Format Indicator¶
1. Nombre del Patrón¶
- Nombre oficial: Format Indicator
- Categoría: Message Construction (Construcción de Mensajes)
- Traducción contextual: Indicador de Formato / Marcador de Versión del Mensaje
2. Resumen Ejecutivo¶
Format Indicator es un patrón de construcción de mensajes que consiste en incluir dentro del propio mensaje información explícita sobre su formato, versión o esquema, de modo que el consumidor pueda determinar cómo interpretar y deserializar el contenido sin depender de suposiciones implícitas ni de conocimiento externo al mensaje.
El patrón existe porque en sistemas distribuidos donde múltiples productores y consumidores intercambian mensajes a través de un broker, el formato de los mensajes evoluciona inevitablemente. Se añaden campos, se eliminan campos obsoletos, se cambian tipos de datos, se reestructuran secciones. Sin un indicador de formato dentro del mensaje, el consumidor no tiene forma de saber qué versión del esquema utilizar para deserializar, lo cual resulta en errores de parsing, datos malinterpretados y fallos silenciosos.
Aparece de forma ubicua en toda arquitectura de mensajería moderna. El Content-Type header en HTTP y AMQP, el schemaId en registros Avro con Confluent Schema Registry, el dataschema attribute de la especificación CloudEvents, el specversion en CloudEvents, los version prefixes en Protobuf, el type field en JSON:API y el campo schemaVersion en webhooks de plataformas SaaS (Stripe, GitHub, Shopify) son manifestaciones del patrón Format Indicator.
3. Definición Detallada¶
Propósito¶
El propósito de Format Indicator es hacer que cada mensaje sea autodescriptivo en cuanto a su formato, permitiendo que el consumidor determine en runtime cómo interpretar el contenido. Esto desacopla la evolución del formato del mensaje del deployment de los consumidores: un productor puede emitir mensajes en una nueva versión de formato y los consumidores existentes pueden detectar la versión y decidir cómo manejarla (procesarla con el deserializador correcto, ignorarla si no la soportan, o alertar si es incompatible).
Lógica Arquitectónica¶
Format Indicator introduce metadatos de formato en el mensaje que informan al consumidor sobre:
- Tipo de contenido (Content Type): el formato de serialización del payload (JSON, Avro, Protobuf, XML, MessagePack).
- Versión del esquema (Schema Version): la versión específica del esquema de datos utilizado para construir el mensaje (v1, v2, v3).
- Referencia al esquema (Schema Reference): un identificador o URL que apunta a la definición formal del esquema, típicamente almacenada en un Schema Registry.
- Tipo de evento (Event Type): en sistemas event-driven, identifica qué tipo de evento es (OrderPlaced, PaymentReceived, UserCreated).
Estos metadatos pueden colocarse en:
- Headers del mensaje: ubicación natural para metadatos que el broker y los intermediarios pueden inspeccionar sin parsear el body.
- Envelope del payload: un wrapper alrededor del payload que incluye la metadata de formato junto con los datos de negocio.
- Magic bytes / prefix: bytes iniciales del payload que indican el formato (común en Avro, Protobuf).
Principio de Diseño Subyacente¶
El principio fundamental es auto-descripción del mensaje. Cada mensaje debe contener suficiente información para ser interpretado correctamente sin conocimiento externo implícito. Este principio se aplica en muchos niveles de la informática: los archivos tienen extensiones y magic numbers, los paquetes de red tienen headers de protocolo, los documentos XML tienen declaraciones de namespace y schema. Format Indicator aplica el mismo principio a los mensajes en un sistema de mensajería.
Problema Estructural que Resuelve¶
Sin Format Indicator, el consumidor asume que todos los mensajes tienen el mismo formato. Esta suposición se rompe inevitablemente cuando:
- El productor actualiza su formato: añade un nuevo campo obligatorio. Los consumidores que asumen el formato anterior fallan al encontrar el campo desconocido o al no encontrar un campo esperado.
- Múltiples productores con diferentes formatos: dos microservicios publican en el mismo topic, cada uno con su propia versión del schema. El consumidor no puede distinguir qué formato tiene cada mensaje.
- Migración gradual: durante una migración de schema, coexisten mensajes en formato v1 y v2 en la misma cola. El consumidor debe procesar ambos.
- Múltiples consumidores con diferentes capacidades: un consumidor soporta v1 y v2, otro solo v1. Sin un indicador de formato, el segundo consumidor no puede filtrar los mensajes que no soporta.
Contexto en el que Emerge¶
Format Indicator emerge tan pronto como el formato de un mensaje cambia por primera vez. En un sistema nuevo donde el formato nunca ha cambiado, la necesidad no es evidente. Pero después del primer cambio de schema — y especialmente después de que ese cambio rompe un consumidor — la necesidad de un indicador de formato se vuelve innegable. Los arquitectos experimentados incluyen Format Indicator desde el primer día, anticipando que la evolución del formato es inevitable.
Por Qué No Es Trivial¶
Las decisiones alrededor de Format Indicator tienen ramificaciones significativas:
- Dónde colocar el indicador: en headers (visible para el broker y los intermediarios, pero no todos los brokers permiten headers arbitrarios) o en el body (visible para el consumidor pero requiere parsing parcial para extraerlo).
- Qué indicar: solo el content type (JSON, Avro), o también la versión del schema, o una referencia completa al schema. Más detalle proporciona más capacidad de evolución pero más complejidad.
- Granularidad del versionado: ¿semántico (v1.2.3)? ¿Incremental (1, 2, 3)? ¿Por fecha (2026-04-07)? La granularidad afecta cómo se gestiona la compatibilidad.
- Compatibilidad: ¿forward compatible (consumidores viejos leen mensajes nuevos)? ¿Backward compatible (consumidores nuevos leen mensajes viejos)? ¿Full compatible (ambos)? El indicador de formato habilita estas estrategias pero no las implementa.
- Centralización vs. descentralización: ¿los schemas se registran en un Schema Registry central o cada equipo gestiona sus propias versiones? El indicador de formato interactúa directamente con esta decisión.
Relación con Sistemas Distribuidos y Mensajería¶
En sistemas distribuidos, la evolución de contratos de comunicación es uno de los problemas más persistentes. El equivalente en APIs HTTP es API versioning (URL path versioning, header versioning, content negotiation). Format Indicator es el equivalente en mensajería asíncrona: un mecanismo para que el consumidor identifique el contrato del mensaje y actúe en consecuencia. La diferencia es que en APIs HTTP el cliente elige qué versión solicitar (content negotiation), mientras que en mensajería el consumidor recibe lo que el productor envió y debe adaptarse.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Format Indicator, cuando un productor cambia el formato de un mensaje:
- Despliegue sincronizado obligatorio: el productor y todos los consumidores deben desplegar simultáneamente para pasar del formato viejo al nuevo. Esto es impracticable en arquitecturas de microservicios con decenas de consumidores independientes.
- Errores de deserialización: consumidores que esperan el formato v1 reciben un mensaje v2 y fallan al parsearlo. El error puede ser explícito (excepción) o silencioso (campos ignorados o malinterpretados).
- Rollback imposible: si un productor despliega la nueva versión del formato y un consumidor falla, no hay forma de distinguir mensajes v1 de v2 en la cola para reprocesar selectivamente.
- Debugging por adivinanza: cuando un consumidor falla con un error de parsing, el equipo de soporte no sabe si el mensaje está en formato v1, v2 o corrupto. Sin un indicador de formato, la única forma de determinarlo es inspeccionar el contenido byte a byte.
Síntomas del Problema¶
- Errores de deserialización frecuentes después de que un equipo despliega una nueva versión de su productor.
- Consumidores que procesan mensajes pero producen datos incorrectos porque interpretaron campos con la semántica equivocada (ej. un campo que cambió de centavos a dólares).
- Despliegues que requieren coordinación estrecha entre múltiples equipos para cambiar el formato de un mensaje simultáneamente.
- Imposibilidad de hacer rollback de un despliegue de productor porque los consumidores ya procesaron mensajes en el nuevo formato.
- Logs de error ambiguos: "unexpected field", "missing required field", "type mismatch" sin indicación de qué versión del formato causó el error.
Impacto Operativo y Arquitectónico¶
Sin indicadores de formato:
- La evolución de schemas se convierte en una operación coordinada de alto riesgo que requiere ventanas de mantenimiento.
- Los equipos evitan cambiar el formato de los mensajes por miedo a romper consumidores, acumulando deuda técnica.
- La adopción de múltiples formatos de serialización (JSON para debugging, Avro para producción) es imposible sin un indicador que distinga cuál se usó.
- El debugging de problemas de integración requiere acceso al código del productor para determinar qué formato utilizó.
Riesgos Si No Se Implementa Correctamente¶
- Versiones fantasma: mensajes sin indicador de formato que coexisten en múltiples versiones sin que nadie pueda distinguirlas. Los consumidores procesan algunos correctamente y otros incorrectamente, generando datos corruptos de forma intermitente.
