Content-Based Router¶
1. Nombre del Patrón¶
- Nombre oficial: Content-Based Router
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Enrutador Basado en Contenido
2. Resumen Ejecutivo¶
Content-Based Router es el patrón que examina el contenido de un mensaje entrante — ya sea un campo del header, un atributo del body o una combinación de ambos — y lo dirige al canal de salida apropiado según reglas predefinidas. Es la implementación en mensajería del concepto de branching condicional: un if/else o switch/case aplicado al flujo de mensajes.
El problema que resuelve es directo pero de impacto arquitectónico profundo: cuando múltiples consumidores especializados procesan diferentes tipos de mensajes, ¿cómo se evita que cada consumidor reciba todos los mensajes y tenga que descartar los que no le corresponden? Content-Based Router centraliza la lógica de decisión en un componente dedicado que inspecciona cada mensaje y lo envía al canal correcto, eliminando la necesidad de que cada consumidor filtre por sí mismo.
Este patrón aparece en prácticamente toda arquitectura de integración que maneja múltiples tipos de mensajes o múltiples consumidores especializados. Es el patrón de routing más básico y más utilizado, equivalente a un punto de decisión en un diagrama de flujo. Su implementación moderna se encuentra en reglas de Amazon EventBridge, branching en Kafka Streams, filtros de suscripción en Azure Service Bus y routing rules en API Gateways.
3. Definición Detallada¶
Propósito¶
Content-Based Router recibe mensajes de un canal de entrada único y los distribuye a uno de varios canales de salida posibles, eligiendo el canal de destino basándose en el contenido del mensaje. Cada mensaje sigue exactamente una ruta: el router evalúa las reglas en orden y dirige el mensaje al primer canal cuya condición se cumple.
Lógica Arquitectónica¶
En un sistema de integración, es común que un productor genere mensajes de diferentes tipos que deben procesarse por consumidores especializados. Sin un router, existen dos alternativas subóptimas:
- El productor decide el destino: el productor debe conocer todos los consumidores y sus canales, acoplándose a la topología de consumo. Si se añade un nuevo consumidor o se cambia un canal, el productor debe modificarse.
- Cada consumidor filtra: todos los consumidores reciben todos los mensajes y descartan los que no les corresponden. Esto desperdicia ancho de banda, capacidad de procesamiento y complejiza el código de cada consumidor.
Content-Based Router elimina ambos problemas introduciendo un componente intermedio que absorbe la lógica de distribución. El productor envía todos los mensajes a un solo canal de entrada. El router los examina y los dirige al canal especializado correspondiente. Los consumidores reciben exclusivamente los mensajes que les corresponden.
Principio de Diseño Subyacente¶
El principio es separación de la lógica de routing de la lógica de negocio. El productor no debería decidir quién procesa sus mensajes. Los consumidores no deberían filtrar lo que no les corresponde. Un componente dedicado — el router — se especializa en la decisión de routing, manteniéndola en un punto único, visible y modificable.
Mecanismos de Routing¶
Content-Based Router puede inspeccionar diferentes partes del mensaje:
- Routing por header: examina metadatos del mensaje (tipo, prioridad, origen, tenant). Es más eficiente porque no requiere deserializar el body. Es el mecanismo preferido en la mayoría de los casos.
- Routing por body: examina campos del payload (tipo de reclamación, categoría de producto, región geográfica). Es más flexible pero más costoso computacionalmente y crea acoplamiento con la estructura del mensaje.
- Routing combinado: usa una combinación de headers y body para tomar la decisión. Ofrece máxima expresividad a costa de máxima complejidad.
Tabla de Routing¶
La lógica del router se expresa típicamente como una tabla de routing que mapea condiciones a canales de salida:
| Condición | Canal de destino |
|---|---|
claim.type == "auto" | claims.auto |
claim.type == "home" | claims.home |
claim.type == "health" | claims.health |
claim.type == "life" | claims.life |
default | claims.unclassified |
Esta tabla puede estar hardcodeada, en configuración externa o en una base de datos.
Ruta por Defecto¶
Un aspecto crítico del diseño es la ruta por defecto (default route). ¿Qué ocurre cuando un mensaje no cumple ninguna condición? Sin ruta por defecto, el mensaje se pierde silenciosamente — uno de los bugs más difíciles de diagnosticar. Una implementación robusta siempre incluye una ruta por defecto que envía mensajes no clasificados a un canal de revisión o dead-letter.
Contexto en el que Emerge¶
Content-Based Router emerge cuando un sistema necesita direccionar mensajes heterogéneos a procesadores especializados. Es la primera herramienta de routing que se considera y la más frecuentemente implementada.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Content-Based Router, un sistema que produce mensajes de diferentes tipos enfrenta un dilema arquitectónico sin solución limpia:
- Opción A — Productor como router: el productor evalúa el tipo de mensaje y lo envía directamente al canal del consumidor especializado. Esto acopla al productor con la topología de consumo: si el equipo de seguros de hogar cambia su canal, el equipo del productor debe redesplegarlo.
- Opción B — Canal único sin routing: todos los mensajes van a un solo canal. Cada consumidor recibe todos los mensajes, evalúa si le corresponden, y descarta los que no. Con 4 tipos de mensajes, cada consumidor descarta el 75% de lo que recibe.
Síntomas del Problema¶
- Consumidores que procesan un porcentaje muy bajo de los mensajes que reciben (la mayoría se descartan tras inspección).
- Productores con lógica de routing embebida que se modifica con cada cambio en la topología de consumo.
- Nuevos consumidores especializados que requieren cambios en el productor para recibir mensajes.
- Incapacidad de monitorear el volumen real por tipo de mensaje porque todo fluye por un solo canal.
- Escalamiento ineficiente: para procesar más mensajes de un tipo, hay que escalar el canal que contiene todos los tipos.
Impacto Operativo y Arquitectónico¶
Sin routing centralizado:
- La adición de un nuevo tipo de mensaje o un nuevo consumidor requiere coordinación entre múltiples equipos.
- La observabilidad por tipo de mensaje es limitada o inexistente.
- La escalabilidad es uniforme: no se puede escalar el procesamiento de un tipo sin escalar el de todos.
- La lógica de routing se dispersa entre productor y consumidores, sin un punto de control único.
Riesgos Si No Se Implementa Correctamente¶
- Routing incompleto: una regla que no cubre todos los casos produce mensajes "perdidos" que no llegan a ningún consumidor.
- Reglas ambiguas: condiciones que se solapan (un mensaje cumple dos reglas) producen routing inconsistente si no se define prioridad.
- Acoplamiento al formato: routing por campos profundos del body acopla el router a la estructura interna del mensaje.
- Single point of failure: el router se convierte en un cuello de botella si no se diseña para alta disponibilidad.
Ejemplos Reales¶
- Seguros: una aseguradora recibe reclamaciones de múltiples tipos (auto, hogar, salud, vida). Cada tipo tiene un flujo de procesamiento completamente diferente con reglas de validación, tasación y aprobación distintas. Un Content-Based Router examina el campo
claim_typey dirige cada reclamación al sistema especializado. - E-commerce: un sistema de notificaciones recibe eventos de diferentes dominios (pedidos, pagos, envíos, devoluciones). El router dirige cada evento al servicio de notificación especializado que sabe qué plantilla usar y a quién notificar.
