Process Manager¶
1. Nombre del Patrón¶
- Nombre oficial: Process Manager
- Categoría: Message Routing (Enrutamiento de Mensajes)
- Traducción contextual: Gestor de Procesos / Orquestador de Procesos
2. Resumen Ejecutivo¶
Process Manager es el patrón de enrutamiento más sofisticado y uno de los más importantes de todo el catálogo de Enterprise Integration Patterns. Es un componente central que orquesta un proceso multi-paso manteniendo estado, tomando decisiones de routing dinámicas basadas en los resultados de cada paso, gestionando timeouts, reintentos y — crucialmente — compensación cuando un paso falla y es necesario deshacer los efectos de pasos anteriores.
El problema que resuelve es la orquestación de flujos de negocio complejos que involucran múltiples servicios o sistemas, donde el flujo no es una secuencia lineal fija sino un grafo con branching condicional, paralelismo, esperas, y recuperación ante fallos. Sin Process Manager, esta coordinación se implementa de forma ad-hoc: flags en bases de datos, cron jobs que verifican estados, retry loops anidados, y lógica de compensación dispersa en múltiples componentes.
Process Manager es la implementación del patrón Saga Orchestrator en el contexto de microservicios. Cuando los arquitectos hablan de "saga orchestration" para gestionar transacciones distribuidas, están describiendo un Process Manager. Frameworks como Temporal, AWS Step Functions, Azure Durable Functions, Camunda y Netflix Conductor son implementaciones directas de este patrón.
La importancia del Process Manager es difícil de sobreestimar: es el patrón que permite implementar procesos de negocio de larga duración (long-running business processes) en arquitecturas distribuidas sin recurrir a transacciones distribuidas (2PC), que son impráticas en sistemas de microservicios.
3. Definición Detallada¶
Propósito¶
El propósito del Process Manager es orquestar un proceso multi-paso con estado, branching condicional, timeout, retry y compensación, manteniendo una representación explícita del estado del proceso que permite visibilidad, recuperación ante fallos y auditoría.
Lógica Arquitectónica¶
La lógica es análoga a un director de orquesta que coordina una pieza musical compleja. El director (Process Manager) conoce la partitura completa (la definición del proceso), sabe qué instrumento (servicio) debe tocar en cada momento, escucha el resultado de cada sección, decide si avanzar al siguiente movimiento o repetir uno anterior, y puede detener la ejecución y revertir al estado anterior si algo sale mal. Los músicos (servicios) no se conocen entre sí — solo conocen al director.
En términos técnicos:
- Process Manager: componente stateful que mantiene el estado de cada instancia del proceso, decide el siguiente paso basándose en el estado actual y los resultados recibidos, y ejecuta compensaciones cuando es necesario.
- Process Definition: la definición del flujo (estados, transiciones, condiciones, compensaciones). Puede ser código, DSL, BPMN, o configuración.
- Steps/Activities: los servicios o componentes que ejecutan cada paso del proceso.
- State Store: el almacén persistente que mantiene el estado de cada instancia del proceso.
Principio de Diseño Subyacente¶
El principio es orquestación centralizada con estado explícito. A diferencia de la coreografía (donde cada servicio reacciona a eventos y no hay coordinador), la orquestación centraliza la lógica del flujo en un único componente que mantiene una visión completa del estado. Esto proporciona:
- Visibilidad: se puede consultar el estado de cualquier instancia del proceso en cualquier momento.
- Control: se puede pausar, reanudar, cancelar o modificar cualquier instancia.
- Compensación: se puede ejecutar la lógica de compensación en orden inverso cuando un paso falla.
- Debugging: se puede rastrear la secuencia exacta de pasos, decisiones y resultados de cada instancia.
Diferencia con Routing Slip¶
| Aspecto | Routing Slip | Process Manager |
|---|---|---|
| Estado | En el mensaje (no persistente) | En el Process Manager (persistente) |
| Branching | No soporta | Soporta branching condicional complejo |
| Compensación | No soporta | Soporta compensación (saga) |
| Paralelismo | No soporta | Soporta pasos en paralelo |
| Timeout | No gestiona | Gestiona timeouts por paso y por proceso |
| Visibilidad | Solo inspeccionando el mensaje | Dashboard centralizado con estado de todos los procesos |
| Complejidad | Baja | Alta |
| Caso de uso | Secuencias lineales variables | Flujos complejos con estado, branching y compensación |
El Concepto de Saga¶
El Process Manager es la pieza central del patrón Saga en microservicios. Una saga es una secuencia de transacciones locales donde:
- Cada paso ejecuta una transacción local en su propio servicio.
- Si un paso falla, se ejecutan compensating transactions en orden inverso para deshacer los efectos de los pasos anteriores.
- El resultado final es consistencia eventual (no ACID inmediato).
Existen dos formas de implementar sagas:
- Orchestration-based saga (Process Manager): un orquestador central decide cada paso y ejecuta compensaciones. Es lo que describe este patrón.
- Choreography-based saga: cada servicio publica eventos y reacciona a eventos de otros servicios. No hay orquestador central. Es más desacoplado pero más difícil de entender y debuggear.
Por Qué Es Uno de los Patrones Más Importantes¶
Process Manager es crítico porque resuelve el problema más difícil de las arquitecturas distribuidas: la coordinación de operaciones multi-servicio con garantías de consistencia. Sin Process Manager:
- Las transacciones que cruzan servicios se implementan con 2PC (two-phase commit), que es impráctica en microservicios por su alto acoplamiento y baja disponibilidad.
- La compensación se implementa de forma ad-hoc con "cleanup jobs" y flags booleanos, produciendo estados inconsistentes difíciles de diagnosticar.
- Los procesos de larga duración (horas, días, semanas) se gestionan con cron jobs y tablas de estado artesanales.
- La visibilidad del estado del proceso requiere consultar múltiples sistemas y correlacionar manualmente.
Anatomía del Estado del Proceso¶
El estado de una instancia del Process Manager incluye:
ProcessInstance:
process_id: "WIRE-2026-04-07-00847"
process_definition: "international_wire_transfer_v3"
current_state: "AWAITING_FX_CONVERSION"
created_at: "2026-04-07T10:23:45Z"
updated_at: "2026-04-07T10:24:12Z"
variables:
amount: 250000.00
currency: "USD"
source_account: "ES9121000418450200051332"
destination_account: "US021000089742091837"
fx_rate: null (pending)
settlement_reference: null (pending)
completed_steps:
- step: "validation", status: "SUCCESS", completed_at: "...", result: {...}
- step: "sanctions_screening", status: "SUCCESS", completed_at: "...", result: {...}
- step: "funds_hold", status: "SUCCESS", completed_at: "...", result: {hold_ref: "HOLD-9921"}
compensations_available:
- step: "funds_hold", compensation: "release_funds_hold", params: {hold_ref: "HOLD-9921"}
pending_step:
step: "fx_conversion"
sent_at: "2026-04-07T10:24:02Z"
timeout_at: "2026-04-07T10:24:32Z"
timeout_policy:
step_timeout: 30s
process_timeout: 5m
Este estado explícito permite: - Consultar el estado del proceso en cualquier momento. - Retomar el proceso después de un crash del Process Manager (el estado se reconstruye desde el state store). - Ejecutar compensaciones en orden inverso (release funds hold → ...) si un paso posterior falla.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Process Manager, la coordinación de procesos multi-paso en sistemas distribuidos se resuelve de formas inadecuadas:
Distributed transactions (2PC): el coordinador bloquea recursos en todos los participantes hasta que todos confirmen. Problemas: alta latencia, baja disponibilidad (si cualquier participante está caído, la transacción se bloquea), acoplamiento temporal fuerte. En microservicios con 5+ participantes, 2PC es impráctica.
Ad-hoc state management: cada servicio mantiene flags y estados parciales en su propia base de datos. Un servicio marca "payment_initiated=true", otro marca "sanctions_cleared=true", otro "funds_held=true". El estado global del proceso está disperso en múltiples bases de datos y solo se puede reconstruir consultando todas. La inconsistencia es frecuente y difícil de detectar.
Cleanup cron jobs: cuando un paso falla, un cron job periódico escanea las tablas buscando registros en estados inconsistentes y ejecuta lógica de compensación. Problemas: latencia de detección (el cron ejecuta cada N minutos), lógica de compensación frágil (el cron debe entender el estado de todos los servicios), y race conditions (el cron puede competir con el flujo normal).
Fire-and-forget with retry: el servicio que inicia el proceso envía requests a cada servicio posterior y espera. Si falla, reintenta. No hay visibilidad del progreso, no hay compensación estructurada, y los reintentos pueden producir efectos duplicados si los servicios no son idempotentes.
Síntomas del Problema¶
- Estados inconsistentes entre servicios que participan en el mismo proceso de negocio (un servicio cree que el proceso está completado, otro cree que está pendiente).
- Operaciones de "limpieza manual" frecuentes por parte del equipo de operaciones para arreglar estados inconsistentes.
- Imposibilidad de responder a la pregunta "¿en qué estado está el proceso X?" sin consultar múltiples sistemas.
- Compensaciones que no se ejecutan cuando un paso falla, dejando recursos bloqueados indefinidamente (fondos retenidos, inventario reservado, asientos bloqueados).
- Procesos de larga duración que se "pierden" sin que nadie se entere hasta que un cliente reclama.
