Splitter¶
1. Nombre del Patrón¶
- Nombre oficial: Splitter
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Divisor de Mensajes
2. Resumen Ejecutivo¶
Splitter es un patrón de enrutamiento que recibe un único mensaje compuesto — un mensaje que contiene múltiples elementos lógicamente independientes — y lo descompone en una secuencia de mensajes individuales, uno por cada elemento contenido en el mensaje original. Cada mensaje resultante puede procesarse de forma independiente y, potencialmente, en paralelo.
El problema fundamental que resuelve es la incompatibilidad entre la granularidad de producción y la granularidad de procesamiento. Los sistemas productores frecuentemente generan mensajes batch o compuestos (una orden con múltiples líneas, un archivo con múltiples registros, un evento con múltiples sub-eventos) porque es eficiente para el productor agrupar datos. Sin embargo, los sistemas consumidores frecuentemente necesitan procesar cada elemento individualmente porque la lógica de negocio, el routing, la validación o el escalamiento opera a nivel de elemento individual.
Splitter aparece en prácticamente toda arquitectura de integración que procesa datos batch o mensajes compuestos: descomposición de órdenes de compra en líneas individuales, extracción de registros individuales de archivos batch, conversión de eventos agregados en eventos atómicos, y expansión de colecciones contenidas en payloads JSON o XML.
3. Definición Detallada¶
Propósito¶
El propósito de Splitter es transformar la granularidad de un flujo de mensajes, convirtiendo un mensaje compuesto en múltiples mensajes simples. Esto permite que la lógica downstream opere sobre elementos individuales sin necesidad de conocer la estructura del contenedor original.
Lógica Arquitectónica¶
Splitter actúa como un punto de divergencia en el flujo de mensajes. Recibe un mensaje en su canal de entrada, inspecciona su contenido para identificar los elementos repetitivos, y produce N mensajes en su canal de salida, donde N es la cantidad de elementos encontrados en el mensaje original. Cada mensaje de salida contiene un único elemento, opcionalmente enriquecido con metadata del mensaje original (correlation ID, índice de posición, total de elementos).
La analogía operacional es una estación de desempaque en una línea de producción: llega una caja con múltiples productos, la estación abre la caja, extrae cada producto individualmente y lo coloca en la línea de producción para procesamiento independiente.
Principio de Diseño Subyacente¶
El principio fundamental es la descomposición para procesamiento granular. En sistemas de integración, la granularidad óptima para producción raramente coincide con la granularidad óptima para procesamiento. Splitter resuelve esta discordancia al permitir que cada sistema opere en su granularidad natural: el productor genera mensajes compuestos eficientemente, y los consumidores procesan elementos individuales eficientemente.
Este principio está alineado con el operador flatMap en programación funcional: una función que transforma cada elemento de una colección en una colección y luego aplana el resultado en una única secuencia.
Problema Estructural que Resuelve¶
Sin Splitter, el procesamiento de mensajes compuestos requiere que cada consumidor downstream implemente su propia lógica de iteración sobre los elementos del mensaje. Esto genera varios problemas:
- Duplicación de lógica de parsing: cada consumidor debe saber cómo extraer los elementos del mensaje compuesto.
- Imposibilidad de routing individual: si diferentes elementos requieren routing a diferentes destinos, el consumidor debe implementar tanto la extracción como el routing.
- Limitación de paralelismo: procesar todos los elementos dentro del mismo mensaje fuerza procesamiento secuencial dentro del consumidor.
- Acoplamiento a la estructura del contenedor: los consumidores deben conocer la estructura del mensaje compuesto, no solo la estructura del elemento individual.
Contexto en el que Emerge¶
Splitter emerge en contextos donde:
- Los sistemas upstream producen mensajes batch o compuestos por eficiencia de transmisión.
- La lógica de negocio downstream opera a nivel de elemento individual.
- Diferentes elementos dentro del mismo mensaje requieren diferentes rutas o tratamientos.
- Se necesita paralelismo a nivel de elemento para mejorar throughput o latencia.
- Se requiere tracking individual del procesamiento de cada elemento.
Por Qué No Es Trivial¶
Las decisiones de diseño de un Splitter son más complejas de lo aparente:
- Preservación de contexto: al dividir el mensaje, ¿qué información del contenedor original se propaga a cada elemento? ¿Se incluye un correlation ID para reagrupar posteriormente? ¿Se incluyen datos del header?
- Orden: ¿los mensajes resultantes deben mantener el orden original? En sistemas distribuidos, el orden puede perderse después del split.
- Mensajes vacíos: ¿qué ocurre si el mensaje compuesto no contiene elementos? ¿Se produce un mensaje vacío? ¿Se descarta silenciosamente? ¿Se envía a un canal de error?
- Error en un elemento: si un elemento es inválido, ¿se descarta solo ese elemento o se rechaza todo el mensaje original?
- Tamaño variable: si un mensaje contiene 3 elementos y otro contiene 30,000, el Splitter debe manejar ambos sin degradar performance.
Relación con Sistemas Distribuidos y Mensajería¶
En stream processing, Splitter es el operador flatMap: transforma cada registro de un stream en cero o más registros, expandiendo el stream. En Kafka Streams, flatMap y flatMapValues son implementaciones directas del Splitter. En Apache Flink, flatMap en un DataStream cumple la misma función.
En sistemas de mensajería tradicional, el Splitter consume un mensaje de un canal y produce múltiples mensajes en otro canal (o el mismo canal). El broker de mensajería se encarga de la distribución a los consumidores downstream.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Splitter, un sistema que recibe un mensaje compuesto (por ejemplo, una orden de compra con 50 líneas de detalle) tiene tres opciones:
- Procesamiento monolítico: un único consumidor itera internamente sobre las 50 líneas, procesándolas secuencialmente. No hay paralelismo, no hay routing individual, y si falla en la línea 30, las líneas 31-50 no se procesan.
- Duplicación de lógica: cada consumidor que necesita procesar las líneas implementa su propia lógica de extracción. Si el formato del mensaje compuesto cambia, todos los consumidores deben actualizarse.
- Transformación ad-hoc: un script o proceso previo convierte el mensaje compuesto en mensajes individuales fuera del flujo de integración, sin las garantías del sistema de mensajería.
Síntomas del Problema¶
- Consumidores con lógica de iteración sobre colecciones dentro de mensajes que duplican código entre diferentes flujos.
- Incapacidad de escalar el procesamiento de elementos individuales independientemente del procesamiento del mensaje contenedor.
- Elementos que requieren routing diferente pero que llegan empaquetados en un mismo mensaje, forzando al consumidor a combinar lógica de extracción y routing.
- Procesamiento batch que no puede paralelizarse porque los elementos están contenidos en un único mensaje.
- Fallos en un elemento que provocan el fallo de todo el mensaje compuesto porque no hay aislamiento de errores.
Impacto Operativo y Arquitectónico¶
- Bottleneck de procesamiento: un mensaje con 10,000 elementos se procesa secuencialmente en un único consumer, mientras que 10,000 mensajes individuales podrían distribuirse entre múltiples consumers en paralelo.
- Blast radius amplificado: un error en un elemento contamina el procesamiento de todos los demás elementos del mismo mensaje.
- Complejidad de retry: si el procesamiento falla a mitad del mensaje compuesto, ¿se reintenta todo el mensaje? ¿Se omiten los elementos ya procesados? La idempotencia a nivel de mensaje compuesto es más compleja que a nivel de elemento individual.
- Monitoreo impreciso: métricas a nivel de mensaje compuesto no reflejan la realidad del procesamiento a nivel de elemento.
Riesgos Si No Se Implementa Correctamente¶
- Explosión de mensajes: un mensaje con millones de elementos puede generar millones de mensajes individuales, saturando los canales downstream.
- Pérdida de correlación: si no se propaga un correlation ID, es imposible reagrupar los elementos procesados o rastrear qué elementos pertenecían al mismo mensaje original.