- Banca: transacciones financieras se enrutan según el monto: transacciones menores a cierto umbral se procesan automáticamente; transacciones mayores requieren aprobación manual y se enrutan a un canal de revisión.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un canal de entrada recibe mensajes de múltiples tipos que requieren procesamiento diferenciado.
- Cuando se desea desacoplar al productor de los consumidores especializados.
- Cuando las reglas de routing son conocidas en diseño o configuración (no requieren descubrimiento dinámico en runtime).
- Cuando cada mensaje debe seguir exactamente una ruta (routing exclusivo, no distribución a múltiples destinos).
Cuándo No Usarlo¶
- Si las reglas de routing cambian frecuentemente y requieren actualización sin redespliegue, considere Dynamic Router.
- Si un mensaje debe enviarse a múltiples destinos simultáneamente, use Recipient List o Publish-Subscribe Channel.
- Si la decisión es binaria (procesar o descartar), use Message Filter, que es un caso degenerado más simple.
- Si la lógica de routing es tan trivial que un header de tipo de mensaje basta, una subscription con filtro nativo del broker puede ser suficiente sin un componente router explícito.
Precondiciones¶
- Existe un canal de entrada donde llegan mensajes heterogéneos.
- Existen canales de salida diferenciados para cada tipo de procesamiento.
- El contenido del mensaje contiene suficiente información para determinar la ruta.
- Las reglas de routing están definidas y son evaluables sin efectos colaterales.
Restricciones¶
- El router debe ser stateless: la decisión de routing de un mensaje no debe depender de mensajes anteriores.
- La evaluación de reglas debe ser determinista: el mismo mensaje debe producir siempre la misma ruta.
- El router no debe modificar el mensaje (routing puro, no transformación).
Dependencias¶
- Canal de entrada configurado y con mensajes disponibles.
- Canales de salida creados y con consumidores activos.
- Mecanismo de evaluación de reglas (código, configuración, motor de reglas).
Supuestos Arquitectónicos¶
- Los mensajes contienen la información necesaria para el routing (no se necesitan lookups externos).
- Los canales de salida están disponibles; si uno no está disponible, el router debe manejar el error.
- Las reglas de routing son mutuamente excluyentes o tienen prioridad definida.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Plataformas de seguros, banca y finanzas (routing por tipo de producto o transacción).
- Sistemas de integración enterprise (ESB, iPaaS).
- Event-driven architectures con múltiples consumidores especializados.
- API Gateways que enrutan requests a diferentes backends según path, header o body.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Content-Based Router desacopla al productor de los consumidores: el productor solo conoce el canal de entrada. Sin embargo, el router se acopla tanto al formato del mensaje (debe saber qué campo inspeccionar) como a la topología de canales de salida (debe conocer todos los destinos). Este acoplamiento se puede mitigar externalizando las reglas de routing a configuración.
Centralización vs. Distribución de Lógica¶
Centralizar la lógica de routing en un solo componente facilita la comprensión, el monitoreo y la modificación de las reglas. Pero también crea un punto de control que, si no se escala adecuadamente, se convierte en cuello de botella. La alternativa — distribuir la lógica en cada consumidor — elimina el cuello de botella pero dispersa la lógica.
Eficiencia vs. Expresividad¶
Routing por header es muy eficiente (no requiere deserializar el body) pero limitado en expresividad. Routing por body es muy expresivo (puede evaluar cualquier campo, incluso campos anidados) pero requiere deserialización completa y acopla el router a la estructura del payload. La tensión entre eficiencia y expresividad es constante.
Simplicidad vs. Completitud¶
Un router con pocas reglas simples es fácil de entender y mantener. Pero a medida que se añaden tipos de mensajes, excepciones y reglas condicionales complejas, el router puede convertirse en un componente complejo y frágil. La disciplina de mantener reglas simples y mutuamente excluyentes es fundamental.
Latencia vs. Correctitud¶
El router añade un hop de latencia al flujo del mensaje. En escenarios de alta frecuencia (streaming de eventos a miles por segundo), esta latencia adicional puede ser significativa. La alternativa — routing directamente en el productor — elimina el hop pero sacrifica desacoplamiento.
Operabilidad vs. Autonomía¶
Un router centralizado facilita la operación (un solo componente a monitorear) pero reduce la autonomía de los equipos consumidores: si un equipo necesita una nueva ruta, depende del equipo que gestiona el router. Con filtros nativos del broker (subscriptions), cada equipo puede gestionar su propio filtro.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): envía mensajes heterogéneos al canal de entrada.
- Canal de Entrada (Input Channel): canal único donde llegan todos los mensajes sin clasificar.
- Content-Based Router: componente que consume del canal de entrada, evalúa el contenido de cada mensaje y lo produce al canal de salida correspondiente.
- Reglas de Routing (Routing Rules): conjunto de condiciones que mapean contenido del mensaje a canales de salida.
- Canales de Salida (Output Channels): canales especializados, uno por cada destino posible.
- Consumidores Especializados (Specialized Consumers): procesan los mensajes de su canal asignado.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[(Canal de Entrada)]
B --> C[Router consume mensaje]
C --> D[Inspeccionar contenido\nheader, body o ambos]
D --> E[Evaluar reglas de routing\nen orden de prioridad]
E --> F{Alguna regla\nse cumple?}
F -- Sí --> G[Identificar canal de salida\nde la primera regla cumplida]
F -- No --> H[(Canal por Defecto)]
G --> I[(Canal de Salida seleccionado)]
I --> J[Confirmar procesamiento\nack]
H --> J
J --> K[Consumidor Especializado\nprocesa con lógica específica]
K --> L([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Enviar mensajes al canal de entrada con información suficiente para routing |
| Canal de Entrada | Almacenar y entregar mensajes al router |
| Router | Evaluar reglas, dirigir mensajes al canal correcto, manejar mensajes no clasificados |
| Reglas de Routing | Definir el mapeo condición → canal de salida |
| Canales de Salida | Almacenar y entregar mensajes a consumidores especializados |
| Consumidores | Procesar mensajes de su tipo específico |
Interacciones¶
- Productor → Canal de Entrada: producción de mensajes sin conocimiento de routing.
- Canal de Entrada → Router: consumo de mensajes para evaluación.
- Router → Reglas: evaluación de cada regla contra el contenido del mensaje.
- Router → Canal de Salida: producción del mensaje en el canal seleccionado.
- Canal de Salida → Consumidor: entrega del mensaje al consumidor especializado.
Contratos Implícitos¶
- El mensaje debe contener los campos que el router inspecciona para tomar la decisión.
- Las reglas de routing deben cubrir todos los valores posibles (o existir una ruta por defecto).
- El mensaje no se modifica durante el routing (se reenvía tal cual).
Decisiones de Diseño Clave¶
- Routing por header vs. por body: determina el nivel de acoplamiento y la performance.
- Reglas estáticas vs. externalizadas: reglas en código vs. en configuración o base de datos.
- Evaluación ordenada vs. hash map: las reglas se evalúan secuencialmente (con prioridad) o se usa un lookup directo (más rápido pero solo para igualdad exacta).
- Ruta por defecto: canal dead-letter, canal de revisión manual o error.
