Normalizer¶
1. Nombre del Patrón¶
- Nombre oficial: Normalizer
- Categoría: Message Transformation (Transformación de Mensajes)
- Traducción contextual: Normalizador
2. Resumen Ejecutivo¶
Normalizer es el patrón que procesa mensajes de diferentes fuentes — cada una con su propio formato, estructura y convenciones — y los transforma en un formato común unificado. Cuando múltiples productores envían datos semánticamente equivalentes pero sintácticamente diferentes, el Normalizer actúa como punto de convergencia que elimina la variedad de formatos y produce un flujo homogéneo que los consumidores pueden procesar sin conocer el formato original de cada fuente.
El problema que resuelve es la heterogeneidad de formatos en un mundo donde los datos provienen de múltiples fuentes que no coordinaron sus formatos: proveedores que envían catálogos en CSV, XML y JSON; sistemas legacy que producen archivos de texto plano de ancho fijo; APIs modernas que retornan JSON con convenciones de naming diferentes; y feeds de terceros con estructuras completamente diferentes para datos semánticamente equivalentes.
En el contexto actual, Normalizer es más relevante que nunca por la proliferación de integraciones: las empresas modernas integran decenas o cientos de fuentes de datos (SaaS APIs, IoT devices, partner feeds, legacy systems). Sin normalización, cada consumidor debe implementar parsers para cada formato de cada fuente, multiplicando la complejidad. El Normalizer centraliza la complejidad de la heterogeneidad en un punto gobernado y produce un flujo normalizado que todos los consumidores comparten.
3. Definición Detallada¶
Propósito¶
Normalizer recibe mensajes de diferentes fuentes, identifica el formato de cada mensaje, aplica la transformación apropiada para ese formato, y produce un mensaje en el formato canónico común. Es la combinación de un Content-Based Router (para identificar el formato) con múltiples Message Translators (uno por formato de entrada) convergiendo en una única salida.
Lógica Arquitectónica¶
En sistemas de integración, la realidad es que las fuentes de datos no coordinan sus formatos. Un retailer que recibe catálogos de productos de 50 proveedores recibe 50 formatos diferentes:
- Proveedor A: CSV con columnas
product_name,price,sku_code. - Proveedor B: XML con elementos
<Item><Description/><UnitCost/><ArticleNumber/></Item>. - Proveedor C: JSON con campos
{"productTitle": ..., "retailPrice": ..., "supplierSKU": ...}. - Proveedor D: archivo de texto plano con campos de ancho fijo (posiciones 1-30: nombre, 31-40: precio).
Los datos son semánticamente equivalentes (nombre del producto, precio, SKU) pero sintácticamente incompatibles. Sin Normalizer, cada sistema consumidor (catálogo online, sistema de precios, sistema de inventario) debe implementar parsers para los 50 formatos, resultando en 50 × N consumidores = 50N integraciones.
Normalizer resuelve esto posicionándose como punto de convergencia:
- Detectar el formato: ¿es CSV, XML, JSON, texto plano? ¿De qué proveedor es?
- Seleccionar el translator: aplicar la transformación específica para ese formato/proveedor.
- Producir formato canónico: generar un mensaje en el formato interno estándar que todos los consumidores entienden.
Principio de Diseño Subyacente¶
El principio es absorber la variedad en la frontera del sistema: la heterogeneidad de las fuentes externas se resuelve una sola vez, en el punto de entrada, produciendo un flujo interno homogéneo. Los consumidores internos solo necesitan entender un formato — el formato canónico — independientemente de cuántas fuentes externas existan.
Problema Estructural que Resuelve¶
Sin Normalizer:
- Cada consumidor debe conocer y parsear todos los formatos de todas las fuentes.
- Añadir un nuevo proveedor requiere actualizar todos los consumidores con el nuevo formato.
- La lógica de transformación está dispersa en múltiples consumidores, sin gobernanza ni reutilización.
- Los errores de parsing se descubren en diferentes consumidores en diferentes momentos, dificultando el diagnóstico.
Contexto en el que Emerge¶
Normalizer emerge cuando:
- Múltiples fuentes envían datos semánticamente equivalentes en formatos diferentes.
- Los consumidores no deberían conocer ni manejar la diversidad de formatos.
- Se necesita un formato interno estándar para procesamiento uniforme.
- Las fuentes externas no pueden (o no quieren) cambiar su formato.
Por Qué No Es Trivial¶
- Detección de formato: ¿cómo se identifica el formato del mensaje? ¿Por header? ¿Por el canal de entrada? ¿Por inspección del contenido?
- Mapping semántico: los mismos datos tienen nombres diferentes en cada fuente.
price,UnitCost,retailPrice,precio_unitarioson el mismo concepto pero con diferentes nombres. - Tipos de datos: una fuente envía precios como strings ("12.50"), otra como números (12.5), otra con moneda incluida ("12,50 EUR"). La normalización debe homogeneizar los tipos.
- Datos faltantes: una fuente incluye
weighty otra no. ¿El formato canónico permiteweight: null? ¿O se rechaza el mensaje? - Evolución de formatos: cuando un proveedor cambia su formato (añade un campo, renombra otro), el translator correspondiente debe actualizarse sin afectar a los demás.
Relación con Sistemas Distribuidos y Mensajería¶
Normalizer implementa el patrón Anti-Corruption Layer de Domain-Driven Design aplicado a la mensajería. El Anti-Corruption Layer protege el modelo de dominio interno de las idiosincrasias de los sistemas externos. El Normalizer es su implementación concreta en el contexto de integración por mensajes: transforma los formatos externos al modelo canónico interno.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Un retailer de moda online opera en 5 países y recibe catálogos de productos de 30 proveedores. Cada proveedor envía su catálogo en un formato diferente:
Proveedor A (España, CSV):
codigo_articulo;nombre;precio_euros;talla;color;stock
ESP-NIKE-001;Zapatillas Air Max 90;129.99;42;Negro;150
ESP-NIKE-002;Camiseta Dri-FIT;34.99;M;Blanco;300
Proveedor B (Italia, XML):
<Catalogo>
<Articolo>
<CodiceFornitore>IT-GUCCI-2026-A1</CodiceFornitore>
<Descrizione>Scarpe Mocassino</Descrizione>
<Prezzo valuta="EUR">450.00</Prezzo>
<Taglie>
<Taglia>40</Taglia><Taglia>41</Taglia><Taglia>42</Taglia>
</Taglie>
<Colore>Nero</Colore>
<Disponibilita>85</Disponibilita>
</Articolo>
</Catalogo>
Proveedor C (UK, JSON via API):
{
"products": [
{
"supplier_ref": "UK-BURBERRY-7891",
"product_name": "Trench Coat Heritage",
"price": { "amount": 1890, "currency": "GBP" },
"sizes": ["S", "M", "L", "XL"],
"colour": "Honey",
"available_qty": 42
}
]
}
Proveedor D (Alemania, archivo de ancho fijo):
DE-ADIDAS-3310 Ultraboost 22 00014999EUR44 Schwarz 00200
DE-ADIDAS-3311 Tiro Track Pants 00005999EUR L Schwarz 00450
Síntomas del Problema¶
- El equipo de catálogo mantiene 30 parsers diferentes, uno por proveedor. Cada parser fue escrito por un desarrollador diferente en un momento diferente.
- Cuando el proveedor B cambió de
PrezzoaPrezzoVenditaen su XML, el parser se rompió y 200 productos desaparecieron del catálogo durante 6 horas. - El sistema de pricing tiene sus propios parsers (duplicados) porque se desarrolló después del catálogo y no reutilizó los parsers existentes.
