Claim Check¶
1. Nombre del Patrón¶
- Nombre oficial: Claim Check
- Categoría: Message Transformation (Transformación de Mensajes)
- Traducción contextual: Resguardo de Equipaje (analogía con el ticket de recogida de equipaje)
2. Resumen Ejecutivo¶
Claim Check es el patrón que reemplaza el contenido voluminoso de un mensaje con una referencia (el "claim check" o resguardo), almacenando el contenido original en un almacén externo persistente. El consumidor usa la referencia para recuperar el contenido completo del almacén externo cuando lo necesita. El mensaje que viaja por la infraestructura de mensajería es pequeño y ligero; el payload pesado viaja fuera de banda.
El problema que resuelve es la limitación de tamaño y el costo de transportar mensajes grandes a través de la infraestructura de mensajería. Los brokers de mensajes tienen límites de tamaño por mensaje (Kafka: 1MB por defecto, SQS: 256KB, RabbitMQ: configurable pero con impacto en memoria), y incluso cuando permiten mensajes grandes, transportarlos degrada el rendimiento del broker, consume bandwidth de red y aumenta la latencia de todos los mensajes en el sistema.
En el contexto actual, Claim Check ha ganado relevancia crítica por la proliferación de datos binarios en las integraciones modernas: imágenes de documentos en procesos de onboarding, fotos de siniestros en seguros, archivos adjuntos en workflows, resultados de ML models (embeddings, imágenes generadas) y datasets en pipelines de datos. La combinación de Claim Check con object storage en la nube (S3, Azure Blob, GCS) se ha convertido en un patrón estándar para cualquier integración que involucre payloads mayores a unos pocos kilobytes.
3. Definición Detallada¶
Propósito¶
Claim Check intercepta un mensaje con payload voluminoso, extrae el payload, lo almacena en un almacén externo persistente, y reemplaza el payload en el mensaje con una referencia (URL, key, token) que permite al consumidor recuperar el contenido original cuando lo necesite. El mensaje "ligero" viaja por el canal de mensajería; el payload "pesado" viaja fuera de banda.
Lógica Arquitectónica¶
En sistemas de integración, los mensajes varían enormemente en tamaño. Los mensajes de eventos de negocio (pedido creado, pago procesado) son típicamente pequeños (1-10 KB). Pero ciertos tipos de integración involucran datos voluminosos:
- Documentos adjuntos: PDFs de contratos, facturas escaneadas, formularios firmados.
- Imágenes: fotos de siniestros de seguros, imágenes médicas (radiografías, resonancias), fotos de propiedades inmobiliarias.
- Datos binarios: archivos CAD, modelos 3D, datasets de training de ML.
- Reportes: extractos bancarios, estados de cuenta, informes de auditoría generados.
Transportar estos payloads a través del broker de mensajes es problemático:
- Límites técnicos: muchos brokers tienen límites estrictos de tamaño por mensaje.
- Rendimiento del broker: mensajes grandes saturan los buffers internos del broker, aumentando la latencia para todos los mensajes.
- Consumo de red: un mensaje de 10MB que se replica 3 veces en Kafka y se consume por 5 consumer groups genera 150MB de tráfico de red.
- Almacenamiento ineficiente: los brokers no están optimizados para almacenar blobs binarios; los object stores sí.
Principio de Diseño Subyacente¶
El principio es separación de plano de control y plano de datos: el mensaje de control (metadata, referencia al payload) viaja por el canal de mensajería optimizado para latencia y throughput de mensajes pequeños. El payload de datos viaja por un canal de datos optimizado para almacenamiento y transferencia de blobs grandes (S3, Azure Blob, GCS). Cada canal opera en su zona de eficiencia.
Problema Estructural que Resuelve¶
Sin Claim Check:
- Los mensajes grandes exceden los límites del broker y no pueden publicarse.
- Los mensajes grandes degradan el rendimiento del broker para todos los demás mensajes.
- El broker consume más almacenamiento del necesario (datos binarios que solo ciertos consumidores necesitan).
- Los consumidores que no necesitan el payload completo (solo la metadata) deben descargar y descartar el payload grande.
- La retención de mensajes en el broker se vuelve costosa con payloads grandes.
Contexto en el que Emerge¶
Claim Check emerge cuando:
- Los mensajes contienen payloads binarios (imágenes, documentos, archivos) que exceden los límites del broker.
- Múltiples consumidores necesitan la metadata del mensaje pero solo un subconjunto necesita el payload completo.
- El costo de almacenamiento en el broker es significativamente mayor que en un object store.
- Se necesita retención a largo plazo del payload que excede la retención del broker.
Por Qué No Es Trivial¶
- Consistencia entre referencia y payload: ¿qué sucede si el mensaje se publica exitosamente pero el payload no se almacenó? El consumidor tiene una referencia a nada.
- Lifecycle management: ¿cuándo se puede eliminar el payload del almacén externo? ¿Después de que todos los consumidores lo recuperaron? ¿Después de un TTL?
- Seguridad de la referencia: la referencia (URL, key) debe ser segura — un consumidor no autorizado no debe poder recuperar el payload.
- Latencia de recuperación: el consumidor necesita una llamada adicional al almacén externo para recuperar el payload, añadiendo latencia.
- Atomicidad de almacenamiento: almacenar el payload y publicar el mensaje deben ser operaciones atómicas o al menos eventualmente consistentes.
Relación con Sistemas Distribuidos y Mensajería¶
Claim Check implementa el principio de reference passing en lugar de value passing en sistemas distribuidos. Es análogo a pasar un puntero en lugar de una copia del dato en programación: el mensaje contiene la referencia, no el dato. Esta técnica es fundamental en sistemas distribuidos para evitar copias innecesarias de datos grandes.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Una compañía de seguros procesa reclamaciones (claims) de siniestros de automóviles. Cuando un asegurado reporta un siniestro, el proceso requiere:
- Datos del siniestro (fecha, ubicación, descripción) — ~2 KB.
- Datos del asegurado y la póliza — ~5 KB.
- Fotografías del daño al vehículo: entre 5 y 20 fotos de alta resolución, cada una de 3-8 MB. Total: 15-160 MB.
- Informe policial escaneado: PDF de 2-5 páginas, 1-3 MB.
- Presupuesto del taller: PDF escaneado, 500 KB - 2 MB.
El mensaje total puede alcanzar 170 MB. El sistema utiliza Kafka como backbone de mensajería, configurado con un límite de 1 MB por mensaje (el default).
{
"claim_id": "CLM-2026-778899",
"policy_id": "POL-AUTO-2026-112233",
"incident": {
"date": "2026-04-05",
"location": { "lat": 40.4168, "lon": -3.7038 },
"description": "Colisión trasera en semáforo"
},
"insured": {
"name": "María García Ruiz",
"id_number": "87654321-B"
},
"photos": [
{ "filename": "frontal_damage.jpg", "data": "BASE64_ENCODED_8MB..." },
{ "filename": "rear_damage.jpg", "data": "BASE64_ENCODED_5MB..." },
{ "filename": "interior_damage.jpg", "data": "BASE64_ENCODED_3MB..." }
],
"police_report": { "filename": "police_report.pdf", "data": "BASE64_ENCODED_2MB..." },
"repair_estimate": { "filename": "estimate.pdf", "data": "BASE64_ENCODED_1MB..." }
}
Síntomas del Problema¶
- El mensaje de 170 MB no cabe en Kafka (límite 1 MB). Aumentar el límite a 200 MB degradaría el rendimiento de todo el cluster.
- Incluso con límite aumentado, los consumidores que solo necesitan la metadata del siniestro (para routing, priorización, estadísticas) deben descargar 170 MB de fotos que no necesitan.
- La retención de 7 días en Kafka con 1000 reclamaciones diarias de 50 MB promedio consume 350 GB de almacenamiento en el broker. En S3, el mismo almacenamiento cuesta una fracción.
