Message Filter¶
1. Nombre del Patrón¶
- Nombre oficial: Message Filter
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Filtro de Mensajes
2. Resumen Ejecutivo¶
Message Filter es el patrón que examina cada mensaje en un canal y decide si lo deja pasar o lo descarta, basándose en criterios predefinidos. A diferencia de un Content-Based Router que dirige mensajes a diferentes destinos, el Message Filter tiene solo dos resultados posibles: el mensaje pasa (cumple los criterios) o el mensaje se elimina (no los cumple). Es el equivalente en mensajería de una cláusula WHERE en SQL o un filter() en una API de streaming.
El problema que resuelve es la contaminación de canales con mensajes irrelevantes que los consumidores deben recibir, inspeccionar y descartar, desperdiciando ancho de banda, procesamiento y complejidad de código. Message Filter elimina los mensajes no deseados antes de que lleguen al consumidor, garantizando que el consumidor solo recibe mensajes que le interesan y que puede procesar productivamente.
Este patrón es ubicuo en arquitecturas de IoT, streaming y procesamiento de eventos donde el volumen de datos crudos es órdenes de magnitud superior al volumen de datos relevantes. En un sistema de sensores industriales que genera millones de lecturas por minuto, el 99% puede ser ruido — lecturas normales que no requieren acción. Message Filter descarta el ruido en una etapa temprana del pipeline, reduciendo drásticamente la carga en los componentes downstream.
3. Definición Detallada¶
Propósito¶
Message Filter consume mensajes de un canal de entrada, evalúa cada mensaje contra un criterio de filtrado y produce únicamente los mensajes que cumplen el criterio en el canal de salida. Los mensajes que no cumplen se descartan (o se envían a un canal de descarte para auditoría).
Lógica Arquitectónica¶
En muchas arquitecturas de integración, un canal transporta mensajes que son relevantes para algunos consumidores pero irrelevantes para otros. Sin un filtro, los consumidores tienen dos opciones:
- Filtrar en el consumidor: el consumidor recibe todos los mensajes, evalúa cuáles le interesan y descarta el resto. Esto es simple pero ineficiente: el consumidor gasta recursos procesando mensajes que inmediatamente descarta.
- Canales granulares desde el origen: el productor publica en canales muy específicos para que cada consumidor solo reciba lo relevante. Esto es eficiente pero acopla al productor a las necesidades de filtrado de cada consumidor.
Message Filter resuelve este dilema insertándose entre el canal de origen y el consumidor, eliminando los mensajes irrelevantes antes de que lleguen al consumidor. El productor no necesita cambiar; el consumidor recibe un flujo limpio.
Diferencia Fundamental con Content-Based Router¶
La distinción es conceptual y arquitectónicamente importante:
- Content-Based Router: N canales de salida. Cada mensaje va a algún canal. No se pierde ningún mensaje (incluyendo la ruta por defecto). El propósito es distribuir.
- Message Filter: 1 canal de salida (más un opcional canal de descarte). Los mensajes que no cumplen el criterio se eliminan deliberadamente. El propósito es reducir volumen.
El Message Filter acepta la pérdida intencional de mensajes. El Content-Based Router no pierde ninguno.
Criterios de Filtrado¶
Los criterios pueden basarse en:
- Umbral numérico: temperatura > 80°C, vibración > 5mm/s, presión fuera de rango.
- Presencia de campo: mensajes que contienen (o no) un campo específico.
- Patrón de texto: mensajes cuyo contenido coincide con una expresión regular.
- Deduplicación: mensajes cuyo ID ya fue procesado (Message Filter como deduplicador).
- Ventana temporal: solo mensajes dentro de las últimas N horas.
- Combinación: condiciones compuestas con AND/OR.
Posición en el Pipeline¶
La posición del filtro en el pipeline de procesamiento tiene impacto directo en la eficiencia:
- Filtro temprano (cerca del productor): reduce el volumen lo antes posible, aliviando toda la cadena downstream. Es la posición preferida.
- Filtro tardío (cerca del consumidor): permite que transformaciones o enriquecimientos previos generen los campos necesarios para el filtrado. Es necesario cuando el criterio depende de información que el mensaje crudo no tiene.
- Filtro en cascada: múltiples filtros en serie, cada uno reduciendo el volumen progresivamente con criterios diferentes.
Contexto en el que Emerge¶
Message Filter emerge en escenarios de alto volumen donde la mayoría de los mensajes son ruido o no relevantes para un consumidor específico: telemetría IoT, logs de aplicaciones, feeds de datos de mercados financieros, flujos de eventos de auditoría.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
En un sistema de manufactura con 10,000 sensores que reportan cada segundo, se generan 600,000 lecturas por minuto. El 99% son lecturas normales dentro de rangos operativos que no requieren ninguna acción. Solo el 1% (6,000 lecturas/minuto) son lecturas anómalas que indican condiciones que requieren atención: temperaturas elevadas, vibraciones excesivas, presiones fuera de rango.
Sin filtrado, el sistema de alertas debe: 1. Recibir las 600,000 lecturas por minuto. 2. Evaluar cada una contra umbrales de alerta. 3. Descartar 594,000 (99%) y procesar 6,000 (1%).
Esto implica dimensionar la infraestructura de alertas para 600,000 mensajes/minuto cuando solo necesita procesar 6,000.
Síntomas del Problema¶
- Consumidores sobredimensionados para manejar un volumen de mensajes del cual solo procesan un porcentaje mínimo.
- Costos de red y storage inflados por tráfico de mensajes irrelevantes.
- Latencia de procesamiento elevada porque los mensajes relevantes compiten por recursos con los irrelevantes.
- Código de consumidores contaminado con lógica de filtrado que es ortogonal a su responsabilidad de negocio.
- Métricas de throughput engañosas: "procesamos 600,000 mensajes/minuto" cuando realmente solo 6,000 generan valor.
Impacto Operativo y Arquitectónico¶
Sin Message Filter:
- La infraestructura se dimensiona por el volumen bruto, no por el volumen relevante, multiplicando costos.
- Los consumidores mezclan lógica de filtrado con lógica de negocio, reduciendo cohesión y aumentando complejidad.
- La adición de nuevos criterios de filtrado requiere cambios en el consumidor, que es el componente equivocado para esa responsabilidad.
- El monitoreo no distingue entre mensajes descartados y mensajes procesados, dificultando la observabilidad real.
Riesgos Si No Se Implementa Correctamente¶
- Filtro demasiado agresivo: un criterio de filtrado incorrecto descarta mensajes que deberían procesarse, causando pérdida de datos o alertas no generadas.
- Filtro silencioso: un filtro que descarta mensajes sin logging ni métricas hace imposible saber cuántos mensajes se están perdiendo y por qué.
- Filtro no testeable: criterios de filtrado embebidos en código sin tests unitarios que validen los edge cases.
- Filtro en posición incorrecta: un filtro colocado después de una transformación costosa desperdicia el trabajo de transformación en mensajes que luego se descartan.
Ejemplos Reales¶
- Manufactura: sensores de vibración en una turbina eólica reportan cada 100ms. Solo las lecturas que exceden 4mm/s (indicadoras de desalineamiento) se envían al sistema de mantenimiento predictivo. El 99.5% se descarta.
- Seguridad informática: un SIEM recibe millones de eventos de log por minuto. Un Message Filter descarta eventos de nivel DEBUG y INFO, dejando pasar solo WARNING, ERROR y CRITICAL para análisis de seguridad.
