Composed Message Processor¶
1. Nombre del Patrón¶
- Nombre oficial: Composed Message Processor
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Procesador de Mensajes Compuestos
2. Resumen Ejecutivo¶
Composed Message Processor es el patrón que maneja mensajes compuestos — mensajes que contienen múltiples elementos que requieren procesamiento individual diferenciado — dividiéndolos en sus partes constituyentes, enrutando cada parte al procesador adecuado, y reagregando los resultados en un único mensaje de respuesta coherente. Es la composición coordinada de tres patrones: Splitter, Router y Aggregator.
El problema que resuelve es el procesamiento de mensajes heterogéneos: un mensaje compuesto contiene elementos que pertenecen a diferentes dominios o requieren diferentes tipos de procesamiento, pero el resultado debe ser una respuesta unificada. Procesar el mensaje como una unidad monolítica forzaría a un solo componente a conocer la lógica de todos los dominios. Procesar las partes por separado sin coordinación produciría resultados parciales sin una respuesta unificada.
En arquitecturas modernas de microservicios, Composed Message Processor es la solución natural para orquestaciones donde un request compuesto debe ser procesado por múltiples servicios especializados. Un pedido de e-commerce con productos de diferentes categorías (electrónica, ropa, alimentación perecedera) que requieren diferentes flujos de fulfillment es el ejemplo paradigmático. El patrón garantiza que cada parte sea procesada por el servicio correcto y que el resultado final sea una respuesta unificada al cliente.
3. Definición Detallada¶
Propósito¶
Composed Message Processor coordina el procesamiento de un mensaje compuesto dividiendo el mensaje en sus partes, enrutando cada parte al procesador especializado correspondiente, y combinando los resultados parciales en una respuesta unificada. Es un meta-patrón que orquesta Splitter, Content-Based Router y Aggregator en una secuencia cohesiva.
Lógica Arquitectónica¶
En sistemas de integración, los mensajes frecuentemente representan entidades compuestas: un pedido con múltiples líneas, una solicitud de seguro con múltiples coberturas, una transacción bancaria con múltiples operaciones. Cada parte del mensaje puede requerir:
- Procesamiento diferente: una línea de pedido de electrónica requiere verificación de inventario en un almacén; una línea de alimentación perecedera requiere verificación de fecha de caducidad y cadena de frío.
- Sistemas diferentes: cada categoría de producto puede tener su propio sistema de gestión de inventario, precios o logística.
- Tiempos diferentes: la disponibilidad de un producto digital es instantánea; la verificación de stock de un producto físico en almacén puede tomar segundos.
Composed Message Processor resuelve esto con tres fases coordinadas:
- Split: dividir el mensaje compuesto en sus partes individuales, preservando la identidad del mensaje original (correlation ID).
- Route & Process: enrutar cada parte al procesador especializado apropiado según su tipo o contenido.
- Aggregate: recopilar todos los resultados parciales y combinarlos en una respuesta unificada cuando todos los procesadores han respondido (o cuando se alcanza un timeout).
Principio de Diseño Subyacente¶
El principio es divide et impera con reagregación: dividir un problema complejo en subproblemas especializados, resolverlos independientemente con componentes especializados, y combinar las soluciones parciales en una solución completa. La clave es la coordinación: las partes deben correlacionarse con el mensaje original y los resultados deben combinarse correctamente.
Problema Estructural que Resuelve¶
Sin Composed Message Processor:
- Un solo componente debe conocer la lógica de procesamiento de todos los tipos de elementos del mensaje.
- Los cambios en la lógica de un tipo de elemento afectan al componente monolítico.
- No es posible escalar independientemente el procesamiento de diferentes tipos de elementos.
- La adición de un nuevo tipo de elemento requiere modificar el procesador monolítico.
Contexto en el que Emerge¶
Composed Message Processor emerge cuando:
- Un mensaje contiene múltiples elementos que requieren procesamiento diferenciado.
- Existen procesadores especializados para cada tipo de elemento.
- Se necesita una respuesta unificada que combine los resultados de todos los procesadores.
- Los elementos pueden procesarse en paralelo para optimizar latencia.
Por Qué No Es Trivial¶
- Correlación: cada parte dividida debe mantener referencia al mensaje original para poder reagregar.
- Completitud: el aggregator debe saber cuántas partes esperar y qué hacer si una parte no llega.
- Orden: los resultados parciales pueden llegar en cualquier orden; el aggregator debe reconstruir el resultado correcto.
- Errores parciales: ¿qué sucede si el procesamiento de una parte falla pero las demás tienen éxito? ¿Se rechaza todo o se acepta parcialmente?
- Timeouts: ¿cuánto tiempo espera el aggregator antes de declarar un timeout? ¿Cómo maneja resultados tardíos?
Relación con Sistemas Distribuidos y Mensajería¶
Composed Message Processor es la implementación en mensajería del patrón Fork-Join de computación paralela. En sistemas distribuidos, enfrenta los mismos desafíos: coordinación de tareas paralelas, manejo de fallos parciales y garantías de completitud. La mensajería añade el desafío adicional de que las "tareas" son mensajes asíncronos que pueden perderse, duplicarse o llegar fuera de orden.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Una plataforma de e-commerce recibe un pedido que contiene tres líneas de producto:
{
"order_id": "ORD-2026-445210",
"customer_id": "CUST-78123",
"items": [
{
"line_id": 1,
"product_id": "ELEC-LAPTOP-001",
"category": "electronics",
"quantity": 1,
"unit_price": 1299.99
},
{
"line_id": 2,
"product_id": "FOOD-ORGANIC-042",
"category": "perishable_food",
"quantity": 3,
"unit_price": 8.50
},
{
"line_id": 3,
"product_id": "DIGI-EBOOK-789",
"category": "digital",
"quantity": 1,
"unit_price": 14.99
}
],
"shipping_address": {
"street": "Calle Mayor 15",
"city": "Barcelona",
"postal_code": "08001"
}
}
Cada categoría tiene requisitos de fulfillment completamente diferentes:
- Electronics: verificar stock en almacén central, reservar unidad, programar envío con seguro, generar garantía.
- Perishable food: verificar stock en almacén refrigerado local (cercano al destino), verificar fecha de caducidad, programar envío con cadena de frío en menos de 24 horas.
- Digital: no requiere stock físico, generar licencia/link de descarga inmediatamente.
Síntomas del Problema¶
Sin Composed Message Processor, el sistema tiene un servicio monolítico de order fulfillment que conoce la lógica de todas las categorías:
- Cada vez que se añade una nueva categoría de producto (por ejemplo, "farmacia"), se modifica el monolito.