- Desequilibrio de carga: mensajes con pocos elementos y mensajes con muchos elementos generan cargas radicalmente diferentes en el sistema.
- Mensajes huérfanos: si el split falla a mitad de proceso (el sistema se cae después de emitir 25 de 50 mensajes), quedan mensajes parcialmente emitidos que pueden causar estados inconsistentes downstream.
Ejemplos Reales¶
- Retail: un sistema ERP genera una orden de compra con 200 líneas de producto. El Splitter descompone la orden en 200 mensajes individuales, cada uno representando una línea de producto que se enruta al sistema de inventario correspondiente según el warehouse asignado.
- Telecom: una estación base envía un reporte periódico con miles de CDRs (Call Detail Records) agrupados. El Splitter extrae cada CDR individualmente para procesamiento de rating y facturación.
- Banca: un mensaje SWIFT MT940 (extracto bancario) contiene múltiples transacciones. El Splitter extrae cada transacción para conciliación individual.
- Healthcare: un mensaje HL7 batch contiene múltiples resultados de laboratorio. Cada resultado se extrae para procesamiento individual en el sistema de historia clínica.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando los mensajes entrantes contienen colecciones de elementos que deben procesarse individualmente.
- Cuando diferentes elementos dentro del mismo mensaje requieren routing a diferentes destinos.
- Cuando se necesita paralelismo a nivel de elemento para cumplir requisitos de throughput o latencia.
- Cuando la lógica de error handling debe operar a nivel de elemento individual, no a nivel de mensaje compuesto.
- Cuando se necesita tracking y auditoría individual de cada elemento procesado.
- Cuando downstream consumers esperan mensajes con un único elemento (contratos de servicio definidos a nivel de item).
Cuándo No Usarlo¶
- Cuando los elementos del mensaje compuesto tienen dependencias mutuas que requieren procesamiento conjunto (por ejemplo, un mensaje donde los totales deben cuadrar con los detalles).
- Cuando el volumen de elementos por mensaje es potencialmente enorme y podría saturar los canales downstream sin mecanismos de backpressure.
- Cuando el overhead de producir N mensajes individuales excede el beneficio de la granularidad (mensajes con 2-3 elementos donde el procesamiento es trivial).
- Cuando no existe infraestructura para reagrupar los elementos posteriormente (si se necesita reagrupación y no hay Aggregator disponible).
Precondiciones¶
- El formato del mensaje compuesto es conocido y parseable (se sabe dónde están los elementos repetitivos).
- Existe un canal de salida capaz de manejar el volumen de mensajes resultantes.
- Los consumidores downstream pueden procesar elementos individuales.
Restricciones¶
- El Splitter aumenta el número de mensajes en el sistema por un factor igual al número promedio de elementos por mensaje.
- El orden de los mensajes resultantes no está garantizado en sistemas distribuidos a menos que se usen mecanismos explícitos de ordering.
- La atomicidad del split (todos o ninguno) depende de la implementación y la infraestructura subyacente.
Dependencias¶
- Formato definido del mensaje compuesto (schema, XPath, JSONPath, delimiter).
- Canal de salida con capacidad suficiente para el volumen expandido.
- Opcional: Aggregator downstream para reagrupación.
Supuestos Arquitectónicos¶
- Cada elemento extraído puede procesarse de forma independiente (no hay dependencias inter-elemento que requieran procesamiento conjunto).
- El volumen de mensajes resultantes es manejable por la infraestructura downstream.
- Los consumidores downstream tienen el contrato definido a nivel de elemento individual.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Stream processing platforms (Kafka Streams, Apache Flink, Apache Beam).
- Integration platforms (Apache Camel, MuleSoft, Spring Integration, Azure Logic Apps).
- ETL/ELT pipelines que procesan archivos batch con múltiples registros.
- Event-driven architectures que reciben eventos batch de sistemas legacy.
- API gateways que descomponen bulk requests en operaciones individuales.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Splitter reduce el acoplamiento entre el formato del mensaje compuesto y la lógica de procesamiento downstream. Los consumidores no necesitan conocer la estructura del contenedor — solo la estructura del elemento individual. Esto proporciona flexibilidad: el formato del contenedor puede evolucionar (cambiar el wrapper, añadir metadata de batch) sin afectar a los consumidores, siempre que la estructura del elemento individual se mantenga.
Throughput vs. Overhead¶
El split incrementa el número de mensajes en el sistema, lo que permite mayor paralelismo (mayor throughput potencial) pero también introduce overhead por mensaje (serialización, transmisión, deserialización de cada mensaje individual vs. un único mensaje batch). Para mensajes con muchos elementos pequeños, el overhead puede ser significativo. La granularidad óptima depende del balance entre paralelismo y overhead.
Simplicidad vs. Control¶
Un Splitter simple que extrae elementos sin enriquecerlos con metadata del contenedor es fácil de implementar pero dificulta la reagrupación posterior. Un Splitter que propaga correlation IDs, índices de posición y tamaño total es más complejo pero habilita Aggregator downstream. La decisión depende de si se necesita reagrupación.
Consistencia vs. Disponibilidad¶
En un sistema distribuido, emitir N mensajes de forma atómica es complejo. Si el sistema falla después de emitir 25 de 50 mensajes, hay inconsistencia: algunos elementos se procesaron y otros no. Las opciones son transacciones distribuidas (costosas), idempotencia en el Splitter (re-split produce los mismos mensajes) o aceptar inconsistencia temporal con reconciliación posterior.
Latencia vs. Resiliencia¶
Emitir todos los mensajes en memoria (in-process split) tiene la menor latencia pero no sobrevive a fallos del proceso. Emitir cada mensaje a un broker persistente es más resiliente pero introduce latencia por cada operación de escritura. La elección depende de los requisitos de durabilidad.
Escalabilidad vs. Complejidad Operacional¶
Un Splitter que multiplica mensajes por un factor alto (archivos batch con millones de registros) puede requerir mecanismos de backpressure, rate limiting o throttling para no saturar los sistemas downstream. Esto añade complejidad operacional que debe balancearse contra la necesidad de escalar el procesamiento.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Mensaje Compuesto (Composite Message): el mensaje entrante que contiene múltiples elementos. Puede ser un array JSON, una colección XML, un archivo con múltiples registros, o cualquier estructura que contenga elementos repetitivos.
- Splitter: el componente que recibe el mensaje compuesto, identifica los elementos individuales y emite un mensaje por cada elemento.
- Canal de Entrada (Input Channel): el canal por donde llega el mensaje compuesto.
- Canal de Salida (Output Channel): el canal donde se depositan los mensajes individuales.
- Consumidores Downstream: los componentes que procesan cada mensaje individual.
Flujo Lógico¶
flowchart TD
A([Mensaje Compuesto]) --> B[(Canal de Entrada)]
B --> C[Splitter parsea mensaje\ny extrae N elementos]
C --> D[Para cada elemento i = 1..N]
D --> E[Crear mensaje con\ncontenido del elemento]
E --> F[Añadir metadata\ncorrelation_id, split_index, split_size]
F --> G[(Canal de Salida)]
G --> H[Mensaje 1\nsplit_index=1]
G --> I[Mensaje 2\nsplit_index=2]
G --> J[Mensaje N\nsplit_index=N]
H --> K[Consumidor Downstream\nprocesa independientemente]
I --> K
J --> K
K --> L([Fin])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Mensaje Compuesto | Contener los elementos en un formato parseable |
| Splitter | Extraer elementos, crear mensajes individuales, propagar metadata de correlación |
| Canal de Salida | Transportar mensajes individuales a los consumidores downstream |
| Consumidores Downstream | Procesar cada elemento individualmente |
Interacciones¶
- Canal de Entrada → Splitter: entrega del mensaje compuesto.
- Splitter → Canal de Salida: emisión de N mensajes individuales.
- Canal de Salida → Consumidores: distribución de mensajes para procesamiento paralelo.
