Content Enricher¶
1. Nombre del Patrón¶
- Nombre oficial: Content Enricher
- Categoría: Message Transformation (Transformación de Mensajes)
- Traducción contextual: Enriquecedor de Contenido
2. Resumen Ejecutivo¶
Content Enricher es el patrón que complementa un mensaje con datos faltantes consultando fuentes externas durante el flujo de integración. Cuando un sistema productor envía un mensaje que contiene solo una parte de la información que el consumidor necesita, el Content Enricher intercepta el mensaje, consulta una o más fuentes de datos adicionales para obtener la información faltante, y produce un mensaje enriquecido que contiene toda la información requerida por el consumidor.
El problema que resuelve es la asimetría de información entre productores y consumidores: el productor genera un mensaje con los datos que conoce (por ejemplo, un pedido con el ID del cliente y los productos), pero el consumidor necesita datos adicionales que el productor no tiene o no debería tener (por ejemplo, la dirección de envío del cliente, los precios actuales del catálogo, el estado crediticio del cliente). Sin Content Enricher, el consumidor debería consultar estas fuentes por sí mismo, mezclando lógica de integración con lógica de negocio, o el productor debería consultar fuentes que no le corresponden.
Este patrón es fundamental en arquitecturas de microservicios donde los datos están distribuidos entre múltiples servicios y ningún servicio tiene la vista completa. Es el mecanismo central de lo que en microservicios se denomina API Composition: componer una respuesta a partir de múltiples fuentes de datos.
3. Definición Detallada¶
Propósito¶
Content Enricher intercepta un mensaje en tránsito y le añade información obtenida de fuentes externas, produciendo un mensaje más completo que satisface los requisitos del consumidor. El propósito es que ni el productor ni el consumidor necesiten conocer o consultar las fuentes de datos del otro.
Lógica Arquitectónica¶
En un sistema distribuido, la información está naturalmente fragmentada entre múltiples servicios y bases de datos. Cuando un evento ocurre (un pedido se crea, un paciente ingresa, una transacción se autoriza), el sistema que genera el evento típicamente tiene solo un subconjunto de la información relevante. Los consumidores del evento frecuentemente necesitan una vista más completa.
Content Enricher resuelve este problema posicionándose entre el productor y el consumidor:
- Lee el mensaje original: identifica qué datos están presentes y cuáles faltan.
- Consulta fuentes externas: usa claves del mensaje original (customer_id, product_id, account_number) para consultar servicios, APIs o bases de datos que contienen los datos faltantes.
- Combina los datos: merge la información original con la información obtenida, produciendo un mensaje enriquecido.
- Envía el mensaje enriquecido: el consumidor recibe toda la información que necesita en un solo mensaje.
Principio de Diseño Subyacente¶
El principio es completitud de mensaje en la capa de integración (message completeness at integration layer). En lugar de que el consumidor realice múltiples llamadas para obtener la información que necesita, la capa de integración se encarga de componer un mensaje completo. Esto es análogo al patrón Facade en diseño orientado a objetos: el enricher proporciona una vista unificada compuesta de múltiples fuentes.
Problema Estructural que Resuelve¶
Sin Content Enricher:
- El consumidor debe consultar múltiples fuentes de datos para complementar cada mensaje que recibe, mezclando lógica de integración con lógica de procesamiento.
- El productor debe conocer y consultar fuentes que no le corresponden para enviar un mensaje "completo", aumentando su acoplamiento y complejidad.
- Múltiples consumidores que necesitan los mismos datos adicionales duplican la lógica de consulta y enriquecimiento.
Contexto en el que Emerge¶
Content Enricher emerge en escenarios donde:
- Los datos están distribuidos entre múltiples sistemas y ninguno tiene la vista completa.
- El productor envía mensajes "delgados" (thin messages) con solo los datos que conoce.
- El consumidor necesita un mensaje "gordo" (fat message) con datos de múltiples fuentes.
- Se quiere evitar que el consumidor tenga acoplamiento directo con las fuentes de datos del productor.
Por Qué No Es Trivial¶
El enriquecimiento introduce complejidades significativas:
- Latencia: cada consulta a una fuente externa añade latencia al flujo del mensaje. Con múltiples fuentes, la latencia se acumula.
- Disponibilidad: si una fuente externa no está disponible, ¿se rechaza el mensaje? ¿Se envía parcialmente enriquecido? ¿Se reintenta?
- Consistencia: los datos del mensaje original y los datos obtenidos de fuentes externas corresponden a momentos diferentes en el tiempo. ¿Es aceptable esta inconsistencia temporal?
- Volumen: si cada mensaje requiere N consultas a fuentes externas, y hay M mensajes por segundo, el enricher genera N×M requests por segundo a las fuentes — potencial cuello de botella.
Relación con Sistemas Distribuidos y Mensajería¶
Content Enricher es una implementación del problema de data composition en sistemas distribuidos. En la teoría de microservicios, corresponde al patrón API Composition. En event-driven architectures, corresponde al concepto de event enrichment en un stream processor. En ambos casos, el desafío fundamental es el mismo: componer una vista consistente a partir de datos distribuidos sin violar la autonomía de los servicios que los poseen.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Un sistema de e-commerce genera un evento cuando se crea un nuevo pedido. El evento contiene:
{
"order_id": "ORD-2026-847291",
"customer_id": "CUST-12345",
"items": [
{ "product_id": "SKU-A100", "quantity": 2 },
{ "product_id": "SKU-B200", "quantity": 1 }
],
"created_at": "2026-04-07T14:30:00Z"
}
Sin embargo, el sistema de fulfillment que procesa los envíos necesita: nombre y dirección del cliente, nombre y precio de cada producto, peso y dimensiones para calcular el envío, estado crediticio del cliente para verificación de fraude. El evento original no tiene ninguno de estos datos porque el servicio de pedidos no es el dueño de esa información.
Síntomas del Problema¶
- El consumidor (fulfillment) realiza 3-4 llamadas API por cada pedido que recibe: una al CRM para el cliente, una al catálogo de productos por cada SKU, una al servicio de crédito. Esto hace que la lógica de fulfillment esté saturada de lógica de integración.
- Si el CRM está temporalmente no disponible, el fulfillment no puede procesar ningún pedido, aunque los datos del cliente no cambien frecuentemente.
- Múltiples consumidores (fulfillment, facturación, analytics) realizan las mismas consultas para enriquecer el mismo evento, multiplicando la carga en los servicios de datos.
- El tiempo de procesamiento por pedido incluye la latencia de todas las consultas externas, degradando el throughput del consumidor.
Impacto Operativo y Arquitectónico¶
Sin Content Enricher:
- Los consumidores están acoplados a las fuentes de datos que necesitan para enriquecer los mensajes. Un cambio en la API del CRM impacta a todos los consumidores que la consultan.
- La disponibilidad del consumidor depende de la disponibilidad de todas las fuentes externas que consulta. La disponibilidad compuesta es el producto de las disponibilidades individuales (si cada fuente tiene 99.9%, con 3 fuentes la disponibilidad es 99.7%).
- No hay un punto centralizado donde monitorear y optimizar el enriquecimiento (caching, batching, circuit breaking).
Riesgos Si No Se Implementa Correctamente¶
- Enricher como cuello de botella: si el enricher no escala o no maneja la carga de las fuentes externas, se convierte en el punto más lento del flujo.
- Consultas innecesarias: enriquecer campos que el consumidor no necesita, desperdiciando latencia y recursos.
- Falta de caching: consultar fuentes externas para datos que cambian raramente (datos maestros de clientes, catálogo de productos) en cada mensaje, en lugar de cachear.