- La verificación de stock de electrónica bloquea el procesamiento de la línea digital (que es instantánea).
- Un error en el procesamiento de alimentación perecedera bloquea la confirmación de las líneas que ya se procesaron correctamente.
- El servicio monolítico es el componente más grande, más complejo y más propenso a fallos de toda la plataforma.
- No se puede escalar independientemente el procesamiento de electrónica (Black Friday) vs. alimentación (consumo estable).
Impacto Operativo y Arquitectónico¶
- Latencia innecesaria: el pedido completo espera al elemento más lento, incluso cuando los demás están listos.
- Acoplamiento organizacional: el equipo del monolito debe conocer la lógica de todos los dominios de producto.
- Despliegues arriesgados: un cambio en la lógica de electrónica requiere redesplegar el monolito, arriesgando funcionalidad de todas las categorías.
- Escalabilidad limitada: el monolito se escala como una unidad, no por categoría.
Riesgos Si No Se Implementa Correctamente¶
- Correlation lost: si las partes divididas pierden referencia al pedido original, los resultados parciales no pueden reagregarse.
- Aggregator leak: si el aggregator no maneja timeouts, los pedidos con una parte perdida quedan en estado indefinido, consumiendo memoria.
- Partial failure ignored: si se ignoran los errores parciales, el cliente recibe una confirmación de pedido completo cuando en realidad una línea falló.
Ejemplos Reales¶
- E-commerce multi-warehouse: pedido con items en diferentes almacenes, cada uno procesado por el sistema de gestión del almacén correspondiente.
- Insurance policy: solicitud de seguro con múltiples coberturas (auto, hogar, vida), cada una evaluada por un motor de underwriting diferente.
- Travel booking: reserva de viaje con vuelo, hotel y coche, cada componente gestionado por un proveedor diferente.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un mensaje contiene múltiples elementos que requieren procesamiento por diferentes servicios especializados.
- Cuando los elementos pueden procesarse en paralelo para reducir latencia.
- Cuando se necesita una respuesta unificada que combine los resultados de todos los procesadores.
- Cuando la lógica de procesamiento de cada tipo de elemento es suficientemente compleja como para justificar servicios separados.
Cuándo No Usarlo¶
- Cuando todos los elementos del mensaje se procesan con la misma lógica (un simple loop es suficiente).
- Cuando no se necesita una respuesta unificada (cada parte puede procesarse de forma fire-and-forget).
- Cuando el overhead de split/route/aggregate es mayor que el beneficio (mensajes con muy pocos elementos).
- Cuando el procesamiento debe ser estrictamente secuencial y cada parte depende del resultado de la anterior.
Precondiciones¶
- El mensaje compuesto tiene una estructura que permite identificar y separar las partes individuales.
- Existen procesadores especializados para cada tipo de parte.
- Existe un criterio de routing claro que determina qué procesador maneja cada parte.
Restricciones¶
- Todas las partes deben mantener un correlation ID que las vincule al mensaje original.
- El aggregator debe conocer el número esperado de partes para determinar completitud.
- Los timeouts del aggregator deben ser suficientes para el procesador más lento.
Dependencias¶
- Splitter: componente que divide el mensaje compuesto en partes.
- Content-Based Router: componente que enruta cada parte al procesador correcto.
- Aggregator: componente que recopila los resultados parciales y los combina.
- Correlation store: mecanismo para trackear qué partes pertenecen a qué mensaje original.
Supuestos Arquitectónicos¶
- Las partes del mensaje son suficientemente independientes como para procesarse en paralelo.
- La combinación de resultados parciales produce un resultado correcto y completo.
- Los procesadores especializados son idempotentes o al menos tolerantes a reintentos.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Plataformas de e-commerce con múltiples categorías de producto.
- Sistemas de seguros con múltiples tipos de cobertura.
- Plataformas de viajes con múltiples proveedores.
- Sistemas de procesamiento de órdenes con múltiples centros de fulfillment.
- ETL pipelines que procesan registros heterogéneos.
6. Fuerzas Arquitectónicas¶
Especialización vs. Coordinación¶
Dividir el procesamiento en servicios especializados mejora la separación de responsabilidades y la escalabilidad, pero requiere coordinación compleja para split, route y aggregate. Cada servicio especializado es más simple, pero el flujo compuesto es más complejo.
Paralelismo vs. Consistencia¶
Procesar las partes en paralelo reduce la latencia total, pero complica el manejo de errores y la consistencia. Si la parte A se procesa exitosamente pero la parte B falla, ¿se revierte A? La respuesta depende de si se requiere atomicidad (todo o nada) o se acepta procesamiento parcial.
Latencia de Respuesta vs. Completitud¶
¿Se espera a que todas las partes se procesen antes de responder, o se responde con resultados parciales a medida que llegan? Esperar completitud maximiza la coherencia de la respuesta pero aumenta la latencia. Responder parcialmente reduce latencia pero requiere que el cliente maneje actualizaciones incrementales.
Granularidad del Split vs. Overhead¶
¿Se divide por línea de pedido, por categoría de producto, por almacén? Una granularidad más fina permite mayor especialización y paralelismo pero aumenta el overhead de coordinación. Una granularidad gruesa simplifica la coordinación pero puede no aprovechar completamente los procesadores especializados.
Timeout Agresivo vs. Conservador¶
Un timeout corto en el aggregator reduce el riesgo de pedidos colgados pero puede descartar resultados válidos de procesadores lentos. Un timeout largo permite procesar todas las partes pero retrasa la detección de fallos.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Mensaje Compuesto: el mensaje de entrada que contiene múltiples elementos heterogéneos.
- Splitter: divide el mensaje compuesto en partes individuales, cada una con un correlation ID.
- Content-Based Router: examina cada parte y la enruta al procesador apropiado según su tipo.
- Procesadores Especializados: servicios que procesan cada tipo de parte según su lógica específica.
- Aggregator: recopila los resultados de todos los procesadores y los combina en una respuesta unificada.
- Correlation Store: almacén que trackea el estado de cada mensaje compuesto (qué partes se enviaron, cuáles han respondido).