- El replication factor de 3 triplica el tráfico de red: 170 MB × 3 réplicas = 510 MB por cada reclamación.
- Los consumer groups que re-procesan mensajes (replay) deben descargar todos los payloads grandes de nuevo.
Impacto Operativo y Arquitectónico¶
- Broker saturado: los mensajes grandes compiten por los buffers de Kafka con mensajes pequeños de eventos de negocio, degradando la latencia de todo el sistema.
- Costo de almacenamiento: Kafka utiliza discos SSD de alto rendimiento; almacenar blobs binarios en SSD de Kafka es 10-50x más caro que en S3.
- Red saturada: la replicación de mensajes grandes consume un porcentaje desproporcionado del bandwidth de red del cluster.
- Imposibilidad de procesar: el mensaje simplemente no se puede publicar en Kafka con el límite por defecto.
Riesgos Si No Se Implementa Correctamente¶
- Referencia huérfana (dangling reference): el mensaje se publica con la referencia pero el payload no se almacenó en S3 (error de red). El consumidor recibe una referencia que apunta a nada.
- Payload huérfano (orphan payload): el payload se almacena en S3 pero el mensaje no se publica en Kafka (error del productor). El payload queda en S3 sin que nadie lo solicite, consumiendo almacenamiento indefinidamente.
- Referencia insegura: la URL de S3 es pública o predecible, permitiendo a actores no autorizados acceder a fotos de siniestros y datos personales.
- Lifecycle no gestionado: los payloads se acumulan en S3 sin política de retención, generando costos crecientes de almacenamiento.
Ejemplos Reales¶
- Seguros: fotos de siniestros almacenadas en S3, referenciadas en el mensaje de reclamación que viaja por Kafka.
- Healthcare: imágenes médicas (DICOM) almacenadas en un PACS, referenciadas en mensajes HL7/FHIR.
- Banca: documentos de KYC (pasaporte escaneado, comprobante de domicilio) almacenados en blob storage, referenciados en el evento de onboarding.
- E-commerce: imágenes de productos en CDN, referenciadas en mensajes de catálogo.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el payload del mensaje excede los límites del broker de mensajes.
- Cuando el payload es significativamente más grande que la metadata y no todos los consumidores necesitan el payload completo.
- Cuando el costo de almacenar el payload en el broker es mucho mayor que en un object store.
- Cuando se necesita retención a largo plazo del payload que excede la retención del broker.
- Cuando el payload es binario (imágenes, documentos, archivos) y el canal de mensajería está optimizado para texto/JSON.
Cuándo No Usarlo¶
- Cuando el mensaje completo es pequeño (menos de 100 KB) y cabe cómodamente en el broker.
- Cuando todos los consumidores siempre necesitan el payload completo (no hay beneficio en separar).
- Cuando la latencia adicional de recuperar el payload del almacén externo es inaceptable.
- Cuando la complejidad de gestionar consistencia entre referencia y payload no se justifica.
Precondiciones¶
- Existe un almacén externo adecuado para el tipo de payload (S3, Azure Blob, GCS, NFS).
- El almacén externo es accesible tanto para el productor (almacenamiento) como para el consumidor (recuperación).
- Existe un esquema de identificación que permite generar referencias únicas y seguras.
Restricciones¶
- La recuperación del payload requiere una llamada adicional al almacén externo (latencia añadida).
- La consistencia entre referencia y payload debe manejarse explícitamente (no es transaccional por defecto).
- El lifecycle del payload debe gestionarse: retención, eliminación, archivado.
Dependencias¶
- Almacén externo persistente (S3, Azure Blob, GCS).
- Mecanismo de generación de referencias seguras (pre-signed URLs, SAS tokens).
- Políticas de lifecycle del payload (retención, tiering, eliminación).
Supuestos Arquitectónicos¶
- El payload es significativamente más grande que la metadata del mensaje.
- El almacén externo tiene disponibilidad comparable o superior al broker de mensajes.
- Los consumidores pueden tolerar la latencia adicional de recuperar el payload del almacén externo.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Procesos de reclamaciones de seguros con evidencia fotográfica.
- Sistemas de healthcare con imágenes médicas.
- Procesos de onboarding bancario con documentos de identidad.
- Workflows documentales con archivos adjuntos.
- Pipelines de datos con datasets grandes.
6. Fuerzas Arquitectónicas¶
Tamaño del Mensaje vs. Rendimiento del Broker¶
Mensajes más grandes degradan el rendimiento del broker para todos los mensajes. Separar el payload grande mantiene al broker operando en su zona de eficiencia (mensajes pequeños, alta throughput).
Latencia de Publicación vs. Latencia de Recuperación¶
Con Claim Check, la publicación es rápida (mensaje pequeño) pero la recuperación del payload requiere una llamada adicional. Sin Claim Check, la publicación es lenta (mensaje grande) pero el consumidor tiene todo el payload inmediatamente.
Costo de Almacenamiento en Broker vs. Object Store¶
Los brokers de mensajes usan almacenamiento de alto rendimiento (SSD). Los object stores usan almacenamiento optimizado para blobs con costos 10-50x menores. Para payloads que se almacenan días o semanas, la diferencia de costo es significativa.
Consistencia vs. Simplicidad¶
Garantizar que la referencia y el payload son consistentes (ambos existen o ninguno) requiere mecanismos de coordinación (write-ahead, outbox pattern, compensación). La alternativa simple (almacenar primero, publicar después) acepta el riesgo de payloads huérfanos a cambio de simplicidad.
Seguridad de la Referencia vs. Accesibilidad¶
Las referencias deben ser suficientemente seguras para que actores no autorizados no puedan acceder al payload, pero suficientemente accesibles para que los consumidores autorizados puedan recuperarlo sin fricción excesiva.
Retención del Payload vs. Costo¶
¿Cuánto tiempo se retiene el payload en el almacén externo? Retener indefinidamente es seguro pero costoso. Eliminar agresivamente ahorra costos pero arriesga que un consumidor necesite el payload después de que se eliminó.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: genera el mensaje con payload voluminoso.
- Check-In (Store): componente que extrae el payload, lo almacena en el almacén externo, y reemplaza el payload con una referencia.
- Almacén Externo: object store que persiste el payload (S3, Azure Blob, GCS).
- Mensaje con Claim Check: el mensaje "ligero" que viaja por el canal con la referencia al payload.
- Canal de Mensajería: broker que transporta el mensaje ligero.
- Check-Out (Retrieve): componente que usa la referencia para recuperar el payload del almacén externo.
- Consumidor: procesa el mensaje con el payload recuperado.
Flujo Lógico¶
flowchart TD
A([Productor]) --> B[Mensaje con payload grande\n100 MB de fotos y documentos]
B --> C[Check-In extrae\npayload grande del mensaje]
C --> D[(Almacén externo - S3\nalmacenar fotos y documentos)]
C --> E[Reemplazar payload\ncon referencias a S3]
E --> F[(Canal de Mensajería\nmensaje ligero ~5 KB)]
F --> G[Check-Out recibe mensaje\ndetecta referencias]
G --> H[Recuperar payload\nGET desde S3]
D --> H
H --> I([Consumidor procesa mensaje\ncon payload recuperado])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Generar el mensaje completo con payload |
| Check-In | Almacenar payload, generar referencia, producir mensaje ligero |
| Almacén Externo | Persistir payload con durabilidad y disponibilidad |
| Canal de Mensajería | Transportar mensaje ligero eficientemente |
| Check-Out | Recuperar payload usando la referencia |
| Consumidor | Procesar el mensaje y decidir si necesita recuperar el payload |
Interacciones¶
- Productor → Check-In: el productor envía el mensaje completo al check-in.
