean con las mismas herramientas que el resto de los mensajes.
- Retry granular: si un fragmento falla, solo se reenvía ese fragmento, no el dataset completo.
- Backpressure natural: el broker puede aplicar flow control a nivel de mensaje individual, evitando que un dataset grande sature al consumidor.
Beneficios de Mantenibilidad y Evolución¶
- Tamaño de fragmento configurable: se puede ajustar sin cambiar la lógica del productor ni del consumidor.
- Evolución del payload: el formato del dataset puede evolucionar independientemente del mecanismo de fragmentación.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Lógica de reensamblaje: el consumidor debe implementar buffering, reordenamiento, detección de completitud, manejo de duplicados y timeout de secuencias incompletas. Esta lógica es no trivial y propensa a errores.
- Gestión de estado: el consumidor se convierte en stateful (mantiene buffers de secuencias en progreso), lo cual complica escalado horizontal, failover y deployment.
- Incremento del número de mensajes: un dataset se convierte en N mensajes, incrementando la carga sobre el broker en volumen de mensajes.
Riesgos de Mal Uso¶
- Usar Message Sequence cuando Claim Check es más apropiado: para datasets muy grandes (GB), fragmentar en miles de mensajes genera más complejidad que subir el dataset a object storage y enviar una referencia. El umbral típico donde Claim Check supera a Message Sequence es alrededor de 100 MB, aunque depende del contexto.
- No implementar timeout de secuencias: si una secuencia nunca se completa, los fragmentos parciales consumen memoria indefinidamente, generando un memory leak lento.
- Asumir orden de entrega: en sistemas con múltiples particiones, consumers paralelos o rebalanceo, los mensajes pueden llegar desordenados. El consumidor debe manejar esto.
Sobreingeniería¶
- Implementar Message Sequence para payloads que caben en un mensaje: si el dato cabe en el límite del broker, no hay razón para fragmentar. La complejidad no se justifica.
- Construir un framework genérico de secuencias: la lógica de reensamblaje es específica del caso de uso. Un framework genérico puede terminar siendo más complejo que la solución particular.
Costos de Operación¶
- Monitoreo de secuencias: además de monitorear mensajes individuales, se necesita monitorear secuencias (tasa de completitud, secuencias expiradas, latencia de reensamblaje).
- Debugging complejo: investigar un problema en una secuencia requiere rastrear múltiples mensajes relacionados por Sequence ID.
- Capacidad del buffer: el almacenamiento temporal para fragmentos puede consumir recursos significativos si hay muchas secuencias concurrentes o si los datasets son muy grandes.
Anti-Patterns Relacionados¶
- Infinite Sequence: una secuencia sin Size ni end-of-sequence flag donde el consumidor nunca sabe cuándo está completa.
- Fragment Soup: múltiples secuencias intercaladas sin Sequence ID, donde el consumidor no puede distinguir qué fragmento pertenece a qué secuencia.
- Sequence Without Timeout: buffers que crecen indefinidamente porque nunca se limpian secuencias incompletas.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Claim Check: es la alternativa principal a Message Sequence para datos grandes. Claim Check almacena el dato completo en un almacenamiento externo y envía solo una referencia (claim check ticket) por el sistema de mensajería. Es más simple para el consumidor (no necesita reensamblar) pero introduce dependencia en el almacenamiento externo. En arquitecturas modernas cloud-native, Claim Check (S3 + referencia, Azure Blob + referencia) es generalmente la opción preferida para payloads mayores a 50-100 MB.
- Splitter: Message Sequence es una aplicación específica del patrón Splitter, donde el criterio de split es el tamaño del payload. La diferencia es que Splitter puede dividir por criterios de negocio (ej. dividir un pedido en sus líneas), mientras que Message Sequence divide exclusivamente por tamaño.
- Aggregator: el componente de reensamblaje en el consumidor es una implementación del patrón Aggregator, configurado con una estrategia de completitud basada en sequence position/size.
Patrones que Suelen Aparecer Antes o Después¶
- Message Expiration: cada fragmento de la secuencia puede tener un TTL para evitar que fragmentos huérfanos permanezcan indefinidamente en el sistema.
- Correlation Identifier: el Sequence ID funciona como un Correlation Identifier que agrupa los mensajes de la misma secuencia.