- Schema drift silencioso: el formato evoluciona gradualmente (un campo aquí, un tipo allá) sin versionado explícito. Eventualmente, la divergencia entre lo que el consumidor espera y lo que el productor envía es significativa, pero nadie sabe exactamente cuándo se produjo la divergencia.
- Falsos positivos de compatibilidad: un formato que parece compatible (tiene los mismos campos) pero tiene diferencias semánticas (un campo que cambió de UTC a local time). Sin versionado explícito, este cambio es invisible.
Ejemplos Reales¶
- SaaS B2B — Webhooks: Stripe envía webhooks con un campo
api_versionque indica qué versión del API generó el evento. Los consumidores pueden registrarse para recibir una versión específica y migrar a su propio ritmo. Sin este campo, un cambio en el formato del webhook de Stripe rompería a todos los consumidores simultáneamente. - Event-Driven Architecture: un sistema de e-commerce publica eventos
OrderPlaceden Kafka. La versión 1 tienetotalAmountcomo integer en centavos. La versión 2 tienetotalAmountcomo un objeto{value: 18742, currency: "USD"}. El headerschema-version: 2permite al consumidor usar el deserializador correcto. - IoT — Telemetría de Dispositivos: dispositivos IoT de diferentes generaciones de firmware envían telemetría con diferentes formatos. El campo
firmwareVersionen el mensaje permite al backend determinar qué formato esperar. - Healthcare — FHIR: los recursos FHIR incluyen
resourceTypeymeta.versionIdque identifican el tipo y la versión del recurso, permitiendo a los consumidores determinar el schema aplicable.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En todo sistema de mensajería donde el formato de los mensajes pueda evolucionar (es decir, siempre).
- Cuando múltiples productores publican en el mismo canal con formatos potencialmente diferentes.
- Cuando múltiples consumidores con diferentes versiones coexisten procesando la misma cola o topic.
- Cuando se requiere despliegue independiente de productores y consumidores (microservicios, equipos autónomos).
- Cuando se usan múltiples formatos de serialización en el mismo ecosistema (JSON en desarrollo, Avro en producción).
- En plataformas B2B y SaaS donde los consumidores externos no están bajo el control del productor.
Cuándo No Usarlo¶
- Nunca. Format Indicator debe incluirse en todo mensaje. El costo de incluir un header con el tipo y versión es negligible comparado con el costo de no tenerlo cuando el formato cambia. Incluso en un sistema donde "el formato nunca va a cambiar", incluir un indicador de formato es una inversión de seguridad barata.
Precondiciones¶
- Existe acuerdo sobre cómo representar el indicador de formato (nombre del header, formato del valor).
- Existe un mecanismo de versionado de schemas (semántico, incremental, por fecha).
- Los consumidores implementan lógica para leer el indicador de formato y actuar en consecuencia.
Restricciones¶
- El indicador de formato debe ser accesible sin parsear el body completo (preferiblemente en headers).
- El tamaño del indicador debe ser negligible comparado con el payload.
- El schema al que referencia el indicador debe estar disponible para el consumidor (Schema Registry, documentación, código).
Dependencias¶
- Schema Registry (opcional pero recomendado): almacenamiento centralizado de schemas versionados. Confluent Schema Registry, AWS Glue Schema Registry, Azure Schema Registry.
- Serialización con soporte de schema: Avro (embeds schema ID), Protobuf (field numbers implican version), JSON Schema.
- Convenciones de equipo: acuerdo sobre el formato del indicador y la política de compatibilidad.
Supuestos Arquitectónicos¶
- Los productores incluyen el indicador de formato en todo mensaje.
- Los consumidores verifican el indicador antes de deserializar.
- Existe un proceso de gobernanza para evolución de schemas (quién aprueba cambios, qué compatibilidad se exige).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Plataformas SaaS y B2B con webhooks versionados.
- Arquitecturas event-driven con Kafka y Schema Registry.
- Microservicios con contratos de mensajería versionados.
- Sistemas IoT con dispositivos de múltiples generaciones.
- APIs asíncronas (AsyncAPI) con múltiples versiones de eventos.
6. Fuerzas Arquitectónicas¶
Autonomía de Equipos vs. Coherencia de Formato¶
Format Indicator habilita la autonomía de equipos al permitir que cada equipo evolucione su formato de mensajes independientemente. Pero sin gobernanza, esta autonomía puede generar fragmentación: decenas de versiones activas sin política de deprecación, consumidores que soportan solo subconjuntos de versiones, y una matriz de compatibilidad imposible de gestionar.
Simplicidad vs. Capacidad de Evolución¶
Un mensaje sin indicador de formato es más simple de producir y consumir (no hay overhead de metadata). Pero esta simplicidad se paga cuando el formato necesita cambiar: sin indicador, la migración es un Big Bang coordinado. Con indicador, la migración puede ser gradual.
Tamaño del Indicador vs. Precisión¶
Un indicador simple (version: 2) es compacto pero poco informativo. Un indicador rico ({"schema": "https://registry.example.com/schemas/order-placed/v2.3.1", "contentType": "application/avro", "encoding": "binary"}) es preciso pero añade overhead. La elección depende de la complejidad del ecosistema.
Centralización vs. Descentralización de Schemas¶
Un Schema Registry centralizado proporciona gobierno, validación de compatibilidad y un punto único de verdad para schemas. Pero introduce una dependencia operacional: si el Schema Registry no está disponible, los productores no pueden serializar y los consumidores no pueden deserializar (en implementaciones que validan en runtime). Un enfoque descentralizado (schemas embebidos en código) elimina la dependencia pero pierde gobierno y validación.
Compatibilidad Hacia Atrás vs. Hacia Adelante¶
- Backward compatibility: consumidores nuevos pueden leer mensajes viejos. Requiere que los nuevos schemas puedan parsear datos escritos con schemas anteriores.
- Forward compatibility: consumidores viejos pueden leer mensajes nuevos. Requiere que los schemas anteriores puedan parsear datos escritos con schemas nuevos (típicamente ignorando campos desconocidos).
- Full compatibility: ambas direcciones. La más segura pero la más restrictiva en qué cambios de schema están permitidos.
El indicador de formato habilita estas estrategias al permitir que el consumidor identifique la versión y seleccione el deserializador correcto.
Validación en Escritura vs. Validación en Lectura¶
¿El productor valida que el mensaje cumple el schema antes de publicar (schema-on-write), o el consumidor valida al recibir (schema-on-read)? Schema-on-write garantiza que solo mensajes válidos entren al sistema pero añade latencia al productor. Schema-on-read es más flexible pero permite mensajes inválidos en la cola.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: construye el mensaje, serializa el payload según un schema específico e incluye el indicador de formato en headers o body.
- Schema Registry (recomendado): almacena schemas versionados, valida compatibilidad entre versiones y proporciona schemas a productores y consumidores.
- Broker / Canal: transporta el mensaje con su indicador de formato. Puede inspeccionar headers pero no modifica el indicador.
- Consumidor: lee el indicador de formato, obtiene el schema correspondiente (del registro local, del Schema Registry, del código), deserializa el payload y procesa los datos.
- Governance / CI-CD: procesos que validan compatibilidad de schemas antes del deployment (schema validation en pipeline de CI/CD).
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Serializar datos D\nsegún schema S versión V]
B --> C{Schema nueva?}
C -- Sí --> D[(Schema Registry\nregistrar S:V)]
C -- No --> E[Construir mensaje con headers\ncontent-type, schema-version, event-type]
D --> E
E --> F[(Canal de mensajería)]
F --> G[Consumidor recibe mensaje\nlee headers]
G --> H[content-type\nseleccionar deserializador]
G --> I[schema-version\nobtener schema del Registry]
G --> J[event-type\nseleccionar handler]
H --> K[Deserializar payload\ncon schema correspondiente]
I --> K
J --> L[Procesar datos con\nhandler seleccionado]
K --> L
L --> M([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Serializar con schema correcto, incluir indicador de formato preciso |
| Schema Registry | Almacenar schemas, validar compatibilidad, servir schemas on-demand |
| Canal | Transportar mensaje con headers intactos |
| Consumidor | Leer indicador, obtener schema, deserializar, manejar versiones no soportadas |
| Governance | Definir política de compatibilidad, validar schemas en CI/CD |
Interacciones¶
- Productor → Schema Registry: registro de nuevos schemas, obtención de schema ID.
- Productor → Canal: envío de mensaje con indicador de formato.
- Canal → Consumidor: entrega de mensaje con headers intactos.
- Consumidor → Schema Registry: obtención del schema por ID o versión para deserialización.
Contratos Implícitos¶
- Nombre y ubicación del indicador: qué header contiene el indicador y con qué formato (ej.
content-type: application/vnd.company.order-placed.v2+avro). - Formato del version number: semántico (1.2.3), incremental (1, 2, 3), por fecha (2026-04-07).
- Política de compatibilidad: qué tipo de cambios están permitidos entre versiones.
- Disponibilidad del schema: cómo y dónde el consumidor obtiene el schema referenciado por el indicador.