Impacto Operativo y Arquitectónico¶
- Inconsistencia de datos: sin compensación estructurada, los fallos parciales dejan datos inconsistentes entre servicios.
- Dinero bloqueado: en banca, fondos retenidos por un proceso fallido que nunca se liberaron pueden sumar millones.
- Experiencia degradada: el cliente no puede consultar el estado de su operación porque nadie tiene una visión completa.
- Operaciones manuales: el equipo de operaciones debe resolver manualmente estados inconsistentes, lo que no escala.
- Compliance failures: en industrias reguladas, la incapacidad de auditar el flujo completo de un proceso es un riesgo regulatorio.
Ejemplos Reales del Problema¶
- Banca: una transferencia internacional que se aprobó y retuvo fondos, pero falló en la conversión de divisas. Sin compensación, los fondos quedan retenidos indefinidamente. El cliente no puede usar su dinero ni sabe por qué.
- E-commerce: un pedido que reservó inventario y procesó el pago, pero falló en la generación de envío. Sin compensación, el inventario queda reservado y el pago cobrado para un pedido que no se enviará.
- Healthcare: una orden de procedimiento médico que pasó pre-autorización y reservó quirófano, pero el paciente canceló. Sin compensación, el quirófano queda reservado y la pre-autorización consumida.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el proceso de negocio involucra múltiples servicios que deben coordinarse.
- Cuando el proceso tiene branching condicional (el siguiente paso depende del resultado del paso anterior).
- Cuando se necesita compensación (deshacer pasos anteriores si un paso posterior falla).
- Cuando el proceso puede ser de larga duración (minutos, horas, días).
- Cuando se necesita visibilidad del estado del proceso (dashboard, auditoría, compliance).
- Cuando se necesita gestionar timeouts por paso y por proceso.
- Cuando se necesitan reintentos con backoff y circuit breaking por paso.
- Cuando se necesita pausar, reanudar o cancelar procesos en vuelo.
Cuándo No Usarlo¶
- Cuando el flujo es una secuencia lineal fija sin branching ni compensación (Pipes and Filters o Routing Slip son más simples).
- Cuando la operación es atómica (una sola llamada a un solo servicio).
- Cuando la consistencia entre servicios se puede lograr con consistencia eventual basada en eventos (choreography-based saga) y el flujo es simple.
- Cuando la latencia es ultra-crítica y el overhead de persistir estado en cada paso es inaceptable.
Precondiciones¶
- Los servicios participantes exponen operaciones idempotentes (para que los retries sean seguros).
- Los servicios que necesitan compensación exponen operaciones de compensación explícitas (release hold, refund, cancel reservation).
- Existe un state store durable y de alta disponibilidad para el estado del proceso.
- Existe infraestructura de mensajería o RPC para la comunicación entre el Process Manager y los servicios.
Restricciones¶
- El Process Manager es un componente stateful que requiere alta disponibilidad y durabilidad.
- Cada paso introduce latencia (ida al servicio + persistencia del estado).
- La definición del proceso debe versionarse cuidadosamente (procesos en vuelo con la versión anterior deben completarse o migrarse).
- El Process Manager puede convertirse en un bottleneck si no se escala correctamente.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Banking: transferencias internacionales, apertura de cuentas, onboarding de clientes.
- E-commerce: procesamiento de pedidos, devoluciones y refunds.
- Insurance: emisión de pólizas, procesamiento de reclamaciones.
- Telecommunications: provisioning de servicios, portabilidad numérica.
- Healthcare: procesamiento de órdenes médicas, gestión de autorizaciones.
- Travel: reservas multi-segmento (vuelo + hotel + auto).
- Supply chain: gestión de órdenes de compra, fulfillment multi-almacén.
6. Fuerzas Arquitectónicas¶
Orquestación vs. Coreografía¶
Esta es la tensión más fundamental. La orquestación (Process Manager) centraliza el control: un componente conoce el flujo completo y dirige cada paso. La coreografía descentraliza: cada servicio publica eventos y reacciona a eventos de otros, sin coordinador central.
| Aspecto | Orquestación (Process Manager) | Coreografía |
|---|---|---|
| Visibilidad | Alta (estado centralizado) | Baja (estado distribuido en eventos) |
| Acoplamiento | Servicios acoplados al orquestador | Servicios acoplados a eventos |
| Flujos complejos | Fácil (branching, parallel, compensation) | Difícil (distributed decision making) |
| Single point of failure | El orquestador es SPOF (mitigable) | No hay SPOF |
| Evolución | Cambiar el flujo es cambiar el orquestador | Cambiar el flujo es cambiar eventos/reacciones |
| Testing | Un único componente con la lógica del flujo | Lógica distribuida en múltiples servicios |
En la práctica, la mayoría de los sistemas maduros usan una combinación: orquestación para flujos de negocio complejos (donde la visibilidad y la compensación son críticas) y coreografía para reacciones simples a eventos (donde el desacoplamiento es más valioso que la visibilidad).
Consistencia vs. Disponibilidad¶
Process Manager implementa consistencia eventual, no consistencia fuerte. Cada paso ejecuta una transacción local en su servicio. Si el paso 5 falla, los efectos de los pasos 1-4 ya están committed en sus respectivos servicios. La compensación los revierte eventualmente, pero hay una ventana de tiempo donde los datos son inconsistentes. Cuanto más rápida la compensación, menor la ventana de inconsistencia.
Durabilidad vs. Latencia¶
Cada transición de estado del proceso debe persistirse en el state store para sobrevivir a crashes del Process Manager. Esta persistencia añade latencia (típicamente 1-10ms por paso dependiendo del store). Para procesos con muchos pasos, la latencia acumulada puede ser significativa. Frameworks como Temporal optimizan esto con persistencia asíncrona y replay.
Simplicidad vs. Control¶
Un Process Manager simple (secuencia lineal con compensación) es relativamente fácil de implementar. Pero los requerimientos de negocio tienden a crecer: branching, parallel execution, timers, human approval steps, subprocess invocation, dynamic routing. Cada capacidad añade complejidad al Process Manager. La tentación de añadir "un feature más" puede convertir un Process Manager limpio en un motor de workflow inmantenible.
Acoplamiento Temporal vs. Autonomía¶
El Process Manager introduce acoplamiento temporal: el paso N+1 no puede ejecutarse hasta que el paso N complete y el Process Manager decida el siguiente paso. Si el Process Manager está caído, todos los procesos en vuelo se detienen. Esto se mitiga con alta disponibilidad del Process Manager, pero el riesgo de SPOF existe.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Process Manager (Orquestador): el componente central que mantiene el estado de cada instancia del proceso, decide los próximos pasos, gestiona timeouts y ejecuta compensaciones.
- Process Definition (Definición del Proceso): la especificación del flujo — estados, transiciones, condiciones, compensaciones. Puede ser código, BPMN, JSON, o DSL.
- State Store (Almacén de Estado): base de datos durable que almacena el estado de cada instancia del proceso.
- Step Handlers / Activities (Actividades): los servicios o componentes que ejecutan cada paso del proceso.
- Timer Service: componente que gestiona timeouts y timers (esperar N segundos, deadline de proceso).
- Compensation Handlers: lógica que deshace los efectos de un paso cuando se necesita revertir (release hold, refund, cancel).
Flujo Lógico¶
flowchart TD
A([Trigger Event]) --> B[Process Manager crea\nnueva instancia de proceso]
B --> C[(State Store\npersistir estado inicial)]
C --> D[Determinar primer paso\nsegún definición del proceso]
D --> E[Enviar comando\nal Step actual]
E --> F[Step ejecuta y\nretorna resultado]
F --> G[PM recibe resultado\npersiste estado actualizado]
G --> H{Evaluar condiciones\npara siguiente paso}
H -- Condición A --> I[Seleccionar Step 2A]
H -- Condición B --> J[Seleccionar Step 2B]
I --> E
J --> E
F --> K{Step falló?}
K -- Sí --> L[Evaluar estrategia\nde compensación]
L --> M[Ejecutar transacciones\ncompensatorias en reversa]
M --> N([COMPENSATED])
K -- No --> O{Todos los pasos\ncompletados?}
O -- No --> G
O -- Sí --> P([COMPLETED])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Process Manager | Mantener estado, decidir próximo paso, gestionar timeouts, ejecutar compensaciones |
| Process Definition | Definir estados, transiciones, condiciones, compensaciones del proceso |
| State Store | Persistir estado de forma durable y con alta disponibilidad |
| Step Handlers | Ejecutar la lógica de negocio de cada paso (idempotent) |
| Timer Service | Disparar eventos de timeout cuando un paso o proceso excede su ventana |
| Compensation Handlers | Deshacer los efectos de un paso completado |
Máquina de Estados¶
El Process Manager se modela como una máquina de estados finita (FSM) donde:
- Estados: INITIATED, VALIDATING, SANCTIONS_SCREENING, FUNDS_HOLDING, FX_CONVERTING, ROUTING, SETTLING, COMPLETED, COMPENSATING, COMPENSATED, FAILED.
- Transiciones: comandos enviados a servicios y respuestas recibidas.
- Guards: condiciones que determinan qué transición seguir (branching).
- Actions: efectos secundarios en cada transición (enviar comando, persistir estado, iniciar timer).