- Trading: un feed de precios de mercado genera actualizaciones cada milisegundo para miles de instrumentos. Un trader solo está interesado en instrumentos de su portfolio. Un Message Filter descarta las actualizaciones de instrumentos irrelevantes.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un canal transporta un volumen de mensajes significativamente mayor al que un consumidor necesita procesar.
- Cuando los criterios de filtrado son evaluables localmente (sin lookups externos a bases de datos o servicios).
- Cuando la pérdida deliberada de mensajes filtrados es aceptable y deseada.
- Cuando se quiere reducir carga en componentes downstream sin modificar al productor.
Cuándo No Usarlo¶
- Si todos los mensajes del canal son relevantes para el consumidor (no hay nada que filtrar).
- Si los mensajes descartados deben procesarse por otro consumidor: use Content-Based Router en lugar de Message Filter.
- Si el criterio de filtrado requiere información de múltiples mensajes (correlación): use Aggregator.
- Si la tasa de filtrado es muy baja (se descarta menos del 5%), el overhead del filtro puede no justificar el beneficio.
Precondiciones¶
- Los mensajes contienen la información necesaria para evaluar el criterio de filtrado.
- La pérdida de mensajes filtrados es aceptable por diseño (no es un bug, es la intención).
- Existe un criterio claro y determinista para distinguir mensajes relevantes de irrelevantes.
Restricciones¶
- El filtro debe ser stateless (la decisión sobre un mensaje no depende de mensajes anteriores, a menos que sea un filtro de deduplicación que mantiene un cache de IDs).
- El criterio de filtrado debe ser evaluable rápidamente para no convertirse en cuello de botella.
- Los mensajes descartados no se pueden recuperar una vez eliminados (a menos que haya un canal de descarte).
Dependencias¶
- Canal de entrada con mensajes disponibles.
- Canal de salida para mensajes que pasan el filtro.
- Opcionalmente, canal de descarte para mensajes eliminados (para auditoría o reprocesamiento).
Supuestos Arquitectónicos¶
- Los productores no pueden (o no deben) filtrar en origen por razones de desacoplamiento.
- El volumen de mensajes irrelevantes justifica un componente de filtrado.
- El criterio de filtrado es estable; si cambia frecuentemente, considere externalizarlo en configuración.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- IoT y telemetría industrial (filtrado de ruido de sensores).
- Observabilidad y logging (filtrado por severidad).
- Streaming financiero (filtrado por instrumentos de interés).
- Event-driven architectures con eventos de granularidad fina que no todos los consumidores necesitan.
6. Fuerzas Arquitectónicas¶
Eficiencia vs. Completitud¶
El propósito del filtro es descartar mensajes, lo cual mejora la eficiencia del pipeline pero introduce el riesgo de descartar mensajes que deberían haberse procesado. La tensión entre filtrar agresivamente (máxima eficiencia) y filtrar conservadoramente (mínimo riesgo de pérdida) es la fuerza dominante.
Posición del Filtro vs. Costo de Evaluación¶
Un filtro temprano en el pipeline reduce el volumen lo antes posible, pero puede no tener acceso a toda la información necesaria para filtrar correctamente (campos que se añaden por transformación posterior). Un filtro tardío tiene toda la información pero no reduce el volumen en las etapas intermedias.
Simplicidad de Criterio vs. Precisión¶
Criterios simples (campo == valor, campo > umbral) son rápidos de evaluar y fáciles de entender, pero pueden ser imprecisos (falsos positivos que pasan, o falsos negativos que se descartan incorrectamente). Criterios complejos (combinaciones de condiciones, patrones, lookups) son más precisos pero más lentos y difíciles de mantener.
Descarte Silencioso vs. Auditable¶
Descartar mensajes sin registro es eficiente pero opaco: no hay forma de saber qué se perdió ni por qué. Enviar mensajes descartados a un canal de auditoría ofrece visibilidad pero reduce el beneficio de eficiencia (se sigue moviendo el mensaje, solo que a un destino diferente). El compromiso típico es logging de métricas (contadores de descarte por criterio) sin almacenar el contenido del mensaje descartado.
Acoplamiento al Formato vs. Flexibilidad¶
El filtro se acopla a la estructura del mensaje (debe saber qué campo inspeccionar y qué formato tiene). Si el formato del mensaje cambia, el filtro puede fallar silenciosamente (evaluar un campo que ya no existe, siempre pasar o siempre descartar).
Stateless vs. Stateful Filtering¶
Un filtro stateless evalúa cada mensaje independientemente: simple, escalable, predecible. Un filtro stateful mantiene estado entre mensajes (deduplicación, rate limiting, ventanas temporales): más potente pero más complejo y difícil de escalar.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor (Sender): genera mensajes sin conocimiento del filtrado posterior.
- Canal de Entrada (Input Channel): canal con todos los mensajes, relevantes e irrelevantes.
- Message Filter: componente que evalúa cada mensaje y decide si pasa o se descarta.
- Criterio de Filtrado (Filter Predicate): condición evaluable que determina si un mensaje es relevante.
- Canal de Salida (Output Channel): canal con solo los mensajes que pasaron el filtro.
- Canal de Descarte (Discard Channel): canal opcional para mensajes eliminados (auditoría).
- Consumidor (Receiver): recibe y procesa exclusivamente mensajes filtrados.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[(Canal de Entrada)]
B --> C[Filter consume mensaje]
C --> D{Cumple criterio\nde filtrado?}
D -- Sí --> E[(Canal de Salida)]
E --> F[Hacer ack en\ncanal de entrada]
D -- No --> G[(Canal de Descarte\nopcional)]
G --> H[Incrementar contador\nde descartados]
H --> I[Hacer ack en\ncanal de entrada]
F --> J[Consumidor procesa\nmensajes filtrados]
J --> K([Fin])
I --> KResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Enviar mensajes sin preocuparse por filtrado |
| Canal de Entrada | Transportar todos los mensajes |
| Message Filter | Evaluar criterio, pasar o descartar, registrar métricas |
| Criterio de Filtrado | Definir qué constituye un mensaje relevante |
| Canal de Salida | Transportar solo mensajes filtrados |
| Canal de Descarte | Almacenar mensajes descartados para auditoría |
| Consumidor | Procesar mensajes relevantes |
Interacciones¶
- Canal de Entrada → Filter: consumo de cada mensaje para evaluación.
- Filter → Criterio: evaluación de la condición.
- Filter → Canal de Salida: producción del mensaje si pasa el filtro.
- Filter → Canal de Descarte: producción del mensaje si no pasa (opcional).
- Filter → Métricas: incremento de contadores (passed, discarded).
Contratos Implícitos¶
- El mensaje contiene los campos que el criterio de filtrado necesita evaluar.
- Los mensajes descartados no se recuperan (a menos que exista el canal de descarte).
- El filtro no modifica el mensaje: lo pasa tal cual o lo descarta.
Decisiones de Diseño Clave¶
- Criterio inclusivo vs. exclusivo: ¿el filtro define qué pasa (whitelist) o qué se descarta (blacklist)?
- Descarte silencioso vs. auditable: ¿se registra qué mensajes se descartaron y por qué?
- Filtro en el broker vs. en un componente: ¿se usa un filtro nativo del broker (subscription filter) o un componente explícito?
- Stateless vs. stateful: ¿la evaluación es por mensaje individual o requiere contexto (deduplicación, ventana)?
