Content Filter¶
1. Nombre del Patrón¶
- Nombre oficial: Content Filter
- Categoría: Message Transformation (Transformación de Mensajes)
- Traducción contextual: Filtro de Contenido
2. Resumen Ejecutivo¶
Content Filter es el patrón que elimina datos innecesarios o no deseados de un mensaje, produciendo un mensaje más pequeño y más enfocado que contiene solo la información relevante para el consumidor. A diferencia de un Message Filter (que descarta mensajes completos), Content Filter opera dentro del mensaje, removiendo campos, secciones o elementos que el consumidor no necesita o no debe recibir.
El problema que resuelve es la sobrecarga informacional: un mensaje puede contener mucha más información de la que un consumidor específico necesita o tiene derecho a ver. Enviar toda la información a todos los consumidores desperdicia ancho de banda, aumenta el tiempo de procesamiento, y — más críticamente — puede violar regulaciones de privacidad al exponer datos sensibles a sistemas que no deberían acceder a ellos.
En el contexto actual de regulaciones como GDPR, HIPAA y LGPD, Content Filter ha pasado de ser una optimización técnica a ser un requisito de compliance. El principio de data minimization (enviar solo los datos estrictamente necesarios para el propósito) se implementa directamente con este patrón. En arquitecturas de microservicios, Content Filter es el mecanismo que permite que un mismo evento se distribuya a múltiples consumidores con diferentes niveles de autorización, filtrando los datos sensibles antes de que alcancen sistemas no autorizados.
3. Definición Detallada¶
Propósito¶
Content Filter intercepta un mensaje y elimina campos, secciones o elementos que no son necesarios para el consumidor destino, produciendo un mensaje reducido que contiene solo la información pertinente. El contenido eliminado puede ser innecesario (el consumidor no lo usa), sensible (el consumidor no debe verlo), o voluminoso (el consumidor no necesita la versión completa).
Lógica Arquitectónica¶
En un sistema de integración, los mensajes frecuentemente transportan más información de la que cualquier consumidor individual necesita. Esto ocurre por varias razones:
- El productor no conoce las necesidades específicas de cada consumidor: genera un mensaje genérico con toda la información disponible.
- Los mensajes se producen una vez y se consumen múltiples veces: el formato del mensaje es la unión de las necesidades de todos los consumidores, pero cada consumidor individual necesita solo un subconjunto.
- Los mensajes incluyen datos sensibles: información personal (PII), datos médicos (PHI), datos financieros que solo ciertos consumidores están autorizados a procesar.
Content Filter resuelve esto posicionándose entre el canal genérico y cada consumidor, removiendo los datos que ese consumidor no necesita o no debe recibir:
- Filtrado por necesidad: eliminar campos irrelevantes para simplificar el procesamiento del consumidor.
- Filtrado por seguridad: eliminar datos sensibles que el consumidor no está autorizado a ver.
- Filtrado por eficiencia: eliminar datos voluminosos que el consumidor no necesita para reducir bandwidth y tiempo de procesamiento.
Principio de Diseño Subyacente¶
El principio es data minimization (minimización de datos): cada consumidor debe recibir solo los datos estrictamente necesarios para cumplir su función. Este principio está codificado en regulaciones como GDPR (Artículo 5.1.c: "adecuados, pertinentes y limitados a lo necesario en relación con los fines para los que son tratados") y HIPAA (Minimum Necessary Rule).
Problema Estructural que Resuelve¶
Sin Content Filter:
- Todos los consumidores reciben la misma información, incluyendo datos que no necesitan y datos que no deberían ver.
- Los datos sensibles se propagan a sistemas que no tienen justificación para procesarlos, creando riesgo regulatorio.
- Los mensajes son más grandes de lo necesario, consumiendo más bandwidth, almacenamiento y tiempo de parsing.
- El consumidor debe implementar su propia lógica de selección/descarte, mezclando preocupaciones de filtrado con lógica de negocio.
Contexto en el que Emerge¶
Content Filter emerge en escenarios donde:
- Un mensaje contiene más datos de los que un consumidor específico necesita.
- Existen requisitos de privacidad o regulación que prohiben enviar ciertos datos a ciertos sistemas.
- Se necesita optimizar el tamaño de los mensajes para canales con limitaciones de bandwidth o almacenamiento.
- Múltiples consumidores necesitan vistas diferentes del mismo mensaje.
Por Qué No Es Trivial¶
Las decisiones de filtrado tienen implicaciones significativas:
- ¿Qué filtrar?: la decisión de qué datos son "innecesarios" depende del consumidor. Un campo irrelevante para un consumidor puede ser crítico para otro.
- ¿Cómo filtrar datos sensibles?: ¿se eliminan completamente? ¿Se reemplazan con máscaras (****)? ¿Se pseudonimizan (hash)? ¿Se tokenizan?
- ¿Dónde filtrar?: ¿en el productor, en un intermediario, en un stream processor, en un API gateway?
- Filtrado vs. proyección: ¿se crea un mensaje nuevo con los campos seleccionados (proyección), o se modifica el mensaje original eliminando campos (mutación)?
- Evolución del schema: cuando el schema del mensaje original evoluciona (nuevo campo), ¿el filtro debe actualizarse? ¿El nuevo campo se filtra por defecto o pasa?
Relación con Sistemas Distribuidos y Mensajería¶
Content Filter implementa el principio de need-to-know basis en sistemas distribuidos. En seguridad de la información, este principio establece que cada componente debe acceder solo a la información que necesita para su función. En la práctica, Content Filter es el mecanismo técnico que implementa este principio en la capa de mensajería.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Un hospital genera un mensaje clínico cuando se completa un resultado de laboratorio. El mensaje contiene toda la información del caso:
{
"lab_result_id": "LR-2026-449821",
"patient": {
"mrn": "MRN-78945",
"name": "Juan Pérez García",
"date_of_birth": "1985-03-15",
"ssn": "123-45-6789",
"address": "Calle del Sol 42, 28004 Madrid",
"phone": "+34 612 345 678",
"insurance_id": "SEG-2026-112233"
},
"test": {
"code": "CBC",
"name": "Complete Blood Count",
"results": [
{ "component": "WBC", "value": 7.5, "unit": "10^3/uL", "flag": "normal" },
{ "component": "RBC", "value": 4.8, "unit": "10^6/uL", "flag": "normal" },
{ "component": "HGB", "value": 14.2, "unit": "g/dL", "flag": "normal" }
]
},
"ordering_physician": {
"npi": "1234567890",
"name": "Dra. Ana López"
},
"performed_at": "2026-04-07T09:15:00Z"
}
Este mensaje necesita distribuirse a tres sistemas: 1. Electronic Medical Record (EMR): necesita todo — datos del paciente, resultados, médico. 2. Sistema de Investigación Clínica: necesita resultados de laboratorio para estudios estadísticos, pero NO debe recibir datos identificativos del paciente (HIPAA, GDPR). 3. Sistema de Facturación: necesita datos del seguro y códigos de tests, pero NO debe recibir resultados clínicos (principio de mínimo acceso).
Sin Content Filter, los tres sistemas reciben el mensaje completo, violando regulaciones de privacidad y exponiendo datos sensibles a sistemas no autorizados.
Síntomas del Problema¶
- Sistemas de investigación que almacenan datos personales de pacientes sin justificación, creando riesgo de multas GDPR (hasta 4% de facturación global).
- Sistemas de facturación que tienen acceso a resultados clínicos que no necesitan, ampliando innecesariamente la superficie de ataque.
- Auditorías de compliance que detectan flujos de datos no conformes.
- Mensajes oversized que consumen más bandwidth y almacenamiento del necesario.
- Consumidores que parsean y descartan campos irrelevantes, desperdiciando CPU.
