Aggregator¶
1. Nombre del Patrón¶
- Nombre oficial: Aggregator
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Agregador de Mensajes
2. Resumen Ejecutivo¶
Aggregator es un patrón de enrutamiento stateful que recibe un flujo de mensajes individuales relacionados entre sí, los acumula en un almacén interno y, cuando se cumple una condición de completitud, emite un único mensaje consolidado que combina la información de todos los mensajes acumulados. Es uno de los patrones más complejos del catálogo de Enterprise Integration Patterns porque requiere gestionar estado persistente, correlación entre mensajes, estrategias de completitud, timeouts, concurrencia y recuperación ante fallos.
El problema fundamental que resuelve es la necesidad de recomponer información que viaja fragmentada en múltiples mensajes. Esta fragmentación puede ser consecuencia directa de un Splitter previo (que dividió un mensaje compuesto en partes), de la naturaleza distribuida de los sistemas que generan los mensajes (múltiples servicios producen piezas de información que deben combinarse), o de protocolos que transmiten datos en chunks.
Aggregator aparece en escenarios empresariales críticos: consolidación de confirmaciones parciales en liquidaciones bancarias, reagrupación de líneas de pedido procesadas individualmente, combinación de respuestas de múltiples servicios en Scatter-Gather, ventanas de agregación temporal en stream processing, y acumulación de eventos para generación de reportes.
La complejidad del Aggregator reside en que es inherentemente un componente stateful en un mundo que prefiere componentes stateless. Debe mantener estado entre mensajes (los mensajes acumulados hasta el momento), gestionar la correlación (determinar qué mensajes pertenecen al mismo grupo), definir condiciones de completitud (cuándo dejar de esperar y emitir el resultado), manejar timeouts (qué hacer si un mensaje esperado nunca llega) y ser resiliente ante fallos (no perder el estado acumulado si el proceso se reinicia).
3. Definición Detallada¶
Propósito¶
El propósito de Aggregator es recomponer un conjunto de mensajes relacionados en un único mensaje consolidado, actuando como el punto de convergencia en un flujo de mensajes distribuido. Donde el Splitter es un punto de divergencia (1 → N), el Aggregator es un punto de convergencia (N → 1).
Lógica Arquitectónica¶
El Aggregator mantiene un estado interno organizado por grupos de correlación. Cada grupo se identifica por una correlation key (un valor presente en todos los mensajes que pertenecen al mismo grupo). Cuando llega un mensaje, el Aggregator:
- Extrae la correlation key del mensaje.
- Busca (o crea) el grupo de correlación correspondiente.
- Añade el mensaje al grupo.
- Evalúa la condición de completitud del grupo.
- Si el grupo está completo, ejecuta la función de agregación que combina los mensajes acumulados en un único mensaje de salida y lo emite.
- Si el grupo no está completo, lo mantiene en estado de espera.
La analogía operacional es una estación de ensamblaje en una fábrica: las piezas de un producto llegan por diferentes líneas de producción en momentos diferentes. La estación de ensamblaje tiene bandejas etiquetadas por producto (correlation key). Cada pieza se coloca en la bandeja correcta. Cuando una bandeja tiene todas las piezas requeridas (condición de completitud), se ensambla el producto y se envía a la siguiente estación.
Principio de Diseño Subyacente¶
El principio fundamental es la recomposición con estado. En un flujo de mensajes distribuido, la información que lógicamente pertenece a una misma unidad de trabajo puede viajar en mensajes separados. El Aggregator proporciona el mecanismo para recombinar esa información, actuando como un buffer con inteligencia sobre cuándo la acumulación está completa.
Este principio tiene analogía directa con la operación reduce en programación funcional: dada una colección de elementos y una función combinadora, producir un único valor resultado. En stream processing, se manifiesta como operaciones de windowed aggregation (aggregate, reduce, count, sum).
Problema Estructural que Resuelve¶
Sin Aggregator, la recomposición de mensajes fragmentados requiere:
- Lógica ad-hoc en cada consumer: cada servicio que necesita la información completa implementa su propia lógica de acumulación, duplicando código y complejidad de gestión de estado.
- Polling a base de datos: los consumers almacenan partes en una base de datos compartida y periódicamente verifican si todas las partes están disponibles, introduciendo latencia y acoplamiento.
- Procesamiento síncrono forzado: se elimina el paralelismo y se fuerza procesamiento secuencial para evitar la necesidad de recomposición.
Contexto en el que Emerge¶
Aggregator emerge en contextos donde:
- Un Splitter previo dividió un mensaje compuesto y se necesita reconstruir el resultado después del procesamiento individual.
- Un Scatter-Gather envió requests a múltiples servicios y necesita combinar las respuestas.
- Múltiples sistemas independientes producen piezas de información que deben consolidarse (confirmaciones parciales, votos, aprobaciones).
- Stream processing requiere agregación temporal (contar eventos por ventana de tiempo, sumar valores, calcular promedios).
- Procesos de negocio multi-paso acumulan resultados parciales que deben consolidarse al final.
Por Qué No Es Trivial¶
El Aggregator es el patrón más complejo del catálogo de EIP por las siguientes razones:
- Gestión de estado: el Aggregator debe mantener estado persistente para cada grupo de correlación activo. Este estado debe sobrevivir a reinicios del proceso, lo que requiere persistencia (base de datos, changelog topic en Kafka, state store).
- Estrategia de correlación: ¿cómo se determina qué mensajes pertenecen al mismo grupo? ¿Un campo del payload? ¿Un header? ¿Una combinación? La correlation key debe estar presente en todos los mensajes del grupo.
- Condición de completitud: ¿cómo sabe el Aggregator que un grupo está completo? Las estrategias principales son:
- Count-based: el grupo está completo cuando se han recibido N mensajes (requiere conocer N de antemano, típicamente incluido en un campo
split_size). - Timeout-based: el grupo está completo cuando han pasado T segundos sin recibir un nuevo mensaje para ese grupo.
- Predicate-based: el grupo está completo cuando se cumple una condición de negocio (por ejemplo, cuando se recibe un mensaje con flag
last=true, o cuando la suma de los montos alcanza un umbral). - Combinación: el grupo está completo cuando se reciben N mensajes O cuando pasan T segundos (lo que ocurra primero).
- Timeout de inactividad: ¿qué hacer si un grupo nunca se completa porque un mensaje esperado nunca llega? El Aggregator necesita mecanismos de timeout para evitar acumular grupos incompletos indefinidamente.
- Concurrencia: si múltiples threads/consumers procesan mensajes del mismo grupo simultáneamente, la actualización del estado del grupo debe ser thread-safe.
- Orden de llegada: los mensajes de un grupo pueden llegar en cualquier orden. El Aggregator debe funcionar correctamente independientemente del orden de llegada.
- Función de agregación: ¿cómo se combinan los mensajes acumulados en el mensaje de salida? ¿Se concatenan los payloads? ¿Se mergean? ¿Se aplica una función de reducción?
- Mensajes duplicados: si un mensaje se entrega dos veces (redelivery), el Aggregator no debe duplicar su contribución al grupo.
- Recuperación ante fallos: si el Aggregator falla y se reinicia, ¿puede recuperar el estado de los grupos de correlación activos? Sin persistencia, se pierden todos los mensajes acumulados.
Relación con Sistemas Distribuidos y Mensajería¶
En stream processing, el Aggregator se implementa como operaciones stateful de windowed aggregation:
- En Kafka Streams,
aggregate(),reduce()ycount()sobreKGroupedStreamson implementaciones directas del Aggregator. El state store de Kafka Streams proporciona persistencia y fault-tolerance automáticas. - En Apache Flink, las window functions (
TumblingWindow,SlidingWindow,SessionWindow) con funciones de agregación son implementaciones del Aggregator con diferentes estrategias de completitud temporal. - En Temporal/Cadence, los workflows que acumulan señales y producen un resultado al completar son una forma de Aggregator orquestado.
En sistemas de mensajería tradicional, el Aggregator es un componente stateful que consume de un canal, mantiene estado en un almacén (base de datos, cache, state store) y produce en otro canal cuando se cumple la condición de completitud.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Aggregator, un sistema que necesita la información combinada de múltiples mensajes relacionados tiene opciones limitadas:
-
Polling a base de datos: cada consumer almacena su resultado en una tabla de base de datos indexada por correlation ID. Un proceso periódico consulta la tabla para verificar si todas las partes están presentes. Si lo están, las lee, las combina y las elimina. Esto introduce latencia (frecuencia de polling), acoplamiento (base de datos compartida), y complejidad (limpieza de datos, manejo de duplicados).
-
Último en ganar: cada parte se procesa independientemente y se espera que el último consumer en completar tenga acceso a los resultados de los demás (por ejemplo, leyéndolos de la base de datos). Esto introduce dependencias de orden y race conditions.
-
Orquestación síncrona: un orquestador llama a cada servicio secuencialmente, esperando la respuesta de cada uno antes de llamar al siguiente. Esto elimina el paralelismo y convierte N operaciones paralelas en N operaciones secuenciales, multiplicando la latencia.
-
Implementación ad-hoc: cada punto del sistema que necesita recomposición implementa su propia lógica de acumulación con su propio almacén de estado, su propia gestión de timeouts y su propio manejo de errores. La duplicación de esta lógica compleja es costosa y propensa a bugs.
Síntomas del Problema¶
- Procesos de consolidación que dependen de polling a base de datos para detectar completitud, con latencia proporcional al intervalo de polling.
- Race conditions cuando múltiples partes del sistema intentan verificar y actualizar el estado de un grupo de correlación simultáneamente.