- Falta de resiliencia: si una fuente externa falla, el enricher bloquea todo el flujo sin fallback ni degradación graceful.
Ejemplos Reales¶
- E-commerce: un evento de pedido se enriquece con datos del cliente (CRM), precios actuales (catálogo), estado crediticio (scoring) y costos de envío (logística) antes de enviarlo al sistema de fulfillment.
- Banca: una transacción de pago se enriquece con datos del titular de la cuenta, categorización del comercio (MCC), y tipo de cambio actual antes de enviarla al sistema de compliance/AML.
- Salud: un resultado de laboratorio se enriquece con datos demográficos del paciente (ADT), historial médico relevante (EMR) y datos del médico solicitante antes de enviarlo al sistema de reporting clínico.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el productor envía mensajes con datos incompletos que el consumidor necesita completar para su procesamiento.
- Cuando los datos faltantes residen en sistemas externos que el consumidor no debería consultar directamente.
- Cuando múltiples consumidores necesitan los mismos datos adicionales y se quiere evitar duplicación de lógica de enriquecimiento.
- Cuando se necesita un punto centralizado para aplicar caching, batching y circuit breaking en las consultas de enriquecimiento.
Cuándo No Usarlo¶
- Cuando el productor puede incluir todos los datos necesarios en el mensaje original sin acoplamiento inaceptable (en ese caso, es preferible un mensaje completo desde el origen).
- Cuando el consumidor necesita datos que cambian muy frecuentemente y el enriquecimiento introduciría inconsistencia temporal inaceptable (el dato ya está obsoleto cuando el consumidor lo recibe).
- Cuando la fuente externa tiene latencia extremadamente alta y el enriquecimiento degradaría inaceptablemente el throughput.
Precondiciones¶
- El mensaje original contiene claves (IDs) que permiten consultar las fuentes externas.
- Las fuentes externas son accesibles desde la capa de integración (APIs, bases de datos, servicios).
- Existe un contrato claro sobre qué campos debe añadir el enricher.
Restricciones¶
- La latencia del enriquecimiento depende de la latencia de las fuentes externas.
- La disponibilidad del enricher depende de la disponibilidad de las fuentes externas (mitigable con caching y fallbacks).
- El enriquecimiento produce un punto-en-el-tiempo snapshot: los datos enriquecidos reflejan el estado de las fuentes en el momento de la consulta.
Dependencias¶
- Acceso de red a las fuentes externas.
- Autenticación y autorización para consultar las fuentes.
- Mecanismo de caching para datos que cambian raramente.
- Circuit breaker para manejar fallos de fuentes externas.
Supuestos Arquitectónicos¶
- Las fuentes externas ofrecen APIs de consulta por clave (get by ID) con latencia razonable.
- Los datos enriquecidos tienen una validez temporal aceptable para el caso de uso (eventual consistency es suficiente).
- El volumen de consultas de enriquecimiento está dentro de la capacidad de las fuentes externas (o se mitiga con caching/batching).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Arquitecturas de microservicios con API Composition.
- Pipelines de eventos con stream processing (Kafka Streams, Flink, Azure Stream Analytics).
- Integraciones enterprise con ESB (Enterprise Service Bus) o integration middleware.
- Data pipelines ETL/ELT que complementan registros con datos de referencia.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Content Enricher reduce el acoplamiento entre el consumidor y las fuentes de datos externas: el consumidor ya no necesita conocer ni consultar el CRM, el catálogo o el servicio de crédito. Sin embargo, el enricher mismo está acoplado a todas esas fuentes. El acoplamiento no desaparece, se centraliza en un componente dedicado que es más fácil de gestionar.
Latencia vs. Completitud¶
Cada fuente externa consultada añade latencia. Un mensaje enriquecido con datos de 3 fuentes toma al menos la latencia de la fuente más lenta (si se consultan en paralelo) o la suma de todas (si se consultan secuencialmente). La tensión entre "mensaje más completo" y "mensaje más rápido" es constante.
Consistencia vs. Rendimiento¶
Los datos enriquecidos son un snapshot del estado de las fuentes en un momento dado. Si un precio cambió entre la creación del pedido y el enriquecimiento (milisegundos o segundos después), el mensaje contiene un precio ligeramente desactualizado. El caching agrava esta inconsistencia temporal pero mejora el rendimiento.
Disponibilidad vs. Completitud¶
Si una fuente externa no está disponible, ¿se envía el mensaje sin enriquecer, parcialmente enriquecido, o se bloquea hasta que la fuente vuelva? Cada opción tiene trade-offs: bloquear maximiza completitud pero sacrifica disponibilidad; enviar parcial maximiza disponibilidad pero el consumidor recibe datos incompletos.
Centralización vs. Distribución del Enriquecimiento¶
¿Un solo enricher central que enriquece todos los mensajes, o enrichers distribuidos cerca de cada consumidor? La centralización evita duplicación pero crea un punto único de fallo y un potencial cuello de botella. La distribución es más resiliente pero duplica lógica y carga en las fuentes.
Caching vs. Frescura¶
Cachear datos de enriquecimiento reduce drásticamente la latencia y la carga en las fuentes externas. Pero datos cacheados pueden estar desactualizados. La estrategia de caching (TTL, invalidación, write-through) debe alinearse con los requisitos de frescura del caso de uso.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: envía el mensaje original con datos parciales.
- Content Enricher: intercepta el mensaje, consulta fuentes externas, combina datos, produce mensaje enriquecido.
- Fuentes de Datos Externas: servicios, APIs o bases de datos que contienen los datos faltantes (CRM, catálogo, pricing, etc.).
- Cache: almacén de datos consultados recientemente para evitar consultas repetitivas.
- Consumidor: recibe y procesa el mensaje enriquecido con toda la información necesaria.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Mensaje original\ncon datos parciales]
B --> C[Enricher recibe mensaje\ne identifica datos faltantes]
C --> D[Consultar CRM API\nnombre, dirección, email]
C --> E[Consultar Catalog API\nnombre, precio, peso]
C --> F[Consultar Credit API\nscore crediticio]
D --> G[Combinar datos originales\n+ datos obtenidos]
E --> G
F --> G
G --> H[(Canal de Salida\nmensaje enriquecido)]
H --> I([Consumidor procesa\nmensaje enriquecido completo])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Enviar mensaje con datos disponibles y claves para enriquecimiento |
| Enricher | Identificar datos faltantes, consultar fuentes, combinar, manejar errores |
| Fuentes externas | Responder consultas por clave con datos actualizados |
| Cache | Almacenar respuestas recientes para reducir latencia y carga |
| Consumidor | Procesar el mensaje enriquecido; no necesita conocer las fuentes de datos |
Interacciones¶
- Productor → Enricher: el mensaje original llega al enricher (por canal directo, por routing en el broker, o por interceptor en un pipeline).
- Enricher → Fuentes externas: consultas de lookup por clave. Pueden ser síncronas (HTTP GET) o asíncronas (request-reply sobre messaging).
- Enricher → Cache: check before calling external source; store after successful response.
- Enricher → Consumidor: el mensaje enriquecido se envía al canal del consumidor.
Contratos Implícitos¶
- Claves de enriquecimiento: el mensaje original debe contener los IDs necesarios para consultar las fuentes externas.
- Formato del mensaje enriquecido: el consumidor espera un schema específico con los campos enriquecidos.
- SLA de las fuentes externas: el enricher depende de que las fuentes respondan dentro de un timeout aceptable.
Decisiones de Diseño Clave¶
- Paralelo vs. secuencial: ¿consultar todas las fuentes en paralelo (menor latencia, más complejidad) o secuencialmente (más simple, mayor latencia)?