Flujo Lógico¶
flowchart TD
A([Mensaje Compuesto\nPedido con N items]) --> B[Splitter divide\nen partes individuales]
B --> C[(Correlation Store\nregistrar partes esperadas)]
B --> D[Router enruta cada parte\nsegún categoría]
D --> E[Electronics\nFulfillment Service]
D --> F[Perishable\nFulfillment Service]
D --> G[Digital\nDelivery Service]
E --> H[Reservar stock\nprogramar envío]
F --> I[Verificar stock refrigerado\nprogramar envío frío]
G --> J[Generar licencia\ncrear link de descarga]
H --> K[Aggregator recopila\nresultados]
I --> K
J --> K
K --> C
K --> L{Todas las partes\ncompletadas?}
L -- Sí --> M[Combinar resultados en\nrespuesta unificada]
M --> N([Fin])
L -- No --> O[Esperar partes\nrestantes]
O --> KResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Splitter | Dividir el mensaje compuesto preservando correlation ID |
| Router | Determinar el procesador correcto para cada parte |
| Procesadores | Procesar cada parte según su lógica de dominio |
| Aggregator | Recopilar resultados y combinar en respuesta unificada |
| Correlation Store | Trackear estado de completitud de cada mensaje compuesto |
Interacciones¶
- Splitter → Router: cada parte individual se envía al router para enrutamiento.
- Router → Procesador: cada parte se enruta al procesador correcto según su tipo.
- Procesador → Aggregator: cada procesador envía su resultado al aggregator.
- Aggregator → Correlation Store: el aggregator actualiza el estado de cada mensaje compuesto.
Contratos Implícitos¶
- Correlation: todas las partes y resultados mantienen el correlation ID del mensaje original.
- Completitud: el aggregator conoce el número total de partes y espera todas (o aplica timeout).
- Idempotencia de resultados: si un resultado llega duplicado, el aggregator lo detecta y descarta.
Decisiones de Diseño Clave¶
- Split estático vs. dinámico: ¿se divide por un criterio fijo (por línea) o dinámico (por criterio de negocio)?
- Routing estático vs. dinámico: ¿la tabla de routing es fija o se resuelve dinámicamente?
- Aggregation strategy: ¿esperar todas las partes, mayoría, o responder cuando llegue la primera?
- Error handling: ¿fallo total (si una parte falla, todo falla) o degradación graceful (resultados parciales)?
- Timeout handling: ¿qué mensaje de respuesta se genera cuando se alcanza timeout con partes pendientes?
8. Ejemplo Arquitectónico Detallado¶
Dominio: E-commerce — Fulfillment de Pedido Multi-Categoría¶
Contexto del Negocio¶
Una plataforma de e-commerce vende productos de tres categorías principales, cada una con su propia cadena de fulfillment: electrónica (almacén central con seguro de envío), alimentación perecedera (almacenes refrigerados locales con envío express) y productos digitales (entrega inmediata por descarga). Un pedido puede contener items de cualquier combinación de categorías.
Necesidad de Integración¶
Cuando un cliente realiza un pedido con items de múltiples categorías, cada categoría debe procesarse por su servicio especializado de fulfillment, pero el cliente debe recibir una confirmación unificada con el estado de todas las líneas del pedido.
Sistemas Involucrados¶
- Order Service: recibe el pedido del cliente y publica el evento de nuevo pedido.
- Order Splitter: divide el pedido en líneas individuales.
- Fulfillment Router: enruta cada línea al servicio de fulfillment apropiado.
- Electronics Fulfillment: gestiona stock, reserva, envío asegurado y garantía.
- Perishable Fulfillment: gestiona stock refrigerado, caducidad y envío con cadena de frío.
- Digital Delivery: genera licencias y links de descarga.
- Order Aggregator: recopila resultados y genera la confirmación unificada.
- Notification Service: envía la confirmación al cliente.
Restricciones Técnicas¶
- La confirmación del pedido debe enviarse al cliente en menos de 30 segundos para digital y perishable, y en menos de 2 minutos para electrónica (verificación de stock más lenta).
- Si una línea falla, las demás deben procesarse normalmente (degradación graceful, no atomicidad).
- Los servicios de fulfillment son idempotentes: recibir la misma línea dos veces no duplica la reserva.
- El aggregator debe manejar resultados tardíos (llegados después del timeout) sin duplicar notificaciones.
Diseño del Composed Message Processor¶
Estructura de la línea individual (después del split):
{
"correlation_id": "ORD-2026-445210",
"total_parts": 3,
"part_index": 1,
"line": {
"line_id": 1,
"product_id": "ELEC-LAPTOP-001",
"category": "electronics",
"quantity": 1,
"unit_price": 1299.99
},
"shipping_address": {
"street": "Calle Mayor 15",
"city": "Barcelona",
"postal_code": "08001"
}
}
Resultado de un procesador:
{
"correlation_id": "ORD-2026-445210",
"part_index": 1,
"status": "fulfilled",
"fulfillment_details": {
"warehouse": "WH-CENTRAL-MAD",
"estimated_delivery": "2026-04-10",
"tracking_number": "TRK-ELEC-998877",
"warranty_id": "WRN-2026-554433"
}
}
Decisiones Arquitectónicas¶
- Degradación graceful: si una línea falla, las demás se procesan normalmente. El cliente recibe confirmación con líneas exitosas y líneas fallidas claramente identificadas.
- Timeout diferenciado: el aggregator espera hasta 120 segundos para todas las partes, pero puede enviar una notificación parcial a los 30 segundos para las líneas digitales ya completadas.
- Idempotencia end-to-end: el correlation_id + part_index actúa como clave de idempotencia. Un resultado duplicado actualiza pero no duplica.
- Compensation: si el cliente cancela el pedido mientras se está procesando, se envían mensajes de compensación (cancel) a los procesadores que ya confirmaron.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Parte perdida (procesador no responde) | Timeout + retry + dead-letter + notificación parcial al cliente |
| Resultado duplicado | Idempotencia en el aggregator basada en correlation_id + part_index |
| Aggregator pierde estado (crash) | Correlation store en Redis con persistencia o en base de datos |
| Nuevo tipo de categoría | Añadir nuevo procesador y regla de routing sin modificar splitter ni aggregator |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción del Pedido¶
El Order Service recibe el pedido del cliente con tres líneas (laptop, comida orgánica, eBook). Valida el pedido (datos completos, cliente existente, stock disponible a nivel de catálogo) y publica el evento order.created en el topic Kafka orders.new.
Paso 2: Split del Pedido¶
El Order Splitter consume el evento order.created y divide el pedido en tres mensajes individuales, uno por línea:
- Mensaje 1:
{correlation_id: "ORD-445210", total_parts: 3, part_index: 1, category: "electronics", ...} - Mensaje 2:
{correlation_id: "ORD-445210", total_parts: 3, part_index: 2, category: "perishable_food", ...} - Mensaje 3:
{correlation_id: "ORD-445210", total_parts: 3, part_index: 3, category: "digital", ...}
Cada mensaje incluye total_parts: 3 para que el aggregator sepa cuántas respuestas esperar. El splitter registra en Redis: ORD-445210 → {total: 3, completed: 0, parts: []}.
