Routing Slip¶
1. Nombre del Patrón¶
- Nombre oficial: Routing Slip
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Hoja de Ruta / Itinerario de Enrutamiento
2. Resumen Ejecutivo¶
Routing Slip es un patrón de enrutamiento dinámico en el que el propio mensaje transporta su itinerario de procesamiento: una lista ordenada de pasos (processing steps) por los que debe pasar. Cada componente de procesamiento examina el itinerario, ejecuta su paso correspondiente, elimina ese paso de la lista y envía el mensaje al siguiente componente indicado en el itinerario. No existe un orquestador central que dirija el flujo — el flujo está embebido en el mensaje mismo.
El problema que resuelve es el enrutamiento dinámico multi-paso sin un orquestador central. En muchos sistemas, diferentes mensajes requieren diferentes secuencias de procesamiento según su contenido, tipo o contexto. Un Content-Based Router podría manejar la primera decisión de enrutamiento, pero si la secuencia de pasos varía dinámicamente (diferentes mensajes necesitan diferentes combinaciones y órdenes de procesamiento), implementar todas las combinaciones posibles con routers estáticos se vuelve inviable.
Routing Slip resuelve esto delegando la responsabilidad de enrutamiento al mensaje mismo: el itinerario se adjunta al mensaje al inicio del pipeline, y cada componente de procesamiento sabe cómo leer el itinerario, ejecutar su paso y pasar el mensaje al siguiente. La analogía es un paquete postal con una lista de estafetas por las que debe pasar, donde cada estafeta marca su paso como completado y envía el paquete a la siguiente.
En arquitecturas modernas, Routing Slip aparece en middleware chains (Express.js middleware, Spring interceptors), pipeline processing (Apache Camel routing slips), y en headers de mensajes que dictan la secuencia de procesamiento.
3. Definición Detallada¶
Propósito¶
El propósito de Routing Slip es permitir que un mensaje defina su propia ruta de procesamiento como una secuencia de pasos embebida en el propio mensaje, eliminando la necesidad de un orquestador central que gestione el flujo.
Lógica Arquitectónica¶
La lógica es análoga a un viajero con un itinerario de viaje: el viajero (mensaje) lleva consigo su lista de destinos (routing slip). En cada destino (processing component), el viajero recibe un servicio, la estación marca el destino como visitado y le indica cuál es el siguiente destino de su itinerario. El viajero no necesita un agente de viajes (orquestador) que lo guíe en cada paso — su itinerario contiene toda la información necesaria.
En términos de mensajería:
- Routing Slip: una estructura de datos adjunta al mensaje (típicamente en un header) que contiene la lista ordenada de pasos de procesamiento restantes.
- Processing Component: un componente que sabe cómo leer el routing slip, ejecutar su procesamiento, actualizar el slip (eliminar su paso) y enviar el mensaje al siguiente componente.
- Slip Router: la lógica (presente en cada processing component o como wrapper) que examina el routing slip y determina el siguiente destino.
Principio de Diseño Subyacente¶
El principio es descentralización del control de flujo. En lugar de centralizar las decisiones de enrutamiento en un orquestador (Process Manager) o en una cadena de routers estáticos, el control se distribuye: cada componente tiene la capacidad mínima de leer el siguiente paso del itinerario y enviar el mensaje allí. La inteligencia de enrutamiento reside en el mensaje, no en la infraestructura.
Cómo Se Construye el Routing Slip¶
El routing slip se construye al inicio del procesamiento, típicamente por un componente dedicado que:
- Examina el contenido del mensaje (tipo, origen, destino, atributos).
- Consulta reglas de negocio o configuración para determinar qué pasos de procesamiento necesita este mensaje específico.
- Construye la lista ordenada de pasos y la adjunta al mensaje como header o propiedad.
Por ejemplo, una declaración aduanera para mercancía textil desde China a España podría requerir: [validación_formato → clasificación_arancelaria → verificación_origen → cálculo_aranceles → inspección_sanitaria → aprobación_final]. Pero una declaración para maquinaria desde Alemania a España podría necesitar solo: [validación_formato → clasificación_arancelaria → cálculo_aranceles → aprobación_final].
Problema Estructural que Resuelve¶
Sin Routing Slip, las rutas dinámicas multi-paso se implementan con alguna de estas alternativas inadecuadas:
Cadena de routers: cada router decide el siguiente paso basándose en el contenido del mensaje. Pero si hay 10 posibles pasos y las combinaciones varían por tipo de mensaje, los routers deben conocer todas las posibles combinaciones — la complejidad es exponencial.
Orquestador central (Process Manager): un componente central gestiona el flujo completo. Funciona, pero introduce un single point of failure y acoplamiento entre el orquestador y todos los componentes. Para flujos simples y lineales, es over-engineering.
Hardcoded pipelines: una pipeline diferente para cada combinación de pasos. Con 10 pasos opcionales, hay potencialmente 2^10 = 1024 pipelines diferentes. Inmantenible.
Diferencia Fundamental con Process Manager¶
El Routing Slip es una alternativa más ligera al Process Manager:
| Aspecto | Routing Slip | Process Manager |
|---|---|---|
| Control de flujo | En el mensaje (descentralizado) | En el orquestador (centralizado) |
| Estado | No mantiene estado externo | Mantiene estado de cada proceso |
| Branching | No soporta branching dinámico | Soporta branching, loops, compensación |
| Complejidad | Baja | Alta |
| Caso de uso | Secuencias lineales variables | Flujos complejos con condicionales y estado |
Routing Slip es apropiado cuando la ruta es una secuencia lineal sin branching. Si el flujo necesita decisiones condicionales intermedias, loops o compensación, Process Manager es la opción correcta.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Routing Slip, los flujos de procesamiento multi-paso con rutas variables se implementan de formas problemáticas:
Pipeline estática por tipo: se crea un pipeline diferente para cada combinación de pasos de procesamiento. Un sistema con 8 pasos opcionales tiene 256 posibles combinaciones. Crear y mantener 256 pipelines es inviable. Cada nuevo paso duplica el número de combinaciones.
Router en cascada: una cadena de Content-Based Routers donde cada router decide si incluir o saltar un paso. Esto funciona pero distribuye la lógica de composición de la ruta en múltiples routers, dificultando la comprensión del flujo completo y la modificación de reglas.
Monolito de procesamiento con condicionales: un componente único que contiene toda la lógica y ejecuta los pasos condicionalmente con if/else. Esto acopla todos los pasos en un solo componente y hace imposible escalar o desplegar pasos independientemente.
Síntomas del Problema¶
- Proliferación de pipelines que difieren solo en la combinación de pasos incluidos.
- Lógica de routing duplicada en múltiples routers que toman decisiones similares.
- Cambios frecuentes en las reglas de composición de ruta que requieren modificar múltiples componentes.