- Grupos de correlación que quedan incompletos indefinidamente porque un mensaje esperado nunca llegó y no hay mecanismo de timeout.
- Duplicación de lógica de acumulación en múltiples puntos del sistema, cada una con diferentes bugs y diferentes niveles de robustez.
- Incapacidad de procesar partes en paralelo porque el sistema fuerza procesamiento secuencial para evitar la complejidad de recomposición.
Impacto Operativo y Arquitectónico¶
- Memory leaks: grupos de correlación incompletos que se acumulan indefinidamente porque no hay mecanismo de expiración, consumiendo memoria progresivamente.
- Inconsistencia de estado: cuando la lógica de acumulación tiene bugs, algunos grupos se marcan como completos prematuramente (faltan partes) o nunca se marcan como completos (bug en la condición de completitud).
- Throughput limitado: si la recomposición se implementa con procesamiento secuencial, el throughput está limitado por la velocidad de la parte más lenta.
- Debugging complejo: rastrear por qué un grupo de correlación no se completó requiere inspeccionar qué partes llegaron, cuáles faltan, cuándo llegó cada una y si hay duplicados.
Riesgos Si No Se Implementa Correctamente¶
- Grupos zombie: grupos de correlación que nunca se completan y consumen recursos indefinidamente. Sin mecanismos de timeout y expiración, estos grupos se acumulan hasta causar problemas de memoria o storage.
- Emisión prematura: emitir el mensaje consolidado antes de que todas las partes estén disponibles, produciendo resultados incompletos.
- Duplicación en el resultado: si el Aggregator no maneja mensajes duplicados (redelivery), una parte puede contarse dos veces en el resultado consolidado.
- Pérdida de estado: si el Aggregator falla y no tiene persistencia, se pierden todos los grupos de correlación en progreso, obligando a reprocesar todos los mensajes individuales.
- Deadlock de recursos: si el número de grupos de correlación activos excede la capacidad del almacén de estado, el Aggregator puede bloquearse o degradarse.
Ejemplos Reales¶
- Banca: en un proceso de liquidación, múltiples contrapartes envían confirmaciones parciales de una operación. El Aggregator acumula las confirmaciones y, cuando todas las contrapartes han confirmado, emite un mensaje de liquidación completa que inicia la transferencia de fondos.
- E-commerce: después de un Splitter que descompuso una orden en líneas individuales para fulfillment paralelo, el Aggregator reagrupa los resultados de fulfillment (shipped, backordered, cancelled) para producir un mensaje de estado completo de la orden.
- Healthcare: múltiples laboratorios envían resultados parciales de un panel de análisis. El Aggregator combina todos los resultados cuando el panel está completo y emite el resultado consolidado al médico.
- IoT: sensores envían lecturas individuales cada segundo. El Aggregator acumula las lecturas en ventanas de 5 minutos y emite un resumen estadístico (promedio, máximo, mínimo, desviación estándar) por ventana.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un Splitter previo dividió un mensaje compuesto y se necesita reconstruir el resultado después del procesamiento individual de las partes.
- Cuando un Scatter-Gather envió requests a múltiples servicios y necesita combinar las respuestas en un resultado unificado.
- Cuando múltiples sistemas independientes producen piezas de información que lógicamente pertenecen a la misma unidad de trabajo y deben consolidarse.
- Cuando stream processing requiere agregación temporal (conteos, sumas, promedios por ventana de tiempo).
- Cuando un proceso de negocio acumula aprobaciones, confirmaciones o resultados parciales antes de tomar una decisión.
- Cuando se necesita convertir un flujo granular de eventos en reportes o resúmenes consolidados.
Cuándo No Usarlo¶
- Cuando la información no necesita combinarse: si cada mensaje individual es autosuficiente y no necesita recomponerse con otros, el Aggregator introduce complejidad innecesaria.
- Cuando la recomposición puede hacerse en el destino final: si el consumer final puede procesar los mensajes individuales independientemente (por ejemplo, insertarlos en una base de datos donde una query posterior los combina), el Aggregator es innecesario.
- Cuando el volumen de grupos de correlación activos es inmanejable: si hay millones de grupos activos simultáneamente, el Aggregator puede requerir más estado del que es económicamente viable mantener.
- Cuando no se puede definir una condición de completitud confiable: si no se sabe cuántas partes tiene un grupo ni se puede definir un timeout razonable, el Aggregator no puede funcionar correctamente.
Precondiciones¶
- Todos los mensajes de un grupo comparten una correlation key identificable.
- Existe una condición de completitud definible (count, timeout, predicate o combinación).
- Existe infraestructura para persistir el estado del Aggregator (state store, base de datos, changelog topic).
- Los consumidores downstream pueden procesar el mensaje consolidado.
Restricciones¶
- El Aggregator es stateful: requiere almacenamiento proporcional al número de grupos activos y al tamaño de los mensajes acumulados.
- La latencia del Aggregator incluye el tiempo de espera hasta la completitud del grupo (puede ser segundos, minutos u horas).
- La escalabilidad horizontal del Aggregator está limitada por la necesidad de que todos los mensajes del mismo grupo sean procesados por la misma instancia (afinidad de partición).
Dependencias¶
- Almacén de estado persistente (Kafka state store, Redis, base de datos relacional, RocksDB).
- Mecanismo de timeout (scheduler, timer service).
- Correlation key presente en todos los mensajes del grupo.
- Definición de condición de completitud.
- Definición de función de agregación.
Supuestos Arquitectónicos¶
- Todos los mensajes de un grupo llegarán eventualmente (o se define un timeout para cuando no lleguen).
- La correlation key es consistente y correcta en todos los mensajes del grupo.
- El almacén de estado tiene capacidad suficiente para los grupos activos simultáneos.
- La función de agregación es determinista y produce el mismo resultado independientemente del orden de llegada de los mensajes.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Stream processing platforms (Kafka Streams, Apache Flink, Apache Beam) con windowed aggregations.
- Integration platforms (Apache Camel, Spring Integration, MuleSoft) con aggregation components.
- Workflow engines (Temporal, Cadence, AWS Step Functions) con signal accumulation.
- Event-driven architectures que consolidan eventos de múltiples fuentes.
- Sistemas de liquidación y clearing financiero.
6. Fuerzas Arquitectónicas¶
Estado vs. Simplicidad¶
El Aggregator es inherentemente stateful, lo que contradice la preferencia por componentes stateless en arquitecturas modernas. El estado debe gestionarse cuidadosamente: persistirse para recuperación, particionarse para escalabilidad, y expirar para evitar acumulación. La complejidad del estado es el costo de la recomposición.
Completitud vs. Latencia¶
La condición de completitud más precisa (esperar todas las partes) puede tener la mayor latencia (la parte más lenta determina la latencia total). Las condiciones menos estrictas (timeout, umbral) reducen latencia a costa de emitir resultados potencialmente incompletos. Esta tensión entre completitud y latencia es la decisión de diseño más crítica del Aggregator.
Consistencia vs. Disponibilidad¶
Un Aggregator que persiste estado en una base de datos con consistencia fuerte (strong consistency) es consistente pero puede tener menor disponibilidad (si la base de datos no está disponible, el Aggregator se detiene). Un Aggregator con estado in-memory es altamente disponible pero pierde estado ante fallos. El balance depende de la criticidad del proceso.
Memoria vs. Persistencia¶
Mantener el estado de los grupos en memoria es rápido pero volátil. Persistir en disco o base de datos es durable pero introduce latencia de I/O en cada actualización. Los state stores de Kafka Streams (RocksDB con changelog topic) ofrecen un balance: acceso rápido con persistencia local y replicación asíncrona.
Throughput vs. Afinidad¶
El Aggregator requiere que todos los mensajes del mismo grupo sean procesados por la misma instancia (para actualizar el mismo estado del grupo). Esto impone afinidad de partición: los mensajes deben particionarse por correlation key. Si un grupo tiene muchos mensajes, la instancia que lo procesa puede convertirse en un hotspot. El throughput está limitado por la distribución de grupos entre instancias.
Precisión vs. Recursos¶
Mantener grupos de correlación abiertos durante largos períodos (esperando partes tardías) consume más recursos pero produce resultados más precisos. Cerrar grupos agresivamente (timeout corto) libera recursos pero puede emitir resultados incompletos. La configuración óptima depende del SLA y de la confiabilidad de la entrega de mensajes.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Mensajes Individuales (Parts): los mensajes entrantes que pertenecen a un grupo de correlación. Cada uno lleva una correlation key y, opcionalmente, metadata de sequencing (índice, total).
- Aggregator: el componente stateful que acumula mensajes, evalúa completitud y emite el resultado.
- Correlation Strategy: la lógica que extrae la correlation key de cada mensaje para determinar a qué grupo pertenece.
- Completion Condition: la regla que determina cuándo un grupo está completo y listo para emitir.
- Aggregation Function: la lógica que combina los mensajes acumulados en un único mensaje de salida.
- State Store: el almacén donde se persisten los grupos de correlación activos.
- Timeout Manager: el componente que gestiona timeouts para grupos que no se completan en tiempo razonable.
- Canal de Entrada: el canal por donde llegan los mensajes individuales.
- Canal de Salida: el canal donde se emite el mensaje consolidado.
- Canal de Timeout/Error: el canal donde se emiten grupos incompletos que expiraron.
