Polling Consumer¶
1. Nombre del Patrón¶
- Nombre oficial: Polling Consumer
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Consumidor por Sondeo
2. Resumen Ejecutivo¶
Polling Consumer es un patrón en el que la aplicación consumidora solicita explícitamente mensajes al sistema de mensajería cuando está lista para procesarlos, en lugar de recibir mensajes automáticamente cuando estos llegan. El consumidor controla el ritmo de consumo invocando activamente una operación de "poll" o "receive" sobre el canal de mensajes.
El problema que resuelve es el control de flujo desde la perspectiva del consumidor. En muchos escenarios, el consumidor necesita decidir cuándo está listo para procesar el siguiente batch de mensajes: cuando un ciclo de procesamiento anterior ha completado, cuando hay recursos disponibles, cuando se alcanza una ventana de tiempo específica, o cuando se acumula un número mínimo de mensajes para procesamiento eficiente.
Aparece como modelo fundamental de consumo en brokers modernos. Kafka, notablemente, está diseñado enteramente alrededor del polling consumer: el KafkaConsumer.poll() es la operación central de todo consumo en Kafka. SQS de AWS opera igualmente con un modelo pull-based donde el consumidor invoca ReceiveMessage cuando está listo. Este patrón es la base del procesamiento batch, del procesamiento a ritmo controlado y de las arquitecturas donde el consumidor necesita backpressure natural.
3. Definición Detallada¶
Propósito¶
El propósito de Polling Consumer es dar al consumidor control explícito sobre cuándo se reciben y procesan mensajes, permitiéndole adaptar el ritmo de consumo a su capacidad de procesamiento, a la disponibilidad de recursos y a las necesidades del negocio.
Lógica Arquitectónica¶
En un Polling Consumer, el flujo de control es pull-based: el consumidor decide cuándo pedir mensajes. Esto contrasta con Event-Driven Consumer, donde el flujo es push-based y el broker decide cuándo entregar mensajes al consumidor.
El poll loop típico sigue esta estructura:
while (running) {
messages = consumer.poll(timeout)
for each message in messages:
process(message)
consumer.commit()
}
Esta estructura aparentemente simple tiene implicaciones arquitectónicas profundas:
- Backpressure natural: si el consumidor procesa lento, simplemente pide menos frecuentemente. No hay riesgo de sobrecarga porque el consumidor controla el ritmo.
- Batching: el poll puede devolver múltiples mensajes que se procesan como batch, optimizando I/O y transacciones.
- Control de recursos: el consumidor puede pausar el polling cuando detecta que los recursos están saturados (CPU, memoria, conexiones de DB).
Principio de Diseño Subyacente¶
El principio es control de flujo en el consumidor. El consumidor sabe mejor que el broker cuándo tiene capacidad para procesar mensajes. Delegar al consumidor la decisión de cuándo consumir permite una regulación natural del throughput sin necesidad de mecanismos externos de throttling.
Problema Estructural que Resuelve¶
En un sistema push-based sin control de flujo, el broker envía mensajes al consumidor tan rápido como puede. Si el consumidor no puede procesar al mismo ritmo, se produce una de estas situaciones:
- Buffer overflow: los mensajes se acumulan en un buffer local del consumidor hasta que se agota la memoria.
- Procesamiento degradado: el consumidor intenta procesar todo pero la calidad se degrada (timeouts, errores, OOM).
- Desconexión: el broker desconecta al consumidor lento, perdiendo mensajes o requiriendo reconexión.
Polling Consumer elimina estas situaciones porque el consumidor solo recibe mensajes cuando los pide.
Contexto en el que Emerge¶
Polling Consumer emerge naturalmente en escenarios donde:
- El procesamiento de cada mensaje es costoso (queries de DB, llamadas a APIs externas, cálculos complejos) y el consumidor necesita controlar el ritmo.
- El procesamiento es batch-oriented: acumular N mensajes y procesarlos juntos es más eficiente que procesarlos uno a uno.
- El consumidor tiene ventanas de procesamiento (scheduled jobs, batch windows) y solo debe consumir durante esas ventanas.
- El broker es fundamentalmente pull-based (Kafka, SQS).
Por Qué No Es Trivial¶
Las decisiones de diseño del poll loop son complejas:
- Poll timeout: ¿cuánto tiempo esperar si no hay mensajes? Un timeout corto consume CPU en polling vacío; un timeout largo retrasa la detección de nuevos mensajes.
- Batch size: ¿cuántos mensajes pedir en cada poll? Un batch grande mejora throughput pero aumenta latencia y riesgo de procesamiento perdido si el consumidor falla a mitad del batch.
- Commit strategy: ¿commit después de cada mensaje, después de cada batch, o periódicamente? Cada estrategia tiene diferentes trade-offs de durabilidad vs. performance.
- Rebalance handling: en Kafka, cuando el consumer group se rebalancea, el polling consumer debe manejar la revocación y asignación de particiones.
- Error handling: ¿qué ocurre cuando un mensaje en un batch falla? ¿Se reintenta, se salta, se detiene el procesamiento?
Relación con Sistemas Distribuidos y Mensajería¶
Polling Consumer es el modelo nativo de Kafka y SQS, dos de los brokers más utilizados:
- En Kafka,
consumer.poll(Duration)es la única forma de consumir mensajes. Todo consumo es polling. El consumer controla offset commits, rebalance listeners y fetch configuration. - En SQS,
receiveMessage(ReceiveMessageRequest)es pull-based. SQS soporta long polling (esperar hasta que haya mensajes o timeout) para reducir polling vacío. - En RabbitMQ,
basicGet()implementa polling (aunque el modo predominante es push conbasicConsume()). - En Azure Service Bus,
receiveMessages(maxMessages, timeout)proporciona polling con batching.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Polling Consumer, en un modelo puramente push-based, el consumidor está a merced del ritmo de producción. Si el productor envía 10,000 mensajes/segundo y el consumidor solo puede procesar 1,000/segundo, el resultado es una de estas situaciones:
- Los mensajes se acumulan en un buffer local hasta que el consumidor se queda sin memoria.
- El broker implementa throttling y ralentiza al productor, afectando a todos los consumidores del mismo canal.
- El consumidor descarta mensajes o se desconecta.
Síntomas del Problema¶
- Consumidores que se quedan sin memoria (OOM) durante picos de producción.
- Latencia de procesamiento que crece linealmente con la carga porque el consumidor no puede regularse.
- Necesidad de dimensionar el consumidor para el pico máximo de producción, desperdiciando recursos durante el 95% del tiempo.
- Incapacidad de implementar procesamiento batch eficiente porque los mensajes llegan uno a uno.
- Jobs de procesamiento batch que no pueden controlar cuándo ejecutarse.