Contratos Implícitos¶
- Formato de extracción: la expresión que define dónde están los elementos dentro del mensaje compuesto (XPath, JSONPath, delimiter, schema).
- Metadata de correlación: los campos que se propagan del mensaje original a cada mensaje individual para permitir trazabilidad y reagrupación.
- Orden de emisión: si los consumidores asumen que los mensajes llegan en el orden de los elementos originales.
Decisiones de Diseño Clave¶
-
Expresión de split: ¿qué define la colección de elementos? Un JSONPath (
$.order.items[*]), un XPath (//lineItem), un delimiter (cada línea de un archivo), un schema Avro (un array field). -
Propagación de contexto: ¿qué información del mensaje original se incluye en cada mensaje individual? Opciones: solo el elemento (mínimo), elemento + correlation ID (para reagrupación), elemento + header completo del original (máximo contexto).
-
Streaming vs. buffering: ¿el Splitter carga todo el mensaje compuesto en memoria y luego emite los elementos? ¿O procesa y emite en streaming sin cargar todo? Para mensajes con millones de elementos, el streaming es esencial.
-
Manejo de elementos inválidos: ¿se detiene el split si un elemento es inválido? ¿Se omite el elemento inválido y se continúa? ¿Se envía a un dead-letter?
-
Atomicidad: ¿se emiten todos los mensajes o ninguno (transaccional)? ¿O se emite cada uno independientemente (best-effort)?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail — División de Órdenes de Compra para Fulfillment Paralelo¶
Contexto del Negocio¶
Una cadena de retail con presencia online y física opera 15 centros de distribución (warehouses) especializados por categoría de producto. Cuando un cliente realiza un pedido en el e-commerce, la orden puede contener productos de múltiples categorías: electrónica, ropa, hogar, alimentación. Cada categoría se gestiona y despacha desde un warehouse diferente. El objetivo es procesar los ítems de cada orden en paralelo, enviando cada línea al warehouse correspondiente para minimizar el tiempo total de fulfillment.
Necesidad de Integración¶
El sistema de e-commerce genera una orden consolidada con todas las líneas de producto. El sistema de fulfillment opera a nivel de línea individual: cada línea se asigna a un warehouse, se verifica stock, se reserva inventario, se genera la orden de picking y se despacha. La granularidad de producción (orden completa) no coincide con la granularidad de procesamiento (línea individual).
Sistemas Involucrados¶
- E-Commerce Platform: sistema que genera las órdenes de compra consolidadas.
- Kafka Cluster: infraestructura de streaming que transporta y distribuye los mensajes.
- Splitter Service: servicio que descompone órdenes en líneas individuales.
- Inventory Service: servicio que verifica y reserva stock por warehouse.
- Fulfillment Service (x15): un servicio por warehouse que gestiona picking, packing y shipping.
- Order Tracking Service: servicio que rastrea el estado global de la orden.
Restricciones Técnicas¶
- Las órdenes pueden tener entre 1 y 500 líneas de producto.
- El volumen pico es de 50,000 órdenes por hora (promedio de 8 líneas por orden = 400,000 mensajes de línea por hora).
- Cada línea debe procesarse en menos de 30 segundos desde la recepción de la orden.
- El estado global de la orden debe poder reconstruirse a partir de los estados individuales de cada línea.
- El sistema debe tolerar fallos en warehouses individuales sin afectar las líneas dirigidas a otros warehouses.
Flujos de Datos¶
E-Commerce → [orders.created] → Splitter → [order-lines.pending]
→ Content-Based Router → [order-lines.warehouse-{1..15}]
→ Fulfillment Services → [order-lines.fulfilled]
→ Aggregator → [orders.fulfilled] → Order Tracking
Decisiones Arquitectónicas¶
-
Split en servicio dedicado (no en el consumer de fulfillment): permite que el split se escale independientemente y centraliza la lógica de extracción de líneas.
-
Correlation ID = order_id: cada mensaje de línea incluye el
order_idoriginal, elline_indexy eltotal_linespara permitir reagrupación posterior. -
Kafka partitioning por order_id en el topic intermedio: garantiza que todas las líneas de una misma orden se procesan en orden dentro de la misma partición, lo que facilita la reagrupación por el Aggregator.
-
Routing post-split: un Content-Based Router examina el campo
warehouse_idde cada línea y la dirige al topic específico del warehouse correspondiente. -
Dead-letter per line: si una línea individual falla en fulfillment, solo esa línea va a dead-letter; las demás líneas de la misma orden continúan su procesamiento.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Orden con 500 líneas satura el topic downstream | Rate limiting en el Splitter: emitir máximo 100 líneas/segundo por orden |
| Fallo del Splitter a mitad de una orden | Splitter idempotente: re-split de la misma orden produce exactamente los mismos mensajes (dedup por order_id + line_index) |
| Líneas huérfanas si el Aggregator no recibe todas las líneas | Timeout en el Aggregator: si no llegan todas las líneas en 5 minutos, escalar a operaciones |
| Pérdida de correlación | Correlation ID en header de Kafka (no solo en payload) para trazabilidad end-to-end |
| Desequilibrio de carga entre warehouses | Monitoreo de lag por partition en cada topic de warehouse; autoscaling de consumers |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción de la Orden¶
El e-commerce publica la orden en el topic orders.created:
{
"order_id": "ORD-2026-0407-78432",
"customer_id": "CUST-12345",
"timestamp": "2026-04-07T14:23:15Z",
"shipping_address": {
"street": "Calle Gran Vía 45",
"city": "Madrid",
"postal_code": "28013"
},
"items": [
{"line": 1, "sku": "ELEC-TV-55-4K", "qty": 1, "price": 599.99, "warehouse_id": "WH-03"},
{"line": 2, "sku": "CLOTH-JACKET-L", "qty": 2, "price": 89.50, "warehouse_id": "WH-07"},
{"line": 3, "sku": "HOME-LAMP-LED", "qty": 1, "price": 34.99, "warehouse_id": "WH-11"},
{"line": 4, "sku": "FOOD-OLIVE-OIL-1L", "qty": 3, "price": 12.99, "warehouse_id": "WH-15"}
],
"total": 813.46
}
Paso 2: Splitter Descompone la Orden¶
El Splitter Service consume del topic orders.created y ejecuta la lógica de split:
- Parsea el mensaje JSON y extrae el array
items. - Determina el
split_size= 4 (número de líneas). - Para cada línea, construye un mensaje individual que incluye:
- El contenido de la línea.
- Datos del header de la orden (order_id, customer_id, shipping_address).
- Metadata de split (split_index, split_size, correlation_id).
- Publica cada mensaje en el topic
order-lines.pending.
Mensaje resultante para la línea 1:
{
"correlation_id": "ORD-2026-0407-78432",
"split_index": 1,
"split_size": 4,
"order_id": "ORD-2026-0407-78432",
"customer_id": "CUST-12345",
"shipping_address": {
"street": "Calle Gran Vía 45",
"city": "Madrid",
"postal_code": "28013"
},
"line": 1,
"sku": "ELEC-TV-55-4K",
"qty": 1,
"price": 599.99,
"warehouse_id": "WH-03"
}
Paso 3: Routing por Warehouse¶
Un Content-Based Router consume del topic order-lines.pending y examina el campo warehouse_id. Según el valor, publica cada mensaje en el topic correspondiente:
- Línea 1 (WH-03) →
order-lines.warehouse-03 - Línea 2 (WH-07) →
order-lines.warehouse-07 - Línea 3 (WH-11) →
order-lines.warehouse-11 - Línea 4 (WH-15) →
order-lines.warehouse-15
Paso 4: Fulfillment por Warehouse¶
Cada Fulfillment Service consume de su topic de warehouse y procesa la línea:
- Verifica stock del SKU en el warehouse asignado.
- Reserva inventario.
- Genera orden de picking.