- Imposibilidad de añadir un nuevo paso de procesamiento sin modificar toda la infraestructura de routing.
- Dificultad para entender la ruta completa que seguirá un mensaje específico.
Impacto Operativo y Arquitectónico¶
- Rigidez: añadir un nuevo paso de procesamiento requiere modificar múltiples routers o crear nuevas pipelines.
- Opacidad: la ruta de un mensaje solo se puede determinar rastreando la lógica de múltiples routers.
- Acoplamiento: la lógica de composición de ruta está acoplada a la infraestructura de routing, no al dominio.
- Testing combinatorio: testear todas las posibles combinaciones de ruta es exponencialmente complejo.
Ejemplos Reales¶
- Aduanas: declaraciones de importación que requieren diferentes verificaciones según el país de origen, tipo de mercancía, valor declarado y acuerdos comerciales.
- Seguros: procesamiento de reclamaciones donde los pasos varían según el tipo de póliza, monto y complejidad del siniestro.
- Telecomunicaciones: provisioning de servicios donde los pasos de configuración varían según el tipo de servicio, el hardware del cliente y la región.
- Healthcare: procesamiento de órdenes médicas donde los pasos de aprobación varían según el tipo de procedimiento, la cobertura del paciente y los requisitos regulatorios.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando diferentes mensajes requieren diferentes secuencias de procesamiento.
- Cuando la secuencia de pasos se puede determinar al inicio del procesamiento (no requiere decisiones intermedias basadas en resultados de pasos anteriores).
- Cuando la secuencia es lineal (sin branching, sin loops).
- Cuando se desea evitar un orquestador central para flujos que no lo necesitan.
- Cuando los pasos de procesamiento son componentes independientes que pueden participar en múltiples rutas.
- Cuando se necesita visibilidad de la ruta completa de un mensaje (el routing slip es auditable).
Cuándo No Usarlo¶
- Cuando la ruta tiene branching condicional (si el paso 3 falla, ir al paso 7 en lugar del paso 4). Esto requiere Process Manager.
- Cuando se necesita compensación (deshacer pasos anteriores si un paso posterior falla). Esto requiere Process Manager con saga.
- Cuando la ruta es fija para todos los mensajes (una pipeline estática Pipes and Filters es más simple).
- Cuando el número de pasos es muy grande (>20) y la ruta necesita gestión de estado compleja.
Precondiciones¶
- Los pasos de procesamiento son componentes independientes con interfaces estandarizadas.
- Cada componente puede leer y actualizar el routing slip del mensaje.
- La ruta completa se puede determinar al inicio del procesamiento.
- Los pasos son lineales (el orden no cambia durante el procesamiento).
Restricciones¶
- No soporta branching dinámico basado en resultados intermedios.
- No soporta compensación de pasos anteriores.
- No mantiene estado centralizado del progreso (si se pierde el mensaje, se pierde el estado).
- El tamaño del routing slip añade overhead al mensaje.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Middleware chains (Express.js, Spring Security filter chain, ASP.NET middleware pipeline).
- Integration platforms (Apache Camel routing slip, Spring Integration).
- Document processing pipelines (verificación de documentos multi-paso).
- Customs and compliance systems.
- Insurance claims processing.
6. Fuerzas Arquitectónicas¶
Descentralización vs. Visibilidad¶
El Routing Slip descentraliza el control de flujo — no hay un orquestador que conozca el estado global. Esto simplifica la arquitectura pero reduce la visibilidad: para saber en qué paso está un mensaje, hay que examinar el mensaje mismo (su routing slip). No hay un dashboard central que muestre el progreso de todos los mensajes en vuelo.
Simplicidad vs. Capacidad¶
Routing Slip es intencionalmente simple: secuencias lineales sin branching ni estado. Esta simplicidad es su fortaleza (fácil de implementar, fácil de entender) y su limitación (no sirve para flujos complejos). Escalar la capacidad del patrón (añadir branching, estado, compensación) lo convierte en un Process Manager.
Autonomía del Mensaje vs. Overhead¶
Adjuntar el routing slip al mensaje hace al mensaje autónomo (contiene toda la información necesaria para su propio routing). Pero esto incrementa el tamaño del mensaje. En sistemas de alto throughput, el overhead del routing slip en cada mensaje puede ser significativo si la lista de pasos es larga.
Flexibilidad de Ruta vs. Complejidad de Construcción¶
La flexibilidad del Routing Slip (cada mensaje puede tener una ruta diferente) traslada la complejidad al componente que construye el slip. Este componente debe conocer todas las reglas de negocio que determinan qué pasos necesita cada mensaje. La complejidad no desaparece — se concentra en un único punto.
Acoplamiento al Formato del Slip¶
Todos los componentes de procesamiento deben entender el formato del routing slip: cómo leerlo, cómo actualizarlo, cómo determinar el siguiente destino. Esto introduce un acoplamiento implícito al formato del slip. Si el formato cambia, todos los componentes deben actualizarse.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Slip Builder (Constructor del Itinerario): componente que examina el mensaje y construye el routing slip basándose en reglas de negocio.
- Slip Router (Router del Itinerario): lógica que examina el routing slip del mensaje, determina el siguiente destino, y envía el mensaje allí. Puede estar integrada en cada processing component o implementarse como un componente wrapper separado.
- Processing Component (Componente de Procesamiento): componente que realiza una tarea específica de procesamiento sobre el mensaje.
- Routing Slip (Itinerario): estructura de datos adjunta al mensaje que contiene la lista ordenada de pasos restantes.
Flujo Lógico¶
flowchart TD
A([Mensaje llega]) --> B[Slip Builder examina\nel mensaje]
B --> C[Construir routing slip\nstep_A, step_C, step_E, step_G]
C --> D[Adjuntar slip al mensaje\ncomo header]
D --> E[Slip Router lee\nprimer paso del slip]
E --> F[Enviar a Processing\nComponent correspondiente]
F --> G[Component procesa\nel mensaje]
G --> H[Actualizar slip\nremover paso completado]
H --> I{Slip vacío?}
I -- No --> E
I -- Sí --> J([Enviar mensaje\nal destino final])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Slip Builder | Determinar la ruta y construir el routing slip |
| Slip Router | Leer el slip, determinar el siguiente destino, enviar el mensaje |
| Processing Component | Realizar su procesamiento específico |
| Routing Slip (data) | Transportar la secuencia de pasos restantes dentro del mensaje |
Formato del Routing Slip¶
El routing slip es típicamente una lista ordenada en un header del mensaje:
{
"headers": {
"routing_slip": ["format_validator", "tariff_classifier", "origin_verifier", "duty_calculator"],
"routing_slip_completed": [],
"correlation_id": "DECL-2026-04-07-003291"
},
"body": { ... }
}
A medida que cada paso se completa, se mueve de routing_slip a routing_slip_completed:
{
"headers": {
"routing_slip": ["duty_calculator"],
"routing_slip_completed": ["format_validator", "tariff_classifier", "origin_verifier"],
"correlation_id": "DECL-2026-04-07-003291"
},
"body": { ... }
}
Decisiones de Diseño Clave¶
-
Slip en header vs. en body: el slip debe ir en el header del mensaje (metadatos de routing) no en el body (datos de negocio). Esto separa la lógica de routing de los datos del dominio.
