Resequencer¶
1. Nombre del Patrón¶
- Nombre oficial: Resequencer
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Resecuenciador de Mensajes
2. Resumen Ejecutivo¶
Resequencer es un patrón de enrutamiento stateful que recibe un flujo de mensajes que pueden llegar desordenados y los re-emite en el orden correcto, según un criterio de secuencia definido (número de secuencia, timestamp, o cualquier campo ordenable). A diferencia del Aggregator, que combina N mensajes en 1, el Resequencer emite los mismos N mensajes que recibió, pero en el orden correcto.
El problema fundamental que resuelve es la pérdida de orden en sistemas distribuidos. Cuando los mensajes pasan por procesamiento paralelo, múltiples canales, o sistemas con diferentes latencias, el orden original de producción se pierde. Si la lógica downstream requiere procesamiento en orden (aplicar actualizaciones secuencialmente, reconstruir un flujo cronológico, cumplir requisitos regulatorios de ordenamiento), el Resequencer restaura ese orden antes de la entrega.
Resequencer aparece en escenarios donde el orden es semánticamente significativo: procesamiento de eventos de red en telecom donde el orden de los eventos determina el estado del circuito, aplicación de transacciones financieras en orden cronológico, reconstrucción de sesiones de usuario a partir de eventos desordenados, y reordenamiento de paquetes de datos que viajaron por rutas paralelas.
3. Definición Detallada¶
Propósito¶
El propósito de Resequencer es restaurar el orden correcto en un flujo de mensajes que han perdido su secuencia original debido al procesamiento paralelo, routing a través de múltiples canales, diferencias de latencia entre paths, o cualquier otra causa de reordenamiento en un sistema distribuido.
Lógica Arquitectónica¶
El Resequencer mantiene un buffer interno donde acumula mensajes hasta que puede emitirlos en el orden correcto. Cada mensaje lleva un indicador de secuencia (sequence number, timestamp, o campo ordenable). El Resequencer inspecciona este indicador, almacena los mensajes en el buffer ordenado, y emite mensajes cuando puede garantizar que no llegarán mensajes con un indicador de secuencia anterior al que está por emitir.
Existen dos variantes fundamentales:
-
Batch Resequencer: acumula todos los mensajes de un grupo (conoce el tamaño total), los ordena y los emite todos de una vez cuando el grupo está completo. Es más simple pero requiere conocer el tamaño del grupo y tiene mayor latencia.
-
Stream Resequencer: emite mensajes tan pronto como puede garantizar que el siguiente mensaje en secuencia ha llegado, sin esperar a tener todos los mensajes. Es más complejo pero tiene menor latencia. Requiere un mecanismo para determinar cuándo es seguro emitir (timeout de espera para mensajes faltantes).
La analogía es un servicio postal que recibe paquetes numerados de una serie y debe entregarlos en orden al destinatario. El cartero espera a tener el paquete #3 antes de entregar el #4, aunque el #4 haya llegado primero.
Principio de Diseño Subyacente¶
El principio fundamental es la restauración de causalidad en flujos asíncronos. En muchos dominios de negocio, el orden de los eventos tiene significado causal: el evento A debe procesarse antes que el evento B porque B depende del resultado de A, o porque la secuencia A→B representa una transición de estado válida mientras que B→A no. El Resequencer garantiza que este orden causal se preserva en el procesamiento, incluso si se perdió durante el transporte.
Problema Estructural que Resuelve¶
Sin Resequencer, un sistema que recibe mensajes desordenados y requiere procesamiento en orden tiene opciones limitadas:
- Procesamiento secuencial punto a punto: eliminar todo el paralelismo y procesar en un solo hilo para garantizar orden. Esto sacrifica throughput y escalabilidad.
- Lógica de reordenamiento en cada consumer: cada consumer que requiere orden implementa su propia lógica de buffering y reordenamiento, duplicando complejidad.
- Ignorar el desorden: procesar mensajes en el orden de llegada y manejar las inconsistencias resultantes. Esto puede ser aceptable en algunos casos pero inaceptable en otros (transacciones financieras, aplicación de estados).
Contexto en el que Emerge¶
Resequencer emerge en contextos donde:
- Mensajes que originalmente estaban en orden pasan por procesamiento paralelo que altera su secuencia.
- Mensajes viajan por múltiples paths con diferentes latencias (routing dinámico, load balancing).
- Un Splitter dividió un mensaje y las partes se procesaron en paralelo, alterando el orden original de las líneas.
- Sistemas distribuidos con múltiples productores generan eventos que deben procesarse en orden cronológico global.
- Protocolos de comunicación que no garantizan orden de entrega (UDP, mensajería sin ordering guarantees).
Por Qué No Es Trivial¶
- Detección de gaps: ¿cómo sabe el Resequencer que falta un mensaje? Si tiene los mensajes 1, 2, 4, ¿cuánto espera al mensaje 3 antes de decidir que se perdió?
- Timeout vs. completitud: esperar indefinidamente al mensaje faltante bloquea todo el flujo. No esperar y emitir con un gap puede producir procesamiento fuera de orden.
- Mensajes perdidos: si un mensaje nunca llega (el productor falló, el mensaje se perdió en tránsito), el Resequencer debe tener un plan: emitir lo que tiene, generar un placeholder, escalar.
- Tamaño del buffer: si la diferencia de secuencia entre el mensaje más antiguo en el buffer y el más reciente es grande, el buffer puede consumir mucha memoria.
- Definición de "orden": ¿el orden es por sequence number (asignado por el productor), por timestamp (que puede tener clock skew entre productores), o por otro criterio?
- Scope del reordenamiento: ¿se reordena globalmente (todos los mensajes) o por grupo (mensajes de la misma correlación)?
Relación con Sistemas Distribuidos y Mensajería¶
En sistemas de mensajería modernos, el ordering se gestiona frecuentemente a nivel de infraestructura:
- Kafka: garantiza orden dentro de una partición. Si los mensajes de un mismo grupo se asignan a la misma partición (partitioning by key), el orden se preserva sin necesidad de Resequencer. El Resequencer se necesita cuando los mensajes cruzan particiones o cuando el procesamiento entre particiones altera el orden.
- SQS: las colas estándar de AWS SQS no garantizan orden. SQS FIFO garantiza orden pero con throughput limitado. Un Resequencer sobre SQS estándar puede proporcionar orden con mayor throughput que FIFO.
- Event Hubs: similar a Kafka, orden dentro de una partición pero no entre particiones.
En stream processing, el Resequencer se implementa como una operación de buffering con reordenamiento, frecuentemente basada en event time y watermarks:
- En Flink, los watermarks indican al sistema que no llegarán más eventos con timestamp anterior a cierto valor, permitiendo emitir resultados ordenados. Esto es conceptualmente un Resequencer basado en timestamp.
- En Kafka Streams, el ordering dentro de una partición es nativo, pero el reordenamiento cross-partition requiere implementación explícita.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Resequencer, un sistema que procesa mensajes desordenados que deberían estar en orden experimenta:
- Transiciones de estado inválidas: si el evento "orden creada" llega después del evento "orden enviada", el consumer intenta registrar un envío para una orden que aún no existe en su estado local.
- Sobrescritura de datos correctos: si un update con timestamp T2 llega antes que un update con timestamp T1, el consumer aplica T2 y luego T1, quedando con datos obsoletos.
- Cálculos acumulativos incorrectos: si las transacciones financieras se procesan fuera de orden, los saldos intermedios son incorrectos (pueden mostrar saldo negativo transitoriamente).
- Reportes inconsistentes: eventos cronológicos presentados fuera de orden confunden al analista o al sistema de compliance.
Síntomas del Problema¶
- Errores de "entity not found" cuando un consumer intenta procesar un evento que referencia una entidad aún no creada (porque el evento de creación llegó después).
- Saldos o contadores que temporalmente muestran valores incorrectos antes de "corregirse" cuando llegan los mensajes faltantes.
- Logs de procesamiento que muestran secuencias ilógicas de eventos.
- Race conditions en consumers que asumen orden de llegada.