- Check-In → Almacén Externo: el check-in almacena el payload y obtiene la referencia.
- Check-In → Canal: el check-in publica el mensaje ligero con la referencia.
- Canal → Consumidor: el consumidor recibe el mensaje ligero.
- Consumidor → Almacén Externo: el consumidor recupera el payload usando la referencia (solo si lo necesita).
Contratos Implícitos¶
- Referencia válida: la referencia en el mensaje apunta a un payload existente y recuperable.
- Payload inmutable: el payload almacenado no cambia después de almacenarse (la referencia siempre retorna los mismos datos).
- Disponibilidad del almacén: el almacén externo está disponible cuando el consumidor necesita recuperar el payload.
Decisiones de Diseño Clave¶
- Check-in en el productor vs. en un intermediario: ¿el productor almacena el payload directamente, o un componente intermedio lo hace?
- Tipo de referencia: ¿URL directa, pre-signed URL con expiración, key que requiere autenticación, o token opaco?
- Granularidad del claim check: ¿un claim check por todo el payload, o uno por cada archivo individual?
- Check-out explícito vs. transparente: ¿el consumidor debe saber que está usando claim check, o un proxy lo resuelve transparentemente?
- Lifecycle del payload: ¿quién decide cuándo eliminar el payload? ¿TTL fijo, referencia a conteo de consumidores, o eliminación manual?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Seguros — Procesamiento de Reclamaciones con Evidencia Fotográfica¶
Contexto del Negocio¶
Una compañía de seguros de automóviles procesa 5000 reclamaciones diarias. Cada reclamación incluye entre 5 y 20 fotografías del daño al vehículo, más documentos escaneados (informe policial, presupuesto del taller, fotos del DNI del conductor). El payload fotográfico promedio es de 50 MB, con máximos de 160 MB.
La reclamación debe ser procesada por múltiples sistemas: clasificación automática (ML para detectar tipo de daño), evaluación de perito (asignación y workflow), detección de fraude (análisis de metadata de fotos, comparación con reclamaciones anteriores) y liquidación (cálculo del monto a pagar).
Necesidad de Integración¶
Los mensajes de reclamación deben fluir por Kafka hacia múltiples consumidores, pero el payload fotográfico no puede viajar por Kafka (límite de 1 MB, rendimiento, costo). Las fotos deben almacenarse en S3 y el mensaje de Kafka debe contener solo la metadata con referencias a las fotos.
Sistemas Involucrados¶
- Claims Intake App: aplicación móvil/web donde el asegurado sube fotos y datos del siniestro.
- Claims API: backend que recibe la reclamación y orquesta el check-in.
- Amazon S3: almacén de fotos y documentos.
- Kafka: backbone de mensajería para eventos de reclamaciones.
- ML Classification Service: clasifica tipo de daño a partir de las fotos.
- Fraud Detection Service: analiza metadata de fotos y patrones de fraude.
- Adjuster Workflow Service: asigna perito y gestiona el workflow de evaluación.
- Settlement Service: calcula liquidación basada en la evaluación.
Restricciones Técnicas¶
- Kafka message size limit: 1 MB (no se aumentará para proteger el rendimiento del cluster).
- S3 durabilidad: 99.999999999% (11 nines), superior a la persistencia de Kafka.
- Las fotos deben retenerse por 7 años (regulación de seguros).
- La retención de Kafka es 7 días (suficiente para procesamiento, no para compliance).
- Las pre-signed URLs deben expirar en 24 horas máximo (seguridad).
- Los consumidores que solo necesitan metadata (routing, priorización) no deben descargar fotos.
Diseño del Claim Check¶
Mensaje original (antes del check-in):
{
"claim_id": "CLM-2026-778899",
"policy_id": "POL-AUTO-2026-112233",
"incident": {
"date": "2026-04-05",
"location": { "lat": 40.4168, "lon": -3.7038 },
"description": "Colisión trasera en semáforo"
},
"photos": [
{ "filename": "frontal_damage.jpg", "data": "<8MB base64>", "content_type": "image/jpeg" },
{ "filename": "rear_damage.jpg", "data": "<5MB base64>", "content_type": "image/jpeg" }
],
"police_report": { "filename": "police_report.pdf", "data": "<2MB base64>", "content_type": "application/pdf" }
}
Mensaje después del check-in (viaja por Kafka):
{
"claim_id": "CLM-2026-778899",
"policy_id": "POL-AUTO-2026-112233",
"incident": {
"date": "2026-04-05",
"location": { "lat": 40.4168, "lon": -3.7038 },
"description": "Colisión trasera en semáforo"
},
"attachments": [
{
"type": "photo",
"filename": "frontal_damage.jpg",
"content_type": "image/jpeg",
"size_bytes": 8388608,
"storage_ref": "s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/frontal_damage.jpg",
"checksum_sha256": "a3f2b8c9..."
},
{
"type": "photo",
"filename": "rear_damage.jpg",
"content_type": "image/jpeg",
"size_bytes": 5242880,
"storage_ref": "s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/rear_damage.jpg",
"checksum_sha256": "d1e4f7a2..."
},
{
"type": "document",
"filename": "police_report.pdf",
"content_type": "application/pdf",
"size_bytes": 2097152,
"storage_ref": "s3://insurance-claims-prod/2026/04/CLM-2026-778899/documents/police_report.pdf",
"checksum_sha256": "b5c8d1e4..."
}
],
"_claim_check": {
"storage_bucket": "insurance-claims-prod",
"storage_prefix": "2026/04/CLM-2026-778899/",
"total_attachments": 3,
"total_size_bytes": 15728640,
"stored_at": "2026-04-05T14:30:00Z"
}
}
El mensaje ha pasado de ~16 MB (con fotos embebidas) a ~2 KB (solo metadata y referencias). Reducción del 99.98%.
Decisiones Arquitectónicas¶
- Check-in en el backend API: el Claims API almacena las fotos en S3 antes de publicar el mensaje en Kafka, asegurando que las fotos existen antes de que el mensaje sea publicado.
- Referencias individuales por archivo: cada foto y documento tiene su propia referencia S3, permitiendo que un consumidor descargue solo las fotos que necesita.
- Checksum SHA-256: cada referencia incluye el checksum del contenido para verificar integridad en la recuperación.
- S3 lifecycle policy: las fotos se almacenan en S3 Standard por 90 días (procesamiento activo), luego se mueven a S3 Glacier por 7 años (compliance regulatorio).
- IAM-based access: los consumidores acceden a S3 con roles IAM específicos por servicio, no con pre-signed URLs.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Upload a S3 falla después de recibir fotos | Retry con idempotencia (mismo S3 key); el Claims API no publica a Kafka hasta que S3 confirma |
| Consumidor no puede descargar de S3 (temporal) | Retry con backoff exponencial; S3 tiene SLA de 99.99% disponibilidad |
| Referencia apunta a archivo eliminado | Lifecycle policy de 7 años; nunca eliminar antes de la retención regulatoria |
| Archivos en S3 accedidos por servicio no autorizado | IAM policies restrictivas por servicio; S3 bucket policy; VPC endpoints |
| Checksum mismatch | Reintento de descarga; si persiste, alertar (posible corrupción) |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Asegurado Reporta el Siniestro¶
María García Ruiz abre la app móvil de su aseguradora y reporta un siniestro: colisión trasera en un semáforo. Toma 8 fotos del daño (frontal, trasero, lateral, interior, detalle de rayones, matrícula del otro vehículo). Adjunta el informe policial escaneado y el presupuesto del taller. La app envía todo al Claims API via multipart upload.
Paso 2: Check-In — Almacenamiento en S3¶
El Claims API recibe la reclamación. Antes de publicar en Kafka, almacena las fotos y documentos en S3:
PUT s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/frontal_damage.jpg
PUT s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/rear_damage.jpg
PUT s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/lateral_damage.jpg
...