Impacto Operativo y Arquitectónico¶
Sin Content Filter:
- La organización no puede demostrar compliance con el principio de data minimization de GDPR/HIPAA.
- Una brecha de seguridad en cualquier sistema consumidor expone todos los datos del mensaje, no solo los que ese sistema necesita.
- Los data protection officers no pueden aprobar nuevos flujos de datos porque no hay mecanismo para restringir qué datos llegan a cada sistema.
- La proliferación de datos sensibles en sistemas no autorizados crea un "data sprawl" que es imposible de auditar o limpiar.
Riesgos Si No Se Implementa Correctamente¶
- Filtrado incompleto: olvidar un campo sensible que pasa al consumidor no autorizado. Esto es especialmente peligroso con PII embebido en campos de texto libre (notas clínicas que mencionan nombres de pacientes).
- Filtrado excesivo: eliminar datos que el consumidor necesita, causando errores silenciosos o procesamiento incorrecto.
- Filtrado inconsistente: aplicar filtros diferentes en distintos puntos del flujo, resultando en que el mismo consumidor recibe datos diferentes según la ruta del mensaje.
- Filtrado que no se actualiza: cuando el schema del mensaje evoluciona (nuevo campo sensible), el filtro no se actualiza y el nuevo campo sensible pasa sin filtrar.
Ejemplos Reales¶
- Healthcare: resultado de laboratorio se filtra para eliminar PII antes de enviarlo al sistema de investigación. Solo pasan códigos de test, resultados numéricos y un pseudoidentificador del paciente (hash del MRN).
- Banca: transacciones se filtran para eliminar datos del titular de la cuenta antes de enviarse al sistema de analytics, cumpliendo con PCI-DSS y data minimization.
- E-commerce: evento de pedido se filtra para eliminar datos de pago (número de tarjeta, CVV) antes de enviarse al sistema de logística que solo necesita dirección y productos.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un mensaje contiene datos sensibles (PII, PHI, PCI) que ciertos consumidores no deben recibir.
- Cuando regulaciones (GDPR, HIPAA, PCI-DSS) exigen minimización de datos en los flujos de integración.
- Cuando un consumidor solo necesita un subconjunto del mensaje y enviar el mensaje completo es ineficiente.
- Cuando diferentes consumidores necesitan vistas diferentes del mismo mensaje original.
Cuándo No Usarlo¶
- Cuando el productor puede generar mensajes específicos para cada consumidor (preferible a generar un mensaje genérico y filtrarlo después).
- Cuando todos los consumidores necesitan y están autorizados a ver toda la información del mensaje.
- Cuando el overhead de filtrado es mayor que el ahorro de bandwidth (mensajes pequeños con pocos campos innecesarios).
Precondiciones¶
- Existe una definición clara de qué datos debe (y no debe) recibir cada consumidor.
- Existe un data classification scheme que identifica datos sensibles (PII, PHI, PCI, etc.).
- El formato del mensaje permite filtrado selectivo de campos (JSON, XML, Avro con named fields).
Restricciones¶
- El filtrado es una transformación destructiva: una vez eliminados los datos, no se pueden recuperar del mensaje filtrado.
- El filtro debe mantenerse sincronizado con la evolución del schema del mensaje: nuevos campos potencialmente sensibles deben evaluarse.
- El rendimiento del filtrado depende de la complejidad del schema y del tamaño del mensaje.
Dependencias¶
- Definición de políticas de filtrado por consumidor o por clasificación de datos.
- Mecanismo de filtrado (stream processor, API gateway, middleware).
- Governance que mantenga actualizadas las políticas de filtrado ante evolución del schema.
Supuestos Arquitectónicos¶
- El mensaje original contiene más datos de los que al menos un consumidor necesita.
- Los datos que se filtran no son necesarios para el consumidor y su ausencia no causa errores.
- Existe un componente con autorización para leer el mensaje completo y producir versiones filtradas.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Integraciones healthcare (HL7/FHIR) con requisitos HIPAA.
- Sistemas financieros con requisitos PCI-DSS.
- Cualquier sistema bajo regulación GDPR/LGPD con flujos de datos personales.
- Event-driven architectures donde un evento se distribuye a consumidores con diferentes necesidades.
6. Fuerzas Arquitectónicas¶
Seguridad vs. Funcionalidad¶
El filtrado más estricto (eliminar todo dato potencialmente sensible) maximiza la seguridad pero puede eliminar datos que el consumidor necesita para funcionar. El filtrado más permisivo mantiene funcionalidad pero aumenta riesgo de exposición de datos sensibles.
Centralización vs. Proximidad al Consumidor¶
¿Un filtro central que produce versiones filtradas para todos los consumidores, o filtros específicos cerca de cada consumidor? El filtro central es más fácil de auditar pero es un single point of failure. Los filtros distribuidos son más resilientes pero más difíciles de gobernar.
Performance vs. Granularidad¶
Filtrar a nivel de campo es más preciso pero requiere parsing completo del mensaje. Filtrar a nivel de sección (eliminar una rama entera del JSON/XML) es más rápido pero menos granular. La elección depende de los requisitos de precisión y los constraints de latencia.
Compliance vs. Agilidad¶
Las políticas de filtrado estrictas (whitelisting: solo pasan campos explícitamente permitidos) maximizan compliance pero requieren actualizar el filtro cada vez que el consumidor necesita un nuevo campo. Las políticas permisivas (blacklisting: se bloquean campos explícitamente prohibidos) son más ágiles pero arriesgan que un nuevo campo sensible pase sin filtrar.
Eliminación vs. Enmascaramiento¶
¿Eliminar el campo por completo o enmascararlo (reemplazar con asteriscos, hash, token)? La eliminación es más segura pero el consumidor pierde incluso la noción de que el campo existe. El enmascaramiento preserva la estructura del mensaje pero puede ser insuficiente si incluso la presencia del campo revela información.
Reversibilidad vs. Seguridad¶
La tokenización (reemplazar datos con tokens reversibles) permite recuperar los datos originales si es necesario, pero añade complejidad y requiere gestión segura del servicio de tokenización. La eliminación es irreversible pero más simple y segura.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: genera el mensaje completo con todos los datos disponibles.
- Content Filter: intercepta el mensaje y elimina/enmascara datos según las políticas de filtrado.
- Política de Filtrado: define qué campos eliminar/enmascarar para cada consumidor o categoría de consumidor.
- Consumidor: recibe y procesa el mensaje filtrado con solo los datos pertinentes.
- Governance/DPO: define y actualiza las políticas de filtrado según regulaciones y necesidades de negocio.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Mensaje completo\ncon todos los datos]
B --> C[Content Filter\nrecibe mensaje completo]
C --> D{Consumidor\ndestino?}
D -- Research System --> E[Eliminar datos personales\nPseudonimizar mrn]
D -- Billing System --> F[Eliminar resultados clínicos\nMantener datos de facturación]
E --> G[Mantener test.code\ntest.results]
F --> H[Mantener patient.name\ninsurance_id, test.code]
G --> I[(Canal Research\nmensaje filtrado)]
H --> J[(Canal Billing\nmensaje filtrado)]
I --> K([Consumidor procesa mensaje\nsin saber qué se eliminó])
J --> KResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Generar mensaje completo y clasificar datos por sensibilidad (opcional) |
| Content Filter | Aplicar políticas de filtrado sin alterar los datos que permanecen |
| Política de filtrado | Definir qué datos se eliminan/enmascaran para cada destino |
| Consumidor | Procesar el mensaje filtrado; su schema no incluye los campos eliminados |
| Governance | Mantener las políticas actualizadas ante cambios de regulación o schema |
Interacciones¶
- Productor → Canal genérico: el mensaje completo se publica en un canal compartido.
- Canal genérico → Content Filter: el filtro consume del canal genérico.