- Acknowledgment: ack del canal de entrada antes o después de producir al canal de salida (at-most-once vs. at-least-once).
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Routing de Reclamaciones por Tipo¶
Contexto del Negocio¶
Una compañía aseguradora multinacional opera cuatro líneas de negocio: auto, hogar, salud y vida. Cada línea tiene su propio equipo de procesamiento con reglas de validación, tasación, investigación y resolución completamente diferentes. La compañía recibe aproximadamente 15,000 reclamaciones diarias a través de múltiples canales de ingreso: portal web, app móvil, call center e intermediarios.
Necesidad de Integración¶
Todas las reclamaciones ingresan por un sistema unificado de recepción (Claims Intake) que normaliza el formato independientemente del canal de ingreso. Una vez normalizadas, las reclamaciones deben dirigirse al sistema de procesamiento correcto según su tipo. Cada sistema de procesamiento es un microservicio independiente gestionado por un equipo diferente.
Sistemas Involucrados¶
- Claims Intake Service: recibe y normaliza reclamaciones de todos los canales.
- Claims Router: Content-Based Router que dirige reclamaciones al procesador correcto.
- Auto Claims Processor: procesa reclamaciones de seguros de automóvil (valuación de daños, verificación de póliza, coordinación con talleres).
- Home Claims Processor: procesa reclamaciones de seguros de hogar (inspección de daños, verificación de cobertura, coordinación con contratistas).
- Health Claims Processor: procesa reclamaciones de seguros de salud (verificación de prestaciones, codificación CIE-10, adjudicación médica).
- Life Claims Processor: procesa reclamaciones de seguros de vida (verificación de beneficiarios, certificados de defunción, compliance regulatorio).
- Unclassified Claims Handler: maneja reclamaciones que no se pueden clasificar automáticamente.
Restricciones Técnicas¶
- Latencia máxima aceptable del routing: 500ms por reclamación.
- Las reclamaciones deben procesarse en orden dentro de cada tipo (una reclamación de auto no debe adelantar a otra de auto más antigua).
- Cero pérdida de reclamaciones: toda reclamación debe llegar a un procesador o al handler de no clasificadas.
- Cada línea de negocio debe poder escalar su procesamiento independientemente.
- La configuración de routing debe poder modificarse sin redespliegue del router (nuevos tipos de reclamación, nuevos sub-tipos).
Diseño del Router¶
| Canal | Tipo | Productor | Consumidor |
|---|---|---|---|
claims.intake | Input | Claims Intake Service | Claims Router |
claims.auto | Output | Claims Router | Auto Claims Processor |
claims.home | Output | Claims Router | Home Claims Processor |
claims.health | Output | Claims Router | Health Claims Processor |
claims.life | Output | Claims Router | Life Claims Processor |
claims.unclassified | Default | Claims Router | Unclassified Claims Handler |
Reglas de Routing¶
routing_rules:
- condition: "header.claim_type == 'AUTO'"
destination: "claims.auto"
priority: 1
- condition: "header.claim_type == 'HOME'"
destination: "claims.home"
priority: 2
- condition: "header.claim_type == 'HEALTH'"
destination: "claims.health"
priority: 3
- condition: "header.claim_type == 'LIFE'"
destination: "claims.life"
priority: 4
default_destination: "claims.unclassified"
Decisiones Arquitectónicas¶
-
Routing por header: el campo
claim_typese coloca en el header del mensaje por el Claims Intake Service. El router no necesita deserializar el body, lo que permite routing de muy baja latencia. El body puede ser un JSON grande con documentos adjuntos codificados en base64. -
Reglas externalizadas en YAML: las reglas de routing no están en código sino en un archivo de configuración que se carga al inicio y se puede recargar vía señal o endpoint de administración. Esto permite añadir un nuevo tipo (por ejemplo,
TRAVELpara seguros de viaje) sin redesplegar el router. -
Canal por defecto obligatorio: toda reclamación que no coincida con ninguna regla va a
claims.unclassified. Este canal tiene alertas configuradas: si recibe más de 10 mensajes por hora, se genera un incidente porque indica un problema en el Claims Intake o en las reglas. -
Particionamiento por policy_number: dentro de cada canal de salida, las reclamaciones se particionan por número de póliza para garantizar orden de procesamiento por cliente.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de reclamación en routing | At-least-once: ack solo después de producir al canal de salida |
| Router como cuello de botella | Múltiples instancias con consumer group compartido |
| Regla de routing incorrecta | Tests automatizados de reglas, canal de unclassified monitoreado |
| Nuevo tipo sin regla configurada | Canal por defecto + alerta de volumen anómalo |
| Body demasiado grande para inspección | Routing exclusivo por header, body opaco para el router |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Ingreso de la Reclamación¶
Un asegurado reporta un accidente automovilístico a través de la app móvil. El Claims Intake Service recibe la reclamación:
{
"headers": {
"message_id": "msg-2026-04-07-00847291",
"claim_type": "AUTO",
"source_channel": "MOBILE_APP",
"policy_number": "POL-ES-2024-38291",
"timestamp": "2026-04-07T09:15:32Z"
},
"body": {
"claimant": {
"name": "María García López",
"policy_number": "POL-ES-2024-38291",
"contact_phone": "+34612345678"
},
"incident": {
"date": "2026-04-06",
"location": "Av. de la Constitución 15, Madrid",
"description": "Colisión trasera en semáforo. Daños en parachoques y maletero.",
"police_report_number": "ATT-2026-18472"
},
"vehicle": {
"plate": "1234-ABC",
"make": "Toyota",
"model": "Corolla",
"year": 2023
},
"photos": ["base64_encoded_photo_1", "base64_encoded_photo_2"]
}
}
El Claims Intake normaliza el formato, asigna un message_id y establece el header claim_type: AUTO y lo publica en el canal claims.intake.
Paso 2: Evaluación del Router¶
El Claims Router consume el mensaje del canal claims.intake:
- Lee el header
claim_typedel mensaje: valorAUTO. - Evalúa las reglas de routing secuencialmente:
- Regla 1:
header.claim_type == 'AUTO'→ MATCH - Destino:
claims.auto - No necesita evaluar las reglas restantes (primera coincidencia gana).
La evaluación toma menos de 1ms porque solo inspecciona el header, sin deserializar el body (que incluye fotos en base64 de varios MB).
Paso 3: Producción al Canal de Salida¶
El router produce el mensaje completo (headers + body sin modificar) al canal claims.auto usando policy_number como partition key:
- Serializa el mensaje al canal
claims.auto, partición determinada por hash dePOL-ES-2024-38291. - Espera confirmación del broker (ack).
- Una vez confirmada la producción, hace ack del mensaje en
claims.intake.
Este orden (produce → ack del input) garantiza at-least-once delivery: si el router falla después de producir pero antes de hacer ack, el mensaje se reprocesará (duplicado potencial que el consumidor debe manejar con idempotencia).
Paso 4: Procesamiento Especializado¶
El Auto Claims Processor consume del canal claims.auto:
- Deserializa el body completo.
- Verifica la póliza
POL-ES-2024-38291contra el sistema de pólizas (cobertura vigente, tipo de cobertura, deducible). - Registra la reclamación con ID
CLM-2026-00847291. - Inicia el flujo de auto claims: asigna perito, programa inspección del vehículo, solicita informe policial.