- Posición en el pipeline: ¿dónde se inserta el filtro para máxima eficiencia?
8. Ejemplo Arquitectónico Detallado¶
Dominio: IoT/Manufactura — Filtrado de Ruido en Sensores Industriales¶
Contexto del Negocio¶
Una planta de manufactura de componentes automotrices opera 200 máquinas CNC distribuidas en 4 líneas de producción. Cada máquina tiene 8 sensores que monitorean temperatura del husillo, vibración, presión de refrigerante, consumo eléctrico, velocidad de corte, temperatura del refrigerante, humedad ambiental y estado de herramienta. Los sensores reportan cada 500ms, generando 3,200 lecturas por segundo (200 máquinas × 8 sensores × 1 lectura cada 500ms = 3,200/s), equivalente a 192,000 lecturas por minuto.
Necesidad de Integración¶
De las 192,000 lecturas por minuto, solo un pequeño porcentaje requiere acción:
- Lecturas normales (~95%): valores dentro de rangos operativos. No requieren ninguna acción.
- Lecturas de advertencia (~4%): valores cercanos a los límites pero aún aceptables. Requieren registro para tendencias pero no acción inmediata.
- Lecturas críticas (~1%): valores fuera de rangos operativos. Requieren alerta inmediata, posible parada de máquina y notificación a mantenimiento.
El sistema de mantenimiento predictivo, las alertas de planta y el dashboard operativo no necesitan recibir las 192,000 lecturas/minuto. Necesitan solo las ~9,600 lecturas/minuto de advertencia y las ~1,920 lecturas/minuto críticas.
Sistemas Involucrados¶
- Sensor Gateway: recibe datos de los 1,600 sensores vía protocolo OPC-UA y los publica en Kafka.
- Message Filter — Noise Reducer: filtra lecturas normales, dejando pasar solo advertencias y críticas.
- Predictive Maintenance Service: analiza tendencias de lecturas de advertencia para predecir fallos.
- Real-Time Alert Service: genera alertas inmediatas para lecturas críticas.
- Plant Dashboard: visualiza el estado de la planta en tiempo real.
- Data Lake: almacena todas las lecturas (incluyendo normales) para análisis histórico.
Restricciones Técnicas¶
- Latencia máxima para alertas críticas: 2 segundos desde la lectura del sensor.
- El Data Lake necesita todas las lecturas, no solo las filtradas.
- Los umbrales de filtrado varían por tipo de sensor y modelo de máquina.
- Los umbrales deben poder modificarse sin redespliegue (ajustes estacionales, calibración).
Diseño del Filtro¶
| Canal | Contenido | Volumen |
|---|---|---|
sensors.readings.raw | Todas las lecturas de todos los sensores | 192,000/min |
sensors.readings.significant | Lecturas de advertencia + críticas | ~11,520/min |
sensors.readings.critical | Solo lecturas críticas | ~1,920/min |
sensors.readings.discarded | Métricas de descarte (no el contenido) | Agregado cada minuto |
Configuración de Umbrales¶
filter_thresholds:
spindle_temperature:
warning: 65.0 # °C
critical: 80.0
vibration:
warning: 3.5 # mm/s
critical: 5.0
coolant_pressure:
warning_low: 2.0 # bar
warning_high: 6.0
critical_low: 1.5
critical_high: 7.0
power_consumption:
warning_high: 45.0 # kW (relativo al baseline de la máquina)
critical_high: 55.0
Decisiones Arquitectónicas¶
-
Filtrado en cascada: dos filtros en serie. El primero separa lecturas significativas (warning + critical) de normales. El segundo separa críticas de warnings. Esto permite que el Predictive Maintenance consuma del canal intermedio (warning + critical) y el Alert Service consuma del canal final (solo critical).
-
Data Lake consume del raw: el Data Lake no pasa por el filtro. Consume directamente del canal
sensors.readings.rawpara almacenar todas las lecturas sin excepción. El filtro no está en el camino del Data Lake. -
Umbrales externalizados: los umbrales están en un archivo YAML que se recarga periódicamente (cada 60 segundos). Si un ingeniero de planta ajusta un umbral, el filtro lo aplica sin redespliegue.
-
Métricas de descarte: en lugar de enviar cada lectura descartada a un canal de auditoría (lo cual anularía el beneficio del filtrado), se envía un resumen agregado cada minuto: cuántas lecturas se descartaron por tipo de sensor, por máquina, por criterio.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Lectura del Sensor¶
La máquina CNC-047 en la Línea 2 genera una lectura de su sensor de temperatura de husillo:
{
"sensor_id": "CNC-047-SPINDLE-TEMP",
"machine_id": "CNC-047",
"production_line": "LINE-2",
"sensor_type": "spindle_temperature",
"timestamp": "2026-04-07T14:32:15.500Z",
"value": 42.3,
"unit": "celsius",
"quality": "GOOD"
}
El Sensor Gateway publica esta lectura en el canal sensors.readings.raw con machine_id como partition key.
Paso 2: Evaluación del Primer Filtro (Noise Reducer)¶
El Message Filter consume la lectura del canal sensors.readings.raw:
- Lee el campo
sensor_type:spindle_temperature. - Busca los umbrales para
spindle_temperature: warning = 65.0°C, critical = 80.0°C. - Compara el valor (42.3°C) contra los umbrales.
- 42.3°C < 65.0°C (umbral de warning) → LECTURA NORMAL → DESCARTAR.
- Incrementa el contador
discarded_count[CNC-047][spindle_temperature]. - Hace ack del mensaje en el canal de entrada.
- No produce nada al canal de salida.
Paso 3: Lectura Significativa¶
Treinta minutos después, la misma máquina reporta:
{
"sensor_id": "CNC-047-SPINDLE-TEMP",
"machine_id": "CNC-047",
"production_line": "LINE-2",
"sensor_type": "spindle_temperature",
"timestamp": "2026-04-07T15:02:45.000Z",
"value": 71.8,
"unit": "celsius",
"quality": "GOOD"
}
El filtro evalúa: 1. Valor 71.8°C ≥ 65.0°C (warning) pero < 80.0°C (critical) → WARNING → PASAR. 2. Produce el mensaje al canal sensors.readings.significant con clasificación añadida en header: severity: WARNING. 3. Hace ack del mensaje en el canal de entrada.
Paso 4: Lectura Crítica¶
Cinco minutos después:
{
"sensor_id": "CNC-047-SPINDLE-TEMP",
"machine_id": "CNC-047",
"production_line": "LINE-2",
"sensor_type": "spindle_temperature",
"timestamp": "2026-04-07T15:07:12.500Z",
"value": 83.4,
"unit": "celsius",
"quality": "GOOD"
}
El primer filtro evalúa: 1. Valor 83.4°C ≥ 65.0°C → PASAR al canal sensors.readings.significant con severity: CRITICAL.
El segundo filtro (que consume de sensors.readings.significant) evalúa: 1. Header severity == CRITICAL → PASAR al canal sensors.readings.critical.
El Real-Time Alert Service consume del canal sensors.readings.critical: 1. Genera alerta inmediata: "CNC-047 SPINDLE TEMPERATURE CRITICAL: 83.4°C (threshold: 80.0°C)". 2. Envía notificación push al supervisor de Línea 2. 3. Registra la alerta en el sistema de incidentes. 4. Evalúa si debe solicitar parada automática de la máquina (basándose en la tendencia: 42.3 → 71.8 → 83.4 en 35 minutos indica un fallo progresivo).