┌──────────────────┐
┌─────────────────│ INITIATED │
│ └────────┬───────────┘
│ │ start
│ ┌────────▼───────────┐
│ │ VALIDATING │
│ └────────┬───────────┘
│ │ validation_ok
│ ┌────────▼───────────┐
│ │ SANCTIONS_SCREENING │
│ └────────┬───────────┘
│ │ sanctions_clear
│ ┌────────▼───────────┐
│ │ FUNDS_HOLDING │
│ └────────┬───────────┘
│ │ funds_held
│ ┌────────▼───────────┐
│ │ FX_CONVERTING │──── fx_not_needed ────┐
│ └────────┬───────────┘ │
│ │ fx_converted │
│ ┌────────▼───────────┐ │
│ │ ROUTING │◄───────────────────────┘
│ └────────┬───────────┘
│ │ routed
│ ┌────────▼───────────┐
│ │ SETTLING │
│ └────────┬───────────┘
│ │ settled
│ ┌────────▼───────────┐
│ │ COMPLETED │
│ └────────────────────┘
│
any_step_fails ┌────────────────────┐
└────────────────►│ COMPENSATING │
└────────┬───────────┘
│ all_compensated
┌────────▼───────────┐
│ COMPENSATED │
└────────────────────┘
Decisiones de Diseño Clave¶
-
Persistencia del estado: cada transición de estado se persiste antes de ejecutar el siguiente paso. Si el Process Manager cae, reconstruye el estado desde el store al reiniciar.
-
Idempotencia de steps: cada step handler debe ser idempotente para que los retries sean seguros. Si el Process Manager envía el mismo comando dos veces (porque cayó después de enviar pero antes de recibir la respuesta), el resultado debe ser el mismo.
-
Compensación como operación explícita: cada paso que tiene efectos secundarios debe tener una compensating transaction explícita (hold → release, charge → refund, reserve → cancel). La compensación se registra en el estado del proceso al completar cada paso.
-
Versionado del proceso: los procesos en vuelo usan la definición con la que fueron iniciados. Un cambio en la definición del proceso solo afecta a nuevas instancias. Las instancias existentes completan con su definición original o se migran explícitamente.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Transferencia Internacional (Wire Transfer Saga)¶
Contexto del Negocio¶
Un banco multinacional procesa 500,000 transferencias internacionales diarias. Cada transferencia involucra múltiples sistemas: validación, screening de sanciones, retención de fondos, conversión de divisas, routing interbancario, liquidación (settlement) y confirmación. El proceso completo toma entre 2 y 30 segundos según la complejidad. Cualquier paso puede fallar, y los fallos requieren compensación.
Necesidad de Integración¶
La transferencia internacional es una saga distribuida que involucra:
- Validation Service: valida la orden de transferencia (formato, cuentas, límites).
- Sanctions Service: verifica emisor y receptor contra listas de sanciones internacionales.
- Account Service: retiene fondos en la cuenta del ordenante (funds hold).
- FX Service: convierte divisas si la moneda de origen difiere de la de destino.
- Routing Service: determina el corredor de pago (SWIFT, SEPA, Fedwire, etc.) y formatea el mensaje.
- Settlement Service: envía la orden al sistema de compensación y espera confirmación.
- Notification Service: notifica al ordenante y al beneficiario.
Si cualquier paso falla después de los pasos anteriores, se debe compensar:
| Paso | Compensación |
|---|---|
| Funds Hold | Release Funds Hold |
| FX Conversion | Reverse FX Conversion |
| Settlement | Cancel Settlement (si es posible) / Reversal |
Diseño del Process Manager¶
Transfer Request → Wire Transfer Process Manager
→ [1] Validate → success/fail
→ [2] Sanctions Screen → clear/blocked
→ [3] Hold Funds → held/insufficient
→ [4] FX Convert (if needed) → converted/failed
→ [5] Route → routed/failed
→ [6] Settle → settled/failed
→ [7] Notify → notified
→ COMPLETED
On failure at any step after [3]:
→ Compensate in reverse:
→ [4'] Reverse FX (if FX was done)
→ [3'] Release Funds
→ COMPENSATED
Sistemas Involucrados¶
- Wire Transfer Process Manager: el orquestador (implementado en Temporal).
- PostgreSQL: state store para el estado de cada transferencia.
- Kafka: canales de comunicación entre el Process Manager y los servicios.
- Validation Service: microservicio de validación.
- Sanctions Service: microservicio que consulta APIs de sanciones.
- Account Service: microservicio conectado al core bancario.
- FX Service: microservicio conectado a la mesa de cambio.
- Routing Service: microservicio que formatea y enruta mensajes interbancarios.
- Settlement Gateway: gateway hacia SWIFT, SEPA, Fedwire.
- Notification Service: microservicio de notificaciones (email, push, SMS).
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Inicio del Proceso¶
Un cliente inicia una transferencia de EUR 250,000 desde su cuenta en España a una cuenta en USA:
{
"transfer_id": "WIRE-2026-04-07-00847",
"debtor": {
"account": "ES9121000418450200051332",
"name": "Empresa Importadora S.L.",
"bic": "CAIXESBBXXX"
},
"creditor": {
"account": "US021000089742091837",
"name": "US Machinery Corp",
"bic": "BOFAUS3NXXX"
},
"amount": 250000.00,
"currency": "EUR",
"destination_currency": "USD",
"value_date": "2026-04-07",
"purpose": "MACHINERY_PURCHASE",
"charge_bearer": "SHA"
}
El Process Manager crea una nueva instancia con estado INITIATED y persiste en PostgreSQL:
INSERT INTO process_instances (
process_id, definition, state, variables, created_at
) VALUES (
'WIRE-2026-04-07-00847', 'wire_transfer_v3', 'INITIATED', '{...}', NOW()
);
Paso 2: Validation¶
El Process Manager envía un comando al Validation Service:
El Validation Service verifica: - Formato IBAN de la cuenta ES válido. - Formato de account number US válido. - BIC codes válidos. - Monto dentro de los límites del cliente (EUR 250,000 < límite de EUR 500,000). - Fecha de valor no es pasada.
Resultado: VALIDATION_SUCCESS. El Process Manager actualiza el estado a VALIDATED y persiste.
Paso 3: Sanctions Screening¶
El Process Manager envía el comando SCREEN_SANCTIONS al Sanctions Service.
El Sanctions Service consulta: - Lista OFAC (USA): no match para ordenante ni beneficiario. - Lista EU Sanctions: no match. - Lista ONU: no match.
Resultado: SANCTIONS_CLEAR. El Process Manager actualiza a SANCTIONS_CLEARED. El screening tardó 180ms.
Paso 4: Funds Hold¶
El Process Manager envía HOLD_FUNDS al Account Service.
El Account Service: 1. Consulta el saldo de la cuenta ES9121000418450200051332: EUR 1,200,000. 2. Verifica fondos disponibles: EUR 1,200,000 - EUR 85,000 (holds existentes) = EUR 1,115,000 disponible. 3. EUR 250,000 < EUR 1,115,000 → fondos suficientes. 4. Crea un hold: HOLD-2026-04-07-9921 por EUR 250,000.
Resultado: FUNDS_HELD con hold_reference: "HOLD-2026-04-07-9921".
Crucialmente, el Process Manager registra la compensación disponible:
{
"compensation": {
"action": "RELEASE_FUNDS_HOLD",
"service": "account_service",
"params": { "hold_reference": "HOLD-2026-04-07-9921" }
}
}
Estado actualizado a FUNDS_HELD.
Paso 5: FX Conversion¶
El Process Manager detecta que currency (EUR) difiere de destination_currency (USD), por lo tanto se necesita conversión de divisas.
Envía CONVERT_FX al FX Service:
{
"command": "CONVERT_FX",
"process_id": "WIRE-2026-04-07-00847",
"sell_currency": "EUR",
"sell_amount": 250000.00,
"buy_currency": "USD",
"value_date": "2026-04-07"
}
El FX Service: 1. Obtiene el tipo de cambio EUR/USD: 1.0842. 2. Calcula el monto en USD: 250,000 * 1.0842 = USD 271,050.00. 3. Ejecuta la conversión y genera referencia FX-2026-04-07-4471.
Resultado: FX_CONVERTED con rate=1.0842, usd_amount=271050.00, fx_reference="FX-2026-04-07-4471".
El Process Manager registra la compensación:
{
"compensation": {
"action": "REVERSE_FX",
"service": "fx_service",
"params": { "fx_reference": "FX-2026-04-07-4471" }
}
}
Estado actualizado a FX_CONVERTED.
Paso 6: Routing¶
El Process Manager envía ROUTE_TRANSFER al Routing Service.
El Routing Service: 1. Determina que ES → US requiere corredor SWIFT (no es intra-EU para SEPA ni doméstico US para Fedwire). 2. Selecciona el banco corresponsal: JP Morgan (CHASUS33XXX). 3. Formatea el mensaje SWIFT MT103 con los datos de la transferencia. 4. Incluye el monto en USD (post-FX conversion): USD 271,050.00.
Resultado: TRANSFER_ROUTED con corridor="SWIFT", correspondent="CHASUS33XXX".
Paso 7: Settlement¶
El Process Manager envía SETTLE_TRANSFER al Settlement Gateway.
El Settlement Gateway: 1. Envía el mensaje MT103 a la red SWIFT. 2. Espera confirmación del banco corresponsal. 3. Recibe ACK del banco corresponsal en 8 segundos. 4. El banco corresponsal confirma crédito al beneficiario.
Resultado: TRANSFER_SETTLED con settlement_reference="SWIFT-REF-20260407-8847291".