Decisiones de Diseño Clave¶
- Ubicación del indicador: header del mensaje (más accesible, inspectable por intermediarios) o envelope en el body (más portable, no depende de soporte de headers del broker).
- Tipo de indicador: version number simple (
v2), schema ID del registry (schema-id: 42), URL del schema (dataschema: https://registry.example.com/schemas/42), o content-type cualificado (application/vnd.company.event.v2+json). - Schema Registry vs. schemas locales: registry centralizado (gobierno, compatibilidad automatizada) vs. schemas embebidos en código (sin dependencia externa, más simple).
- Validación en productor vs. consumidor: schema-on-write (productor valida) vs. schema-on-read (consumidor valida) vs. ambos.
- Estrategia de compatibilidad: BACKWARD, FORWARD, FULL, NONE. Configurada típicamente en el Schema Registry.
8. Ejemplo Arquitectónico Detallado¶
Dominio: SaaS B2B — Webhook Events con Schema Version para Consumidores Multi-Tenant¶
Contexto del Negocio¶
Una plataforma SaaS de gestión de pedidos (OrderHub) sirve a 2,000 empresas (tenants) que integran sus sistemas con la plataforma mediante webhooks. Cuando un evento ocurre en OrderHub (pedido creado, pedido enviado, pago recibido, devolución procesada), la plataforma envía un webhook HTTP a la URL registrada por cada tenant. Los consumidores de estos webhooks son sistemas heterogéneos: ERPs (SAP, Oracle, Dynamics), plataformas de e-commerce (Shopify, WooCommerce), sistemas de contabilidad (QuickBooks, Xero), sistemas propietarios y scripts custom.
Necesidad de Integración¶
OrderHub evoluciona continuamente: nuevas funcionalidades generan nuevos campos en los eventos, requisitos regulatorios añaden datos obligatorios (impuestos digitales, códigos de trazabilidad), cambios de dominio reestructuran entidades. Sin embargo, los 2,000 consumidores no se actualizan simultáneamente. Algunos consumidores grandes (SAP integrations) solo actualizan su integración una vez al año. Otros (scripts custom) pueden no actualizarse nunca. OrderHub necesita evolucionar su formato de eventos sin romper a ningún consumidor existente, mientras permite que los consumidores nuevos aprovechen los datos más recientes.
Sistemas Involucrados¶
- OrderHub Platform: plataforma SaaS que genera eventos de negocio.
- Event Publisher Service: microservicio que construye los mensajes de webhook y los encola para envío.
- Schema Registry (Confluent Cloud): almacenamiento centralizado de schemas de eventos versionados.
- Webhook Delivery Service: microservicio que envía webhooks HTTP a los endpoints de los tenants, con retry y circuit breaker.
- Apache Kafka: broker interno que almacena eventos antes de la entrega por webhook.
- Tenant Webhook Endpoints: los endpoints HTTP de cada tenant que reciben los webhooks. Heterogéneos, no controlados por OrderHub.
- AsyncAPI Portal: documentación de eventos publicados con todas las versiones de schema disponibles.
Restricciones Técnicas¶
- Los consumidores externos no se actualizan simultáneamente y algunos nunca se actualizan.
- Cada tenant está registrado para recibir una versión específica del schema (ej. tenant A recibe v2, tenant B recibe v3).
- La plataforma debe soportar al menos las 3 últimas versiones del schema de cada evento (N, N-1, N-2).
- Los webhooks deben incluir suficiente información para que el consumidor identifique la versión sin conocimiento previo.
- El formato de serialización es JSON (universal para webhooks HTTP).
- Los schemas deben estar documentados y accesibles públicamente para los desarrolladores de los tenants.
Flujos de Datos¶
[OrderHub] → Evento de negocio (ej. OrderShipped)
→ [Event Publisher] → Serializa según schema del tenant
→ [Kafka: topic "webhook-events"] → Mensaje con Format Indicator
→ [Webhook Delivery Service] → Lee schema version
→ HTTP POST al endpoint del tenant con payload versionado
→ [Tenant System] → Lee Format Indicator, deserializa, procesa
Eventos o Mensajes¶
Cada webhook tiene la siguiente estructura (ejemplo de evento order.shipped v3):
{
"specversion": "1.0",
"type": "com.orderhub.order.shipped",
"source": "https://api.orderhub.com/tenants/acme-corp",
"id": "evt-2026-04-07-abc123",
"time": "2026-04-07T14:30:00.000Z",
"datacontenttype": "application/json",
"dataschema": "https://schemas.orderhub.com/events/order.shipped/v3",
"subject": "orders/ORD-2026-78901",
"data": {
"orderId": "ORD-2026-78901",
"status": "shipped",
"shipment": {
"carrier": "FedEx",
"trackingNumber": "7489204723849",
"estimatedDelivery": "2026-04-10",
"shippingMethod": "express"
},
"items": [
{
"sku": "WIDGET-001",
"quantity": 5,
"unitPrice": {"value": 1299, "currency": "USD"}
}
],
"totals": {
"subtotal": {"value": 6495, "currency": "USD"},
"tax": {"value": 520, "currency": "USD"},
"shipping": {"value": 1500, "currency": "USD"},
"total": {"value": 8515, "currency": "USD"}
}
}
}
Los Format Indicators en este mensaje son:
| Indicador | Ubicación | Valor | Propósito |
|---|---|---|---|
specversion | Envelope | "1.0" | Versión de la especificación CloudEvents |
type | Envelope | "com.orderhub.order.shipped" | Tipo de evento (qué pasó) |
datacontenttype | Envelope | "application/json" | Formato de serialización del data |
dataschema | Envelope | URL al schema v3 | Referencia al JSON Schema específico |
Decisiones Arquitectónicas¶
- Adopción de CloudEvents: OrderHub adopta la especificación CloudEvents (CNCF) como envelope estándar para todos los eventos. Esto proporciona un formato de metadata estandarizado que los consumidores pueden parsear con librerías CloudEvents disponibles en todos los lenguajes.
- Schema por URL: el
dataschemaapunta a una URL pública donde el JSON Schema está disponible. Esto permite que consumidores desconocidos obtengan el schema sin necesidad de acceso al Schema Registry interno. - Versión en la URL del schema:
https://schemas.orderhub.com/events/order.shipped/v3— la versión está en la URL, no en un header separado. Esto simplifica la lectura para consumidores humanos y sistemas. - Soporte de 3 versiones simultáneas: la plataforma mantiene 3 versiones activas de cada schema. Cada tenant está configurado para recibir una versión específica. Cuando se lanza v4, se depreca v1.
- Backward + Forward compatibility: los schemas se diseñan para que un consumidor v2 pueda leer un evento v3 (campos nuevos se ignoran) y un consumidor v3 pueda leer un evento v2 (campos nuevos tienen defaults). Confluent Schema Registry valida esta compatibilidad automáticamente.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Consumidor no reconoce la versión del schema | CloudEvents type + dataschema permiten identificar el evento. El consumidor puede alertar y rechazar gracefully. |
| Schema Registry no disponible durante publicación | Cache local de schemas en el Event Publisher; fallback a última versión cacheada. |
| Tenant no migra a tiempo cuando se depreca su versión | Notificación por email 90 días antes de deprecación; período de gracia de 30 días; alerta en dashboard del tenant. |
| Breaking change no detectado | Validación de compatibilidad en CI/CD pipeline: el merge se bloquea si el schema no es compatible. |
Consumidor parsea solo data sin leer metadata | Documentación enfatiza que los indicadores de formato deben leerse primero. SDK oficial incluye parsing de metadata. |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Definición del Schema Inicial (v1)¶
El equipo de OrderHub define el primer schema del evento order.shipped:
- Escribe el JSON Schema v1 en el repositorio de schemas:
schemas/events/order.shipped/v1.json. - Registra el schema en Confluent Schema Registry bajo el subject
order.shipped-value. - Publica el schema en el portal AsyncAPI público:
https://docs.orderhub.com/events/order.shipped/v1. - El schema v1 incluye:
orderId,status,trackingNumber,carrier. - Pipeline de CI/CD valida que el schema es parseable y genera código de ejemplo en 5 lenguajes.
Paso 2: Producción de Eventos con Format Indicator¶
Cuando un pedido se marca como enviado:
- El Event Publisher Service recibe el evento interno de dominio.
- Consulta la configuración del tenant ACME Corp:
schema_version: v1. - Serializa el evento según el schema v1 del tenant.
- Construye el envelope CloudEvents con los indicadores de formato:
specversion: "1.0"type: "com.orderhub.order.shipped"datacontenttype: "application/json"dataschema: "https://schemas.orderhub.com/events/order.shipped/v1"- Publica el mensaje en Kafka topic
webhook-eventscon el tenant ID como partition key.
Paso 3: Entrega del Webhook¶
El Webhook Delivery Service:
- Consume el mensaje de Kafka.
- Lee el tenant ID y obtiene la URL de webhook del tenant.
- Envía un HTTP POST al endpoint del tenant con:
- Body: el mensaje completo CloudEvents en JSON.