Impacto Operativo y Arquitectónico¶
- Errores transitorios: el desorden produce errores que se "auto-corrigen" cuando los mensajes faltantes llegan, pero que generan alertas, retries y confusión operacional.
- Complejidad en consumers: los consumers deben implementar lógica defensiva para manejar eventos fuera de orden (buffering, reintentos, upserts idempotentes), lo que complica significativamente su implementación.
- Inconsistencia temporal: las vistas derivadas de un stream desordenado son temporalmente inconsistentes, lo que puede producir decisiones de negocio incorrectas basadas en datos intermedios.
Riesgos Si No Se Implementa Correctamente¶
- Buffer overflow: si el Resequencer acumula mensajes sin emitir (porque un mensaje de secuencia temprana no llega), el buffer crece indefinidamente hasta causar out-of-memory.
- Deadlock lógico: si el Resequencer espera un mensaje que nunca llega (porque se perdió) y bloquea la emisión de todos los mensajes posteriores, el flujo se detiene completamente.
- Latencia excesiva: si el desorden es grande (el mensaje más tardío puede llegar minutos después del más temprano), el Resequencer introduce una latencia proporcional al máximo desorden posible.
- Timeout prematuro: si el timeout es demasiado corto, el Resequencer emite mensajes con gaps, derrotando su propósito.
Ejemplos Reales¶
- Telecom: una estación base envía eventos de red (session start, data transfer, session end) que pasan por procesamiento paralelo en el rating engine. Los eventos llegan desordenados al sistema de facturación. El Resequencer los reordena por session_id + sequence_number para garantizar que el "session start" se procese antes que los "data transfers" y que el "session end" se procese al final.
- Banca: transacciones de una cuenta que se procesan en paralelo (validación de fraude en servicio A, verificación de fondos en servicio B) llegan al ledger desordenadas. El Resequencer las reordena por timestamp de ejecución para que el ledger refleje el orden cronológico real.
- Logistics: eventos de tracking de un paquete (picked up, in transit, customs, delivered) llegan desordenados porque diferentes scanners reportan con diferentes latencias. El Resequencer los ordena para presentar una timeline coherente al cliente.
- IoT: lecturas de sensores que viajan por rutas de red diferentes llegan desordenadas al sistema de análisis. El Resequencer las ordena por timestamp para cálculos de series temporales.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando los mensajes tienen un orden semántico (cronológico, causal, secuencial) que debe preservarse para el procesamiento correcto downstream.
- Cuando el paralelismo en etapas intermedias del pipeline altera el orden original de los mensajes.
- Cuando los consumers downstream no pueden manejar mensajes fuera de orden (no implementan lógica de reordenamiento propia).
- Cuando el protocolo de transporte no garantiza orden de entrega (múltiples paths, load balancing, multi-partition routing).
- Cuando se necesita presentar un flujo de eventos en orden cronológico para auditoría, compliance o análisis.
Cuándo No Usarlo¶
- Cuando la infraestructura de mensajería ya garantiza orden (Kafka con single partition por key, SQS FIFO, colas con ordering guarantees). El Resequencer añadiría overhead sin beneficio.
- Cuando los consumers son order-agnostic (idempotentes y conmutativos): si el resultado es el mismo independientemente del orden, el Resequencer es innecesario.
- Cuando el costo de latencia del reordenamiento es inaceptable para el caso de uso (real-time processing donde cada milisegundo cuenta).
- Cuando no existe un criterio de orden definido en los mensajes (no hay sequence number, no hay timestamp confiable).
Precondiciones¶
- Cada mensaje lleva un indicador de secuencia (sequence number, timestamp, o campo ordenable).
- El indicador de secuencia es consistente y correcto (no hay duplicados de sequence number, los timestamps son razonablemente sincronizados).
- Existe una expectativa de cuánto desorden es tolerable (máximo gap, máximo delay).
- El sistema puede tolerar la latencia que el reordenamiento introduce.
Restricciones¶
- El Resequencer introduce latencia proporcional al máximo desorden esperado.
- El buffer del Resequencer consume memoria proporcional al número de mensajes desordenados retenidos.
- Si un mensaje se pierde, el Resequencer debe decidir entre esperar indefinidamente o emitir con un gap.
Dependencias¶
- Indicador de secuencia en cada mensaje.
- Buffer de almacenamiento temporal (in-memory o persistente).
- Mecanismo de timeout para mensajes faltantes.
Supuestos Arquitectónicos¶
- El desorden es acotado: el máximo gap entre el mensaje más tardío y su posición esperada es finito y predecible.
- Los indicadores de secuencia son correctos y monótonamente crecientes (para sequence numbers) o razonablemente sincronizados (para timestamps).
- El volumen de mensajes desordenados retenidos simultáneamente es manejable en memoria o storage.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Telecom (reordenamiento de CDRs y eventos de red).
- Financial services (reordenamiento de transacciones para ledger).
- IoT (reordenamiento de lecturas de sensores por timestamp).
- Stream processing con múltiples particiones o fuentes.
- Sistemas de replay de eventos (event sourcing) donde los eventos deben aplicarse en orden.
6. Fuerzas Arquitectónicas¶
Orden vs. Latencia¶
El Resequencer introduce latencia: debe esperar a que el mensaje con la secuencia esperada llegue antes de emitir los mensajes siguientes. Cuanto mayor es el desorden potencial, mayor es la latencia del buffer. La tensión fundamental es entre la garantía de orden (esperar más) y la latencia (esperar menos).
Completitud vs. Disponibilidad¶
Si un mensaje se pierde (nunca llega), el Resequencer debe decidir: esperar indefinidamente (alta completitud, baja disponibilidad del flujo) o emitir con un gap después de un timeout (baja completitud, alta disponibilidad). Esta decisión depende del dominio: en un ledger financiero, un gap es inaceptable; en un dashboard de monitoreo, un gap es tolerable.
Memoria vs. Durabilidad¶
Mantener el buffer en memoria es rápido pero volátil. Persistir en disco es durable pero introduce I/O. Para flujos de alto volumen con poco desorden, in-memory es adecuado. Para flujos con desorden significativo y requerimientos de durabilidad, se necesita persistencia.
Simplicidad vs. Throughput¶
El Resequencer batch (acumula todo, ordena, emite) es simple pero tiene throughput limitado (no emite nada hasta tener todo). El Resequencer stream (emite tan pronto como es seguro) tiene mayor throughput pero es significativamente más complejo de implementar correctamente.
Precisión vs. Escalabilidad¶
El reordenamiento global (todos los mensajes en un solo Resequencer) es preciso pero no escala. El reordenamiento por grupo (cada grupo tiene su propio Resequencer) escala pero requiere que el orden solo sea significativo dentro de cada grupo, no globalmente.
Costo vs. Necesidad¶
En muchos sistemas modernos, el ordering se puede garantizar a nivel de infraestructura (Kafka partitions, FIFO queues) sin necesidad de un Resequencer explícito. El costo de implementar y operar un Resequencer solo se justifica cuando la infraestructura no puede proporcionar las garantías de orden requeridas.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Mensajes Desordenados: los mensajes entrantes que han perdido su orden original. Cada uno lleva un indicador de secuencia.
- Resequencer: el componente stateful que bufferiza, reordena y emite mensajes.
- Buffer Ordenado: la estructura de datos interna que mantiene los mensajes pendientes de emisión, ordenados por indicador de secuencia.
- Sequence Tracker: el componente que rastrea cuál es el siguiente número de secuencia esperado.
- Timeout Manager: el componente que gestiona timeouts para mensajes faltantes.
- Canal de Entrada: el canal por donde llegan los mensajes desordenados.
- Canal de Salida: el canal donde se emiten los mensajes reordenados.