Estado actualizado a SETTLED.
Paso 8: Notification¶
El Process Manager envía NOTIFY_PARTIES al Notification Service.
El Notification Service envía: - Email al ordenante: "Su transferencia WIRE-2026-04-07-00847 por EUR 250,000.00 (USD 271,050.00) ha sido completada. Referencia: SWIFT-REF-20260407-8847291." - Push notification al ordenante (si tiene app móvil). - Notificación SWIFT al banco del beneficiario.
Resultado: PARTIES_NOTIFIED.
Estado final: COMPLETED. Duración total del proceso: 12.3 segundos.
Escenario Alternativo: Fallo en Settlement con Compensación¶
Supongamos que en el Paso 7, el Settlement Gateway falla:
{
"result": "SETTLEMENT_FAILED",
"reason": "CORRESPONDENT_BANK_UNAVAILABLE",
"details": "JP Morgan SWIFT gateway timeout after 30s"
}
El Process Manager inicia la compensación en orden inverso:
- No compensation needed for Routing (routing solo formateo, no efectos persistentes).
- Reverse FX: envía
REVERSE_FXal FX Service confx_reference: "FX-2026-04-07-4471". El FX Service revierte la conversión. - Release Funds Hold: envía
RELEASE_FUNDS_HOLDal Account Service conhold_reference: "HOLD-2026-04-07-9921". El Account Service libera los EUR 250,000 retenidos.
El Process Manager actualiza el estado a COMPENSATED y persiste:
{
"state": "COMPENSATED",
"failure_reason": "Settlement failed: correspondent bank unavailable",
"compensations_executed": [
{ "action": "REVERSE_FX", "status": "SUCCESS", "executed_at": "..." },
{ "action": "RELEASE_FUNDS_HOLD", "status": "SUCCESS", "executed_at": "..." }
]
}
El Notification Service envía al cliente: "Su transferencia WIRE-2026-04-07-00847 no pudo completarse. Los fondos han sido liberados en su cuenta. Motivo: banco corresponsal no disponible."
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.queue import Kafka
from diagrams.onprem.client import User
from diagrams.onprem.network import Nginx
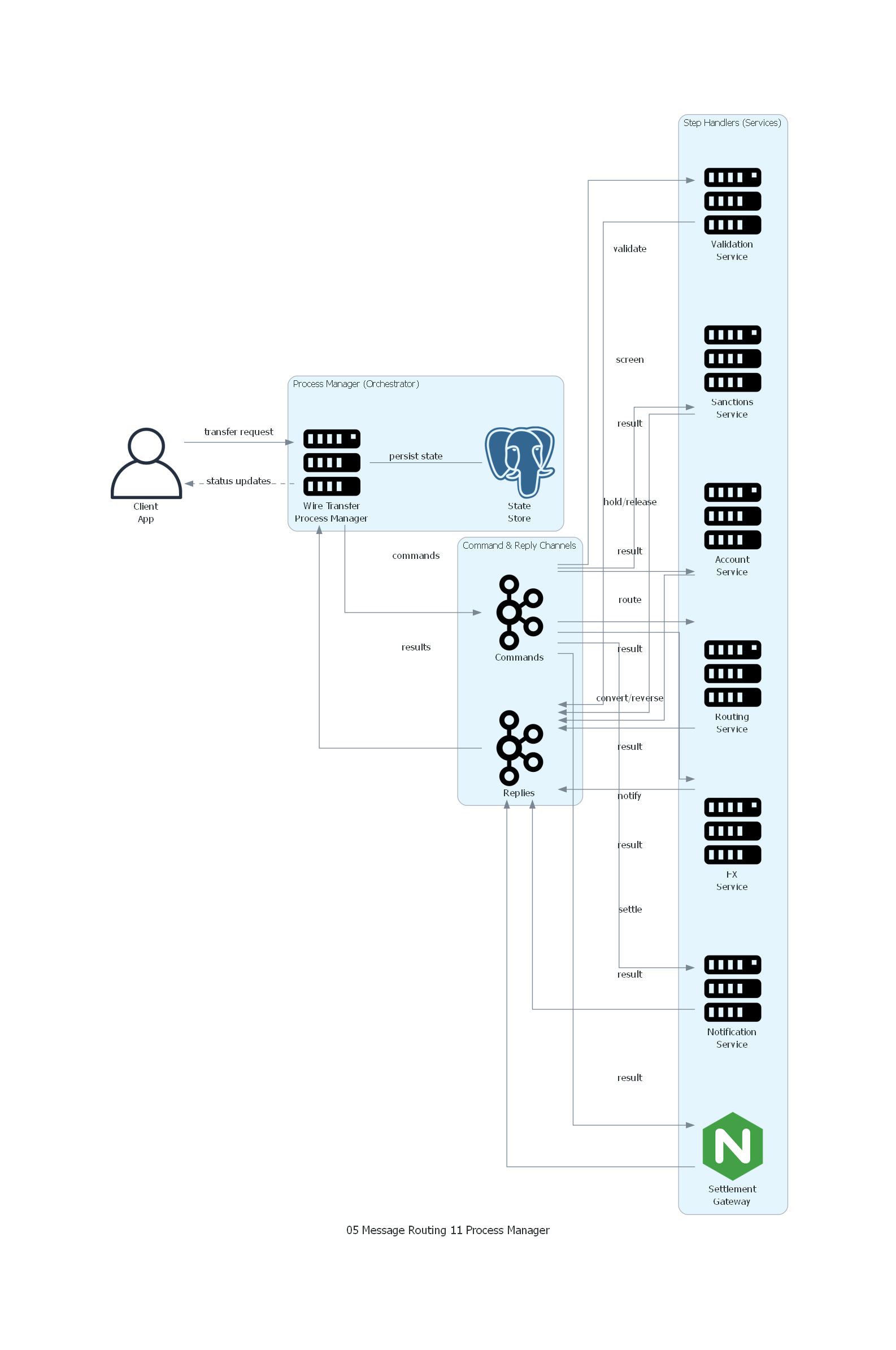
with Diagram("Process Manager - Wire Transfer Saga", show=False, direction="TB"):
client = User("Client\nApp")
with Cluster("Process Manager (Orchestrator)"):
pm = Server("Wire Transfer\nProcess Manager")
state_store = PostgreSQL("State\nStore")
pm - Edge(label="persist state") - state_store
with Cluster("Command & Reply Channels"):
cmd_bus = Kafka("Commands")
reply_bus = Kafka("Replies")
with Cluster("Step Handlers (Services)"):
validator = Server("Validation\nService")
sanctions = Server("Sanctions\nService")
accounts = Server("Account\nService")
fx = Server("FX\nService")
routing = Server("Routing\nService")
settlement = Nginx("Settlement\nGateway")
notifications = Server("Notification\nService")
# Client triggers process
client >> Edge(label="transfer request") >> pm
# Process Manager sends commands
pm >> Edge(label="commands") >> cmd_bus
cmd_bus >> Edge(label="validate") >> validator
cmd_bus >> Edge(label="screen") >> sanctions
cmd_bus >> Edge(label="hold/release") >> accounts
cmd_bus >> Edge(label="convert/reverse") >> fx
cmd_bus >> Edge(label="route") >> routing
cmd_bus >> Edge(label="settle") >> settlement
cmd_bus >> Edge(label="notify") >> notifications
# Services reply
validator >> Edge(label="result") >> reply_bus
sanctions >> Edge(label="result") >> reply_bus
accounts >> Edge(label="result") >> reply_bus
fx >> Edge(label="result") >> reply_bus
routing >> Edge(label="result") >> reply_bus
settlement >> Edge(label="result") >> reply_bus
notifications >> Edge(label="result") >> reply_bus
# PM receives replies
reply_bus >> Edge(label="results") >> pm
# PM notifies client
pm >> Edge(label="status updates", style="dashed") >> client
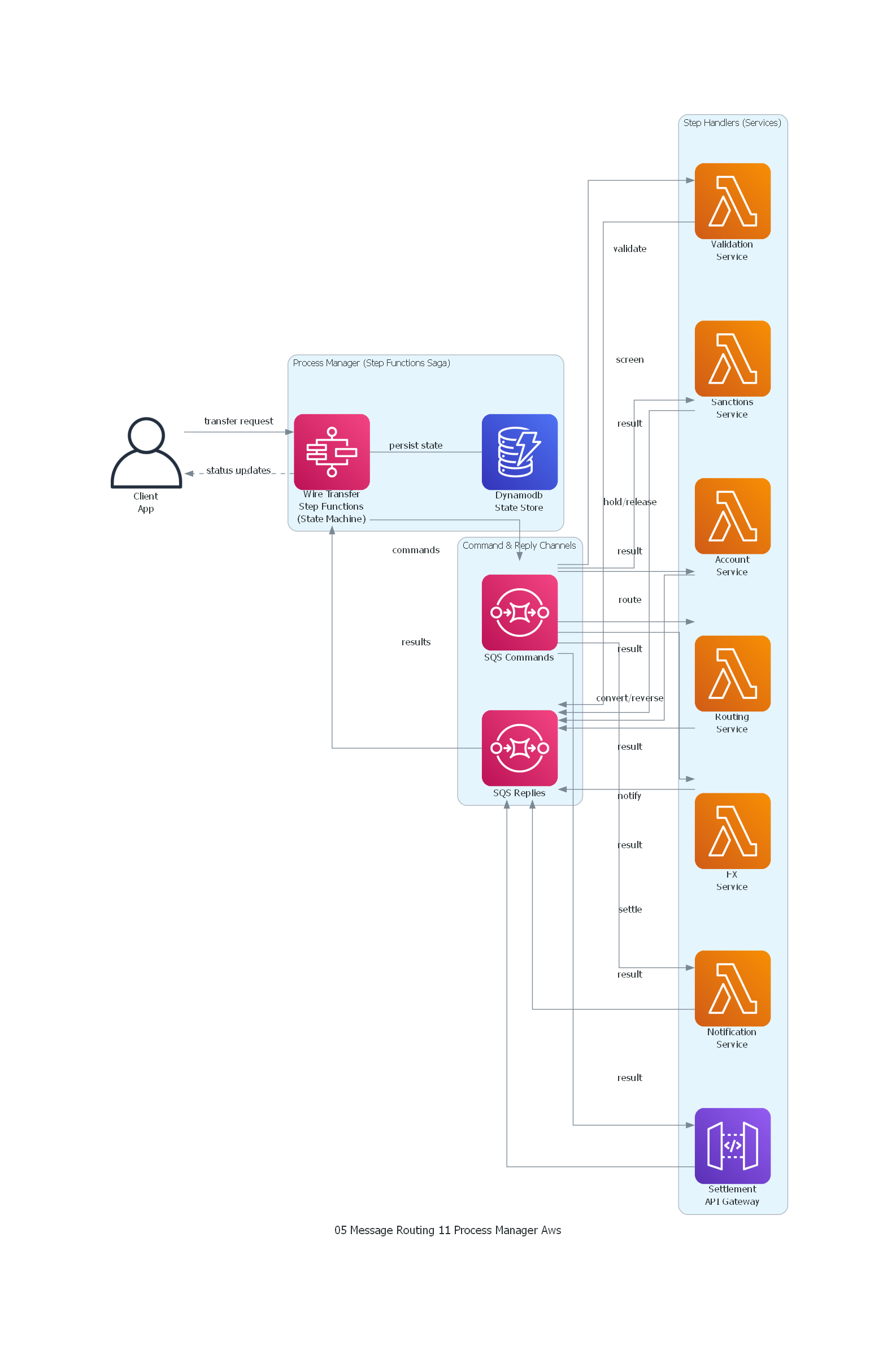
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS, StepFunctions
from diagrams.aws.network import APIGateway
with Diagram("Process Manager - Wire Transfer Saga (AWS)", show=False, direction="TB"):
client = User("Client\nApp")
with Cluster("Process Manager (Step Functions Saga)"):