- Headers:
Content-Type: application/cloudevents+json; charset=utf-8. - Header:
Ce-Specversion: 1.0,Ce-Type: com.orderhub.order.shipped. - Espera respuesta 2xx en 10 segundos.
- Si falla, aplica retry con backoff exponencial (1s, 2s, 4s, 8s, 16s) hasta 5 intentos.
- Si falla después de 5 intentos, mueve al dead letter topic.
Paso 4: Evolución del Schema a v2¶
Seis meses después, se añade información de impuestos digitales (requisito regulatorio):
- El equipo de desarrollo crea
schemas/events/order.shipped/v2.json: - Nuevo campo:
totals.tax(objeto convalueycurrency). - Nuevo campo:
totals.digitalTaxId(string, opcional). - Todos los campos de v1 se mantienen con la misma semántica.
- Pipeline de CI/CD ejecuta compatibility check contra v1:
- ¿Es backward compatible? Sí (v2 puede leer datos v1 porque los campos nuevos son opcionales/tienen defaults).
- ¿Es forward compatible? Sí (v1 puede leer datos v2 porque los campos nuevos se ignoran en JSON).
- Resultado: FULL compatibility. El merge se aprueba.
- Se registra v2 en Schema Registry.
- Se publica v2 en el portal AsyncAPI.
- Se notifica a todos los tenants: "v2 disponible con datos de impuestos digitales. v1 seguirá soportada hasta 2027-01-01."
Paso 5: Coexistencia de Versiones¶
Durante el período de migración:
- Tenant ACME Corp (v1): el Event Publisher serializa como v1 y el
dataschemaapunta a/v1. ACME Corp recibe el formato que conoce, sin campos nuevos. - Tenant GlobalTrade Inc (v2): el Event Publisher serializa como v2 y el
dataschemaapunta a/v2. GlobalTrade recibe los campos de impuestos digitales. - Tenant NewStartup (v2): nuevo tenant que se registra directamente en v2.
- Kafka almacena ambas versiones. El Event Publisher genera la versión correcta para cada tenant.
Paso 6: Deprecación de v1¶
Cuando se lanza v3 (un año después):
- v1 entra en período de deprecación (90 días de aviso + 30 días de gracia).
- Se envían emails a tenants en v1: "Migre a v2 o v3 antes de 2027-04-01."
- El dashboard del tenant muestra un warning: "Está recibiendo eventos en formato v1 (deprecated)."
- Después del período de gracia, los tenants en v1 son migrados automáticamente a v2 (backward compatible, no rompe su integración).
- v1 se marca como "retired" en Schema Registry y AsyncAPI portal.
Manejo de Errores¶
- Consumidor no reconoce la versión: el consumidor lee
dataschemay no lo reconoce. Según best practices de CloudEvents, debe loguear el evento, almacenarlo para debugging y responder 202 (acepted) para evitar retries innecesarios del productor. - Schema URL no disponible: si
https://schemas.orderhub.com/...no está disponible, el consumidor no puede obtener el schema. Mitigation: los consumidores deben cachear schemas localmente y no depender del fetch en runtime para cada mensaje. - Formato inválido: si el payload no cumple el schema indicado, el consumidor descarta el mensaje y alerta. El Webhook Delivery Service puede recibir un HTTP 400 del consumidor y mover a dead letter.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
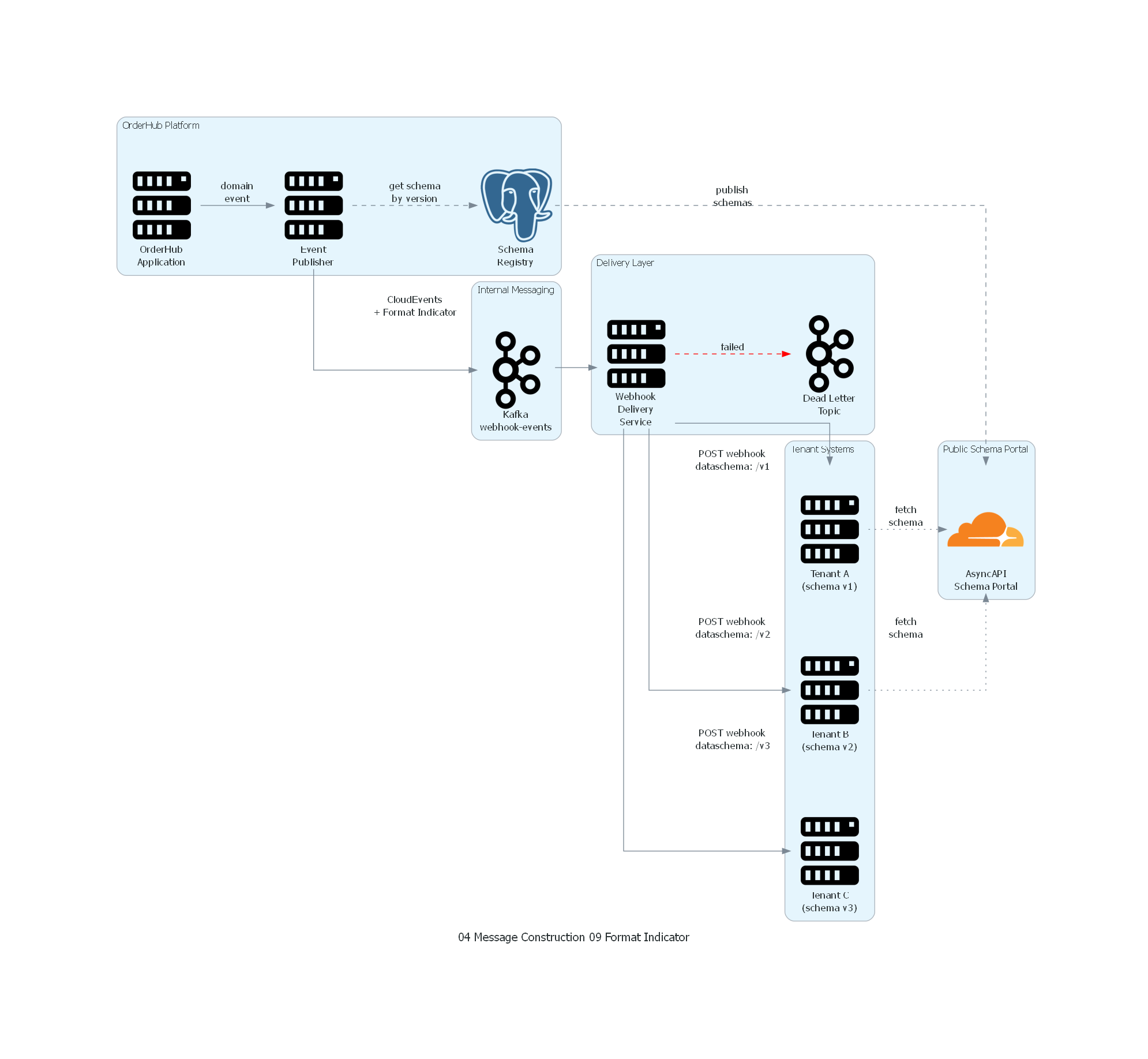
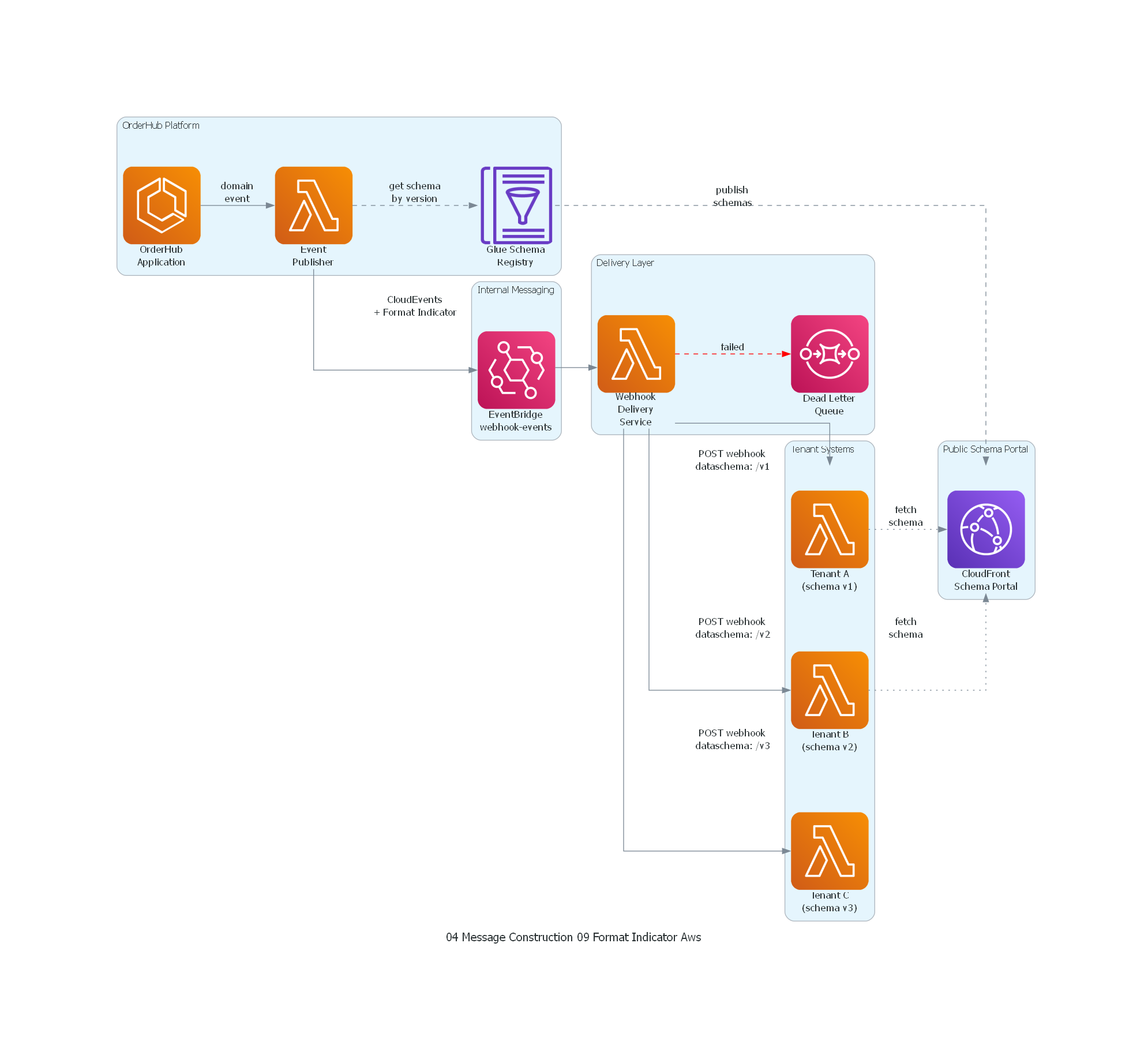
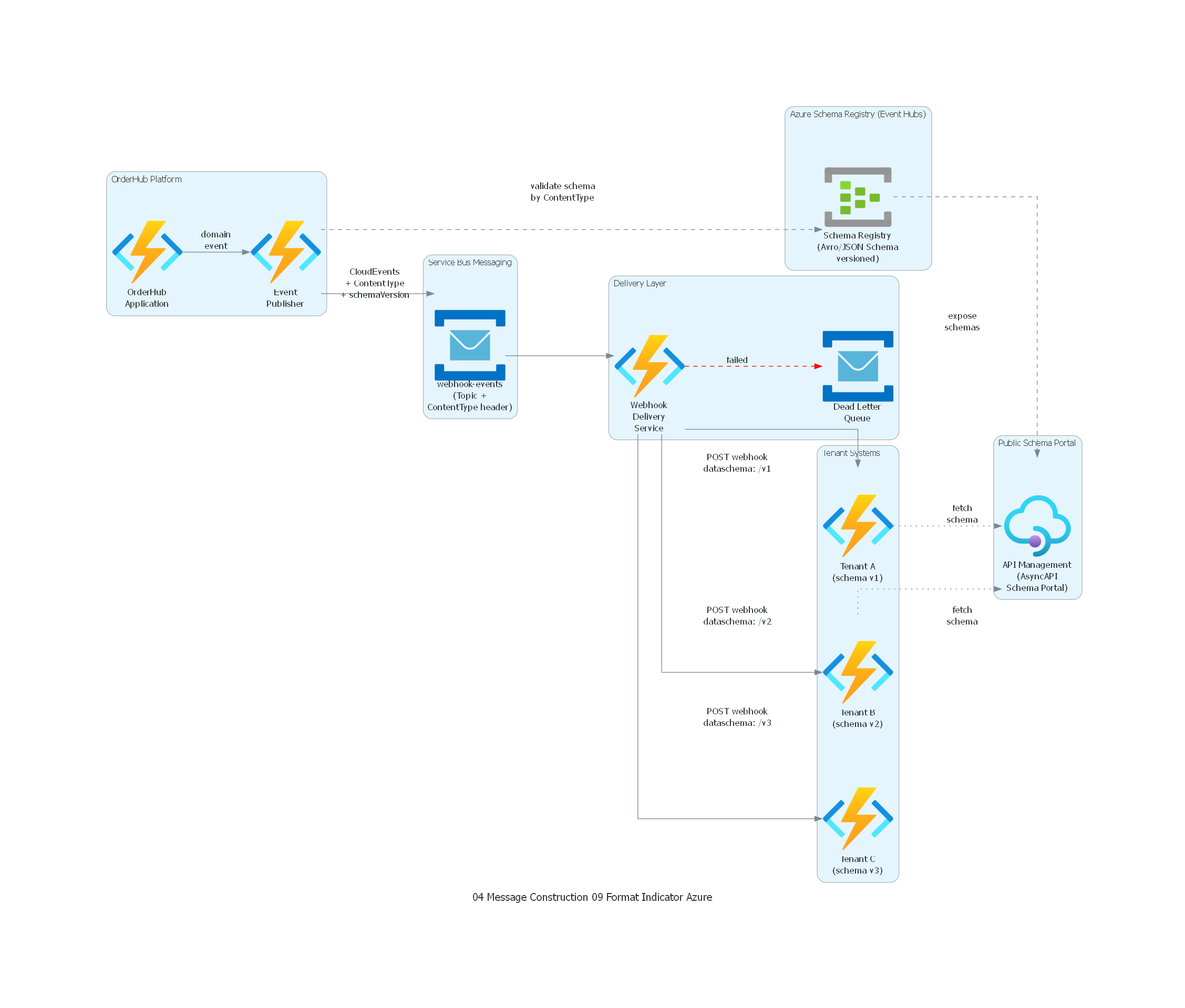
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.client import Users
from diagrams.saas.cdn import Cloudflare
from diagrams.generic.storage import Storage
with Diagram("Format Indicator - SaaS Webhook Events", show=False, direction="LR"):
with Cluster("OrderHub Platform"):
app = Server("OrderHub\nApplication")
publisher = Server("Event\nPublisher")
schema_reg = PostgreSQL("Schema\nRegistry")
app >> Edge(label="domain\nevent") >> publisher
publisher >> Edge(label="get schema\nby version", style="dashed") >> schema_reg
with Cluster("Internal Messaging"):
kafka = Kafka("Kafka\nwebhook-events")
publisher >> Edge(label="CloudEvents\n+ Format Indicator") >> kafka
with Cluster("Delivery Layer"):
delivery = Server("Webhook\nDelivery\nService")
dlq = Kafka("Dead Letter\nTopic")
kafka >> delivery
with Cluster("Public Schema Portal"):
portal = Cloudflare("AsyncAPI\nSchema Portal")
schema_reg >> Edge(label="publish\nschemas", style="dashed") >> portal
with Cluster("Tenant Systems"):
tenant_v1 = Server("Tenant A\n(schema v1)")
tenant_v2 = Server("Tenant B\n(schema v2)")
tenant_v3 = Server("Tenant C\n(schema v3)")
delivery >> Edge(label="POST webhook\ndataschema: /v1") >> tenant_v1
delivery >> Edge(label="POST webhook\ndataschema: /v2") >> tenant_v2
delivery >> Edge(label="POST webhook\ndataschema: /v3") >> tenant_v3
delivery >> Edge(label="failed", style="dashed", color="red") >> dlq
tenant_v1 >> Edge(label="fetch\nschema", style="dotted") >> portal
tenant_v2 >> Edge(label="fetch\nschema", style="dotted") >> portal
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.integration import Eventbridge, SQS
from diagrams.aws.analytics import GlueDataCatalog
from diagrams.aws.network import CloudFront
with Diagram("Format Indicator - SaaS Webhook Events (AWS)", show=False, direction="LR"):
with Cluster("OrderHub Platform"):
app = ECS("OrderHub\nApplication")
publisher = Lambda("Event\nPublisher")