- Los precios en GBP del proveedor C no se convirtieron a EUR en el parser del catálogo pero sí en el parser de pricing, causando una discrepancia de precios visible para el cliente.
- Añadir un nuevo proveedor (Proveedor E, Japón, formato JSON diferente) requiere modificar el catálogo, pricing y el sistema de inventario — tres equipos, tres sprints.
- Los nombres de colores están en el idioma de cada proveedor: "Negro", "Nero", "Schwarz", "Black". El sistema de filtrado por color no funciona correctamente.
Impacto Operativo y Arquitectónico¶
- 30 parsers × 3 consumidores = 90 integraciones de formato, cada una mantenida independientemente.
- Inconsistencias de datos: el mismo producto tiene precios diferentes en catálogo y pricing por discrepancias en la conversión de moneda.
- Fragilidad ante cambios: un cambio de formato de un proveedor puede romper múltiples consumidores.
- Time-to-market lento: integrar un nuevo proveedor tarda semanas porque múltiples equipos deben implementar el parser.
Riesgos Si No Se Implementa Correctamente¶
- Normalización incompleta: normalizar la estructura (JSON) pero no los valores (colores en diferentes idiomas, precios en diferentes monedas).
- Normalizer monolítico: un solo componente que conoce los 30 formatos, difícil de mantener y probar.
- Pérdida de datos: un translator que no mapea un campo del proveedor, perdiendo información silenciosamente.
Ejemplos Reales¶
- Retail: normalización de catálogos de múltiples proveedores.
- Healthcare: normalización de mensajes HL7v2, HL7 FHIR, CDA de diferentes hospitales al formato interno del HIE.
- Finanzas: normalización de feeds de mercado de Bloomberg, Reuters, exchanges en formato FIX.
- IoT: normalización de datos de sensores de diferentes fabricantes con diferentes formatos de telemetría.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando múltiples fuentes envían datos semánticamente equivalentes en formatos diferentes.
- Cuando los consumidores deben procesar datos de todas las fuentes de forma uniforme.
- Cuando las fuentes externas no pueden cambiar su formato para adaptarse al sistema interno.
- Cuando la lógica de transformación debe centralizarse para gobernabilidad y reutilización.
Cuándo No Usarlo¶
- Cuando todas las fuentes ya usan el mismo formato (no hay heterogeneidad que normalizar).
- Cuando cada fuente tiene consumidores dedicados que entienden su formato específico (no hay beneficio en un formato común).
- Cuando la transformación es tan simple que un Message Translator inline en el consumidor es suficiente.
Precondiciones¶
- Existe (o se puede definir) un formato canónico interno para los datos normalizados.
- Existe un mecanismo para identificar el formato de cada mensaje entrante (canal, header, inspección de contenido).
- Las diferencias entre formatos son mapeables: los datos de cada fuente pueden transformarse al formato canónico sin pérdida de información esencial.
Restricciones¶
- Cada formato de entrada requiere su propio translator. Con N proveedores, hay N translators que mantener.
- El formato canónico debe ser lo suficientemente expresivo para representar todos los datos de todas las fuentes.
- La normalización puede perder información específica de una fuente que no tiene equivalente en el formato canónico.
Dependencias¶
- Definición del formato canónico (schema).
- Mecanismo de detección de formato (router o identificador).
- Translators específicos para cada formato de entrada.
- Governance que mantenga los translators actualizados ante cambios de formato de los proveedores.
Supuestos Arquitectónicos¶
- Los datos de todas las fuentes son semánticamente equivalentes (representan el mismo concepto de negocio).
- El formato canónico puede representar todos los datos esenciales de todas las fuentes.
- Las fuentes no cambiarán para adaptarse al sistema interno; el sistema interno se adapta a las fuentes.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Plataformas de e-commerce con múltiples proveedores.
- Health Information Exchanges con múltiples hospitales.
- Plataformas de trading con múltiples feeds de mercado.
- IoT platforms con múltiples fabricantes de dispositivos.
- Data lakes que ingestan datos de múltiples fuentes heterogéneas.
6. Fuerzas Arquitectónicas¶
Variedad de Fuentes vs. Uniformidad Interna¶
Más fuentes significa más formatos que normalizar, pero el beneficio de la uniformidad interna crece con el número de consumidores. Con 30 fuentes y 5 consumidores, el normalizer elimina 30×5 = 150 integraciones de formato, reemplazándolas con 30 translators + 5 consumidores que entienden un formato.
Fidelidad de la Transformación vs. Simplicidad del Formato Canónico¶
Un formato canónico complejo que capture todas las sutilezas de cada fuente es difícil de mantener pero no pierde información. Un formato canónico simple es fácil de usar pero puede no representar datos específicos de ciertas fuentes.
Centralización vs. Proximidad a la Fuente¶
¿Un normalizer centralizado que maneja todos los formatos, o normalizers distribuidos cerca de cada fuente? El centralizado es más fácil de gobernar pero es un monolito. Los distribuidos son más resilientes pero más difíciles de coordinar.
Detección Automática vs. Explícita¶
¿Detectar el formato automáticamente (inspección de contenido) o explícitamente (canal dedicado por fuente, header de formato)? La detección automática es más flexible pero propensa a errores. La detección explícita es más confiable pero requiere configuración por fuente.
Normalización Completa vs. Incremental¶
¿Normalizar todos los campos del mensaje o solo los campos que los consumidores necesitan actualmente? La normalización completa es más robusta pero más costosa de implementar. La normalización incremental es más ágil pero puede requerir actualizaciones cuando un consumidor necesita un campo que no se había normalizado.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Fuentes Externas: sistemas que producen mensajes en formatos heterogéneos.
- Format Detector / Router: identifica el formato del mensaje entrante y lo enruta al translator apropiado.
- Message Translators: uno por cada formato de entrada, transforma al formato canónico.
- Formato Canónico: el schema común al que se normalizan todos los mensajes.
- Canal de Salida: el canal donde se publican los mensajes normalizados.
- Consumidores: sistemas que procesan los mensajes normalizados sin conocer la fuente original.
Flujo Lógico¶
flowchart TD
A([Fuente A\nCSV español]) --> D[Format Detector]
B([Fuente B\nXML italiano]) --> D
C([Fuente C\nJSON inglés]) --> D
D --> E{Formato\ndetectado?}
E -- csv-proveedor-espana --> F[CSV Translator]
E -- xml-proveedor-italia --> G[XML Translator]
E -- json-proveedor-uk --> H[JSON Translator]
F --> I[Formato canónico\nsku, name, price, stock...]
G --> I
H --> I
I --> J[(Topic: catalog.products.normalized)]
J --> K([Consumidores procesan\nsin conocer la fuente])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Fuentes externas | Enviar datos en su formato propio |
| Format Detector | Identificar el formato/fuente del mensaje |
| Translators | Transformar del formato específico al canónico |
| Formato Canónico | Definir el contrato común para todos los datos normalizados |
| Consumidores | Procesar mensajes normalizados sin conocer la fuente |
Interacciones¶
- Fuente → Canal de entrada: cada fuente publica en su canal o en un canal compartido.
- Canal → Format Detector: el detector identifica el formato.
- Format Detector → Translator: enruta al translator correcto.
- Translator → Canal de salida: el translator publica el mensaje normalizado.
Contratos Implícitos¶
- Completitud: el mensaje normalizado contiene al menos los campos requeridos del formato canónico.
- Fidelidad: los datos no se pierden ni se alteran en la transformación (excepto conversiones de formato).
- Consistencia: el mismo dato en fuentes diferentes produce el mismo valor en el formato canónico.
