Event-Driven Consumer¶
1. Nombre del Patrón¶
- Nombre oficial: Event-Driven Consumer
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Consumidor Dirigido por Eventos
2. Resumen Ejecutivo¶
Event-Driven Consumer es un patrón en el que el consumidor se registra como listener o callback en el sistema de mensajería, y recibe mensajes automáticamente cuando estos llegan al canal, sin necesidad de solicitarlos explícitamente. El broker "empuja" los mensajes al consumidor en lugar de que el consumidor los "tire" del broker.
El problema que resuelve es la latencia de procesamiento. En escenarios donde cada mensaje debe procesarse lo antes posible después de su llegada — notificaciones en tiempo real, detección de fraude, actualizaciones de inventario, alertas de monitoreo — esperar a que un poll loop itere no es aceptable. Event-Driven Consumer minimiza la latencia al procesar el mensaje en el momento de su entrega.
Aparece como modelo predominante en RabbitMQ (basicConsume con callback), en frameworks como Spring Kafka (@KafkaListener), en serverless (AWS Lambda triggered by SQS/SNS/EventBridge), en Azure Functions triggered by Service Bus, y en todo sistema de webhooks. Es el modelo natural para aplicaciones que reaccionan a eventos en tiempo real.
3. Definición Detallada¶
Propósito¶
El propósito de Event-Driven Consumer es eliminar la latencia entre la llegada de un mensaje y el inicio de su procesamiento, registrando un handler que el sistema de mensajería invoca automáticamente cuando un mensaje está disponible.
Lógica Arquitectónica¶
En un Event-Driven Consumer, el flujo de control se invierte respecto al Polling Consumer. En lugar de que la aplicación llame al broker (consumer.poll()), el broker llama a la aplicación (invoca el callback o listener registrado). Esto sigue el principio de Hollywood: "Don't call us, we'll call you".
Arquitectónicamente, el consumer se registra como listener en un canal específico y define un callback (método, función, handler) que se invocará para cada mensaje:
@KafkaListener(topics = "notifications.push")
public void handlePushNotification(PushNotificationEvent event) {
notificationService.sendPush(event);
}
El framework (Spring Kafka, MassTransit, AWS Lambda runtime) se encarga del poll loop subyacente, la deserialización, la invocación del handler, el manejo de errores y el commit de offsets. El desarrollador solo implementa la lógica de procesamiento.
Principio de Diseño Subyacente¶
El principio es Inversion of Control (IoC) aplicada a messaging. La aplicación no controla el flujo de recepción de mensajes; delega ese control al framework o al broker. La aplicación solo define qué hacer cuando un mensaje llega (el handler), no cuándo ni cómo obtenerlo.
Problema Estructural que Resuelve¶
En un Polling Consumer, la latencia entre la llegada del mensaje y su procesamiento depende de la frecuencia del poll y del estado del poll loop. Si el poll loop está procesando un batch anterior, el nuevo mensaje espera. Si el poll tiene un timeout largo, el mensaje espera.
Event-Driven Consumer elimina esta latencia porque el handler se invoca inmediatamente (o casi inmediatamente) cuando el mensaje está disponible. No hay loop de espera, no hay batching obligatorio, no hay timeout que retrasar.
Contexto en el que Emerge¶
Event-Driven Consumer emerge en escenarios donde:
- La latencia de procesamiento debe ser mínima (real-time processing).
- El consumidor procesa mensajes individualmente, no en batch.
- El desarrollador prefiere un modelo declarativo (anotar un método como listener) sobre un modelo imperativo (escribir un poll loop).
- Se usa un broker push-based (RabbitMQ) o un framework que abstrae el poll loop (Spring Kafka, MassTransit).
- La aplicación es serverless y la plataforma gestiona la infraestructura de consumo.
Por Qué No Es Trivial¶
El modelo event-driven parece más simple que polling, pero tiene sus propias complejidades:
- Concurrency management: si múltiples mensajes llegan simultáneamente, ¿se procesan en paralelo o en secuencia? ¿Cuántos threads concurrentes se permiten?
- Backpressure: si los mensajes llegan más rápido de lo que el consumidor puede procesar, ¿qué ocurre? Sin backpressure explícita, el consumidor se satura.
- Error handling: si el handler falla, ¿se reintenta automáticamente? ¿Cuántas veces? ¿Hay dead-letter queue?
- Ordering: si los mensajes deben procesarse en orden, la concurrencia debe ser controlada cuidadosamente.
- Resource management: cada invocación del handler consume recursos (threads, conexiones, memoria). Sin control, la concurrencia ilimitada puede agotar recursos.
Relación con Sistemas Distribuidos y Mensajería¶
Event-Driven Consumer es el modelo nativo de RabbitMQ y del ecosistema serverless:
- En RabbitMQ,
Channel.basicConsume(queue, callback)registra un callback que se invoca para cada mensaje entregado. Es push puro. - En Spring Kafka,
@KafkaListeneres un Event-Driven Consumer implementado sobre un Polling Consumer. Spring gestiona el poll loop internamente e invoca el método anotado para cada mensaje o batch. - En AWS Lambda + SQS/SNS/EventBridge, Lambda es un event-driven consumer serverless. AWS poll el source (SQS, DynamoDB Streams) e invoca la función con cada batch.
- En Azure Functions + Service Bus, Functions con trigger de Service Bus reciben mensajes automáticamente cuando llegan a la queue o subscription.