- Content Filter → Política de filtrado: consulta la política para determinar qué filtrar.
- Content Filter → Canal filtrado: produce el mensaje filtrado en un canal específico por consumidor.
Contratos Implícitos¶
- Completitud del mensaje filtrado: el consumidor confía en que todos los campos que necesita están presentes en el mensaje filtrado.
- Integridad de datos no filtrados: los datos que pasan el filtro no deben ser alterados.
- Irreversibilidad: los datos eliminados no son recuperables del mensaje filtrado (el consumidor no puede "pedir más").
Decisiones de Diseño Clave¶
- Whitelist vs. Blacklist: ¿definir qué campos pasan (whitelist, más seguro) o qué campos se bloquean (blacklist, más ágil)?
- Eliminar vs. enmascarar vs. pseudonimizar: ¿quitar el campo, reemplazar con máscara, o reemplazar con pseudoidentificador?
- Un filtro por consumidor vs. un filtro por clasificación: ¿filtros específicos por cada consumidor, o filtros por nivel de autorización (público, interno, confidencial)?
- Posición del filtro: ¿en el broker (subscription filter), en un stream processor, en un API gateway, o en un sidecar del consumidor?
- Policy-as-code: ¿las políticas de filtrado están en código, en configuración, o en un policy engine externo?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Healthcare — Desidentificación de Datos Clínicos para Investigación¶
Contexto del Negocio¶
Un hospital universitario opera un sistema de información clínica que genera mensajes cuando se producen resultados de laboratorio, diagnósticos, procedimientos y notas clínicas. La universidad tiene un departamento de investigación clínica que necesita estos datos para estudios epidemiológicos, ensayos clínicos retrospectivos y modelos de machine learning.
Las regulaciones HIPAA (EE.UU.) y GDPR (UE) prohíben enviar datos identificativos de pacientes al sistema de investigación sin consentimiento explícito. Sin embargo, los datos clínicos desidentificados (sin PII/PHI) sí pueden usarse para investigación bajo la excepción de investigación de GDPR (Art. 89) y la regla Safe Harbor de HIPAA.
Necesidad de Integración¶
Los resultados de laboratorio deben fluir a tres destinos con diferentes requisitos de datos:
- EMR (Electronic Medical Record): recibe el mensaje completo — todos los datos del paciente y resultados clínicos. Autorizado para PII y PHI.
- Sistema de Investigación: recibe resultados clínicos sin datos identificativos del paciente. No autorizado para PII.
- Sistema de Billing/Insurance: recibe datos de facturación (código de test, insurance ID, datos del paciente para facturación). No autorizado para resultados clínicos detallados.
Sistemas Involucrados¶
- Laboratory Information System (LIS): genera el mensaje de resultado de laboratorio completo.
- Event Bus (Kafka): distribuye el mensaje a los Content Filters.
- Clinical Data Filter: filtra datos para el sistema de investigación (elimina PII).
- Billing Data Filter: filtra datos para el sistema de facturación (elimina resultados clínicos).
- EMR: recibe el mensaje completo sin filtrar.
- Research Data Warehouse: recibe datos desidentificados.
- Billing System: recibe datos de facturación.
- Data Privacy Officer (DPO): define y audita las políticas de filtrado.
Restricciones Técnicas¶
- HIPAA Safe Harbor requiere eliminar 18 tipos de identificadores del paciente (nombre, SSN, fecha de nacimiento exacta, dirección, teléfono, email, MRN, etc.).
- Las fechas pueden generalizarse a nivel de año (no eliminar completamente) para mantener utilidad para investigación.
- El MRN del paciente debe pseudonimizarse con un hash consistente para que el sistema de investigación pueda correlacionar resultados del mismo paciente sin identificarlo.
- El filtrado debe ser auditable: registrar qué campos se eliminaron de cada mensaje.
- Latencia aceptable: el filtrado puede tomar hasta 2 segundos sin impacto en los flujos clínicos.
Diseño del Filtrado¶
Política para Research System (Clinical Data Filter):
| Campo | Acción | Justificación |
|---|---|---|
| patient.name | ELIMINAR | PII directo |
| patient.ssn | ELIMINAR | PII directo |
| patient.date_of_birth | GENERALIZAR a año | Utilidad para investigación, reduce identificabilidad |
| patient.address | ELIMINAR | PII directo |
| patient.phone | ELIMINAR | PII directo |
| patient.mrn | PSEUDONIMIZAR (SHA-256 + salt) | Permite correlación sin identificación |
| patient.insurance_id | ELIMINAR | PII directo |
| test.* | MANTENER | Datos clínicos necesarios para investigación |
| ordering_physician.name | ELIMINAR | Podría permitir re-identificación |
| ordering_physician.npi | MANTENER | Identificador profesional, no PII del paciente |
Política para Billing System (Billing Data Filter):
| Campo | Acción | Justificación |
|---|---|---|
| patient.name | MANTENER | Necesario para facturación |
| patient.insurance_id | MANTENER | Necesario para facturación |
| patient.ssn | ELIMINAR | No necesario para facturación |
| patient.address | MANTENER | Necesario para facturación |
| test.code, test.name | MANTENER | Necesario para codificación de procedimiento |
| test.results | ELIMINAR | No necesario para facturación, clínicamente sensible |
| ordering_physician.* | MANTENER | Necesario para facturación |
Decisiones Arquitectónicas¶
- Filtros separados por destino: en lugar de un filtro genérico, cada consumidor tiene su propio Content Filter con política específica. Esto es más seguro: una política incorrecta afecta a un solo consumidor.
- Whitelist approach: la política define explícitamente qué campos pasan. Los campos no listados se eliminan por defecto. Esto protege contra nuevos campos sensibles que se añadan al schema.
- Pseudonimización consistente: el MRN se hashea con SHA-256 + salt secreto. El salt es conocido solo por el Content Filter, no por el sistema de investigación. El hash es determinista para el mismo MRN, permitiendo correlación.
- Audit log: cada operación de filtrado genera un registro de auditoría con: message_id, campos eliminados, campos enmascarados, política aplicada, timestamp.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Nuevo campo PII no incluido en la política | Whitelist approach: nuevos campos no pasan por defecto |
| Re-identificación por combinación de datos | Revisión periódica de k-anonimidad de los datos filtrados |
| Salt de pseudonimización comprometido | Salt almacenado en HSM, rotación anual |
| Filtro falla y envía datos sin filtrar | Circuit breaker: si el filtro falla, el mensaje NO se envía |
| Política desactualizada tras cambio regulatorio | Revisión trimestral de políticas con DPO |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación del Resultado de Laboratorio¶
El LIS (Laboratory Information System) completa un resultado de laboratorio para el paciente MRN-78945. Genera el mensaje completo:
{
"lab_result_id": "LR-2026-449821",
"patient": {
"mrn": "MRN-78945",
"name": "Juan Pérez García",
"date_of_birth": "1985-03-15",
"ssn": "123-45-6789",
"address": "Calle del Sol 42, 28004 Madrid",
"phone": "+34 612 345 678",
"insurance_id": "SEG-2026-112233"
},
"test": {
"code": "CBC",
"name": "Complete Blood Count",
"results": [
{ "component": "WBC", "value": 7.5, "unit": "10^3/uL", "flag": "normal" },
{ "component": "RBC", "value": 4.8, "unit": "10^6/uL", "flag": "normal" },
{ "component": "HGB", "value": 14.2, "unit": "g/dL", "flag": "normal" }
]
},
"ordering_physician": {
"npi": "1234567890",
"name": "Dra. Ana López"
},
"performed_at": "2026-04-07T09:15:00Z"
}
El LIS publica este mensaje en el topic Kafka clinical.lab-results.raw.