Flujo Lógico¶
flowchart TD
A([Mensaje Individual]) --> B[Correlation Strategy\nextraer correlation key]
B --> C{Grupo existe\nen State Store?}
C -- No --> D[Crear nuevo grupo\niniciar timer de timeout]
C -- Sí --> E[Recuperar grupo actual]
D --> F[Añadir mensaje al grupo]
E --> F
F --> G{Grupo completo?\nCompletion Condition}
G -- Sí --> H[Ejecutar Aggregation Function]
H --> I[(Canal de Salida\nmensaje consolidado)]
I --> J[Limpiar grupo del\nState Store]
J --> K[Cancelar timer\nde timeout]
K --> L([Fin])
G -- No --> M[(State Store\npersistir grupo actualizado)]
M --> N[Continuar esperando\nmás mensajes]
N --> A
O[Timeout Manager\ntimer expira] --> P{Política de\ntimeout?}
P --> Q[(Canal de error\ngrupo parcial)]
P --> R[(Canal de salida\ncon flag incomplete)]
Q --> S[Limpiar grupo\ndel State Store]
R --> S
S --> LResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Correlation Strategy | Determinar a qué grupo pertenece cada mensaje entrante |
| State Store | Persistir el estado de cada grupo de correlación activo |
| Completion Condition | Evaluar si un grupo tiene todas las partes necesarias |
| Aggregation Function | Combinar los mensajes acumulados en un resultado consolidado |
| Timeout Manager | Gestionar la expiración de grupos incompletos |
| Aggregator (orquestador) | Coordinar todos los componentes anteriores |
Interacciones¶
- Canal de Entrada → Aggregator: entrega de mensajes individuales.
- Aggregator → State Store: lectura y escritura del estado de grupos.
- Aggregator → Completion Condition: evaluación de completitud después de cada adición.
- Aggregator → Aggregation Function: invocación cuando un grupo está completo.
- Aggregator → Canal de Salida: emisión del mensaje consolidado.
- Timeout Manager → Aggregator: notificación de expiración de un grupo.
- Aggregator → Canal de Timeout: emisión de grupos expirados.
Contratos Implícitos¶
- Correlation key consistency: todos los mensajes de un grupo deben llevar la misma correlation key.
- Completion metadata: si la condición es count-based, cada mensaje debe incluir
split_size(o el primer mensaje del grupo debe incluirlo). - Aggregation compatibility: los mensajes deben ser combinables por la función de agregación (formatos compatibles).
Decisiones de Diseño Clave¶
-
Correlation strategy: ¿qué campo o combinación de campos identifica el grupo? ¿Un solo campo (
order_id) o una clave compuesta (order_id + warehouse_id)? -
Completion condition: ¿count, timeout, predicate o combinación?
- Count:
grupo.size() == split_size. Simple y preciso, pero requiere conocer el tamaño esperado. - Timeout de inactividad:
tiempo_desde_último_mensaje > T. Flexible, no requiere conocer el tamaño, pero puede emitir prematuramente si un mensaje se retrasa. - Timeout absoluto:
tiempo_desde_primer_mensaje > T. Limita el tiempo total de espera. - Predicate:
grupo.contains(message_with_flag_last_true). Flexible, pero depende de que el productor envíe la señal correctamente. -
Combinación:
count == split_size OR timeout > 5min. Robustez máxima. -
State store technology: ¿in-memory (rápido, volátil), local disk (RocksDB, LevelDB — rápido, persistente), base de datos externa (durable, lento), changelog topic (Kafka — durable, recuperable)?
-
Aggregation function: ¿lista de payloads? ¿Merge de objetos? ¿Reducción (suma, promedio)? ¿Función custom de negocio?
-
Handling de grupos incompletos: ¿emitir resultado parcial con flag? ¿Enviar a dead-letter? ¿Reintentar? ¿Notificar operaciones?
-
Deduplicación: ¿cómo manejar mensajes duplicados (redelivery)? ¿Idempotencia en la función de acumulación? ¿Tracking de message IDs ya procesados por grupo?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Agregación de Confirmaciones de Liquidación¶
Contexto del Negocio¶
Un banco de inversión opera como intermediario en operaciones de renta fija (bonos corporativos). Cuando se ejecuta una operación de compraventa, la liquidación (settlement) requiere la confirmación de múltiples contrapartes: el banco vendedor, el banco comprador, el custodio (que mantiene los valores en custodia), la cámara de compensación (que garantiza la operación) y, opcionalmente, el regulador (para operaciones que superan un umbral). Cada contraparte envía su confirmación de forma independiente y asíncrona. El banco necesita agregar todas las confirmaciones para producir un reporte de liquidación completo que determine si la operación puede liquidarse.
Necesidad de Integración¶
Las confirmaciones parciales llegan a través de diferentes canales (SWIFT, API REST, FIX protocol) en momentos diferentes (minutos a horas de diferencia). El banco necesita:
- Correlacionar las confirmaciones que pertenecen a la misma operación.
- Acumular confirmaciones hasta tener todas las requeridas.
- Emitir un reporte de liquidación cuando todas las confirmaciones están presentes.
- Manejar el caso de confirmaciones que no llegan dentro del plazo regulatorio (T+2 para bonos, T+1 para acciones).
- Detectar discrepancias entre confirmaciones (montos, fechas, identificadores).
Sistemas Involucrados¶
- SWIFT Gateway: recibe confirmaciones MT518 de bancos contrapartes.
- FIX Engine: recibe confirmaciones de brokers vía protocolo FIX 4.4.
- REST API Gateway: recibe confirmaciones de custodios y cámaras vía API REST.
- Normalizer: transforma confirmaciones de diferentes formatos a un formato canónico JSON.
- Kafka Cluster: infraestructura de streaming.
- Aggregator Service: servicio stateful que acumula confirmaciones por operación.
- Settlement Engine: sistema que ejecuta la liquidación cuando la agregación está completa.
- Operations Dashboard: interfaz para el equipo de operaciones que muestra el estado de cada operación.
Restricciones Técnicas¶
- El volumen diario es de 50,000 operaciones, cada una con 3 a 5 confirmaciones requeridas.
- El plazo máximo de liquidación es T+2 (dos días hábiles) para bonos y T+1 para acciones.
- Las confirmaciones pueden llegar en cualquier orden y con intervalos de horas entre ellas.
- El estado de cada operación debe ser persistente y recuperable ante fallos.
- Las confirmaciones duplicadas (mismo banco confirma dos veces) deben detectarse y no duplicar en el grupo.
- Si falta una confirmación al cierre del plazo, la operación debe escalarse a operations para resolución manual.
Flujos de Datos¶
SWIFT GW → [confirmations.swift]
FIX Engine → [confirmations.fix] → Normalizer → [confirmations.canonical]
REST API → [confirmations.rest]
[confirmations.canonical] → Aggregator → [settlements.complete]
→ [settlements.timeout] (para escalación)
[settlements.complete] → Settlement Engine
[settlements.timeout] → Operations Dashboard
Decisiones Arquitectónicas¶
-
Correlation key =
trade_id: cada confirmación incluye el identificador único de la operación (trade ID) asignado al momento de la ejecución. Todas las confirmaciones de la misma operación comparten este ID. -
Completion condition = predicate-based: una operación está completa cuando se han recibido confirmaciones de todas las contrapartes requeridas. El número de confirmaciones requeridas varía por tipo de operación (3 para operaciones estándar, 4 para operaciones con regulador). La lista de contrapartes esperadas se incluye en el primer mensaje del grupo (o se consulta al Trade Management System).
-
State store = Kafka Streams con RocksDB: estado local persistente con changelog topic para replicación. Permite recuperación automática ante fallos y escalabilidad horizontal por partición.
-
Timeout = T+2 business days: si una operación no está completa al cierre del día T+1, se genera una alerta. Si no está completa al cierre de T+2, se emite al canal de timeout para escalación manual.
-
Deduplicación: cada confirmación se identifica por
trade_id + confirming_party. Si el Aggregator recibe dos confirmaciones del mismo banco para la misma operación, la segunda se descarta (idempotencia). -
Validación cruzada: al completar el grupo, la Aggregation Function no solo combina sino que verifica consistencia: ¿coinciden los montos? ¿Coinciden las fechas de valor? ¿Coinciden los instrumentos? Las discrepancias se reportan en el mensaje de salida.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Confirmación con trade_id incorrecto | Validación de trade_id contra Trade Management System antes de agregar al grupo |
| Pérdida de estado del Aggregator | Kafka changelog topic con replication factor 3; recuperación automática de state store al reiniciar |
| Confirmación duplicada | Deduplicación por trade_id + confirming_party; idempotencia en la acumulación |
| Timeout prematuro por latencia de un canal | Timeout generoso (T+2); alertas tempranas al cierre de T+1 |
| Discrepancia en montos entre confirmaciones | Validación cruzada en Aggregation Function; flag de discrepancia en el mensaje de salida |
| Hotspot por operaciones de alto volumen | Partitioning por trade_id distribuye uniformemente; monitoreo de lag por partición |
| Cambio en el número de contrapartes requeridas | Lista de contrapartes consultada dinámicamente al crear el grupo, no hardcoded |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Ejecución de la Operación¶
El sistema de trading ejecuta una compraventa de bonos corporativos:
{
"trade_id": "TRD-2026-0407-00123",
"instrument": "ISIN ES0378165011",
"type": "BUY",
"quantity": 500000,
"price": 101.25,
"settlement_amount": 506250.00,
"currency": "EUR",
"trade_date": "2026-04-07",
"settlement_date": "2026-04-09",
"buyer": "BANK-A (BSCHESMM)",
"seller": "BANK-B (BBVAESMM)",
"custodian": "CUSTODIAN-C (CECAESMM)",
"clearing_house": "IBERCLEAR",
"required_confirmations": ["BANK-B", "CUSTODIAN-C", "IBERCLEAR"]
}
La operación requiere 3 confirmaciones: del banco vendedor (BANK-B), del custodio (CUSTODIAN-C) y de la cámara de compensación (IBERCLEAR).