- Actualiza estado de la línea a
PICKING. - Al completar el despacho, publica en
order-lines.fulfilled:
{
"correlation_id": "ORD-2026-0407-78432",
"split_index": 1,
"split_size": 4,
"line": 1,
"sku": "ELEC-TV-55-4K",
"status": "SHIPPED",
"tracking_number": "ES-TRK-9876543",
"shipped_from": "WH-03",
"shipped_at": "2026-04-07T15:45:22Z"
}
Paso 5: Reagrupación (Aggregator)¶
Un Aggregator consume del topic order-lines.fulfilled y reagrupa las líneas por correlation_id:
- Recibe la línea 1 con
split_index=1, split_size=4. Almacena en estado interno. - Recibe las líneas 2, 3 y 4 a medida que se completan.
- Cuando tiene las 4 líneas (
split_sizecompleto), emite un mensaje consolidado enorders.fulfilled. - Si no recibe todas las líneas en 5 minutos, emite un mensaje parcial con alerta.
Manejo de Errores¶
- Línea con stock insuficiente: el Fulfillment Service publica un mensaje con
status: "BACKORDERED"en lugar de"SHIPPED". El Aggregator incluye este estado en el consolidado. - Fallo del Splitter: al reiniciarse, el Splitter re-consume el mensaje original de Kafka (offset no committed). La re-emisión de mensajes con el mismo
order_id + line_indexpermite deduplicación por los consumers downstream. - Fallo de un Fulfillment Service: las líneas de otros warehouses no se ven afectadas. El topic del warehouse caído acumula mensajes hasta que el servicio se recupere.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.generic.compute import Rack
from diagrams.programming.flowchart import Decision
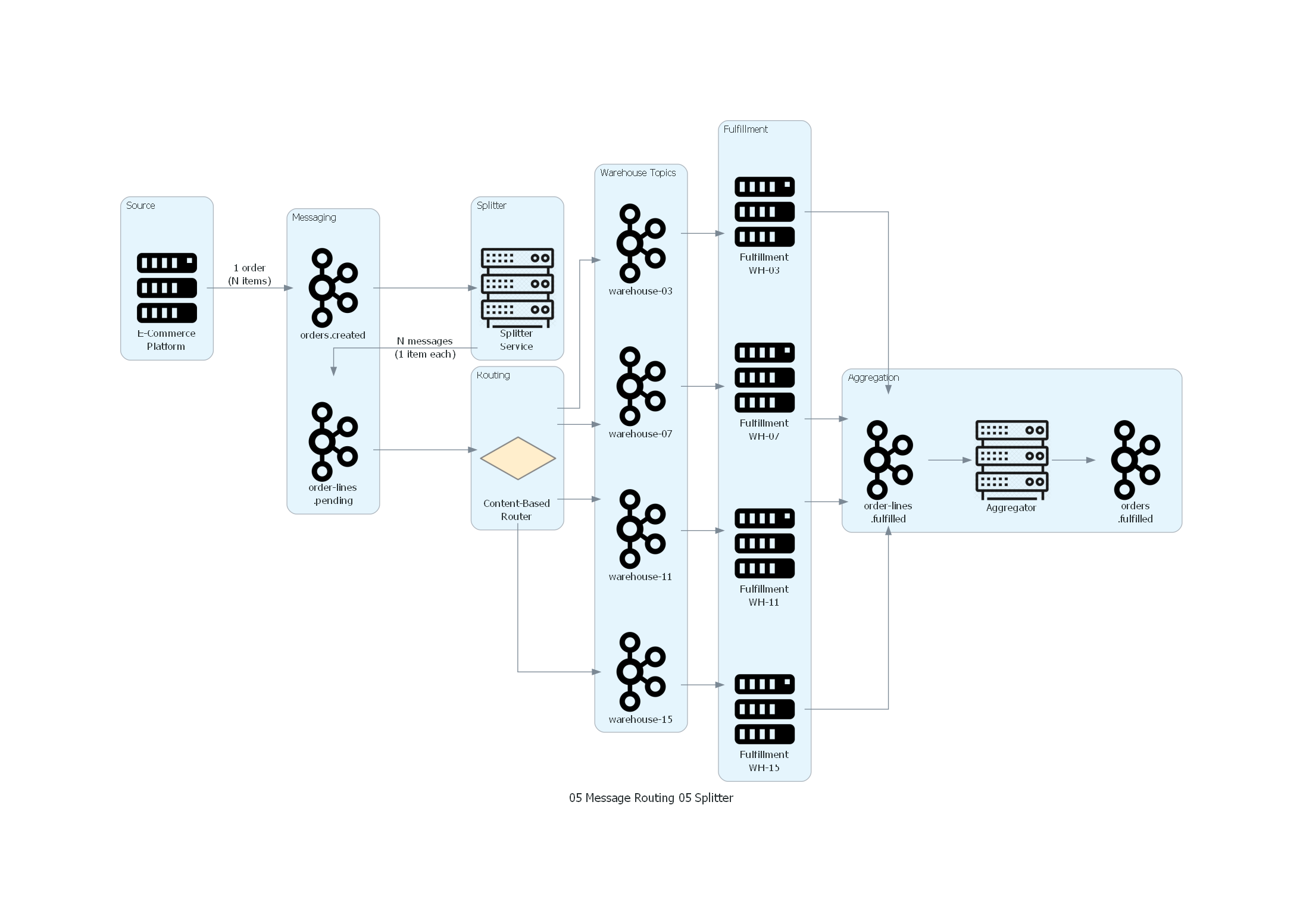
with Diagram("Splitter - Retail Order Line Decomposition", show=False, direction="LR"):
with Cluster("Source"):
ecommerce = Server("E-Commerce\nPlatform")
with Cluster("Messaging"):
topic_orders = Kafka("orders.created")
topic_lines = Kafka("order-lines\n.pending")
with Cluster("Splitter"):
splitter = Rack("Splitter\nService")
with Cluster("Routing"):
router = Decision("Content-Based\nRouter")
with Cluster("Warehouse Topics"):
wh_03 = Kafka("warehouse-03")
wh_07 = Kafka("warehouse-07")
wh_11 = Kafka("warehouse-11")
wh_15 = Kafka("warehouse-15")
with Cluster("Fulfillment"):
ff_03 = Server("Fulfillment\nWH-03")
ff_07 = Server("Fulfillment\nWH-07")
ff_11 = Server("Fulfillment\nWH-11")
ff_15 = Server("Fulfillment\nWH-15")
with Cluster("Aggregation"):
topic_fulfilled = Kafka("order-lines\n.fulfilled")
aggregator = Rack("Aggregator")
topic_complete = Kafka("orders\n.fulfilled")
ecommerce >> Edge(label="1 order\n(N items)") >> topic_orders
topic_orders >> splitter
splitter >> Edge(label="N messages\n(1 item each)") >> topic_lines
topic_lines >> router
router >> wh_03 >> ff_03
router >> wh_07 >> ff_07
router >> wh_11 >> ff_11
router >> wh_15 >> ff_15
ff_03 >> topic_fulfilled
ff_07 >> topic_fulfilled
ff_11 >> topic_fulfilled
ff_15 >> topic_fulfilled
topic_fulfilled >> aggregator >> topic_complete
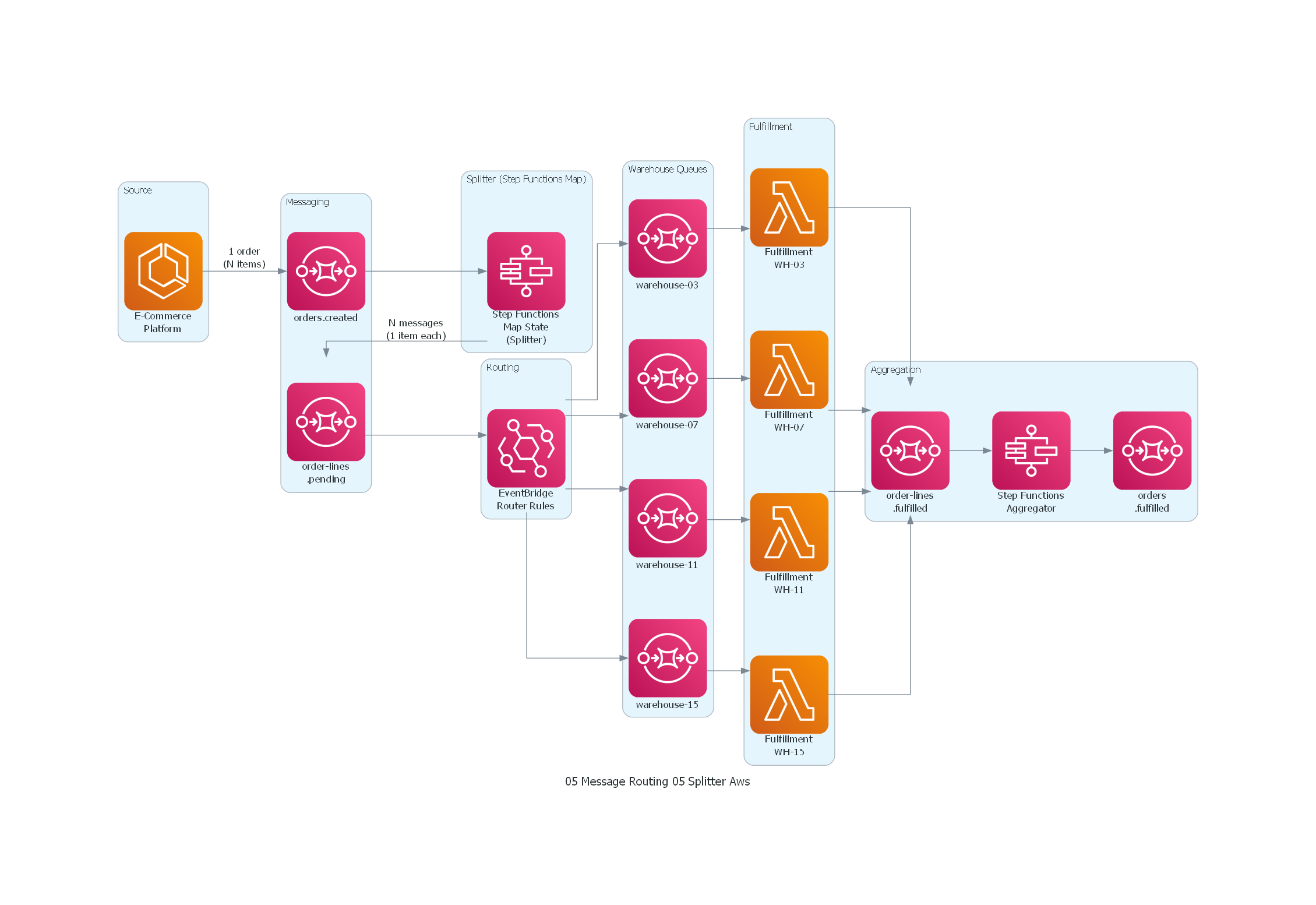
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.integration import SQS, StepFunctions, Eventbridge
with Diagram("Splitter - Retail Order Line Decomposition (AWS)", show=False, direction="LR"):
with Cluster("Source"):
ecommerce = ECS("E-Commerce\nPlatform")
with Cluster("Messaging"):
topic_orders = SQS("orders.created")
topic_lines = SQS("order-lines\n.pending")
with Cluster("Splitter (Step Functions Map)"):
splitter = StepFunctions("Step Functions\nMap State\n(Splitter)")
with Cluster("Routing"):
router = Eventbridge("EventBridge\nRouter Rules")
with Cluster("Warehouse Queues"):
wh_03 = SQS("warehouse-03")
wh_07 = SQS("warehouse-07")
wh_11 = SQS("warehouse-11")
wh_15 = SQS("warehouse-15")
with Cluster("Fulfillment"):
ff_03 = Lambda("Fulfillment\nWH-03")
ff_07 = Lambda("Fulfillment\nWH-07")
ff_11 = Lambda("Fulfillment\nWH-11")
ff_15 = Lambda("Fulfillment\nWH-15")