Decisiones de Diseño Clave¶
- Detección de formato: ¿por canal (cada fuente publica en su propio topic), por header (metadata del mensaje), o por inspección (análisis del contenido)?
- Translator por fuente vs. por formato: ¿un translator por proveedor (más específico) o uno por tipo de formato (CSV, XML, JSON) con configuración por proveedor?
- Normalización de valores: ¿normalizar solo la estructura o también los valores (colores, monedas, unidades de medida)?
- Datos no mapeables: ¿descartar datos que no tienen equivalente en el formato canónico, o preservarlos en un campo "extras"?
- Validación post-normalización: ¿validar que el mensaje normalizado conforma al schema canónico antes de publicar?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail — Normalización de Catálogos de Múltiples Proveedores¶
Contexto del Negocio¶
Un retailer de moda online recibe catálogos de productos de 30 proveedores internacionales. Cada proveedor envía sus datos en un formato diferente (CSV, XML, JSON, texto plano). Los datos incluyen nombre del producto, precio (en diferentes monedas), tallas (en diferentes sistemas), colores (en diferentes idiomas) y stock. El retailer necesita un catálogo unificado para su tienda online, sistema de pricing y gestión de inventario.
Necesidad de Integración¶
Normalizar los catálogos de todos los proveedores a un formato canónico interno para que los sistemas consumidores (catálogo online, pricing engine, inventory management) procesen datos homogéneos independientemente del proveedor de origen.
Sistemas Involucrados¶
- Supplier Feeds: 30 proveedores con diferentes formatos y canales (SFTP, API, email, EDI).
- Ingestion Adapters: Channel Adapters que reciben los feeds y los publican en Kafka.
- Format Detector: identifica el proveedor/formato de cada mensaje.
- Supplier Translators: 30 translators, uno por proveedor.
- Value Normalizer: normaliza colores, monedas, tallas a valores internos.
- Schema Validator: valida que el mensaje normalizado conforma al schema canónico.
- Kafka: backbone de mensajería.
- Consumidores: Catalog Service, Pricing Engine, Inventory Service.
Restricciones Técnicas¶
- Los proveedores no cambiarán su formato. El retailer se adapta a ellos.
- Nuevos proveedores se integran cada trimestre (3-5 nuevos proveedores por año).
- Los precios deben convertirse a EUR usando la tasa de cambio del día.
- Las tallas deben mapearse al sistema EU (36-50 para calzado, XS-XXL para ropa).
- Los colores deben mapearse a un catálogo interno de 48 colores estándar.
Diseño del Normalizer¶
Formato canónico (schema del producto normalizado):
{
"$schema": "https://catalog.retailer.com/schemas/product/v3",
"sku": "string (formato interno: PROV-ORIG-SKU)",
"supplier_code": "string",
"name": "string (normalizado a español)",
"price": {
"amount_eur": "number (convertido a EUR)",
"original_amount": "number",
"original_currency": "string (ISO 4217)"
},
"sizes": ["string (sistema EU)"],
"color": {
"code": "string (código interno: COL-001 a COL-048)",
"name_es": "string (nombre en español)"
},
"stock_quantity": "integer",
"source": {
"supplier": "string",
"original_ref": "string",
"normalized_at": "datetime"
}
}
Ejemplo de normalización del proveedor UK (GBP, UK sizes):
Entrada:
{
"supplier_ref": "UK-BURBERRY-7891",
"product_name": "Trench Coat Heritage",
"price": { "amount": 1890, "currency": "GBP" },
"sizes": ["S", "M", "L", "XL"],
"colour": "Honey",
"available_qty": 42
}
Salida normalizada:
{
"sku": "BURB-UK-BURBERRY-7891",
"supplier_code": "BURBERRY-UK",
"name": "Trench Coat Heritage",
"price": {
"amount_eur": 2192.40,
"original_amount": 1890,
"original_currency": "GBP"
},
"sizes": ["S", "M", "L", "XL"],
"color": {
"code": "COL-012",
"name_es": "Miel"
},
"stock_quantity": 42,
"source": {
"supplier": "BURBERRY-UK",
"original_ref": "UK-BURBERRY-7891",
"normalized_at": "2026-04-07T10:15:00Z"
}
}
Decisiones Arquitectónicas¶
- Un translator por proveedor: cada proveedor tiene su propio translator (microservicio o función) que conoce el formato exacto de ese proveedor. Los translators comparten una librería común de normalización de valores.
- Detección por canal de entrada: cada proveedor publica en su propio topic (por ejemplo,
supplier.burberry-uk.raw). No se necesita detección de formato — el canal identifica el proveedor. - Normalización de valores centralizada: una librería compartida normaliza colores (mapping table), monedas (API de tasas de cambio) y tallas (mapping table por categoría).
- Preservación del valor original: el formato canónico preserva el precio original y la moneda original junto con el precio normalizado a EUR. Esto permite auditoría y reconciliación.
- Validación post-normalización: cada mensaje normalizado se valida contra el JSON Schema canónico antes de publicarse. Los mensajes que no validan van a dead-letter con el error de validación.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Proveedor cambia su formato sin avisar | Translator falla y envía a dead-letter; alerta al equipo |
| Tasa de cambio incorrecta | Usar API confiable (ECB, Bloomberg); cachear con TTL de 1 hora |
| Color no reconocido (no está en el mapping) | Default a "COL-000" (Sin clasificar) + alerta para actualizar mapping |
| Translator incorrecto que mapea campos mal | Testing automatizado por proveedor con datos de referencia |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Ingestion del Feed del Proveedor¶
El proveedor Burberry (UK) publica su catálogo actualizado via API REST. El Ingestion Adapter para Burberry (un scheduled job que ejecuta cada hora) llama a la API del proveedor, obtiene los productos actualizados, y publica cada producto como un mensaje individual en el topic Kafka supplier.burberry-uk.raw.
Paso 2: Format Detection (Implícita por Canal)¶
El Normalizer Service está suscrito a todos los topics supplier.*.raw. Cuando recibe un mensaje de supplier.burberry-uk.raw, sabe que es del proveedor Burberry UK y selecciona el translator correspondiente: BurberryUKTranslator.
Paso 3: Structural Transformation¶
El BurberryUKTranslator mapea la estructura del JSON del proveedor al formato canónico:
supplier_ref→sku(con prefijoBURB-)product_name→nameprice.amount→price.original_amountprice.currency→price.original_currencysizes→sizes(ya es un array, pero necesita normalización de valores)colour→color(necesita normalización de valores)available_qty→stock_quantity
Paso 4: Value Normalization¶
Después de la transformación estructural, el Value Normalizer procesa los valores:
Conversión de moneda: 1890 GBP × 1.16 (tasa del día) = 2192.40 EUR.
Normalización de color: el color "Honey" no es un color estándar. El mapping table busca: - "Honey" → encontrado como alias de "Miel" → código COL-012. - Si no se encontrara, se asignaría COL-000 (Sin clasificar) y se generaría una alerta.
Normalización de tallas: para la categoría "outerwear", las tallas S/M/L/XL son universales y no requieren conversión. Si fueran tallas UK de calzado (UK 7 → EU 40.5), el mapping las convertiría.
Paso 5: Validación y Publicación¶
El mensaje normalizado se valida contra el JSON Schema canónico v3: - ¿Tiene todos los campos requeridos? Sí. - ¿Los tipos son correctos? Sí (amount_eur es number, stock_quantity es integer). - ¿El código de color es válido? Sí (COL-012 existe en el catálogo).
Validación exitosa. El mensaje normalizado se publica en catalog.products.normalized.
