Canonical Data Model¶
1. Nombre del Patrón¶
- Nombre oficial: Canonical Data Model
- Categoría: Message Transformation (Transformación de Mensajes)
- Traducción contextual: Modelo de Datos Canónico
2. Resumen Ejecutivo¶
Canonical Data Model es el patrón que define un modelo de datos intermedio — independiente de cualquier sistema específico — que actúa como lingua franca para la comunicación entre sistemas. En lugar de crear transformaciones punto a punto entre cada par de sistemas (cada uno con su propio modelo de datos), todos los sistemas traducen sus datos al modelo canónico y desde él, reduciendo el número de transformaciones de N×(N-1) a 2×N.
El problema que resuelve es la explosión combinatoria de transformaciones: con N sistemas que necesitan intercambiar datos, cada par requiere dos transformaciones (A→B y B→A), resultando en N×(N-1) transformaciones. Con un modelo canónico, cada sistema necesita solo dos transformaciones: sistema→canónico y canónico→sistema, resultando en 2×N transformaciones.
En el contexto actual, Canonical Data Model presenta una tensión productiva con los principios de Domain-Driven Design (DDD). DDD establece que cada bounded context tiene su propio modelo de dominio, y que los modelos no deben compartirse entre contextos. El modelo canónico, por definición, es un modelo compartido. Esta tensión no invalida ninguno de los dos enfoques — más bien, obliga al arquitecto a elegir cuidadosamente dónde aplicar cada uno. En la práctica, los estándares de industria como HL7 FHIR en healthcare, FIX en finanzas y EDIFACT en supply chain son canonical data models que han demostrado su valor precisamente porque son modelos de intercambio, no modelos de dominio.
3. Definición Detallada¶
Propósito¶
Canonical Data Model define un schema de datos intermedio que todos los sistemas de la organización (o del sector) utilizan como formato de intercambio. Cada sistema mantiene su propio modelo interno, pero cuando necesita comunicarse con otros sistemas, traduce sus datos al formato canónico. El receptor traduce del formato canónico a su propio formato interno.
Lógica Arquitectónica¶
En cualquier organización con múltiples sistemas, los datos de negocio (clientes, pedidos, productos, transacciones) se representan de forma diferente en cada sistema:
- CRM:
{customer_id: "C-001", first_name: "María", last_name: "García", email: "maria@example.com"} - ERP:
{KUNNR: "0001000001", NAME1: "García, María", SMTP_ADDR: "maria@example.com"} - E-commerce:
{userId: 7891, fullName: "María García", contactEmail: "maria@example.com"} - Data Warehouse:
{dim_customer_key: 4567, customer_name: "GARCIA MARIA", email_address: "maria@example.com"}
Son el mismo cliente, pero representado de cuatro formas diferentes. Cuando el CRM necesita sincronizar con el ERP, necesita una transformación CRM→ERP. Cuando el e-commerce necesita enviar datos al CRM, necesita una transformación E-commerce→CRM. Y así para cada par de sistemas.
Con un Canonical Data Model, se define un formato intermedio:
{
"$type": "canonical.customer.v2",
"customer_id": "C-001",
"name": {
"given": "María",
"family": "García"
},
"email": "maria@example.com"
}
Cada sistema solo necesita saber cómo traducir entre su formato y el canónico: - CRM ↔ Canónico (2 transformaciones) - ERP ↔ Canónico (2 transformaciones) - E-commerce ↔ Canónico (2 transformaciones) - DWH ↔ Canónico (2 transformaciones)
Total: 8 transformaciones en lugar de 12 (y la diferencia crece cuadráticamente con N).
Principio de Diseño Subyacente¶
El principio es modelo intermedio como contrato compartido: en lugar de que cada par de sistemas negocie bilateralmente su formato de intercambio, todos acuerdan un modelo intermedio que sirve como contrato explícito y compartido. Este modelo no pertenece a ningún sistema — es propiedad de la organización.
Problema Estructural que Resuelve¶
Sin Canonical Data Model:
- El número de transformaciones crece cuadráticamente: N×(N-1) para N sistemas.
- Cada transformación es un acuerdo bilateral entre dos equipos.
- No existe un vocabulario compartido para los datos de negocio.
- Las diferencias semánticas (¿qué es un "customer"? ¿incluye prospects?) se resuelven ad hoc en cada integración.
- Un cambio en el modelo de un sistema puede afectar a múltiples transformaciones.
Contexto en el que Emerge¶
Canonical Data Model emerge cuando:
- La organización tiene más de 4-5 sistemas que necesitan intercambiar los mismos conceptos de negocio.
- El número de transformaciones punto a punto se ha vuelto ingobernable.
- Existe necesidad de un vocabulario compartido para los datos de negocio.
- El sector tiene estándares de datos que pueden servir como base del modelo canónico.
Por Qué No Es Trivial¶
- Diseño del modelo: ¿quién decide qué campos incluir? ¿Cómo se resuelven las diferencias semánticas entre sistemas? (El CRM define "customer" como alguien con una cuenta; el e-commerce como alguien que ha comprado alguna vez.)
- Granularidad: ¿un modelo canónico global o modelos por dominio de negocio? Un modelo global es más ambicioso pero más difícil de gestionar.
- Evolución: ¿cómo se evoluciona el modelo canónico sin romper a los consumidores existentes?
- Tensión con DDD: ¿el modelo canónico es un shared kernel que todos los bounded contexts deben respetar, o una capa de traducción entre contextos autónomos?
- Nivel de detalle: un modelo canónico demasiado detallado es difícil de mantener; uno demasiado simple pierde información.
Relación con Sistemas Distribuidos y Mensajería¶
Canonical Data Model es el complemento semántico del Message Bus. Mientras el Message Bus proporciona la infraestructura de transporte, el Canonical Data Model proporciona el contrato de datos. Juntos, implementan una plataforma de integración donde los sistemas se comunican a través de una infraestructura compartida (bus) usando un lenguaje compartido (modelo canónico).
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Un sistema de salud regional integra datos clínicos entre múltiples instituciones:
- Hospital A: usa Epic EHR, que produce mensajes en formato HL7v2.
- Hospital B: usa Cerner EHR, que produce mensajes en formato FHIR R4.
- Laboratorio C: usa un LIS propietario que produce resultados en formato CSV.
- Farmacia D: usa un sistema que acepta recetas en formato NCPDP SCRIPT.
- Aseguradora E: necesita datos en formato X12 837 para procesamiento de claims.
- Registro de Salud Pública: necesita datos en formato CDA (Clinical Document Architecture).
Sin un modelo canónico, cada par de sistemas necesita su propia transformación:
Hospital A (HL7v2) ↔ Hospital B (FHIR): 2 transformaciones
Hospital A (HL7v2) ↔ Laboratorio C (CSV): 2 transformaciones
Hospital A (HL7v2) ↔ Farmacia D (NCPDP): 2 transformaciones
Hospital A (HL7v2) ↔ Aseguradora E (X12): 2 transformaciones
Hospital B (FHIR) ↔ Laboratorio C (CSV): 2 transformaciones
Hospital B (FHIR) ↔ Farmacia D (NCPDP): 2 transformaciones
... (total: 6×5 = 30 transformaciones)
Síntomas del Problema¶
- El equipo de integración mantiene 30 transformaciones diferentes, cada una con su propia lógica de mapping.