Paso 5: Resumen de Descarte¶
Cada minuto, el filtro emite un resumen agregado:
{
"timestamp": "2026-04-07T15:07:00Z",
"window": "1_minute",
"total_received": 3200,
"total_passed": 148,
"total_discarded": 3052,
"pass_rate": 0.046,
"by_sensor_type": {
"spindle_temperature": {"received": 400, "passed": 22, "discarded": 378},
"vibration": {"received": 400, "passed": 45, "discarded": 355},
"coolant_pressure": {"received": 400, "passed": 18, "discarded": 382},
"power_consumption": {"received": 400, "passed": 31, "discarded": 369}
}
}
Este resumen se envía al canal sensors.readings.discarded y alimenta el dashboard de operaciones del filtro.
Paso 6: Consumo Paralelo del Data Lake¶
Mientras el filtro descarta lecturas normales, el Data Lake Ingestion consume directamente del canal sensors.readings.raw sin filtrar:
- Recibe las 192,000 lecturas/minuto.
- Las acumula en micro-batches de 5 minutos.
- Escribe en formato Parquet particionado por
production_lineydate. - Los data scientists acceden al histórico completo para entrenar modelos de mantenimiento predictivo.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
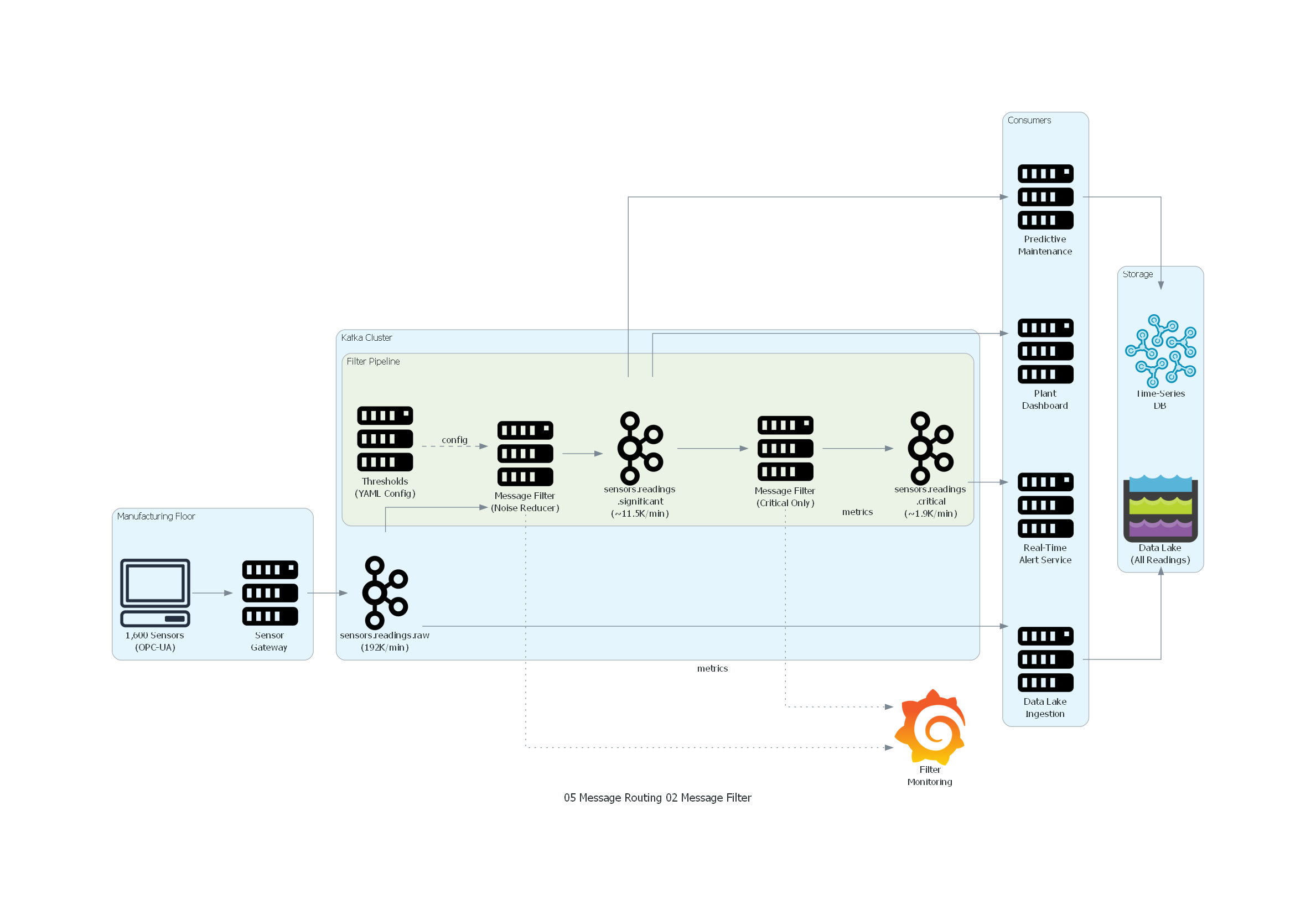
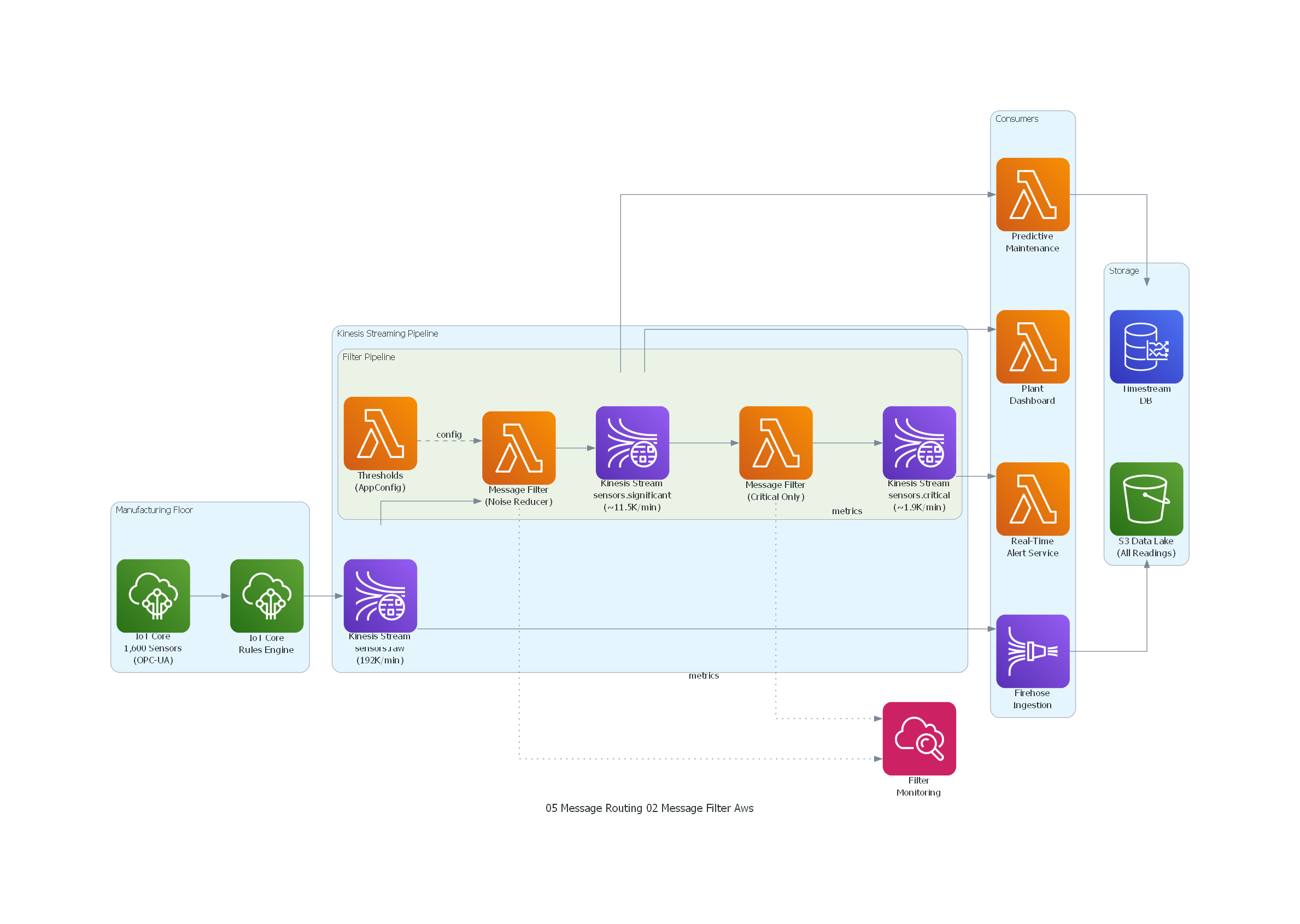
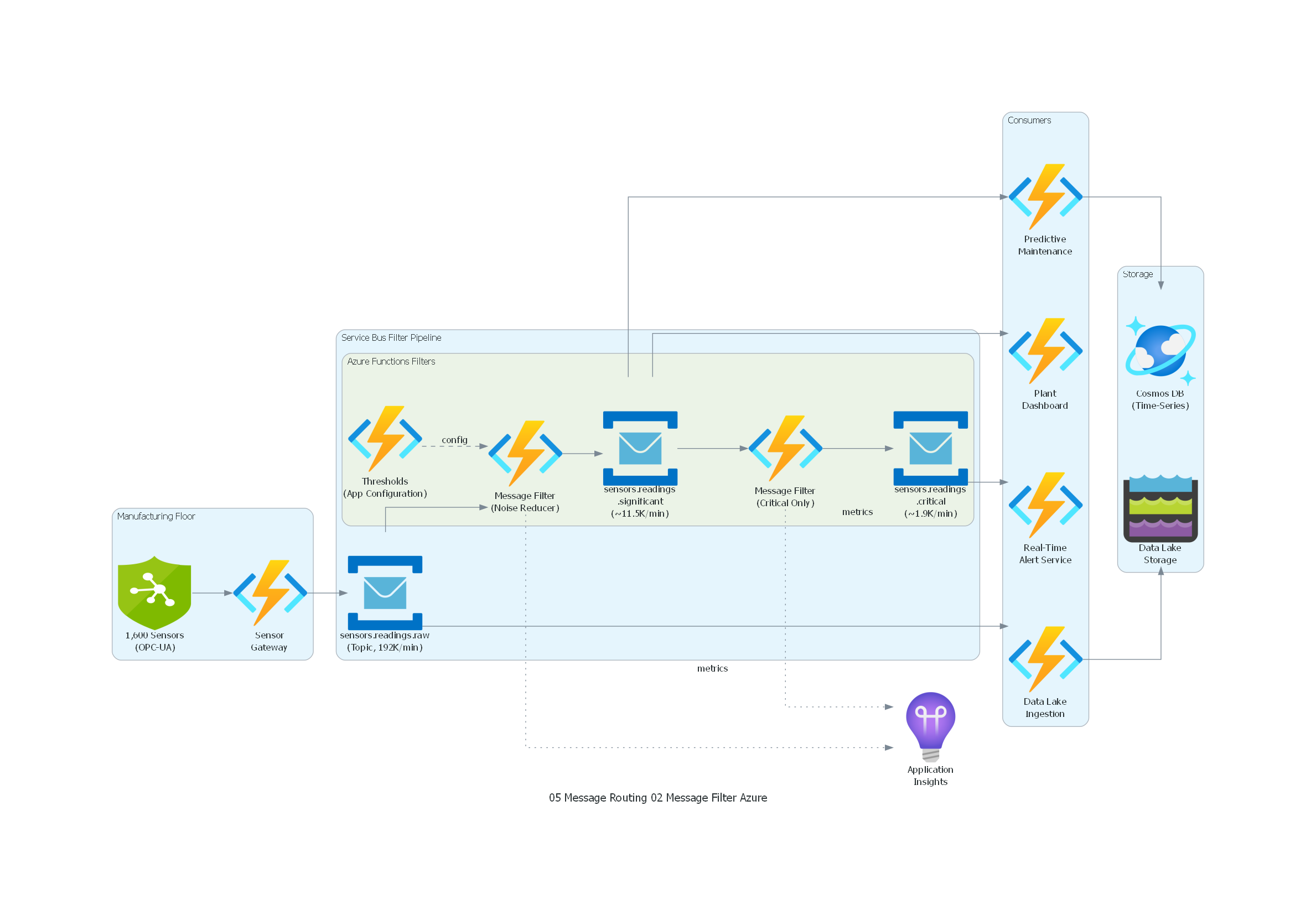
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.client import Client
from diagrams.onprem.monitoring import Grafana
from diagrams.onprem.database import InfluxDB
from diagrams.azure.storage import DataLakeStorage
with Diagram("Message Filter - IoT Sensor Noise Reduction", show=False, direction="LR"):
with Cluster("Manufacturing Floor"):
sensors = Client("1,600 Sensors\n(OPC-UA)")
gateway = Server("Sensor\nGateway")
with Cluster("Kafka Cluster"):
raw = Kafka("sensors.readings.raw\n(192K/min)")
with Cluster("Filter Pipeline"):
filter1 = Server("Message Filter\n(Noise Reducer)")
thresholds = Server("Thresholds\n(YAML Config)")
significant = Kafka("sensors.readings\n.significant\n(~11.5K/min)")
filter2 = Server("Message Filter\n(Critical Only)")
critical = Kafka("sensors.readings\n.critical\n(~1.9K/min)")
with Cluster("Consumers"):
predictive = Server("Predictive\nMaintenance")
alerts = Server("Real-Time\nAlert Service")
dashboard = Server("Plant\nDashboard")
datalake = Server("Data Lake\nIngestion")
with Cluster("Storage"):
tsdb = InfluxDB("Time-Series\nDB")
lake = DataLakeStorage("Data Lake\n(All Readings)")
monitoring = Grafana("Filter\nMonitoring")
# Flow
sensors >> gateway >> raw
raw >> filter1
thresholds >> Edge(style="dashed", label="config") >> filter1
filter1 >> significant
significant >> filter2
filter2 >> critical
significant >> predictive >> tsdb
critical >> alerts
significant >> dashboard
raw >> datalake >> lake
filter1 >> Edge(style="dotted", label="metrics") >> monitoring
filter2 >> Edge(style="dotted", label="metrics") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Timestream
from diagrams.aws.analytics import KinesisDataStreams, KinesisDataFirehose
from diagrams.aws.iot import IotCore
from diagrams.aws.management import Cloudwatch
from diagrams.aws.storage import S3
with Diagram("Message Filter - IoT Sensor Noise Reduction (AWS)", show=False, direction="LR"):
with Cluster("Manufacturing Floor"):
sensors = IotCore("IoT Core\n1,600 Sensors\n(OPC-UA)")
gateway = IotCore("IoT Core\nRules Engine")