Los tres mensajes se publican en el topic orders.lines.to-route.
Paso 3: Routing por Categoría¶
El Fulfillment Router consume cada mensaje de orders.lines.to-route y lo enruta al topic del procesador correspondiente según la categoría:
electronics→ topicfulfillment.electronicsperishable_food→ topicfulfillment.perishabledigital→ topicfulfillment.digital
El routing es un simple Content-Based Router con tabla de categoría → topic.
Paso 4: Procesamiento Paralelo¶
Los tres procesadores procesan en paralelo:
Digital Delivery (completa en 200ms): 1. Genera licencia para el eBook. 2. Crea link de descarga con token de expiración de 72 horas. 3. Publica resultado en fulfillment.results: {correlation_id: "ORD-445210", part_index: 3, status: "fulfilled", download_url: "https://..."}.
Perishable Fulfillment (completa en 3 segundos): 1. Busca almacén refrigerado más cercano a Barcelona con stock de FOOD-ORGANIC-042. 2. Verifica fecha de caducidad (debe tener al menos 5 días). 3. Reserva 3 unidades. 4. Programa envío con cadena de frío para mañana antes de las 10:00. 5. Publica resultado: {correlation_id: "ORD-445210", part_index: 2, status: "fulfilled", estimated_delivery: "2026-04-08T10:00:00Z"}.
Electronics Fulfillment (completa en 15 segundos): 1. Consulta inventario del almacén central. 2. Reserva 1 unidad de ELEC-LAPTOP-001. 3. Genera póliza de seguro de envío. 4. Genera certificado de garantía de 2 años. 5. Programa envío con tracking. 6. Publica resultado: {correlation_id: "ORD-445210", part_index: 1, status: "fulfilled", tracking: "TRK-ELEC-998877", estimated_delivery: "2026-04-10"}.
Paso 5: Aggregation¶
El Order Aggregator consume del topic fulfillment.results:
- Recibe resultado de digital (part_index: 3). Actualiza Redis:
ORD-445210 → {total: 3, completed: 1}. No todas las partes listas, espera. - Recibe resultado de perishable (part_index: 2). Actualiza:
{total: 3, completed: 2}. Espera. - Recibe resultado de electronics (part_index: 1). Actualiza:
{total: 3, completed: 3}. Todas las partes completas.
El aggregator combina los tres resultados en una confirmación unificada:
{
"order_id": "ORD-2026-445210",
"status": "fully_fulfilled",
"lines": [
{
"line_id": 1,
"product": "ELEC-LAPTOP-001",
"status": "fulfilled",
"estimated_delivery": "2026-04-10",
"tracking": "TRK-ELEC-998877"
},
{
"line_id": 2,
"product": "FOOD-ORGANIC-042",
"status": "fulfilled",
"estimated_delivery": "2026-04-08"
},
{
"line_id": 3,
"product": "DIGI-EBOOK-789",
"status": "fulfilled",
"download_url": "https://downloads.example.com/..."
}
]
}
Publica la confirmación en orders.confirmed y limpia el estado de Redis.
Paso 6: Notificación al Cliente¶
El Notification Service consume de orders.confirmed y envía un email al cliente con el resumen del pedido, incluyendo el link de descarga del eBook (disponible inmediatamente), la fecha estimada de entrega de la comida (mañana) y la fecha estimada del laptop (3 días).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
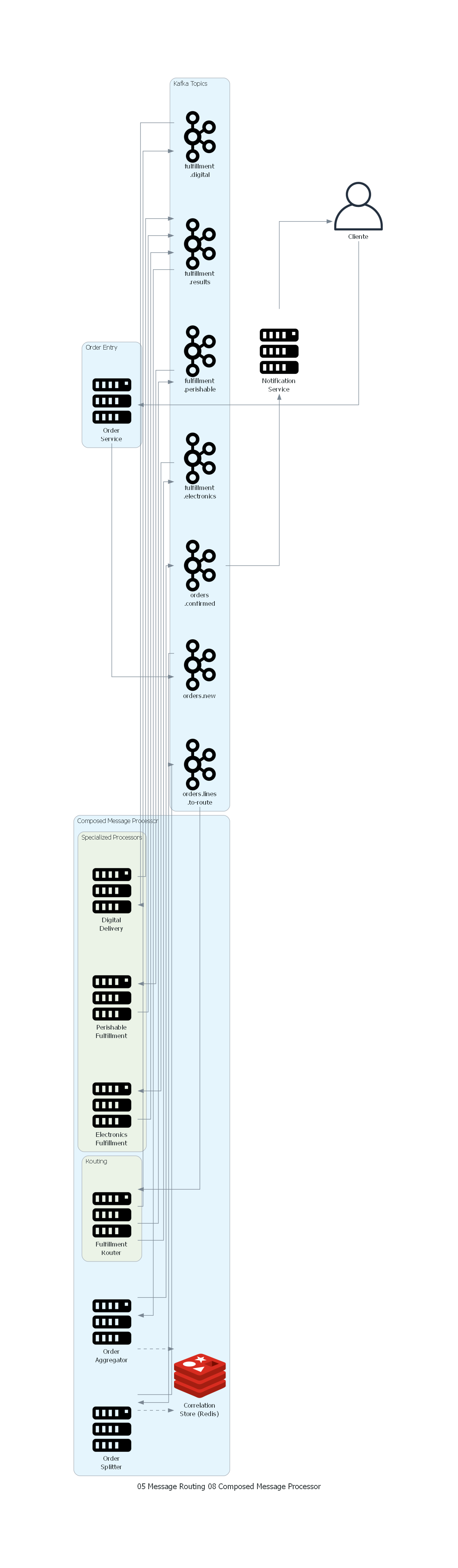
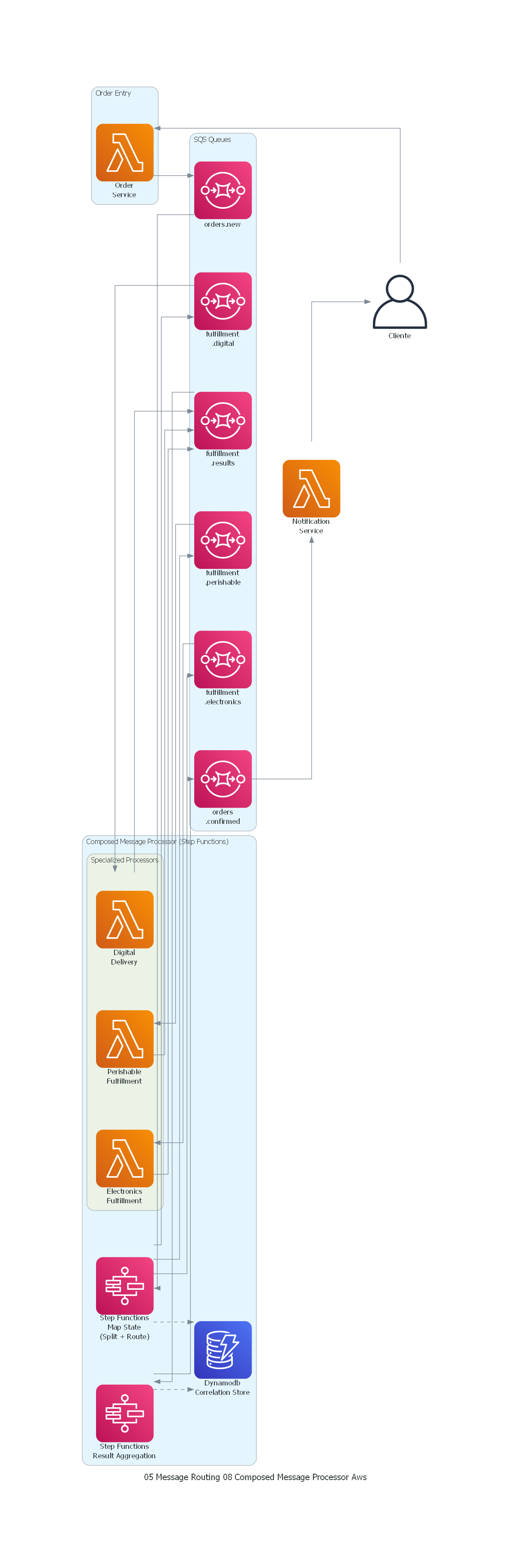
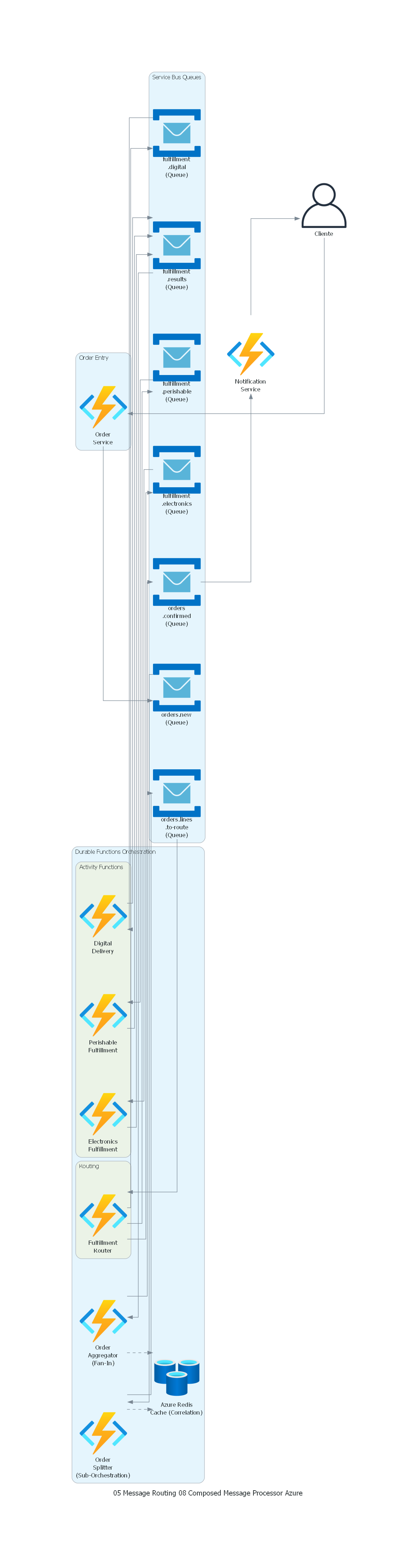
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.client import User
with Diagram("Composed Message Processor - E-commerce Multi-Category Fulfillment", show=False, direction="LR"):
customer = User("Cliente")
with Cluster("Order Entry"):
order_svc = Server("Order\nService")
with Cluster("Composed Message Processor"):
splitter = Server("Order\nSplitter")
with Cluster("Routing"):
router = Server("Fulfillment\nRouter")
with Cluster("Specialized Processors"):
electronics = Server("Electronics\nFulfillment")
perishable = Server("Perishable\nFulfillment")
digital = Server("Digital\nDelivery")
aggregator = Server("Order\nAggregator")
correlation = Redis("Correlation\nStore (Redis)")
with Cluster("Kafka Topics"):
t_new = Kafka("orders.new")
t_lines = Kafka("orders.lines\n.to-route")
t_elec = Kafka("fulfillment\n.electronics")
t_perish = Kafka("fulfillment\n.perishable")
t_digital = Kafka("fulfillment\n.digital")