Flujo Lógico¶
flowchart TD
A([Mensaje llega\nsequence_number = S]) --> B{Comparar S con\nnext_expected_sequence}
B -- "S == next_expected" --> C[Emitir mensaje al\ncanal de salida]
C --> D[Incrementar\nnext_expected_sequence]
D --> E{Buffer tiene\nel siguiente esperado?}
E -- Sí --> F[Emitir en cascada\ndesde buffer]
F --> E
E -- No --> G([Esperar siguiente mensaje])
B -- "S > next_expected" --> H[(Buffer\nalmacenar mensaje adelantado)]
H --> I[Iniciar/resetear timer\nde timeout para gap]
I --> G
B -- "S < next_expected" --> J[Descartar mensaje\nduplicado o retrasado]
J --> G
K[Timeout Manager\ntimer expira por gap] --> L{Política de\ngap?}
L -- Saltar faltante --> M[Emitir desde el siguiente\ndisponible en buffer]
L -- Placeholder --> N[Emitir placeholder\nindicando gap]
L -- Alerta --> O[Enviar alerta y esperar\ninstrucción manual]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Mensaje | Llevar un indicador de secuencia correcto |
| Resequencer | Bufferizar, reordenar y emitir mensajes en secuencia |
| Buffer Ordenado | Mantener mensajes pendientes ordenados por secuencia |
| Sequence Tracker | Rastrear cuál es el siguiente número de secuencia esperado |
| Timeout Manager | Detectar cuando un mensaje esperado no llega en tiempo razonable |
Interacciones¶
- Canal de Entrada → Resequencer: entrega de mensajes desordenados.
- Resequencer → Buffer: almacenamiento de mensajes adelantados.
- Resequencer → Canal de Salida: emisión de mensajes en orden correcto.
- Timeout Manager → Resequencer: notificación de gap timeout.
Contratos Implícitos¶
- Indicador de secuencia: todos los mensajes de un grupo llevan un indicador de secuencia comparable y correcto.
- Monotonía: los indicadores de secuencia son monótonamente crecientes (para sequence numbers) o al menos parcialmente ordenados (para timestamps).
- Acotamiento del desorden: existe un límite razonable para el máximo desorden (máximo gap en secuencia o máximo delay en tiempo).
Decisiones de Diseño Clave¶
- Tipo de indicador de secuencia:
- Sequence number (entero incremental): preciso, sin ambigüedad, pero requiere que el productor asigne secuencias.
- Timestamp: no requiere secuencia explícita, pero tiene problemas de clock skew entre productores y resolución (dos mensajes con el mismo timestamp).
-
Offset/position: posición en el stream original (Kafka offset, log position).
-
Variante de Resequencer:
- Batch: acumula todo, ordena, emite. Simple, alta latencia.
-
Stream: emite progresivamente tan pronto como es seguro. Complejo, baja latencia.
-
Estrategia de timeout:
- Timeout fijo: esperar T milisegundos al mensaje faltante. Si no llega, saltar.
- Timeout adaptativo: ajustar el timeout según el patrón de desorden observado.
-
Watermark: usar el concepto de event time watermark (como en Flink) para determinar cuándo es seguro emitir.
-
Manejo de gaps: ¿emitir un placeholder? ¿Saltar? ¿Alertar? ¿Bloquear?
-
Scope: ¿reordenar globalmente o por grupo de correlación?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Telecom — Reordenamiento de Eventos de Red para Facturación¶
Contexto del Negocio¶
Un operador de telecomunicaciones procesa 500 millones de eventos de red diarios (CDRs — Call Detail Records, data sessions, SMS, VoLTE calls). Estos eventos se generan en estaciones base distribuidas geográficamente y se envían al sistema central de rating y facturación. El rating de cada evento (cálculo del costo) depende del contexto de la sesión: una sesión de datos tiene un "session start" que establece el plan tarifario, seguido de "data chunks" que se tarifan según ese plan, y un "session end" que cierra la sesión. Si los eventos llegan desordenados, el rating engine no puede calcular correctamente el costo porque no conoce el plan tarifario (session start no ha llegado) o intenta cerrar una sesión que no ha abierto.
Necesidad de Integración¶
Los eventos viajan desde las estaciones base al sistema central a través de múltiples paths de red con diferentes latencias. Además, el sistema de pre-procesamiento (normalización de formatos) tiene múltiples instancias que procesan en paralelo, alterando el orden. Los eventos de una misma sesión deben llegar al rating engine en orden cronológico para procesamiento correcto.
Sistemas Involucrados¶
- Estaciones Base (eNodeB/gNodeB): generan los eventos de red con timestamps.
- Event Collection Platform: plataforma distribuida que recibe eventos de miles de estaciones.
- Normalizer (multi-instance): normaliza formatos de diferentes vendors de equipos.
- Kafka Cluster: infraestructura de streaming.
- Resequencer Service: servicio stateful que reordena eventos por sesión.
- Rating Engine: calcula el costo de cada evento según el plan tarifario.
- Billing System: genera facturas a partir de los eventos rateados.
Restricciones Técnicas¶
- Volumen: 500 millones de eventos diarios (~5,800 eventos/segundo sostenido, picos de 20,000/segundo).
- El desorden máximo observado es de 30 segundos (un evento puede llegar hasta 30 segundos después de un evento posterior de la misma sesión).
- Las sesiones tienen duración variable: segundos a horas.
- El rating engine requiere orden estricto por sesión: session_start antes de data_chunks antes de session_end.
- El número de sesiones activas simultáneas es de aproximadamente 2 millones.
Flujos de Datos¶
Estaciones Base → Event Collection → Normalizer (x10) → [events.normalized]
→ Resequencer (partitioned by session_id) → [events.ordered]
→ Rating Engine → [events.rated] → Billing System
Decisiones Arquitectónicas¶
-
Scope: por sesión: el reordenamiento se hace por
session_id. Los eventos de diferentes sesiones no necesitan orden relativo entre sí. Esto permite particionar el Resequencer por session_id y escalar horizontalmente. -
Indicador de secuencia: timestamp del evento (asignado por la estación base). Los timestamps tienen resolución de milisegundos y están sincronizados por NTP entre estaciones.
-
Variante: Stream Resequencer: dada la latencia requerida (<2 segundos end-to-end), se usa la variante streaming que emite progresivamente.
-
Timeout: 30 segundos: si un evento esperado no llega en 30 segundos (el máximo desorden observado + margen), se salta el gap y se emite desde el siguiente disponible. Se genera una alerta para investigación.
-
Kafka partitioning by session_id: asegura que todos los eventos de la misma sesión llegan a la misma instancia del Resequencer.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Clock skew entre estaciones base | NTP sincronización cada 5 minutos; margen de tolerancia de 2 segundos en el reordenamiento |
| Sesión con millones de eventos (streaming de video largo) | Límite de buffer por sesión (10,000 eventos); si se excede, flush parcial con alerta |
| Evento perdido que bloquea el reordenamiento | Timeout de 30 segundos; después del timeout, emitir desde el siguiente disponible |
| Pico de tráfico que satura el buffer | Backpressure en el consumer de Kafka; autoscaling de instancias del Resequencer |
| Fallo del Resequencer con pérdida de buffer | State store en RocksDB con changelog topic en Kafka; recuperación automática |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación de Eventos en Estaciones Base¶
Una sesión de datos móviles (session_id: SES-2026-0407-ABC123) genera tres eventos:
Evento 1: {session_id: "SES-...-ABC123", type: "SESSION_START", timestamp: "14:00:00.100", plan: "UNLIMITED_5G"}
Evento 2: {session_id: "SES-...-ABC123", type: "DATA_CHUNK", timestamp: "14:00:05.200", bytes: 1048576}
Evento 3: {session_id: "SES-...-ABC123", type: "DATA_CHUNK", timestamp: "14:00:10.300", bytes: 2097152}
Paso 2: Procesamiento Paralelo Altera el Orden¶
Los eventos pasan por el Normalizer multi-instancia. Debido a diferentes latencias de procesamiento:
- Evento 3 (14:00:10.300) llega primero al topic
events.normalized. - Evento 1 (14:00:00.100) llega segundo.
- Evento 2 (14:00:05.200) llega tercero.
Orden en el topic: [3, 1, 2]
Paso 3: Resequencer Recibe y Bufferiza¶
El Resequencer (asignado a la partición de SES-...-ABC123) procesa:
Llega Evento 3 (timestamp 14:00:10.300): 1. Sesión SES-...-ABC123 no existe en el state store → crea nueva sesión. 2. No hay "next_expected" definido → almacena en buffer. 3. Buffer: {14:00:10.300: evento3}. Esperando un evento anterior. 4. Inicia timer de timeout: si no llega un evento anterior en 30s, emitir lo que hay.