-
Slip consumible vs. auditable: un slip consumible elimina el paso completado de la lista (solo quedan los pasos pendientes). Un slip auditable mantiene la historia de pasos completados y pendientes. El auditable es más útil para trazabilidad.
-
Router integrado vs. wrapper: el Slip Router puede estar integrado en cada processing component (el component sabe leer el slip y enviarse al siguiente paso) o puede ser un wrapper separado que decora cada component. El wrapper es más limpio (separación de responsabilidades) pero añade un componente por paso.
-
Resolución de destinos: los pasos en el slip pueden ser nombres lógicos (que se resuelven a direcciones físicas via un registry) o direcciones físicas directas. Los nombres lógicos son más flexibles (un paso puede cambiar de dirección sin modificar el slip builder).
8. Ejemplo Arquitectónico Detallado¶
Dominio: Logística — Procesamiento de Declaraciones Aduaneras¶
Contexto del Negocio¶
Una agencia de aduanas procesa 50,000 declaraciones de importación diarias. Cada declaración debe pasar por una serie de verificaciones y cálculos antes de ser aprobada. Los pasos requeridos varían significativamente según:
- País de origen: mercancías de ciertos países requieren verificación de origen adicional.
- Tipo de mercancía: productos alimentarios requieren inspección sanitaria, productos químicos requieren verificación medioambiental, textiles requieren verificación anti-dumping.
- Valor declarado: declaraciones por encima de cierto umbral requieren auditoría de valoración.
- Acuerdos comerciales: mercancías cubiertas por TLC (Tratado de Libre Comercio) requieren verificación de certificado de origen para aplicar aranceles preferenciales.
Necesidad de Integración¶
Con 8 posibles pasos de verificación y múltiples combinaciones según los atributos de cada declaración, la agencia necesita un mecanismo que determine dinámicamente la secuencia de procesamiento para cada declaración y la ejecute sin un orquestador central.
Los pasos posibles son:
| Paso | Condición | Descripción |
|---|---|---|
format_validator | Siempre | Valida formato de la declaración |
tariff_classifier | Siempre | Clasifica la mercancía según el código arancelario |
origin_verifier | País de origen en lista de alto riesgo | Verifica documentos de origen |
ftc_verifier | Mercancía cubierta por TLC | Verifica certificado de origen TLC |
sanitary_inspector | Mercancía alimentaria o animal | Inspección sanitaria |
environmental_checker | Mercancía química o peligrosa | Verificación medioambiental |
anti_dumping_checker | Textiles de ciertos países | Verificación anti-dumping |
valuation_auditor | Valor > EUR 100,000 | Auditoría de valoración aduanera |
duty_calculator | Siempre | Cálculo de aranceles e impuestos |
final_approver | Siempre | Aprobación final |
Sistemas Involucrados¶
- Customs Portal: portal web donde los declarantes envían las declaraciones.
- Slip Builder Service: servicio que examina la declaración y construye el routing slip.
- Processing Services: 10 microservicios independientes, uno por paso de verificación.
- Kafka Cluster: infraestructura de mensajería para los canales entre servicios.
- Customs Database: base de datos de declaraciones procesadas.
Diseño del Routing Slip¶
Customs Portal → [declarations.incoming] → Slip Builder
→ Slip Builder examina declaración y construye routing slip
→ Adjunta slip al mensaje
→ Publica en [declarations.processing]
Slip Router en cada Processing Service:
→ Lee primer paso del slip
→ Si es su propio paso: procesa y actualiza slip
→ Si no es su paso: error (mal routing)
→ Si slip no está vacío: publica en [declarations.processing]
→ Si slip está vacío: publica en [declarations.completed]
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción de la Declaración¶
Un importador envía una declaración para un cargamento de textiles desde Vietnam:
{
"declaration_id": "DECL-2026-04-07-003291",
"declarant": "Importaciones Textiles S.L.",
"origin_country": "VN",
"destination_country": "ES",
"commodity_code": "6204.62.00",
"commodity_description": "Women's cotton trousers",
"commodity_category": "textiles",
"declared_value_eur": 85000,
"weight_kg": 2400,
"containers": 1,
"ftc_applicable": true,
"ftc_agreement": "EU-Vietnam FTA"
}
Paso 2: Construcción del Routing Slip¶
El Slip Builder examina la declaración:
format_validator→ siempre → incluidotariff_classifier→ siempre → incluidoorigin_verifier→ VN está en lista de alto riesgo → incluidoftc_verifier→ EU-Vietnam FTA aplicable → incluidosanitary_inspector→ textiles no es alimentario → excluidoenvironmental_checker→ textiles no es químico → excluidoanti_dumping_checker→ textiles desde VN → incluidovaluation_auditor→ EUR 85,000 < 100,000 → excluidoduty_calculator→ siempre → incluidofinal_approver→ siempre → incluido
Routing slip construido:
{
"routing_slip": [
"format_validator",
"tariff_classifier",
"origin_verifier",
"ftc_verifier",
"anti_dumping_checker",
"duty_calculator",
"final_approver"
],
"routing_slip_completed": []
}
Paso 3: Format Validator¶
El Format Validator consume el mensaje, verifica que todos los campos obligatorios están presentes y tienen formato válido, y actualiza el slip:
{
"routing_slip": ["tariff_classifier", "origin_verifier", "ftc_verifier", "anti_dumping_checker", "duty_calculator", "final_approver"],
"routing_slip_completed": ["format_validator"]
}
Resultado: formato válido. El Slip Router envía el mensaje al tariff_classifier.
Paso 4: Tariff Classifier¶
Clasifica la mercancía usando el código 6204.62.00: - Capítulo 62: Prendas y complementos de vestir, excepto los de punto. - Partida 6204: Trajes, conjuntos, chaquetas, vestidos, faldas, pantalones de mujer. - Subpartida 6204.62.00: De algodón. - Arancel NMF (Nación Más Favorecida): 12%. - Posible arancel preferencial EU-Vietnam FTA: 0% (pendiente verificación FTC).
Actualiza el slip y envía al siguiente paso: origin_verifier.
Paso 5: Origin Verifier¶
Vietnam está clasificado como país de alto riesgo para textiles (historial de triangulación de origen con China). El Origin Verifier:
- Verifica el certificado de origen EUR.1 adjunto.
- Valida el número de certificado contra el registro de certificados emitidos por la autoridad vietnamita.