Paso 6: Consumo Uniforme¶
Los consumidores procesan mensajes de catalog.products.normalized sin saber que vino de Burberry UK:
- Catalog Service: actualiza la ficha del producto en la tienda online.
- Pricing Engine: actualiza el precio (2192.40 EUR) aplicando su regla de markup.
- Inventory Service: actualiza el stock disponible (42 unidades).
Todos procesan el mismo formato canónico, independientemente de que el producto haya venido de Burberry (JSON/GBP) o de un proveedor español (CSV/EUR).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
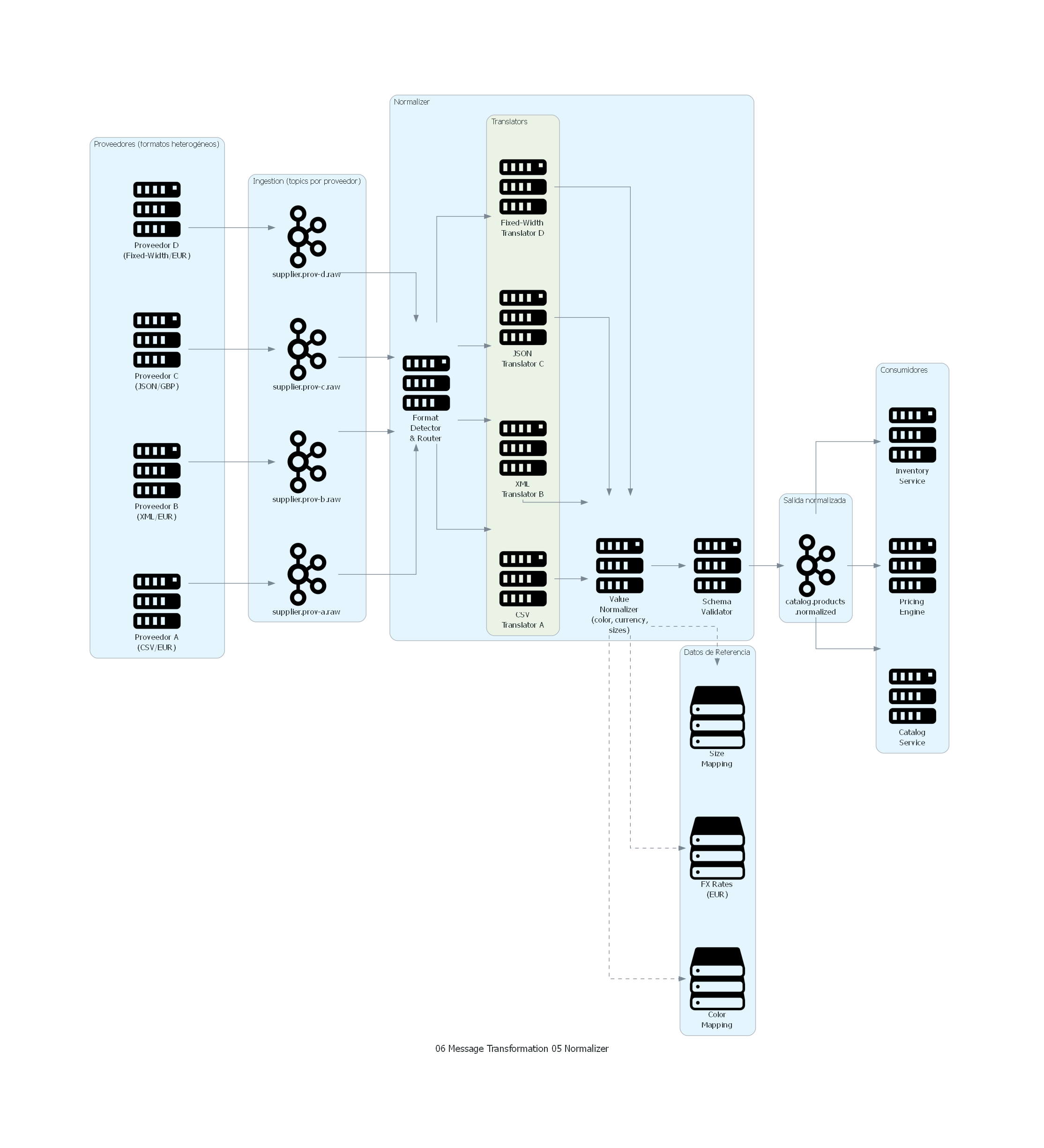
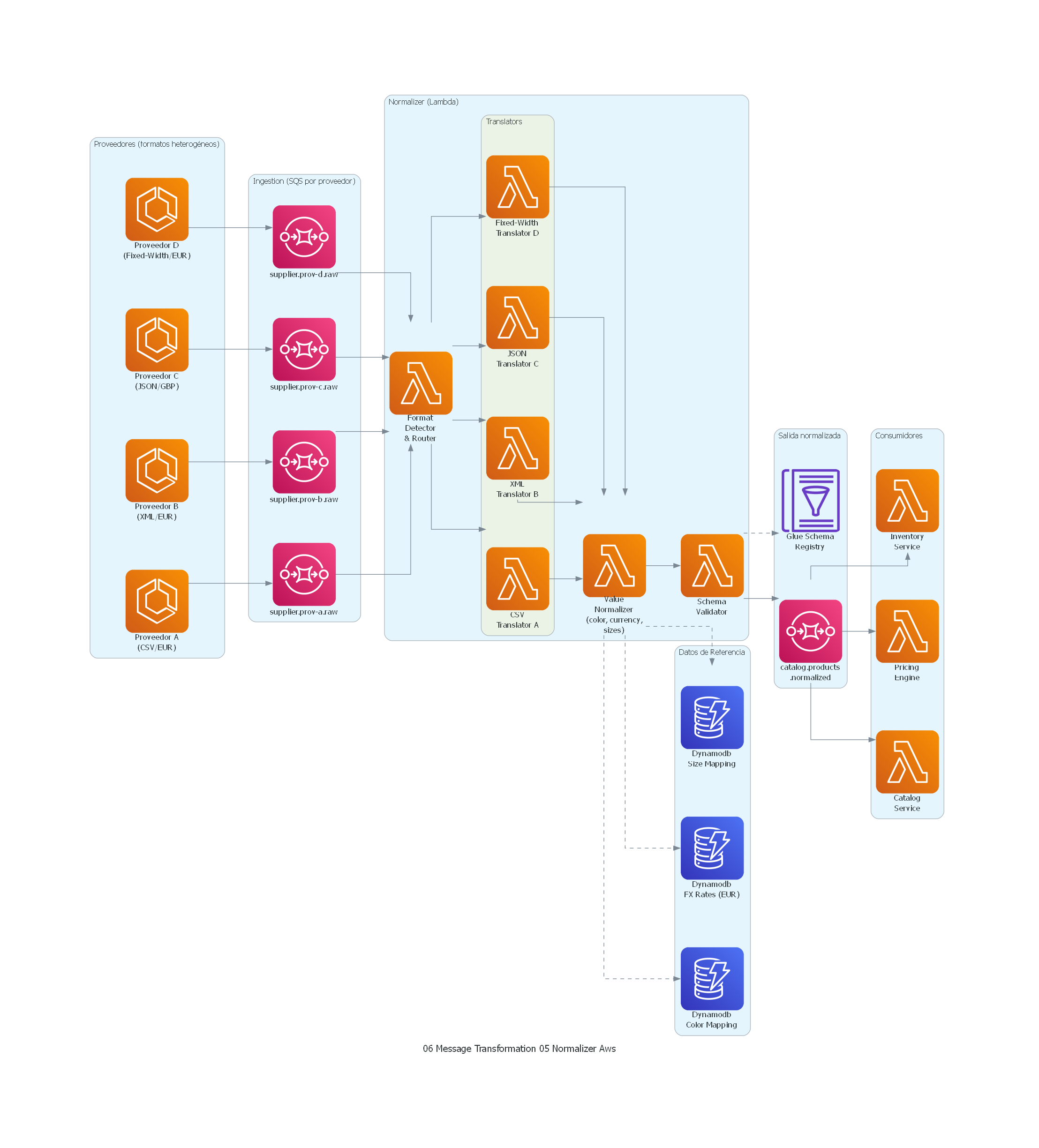
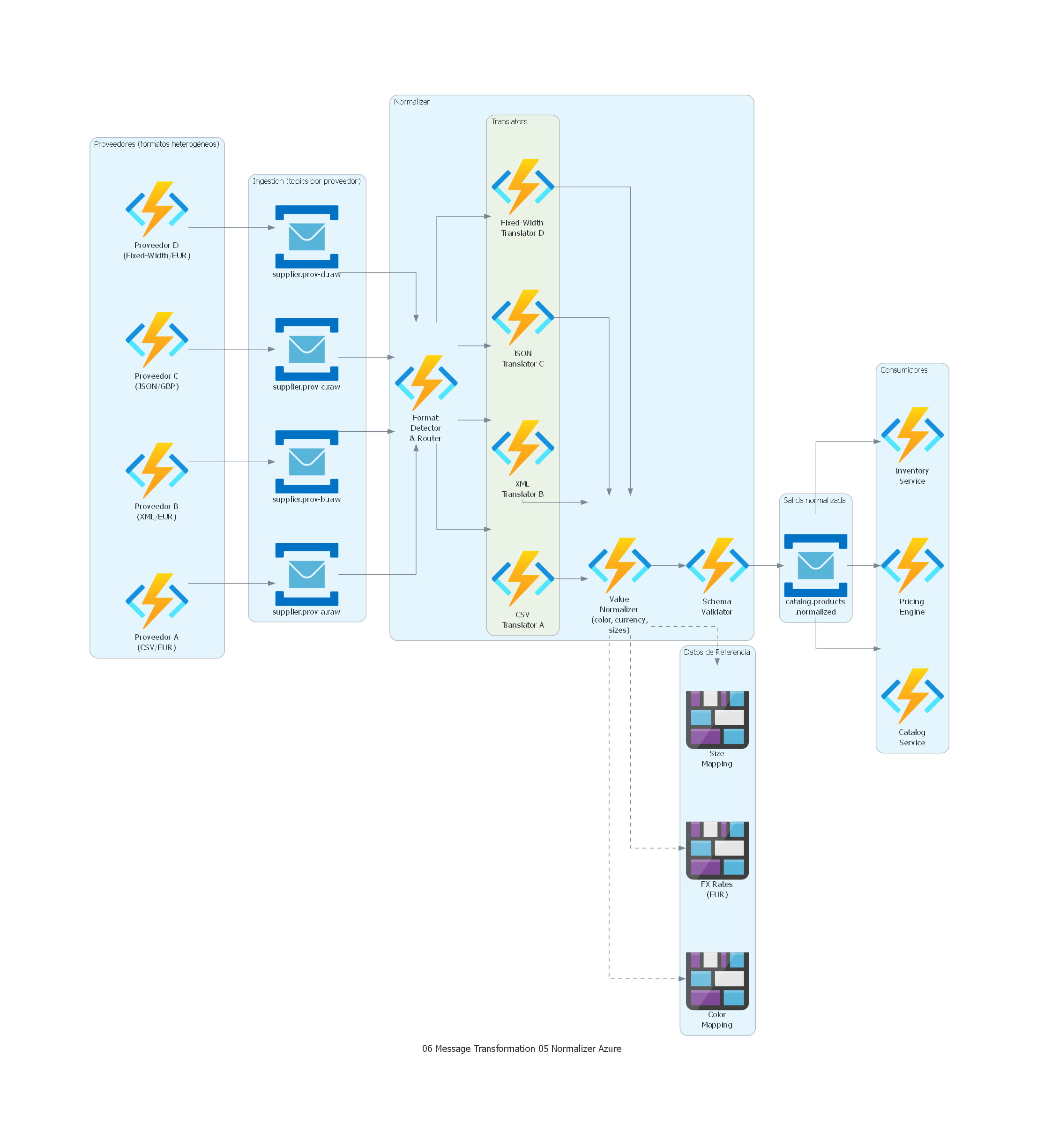
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.generic.storage import Storage
from diagrams.onprem.database import PostgreSQL
with Diagram("Normalizer - Retail Multi-Supplier Product Catalog", show=False, direction="LR"):
with Cluster("Proveedores (formatos heterogéneos)"):
supplier_a = Server("Proveedor A\n(CSV/EUR)")
supplier_b = Server("Proveedor B\n(XML/EUR)")
supplier_c = Server("Proveedor C\n(JSON/GBP)")
supplier_d = Server("Proveedor D\n(Fixed-Width/EUR)")
with Cluster("Ingestion (topics por proveedor)"):
t_a = Kafka("supplier.prov-a.raw")
t_b = Kafka("supplier.prov-b.raw")
t_c = Kafka("supplier.prov-c.raw")
t_d = Kafka("supplier.prov-d.raw")
with Cluster("Normalizer"):
router = Server("Format\nDetector\n& Router")
with Cluster("Translators"):
trans_a = Server("CSV\nTranslator A")
trans_b = Server("XML\nTranslator B")
trans_c = Server("JSON\nTranslator C")
trans_d = Server("Fixed-Width\nTranslator D")
value_norm = Server("Value\nNormalizer\n(color, currency,\nsizes)")
validator = Server("Schema\nValidator")
with Cluster("Datos de Referencia"):
color_map = Storage("Color\nMapping")
fx_rates = Storage("FX Rates\n(EUR)")
size_map = Storage("Size\nMapping")
with Cluster("Salida normalizada"):
t_normalized = Kafka("catalog.products\n.normalized")
with Cluster("Consumidores"):
catalog = Server("Catalog\nService")
pricing = Server("Pricing\nEngine")
inventory = Server("Inventory\nService")
# Ingestion
supplier_a >> t_a
supplier_b >> t_b
supplier_c >> t_c
supplier_d >> t_d
# Routing
t_a >> router >> trans_a
t_b >> router >> trans_b
t_c >> router >> trans_c
t_d >> router >> trans_d
# Value normalization
trans_a >> value_norm
trans_b >> value_norm
trans_c >> value_norm
trans_d >> value_norm
value_norm >> Edge(style="dashed") >> color_map
value_norm >> Edge(style="dashed") >> fx_rates
value_norm >> Edge(style="dashed") >> size_map
# Validation & output
value_norm >> validator >> t_normalized
# Consumption
t_normalized >> catalog
t_normalized >> pricing
t_normalized >> inventory
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SQS
from diagrams.aws.analytics import GlueDataCatalog
with Diagram("Normalizer - Retail Multi-Supplier Product Catalog (AWS)", show=False, direction="LR"):
with Cluster("Proveedores (formatos heterogéneos)"):
supplier_a = ECS("Proveedor A\n(CSV/EUR)")
supplier_b = ECS("Proveedor B\n(XML/EUR)")
supplier_c = ECS("Proveedor C\n(JSON/GBP)")
supplier_d = ECS("Proveedor D\n(Fixed-Width/EUR)")
with Cluster("Ingestion (SQS por proveedor)"):
t_a = SQS("supplier.prov-a.raw")
t_b = SQS("supplier.prov-b.raw")
t_c = SQS("supplier.prov-c.raw")
t_d = SQS("supplier.prov-d.raw")
with Cluster("Normalizer (Lambda)"):
router = Lambda("Format\nDetector\n& Router")