with Cluster("Aggregation"):
topic_fulfilled = SQS("order-lines\n.fulfilled")
aggregator = StepFunctions("Step Functions\nAggregator")
topic_complete = SQS("orders\n.fulfilled")
ecommerce >> Edge(label="1 order\n(N items)") >> topic_orders
topic_orders >> splitter
splitter >> Edge(label="N messages\n(1 item each)") >> topic_lines
topic_lines >> router
router >> wh_03 >> ff_03
router >> wh_07 >> ff_07
router >> wh_11 >> ff_11
router >> wh_15 >> ff_15
ff_03 >> topic_fulfilled
ff_07 >> topic_fulfilled
ff_11 >> topic_fulfilled
ff_15 >> topic_fulfilled
topic_fulfilled >> aggregator >> topic_complete
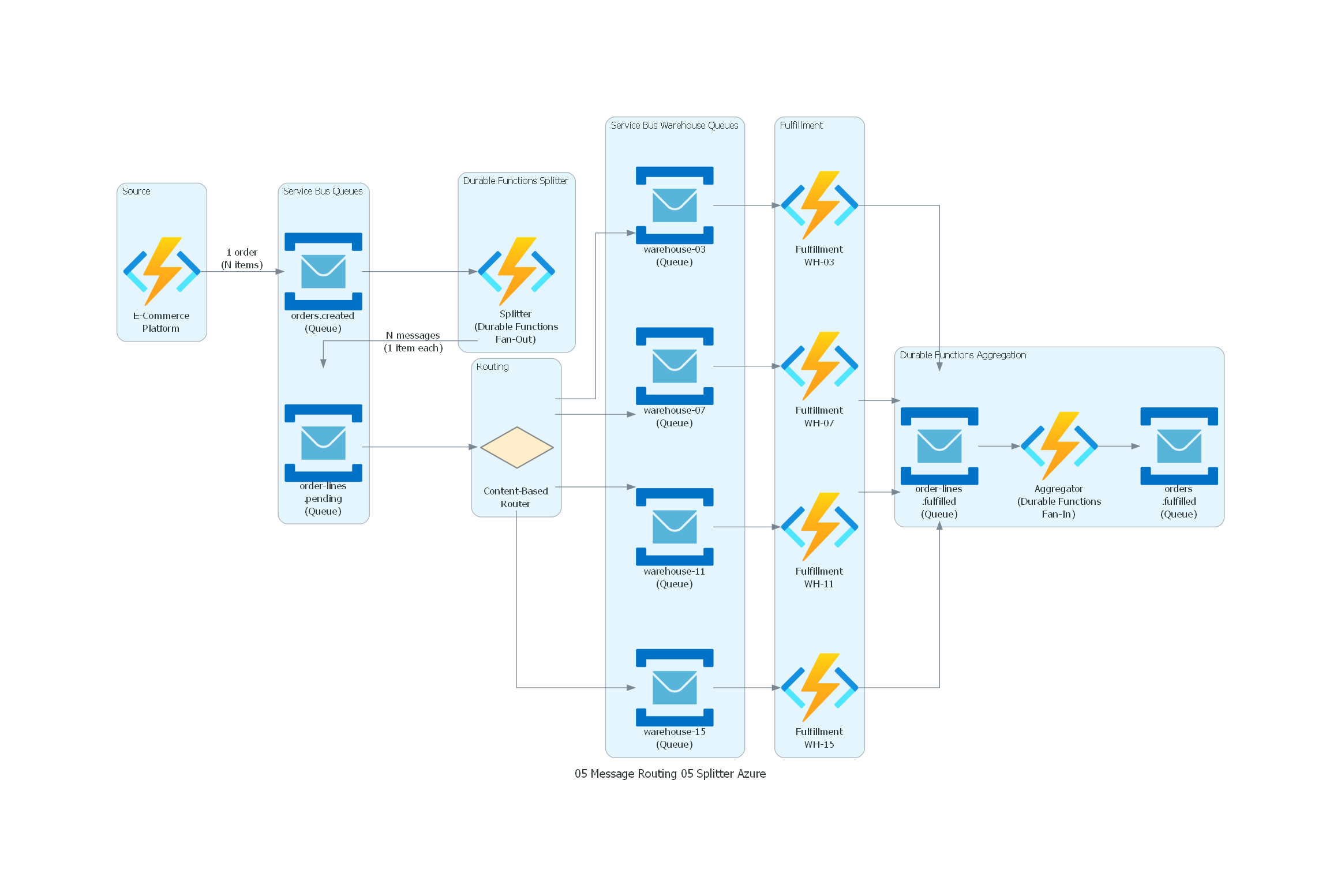
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.compute import Rack
from diagrams.programming.flowchart import Decision
from diagrams.azure.compute import FunctionApps
from diagrams.azure.integration import ServiceBus
with Diagram("Splitter - Retail Order Line Decomposition (Azure)", show=False, direction="LR"):
with Cluster("Source"):
ecommerce = FunctionApps("E-Commerce\nPlatform")
with Cluster("Service Bus Queues"):
topic_orders = ServiceBus("orders.created\n(Queue)")
topic_lines = ServiceBus("order-lines\n.pending\n(Queue)")
with Cluster("Durable Functions Splitter"):
splitter = FunctionApps("Splitter\n(Durable Functions\nFan-Out)")
with Cluster("Routing"):
router = Decision("Content-Based\nRouter")
with Cluster("Service Bus Warehouse Queues"):
wh_03 = ServiceBus("warehouse-03\n(Queue)")
wh_07 = ServiceBus("warehouse-07\n(Queue)")
wh_11 = ServiceBus("warehouse-11\n(Queue)")
wh_15 = ServiceBus("warehouse-15\n(Queue)")
with Cluster("Fulfillment"):
ff_03 = FunctionApps("Fulfillment\nWH-03")
ff_07 = FunctionApps("Fulfillment\nWH-07")
ff_11 = FunctionApps("Fulfillment\nWH-11")
ff_15 = FunctionApps("Fulfillment\nWH-15")
with Cluster("Durable Functions Aggregation"):
topic_fulfilled = ServiceBus("order-lines\n.fulfilled\n(Queue)")
aggregator = FunctionApps("Aggregator\n(Durable Functions\nFan-In)")
topic_complete = ServiceBus("orders\n.fulfilled\n(Queue)")
ecommerce >> Edge(label="1 order\n(N items)") >> topic_orders
topic_orders >> splitter
splitter >> Edge(label="N messages\n(1 item each)") >> topic_lines
topic_lines >> router
router >> wh_03 >> ff_03
router >> wh_07 >> ff_07
router >> wh_11 >> ff_11
router >> wh_15 >> ff_15
ff_03 >> topic_fulfilled
ff_07 >> topic_fulfilled
ff_11 >> topic_fulfilled
ff_15 >> topic_fulfilled
topic_fulfilled >> aggregator >> topic_complete
Explicación del Diagrama¶
El diagrama muestra el flujo completo de Splitter en el contexto de retail:
- Source: el e-commerce publica una orden consolidada con N ítems.
- Splitter: descompone la orden en N mensajes individuales (una línea por mensaje).
- Routing: un Content-Based Router dirige cada línea al topic del warehouse correspondiente.
- Fulfillment: cada warehouse procesa sus líneas asignadas de forma independiente y paralela.
- Aggregation: un Aggregator reagrupa las líneas procesadas por correlation_id para reconstruir el estado completo de la orden.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensaje Compuesto | Orden de compra en orders.created |
| Splitter | Splitter Service |
| Canal de Entrada | Topic orders.created |
| Canal de Salida | Topic order-lines.pending |
| Mensajes Individuales | Una línea de producto por mensaje |
| Metadata de Correlación | correlation_id, split_index, split_size en cada mensaje |
| Consumidores Downstream | Content-Based Router → Fulfillment Services |
| Reagrupación (opcional) | Aggregator reconstruye estado de orden completa |
11. Beneficios¶
Impacto Técnico¶
- Paralelismo granular: cada elemento puede procesarse en un consumer diferente, permitiendo distribución de carga y procesamiento paralelo. Una orden con 20 líneas puede procesarse hasta 20x más rápido si hay suficientes consumers.