with Cluster("Kinesis Streaming Pipeline"):
raw = KinesisDataStreams("Kinesis Stream\nsensors.raw\n(192K/min)")
with Cluster("Filter Pipeline"):
filter1 = Lambda("Message Filter\n(Noise Reducer)")
thresholds = Lambda("Thresholds\n(AppConfig)")
significant = KinesisDataStreams("Kinesis Stream\nsensors.significant\n(~11.5K/min)")
filter2 = Lambda("Message Filter\n(Critical Only)")
critical = KinesisDataStreams("Kinesis Stream\nsensors.critical\n(~1.9K/min)")
with Cluster("Consumers"):
predictive = Lambda("Predictive\nMaintenance")
alerts = Lambda("Real-Time\nAlert Service")
dashboard = Lambda("Plant\nDashboard")
datalake = KinesisDataFirehose("Firehose\nIngestion")
with Cluster("Storage"):
tsdb = Timestream("Timestream\nDB")
lake = S3("S3 Data Lake\n(All Readings)")
monitoring = Cloudwatch("Filter\nMonitoring")
# Flow
sensors >> gateway >> raw
raw >> filter1
thresholds >> Edge(style="dashed", label="config") >> filter1
filter1 >> significant
significant >> filter2
filter2 >> critical
significant >> predictive >> tsdb
critical >> alerts
significant >> dashboard
raw >> datalake >> lake
filter1 >> Edge(style="dotted", label="metrics") >> monitoring
filter2 >> Edge(style="dotted", label="metrics") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.iot import IotHubSecurity
from diagrams.azure.storage import DataLakeStorage
with Diagram("Message Filter - IoT Sensor Noise Reduction (Azure)", show=False, direction="LR"):
with Cluster("Manufacturing Floor"):
sensors = IotHubSecurity("1,600 Sensors\n(OPC-UA)")
gateway = FunctionApps("Sensor\nGateway")
with Cluster("Service Bus Filter Pipeline"):
raw = ServiceBus("sensors.readings.raw\n(Topic, 192K/min)")
with Cluster("Azure Functions Filters"):
filter1 = FunctionApps("Message Filter\n(Noise Reducer)")
thresholds = FunctionApps("Thresholds\n(App Configuration)")
significant = ServiceBus("sensors.readings\n.significant\n(~11.5K/min)")
filter2 = FunctionApps("Message Filter\n(Critical Only)")
critical = ServiceBus("sensors.readings\n.critical\n(~1.9K/min)")
with Cluster("Consumers"):
predictive = FunctionApps("Predictive\nMaintenance")
alerts = FunctionApps("Real-Time\nAlert Service")
dashboard = FunctionApps("Plant\nDashboard")
datalake = FunctionApps("Data Lake\nIngestion")
with Cluster("Storage"):
tsdb = CosmosDb("Cosmos DB\n(Time-Series)")
lake = DataLakeStorage("Data Lake\nStorage")
monitoring = ApplicationInsights("Application\nInsights")
# Flow
sensors >> gateway >> raw
raw >> filter1
thresholds >> Edge(style="dashed", label="config") >> filter1
filter1 >> significant
significant >> filter2
filter2 >> critical
significant >> predictive >> tsdb
critical >> alerts
significant >> dashboard
raw >> datalake >> lake
filter1 >> Edge(style="dotted", label="metrics") >> monitoring
filter2 >> Edge(style="dotted", label="metrics") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura de filtrado en cascada para el sistema de manufactura:
- Manufacturing Floor: 1,600 sensores envían lecturas al Sensor Gateway que las publica en el canal raw.
- Filter Pipeline: dos filtros en serie. El primero reduce 192K lecturas/min a ~11.5K (solo warning + critical). El segundo reduce a ~1.9K (solo critical).
- Consumers: el Predictive Maintenance y el Dashboard consumen del canal intermedio (todas las lecturas significativas). El Alert Service consume del canal final (solo críticas). El Data Lake consume del canal raw (todas sin filtrar).