PUT s3://insurance-claims-prod/2026/04/CLM-2026-778899/documents/police_report.pdf
PUT s3://insurance-claims-prod/2026/04/CLM-2026-778899/documents/repair_estimate.pdf
Cada upload usa PutObject con ChecksumSHA256 para verificar integridad. El Claims API espera confirmación de todos los uploads antes de continuar.
Paso 3: Publicación del Mensaje Ligero en Kafka¶
Una vez confirmados todos los uploads, el Claims API publica el mensaje ligero (solo metadata y referencias S3) en el topic insurance.claims.new. El mensaje es de ~3 KB — bien dentro del límite de 1 MB de Kafka.
Paso 4: ML Classification Service — Check-Out Selectivo¶
El ML Classification Service consume el mensaje y necesita las fotos para clasificar el tipo de daño. Realiza check-out selectivo: descarga solo las fotos (no los documentos PDF):
GET s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/frontal_damage.jpg
GET s3://insurance-claims-prod/2026/04/CLM-2026-778899/photos/rear_damage.jpg
...
Verifica checksum SHA-256 de cada foto contra el valor en el mensaje. Ejecuta el modelo de ML y publica el resultado de clasificación: {claim_id: "CLM-2026-778899", damage_type: "rear_collision", severity: "moderate", confidence: 0.87}.
Paso 5: Fraud Detection Service — Check-Out con Metadata¶
El Fraud Detection Service consume el mensaje y necesita las fotos para analizar metadata EXIF (verificar que las fotos se tomaron en la fecha y ubicación declaradas). Descarga las fotos, extrae metadata EXIF (fecha, hora, GPS, modelo de cámara) y la compara con los datos declarados en la reclamación.
También compara las fotos con un repositorio de reclamaciones anteriores usando perceptual hashing (detectar si las mismas fotos se usaron en otra reclamación — indicador de fraude).
Paso 6: Adjuster Workflow — Check-Out Completo¶
El perito asignado recibe la reclamación en su app y necesita ver todas las fotos y documentos. La app del perito usa las referencias S3 para generar pre-signed URLs temporales (15 minutos) que el perito abre en su navegador. No se almacenan copias locales de las fotos en el dispositivo del perito (seguridad).
Paso 7: Lifecycle del Payload¶
La lifecycle policy de S3 gestiona la retención:
- Días 0-90: S3 Standard (acceso frecuente durante procesamiento activo).
- Días 91-365: S3 Intelligent-Tiering (acceso ocasional durante revisiones).
- Años 2-7: S3 Glacier Deep Archive (retención regulatoria, acceso rarísimo).
- Año 7+: eliminación automática (fin de obligación regulatoria).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.storage import S3
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.client import User
from diagrams.onprem.mlops import Mlflow
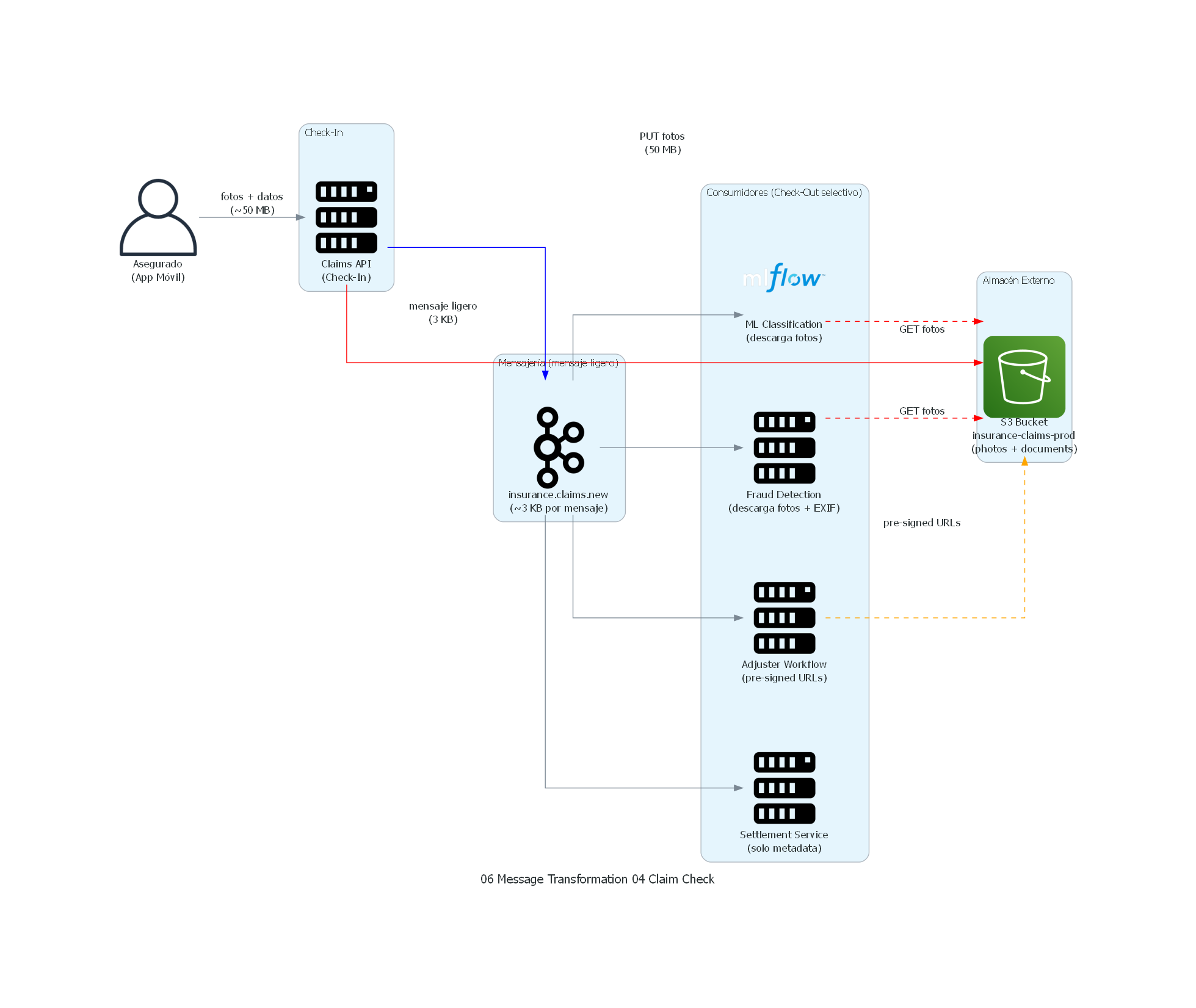
with Diagram("Claim Check - Insurance Claims with Photo Evidence", show=False, direction="LR"):
insured = User("Asegurado\n(App Móvil)")
with Cluster("Check-In"):
claims_api = Server("Claims API\n(Check-In)")
with Cluster("Almacén Externo"):
s3 = S3("S3 Bucket\ninsurance-claims-prod\n(photos + documents)")
with Cluster("Mensajería (mensaje ligero)"):
kafka = Kafka("insurance.claims.new\n(~3 KB por mensaje)")
with Cluster("Consumidores (Check-Out selectivo)"):
ml_service = Mlflow("ML Classification\n(descarga fotos)")
fraud_svc = Server("Fraud Detection\n(descarga fotos + EXIF)")
adjuster = Server("Adjuster Workflow\n(pre-signed URLs)")
settlement = Server("Settlement Service\n(solo metadata)")
# Flujo check-in
insured >> Edge(label="fotos + datos\n(~50 MB)") >> claims_api
claims_api >> Edge(label="PUT fotos\n(50 MB)", color="red") >> s3
claims_api >> Edge(label="mensaje ligero\n(3 KB)", color="blue") >> kafka