- Verifica coherencia entre el fabricante declarado y los fabricantes registrados en Vietnam.
Resultado: origen verificado. Actualiza el slip y envía al ftc_verifier.
Paso 6: FTC Verifier¶
El EU-Vietnam FTA permite arancel 0% para textiles de algodón si se cumple la regla de origen del acuerdo (doble transformación: el tejido debe haberse fabricado en Vietnam, no solo confeccionado):
- Verifica el certificado REX (Registered Exporter System).
- Valida que la declaración de origen del exportador cumple con la regla de doble transformación.
Resultado: FTC verificado, arancel preferencial 0% aplicable. Actualiza el slip y envía al anti_dumping_checker.
Paso 7: Anti-Dumping Checker¶
La UE tiene medidas anti-dumping vigentes para ciertos textiles de algodón de origen vietnamita:
- Verifica si el código arancelario
6204.62.00está sujeto a medidas anti-dumping. - Consulta la base de datos de medidas vigentes: no hay medida anti-dumping activa para esta subpartida desde VN.
Resultado: sin medidas anti-dumping aplicables. Actualiza el slip y envía al duty_calculator.
Paso 8: Duty Calculator¶
Con toda la información recolectada por los pasos anteriores:
- Arancel aplicable: 0% (preferencial EU-Vietnam FTA, verificado por FTC Verifier).
- IVA de importación: 21% sobre valor declarado = EUR 17,850.
- Derechos anti-dumping: EUR 0 (verificado por Anti-Dumping Checker).
- Total a pagar: EUR 17,850.
Actualiza el slip y envía al final_approver.
Paso 9: Final Approver¶
Realiza la aprobación final:
- Verifica que todos los pasos del slip se completaron correctamente (examina
routing_slip_completed). - Genera el número de DUA (Documento Único Administrativo).
- Registra la declaración en la base de datos de aduanas.
- Notifica al declarante.
El routing slip está ahora vacío:
{
"routing_slip": [],
"routing_slip_completed": [
"format_validator", "tariff_classifier", "origin_verifier",
"ftc_verifier", "anti_dumping_checker", "duty_calculator", "final_approver"
]
}
La declaración se publica en declarations.completed.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
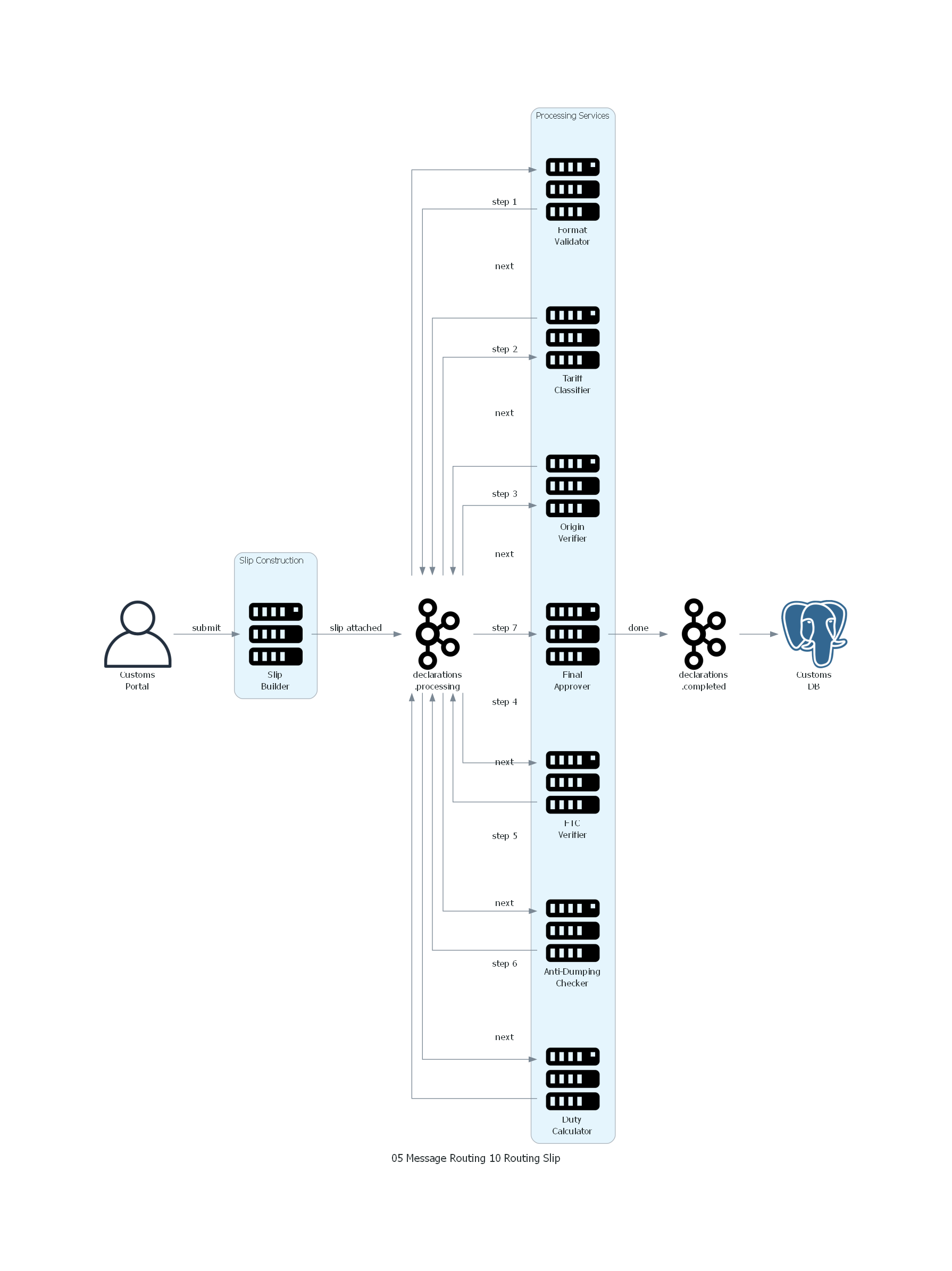
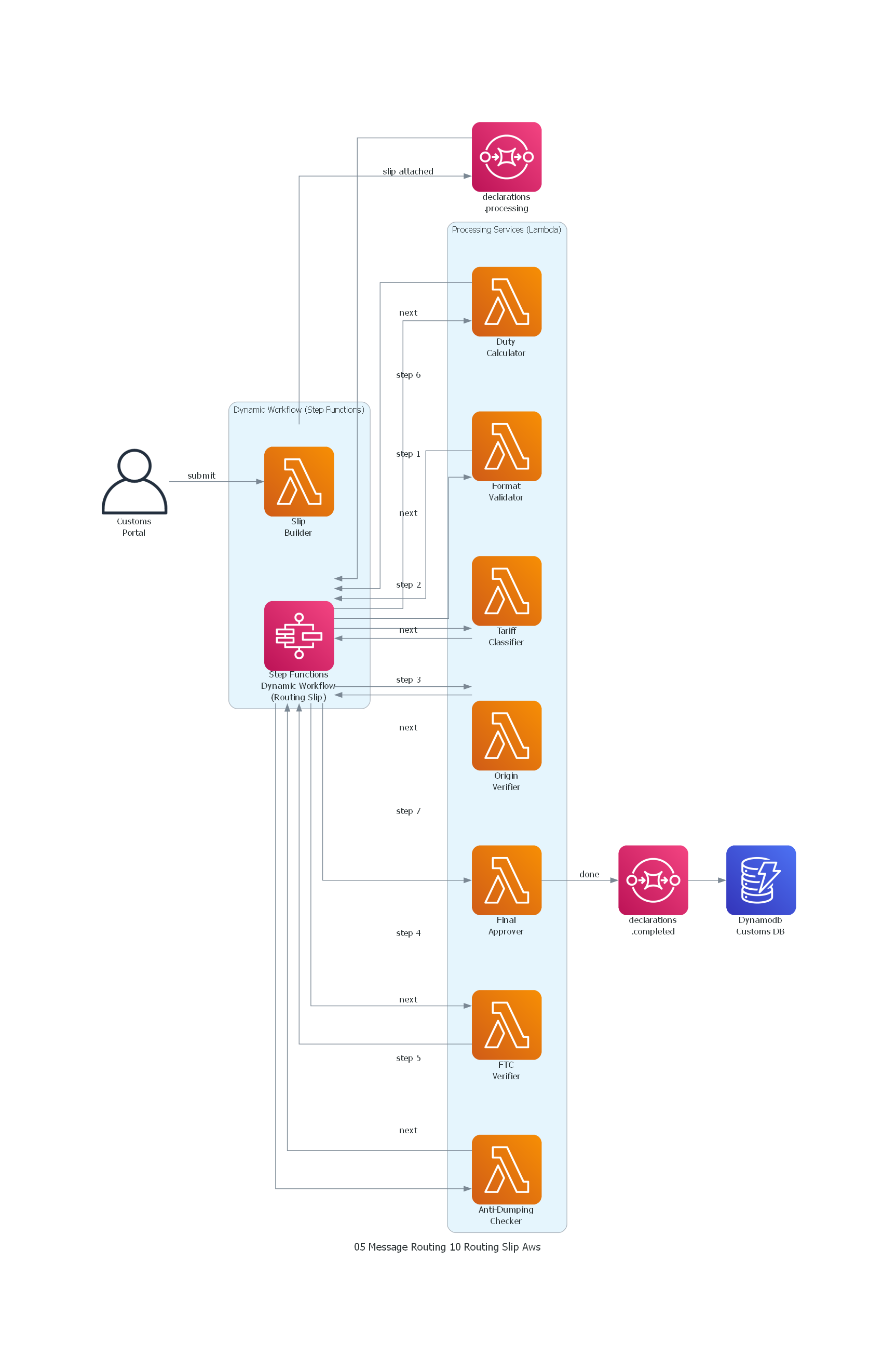
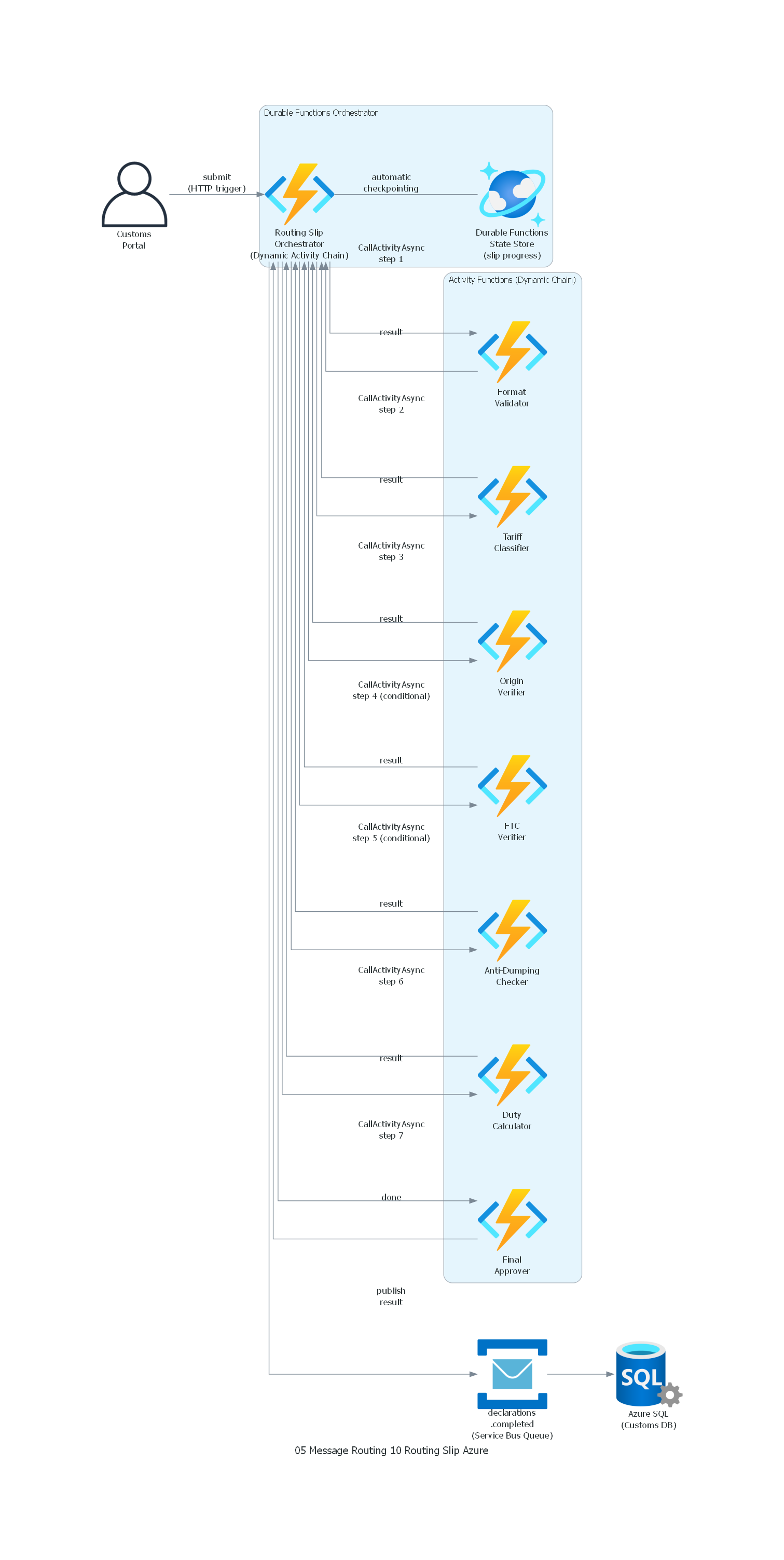
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.client import User
with Diagram("Routing Slip - Customs Declaration Processing", show=False, direction="LR"):
portal = User("Customs\nPortal")
with Cluster("Slip Construction"):
slip_builder = Server("Slip\nBuilder")
processing = Kafka("declarations\n.processing")
with Cluster("Processing Services"):
format_val = Server("Format\nValidator")
tariff = Server("Tariff\nClassifier")
origin = Server("Origin\nVerifier")
ftc = Server("FTC\nVerifier")
anti_dump = Server("Anti-Dumping\nChecker")
duty = Server("Duty\nCalculator")
approver = Server("Final\nApprover")