- Monitoring: Grafana monitorea la tasa de descarte, throughput y latencia de ambos filtros.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Productor | Sensor Gateway |
| Canal de Entrada | sensors.readings.raw |
| Message Filter | Noise Reducer, Critical Only |
| Criterio de Filtrado | Thresholds (YAML Config) |
| Canal de Salida | sensors.readings.significant, sensors.readings.critical |
| Mensajes Descartados | 95% descartados por primer filtro, 83% del resto por segundo |
| Consumidores | Predictive Maintenance, Alert Service, Dashboard, Data Lake |
11. Beneficios¶
Impacto Técnico¶
- Reducción drástica de volumen: de 192,000 lecturas/minuto a 11,520 para procesamiento analítico y a 1,920 para alertas. Una reducción del 94% y 99% respectivamente.
- Infraestructura dimensionada correctamente: el servicio de alertas se dimensiona para 1,920 mensajes/minuto en lugar de 192,000. Reducción de costos de cómputo de ~99%.
- Latencia reducida: los mensajes críticos no compiten por recursos con lecturas normales. La latencia end-to-end para alertas se reduce significativamente.
- Separación de concerns: el filtro absorbe la lógica de clasificación por umbral. Los consumidores no necesitan conocer los umbrales.
Impacto Organizacional¶
- Equipos enfocados: el equipo de alertas trabaja con un stream limpio de lecturas críticas, sin preocuparse por filtrar ruido.
- Configuración operacional: los ingenieros de planta pueden ajustar umbrales sin involucrar al equipo de desarrollo.
- Vocabulario compartido: la clasificación en "normal", "warning", "critical" establece un lenguaje común entre operaciones, ingeniería y mantenimiento.
Impacto Operacional¶
- Observabilidad del filtrado: las métricas de descarte revelan patrones: si el porcentaje de lecturas significativas sube del 5% habitual al 15%, algo está cambiando en la planta (degradación generalizada, problema ambiental).
- Ajuste de sensibilidad: los umbrales se pueden ajustar operacionalmente para equilibrar entre falsos positivos (demasiadas alertas) y falsos negativos (alertas perdidas).
- Costo proporcional al valor: los recursos de procesamiento se gastan en mensajes que generan valor, no en ruido.
Beneficios de Mantenibilidad y Evolución¶
- Umbrales como configuración: nuevos modelos de máquina con umbrales diferentes se añaden sin cambiar código.
- Filtros adicionales: se pueden añadir filtros en cascada (por ejemplo, un filtro que solo deja pasar lecturas de la Línea 2 para un análisis específico) sin modificar los existentes.
- Evolución del criterio: si los data scientists descubren que la combinación temperatura + vibración es mejor predictor que cada uno individualmente, el criterio del filtro se puede actualizar.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente adicional en el pipeline: cada filtro es un componente que hay que desplegar, monitorear y escalar.
- Configuración de umbrales: los umbrales correctos requieren conocimiento de dominio (ingeniería de manufactura) que el equipo de desarrollo puede no tener.
- Testing de filtrado: verificar que el filtro descarta exactamente lo que debe y pasa exactamente lo que debe requiere datasets de prueba representativos.