Impacto Operativo y Arquitectónico¶
Sin control de flujo pull-based:
- El dimensionamiento del consumidor depende del throughput máximo del productor, lo cual puede ser impredecible.
- Los picos de producción impactan directamente la estabilidad del consumidor.
- No es posible implementar procesamiento batch eficiente (agrupar N mensajes, procesarlos juntos, commit una vez).
- El consumidor no puede pausarse voluntariamente (para mantenimiento, recalibración, window-based processing).
Riesgos Si No Se Implementa Correctamente¶
- Busy polling: poll con timeout de 0ms consume CPU innecesariamente cuando no hay mensajes. La solución es long polling o timeout razonable.
- Batch demasiado grande: pedir miles de mensajes en un poll puede causar que el consumidor falle a mitad del batch, requiriendo reprocesamiento de todo el batch.
- Session timeout en Kafka: si el procesamiento de un batch es más lento que el
session.timeout.ms, Kafka considera al consumidor muerto y lo remueve del grupo, causando un rebalance. - Commit antes de procesar: hacer commit de offsets antes de completar el procesamiento puede causar pérdida de mensajes si el consumidor falla.
Ejemplos Reales¶
- Batch processing: un job de conciliación bancaria que se ejecuta a las 02:00, poll mensajes de transacciones del día, los procesa en batch, y para hasta el día siguiente.
- Rate-limited API calls: un consumidor que debe llamar a una API externa con rate limit de 100 requests/segundo. El consumidor poll exactamente 100 mensajes, los procesa, espera 1 segundo, y repite.
- Resource-aware processing: un consumidor de procesamiento de imágenes que solo poll nuevas imágenes cuando la GPU tiene capacidad disponible.
- Kafka consumers: todo consumo en Kafka es inherentemente polling. El
poll()loop es el mecanismo fundamental.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el consumidor necesita controlar el ritmo de consumo basándose en su capacidad de procesamiento.
- Cuando el procesamiento es batch-oriented y acumular mensajes antes de procesarlos es más eficiente.
- Cuando el consumidor tiene ventanas de procesamiento (scheduled, time-boxed).
- Cuando se usa un broker pull-based (Kafka, SQS).
- Cuando el procesamiento de cada mensaje es costoso y el consumidor necesita backpressure natural.
- Cuando el consumidor necesita pausar y resumir el consumo programáticamente.
Cuándo No Usarlo¶
- Cuando se necesita latencia mínima de procesamiento (el mensaje debe procesarse inmediatamente al llegar).
- Cuando el procesamiento es ligero y no requiere control de ritmo.
- Cuando el framework proporciona push-based consumption que se adapta mejor al caso de uso (Spring
@KafkaListenercon concurrency configurada, por ejemplo).
Precondiciones¶
- El broker soporta operación pull-based (poll, receive, get).
- El consumidor tiene lógica para determinar cuándo está listo para el siguiente poll.
- Existe un thread o proceso dedicado al poll loop.
Restricciones¶
- La latencia mínima de procesamiento está determinada por el poll interval y el timeout.
- El consumidor debe manejar el caso de poll vacío (no hay mensajes disponibles) sin consumir recursos innecesariamente.
- En Kafka, el poll loop debe invocarse con frecuencia suficiente para mantener vivo el consumer (heartbeats se envían durante
poll()).
Dependencias¶
- API del broker para operaciones pull (KafkaConsumer, SqsClient, etc.).
- Thread o scheduler que ejecute el poll loop.
- Mecanismo de commit de offsets o acknowledgment.
Supuestos Arquitectónicos¶
- El broker retiene mensajes hasta que el consumidor los recoja (durabilidad del broker).
- El consumidor tiene la capacidad de determinar su propia capacidad de procesamiento.
- La latencia entre producción y procesamiento es tolerable (no es ultra-low-latency).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Procesamiento batch (ETL, reconciliación, reporting).
- Kafka consumers (todo consumo en Kafka es polling).
- SQS consumers (polling o long-polling).
- Workers que procesan jobs de una cola.
- Sistemas con rate-limiting hacia APIs externas.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Polling Consumer desacopla el ritmo de producción del ritmo de consumo. El productor puede producir a su máxima velocidad sin preocuparse por la capacidad del consumidor. El broker absorbe la diferencia como buffer. Esto proporciona flexibilidad para escalar productor y consumidor independientemente.
Simplicidad vs. Robustez¶
El poll loop básico es simple. Pero un poll loop robusto debe manejar: timeouts, errores de procesamiento, rebalances (Kafka), session management, commit strategies, graceful shutdown y métricas. La robustez requiere consideración cuidadosa de cada uno de estos aspectos.
Latencia vs. Eficiencia¶
Polling introduce latencia inherente: el mensaje no se procesa inmediatamente al llegar sino cuando el consumidor ejecuta el siguiente poll. La latencia promedio es la mitad del poll interval. Reducir el poll interval mejora la latencia pero aumenta el overhead de polling. La eficiencia de batch processing se logra aumentando el poll interval y el batch size, lo cual incrementa la latencia.
Throughput vs. Confiabilidad¶
Batching múltiples mensajes por poll y haciendo commit al final del batch maximiza throughput. Pero si el consumidor falla a mitad del batch, los mensajes procesados exitosamente se reentregarán (si el commit no se hizo). Commit por mensaje es más confiable pero tiene menor throughput.
Control vs. Complejidad¶
El polling consumer da control total sobre cuándo y cuánto consumir. Pero este control viene con la responsabilidad de implementar correctamente el poll loop, los commits, el manejo de errores, el shutdown graceful y el handling de rebalances.
Backpressure Natural vs. Latencia Variable¶
El backpressure natural del polling es una ventaja significativa: el consumidor solo pide lo que puede procesar. Pero la latencia se vuelve variable: durante baja carga, la latencia es baja; durante alta carga, la latencia aumenta porque los mensajes esperan a que el consumidor tenga capacidad.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Poll Loop: el thread o proceso que ejecuta el ciclo de polling.
- Consumer Client: la API del broker que proporciona la operación de poll (KafkaConsumer, SqsClient).
- Message Channel: el topic, queue o subscription del que se leen mensajes.
- Message Processor: la lógica de negocio que procesa cada mensaje.
- Offset/Acknowledgment Manager: el componente que confirma el procesamiento exitoso de mensajes.
Flujo Lógico¶
flowchart TD
A([Inicio Poll Loop]) --> B[Invoca consumer.poll con timeout]
B --> C[(Broker)]
C -->|Retorna batch de mensajes| D{Hay mensajes?}
D -->|No: batch vacío| B
D -->|Sí| E[Itera sobre mensajes recibidos]
E --> F[Message Processor: lógica de negocio]
F --> G[Commit de offsets]
G --> BResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Poll Loop | Controlar el ritmo de consumo, manejar el ciclo de vida del consumer |
| Consumer Client | Comunicarse con el broker, gestionar conexiones y fetch |
| Message Processor | Ejecutar la lógica de negocio para cada mensaje |
| Offset Manager | Confirmar procesamiento exitoso, manejar retries |
Interacciones¶
- Poll Loop → Consumer Client: invocación de
poll(timeout). - Consumer Client → Broker: fetch request con offset actual y max batch size.