completed = Kafka("declarations\n.completed")
db = PostgreSQL("Customs\nDB")
portal >> Edge(label="submit") >> slip_builder
slip_builder >> Edge(label="slip attached") >> processing
processing >> Edge(label="step 1") >> format_val
format_val >> Edge(label="next") >> processing
processing >> Edge(label="step 2") >> tariff
tariff >> Edge(label="next") >> processing
processing >> Edge(label="step 3") >> origin
origin >> Edge(label="next") >> processing
processing >> Edge(label="step 4") >> ftc
ftc >> Edge(label="next") >> processing
processing >> Edge(label="step 5") >> anti_dump
anti_dump >> Edge(label="next") >> processing
processing >> Edge(label="step 6") >> duty
duty >> Edge(label="next") >> processing
processing >> Edge(label="step 7") >> approver
approver >> Edge(label="done") >> completed
completed >> db
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import StepFunctions, SQS
with Diagram("Routing Slip - Customs Declaration Processing (AWS)", show=False, direction="LR"):
portal = User("Customs\nPortal")
with Cluster("Dynamic Workflow (Step Functions)"):
slip_builder = Lambda("Slip\nBuilder")
workflow = StepFunctions("Step Functions\nDynamic Workflow\n(Routing Slip)")
processing = SQS("declarations\n.processing")
with Cluster("Processing Services (Lambda)"):
format_val = Lambda("Format\nValidator")
tariff = Lambda("Tariff\nClassifier")
origin = Lambda("Origin\nVerifier")
ftc = Lambda("FTC\nVerifier")
anti_dump = Lambda("Anti-Dumping\nChecker")
duty = Lambda("Duty\nCalculator")
approver = Lambda("Final\nApprover")
completed = SQS("declarations\n.completed")
db = Dynamodb("Dynamodb\nCustoms DB")
portal >> Edge(label="submit") >> slip_builder
slip_builder >> Edge(label="slip attached") >> processing
processing >> workflow
workflow >> Edge(label="step 1") >> format_val
format_val >> Edge(label="next") >> workflow
workflow >> Edge(label="step 2") >> tariff
tariff >> Edge(label="next") >> workflow
workflow >> Edge(label="step 3") >> origin
origin >> Edge(label="next") >> workflow
workflow >> Edge(label="step 4") >> ftc
ftc >> Edge(label="next") >> workflow
workflow >> Edge(label="step 5") >> anti_dump
anti_dump >> Edge(label="next") >> workflow
workflow >> Edge(label="step 6") >> duty
duty >> Edge(label="next") >> workflow
workflow >> Edge(label="step 7") >> approver
approver >> Edge(label="done") >> completed
completed >> db
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import SQLServers, CosmosDb
from diagrams.azure.integration import ServiceBus
with Diagram("Routing Slip - Customs Declaration Processing (Azure)", show=False, direction="LR"):
portal = User("Customs\nPortal")
with Cluster("Durable Functions Orchestrator"):
orchestrator = FunctionApps("Routing Slip\nOrchestrator\n(Dynamic Activity Chain)")
state = CosmosDb("Durable Functions\nState Store\n(slip progress)")