Riesgos de Mal Uso¶
- Filtro como sustituto de diseño de canales: usar filtros en cadena para reducir un canal sobrecargado cuando la solución correcta es diseñar canales con granularidad adecuada desde el origen.
- Descarte irrecuperable: si no existe un canal de descarte ni el Data Lake consume el raw, las lecturas descartadas son irrecuperables. Si posteriormente se descubre que un umbral era incorrecto, los datos se perdieron.
- Filtro opaco: un filtro sin métricas de descarte es una caja negra. Si el pass rate baja del 5% al 0.1%, podría indicar un cambio en los datos de entrada o un bug en el filtro, pero sin métricas no se puede distinguir.
Sobreingeniería¶
- Filtro cuando el broker ya filtra: si la plataforma ofrece filtrado nativo (Azure Service Bus subscription filters, SNS filter policies, Kafka Streams
filter()), implementar un componente externo es redundante. - Pipeline de filtros demasiado largo: más de 2-3 filtros en cascada indica que la lógica de filtrado debería consolidarse en un solo componente más inteligente.
Costos de Operación¶
- Mantenimiento de umbrales: los umbrales requieren revisión periódica. Lo que era "normal" hace un año puede ser "warning" hoy si la máquina se ha desgastado.
- Falsos negativos costosos: si un umbral de critical es demasiado alto, una condición peligrosa no genera alerta, con potencial daño a la máquina o riesgo de seguridad.
Anti-Patterns Relacionados¶
- Filter as Router: usar múltiples Message Filters en paralelo, cada uno dejando pasar un tipo diferente, cuando lo correcto es un Content-Based Router.
- Late Filter: colocar el filtro al final del pipeline después de transformaciones costosas, desperdiciando el trabajo de transformación en mensajes que se descartan.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Channel (Capítulo 2): el filtro opera entre dos canales — consume de uno y produce al otro.
- Content-Based Router (este capítulo): el router generaliza el filtro a N destinos. El filtro es un caso especial con 1 destino (pasar) y 1 descarte.
- Wire Tap (Capítulo 3): se puede usar un Wire Tap antes del filtro para copiar todos los mensajes a un canal de auditoría antes de que el filtro descarte algunos.
- Dead Letter Channel (Capítulo 3): mensajes que el filtro no puede evaluar (formato corrupto, campo faltante) deben ir a dead-letter, no descartarse como "normales".
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Translator — normaliza el formato para que el filtro pueda evaluar campos de forma consistente.
- Después: Content-Based Router o procesamiento especializado sobre el stream filtrado.
Combinaciones Comunes¶
- Message Filter + Aggregator: filtrar mensajes individuales y luego agregar los que pasan (por ejemplo, filtrar lecturas significativas y luego calcular promedios por máquina por hora).
- Message Filter + Content-Based Router: primero filtrar ruido, luego enrutar los mensajes relevantes a procesadores especializados.
- Splitter + Message Filter: dividir un mensaje compuesto y luego filtrar las partes irrelevantes.
Diferencias con Patrones Similares¶
- vs. Content-Based Router: el router conserva todos los mensajes (los envía a diferentes destinos); el filtro descarta deliberadamente. Son conceptos complementarios, no alternativos.
- vs. Recipient List: la Recipient List envía a múltiples destinos; el filtro tiene un solo destino (o descarte).
- vs. Idempotent Receiver: el Idempotent Receiver descarta duplicados; el Message Filter descarta según criterio de contenido. Un filtro de deduplicación es la intersección de ambos.
Encaje en un Flujo Mayor de Integración¶
Message Filter se ubica típicamente al inicio de un pipeline de procesamiento, inmediatamente después del canal de ingestión. Su función es reducir el volumen lo antes posible para que los componentes downstream (routers, transformadores, aggregators) trabajen con un stream más limpio y manejable. En pipelines complejos, múltiples filtros en cascada reducen progresivamente el volumen en diferentes puntos del flujo.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Message Filter es más relevante hoy que cuando se formalizó, debido a la explosión del volumen de datos en arquitecturas modernas:
- IoT: billones de eventos de sensores requieren filtrado agresivo antes de procesamiento.
- Observabilidad: las plataformas de logging y tracing generan volúmenes masivos donde solo una fracción es accionable.
- Event streaming: arquitecturas event-driven con eventos de granularidad fina (cada click, cada movimiento del mouse) necesitan filtrar para analytics.
- Cloud costs: en cloud, cada mensaje procesado tiene un costo. Filtrar temprano reduce costos directamente.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación | Ejemplo |
|---|---|---|
| Kafka Streams | filter() operator | stream.filter((k, v) -> v.getTemp() > 65.0) |
| Apache Flink | filter() en DataStream | readings.filter(r -> r.value > threshold) |
| AWS EventBridge | Event patterns | Content-based filtering en reglas |
| Azure Service Bus | Subscription filters | SQL filter: temperature > 65 |
| AWS SNS | Filter policies | Attribute-based filtering |
| Google Pub/Sub | Subscription filters | Attribute-based filtering |
| Apache Camel | .filter() DSL | filter(body().method("isSignificant")) |
| Spring Cloud Stream | Function<Flux<T>, Flux<T>> | Reactive filter en el processor |
Qué Parte Sigue Siendo Esencial¶
- El concepto de filtrado como etapa explícita y configurable en un pipeline de mensajes.
- La posición del filtro en el pipeline como decisión de diseño con impacto en eficiencia.
- La necesidad de métricas de descarte para detectar anomalías en el ratio de filtrado.
- La distinción entre filtrar (descartar intencionalmente) y enrutar (dirigir a destinos diferentes), que permanece como una decisión arquitectónica fundamental.
15. Implementación en Arquitecturas Modernas¶
Kafka Streams¶
StreamsBuilder builder = new StreamsBuilder();
KStream<String, SensorReading> raw = builder.stream("sensors.readings.raw");
// Primer filtro: significativas (warning + critical)
KStream<String, SensorReading> significant = raw.filter(
(machineId, reading) -> {
Threshold threshold = thresholdStore.get(reading.getSensorType());
return reading.getValue() >= threshold.getWarning();
}
);
significant.to("sensors.readings.significant");
// Segundo filtro: solo críticas
KStream<String, SensorReading> critical = significant.filter(
(machineId, reading) -> {
Threshold threshold = thresholdStore.get(reading.getSensorType());
return reading.getValue() >= threshold.getCritical();
}
);
critical.to("sensors.readings.critical");
Apache Flink¶
DataStream<SensorReading> raw = env
.addSource(new FlinkKafkaConsumer<>("sensors.readings.raw", ...));
DataStream<SensorReading> significant = raw
.filter(reading -> {
double threshold = getWarningThreshold(reading.getSensorType());
return reading.getValue() >= threshold;
});
DataStream<SensorReading> critical = significant
.filter(reading -> {
double threshold = getCriticalThreshold(reading.getSensorType());
return reading.getValue() >= threshold;
});
significant.addSink(new FlinkKafkaProducer<>("sensors.readings.significant", ...));
critical.addSink(new FlinkKafkaProducer<>("sensors.readings.critical", ...));
Azure Service Bus¶
Topic: sensors-readings-raw
Subscription: significant-readings
SQL Filter: (sensor_type = 'spindle_temperature' AND value >= 65.0)
OR (sensor_type = 'vibration' AND value >= 3.5)
OR (sensor_type = 'coolant_pressure' AND (value <= 2.0 OR value >= 6.0))
OR (sensor_type = 'power_consumption' AND value >= 45.0)
Subscription: critical-readings
SQL Filter: (sensor_type = 'spindle_temperature' AND value >= 80.0)
OR (sensor_type = 'vibration' AND value >= 5.0)
OR (sensor_type = 'coolant_pressure' AND (value <= 1.5 OR value >= 7.0))
OR (sensor_type = 'power_consumption' AND value >= 55.0)
AWS — SNS + SQS con Filter Policy¶
Requiere que el productor clasifique la severidad como message attribute antes de publicar en SNS. Esto mueve la lógica de umbral al productor, lo cual puede o no ser deseable.