schema_reg = GlueDataCatalog("Glue Schema\nRegistry")
app >> Edge(label="domain\nevent") >> publisher
publisher >> Edge(label="get schema\nby version", style="dashed") >> schema_reg
with Cluster("Internal Messaging"):
event_bus = Eventbridge("EventBridge\nwebhook-events")
publisher >> Edge(label="CloudEvents\n+ Format Indicator") >> event_bus
with Cluster("Delivery Layer"):
delivery = Lambda("Webhook\nDelivery\nService")
dlq = SQS("Dead Letter\nQueue")
event_bus >> delivery
with Cluster("Public Schema Portal"):
portal = CloudFront("CloudFront\nSchema Portal")
schema_reg >> Edge(label="publish\nschemas", style="dashed") >> portal
with Cluster("Tenant Systems"):
tenant_v1 = Lambda("Tenant A\n(schema v1)")
tenant_v2 = Lambda("Tenant B\n(schema v2)")
tenant_v3 = Lambda("Tenant C\n(schema v3)")
delivery >> Edge(label="POST webhook\ndataschema: /v1") >> tenant_v1
delivery >> Edge(label="POST webhook\ndataschema: /v2") >> tenant_v2
delivery >> Edge(label="POST webhook\ndataschema: /v3") >> tenant_v3
delivery >> Edge(label="failed", style="dashed", color="red") >> dlq
tenant_v1 >> Edge(label="fetch\nschema", style="dotted") >> portal
tenant_v2 >> Edge(label="fetch\nschema", style="dotted") >> portal
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import Users
from diagrams.azure.compute import FunctionApps
from diagrams.azure.analytics import EventHubs
from diagrams.azure.integration import ServiceBus, APIManagement
with Diagram("Format Indicator - SaaS Webhook Events (Azure)", show=False, direction="LR"):
with Cluster("OrderHub Platform"):
app = FunctionApps("OrderHub\nApplication")
publisher = FunctionApps("Event\nPublisher")
app >> Edge(label="domain\nevent") >> publisher
with Cluster("Azure Schema Registry (Event Hubs)"):
schema_reg = EventHubs("Schema Registry\n(Avro/JSON Schema\nversioned)")
publisher >> Edge(label="validate schema\nby ContentType", style="dashed") >> schema_reg
with Cluster("Service Bus Messaging"):
topic = ServiceBus("webhook-events\n(Topic +\nContentType header)")
publisher >> Edge(label="CloudEvents\n+ ContentType\n+ schemaVersion") >> topic
with Cluster("Delivery Layer"):
delivery = FunctionApps("Webhook\nDelivery\nService")
dlq = ServiceBus("Dead Letter\nQueue")
topic >> delivery
with Cluster("Public Schema Portal"):
portal = APIManagement("API Management\n(AsyncAPI\nSchema Portal)")
schema_reg >> Edge(label="expose\nschemas", style="dashed") >> portal
with Cluster("Tenant Systems"):
tenant_v1 = FunctionApps("Tenant A\n(schema v1)")
tenant_v2 = FunctionApps("Tenant B\n(schema v2)")
tenant_v3 = FunctionApps("Tenant C\n(schema v3)")
delivery >> Edge(label="POST webhook\ndataschema: /v1") >> tenant_v1
delivery >> Edge(label="POST webhook\ndataschema: /v2") >> tenant_v2
delivery >> Edge(label="POST webhook\ndataschema: /v3") >> tenant_v3
delivery >> Edge(label="failed", style="dashed", color="red") >> dlq
tenant_v1 >> Edge(label="fetch\nschema", style="dotted") >> portal
tenant_v2 >> Edge(label="fetch\nschema", style="dotted") >> portal
Explicación del Diagrama¶
El diagrama representa el flujo completo de Format Indicator en un sistema de webhooks SaaS:
- OrderHub Platform (izquierda): la aplicación genera eventos de dominio. El Event Publisher consulta el Schema Registry para obtener el schema correcto según la versión configurada para cada tenant.
- Internal Messaging: Kafka almacena los eventos como mensajes CloudEvents con Format Indicator incluido.
- Delivery Layer: el Webhook Delivery Service consume los mensajes y los envía como HTTP POST a cada tenant. Los mensajes fallidos van a Dead Letter Topic.
- Public Schema Portal: los schemas versionados están publicados en un portal AsyncAPI público, accesible para todos los tenants.
- Tenant Systems (derecha): cada tenant recibe webhooks en su versión configurada. Los indicadores de formato (
type,dataschema,datacontenttype) permiten al tenant deserializar correctamente. Los tenants pueden consultar el portal de schemas para obtener la definición formal del schema.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor con Format Indicator | Event Publisher (incluye CloudEvents headers) |
| Schema Registry | Schema Registry (PostgreSQL) + AsyncAPI Portal |
| Canal de mensajería | Kafka topic: webhook-events |
| Indicador de formato | CloudEvents type, dataschema, datacontenttype |
| Consumidores multi-versión | Tenant A (v1), Tenant B (v2), Tenant C (v3) |
| Schema resolution | Tenants consultando AsyncAPI Schema Portal |
11. Beneficios¶
Impacto Técnico¶
- Despliegue independiente: productores y consumidores pueden desplegar nuevas versiones de forma independiente. El productor puede emitir un nuevo formato y los consumidores migrar a su propio ritmo, porque el indicador de formato permite la coexistencia de versiones.
- Deserialización correcta: el consumidor siempre sabe qué deserializador usar, eliminando errores de parsing por formato inesperado.
- Soporte multi-formato: un ecosistema puede usar JSON, Avro y Protobuf simultáneamente si cada mensaje incluye su content type.