t_results = Kafka("fulfillment\n.results")
t_confirmed = Kafka("orders\n.confirmed")
notification = Server("Notification\nService")
# Flujo
customer >> order_svc >> t_new >> splitter
splitter >> t_lines >> router
splitter >> Edge(style="dashed") >> correlation
router >> t_elec >> electronics
router >> t_perish >> perishable
router >> t_digital >> digital
electronics >> t_results
perishable >> t_results
digital >> t_results
t_results >> aggregator
aggregator >> Edge(style="dashed") >> correlation
aggregator >> t_confirmed >> notification >> customer
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS, StepFunctions
with Diagram("Composed Message Processor - E-commerce Multi-Category Fulfillment (AWS)", show=False, direction="LR"):
customer = User("Cliente")
with Cluster("Order Entry"):
order_svc = Lambda("Order\nService")
with Cluster("Composed Message Processor (Step Functions)"):
splitter = StepFunctions("Step Functions\nMap State\n(Split + Route)")
with Cluster("Specialized Processors"):
electronics = Lambda("Electronics\nFulfillment")
perishable = Lambda("Perishable\nFulfillment")
digital = Lambda("Digital\nDelivery")
aggregator = StepFunctions("Step Functions\nResult Aggregation")
correlation = Dynamodb("Dynamodb\nCorrelation Store")
with Cluster("SQS Queues"):
t_new = SQS("orders.new")
t_elec = SQS("fulfillment\n.electronics")
t_perish = SQS("fulfillment\n.perishable")
t_digital = SQS("fulfillment\n.digital")
t_results = SQS("fulfillment\n.results")
t_confirmed = SQS("orders\n.confirmed")
notification = Lambda("Notification\nService")
# Flujo
customer >> order_svc >> t_new >> splitter
splitter >> Edge(style="dashed") >> correlation
splitter >> t_elec >> electronics
splitter >> t_perish >> perishable
splitter >> t_digital >> digital
electronics >> t_results
perishable >> t_results
digital >> t_results
t_results >> aggregator
aggregator >> Edge(style="dashed") >> correlation
aggregator >> t_confirmed >> notification >> customer
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis
from diagrams.azure.integration import ServiceBus
with Diagram("Composed Message Processor - E-commerce Multi-Category Fulfillment (Azure)", show=False, direction="LR"):
customer = User("Cliente")
with Cluster("Order Entry"):
order_svc = FunctionApps("Order\nService")
with Cluster("Durable Functions Orchestration"):
splitter = FunctionApps("Order\nSplitter\n(Sub-Orchestration)")
with Cluster("Routing"):
router = FunctionApps("Fulfillment\nRouter")
with Cluster("Activity Functions"):
electronics = FunctionApps("Electronics\nFulfillment")
perishable = FunctionApps("Perishable\nFulfillment")
digital = FunctionApps("Digital\nDelivery")
aggregator = FunctionApps("Order\nAggregator\n(Fan-In)")
correlation = CacheForRedis("Azure Redis\nCache (Correlation)")
with Cluster("Service Bus Queues"):
t_new = ServiceBus("orders.new\n(Queue)")
t_lines = ServiceBus("orders.lines\n.to-route\n(Queue)")
t_elec = ServiceBus("fulfillment\n.electronics\n(Queue)")
t_perish = ServiceBus("fulfillment\n.perishable\n(Queue)")
t_digital = ServiceBus("fulfillment\n.digital\n(Queue)")
t_results = ServiceBus("fulfillment\n.results\n(Queue)")
t_confirmed = ServiceBus("orders\n.confirmed\n(Queue)")
notification = FunctionApps("Notification\nService")
# Flujo
customer >> order_svc >> t_new >> splitter
splitter >> t_lines >> router
splitter >> Edge(style="dashed") >> correlation
router >> t_elec >> electronics
router >> t_perish >> perishable
router >> t_digital >> digital
electronics >> t_results
perishable >> t_results
digital >> t_results
t_results >> aggregator
aggregator >> Edge(style="dashed") >> correlation
aggregator >> t_confirmed >> notification >> customer
Explicación del Diagrama¶
El diagrama muestra el flujo completo del Composed Message Processor:
- El Order Service recibe el pedido y lo publica en
orders.new. - El Order Splitter divide el pedido en líneas individuales, publicándolas en
orders.lines.to-routey registrando el estado en el Correlation Store. - El Fulfillment Router enruta cada línea al topic del procesador apropiado.