- Envía notificación al asegurado confirmando recepción.
Paso 5: Caso de Ruta por Defecto¶
Una reclamación llega con claim_type: PET (seguros de mascotas, producto nuevo no configurado aún):
- El router evalúa todas las reglas: ninguna coincide con
PET. - Aplica la ruta por defecto: produce al canal
claims.unclassified. - El Unclassified Claims Handler recibe el mensaje y genera una alerta operacional.
- El equipo de operaciones identifica que se necesita una nueva regla de routing y un nuevo procesador para reclamaciones de mascotas.
- Se añade la regla
claim_type == 'PET' → claims.peta la configuración y se recarga el router sin redespliegue.
Paso 6: Monitoreo del Router¶
Un dashboard muestra en tiempo real:
- Throughput por canal de salida: auto (6,200/día), home (3,800/día), health (3,500/día), life (1,200/día), unclassified (15/día).
- Latencia de routing: p50=0.3ms, p99=2.1ms.
- Tasa de unclassified: 0.1% (dentro de umbral aceptable).
- Distribución de reglas evaluadas: 41% se resuelve en la primera regla, 67% en las dos primeras.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.programming.flowchart import Decision
from diagrams.onprem.monitoring import Grafana
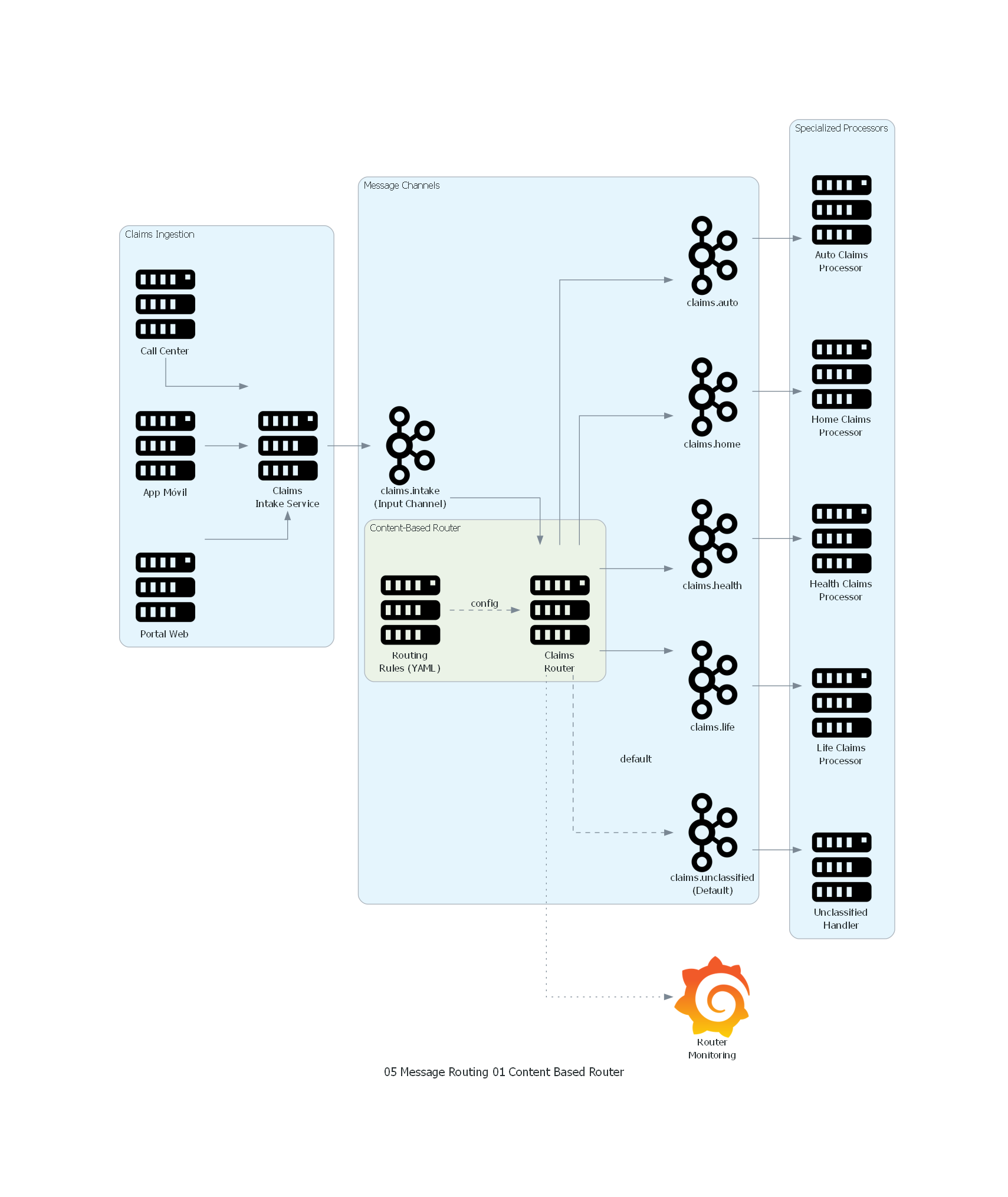
with Diagram("Content-Based Router - Insurance Claims", show=False, direction="LR"):
with Cluster("Claims Ingestion"):
web = Server("Portal Web")
mobile = Server("App Móvil")
callcenter = Server("Call Center")
intake = Server("Claims\nIntake Service")
with Cluster("Message Channels"):
input_ch = Kafka("claims.intake\n(Input Channel)")
with Cluster("Content-Based Router"):
router = Server("Claims\nRouter")
rules = Server("Routing\nRules (YAML)")
auto_ch = Kafka("claims.auto")
home_ch = Kafka("claims.home")
health_ch = Kafka("claims.health")
life_ch = Kafka("claims.life")
default_ch = Kafka("claims.unclassified\n(Default)")
with Cluster("Specialized Processors"):
auto_proc = Server("Auto Claims\nProcessor")
home_proc = Server("Home Claims\nProcessor")
health_proc = Server("Health Claims\nProcessor")
life_proc = Server("Life Claims\nProcessor")
unclass_proc = Server("Unclassified\nHandler")
monitoring = Grafana("Router\nMonitoring")
# Ingestion flow
web >> intake
mobile >> intake
callcenter >> intake
intake >> input_ch
# Routing flow
input_ch >> router
rules >> Edge(style="dashed", label="config") >> router
router >> auto_ch >> auto_proc
router >> home_ch >> home_proc
router >> health_ch >> health_proc
router >> life_ch >> life_proc
router >> Edge(style="dashed", label="default") >> default_ch >> unclass_proc
# Monitoring
router >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.integration import Eventbridge, SQS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
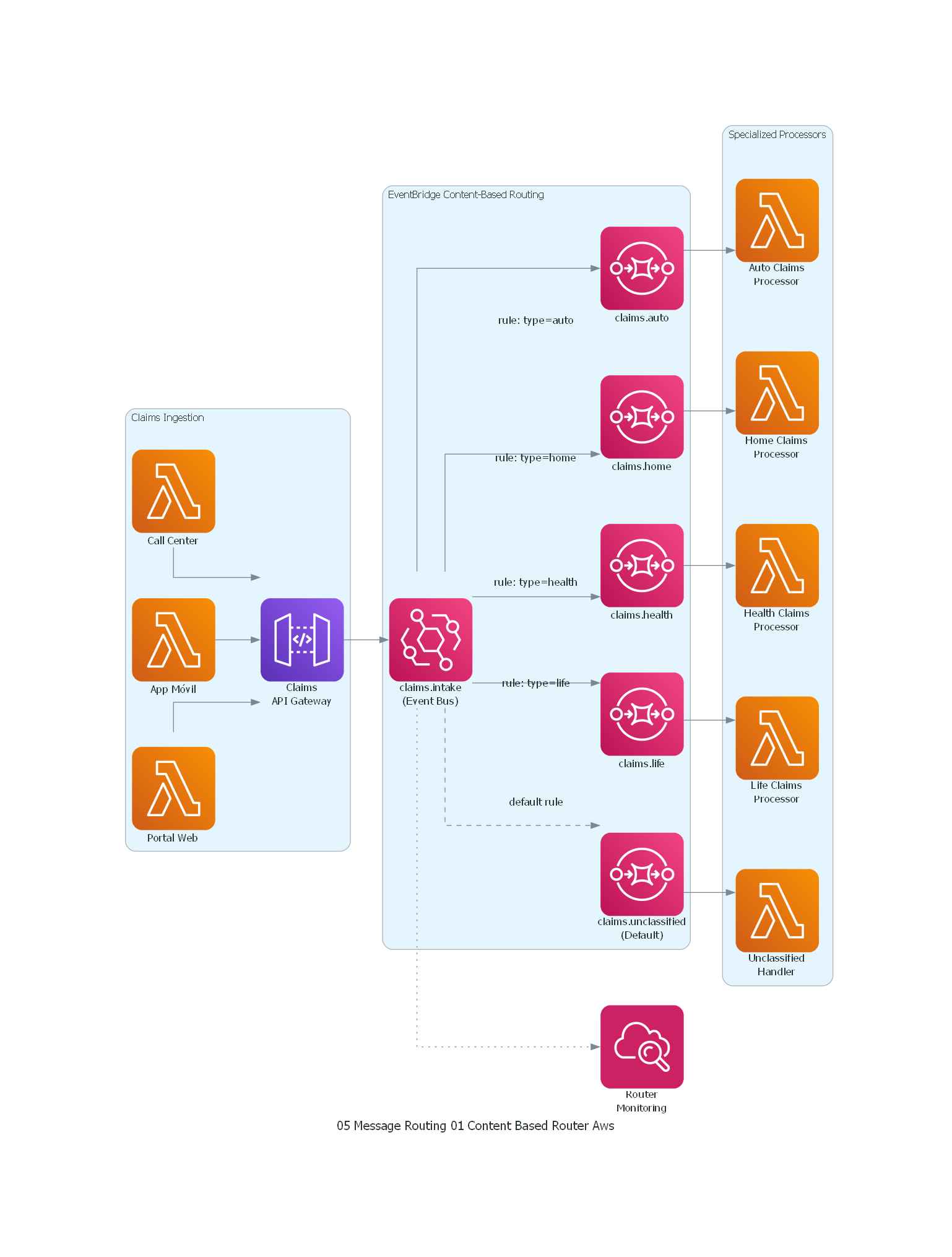
with Diagram("Content-Based Router - Insurance Claims (AWS)", show=False, direction="LR"):
with Cluster("Claims Ingestion"):
web = Lambda("Portal Web")
mobile = Lambda("App Móvil")
callcenter = Lambda("Call Center")
intake = APIGateway("Claims\nAPI Gateway")
with Cluster("EventBridge Content-Based Routing"):
input_ch = Eventbridge("claims.intake\n(Event Bus)")
auto_ch = SQS("claims.auto")
home_ch = SQS("claims.home")
health_ch = SQS("claims.health")
life_ch = SQS("claims.life")
default_ch = SQS("claims.unclassified\n(Default)")