- Caching strategy: ¿TTL-based, event-driven invalidation, write-through? ¿Qué TTL por tipo de dato?
- Fallback policy: ¿qué hacer si una fuente falla? ¿Valores por defecto? ¿Mensaje parcial? ¿Retry? ¿Dead-letter?
- Posición en el flujo: ¿enricher como step en un pipeline, como microservicio independiente, o como lógica en un stream processor?
- Granularidad: ¿un enricher que consulta todas las fuentes, o enrichers especializados en cadena (uno para CRM, otro para catálogo)?
8. Ejemplo Arquitectónico Detallado¶
Dominio: E-commerce — Enriquecimiento de Pedidos para Fulfillment¶
Contexto del Negocio¶
Una plataforma de e-commerce procesa 50,000 pedidos diarios. Cuando un cliente crea un pedido, el servicio de pedidos emite un evento order.created con los datos mínimos: ID del pedido, ID del cliente, lista de productos con cantidades. Sin embargo, el sistema de fulfillment necesita información completa para procesar el envío: dirección del cliente, nombre y peso de cada producto, precio actual para la factura, y evaluación de riesgo de fraude.
Esta información reside en cuatro servicios diferentes: Customer Service (CRM), Product Catalog Service, Pricing Service y Fraud Detection Service.
Necesidad de Integración¶
Tres consumidores necesitan el pedido enriquecido con diferentes niveles de completitud: - Fulfillment: necesita dirección, productos (nombre, peso), evaluación de fraude. - Facturación: necesita datos fiscales del cliente, precios actuales con impuestos. - Analytics: necesita todos los datos para reporting.
Sin un Content Enricher, cada consumidor realizaría sus propias consultas, triplicando la carga en los servicios de datos.
Sistemas Involucrados¶
- Order Service: emite evento
order.createden Kafka. - Order Enricher (Kafka Streams application): consume el evento, lo enriquece, lo produce enriquecido.
- Customer Service: API REST con datos del cliente (nombre, dirección, datos fiscales).
- Product Catalog Service: API REST con datos de producto (nombre, descripción, peso, dimensiones).
- Pricing Service: API REST con precios actuales e impuestos.
- Fraud Detection Service: API REST que evalúa riesgo por customer_id y order_amount.
- Fulfillment Service: consume pedidos enriquecidos.
- Billing Service: consume pedidos enriquecidos.
- Analytics Pipeline: consume pedidos enriquecidos.
Restricciones Técnicas¶
- Latencia máxima aceptable del enriquecimiento: 500ms (p99).
- Los datos del cliente cambian raramente (dirección ~ mensualmente); los precios cambian diariamente.
- El servicio de fraude tiene latencia variable (50ms-300ms) y tasa de error del 0.1%.
- Si el servicio de fraude no responde, el pedido debe marcarse como "pending_fraud_review" y procesarse con review manual.
- El enricher debe procesar 50,000 pedidos/día (~35 pedidos/minuto en promedio, picos de 200/minuto).
Diseño del Enriquecimiento¶
| Fuente | Datos que aporta | Caching | Fallback |
|---|---|---|---|
| Customer Service | nombre, dirección, email, datos fiscales | Cache 1 hora (TTL) | Retry 2x, luego dead-letter |
| Product Catalog | nombre, descripción, peso, dimensiones | Cache 24 horas (TTL) | Retry 2x, luego dead-letter |
| Pricing Service | precio unitario, impuestos, descuentos | Cache 15 minutos | Retry 1x, luego usar precio del cache expirado |
| Fraud Detection | score de riesgo, recomendación | No cache (cada evaluación es única) | Default: "pending_fraud_review" |
Decisiones Arquitectónicas¶
- Consultas en paralelo: las 4 fuentes se consultan simultáneamente para minimizar latencia. La latencia total es max(latencia_fuente_más_lenta), no la suma.
- Cache local en el enricher: Redis como cache compartido entre instancias del enricher, con TTL diferenciado por tipo de dato.
- Fallback degradado: si la fuente de fraude falla, el pedido se enriquece parcialmente con flag
fraud_status: "pending_review". El consumidor sabe manejar este caso. - Enricher como Kafka Streams app: consume de
orders.raw, produce enorders.enriched. Escala horizontalmente con el número de particiones del topic de entrada.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Fuente externa lenta degrada throughput | Timeout de 400ms + circuit breaker por fuente |
| Cache miss masivo tras reinicio | Cache warmup al inicio consultando top-1000 clientes y productos |
| Inconsistencia temporal (precio cambió) | Aceptable para analytics; para facturación, pricing service devuelve precio vigente al timestamp del pedido |
| Enricher como single point of failure | 3 instancias en cluster con particiones distribuidas |
| Explosión de carga en fuentes durante picos | Bulkhead pattern: máximo 20 requests concurrentes por fuente |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Evento Original del Order Service¶
Un cliente (CUST-12345) crea un pedido en la plataforma. El Order Service emite un evento en el topic Kafka orders.raw:
{
"event_type": "order.created",
"order_id": "ORD-2026-847291",
"customer_id": "CUST-12345",
"items": [
{ "product_id": "SKU-A100", "quantity": 2 },
{ "product_id": "SKU-B200", "quantity": 1 }
],
"created_at": "2026-04-07T14:30:00Z"
}
El evento es "delgado" (thin): contiene IDs y cantidades, pero no los datos completos que los consumidores necesitan.
Paso 2: Recepción por el Content Enricher¶
El Order Enricher (una Kafka Streams application) consume el evento de orders.raw. Al recibir el evento, ejecuta la lógica de enriquecimiento:
- Extrae
customer_id: CUST-12345. - Extrae lista de
product_id: [SKU-A100, SKU-B200]. - Identifica las 4 fuentes a consultar.
Paso 3: Consultas en Paralelo con Caching¶
El enricher lanza 4 consultas concurrentes:
Consulta 1 — Customer Service: - Check cache (Redis key: customer:CUST-12345). - Cache hit (dato cacheado hace 20 minutos, TTL 1 hora). No llama al API. - Resultado: { "name": "María García López", "address": "Calle Mayor 15, 28001 Madrid", "email": "maria@example.com", "tax_id": "12345678A" }
Consulta 2 — Product Catalog (por cada producto): - Check cache: SKU-A100 → cache hit; SKU-B200 → cache miss. - Llama API solo para SKU-B200: GET /products/SKU-B200. - Respuesta en 35ms: { "name": "Auriculares Bluetooth Pro", "weight_kg": 0.3, "dimensions": "20x15x8cm" } - Almacena en cache con TTL 24h.
Consulta 3 — Pricing Service: - Llama API para ambos productos: POST /pricing/bulk con [SKU-A100, SKU-B200]. - Respuesta en 45ms: [{ "product_id": "SKU-A100", "unit_price": 29.99, "tax_rate": 0.21 }, { "product_id": "SKU-B200", "unit_price": 49.99, "tax_rate": 0.21 }] - Almacena en cache con TTL 15min.
Consulta 4 — Fraud Detection: - Llama API: POST /fraud/evaluate con customer_id y order_amount (109.97€). - Respuesta en 120ms: { "risk_score": 0.05, "recommendation": "approve" } - No se cachea (cada evaluación es contextual).
Latencia total del enriquecimiento: 120ms (máximo de las 4 consultas, ejecutadas en paralelo).