- Routing individual: cada elemento puede dirigirse a un destino diferente según su contenido, sin que el consumidor final necesite lógica de extracción y routing combinada.
- Aislamiento de errores: un fallo en el procesamiento de un elemento no afecta a los demás elementos del mismo mensaje original.
- Escalabilidad horizontal: el número de consumers que procesan elementos individuales se escala independientemente del productor de mensajes compuestos.
Impacto Organizacional¶
- Separación de responsabilidades: el equipo que mantiene el Splitter se encarga de la lógica de extracción. Los equipos downstream solo necesitan conocer el formato del elemento individual, no el formato del contenedor.
- Contratos simples: los servicios downstream tienen contratos más simples (un solo elemento) que si tuvieran que manejar mensajes con colecciones de tamaño variable.
- Testing simplificado: testear un consumer que procesa un elemento individual es más simple que testear un consumer que procesa un mensaje con N elementos.
Impacto Operacional¶
- Monitoreo granular: métricas a nivel de elemento (elementos procesados/segundo, elementos fallidos, latencia por elemento) proporcionan visibilidad más precisa que métricas a nivel de mensaje compuesto.
- Retry selectivo: un elemento fallido puede reintentarse individualmente sin reprocesar los demás elementos del mismo mensaje.
- Dead-letter preciso: solo los elementos problemáticos llegan al dead-letter, no mensajes completos con información de contexto innecesaria.
Beneficios de Mantenibilidad y Evolución¶
- Evolución del formato: si se añade un nuevo campo al elemento individual, los consumers se adaptan. Si se cambia el formato del contenedor (de XML a JSON), solo el Splitter se modifica; los consumers downstream no se ven afectados.
- Reutilización del Splitter: la lógica de split es reutilizable para diferentes flujos que procesan el mismo tipo de mensaje compuesto.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Multiplicación de mensajes: el Splitter amplifica el volumen de mensajes en el sistema. Un topic que recibe 10,000 mensajes compuestos con promedio de 50 elementos cada uno genera 500,000 mensajes downstream.
- Necesidad de reagrupación: si el procesamiento downstream requiere un resultado consolidado (por ejemplo, una confirmación de orden completa), se necesita un Aggregator que reúna todos los elementos procesados, lo cual añade complejidad significativa.
- Gestión de estado de correlación: mantener la relación entre mensajes individuales y el mensaje original requiere propagar y gestionar metadata de correlación consistentemente.
Riesgos de Mal Uso¶
- Split sin necesidad: aplicar Splitter a mensajes donde el procesamiento downstream no necesita granularidad individual introduce overhead sin beneficio.
- Split de elementos dependientes: dividir un mensaje cuyos elementos tienen dependencias mutuas (por ejemplo, una transacción financiera donde débito y crédito deben procesarse juntos) puede producir estados inconsistentes.
- Split sin backpressure: un mensaje con millones de elementos emitidos de golpe puede saturar los canales downstream y provocar out-of-memory en consumers.
Sobreingeniería¶
- Split multinivel: dividir un mensaje en sub-mensajes que a su vez se dividen en sub-sub-mensajes crea cadenas de splits difíciles de rastrear y depurar.
- Propagación excesiva de contexto: incluir todo el payload del mensaje original en cada mensaje individual incrementa el tamaño total transmitido significativamente.
Costos de Operación¶
- Storage: N mensajes individuales consumen más storage que un mensaje compuesto por el overhead de metadata, headers y envelopes por mensaje.
- Network: N transmisiones de red vs. una sola incrementa el tráfico de red total.