- Cuando el Hospital A actualiza de HL7v2.5 a HL7v2.8, se deben actualizar 5 transformaciones (A↔B, A↔C, A↔D, A↔E, A↔Registro).
- El concepto de "diagnóstico" se representa de 6 formas diferentes, con sutiles diferencias semánticas que causan errores de interoperabilidad.
- La aseguradora rechaza el 12% de los claims porque la transformación Hospital A → X12 no mapea correctamente los códigos de procedimiento.
- Añadir un nuevo participante (Clínica F) requiere crear 5 nuevas transformaciones bilaterales.
Impacto Operativo y Arquitectónico¶
- Costo de integración creciente: cada nuevo participante multiplica el número de transformaciones.
- Errores de mapping acumulativos: con 30 transformaciones, cada una es una fuente potencial de error.
- No hay vocabulario compartido: el concepto de "alergia del paciente" se representa de 6 formas, sin una definición autoritativa.
- Interoperabilidad frágil: un cambio en un sistema puede romper múltiples transformaciones.
Riesgos Si No Se Implementa Correctamente¶
- Modelo canónico demasiado ambicioso: intentar modelar toda la información clínica en un solo schema desde el inicio. El resultado es un proyecto de 2 años que nunca se completa.
- Modelo canónico controlado por un sistema: si el modelo canónico se parece demasiado al modelo de un sistema dominante (por ejemplo, Epic), los demás sistemas tienen transformaciones complejas y el modelo no es verdaderamente neutral.
- Modelo canónico sin gobernanza: un modelo definido una vez y nunca actualizado, que se vuelve obsoleto a medida que los sistemas evolucionan.
Ejemplos Reales¶
- HL7 FHIR: el estándar de interoperabilidad en salud que actúa como modelo canónico para datos clínicos (Patient, Observation, Condition, MedicationRequest).
- FIX Protocol: modelo canónico para trading financiero (Order, Execution, MarketData).
- EDIFACT / GS1: modelos canónicos para supply chain y comercio (Order, Invoice, DespatchAdvice).
- Open Banking (PSD2): modelo canónico para datos financieros del consumidor (Account, Transaction, Balance).
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando múltiples sistemas intercambian los mismos conceptos de negocio y el número de transformaciones punto a punto es insostenible.
- Cuando existe un estándar de industria que puede servir como base del modelo canónico (FHIR, FIX, EDIFACT).
- Cuando la organización necesita un vocabulario compartido para los datos de negocio.
- Cuando se integran sistemas de diferentes organizaciones (interoperabilidad inter-empresa).
Cuándo No Usarlo¶
- Cuando los sistemas intercambian datos en formatos ya compatibles o suficientemente similares.
- Cuando solo hay 2-3 sistemas que se integran (las transformaciones punto a punto son más simples).
- Cuando cada sistema tiene necesidades tan específicas que un modelo común no puede representarlas sin pérdida significativa de información.
- Cuando la organización no tiene la capacidad de gobernar un modelo canónico (definirlo, evolucionarlo, mantenerlo).
Precondiciones¶
- Existe consenso organizacional sobre la necesidad de un modelo compartido.
- Existe un equipo o cuerpo de gobernanza que mantendrá el modelo.
- Los sistemas participantes pueden adaptarse para traducir entre su modelo y el canónico.
Restricciones¶
- El modelo canónico es un compromiso: no representa perfectamente el modelo de ningún sistema, sino un modelo suficiente para el intercambio.
- La evolución del modelo canónico debe ser backward-compatible para no romper integraciones existentes.
- El modelo canónico es un asset organizacional que requiere gobernanza continua.
Dependencias¶
- Gobernanza del modelo canónico (equipo, proceso, herramientas).
- Schema Registry o repositorio de schemas para publicar y versionar el modelo.
- Translators que implementen la transformación entre cada sistema y el modelo canónico.
Supuestos Arquitectónicos¶
- Los conceptos de negocio que se intercambian son suficientemente comunes como para tener un modelo compartido.
- Los sistemas participantes están dispuestos a invertir en traducir entre su modelo y el canónico.
- El modelo canónico puede evolucionar sin romper las integraciones existentes.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Health Information Exchanges (HL7 FHIR como modelo canónico).
- Plataformas de trading financiero (FIX Protocol).
- Supply chain con múltiples partners (EDIFACT, GS1).
- Ecosistemas de microservicios con domain events compartidos.
- Integraciones gobierno-empresa (factura electrónica, reporting regulatorio).
6. Fuerzas Arquitectónicas¶
Universalidad vs. Especificidad¶
Un modelo canónico universal que cubra todos los casos de uso es difícil de diseñar y mantener. Un modelo específico por dominio es más manejable pero puede requerir múltiples modelos canónicos con sus propias transformaciones entre ellos.
Estabilidad vs. Evolución¶
El modelo canónico debe ser estable (los consumidores confían en su estructura) pero también debe evolucionar (nuevos campos, nuevos conceptos). La backward compatibility es el mecanismo para conciliar ambas fuerzas.
Centralización del Modelo vs. Autonomía de Dominio (DDD)¶
Un modelo canónico centralizado choca con el principio de DDD de que cada bounded context tiene su propio modelo. La tensión se resuelve tratando el modelo canónico como un published language (lenguaje publicado) en términos de DDD — un modelo de intercambio que no reemplaza los modelos de dominio internos.
Completitud vs. Minimalismo¶
¿El modelo canónico incluye todos los campos posibles de todos los sistemas, o solo los campos necesarios para el intercambio? Un modelo completo facilita las transformaciones pero es enorme y difícil de evolucionar. Un modelo mínimo es más ágil pero puede requerir extensiones ad hoc.
Estándar de Industria vs. Modelo Propio¶
Adoptar un estándar de industria (FHIR, FIX) proporciona un modelo probado y herramientas existentes, pero puede no ajustarse perfectamente a las necesidades específicas de la organización. Un modelo propio se ajusta mejor pero carece de ecosistema y requiere más esfuerzo de diseño.
Gobernanza Estricta vs. Adopción Orgánica¶
Gobernanza estricta (comité de revisión, proceso de aprobación) mantiene la calidad del modelo pero ralentiza la evolución. Adopción orgánica (los equipos proponen cambios vía pull request) es más ágil pero puede degradar la coherencia del modelo.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Sistemas Participantes: cada sistema con su propio modelo de datos interno.
- Canonical Data Model: el schema de datos intermedio compartido.
- Translators (Inbound): transforman del formato del sistema al formato canónico.
- Translators (Outbound): transforman del formato canónico al formato del sistema.
- Schema Registry: repositorio donde se publica y versiona el modelo canónico.
- Gobernanza: equipo y proceso que mantiene, evoluciona y aprueba cambios al modelo.