- Broker → Consumer Client: respuesta con batch de mensajes.
- Poll Loop → Message Processor: invocación de lógica de negocio para cada mensaje.
- Poll Loop → Consumer Client: commit de offsets tras procesamiento.
Contratos Implícitos¶
- El broker retiene mensajes hasta que el consumidor confirme su procesamiento.
- El consumidor invoca
poll()con frecuencia suficiente para mantener su sesión activa (en Kafka, dentro desession.timeout.ms). - El commit de offsets refleja el procesamiento real (no se commitea antes de procesar).
Decisiones de Diseño Clave¶
- Poll timeout: duración de espera cuando no hay mensajes. Impacta latencia vs. CPU usage.
- Max batch size: máximo de mensajes por poll (
max.poll.recordsen Kafka). Impacta throughput vs. latencia vs. riesgo de fallo a mitad de batch. - Commit strategy: auto-commit, sync commit after batch, async commit. Impacta durabilidad vs. performance.
- Error handling: skip message, retry, stop processing, dead-letter. Define el comportamiento ante fallos.
- Concurrency model: single-thread poll + multi-thread process, o single-thread todo. Kafka requiere single-thread para
poll()pero permite multi-thread para procesamiento.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Batch Processing — Job de Conciliación de Pagos Pendientes¶
Contexto del Negocio¶
Una fintech procesa pagos entre comercios y sus clientes. Cada pago tiene un ciclo de vida: creado → procesado → liquidado. Los pagos procesados deben conciliarse contra los registros del adquirente (banco) para verificar que todos los pagos se liquidaron correctamente. Este proceso de conciliación se ejecuta cada hora, procesando todos los pagos que pasaron a estado "procesado" durante la última hora.
Necesidad de Integración¶
Los eventos PaymentProcessed se publican en un topic de Kafka por el Payment Service. Un job de conciliación debe consumir estos eventos en batch (cada hora), agruparlos por adquirente, consultar el estado de liquidación en la API del adquirente, y generar un reporte de discrepancias.
Sistemas Involucrados¶
- Payment Service: publica eventos
PaymentProcesseden Kafka. - Apache Kafka: topic
fintech.payments.processedcon retención de 7 días. - Reconciliation Job: aplicación Java que ejecuta el poll cada hora.
- Acquirer API: API REST del banco adquirente para consultar estado de liquidación.
- PostgreSQL: base de datos donde se almacenan resultados de conciliación.
- Alerting System: recibe alertas cuando hay discrepancias significativas.
Restricciones Técnicas¶
- El job se ejecuta cada hora, no continuamente.
- La API del adquirente tiene rate limit de 50 requests/segundo.
- Cada batch de conciliación puede contener entre 1,000 y 50,000 pagos.
- El procesamiento debe completarse en menos de 30 minutos.
- Los offsets solo deben commitearse después de que la conciliación completa haya terminado.
Flujos de Datos¶
Payment Service → Kafka (fintech.payments.processed)
→ [Reconciliation Job polls hourly]
→ Batch de PaymentProcessed events
→ Agrupación por adquirente
→ Consulta a Acquirer API (rate-limited)
→ Comparación y generación de discrepancias
→ PostgreSQL (resultados)
→ Commit offsets en Kafka
Decisiones Arquitectónicas¶
- Scheduled polling: el job usa un scheduler (Quartz) para activar el poll cada hora, no un poll loop continuo.
- Batch accumulation: el job acumula todos los mensajes disponibles antes de procesarlos (múltiples polls hasta que no haya más mensajes).
- Manual commit: los offsets se commitean solo después de que todo el batch haya sido procesado y persistido exitosamente.
- Rate-limited API calls: se usa un Semaphore con 50 permits para respetar el rate limit del adquirente.
- Idempotency: el job almacena un hash del batch procesado para evitar duplicación si se re-ejecuta.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Configuración del Kafka Consumer¶
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "reconciliation-job");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false"); // Manual commit
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "1000"); // 1000 per poll
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class);
ENABLE_AUTO_COMMIT = false es clave: los offsets solo se commitean manualmente después del procesamiento completo.
Paso 2: Accumulation Loop¶
@Scheduled(cron = "0 0 * * * *") // Cada hora
public void runReconciliation() {
KafkaConsumer<String, PaymentProcessedEvent> consumer = createConsumer();
consumer.subscribe(List.of("fintech.payments.processed"));
List<PaymentProcessedEvent> batch = new ArrayList<>();
boolean hasMore = true;
// Acumular todos los mensajes disponibles
while (hasMore) {
ConsumerRecords<String, PaymentProcessedEvent> records = consumer.poll(Duration.ofSeconds(5));
if (records.isEmpty()) {
hasMore = false; // No hay más mensajes
} else {
for (ConsumerRecord<String, PaymentProcessedEvent> record : records) {
batch.add(record.value());
}
}
}
if (batch.isEmpty()) {
log.info("No payments to reconcile this hour");
consumer.close();
return;
}
log.info("Accumulated {} payments for reconciliation", batch.size());
processReconciliation(batch);
// Commit solo después de procesamiento exitoso
consumer.commitSync();
consumer.close();
}
Paso 3: Procesamiento Batch con Rate Limiting¶
private void processReconciliation(List<PaymentProcessedEvent> payments) {
// Agrupar por adquirente
Map<String, List<PaymentProcessedEvent>> byAcquirer =
payments.stream().collect(Collectors.groupingBy(PaymentProcessedEvent::getAcquirerId));
List<ReconciliationResult> results = new ArrayList<>();
RateLimiter rateLimiter = RateLimiter.create(50.0); // 50 requests/segundo
for (Map.Entry<String, List<PaymentProcessedEvent>> entry : byAcquirer.entrySet()) {
String acquirerId = entry.getKey();
List<PaymentProcessedEvent> acquirerPayments = entry.getValue();
// Consultar estado en la API del adquirente (rate-limited)
for (PaymentProcessedEvent payment : acquirerPayments) {
rateLimiter.acquire();
AcquirerStatus status = acquirerApi.getPaymentStatus(
acquirerId, payment.getPaymentId());
ReconciliationResult result = reconcile(payment, status);
results.add(result);
}
}
// Persistir resultados
reconciliationRepository.saveAll(results);
// Alertar si hay discrepancias significativas
long discrepancies = results.stream()
.filter(r -> r.getStatus() == ReconciliationStatus.DISCREPANCY).count();
if (discrepancies > results.size() * 0.01) { // >1%
alertingService.sendAlert("High discrepancy rate: " +
discrepancies + "/" + results.size());
}
}
Paso 4: Manejo de Errores y Recovery¶
@Scheduled(cron = "0 0 * * * *")
public void runReconciliation() {
KafkaConsumer<String, PaymentProcessedEvent> consumer = null;
try {
consumer = createConsumer();
consumer.subscribe(List.of("fintech.payments.processed"));
List<PaymentProcessedEvent> batch = accumulateBatch(consumer);
if (batch.isEmpty()) return;
processReconciliation(batch);
consumer.commitSync();
log.info("Reconciliation completed: {} payments processed", batch.size());
} catch (ReconciliationException e) {
// Error de procesamiento: NO commitear offsets
// Los mensajes se reprocesarán en la siguiente ejecución
log.error("Reconciliation failed, offsets not committed", e);
alertingService.sendAlert("Reconciliation failed: " + e.getMessage());
} finally {
if (consumer != null) consumer.close();
}
}
El patrón clave es: si el procesamiento falla, no se commitean offsets. En la siguiente ejecución horaria, los mismos mensajes se recibirán de nuevo (at-least-once).