- Monitoreo: el volumen amplificado de mensajes requiere infraestructura de monitoreo con mayor capacidad.
Errores Frecuentes de Implementación¶
- No propagar correlation ID, haciendo imposible la reagrupación posterior.
- Cargar todo el mensaje compuesto en memoria antes de emitir, causando OutOfMemory con mensajes grandes.
- No manejar el caso de mensaje compuesto vacío (sin elementos).
- No implementar idempotencia en el split, causando duplicación de elementos ante retries.
- Asumir que el orden de emisión se preserva end-to-end en sistemas distribuidos.
Anti-Patterns Relacionados¶
- Split and Forget: dividir un mensaje compuesto sin propagar metadata de correlación, haciendo imposible rastrear qué elementos pertenecían al mismo mensaje original.
- Mega-Split: dividir mensajes con millones de elementos sin mecanismos de throttling o backpressure.
- Redundant Split: múltiples Splitters en el pipeline que dividen el mismo contenido a diferentes niveles sin necesidad.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Aggregator: el complemento natural y más frecuente del Splitter. Si Splitter divide un mensaje en partes, Aggregator las reagrupa después del procesamiento individual. La combinación Splitter → Processing → Aggregator es uno de los patrones compuestos más comunes en integración.
- Content-Based Router: frecuentemente aparece después del Splitter para dirigir cada mensaje individual a un destino diferente según su contenido.
- Message Filter: puede aparecer después del Splitter para descartar elementos individuales que no cumplen ciertos criterios.
Patrones que Suelen Aparecer Antes o Después¶
- Message Translator: antes del Splitter para normalizar el formato del mensaje compuesto, o después del Splitter para transformar cada elemento individual.
- Content Enricher: después del Splitter para enriquecer cada elemento con datos adicionales de fuentes externas.
- Wire Tap: después del Splitter para capturar una copia de cada elemento individual para auditoría o monitoreo.
Combinaciones Comunes¶
- Splitter + Content-Based Router: divide y luego enruta cada elemento a un destino diferente según su contenido.
- Splitter + Aggregator (Composed Message Processor): divide, procesa individualmente y reagrupa. Es el patrón Composed Message Processor.
- Splitter + Parallel Processing + Aggregator (Scatter-Gather): divide, procesa en paralelo y combina resultados.
Diferencias con Patrones Similares¶
- vs. Recipient List: Recipient List envía copias del mismo mensaje a múltiples destinos. Splitter descompone un mensaje en diferentes mensajes y los envía (potencialmente al mismo destino).
- vs. Composed Message Processor: CMP es un patrón compuesto que usa Splitter internamente. Splitter es un patrón atómico que solo divide.
- vs. Message Filter: Filter reduce el número de mensajes (descarta algunos). Splitter incrementa el número de mensajes (uno se convierte en muchos).
Encaje en un Flujo Mayor de Integración¶
Splitter típicamente aparece en las primeras etapas de un pipeline de procesamiento, después de la recepción y validación del mensaje compuesto. Es un punto de divergencia que incrementa el paralelismo del flujo. Frecuentemente se complementa con un Aggregator en las etapas finales para consolidar resultados.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Splitter es uno de los patrones de routing más vigentes porque el problema que resuelve — la discordancia de granularidad entre producción y procesamiento — es inherente a la naturaleza de los sistemas distribuidos y las arquitecturas modernas.
A favor de la vigencia:
- En stream processing,
flatMapes uno de los operadores más utilizados en Kafka Streams, Flink y Spark Streaming. Es la implementación directa del Splitter. - En event-driven architectures, los batch events de sistemas legacy frecuentemente necesitan descomponerse en eventos individuales antes de ingresar al event mesh moderno.
- En microservices, los bulk API calls frecuentemente se descomponen en operaciones individuales para distribución entre instancias de servicio.
- En data pipelines, la extracción de registros individuales de archivos batch (CSV, JSON Lines, Parquet) es esencialmente un split.
En contra de la vigencia:
- Algunos frameworks modernos manejan colecciones de forma nativa sin necesidad de split explícito (forEach de MuleSoft, batch module de Mule, reactive streams que procesan colecciones element-by-element).
- La tendencia hacia event sourcing con eventos atómicos reduce la necesidad de split, ya que los eventos se producen con la granularidad correcta desde el origen.
Contexto Moderno Donde Sigue Siendo Útil¶
- Procesamiento de archivos batch de sistemas legacy que generan registros agrupados.
- Conversión de batch API responses a eventos individuales en un event mesh.
- Descomposición de mensajes IoT que agrupan múltiples lecturas de sensores en un solo payload.
- Procesamiento de webhooks que contienen arrays de eventos.
Cómo Se Implementa Hoy¶
- Kafka Streams:
flatMap()yflatMapValues()implementan Splitter como operadores nativos del DSL. - Apache Flink:
flatMap()en DataStream API. - Apache Camel: componente
split()con expresiones XPath, JSONPath o Tokenizer. - MuleSoft: componente
for-eachybatch:jobpara procesamiento iterativo. - Spring Integration:
AbstractMessageSplittercon implementaciones para XML, JSON, file line-by-line. - Azure Logic Apps:
For eachaction que itera sobre arrays y procesa cada elemento. - AWS Step Functions:
Mapstate que ejecuta un sub-workflow para cada elemento de un array.
Qué Parte Sigue Siendo Esencial¶
Independientemente de la tecnología, los principios esenciales del Splitter que permanecen son:
- Correlation metadata: propagar un identificador que vincule cada mensaje individual con el mensaje original.
- Streaming emission: para colecciones grandes, emitir elementos en streaming sin cargar todo en memoria.
- Idempotent split: garantizar que re-ejecutar el split produce los mismos mensajes individuales para evitar duplicaciones ante retries.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka / Kafka Streams¶
Splitter se implementa con flatMap o flatMapValues:
KStream<String, Order> orders = builder.stream("orders.created");
KStream<String, OrderLine> orderLines = orders.flatMap(
(orderId, order) -> order.getItems().stream()
.map(item -> KeyValue.pair(
orderId + "-" + item.getLine(),
new OrderLine(orderId, item, order.getItems().size())
))
.collect(Collectors.toList())
);
orderLines.to("order-lines.pending");
La key del mensaje resultante es orderId-lineNumber, lo que permite partitioning por línea individual. El OrderLine incluye el split_size para facilitar reagrupación.
Apache Camel¶
from("kafka:orders.created")
.split(jsonpath("$.items"))
.setHeader("correlationId", jsonpath("$.order_id"))
.setHeader("splitIndex", simple("${exchangeProperty.CamelSplitIndex}"))
.setHeader("splitSize", simple("${exchangeProperty.CamelSplitSize}"))
.to("kafka:order-lines.pending")
.end();
Camel proporciona propiedades automáticas de split (CamelSplitIndex, CamelSplitSize, CamelSplitComplete) que facilitan la metadata de correlación.
MuleSoft¶
<flow name="order-splitter">
<kafka:listener config-ref="kafka-config" topic="orders.created" />
<for-each collection="#[payload.items]">
<set-variable variableName="correlationId" value="#[payload.order_id]" />
<set-variable variableName="splitIndex" value="#[vars.counter]" />
<kafka:publish config-ref="kafka-config" topic="order-lines.pending">
<kafka:message>
<kafka:body>#[output application/json --- payload]</kafka:body>
</kafka:message>
</kafka:publish>
</for-each>
</flow>
Spring Integration¶
@Splitter(inputChannel = "ordersChannel", outputChannel = "orderLinesChannel")
public List<Message<OrderLine>> splitOrder(Message<Order> orderMessage) {
Order order = orderMessage.getPayload();
List<Message<OrderLine>> lines = new ArrayList<>();
for (int i = 0; i < order.getItems().size(); i++) {
OrderLine line = new OrderLine(order.getOrderId(), order.getItems().get(i));
lines.add(MessageBuilder.withPayload(line)
.setHeader("correlationId", order.getOrderId())
.setHeader("splitIndex", i)
.setHeader("splitSize", order.getItems().size())
.build());
}
return lines;
}
Azure / AWS¶
- Azure Logic Apps:
For eachaction conSplitOntrigger para descomponer arrays automáticamente al recibir un mensaje. - AWS Step Functions:
Mapstate que ejecuta un sub-workflow para cada elemento, con soporte para paralelismo configurable (maxConcurrency). - AWS Lambda + SQS: un Lambda consume un mensaje batch de SQS y publica N mensajes individuales en otro SQS queue.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: mensajes compuestos recibidos/minuto, elementos emitidos/minuto, ratio de expansión (promedio de elementos por mensaje compuesto), mensajes compuestos vacíos, latencia del split.