Paso 2: Llegada de Confirmaciones (Asíncrona)¶
14:35 UTC — Confirmación de IBERCLEAR (vía REST API):
{
"trade_id": "TRD-2026-0407-00123",
"confirming_party": "IBERCLEAR",
"confirmation_type": "CLEARING_CONFIRMED",
"confirmed_amount": 506250.00,
"confirmed_settlement_date": "2026-04-09",
"timestamp": "2026-04-07T14:35:22Z"
}
El Aggregator recibe esta confirmación: 1. Extrae correlation key: TRD-2026-0407-00123. 2. No existe grupo → crea nuevo grupo con required_confirmations: ["BANK-B", "CUSTODIAN-C", "IBERCLEAR"]. 3. Añade confirmación de IBERCLEAR al grupo. Estado: {IBERCLEAR: confirmed} — 1/3. 4. Evalúa completitud: 1 < 3 → no completo. 5. Inicia timer de timeout: T+2 = 2026-04-09 18:00 UTC. 6. Persiste grupo en state store.
15:12 UTC — Confirmación de CUSTODIAN-C (vía SWIFT MT518):
{
"trade_id": "TRD-2026-0407-00123",
"confirming_party": "CUSTODIAN-C",
"confirmation_type": "CUSTODY_CONFIRMED",
"confirmed_amount": 506250.00,
"confirmed_settlement_date": "2026-04-09",
"timestamp": "2026-04-07T15:12:45Z"
}
El Aggregator: 1. Extrae correlation key: TRD-2026-0407-00123. 2. Encuentra grupo existente → recupera estado. 3. Añade confirmación de CUSTODIAN-C. Estado: {IBERCLEAR: confirmed, CUSTODIAN-C: confirmed} — 2/3. 4. Evalúa completitud: 2 < 3 → no completo. 5. Persiste grupo actualizado.
16:48 UTC — Confirmación de BANK-B (vía FIX):
{
"trade_id": "TRD-2026-0407-00123",
"confirming_party": "BANK-B",
"confirmation_type": "SELLER_CONFIRMED",
"confirmed_amount": 506250.00,
"confirmed_settlement_date": "2026-04-09",
"timestamp": "2026-04-07T16:48:03Z"
}
El Aggregator: 1. Extrae correlation key: TRD-2026-0407-00123. 2. Encuentra grupo existente → recupera estado. 3. Añade confirmación de BANK-B. Estado: {IBERCLEAR: confirmed, CUSTODIAN-C: confirmed, BANK-B: confirmed} — 3/3. 4. Evalúa completitud: 3 == 3 → COMPLETO.
Paso 3: Aggregation Function — Generación del Reporte de Liquidación¶
Al detectar completitud, el Aggregator ejecuta la Aggregation Function:
- Validación cruzada: verifica que los montos confirmados coinciden entre todas las contrapartes (506,250.00 EUR en las tres → OK).
- Verificación de fechas: todas las contrapartes confirman settlement_date 2026-04-09 → OK.
- Detección de discrepancias: ninguna → settlement puede proceder.
- Generación del mensaje consolidado:
{
"trade_id": "TRD-2026-0407-00123",
"settlement_status": "FULLY_CONFIRMED",
"settlement_amount": 506250.00,
"settlement_date": "2026-04-09",
"confirmations": [
{"party": "IBERCLEAR", "type": "CLEARING_CONFIRMED", "at": "2026-04-07T14:35:22Z"},
{"party": "CUSTODIAN-C", "type": "CUSTODY_CONFIRMED", "at": "2026-04-07T15:12:45Z"},
{"party": "BANK-B", "type": "SELLER_CONFIRMED", "at": "2026-04-07T16:48:03Z"}
],
"discrepancies": [],
"aggregation_completed_at": "2026-04-07T16:48:03Z",
"time_to_complete": "2h12m41s"
}
- Emisión: publica en
settlements.complete. - Limpieza: elimina el grupo del state store, cancela el timer de timeout.
Paso 4: Settlement Engine Procesa¶
El Settlement Engine consume de settlements.complete: 1. Verifica que settlement_status == "FULLY_CONFIRMED". 2. Verifica que no hay discrepancias. 3. Inicia el proceso de liquidación con Iberclear. 4. Actualiza el estado de la operación en el Trade Management System.
Paso 5: Escenario de Timeout¶
Para otra operación (TRD-2026-0407-00456), solo llegan 2 de 3 confirmaciones antes del deadline:
- Al cierre de T+1 (2026-04-08 18:00 UTC): el Aggregator emite una alerta al Operations Dashboard indicando que falta la confirmación de BANK-X.
- Al cierre de T+2 (2026-04-09 18:00 UTC): si aún falta, el Aggregator emite un mensaje al canal
settlements.timeout:
{
"trade_id": "TRD-2026-0407-00456",
"settlement_status": "INCOMPLETE_TIMEOUT",
"received_confirmations": ["IBERCLEAR", "CUSTODIAN-D"],
"missing_confirmations": ["BANK-X"],
"timeout_at": "2026-04-09T18:00:00Z"
}
El equipo de operaciones investiga y resuelve manualmente.
Manejo de Errores¶
- Confirmación con monto discrepante: el Aggregator acumula la confirmación pero marca la discrepancia. Al completar, el mensaje de salida incluye
"discrepancies": [{"field": "amount", "party": "BANK-B", "expected": 506250.00, "received": 506300.00}]. El Settlement Engine aplica reglas de tolerancia o escala. - Confirmación duplicada: si IBERCLEAR envía la confirmación dos veces, la segunda se detecta por
trade_id + confirming_partyy se descarta. - Fallo del Aggregator: al reiniciarse, el state store se reconstruye desde el changelog topic de Kafka. Los grupos en progreso se recuperan exactamente como estaban.
- Confirmación tardía (después del timeout): si llega una confirmación para un grupo ya expirado, se envía al dead-letter con contexto para resolución manual.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.compute import Rack
from diagrams.generic.storage import Storage
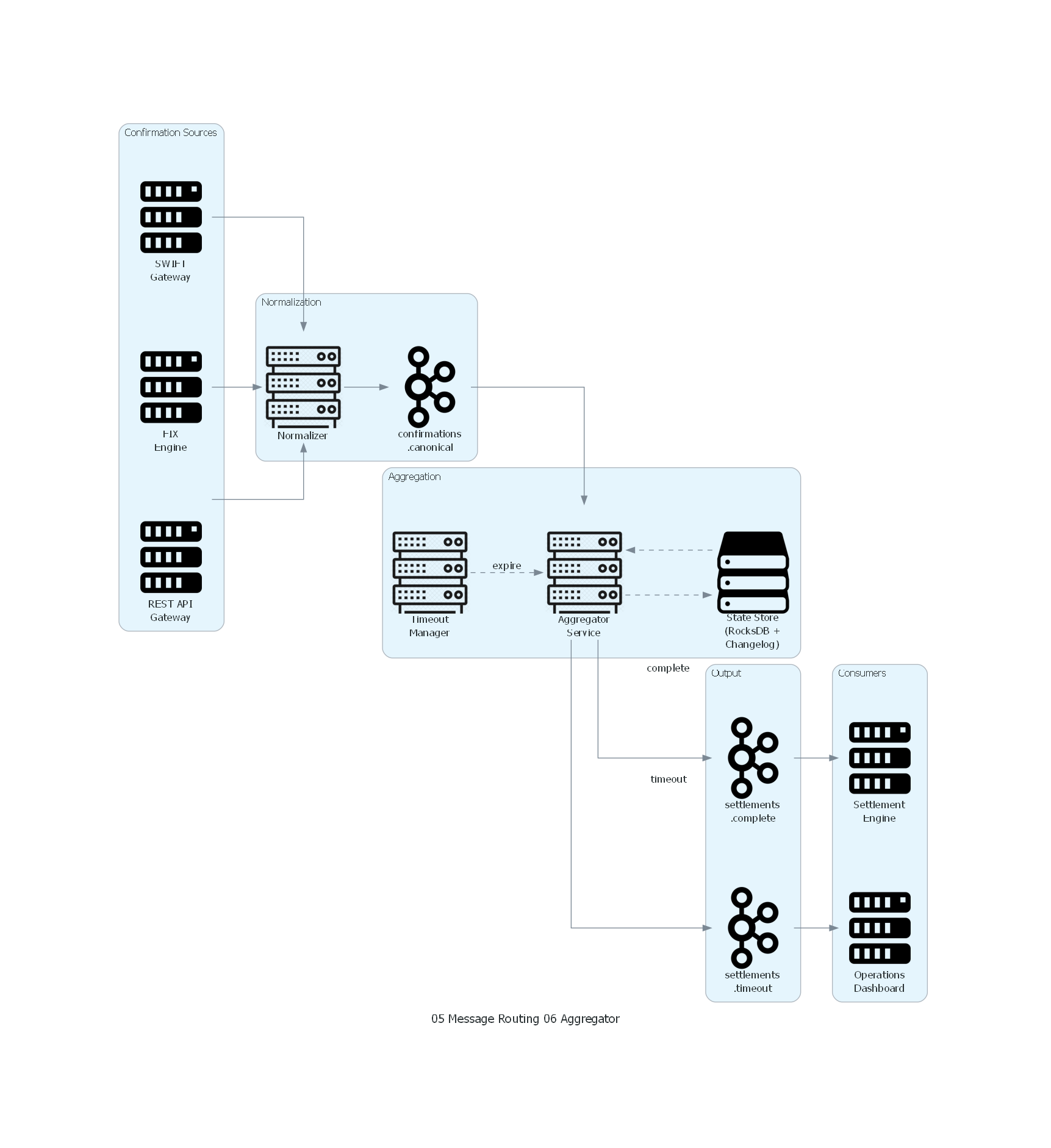
with Diagram("Aggregator - Settlement Confirmation Aggregation", show=False, direction="LR"):
with Cluster("Confirmation Sources"):
swift = Server("SWIFT\nGateway")
fix = Server("FIX\nEngine")
rest = Server("REST API\nGateway")
with Cluster("Normalization"):
normalizer = Rack("Normalizer")
topic_canonical = Kafka("confirmations\n.canonical")
with Cluster("Aggregation"):
aggregator = Rack("Aggregator\nService")
state_store = Storage("State Store\n(RocksDB +\nChangelog)")
timeout_mgr = Rack("Timeout\nManager")
with Cluster("Output"):