Llega Evento 1 (timestamp 14:00:00.100): 1. Sesión existe. Evento 1 tiene timestamp 14:00:00.100 < 14:00:10.300. 2. Evento 1 es anterior a lo que hay en buffer → es el primer evento conocido. 3. Emite Evento 1 (14:00:00.100) al canal de salida. next_expected = 14:00:00.101 (siguiente al emitido). 4. Verifica buffer: ¿hay algún evento con timestamp entre 14:00:00.101 y 14:00:10.300? No. 5. Buffer sigue con: {14:00:10.300: evento3}. Esperando eventos intermedios.
Llega Evento 2 (timestamp 14:00:05.200): 1. Sesión existe. Evento 2 tiene timestamp 14:00:05.200 > next_expected (14:00:00.101). 2. Emite Evento 2 (14:00:05.200). next_expected = 14:00:05.201. 3. Verifica buffer: ¿hay algún evento con timestamp >= 14:00:05.201? Sí: evento3 (14:00:10.300). 4. Emite Evento 3 (14:00:10.300). next_expected = 14:00:10.301. 5. Buffer vacío.
Salida del Resequencer: Evento 1, Evento 2, Evento 3 (en orden correcto).
Paso 4: Rating Engine Procesa en Orden¶
El Rating Engine consume de events.ordered: 1. Recibe SESSION_START → establece plan "UNLIMITED_5G" para la sesión. 2. Recibe DATA_CHUNK (1MB) → calcula costo según plan UNLIMITED_5G (incluido en el plan, costo = 0). 3. Recibe DATA_CHUNK (2MB) → calcula costo según plan UNLIMITED_5G (incluido en el plan, costo = 0).
Si los eventos hubieran llegado sin reordenar (evento 3 primero), el Rating Engine habría intentado tarificar un DATA_CHUNK sin conocer el plan tarifario, generando un error.
Paso 5: Escenario de Timeout¶
Para otra sesión (SES-...-XYZ789), el Resequencer recibe los eventos 1, 3 y 4, pero el evento 2 se pierde:
- Emite Evento 1.
- Espera Evento 2. Timer de 30 segundos.
- Recibe Evento 3 y 4 → almacena en buffer.
- Timer expira después de 30 segundos → Evento 2 considerado perdido.
- Emite Evento 3 y Evento 4 (en orden).
- Genera alerta:
RESEQUENCER_GAP: session=SES-...-XYZ789, missing_between=evento1_and_evento3.
Manejo de Errores¶
- Mensaje sin timestamp: se envía al dead-letter. Sin indicador de secuencia, el Resequencer no puede posicionar el mensaje.
- Timestamp duplicado: dos eventos de la misma sesión con el mismo timestamp se emiten en orden de llegada (desambiguación por arrival order).
- Buffer overflow: si una sesión acumula más de 10,000 eventos en el buffer, se emite un flush parcial de los eventos más antiguos y se genera alerta.
- Fallo del Resequencer: al reiniciarse, el state store se reconstruye desde el changelog topic. Los buffers de sesión se restauran y el reordenamiento continúa.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
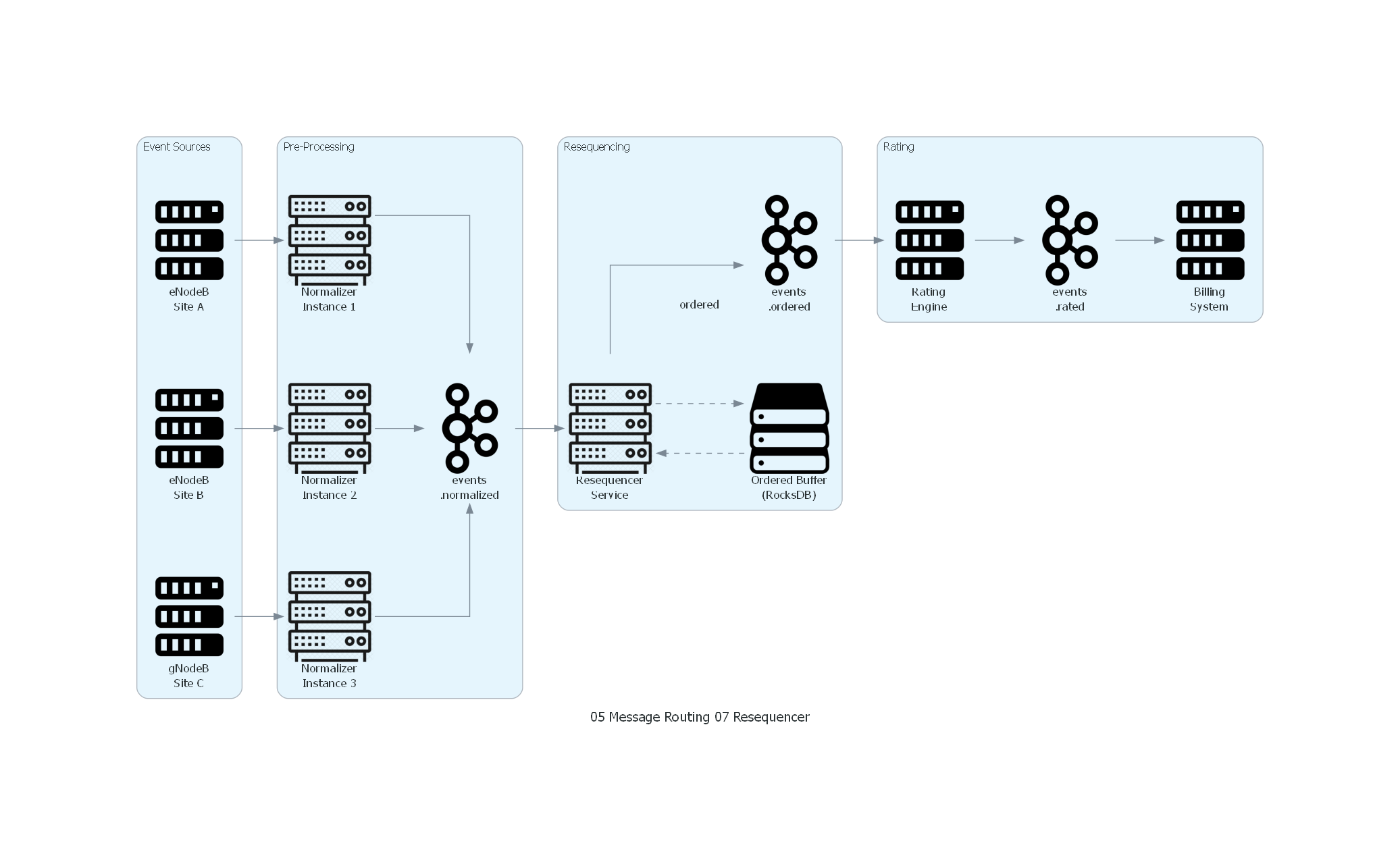
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.generic.compute import Rack
from diagrams.generic.storage import Storage
with Diagram("Resequencer - Telecom Event Reordering", show=False, direction="LR"):
with Cluster("Event Sources"):
enodeb1 = Server("eNodeB\nSite A")
enodeb2 = Server("eNodeB\nSite B")
enodeb3 = Server("gNodeB\nSite C")
with Cluster("Pre-Processing"):
norm1 = Rack("Normalizer\nInstance 1")
norm2 = Rack("Normalizer\nInstance 2")
norm3 = Rack("Normalizer\nInstance 3")
topic_norm = Kafka("events\n.normalized")
with Cluster("Resequencing"):
resequencer = Rack("Resequencer\nService")
buffer = Storage("Ordered Buffer\n(RocksDB)")
topic_ordered = Kafka("events\n.ordered")
with Cluster("Rating"):
rating = Server("Rating\nEngine")
topic_rated = Kafka("events\n.rated")
billing = Server("Billing\nSystem")
enodeb1 >> norm1
enodeb2 >> norm2
enodeb3 >> norm3
norm1 >> topic_norm
norm2 >> topic_norm
norm3 >> topic_norm
topic_norm >> resequencer
resequencer >> Edge(style="dashed") >> buffer
buffer >> Edge(style="dashed") >> resequencer
resequencer >> Edge(label="ordered") >> topic_ordered
topic_ordered >> rating >> topic_rated >> billing
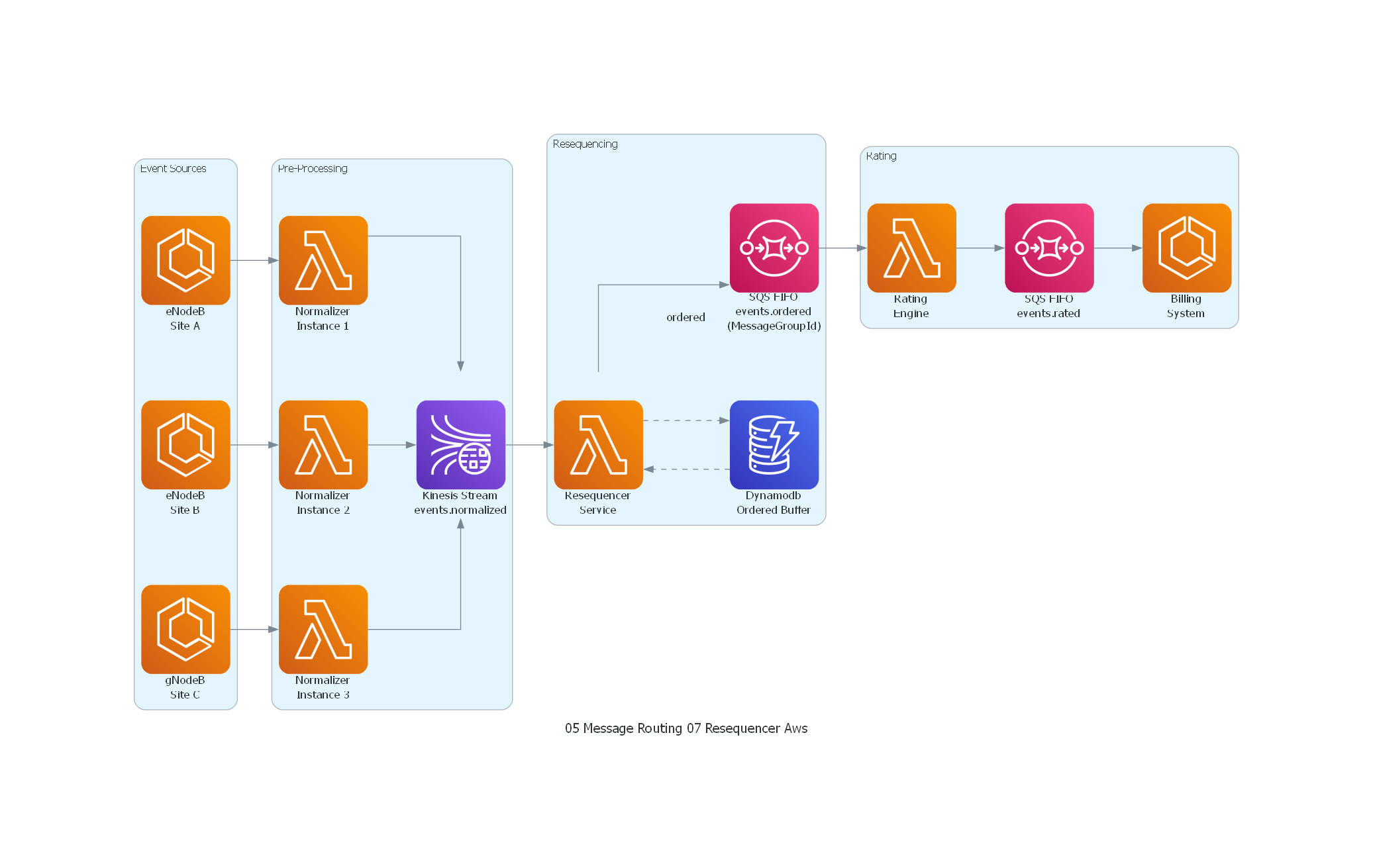
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import Dynamodb