Paso 5: Monitoreo del Job¶
@Component
public class ReconciliationMetrics {
private final MeterRegistry meterRegistry;
public void recordExecution(int batchSize, Duration duration, int discrepancies) {
meterRegistry.counter("reconciliation.executions").increment();
meterRegistry.gauge("reconciliation.batch_size", batchSize);
meterRegistry.timer("reconciliation.duration").record(duration);
meterRegistry.gauge("reconciliation.discrepancies", discrepancies);
}
}
Manejo de Errores¶
- Kafka no disponible: el poll lanza excepción, el job registra el error y se reintenta en la siguiente hora.
- API del adquirente no disponible: retry con exponential backoff por request. Si falla después de 3 intentos, el pago se marca como "pending_reconciliation" para revisión manual.
- Processing timeout: si el job no completa en 30 minutos, un watchdog lo cancela. Los offsets no se commitean y los mensajes se reprocesarán.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.language import Java
from diagrams.onprem.queue import Kafka
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.compute import Rack
from diagrams.onprem.monitoring import Grafana
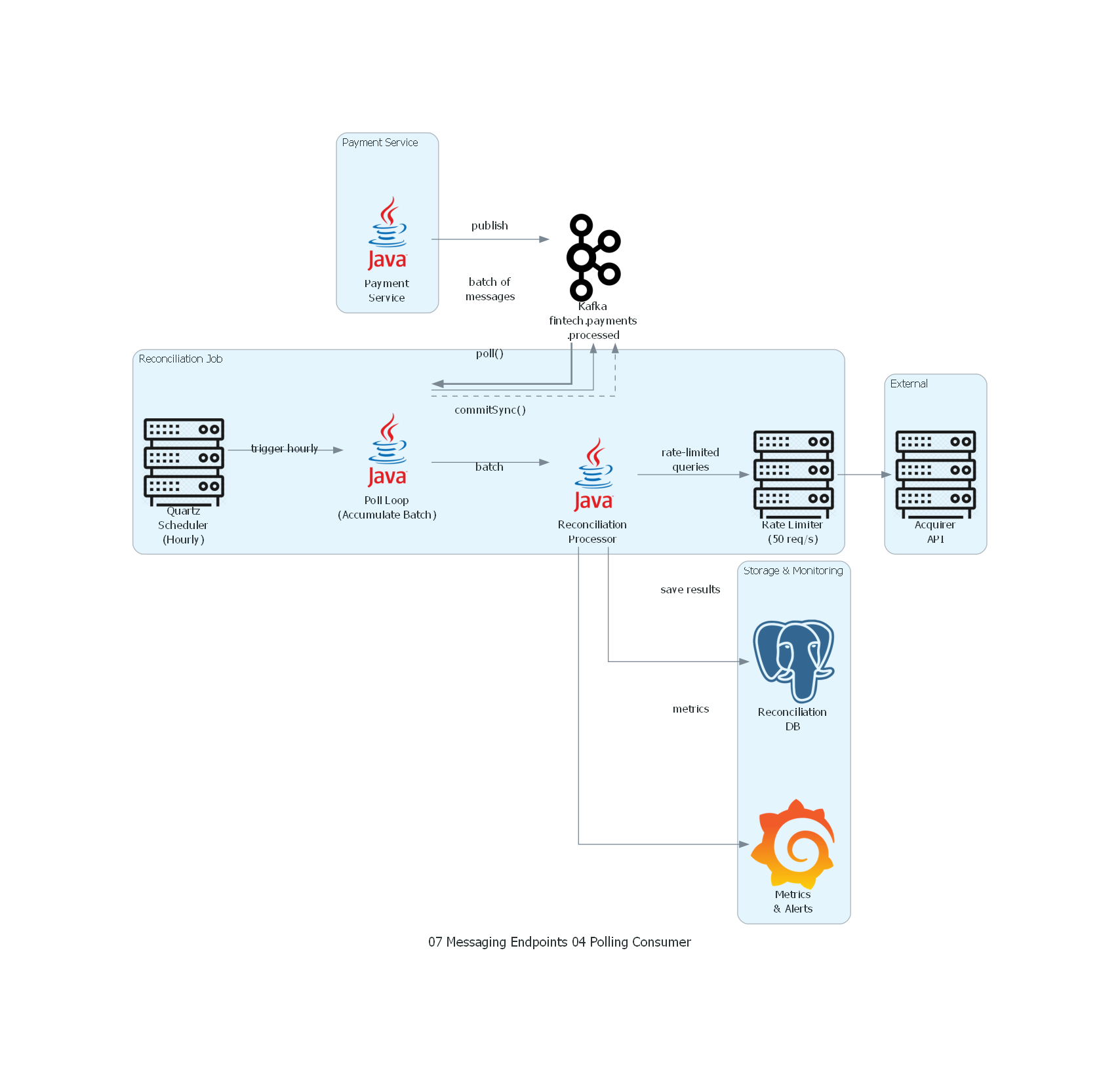
with Diagram("Polling Consumer - Payment Reconciliation Job", show=False, direction="LR"):
with Cluster("Payment Service"):
payment_svc = Java("Payment\nService")
kafka = Kafka("Kafka\nfintech.payments\n.processed")
with Cluster("Reconciliation Job"):
scheduler = Rack("Quartz\nScheduler\n(Hourly)")
poll_loop = Java("Poll Loop\n(Accumulate Batch)")
processor = Java("Reconciliation\nProcessor")
rate_limiter = Rack("Rate Limiter\n(50 req/s)")
with Cluster("External"):
acquirer_api = Rack("Acquirer\nAPI")
with Cluster("Storage & Monitoring"):
db = PostgreSQL("Reconciliation\nDB")
monitoring = Grafana("Metrics\n& Alerts")
payment_svc >> Edge(label="publish") >> kafka
scheduler >> Edge(label="trigger hourly") >> poll_loop
poll_loop >> Edge(label="poll()") >> kafka
kafka >> Edge(label="batch of\nmessages", style="bold") >> poll_loop
poll_loop >> Edge(label="batch") >> processor
processor >> Edge(label="rate-limited\nqueries") >> rate_limiter
rate_limiter >> acquirer_api
processor >> Edge(label="save results") >> db
processor >> Edge(label="metrics") >> monitoring
poll_loop >> Edge(label="commitSync()", style="dashed") >> kafka
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda, ECS