topic_complete = Kafka("settlements\n.complete")
topic_timeout = Kafka("settlements\n.timeout")
with Cluster("Consumers"):
settlement = Server("Settlement\nEngine")
ops_dash = Server("Operations\nDashboard")
# Flows
swift >> normalizer
fix >> normalizer
rest >> normalizer
normalizer >> topic_canonical
topic_canonical >> aggregator
aggregator >> Edge(style="dashed") >> state_store
state_store >> Edge(style="dashed") >> aggregator
timeout_mgr >> Edge(style="dashed", label="expire") >> aggregator
aggregator >> Edge(label="complete") >> topic_complete
aggregator >> Edge(label="timeout") >> topic_timeout
topic_complete >> settlement
topic_timeout >> ops_dash
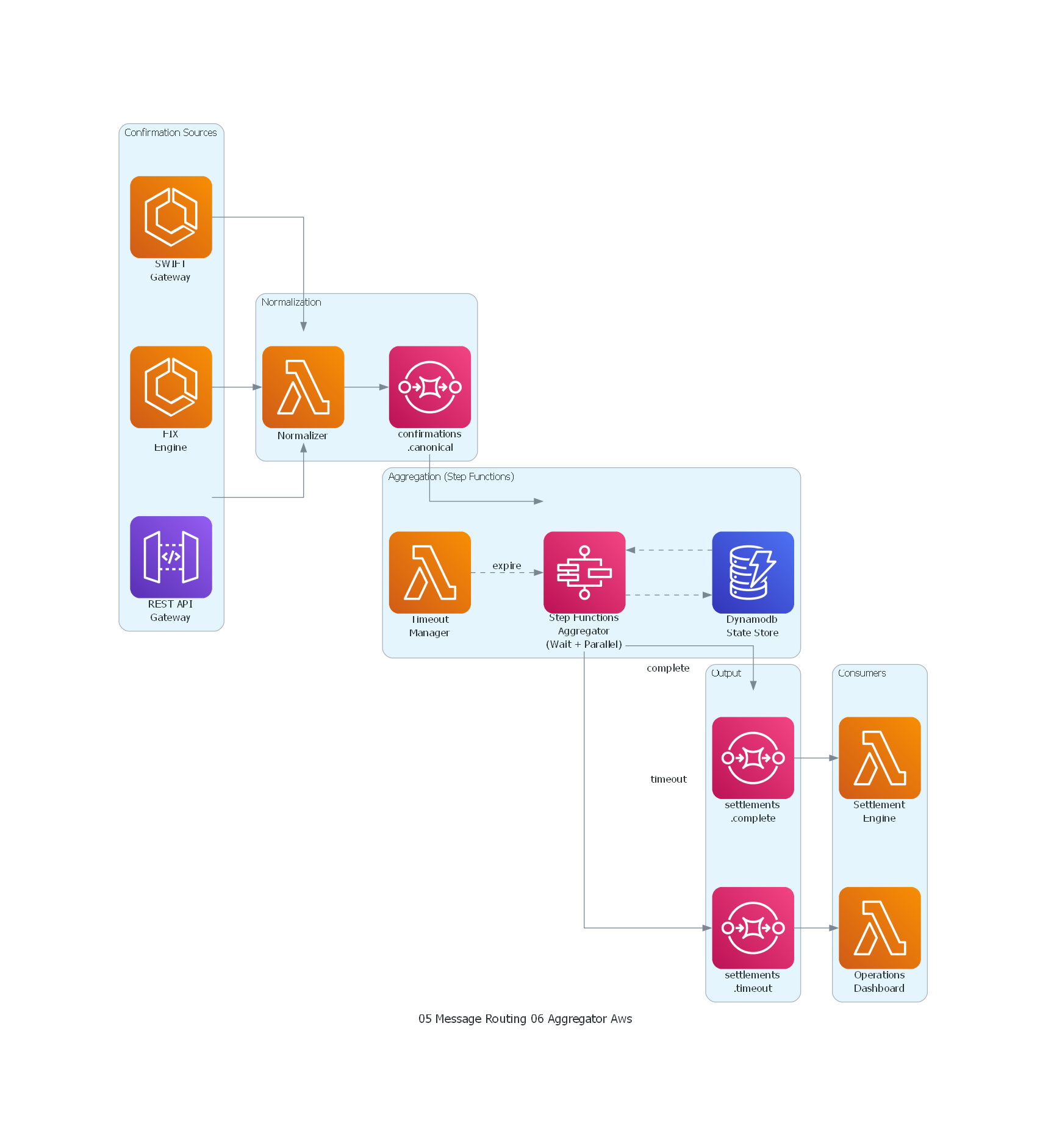
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS, StepFunctions
from diagrams.aws.network import APIGateway
with Diagram("Aggregator - Settlement Confirmation Aggregation (AWS)", show=False, direction="LR"):
with Cluster("Confirmation Sources"):
swift = ECS("SWIFT\nGateway")
fix = ECS("FIX\nEngine")
rest = APIGateway("REST API\nGateway")
with Cluster("Normalization"):
normalizer = Lambda("Normalizer")
topic_canonical = SQS("confirmations\n.canonical")
with Cluster("Aggregation (Step Functions)"):
aggregator = StepFunctions("Step Functions\nAggregator\n(Wait + Parallel)")
state_store = Dynamodb("Dynamodb\nState Store")
timeout_mgr = Lambda("Timeout\nManager")
with Cluster("Output"):
topic_complete = SQS("settlements\n.complete")
topic_timeout = SQS("settlements\n.timeout")
with Cluster("Consumers"):
settlement = Lambda("Settlement\nEngine")
ops_dash = Lambda("Operations\nDashboard")
# Flows
swift >> normalizer
fix >> normalizer
rest >> normalizer
normalizer >> topic_canonical
topic_canonical >> aggregator
aggregator >> Edge(style="dashed") >> state_store
state_store >> Edge(style="dashed") >> aggregator
timeout_mgr >> Edge(style="dashed", label="expire") >> aggregator
aggregator >> Edge(label="complete") >> topic_complete
aggregator >> Edge(label="timeout") >> topic_timeout
topic_complete >> settlement
topic_timeout >> ops_dash
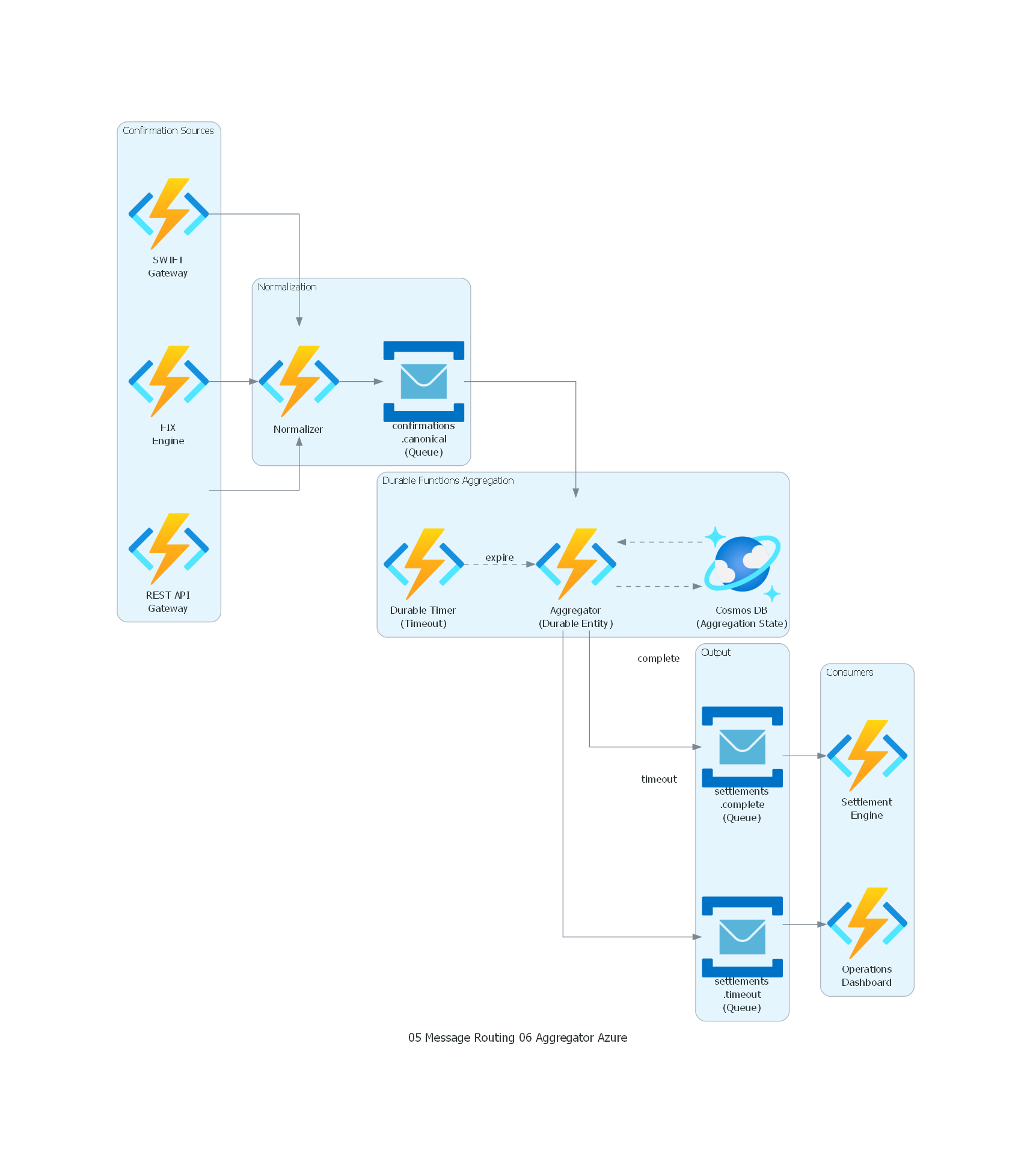
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.compute import Rack
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
with Diagram("Aggregator - Settlement Confirmation Aggregation (Azure)", show=False, direction="LR"):
with Cluster("Confirmation Sources"):
swift = FunctionApps("SWIFT\nGateway")
fix = FunctionApps("FIX\nEngine")
rest = FunctionApps("REST API\nGateway")
with Cluster("Normalization"):
normalizer = FunctionApps("Normalizer")
topic_canonical = ServiceBus("confirmations\n.canonical\n(Queue)")
with Cluster("Durable Functions Aggregation"):
aggregator = FunctionApps("Aggregator\n(Durable Entity)")
state_store = CosmosDb("Cosmos DB\n(Aggregation State)")
timeout_mgr = FunctionApps("Durable Timer\n(Timeout)")
with Cluster("Output"):
topic_complete = ServiceBus("settlements\n.complete\n(Queue)")
topic_timeout = ServiceBus("settlements\n.timeout\n(Queue)")
with Cluster("Consumers"):
settlement = FunctionApps("Settlement\nEngine")
ops_dash = FunctionApps("Operations\nDashboard")
# Flows
swift >> normalizer
fix >> normalizer
rest >> normalizer
normalizer >> topic_canonical
topic_canonical >> aggregator
aggregator >> Edge(style="dashed") >> state_store
state_store >> Edge(style="dashed") >> aggregator
timeout_mgr >> Edge(style="dashed", label="expire") >> aggregator
aggregator >> Edge(label="complete") >> topic_complete
aggregator >> Edge(label="timeout") >> topic_timeout
topic_complete >> settlement
topic_timeout >> ops_dash
Explicación del Diagrama¶
El diagrama muestra el flujo completo del Aggregator en el contexto de liquidación bancaria:
- Confirmation Sources: tres canales de entrada (SWIFT, FIX, REST API) que reciben confirmaciones de diferentes contrapartes.
- Normalization: un Normalizer transforma las confirmaciones de diferentes formatos a un formato canónico JSON.
- Aggregation: el Aggregator Service consume confirmaciones canónicas, las acumula en el State Store por trade_id, y evalúa completitud. El Timeout Manager monitorea grupos que exceden su plazo.
- Output: dos canales de salida:
settlements.completepara operaciones completamente confirmadas, ysettlements.timeoutpara operaciones que expiraron sin todas las confirmaciones. - Consumers: el Settlement Engine procesa operaciones completas, y el Operations Dashboard gestiona operaciones con timeout.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensajes Individuales | Confirmaciones canónicas en confirmations.canonical |
| Correlation Strategy | Extracción de trade_id de cada confirmación |
| State Store | RocksDB + Changelog Topic |
| Completion Condition | Todas las contrapartes requeridas han confirmado |
| Aggregation Function | Combinación de confirmaciones + validación cruzada |
| Timeout Manager | Componente que monitorea plazos T+1 y T+2 |
| Canal de Salida (completo) | settlements.complete |
| Canal de Salida (timeout) | settlements.timeout |
| Mensaje Consolidado | Settlement report con todas las confirmaciones y validaciones |
11. Beneficios¶
Impacto Técnico¶
- Recomposición centralizada: la lógica de acumulación, correlación, completitud y timeout se implementa una vez en el Aggregator, no se duplica en múltiples consumers.
- Paralelismo habilitado: el Aggregator permite que los mensajes individuales se procesen en paralelo (por ejemplo, fulfillment paralelo de líneas de orden) y luego se reagrupen. Sin Aggregator, el paralelismo requiere mecanismos ad-hoc de sincronización.