pm = StepFunctions("Wire Transfer\nStep Functions\n(State Machine)")
state_store = Dynamodb("Dynamodb\nState Store")
pm - Edge(label="persist state") - state_store
with Cluster("Command & Reply Channels"):
cmd_bus = SQS("SQS Commands")
reply_bus = SQS("SQS Replies")
with Cluster("Step Handlers (Services)"):
validator = Lambda("Validation\nService")
sanctions = Lambda("Sanctions\nService")
accounts = Lambda("Account\nService")
fx = Lambda("FX\nService")
routing = Lambda("Routing\nService")
settlement = APIGateway("Settlement\nAPI Gateway")
notifications = Lambda("Notification\nService")
# Client triggers process
client >> Edge(label="transfer request") >> pm
# Process Manager sends commands
pm >> Edge(label="commands") >> cmd_bus
cmd_bus >> Edge(label="validate") >> validator
cmd_bus >> Edge(label="screen") >> sanctions
cmd_bus >> Edge(label="hold/release") >> accounts
cmd_bus >> Edge(label="convert/reverse") >> fx
cmd_bus >> Edge(label="route") >> routing
cmd_bus >> Edge(label="settle") >> settlement
cmd_bus >> Edge(label="notify") >> notifications
# Services reply
validator >> Edge(label="result") >> reply_bus
sanctions >> Edge(label="result") >> reply_bus
accounts >> Edge(label="result") >> reply_bus
fx >> Edge(label="result") >> reply_bus
routing >> Edge(label="result") >> reply_bus
settlement >> Edge(label="result") >> reply_bus
notifications >> Edge(label="result") >> reply_bus
# PM receives replies
reply_bus >> Edge(label="results") >> pm
# PM notifies client
pm >> Edge(label="status updates", style="dashed") >> client
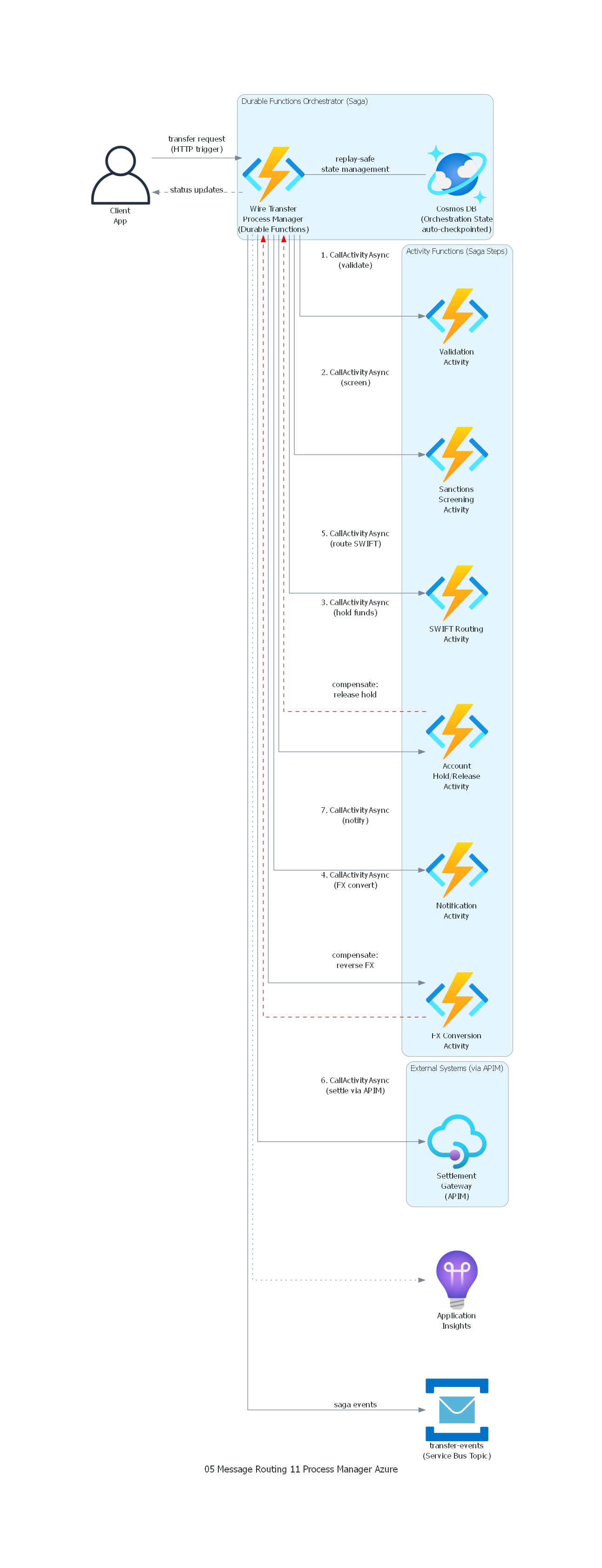
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus, APIManagement
from diagrams.azure.devops import ApplicationInsights
with Diagram("Process Manager - Wire Transfer Saga (Azure)", show=False, direction="TB"):
client = User("Client\nApp")
with Cluster("Durable Functions Orchestrator (Saga)"):
pm = FunctionApps("Wire Transfer\nProcess Manager\n(Durable Functions)")
state_store = CosmosDb("Cosmos DB\n(Orchestration State\nauto-checkpointed)")
pm - Edge(label="replay-safe\nstate management") - state_store
with Cluster("Activity Functions (Saga Steps)"):
validator = FunctionApps("Validation\nActivity")
sanctions = FunctionApps("Sanctions\nScreening\nActivity")
accounts = FunctionApps("Account\nHold/Release\nActivity")
fx = FunctionApps("FX Conversion\nActivity")
routing = FunctionApps("SWIFT Routing\nActivity")
notifications = FunctionApps("Notification\nActivity")
with Cluster("External Systems (via APIM)"):
settlement = APIManagement("Settlement\nGateway\n(APIM)")
events = ServiceBus("transfer-events\n(Service Bus Topic)")
monitoring = ApplicationInsights("Application\nInsights")
# Client triggers orchestration
client >> Edge(label="transfer request\n(HTTP trigger)") >> pm
# Orchestrator calls activities sequentially (saga steps)
pm >> Edge(label="1. CallActivityAsync\n(validate)") >> validator
pm >> Edge(label="2. CallActivityAsync\n(screen)") >> sanctions
pm >> Edge(label="3. CallActivityAsync\n(hold funds)") >> accounts
pm >> Edge(label="4. CallActivityAsync\n(FX convert)") >> fx
pm >> Edge(label="5. CallActivityAsync\n(route SWIFT)") >> routing
pm >> Edge(label="6. CallActivityAsync\n(settle via APIM)") >> settlement
pm >> Edge(label="7. CallActivityAsync\n(notify)") >> notifications
# Compensation on failure (saga rollback)
accounts >> Edge(label="compensate:\nrelease hold", style="dashed", color="red") >> pm
fx >> Edge(label="compensate:\nreverse FX", style="dashed", color="red") >> pm
# Events and monitoring
pm >> Edge(label="saga events") >> events
pm >> Edge(label="status updates", style="dashed") >> client
pm >> Edge(style="dotted") >> monitoring
Notas del Diagrama¶
- El Process Manager es el centro del flujo: recibe el trigger, envía comandos a cada servicio vía el command bus, y recibe resultados vía el reply bus.