Apache Camel¶
from("kafka:sensors.readings.raw")
.filter(exchange -> {
SensorReading reading = exchange.getIn().getBody(SensorReading.class);
double threshold = getWarningThreshold(reading.getSensorType());
return reading.getValue() >= threshold;
})
.to("kafka:sensors.readings.significant");
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas del filtro: total_received, total_passed, total_discarded, pass_rate, latencia de evaluación, por tipo de sensor, por máquina, por criterio.
- Alertas de anomalía en pass_rate: si el pass_rate cambia significativamente (de 5% a 15%, o de 5% a 0.1%), algo cambió en el entorno o en el filtro.
- Distributed tracing: los mensajes que pasan el filtro deben propagar trace ID para trazabilidad end-to-end.
Monitoreo¶
- Pass rate por ventana temporal: dashboards que muestren la evolución del pass_rate en ventanas de 1min, 5min, 1h. Patrones temporales (más lecturas significativas durante el turno de noche) revelan condiciones operacionales.
- Latencia del filtro: si la evaluación del criterio se vuelve lenta, puede indicar que el criterio es demasiado complejo o que el lookup de umbrales tiene problemas.
- Consumer lag del filtro: si el filtro acumula lag, no puede procesar al ritmo de entrada, y los mensajes significativos se retrasan.
Versionado¶
- Versionado de umbrales: los archivos de configuración de umbrales deben estar en control de versiones (Git) con historial de cambios, justificación y aprobación.
- Rollback de umbrales: si un cambio de umbral produce falsos negativos (alertas perdidas), debe poder revertirse inmediatamente.
Seguridad¶
- Acceso a umbrales: solo ingenieros de planta autorizados deben poder modificar umbrales (un cambio incorrecto puede ocultar alertas de seguridad).
- Auditoría de cambios: cada cambio de umbral debe registrarse con quién, cuándo, por qué y qué valor anterior reemplazó.
Manejo de Errores¶
- Mensajes con formato corrupto o campos faltantes no deben descartarse como "normales". Deben enviarse a un canal de error con contexto diagnóstico.
- Si el filtro no puede cargar la configuración de umbrales, debe fallar ruidosamente (no silenciosamente dejar pasar todo o descartar todo).
Idempotencia¶
- El filtro debe ser idempotente: si recibe el mismo mensaje dos veces (por reintento), la decisión debe ser la misma y no debe producir duplicados en el canal de salida. Deduplicación por message_id si es necesario.
Performance¶
- Evaluación de umbrales en memoria: los umbrales deben estar cacheados en memoria, no consultados por red para cada mensaje.
- Batch evaluation: en frameworks de streaming (Flink, Kafka Streams), el filtro se evalúa como operador nativo del framework, aprovechando batch processing interno.
- Filtro temprano: colocar el filtro lo antes posible en el pipeline para reducir el volumen que procesan los componentes downstream.
Escalabilidad¶
- El filtro escala horizontalmente con el canal de entrada: más particiones = más instancias del filtro en paralelo.
- Stateless por diseño: cada instancia del filtro puede evaluar cualquier mensaje sin coordinación con otras instancias.
17. Errores Comunes¶
Umbral Incorrecto Que Oculta Alertas¶
El error más peligroso en un filtro industrial. Si el umbral de critical para temperatura se configura en 90°C cuando debería ser 80°C, las lecturas entre 80-90°C no generan alerta, y la máquina puede sufrir daños antes de que se detecte el problema. Los umbrales deben validarse con ingeniería y revisarse periódicamente.
Filtro Sin Métricas de Descarte¶
Un filtro que descarta mensajes sin registrar cuántos, de qué tipo y por qué criterio es una caja negra. Si el pass_rate baja del 5% al 0% (el filtro está descartando todo) por un bug, nadie lo nota hasta que el consumidor deja de recibir mensajes y un proceso de negocio falla.
Confundir Message Filter con Content-Based Router¶
Si los mensajes descartados deberían ir a otro procesador (no descartarse, sino procesarse de forma diferente), lo que se necesita es un Content-Based Router, no un Message Filter. Usar un filtro cuando se necesita un router produce pérdida de datos que debían procesarse.
Filtro Tardío en el Pipeline¶
Colocar el filtro después de una transformación costosa (deserialización de XML, enriquecimiento con lookup a base de datos, validación de schema) desperdicia el trabajo de transformación en mensajes que luego se descartan. Mover el filtro antes de la transformación es una optimización simple pero frecuentemente ignorada.
Filtro Con Criterio Estático Cuando Debería Ser Dinámico¶
Hardcodear umbrales en código cuando varían por tipo de sensor, modelo de máquina y estación del año produce un filtro inflexible que requiere redespliegue para cada ajuste. Los umbrales deben estar en configuración externa desde el diseño inicial.
Asumir Que el Data Lake También Se Filtra¶
Si el Data Lake consume del canal ya filtrado en lugar del raw, se pierden las lecturas normales que son necesarias para el análisis histórico y el entrenamiento de modelos de ML. El Data Lake generalmente debe consumir del canal sin filtrar.
18. Conclusión Técnica¶
Message Filter es el patrón de routing más simple pero uno de los más impactantes en términos de eficiencia. Su concepto — descartar mensajes irrelevantes antes de que lleguen al consumidor — es directo, pero su implementación correcta requiere disciplina en la definición de criterios, posicionamiento en el pipeline y observabilidad del descarte.
Cuándo aporta valor: en cualquier escenario donde el volumen de mensajes brutos es significativamente mayor que el volumen de mensajes relevantes para un consumidor. IoT industrial, observabilidad, streaming financiero y event-driven architectures con eventos de granularidad fina son los dominios donde Message Filter tiene mayor impacto.
Cuándo evita problemas importantes: un filtro bien posicionado — temprano en el pipeline, con umbrales externalizados, métricas de descarte y monitoreo de pass_rate — evita los problemas más costosos: infraestructura sobredimensionada para procesar ruido, consumidores contaminados con lógica de filtrado, y latencia excesiva por competencia de mensajes relevantes con irrelevantes.
Cuándo no conviene adoptarlo: si el volumen de mensajes irrelevantes es bajo (menos del 5%), el overhead del filtro puede no justificarse. Si los mensajes "irrelevantes" deben procesarse por otro sistema (no descartarse), lo que se necesita es un Content-Based Router. Si el criterio de filtrado requiere correlación entre mensajes, un Aggregator es más apropiado.
Recomendación para arquitectos: trate el Message Filter como la primera línea de defensa en un pipeline de alto volumen. Posiciónelo lo más temprano posible, externalice los criterios de filtrado en configuración, implemente métricas de descarte desde el día uno y monitoree el pass_rate como indicador de salud tanto del filtro como del sistema que genera los mensajes. La diferencia entre un filtro y un router es intencional y semántica: el filtro descarta, el router distribuye. No confunda los dos conceptos.