- Schema evolution controlada: combinado con Schema Registry y compatibility checks, permite evolucionar schemas de forma segura y automatizada.
Impacto Organizacional¶
- Autonomía de equipos: cada equipo puede evolucionar el formato de sus eventos sin coordinar despliegues con todos los consumidores.
- Onboarding de consumidores: nuevos consumidores pueden leer el indicador de formato, obtener el schema del registry o portal, e implementar su integración sin conocimiento implícito.
- Documentación viviente: el indicador de formato combinado con Schema Registry/AsyncAPI portal proporciona documentación siempre actualizada de los contratos de mensajería.
Impacto Operacional¶
- Debugging acelerado: cuando un consumidor falla, el indicador de formato en el mensaje permite identificar inmediatamente qué versión del schema causó el problema.
- Migración gradual: la migración de formato se realiza tenant por tenant o consumidor por consumidor, reduciendo el riesgo de Big Bang.
- Rollback seguro: si un nuevo formato causa problemas, se puede revertir el productor a la versión anterior. Los consumidores identifican la versión y procesan correctamente.
Beneficios de Mantenibilidad y Evolución¶
- Versionado explícito: el historial de versiones es visible en el Schema Registry, lo cual facilita auditoría, rollback y análisis de impacto.
- Compatibility validation en CI/CD: los cambios de schema se validan automáticamente contra la política de compatibilidad, previniendo breaking changes antes del despliegue.
- Deprecación gestionada: las versiones antiguas pueden deprecarse explícitamente con períodos de gracia, en lugar de eliminarse abruptamente.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Schema Registry como dependencia operacional: un Schema Registry centralizado es un single point of failure. Si no está disponible, productores y consumidores pueden no poder serializar/deserializar. Requiere alta disponibilidad, caching y fallback strategies.
- Múltiples versiones activas: soportar N versiones simultáneas incrementa la complejidad del código del productor (que debe serializar en la versión correcta para cada consumidor) y del consumidor (que debe manejar múltiples versiones).
- Overhead de metadata: cada mensaje lleva headers adicionales (type, version, schema URL). El overhead es típicamente negligible (<1% del tamaño total del mensaje) pero existe.
Riesgos de Mal Uso¶
- Versionado sin política de compatibilidad: incluir un version number sin validar compatibilidad entre versiones no previene breaking changes. El indicador de formato es necesario pero no suficiente — debe acompañarse de compatibility checks.
- Too many versions: no deprecar versiones antiguas lleva a una acumulación de versiones activas que incrementa la complejidad de soporte. Se recomienda mantener un máximo de 3 versiones activas (N, N-1, N-2).
- Indicador mentiroso: el productor establece
schema-version: 3pero serializa según schema v2 (por un bug). El consumidor confía en el indicador, usa el deserializador v3 y falla o malinterpreta los datos. Validación en el productor (schema-on-write) previene esto.
Sobreingeniería¶
- Schema Registry para un sistema de 2 servicios: para ecosistemas muy pequeños (2-3 servicios con un equipo), un Schema Registry puede ser overhead excesivo. Un simple header
version: 1con schemas en código es suficiente. - Content negotiation compleja: implementar negociación de formato al estilo HTTP (Accept headers, quality factors) en un sistema de mensajería asíncrona donde el consumidor no puede negociar con el productor. En mensajería, el productor decide el formato; el consumidor se adapta.
Costos de Operación¶
- Mantenimiento del Schema Registry: alta disponibilidad, backups, monitoreo, upgrades.
- Mantenimiento del portal de schemas: documentación actualizada, ejemplos de código, guías de migración.
- Soporte de versiones antiguas: mantener código y tests para versiones deprecated consume recursos de engineering.
Anti-Patterns Relacionados¶
- Magic Format: el consumidor infiere el formato basándose en heurísticas (ej. "si el primer byte es '{', es JSON; si es '<', es XML"). Frágil, error-prone, no escalable.
- Version in Body Only: el indicador de formato está embebido dentro del payload serializado, requiriendo que el consumidor parsee parcialmente el body para descubrir el formato con el cual debería parsear el body. Circular y frágil.
- Semantic Versioning Overkill: usar semantic versioning completo (1.2.3) para schemas cuando solo la versión major indica incompatibilidad. Añade complejidad sin valor si los cambios menores y patches no afectan la deserialización.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Canonical Data Model: Format Indicator indica la versión de un schema; Canonical Data Model define un schema único al que todos los sistemas se transforman. Combinados, el indicador permite transición gradual hacia el modelo canónico: mensajes con formato legacy y mensajes con formato canónico coexisten y se distinguen por su indicador.