- Dead Letter Channel: fragmentos que no pueden procesarse se envían a una dead letter queue para inspección.
Combinaciones Comunes¶
- Message Sequence + Claim Check híbrido: el productor divide el dataset en fragmentos, almacena cada fragmento en object storage y envía mensajes ligeros con la referencia de cada fragmento. Combina las ventajas de ambos patrones.
- Message Sequence + Content Enricher: el consumidor reensambla la secuencia y luego enriquece el dataset con datos de otros sistemas antes de procesarlo.
Diferencias con Patrones Similares¶
- vs. Claim Check: Message Sequence transmite los datos por el canal de mensajería; Claim Check transmite una referencia y los datos viajan fuera de banda. Message Sequence requiere reensamblaje; Claim Check requiere acceso al almacenamiento externo.
- vs. Splitter: Splitter divide por criterios de negocio y cada fragmento puede procesarse independientemente. Message Sequence divide por tamaño y los fragmentos no tienen significado independiente — solo son útiles una vez reensamblados.
Encaje en un Flujo Mayor de Integración¶
Message Sequence típicamente aparece en el borde de un flujo de integración, en el punto donde un sistema con datos grandes necesita inyectarlos al sistema de mensajería. Una vez reensamblados, los datos fluyen normalmente por el resto de la arquitectura de integración.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
Message Sequence fue un patrón de alta relevancia cuando los límites de tamaño de los brokers eran estrictos y no existían alternativas como object storage cloud con acceso de baja latencia. En el contexto moderno, su relevancia ha disminuido significativamente pero no ha desaparecido.
A favor de la vigencia:
- Los brokers siguen teniendo límites de tamaño. SQS tiene un límite de 256 KB (extendido a 2 GB con SQS Extended Client Library, que internamente usa Claim Check con S3). Azure Service Bus Standard tiene 256 KB. Kafka tiene 1 MB por defecto. Estos límites siguen forzando decisiones cuando los datos son grandes.
- En sistemas legacy y de nicho (imagen médica, telecomunicaciones, sistemas militares), la fragmentación y reensamblaje de mensajes sigue siendo práctica estándar, particularmente donde los estándares del dominio (DICOM, HL7) definen mecanismos de secuenciación.
- El concepto de sequence numbers sigue vigente en streaming: Kafka record offsets, Kinesis sequence numbers, Event Hubs sequence numbers son esencialmente sequence indicators que permiten procesamiento ordenado.
En contra de la vigencia:
- Claim Check es generalmente preferible: en arquitecturas cloud-native, subir un dato grande a S3/Blob Storage y enviar una referencia es más simple, más robusto y más escalable que fragmentar en decenas de mensajes. El consumidor descarga el dato completo con una sola operación en lugar de reensamblar fragmentos.
- Kafka soporta mensajes grandes:
max.message.bytespuede configurarse a varios MB (o incluso cientos de MB con tiered storage). Aunque no es recomendable abusar de esta configuración, elimina la necesidad de fragmentar para payloads de tamaño moderado. - SQS Extended Client: AWS SQS ofrece una librería oficial que implementa Claim Check transparentemente, almacenando payloads grandes en S3. El productor y consumidor no necesitan implementar fragmentación manual.
- La complejidad de reensamblaje es alta: la lógica de buffering, reordenamiento, timeout y limpieza es error-prone y difícil de testear exhaustivamente.
Contexto Moderno Donde Sigue Siendo Útil¶
- Transmisión de datos grandes dentro de un sistema de mensajería cuando no hay object storage disponible.
- Dominios regulados donde el estándar técnico define fragmentación (DICOM, HL7v2 batch).
- Escenarios donde el consumidor puede procesar fragmentos progresivamente sin esperar al dataset completo.
- Sistemas legacy que implementan secuenciación como mecanismo nativo.
Cómo Se Implementa Hoy¶
La implementación moderna de Message Sequence ha evolucionado:
- Kafka: los productores pueden usar particiones con ordering guarantees. Los consumers usan offsets como sequence numbers nativos. Para datos realmente grandes, la práctica recomendada es Claim Check (producir referencia a S3) en lugar de fragmentar.
- RabbitMQ: fragmentación manual con headers customizados. Plugins como Shovel o Federation no implementan secuencias nativamente, pero el protocolo AMQP permite headers arbitrarios.