Paso 2: Distribución a Content Filters¶
El topic clinical.lab-results.raw tiene tres consumer groups: - cg-emr: consume directamente sin filtrar (autorizado para datos completos). - cg-research-filter: Content Filter que produce datos desidentificados. - cg-billing-filter: Content Filter que produce datos de facturación.
Paso 3: Clinical Data Filter (para Investigación)¶
El Clinical Data Filter consume el mensaje y aplica la política de filtrado para investigación:
- ELIMINA
patient.name→ campo removido del mensaje. - ELIMINA
patient.ssn→ campo removido. - GENERALIZA
patient.date_of_birth: "1985-03-15" → "1985" (solo año). - ELIMINA
patient.address→ campo removido. - ELIMINA
patient.phone→ campo removido. - PSEUDONIMIZA
patient.mrn: "MRN-78945" → SHA-256("MRN-78945" + salt) → "a3f2b8c9d1e4...". - ELIMINA
patient.insurance_id→ campo removido. - MANTIENE todos los datos clínicos (
test.*). - ELIMINA
ordering_physician.name. - MANTIENE
ordering_physician.npi.
Mensaje filtrado para investigación:
{
"lab_result_id": "LR-2026-449821",
"patient": {
"pseudo_id": "a3f2b8c9d1e4f7a2b5c8d1e4f7a2b5c8",
"birth_year": 1985
},
"test": {
"code": "CBC",
"name": "Complete Blood Count",
"results": [
{ "component": "WBC", "value": 7.5, "unit": "10^3/uL", "flag": "normal" },
{ "component": "RBC", "value": 4.8, "unit": "10^6/uL", "flag": "normal" },
{ "component": "HGB", "value": 14.2, "unit": "g/dL", "flag": "normal" }
]
},
"ordering_physician": {
"npi": "1234567890"
},
"performed_at": "2026-04-07T09:15:00Z",
"_filtering": {
"policy": "research-deidentification-v3",
"filtered_at": "2026-04-07T09:15:00.450Z",
"fields_removed": ["patient.name", "patient.ssn", "patient.dob", "patient.address", "patient.phone", "patient.insurance_id", "ordering_physician.name"],
"fields_generalized": ["patient.date_of_birth → birth_year"],
"fields_pseudonymized": ["patient.mrn → pseudo_id"]
}
}
El filtro publica este mensaje en clinical.lab-results.research.
Paso 4: Billing Data Filter (para Facturación)¶
El Billing Data Filter consume el mismo mensaje original y aplica la política de facturación:
{
"lab_result_id": "LR-2026-449821",
"patient": {
"name": "Juan Pérez García",
"address": "Calle del Sol 42, 28004 Madrid",
"insurance_id": "SEG-2026-112233"
},
"test": {
"code": "CBC",
"name": "Complete Blood Count"
},
"ordering_physician": {
"npi": "1234567890",
"name": "Dra. Ana López"
},
"performed_at": "2026-04-07T09:15:00Z"
}
Nótese: los resultados clínicos (test.results) se han eliminado completamente. El sistema de facturación sabe qué test se realizó pero no los resultados.
Paso 5: Audit Trail¶
Cada operación de filtrado genera un registro de auditoría inmutable:
{
"audit_id": "AUD-2026-991827",
"original_message_id": "LR-2026-449821",
"filter": "clinical-data-filter",
"policy_applied": "research-deidentification-v3",
"destination": "clinical.lab-results.research",
"fields_removed": 7,
"fields_generalized": 1,
"fields_pseudonymized": 1,
"filtered_at": "2026-04-07T09:15:00.450Z",
"filter_version": "2.1.0"
}
Este audit trail es esencial para demostrar compliance ante reguladores y para responder a Data Subject Access Requests (DSAR) bajo GDPR.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
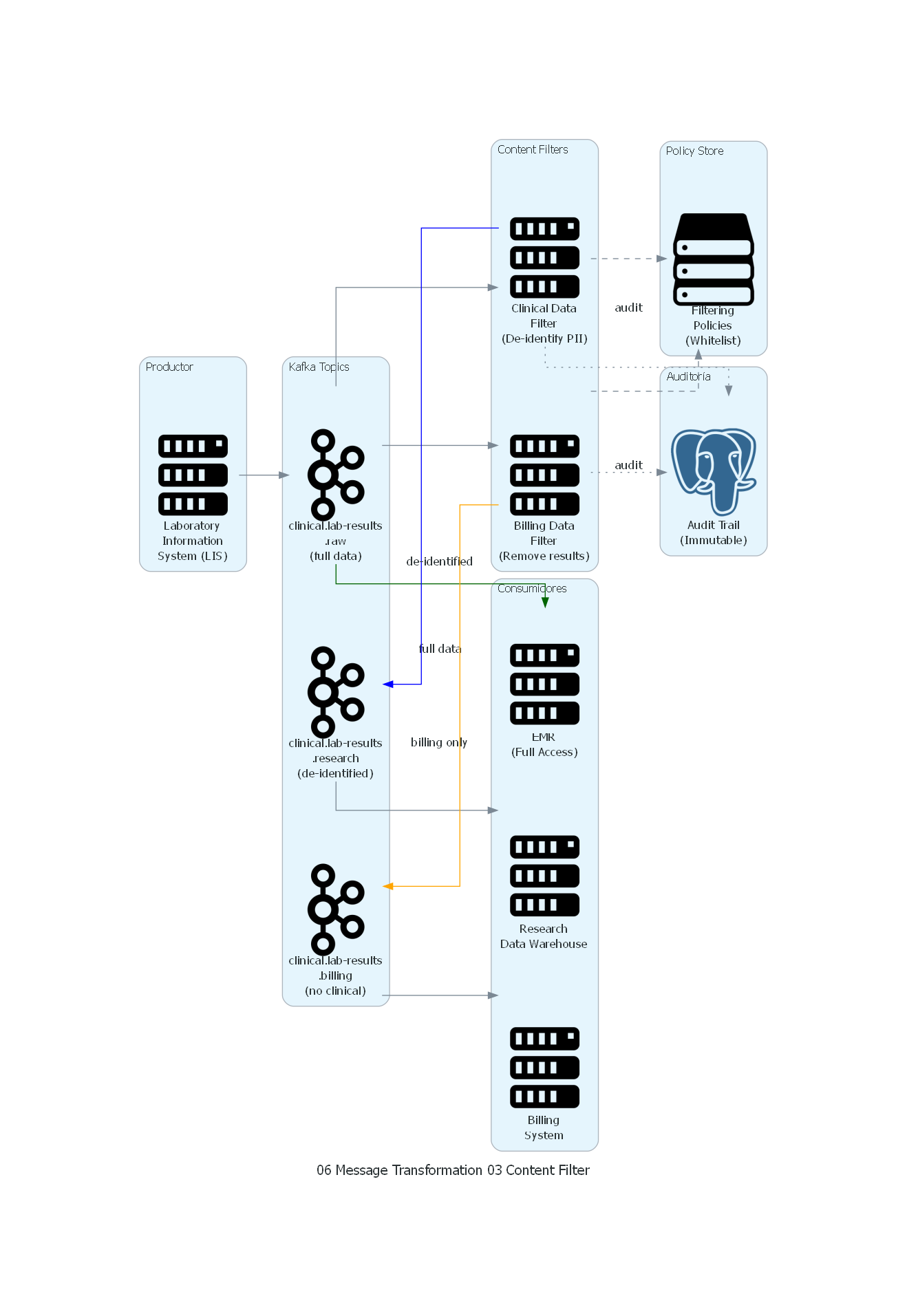
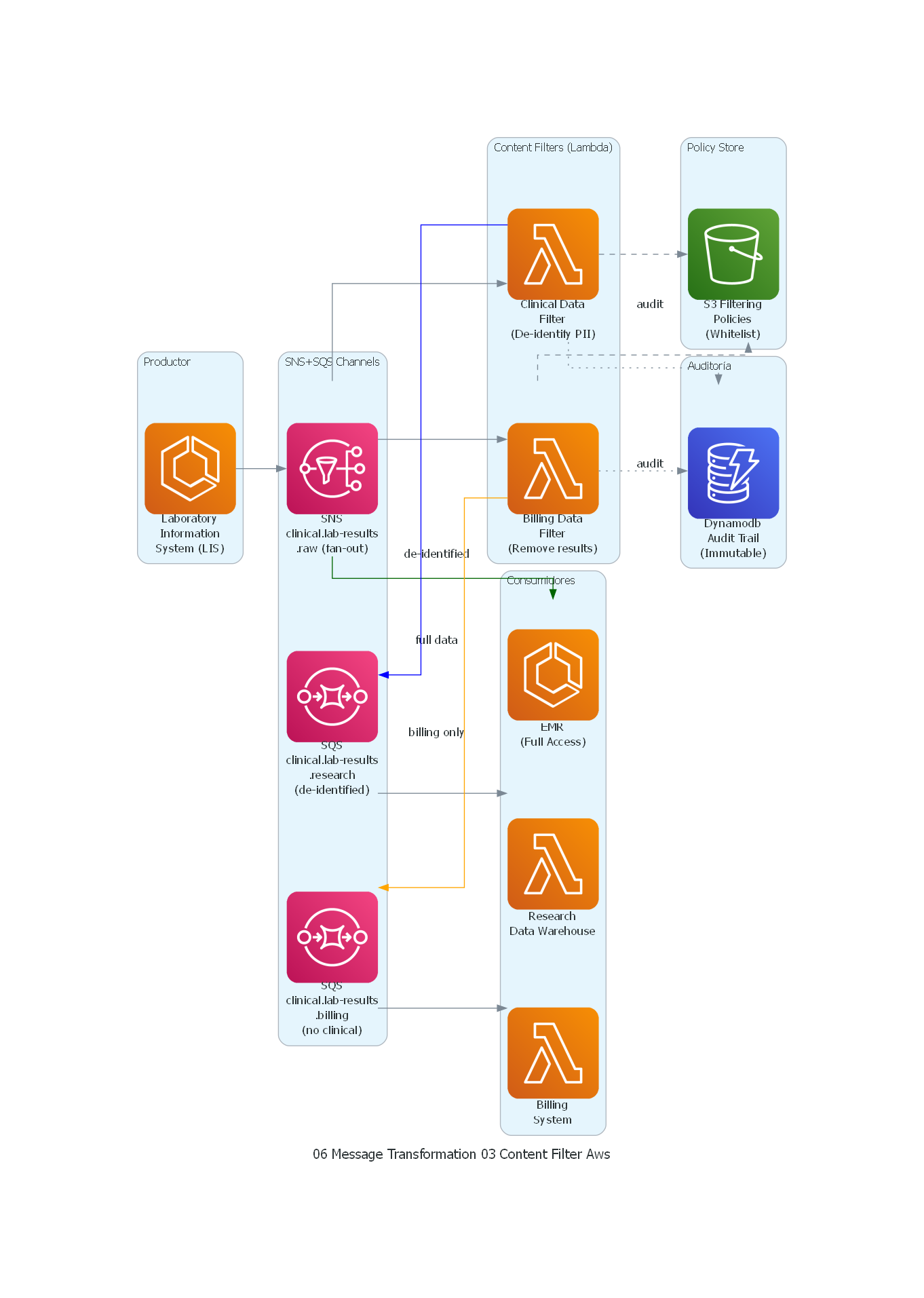
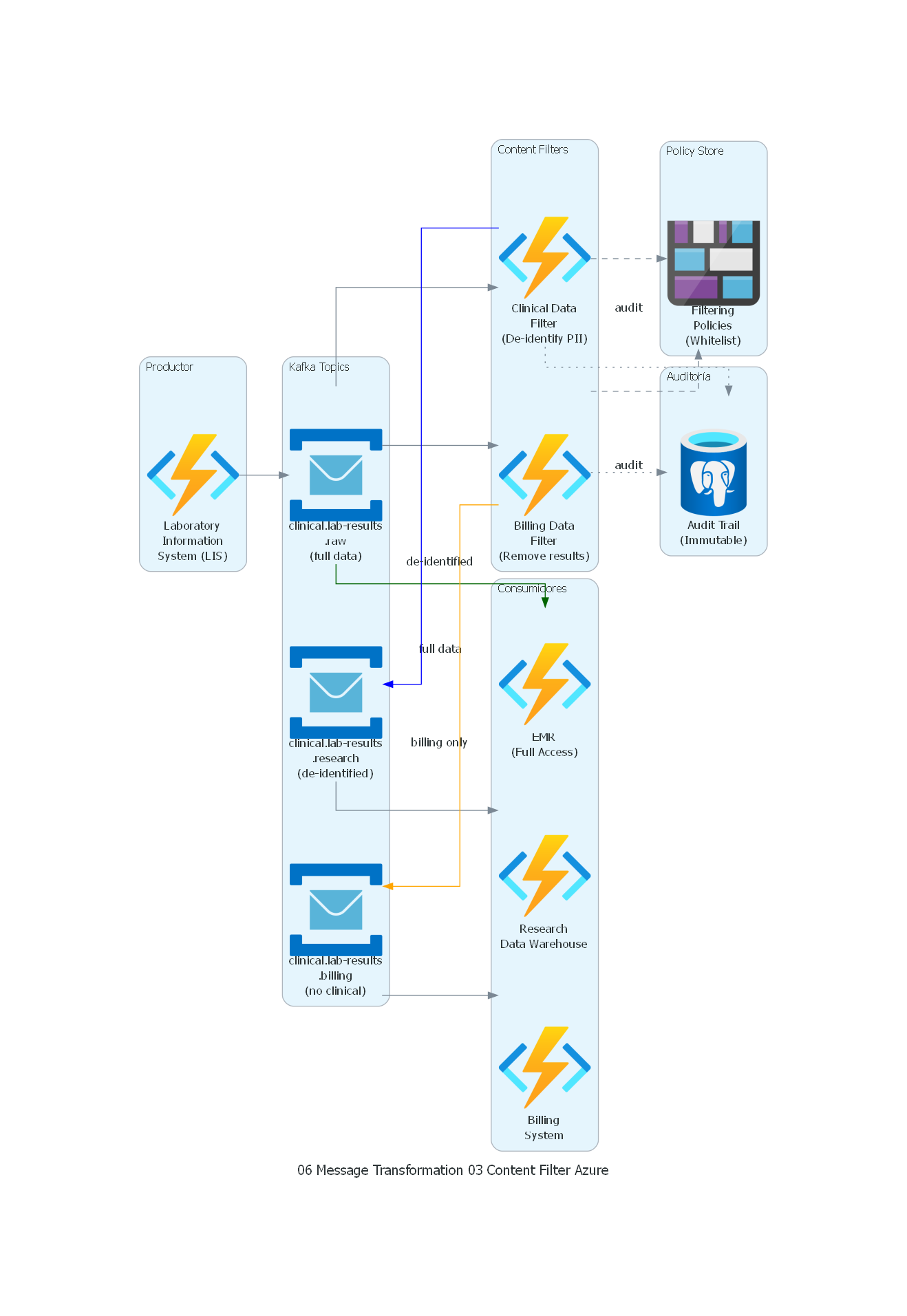
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.storage import Storage
with Diagram("Content Filter - Clinical Data Deidentification", show=False, direction="LR"):
with Cluster("Productor"):
lis = Server("Laboratory\nInformation\nSystem (LIS)")
with Cluster("Kafka Topics"):
raw_topic = Kafka("clinical.lab-results\n.raw\n(full data)")