orchestrator - Edge(label="automatic\ncheckpointing") - state
with Cluster("Activity Functions (Dynamic Chain)"):
format_val = FunctionApps("Format\nValidator")
tariff = FunctionApps("Tariff\nClassifier")
origin = FunctionApps("Origin\nVerifier")
ftc = FunctionApps("FTC\nVerifier")
anti_dump = FunctionApps("Anti-Dumping\nChecker")
duty = FunctionApps("Duty\nCalculator")
approver = FunctionApps("Final\nApprover")
completed = ServiceBus("declarations\n.completed\n(Service Bus Queue)")
db = SQLServers("Azure SQL\n(Customs DB)")
portal >> Edge(label="submit\n(HTTP trigger)") >> orchestrator
# Dynamic activity chain - orchestrator calls each step sequentially
orchestrator >> Edge(label="CallActivityAsync\nstep 1") >> format_val
format_val >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 2") >> tariff
tariff >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 3") >> origin
origin >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 4 (conditional)") >> ftc
ftc >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 5 (conditional)") >> anti_dump
anti_dump >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 6") >> duty
duty >> Edge(label="result") >> orchestrator
orchestrator >> Edge(label="CallActivityAsync\nstep 7") >> approver
approver >> Edge(label="done") >> orchestrator
orchestrator >> Edge(label="publish\nresult") >> completed
completed >> db
Notas del Diagrama¶
- El canal
declarations.processinges el hub central por el que el mensaje pasa entre cada step. Cada processing service consume del canal, verifica si el primer paso del slip le corresponde, procesa, actualiza el slip, y republica en el mismo canal. - En una implementación más eficiente, cada processing service tiene su propio canal de entrada y el Slip Router envía directamente al canal del siguiente paso (evitando el hub central). El diagrama muestra la variante con hub central por claridad.
- La flecha final al
declarations.completedse activa cuando el routing slip está vacío.
11. Beneficios¶
Flexibilidad de Ruta sin Explosión Combinatoria¶
Cada mensaje puede tener una ruta diferente sin necesidad de crear una pipeline por combinación. Con 10 pasos opcionales, el Slip Builder genera dinámicamente la ruta correcta para cada mensaje, en lugar de mantener 1024 pipelines estáticas.
Simplicidad del Control de Flujo¶
No hay orquestador central que gestionar, monitorear ni escalar. El control de flujo es emergente: cada componente de procesamiento hace su trabajo y pasa el mensaje al siguiente paso del slip. La complejidad del flujo se reduce a la construcción del slip (un único punto).
Trazabilidad Embebida¶
El routing slip completado (con los pasos ya ejecutados) proporciona un registro de auditoría embebido en el mensaje. Se puede inspeccionar el slip de cualquier mensaje para saber exactamente qué pasos siguió, sin consultar logs externos.