Paso 4: Composición del Mensaje Enriquecido¶
El enricher combina el mensaje original con los datos obtenidos:
{
"event_type": "order.created",
"order_id": "ORD-2026-847291",
"customer": {
"id": "CUST-12345",
"name": "María García López",
"address": "Calle Mayor 15, 28001 Madrid",
"email": "maria@example.com",
"tax_id": "12345678A"
},
"items": [
{
"product_id": "SKU-A100",
"name": "Teclado Mecánico RGB",
"quantity": 2,
"unit_price": 29.99,
"tax_rate": 0.21,
"weight_kg": 0.8
},
{
"product_id": "SKU-B200",
"name": "Auriculares Bluetooth Pro",
"quantity": 1,
"unit_price": 49.99,
"tax_rate": 0.21,
"weight_kg": 0.3
}
],
"fraud_evaluation": {
"risk_score": 0.05,
"recommendation": "approve"
},
"order_total": 109.97,
"total_weight_kg": 1.9,
"enriched_at": "2026-04-07T14:30:00.120Z",
"created_at": "2026-04-07T14:30:00Z"
}
Paso 5: Publicación del Mensaje Enriquecido¶
El enricher publica el mensaje enriquecido en el topic Kafka orders.enriched con order_id como partition key.
Paso 6: Consumo por Servicios Downstream¶
- Fulfillment Service consume de
orders.enriched: tiene dirección, productos con peso y fraud approval. Puede crear el shipment directamente sin consultar ningún servicio adicional. - Billing Service consume de
orders.enriched: tiene datos fiscales del cliente (tax_id), precios con impuestos. Genera la factura directamente. - Analytics Pipeline consume de
orders.enriched: almacena el pedido completo en el data warehouse para reporting.
Ningún consumidor necesita consultar fuentes externas. Toda la información está en el mensaje enriquecido.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
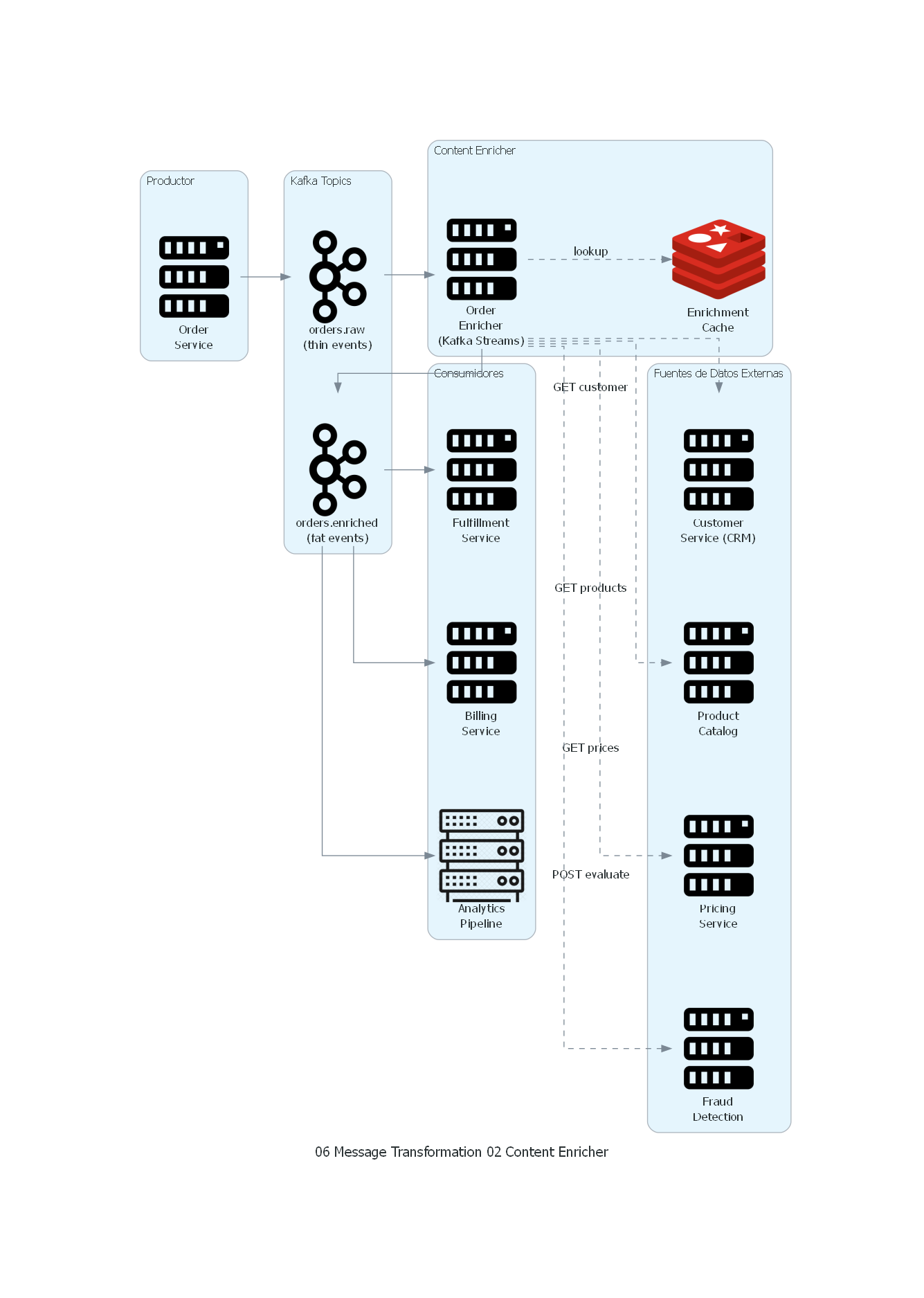
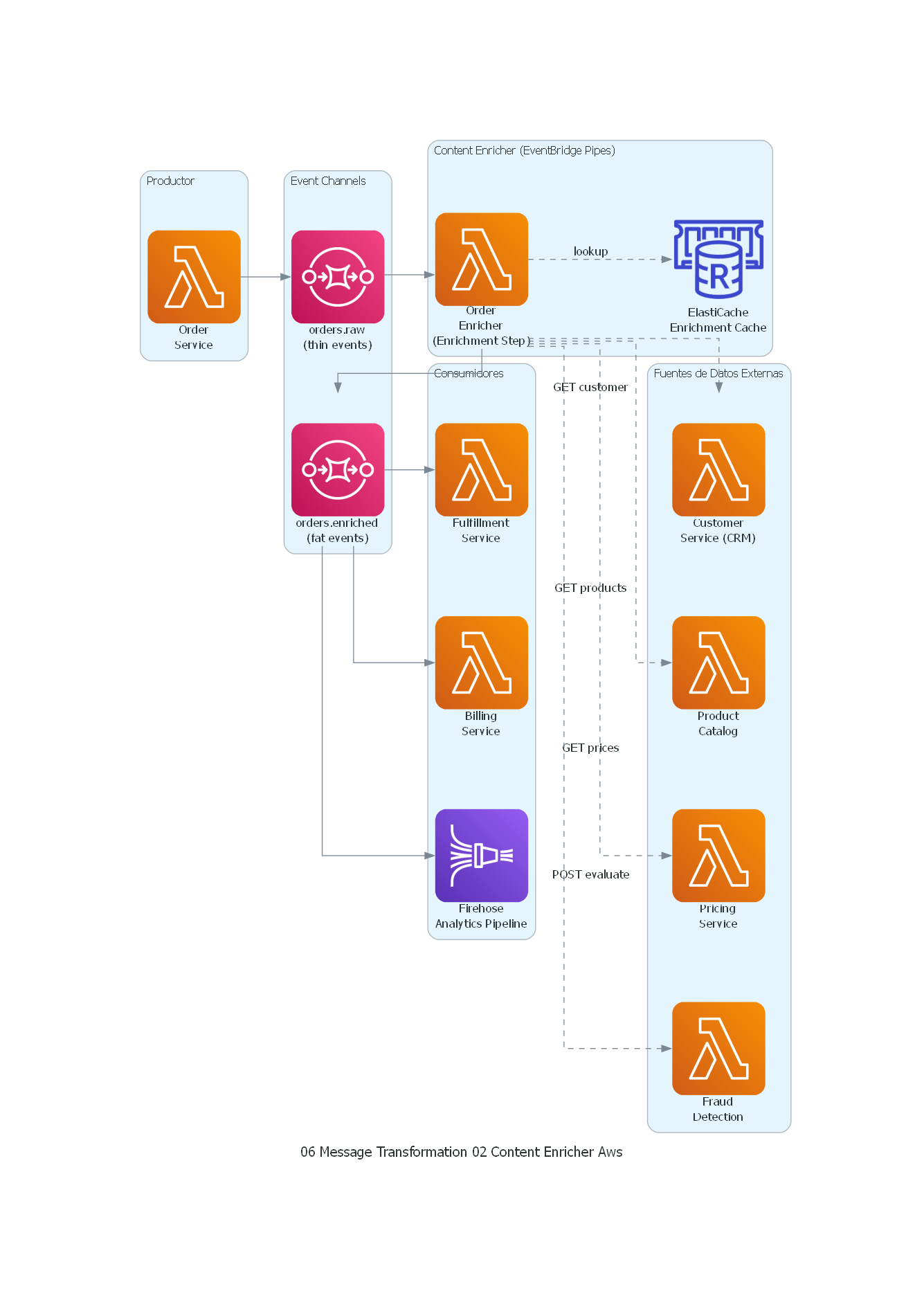
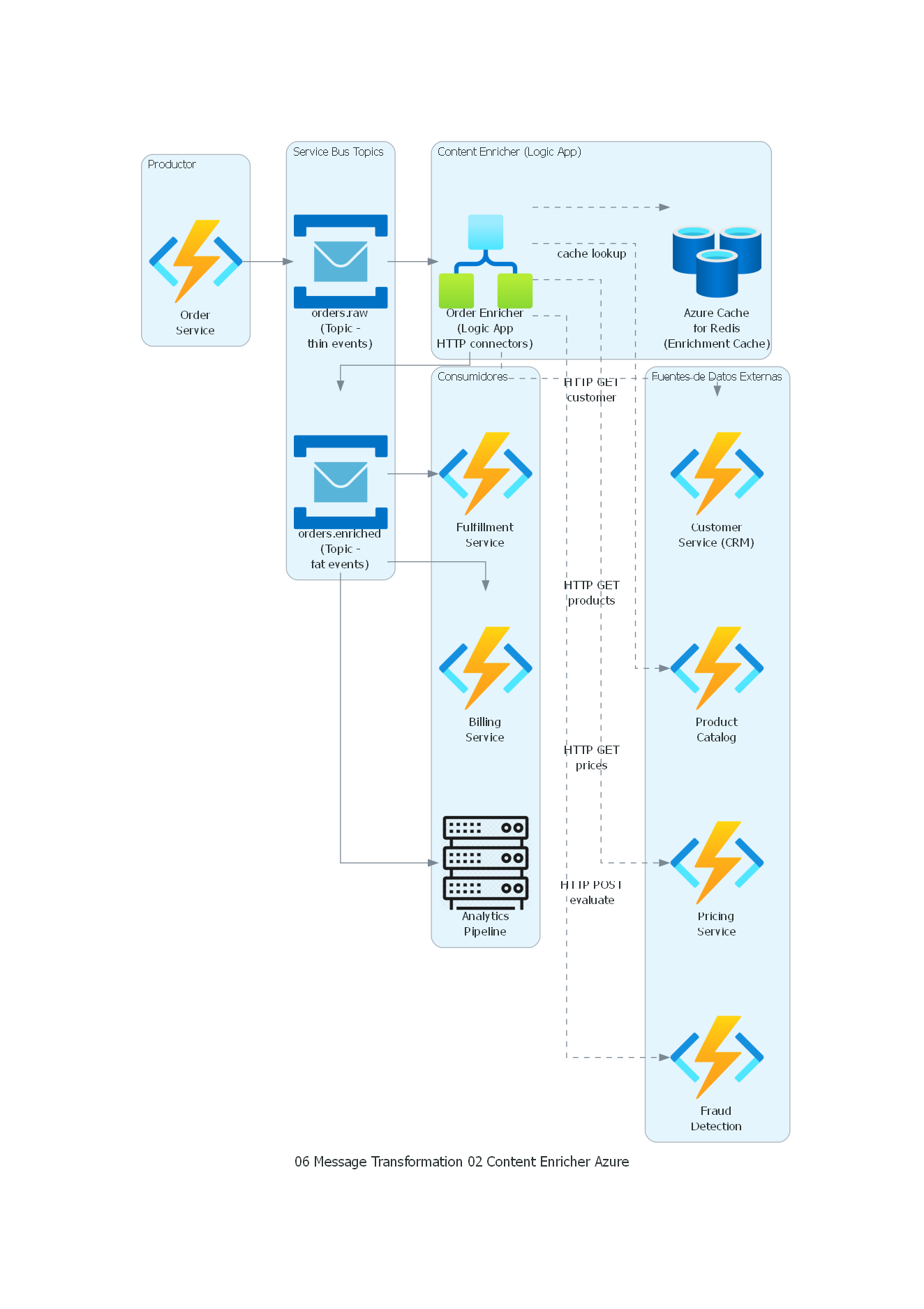
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.compute import Rack
with Diagram("Content Enricher - Order Enrichment", show=False, direction="LR"):
with Cluster("Productor"):
order_svc = Server("Order\nService")
with Cluster("Kafka Topics"):
raw_topic = Kafka("orders.raw\n(thin events)")
enriched_topic = Kafka("orders.enriched\n(fat events)")
with Cluster("Content Enricher"):
enricher = Server("Order\nEnricher\n(Kafka Streams)")
cache = Redis("Enrichment\nCache")
with Cluster("Fuentes de Datos Externas"):
customer_svc = Server("Customer\nService (CRM)")
catalog_svc = Server("Product\nCatalog")
pricing_svc = Server("Pricing\nService")
fraud_svc = Server("Fraud\nDetection")
with Cluster("Consumidores"):
fulfillment = Server("Fulfillment\nService")
billing = Server("Billing\nService")
analytics = Rack("Analytics\nPipeline")
# Flujo principal
order_svc >> raw_topic >> enricher
# Consultas de enriquecimiento
enricher >> Edge(style="dashed", label="lookup") >> cache
enricher >> Edge(style="dashed", label="GET customer") >> customer_svc
enricher >> Edge(style="dashed", label="GET products") >> catalog_svc
enricher >> Edge(style="dashed", label="GET prices") >> pricing_svc
enricher >> Edge(style="dashed", label="POST evaluate") >> fraud_svc
# Salida enriquecida
enricher >> enriched_topic
# Consumidores
enriched_topic >> fulfillment
enriched_topic >> billing
enriched_topic >> analytics
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import ElasticacheForRedis
from diagrams.aws.integration import SQS, Eventbridge
from diagrams.aws.analytics import KinesisDataFirehose
with Diagram("Content Enricher - Order Enrichment (AWS)", show=False, direction="LR"):
with Cluster("Productor"):
order_svc = Lambda("Order\nService")
with Cluster("Event Channels"):
raw_topic = SQS("orders.raw\n(thin events)")