with Cluster("Translators"):
trans_a = Lambda("CSV\nTranslator A")
trans_b = Lambda("XML\nTranslator B")
trans_c = Lambda("JSON\nTranslator C")
trans_d = Lambda("Fixed-Width\nTranslator D")
value_norm = Lambda("Value\nNormalizer\n(color, currency,\nsizes)")
validator = Lambda("Schema\nValidator")
with Cluster("Datos de Referencia"):
color_map = Dynamodb("Dynamodb\nColor Mapping")
fx_rates = Dynamodb("Dynamodb\nFX Rates (EUR)")
size_map = Dynamodb("Dynamodb\nSize Mapping")
with Cluster("Salida normalizada"):
t_normalized = SQS("catalog.products\n.normalized")
schema_reg = GlueDataCatalog("Glue Schema\nRegistry")
with Cluster("Consumidores"):
catalog = Lambda("Catalog\nService")
pricing = Lambda("Pricing\nEngine")
inventory = Lambda("Inventory\nService")
# Ingestion
supplier_a >> t_a
supplier_b >> t_b
supplier_c >> t_c
supplier_d >> t_d
# Routing
t_a >> router >> trans_a
t_b >> router >> trans_b
t_c >> router >> trans_c
t_d >> router >> trans_d
# Value normalization
trans_a >> value_norm
trans_b >> value_norm
trans_c >> value_norm
trans_d >> value_norm
value_norm >> Edge(style="dashed") >> color_map
value_norm >> Edge(style="dashed") >> fx_rates
value_norm >> Edge(style="dashed") >> size_map
# Validation & output
value_norm >> validator >> t_normalized
validator >> Edge(style="dashed") >> schema_reg
# Consumption
t_normalized >> catalog
t_normalized >> pricing
t_normalized >> inventory
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import DatabaseForPostgresqlServers
from diagrams.azure.integration import ServiceBus
from diagrams.azure.storage import BlobStorage
with Diagram("Normalizer - Retail Multi-Supplier Product Catalog (Azure)", show=False, direction="LR"):
with Cluster("Proveedores (formatos heterogéneos)"):
supplier_a = FunctionApps("Proveedor A\n(CSV/EUR)")
supplier_b = FunctionApps("Proveedor B\n(XML/EUR)")
supplier_c = FunctionApps("Proveedor C\n(JSON/GBP)")
supplier_d = FunctionApps("Proveedor D\n(Fixed-Width/EUR)")
with Cluster("Ingestion (topics por proveedor)"):
t_a = ServiceBus("supplier.prov-a.raw")
t_b = ServiceBus("supplier.prov-b.raw")
t_c = ServiceBus("supplier.prov-c.raw")
t_d = ServiceBus("supplier.prov-d.raw")
with Cluster("Normalizer"):
router = FunctionApps("Format\nDetector\n& Router")
with Cluster("Translators"):
trans_a = FunctionApps("CSV\nTranslator A")
trans_b = FunctionApps("XML\nTranslator B")
trans_c = FunctionApps("JSON\nTranslator C")
trans_d = FunctionApps("Fixed-Width\nTranslator D")
value_norm = FunctionApps("Value\nNormalizer\n(color, currency,\nsizes)")
validator = FunctionApps("Schema\nValidator")
with Cluster("Datos de Referencia"):
color_map = BlobStorage("Color\nMapping")
fx_rates = BlobStorage("FX Rates\n(EUR)")
size_map = BlobStorage("Size\nMapping")
with Cluster("Salida normalizada"):
t_normalized = ServiceBus("catalog.products\n.normalized")
with Cluster("Consumidores"):
catalog = FunctionApps("Catalog\nService")
pricing = FunctionApps("Pricing\nEngine")
inventory = FunctionApps("Inventory\nService")
# Ingestion
supplier_a >> t_a
supplier_b >> t_b
supplier_c >> t_c
supplier_d >> t_d
# Routing
t_a >> router >> trans_a
t_b >> router >> trans_b
t_c >> router >> trans_c
t_d >> router >> trans_d
# Value normalization
trans_a >> value_norm
trans_b >> value_norm
trans_c >> value_norm
trans_d >> value_norm
value_norm >> Edge(style="dashed") >> color_map