Independencia de Componentes¶
Los processing components no se conocen entre sí. El Format Validator no sabe que después vendrá el Tariff Classifier. Solo sabe que debe leer su paso del slip, procesarlo, y pasar el mensaje al siguiente. Esto permite añadir, eliminar o reordenar pasos sin modificar los componentes existentes.
Separación de Construcción y Ejecución de la Ruta¶
La lógica de negocio que determina qué pasos necesita un mensaje está concentrada en el Slip Builder. Los processing components ejecutan su lógica de procesamiento sin preocuparse de la composición de la ruta. Esto separa claramente las responsabilidades.
12. Desventajas y Riesgos¶
No Soporta Branching¶
Si un paso intermedio necesita decidir el siguiente paso basándose en su resultado (por ejemplo, si la verificación de origen falla, ir directamente al paso de rechazo en lugar del siguiente paso del slip), el Routing Slip estándar no lo soporta. El slip es una secuencia lineal fija.
Recuperación Limitada ante Fallos¶
Si un mensaje se pierde después de completar el paso 3 de 7, no hay estado centralizado que registre este progreso. Un Process Manager mantendría el estado y podría retomar desde el paso 4. Con Routing Slip, el mensaje se debe reprocesar desde el inicio o implementar mecanismos de checkpoint externos.
Acoplamiento al Formato del Slip¶
Todos los processing components y el Slip Builder deben acordar el formato del routing slip, los nombres de los pasos, y la convención para leer/actualizar el slip. Un cambio en este contrato implícito afecta a todos los componentes.
Complejidad del Slip Builder¶
La complejidad de determinar la ruta correcta se concentra en el Slip Builder. Si las reglas de negocio son complejas (múltiples condiciones combinadas, excepciones, overrides), el Slip Builder se convierte en un componente complejo que requiere testing exhaustivo.
Overhead en el Mensaje¶
El routing slip añade tamaño al mensaje. En sistemas de ultra-alto throughput con mensajes pequeños, el overhead del slip puede ser proporcionalmente significativo.
Debugging Distribuido¶
Cuando un mensaje falla en un paso intermedio, el debugging requiere rastrear el mensaje a través de múltiples servicios. No hay un punto centralizado donde se pueda ver el estado global del procesamiento.
13. Relación con Otros Patrones¶
Patrones que Routing Slip Utiliza¶
- Message Channel: los canales entre processing components transportan los mensajes con su routing slip.
- Content-Based Router: el Slip Router es un tipo de Content-Based Router que enruta basándose en el contenido del routing slip (no del body del mensaje).
Patrones Relacionados¶
- Process Manager: la alternativa más potente al Routing Slip. Añade estado centralizado, branching, loops y compensación. Routing Slip es preferible cuando estas capacidades no son necesarias (secuencias lineales simples).
- Pipes and Filters: Routing Slip es un Pipes and Filters dinámico donde la secuencia de filtros varía por mensaje. Si la secuencia es fija para todos los mensajes, Pipes and Filters estático es más simple.
- Recipient List: el Slip Builder es conceptualmente similar a un Recipient List que determina los destinatarios — pero en Routing Slip los destinatarios se visitan secuencialmente, no en paralelo.
- Content-Based Router: una cadena de Content-Based Routers podría lograr un efecto similar al Routing Slip, pero la lógica de routing estaría distribuida en múltiples routers en lugar de concentrada en el slip.
- Claim Check: en implementaciones donde el routing slip es muy grande, se puede usar un Claim Check para almacenar el slip externamente y transportar solo una referencia en el mensaje.
Routing Slip como Middleware Chain¶
En frameworks web modernos, el middleware chain (Express.js app.use(), ASP.NET middleware pipeline, Spring Security filter chain) es una implementación del patrón Routing Slip donde: - El request es el "mensaje". - La lista de middleware registrados es el "routing slip" (aunque es la misma lista para todos los requests). - Cada middleware puede modificar el request/response y llamar a next() (equivalente a avanzar en el slip). - Cada middleware puede decidir no llamar a next() (equivalente a terminar la ruta prematuramente).
14. Relevancia Actual¶
Vigencia del Patrón¶
MEDIA. El Routing Slip es un patrón válido pero con un nicho de aplicación más estrecho que otros patrones de routing:
-
Middleware chains: Express.js, ASP.NET Core, Spring WebFlux implementan el concepto de Routing Slip como middleware pipeline. Es uno de los patrones más usados en desarrollo web, aunque los desarrolladores raramente lo identifican como Routing Slip.
-
Apache Camel: soporta Routing Slip como patrón nativo (
routingSlip()) para flujos donde la ruta se determina dinámicamente en runtime. -
Interceptor patterns: frameworks como gRPC interceptors, Kafka Streams processors y Servlet filters implementan variantes del Routing Slip.
-
Cloud workflows: AWS Step Functions y Azure Durable Functions pueden implementar routing slips como secuencias dinámicas de tasks, aunque típicamente se usan más como Process Managers.
Por Qué "Media" y No "Alta"¶
El Routing Slip pierde relevancia frente al Process Manager en contextos donde se necesita estado, branching o compensación — que son la mayoría de los flujos de negocio no triviales en microservices. Temporal, Step Functions y Camunda han hecho que implementar un Process Manager sea casi tan simple como implementar un Routing Slip, reduciendo la ventaja de simplicidad del Routing Slip.
Sin embargo, para flujos lineales simples donde un Process Manager sería over-engineering, el Routing Slip sigue siendo la opción correcta.
15. Implementación Moderna¶
Con Apache Camel¶
from("kafka:declarations.incoming")
.process(exchange -> {
Declaration decl = exchange.getIn().getBody(Declaration.class);
String slip = buildSlip(decl); // "format_validator,tariff_classifier,origin_verifier,duty_calculator"
exchange.getIn().setHeader("routingSlip", slip);
})
.routingSlip(header("routingSlip"))
.to("kafka:declarations.completed");
Con Express.js (Middleware Chain como Routing Slip)¶
function buildMiddlewareChain(declaration) {
const steps = [formatValidator]; // siempre
if (declaration.commodity_category === 'food') {
steps.push(sanitaryInspector);
}
if (declaration.origin_country === 'VN') {
steps.push(originVerifier);
}
if (declaration.ftc_applicable) {
steps.push(ftcVerifier);
}
steps.push(dutyCalculator, finalApprover); // siempre
return steps;
}
app.post('/declarations', (req, res) => {
const chain = buildMiddlewareChain(req.body);
// Execute chain sequentially
executeChain(chain, req, res);
});
function executeChain(steps, req, res, index = 0) {
if (index >= steps.length) {
return res.json({ status: 'APPROVED', declaration_id: req.body.declaration_id });
}
steps[index](req, res, () => executeChain(steps, req, res, index + 1));
}
Con Spring Integration¶
@Bean
public IntegrationFlow declarationFlow() {
return IntegrationFlow.from("declarations.incoming")
.handle((payload, headers) -> {
Declaration decl = (Declaration) payload;
List<String> slip = buildRoutingSlip(decl);
return MessageBuilder.withPayload(payload)
.setHeader("routing_slip", slip)
.build();
})
.routingSlip("routing_slip")
.channel("declarations.completed")
.get();
}
Con Kafka y Python¶
import json
from kafka import KafkaConsumer, KafkaProducer
STEP_CHANNELS = {
"format_validator": "declarations.format_validator",
"tariff_classifier": "declarations.tariff_classifier",
"origin_verifier": "declarations.origin_verifier",
"duty_calculator": "declarations.duty_calculator",
"final_approver": "declarations.final_approver",
}
def process_and_forward(message, step_name, process_fn):
"""Generic Routing Slip handler for any processing step."""