- Los procesadores especializados procesan en paralelo y publican resultados en
fulfillment.results. - El Order Aggregator recopila los resultados, actualiza el Correlation Store y, cuando todas las partes llegan, genera la confirmación unificada.
- El Notification Service envía la confirmación al cliente.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensaje compuesto | Pedido con múltiples líneas en orders.new |
| Splitter | Order Splitter |
| Content-Based Router | Fulfillment Router |
| Procesadores especializados | Electronics, Perishable, Digital Fulfillment |
| Aggregator | Order Aggregator + Correlation Store |
| Respuesta unificada | Confirmación en orders.confirmed |
11. Beneficios¶
Impacto Técnico¶
- Procesamiento paralelo: las partes se procesan simultáneamente, reduciendo la latencia total al tiempo del procesador más lento (en lugar de la suma de todos).
- Escalabilidad independiente: cada procesador se escala según su demanda (electrónica en Black Friday, perecederos en verano).
- Separación de responsabilidades: cada procesador contiene solo la lógica de su dominio.
- Extensibilidad: añadir una nueva categoría requiere solo un nuevo procesador y una regla de routing.
Impacto Organizacional¶
- Ownership por dominio: el equipo de electrónica mantiene su servicio de fulfillment; el equipo de alimentación el suyo.
- Despliegues independientes: un cambio en la lógica de digital delivery no requiere redesplegar electronics fulfillment.
- Velocidad de desarrollo: equipos trabajan en paralelo en sus procesadores sin conflictos.
Impacto Operacional¶
- Aislamiento de fallos: el fallo de un procesador no afecta a los demás.
- Observabilidad granular: métricas por procesador permiten identificar cuellos de botella específicos.
- Debugging facilitado: el correlation_id permite rastrear el flujo completo de un pedido a través de todos los componentes.
Beneficios de Mantenibilidad y Evolución¶
- Open/Closed principle: el sistema está abierto a extensión (nuevo procesador) pero cerrado a modificación (no se modifica el splitter ni el aggregator).
- Testing aislado: cada procesador se puede testear con mensajes de entrada y resultados esperados sin necesidad de los demás.
- Evolución independiente: la lógica de fulfillment de cada categoría puede evolucionar a su propio ritmo.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Coordinación distribuida: el flujo split → route → process → aggregate involucra múltiples servicios y topics, cada uno que puede fallar.
- Manejo de estado: el aggregator necesita un correlation store para trackear el estado de cada mensaje compuesto.
- Debugging complejo: seguir el flujo de un pedido a través de 7+ componentes y topics requiere tooling de observabilidad distribuida.
Riesgos de Mal Uso¶
- Over-splitting: dividir un mensaje que no lo necesita (por ejemplo, un pedido con una sola línea) añade overhead sin beneficio.
- Aggregator como cuello de botella: si el aggregator es un solo servicio sin particionamiento, puede convertirse en el punto más lento del flujo.
- Timeout sin acción: definir un timeout pero no manejar el caso de timeout (partes pendientes quedan en el correlation store indefinidamente, memory leak).
Sobreingeniería¶
- Implementar un Composed Message Processor completo cuando un simple loop secuencial es suficiente.
- Crear procesadores especializados para cada variante menor de un producto cuando la lógica es casi idéntica.
- Implementar compensación transaccional completa (saga) cuando degradación graceful es aceptable.
Costos de Operación¶
- Infraestructura de topics: N topics para N tipos de procesadores, más topics de resultados y dead-letter.
- Correlation store: Redis o base de datos para mantener el estado de cada mensaje compuesto en vuelo.
- Monitoreo: dashboards específicos para tracking de completitud de mensajes compuestos.
Anti-Patterns Relacionados¶
- Infinite Aggregation: el aggregator nunca libera mensajes compuestos incompletos, acumulando estado indefinidamente.