# Flujo check-out
kafka >> ml_service
kafka >> fraud_svc
kafka >> adjuster
kafka >> settlement
ml_service >> Edge(label="GET fotos", style="dashed", color="red") >> s3
fraud_svc >> Edge(label="GET fotos", style="dashed", color="red") >> s3
adjuster >> Edge(label="pre-signed URLs", style="dashed", color="orange") >> s3
# settlement no descarga de S3 (solo usa metadata)
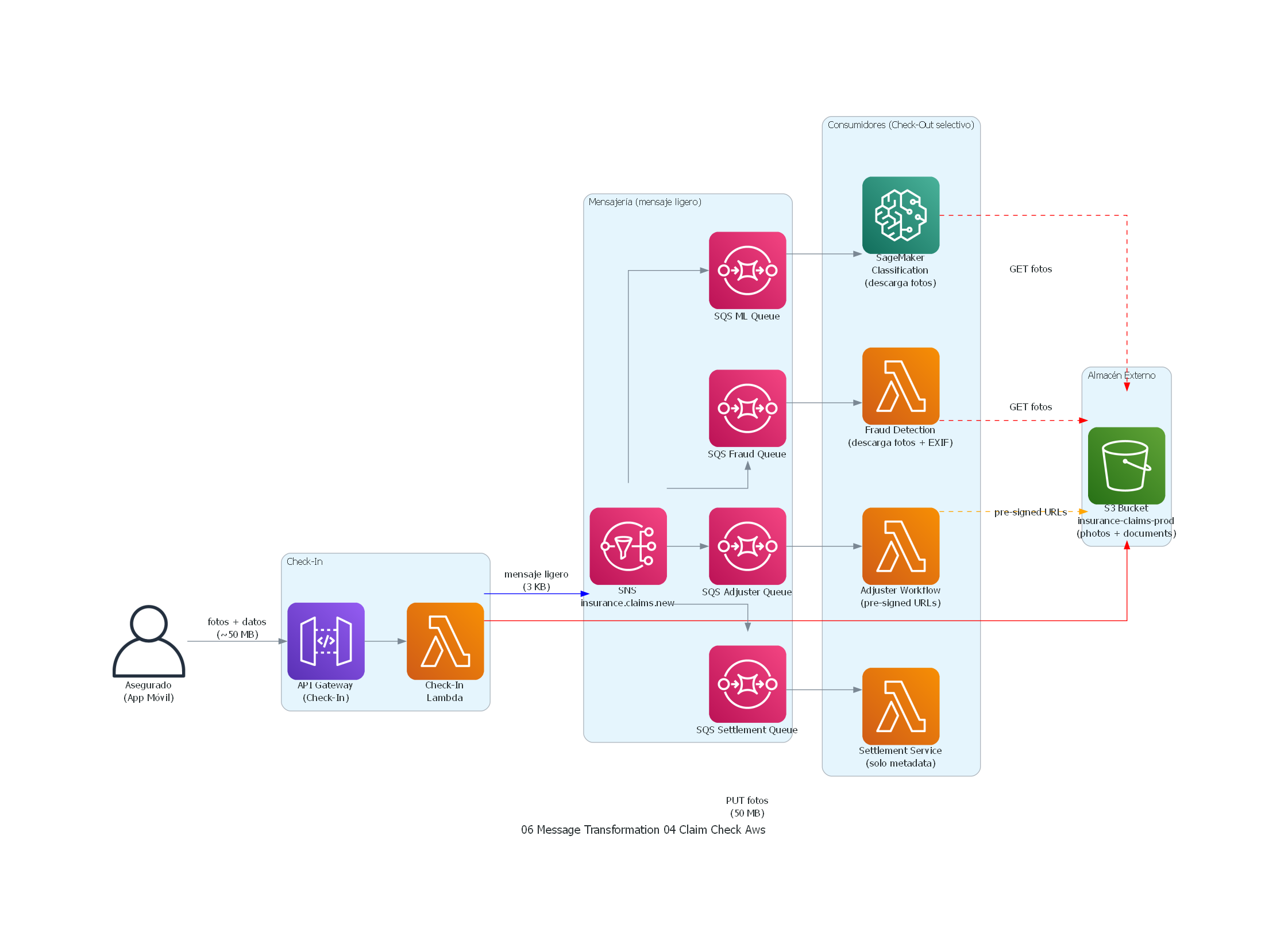
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.storage import S3
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.ml import Sagemaker
from diagrams.aws.network import APIGateway
with Diagram("Claim Check - Insurance Claims with Photo Evidence (AWS)", show=False, direction="LR"):
insured = User("Asegurado\n(App Móvil)")
with Cluster("Check-In"):
claims_api = APIGateway("API Gateway\n(Check-In)")
check_in = Lambda("Check-In\nLambda")
with Cluster("Almacén Externo"):
s3 = S3("S3 Bucket\ninsurance-claims-prod\n(photos + documents)")
with Cluster("Mensajería (mensaje ligero)"):
topic = SNS("SNS\ninsurance.claims.new")
q_ml = SQS("SQS ML Queue")
q_fraud = SQS("SQS Fraud Queue")
q_adjuster = SQS("SQS Adjuster Queue")
q_settlement = SQS("SQS Settlement Queue")
with Cluster("Consumidores (Check-Out selectivo)"):
ml_service = Sagemaker("SageMaker\nClassification\n(descarga fotos)")
fraud_svc = Lambda("Fraud Detection\n(descarga fotos + EXIF)")
adjuster = Lambda("Adjuster Workflow\n(pre-signed URLs)")
settlement = Lambda("Settlement Service\n(solo metadata)")
# Flujo check-in
insured >> Edge(label="fotos + datos\n(~50 MB)") >> claims_api >> check_in
check_in >> Edge(label="PUT fotos\n(50 MB)", color="red") >> s3
check_in >> Edge(label="mensaje ligero\n(3 KB)", color="blue") >> topic
# SNS fan-out to SQS queues
topic >> q_ml >> ml_service
topic >> q_fraud >> fraud_svc
topic >> q_adjuster >> adjuster
topic >> q_settlement >> settlement
ml_service >> Edge(label="GET fotos", style="dashed", color="red") >> s3
fraud_svc >> Edge(label="GET fotos", style="dashed", color="red") >> s3
adjuster >> Edge(label="pre-signed URLs", style="dashed", color="orange") >> s3
# settlement no descarga de S3 (solo usa metadata)
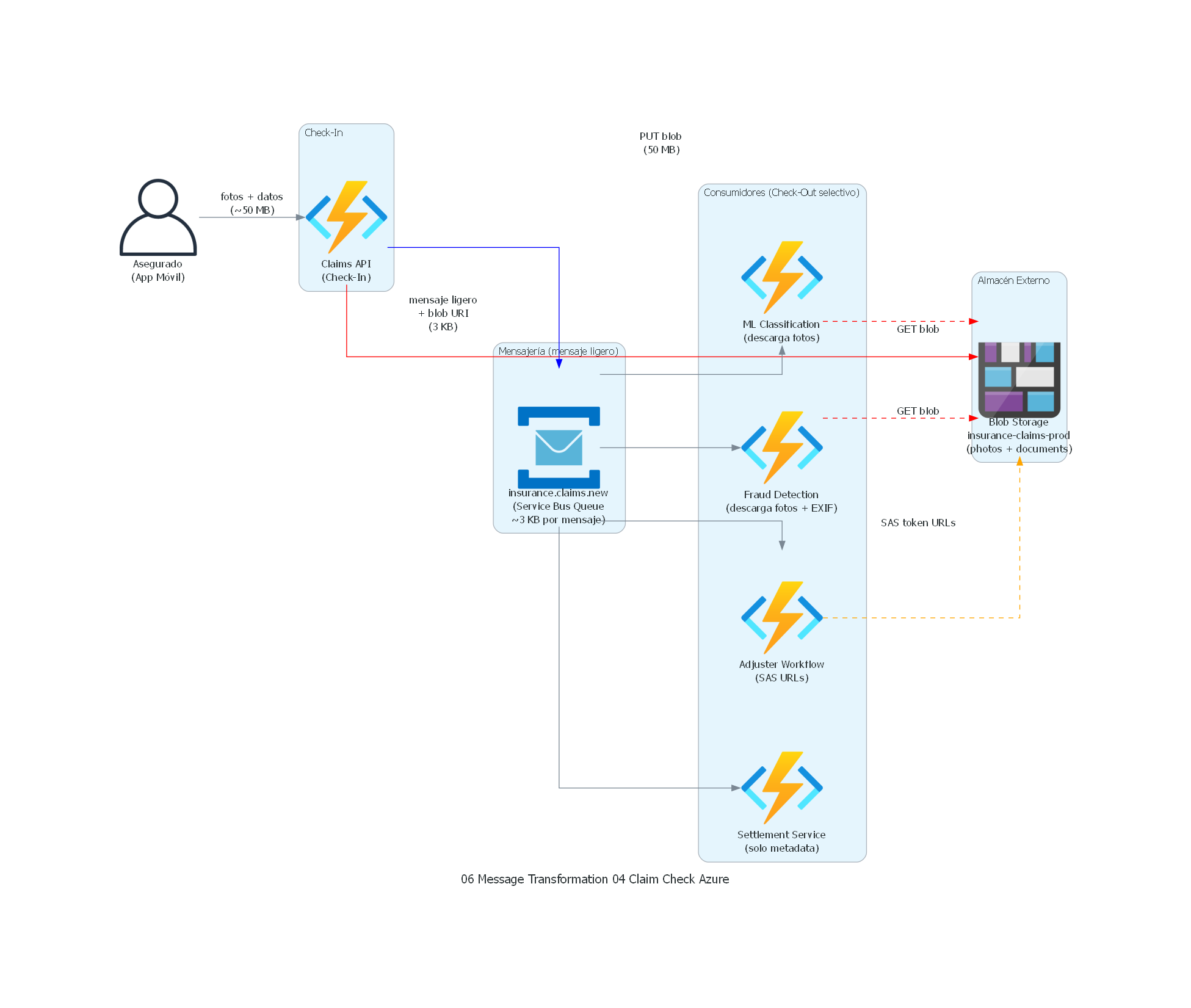
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps
from diagrams.azure.integration import ServiceBus
from diagrams.azure.storage import BlobStorage
with Diagram("Claim Check - Insurance Claims with Photo Evidence (Azure)", show=False, direction="LR"):
insured = User("Asegurado\n(App Móvil)")
with Cluster("Check-In"):
claims_api = FunctionApps("Claims API\n(Check-In)")
with Cluster("Almacén Externo"):
blob = BlobStorage("Blob Storage\ninsurance-claims-prod\n(photos + documents)")
with Cluster("Mensajería (mensaje ligero)"):
sb_queue = ServiceBus("insurance.claims.new\n(Service Bus Queue\n~3 KB por mensaje)")
with Cluster("Consumidores (Check-Out selectivo)"):
ml_service = FunctionApps("ML Classification\n(descarga fotos)")
fraud_svc = FunctionApps("Fraud Detection\n(descarga fotos + EXIF)")
adjuster = FunctionApps("Adjuster Workflow\n(SAS URLs)")
settlement = FunctionApps("Settlement Service\n(solo metadata)")
# Flujo check-in (well-documented Azure Claim Check pattern)
insured >> Edge(label="fotos + datos\n(~50 MB)") >> claims_api
claims_api >> Edge(label="PUT blob\n(50 MB)", color="red") >> blob
claims_api >> Edge(label="mensaje ligero\n+ blob URI\n(3 KB)", color="blue") >> sb_queue
# Flujo check-out
sb_queue >> ml_service
sb_queue >> fraud_svc
sb_queue >> adjuster
sb_queue >> settlement
ml_service >> Edge(label="GET blob", style="dashed", color="red") >> blob