Flujo Lógico¶
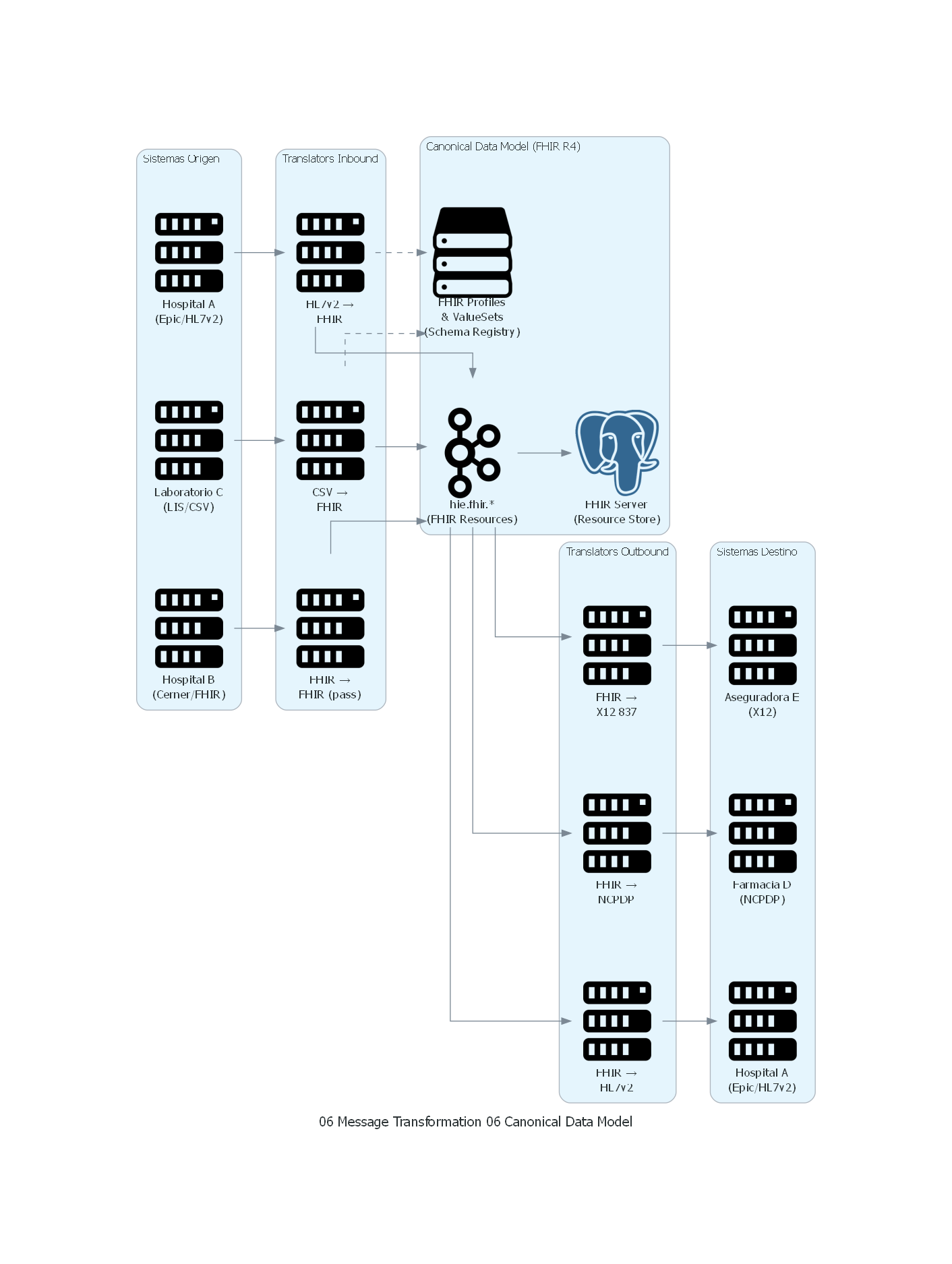
flowchart LR
A([Sistema A\nEpic EHR - HL7v2]) --> B[Translator A a Canónico\nHL7v2 a FHIR Observation]
B --> C[Modelo Canónico\nFHIR Observation resource]
C --> D[Translator Canónico a B\nFHIR a formato Cerner]
D --> E([Sistema B\nCerner - formato interno])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Canonical Data Model | Definir el contrato semántico compartido |
| Translators Inbound | Convertir del formato del sistema al canónico |
| Translators Outbound | Convertir del canónico al formato del sistema |
| Schema Registry | Publicar, versionar y documentar el modelo |
| Gobernanza | Mantener coherencia, aprobar cambios, resolver conflictos |
Interacciones¶
- Sistema → Translator Inbound → Canal (mensaje canónico): el sistema publica a través de su translator.
- Canal → Translator Outbound → Sistema: el sistema consume a través de su translator.
- Gobernanza → Schema Registry: la gobernanza actualiza el modelo en el registry.
- Translators → Schema Registry: los translators consultan el schema para validar.
Contratos Implícitos¶
- Semántica unívoca: cada concepto del modelo canónico tiene una definición clara y compartida.
- Backward compatibility: las nuevas versiones del modelo no rompen los consumidores existentes.
- Neutralidad: el modelo canónico no favorece la representación de ningún sistema particular.
Decisiones de Diseño Clave¶
- Estándar de industria vs. modelo propio: ¿adoptar FHIR/FIX/EDIFACT o diseñar un modelo propio?
- Scope del modelo: ¿un modelo canónico global o modelos por dominio de negocio?
- Nivel de detalle: ¿modelo detallado que capture todas las sutilezas o modelo conciso centrado en los datos de intercambio?
- Extensibility: ¿el modelo permite extensiones (campos custom) o es estrictamente fijo?
- Governance model: ¿comité central, RFC process, o pull-request based?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Healthcare — FHIR como Modelo Canónico para un Health Information Exchange¶
Contexto del Negocio¶
Un Health Information Exchange (HIE) regional conecta hospitales, laboratorios, farmacias y aseguradoras para compartir datos clínicos de los pacientes. Cada institución usa su propio Electronic Health Record (EHR) con su propio formato de datos. El HIE necesita un modelo canónico que permita a cualquier institución enviar datos que cualquier otra pueda entender.
Necesidad de Integración¶
Cuando un laboratorio produce un resultado, el resultado debe ser accesible para el médico del paciente (en cualquier hospital), la farmacia (para ajustar medicación) y la aseguradora (para procesamiento de claims). Cada sistema espera los datos en un formato diferente.
Sistemas Involucrados¶
- Hospital A (Epic): produce/consume datos en HL7v2.
- Hospital B (Cerner): produce/consume datos en FHIR R4 nativo.
- Laboratorio C (LIS propietario): produce resultados en CSV.
- Farmacia D: consume recetas en NCPDP SCRIPT.
- Aseguradora E: consume claims en X12 837.
- HIE Platform: Kafka + FHIR Server como backbone.
Elección del Modelo Canónico: FHIR R4¶
El HIE adopta FHIR R4 (Fast Healthcare Interoperability Resources) como modelo canónico porque:
- Es un estándar de industria mantenido por HL7 International.
- Tiene recursos definidos para todos los conceptos clínicos: Patient, Observation, Condition, MedicationRequest, Claim.
- Soporta extensiones para datos específicos que el estándar base no cubre.
- Tiene un ecosistema de herramientas: FHIR servers, validators, transformadores.
- Es mandatorio en regulaciones como ONC en EE.UU. y está ganando adopción en Europa y Latinoamérica.