value_norm >> Edge(style="dashed") >> fx_rates
value_norm >> Edge(style="dashed") >> size_map
# Validation & output
value_norm >> validator >> t_normalized
# Consumption
t_normalized >> catalog
t_normalized >> pricing
t_normalized >> inventory
Explicación del Diagrama¶
El diagrama muestra el flujo de normalización:
- Los proveedores envían datos en formatos heterogéneos (CSV, XML, JSON, Fixed-Width).
- Los Ingestion Adapters publican en topics específicos por proveedor.
- El Format Detector & Router identifica el proveedor y enruta al translator correcto.
- Los Translators transforman la estructura al formato canónico.
- El Value Normalizer normaliza colores, monedas y tallas usando datos de referencia.
- El Schema Validator verifica conformidad con el schema canónico.
- Los mensajes normalizados se publican en
catalog.products.normalized. - Los consumidores procesan mensajes homogéneos sin conocer la fuente original.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Fuentes heterogéneas | Proveedores A, B, C, D |
| Format Detector | Format Detector & Router |
| Message Translators | CSV, XML, JSON, Fixed-Width Translators |
| Value Normalization | Value Normalizer + mapping tables |
| Formato canónico | Schema validado, topic normalizado |
| Consumidores uniformes | Catalog, Pricing, Inventory Services |
11. Beneficios¶
Impacto Técnico¶
- Reducción de integraciones de N×M a N+M: con N proveedores y M consumidores, se pasa de N×M parsers a N translators + M consumidores de un formato.
- Single source of truth del formato: el formato canónico es la única definición que los consumidores necesitan conocer.
- Aislamiento de cambios: un cambio de formato de un proveedor afecta solo a su translator, no a los consumidores.
- Normalización de valores: no solo estructura, sino también semántica — colores, monedas, tallas unificados.
Impacto Organizacional¶
- Onboarding de proveedores más rápido: integrar un nuevo proveedor requiere solo un nuevo translator, no modificar los consumidores.
- Onboarding de consumidores más rápido: un nuevo consumidor solo necesita entender el formato canónico, no los 30 formatos de proveedores.
- Ownership claro: el equipo de integración mantiene los translators; los equipos de dominio mantienen los consumidores.
Impacto Operacional¶
- Debugging centralizado: los errores de parsing se detectan y registran en el Normalizer, no dispersos en múltiples consumidores.
- Calidad de datos uniforme: la validación post-normalización garantiza que todos los mensajes cumplen el schema canónico.
- Monitoreo por proveedor: métricas de éxito/fallo de normalización por proveedor permiten identificar proveedores problemáticos.
Beneficios de Mantenibilidad y Evolución¶
- Evolución del formato canónico: si se añade un campo al schema canónico, se actualizan los translators que pueden proveer ese dato.
- Testing por proveedor: cada translator se puede testear independientemente con datos de referencia del proveedor.
- Configuración declarativa: los mappings de colores, monedas y tallas se definen en tablas de configuración, no en código.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- N translators que mantener: con 30 proveedores, hay 30 translators que deben actualizarse cuando el proveedor cambia su formato.
- Mapping tables: las tablas de mapeo de colores, tallas y monedas deben mantenerse actualizadas y completas.