- Message Translator: cuando un consumidor recibe un mensaje en una versión que no soporta, un Message Translator puede transformar el mensaje de la versión recibida a la versión esperada. El Format Indicator proporciona la información necesaria para seleccionar la transformación correcta.
- Content-Based Router: puede usar el indicador de formato para enrutar mensajes a diferentes consumidores según su versión. Mensajes v1 van a un consumer legacy; mensajes v2 van al consumer moderno.
Patrones que Suelen Aparecer Antes o Después¶
- Message (patrón base): Format Indicator es un refinamiento del concepto de headers del mensaje. Los headers de formato son un subset de los headers del Message.
- Envelope Wrapper: el envelope CloudEvents es una implementación de Envelope Wrapper que incluye Format Indicators como parte del wrapper estándar.
- Wire Tap: puede capturar mensajes con sus indicadores de formato para auditoría y análisis de distribución de versiones.
Combinaciones Comunes¶
- Format Indicator + Schema Registry + Compatibility Validation: la combinación más poderosa y recomendada. El indicador referencia un schema en el registry; el registry valida compatibilidad entre versiones; CI/CD bloquea breaking changes.
- Format Indicator + Dead Letter Channel: mensajes con formatos no reconocidos se envían a DLQ para inspección, en lugar de descartarse silenciosamente.
- Format Indicator + Message Expiration: el indicador de formato incluye la versión; la expiración asegura que mensajes en versiones muy antiguas no persistan indefinidamente.
Diferencias con Patrones Similares¶
- vs. Datatype Channel: Datatype Channel usa un canal separado por tipo de dato. Format Indicator usa un solo canal con indicador en el mensaje. Datatype Channel es más simple pero menos flexible; Format Indicator permite múltiples tipos y versiones en un mismo canal.
- vs. Canonical Data Model: Canonical Data Model busca un formato único; Format Indicator acepta múltiples formatos con versionado explícito. Son complementarios, no alternativos.
Encaje en un Flujo Mayor de Integración¶
Format Indicator es un patrón fundacional que afecta toda la cadena de integración. Cada mensaje en el sistema lleva un indicador que permite a routers, translators, wire taps, enrichers y consumers operar correctamente. Es, junto con Message ID y Correlation ID, uno de los headers esenciales que todo mensaje debería tener.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Format Indicator es uno de los patrones de mayor relevancia en la arquitectura moderna. La evolución de schemas es uno de los problemas más importantes y más frecuentes en arquitecturas de microservicios y event-driven, y el indicador de formato es el mecanismo fundamental que lo habilita.
A favor de la vigencia:
- Schema Registry es estándar de facto: Confluent Schema Registry, AWS Glue Schema Registry, Azure Schema Registry y Apicurio Registry son componentes estándar en implementaciones enterprise de Kafka y event-driven architectures. Todos operan sobre el principio de Format Indicator (schema ID embebido en el mensaje).
- CloudEvents: la especificación CloudEvents (CNCF, adoptada por Azure Event Grid, Google Eventarc, Knative) define explícitamente
type,datacontenttypeydataschemacomo atributos obligatorios o recomendados. CloudEvents es, en esencia, una estandarización del patrón Format Indicator. - AsyncAPI: la especificación AsyncAPI para documentación de APIs asíncronas incluye schema versioning como concepto central. Cada message definition tiene un
schemaFormaty un schema reference. - Protobuf y Avro: ambos formatos de serialización implementan Format Indicator de forma nativa. Avro embebe el schema ID en los primeros bytes del payload (Confluent wire format: magic byte + 4-byte schema ID). Protobuf usa field numbers que permiten forward y backward compatibility.
- Webhook versioning: las principales plataformas SaaS (Stripe, GitHub, Shopify, Twilio) implementan versionado de webhooks con indicadores de formato en el payload.
No hay argumento significativo en contra: Format Indicator no tiene alternativa viable. Todo mensaje en un sistema distribuido necesita alguna forma de indicar su formato. La única decisión es cómo implementarlo (header vs. body, simple version vs. schema reference, etc.), no si implementarlo.
Contexto Moderno Donde Se Utiliza¶
- Toda implementación de Kafka con Schema Registry.
- Todo sistema de webhooks B2B/SaaS.
- Toda API asíncrona documentada con AsyncAPI.
- Todo sistema event-driven con CloudEvents.
- Toda implementación que usa Avro o Protobuf.
Cómo Se Implementa Hoy¶
- Confluent Schema Registry + Avro: el serializer de Confluent embebe automáticamente el schema ID (4 bytes) en cada record de Kafka. El deserializador lee el schema ID, obtiene el schema del registry y deserializa. El Format Indicator es transparente para el desarrollador.
- CloudEvents: el productor incluye
type,datacontenttypeydataschemaen el envelope. Las librerías CloudEvents (disponibles en Java, Python, Go, C#, JavaScript) parsean los indicadores automáticamente. - AsyncAPI: la documentación define explícitamente el schema de cada versión del mensaje, vinculado al canal y al tipo de operación.
- Protobuf: los descriptors y field numbers actúan como indicadores de formato implícitos. Proto files versionados en el repositorio definen la evolución.
- JSON Schema + custom header: el productor incluye
schema-version: 3en los headers del mensaje y publica el JSON Schema versionado en un repositorio.
Qué Parte Sigue Siendo Esencial¶
- El principio de auto-descripción del mensaje es universal y permanente. Nunca será obsoleto que un mensaje indique su propio formato.
- Schema versioning es esencial en toda arquitectura donde los contratos evolucionan (es decir, en toda arquitectura del mundo real).
- Compatibility validation en CI/CD es una best practice que previene breaking changes de forma automatizada.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka + Confluent Schema Registry¶
La implementación más madura y ampliamente adoptada:
- Confluent wire format: cada record Avro/Protobuf/JSON Schema en Kafka comienza con un magic byte (0x0) seguido de 4 bytes con el schema ID del registry. Esto es un Format Indicator embebido directamente en el payload.
- Schema Registry REST API:
GET /schemas/ids/{id}retorna el schema correspondiente a un ID. Los consumers cachean schemas localmente. - Compatibility modes: BACKWARD, FORWARD, FULL, NONE. Configurados por subject en el registry. Un intento de registrar un schema incompatible falla.
- Subject naming strategies:
TopicNameStrategy,RecordNameStrategy,TopicRecordNameStrategydeterminan cómo se asignan schemas a subjects. - Serializers/Deserializers:
KafkaAvroSerializer,KafkaProtobufSerializer,KafkaJsonSchemaSerializerembeben automáticamente el schema ID. Los deserializadores correspondientes lo leen y obtienen el schema.
Azure Schema Registry + Event Hubs¶
- Azure Schema Registry: almacena schemas Avro en Azure Event Hubs namespace.
- Avro serialization: los serializers de Azure embeben el schema ID en el payload, similar al formato de Confluent.
- Event Grid + CloudEvents: Azure Event Grid requiere CloudEvents format, que incluye
typeydatacontenttypecomo indicadores de formato nativos.
AWS Glue Schema Registry¶
- Schemas en AWS Glue: almacena schemas Avro, JSON Schema y Protobuf.
- Integración con Kafka/MSK: serializers de AWS embeben el schema version ID en los records.
- Compatibility modes: BACKWARD, FORWARD, FULL, NONE, BACKWARD_ALL, FORWARD_ALL, FULL_ALL.
- Lambda integration: schema validation en Lambda consumers.
CloudEvents (CNCF)¶
- Especificación agnóstica de transporte: define atributos de formato como parte del envelope, transportable sobre HTTP, Kafka, AMQP, MQTT, NATS.
- Atributos de formato:
specversion: versión de CloudEvents spec.type: tipo de evento (reverse DNS:com.company.domain.event).datacontenttype: MIME type deldata.dataschema: URI del schema deldata.- SDKs: disponibles en Java, Python, Go, C#, JavaScript, Ruby.
AsyncAPI¶
- Especificación para APIs asíncronas: define channels, messages, schemas y bindings.
- Schema versioning: cada mensaje tiene un
schemaFormat(Avro, JSON Schema, Protobuf) y un schema reference. - Code generation: herramientas como AsyncAPI Generator crean código de serialización/deserialización a partir de la spec.
- Studio: editor visual para diseñar y documentar APIs asíncronas con schemas versionados.
Protobuf¶
- Field numbers como indicador implícito: cada campo en un proto file tiene un número único que no cambia entre versiones. Campos nuevos tienen números nuevos. Campos eliminados se reservan. Esto permite forward y backward compatibility sin un indicador explícito de versión en el payload.
oneofyoptional: mecanismos de Protobuf para campos que pueden o no estar presentes, habilitando evolución gradual.- Descriptors: los proto files compilados generan descriptors que actúan como schemas registrables.
MuleSoft / Apache Camel¶
- MuleSoft: DataWeave permite inspeccionar headers de mensaje y seleccionar transformaciones basadas en el indicador de formato. API Manager soporta versionado de APIs.