- El state store es consultado y actualizado en cada transición de estado.
- Las flechas de commands y replies representan comunicación asíncrona vía Kafka.
- La flecha dashed hacia el client representa notificaciones de status (opcional, puede ser via WebSocket o polling).
11. Beneficios¶
Estado Explícito y Consultable¶
El estado de cada instancia del proceso está persistido y es consultable en cualquier momento. "¿En qué estado está la transferencia WIRE-2026-04-07-00847?" se responde con una query al state store, no con una correlación manual de logs de múltiples servicios.
Compensación Estructurada¶
Las compensaciones se definen como parte del proceso y se ejecutan automáticamente cuando un paso falla. No hay "cleanup jobs" ad-hoc ni intervención manual. Los fondos se liberan, las conversiones se revierten, las reservas se cancelan — todo de forma programática y auditable.
Visibilidad Operativa¶
Un dashboard puede mostrar en tiempo real: cuántos procesos están en cada estado, cuáles están retrasados, cuáles están en compensación, cuáles han fallado. Esta visibilidad es imposible sin un componente centralizado que mantenga el estado.
Recuperación ante Crashes¶
Si el Process Manager cae, al reiniciarse reconstruye el estado de todos los procesos en vuelo desde el state store y retoma la ejecución. Los procesos no se pierden.
Branching y Lógica Condicional¶
El Process Manager puede tomar decisiones intermedias: si la moneda de origen y destino son iguales, saltar el paso de FX conversion. Si el monto supera un umbral, añadir un paso de aprobación manual. Esta lógica reside en un único componente, no dispersa en múltiples servicios.
Timeout y Retry Gestionados¶
Cada paso tiene un timeout configurable. Si un servicio no responde dentro del timeout, el Process Manager puede reintentar, escalar, o compensar. Los retries usan backoff exponencial y son idempotentes.
Auditoría Completa¶
El historial completo de cada instancia del proceso — cada paso, cada resultado, cada decisión, cada compensación — está persistido. Esto satisface requisitos regulatorios de auditoría en industrias como banca y seguros.
12. Desventajas y Riesgos¶
Complejidad de Implementación¶
Implementar un Process Manager from scratch es significativamente complejo: state machine, state persistence, timeout handling, retry logic, compensation logic, crash recovery, concurrency control. Mitigación: usar frameworks como Temporal, Step Functions o Camunda que proporcionan estas capacidades out-of-the-box.
Single Point of Failure¶
El Process Manager es un componente crítico: si está caído, ningún proceso avanza. Mitigación: alta disponibilidad con múltiples instancias y state store replicado. Frameworks como Temporal proporcionan HA nativa.
Acoplamiento al Orquestador¶
Todos los servicios están acoplados al Process Manager (reciben comandos de él, envían resultados a él). Si el Process Manager cambia su protocolo de comunicación, todos los servicios se ven afectados. Mitigación: protocolos versionados y backward compatibility.
Latencia Adicional¶
Cada paso añade latencia: el Process Manager recibe el resultado, persiste el estado, evalúa la condición, envía el siguiente comando. Este overhead (típicamente 5-20ms por transición) se acumula en procesos con muchos pasos. Para un proceso de 7 pasos, el overhead total es 35-140ms.
Versionado de Procesos¶
Cuando se modifica la definición del proceso (añadir un paso, cambiar una condición), los procesos en vuelo con la definición anterior deben completarse con su definición original o migrarse a la nueva. El versionado de process definitions es un problema de ingeniería no trivial.
State Store como Bottleneck¶
Todas las instancias del proceso leen y escriben al state store en cada transición. Con 500,000 transferencias diarias y 7 transiciones por transferencia, son 3.5 millones de escrituras diarias al state store. El store debe ser de alta performance y alta disponibilidad.
Complejidad de Compensación¶
Diseñar compensaciones correctas es difícil. No todos los efectos se pueden deshacer (un email enviado no se puede "des-enviar"). Algunas compensaciones son semánticas, no técnicas (reversar una FX conversion al tipo de cambio original puede tener un tipo de cambio diferente al momento de la reversión).
Over-Engineering para Flujos Simples¶
Usar un Process Manager para un flujo de 2 pasos sin compensación es over-engineering. Un simple request-reply o un Routing Slip sería suficiente. El overhead de state persistence, timeout handling y compensation logic no se justifica para flujos triviales.
13. Relación con Otros Patrones¶
Patrones que Process Manager Utiliza¶
- Message Channel: para la comunicación entre el Process Manager y los servicios (command channels y reply channels).
- Request-Reply: cada interacción Process Manager → Service → Process Manager es un Request-Reply.
- Correlation Identifier: cada comando incluye el process_id para correlacionar la respuesta con la instancia del proceso correcta.
- Return Address: el comando incluye el reply channel al que el servicio debe enviar su respuesta.
- Aggregator: conceptualmente, el Process Manager agrega los resultados de múltiples pasos.
- Content-Based Router: el Process Manager decide el siguiente paso basándose en el resultado del paso actual (routing condicional).
Patrones Relacionados¶
- Routing Slip: la alternativa más simple al Process Manager para secuencias lineales sin branching ni compensación. Si el flujo es lineal, preferir Routing Slip.
- Scatter-Gather: el Process Manager puede incluir un Scatter-Gather como uno de sus pasos (por ejemplo, solicitar cotizaciones de FX a múltiples proveedores en paralelo).
- Pipes and Filters: el Process Manager se diferencia de Pipes and Filters en que mantiene estado, soporta branching y gestiona compensaciones. Pipes and Filters es stateless y lineal.
- Claim Check: para reducir el tamaño de los mensajes entre el Process Manager y los servicios, se puede usar Claim Check para almacenar payloads grandes externamente.
- Dead Letter Channel: mensajes que el Process Manager no puede procesar (formato inválido, proceso desconocido) se envían a un dead letter channel para investigación.
Process Manager vs. Saga Orchestrator¶
En la literatura moderna de microservices, "saga orchestrator" es sinónimo de Process Manager. No son patrones diferentes — son el mismo patrón con diferente nombre según el contexto:
- EIP (2003): Process Manager — orquesta un proceso multi-paso con estado.
- Microservices (2015+): Saga Orchestrator — orquesta una saga (secuencia de transacciones locales con compensación).
14. Relevancia Actual¶
Vigencia del Patrón¶
MUY ALTA. Process Manager es probablemente el patrón de routing más relevante en arquitecturas modernas de microservicios. Su vigencia se sostiene por múltiples razones convergentes:
-
Sagas en microservicios: la transacción distribuida es el problema más difícil de microservicios. El consenso de la industria es que 2PC no funciona a escala, y las sagas (orquestadas o coreografiadas) son la alternativa. El Process Manager es la implementación natural de saga orchestration.
-
Frameworks maduros: la explosión de frameworks de orquestación de workflows ha hecho que implementar un Process Manager sea accesible:
- Temporal (successor de Cadence, creado por ingenieros de Uber): orquestación de workflows as-code con durabilidad, compensación y replay.
- AWS Step Functions: state machine serverless para orquestación en AWS.
- Azure Durable Functions: orquestación durable en Azure.
- Camunda Platform 8: BPMN-based process orchestration con Zeebe engine.
- Netflix Conductor: orquestación de microservices open-source.
-
Apache Airflow: orquestación de workflows de datos (aunque es más batch que event-driven).
-
Observabilidad de procesos: en organizaciones grandes, la pregunta "¿qué está pasando con el pedido/transferencia/reclamación X?" es constante. Process Manager proporciona la respuesta de forma nativa.
-
Compliance y auditoría: en industrias reguladas (banca, seguros, healthcare), la capacidad de auditar el flujo completo de un proceso de negocio es un requisito regulatorio, no un nice-to-have.
Evolución del Patrón¶
El Process Manager ha evolucionado significativamente desde su descripción original en EIP (2003):
- De messaging a code: originalmente descrito en términos de canales de mensajería, ahora se implementa frecuentemente como "workflow as code" (Temporal, Durable Functions) donde la definición del proceso es código convencional (Go, Java, Python) en lugar de XML o BPMN.
- De on-premise a serverless: AWS Step Functions permite implementar Process Managers sin gestionar infraestructura.
- De síncrono a event-sourced: implementaciones modernas usan event sourcing para el state store, proporcionando replay y auditoría nativa.
- De proceso único a distributed: el Process Manager puede distribuirse en múltiples instancias con partitioning por process_id, eliminando el bottleneck de un único orquestador.