from diagrams.aws.database import RDS
from diagrams.aws.integration import SQS, Eventbridge
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
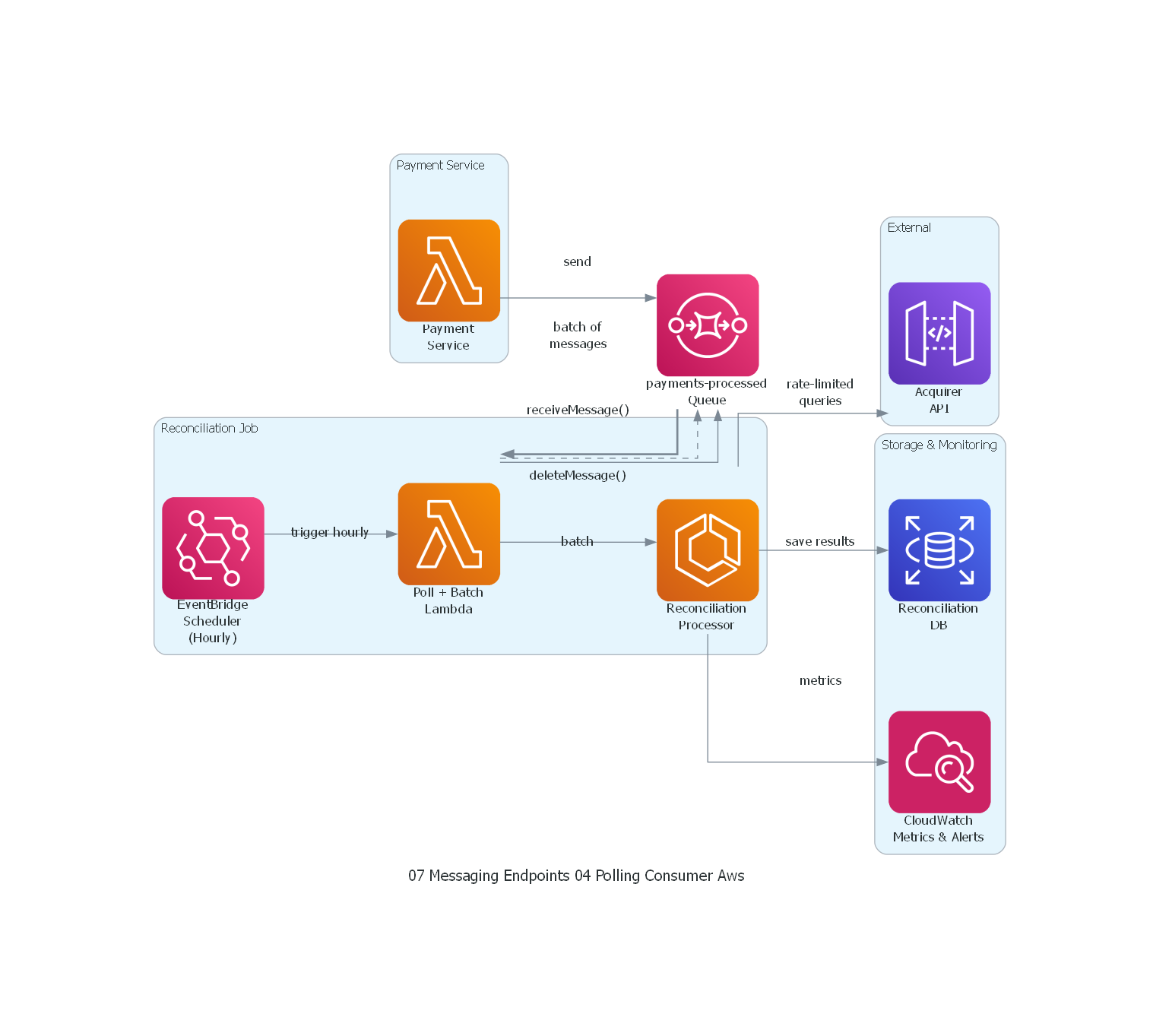
with Diagram("Polling Consumer - Payment Reconciliation Job (AWS)", show=False, direction="LR"):
with Cluster("Payment Service"):
payment_svc = Lambda("Payment\nService")
sqs = SQS("payments-processed\nQueue")
with Cluster("Reconciliation Job"):
scheduler = Eventbridge("EventBridge\nScheduler\n(Hourly)")
poll_loop = Lambda("Poll + Batch\nLambda")
processor = ECS("Reconciliation\nProcessor")
with Cluster("External"):
acquirer_api = APIGateway("Acquirer\nAPI")
with Cluster("Storage & Monitoring"):
db = RDS("Reconciliation\nDB")
monitoring = Cloudwatch("CloudWatch\nMetrics & Alerts")
payment_svc >> Edge(label="send") >> sqs
scheduler >> Edge(label="trigger hourly") >> poll_loop
poll_loop >> Edge(label="receiveMessage()") >> sqs
sqs >> Edge(label="batch of\nmessages", style="bold") >> poll_loop
poll_loop >> Edge(label="batch") >> processor
processor >> Edge(label="rate-limited\nqueries") >> acquirer_api
processor >> Edge(label="save results") >> db
processor >> Edge(label="metrics") >> monitoring
poll_loop >> Edge(label="deleteMessage()", style="dashed") >> sqs
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import SQLDatabases
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus, APIManagement
from diagrams.generic.compute import Rack
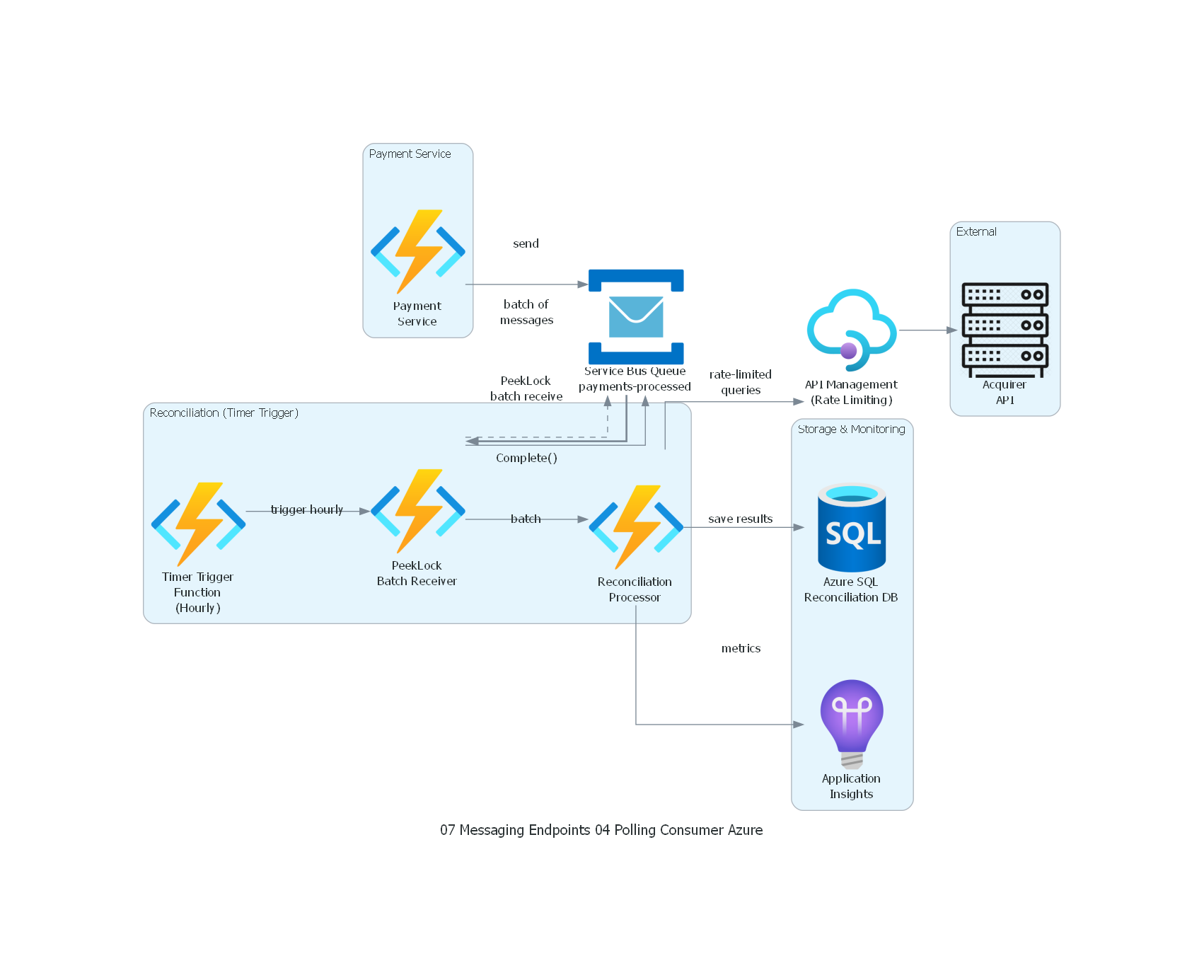
with Diagram("Polling Consumer - Payment Reconciliation Job (Azure)", show=False, direction="LR"):
with Cluster("Payment Service"):
payment_svc = FunctionApps("Payment\nService")
queue = ServiceBus("Service Bus Queue\npayments-processed")
with Cluster("Reconciliation (Timer Trigger)"):
timer_func = FunctionApps("Timer Trigger\nFunction\n(Hourly)")
poll_loop = FunctionApps("PeekLock\nBatch Receiver")
processor = FunctionApps("Reconciliation\nProcessor")
with Cluster("External"):
acquirer_api = Rack("Acquirer\nAPI")
apim = APIManagement("API Management\n(Rate Limiting)")
with Cluster("Storage & Monitoring"):
db = SQLDatabases("Azure SQL\nReconciliation DB")
monitoring = ApplicationInsights("Application\nInsights")
payment_svc >> Edge(label="send") >> queue
timer_func >> Edge(label="trigger hourly") >> poll_loop
poll_loop >> Edge(label="PeekLock\nbatch receive") >> queue
queue >> Edge(label="batch of\nmessages", style="bold") >> poll_loop