- Azure Service Bus: sessions proporcionan ordering guarantees para mensajes con el mismo session ID, lo cual facilita implementar secuencias sin reordenamiento manual.
- AWS SQS: SQS Extended Client Library implementa Claim Check automáticamente para mensajes grandes, haciendo innecesaria la fragmentación manual.
Qué Parte Sigue Siendo Esencial¶
Independientemente de la tecnología, los conceptos de Message Sequence que permanecen vigentes son:
- Sequence numbering: numerar mensajes para garantizar orden y detectar gaps es esencial en cualquier protocolo de comunicación ordenada.
- Completeness detection: saber cuándo se han recibido todos los fragmentos/mensajes de un conjunto es un problema recurrente (en sagas, en Aggregator, en batch processing).
- Timeout de secuencias incompletas: no esperar indefinidamente a datos que pueden no llegar es un principio fundamental de resiliencia.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
Kafka no implementa Message Sequence como primitiva nativa, pero proporciona las herramientas necesarias:
- Ordering within partition: los mensajes en una partición mantienen orden estricto. Usando el Sequence ID como partition key, todos los fragmentos llegan al mismo consumer en orden.
- Offsets como sequence numbers: el offset de cada record es un sequence number natural.
max.message.bytes: configurable por topic. Para datos moderadamente grandes (10-50 MB), aumentar este límite es más simple que implementar secuenciación.- Tiered storage: en Kafka 3.x+, tiered storage permite retener segmentos grandes sin presionar el almacenamiento local del broker.
- Recomendación: para datos >50 MB, usar Claim Check con S3 en lugar de Message Sequence.
RabbitMQ¶
- Headers personalizados: AMQP 0-9-1 permite headers arbitrarios para los metadatos de secuencia.
- Quorum queues: garantizan durabilidad y orden para los fragmentos.
- Publisher confirms: garantizan que cada fragmento fue persistido antes de enviar el siguiente.
max-message-size: por defecto ilimitado en versiones modernas, pero se recomienda configurarlo para proteger el cluster.- Consumer acknowledgment: el consumer puede hacer ACK de cada fragmento individualmente.
Azure Service Bus¶
- Sessions: los mensajes con el mismo
SessionIdse entregan ordenados al mismo consumer. Usando el Sequence ID como SessionId, se obtiene ordering nativo sin implementación custom. SequenceNumber: Service Bus asigna un sequence number a cada mensaje, útil para deduplicación.- Message deferral: permite aplazar el procesamiento de un mensaje hasta que los fragmentos previos estén disponibles.
- Tamaño máximo: 256 KB (Standard) o 100 MB (Premium). Premium elimina la necesidad de secuencias para la mayoría de los casos.
AWS SQS¶
- SQS Extended Client Library: implementa Claim Check transparentemente para mensajes que exceden 256 KB. Los datos se almacenan en S3 y SQS transporta solo la referencia. Esto hace innecesaria la fragmentación manual en la mayoría de los casos.
- FIFO queues: garantizan orden dentro de un Message Group ID, útil si se implementa Message Sequence manualmente.
MuleSoft / Apache Camel¶
Ambos frameworks proporcionan implementaciones del patrón Splitter-Aggregator que pueden usarse para implementar Message Sequence:
- MuleSoft:
batch:jobconbatch:stepdivide y procesa fragmentos.scatter-gatherreensambla resultados. - Apache Camel:
split().streaming()divide un payload grande en fragmentos.aggregate()conAggregationStrategyreensambla. Camel soportacompletionSize,completionTimeoutycompletionPredicatepara control de completitud.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: secuencias iniciadas/hora, secuencias completadas/hora, secuencias expiradas/hora, latencia promedio de reensamblaje, número de fragmentos por secuencia, fragmentos duplicados descartados.
- Health checks: tamaño del buffer de reensamblaje, número de secuencias en progreso, edad de la secuencia más antigua en el buffer.
- Alertas: secuencia expirada sin completarse, buffer de reensamblaje al 80% de capacidad, latencia de reensamblaje excediendo SLA.
Tracing¶
- El Sequence ID debe propagarse como parte del trace context (OpenTelemetry o similar) para vincular los N mensajes de una secuencia en una única traza.
- Cada fragmento debe tener un span individual dentro del trace, vinculado al span padre de la secuencia.
- El reensamblaje debe tener su propio span que agrupe los fragmentos.