from diagrams.aws.analytics import KinesisDataStreams
from diagrams.aws.integration import SQS
with Diagram("Resequencer - Telecom Event Reordering (AWS)", show=False, direction="LR"):
with Cluster("Event Sources"):
enodeb1 = ECS("eNodeB\nSite A")
enodeb2 = ECS("eNodeB\nSite B")
enodeb3 = ECS("gNodeB\nSite C")
with Cluster("Pre-Processing"):
norm1 = Lambda("Normalizer\nInstance 1")
norm2 = Lambda("Normalizer\nInstance 2")
norm3 = Lambda("Normalizer\nInstance 3")
topic_norm = KinesisDataStreams("Kinesis Stream\nevents.normalized")
with Cluster("Resequencing"):
resequencer = Lambda("Resequencer\nService")
buffer = Dynamodb("Dynamodb\nOrdered Buffer")
topic_ordered = SQS("SQS FIFO\nevents.ordered\n(MessageGroupId)")
with Cluster("Rating"):
rating = Lambda("Rating\nEngine")
topic_rated = SQS("SQS FIFO\nevents.rated")
billing = ECS("Billing\nSystem")
enodeb1 >> norm1
enodeb2 >> norm2
enodeb3 >> norm3
norm1 >> topic_norm
norm2 >> topic_norm
norm3 >> topic_norm
topic_norm >> resequencer
resequencer >> Edge(style="dashed") >> buffer
buffer >> Edge(style="dashed") >> resequencer
resequencer >> Edge(label="ordered") >> topic_ordered
topic_ordered >> rating >> topic_rated >> billing
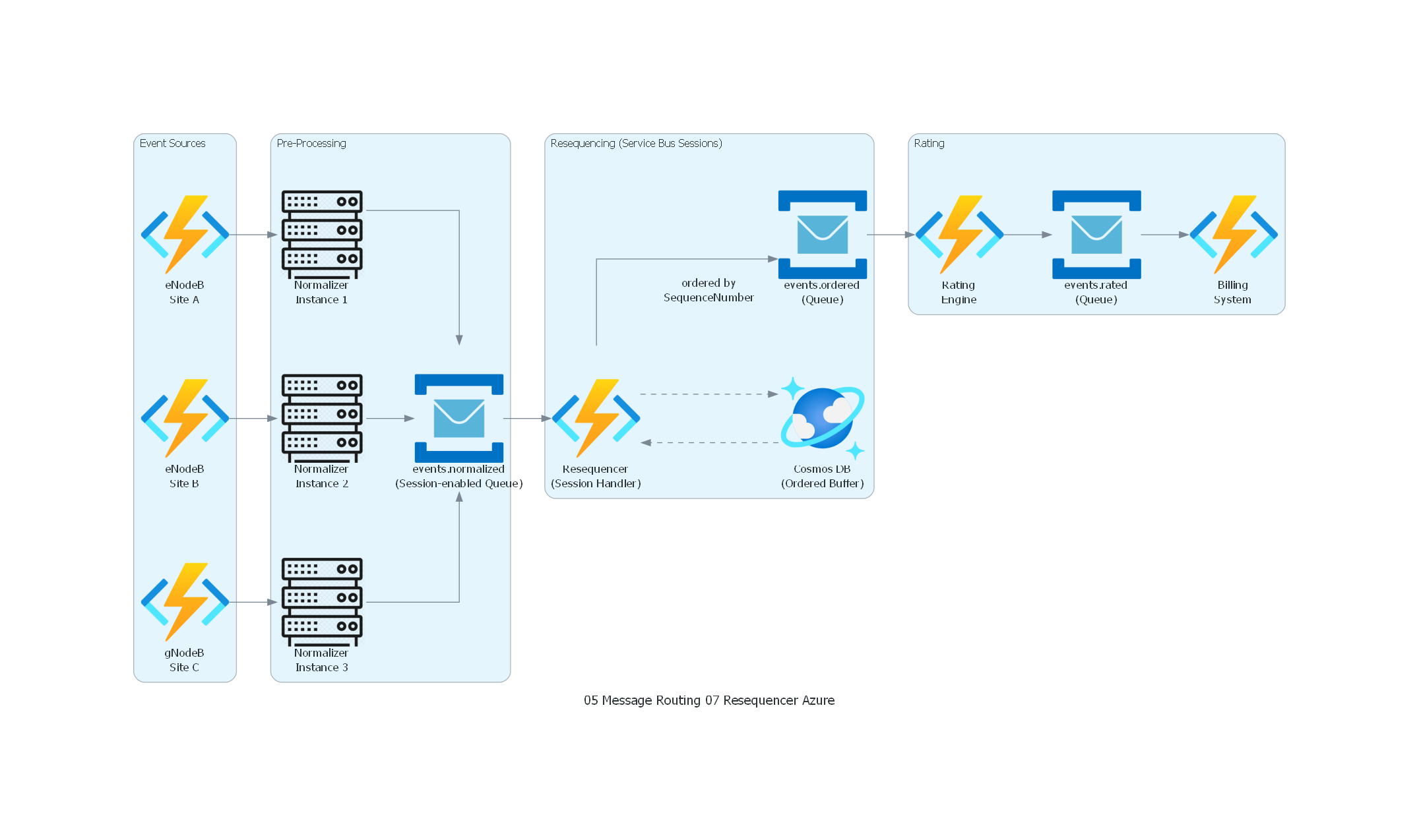
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.compute import Rack
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
with Diagram("Resequencer - Telecom Event Reordering (Azure)", show=False, direction="LR"):
with Cluster("Event Sources"):
enodeb1 = FunctionApps("eNodeB\nSite A")
enodeb2 = FunctionApps("eNodeB\nSite B")
enodeb3 = FunctionApps("gNodeB\nSite C")
with Cluster("Pre-Processing"):
norm1 = Rack("Normalizer\nInstance 1")
norm2 = Rack("Normalizer\nInstance 2")
norm3 = Rack("Normalizer\nInstance 3")
topic_norm = ServiceBus("events.normalized\n(Session-enabled Queue)")
with Cluster("Resequencing (Service Bus Sessions)"):
resequencer = FunctionApps("Resequencer\n(Session Handler)")
buffer = CosmosDb("Cosmos DB\n(Ordered Buffer)")
topic_ordered = ServiceBus("events.ordered\n(Queue)")
with Cluster("Rating"):
rating = FunctionApps("Rating\nEngine")
topic_rated = ServiceBus("events.rated\n(Queue)")
billing = FunctionApps("Billing\nSystem")
enodeb1 >> norm1
enodeb2 >> norm2
enodeb3 >> norm3
norm1 >> topic_norm
norm2 >> topic_norm
norm3 >> topic_norm
topic_norm >> resequencer
resequencer >> Edge(style="dashed") >> buffer
buffer >> Edge(style="dashed") >> resequencer
resequencer >> Edge(label="ordered by\nSequenceNumber") >> topic_ordered
topic_ordered >> rating >> topic_rated >> billing
Explicación del Diagrama¶
El diagrama muestra el flujo del Resequencer en el contexto de telecom:
- Event Sources: estaciones base de diferentes sitios generan eventos de red.
- Pre-Processing: tres instancias del Normalizer procesan eventos en paralelo, introduciendo desorden.
- Resequencing: el Resequencer Service consume eventos desordenados, los bufferiza en un estado ordenado (RocksDB) y los emite en el orden correcto por session_id.
- Rating: el Rating Engine consume eventos en orden y calcula costos correctamente basándose en el contexto de la sesión.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensajes Desordenados | Eventos en events.normalized (orden alterado por Normalizers paralelos) |
| Resequencer | Resequencer Service |
| Buffer Ordenado | RocksDB state store |
| Indicador de Secuencia | Timestamp del evento (asignado por estación base) |
| Canal de Entrada | events.normalized |
| Canal de Salida | events.ordered |
| Mensajes Reordenados | Eventos en events.ordered (orden correcto por session + timestamp) |
11. Beneficios¶
Impacto Técnico¶
- Habilitación de paralelismo sin sacrificar orden: el sistema puede procesar en paralelo (múltiples Normalizers) y luego restaurar el orden. Sin Resequencer, el paralelismo en etapas intermedias estaría prohibido para flujos que requieren orden.