- Formato canónico como cuello de botella: si el formato canónico no es suficientemente expresivo, los translators pierden información.
Riesgos de Mal Uso¶
- Normalización solo estructural: normalizar la estructura (JSON) sin normalizar los valores (colores en diferentes idiomas siguen diferentes). El consumidor sigue viendo inconsistencias.
- Formato canónico demasiado genérico: un formato tan flexible que no obliga a nada (todos los campos opcionales, tipos laxos). Los consumidores reciben mensajes "normalizados" que siguen siendo heterogéneos.
- Normalizer como God Service: añadir lógica de negocio al normalizer (cálculo de precios finales, reglas de descuento) en lugar de solo transformación de formato.
Sobreingeniería¶
- Implementar un motor de transformación genérico configurable cuando translators simples por proveedor son suficientes.
- Normalizar todos los campos de cada proveedor cuando los consumidores solo usan un subconjunto.
- Implementar un sistema de detección automática de formato con ML cuando la detección por canal es suficiente.
Costos de Operación¶
- Mantenimiento de translators: cada cambio de formato de un proveedor requiere actualización del translator correspondiente.
- Mantenimiento de mapping tables: nuevos colores, nuevas monedas, nuevos sistemas de tallas deben añadirse.
- Testing continuo: los datos de referencia por proveedor deben actualizarse periódicamente para reflejar cambios.
Anti-Patterns Relacionados¶
- Leaky Normalization: el mensaje "normalizado" aún contiene artefactos del formato original (campo
originalFormat: "xml"que los consumidores usan para branching). - Normalization to Nothing: el formato canónico es tan simple que pierde información importante. Los consumidores complementan con llamadas directas al proveedor.
- Copy-Paste Translators: translators duplicados con variaciones mínimas que deberían ser un solo translator configurable.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Canonical Data Model (este capítulo): define el formato al que el Normalizer transforma. El Normalizer es la implementación práctica del Canonical Data Model.
- Channel Adapter (Messaging Channels): los adapters de ingestion que reciben feeds de proveedores y los publican en Kafka son Channel Adapters.
- Content-Based Router (Message Routing): el Format Detector dentro del Normalizer es un Content-Based Router que examina el formato y enruta al translator correcto.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Channel Adapter recibe el feed del proveedor (SFTP, API, email) y lo publica en el canal de entrada del Normalizer.
- Después: Content Filter puede eliminar campos no necesarios del mensaje normalizado para consumidores específicos.
Combinaciones Comunes¶
- Normalizer + Content Enricher: después de normalizar la estructura, el enricher añade datos que el proveedor no provee (categoría interna, marca, temporada).
- Normalizer + Dead Letter Channel: mensajes que no se pueden normalizar (formato inesperado, campos requeridos faltantes) van a dead-letter para revisión manual.
- Normalizer + Wire Tap: capturar el mensaje original antes de normalizar para auditoría y debugging.
Diferencias con Patrones Similares¶
- vs. Message Translator: Message Translator transforma un formato específico a otro. Normalizer es la composición de Router + múltiples Translators para manejar N formatos de entrada convergiendo a un formato de salida.
- vs. Canonical Data Model: Canonical Data Model es el concepto del formato común. Normalizer es el mecanismo que lo implementa transformando mensajes heterogéneos al formato canónico.
- vs. Content-Based Router: el router solo enruta; el Normalizer enruta Y transforma.
Encaje en un Flujo Mayor de Integración¶
El Normalizer se posiciona en la frontera del sistema, entre las fuentes externas y los sistemas internos. Es el primer paso del pipeline de procesamiento: ingest → normalize → enrich → route → consume. Todos los datos que entran al sistema pasan por el Normalizer antes de ser procesados.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Normalizer tiene relevancia alta y creciente por la explosión del número de fuentes de datos en las organizaciones modernas:
- SaaS proliferation: las empresas usan 50-200 aplicaciones SaaS, cada una con su propia API y formato de datos. Normalizar datos de Salesforce, HubSpot, Zendesk, Shopify, etc. al formato interno es esencial.
- API economy: los partners comerciales exponen APIs con formatos diferentes. Las plataformas de marketplace integran datos de miles de vendedores.
- IoT heterogeneity: una fábrica tiene sensores de 10 fabricantes diferentes, cada uno con su protocolo y formato de telemetría.
- Data mesh: los data products de diferentes dominios exponen datos en formatos potencialmente diferentes. Los consumidores de datos cross-domain necesitan normalización.
Cómo Se Implementa Hoy¶
| Tecnología | Mecanismo de Normalización |
|---|---|
| Apache Kafka + Connect | Kafka Connect SMT (Single Message Transforms) por connector |
| AWS Glue | ETL jobs con DataBrew para normalización visual |
| dbt (Data Build Tool) | SQL transformations para normalización en data warehouse |
| Apache Camel | Normalizer EIP con Routing + multiple Translators |
| Mulesoft | DataWeave transformations por fuente |
| Airbyte / Fivetran | Connectors con normalización automática a schema estándar |
Qué Parte Sigue Siendo Esencial¶
- La absorción de heterogeneidad en la frontera: el principio de normalizar en el punto de entrada, no en los consumidores.
- Normalización de valores además de estructura: colores, monedas, unidades, códigos deben homogeneizarse.
- Validación post-normalización: garantizar que el mensaje normalizado cumple el schema canónico.
- Observabilidad por fuente: monitorear tasa de éxito/fallo de normalización por fuente para detectar cambios de formato.