headers = message["headers"]
slip = headers["routing_slip"]
assert slip[0] == step_name, f"Expected {step_name}, got {slip[0]}"
# Process
result = process_fn(message["body"])
message["body"] = result
# Update slip
headers["routing_slip_completed"].append(slip.pop(0))
# Route to next step
if slip:
next_step = slip[0]
producer.send(STEP_CHANNELS[next_step], json.dumps(message).encode())
else:
producer.send("declarations.completed", json.dumps(message).encode())
16. Gobierno y Operación¶
Métricas Clave¶
| Métrica | Descripción | Umbral de Alerta |
|---|---|---|
slip.steps.avg | Promedio de pasos por slip | Monitoreo de tendencia |
step.latency.p95 | Latencia P95 por paso | >SLA del paso |
step.error.rate | Tasa de error por paso | >5% |
slip.completion.rate | % de mensajes que completan todos los pasos | <95% |
slip.abandoned.count | Mensajes que se pierden entre pasos | >0 |
slip_builder.rule_errors | Errores en la construcción del slip | >0 |
Trazabilidad¶
Cada mensaje debe incluir un correlation_id que permita rastrear su paso a través de todos los processing components. El distributed tracing (OpenTelemetry) es esencial para visualizar la ruta completa de un mensaje con su routing slip.
Monitoreo del Slip Builder¶
El Slip Builder es el componente más crítico para el gobierno: - Verificar que las reglas de construcción del slip son correctas y completas. - Alertar si se genera un slip vacío (ningún paso aplicable) o inusualmente largo. - Auditar cambios en las reglas de construcción del slip.
Operaciones de Runbook¶
-
Mensaje estancado entre pasos: verificar que el processing component del paso actual está activo y consumiendo mensajes. Si el componente está caído, reiniciarlo. El mensaje debería procesarse automáticamente una vez el componente esté disponible.
-
Slip con paso desconocido: si un slip contiene un paso que ningún processing component reconoce, el mensaje se queda indefinidamente en el canal. Solución: un dead-letter handler que detecte mensajes no consumidos después de un timeout.
-
Cambio en reglas de slip: al cambiar las reglas del Slip Builder, los mensajes que ya están en vuelo con slips construidos bajo las reglas anteriores completarán con su slip original. Solo los nuevos mensajes usarán las nuevas reglas.
17. Errores Comunes¶
Error 1: Usar Routing Slip Cuando Se Necesita Process Manager¶
Intentar implementar branching, compensación o estado en un Routing Slip añadiendo hacks al patrón. Si el flujo necesita decisiones intermedias, el patrón correcto es Process Manager. Solución: evaluar honestamente si el flujo es verdaderamente lineal antes de elegir Routing Slip.
Error 2: Slip Builder con Reglas Incompletas¶
El Slip Builder no cubre todas las combinaciones posibles de atributos del mensaje, produciendo slips incorrectos o vacíos para ciertos tipos de mensaje. Solución: testing exhaustivo del Slip Builder con cobertura de todas las combinaciones relevantes de atributos.
Error 3: Processing Components Acoplados al Orden¶
Un processing component asume que siempre se ejecuta después de un paso específico (por ejemplo, Duty Calculator asume que Origin Verifier ya se ejecutó). Si el slip no incluye Origin Verifier, Duty Calculator falla. Solución: cada component debe validar sus propias precondiciones sin asumir el orden de pasos anteriores.
Error 4: No Manejar Mensajes Huérfanos¶
Un mensaje cuyo routing slip referencia un processing component que no existe (fue eliminado o renombrado) queda indefinidamente sin procesar. Solución: implementar un timeout de permanencia en canal y un dead-letter handler para mensajes no consumidos.
Error 5: Routing Slip en el Body del Mensaje¶
Mezclar metadatos de routing (el slip) con datos de negocio (el body). Esto contamina el modelo de dominio con infraestructura de routing. Solución: el routing slip siempre va en los headers del mensaje, separado del body.
Error 6: No Registrar los Pasos Completados¶
Un slip que solo contiene los pasos pendientes (sin registro de los completados) pierde trazabilidad. Si un mensaje falla en el paso 5, no se sabe qué pasos se completaron exitosamente. Solución: mantener tanto routing_slip (pendientes) como routing_slip_completed (completados) en el header.
18. Conclusión Técnica¶
Routing Slip es un patrón de enrutamiento que resuelve el problema de flujos de procesamiento multi-paso con rutas variables sin requerir un orquestador central. Su valor principal es la eliminación de la explosión combinatoria que surge cuando diferentes mensajes necesitan diferentes combinaciones de pasos de procesamiento, y la descentralización del control de flujo al embeber el itinerario en el propio mensaje.
El patrón es intencionalmente simple: soporta secuencias lineales de pasos sin branching, loops ni compensación. Esta simplicidad es su fortaleza para casos de uso adecuados (flujos lineales con ruta variable) y su limitación para casos más complejos (donde Process Manager es la alternativa correcta).
La decisión clave de diseño es la construcción del slip: el Slip Builder concentra toda la lógica de negocio que determina qué pasos necesita cada mensaje. La calidad del Routing Slip depende enteramente de la correctitud y completitud de estas reglas.
En arquitecturas modernas, el Routing Slip se manifiesta principalmente como middleware chains en frameworks web y como routing slips explícitos en integration platforms como Apache Camel. Su relevancia es media — válida pero cada vez más eclipsada por Process Managers que ofrecen más capacidad con complejidad comparable gracias a frameworks como Temporal y Step Functions.
La regla de decisión es clara: si el flujo es una secuencia lineal de pasos sin branching ni compensación, Routing Slip es la opción más simple. Si hay cualquier necesidad de condicionales intermedios, estado o compensación, usar Process Manager desde el inicio.
Routing Slip es el patrón que convierte al mensaje en su propio guía de viaje: cada mensaje lleva consigo su itinerario, y cada estación simplemente sigue las instrucciones del viajero.