Diseño del Modelo Canónico¶
Ejemplo: Resultado de laboratorio en FHIR Observation:
{
"resourceType": "Observation",
"id": "obs-lab-2026-449821",
"status": "final",
"category": [
{
"coding": [
{
"system": "http://terminology.hl7.org/CodeSystem/observation-category",
"code": "laboratory"
}
]
}
],
"code": {
"coding": [
{
"system": "http://loinc.org",
"code": "58410-2",
"display": "Complete blood count (CBC)"
}
]
},
"subject": {
"reference": "Patient/pat-78945"
},
"effectiveDateTime": "2026-04-07T09:15:00Z",
"component": [
{
"code": {
"coding": [{"system": "http://loinc.org", "code": "6690-2", "display": "WBC"}]
},
"valueQuantity": {
"value": 7.5,
"unit": "10^3/uL",
"system": "http://unitsofmeasure.org",
"code": "10*3/uL"
}
},
{
"code": {
"coding": [{"system": "http://loinc.org", "code": "789-8", "display": "RBC"}]
},
"valueQuantity": {
"value": 4.8,
"unit": "10^6/uL",
"system": "http://unitsofmeasure.org",
"code": "10*6/uL"
}
}
]
}
Decisiones Arquitectónicas¶
- FHIR como modelo canónico, no como modelo interno: cada sistema mantiene su propio modelo interno. Solo traducen a/desde FHIR para intercambio. El Hospital B (Cerner) que ya usa FHIR nativamente tiene la ventaja de transformaciones triviales.
- LOINC y SNOMED como vocabularios canónicos: los códigos de laboratorio usan LOINC; los diagnósticos usan SNOMED CT. Estos vocabularios estándar son parte del modelo canónico.
- Extensions para datos regionales: FHIR permite extensiones. El HIE define extensiones para datos específicos de la regulación local que el estándar base no cubre.
- FHIR Profiling: el HIE define profiles (restricciones del estándar) que especifican qué campos son obligatorios, qué vocabularios deben usarse y qué extensiones están permitidas.
- Versionado por recurso: cada recurso FHIR tiene su propia versión. La evolución es por recurso, no del modelo completo.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| FHIR demasiado flexible (no obliga suficiente) | FHIR Profiles que restringen el estándar al uso del HIE |
| Vocabularios inconsistentes (LOINC local vs. nacional) | Mandatar versión específica de LOINC; validar códigos contra ValueSets |
| Modelo canónico evoluciona y rompe consumidores | Versionado semántico de profiles; backward compatibility |
| Sistema no puede mapear al modelo canónico | Servicio de mapeo asistido; dead-letter para mensajes no mapeables |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Laboratorio Produce Resultado en Formato Propietario¶
El Laboratorio C completa un CBC (Complete Blood Count) para el paciente MRN-78945. Su LIS genera el resultado en formato CSV propietario:
RESULT_ID,PATIENT_MRN,TEST_CODE,TEST_NAME,COMPONENT,VALUE,UNIT,FLAG,PERFORMED_AT
LR-449821,MRN-78945,CBC,Complete Blood Count,WBC,7.5,10^3/uL,N,2026-04-07 09:15:00
LR-449821,MRN-78945,CBC,Complete Blood Count,RBC,4.8,10^6/uL,N,2026-04-07 09:15:00
LR-449821,MRN-78945,CBC,Complete Blood Count,HGB,14.2,g/dL,N,2026-04-07 09:15:00
Paso 2: Translator Inbound — CSV a FHIR¶
El translator del Laboratorio C consume el CSV y transforma cada resultado al modelo canónico FHIR:
- Patient mapping:
MRN-78945→ busca en el Patient Index del HIE →Patient/pat-78945. - Test code mapping:
CBC→ busca en la tabla de mapping LOINC →58410-2. - Component codes:
WBC→6690-2,RBC→789-8,HGB→718-7. - Units: verifica que las unidades son UCUM-compliant.
- Flag:
N(normal) → no se añade interpretación (solo se añade para valores anormales).
El resultado es el recurso FHIR Observation mostrado arriba. Se publica en el topic hie.fhir.observations.
Paso 3: Hospital A Consume — FHIR a HL7v2¶
El translator outbound del Hospital A (Epic) consume el recurso FHIR Observation y lo transforma a un mensaje HL7v2 ORU^R01:
MSH|^~\&|HIE|REGIONAL|EPIC|HOSPITAL_A|20260407091500||ORU^R01|MSG-2026-449821|P|2.5.1
PID|1||78945^^^HOSPITAL_A^MR||...
OBR|1|LR-449821||58410-2^Complete blood count^LN|||20260407091500
OBX|1|NM|6690-2^WBC^LN||7.5|10*3/uL|3.5-10.5|N|||F
OBX|2|NM|789-8^RBC^LN||4.8|10*6/uL|4.5-5.5|N|||F
OBX|3|NM|718-7^HGB^LN||14.2|g/dL|12.0-16.0|N|||F
El translator conoce las convenciones de Epic (formato HL7v2.5.1, delimitadores, segmentos) y produce un mensaje que Epic puede ingerir directamente.