poll_loop >> Edge(label="batch") >> processor
processor >> Edge(label="rate-limited\nqueries") >> apim
apim >> acquirer_api
processor >> Edge(label="save results") >> db
processor >> Edge(label="metrics") >> monitoring
poll_loop >> Edge(label="Complete()", style="dashed") >> queue
Explicación del Diagrama¶
- Payment Service publica eventos
PaymentProcesseden Kafka continuamente. - Quartz Scheduler activa el Reconciliation Job cada hora.
- Poll Loop ejecuta múltiples
poll()para acumular todos los mensajes disponibles en un batch. - Reconciliation Processor agrupa los pagos por adquirente y consulta la API externa con rate limiting.
- Results se persisten en PostgreSQL y las métricas se envían a Grafana.
- Commit se ejecuta solo después de procesamiento exitoso (línea discontinua).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Polling Consumer | Poll Loop (accumulate batch) |
| Poll trigger | Quartz Scheduler (hourly) |
| Message Channel | Kafka topic fintech.payments.processed |
| Message Processor | Reconciliation Processor |
| Commit/Acknowledgment | commitSync() al final del batch |
11. Beneficios¶
Impacto Técnico¶
- Backpressure natural: el consumidor solo recibe mensajes cuando los solicita. No hay riesgo de sobrecarga por parte del broker.
- Batch processing eficiente: múltiples mensajes se procesan como batch, amortizando overhead de transacciones, I/O y llamadas a APIs.
- Control total del consumidor: el consumidor decide cuándo, cuánto y con qué frecuencia consumir. Esto permite processing windows, rate limiting y resource-aware consumption.
- Compatibilidad con Kafka: todo consumo en Kafka es polling. Dominar este patrón es dominar Kafka consumption.
Impacto Organizacional¶
- Predictibilidad de recursos: como el consumidor controla el ritmo, el uso de recursos (CPU, memoria, conexiones) es más predecible y dimensionable.
- Operación programable: el polling se puede activar, pausar y configurar programáticamente, facilitando operaciones como mantenimiento, deployment blue-green y scaling.
Impacto Operacional¶
- Graceful shutdown: detener un polling consumer es limpio: se deja de invocar
poll(), se commitean los offsets procesados, y se cierra la conexión. - Lag como métrica: la diferencia entre el último offset producido y el último offset consumido es una métrica directa del estado del consumidor (consumer lag).