research_topic = Kafka("clinical.lab-results\n.research\n(de-identified)")
billing_topic = Kafka("clinical.lab-results\n.billing\n(no clinical)")
with Cluster("Content Filters"):
research_filter = Server("Clinical Data\nFilter\n(De-identify PII)")
billing_filter = Server("Billing Data\nFilter\n(Remove results)")
with Cluster("Policy Store"):
policies = Storage("Filtering\nPolicies\n(Whitelist)")
with Cluster("Consumidores"):
emr = Server("EMR\n(Full Access)")
research = Server("Research\nData Warehouse")
billing = Server("Billing\nSystem")
with Cluster("Auditoría"):
audit_log = PostgreSQL("Audit Trail\n(Immutable)")
# Flujo
lis >> raw_topic
# EMR recibe directo (sin filtro)
raw_topic >> Edge(label="full data", color="darkgreen") >> emr
# Research filter
raw_topic >> research_filter
research_filter >> Edge(style="dashed") >> policies
research_filter >> Edge(label="de-identified", color="blue") >> research_topic
research_topic >> research
# Billing filter
raw_topic >> billing_filter
billing_filter >> Edge(style="dashed") >> policies
billing_filter >> Edge(label="billing only", color="orange") >> billing_topic
billing_topic >> billing
# Audit
research_filter >> Edge(style="dotted", label="audit") >> audit_log
billing_filter >> Edge(style="dotted", label="audit") >> audit_log
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.storage import S3
with Diagram("Content Filter - Clinical Data Deidentification (AWS)", show=False, direction="LR"):
with Cluster("Productor"):
lis = ECS("Laboratory\nInformation\nSystem (LIS)")
with Cluster("SNS+SQS Channels"):
raw_topic = SNS("SNS\nclinical.lab-results\n.raw (fan-out)")
research_topic = SQS("SQS\nclinical.lab-results\n.research\n(de-identified)")
billing_topic = SQS("SQS\nclinical.lab-results\n.billing\n(no clinical)")
with Cluster("Content Filters (Lambda)"):
research_filter = Lambda("Clinical Data\nFilter\n(De-identify PII)")
billing_filter = Lambda("Billing Data\nFilter\n(Remove results)")
with Cluster("Policy Store"):
policies = S3("S3 Filtering\nPolicies\n(Whitelist)")
with Cluster("Consumidores"):
emr = ECS("EMR\n(Full Access)")
research = Lambda("Research\nData Warehouse")
billing = Lambda("Billing\nSystem")
with Cluster("Auditoría"):
audit_log = Dynamodb("Dynamodb\nAudit Trail\n(Immutable)")
# Flujo
lis >> raw_topic
# EMR recibe directo (sin filtro) via SNS subscription
raw_topic >> Edge(label="full data", color="darkgreen") >> emr
# Research filter via SNS subscription
raw_topic >> research_filter
research_filter >> Edge(style="dashed") >> policies
research_filter >> Edge(label="de-identified", color="blue") >> research_topic
research_topic >> research
# Billing filter via SNS subscription
raw_topic >> billing_filter
billing_filter >> Edge(style="dashed") >> policies
billing_filter >> Edge(label="billing only", color="orange") >> billing_topic
billing_topic >> billing
# Audit
research_filter >> Edge(style="dotted", label="audit") >> audit_log
billing_filter >> Edge(style="dotted", label="audit") >> audit_log
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import DatabaseForPostgresqlServers
from diagrams.azure.integration import ServiceBus
from diagrams.azure.storage import BlobStorage
with Diagram("Content Filter - Clinical Data Deidentification (Azure)", show=False, direction="LR"):
with Cluster("Productor"):
lis = FunctionApps("Laboratory\nInformation\nSystem (LIS)")
with Cluster("Kafka Topics"):
raw_topic = ServiceBus("clinical.lab-results\n.raw\n(full data)")
research_topic = ServiceBus("clinical.lab-results\n.research\n(de-identified)")
billing_topic = ServiceBus("clinical.lab-results\n.billing\n(no clinical)")