fraud_svc >> Edge(label="GET blob", style="dashed", color="red") >> blob
adjuster >> Edge(label="SAS token URLs", style="dashed", color="orange") >> blob
# settlement no descarga de Blob (solo usa metadata del mensaje)
Explicación del Diagrama¶
El diagrama muestra la separación de plano de control y plano de datos:
- El Asegurado envía fotos y datos (~50 MB) al Claims API.
- El Claims API (Check-In) almacena las fotos en S3 (plano de datos, línea roja) y publica el mensaje ligero en Kafka (plano de control, línea azul).
- Los consumidores reciben el mensaje ligero de Kafka.
- Solo los consumidores que necesitan las fotos realizan Check-Out descargándolas de S3 (líneas punteadas rojas).
- El Settlement Service solo necesita metadata (monto, clasificación) y no descarga nada de S3.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Payload voluminoso | Fotos y documentos (50 MB) |
| Check-In (Store) | Claims API almacenando en S3 |
| Claim Check (referencia) | storage_ref en el mensaje Kafka |
| Almacén Externo | S3 bucket insurance-claims-prod |
| Mensaje ligero | Evento en Kafka (~3 KB) |
| Check-Out (Retrieve) | Consumidores descargando de S3 |
11. Beneficios¶
Impacto Técnico¶
- Desbloqueo de límites de tamaño: los mensajes caben en Kafka (1 MB) sin necesidad de aumentar el límite.
- Rendimiento del broker protegido: Kafka procesa mensajes de 3 KB en lugar de 50 MB, manteniendo latencia y throughput óptimos.
- Almacenamiento optimizado: las fotos se almacenan en S3 ($0.023/GB/mes) en lugar de en discos SSD de Kafka ($0.10-0.50/GB/mes).
- Check-out selectivo: los consumidores que solo necesitan metadata no descargan fotos, ahorrando bandwidth y tiempo de procesamiento.
Impacto Organizacional¶
- Compliance de retención: S3 lifecycle policy implementa la retención regulatoria de 7 años automáticamente, independiente de la retención de Kafka (7 días).
- Separación de responsabilidades: el equipo de infraestructura gestiona Kafka para mensajería; el equipo de almacenamiento gestiona S3 para blobs.
- Auditoría de acceso: S3 access logs registran exactamente quién accedió a qué foto y cuándo.
Impacto Operacional¶
- Reducción de costos de almacenamiento: con S3 Intelligent-Tiering y Glacier para retención a largo plazo, el costo de almacenar 7 años de fotos se reduce en un 90% comparado con almacenamiento activo.
- Replay sin costo de payload: re-procesar mensajes de Kafka (replay) solo descarga mensajes de 3 KB; las fotos se descargan de S3 solo si el consumidor las necesita.
- Escalabilidad independiente: el broker de Kafka y S3 escalan independientemente.
Beneficios de Mantenibilidad y Evolución¶
- Nuevos consumidores: un nuevo consumidor que solo necesita metadata se conecta a Kafka sin impacto en S3.
- Evolución del payload: si se añaden nuevos tipos de adjuntos (video de dashcam), solo cambia la estructura de attachments; el patrón sigue igual.
- CDN integration: las fotos en S3 pueden servirse a través de CloudFront para acceso rápido global (app del perito en campo).
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Dos sistemas a coordinar: el productor debe interactuar con S3 y Kafka, manejando las fallas de ambos.
- Consistencia eventual: no hay transaccionalidad entre S3 y Kafka; la coordinación es manual.
- Lifecycle management: las políticas de retención de S3 deben mantenerse alineadas con las necesidades de negocio y regulación.
Riesgos de Mal Uso¶
- Claim Check para mensajes pequeños: aplicar el patrón a mensajes de 10 KB añade complejidad sin beneficio. Solo tiene sentido cuando el payload es significativamente mayor que la metadata.