Paso 4: Aseguradora Consume — FHIR a X12¶
El translator outbound de la Aseguradora E transforma el FHIR Observation en un segmento X12 837 para procesamiento de claims. Solo extrae los datos necesarios para facturación (código de procedimiento, fecha, proveedor) y los mapea al formato X12.
Paso 5: Evolución del Modelo¶
El HIE necesita añadir soporte para datos genómicos. En lugar de crear un modelo nuevo, extiende el modelo FHIR con el recurso MolecularSequence y define un profile específico para el HIE. Los translators existentes no se afectan porque el nuevo recurso es adicional (backward compatible). Solo los sistemas que producen o consumen datos genómicos necesitan actualizar sus translators.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.generic.storage import Storage
from diagrams.onprem.database import PostgreSQL
with Diagram("Canonical Data Model - Healthcare FHIR HIE", show=False, direction="TB"):
with Cluster("Sistemas Origen"):
hospital_a = Server("Hospital A\n(Epic/HL7v2)")
hospital_b = Server("Hospital B\n(Cerner/FHIR)")
lab_c = Server("Laboratorio C\n(LIS/CSV)")
with Cluster("Translators Inbound"):
trans_a_in = Server("HL7v2 →\nFHIR")
trans_b_in = Server("FHIR →\nFHIR (pass)")
trans_c_in = Server("CSV →\nFHIR")
with Cluster("Canonical Data Model (FHIR R4)"):
fhir_topic = Kafka("hie.fhir.*\n(FHIR Resources)")
schema_reg = Storage("FHIR Profiles\n& ValueSets\n(Schema Registry)")
fhir_server = PostgreSQL("FHIR Server\n(Resource Store)")
with Cluster("Translators Outbound"):
trans_a_out = Server("FHIR →\nHL7v2")
trans_d_out = Server("FHIR →\nNCPDP")
trans_e_out = Server("FHIR →\nX12 837")
with Cluster("Sistemas Destino"):
hospital_a_recv = Server("Hospital A\n(Epic/HL7v2)")
pharmacy_d = Server("Farmacia D\n(NCPDP)")
insurer_e = Server("Aseguradora E\n(X12)")
# Inbound
hospital_a >> trans_a_in >> fhir_topic
hospital_b >> trans_b_in >> fhir_topic
lab_c >> trans_c_in >> fhir_topic
# Schema validation
trans_a_in >> Edge(style="dashed") >> schema_reg
trans_c_in >> Edge(style="dashed") >> schema_reg
# FHIR Server
fhir_topic >> fhir_server
# Outbound
fhir_topic >> trans_a_out >> hospital_a_recv
fhir_topic >> trans_d_out >> pharmacy_d
fhir_topic >> trans_e_out >> insurer_e
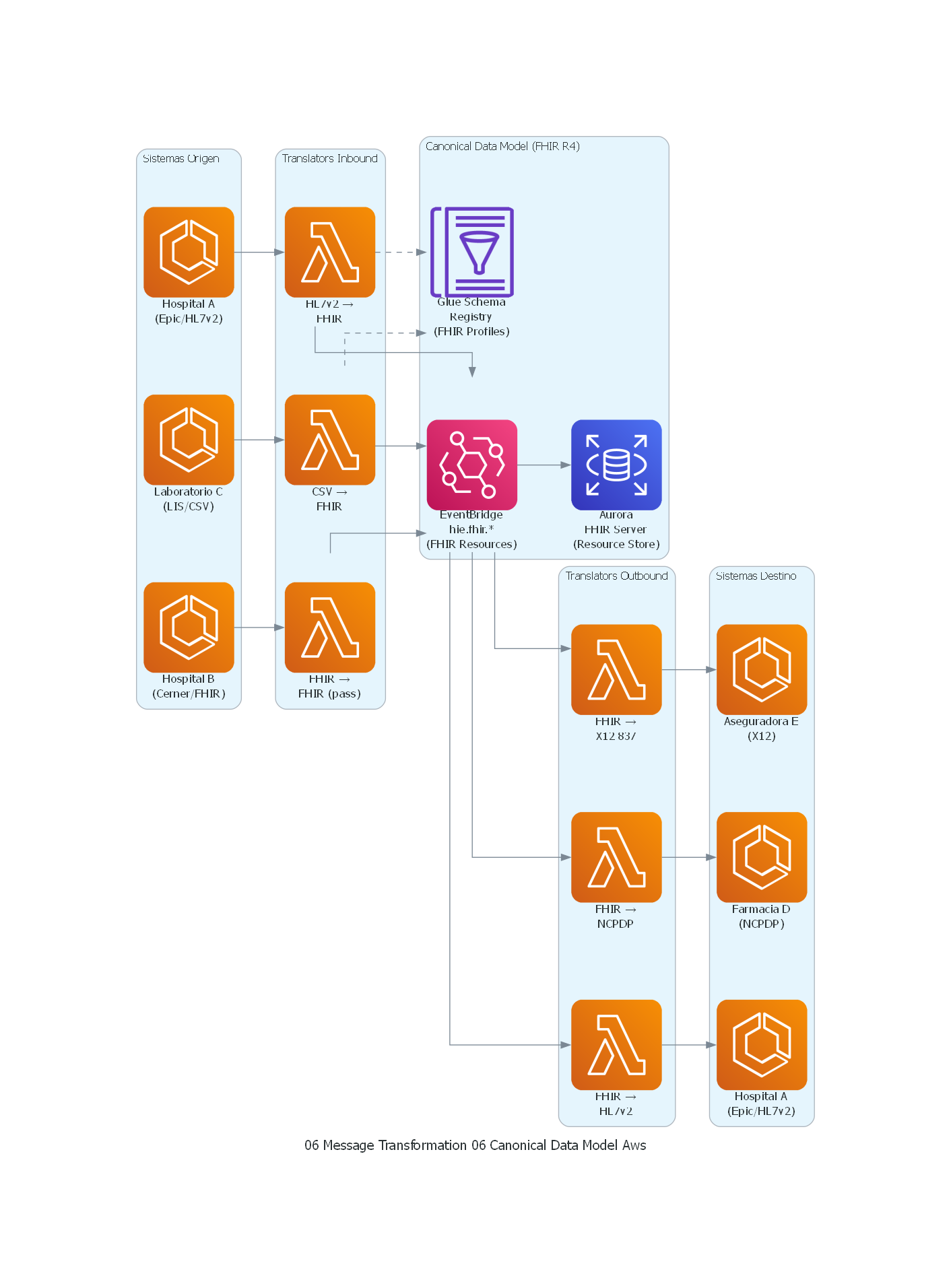
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import RDS
from diagrams.aws.integration import Eventbridge
from diagrams.aws.analytics import GlueDataCatalog
with Diagram("Canonical Data Model - Healthcare FHIR HIE (AWS)", show=False, direction="TB"):
with Cluster("Sistemas Origen"):
hospital_a = ECS("Hospital A\n(Epic/HL7v2)")
hospital_b = ECS("Hospital B\n(Cerner/FHIR)")
lab_c = ECS("Laboratorio C\n(LIS/CSV)")
with Cluster("Translators Inbound"):
trans_a_in = Lambda("HL7v2 →\nFHIR")
trans_b_in = Lambda("FHIR →\nFHIR (pass)")
trans_c_in = Lambda("CSV →\nFHIR")
with Cluster("Canonical Data Model (FHIR R4)"):
fhir_bus = Eventbridge("EventBridge\nhie.fhir.*\n(FHIR Resources)")
schema_reg = GlueDataCatalog("Glue Schema\nRegistry\n(FHIR Profiles)")
fhir_server = RDS("Aurora\nFHIR Server\n(Resource Store)")
with Cluster("Translators Outbound"):
trans_a_out = Lambda("FHIR →\nHL7v2")
trans_d_out = Lambda("FHIR →\nNCPDP")
trans_e_out = Lambda("FHIR →\nX12 837")
with Cluster("Sistemas Destino"):
hospital_a_recv = ECS("Hospital A\n(Epic/HL7v2)")
pharmacy_d = ECS("Farmacia D\n(NCPDP)")
insurer_e = ECS("Aseguradora E\n(X12)")
# Inbound
hospital_a >> trans_a_in >> fhir_bus
hospital_b >> trans_b_in >> fhir_bus
lab_c >> trans_c_in >> fhir_bus
# Schema validation
trans_a_in >> Edge(style="dashed") >> schema_reg
trans_c_in >> Edge(style="dashed") >> schema_reg
# FHIR Server
fhir_bus >> fhir_server
# Outbound
fhir_bus >> trans_a_out >> hospital_a_recv
fhir_bus >> trans_d_out >> pharmacy_d
fhir_bus >> trans_e_out >> insurer_e
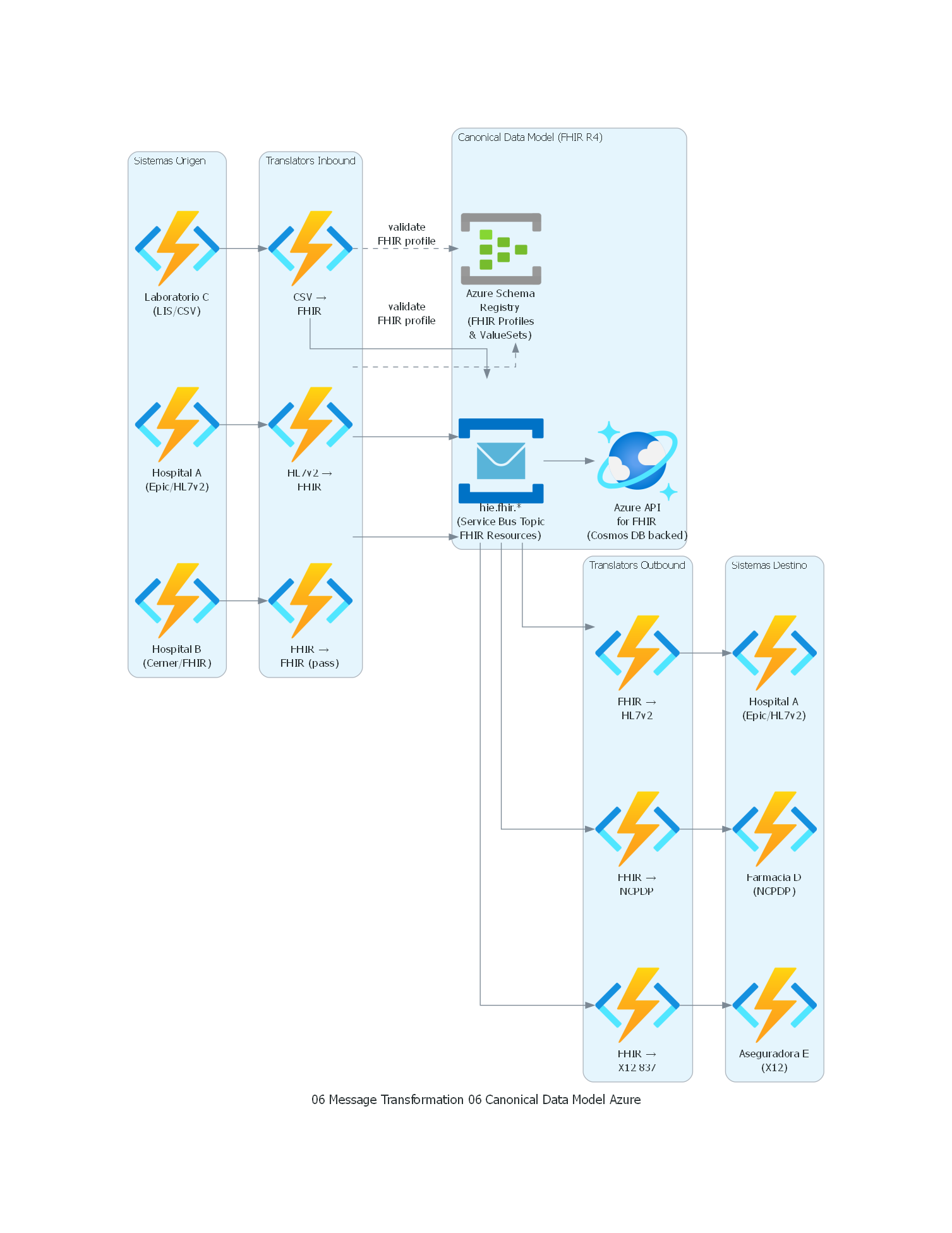
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.analytics import EventHubs
from diagrams.azure.integration import ServiceBus
with Diagram("Canonical Data Model - Healthcare FHIR HIE (Azure)", show=False, direction="TB"):
with Cluster("Sistemas Origen"):
hospital_a = FunctionApps("Hospital A\n(Epic/HL7v2)")