with Cluster("Specialized Processors"):
auto_proc = Lambda("Auto Claims\nProcessor")
home_proc = Lambda("Home Claims\nProcessor")
health_proc = Lambda("Health Claims\nProcessor")
life_proc = Lambda("Life Claims\nProcessor")
unclass_proc = Lambda("Unclassified\nHandler")
monitoring = Cloudwatch("Router\nMonitoring")
# Ingestion flow
web >> intake
mobile >> intake
callcenter >> intake
intake >> input_ch
# EventBridge rules route by event pattern
input_ch >> Edge(label="rule: type=auto") >> auto_ch >> auto_proc
input_ch >> Edge(label="rule: type=home") >> home_ch >> home_proc
input_ch >> Edge(label="rule: type=health") >> health_ch >> health_proc
input_ch >> Edge(label="rule: type=life") >> life_ch >> life_proc
input_ch >> Edge(style="dashed", label="default rule") >> default_ch >> unclass_proc
# Monitoring
input_ch >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.flowchart import Decision
from diagrams.azure.compute import FunctionApps
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
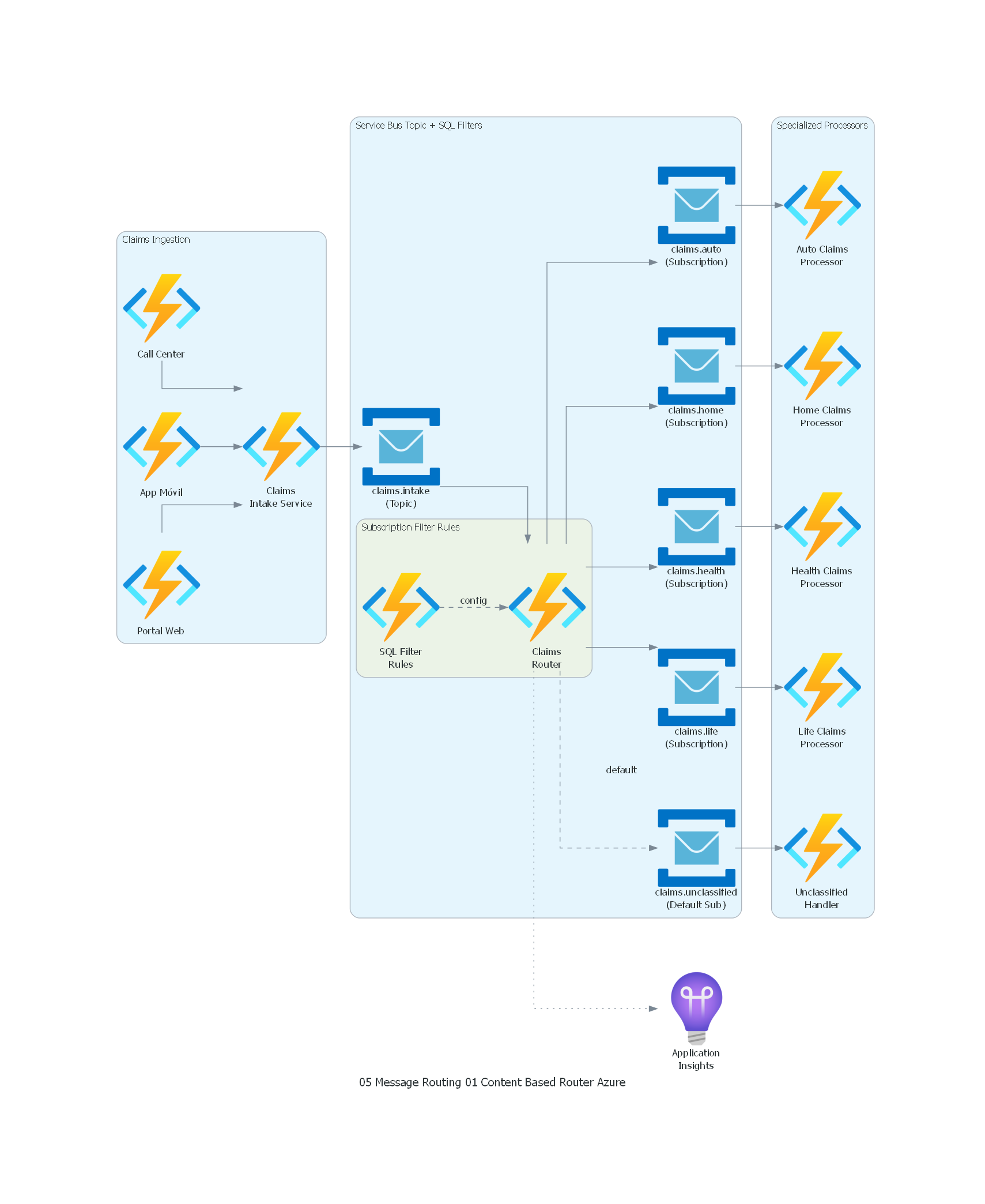
with Diagram("Content-Based Router - Insurance Claims (Azure)", show=False, direction="LR"):
with Cluster("Claims Ingestion"):
web = FunctionApps("Portal Web")
mobile = FunctionApps("App Móvil")
callcenter = FunctionApps("Call Center")
intake = FunctionApps("Claims\nIntake Service")
with Cluster("Service Bus Topic + SQL Filters"):
input_ch = ServiceBus("claims.intake\n(Topic)")
with Cluster("Subscription Filter Rules"):
router = FunctionApps("Claims\nRouter")
rules = FunctionApps("SQL Filter\nRules")
auto_ch = ServiceBus("claims.auto\n(Subscription)")
home_ch = ServiceBus("claims.home\n(Subscription)")
health_ch = ServiceBus("claims.health\n(Subscription)")
life_ch = ServiceBus("claims.life\n(Subscription)")
default_ch = ServiceBus("claims.unclassified\n(Default Sub)")
with Cluster("Specialized Processors"):
auto_proc = FunctionApps("Auto Claims\nProcessor")
home_proc = FunctionApps("Home Claims\nProcessor")
health_proc = FunctionApps("Health Claims\nProcessor")
life_proc = FunctionApps("Life Claims\nProcessor")
unclass_proc = FunctionApps("Unclassified\nHandler")
monitoring = ApplicationInsights("Application\nInsights")
# Ingestion flow
web >> intake
mobile >> intake
callcenter >> intake
intake >> input_ch
# Routing flow
input_ch >> router
rules >> Edge(style="dashed", label="config") >> router
router >> auto_ch >> auto_proc
router >> home_ch >> home_proc
router >> health_ch >> health_proc
router >> life_ch >> life_proc
router >> Edge(style="dashed", label="default") >> default_ch >> unclass_proc
# Monitoring
router >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura completa del Content-Based Router para el sistema de seguros:
- Claims Ingestion: múltiples canales de ingreso (web, móvil, call center) alimentan al Claims Intake Service que normaliza las reclamaciones.
- Input Channel:
claims.intakerecibe todas las reclamaciones normalizadas. - Content-Based Router: el Claims Router consume del canal de entrada, consulta las reglas de routing (configuración YAML) y dirige cada reclamación al canal de salida apropiado.
- Output Channels: cinco canales especializados, uno por tipo de reclamación más el canal por defecto para no clasificadas.
- Specialized Processors: cada procesador consume exclusivamente de su canal asignado.