enriched_topic = SQS("orders.enriched\n(fat events)")
with Cluster("Content Enricher (EventBridge Pipes)"):
enricher = Lambda("Order\nEnricher\n(Enrichment Step)")
cache = ElasticacheForRedis("ElastiCache\nEnrichment Cache")
with Cluster("Fuentes de Datos Externas"):
customer_svc = Lambda("Customer\nService (CRM)")
catalog_svc = Lambda("Product\nCatalog")
pricing_svc = Lambda("Pricing\nService")
fraud_svc = Lambda("Fraud\nDetection")
with Cluster("Consumidores"):
fulfillment = Lambda("Fulfillment\nService")
billing = Lambda("Billing\nService")
analytics = KinesisDataFirehose("Firehose\nAnalytics Pipeline")
# Flujo principal
order_svc >> raw_topic >> enricher
# Consultas de enriquecimiento
enricher >> Edge(style="dashed", label="lookup") >> cache
enricher >> Edge(style="dashed", label="GET customer") >> customer_svc
enricher >> Edge(style="dashed", label="GET products") >> catalog_svc
enricher >> Edge(style="dashed", label="GET prices") >> pricing_svc
enricher >> Edge(style="dashed", label="POST evaluate") >> fraud_svc
# Salida enriquecida
enricher >> enriched_topic
# Consumidores
enriched_topic >> fulfillment
enriched_topic >> billing
enriched_topic >> analytics
from diagrams import Diagram, Cluster, Edge
from diagrams.generic.compute import Rack
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis
from diagrams.azure.integration import ServiceBus, LogicApps
with Diagram("Content Enricher - Order Enrichment (Azure)", show=False, direction="LR"):
with Cluster("Productor"):
order_svc = FunctionApps("Order\nService")
with Cluster("Service Bus Topics"):
raw_topic = ServiceBus("orders.raw\n(Topic -\nthin events)")
enriched_topic = ServiceBus("orders.enriched\n(Topic -\nfat events)")
with Cluster("Content Enricher (Logic App)"):
enricher = LogicApps("Order Enricher\n(Logic App\nHTTP connectors)")
cache = CacheForRedis("Azure Cache\nfor Redis\n(Enrichment Cache)")
with Cluster("Fuentes de Datos Externas"):
customer_svc = FunctionApps("Customer\nService (CRM)")
catalog_svc = FunctionApps("Product\nCatalog")
pricing_svc = FunctionApps("Pricing\nService")
fraud_svc = FunctionApps("Fraud\nDetection")
with Cluster("Consumidores"):
fulfillment = FunctionApps("Fulfillment\nService")
billing = FunctionApps("Billing\nService")
analytics = Rack("Analytics\nPipeline")
# Flujo principal
order_svc >> raw_topic >> enricher
# Consultas de enriquecimiento (HTTP connectors)
enricher >> Edge(style="dashed", label="cache lookup") >> cache
enricher >> Edge(style="dashed", label="HTTP GET\ncustomer") >> customer_svc
enricher >> Edge(style="dashed", label="HTTP GET\nproducts") >> catalog_svc
enricher >> Edge(style="dashed", label="HTTP GET\nprices") >> pricing_svc
enricher >> Edge(style="dashed", label="HTTP POST\nevaluate") >> fraud_svc
# Salida enriquecida
enricher >> enriched_topic
# Consumidores (Service Bus subscriptions)
enriched_topic >> fulfillment
enriched_topic >> billing
enriched_topic >> analytics
Explicación del Diagrama¶
El diagrama muestra la arquitectura de enriquecimiento de pedidos:
- El Order Service produce eventos thin en el topic
orders.raw. - El Order Enricher (Kafka Streams app) consume los eventos y realiza consultas (con cache) a 4 fuentes externas.
- El enricher produce eventos enriquecidos (fat) en el topic
orders.enriched. - Tres consumidores (Fulfillment, Billing, Analytics) consumen los eventos enriquecidos sin necesidad de consultar fuentes adicionales.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensaje original (thin) | Evento en orders.raw |
| Content Enricher | Order Enricher (Kafka Streams) |