Monitoreo¶
- Dashboard operacional: secuencias en progreso, tasa de completitud, fragmentos pendientes, secuencias expiradas en las últimas 24 horas.
- Monitoreo de buffer: uso de memoria de Redis/almacenamiento temporal, keys activas, TTL distribution.
- Alertas de SLA: tiempo desde primer fragmento hasta reensamblaje completo.
Versionado¶
- El formato del payload dentro de los fragmentos puede evolucionar, pero el formato de los headers de secuencia debe ser estable (backward compatible).
- Si se cambia el mecanismo de fragmentación (ej. de 8 MB a 16 MB), productores y consumidores deben coordinarse.
Seguridad¶
- Cifrado: los fragmentos contienen datos de negocio que pueden ser sensibles. Cifrado en tránsito (TLS) y en el buffer de reensamblaje (encryption at rest).
- Integridad: cada fragmento puede incluir un checksum (CRC32, SHA-256) para verificar que no fue alterado en tránsito.
- Control de acceso: solo los consumers autorizados pueden acceder a los fragmentos de una secuencia.
Manejo de Errores¶
- Fragmento inválido: si un fragmento falla la validación (checksum incorrecto, header malformado), se descarta y se solicita retransmisión o se envía a dead letter.
- Secuencia incompleta: tras el timeout, se alerta y se descartan los fragmentos parciales. El productor puede reenviar la secuencia completa.
- Error de reensamblaje: si el dataset reensamblado falla validación de integridad, se descarta y se alerta.
Retries¶
- A nivel de fragmento: si un fragmento no se procesa correctamente, se reenvía individualmente.
- A nivel de secuencia: si la secuencia no se completa, el productor puede reenviar la secuencia completa con un nuevo Sequence ID.
- Idempotencia: el consumer debe manejar fragmentos duplicados sin corromper el buffer.
Dead-Lettering¶
- Fragmentos que no pueden procesarse después de N retries se mueven a una dead letter queue.
- La dead letter queue debe preservar los headers de secuencia para diagnóstico.
- Un fragmento en dead letter implica que la secuencia no se completará; el sistema de monitoreo debe correlacionar ambos eventos.
Idempotencia¶
- Cada fragmento se identifica unívocamente por (Sequence ID, Position).
- El buffer debe aceptar el mismo (SequenceId, Position) múltiples veces sin alterar el resultado del reensamblaje.
- El reensamblaje debe producir el mismo resultado independientemente de cuántas veces se reciba cada fragmento.
Auditoría¶
- Registro de cada secuencia: SequenceId, timestamp de inicio, timestamp de completitud/expiración, número de fragmentos, resultado.
- Registro de fragmentos individuales: SequenceId, Position, timestamp de recepción, tamaño, checksum.
- Los registros deben permitir reconstruir la historia completa de una secuencia para diagnóstico.
Performance¶
- Tamaño de fragmento: fragmentos más grandes reducen el número de mensajes pero incrementan latencia por mensaje y consumo de memoria. Fragmentos más pequeños incrementan overhead de headers y número de mensajes.
- Buffer sizing: dimensionar el buffer para el número máximo esperado de secuencias concurrentes multiplicado por el tamaño promedio de secuencia.
- Compresión: comprimir cada fragmento antes de enviar reduce bandwidth y storage pero incrementa CPU.
Escalabilidad¶
- Horizontal scaling del consumer: requiere que el buffer de reensamblaje sea compartido (Redis, base de datos) para que múltiples instancias del consumer puedan contribuir fragmentos a la misma secuencia.
- Particionamiento: usar Sequence ID como partition key garantiza que todos los fragmentos de una secuencia lleguen a la misma partición, simplificando reensamblaje.
- Límite práctico: cientos de secuencias concurrentes con decenas de fragmentos cada una es manejable. Miles de secuencias con miles de fragmentos cada una requiere dimensionamiento cuidadoso del buffer.
17. Errores Comunes¶
Usar Message Sequence Cuando Claim Check Es Más Apropiado¶
El error más frecuente en arquitecturas modernas es implementar Message Sequence para datos muy grandes cuando Claim Check (S3 + referencia) es más simple, más robusto y más escalable. Message Sequence tiene sentido cuando el dato es moderadamente grande (1-50 MB), cuando no hay object storage disponible, o cuando el consumidor puede procesar fragmentos progresivamente. Para datos de cientos de MB o GB, Claim Check es casi siempre la mejor opción.