hospital_b = FunctionApps("Hospital B\n(Cerner/FHIR)")
lab_c = FunctionApps("Laboratorio C\n(LIS/CSV)")
with Cluster("Translators Inbound"):
trans_a_in = FunctionApps("HL7v2 →\nFHIR")
trans_b_in = FunctionApps("FHIR →\nFHIR (pass)")
trans_c_in = FunctionApps("CSV →\nFHIR")
with Cluster("Canonical Data Model (FHIR R4)"):
fhir_topic = ServiceBus("hie.fhir.*\n(Service Bus Topic\nFHIR Resources)")
schema_reg = EventHubs("Azure Schema\nRegistry\n(FHIR Profiles\n& ValueSets)")
fhir_server = CosmosDb("Azure API\nfor FHIR\n(Cosmos DB backed)")
with Cluster("Translators Outbound"):
trans_a_out = FunctionApps("FHIR →\nHL7v2")
trans_d_out = FunctionApps("FHIR →\nNCPDP")
trans_e_out = FunctionApps("FHIR →\nX12 837")
with Cluster("Sistemas Destino"):
hospital_a_recv = FunctionApps("Hospital A\n(Epic/HL7v2)")
pharmacy_d = FunctionApps("Farmacia D\n(NCPDP)")
insurer_e = FunctionApps("Aseguradora E\n(X12)")
# Inbound
hospital_a >> trans_a_in >> fhir_topic
hospital_b >> trans_b_in >> fhir_topic
lab_c >> trans_c_in >> fhir_topic
# Schema validation via Azure Schema Registry
trans_a_in >> Edge(style="dashed", label="validate\nFHIR profile") >> schema_reg
trans_c_in >> Edge(style="dashed", label="validate\nFHIR profile") >> schema_reg
# FHIR Server (Azure API for FHIR, backed by Cosmos DB)
fhir_topic >> fhir_server
# Outbound
fhir_topic >> trans_a_out >> hospital_a_recv
fhir_topic >> trans_d_out >> pharmacy_d
fhir_topic >> trans_e_out >> insurer_e
Explicación del Diagrama¶
El diagrama muestra el Canonical Data Model en acción:
- Los sistemas origen envían datos en sus formatos propietarios (HL7v2, FHIR nativo, CSV).
- Los translators inbound transforman al formato canónico FHIR, validando contra los FHIR Profiles.
- Los datos canónicos (recursos FHIR) circulan por Kafka y se almacenan en el FHIR Server.
- Los translators outbound transforman del formato canónico al formato de cada sistema destino.
- Los sistemas destino reciben datos en su formato nativo.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Canonical Data Model | FHIR R4 Resources + Profiles + ValueSets |
| Translator Inbound | HL7v2→FHIR, CSV→FHIR |
| Translator Outbound | FHIR→HL7v2, FHIR→NCPDP, FHIR→X12 |
| Schema Registry | FHIR Profiles & ValueSets |
| Canal de intercambio | Kafka topics con recursos FHIR |
11. Beneficios¶
Impacto Técnico¶
- Reducción de transformaciones de N×(N-1) a 2×N: con 6 sistemas, se pasa de 30 transformaciones a 12.
- Vocabulario compartido: LOINC para laboratorio, SNOMED para diagnósticos, UCUM para unidades. Sin ambigüedad.
- Interoperabilidad estructurada: cualquier nuevo sistema solo necesita 2 translators (inbound y outbound) para interoperar con todos los demás.
- Ecosistema de herramientas: al usar FHIR, se accede a validators, FHIR servers, mapping tools y librerías en múltiples lenguajes.
Impacto Organizacional¶
- Estándar compartido: todas las instituciones del HIE comparten un lenguaje para los datos clínicos.
- Onboarding acelerado: integrar una nueva clínica requiere solo 2 translators, no integraciones con cada sistema existente.
- Compliance regulatorio: FHIR es mandatorio en regulaciones como ONC 21st Century Cures Act (EE.UU.).
Impacto Operacional¶
- Validación centralizada: los recursos FHIR se validan contra los profiles antes de aceptarlos, rechazando datos no conformes.
- Audit trail: el FHIR Server mantiene un historial versionado de cada recurso.
- Query API: el FHIR Server provee una API REST estándar para consultar datos clínicos.
Beneficios de Mantenibilidad y Evolución¶
- Evolución por recurso: añadir soporte para genómica (nuevo recurso FHIR) no afecta a los translators existentes.
- Extensions para datos locales: FHIR permite extensiones que no rompen compatibilidad.
- Comunidad y soporte: HL7 International mantiene el estándar con releases periódicos y soporte comunitario.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Diseño del modelo: definir un modelo canónico requiere consenso entre múltiples stakeholders con perspectivas diferentes.
- Doble transformación: cada dato se transforma dos veces (sistema→canónico, canónico→sistema), añadiendo latencia y riesgo de pérdida de información.