- Apache Camel: content-based routing basado en headers de formato (
choice().when(header("schema-version").isEqualTo("2")).to(...)). Camel también integra con Schema Registry a través de componentes Avro y Protobuf.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: distribución de versiones de schema en mensajes procesados (qué porcentaje es v1, v2, v3), errores de deserialización por version mismatch, latencia de schema resolution (tiempo para obtener schema del registry).
- Health checks: Schema Registry disponible, schemas referenciados por mensajes en tránsito están presentes en el registry, no hay schemas huérfanos (referenciados pero no registrados).
- Alertas: mensaje con schema version no registrada en el registry, tasa de errores de deserialización superior al umbral, uso de schema deprecated.
Tracing¶
- El indicador de formato (
type,schema-version) debe incluirse en los spans de tracing (OpenTelemetry) como atributos. Esto permite filtrar traces por tipo de evento y versión de schema. - Los errores de deserialización deben registrar el schema version del mensaje que causó el error.
Monitoreo¶
- Dashboard de versiones: para cada tipo de evento, qué porcentaje de mensajes se produce y consume en cada versión. Útil para rastrear progreso de migración.
- Dashboard de compatibilidad: estado de compatibility checks en Schema Registry. Alertar si se detecta un schema no compatible.
- Tenant version tracking: en escenarios B2B/SaaS, qué tenants están en qué versión y cuáles están en versiones deprecated.
Versionado¶
- Política de versionado: definir qué cambios incrementan qué parte de la versión. Típicamente: cambios backward-compatible incrementan minor/patch; cambios breaking incrementan major.
- Política de deprecación: cuánto tiempo se mantiene una versión deprecated (típicamente 6-12 meses) antes de retirarla.
- Política de soporte: cuántas versiones simultáneas se soportan (típicamente N, N-1, N-2).
Seguridad¶
- Schema Registry access control: solo productores autorizados pueden registrar nuevos schemas. Consumidores tienen acceso de lectura.
- Schema tampering: si un atacante modifica un schema en el registry, los consumidores podrían deserializar incorrectamente. Proteger con RBAC y auditoría de cambios.
- Data classification in schemas: los schemas pueden documentar qué campos contienen PII/PHI, habilitando data governance automatizada.
Manejo de Errores¶
- Schema version no reconocida: el consumidor recibe un mensaje con un schema version que no soporta. Opciones: enviar a DLQ, alertar, almacenar para procesamiento posterior cuando se actualice.
- Schema resolution failure: el consumidor no puede obtener el schema del registry (registry caído). Cache local mitiga esto para schemas ya conocidos. Para schemas nuevos, el mensaje va a DLQ.
- Validation failure: el mensaje no cumple el schema indicado. El consumidor alerta, envía a DLQ y registra el error con el schema version.
Retries¶
- Los errores de schema resolution son retriable (el registry puede estar temporalmente indisponible).
- Los errores de validation no son retriable (el mensaje está malformado; reintentarlo producirá el mismo error).
Dead-Lettering¶
- Mensajes con formato no reconocido, schema version no soportada o validation failure se envían a DLQ.
- La DLQ debe preservar todos los headers originales, incluyendo el indicador de formato, para diagnóstico.
Idempotencia¶
- Format Indicator no afecta la idempotencia directamente. Sin embargo, el cambio de schema version puede cambiar la semántica de un campo (ej.
amountde centavos a unidad completa), lo cual afecta la idempotencia si el consumer no maneja versiones correctamente.
Auditoría¶
- Schema change audit: quién cambió qué schema, cuándo, por qué. El Schema Registry debe mantener historial de versiones con autor y timestamp.
- Compatibility check audit: qué compatibility checks se ejecutaron, cuáles aprobaron, cuáles rechazaron.
- Message format distribution audit: qué porcentaje de mensajes se procesó en cada versión durante un período.
Performance¶
- Schema caching: la resolución de schema desde el registry debe cachearse agresivamente. Un consumer que resuelve el schema en cada mensaje incrementa latencia significativamente. Cache con invalidación por nueva versión es el estándar.
- Overhead de Format Indicator: negligible. Un header de 50 bytes en un mensaje de 1 KB es 5% de overhead. En mensajes más grandes, el overhead es insignificante.
- Serialization efficiency: Avro y Protobuf son más eficientes que JSON en serialización y tamaño, pero requieren Schema Registry. JSON es menos eficiente pero no requiere registry. La elección depende del volumen y la latencia requerida.
Escalabilidad¶
- Schema Registry: es un componente stateful que debe escalar. Confluent Schema Registry escala con read replicas y caching.
- Schema evolution at scale: en ecosistemas con cientos de tipos de eventos y decenas de versiones, la gestión de schemas se convierte en un desafío organizacional tanto como técnico. Governance automation (CI/CD checks, automatic deprecation) es esencial.
17. Errores Comunes¶
No Incluir Indicador de Formato Porque "El Formato No Va a Cambiar"¶
El error más frecuente y más costoso a largo plazo. Todo formato cambia eventualmente. Añadir un indicador de formato después de que ya existen millones de mensajes en producción sin indicador es extremadamente difícil porque requiere manejar mensajes "legacy sin indicador" como un caso especial indefinidamente. Incluir un indicador desde el primer mensaje (aunque sea version: 1) es una inversión trivial con retorno enorme.
Poner el Indicador de Formato Solo en el Body¶
Si el indicador de formato está embebido dentro del payload serializado, el consumidor necesita parsear (al menos parcialmente) el payload para descubrir cómo parsearlo. Esto es circular y frágil. El indicador debe estar en headers (accesibles sin parsear el body) o en un prefix de bytes fijos (Avro wire format).
No Validar Compatibilidad en CI/CD¶
Incluir un version number sin validar que la nueva versión es compatible con la anterior es como tener un semáforo que siempre está en verde. El valor del versionado viene de la validación automática de compatibilidad. Sin ella, los breaking changes pasan a producción y se descubren cuando los consumidores fallan.
No Deprecar Versiones Antiguas¶
Mantener soporte para todas las versiones que se hayan producido desde el inicio del sistema. Con el tiempo, el código acumula handlers para v1, v2, v3, ..., v15, cada uno con su lógica de deserialización, sus tests y sus edge cases. La política de deprecación (máximo N versiones activas) es esencial para contener la complejidad.
Confundir Content Type con Schema Version¶
content-type: application/json indica el formato de serialización (JSON), no la versión del schema de negocio. Un mensaje JSON puede ser schema v1 o v12. Son indicadores complementarios, no sustitutos. El content type indica cómo deserializar los bytes; el schema version indica cómo interpretar los datos deserializados.
Schema Registry como Single Point of Failure sin Mitigación¶
Implementar Schema Registry sin caching local, sin replica de lectura y sin fallback strategy. Cuando el registry falla, toda la producción y consumo de mensajes se detiene. Cache local con invalidación es obligatorio; modo degradado (usar último schema conocido) es recomendado.
Indicador de Formato Inconsistente entre Equipos¶
Cada equipo usa su propia convención: un equipo usa version: 2 en headers, otro usa schema_version: "v2.1" en el body, otro usa content-type: application/vnd.company.event.v2+json. Sin una convención organizacional, los consumidores deben manejar múltiples formatos de indicador, lo cual anula parcialmente el beneficio del patrón. Estandarizar la convención (ej. CloudEvents) a nivel organizacional es esencial.
18. Conclusión Técnica¶
Format Indicator es, junto con Message ID y Correlation ID, uno de los headers fundamentales que todo mensaje en un sistema de mensajería debe incluir. Su propósito es simple — indicar al consumidor cómo interpretar el contenido del mensaje — pero sus implicaciones son profundas: habilita la evolución independiente de productores y consumidores, previene errores de deserialización, facilita debugging y permite migración gradual de formatos.
Para un arquitecto moderno, Format Indicator no es una decisión de diseño — es una práctica obligatoria:
- Cuándo aporta valor máximo: en ecosistemas con múltiples productores y consumidores independientes (microservicios), en plataformas B2B/SaaS con consumidores externos no controlados, en arquitecturas event-driven donde los eventos representan contratos de larga duración que evolucionan.
- Cuándo es crítico: en cualquier sistema donde el formato del mensaje haya cambiado, esté cambiando o vaya a cambiar (es decir, en todo sistema).
- Cuándo la complejidad se justifica: la inversión mínima (un header con type y version) se justifica siempre. La inversión mayor (Schema Registry, compatibility validation, AsyncAPI portal) se justifica en ecosistemas con más de 5-10 tipos de eventos o más de 3-5 consumidores independientes.
Recomendación para arquitectos: desde el día uno, incluya al menos tres indicadores en todo mensaje: type (qué tipo de dato/evento es), content-type (cómo está serializado) y schema-version (qué versión del schema se usó). Adopte una convención organizacional para estos indicadores (CloudEvents es la recomendación por su estandarización CNCF). Implemente Schema Registry cuando el ecosistema crezca más allá de un puñado de servicios. Configure compatibility validation en CI/CD para prevenir breaking changes. Defina una política de deprecación de versiones (máximo 3 activas) y comuníquela a todos los equipos. Y recuerde: el costo de incluir un indicador de formato es trivial; el costo de no tenerlo cuando el formato cambia es enorme.