- Simplificación de consumers downstream: los consumers reciben mensajes en orden y no necesitan implementar lógica de reordenamiento propia. Su código es más simple, más correcto y más fácil de testear.
- Desacoplamiento del transporte y el procesamiento: el transporte puede usar cualquier topología (paralela, multi-path, load-balanced) sin preocuparse por preservar orden, porque el Resequencer lo restaura.
- Correctitud garantizada: los consumers que asumen orden de llegada producen resultados correctos, sin errores transitorios ni inconsistencias temporales.
Impacto Organizacional¶
- Separación de responsabilidades: el equipo de infraestructura puede optimizar el transporte (paralelismo, load balancing) sin coordinar con el equipo de negocio (que asume orden).
- Contratos claros: el canal de salida del Resequencer tiene el contrato explícito de "orden garantizado por grupo", lo que simplifica el diseño de consumers downstream.
Impacto Operacional¶
- Reducción de errores: elimina la categoría completa de errores "fuera de orden" que de otra forma generarían retries, alertas y escalaciones.
- Diagnóstico simplificado: si un consumer falla, se puede descartar "desorden" como causa porque el Resequencer garantiza orden.
- Métricas de desorden: el Resequencer puede medir y reportar el grado de desorden (average reordering delay, max gap, percentage of out-of-order messages), proporcionando visibilidad de la salud del sistema de transporte.
Beneficios de Mantenibilidad y Evolución¶
- Evolución del transporte: cambiar la topología de transporte (añadir más paths paralelos, cambiar de routing) no afecta a los consumers si el Resequencer está en el medio.
- Testing simplificado: los consumers se testean con flujos en orden, sin necesidad de generar datos desordenados para testing.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente stateful: el Resequencer añade un componente stateful al pipeline que requiere persistencia, recovery y monitoreo.
- Latencia: el reordenamiento introduce latencia proporcional al máximo desorden esperado. Para el caso de telecom (30 segundos de desorden máximo), el Resequencer puede añadir hasta 30 segundos de latencia.
- Gestión de timeout: definir el timeout correcto requiere conocimiento del patrón de desorden, que puede cambiar con el tiempo.
Riesgos de Mal Uso¶
- Resequencer cuando la infraestructura puede garantizar orden: añadir un Resequencer cuando Kafka con partitioning by key ya garantiza orden es overhead sin beneficio.
- Resequencer global en lugar de por grupo: intentar reordenar globalmente (todas las sesiones en un solo flujo) es impracticable a escala. El reordenamiento debe ser por grupo.
- Timeout incorrecto: demasiado corto emite con gaps; demasiado largo acumula buffer y latencia.
Sobreingeniería¶
- Resequencer para desorden mínimo: si el desorden real es de milisegundos y los consumers pueden tolerarlo (usando upserts idempotentes), el Resequencer es sobreingeniería.
- Resequencer con persistencia fuerte para datos de baja criticidad: datos de monitoreo que toleran gaps ocasionales no justifican un Resequencer con state store persistente.
Costos de Operación¶
- Memoria/Storage: el buffer consume recursos proporcionales al desorden y al throughput. A 5,800 eventos/segundo con 30 segundos de buffer, se necesita capacidad para ~174,000 eventos en buffer simultáneamente.
- Monitoring adicional: el Resequencer requiere métricas específicas (buffer size, gap count, timeout events, reordering delay).
- Tuning continuo: el timeout y el buffer size pueden necesitar ajuste a medida que cambian los patrones de tráfico.
Errores Frecuentes de Implementación¶
- No definir timeout, dejando que gaps bloqueen todo el flujo indefinidamente.
- Buffer sin límite de tamaño que crece hasta causar out-of-memory.
- Usar timestamps sin considerar clock skew entre diferentes fuentes.