- Synchronous Composed Processor: implementar el patrón con llamadas síncronas en lugar de mensajería, perdiendo el beneficio de procesamiento paralelo y resiliencia.
- Lost Correlation: no propagar el correlation_id correctamente, haciendo imposible la reagregación.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Splitter (este capítulo): Composed Message Processor usa Splitter como su primera fase para dividir el mensaje compuesto.
- Aggregator (este capítulo): Composed Message Processor usa Aggregator como su última fase para reagregar los resultados.
- Content-Based Router (este capítulo): Composed Message Processor usa Content-Based Router para enrutar cada parte al procesador correcto.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Messaging Gateway o Channel Adapter adaptan la solicitud del cliente al formato del mensaje compuesto.
- Después: Message Translator puede transformar la respuesta agregada al formato esperado por el cliente.
- Dentro: cada procesador especializado puede usar internamente otros patrones (Content Enricher para añadir datos, Claim Check para payloads grandes).
Combinaciones Comunes¶
- Composed Message Processor + Process Manager: cuando el procesamiento de las partes tiene estados complejos con decisiones condicionales, un Process Manager coordina el flujo en lugar de un simple aggregator.
- Composed Message Processor + Scatter-Gather: Scatter-Gather es conceptualmente similar pero difunde el mismo mensaje a todos los procesadores. Composed Message Processor divide un mensaje diferente para cada procesador.
Diferencias con Patrones Similares¶
- vs. Scatter-Gather: Scatter-Gather envía el mismo mensaje a múltiples receptores y agrega sus respuestas. Composed Message Processor divide un mensaje en partes diferentes y envía cada parte a un receptor específico.
- vs. Routing Slip: Routing Slip procesa un mensaje secuencialmente a través de múltiples pasos. Composed Message Processor procesa partes en paralelo a través de diferentes procesadores.
- vs. Process Manager: Process Manager coordina un flujo complejo con decisiones y estados. Composed Message Processor tiene un flujo fijo: split → route → process → aggregate.
Encaje en un Flujo Mayor de Integración¶
Composed Message Processor es típicamente una fase dentro de un flujo más amplio de orden-a-entrega. Antes del CMP, el pedido fue validado y el pago autorizado. Después del CMP, la confirmación se envía al cliente y los procesos de envío y tracking se activan independientemente.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
Composed Message Processor sigue siendo relevante en arquitecturas de microservicios, aunque su implementación ha evolucionado significativamente:
Lo que sigue vigente:
- Orquestación de múltiples servicios: cuando un request compuesto requiere procesamiento por múltiples servicios especializados, el patrón proporciona una estructura clara para coordinar el flujo.
- Procesamiento paralelo: la capacidad de procesar partes en paralelo es cada vez más importante con microservicios que pueden escalar independientemente.
- Degradación graceful: el patrón permite manejar fallos parciales de forma explícita, esencial en sistemas distribuidos.
Lo que ha cambiado:
- Orquestación explícita vs. coreografía: en arquitecturas event-driven puras, se prefiere coreografía (cada servicio reacciona a eventos sin un orquestador central) sobre orquestación (un componente central dirige el flujo). Composed Message Processor es inherentemente un patrón de orquestación.
- Saga pattern: para flujos que requieren compensación, el Saga pattern ha emergido como alternativa o complemento al Composed Message Processor.
- Frameworks de workflow: herramientas como Temporal, Step Functions de AWS, y Durable Functions de Azure proporcionan abstracción de alto nivel para flujos split-process-aggregate.
Cómo Se Implementa Hoy¶
| Tecnología | Implementación del Patrón |
|---|---|
| AWS Step Functions | Parallel state con branches por tipo de item |
| Temporal.io | Workflow con activities paralelas y aggregation |
| Apache Camel | Splitter → Recipient List → Aggregator DSL |
| Spring Integration | Split-Route-Aggregate con Java DSL |
| Kafka Streams | Branching + repartition + join |
Qué Parte Sigue Siendo Esencial¶
- El principio de dividir-procesar-reagregar para mensajes compuestos es permanente.
- El correlation ID como mecanismo de rastreo y reagregación.
- El manejo explícito de completitud y timeout en el aggregator.
- La extensibilidad para añadir nuevos tipos de procesadores sin modificar el flujo.
15. Implementación en Arquitecturas Modernas¶
AWS Step Functions — Parallel Processing¶
{
"Comment": "Composed Message Processor - Order Fulfillment",
"StartAt": "SplitOrder",
"States": {
"SplitOrder": {
"Type": "Map",
"ItemsPath": "$.items",
"Parameters": {
"order_id.$": "$.order_id",
"item.$": "$$.Map.Item.Value",
"shipping_address.$": "$.shipping_address"
},
"Iterator": {
"StartAt": "RouteByCategory",
"States": {
"RouteByCategory": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.item.category",
"StringEquals": "electronics",
"Next": "ElectronicsFulfillment"
},
{
"Variable": "$.item.category",
"StringEquals": "perishable_food",
"Next": "PerishableFulfillment"
},
{
"Variable": "$.item.category",
"StringEquals": "digital",
"Next": "DigitalDelivery"
}
]
},
"ElectronicsFulfillment": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:electronics-fulfillment",
"End": true
},
"PerishableFulfillment": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:perishable-fulfillment",
"End": true
},
"DigitalDelivery": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:digital-delivery",
"End": true
}
}
},
"ResultPath": "$.fulfillment_results",
"Next": "AggregateResults"
},
"AggregateResults": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:aggregate-order-results",
"End": true
}
}
}
Step Functions implementa el Composed Message Processor con Map state (splitter), Choice state (router), Task states (procesadores) y el resultado del Map como agregación automática.
Temporal.io — Workflow con Activities Paralelas¶
@WorkflowInterface
public interface OrderFulfillmentWorkflow {
@WorkflowMethod
OrderConfirmation processOrder(Order order);
}
@WorkflowImpl
public class OrderFulfillmentWorkflowImpl implements OrderFulfillmentWorkflow {
@Override
public OrderConfirmation processOrder(Order order) {
// Split: dividir por categoría
Map<String, List<OrderLine>> byCategory = order.getItems().stream()
.collect(Collectors.groupingBy(OrderLine::getCategory));
// Route & Process: procesar en paralelo
List<Promise<FulfillmentResult>> futures = new ArrayList<>();
for (Map.Entry<String, List<OrderLine>> entry : byCategory.entrySet()) {
Promise<FulfillmentResult> future = Async.function(
() -> routeAndProcess(entry.getKey(), entry.getValue(), order)
);
futures.add(future);
}
// Aggregate: esperar todos los resultados
List<FulfillmentResult> results = futures.stream()
.map(Promise::get)
.collect(Collectors.toList());
return aggregateResults(order.getOrderId(), results);
}
private FulfillmentResult routeAndProcess(String category, List<OrderLine> lines, Order order) {
return switch (category) {
case "electronics" -> activities.fulfillElectronics(lines, order.getShippingAddress());
case "perishable_food" -> activities.fulfillPerishable(lines, order.getShippingAddress());
case "digital" -> activities.fulfillDigital(lines, order.getCustomerId());
default -> throw new IllegalArgumentException("Unknown category: " + category);
};
}
}
Temporal.io proporciona el correlation, timeout handling, retry y compensación como infraestructura, simplificando enormemente la implementación del patrón.