- No verificar integridad: no incluir checksums en las referencias, permitiendo que un payload corrupto se procese sin detección.
- Pre-signed URLs de larga duración: generar URLs que no expiran, creando un riesgo de seguridad permanente.
Sobreingeniería¶
- Implementar un servicio de claim check separado con API propia cuando almacenar directamente en S3 desde el productor es suficiente.
- Implementar un sistema de conteo de referencias para determinar cuándo eliminar el payload cuando una lifecycle policy basada en TTL es suficiente.
- Cifrar el payload con una clave por mensaje cuando la encriptación de S3 server-side (SSE-S3 o SSE-KMS) es suficiente.
Costos de Operación¶
- Costo de requests S3: cada check-out es un GET request a S3 ($0.0004 por 1000 requests). Con muchos consumidores y muchos archivos, el costo de requests puede ser significativo.
- Costo de transferencia de datos: la descarga de S3 tiene costo de data transfer ($0.09/GB para transferencias inter-región).
- Monitoreo dual: se debe monitorear tanto Kafka como S3 para garantizar la salud del flujo completo.
Anti-Patterns Relacionados¶
- Forgotten Payload: almacenar payloads en S3 sin lifecycle policy, acumulando terabytes de datos que nadie limpia.
- Eager Check-Out: todos los consumidores descargan todos los payloads inmediatamente, anulando el beneficio de check-out selectivo.
- Insecure Claim Check: referencias S3 con políticas de bucket público o pre-signed URLs que no expiran.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Content Filter (este capítulo): Content Filter elimina datos del mensaje; Claim Check los externaliza. Pueden combinarse: Content Filter elimina datos sensibles; Claim Check externaliza datos voluminosos.
- Envelope Wrapper (este capítulo): el sobre del mensaje puede contener las referencias del claim check como metadata, mientras el cuerpo contiene solo la información de negocio.
- Content Enricher (este capítulo): operación inversa al claim check. El enricher puede hacer el check-out, recuperando el payload y embebiendo los datos relevantes en el mensaje para un consumidor que los necesita.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Channel Adapter en el productor puede implementar el check-in como parte de la adaptación del mensaje.
- Después: Message Translator puede transformar las referencias para diferentes almacenes según el consumidor (S3 para AWS, Azure Blob para Azure).
Combinaciones Comunes¶
- Claim Check + Content-Based Router: el router examina la metadata del mensaje (no el payload) para enrutar. El claim check permite routing sin descargar el payload.
- Claim Check + Competing Consumers: múltiples instancias del consumidor descargan el payload de S3; S3 soporta acceso concurrente sin degradación.
- Claim Check + Dead Letter Channel: si el consumidor no puede procesar el mensaje, va a dead-letter. El payload sigue en S3 para cuando se re-procese.
Diferencias con Patrones Similares¶
- vs. Content Filter: Content Filter elimina datos del mensaje (destructivo). Claim Check los externaliza (recuperable).
- vs. Message Store: Message Store almacena el mensaje completo para auditoría. Claim Check almacena solo el payload voluminoso para eficiencia.
- vs. Wire Tap: Wire Tap captura una copia del mensaje para monitoreo. Claim Check separa el payload del mensaje para eficiencia de transporte.
Encaje en un Flujo Mayor de Integración¶
Claim Check es un patrón de optimización que se inserta transparentemente en cualquier flujo de integración que involucre payloads grandes. El flujo de negocio no cambia: el productor genera la reclamación, los consumidores la procesan. La diferencia es que el payload viaja por un canal optimizado (S3) en lugar de por el canal de mensajería (Kafka).
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Claim Check tiene relevancia alta y creciente por varias tendencias convergentes:
- Proliferación de datos binarios en integraciones: con la digitalización, cada vez más procesos de negocio involucran imágenes, documentos, videos. El onboarding digital (KYC), la telemedicina, los seguros digitales, el e-commerce con imágenes de productos — todos generan payloads binarios que deben fluir por sistemas de integración.
- Límites de los brokers: los brokers de mensajes modernos (Kafka, SQS, EventBridge) siguen teniendo límites de tamaño por mensaje. Estos límites son features, no bugs: mantienen al broker eficiente.
- Object storage commodity: S3, Azure Blob y GCS se han convertido en infraestructura commodity con durabilidad excepcional (11 nines), disponibilidad alta y costos bajos. El almacén externo del claim check es más confiable y más barato que el broker.
- AI/ML pipelines: los pipelines de machine learning generan y consumen payloads grandes (datasets, embeddings, imágenes generadas, modelos). Claim Check es el patrón estándar para transportar metadata por el pipeline de eventos mientras los datos viajan por object storage.
Cómo Se Implementa Hoy¶
| Tecnología | Mecanismo de Claim Check |
|---|---|
| AWS SQS + S3 | Amazon SQS Extended Client Library (nativo) |
| Kafka + S3 | Custom producer/consumer con S3 SDK |
| Azure Service Bus | Azure Service Bus claim check con Azure Blob Storage |
| Apache Camel | Claim Check EIP con S3/Azure/GCS component |
| Spring Cloud Stream | Custom interceptor con S3 check-in/check-out |
| Dapr | State store como almacén externo del claim check |
Qué Parte Sigue Siendo Esencial¶
- La separación de plano de control y plano de datos: mensajes pequeños por el broker, payloads grandes por object storage.
- El check-out selectivo: no todos los consumidores necesitan el payload; solo los que lo necesitan lo descargan.
- Lifecycle management del payload: retención, tiering y eliminación automática.
- Integridad verificable: checksums en las referencias para garantizar que el payload no se corrompió.
15. Implementación en Arquitecturas Modernas¶
AWS SQS Extended Client — Claim Check Nativo¶
// Configuración del Extended Client
AmazonS3 s3Client = AmazonS3ClientBuilder.defaultClient();
AmazonSQS sqsClient = AmazonSQSClientBuilder.defaultClient();
ExtendedClientConfiguration extendedConfig = new ExtendedClientConfiguration()
.withPayloadSupportEnabled(s3Client, "insurance-claims-payloads")
.withPayloadSizeThreshold(256 * 1024); // Claim Check si > 256KB
AmazonSQSExtendedClient extendedSqs = new AmazonSQSExtendedClient(sqsClient, extendedConfig);
// Producir: el Extended Client automáticamente aplica Claim Check si > 256KB
extendedSqs.sendMessage(new SendMessageRequest()
.withQueueUrl(queueUrl)
.withMessageBody(largeClaimJson)); // 50MB → automáticamente almacenado en S3
// Consumir: el Extended Client automáticamente recupera de S3
List<Message> messages = extendedSqs.receiveMessage(queueUrl).getMessages();
String fullPayload = messages.get(0).getBody(); // Transparente: parece un mensaje normal
El SQS Extended Client implementa Claim Check de forma completamente transparente: el productor envía el mensaje grande y el SDK automáticamente lo almacena en S3 si supera el threshold. El consumidor recibe el mensaje y el SDK automáticamente lo recupera de S3.