- Monitoring: Grafana monitorea throughput, latencia y tasa de mensajes no clasificados.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor | Claims Intake Service |
| Canal de Entrada | claims.intake |
| Content-Based Router | Claims Router + Routing Rules |
| Reglas de Routing | YAML configuration |
| Canales de Salida | claims.auto, claims.home, claims.health, claims.life |
| Ruta por Defecto | claims.unclassified |
| Consumidores Especializados | Auto/Home/Health/Life Claims Processors |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento productor-consumidores: el Claims Intake Service no conoce ni depende de los procesadores especializados. Puede evolucionar independientemente.
- Escalabilidad selectiva: si las reclamaciones de auto se duplican por una temporada de lluvias, se escala solo el Auto Claims Processor y el canal
claims.auto, sin afectar a las demás líneas. - Separación de concerns: la lógica de routing está aislada en un componente dedicado, visible y testeable. No se dispersa entre productor y consumidores.
- Procesamiento eficiente: cada consumidor recibe exclusivamente los mensajes que le corresponden. No desperdicia recursos descartando mensajes.
Impacto Organizacional¶
- Autonomía de equipos: el equipo de auto claims puede desarrollar, desplegar y escalar su procesador sin coordinación con los equipos de salud o vida.
- Onboarding de nuevos productos: cuando la compañía lanza un nuevo producto (seguros de viaje), solo se necesita añadir una regla de routing y un nuevo procesador, sin modificar los existentes.
- Visibilidad operacional: el volumen de reclamaciones por tipo es visible a nivel de canal, lo que facilita la planificación de capacidad y la detección de anomalías.
Impacto Operacional¶
- Monitoreo granular: métricas por canal de salida permiten detectar que "las reclamaciones de salud están tardando más de lo habitual" sin inspeccionar cada reclamación.
- Aislamiento de fallos: si el Health Claims Processor falla, las reclamaciones de salud se acumulan en su canal, pero las de auto, hogar y vida siguen procesándose normalmente.
- Diagnóstico simplificado: un volumen anormal en
claims.unclassifiedindica inmediatamente un problema en el intake o en las reglas de routing.
Beneficios de Mantenibilidad y Evolución¶
- Reglas modificables sin código: las reglas de routing externalizadas permiten cambios de routing sin redespliegue.
- Testing aislado: cada procesador se puede probar independientemente enviando mensajes a su canal de entrada.
- Migración gradual: un procesador se puede reemplazar conectando el nuevo al mismo canal, probando con un porcentaje del tráfico.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente adicional: el router es un componente más que hay que desarrollar, desplegar, monitorear y escalar.
- Hop de latencia: el mensaje pasa por un paso intermedio antes de llegar al consumidor, añadiendo latencia.
- Gestión de canales: en lugar de un canal, ahora hay N+1 canales (1 de entrada + N de salida + 1 default) que gestionar.
Riesgos de Mal Uso¶
- Router como orchestrator: si el router empieza a acumular lógica de negocio (validaciones, transformaciones, enriquecimiento) más allá de la decisión de routing, se convierte en un "God component" difícil de mantener.