with Cluster("Content Filters"):
research_filter = FunctionApps("Clinical Data\nFilter\n(De-identify PII)")
billing_filter = FunctionApps("Billing Data\nFilter\n(Remove results)")
with Cluster("Policy Store"):
policies = BlobStorage("Filtering\nPolicies\n(Whitelist)")
with Cluster("Consumidores"):
emr = FunctionApps("EMR\n(Full Access)")
research = FunctionApps("Research\nData Warehouse")
billing = FunctionApps("Billing\nSystem")
with Cluster("Auditoría"):
audit_log = DatabaseForPostgresqlServers("Audit Trail\n(Immutable)")
# Flujo
lis >> raw_topic
# EMR recibe directo (sin filtro)
raw_topic >> Edge(label="full data", color="darkgreen") >> emr
# Research filter
raw_topic >> research_filter
research_filter >> Edge(style="dashed") >> policies
research_filter >> Edge(label="de-identified", color="blue") >> research_topic
research_topic >> research
# Billing filter
raw_topic >> billing_filter
billing_filter >> Edge(style="dashed") >> policies
billing_filter >> Edge(label="billing only", color="orange") >> billing_topic
billing_topic >> billing
# Audit
research_filter >> Edge(style="dotted", label="audit") >> audit_log
billing_filter >> Edge(style="dotted", label="audit") >> audit_log
Explicación del Diagrama¶
El diagrama muestra la arquitectura de filtrado de datos clínicos:
- El LIS publica resultados de laboratorio completos en
clinical.lab-results.raw. - El EMR consume directamente del topic raw (autorizado para datos completos).
- El Clinical Data Filter consume del raw, aplica desidentificación, y produce en
clinical.lab-results.research. - El Billing Data Filter consume del raw, elimina resultados clínicos, y produce en
clinical.lab-results.billing. - Ambos filtros consultan el Policy Store para las reglas de filtrado y escriben en el Audit Trail.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensaje original (completo) | Evento en clinical.lab-results.raw |
| Content Filter | Clinical Data Filter, Billing Data Filter |
| Política de filtrado | Policy Store (Whitelist definitions) |
| Mensaje filtrado | Eventos en topics .research y .billing |
| Consumidor | EMR, Research Data Warehouse, Billing System |
| Audit trail | Base de datos de auditoría inmutable |
11. Beneficios¶
Impacto Técnico¶
- Data minimization automático: cada consumidor recibe solo los datos que necesita, implementando el principio de mínimo privilegio a nivel de datos.
- Reducción de superficie de ataque: una brecha en el sistema de investigación no expone PII de pacientes porque esos datos nunca llegaron al sistema.
- Eficiencia de red y almacenamiento: los mensajes filtrados son más pequeños, consumiendo menos bandwidth y storage en los topics de destino.
- Procesamiento simplificado: los consumidores parsean mensajes más pequeños con solo los campos relevantes.
Impacto Organizacional¶
- Compliance regulatorio: la organización puede demostrar ante reguladores que implementa data minimization con políticas auditables.
- Habilitación de nuevos casos de uso: el departamento de investigación puede acceder a datos clínicos (que antes estaban bloqueados por privacidad) porque ahora se desidentifican automáticamente.
- Claridad de responsabilidades: el DPO define políticas; el equipo de integración las implementa; el equipo de investigación consume datos desidentificados. Cada uno tiene su responsabilidad clara.
Impacto Operacional¶
- Auditabilidad: el audit trail inmutable permite reconstruir exactamente qué datos se enviaron a cada sistema y con qué política.
- Respuesta a DSAR: ante un Data Subject Access Request, se puede determinar qué datos del paciente X se enviaron a cada sistema y en qué forma.