| Fuentes externas | Customer Service, Product Catalog, Pricing, Fraud Detection |
| Cache de enriquecimiento | Redis cache |
| Mensaje enriquecido (fat) | Evento en orders.enriched |
| Consumidores | Fulfillment, Billing, Analytics |
11. Beneficios¶
Impacto Técnico¶
- Desacoplamiento consumidor-fuentes: los consumidores no necesitan conocer ni consultar las fuentes de datos. Solo consumen un mensaje completo de un topic.
- Reducción de carga en fuentes: el enricher con cache centralizado reduce drásticamente el número de consultas a las fuentes externas. Sin cache, 3 consumidores × 50,000 pedidos × 4 consultas = 600,000 consultas/día. Con enricher + cache, se reduce a ~60,000 consultas/día (10x reducción).
- Latencia optimizable: las consultas paralelas + caching reducen la latencia de enriquecimiento a max(latencia_fuente_más_lenta), no a la suma.
- Resiliencia centralizada: circuit breakers, retries y fallbacks se implementan una sola vez en el enricher, no en cada consumidor.
Impacto Organizacional¶
- Autonomía de equipos consumidores: los equipos de fulfillment, billing y analytics no necesitan implementar lógica de integración con el CRM, catálogo o pricing. Se enfocan en su lógica de negocio.
- Contrato claro: el schema del mensaje enriquecido actúa como contrato entre el enricher y los consumidores. Los consumidores saben exactamente qué campos esperar.
- Evolución independiente: si se añade una nueva fuente de datos (por ejemplo, scoring de lealtad del cliente), solo el enricher se modifica. Los consumidores que no necesitan ese dato no se ven afectados.
Impacto Operacional¶
- Monitoreo centralizado: las métricas de enriquecimiento (latencia por fuente, cache hit rate, error rate) se monitorizan en un solo componente.
- Debugging simplificado: si un consumidor recibe datos incorrectos, el problema está en el enricher o en una fuente específica, no disperso en múltiples consumidores.
- Optimización incremental: se puede mejorar el caching, añadir batching, o cambiar una fuente externa sin impactar a los consumidores.
Beneficios de Mantenibilidad y Evolución¶
- Nuevos consumidores: un nuevo consumidor se conecta al topic
orders.enrichedy recibe mensajes completos sin desarrollo de integración adicional. - Cambio de fuente: si el CRM se reemplaza por otro sistema, solo se modifica la integración en el enricher.
- Enriquecimiento incremental: se pueden añadir nuevas fuentes de enriquecimiento (nuevos campos) de forma incremental, con compatibilidad backward para consumidores que no usan los nuevos campos.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Componente adicional: el enricher es un servicio más para desarrollar, desplegar, monitorear y mantener. Tiene sus propias dependencias, configuración y modos de fallo.
- Gestión de concurrencia: consultar múltiples fuentes en paralelo requiere manejo correcto de concurrencia, timeouts, y composición de resultados.
- Gestión de cache: el cache introduce complejidad de invalidación, TTL tuning, y cold-start problems.
Riesgos de Mal Uso¶
- Enriquecimiento excesivo: añadir datos que ningún consumidor necesita actualmente "por si acaso", aumentando latencia y acoplamiento con fuentes innecesarias.
- Enricher como servicio de composición genérico: evolucionar el enricher hasta que se convierta en un servicio que compone cualquier tipo de datos de cualquier fuente para cualquier consumidor — un anti-pattern que recrea el ESB monolítico.
- Ignorar la consistencia temporal: no documentar que los datos enriquecidos son un snapshot del momento del enriquecimiento, no del momento de creación del evento original.