Apache Camel — DSL Declarativo¶
from("kafka:orders.new")
.split(jsonpath("$.items"))
.parallelProcessing()
.streaming()
.choice()
.when(jsonpath("$.category").isEqualTo("electronics"))
.to("kafka:fulfillment.electronics")
.when(jsonpath("$.category").isEqualTo("perishable_food"))
.to("kafka:fulfillment.perishable")
.when(jsonpath("$.category").isEqualTo("digital"))
.to("kafka:fulfillment.digital")
.end()
.end()
.aggregate(header("correlation_id"), new OrderResultAggregator())
.completionSize(header("total_parts"))
.completionTimeout(120000)
.to("kafka:orders.confirmed");
Apache Camel implementa Composed Message Processor como una composición explícita de Splitter, Choice (router) y Aggregator en su DSL.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Completion rate: porcentaje de mensajes compuestos que se completan (todas las partes procesadas) vs. que hacen timeout.
- Part processing time: tiempo de procesamiento por procesador especializado, para identificar cuellos de botella.
- Aggregation latency: tiempo entre la primera parte completada y la agregación final.
- In-flight count: número de mensajes compuestos actualmente en procesamiento (partes pendientes en el correlation store).
Monitoreo¶
- Correlation store size: si crece indefinidamente, indica que los mensajes compuestos no se están completando (memory leak).
- Timeout rate por procesador: si un procesador genera más timeouts que los demás, puede necesitar escalado o debugging.
- Partial failure rate: porcentaje de mensajes compuestos con al menos una parte fallida.
- Stale entries: entradas en el correlation store más antiguas que el timeout máximo, indicando que el cleanup no funciona.
Versionado¶
- Formato del mensaje compuesto: cuando se añade un nuevo campo al pedido, todos los procesadores deben aceptar el nuevo formato (tolerant reader).
- Nuevo tipo de procesador: añadir una regla de routing y desplegar el nuevo procesador sin modificar el splitter ni el aggregator.
- Estrategia de aggregation: si cambia la lógica de combinación de resultados, versionar el aggregator.
Seguridad¶
- Correlation store: contiene datos de pedidos en vuelo; debe estar protegido con autenticación y cifrado.
- Topics de fulfillment: ACLs que permitan solo al router producir y solo al procesador correspondiente consumir.
- Datos sensibles en partes: los datos de pago o PII del cliente deben filtrarse antes de enviar a procesadores que no los necesitan.
Manejo de Errores¶
- Timeout con cleanup: cuando se alcanza el timeout, el aggregator debe liberar el estado del correlation store, enviar resultado parcial y alertar.
- Retry por parte: si una parte falla, el router puede reenviarla al procesador (si es idempotente) sin reenviar las demás.
- Compensación: si se necesita deshacer un pedido parcialmente procesado, enviar mensajes de compensación a los procesadores que ya confirmaron.
- Dead-letter por parte: las partes que agotan reintentos van a dead-letter topic específico del procesador.
17. Errores Comunes¶
No Manejar el Timeout del Aggregator¶
Implementar el aggregator sin timeout. Si un procesador no responde, el mensaje compuesto queda en el correlation store indefinidamente. Con el tiempo, miles de pedidos incompletos acumulan estado, consumiendo memoria hasta que el aggregator falla por OutOfMemoryError.
Perder el Correlation ID¶
No propagar el correlation_id a través de toda la cadena. Un procesador genera el resultado sin el correlation_id original y el aggregator no puede asociarlo con el mensaje compuesto. El pedido nunca se completa.
Aggregator Sin Idempotencia¶
No manejar resultados duplicados en el aggregator. Si un procesador envía el resultado dos veces (por retry), el aggregator cuenta 4 de 3 partes y genera una respuesta corrupta o bloquea esperando una parte que nunca llegará.
Split de Mensajes que No Lo Necesitan¶
Aplicar Composed Message Processor a pedidos con un solo item. El overhead de split → route → process → aggregate no se justifica para un solo elemento. El patrón debe activarse condicionalmente o el caso trivial debe manejarse con un shortcut.
No Planificar la Compensación¶
Procesar partes en paralelo sin plan para el caso en que una parte falla después de que otras ya se confirmaron. El cliente recibe confirmación parcial pero las líneas exitosas ya reservaron stock. Sin compensación, el stock queda bloqueado indefinidamente para un pedido parcialmente fallido.
18. Conclusión Técnica¶
Composed Message Processor es el patrón que coordina el procesamiento de mensajes compuestos dividiendo el mensaje en partes, enrutando cada parte al procesador especializado correspondiente y reagregando los resultados en una respuesta unificada. Es la composición orquestada de Splitter, Content-Based Router y Aggregator.
Cuándo aporta valor: cuando un mensaje contiene elementos heterogéneos que requieren procesamiento por diferentes servicios especializados, especialmente cuando las partes pueden procesarse en paralelo para reducir latencia.
Cuándo evita problemas importantes: cuando sin el patrón, un servicio monolítico debe conocer la lógica de procesamiento de todos los tipos de elementos, creando un componente inflexible, difícil de escalar y con alto riesgo de despliegue.
Cuándo no conviene adoptarlo: cuando todos los elementos se procesan con la misma lógica (un loop es suficiente), cuando no se necesita respuesta unificada, o cuando el número de elementos es tan pequeño que el overhead de coordinación supera el beneficio del procesamiento paralelo.
Recomendación para arquitectos: utilice frameworks de workflow (Temporal, Step Functions) cuando estén disponibles, ya que abstraen la complejidad de correlation, timeout y retry. Si implementa manualmente, invierta especialmente en el aggregator: timeout con cleanup, idempotencia de resultados, manejo de partes tardías y compensación. El aggregator es el componente más propenso a errores del patrón. Y aplique el principio de degradación graceful: en la mayoría de los casos de negocio, es preferible confirmar un pedido con una línea fallida que rechazar todo el pedido porque una línea tuvo un problema transitorio.