- Evolución segura: nuevos campos en el schema se filtran por defecto (whitelist), protegiendo contra exposición accidental de datos sensibles.
Beneficios de Mantenibilidad y Evolución¶
- Políticas configurables: cambiar qué se filtra no requiere cambio de código, solo actualización de la política.
- Nuevos consumidores: añadir un nuevo consumidor solo requiere definir su política de filtrado y crear un nuevo Content Filter.
- Evolución del schema: con whitelist, los nuevos campos se bloquean por defecto hasta que se evalúen y se añadan explícitamente a la política.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Mantenimiento de políticas: cada consumidor necesita una política de filtrado definida y mantenida. Con N consumidores, hay N políticas.
- Componentes adicionales: cada Content Filter es un servicio que debe desplegarse, monitorearse y escalarse.
- Latencia adicional: el paso de filtrado añade latencia entre el productor y el consumidor.
Riesgos de Mal Uso¶
- Falsa sensación de seguridad: asumir que el filtrado es suficiente para anonimización cuando en realidad la combinación de datos no filtrados puede permitir re-identificación (ataque de vinculación).
- Blacklist en lugar de whitelist: usar una política que bloquea campos específicos en lugar de permitir campos específicos. Cuando se añade un nuevo campo sensible al schema, pasa sin filtrar.
- Filtrado solo en producción: no aplicar las mismas políticas de filtrado en entornos de testing/staging, exponiendo datos reales a entornos menos seguros.
Sobreingeniería¶
- Implementar un motor de políticas complejo con reglas dinámicas cuando políticas estáticas simples son suficientes.
- Crear filtros separados para cada campo individual cuando un solo filtro con una política por consumidor es suficiente.
- Implementar tokenización reversible cuando la eliminación simple es suficiente y más segura.
Costos de Operación¶
- Gobierno de políticas: las políticas de filtrado deben revisarse periódicamente (al menos trimestralmente) por el DPO y actualizarse ante cambios regulatorios o de schema.
- Testing de políticas: cada política debe testearse para verificar que filtra lo esperado y no filtra lo que debe pasar.
- Infraestructura: los topics filtrados consumen storage adicional (aunque menos que si no se filtrara).
Anti-Patterns Relacionados¶
- Security Through Obscurity Filter: filtrar campos renombrándolos o ofuscándolos en lugar de eliminarlos. El dato sigue presente, solo difícil de encontrar.
- Late Filter: filtrar en el consumidor en lugar de antes del consumidor. El dato sensible ya llegó al sistema no autorizado; filtrarlo en el procesamiento no elimina la exposición.
- Inconsistent Filters: filtros que aplican reglas diferentes según el path del mensaje, resultando en que el mismo consumidor recibe datos diferentes según la ruta.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Content Enricher (este capítulo): operación opuesta. El enricher añade datos; el filter los elimina. A menudo se usan en secuencia: enriquecer con todas las fuentes y luego filtrar para cada consumidor.
- Envelope Wrapper (este capítulo): el wrapper puede añadir metadata de clasificación de datos al sobre que el Content Filter usa para determinar qué filtrar.
- Claim Check (este capítulo): en lugar de filtrar datos sensibles del mensaje, se externalizan con Claim Check. El consumidor autorizado puede recuperarlos con el token; el no autorizado no puede.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Publish-Subscribe Channel distribuye el mensaje a múltiples consumidores; Content Filter se aplica antes de cada consumidor.
- Después: Message Translator puede transformar el mensaje filtrado al formato específico del consumidor.
Combinaciones Comunes¶
- Content Filter + Content-Based Router: el router dirige el mensaje al filtro apropiado según su tipo o clasificación.
- Content Filter + Message Filter: Message Filter descarta mensajes completos (por ejemplo, resultados de tests no relevantes); Content Filter reduce los campos de los mensajes que pasan.
- Content Filter + Wire Tap: Wire Tap captura una copia del mensaje antes del filtrado para auditoría, mientras el mensaje filtrado llega al consumidor.
Diferencias con Patrones Similares¶
- vs. Message Filter: Message Filter descarta mensajes enteros basándose en criterios; Content Filter elimina campos dentro de un mensaje que se mantiene.
- vs. Content Enricher: operación inversa. Enricher añade datos; Filter los elimina.
- vs. Message Translator: Translator transforma datos de un formato a otro; Filter elimina datos sin transformar los que permanecen.
Encaje en un Flujo Mayor de Integración¶
Content Filter se posiciona entre el canal de distribución y los consumidores. En un pipeline típico con múltiples consumidores, el flujo es: Productor → Canal compartido → Content Filter (por consumidor) → Canal filtrado → Consumidor. El Content Filter actúa como un guardián de datos que implementa políticas de acceso a nivel de campo.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Content Filter ha pasado de ser una optimización técnica a ser un requisito regulatorio en la era post-GDPR:
- GDPR Art. 5.1.c (Data Minimization): los datos personales deben ser "adecuados, pertinentes y limitados a lo necesario".
- HIPAA Minimum Necessary Rule: los covered entities deben hacer "reasonable efforts" para limitar los PHI a lo mínimo necesario.
- PCI-DSS Requirement 3: minimizar el almacenamiento de datos de tarjetas.
- LGPD (Brasil): principio de necesidad — tratamiento limitado al mínimo necesario.
Además de compliance, Content Filter es esencial en arquitecturas modernas por razones técnicas:
- Event-driven architectures: un evento se publica una vez y se consume por múltiples servicios con diferentes necesidades y autorizaciones. Content Filter crea vistas filtradas del mismo evento.
- Zero Trust architectures: cada servicio debe tener acceso solo a los datos que necesita. Content Filter implementa este principio a nivel de datos.
- Data mesh: los data products exponen datos filtrados según las necesidades del consumidor, no un dataset monolítico.
Cómo Se Implementa Hoy¶
| Plataforma / Tecnología | Mecanismo de Content Filter |
|---|---|
| Kafka + Kafka Streams | Stream processing que proyecta/filtra campos |
| Azure Service Bus | Subscription filters (operan sobre properties, no sobre body) |
| AWS EventBridge | Input Transformers que seleccionan campos específicos |
| GraphQL | Los resolvers retornan solo los campos solicitados por el client |
| API Gateway (Kong, APIM) | Response transformation policies que eliminan campos |
| Apache Camel | .process() o .transform() con lógica de filtrado |
| Data Loss Prevention (DLP) | Scanning y redacción automática de PII en flujos de datos |
Qué Parte Sigue Siendo Esencial¶
- El principio de data minimization: es permanente e independiente de la tecnología.
- Whitelist approach para datos sensibles: definir explícitamente qué pasa es más seguro que definir qué se bloquea.
- Auditabilidad del filtrado: registrar qué se filtró, cuándo, con qué política, para cada mensaje.
- Filtrado como componente explícito: no dejar el filtrado como responsabilidad implícita del consumidor.
15. Implementación en Arquitecturas Modernas¶
Kafka Streams — Proyección de Campos¶
KStream<String, LabResult> fullResults = builder.stream("clinical.lab-results.raw");
// Filtro para investigación: eliminar PII, pseudonimizar MRN
KStream<String, DeidentifiedResult> researchResults = fullResults
.mapValues(result -> DeidentifiedResult.builder()
.labResultId(result.getLabResultId())
.pseudoId(sha256WithSalt(result.getPatient().getMrn()))
.birthYear(result.getPatient().getDateOfBirth().getYear())
.testCode(result.getTest().getCode())
.testName(result.getTest().getName())
.testResults(result.getTest().getResults())
.physicianNpi(result.getOrderingPhysician().getNpi())
.performedAt(result.getPerformedAt())
.build());
researchResults.to("clinical.lab-results.research");
AWS EventBridge — Input Transformer¶
{
"Rule": "lab-results-to-research",
"InputTransformer": {
"InputPathsMap": {
"resultId": "$.detail.lab_result_id",
"testCode": "$.detail.test.code",
"testResults": "$.detail.test.results",
"performedAt": "$.detail.performed_at"
},
"InputTemplate": "{\"lab_result_id\": <resultId>, \"test\": {\"code\": <testCode>, \"results\": <testResults>}, \"performed_at\": <performedAt>}"
}
}
EventBridge Input Transformers seleccionan explícitamente qué campos pasan a la regla destino, implementando un whitelist approach nativo.