- No manejar mensajes duplicados (mismo sequence number dos veces).
- No persistir el buffer, perdiendo el estado de reordenamiento ante reinicios.
Anti-Patterns Relacionados¶
- Infinite Wait Resequencer: un Resequencer sin timeout que espera indefinidamente a un mensaje faltante, bloqueando todo el flujo.
- Global Resequencer: intentar reordenar todos los mensajes globalmente en lugar de por grupo, creando un cuello de botella que no escala.
- Premature Flush: un timeout demasiado agresivo que emite mensajes antes de que los retrasados tengan oportunidad de llegar.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Splitter: un Splitter divide un mensaje en partes que se procesan en paralelo, alterando potencialmente el orden. El Resequencer restaura el orden después del procesamiento paralelo.
- Aggregator: puede combinarse con Resequencer. Primero se reordenan los mensajes, luego se agregan. O viceversa: se agregan por grupo y luego se reordenan los resultados agregados.
- Correlation Identifier: el Resequencer necesita un indicador de secuencia en cada mensaje, que funciona como un Correlation Identifier especial orientado al orden.
Patrones que Suelen Aparecer Antes o Después¶
- Splitter (antes): divide un mensaje, las partes se procesan en paralelo, el Resequencer reordena las partes procesadas.
- Content-Based Router (antes): distribuye mensajes por diferentes paths, cada path con diferente latencia. El Resequencer reordena después de la convergencia.
- Aggregator (después): una vez reordenados, los mensajes se agregan en un resultado consolidado.
Combinaciones Comunes¶
- Splitter + Parallel Processing + Resequencer: divide, procesa en paralelo, reordena. Maximiza throughput preservando orden.
- Resequencer + Aggregator: reordena y luego agrega. Útil cuando la función de agregación es sensible al orden (por ejemplo, aplicar transacciones secuencialmente a un saldo).
- Content-Based Router + Resequencer: routing a diferentes destinos seguido de reordenamiento en la convergencia.
Diferencias con Patrones Similares¶
- vs. Aggregator: el Aggregator combina N mensajes en 1. El Resequencer emite los mismos N mensajes en orden diferente. No hay reducción de cardinalidad.
- vs. Message Filter: el Filter reduce la cantidad de mensajes (descarta algunos). El Resequencer no descarta ni añade mensajes, solo reordena.
- vs. Composed Message Processor: el CMP incluye split + process + aggregate. El Resequencer es más simple: solo reordena.
Encaje en un Flujo Mayor de Integración¶
El Resequencer aparece típicamente después de una etapa de procesamiento paralelo (Splitter + parallel processing, multi-path routing, multi-instance processing) y antes de consumers que requieren orden. Es un punto de reordenamiento que reconcilia el paralelismo del procesamiento con los requisitos de orden del consumo.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
La relevancia del Resequencer ha disminuido parcialmente gracias a las garantías de orden proporcionadas por las plataformas modernas de mensajería, pero sigue siendo relevante en escenarios específicos.
A favor de la vigencia:
- Cross-partition ordering: Kafka garantiza orden dentro de una partición pero no entre particiones. Si los mensajes de un grupo se distribuyen entre múltiples particiones (repartitioning, join entre streams), se necesita reordenamiento.
- Event time vs. processing time: en stream processing, los eventos pueden llegar con event timestamps desordenados respecto al processing time. Los mecanismos de watermark en Flink y Beam son esencialmente Resequencers basados en event time.
- Multi-source correlation: cuando eventos de diferentes sistemas (cada uno con su propio ritmo) deben procesarse en orden cronológico global, se necesita reordenamiento.
- Replay con orden: en event sourcing, al replaying eventos para reconstruir estado, el orden es crítico. Si los eventos provienen de múltiples streams, se necesita merge ordenado.
En contra de la vigencia:
- Kafka partitioning: si los mensajes de un grupo se asignan a la misma partición (que es la configuración estándar), Kafka garantiza orden sin necesidad de Resequencer.
- SQS FIFO: AWS SQS FIFO garantiza orden dentro de un message group.
- Consumers idempotentes y conmutativos: muchos diseños modernos (event sourcing con snapshots, CRDT, eventual consistency) son deliberadamente order-agnostic, reduciendo la necesidad de Resequencer.
- Costo de mantener estado: en arquitecturas serverless o cloud-native que buscan statelessness, un Resequencer stateful es un componente incómodo.
Contexto Moderno Donde Sigue Siendo Útil¶
- Procesamiento de streams cross-partition que requieren orden global.
- Event time ordering en Flink/Beam (watermarks son Resequencers implícitos).
- Integración de eventos de múltiples fuentes en un flujo cronológico unificado.
- Telecom: CDR processing con eventos de múltiples elementos de red.
- Replay de event logs para reconstrucción de estado.
Cómo Se Implementa Hoy¶
- Apache Flink: watermarks y event time windowing proporcionan reordenamiento implícito por event time.
- Apache Camel:
resequence()DSL con batch mode y stream mode, configurable con timeout y buffer size. - Spring Integration:
ResequencingMessageHandlercon correlation strategy y release strategy basada en sequence numbers. - Custom en Kafka Streams: no hay operador nativo de resequencing, pero se puede implementar con un state store y un punctuator que emite mensajes en orden.
- AWS Step Functions:
Mapstate conMaxConcurrency=1fuerza procesamiento secuencial (evita el desorden pero elimina paralelismo).
Qué Parte Sigue Siendo Esencial¶
- Concepto de watermark: la idea de que "no llegarán más eventos con timestamp anterior a T" es el fundamento del Resequencer en stream processing moderno y está implementado en todas las plataformas de streaming.
- Timeout para gaps: la necesidad de decidir cuánto esperar a un mensaje faltante antes de continuar es universal en cualquier sistema que necesite orden.
- Buffering acotado: la disciplina de limitar el buffer de reordenamiento para evitar crecimiento indefinido es esencial en sistemas de alta volumetría.
15. Implementación en Arquitecturas Modernas¶
Apache Camel¶
// Batch Resequencer: acumula todo, ordena, emite
from("kafka:events.normalized")
.resequence(header("sequenceNumber"))
.batch()
.size(100)
.timeout(30000)
.to("kafka:events.ordered");
// Stream Resequencer: emite progresivamente
from("kafka:events.normalized")
.resequence(header("timestamp"))
.stream()
.timeout(30000)
.capacity(5000)
.comparator(new TimestampComparator())
.to("kafka:events.ordered");
Spring Integration¶
@Bean
public IntegrationFlow resequencingFlow() {
return IntegrationFlow
.from("normalizedEventsChannel")
.resequence(r -> r
.correlationStrategy(m -> m.getHeaders().get("sessionId"))
.releaseStrategy(new TimeoutCountSequenceReleaseStrategy(100, 30000))
.messageStore(new SimpleMessageStore())
)
.channel("orderedEventsChannel")
.get();
}
Apache Flink (Event Time Ordering via Watermarks)¶
DataStream<NetworkEvent> events = env
.addSource(kafkaSource)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<NetworkEvent>forBoundedOutOfOrderness(Duration.ofSeconds(30))
.withTimestampAssigner((event, timestamp) -> event.getEventTimestamp())
);
// Los eventos se procesan en event time order dentro de cada window
events
.keyBy(NetworkEvent::getSessionId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.process(new OrderedEventProcessor())
.addSink(kafkaSink);
En Flink, forBoundedOutOfOrderness(Duration.ofSeconds(30)) indica que los eventos pueden llegar hasta 30 segundos tarde. El watermark avanza y los eventos se procesan en event time order.
Kafka Streams (Custom Implementation)¶
// No hay operador nativo de resequencing en Kafka Streams.