15. Implementación Moderna¶
Con Temporal (Go) — La Implementación de Referencia¶
// Wire Transfer Workflow Definition
func WireTransferWorkflow(ctx workflow.Context, req TransferRequest) (TransferResult, error) {
logger := workflow.GetLogger(ctx)
var compensations []func(ctx workflow.Context) error
// Step 1: Validate
actOpts := workflow.ActivityOptions{
StartToCloseTimeout: 10 * time.Second,
RetryPolicy: &temporal.RetryPolicy{MaximumAttempts: 3},
}
ctx = workflow.WithActivityOptions(ctx, actOpts)
var validationResult ValidationResult
err := workflow.ExecuteActivity(ctx, ValidateTransfer, req).Get(ctx, &validationResult)
if err != nil {
return TransferResult{}, fmt.Errorf("validation failed: %w", err)
}
// Step 2: Sanctions Screening
var sanctionsResult SanctionsResult
err = workflow.ExecuteActivity(ctx, ScreenSanctions, req).Get(ctx, &sanctionsResult)
if err != nil {
return TransferResult{}, fmt.Errorf("sanctions screening failed: %w", err)
}
if sanctionsResult.Status == "BLOCKED" {
return TransferResult{Status: "BLOCKED", Reason: sanctionsResult.Reason}, nil
}
// Step 3: Hold Funds (compensatable)
var holdResult FundsHoldResult
err = workflow.ExecuteActivity(ctx, HoldFunds, req).Get(ctx, &holdResult)
if err != nil {
return TransferResult{}, fmt.Errorf("funds hold failed: %w", err)
}
// Register compensation
compensations = append(compensations, func(ctx workflow.Context) error {
return workflow.ExecuteActivity(ctx, ReleaseFundsHold,
ReleaseRequest{HoldReference: holdResult.HoldReference}).Get(ctx, nil)
})
// Step 4: FX Conversion (conditional, compensatable)
var fxResult FXResult
if req.Currency != req.DestinationCurrency {
err = workflow.ExecuteActivity(ctx, ConvertFX, FXRequest{
SellCurrency: req.Currency,
SellAmount: req.Amount,
BuyCurrency: req.DestinationCurrency,
}).Get(ctx, &fxResult)
if err != nil {
// Compensate: release funds
runCompensations(ctx, compensations)
return TransferResult{Status: "FAILED", Reason: "FX conversion failed"}, nil
}
// Register FX compensation
compensations = append(compensations, func(ctx workflow.Context) error {
return workflow.ExecuteActivity(ctx, ReverseFX,
ReverseRequest{FXReference: fxResult.FXReference}).Get(ctx, nil)
})
}
// Step 5: Route
var routeResult RouteResult
err = workflow.ExecuteActivity(ctx, RouteTransfer, RouteRequest{
Transfer: req, FXResult: fxResult,
}).Get(ctx, &routeResult)
if err != nil {
runCompensations(ctx, compensations)
return TransferResult{Status: "FAILED", Reason: "routing failed"}, nil
}
// Step 6: Settle (with longer timeout)
settleOpts := workflow.ActivityOptions{
StartToCloseTimeout: 60 * time.Second,
HeartbeatTimeout: 10 * time.Second,
RetryPolicy: &temporal.RetryPolicy{MaximumAttempts: 2},
}
settleCtx := workflow.WithActivityOptions(ctx, settleOpts)
var settleResult SettlementResult
err = workflow.ExecuteActivity(settleCtx, SettleTransfer, SettleRequest{
RouteResult: routeResult,
}).Get(ctx, &settleResult)
if err != nil {
runCompensations(ctx, compensations)
return TransferResult{Status: "FAILED", Reason: "settlement failed"}, nil
}
// Step 7: Notify (fire-and-forget, don't compensate on failure)
_ = workflow.ExecuteActivity(ctx, NotifyParties, NotifyRequest{
Transfer: req, Settlement: settleResult,
}).Get(ctx, nil)
return TransferResult{
Status: "COMPLETED",
SettlementReference: settleResult.Reference,
FXRate: fxResult.Rate,
SettledAmount: fxResult.BuyAmount,
}, nil
}
// Run compensations in reverse order
func runCompensations(ctx workflow.Context, compensations []func(ctx workflow.Context) error) {
for i := len(compensations) - 1; i >= 0; i-- {
err := compensations[i](ctx)
if err != nil {
workflow.GetLogger(ctx).Error("Compensation failed", "index", i, "error", err)
}
}
}
Con AWS Step Functions (State Machine)¶
{
"Comment": "Wire Transfer Saga - Process Manager",
"StartAt": "Validate",
"States": {
"Validate": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:validate-transfer",
"TimeoutSeconds": 10,
"Next": "SanctionsScreen",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "TransferFailed" }]
},
"SanctionsScreen": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:sanctions-screen",
"TimeoutSeconds": 15,
"Next": "CheckSanctionsResult",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "TransferFailed" }]
},
"CheckSanctionsResult": {
"Type": "Choice",
"Choices": [
{ "Variable": "$.sanctions_status", "StringEquals": "BLOCKED", "Next": "TransferBlocked" }
],
"Default": "HoldFunds"
},
"HoldFunds": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:hold-funds",
"TimeoutSeconds": 10,
"Next": "CheckFXNeeded",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "TransferFailed" }]
},
"CheckFXNeeded": {
"Type": "Choice",
"Choices": [
{ "Variable": "$.fx_needed", "BooleanEquals": true, "Next": "ConvertFX" }
],
"Default": "RouteTransfer"
},
"ConvertFX": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:convert-fx",
"TimeoutSeconds": 15,
"Next": "RouteTransfer",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "CompensateFX" }]
},
"RouteTransfer": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:route-transfer",
"Next": "Settle",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "CompensateRoute" }]
},
"Settle": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:settle-transfer",
"TimeoutSeconds": 60,
"Next": "Notify",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "CompensateSettle" }]
},
"Notify": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:notify-parties",
"Next": "TransferCompleted",
"Catch": [{ "ErrorEquals": ["States.ALL"], "Next": "TransferCompleted" }]
},
"TransferCompleted": { "Type": "Succeed" },
"TransferBlocked": { "Type": "Fail", "Error": "SANCTIONS_BLOCKED" },
"CompensateSettle": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:reverse-fx",
"Next": "ReleaseFunds"
},
"CompensateRoute": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:reverse-fx",
"Next": "ReleaseFunds"
},
"CompensateFX": {
"Type": "Pass",
"Next": "ReleaseFunds"
},
"ReleaseFunds": {
"Type": "Task",
"Resource": "arn:aws:lambda:eu-west-1:123:function:release-funds",
"Next": "TransferFailed"
},
"TransferFailed": { "Type": "Fail", "Error": "TRANSFER_FAILED" }
}
}
Con Camunda 8 (BPMN)¶
Camunda permite definir el Process Manager como un diagrama BPMN con service tasks, exclusive gateways, y boundary timer events. La definición es visual (BPMN XML) y la ejecución es sobre el engine Zeebe:
<bpmn:process id="wire_transfer" name="International Wire Transfer">
<bpmn:startEvent id="start" />
<bpmn:serviceTask id="validate" name="Validate Transfer">
<bpmn:extensionElements>
<zeebe:taskDefinition type="validate-transfer" retries="3" />
</bpmn:extensionElements>
</bpmn:serviceTask>
<bpmn:serviceTask id="sanctions" name="Sanctions Screening">
<bpmn:extensionElements>
<zeebe:taskDefinition type="sanctions-screen" retries="3" />
</bpmn:extensionElements>
</bpmn:serviceTask>
<bpmn:exclusiveGateway id="sanctions_check" name="Sanctions Clear?" />
<!-- ... additional tasks and gateways ... -->
<bpmn:boundaryEvent id="settle_timeout" name="Settlement Timeout" attachedToRef="settle">
<bpmn:timerEventDefinition>
<bpmn:timeDuration>PT60S</bpmn:timeDuration>
</bpmn:timerEventDefinition>
</bpmn:boundaryEvent>
<bpmn:subProcess id="compensation" triggeredByEvent="true">
<!-- Compensation logic -->
</bpmn:subProcess>
</bpmn:process>
Con Azure Durable Functions (C#)¶
[FunctionName("WireTransferOrchestrator")]
public static async Task<TransferResult> Run(
[OrchestrationTrigger] IDurableOrchestrationContext ctx)
{
var req = ctx.GetInput<TransferRequest>();
var compensations = new Stack<Func<Task>>();
try
{
// Step 1: Validate
await ctx.CallActivityAsync("ValidateTransfer", req);
// Step 2: Sanctions
var sanctions = await ctx.CallActivityAsync<SanctionsResult>(
"ScreenSanctions", req);
if (sanctions.Status == "BLOCKED")
return new TransferResult { Status = "BLOCKED" };
// Step 3: Hold Funds
var hold = await ctx.CallActivityAsync<HoldResult>("HoldFunds", req);
compensations.Push(async () =>
await ctx.CallActivityAsync("ReleaseFunds",
new ReleaseRequest { HoldRef = hold.Reference }));
// Step 4: FX (conditional)
FXResult fx = null;
if (req.Currency != req.DestCurrency)
{
fx = await ctx.CallActivityAsync<FXResult>("ConvertFX", req);
compensations.Push(async () =>
await ctx.CallActivityAsync("ReverseFX",
new ReverseRequest { FXRef = fx.Reference }));
}
// Step 5-7: Route, Settle, Notify
var route = await ctx.CallActivityAsync<RouteResult>("RouteTransfer", req);
var settle = await ctx.CallActivityWithRetryAsync<SettleResult>(
"SettleTransfer",
new RetryOptions(TimeSpan.FromSeconds(5), 3),
new SettleRequest { Route = route });
await ctx.CallActivityAsync("NotifyParties", settle);
return new TransferResult { Status = "COMPLETED" };
}
catch (Exception ex)
{
// Run compensations in reverse
while (compensations.Count > 0)
{
var comp = compensations.Pop();
try { await comp(); } catch { /* log */ }
}
return new TransferResult { Status = "COMPENSATED", Reason = ex.Message };
}
}
16. Gobierno y Operación¶
Métricas Clave¶
| Métrica | Descripción | Umbral de Alerta |
|---|---|---|
process.active.count | Procesos activos (en vuelo) | Monitoreo de tendencia, pico inesperado |
process.completion.rate | % de procesos que completan exitosamente | <95% |
process.compensation.rate | % de procesos que requieren compensación | >10% |
process.duration.p95 | Duración P95 del proceso completo | >SLA |
step.duration.p95 | Duración P95 por paso | >step timeout |
step.failure.rate | Tasa de fallo por paso | >5% |
compensation.success.rate | % de compensaciones exitosas | <99% (crítico) |
process.stuck.count | Procesos sin transición de estado en >N minutos | >0 |
state_store.write.latency | Latencia de escritura al state store | >50ms |
Dashboard Operativo¶
Un dashboard de Process Manager debe mostrar:
- Vista general: procesos por estado (INITIATED, IN_PROGRESS, COMPLETED, COMPENSATING, COMPENSATED, FAILED).