Kafka + S3 — Claim Check Manual con Check-In Explícito¶
import boto3
import json
import hashlib
from confluent_kafka import Producer
s3_client = boto3.client('s3')
producer = Producer({'bootstrap.servers': 'kafka:9092'})
def publish_claim_with_claim_check(claim_data: dict, photos: list[bytes]):
claim_id = claim_data['claim_id']
attachments = []
# Check-In: almacenar fotos en S3
for i, photo_bytes in enumerate(photos):
s3_key = f"claims/{claim_id}/photos/photo_{i}.jpg"
checksum = hashlib.sha256(photo_bytes).hexdigest()
s3_client.put_object(
Bucket='insurance-claims-prod',
Key=s3_key,
Body=photo_bytes,
ChecksumSHA256=checksum,
ContentType='image/jpeg'
)
attachments.append({
'type': 'photo',
'storage_ref': f"s3://insurance-claims-prod/{s3_key}",
'size_bytes': len(photo_bytes),
'checksum_sha256': checksum
})
# Mensaje ligero con referencias
message = {
**claim_data,
'attachments': attachments,
'_claim_check': {
'total_attachments': len(attachments),
'total_size_bytes': sum(a['size_bytes'] for a in attachments)
}
}
# Publicar mensaje ligero en Kafka
producer.produce(
topic='insurance.claims.new',
key=claim_id,
value=json.dumps(message)
)
producer.flush()
Azure Service Bus — Claim Check con Blob Storage¶
// Check-In: almacenar payload en Azure Blob
var blobClient = new BlobServiceClient(connectionString);
var container = blobClient.GetBlobContainerClient("claim-attachments");
string blobName = $"{claimId}/photos/{fileName}";
await container.GetBlobClient(blobName).UploadAsync(photoStream);
// Mensaje ligero con referencia
var message = new ServiceBusMessage(JsonSerializer.Serialize(new
{
claim_id = claimId,
attachments = new[] {
new {
type = "photo",
blob_ref = $"https://storage.blob.core.windows.net/claim-attachments/{blobName}",
size_bytes = photoStream.Length
}
}
}));
await sender.SendMessageAsync(message);
Pre-Signed URL para Check-Out Seguro¶
# Check-Out: generar pre-signed URL para acceso temporal
def get_photo_url(storage_ref: str, expiration_seconds: int = 3600) -> str:
bucket, key = parse_s3_ref(storage_ref)
url = s3_client.generate_presigned_url(
'get_object',
Params={'Bucket': bucket, 'Key': key},
ExpiresIn=expiration_seconds
)
return url
# El consumidor (app del perito) obtiene URLs temporales
for attachment in message['attachments']:
if attachment['type'] == 'photo':
temp_url = get_photo_url(attachment['storage_ref'])
# temp_url válida por 1 hora, luego expira
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Check-in success rate: porcentaje de payloads almacenados exitosamente en S3 vs. errores.
- Check-out latency: tiempo que tarda un consumidor en descargar el payload de S3 (p50, p95, p99).
- Payload size distribution: histograma de tamaños de payload para dimensionar storage y bandwidth.
- Orphan payloads: payloads en S3 que no tienen un mensaje correspondiente en Kafka (dangling).
Monitoreo¶
- S3 error rate: errores 5xx de S3 que impiden check-in o check-out.
- Kafka message size: verificar que los mensajes con claim check están dentro del límite (alertar si un mensaje excede 100 KB, que indicaría un claim check fallido).
- Storage cost: costo mensual de S3 desglosado por lifecycle tier (Standard, IA, Glacier).
- Data transfer cost: costo de transferencia de datos de S3, indicando volumen de check-outs.
Versionado¶
- Formato de referencia: si cambia el esquema de las referencias (de
s3://a un formato abstracto), los consumidores deben soportar ambos formatos durante la transición. - Bucket restructuring: si se reorganiza la estructura de keys en S3, las referencias existentes en mensajes ya publicados deben seguir funcionando (nunca eliminar keys antiguos sin migración).
- Schema evolution: si se añaden nuevos tipos de attachments (video), el formato de la referencia debe ser extensible.
Seguridad¶
- Bucket policies: el bucket de S3 debe ser privado por defecto, con acceso solo a través de IAM roles de los servicios autorizados.
- Cifrado: SSE-S3 o SSE-KMS para cifrado en reposo; TLS para cifrado en tránsito.
- Pre-signed URL expiration: las pre-signed URLs deben tener expiración corta (1 hora para apps, 15 minutos para APIs).
- No bucket público: bajo ninguna circunstancia el bucket debe tener acceso público, ya que contiene documentos personales e imágenes de siniestros.
Manejo de Errores¶
- S3 upload failure: si el upload a S3 falla, reintentar. Si agota reintentos, no publicar el mensaje en Kafka (fail-closed).
- S3 download failure: si el consumidor no puede descargar de S3, reintentar con backoff. Si agota reintentos, enviar a dead-letter.
- Checksum mismatch: si el checksum del payload descargado no coincide con el del mensaje, alertar y reintentar (posible corrupción en tránsito).
- Orphan cleanup: proceso batch periódico que identifica payloads en S3 sin mensaje correspondiente en Kafka y los mueve a cuarentena.
17. Errores Comunes¶
Publicar el Mensaje Antes de Almacenar el Payload¶
Publicar el mensaje con la referencia en Kafka antes de confirmar que el payload se almacenó en S3. Si el upload a S3 falla, el consumidor recibe una referencia que apunta a nada (dangling reference). El orden correcto es: almacenar primero, publicar después.
No Gestionar el Lifecycle del Payload¶
Almacenar payloads en S3 Standard indefinidamente sin lifecycle policy. Con 5000 reclamaciones diarias × 50 MB × 365 días × 7 años, se acumulan 638 TB en S3 Standard (~$14,700/mes). Con lifecycle policy (Glacier Deep Archive después del año 1), el costo se reduce a ~$640/mes.
Pre-Signed URLs de Larga Duración¶
Generar pre-signed URLs con expiración de 7 días o más. Si una URL se filtra (en un log, en un email), cualquiera puede acceder al payload durante ese período. Las pre-signed URLs deben tener la expiración mínima necesaria (15 minutos a 1 hora).
Claim Check para Todos los Mensajes¶
Aplicar claim check a todos los mensajes, incluyendo los pequeños (1-10 KB). Esto añade una llamada a S3 por cada mensaje sin beneficio, aumentando latencia y costo de requests S3. Claim Check debe activarse solo cuando el payload supera un threshold (por ejemplo, 256 KB).
No Verificar Integridad en el Check-Out¶
No verificar el checksum del payload al descargarlo. Si el payload se corrompió en S3 (extremadamente raro pero posible), el consumidor procesa datos corruptos sin detectarlo. El checksum SHA-256 en la referencia permite verificación de integridad en cada check-out.
18. Conclusión Técnica¶
Claim Check es el patrón que separa el payload voluminoso del mensaje, almacenándolo en un almacén externo optimizado para blobs y reemplazándolo con una referencia en el mensaje que viaja por el canal de mensajería. Es la implementación del principio de separación de plano de control (mensajería) y plano de datos (object storage).
Cuándo aporta valor: siempre que los mensajes contienen payloads binarios (imágenes, documentos, archivos) que exceden los límites del broker o que degradan su rendimiento. Es especialmente valioso cuando múltiples consumidores necesitan la metadata pero solo un subconjunto necesita el payload completo.
Cuándo evita problemas importantes: cuando sin claim check, los mensajes no caben en el broker, el broker se satura con datos binarios, el costo de almacenamiento en el broker es prohibitivo, o los consumidores descargan payloads que no necesitan.
Cuándo no conviene adoptarlo: cuando todos los mensajes son pequeños (menos de 100 KB) y caben cómodamente en el broker, o cuando la latencia adicional del check-out es inaceptable para el caso de uso.
Recomendación para arquitectos: establezca un threshold de tamaño claro (256 KB es un buen punto de partida) a partir del cual se activa claim check. Use el almacén de objetos nativo de su cloud (S3, Azure Blob, GCS) como almacén externo. Implemente lifecycle policy desde el día uno — no espere a que los costos de almacenamiento sean un problema. Siempre almacene primero el payload y publique después el mensaje (nunca al revés). Incluya checksums en las referencias para verificar integridad. Y considere el SQS Extended Client de AWS o equivalentes de su plataforma antes de implementar el patrón manualmente — muchas plataformas ya lo proveen como biblioteca nativa.