// Se implementa con Processor API + state store + punctuator.
public class ResequencerProcessor implements Processor<String, NetworkEvent, String, NetworkEvent> {
private KeyValueStore<String, TreeMap<Long, NetworkEvent>> bufferStore;
private KeyValueStore<String, Long> nextExpectedStore;
@Override
public void process(Record<String, NetworkEvent> record) {
String sessionId = record.key();
long timestamp = record.value().getEventTimestamp();
TreeMap<Long, NetworkEvent> buffer = bufferStore.get(sessionId);
if (buffer == null) buffer = new TreeMap<>();
buffer.put(timestamp, record.value());
bufferStore.put(sessionId, buffer);
flushReady(sessionId);
}
private void flushReady(String sessionId) {
TreeMap<Long, NetworkEvent> buffer = bufferStore.get(sessionId);
Long nextExpected = nextExpectedStore.get(sessionId);
// Emit all consecutive events from the buffer...
}
}
Azure / AWS¶
- Azure Stream Analytics: proporciona event time processing con tolerance para late events, actuando como Resequencer implícito.
- AWS Kinesis Data Analytics (Flink): misma implementación que Flink con watermarks.
- Custom Lambda + Dynamodb: almacenar eventos con TTL en Dynamodb, un scheduled Lambda lee y emite en orden. Solución viable pero operacionalmente más compleja que usar una plataforma de streaming.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: buffer size (mensajes retenidos), reordering delay (tiempo promedio que un mensaje pasa en el buffer), gap count (mensajes faltantes detectados), timeout events (gaps que expiraron), throughput (mensajes emitidos/segundo).
- Health checks: buffer size dentro de límites, no hay crecimiento sostenido del buffer, timeouts dentro de niveles normales.
- Alertas: buffer size excede umbral (posible blocked gap), tasa de timeouts excede umbral (posible pérdida de mensajes upstream), latencia de reordenamiento excede SLA.
Tracing¶
- Cada mensaje que pasa por el Resequencer debe preservar su trace ID original.
- El Resequencer debe añadir metadata de reordenamiento:
resequencer_delay(tiempo en buffer),original_arrival_order,emitted_sequence_position.
Monitoreo¶
- Dashboard: buffer size por grupo, distribución de reordering delay, histograma de gaps, tasa de throughput entrada vs. salida.
- Trend analysis: si el desorden promedio aumenta con el tiempo, puede indicar degradación del sistema de transporte upstream.
Versionado¶
- Si la estructura de los mensajes cambia, el Resequencer necesita actualizarse solo si el indicador de secuencia cambia de formato o posición.
- El buffer del state store debe ser compatible entre versiones del Resequencer.
Seguridad¶
- Los mensajes en el buffer pueden contener datos sensibles. El state store debe estar cifrado en reposo.
- El acceso al buffer (para inspección o debugging) debe estar controlado.
Manejo de Errores¶
- Mensaje sin indicador de secuencia: enviar al dead-letter.
- Indicador de secuencia malformado: enviar al dead-letter.
- Buffer overflow: emitir los mensajes más antiguos del buffer y generar alerta.
- State store unavailable: fail-fast y alerta.
Retries¶
- Si el Resequencer falla al emitir un mensaje, el mensaje permanece en el buffer y se re-emite al recuperarse.
- Si el Resequencer se reinicia, el state store se reconstruye y el reordenamiento continúa desde donde quedó.
Dead-Lettering¶
- Mensajes sin indicador de secuencia van al dead-letter.
- Mensajes que causan buffer overflow pueden ir al dead-letter con contexto de overflow.
Idempotencia¶
- El Resequencer debe manejar mensajes duplicados (mismo sequence number): descartar el duplicado.
- La emisión debe ser idempotente: emitir el mismo mensaje dos veces no causa problemas si los consumers son idempotentes.
Auditoría¶
- Registrar: mensajes recibidos, orden de llegada, orden de emisión, reordering delay, gaps detectados, timeouts.
- Permitir reconstruir el patrón de desorden para análisis de capacidad y tuning.
Performance¶
- Buffer data structure: un TreeMap o priority queue por grupo proporciona O(log N) para inserción y O(1) para emisión del mínimo.
- Serialización del buffer: serializar/deserializar el buffer completo en cada operación es costoso. Usar actualizaciones incrementales si el state store lo soporta.
- Batch emission: cuando múltiples mensajes consecutivos están disponibles, emitirlos en batch para reducir overhead.
Escalabilidad¶
- El Resequencer escala horizontalmente por partición de la correlation key (session_id). Cada partición tiene su propio buffer y sequence tracker.
- El cuello de botella es el state store: si hay muchos grupos con buffers grandes, el I/O del state store puede saturarse.
- La escalabilidad está limitada por la distribución de grupos entre particiones.
17. Errores Comunes¶
No Definir Timeout para Gaps¶
El error más grave es un Resequencer que espera indefinidamente un mensaje faltante. Si el mensaje 5 se pierde y el Resequencer tiene los mensajes 6, 7, 8, 9... todos quedan bloqueados esperando al 5. Sin timeout, el flujo se detiene completamente para ese grupo. Todo Resequencer debe tener un timeout explícito para gaps.
Buffer Sin Límite de Tamaño¶
Permitir que el buffer crezca sin límite es una receta para out-of-memory. Si un gap bloquea la emisión durante un período prolongado y el flujo de mensajes es alto, el buffer acumula miles o millones de mensajes. El buffer debe tener un tamaño máximo configurable con una estrategia de overflow (flush parcial, descarte, backpressure).
Usar Timestamps Sin Considerar Clock Skew¶
Si los mensajes provienen de diferentes fuentes con relojes no sincronizados, los timestamps no representan un orden global confiable. Un evento con timestamp T1 de la fuente A puede ser posterior en tiempo real a un evento con timestamp T2 > T1 de la fuente B, simplemente porque el reloj de B está adelantado. La solución es usar NTP para sincronización, vector clocks para causalidad, o sequence numbers asignados por un coordinador central.
Resequencer Global en Lugar de por Grupo¶
Intentar reordenar todos los mensajes de todos los grupos en un solo Resequencer global crea un cuello de botella monolítico. El reordenamiento debe ser por grupo (session_id, order_id, etc.) para escalar horizontalmente. El orden solo es significativo dentro de un grupo; el orden relativo entre grupos diferentes es irrelevante.
Confundir Resequencer con Aggregator¶
Un error conceptual común es implementar un Aggregator cuando se necesita un Resequencer (o viceversa). El Aggregator combina N mensajes en 1. El Resequencer emite N mensajes en orden. Si lo que se necesita es recibir mensajes desordenados y emitirlos en orden sin combinarlos, se necesita un Resequencer, no un Aggregator.
No Medir ni Reportar el Desorden¶
Si el Resequencer no mide el grado de desorden (promedio, máximo, distribución), no se puede saber si el timeout configurado es adecuado ni detectar degradación en el sistema de transporte. El Resequencer debe reportar métricas de desorden que permitan tuning continuo.
18. Conclusión Técnica¶
Resequencer es un patrón de Message Routing que resuelve la pérdida de orden inherente a los sistemas distribuidos con procesamiento paralelo. Su implementación requiere gestión de estado (buffer ordenado), lógica de secuenciamiento (sequence tracking), y manejo de ausencias (timeout para gaps). A diferencia del Aggregator, que reduce N mensajes a 1, el Resequencer preserva la cardinalidad: emite los mismos N mensajes, pero en el orden correcto.
En el ecosistema moderno, la necesidad de un Resequencer explícito ha disminuido parcialmente gracias a las garantías de orden proporcionadas por Kafka (dentro de particiones), colas FIFO y diseños order-agnostic (CRDTs, idempotent consumers). Sin embargo, el Resequencer sigue siendo relevante en escenarios de cross-partition ordering, event time processing (donde los watermarks de Flink y Beam son Resequencers implícitos), multi-source event correlation, y telecom CDR processing.
Recomendación para arquitectos: antes de implementar un Resequencer, evalúe si la infraestructura de mensajería puede proporcionar las garantías de orden necesarias (Kafka partitioning by key, SQS FIFO). Si es así, el Resequencer es innecesario y añade complejidad. Si no es posible (cross-partition, multi-source, procesamiento paralelo que altera orden), implemente un Resequencer por grupo (no global) con timeout explícito para gaps, buffer con límite de tamaño, y métricas de desorden que permitan tuning continuo. Considere usar las facilidades nativas de la plataforma de streaming (watermarks en Flink, event time processing en Beam) en lugar de implementar un Resequencer custom.