- Gobernanza continua: el modelo canónico requiere un equipo que lo mantenga, evolucione y resuelva conflictos.
Riesgos de Mal Uso¶
- Modelo canónico como modelo de dominio: usar el modelo canónico como modelo interno de los sistemas, perdiendo la especificidad de cada dominio. El modelo canónico es para intercambio, no para lógica de negocio interna.
- One Model to Rule Them All: intentar que un solo modelo canónico global cubra todos los dominios de la organización. Es preferible tener modelos canónicos por dominio (clinical, financial, administrative).
- Diseño por comité paralizante: un comité de gobernanza que tarda meses en aprobar un nuevo campo, paralizando la integración.
Sobreingeniería¶
- Diseñar un modelo canónico completo desde el inicio cuando solo se necesitan 2-3 conceptos para los flujos actuales.
- Implementar un motor de transformación genérico cuando translators simples por sistema son suficientes.
- Definir vocabularios controlados propios cuando existen estándares de industria (LOINC, SNOMED, ISO 4217).
Costos de Operación¶
- Translators por sistema: con N sistemas, hay 2×N translators que mantener.
- Schema evolution: cada cambio en el modelo canónico debe evaluarse contra todos los translators.
- Mapping maintenance: las tablas de mapeo de códigos (LOINC, SNOMED) deben actualizarse con cada release del vocabulario.
Anti-Patterns Relacionados¶
- Canonical Bloat: el modelo canónico crece descontroladamente, incluyendo campos que nadie usa, convirtiéndose en un "God Schema".
- Canonical as Internal Model: usar el modelo canónico como modelo interno de los servicios, creando acoplamiento rígido entre todos los servicios.
- Frozen Canonical: un modelo canónico que nunca se actualiza porque el proceso de gobernanza es demasiado pesado.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Normalizer (este capítulo): el Normalizer es la implementación operativa del Canonical Data Model. El CDM define el modelo; el Normalizer transforma mensajes heterogéneos a ese modelo.
- Message Translator (Messaging Systems): los translators inbound y outbound del CDM son Message Translators específicos.
- Message Bus (Messaging Channels): el CDM complementa al Message Bus. El bus proporciona la infraestructura de transporte; el CDM proporciona el contrato semántico.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Channel Adapter conecta cada sistema al bus y puede implementar la traducción al modelo canónico.
- Después: Content Filter puede reducir el mensaje canónico para consumidores que solo necesitan un subconjunto.
Combinaciones Comunes¶
- CDM + Message Bus + Channel Adapter: la tríada clásica de integración empresarial. Bus para transporte, CDM para semántica, adapters para conexión.
- CDM + Schema Registry: el Schema Registry almacena y versiona los schemas del CDM, permitiendo evolución gobernada.
- CDM + Content-Based Router: el router examina el contenido del mensaje canónico para enrutarlo.
Diferencias con Patrones Similares¶
- vs. Normalizer: el CDM es el modelo al que se normaliza. El Normalizer es el mecanismo de transformación. CDM es el "qué"; Normalizer es el "cómo".
- vs. Shared Database: ambos proveen un formato compartido, pero la Shared Database comparte los datos directamente (acoplamiento fuerte); el CDM comparte el formato de intercambio mientras cada sistema mantiene sus datos (acoplamiento débil).
- vs. Published Language (DDD): el CDM es esencialmente un Published Language — un modelo documentado que los bounded contexts usan para comunicarse en las fronteras.
Encaje en un Flujo Mayor de Integración¶
El Canonical Data Model es el fundamento semántico de toda la arquitectura de integración. Define qué significan los datos que fluyen por el Message Bus, qué estructura tienen y qué vocabularios utilizan. Es la capa que convierte bits en información con significado compartido.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
Canonical Data Model ocupa una posición matizada en la arquitectura moderna, con una tensión saludable entre su utilidad probada y las críticas desde DDD:
La tensión con DDD:
- DDD dice: cada bounded context tiene su propio modelo. Los modelos compartidos crean acoplamiento que reduce la autonomía de los equipos.
- CDM dice: un modelo compartido reduce transformaciones y facilita la interoperabilidad.
- La resolución: el CDM es apropiado como modelo de intercambio (Published Language en DDD), no como modelo de dominio interno. Los bounded contexts mantienen su modelo interno y traducen al CDM solo en las fronteras.
Lo que sigue vigente:
- Estándares de industria: FHIR, FIX, EDIFACT siguen siendo esenciales para interoperabilidad inter-empresa.
- Reducción de complejidad: cuando N es grande (>5 sistemas), la reducción de N×(N-1) a 2×N sigue siendo significativa.
- Schemas de eventos: en arquitecturas event-driven, los schemas de eventos (definidos en Schema Registry con Avro/Protobuf) son esencialmente un CDM para los domain events.
Lo que ha cambiado:
- CDM global → CDMs por dominio: en lugar de un modelo canónico global para toda la organización, las arquitecturas modernas prefieren modelos canónicos por dominio o por bounded context federation.
- CDM estático → Event schemas: los schemas de eventos en Schema Registry evolucionan continuamente, con governance más ágil que un CDM estático.
- CDM impuesto → CDM emergente: en data mesh, el modelo compartido emerge de la interoperabilidad entre data products, no se impone top-down.
Cómo Se Implementa Hoy¶
| Contexto | Implementación del CDM |
|---|---|
| Healthcare | HL7 FHIR como CDM con profiles por región/organización |
| Financial Trading | FIX Protocol como CDM con extensiones por venue |
| Supply Chain | GS1 / EDIFACT como CDM para intercambio B2B |
| Event-Driven Microservices | Avro/Protobuf schemas en Schema Registry |
| Data Mesh | Data product schemas con vocabularios compartidos |
| API Economy | OpenAPI schemas con modelos compartidos |
Qué Parte Sigue Siendo Esencial¶
- Un modelo de intercambio documentado — sea un estándar de industria o un modelo propio.
- Vocabularios controlados — códigos, enumerados y terminologías compartidas.
- Schema evolution gobernada — backward compatibility y versionado.
- Scope limitado — CDM para intercambio, no para lógica de dominio interna.
15. Implementación en Arquitecturas Modernas¶
Schema Registry con Avro — CDM para Event-Driven Architecture¶
{
"type": "record",
"name": "CanonicalPatientEvent",
"namespace": "com.hie.canonical.patient",
"doc": "Canonical Patient representation for HIE event exchange",
"fields": [
{"name": "patient_id", "type": "string", "doc": "HIE-wide patient identifier"},
{"name": "name", "type": {
"type": "record",
"name": "HumanName",
"fields": [
{"name": "given", "type": "string"},
{"name": "family", "type": "string"}
]
}},
{"name": "birth_date", "type": "string", "doc": "ISO 8601 date"},
{"name": "gender", "type": {"type": "enum", "name": "Gender", "symbols": ["male", "female", "other", "unknown"]}},
{"name": "identifiers", "type": {"type": "array", "items": {
"type": "record",
"name": "Identifier",
"fields": [
{"name": "system", "type": "string", "doc": "URI identifying the system"},
{"name": "value", "type": "string"}
]
}}},
{"name": "extensions", "type": ["null", {"type": "map", "values": "string"}], "default": null,
"doc": "Extension fields for regional requirements"}
]
}
El schema Avro registrado en Confluent Schema Registry actúa como CDM. El compatibility mode BACKWARD permite añadir campos opcionales sin romper consumidores existentes.