Sobreingeniería¶
- Crear un framework genérico de enriquecimiento con plugins, configuración dinámica y motor de reglas cuando un enricher simple con lógica explícita es suficiente.
- Implementar enriquecimiento en tiempo real cuando un enriquecimiento batch (nocturno, horario) es suficiente para el caso de uso.
Costos de Operación¶
- Disponibilidad compuesta: aunque el caching mitiga, las fuentes externas deben estar disponibles para que el enricher funcione correctamente. El monitoreo de la disponibilidad de cada fuente es crítico.
- Costo de cache: Redis o el cache elegido requiere infraestructura, monitoreo y scaling.
- Costo de consultas: cada consulta a una fuente externa tiene un costo (latencia de red, carga en la fuente, posiblemente costo monetario en APIs de terceros).
Anti-Patterns Relacionados¶
- God Enricher: un enricher que consulta 20+ fuentes para producir un "super-mensaje" con toda la información posible. Es frágil, lento y difícil de mantener.
- Enrichment Chain of Death: enrichers encadenados donde A enriquece, B re-enriquece el resultado de A, C re-enriquece el resultado de B. La latencia se acumula y la complejidad es inmanejable.
- Synchronous Enrichment in Hot Path: enriquecer síncronamente en el path de un request HTTP, añadiendo la latencia de todas las fuentes al response time del usuario.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Content Filter (este capítulo): el opuesto de Content Enricher. Mientras el enricher añade datos, el filter los elimina. A menudo se usan en secuencia: enriquecer y luego filtrar para cada consumidor.
- Claim Check (este capítulo): mientras Content Enricher añade datos al mensaje, Claim Check los externaliza. Son operaciones inversas en cierto sentido.
- Normalizer (este capítulo): si los datos de enriquecimiento llegan en formatos diferentes, se normalizan antes de combinarlos.
- Canonical Data Model (este capítulo): el mensaje enriquecido puede seguir un modelo canónico que estandariza el formato de los datos combinados.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Router dirige el mensaje al enricher apropiado según su tipo.
- Después: Content-Based Router distribuye el mensaje enriquecido a los consumidores correctos según su contenido enriquecido.
Combinaciones Comunes¶
- Content Enricher + Aggregator: el enricher consulta fuentes y el aggregator combina los resultados. En implementaciones asíncronas, el enricher envía requests a múltiples fuentes y un aggregator combina las respuestas.
- Content Enricher + Message Filter: enriquecer primero, filtrar después. El enricher añade todos los datos; luego un filter por consumidor elimina los que ese consumidor no necesita.
- Content Enricher + Content-Based Router: el router usa datos del mensaje enriquecido (por ejemplo, fraud_status) para dirigir el mensaje a diferentes destinos.
Diferencias con Patrones Similares¶
- vs. Content Filter: el enricher añade datos; el filter los elimina. Son operaciones complementarias.
- vs. Message Translator: el translator transforma datos existentes de un formato a otro; el enricher añade datos nuevos que no estaban en el mensaje.
- vs. Scatter-Gather: Scatter-Gather envía el mismo request a múltiples destinatarios y combina las respuestas. Content Enricher envía requests diferentes a diferentes fuentes basándose en datos del mensaje.
Encaje en un Flujo Mayor de Integración¶
Content Enricher se posiciona en la capa de integración entre productores y consumidores. En un pipeline típico, el flujo es: Productor → [Router] → Content Enricher → [Content Filter] → Consumidor. El enricher actúa como un paso de transformación que eleva el mensaje de "datos mínimos" a "datos completos".
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Content Enricher es uno de los patrones más utilizados en arquitecturas modernas, especialmente en microservicios donde los datos están distribuidos:
- API Composition: en microservicios, el patrón API Composition es exactamente Content Enricher. Un servicio compone una respuesta consultando múltiples microservicios.
- Stream Processing: Kafka Streams, Flink y otros frameworks de stream processing implementan operaciones de enriquecimiento como joins de streams con tablas de lookup.
- Event Enrichment: en event-driven architectures, los eventos se enriquecen en stream processors antes de ser consumidos por los servicios downstream.
- GraphQL resolvers: un resolver de GraphQL que consulta múltiples data sources para componer una respuesta es conceptualmente un Content Enricher.
Cómo Se Implementa Hoy¶
| Plataforma / Framework | Implementación de Content Enricher |
|---|---|
| Kafka Streams | KStream-KTable join (enrich stream con tabla de lookup) |
| Apache Flink | AsyncDataStream + async I/O para consultas externas |
| Apache Camel | .enrich() / .pollEnrich() EIP component |
| Spring Integration | @ServiceActivator con MessageHandler que consulta fuentes |
| AWS Step Functions | Parallel states que consultan Lambda + DynamoDB + APIs |
| Azure Logic Apps | Compose action que combina resultados de múltiples HTTP actions |
| MuleSoft | DataWeave enrichment con HTTP Request connector |
Qué Parte Sigue Siendo Esencial¶
- La necesidad de componer datos distribuidos: mientras los datos estén distribuidos entre servicios (que es la norma en microservicios), habrá necesidad de enriquecimiento.
- El caching como optimización crítica: la diferencia entre un enricher que funciona y uno que colapsa frecuentemente es el caching.
- La resiliencia ante fallos de fuentes: circuit breakers y fallbacks son esenciales en cualquier implementación moderna.
- La posición en el pipeline: enriquecer una vez, consumir muchas veces es el principio económico fundamental del patrón.
15. Implementación en Arquitecturas Modernas¶
Kafka Streams — KStream-KTable Join¶
// Enriquecer stream de órdenes con tabla de clientes
KStream<String, Order> orders = builder.stream("orders.raw");
KTable<String, Customer> customers = builder.table("customers");
KStream<String, EnrichedOrder> enriched = orders
.selectKey((k, v) -> v.getCustomerId())
.join(customers, (order, customer) -> {
EnrichedOrder eo = new EnrichedOrder(order);
eo.setCustomerName(customer.getName());
eo.setCustomerAddress(customer.getAddress());
return eo;
});
enriched.to("orders.enriched");
El KStream-KTable join es la forma más eficiente de enriquecimiento en Kafka: la tabla de clientes se materializa localmente como state store, eliminando la necesidad de consultas externas.
Apache Camel — Enrich EIP¶
from("kafka:orders.raw")
.enrich("http:customer-service/customers/${body.customerId}")
.enrich("http:catalog-service/products/bulk")
.enrich("http:pricing-service/prices/bulk")
.to("kafka:orders.enriched");
Apache Camel implementa Content Enricher como un componente nativo del DSL, con soporte para aggregation strategies que definen cómo combinar el mensaje original con la respuesta de la fuente.