15. Implementación en Arquitecturas Modernas¶
Kafka Connect — SMT por Connector¶
{
"name": "supplier-burberry-uk",
"config": {
"connector.class": "io.confluent.connect.http.HttpSourceConnector",
"http.api.url": "https://api.burberry.com/catalog/v2/products",
"transforms": "extractProduct,normalizePrice,normalizeColor",
"transforms.extractProduct.type": "org.apache.kafka.connect.transforms.ExtractField$Value",
"transforms.extractProduct.field": "products",
"transforms.normalizePrice.type": "com.retailer.kafka.transforms.CurrencyNormalizer",
"transforms.normalizePrice.source.currency.field": "price.currency",
"transforms.normalizePrice.source.amount.field": "price.amount",
"transforms.normalizePrice.target.currency": "EUR",
"transforms.normalizeColor.type": "com.retailer.kafka.transforms.ColorNormalizer",
"transforms.normalizeColor.source.field": "colour",
"transforms.normalizeColor.target.field": "color.code",
"topic": "catalog.products.normalized"
}
}
Python — Normalizer Service con Strategy Pattern¶
from abc import ABC, abstractmethod
class SupplierTranslator(ABC):
@abstractmethod
def translate(self, raw_message: dict) -> dict:
pass
class BurberryUKTranslator(SupplierTranslator):
def translate(self, raw: dict) -> dict:
return {
"sku": f"BURB-{raw['supplier_ref']}",
"supplier_code": "BURBERRY-UK",
"name": raw["product_name"],
"price": {
"original_amount": raw["price"]["amount"],
"original_currency": raw["price"]["currency"],
"amount_eur": self.convert_currency(
raw["price"]["amount"], raw["price"]["currency"]
)
},
"sizes": raw.get("sizes", []),
"color": self.normalize_color(raw.get("colour", "Unknown")),
"stock_quantity": raw.get("available_qty", 0),
"source": {
"supplier": "BURBERRY-UK",
"original_ref": raw["supplier_ref"],
"normalized_at": datetime.utcnow().isoformat()
}
}
class NormalizerService:
def __init__(self):
self.translators: dict[str, SupplierTranslator] = {
"supplier.burberry-uk.raw": BurberryUKTranslator(),
"supplier.nike-es.raw": NikeESTranslator(),
"supplier.gucci-it.raw": GucciITTranslator(),
# ... 30 translators
}
def normalize(self, topic: str, raw_message: dict) -> dict:
translator = self.translators.get(topic)
if not translator:
raise UnknownSupplierError(f"No translator for topic: {topic}")
normalized = translator.translate(raw_message)
self.validate_schema(normalized)
return normalized
Apache Camel — Normalizer EIP¶
from("kafka:supplier.*.raw")
.choice()
.when(header("kafka.TOPIC").contains("burberry-uk"))
.bean(BurberryUKTranslator.class, "translate")
.when(header("kafka.TOPIC").contains("nike-es"))
.bean(NikeESTranslator.class, "translate")
.when(header("kafka.TOPIC").contains("gucci-it"))
.bean(GucciITTranslator.class, "translate")
.end()
.bean(ValueNormalizer.class, "normalizeValues")
.bean(SchemaValidator.class, "validate")
.to("kafka:catalog.products.normalized");
dbt — Normalización en Data Warehouse¶
-- models/normalized/products.sql
WITH raw_burberry AS (
SELECT
'BURB-' || supplier_ref AS sku,
'BURBERRY-UK' AS supplier_code,
product_name AS name,
price_amount * {{ get_fx_rate('GBP', 'EUR') }} AS price_amount_eur,
price_amount AS price_original_amount,
'GBP' AS price_original_currency,
sizes,
{{ normalize_color('colour') }} AS color_code,
available_qty AS stock_quantity
FROM {{ source('suppliers', 'burberry_uk_raw') }}
),
raw_nike AS (
SELECT
'NIKE-' || codigo_articulo AS sku,
'NIKE-ES' AS supplier_code,
nombre AS name,
precio_euros AS price_amount_eur,
precio_euros AS price_original_amount,
'EUR' AS price_original_currency,
ARRAY[talla] AS sizes,
{{ normalize_color('color') }} AS color_code,
stock AS stock_quantity
FROM {{ source('suppliers', 'nike_es_raw') }}
)
SELECT * FROM raw_burberry
UNION ALL
SELECT * FROM raw_nike
-- UNION ALL ... (30 proveedores)
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Normalization success rate por proveedor: porcentaje de mensajes normalizados exitosamente vs. rechazados, por proveedor.
- Unmapped values: colores, tallas o monedas que no se encontraron en las mapping tables (indicador de tablas desactualizadas).
- Schema validation failures: mensajes que pasan la transformación pero no validan contra el schema canónico.
- Translator latency: tiempo de transformación por proveedor, para detectar translators ineficientes.
Monitoreo¶
- Dead-letter rate por proveedor: si un proveedor tiene alta tasa de dead-letter, probablemente cambió su formato.
- Mapping table completeness: alertar cuando más del 5% de los valores de un campo no se pueden mapear.
- FX rate freshness: alertar si la tasa de cambio no se ha actualizado en más de 24 horas.
- Translator version: monitorear qué versión de cada translator está desplegada.
Versionado¶
- Schema canónico: versionado con backward compatibility (nuevos campos opcionales). Los consumidores usan tolerant reader.
- Translators: cada translator tiene su propio ciclo de vida. Un cambio de formato del proveedor requiere un nuevo release del translator.
- Mapping tables: las tablas de mapeo tienen versionado y se actualizan sin necesidad de redesplegar el servicio.
Seguridad¶
- Datos de proveedores: los feeds de proveedores pueden contener información comercial confidencial (precios de compra, stock real). Cifrado en tránsito y en reposo.
- API credentials: las credenciales de las APIs de proveedores deben almacenarse en un vault (AWS Secrets Manager, HashiCorp Vault).
- Access control: solo el equipo de integración tiene acceso a los topics raw; los consumidores acceden al topic normalizado.
Manejo de Errores¶
- Formato inesperado: si el translator no puede parsear el mensaje, enviar a dead-letter con el error de parsing y alertar al equipo.
- Valor no mapeable: si un color o talla no se encuentra en la mapping table, usar un valor default ("Sin clasificar") y alertar para actualización de la tabla.
- FX rate unavailable: si la API de tasas de cambio no responde, usar la última tasa conocida (cacheada) y alertar.
- Schema validation failure: si el mensaje normalizado no valida, enviar a dead-letter con el error de validación.
17. Errores Comunes¶
Normalizar Solo la Estructura, No los Valores¶
Transformar todos los mensajes a JSON pero dejar los colores en diferentes idiomas ("Negro", "Nero", "Black", "Schwarz"), los precios en diferentes monedas y las tallas en diferentes sistemas. Los consumidores reciben JSON "normalizado" pero con valores incomparables. La normalización de valores es tan importante como la normalización de estructura.
No Preservar los Valores Originales¶
Reemplazar el precio original (1890 GBP) con solo el precio convertido (2192.40 EUR) sin guardar el original. Cuando la tasa de cambio se corrige o el proveedor disputa un precio, no se puede verificar qué se recibió originalmente. Siempre preservar los valores originales junto con los normalizados.
Formato Canónico Diseñado por un Solo Consumidor¶
Diseñar el formato canónico basándose en las necesidades de un solo consumidor (por ejemplo, el catálogo online). Cuando otros consumidores (pricing, inventario, analytics) se conectan, el formato no tiene los campos que necesitan y hay que modificarlo. El formato canónico debe diseñarse considerando las necesidades de todos los consumidores conocidos y anticipados.
No Validar Post-Normalización¶
Confiar en que los translators siempre producen mensajes válidos sin validar contra el schema. Un bug en un translator puede producir mensajes con campos faltantes o tipos incorrectos que llegan a los consumidores y causan errores aguas abajo. La validación post-normalización es la red de seguridad que detecta bugs en los translators.
Translator Monolítico¶
Un solo translator gigante con un switch/case de 30 ramas, una por proveedor. Cuando el proveedor 17 cambia su formato, se modifica el monolito y se arriesga la estabilidad de los 29 proveedores restantes. Cada proveedor debe tener su propio translator independiente, desplegable por separado.
18. Conclusión Técnica¶
Normalizer es el patrón que absorbe la heterogeneidad de formatos de múltiples fuentes externas, transformando mensajes diversos en un formato canónico común. Es la combinación de detección de formato, routing al translator apropiado y transformación al modelo canónico.
Cuándo aporta valor: cuando múltiples fuentes envían datos semánticamente equivalentes en formatos diferentes y los consumidores necesitan procesarlos uniformemente. Es especialmente valioso cuando el número de fuentes × el número de consumidores hace que las integraciones punto a punto sean ingobernables.
Cuándo evita problemas importantes: cuando sin normalización, cada consumidor implementa sus propios parsers para cada fuente, creando duplicación de lógica, inconsistencias de datos y fragilidad ante cambios de formato.
Cuándo no conviene adoptarlo: cuando todas las fuentes ya usan el mismo formato, cuando hay una sola fuente, o cuando la transformación es tan simple que un Message Translator inline en el consumidor es suficiente.
Recomendación para arquitectos: invierta tanto en normalización de valores como en normalización de estructura. Colores, monedas, unidades de medida y códigos deben homogeneizarse, no solo la estructura del JSON o XML. Diseñe el formato canónico con todos los consumidores en mente, no solo con el primero. Implemente validación post-normalización como red de seguridad contra bugs en los translators. Use translators independientes por fuente (no un monolito). Y siempre preserve los valores originales junto con los normalizados — la trazabilidad del dato original al normalizado es esencial para debugging, auditoría y disputas comerciales.