- Desacoplamiento temporal: los productores de mensajes individuales no necesitan sincronizarse entre sí. Cada uno puede emitir su mensaje cuando esté listo, y el Aggregator se encarga de acumular y completar.
- Visibilidad del estado: el state store del Aggregator proporciona una vista en tiempo real de qué grupos están activos, qué partes han llegado y cuáles faltan, lo que facilita diagnóstico y monitoreo.
Impacto Organizacional¶
- Separación de responsabilidades: los equipos que producen las partes (confirmaciones, líneas de orden, resultados parciales) no necesitan coordinar entre sí. El equipo del Aggregator se encarga de la recomposición.
- SLA medible: el Aggregator puede medir y reportar el tiempo-a-completitud de cada grupo, proporcionando métricas de SLA del proceso end-to-end.
- Escalación automatizada: los mecanismos de timeout del Aggregator automatizan la detección de procesos estancados y la escalación a operaciones.
Impacto Operacional¶
- Monitoreo granular: métricas como grupos activos, grupos completados/hora, tiempo promedio de completitud, grupos expirados/hora proporcionan visibilidad profunda del flujo de integración.
- Diagnóstico facilitado: inspeccionar el state store del Aggregator permite ver exactamente qué partes llegaron y cuáles faltan para un grupo específico.
- Recuperación ante fallos: con state stores persistentes, el Aggregator puede recuperarse de fallos sin perder el progreso acumulado.
Beneficios de Mantenibilidad y Evolución¶
- Evolución de la condición de completitud: cambiar la condición de completitud (de count-based a predicate-based, por ejemplo) requiere modificar solo el Aggregator, no los productores ni los consumers.
- Evolución de la función de agregación: añadir validaciones cruzadas, cálculos adicionales o transformaciones al resultado consolidado se hace en un solo punto.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Gestión de estado: el Aggregator introduce un componente stateful que requiere persistencia, replicación, backup y gestión de capacidad. En arquitecturas que buscan ser stateless, esto es una excepción significativa.
- Múltiples estrategias de completitud: elegir y configurar la condición de completitud correcta requiere conocimiento profundo del dominio y del comportamiento de los productores de mensajes.
- Timeout management: diseñar la lógica de timeout (cuánto esperar, qué hacer al expirar, cómo manejar mensajes tardíos) añade complejidad significativa.
- Concurrencia: si múltiples mensajes del mismo grupo llegan simultáneamente, el Aggregator debe manejar actualizaciones concurrentes del estado del grupo sin race conditions.
Riesgos de Mal Uso¶
- Aggregator como base de datos: usar el Aggregator para acumular datos durante días o semanas convierte el state store en una base de datos ad-hoc sin las garantías ni herramientas de una base de datos real.
- Condición de completitud incorrecta: una condición que nunca se satisface (requiere confirmaciones que nunca llegan) produce grupos zombie. Una condición que se satisface prematuramente produce resultados incompletos.
- Timeout demasiado corto: emite resultados incompletos frecuentemente. Timeout demasiado largo: acumula grupos activos que consumen recursos.
Sobreingeniería¶
- Aggregator cuando no se necesita recomposición: si cada mensaje individual es autosuficiente y no necesita combinarse con otros, el Aggregator es overhead innecesario.
- Aggregator con función de agregación trivial: si la función simplemente pone los mensajes en un array, considerar si los consumers downstream pueden hacer eso directamente.
Costos de Operación¶
- Storage: el state store consume storage proporcional al número de grupos activos y al tamaño de los mensajes acumulados. En sistemas de alta volumetría, esto puede ser considerable.
- Monitoring: el Aggregator requiere monitoreo especializado (grupos activos, grupos expirados, capacidad del state store, latencia de completitud).
- Recovery: la recuperación del state store ante fallos puede tomar tiempo significativo si el changelog es grande.
Errores Frecuentes de Implementación¶
- No definir timeout, dejando grupos incompletos acumularse indefinidamente (memory leak lógico).
- No manejar mensajes duplicados, provocando que una parte se cuente dos veces en el resultado.
- No persistir el state store, perdiendo todo el estado acumulado ante reinicios.
- Correlation key incorrecta que agrupa mensajes que no deberían estar juntos.
- Función de agregación no determinista que produce diferentes resultados según el orden de llegada.
Anti-Patterns Relacionados¶
- Eternal Aggregator: un Aggregator sin timeout que acumula grupos incompletos indefinidamente, consumiendo recursos sin producir resultados.
- Fat Aggregator: un Aggregator cuya función de agregación es tan compleja que contiene lógica de negocio que debería estar en servicios downstream.
- Aggregator as Database: usar el state store del Aggregator como almacén persistente de datos consultable, en lugar de como buffer temporal para recomposición.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Splitter: el complemento inverso natural. Splitter divide (1 → N), Aggregator recompone (N → 1). La combinación Splitter → Processing → Aggregator es un patrón compuesto extremadamente común.