- Recovery predecible: si el consumidor falla y se reinicia, retoma desde el último offset commiteado. El comportamiento es determinista.
Beneficios de Mantenibilidad y Evolución¶
- Poll loop como punto de control: toda la lógica de consumo está centralizada en el poll loop, facilitando cambios en la estrategia de consumo (batch size, timeout, error handling).
- Testing determinista: el poll loop se testea invocando
poll()con datos de prueba y verificando el resultado del procesamiento. No hay concurrencia implícita del push-based.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Poll loop boilerplate: el poll loop con manejo de errores, commits, rebalances y shutdown requiere código cuidadoso que es fácil de implementar incorrectamente.
- Thread management: el poll loop necesita un thread dedicado (en Kafka, el consumer no es thread-safe). La gestión del thread y su lifecycle es responsabilidad del desarrollador.
Riesgos de Mal Uso¶
- Polling vacío excesivo: si no hay mensajes la mayor parte del tiempo, el polling consume CPU y conexiones innecesariamente. Long polling mitiga esto.
- Batch demasiado grande: acumular demasiados mensajes antes de procesar introduce latencia excesiva y riesgo de OOM.
- Session timeout en Kafka: si el procesamiento de un batch es más lento que
max.poll.interval.ms, Kafka remueve al consumidor del grupo. Esto causa rebalance y reprocesamiento.
Sobreingeniería¶
- Implementar un poll loop custom cuando frameworks como Spring Kafka (
@KafkaListener) proporcionan una abstracción sobre el poll loop con manejo automático de commits, errores y rebalances. - Crear un sistema de scheduling complejo cuando un simple timer o cron job es suficiente.
Costos de Operación¶
- El consumer lag debe monitorearse continuamente para detectar degradación.
- Los rebalances (en Kafka) deben rastrearse porque causan pausas en el procesamiento.
- La configuración del poll (timeout, batch size, session timeout) requiere tuning basado en el caso de uso.
Anti-Patterns Relacionados¶
- Spin Loop: poll con timeout de 0 en un loop tight, consumiendo CPU al 100% cuando no hay mensajes.
- Commit Before Process: commitear offsets antes de completar el procesamiento. Si el consumidor falla, los mensajes no se reentregarán.
- Unbounded Accumulation: acumular mensajes indefinidamente antes de procesar, sin límite de batch size ni timeout, arriesgando OOM.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Competing Consumers: múltiples polling consumers en el mismo consumer group compiten por particiones de Kafka. Cada instancia ejecuta su propio poll loop sobre las particiones asignadas.
- Messaging Gateway: el gateway del lado consumidor puede implementar internamente un polling consumer, ocultando el poll loop detrás de una interfaz de dominio.
- Transactional Client: el commit de offsets puede coordinarse con una transacción local (consume-transform-produce pattern en Kafka).
Patrones que Suelen Aparecer Antes o Después¶
- Message Dispatcher: después del poll, los mensajes del batch pueden distribuirse a diferentes handlers según su tipo (dispatcher).
- Content-Based Router: el polling consumer recibe mensajes de diferentes tipos y los dirige a procesadores específicos.
Combinaciones Comunes¶
- Polling Consumer + Competing Consumers + Kafka: la combinación más frecuente. Múltiples instancias ejecutan poll loops independientes sobre particiones de un topic.
- Polling Consumer + Batch Processing: acumulación de mensajes por poll y procesamiento batch es la combinación natural para ETL, reconciliación y reporting.
Diferencias con Patrones Similares¶
- vs. Event-Driven Consumer: Polling Consumer es pull-based (el consumidor pide); Event-Driven Consumer es push-based (el broker entrega). Polling da control al consumidor; Event-Driven minimiza latencia.
- vs. Selective Consumer: Selective Consumer filtra mensajes que no interesan; Polling Consumer controla cuándo se reciben mensajes, no cuáles.
Encaje en un Flujo Mayor de Integración¶
Polling Consumer es el patrón de consumo nativo de Kafka y SQS. En una arquitectura event-driven con Kafka, todo consumo es polling (aunque frameworks como Spring Kafka lo abstraigan). En pipelines de procesamiento batch, el polling consumer es el punto de entrada que conecta el stream de eventos con el procesamiento batch.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Polling Consumer es el modelo nativo de consumo en Kafka, el broker de mensajería más utilizado en la industria. Todo consumo en Kafka es inherentemente polling. La relevancia del patrón es inseparable de la relevancia de Kafka.
A favor de la vigencia:
- Kafka
consumer.poll()es la operación central de todo consumo en Kafka. Comprender Polling Consumer es comprender Kafka consumption. - SQS, uno de los servicios de colas más usados en cloud, opera con modelo poll-based (
ReceiveMessagecon long polling). - El procesamiento batch sigue siendo fundamental en muchos dominios (finanzas, reporting, ETL, reconciliación) y el polling consumer es el mecanismo natural.
- Los frameworks abstraen el poll loop pero no eliminan su semántica.
@KafkaListenerde Spring es un Event-Driven Consumer implementado sobre un Polling Consumer.
Matiz:
- La mayoría de los desarrolladores no escriben poll loops explícitos porque los frameworks lo hacen por ellos. Sin embargo, comprender el poll loop subyacente es esencial para configurar correctamente
max.poll.records,max.poll.interval.ms,enable.auto.commitysession.timeout.ms.
Cómo Se Implementa Hoy¶
- Kafka Consumer API:
consumer.poll(Duration)es el mecanismo directo. - Spring Kafka:
@KafkaListenerabstrae el poll loop pero permite configurar batch listening, manual commit y error handling. - AWS Lambda + SQS: Lambda poll SQS automáticamente (el event source mapping es un polling consumer gestionado por AWS).
- Azure Functions + Service Bus: Functions con trigger de Service Bus implementan polling internamente.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
El Kafka Consumer API es enteramente polling-based. consumer.poll(Duration timeout) retorna un batch de ConsumerRecords. Configuración clave: max.poll.records (batch size), max.poll.interval.ms (tiempo máximo entre polls antes de que el consumer se considere muerto), fetch.min.bytes y fetch.max.wait.ms (control del batching del lado del broker). Para consumer groups, el poll loop también participa en el protocolo de rebalance.
AWS SQS¶
ReceiveMessage con WaitTimeSeconds > 0 implementa long polling, reduciendo el polling vacío. MaxNumberOfMessages controla el batch size (max 10). Lambda con SQS event source mapping es un polling consumer gestionado donde AWS ejecuta el poll loop y invoca la función con batches de mensajes.
Azure Service Bus¶
ServiceBusReceiverClient.receiveMessages(maxMessages, timeout) proporciona polling con batching. Para Auto-complete mode, Service Bus commitea automáticamente tras entrega; para PeekLock, el consumidor debe completar explícitamente cada mensaje.