No Implementar Timeout de Secuencias Incompletas¶
Si una secuencia nunca se completa (porque un fragmento se perdió o el productor falló a mitad de envío), los fragmentos parciales permanecen en el buffer indefinidamente. Esto es un memory leak que eventualmente agota los recursos del consumidor. Todo buffer de reensamblaje debe tener un timeout configurable.
Asumir Orden de Entrega del Broker¶
En muchos brokers (Kafka con múltiples particiones, RabbitMQ con consumers paralelos), los mensajes pueden llegar desordenados. El consumidor que asume que los fragmentos llegarán en orden (1, 2, 3, ...) fallará cuando reciba (1, 3, 2). El consumidor debe usar el campo Position para posicionar cada fragmento correctamente, independientemente del orden de llegada.
No Manejar Fragmentos Duplicados¶
En sistemas con at-least-once delivery, un fragmento puede llegar múltiples veces (por retry del productor o del broker). Si el consumidor incrementa un contador por cada fragmento recibido sin verificar duplicados, el contador excederá el Size y la lógica de completitud fallará. La verificación debe ser por (SequenceId, Position): si ya existe, ignorar.
Fragmentar Datos que No Lo Necesitan¶
Aplicar Message Sequence a mensajes que caben perfectamente en el límite del broker añade complejidad innecesaria sin beneficio. La fragmentación solo debe activarse cuando el dato excede el límite o cuando el beneficio de procesamiento streaming parcial justifica la complejidad.
No Proporcionar Sequence Size ni End Flag¶
Sin un indicador de cuántos fragmentos componen la secuencia (Size=N) o de cuál es el último (IsLast=true), el consumidor no puede saber cuándo la secuencia está completa. Esperar indefinidamente o usar un timeout como único mecanismo de completitud es frágil y genera latencia innecesaria.
Buffer de Reensamblaje In-Memory Sin Respaldo¶
Almacenar fragmentos solo en memoria del proceso consumidor significa que un reinicio del proceso pierde todos los fragmentos acumulados de todas las secuencias en progreso. Para secuencias con muchos fragmentos o datasets grandes, el buffer debe estar en un almacenamiento externo (Redis, base de datos) que sobreviva al reinicio del proceso.
18. Conclusión Técnica¶
Message Sequence es un patrón que resuelve un problema real y recurrente: transmitir datos que exceden los límites de tamaño del sistema de mensajería. Su mecánica — dividir un dataset en fragmentos numerados, transmitirlos como mensajes individuales y reensamblarlos en el consumidor — es conceptualmente simple pero operacionalmente compleja.
Para un arquitecto moderno, la decisión clave no es cómo implementar Message Sequence, sino cuándo usarlo frente a la alternativa principal: Claim Check.
- Cuándo Message Sequence aporta valor: cuando los datos son moderadamente grandes (1-50 MB), cuando se quiere mantener toda la comunicación dentro del sistema de mensajería, cuando el consumidor puede procesar fragmentos progresivamente, o cuando no hay object storage de baja latencia disponible.
- Cuándo Claim Check es preferible: cuando los datos son muy grandes (>50-100 MB), cuando existe object storage cloud con acceso de baja latencia (S3, Blob Storage, GCS), cuando el consumidor necesita el dataset completo antes de procesar, o cuando la complejidad del reensamblaje no se justifica.
- Cuándo ninguno es necesario: cuando el broker puede manejar el tamaño del mensaje directamente (Kafka con
max.message.bytesconfigurado, Service Bus Premium con 100 MB, etc.) sin degradar el rendimiento del ecosistema.
Recomendación para arquitectos: evalúe primero si puede aumentar el límite de tamaño del broker sin impacto. Si no, evalúe Claim Check como primera opción, especialmente en arquitecturas cloud-native donde S3/Blob Storage están disponibles. Reserve Message Sequence para escenarios donde los datos deben transitar por el canal de mensajería (por requisitos de seguridad, auditoría o uniformidad), donde el consumidor se beneficia de procesamiento incremental, o donde la infraestructura de almacenamiento externo no está disponible. En cualquier caso, implemente siempre: timeout de secuencias incompletas, manejo de fragmentos duplicados, buffer externo persistente y monitoreo de tasa de completitud.