FHIR Profiling — Restricción del Estándar¶
{
"resourceType": "StructureDefinition",
"id": "hie-regional-observation",
"url": "https://hie.regional.org/fhir/StructureDefinition/hie-observation",
"name": "HIERegionalObservation",
"status": "active",
"kind": "resource",
"type": "Observation",
"baseDefinition": "http://hl7.org/fhir/StructureDefinition/Observation",
"derivation": "constraint",
"differential": {
"element": [
{
"id": "Observation.code.coding",
"path": "Observation.code.coding",
"min": 1,
"binding": {
"strength": "required",
"valueSet": "http://loinc.org/vs"
}
},
{
"id": "Observation.subject",
"path": "Observation.subject",
"min": 1,
"type": [{"code": "Reference", "targetProfile": ["https://hie.regional.org/fhir/StructureDefinition/hie-patient"]}]
}
]
}
}
El FHIR Profile restringe el estándar FHIR genérico a las necesidades del HIE: códigos LOINC obligatorios, referencia a paciente obligatoria, etc.
AsyncAPI — Documentación del CDM como API Contract¶
asyncapi: '2.6.0'
info:
title: HIE Canonical Events
version: '3.0.0'
description: Canonical Data Model for regional Health Information Exchange
channels:
hie.fhir.observations:
description: Laboratory and clinical observations in canonical FHIR format
publish:
message:
$ref: '#/components/messages/CanonicalObservation'
subscribe:
message:
$ref: '#/components/messages/CanonicalObservation'
components:
messages:
CanonicalObservation:
schemaFormat: 'application/vnd.oai.openapi;version=3.0.0'
contentType: application/json
payload:
$ref: 'https://hie.regional.org/fhir/StructureDefinition/hie-observation'
headers:
type: object
properties:
fhir_resource_type:
type: string
enum: [Observation]
source_system:
type: string
canonical_version:
type: string
AsyncAPI documenta el CDM como un contrato de API asíncrona, haciendo el modelo canónico discoverable y machine-readable.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Translation success rate: porcentaje de mensajes transformados exitosamente al modelo canónico, por sistema origen.
- Schema validation failures: mensajes que no validan contra el CDM (profiles, ValueSets).
- Data loss in translation: campos del sistema origen que no tienen equivalente en el CDM y se pierden.
- CDM coverage: porcentaje de conceptos de negocio cubiertos por el CDM.
Monitoreo¶
- Translator health: estado y throughput de cada translator (inbound y outbound).
- Schema Registry availability: el Schema Registry es un componente crítico; su caída impide validación.
- Vocabulary freshness: verificar que las terminologías (LOINC, SNOMED) están actualizadas.
- Unmapped codes: códigos de sistemas origen que no tienen mapeo al vocabulario canónico.
Versionado¶
- Semantic versioning: el CDM usa versionado semántico (major.minor.patch). Breaking changes incrementan major; nuevos campos opcionales incrementan minor.
- Backward compatibility: nuevas versiones del CDM deben ser backward-compatible (los consumidores de la versión anterior siguen funcionando).
- Migration path: para breaking changes, documentar el migration path y dar tiempo a los sistemas para migrar.
Seguridad¶
- El CDM puede contener PII: los datos canónicos pueden incluir información personal del paciente. Los mismos controles de privacidad que aplican a los sistemas origen aplican al CDM.
- Access control por recurso: en FHIR, se pueden definir políticas de acceso por tipo de recurso (Observation vs. Patient).
- Audit de acceso: registrar quién accede a qué datos canónicos, especialmente datos sensibles.
Manejo de Errores¶
- Translation failure: si un translator no puede transformar un mensaje al CDM, enviar a dead-letter con el error de mapping.
- Validation failure: si un mensaje canónico no valida contra el profile, rechazar y notificar al sistema origen.
- Code not mapped: si un código del sistema origen no tiene equivalente en el vocabulario canónico, registrar el código no mapeado y usar un código genérico ("other").
17. Errores Comunes¶
Diseñar un Modelo Canónico Global Desde el Inicio¶
Intentar modelar todos los conceptos de negocio de toda la organización en un solo schema antes de implementar la primera integración. El resultado es un proyecto de diseño de 12 meses que produce un modelo de 500 entidades que nadie usa porque es demasiado complejo. Es preferible empezar con los 3-5 conceptos más intercambiados y crecer incrementalmente.
Confundir Modelo Canónico con Modelo de Dominio¶
Usar el modelo canónico como modelo interno de los microservicios. Los servicios importan las clases del CDM, las usan en su lógica de negocio y almacenan datos en formato canónico. Cualquier cambio en el CDM requiere modificar todos los servicios — el acoplamiento que DDD advierte. El CDM es para intercambio en las fronteras; cada servicio tiene su propio modelo interno.
Modelo Canónico Controlado por un Sistema Dominante¶
El modelo canónico se parece sospechosamente al modelo de datos del ERP o del sistema más grande de la organización. Los demás sistemas tienen transformaciones complejas y asimétricas. El CDM debe ser neutral — no debe favorecer la representación de ningún sistema.
No Evolucionar el Modelo¶
Definir el CDM una vez y nunca actualizarlo. Con el tiempo, los sistemas evolucionan, aparecen nuevos conceptos y el CDM se vuelve inadecuado. Los equipos crean "extensiones" ad hoc no gobernadas, degradando la coherencia del modelo. El CDM necesita un proceso de evolución ágil pero gobernado.
Ignorar los Vocabularios Controlados¶
Definir un CDM con campos de texto libre para códigos de diagnóstico, unidades de medida y categorías de producto. Sin vocabularios controlados (LOINC, SNOMED, ISO 4217), el CDM estandariza la estructura pero no la semántica. Dos sistemas pueden enviar el mismo concepto con códigos diferentes y el consumidor no puede compararlos.
18. Conclusión Técnica¶
Canonical Data Model es el patrón que define un modelo de datos intermedio compartido para la comunicación entre sistemas. Reduce el número de transformaciones de N×(N-1) a 2×N y establece un vocabulario compartido para los datos de negocio.
Cuándo aporta valor: cuando múltiples sistemas intercambian los mismos conceptos y el número de transformaciones punto a punto es insostenible. Es especialmente valioso cuando existen estándares de industria (FHIR, FIX, EDIFACT) que pueden servir como base.
Cuándo evita problemas importantes: cuando sin un modelo canónico, cada par de sistemas negocia bilateralmente su formato de intercambio, el vocabulario es inconsistente y los errores de mapping se multiplican.
Cuándo no conviene adoptarlo: cuando hay pocos sistemas (2-3) con integraciones simples, cuando la organización no tiene capacidad de gobernar el modelo, o cuando los modelos de los sistemas son tan diferentes que un modelo intermedio pierde información crítica.
Recomendación para arquitectos: trate el CDM como un modelo de intercambio (Published Language en DDD), no como un modelo de dominio interno. Use estándares de industria cuando existan (FHIR, FIX, GS1) en lugar de diseñar desde cero. Empiece con los 3-5 conceptos más intercambiados y crezca incrementalmente. Implemente vocabularios controlados desde el inicio — la estandarización semántica es tan importante como la estructural. Y establezca un proceso de evolución ágil: los cambios al CDM deben ser tan fáciles de proponer como un pull request, pero tan gobernados como un cambio de API pública. La clave está en el equilibrio entre la estabilidad que los consumidores necesitan y la evolución que el negocio demanda.