- Health checks: verificar que el Splitter consume del canal de entrada y produce en el canal de salida, que no hay lag creciente.
- Alertas: ratio de expansión anormalmente alto (mensaje con 100,000 elementos cuando el promedio es 50), mensajes compuestos que no pueden parsearse, lag creciente en el canal de entrada.
Tracing¶
- Cada mensaje individual debe llevar un trace ID que vincule al mensaje compuesto original.
- El correlation_id del split debe propagarse como header de tracing (no solo en el payload).
- Los sistemas de distributed tracing (Jaeger, Zipkin, OpenTelemetry) deben representar el split como un span padre con N spans hijos.
Monitoreo¶
- Dashboard: volumen de mensajes entrantes vs. salientes, ratio de expansión, latencia de split, elementos con error.
- Capacidad downstream: monitorear que los canales de salida tienen capacidad suficiente para absorber el volumen expandido.
Versionado¶
- Si la estructura del mensaje compuesto cambia (se añaden campos al array de elementos), el Splitter debe actualizarse.
- Si la estructura del elemento individual cambia, los consumidores downstream deben actualizarse.
- Versionado independiente del formato del contenedor y del formato del elemento.
Seguridad¶
- Los mensajes individuales heredan la clasificación de seguridad del mensaje compuesto original.
- Si el mensaje original contiene datos sensibles en el header (PII del cliente), cada mensaje individual que propague ese header debe respetar las mismas políticas de seguridad.
Manejo de Errores¶
- Mensaje no parseable: enviar al dead-letter channel sin dividir; alertar al equipo.
- Elemento individual inválido: dos estrategias: (a) omitir el elemento y continuar con los demás, (b) rechazar todo el mensaje compuesto.
- Fallo durante la emisión: si se emitieron K de N mensajes y el Splitter falla, al reiniciar se re-divide el mensaje completo. Consumers deben ser idempotentes para manejar duplicados de los K mensajes ya emitidos.
Retries¶
- El retry del Splitter es a nivel de mensaje compuesto: si el split falla, se reintenta el mensaje original completo.
- La idempotencia del split (mismo input = mismos outputs) garantiza que los retries no producen duplicados nuevos si los consumers deduplican por correlation_id + split_index.
Dead-Lettering¶
- Mensajes compuestos que no pueden parsearse van al dead-letter del Splitter.
- Elementos individuales que fallan downstream van al dead-letter del consumer correspondiente, no del Splitter.
Idempotencia¶
- El Splitter debe ser determinista: dado el mismo mensaje compuesto, produce exactamente los mismos N mensajes individuales.
- Los consumers downstream deben implementar deduplicación por correlation_id + split_index para tolerar re-splits.
Auditoría¶
- Registrar: mensaje compuesto recibido, número de elementos extraídos, correlation_id asignado, timestamp de cada emisión.
- Permitir reconstruir qué elementos se produjeron a partir de qué mensaje original.
Performance¶
- Streaming vs. buffering: para mensajes compuestos grandes, implementar streaming (emitir elementos a medida que se parsean sin cargar todo en memoria).
- Batch emission: en Kafka, utilizar producer batching para emitir múltiples mensajes en un solo batch de red.
- Compression: si los mensajes individuales tienen datos redundantes (misma shipping_address), considerar si la propagación de contexto es excesiva.
Escalabilidad¶
- El Splitter escala horizontalmente añadiendo más instancias consumidoras del canal de entrada.
- El cuello de botella suele ser el canal de salida: si el split amplifica por un factor de 50x, el canal de salida debe soportar 50x el throughput del canal de entrada.
- Partitioning del canal de salida por correlation_id garantiza que elementos de la misma orden se procesan en la misma partición.
17. Errores Comunes¶
No Propagar Correlation Metadata¶
El error más destructivo es dividir un mensaje sin incluir información que vincule los mensajes individuales con el original. Sin correlation_id, split_index y split_size, es imposible reagrupar los elementos, rastrear su origen o verificar completitud. Toda implementación de Splitter debe propagar metadata de correlación como prioridad.
Cargar Todo en Memoria¶
Implementar el Splitter cargando todo el mensaje compuesto en memoria antes de emitir los elementos funciona para mensajes pequeños, pero falla catastróficamente con mensajes grandes (archivos batch con millones de registros). La implementación correcta usa streaming: parsear y emitir elemento por elemento sin acumular el contenido completo.
Ignorar el Impacto en el Volumen Downstream¶
Un Splitter que amplifica el tráfico por un factor de 100x puede saturar los canales y servicios downstream si estos no fueron dimensionados para el volumen expandido. Antes de implementar un Splitter, se debe evaluar el impacto en throughput, storage y capacidad de procesamiento downstream.
No Manejar Mensajes Vacíos¶
Un mensaje compuesto con un array vacío de elementos es un caso válido que muchas implementaciones ignoran. El Splitter debe definir su comportamiento explícitamente: ¿se emite un mensaje "vacío"? ¿Se descarta silenciosamente? ¿Se loguea y se descarta? La opción más robusta es emitir un evento de "empty split" al canal de monitoreo.
Asumir Orden de Entrega¶
Que el Splitter emita los mensajes en orden (elemento 1, luego 2, luego 3) no garantiza que los consumidores los reciban en ese orden en un sistema distribuido. Si el orden importa para el procesamiento downstream, se debe implementar un Resequencer o usar partitioning que garantice orden.
Split de Elementos con Dependencias Mutuas¶
Dividir un mensaje cuyos elementos tienen dependencias (por ejemplo, una transacción con líneas de débito y crédito que deben cuadrar) sin garantizar procesamiento coordinado puede producir estados inconsistentes. En estos casos, se debe evaluar si el split es apropiado o si se necesita un Composed Message Processor que mantenga la integridad.
18. Conclusión Técnica¶
Splitter es un patrón fundamental de Message Routing que resuelve una de las discordancias más comunes en arquitecturas de integración: la diferencia entre la granularidad de producción (mensajes batch o compuestos) y la granularidad de procesamiento (elementos individuales). Su implementación es conceptualmente simple — extraer elementos de un contenedor y emitirlos como mensajes individuales — pero su implementación correcta requiere atención a detalles críticos: propagación de metadata de correlación, streaming para mensajes grandes, idempotencia del split, manejo de mensajes vacíos y dimensionamiento del canal de salida.
En el ecosistema moderno, Splitter está profundamente integrado en las plataformas de procesamiento como operador nativo (flatMap en Kafka Streams, Flink, Spark; split en Camel; for-each en MuleSoft; Map state en Step Functions). Su relevancia permanece alta porque la producción de datos batch y la necesidad de procesamiento granular son constantes estructurales de las arquitecturas enterprise.
Recomendación para arquitectos: al implementar un Splitter, siempre incluya metadata de correlación (correlation_id, split_index, split_size) en cada mensaje resultante, incluso si actualmente no se necesita reagrupación. El costo de añadir esta metadata es mínimo, pero su ausencia hace imposible implementar Aggregator, tracking o auditoría posteriormente. Evalúe el factor de expansión esperado y dimensione la infraestructura downstream en consecuencia. Para mensajes con potencialmente miles o millones de elementos, implemente el split en streaming con backpressure para evitar saturación de los canales de salida.