- Reglas demasiado complejas: reglas con condiciones compuestas (
claim_type == 'AUTO' AND amount > 50000 AND region == 'NORTH') crean una matriz de condiciones que crece exponencialmente. - Routing sin default: no configurar una ruta por defecto produce mensajes que se "pierden" silenciosamente.
Sobreingeniería¶
- Router innecesario: si el broker soporta filtros nativos en subscriptions (Azure Service Bus, SNS filter policies), un router explícito puede ser innecesario.
- Demasiada granularidad: crear un canal de salida por cada sub-tipo (auto-leve, auto-grave, auto-total, auto-terceros) cuando la diferencia no justifica canales separados.
Costos de Operación¶
- N+2 canales: cada canal adicional requiere monitoreo, gestión de retención y alertas.
- Router como single point of failure: si el router deja de funcionar, ninguna reclamación se procesa. Requiere alta disponibilidad.
- Consistencia de reglas: las reglas deben estar sincronizadas entre todas las instancias del router si hay múltiples.
Anti-Patterns Relacionados¶
- Routing Spaghetti: cadenas de Content-Based Routers encadenados donde la lógica de routing se fragmenta en múltiples niveles, haciendo imposible entender la ruta completa de un mensaje.
- Stateful Router: un router que recuerda mensajes anteriores para tomar decisiones (esto es un Process Manager, no un Content-Based Router).
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): Content-Based Router opera sobre canales. Cada canal de salida es un Message Channel que conecta el router con un consumidor especializado.
- Message Filter (este capítulo): un Message Filter es un caso especial donde solo hay dos destinos: "procesar" y "descartar". Content-Based Router generaliza esto a N destinos.
- Pipes and Filters (Capítulo 2): el router se inserta como un "filter" en un pipeline, con canales como "pipes" entre componentes.
- Guaranteed Delivery (Capítulo 3): el canal de entrada y los canales de salida del router deben garantizar la entrega para evitar pérdida de mensajes durante el routing.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Translator — transforma mensajes a un formato canónico que el router pueda inspeccionar uniformemente.
- Después: los consumidores especializados pueden usar Aggregator, Splitter u otros patrones para procesamiento adicional.
Combinaciones Comunes¶
- Content-Based Router + Message Translator: primero se canonicaliza el formato, luego se enruta.
- Content-Based Router + Dead Letter Channel: mensajes que no se pueden routear van a dead-letter.
- Splitter + Content-Based Router: un mensaje compuesto se divide en partes y cada parte se enruta independientemente.
Diferencias con Patrones Similares¶
- vs. Message Filter: el filter tiene un solo canal de salida (descarta o deja pasar); el router tiene N canales.
- vs. Dynamic Router: el Content-Based Router tiene reglas fijas en configuración; el Dynamic Router modifica sus reglas en runtime basándose en feedback.
- vs. Recipient List: el router envía a un canal; la Recipient List envía a múltiples canales simultáneamente.
- vs. Publish-Subscribe: pub-sub envía a todos los suscriptores; el router envía a exactamente uno.
Encaje en un Flujo Mayor de Integración¶
Content-Based Router es típicamente el primer componente de routing después del ingreso de mensajes. Precede al procesamiento especializado y puede seguir a normalización o enriquecimiento. En una arquitectura completa, múltiples Content-Based Routers pueden operar en diferentes niveles (routing de primer nivel por tipo de producto, routing de segundo nivel por región dentro de cada producto).
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Content-Based Router es uno de los patrones más implementados en arquitecturas modernas, aunque frecuentemente bajo otro nombre o como feature nativa de la plataforma:
- Amazon EventBridge: las reglas de EventBridge son Content-Based Routers puros. Cada regla inspecciona el evento (source, detail-type, campos del detail) y lo dirige a un target (Lambda, SQS, Step Functions). EventBridge evalúa todas las reglas contra cada evento, lo que lo convierte en un híbrido entre Content-Based Router y Recipient List.
- Kafka Streams: el operador
branch()implementa Content-Based Router directamente. Cada branch define un predicado que inspecciona el mensaje y lo dirige a un KStream de salida diferente. - Azure Service Bus: los filtros SQL en subscriptions de un Topic implementan Content-Based Router a nivel de broker. Cada subscription con filtro recibe solo los mensajes que cumplen su condición.
- Apache Camel / Spring Integration: implementan Content-Based Router como componente nativo con DSL para definir condiciones y destinos.
- API Gateways: Kong, Apigee, AWS API Gateway enrutan requests HTTP a diferentes backends según path, header o query parameter — esto es Content-Based Router aplicado a HTTP.
- AWS SNS Filter Policies: permiten filtrar mensajes a nivel de subscription, implementando routing basado en atributos del mensaje.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación | Mecanismo de Evaluación |
|---|---|---|
| EventBridge | Rules | Event patterns (JSON matching) |
| Kafka Streams | branch() | Predicados Java/Kotlin |
| Azure Service Bus | Subscription filters | SQL-like expressions |
| SNS | Filter policies | JSON attribute matching |
| Apache Camel | choice().when() | Simple, XPath, JSONPath |
| Spring Integration | @Router | Método Java que retorna canal |
Qué Parte Sigue Siendo Esencial¶
- La lógica de routing como concepto arquitectónico (decidir a dónde va un mensaje según su contenido) es permanente.
- La decisión de dónde implementar el routing (en un componente explícito, en el broker, en el API Gateway) varía según la plataforma.
- La necesidad de una ruta por defecto para mensajes no clasificados es un principio atemporal.
- La externalización de reglas de routing para modificación sin redespliegue es una práctica madura y ampliamente adoptada.
15. Implementación en Arquitecturas Modernas¶
Amazon EventBridge¶
{
"Source": "claims-intake",
"DetailType": "ClaimSubmitted",
"Detail": {
"claim_type": "AUTO",
"policy_number": "POL-ES-2024-38291"
}
}
Regla EventBridge:
{
"source": ["claims-intake"],
"detail-type": ["ClaimSubmitted"],
"detail": {
"claim_type": ["AUTO"]
}
}
Target: SQS queue claims-auto-queue o Lambda auto-claims-processor.
Kafka Streams (Java)¶
KStream<String, ClaimEvent> claims = builder.stream("claims.intake");
Map<String, KStream<String, ClaimEvent>> branches = claims.split(Named.as("route-"))
.branch((key, claim) -> "AUTO".equals(claim.getClaimType()),
Branched.as("auto"))
.branch((key, claim) -> "HOME".equals(claim.getClaimType()),
Branched.as("home"))
.branch((key, claim) -> "HEALTH".equals(claim.getClaimType()),
Branched.as("health"))
.branch((key, claim) -> "LIFE".equals(claim.getClaimType()),
Branched.as("life"))
.defaultBranch(Branched.as("unclassified"));
branches.get("route-auto").to("claims.auto");
branches.get("route-home").to("claims.home");
branches.get("route-health").to("claims.health");
branches.get("route-life").to("claims.life");
branches.get("route-unclassified").to("claims.unclassified");
Azure Service Bus¶
Topic: claims-intake
Subscription: auto-claims
Filter: claim_type = 'AUTO'
Subscription: home-claims
Filter: claim_type = 'HOME'
Subscription: health-claims
Filter: claim_type = 'HEALTH'
Subscription: life-claims
Filter: claim_type = 'LIFE'
Subscription: unclassified-claims
Filter: 1=1 (catch-all, combined with low priority)
Apache Camel¶
from("kafka:claims.intake")
.choice()
.when(header("claim_type").isEqualTo("AUTO"))
.to("kafka:claims.auto")
.when(header("claim_type").isEqualTo("HOME"))
.to("kafka:claims.home")
.when(header("claim_type").isEqualTo("HEALTH"))
.to("kafka:claims.health")
.when(header("claim_type").isEqualTo("LIFE"))
.to("kafka:claims.life")
.otherwise()
.to("kafka:claims.unclassified");
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas del router: throughput total, throughput por canal de salida, latencia de routing (p50, p95, p99), tasa de mensajes al canal default.