RabbitMQ¶
Channel.basicGet(queue, autoAck) implementa polling síncrono, un mensaje a la vez. Es menos eficiente que basicConsume() (push-based) y se recomienda solo para escenarios donde el consumidor necesita control explícito del ritmo.
Spring Kafka¶
@KafkaListener con batch = true procesa batches de mensajes. Configurar ConcurrentKafkaListenerContainerFactory con setBatchListener(true) y AckMode.MANUAL_IMMEDIATE proporciona batch polling con manual commit.
Apache Camel¶
El componente kafka: de Camel implementa internamente un polling consumer que alimenta la ruta de integración con mensajes de Kafka. El poll interval y batch size se configuran como propiedades del endpoint.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: consumer lag (offsets pendientes), mensajes polled/segundo, batch size promedio, procesamiento/segundo, poll duration, empty polls/minuto.
- Health checks: verificar que el consumer está activo, que el lag no crece, que los polls se ejecutan según schedule.
- Alertas: consumer lag creciente (el consumidor no mantiene el ritmo), consumer removido del grupo (session timeout), incremento de poll vacíos.
Tracing¶
- Cada mensaje polled debe extraer el trace ID de los headers para continuar el distributed trace.
- El batch de procesamiento puede agruparse bajo un trace padre que representa el poll cycle.
Monitoreo¶
- Dashboard de consumer: lag por partición, throughput de procesamiento, batch sizes, commit rates.
- Dashboard de job (si es scheduled): ejecuciones/hora, duración por ejecución, mensajes procesados por ejecución.
Versionado¶
- El consumer debe manejar múltiples versiones de mensajes (schema evolution) porque los mensajes en el topic pueden tener diferentes schema versions.
Seguridad¶
- Las credenciales del broker se configuran en el consumer client.
- SSL/TLS para comunicación con el broker.
- SASL para autenticación del consumer.
Manejo de Errores¶
- Mensaje inválido (poison pill): un mensaje que no puede deserializarse o procesarse bloquea el poll loop. Se debe implementar dead-lettering o skip para mensajes inválidos.
- Error de procesamiento: retry del mensaje, skip con logging, o stop del consumer según la criticidad.
- Timeout de poll:
poll()retorna vacío. El consumer continúa con el siguiente poll.
Retries¶
- Para procesamiento de mensajes individuales, retry con backoff dentro del loop.
- Para batches, retry del batch completo o de los mensajes fallidos.
- Para el poll loop mismo, el loop continúa indefinidamente (o según schedule).
Dead-Lettering¶
- Los mensajes que no pueden procesarse después de N retries se envían a un dead-letter topic/queue.
- En Kafka, no hay dead-letter nativo. Se implementa publicando al DLT manualmente.
- En SQS, el dead-letter queue se configura nativamente.
Idempotencia¶
- Como el poll puede reentregarl mensajes (después de un fallo sin commit), el procesamiento debe ser idempotente.
- Se usa un deduplication store para rastrear mensajes ya procesados.
Performance¶
- Fetch tuning en Kafka:
fetch.min.bytes,fetch.max.wait.mscontrolan el batching del lado del broker. - Max poll records: ajustar al throughput de procesamiento. Demasiados causa timeout; muy pocos reduce throughput.
- Parallel processing: después del poll (single-thread), los mensajes pueden procesarse en parallel con un thread pool.
Escalabilidad¶
- En Kafka, escalar consumers añadiendo instancias al consumer group (hasta el número de particiones).
- En SQS, escalar invocando más polls concurrentes o usando Lambda con concurrency reservada.
17. Errores Comunes¶
No Configurar max.poll.interval.ms Adecuadamente¶
En Kafka, si el procesamiento de un batch tarda más que max.poll.interval.ms (default 5 minutos), el consumer es removido del grupo y se produce un rebalance. Todos los mensajes del batch se reentregarán. Este error se manifiesta como rebalances frecuentes y procesamiento duplicado.
Commit Antes de Procesar¶
Hacer commitSync() antes de completar el procesamiento de los mensajes significa que si el consumer falla después del commit pero antes de completar, los mensajes se pierden (no se reentregarán).
Polling Loop sin Graceful Shutdown¶
Un poll loop que no maneja SIGTERM correctamente deja offsets sin commitear y puede dejar el consumer "zombie" en el grupo. El shutdown debe invocar consumer.wakeup() seguido de consumer.close().
Ignorar el Consumer Lag¶
No monitorear el consumer lag permite que el consumidor se atrase progresivamente sin que nadie lo note. Cuando finalmente se detecta, puede haber horas o días de mensajes pendientes.
Spin Loop sin Long Polling¶
Usar consumer.poll(Duration.ZERO) o timeout muy bajo en un loop tight consume CPU al 100% cuando no hay mensajes. Siempre usar un timeout razonable (100ms-5000ms) o long polling.
No Manejar Poison Pills¶
Un mensaje que no puede deserializarse o procesarse bloquea el poll loop indefinidamente si no hay manejo de errores. El consumidor se queda en un ciclo infinito de poll → error → no commit → poll el mismo mensaje → error.
18. Conclusión Técnica¶
Polling Consumer es el modelo fundamental de consumo en Kafka y SQS, dos de las plataformas de messaging más utilizadas en la industria. Comprender este patrón es esencial para cualquier arquitecto o desarrollador que trabaje con estas tecnologías.
Para un arquitecto de sistemas modernos, las directrices son:
- Comprender el poll loop subyacente aunque se use un framework que lo abstraiga. La configuración correcta de
max.poll.records,max.poll.interval.ms,session.timeout.msyenable.auto.commites imposible sin entender el poll loop. - Usar manual commit para procesamiento crítico. Auto-commit puede causar pérdida de mensajes si el consumer falla entre un auto-commit y el siguiente.
- Configurar batch size según la capacidad de procesamiento. Un batch demasiado grande causa timeouts; uno demasiado pequeño desperdicia throughput.
- Implementar graceful shutdown que commitee offsets procesados y cierre la conexión limpiamente.
- Monitorear consumer lag como métrica principal de salud del consumidor.
- Manejar poison pills con dead-lettering o skip para evitar que un mensaje inválido bloquee todo el procesamiento.
En el contexto del job de conciliación del ejemplo, el polling consumer permite un modelo de procesamiento elegante: cada hora, el job se activa, acumula todos los pagos pendientes mediante múltiples polls, los procesa en batch respetando los rate limits del adquirente, y solo commitea offsets después de confirmar que la conciliación se completó exitosamente. Si algo falla, los offsets no se commitean y los mismos mensajes se reprocesan en la siguiente hora. Este modelo de recovery es una consecuencia natural del diseño pull-based del polling consumer.