- Correlation Identifier: el mecanismo que permite al Aggregator vincular mensajes al mismo grupo. Sin Correlation Identifier, el Aggregator no puede funcionar.
- Message Store: puede complementar al Aggregator almacenando los mensajes originales completos mientras el Aggregator solo almacena metadata de correlación.
Patrones que Suelen Aparecer Antes o Después¶
- Splitter (antes): divide un mensaje compuesto en partes que se procesan individualmente y luego se reagrupan por el Aggregator.
- Content-Based Router (antes): dirige las partes a diferentes procesadores antes de la reagrupación.
- Scatter-Gather (contiene al Aggregator): el Scatter-Gather usa internamente un Aggregator para combinar las respuestas de múltiples destinos.
- Process Manager (contiene al Aggregator): un Process Manager puede usar un Aggregator para acumular resultados de pasos paralelos.
Combinaciones Comunes¶
- Splitter + Aggregator (Composed Message Processor): la combinación más clásica. Divide, procesa individualmente, reagrupa.
- Scatter-Gather: recipient list + routing + Aggregator. Envía a múltiples destinos, procesa en paralelo, combina resultados.
- Aggregator + Resequencer: primero se reordenan los mensajes, luego se agregan. O primero se agregan y luego se reordena el resultado.
- Aggregator + Content Enricher: se enriquecen los mensajes individuales antes de agregarlos, para que el resultado consolidado tenga toda la información necesaria.
Diferencias con Patrones Similares¶
- vs. Resequencer: el Resequencer reordena mensajes pero no los combina en uno solo. El Aggregator combina N mensajes en 1. El Resequencer emite N mensajes reordenados.
- vs. Composed Message Processor: CMP es un patrón compuesto que usa Splitter + Router + Aggregator. El Aggregator es un componente atómico que CMP utiliza internamente.
- vs. Process Manager: Process Manager orquesta un proceso multi-paso con estado. El Aggregator es un caso específico de acumulación sin orquestación de pasos.
Encaje en un Flujo Mayor de Integración¶
El Aggregator típicamente aparece en las etapas finales de un pipeline de procesamiento paralelo, como punto de convergencia que reconstruye la visión completa a partir de las partes procesadas. En flujos Splitter → Processing → Aggregator, es el cierre del ciclo de procesamiento distribuido.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
El Aggregator es más relevante que nunca en el contexto de arquitecturas modernas, donde la distribución, el paralelismo y el stream processing son la norma.
A favor de la vigencia:
- En stream processing, las operaciones de windowed aggregation (
aggregate,reduce,counten Kafka Streams; window functions en Flink y Beam) son implementaciones directas del Aggregator y se usan masivamente en analytics en tiempo real, detección de fraude, monitoreo IoT y personalización. - En event-driven architectures, la necesidad de consolidar eventos de múltiples fuentes (saga completion, multi-service orchestration, event correlation) requiere Aggregators explícitos o implícitos.
- En microservices, el patrón Saga frecuentemente necesita un Aggregator para consolidar los resultados de múltiples servicios participantes antes de tomar una decisión de commit o compensación.
- En data pipelines, la agregación de datos granulares en resúmenes (métricas por ventana temporal, reportes por período) es una operación fundamental.
En contra de la vigencia:
- Algunas plataformas abstraen la complejidad del Aggregator completamente (Flink maneja ventanas automáticamente, Temporal maneja señales con state management built-in), reduciendo la necesidad de implementar el Aggregator como componente explícito.
- En sistemas con bases de datos rápidas, la "agregación" puede delegarse a queries SQL (GROUP BY, window functions) en lugar de un componente de streaming.
Contexto Moderno Donde Sigue Siendo Útil¶
- Agregación de eventos IoT por ventana temporal (promedios, máximos, conteos por minuto/hora).
- Consolidación de resultados de procesamiento paralelo (Splitter → Processing → Aggregator).
- Completitud de sagas en microservices (todas las compensaciones completadas → saga done).
- Generación de reportes periódicos a partir de flujos de eventos granulares.
- Detección de patrones complejos que requieren correlacionar eventos de múltiples fuentes (CEP — Complex Event Processing).
Cómo Se Implementa Hoy¶
La implementación moderna del Aggregator varía según la plataforma:
- Kafka Streams:
aggregate(),reduce(),count()sobreKGroupedStreamconMaterialized.as(stateStoreName). Kafka Streams gestiona automáticamente el state store (RocksDB), changelog topic (para recovery) y partitioning (para escalabilidad). - Apache Flink: window functions (
TumblingEventTimeWindows,SlidingProcessingTimeWindows,SessionWindows) conAggregateFunction. Flink gestiona state, checkpointing y recovery automáticamente. - Apache Camel:
aggregate()DSL conAggregationStrategy,correlationExpression,completionSize,completionTimeout. - Spring Integration:
AggregatingMessageHandlerconCorrelationStrategy,ReleaseStrategy,MessageGroupStore. - Temporal: workflows que acumulan señales (signals) y producen un resultado cuando todas las señales esperadas han llegado.
- AWS Step Functions:
Parallelstate conResultSelectorque combina los outputs de ramas paralelas.
Qué Parte Sigue Siendo Esencial¶
Independientemente de la tecnología, los principios esenciales del Aggregator que permanecen son:
- Correlation strategy: siempre se necesita un mecanismo para vincular mensajes relacionados.
- Completion condition: siempre se necesita definir cuándo dejar de acumular y emitir.
- State management: siempre se necesita almacenar el estado de acumulación, con las garantías apropiadas de persistencia y recovery.
- Timeout handling: siempre se necesita un plan para grupos que no se completan.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka / Kafka Streams¶
KStream<String, Confirmation> confirmations = builder.stream("confirmations.canonical");
KTable<String, SettlementReport> settlements = confirmations
.groupBy((key, confirmation) -> confirmation.getTradeId(),
Grouped.with(Serdes.String(), confirmationSerde))
.aggregate(
() -> new SettlementReport(), // initializer
(tradeId, confirmation, report) -> { // aggregator
report.addConfirmation(confirmation);
return report;
},
Materialized.<String, SettlementReport, KeyValueStore<Bytes, byte[]>>
as("settlement-store")
.withKeySerde(Serdes.String())
.withValueSerde(settlementReportSerde)
);
// Filtrar solo reports completos
settlements.toStream()
.filter((tradeId, report) -> report.isComplete())
.to("settlements.complete");
Para timeout handling, Kafka Streams requiere un mecanismo adicional (punctuator) que periódicamente inspeccione el state store y emita grupos expirados:
context.schedule(Duration.ofMinutes(1), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
KeyValueIterator<String, SettlementReport> iter = stateStore.all();
while (iter.hasNext()) {
KeyValue<String, SettlementReport> entry = iter.next();
if (entry.value.isExpired(timestamp)) {
context.forward(entry.key, entry.value.withStatus("TIMEOUT"));
stateStore.delete(entry.key);
}
}
iter.close();
});
Apache Flink¶
DataStream<Confirmation> confirmations = env.addSource(kafkaSource);
confirmations
.keyBy(Confirmation::getTradeId)
.window(EventTimeSessionWindows.withGap(Time.hours(6)))
.aggregate(new SettlementAggregateFunction())
.addSink(kafkaSink);
Flink proporciona session windows que se cierran automáticamente cuando no llegan mensajes para un key durante un gap definido, actuando como un timeout de inactividad.
Apache Camel¶
from("kafka:confirmations.canonical")
.aggregate(header("tradeId"), new SettlementAggregationStrategy())
.completionPredicate(exchange ->
exchange.getIn().getBody(SettlementReport.class).isComplete())
.completionTimeout(TimeUnit.HOURS.toMillis(48))
.aggregationRepository(new KafkaAggregationRepository())
.to("kafka:settlements.complete");
Camel soporta múltiples condiciones de completitud (size, timeout, predicate, interval) y múltiples tipos de repositorios de estado (in-memory, JDBC, Kafka, Hazelcast).
MuleSoft¶
<flow name="settlement-aggregator">
<kafka:listener config-ref="kafka-config" topic="confirmations.canonical" />
<aggregators:group-based-aggregator
name="settlementAggregator"
groupId="#[payload.trade_id]"
groupSize="#[payload.required_confirmations_count]"
timeout="172800000"
evictionTime="86400000">
<aggregators:aggregation-complete>
<ee:transform>
<ee:message>
<ee:set-payload>
#[output application/json --- { settlement: payload }]
</ee:set-payload>
</ee:message>
</ee:transform>
<kafka:publish config-ref="kafka-config" topic="settlements.complete" />
</aggregators:aggregation-complete>
<aggregators:incremental-aggregation>
<logger level="INFO" message="Partial: #[payload]" />
</aggregators:incremental-aggregation>
</aggregators:group-based-aggregator>
</flow>
Spring Integration¶
@Bean
public IntegrationFlow aggregationFlow() {
return IntegrationFlow
.from("confirmationsChannel")
.aggregate(a -> a
.correlationStrategy(m -> m.getHeaders().get("tradeId"))
.releaseStrategy(g -> {
SettlementReport report = buildReport(g.getMessages());
return report.isComplete();
})
.messageStore(new JdbcMessageStore(dataSource))
.groupTimeout(172800000L) // 48 hours
.sendPartialResultOnExpiry(true)
.expireGroupsUponTimeout(true)
)
.channel("settlementsChannel")
.get();
}
Temporal Workflows¶
@WorkflowInterface
public interface SettlementWorkflow {
@WorkflowMethod
SettlementReport processSettlement(TradeDetails trade);
@SignalMethod
void receiveConfirmation(Confirmation confirmation);
}
@WorkflowImpl
public class SettlementWorkflowImpl implements SettlementWorkflow {
private final List<Confirmation> confirmations = new ArrayList<>();
@Override
public SettlementReport processSettlement(TradeDetails trade) {
Workflow.await(
Duration.ofHours(48),
() -> confirmations.size() >= trade.getRequiredConfirmations().size()
);
if (confirmations.size() < trade.getRequiredConfirmations().size()) {
return SettlementReport.timeout(trade, confirmations);
}
return SettlementReport.complete(trade, confirmations);
}
@Override
public void receiveConfirmation(Confirmation confirmation) {
confirmations.add(confirmation);
}
}
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: grupos activos (current open groups), grupos completados/hora, grupos expirados/hora, tiempo promedio de completitud, mensajes procesados/segundo, tamaño del state store.