- Distributed tracing: propagar correlation ID y trace ID a través del router para trazabilidad end-to-end desde intake hasta procesamiento.
- Logging estructurado: cada decisión de routing debe generar un log con message_id, regla aplicada, canal de destino, latencia de evaluación.
Monitoreo¶
- Distribución de tráfico por canal: dashboards que muestren la proporción de mensajes por tipo. Cambios bruscos en la distribución indican anomalías (un pico de reclamaciones de auto tras una granizada).
- Tasa de unclassified: debe ser cercana a cero. Un incremento indica problemas en intake o reglas incompletas.
- Latencia del router: si crece, puede indicar que las reglas se han vuelto demasiado complejas o que el router está saturado.
- Consumer lag del router: si el router acumula lag en el canal de entrada, no está procesando al ritmo necesario.
Versionado¶
- Versionado de reglas: las reglas de routing deben estar versionadas (en Git o en un config store con historial) para poder auditar cambios y hacer rollback.
- Blue-green de reglas: para cambios significativos en reglas, desplegar las nuevas reglas en una instancia separada y migrar tráfico gradualmente.
Seguridad¶
- Acceso a reglas: solo personal autorizado debe poder modificar las reglas de routing (un cambio erróneo puede enviar reclamaciones de salud al procesador de auto).
- ACLs en canales: el router debe tener permisos de lectura en el canal de entrada y escritura en todos los canales de salida.
Manejo de Errores¶
- Si un canal de salida no está disponible, el router debe reintentar con backoff exponencial, y eventualmente enviar al dead-letter si el canal sigue no disponible.
- Mensajes con formato corrupto que impiden la evaluación de reglas deben enviarse a un canal de errores con contexto diagnóstico.
Idempotencia¶
- El router puede reenviar un mensaje duplicado (por reintentos tras fallo). Los consumidores especializados deben ser idempotentes y deduplicar basándose en
message_id.
Performance¶
- Routing por header: preferir siempre routing por header sobre routing por body para minimizar overhead de deserialización.
- Lookup directo vs. evaluación secuencial: si las reglas son igualdades simples (campo == valor), usar un HashMap es O(1). Si son condiciones complejas, la evaluación secuencial es O(n) donde n es el número de reglas.
- Batch processing: en escenarios de alto throughput, evaluar reglas en lotes puede amortizar overhead.
Escalabilidad¶
- Horizontal: múltiples instancias del router en un consumer group comparten la carga del canal de entrada.
- Stateless: como el router no mantiene estado, escalar horizontalmente es trivial.
- Los canales de salida deben dimensionarse según el volumen esperado por tipo.
17. Errores Comunes¶
No Implementar Ruta por Defecto¶
El error más frecuente y más costoso. Sin ruta por defecto, un mensaje que no cumple ninguna regla desaparece silenciosamente. El router hace ack del canal de entrada, pero no produce a ningún canal de salida. El mensaje se pierde sin traza. Esto puede pasar meses sin detectarse si los tipos de mensajes no clasificados son poco frecuentes.
Evaluar Reglas por Body Sin Necesidad¶
Si la información de routing puede colocarse en un header durante la producción del mensaje, hacerlo ahorra la deserialización completa del body en el router. Evaluar un campo del body de un mensaje de 2MB cuando un header de 20 bytes contiene la misma información es un desperdicio de recursos significativo.
Reglas Solapadas Sin Prioridad Definida¶
Si un mensaje puede cumplir múltiples reglas (por ejemplo, claim_type == 'AUTO' y amount > 50000 ambas evaluadas para el mismo mensaje), y no se define un orden de prioridad, el comportamiento depende de la implementación y puede ser no determinista.
Confundir Content-Based Router con Message Broker¶
Content-Based Router es un componente en un flujo de mensajes. No es una plataforma. No reemplaza al broker. A veces se confunde con un hub centralizado de routing (Message Broker pattern), lo cual lleva a sobrecargar al router con responsabilidades que no le corresponden (transformación, enriquecimiento, orquestación).
No Monitorear la Distribución de Tráfico¶
El router es el punto ideal para detectar anomalías en la distribución de mensajes. Si normalmente el 40% de las reclamaciones son de auto y de repente el 80% lo son, algo cambió en el negocio o en el sistema. No monitorear esta distribución pierde una fuente valiosa de intelligence operacional.
Router Con Estado¶
Implementar un router que recuerda mensajes anteriores para tomar decisiones de routing ("si el último mensaje fue de tipo X, entonces este va al canal Y") convierte el router en un componente stateful con todas las complejidades de persistencia, recovery y escalado que eso implica. Si se necesita routing basado en historial, use Process Manager, no Content-Based Router.
18. Conclusión Técnica¶
Content-Based Router es el patrón de routing más fundamental y más implementado en arquitecturas de integración. Su concepto — examinar el contenido de un mensaje y dirigirlo al canal correcto — es tan básico que aparece implícitamente en toda plataforma de mensajería moderna, desde reglas de EventBridge hasta filtros de suscripción en Service Bus, pasando por branching en Kafka Streams.
Cuándo aporta valor: siempre que un flujo de mensajes heterogéneos necesite distribuirse a procesadores especializados. El valor está en centralizar la lógica de routing en un punto único, visible y modificable, desacoplando al productor de los consumidores.
Cuándo evita problemas importantes: un Content-Based Router bien implementado — con ruta por defecto, reglas externalizadas, routing por header y monitoreo de distribución — evita los problemas más costosos: mensajes perdidos por falta de ruta, lógica de routing dispersa entre múltiples componentes, y acoplamiento del productor a la topología de consumo.
Cuándo no conviene adoptarlo: cuando el broker ofrece filtros nativos que cubren las necesidades de routing (Azure Service Bus subscriptions, SNS filter policies), un router explícito puede ser innecesario overhead. Cuando las reglas de routing cambian frecuentemente en runtime, Dynamic Router es más apropiado. Cuando el mensaje debe enviarse a múltiples destinos simultáneamente, Recipient List o Publish-Subscribe son las opciones correctas.
Recomendación para arquitectos: implemente Content-Based Router como un componente stateless, con reglas externalizadas en configuración, routing por header siempre que sea posible, ruta por defecto obligatoria y monitoreo de distribución de tráfico por canal de salida. Si su plataforma ofrece Content-Based Router como feature nativa (EventBridge rules, Service Bus filters, Kafka Streams branch), utilícela en lugar de implementar un router custom. La lógica de routing debe ser visible, testeable y modificable sin redespliegue.