GraphQL — Client-Driven Content Filter¶
# El cliente de investigación solicita solo datos desidentificados
query LabResultsForResearch {
labResults(limit: 100) {
labResultId
test {
code
name
results {
component
value
unit
flag
}
}
performedAt
# No solicita patient.name, patient.ssn, etc.
}
}
GraphQL implementa Content Filter de forma natural: el cliente solicita solo los campos que necesita. Sin embargo, esto pone la responsabilidad de filtrado en el cliente (que podría solicitar campos no autorizados), por lo que debe combinarse con authorization directives en el schema.
API Gateway — Response Transformation¶
# Kong API Gateway - Response Transformer Plugin
plugins:
- name: response-transformer
config:
remove:
json:
- patient.ssn
- patient.date_of_birth
- patient.address
- patient.phone
- patient.insurance_id
- ordering_physician.name
El API Gateway aplica filtrado como un plugin transparente, sin modificar el servicio origen ni el servicio destino.
Open Policy Agent (OPA) — Policy-Driven Filtering¶
package content_filter
# Política para sistema de investigación
allowed_fields["research"] = {
"lab_result_id",
"test.code",
"test.name",
"test.results",
"ordering_physician.npi",
"performed_at"
}
filter_message(msg, consumer_type) = filtered {
fields := allowed_fields[consumer_type]
filtered := {k: v | some k; v := msg[k]; k in fields}
}
OPA permite definir políticas de filtrado como código declarativo, evaluable en cualquier punto del flujo de integración.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Campos filtrados por mensaje: registrar cuántos y cuáles campos se eliminan en cada operación de filtrado.
- Tamaño antes/después: medir la reducción de tamaño como indicador de eficacia del filtrado.
- Errores de filtrado: monitorear mensajes que no se pudieron filtrar (schema inesperado, campos requeridos faltantes).
- Policy hits: cuántas veces se aplica cada regla de la política, para detectar reglas obsoletas.
Monitoreo¶
- Filter throughput: mensajes filtrados por segundo vs. mensajes entrantes. Una discrepancia indica que el filtro se está atrasando.
- Filter latency: tiempo de procesamiento del filtrado (p50, p95, p99).
- Dead-letter rate: porcentaje de mensajes que no se pueden filtrar y van a dead-letter.
- Policy version: monitorear qué versión de la política está activa en cada instancia del filtro.
Versionado¶
- Policy versioning: cada política de filtrado debe tener una versión. Los cambios de política deben ser tracked y auditables.
- Schema evolution: cuando el schema del mensaje cambia, las políticas de filtrado deben revisarse. Con whitelist, nuevos campos se bloquean por defecto.
- Rollback de políticas: si una nueva política causa problemas, debe poder revertirse rápidamente a la versión anterior.
Seguridad¶
- El filtro tiene acceso completo: el Content Filter es un componente privilegiado que lee mensajes completos con datos sensibles. Debe tener los mismos controles de seguridad que el sistema más restrictivo.
- Audit immutability: el audit trail de filtrado debe ser immutable (append-only) para tener valor probatorio.
- Testing de políticas: las políticas deben testearse con datos sintéticos que contengan todos los tipos de PII para verificar que se filtran correctamente.
Manejo de Errores¶
- Fail-closed: si el Content Filter no puede aplicar la política (error de parsing, política no encontrada, etc.), el mensaje NO debe pasar sin filtrar. Debe ir a dead-letter o bloquearse.
- Partial filter failure: si un campo no se puede procesar (por ejemplo, fecha en formato inesperado que no se puede generalizar), aplicar la acción más restrictiva (eliminar en lugar de generalizar).
17. Errores Comunes¶
Usar Blacklist en Lugar de Whitelist para Datos Sensibles¶
Definir "eliminar patient.ssn, patient.name" (blacklist) en lugar de "permitir test.code, test.results" (whitelist). Cuando se añade patient.biometric_data al schema, la blacklist no lo bloquea y el dato sensible pasa al consumidor no autorizado. La whitelist lo bloquea por defecto.
Filtrar en el Consumidor en Lugar de Antes¶
Dejar que el consumidor reciba el mensaje completo y "ignore" los campos que no necesita. El dato sensible ya llegó al sistema no autorizado — no importa que el consumidor no lo procese. En caso de brecha de seguridad, el dato está expuesto. El filtrado debe ocurrir antes de que el mensaje llegue al consumidor.
No Actualizar las Políticas Ante Cambios de Schema¶
Añadir un campo patient.genetic_markers al schema del mensaje sin actualizar la política de filtrado. Si la política es blacklist, el campo pasa sin filtrar. Incluso con whitelist, la evaluación periódica de la política es necesaria para verificar que los campos permitidos siguen siendo apropiados.
Confundir Content Filter con Anonimización¶
Asumir que eliminar nombre y SSN es suficiente para anonimizar los datos. La combinación de fecha de nacimiento + código postal + género permite re-identificar al 87% de la población de EE.UU. (estudio de Latanya Sweeney). El filtrado debe evaluarse con técnicas formales de anonimización (k-anonimidad, l-diversidad) cuando se usa para investigación o analytics.
No Auditar el Filtrado¶
Filtrar datos sin registrar qué se filtró. Cuando un regulador pregunta "¿qué datos del paciente X enviaron al sistema de investigación?", no se puede responder. El audit trail es tan importante como el filtrado mismo.
Filtrar Solo en Producción¶
No aplicar las mismas políticas de filtrado en entornos de development y staging que usan datos reales (o copies de producción). Los desarrolladores tienen acceso a datos sensibles en entornos menos protegidos.
18. Conclusión Técnica¶
Content Filter es un patrón que ha evolucionado de optimización técnica a requisito de compliance. Su propósito es implementar el principio de data minimization: cada consumidor recibe solo los datos estrictamente necesarios para su función, eliminando datos innecesarios y sensibles antes de que alcancen sistemas no autorizados.
Cuándo aporta valor: siempre que un mensaje contenga datos que ciertos consumidores no necesitan o no deben recibir. Es imprescindible en entornos regulados (healthcare, finanzas, gobierno) donde la exposición de datos sensibles tiene consecuencias legales.
Cuándo evita problemas importantes: cuando sin filtrado, datos sensibles (PII, PHI, PCI) se propagan a sistemas no autorizados, creando riesgo regulatorio, ampliando la superficie de ataque y violando el principio de mínimo privilegio.
Cuándo no conviene adoptarlo: cuando todos los consumidores están autorizados para todos los datos y el mensaje es suficientemente pequeño como para que el overhead de filtrado no se justifique. Incluso en estos casos, considerar si el principio de data minimization aplica como best practice.
Recomendación para arquitectos: adopte el enfoque whitelist (permitir explícitamente qué pasa) en lugar de blacklist (bloquear explícitamente qué se elimina) para datos sensibles. Trate las políticas de filtrado como configuración auditada, no como código enterrado en un stream processor. Implemente audit trail inmutable para cada operación de filtrado. Aplique fail-closed: si el filtro falla, el mensaje no pasa. Y revise las políticas periódicamente con el DPO, especialmente ante cambios de schema o cambios regulatorios. El Content Filter no es un componente técnico menor — es la implementación técnica de una promesa legal de protección de datos.