- Health checks: state store accesible, lag del consumer, timer de timeout activo.
- Alertas: número de grupos activos excede umbral (posible leak), tasa de timeouts excede umbral (problemas upstream), tamaño del state store excede capacidad, tiempo de completitud excede SLA.
Tracing¶
- Cada mensaje individual que ingresa al Aggregator debe llevar un trace ID.
- El mensaje consolidado de salida debe propagar los trace IDs de todos los mensajes individuales que lo componen.
- El distributed tracing debe mostrar el Aggregator como un span que "une" múltiples spans hijos.
Monitoreo¶
- Dashboard de grupos activos: visualizar grupos por estado (waiting, near-completion, near-timeout), por antigüedad, por número de partes recibidas.
- Dashboard de completitud: histograma de tiempos de completitud, tasa de completitud vs. tasa de timeout.
- Dashboard de state store: tamaño, utilización, latencia de lectura/escritura.
Versionado¶
- Si la estructura de los mensajes individuales cambia, la función de agregación debe adaptarse.
- Si la condición de completitud cambia (de count-based a predicate-based), el Aggregator debe reconfigurarse y los grupos activos en el estado anterior deben migrarse o expirarse.
- El versionado del state store (schema de los datos almacenados) es crítico para upgrades del Aggregator.
Seguridad¶
- El state store contiene datos acumulados que pueden incluir información sensible (datos financieros, PII).
- El state store debe estar cifrado en reposo si contiene datos sensibles.
- El acceso al state store (para inspección o debugging) debe estar controlado por RBAC.
Manejo de Errores¶
- Mensaje no correlacionable: un mensaje sin correlation key o con correlation key desconocida se envía al dead-letter.
- Error en la función de agregación: se registra el error, se marca el grupo como fallido, se envía al canal de error con toda la información acumulada.
- State store unavailable: el Aggregator se detiene (fail-fast) para evitar pérdida de estado. Se genera alerta de alta prioridad.
Retries¶
- El retry de un mensaje individual en el Aggregator es idempotente si la función de acumulación detecta duplicados (por message ID o por confirming_party).
- Si el Aggregator falla al emitir el mensaje consolidado, el grupo permanece en el state store y se re-emite cuando el servicio se recupera.
Dead-Lettering¶
- Mensajes que no pueden correlacionarse van al dead-letter del Aggregator.
- Grupos que expiran por timeout pueden dirigirse a un canal de dead-letter dedicado para resolución manual.
- El dead-letter debe incluir toda la información del grupo (partes recibidas, partes faltantes, timestamps).
Idempotencia¶
- La función de acumulación debe ser idempotente: agregar el mismo mensaje dos veces no debe cambiar el estado del grupo.
- Implementación: mantener un set de message IDs procesados por grupo. Si un message ID ya está en el set, descartarlo.
- La función de emisión debe ser idempotente: emitir el mismo resultado consolidado dos veces no debe causar efectos duplicados downstream.
Auditoría¶
- Registrar: qué grupos se crearon, qué mensajes se acumularon en cada grupo, cuándo se completó, cuándo se emitió el resultado, si hubo discrepancias o timeout.
- El state store proporciona una vista auditable del estado de cada grupo en cualquier momento.
Performance¶
- State store performance: la latencia de lectura/escritura del state store es crítica. Cada mensaje entrante requiere una lectura (buscar grupo) y una escritura (actualizar grupo). RocksDB proporciona latencia sub-milisegundo para state stores locales.
- Serialización: la serialización/deserialización del estado del grupo en cada actualización puede ser un cuello de botella con grupos grandes. Usar formatos binarios eficientes (Avro, Protobuf) en lugar de JSON.
- Compactación: en Kafka, el changelog topic del state store debe tener compactación habilitada para evitar crecimiento indefinido.
Escalabilidad¶
- El Aggregator escala horizontalmente por partición de la correlation key. Cada partición se procesa por una instancia diferente del Aggregator.
- La limitación es que todos los mensajes del mismo grupo (misma correlation key) deben procesarse por la misma instancia.
- Si la distribución de correlation keys es uniforme, la carga se distribuye uniformemente entre instancias.
- Si algunas correlation keys tienen muchos más mensajes que otras (hotspots), puede ser necesario re-particionar o usar sub-correlation keys.
17. Errores Comunes¶
No Definir Timeout¶
El error más frecuente y más dañino es implementar un Aggregator sin mecanismo de timeout. Sin timeout, los grupos que nunca se completan (porque un mensaje esperado nunca llega, el productor falló, o la condición de completitud tiene un bug) se acumulan indefinidamente, consumiendo memoria y storage hasta causar un fallo del sistema. Todo Aggregator debe tener un timeout explícito, incluso si es generoso.
Condición de Completitud Incorrecta¶
Una condición de completitud que no refleja la realidad del negocio es fuente de errores sutiles. Si la condición dice "completo cuando se reciben 3 confirmaciones" pero algunas operaciones requieren 4, esas operaciones se marcarán como completas prematuramente. Si la condición dice "completo cuando llega el mensaje con flag last=true" pero el productor a veces no envía ese flag, el grupo nunca se completa. La condición de completitud debe validarse exhaustivamente con casos reales.
No Manejar Mensajes Duplicados¶
En sistemas de mensajería con entrega at-least-once, un mensaje puede entregarse más de una vez. Si el Aggregator no detecta duplicados, una parte puede contarse dos veces, produciendo resultados incorrectos (por ejemplo, una suma que incluye un monto dos veces). La solución es mantener un set de message IDs por grupo y descartar duplicados.
State Store Sin Persistencia¶
Usar un state store in-memory sin respaldo persistente es aceptable para pruebas, pero desastroso en producción. Un reinicio del proceso borra todo el estado acumulado, perdiendo todos los grupos en progreso. La recuperación requiere reprocesar todos los mensajes individuales desde el origen, lo cual puede ser imposible si el canal de entrada no retiene mensajes históricos.
Correlation Key Incorrecta¶
Una correlation key que no identifica unívocamente el grupo produce errores difíciles de diagnosticar. Si la correlation key es demasiado amplia (agrupa mensajes que no deberían estar juntos), el resultado consolidado mezcla datos de diferentes contextos. Si es demasiado estrecha (separa mensajes que deberían estar juntos), los grupos nunca se completan porque "faltan" partes que en realidad se asignaron a otro grupo.
Función de Agregación No Determinista¶
Si la función de agregación produce diferentes resultados según el orden de llegada de los mensajes, el resultado es impredecible. La función debe ser conmutativa y asociativa: el resultado debe ser el mismo independientemente del orden de acumulación. Si el orden importa, se debe implementar un Resequencer antes del Aggregator.
Acumular Mensajes Completos en el State Store¶
Almacenar el payload completo de cada mensaje individual en el state store consume storage rápidamente. Si los mensajes son grandes, considerar almacenar solo la metadata necesaria para la función de agregación, o usar Claim Check para almacenar los payloads externamente y mantener solo referencias en el state store.
18. Conclusión Técnica¶
Aggregator es el patrón más complejo del catálogo de Enterprise Integration Patterns, y esta complejidad es inherente al problema que resuelve: recomponer información fragmentada en un sistema distribuido y asíncrono. La gestión de estado persistente, la estrategia de correlación, la condición de completitud, el manejo de timeouts, la deduplicación y la recuperación ante fallos son desafíos que no pueden simplificarse sin sacrificar correctitud.
En el ecosistema moderno, la complejidad del Aggregator está siendo progresivamente absorbida por las plataformas:
- Kafka Streams gestiona state stores, changelog topics, partitioning y recovery automáticamente.
- Apache Flink gestiona windows, state, checkpointing y exactly-once automáticamente.
- Temporal gestiona durabilidad de workflow state, signals y timeouts automáticamente.
Sin embargo, las decisiones de diseño fundamentales permanecen responsabilidad del arquitecto: qué correlation key usar, qué condición de completitud definir, qué timeout establecer, cómo manejar grupos incompletos, y qué función de agregación aplicar. Estas decisiones son de dominio, no de infraestructura, y ninguna plataforma puede tomarlas automáticamente.
Recomendación para arquitectos: al diseñar un Aggregator, comience por las tres decisiones fundamentales: (1) la correlation strategy (qué agrupa los mensajes), (2) la completion condition (cuándo está el grupo completo), y (3) la timeout strategy (qué hacer cuando no se completa). Elija una plataforma que gestione la complejidad infraestructural (state management, recovery, scaling) automáticamente — Kafka Streams, Flink o Temporal son las opciones más maduras. Implemente deduplicación desde el primer día (no como "mejora futura") y defina timeouts explícitos para todo grupo. Monitoree activamente los grupos activos, los timeouts y la capacidad del state store. Y, fundamentalmente, trate al Aggregator como un componente crítico que merece el mismo nivel de testing, monitoreo y gobernanza que una base de datos, porque en esencia, lo es.