Spring Boot — Async Enrichment¶
@Service
public class OrderEnricher {
@Async
public CompletableFuture<EnrichedOrder> enrich(Order order) {
CompletableFuture<Customer> customer =
customerClient.getAsync(order.getCustomerId());
CompletableFuture<List<Product>> products =
catalogClient.getBulkAsync(order.getProductIds());
CompletableFuture<PricingResult> pricing =
pricingClient.getPricesAsync(order.getProductIds());
CompletableFuture<FraudResult> fraud =
fraudClient.evaluateAsync(order.getCustomerId(), order.getTotal());
return CompletableFuture.allOf(customer, products, pricing, fraud)
.thenApply(v -> compose(order,
customer.join(), products.join(),
pricing.join(), fraud.join()));
}
}
AWS Step Functions — Parallel Enrichment¶
{
"StartAt": "EnrichInParallel",
"States": {
"EnrichInParallel": {
"Type": "Parallel",
"Branches": [
{ "StartAt": "GetCustomer", "States": { "GetCustomer": { "Type": "Task", "Resource": "arn:aws:lambda:...:getCustomer", "End": true } } },
{ "StartAt": "GetProducts", "States": { "GetProducts": { "Type": "Task", "Resource": "arn:aws:lambda:...:getProducts", "End": true } } },
{ "StartAt": "GetPricing", "States": { "GetPricing": { "Type": "Task", "Resource": "arn:aws:lambda:...:getPricing", "End": true } } },
{ "StartAt": "EvaluateFraud", "States": { "EvaluateFraud": { "Type": "Task", "Resource": "arn:aws:lambda:...:evaluateFraud", "End": true } } }
],
"Next": "ComposeEnrichedOrder"
},
"ComposeEnrichedOrder": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:composeOrder",
"End": true
}
}
}
AWS Step Functions implementa el enriquecimiento paralelo como un Parallel state que ejecuta Lambda functions concurrentemente y un paso de composición que combina los resultados.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Latencia por fuente: medir la latencia de cada consulta de enriquecimiento (p50, p95, p99) para identificar fuentes lentas.
- Cache hit rate: monitorear el hit rate del cache por tipo de dato. Un hit rate bajo indica TTL demasiado corto o datos con alta variabilidad.
- Error rate por fuente: tasa de errores (timeouts, 5xx, circuit breaker open) por cada fuente externa.
- Enrichment completeness: porcentaje de mensajes que se enriquecen completamente vs. parcialmente (fallbacks activados).
Monitoreo¶
- Circuit breaker status: monitorear el estado (closed, open, half-open) del circuit breaker de cada fuente.
- Consumer lag del enricher: si el enricher se atrasa en el procesamiento del topic de entrada, los consumidores downstream reciben datos con mayor delay.
- Cache memory usage: el cache puede crecer si los TTLs son largos o el volumen de datos únicos es alto.
- Throughput de enriquecimiento: mensajes enriquecidos por segundo vs. mensajes recibidos por segundo.
Versionado¶
- Schema del mensaje enriquecido: el schema del mensaje enriquecido debe versionarse con un schema registry. Los nuevos campos de enriquecimiento se añaden como opcionales (BACKWARD compatible).
- Versionado de fuentes: si una fuente externa cambia su API (v1 → v2), el enricher debe adaptarse sin impactar el schema del mensaje enriquecido.
Seguridad¶
- Credentials para fuentes: el enricher necesita credenciales para acceder a cada fuente externa. Estas credenciales deben gestionarse con un secret manager (Vault, AWS Secrets Manager).
- Data sensitivity: el enricher combina datos de múltiples fuentes, potencialmente creando un mensaje con datos más sensibles que cualquiera de las fuentes individuales. La clasificación de sensibilidad del mensaje enriquecido debe considerar esto.
- Least privilege: el enricher debe tener acceso de solo lectura a las fuentes externas.
Manejo de Errores¶
- Retry con backoff: reintentar consultas fallidas con exponential backoff antes de activar el fallback.
- Circuit breaker: abrir el circuito si una fuente tiene errores sostenidos, para evitar cascading failures.
- Partial enrichment: definir política por fuente: ¿es el enriquecimiento de esa fuente obligatorio o opcional? Si es obligatorio y falla, dead-letter. Si es opcional, enriquecer parcialmente.
- Dead-letter con contexto: el mensaje en dead-letter debe incluir información sobre qué fuente falló y cuál fue el error.
Idempotencia¶
- El enriquecimiento debe ser idempotente: si el mismo mensaje se procesa dos veces (por replay o retry), el resultado debe ser el mismo. Esto es natural si las fuentes externas devuelven datos deterministas para la misma clave.
Performance¶
- Batch enrichment: si las fuentes soportan consultas bulk (GET /products?ids=A,B,C), usarlas en lugar de consultas individuales.
- Prefetch/warmup: pre-cargar el cache con datos frecuentemente consultados al inicio del enricher.
- Connection pooling: mantener pools de conexiones HTTP a las fuentes externas para evitar el overhead de establecimiento de conexión.
17. Errores Comunes¶
Enriquecer Síncronamente en el Hot Path del Usuario¶
Colocar el Content Enricher en el path síncrono de un HTTP request del usuario, añadiendo la latencia de todas las consultas de enriquecimiento al response time. Solución: enriquecer asíncronamente en un stream processor y que los consumidores lean del topic enriquecido.
No Cachear Datos de Referencia¶
Consultar el catálogo de productos en cada mensaje cuando los datos del catálogo cambian una vez por día. Sin cache, un enricher que procesa 50,000 pedidos/día con 3 productos promedio genera 150,000 consultas innecesarias al catálogo. Con cache (TTL 24h), se reduce a ~5,000.
No Implementar Circuit Breaker¶
Cuando una fuente externa falla, el enricher reintenta cada mensaje indefinidamente, acumulando consumer lag y eventualmente colapsando. Un circuit breaker detecta el fallo sostenido y activa el fallback, manteniendo el throughput.
Crear un God Enricher¶
Un enricher que consulta 15 fuentes diferentes para producir un "super-evento" con todos los datos posibles. Esto crea un componente frágil (15 dependencias), lento (latencia del más lento de 15) y difícil de mantener. Preferir enrichers especializados por dominio o por consumidor.
Ignorar la Consistencia Temporal¶
No documentar ni comunicar que los datos enriquecidos son un snapshot del momento del enriquecimiento. Ejemplo: el precio en el mensaje enriquecido era 29.99€ al momento del enriquecimiento, pero se actualizó a 34.99€ 2 segundos después. Si el consumidor asume que el precio es "actual", puede haber discrepancias.
No Monitorear el Cache Hit Rate¶
Un cache hit rate del 10% indica que el cache es casi inútil (datos demasiado diversos o TTL demasiado corto). Un cache hit rate del 99.9% puede indicar datos estancados (TTL demasiado largo). El hit rate debe monitorearse y el TTL ajustarse según las características de cada tipo de dato.
18. Conclusión Técnica¶
Content Enricher es un patrón fundamental para resolver la fragmentación de datos en arquitecturas distribuidas. Posiciona la lógica de composición de datos en la capa de integración, liberando a productores y consumidores de conocer las fuentes de datos del otro.
Cuándo aporta valor: cuando los mensajes son "delgados" (contienen solo IDs y datos mínimos) y los consumidores necesitan una vista completa con datos de múltiples fuentes. Es especialmente valioso cuando múltiples consumidores necesitan los mismos datos enriquecidos.
Cuándo evita problemas importantes: cuando sin enricher, cada consumidor implementaría su propia lógica de consulta y composición, duplicando código, multiplicando carga en las fuentes y creando acoplamiento directo entre consumidores y fuentes de datos.
Cuándo no conviene adoptarlo: cuando el productor puede incluir todos los datos necesarios sin acoplamiento inaceptable (el ideal es un mensaje completo desde el origen), o cuando el enriquecimiento introduce inconsistencia temporal inaceptable para el caso de uso (datos que cambian en milisegundos y donde un snapshot de hace 100ms es inaceptable).
Recomendación para arquitectos: diseñe el enricher como un componente explícito con responsabilidades claras, no como lógica dispersa. Implemente caching con TTL calibrado por tipo de dato. Use circuit breakers con fallbacks definidos por fuente (¿obligatoria u opcional?). Ejecute las consultas en paralelo. Y monitoree las métricas clave: latencia por fuente, cache hit rate, enrichment completeness y consumer lag. Un enricher bien diseñado es invisible para los consumidores; un enricher mal diseñado es el cuello de botella más frustrante de la arquitectura.