- Funnel view: conversión por paso (cuántos procesos llegan a cada paso y cuántos pasan al siguiente).
- Latency distribution: distribución de latencia por paso y por proceso completo.
- Failure analysis: top reasons de fallo por paso, tendencia temporal.
- Compensation analysis: cuántas compensaciones se ejecutan, éxito/fallo, duración.
- Stuck processes: procesos sin transición de estado en los últimos N minutos.
Operaciones de Runbook¶
-
Proceso stuck (sin transición de estado): consultar el state store para determinar en qué paso está stuck. Verificar que el servicio del paso actual está operativo. Si el servicio está operativo pero no respondió, verificar si el comando se entregó (check message broker). Si se entregó y no se procesó, verificar logs del servicio. Reenviar el comando manualmente si es idempotente.
-
Compensación fallida: una compensación que falla es un escenario crítico porque deja el sistema en un estado inconsistente (por ejemplo, fondos retenidos que no se liberaron). Requiere intervención manual del equipo de operaciones. El runbook debe documentar cómo ejecutar manualmente cada compensación.
-
State store degradado: si el state store tiene alta latencia o está parcialmente caído, el Process Manager no puede persistir transiciones. Los procesos en vuelo se pausan. Priorizar la recuperación del state store.
-
Migración de process definition: al desplegar una nueva versión de la definición del proceso, verificar que los procesos en vuelo con la versión anterior pueden completarse. Implementar backward compatibility o migración explícita de instancias.
Alta Disponibilidad del Process Manager¶
El Process Manager es stateful pero su estado está en el state store, no en memoria. Esto permite:
- Multiple instances: varias instancias del Process Manager consumen del reply channel con partitioning por process_id. Si una instancia cae, su partición se reasigna a otra instancia.
- Crash recovery: al reiniciar, la instancia reconstruye su estado desde el state store y retoma los procesos en vuelo.
- Zero-downtime deployment: blue-green deployment con drain de la instancia anterior (procesos en vuelo completan antes de detener la instancia).
17. Errores Comunes¶
Error 1: Implementar Process Manager from Scratch¶
Construir un Process Manager artesanal con una tabla de estado en PostgreSQL, un scheduler de timeouts, y retry logic manual. Esto es reinventar Temporal/Step Functions/Camunda y producirá un orquestador frágil y difícil de mantener. Solución: usar un framework maduro. Temporal, Step Functions, Azure Durable Functions, Camunda — todos resuelven los problemas difíciles (crash recovery, at-least-once delivery, state persistence, timeout management) que un Process Manager artesanal no resolverá correctamente.
Error 2: Steps No Idempotentes¶
Si un step handler no es idempotente, un retry del Process Manager (que es normal y esperado) produce efectos duplicados: fondos retenidos dos veces, pagos cobrados dos veces, emails enviados dos veces. Solución: cada step handler debe ser idempotente. Usar idempotency keys (el process_id + step_name) para detectar y deduplicar ejecuciones duplicadas.
Error 3: Compensaciones No Definidas¶
Implementar la happy path del proceso pero no definir las compensaciones para cada paso. Cuando un paso falla, no hay forma de deshacer los efectos de pasos anteriores. Solución: para cada paso con efectos secundarios, definir la compensating transaction antes de implementar el happy path. Si un paso no tiene compensación posible, documentarlo explícitamente y diseñar el flujo para minimizar el impacto.
Error 4: Compensaciones No Idempotentes¶
Las compensaciones también pueden necesitar retries (el servicio puede estar temporalmente caído). Si la compensación no es idempotente, un retry puede producir una doble reversión. Solución: las compensaciones deben ser idempotentes. Usar la misma referencia del paso original para asegurar que la compensación solo se ejecuta una vez.
Error 5: Usar Process Manager para Todo¶
Orquestar cada interacción entre servicios con un Process Manager, incluyendo operaciones simples que no lo necesitan. Esto añade latencia y complejidad innecesarias. Solución: usar Process Manager solo para flujos que requieren estado, compensación o branching. Para operaciones simples, usar request-reply directo o eventos.
Error 6: No Versionar Process Definitions¶
Modificar la definición del proceso sin considerar los procesos en vuelo con la definición anterior. Un proceso que está en el paso 4 de 7 con la definición v1 puede encontrarse con que la definición v2 tiene un paso 4 diferente. Solución: cada instancia del proceso se asocia con la versión de la definición con la que fue creada. Los procesos existentes completan con su versión original. Solo las nuevas instancias usan la nueva versión.
Error 7: Timeout Demasiado Largo o Inexistente¶
No configurar timeouts por paso, permitiendo que un proceso quede indefinidamente esperando una respuesta que nunca llegará. Solución: cada paso debe tener un timeout explícito. El proceso completo debe tener un timeout global. Al expirar cualquier timeout, el Process Manager debe decidir: reintentar, compensar, o escalar.
Error 8: Ignorar la Compensación de la Compensación¶
¿Qué ocurre si una compensación falla? Si el release de fondos falla, los fondos quedan bloqueados. Solución: las compensaciones deben tener su propio retry policy. Si una compensación falla después de todos los retries, se debe escalar a intervención manual con toda la información necesaria (process_id, paso fallido, compensación intentada, error recibido).
Error 9: Acoplamiento entre Orquestador y Coreografía¶
Mezclar orquestación y coreografía para el mismo flujo sin una separación clara. Algunos pasos son orquestados por el Process Manager y otros son disparados por eventos que otros servicios emiten. El resultado es un flujo donde nadie tiene la visión completa. Solución: definir claramente qué flujos son orquestados y cuáles son coreografiados. No mezclar ambos modelos para el mismo proceso de negocio.
18. Conclusión Técnica¶
Process Manager es el patrón de routing más sofisticado y uno de los más importantes del catálogo de Enterprise Integration Patterns. Es el patrón que resuelve el problema más difícil de las arquitecturas de microservicios: la coordinación de operaciones multi-servicio con estado, branching, compensación y visibilidad.
Su importancia ha crecido dramáticamente con la adopción de microservices. Cuando una operación de negocio cruza múltiples servicios — y la mayoría de las operaciones de negocio no triviales lo hacen — se necesita un mecanismo para coordinarlas. Las alternativas (2PC, ad-hoc state management, cleanup cron jobs) son inadecuadas para sistemas a escala. Process Manager, implementado como saga orchestrator, es la solución estándar de la industria.
Los frameworks modernos han transformado la implementación de Process Manager de un ejercicio de ingeniería complejo a una tarea relativamente accesible. Temporal permite definir sagas como código convencional con durabilidad y replay. AWS Step Functions permite definir state machines serverless con branching y error handling. Camunda permite definir procesos visualmente con BPMN. Azure Durable Functions permite orquestación durable en C# o JavaScript.
Las decisiones de diseño más críticas son:
- Idempotencia de steps y compensaciones: sin idempotencia, los retries producen efectos duplicados.
- Definición explícita de compensaciones: sin compensaciones, los fallos parciales dejan datos inconsistentes.
- Timeout management: sin timeouts, los procesos pueden quedar indefinidamente en espera.
- Versionado de process definitions: sin versionado, los cambios en el flujo rompen procesos en vuelo.
- Observabilidad: el Process Manager debe proporcionar visibilidad completa del estado de cada instancia.
La regla de decisión para elegir Process Manager es: si el flujo cruza múltiples servicios Y necesita compensación O branching O estado persistente O visibilidad centralizada, usar Process Manager. Si el flujo es una secuencia lineal simple sin compensación, considerar Routing Slip o Pipes and Filters.
Process Manager no es un patrón que se "elige opcionalmente" — en la mayoría de las arquitecturas de microservicios, es un componente necesario para los flujos de negocio críticos. La pregunta no es "¿deberíamos usar Process Manager?" sino "¿con qué framework lo implementamos?"
Process Manager es el director de orquesta de la arquitectura de integración: mantiene la partitura (process definition), coordina a los músicos (services), gestiona los imprevistos (failures), y asegura que la sinfonía se complete — o se detenga gracefully si algo sale irremediablemente mal.