- En Webhooks, el sistema emisor invoca un endpoint HTTP del consumidor cuando un evento ocurre. Es event-driven consumer over HTTP.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Event-Driven Consumer, el consumidor debe implementar un poll loop explícito que consulte periódicamente al broker. Esto introduce:
- Latencia inherente: el mensaje espera hasta el siguiente ciclo de poll para ser procesado. Con poll intervals de 100ms, la latencia promedio es 50ms; con intervals de 1 segundo, es 500ms.
- Complejidad del poll loop: el desarrollador debe escribir y mantener el loop, manejar timeouts, commits, errores, shutdown, y concurrencia.
- Overhead de polling vacío: si los mensajes llegan esporádicamente, la mayoría de los polls son vacíos, desperdiciando CPU y conexiones.
Síntomas del Problema¶
- Latencia de procesamiento innecesariamente alta porque el poll interval no puede reducirse más sin impactar CPU.
- Código boilerplate del poll loop duplicado en múltiples consumers.
- Dificultad para nuevos desarrolladores que deben entender la mecánica del poll loop antes de poder implementar lógica de negocio.
- Inconsistencia en el manejo de errores y commits entre diferentes poll loops escritos por diferentes desarrolladores.
Impacto Operativo y Arquitectónico¶
Sin un modelo event-driven:
- Los equipos de desarrollo gastan tiempo significativo en la infraestructura del poll loop en lugar de en lógica de negocio.
- La latencia de procesamiento es un cuello de botella para escenarios real-time.
- La heterogeneidad de implementaciones de poll loops dificulta la estandarización y el monitoreo.
Riesgos Si No Se Implementa Correctamente¶
- Concurrency sin control: permitir concurrencia ilimitada en el handler puede saturar la base de datos, las APIs externas o la memoria.
- Thread pool exhaustion: si el handler bloquea (I/O lento, HTTP timeout largo), los threads se agotan y el consumer deja de procesar.
- Silent message loss: si el handler falla y no hay retry ni dead-letter, el mensaje se pierde silenciosamente.
- Ordering violations: procesar mensajes en paralelo sin considerar el orden requerido produce inconsistencias.
Ejemplos Reales¶
- Notificaciones push en tiempo real: cuando un usuario recibe un mensaje, un event-driven consumer escucha el topic de mensajes y dispara la notificación push inmediatamente.
- Detección de fraude: cada transacción financiera genera un evento que un consumer procesa inmediatamente para evaluar reglas de fraude antes de que la transacción se complete.
- Actualización de caché: cuando un recurso cambia, un consumer actualiza la caché distribuida inmediatamente para evitar reads stale.
- AWS Lambda triggered by SQS: un archivo se sube a S3, genera un evento en SQS, y Lambda se activa automáticamente para procesarlo.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando la latencia de procesamiento debe ser mínima (near-real-time).
- Cuando el procesamiento es por mensaje individual, no por batch.
- Cuando se prefiere un modelo declarativo (listener annotation) sobre imperativo (poll loop).
- Cuando se usa un framework que abstrae el poll loop (Spring Kafka, MassTransit, NServiceBus).
- En arquitecturas serverless donde la plataforma gestiona el consumo (Lambda, Azure Functions, Cloud Functions).
- Cuando el procesamiento del mensaje es relativamente rápido y no necesita control de ritmo.
Cuándo No Usarlo¶
- Cuando se necesita batch processing eficiente (acumular N mensajes y procesarlos juntos).
- Cuando el consumidor necesita control explícito del ritmo de consumo (rate limiting, resource-aware processing).
- Cuando el procesamiento es costoso y la concurrencia debe controlarse finamente (el poll loop ofrece más control).
- Cuando se necesita procesamiento por ventanas de tiempo (time-windowed aggregation).
Precondiciones¶
- Un framework o plataforma que proporcione el mecanismo de listener/callback (Spring, MassTransit, Lambda, Azure Functions).
- El broker o la plataforma gestionan la entrega de mensajes al handler.
- El handler puede procesar mensajes de forma independiente (sin dependencias entre mensajes consecutivos, salvo cuando el framework garantiza orden).
Restricciones¶
- El control de backpressure es menos explícito que en Polling Consumer. Se gestiona a través de la configuración de concurrencia del listener container.
- El procesamiento concurrente requiere que los handlers sean thread-safe.
- En Kafka, el
@KafkaListenersigue siendo un poll loop internamente, pero con semántica push hacia el handler.
Dependencias¶
- Framework de messaging (Spring Kafka, Spring AMQP, MassTransit, NServiceBus, Lambda runtime).
- Configuración de concurrencia y error handling del listener container.
- Mecanismo de acknowledgment (auto-ack, manual ack).
Supuestos Arquitectónicos¶
- El procesamiento de cada mensaje es suficientemente rápido para mantener el throughput requerido.
- Los handlers son thread-safe si la concurrencia está habilitada.
- El framework maneja correctamente el lifecycle del consumer (connection, session, subscription).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Servicios de notificaciones en tiempo real.
- Sistemas de detección de fraude.
- Microservicios event-driven con Spring Boot.
- Aplicaciones serverless (Lambda, Functions, Cloud Functions).
- Sistemas de procesamiento de webhooks.
- Actualizadores de caché distribuida.
- Aplicaciones de chat y comunicación en tiempo real.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Event-Driven Consumer desacopla la lógica de procesamiento de la mecánica de consumo. El handler solo contiene lógica de negocio; el framework se encarga de la mecánica. Esto proporciona flexibilidad para cambiar la configuración de consumo (concurrencia, retries, error handling) sin modificar el handler.
Simplicidad vs. Robustez¶
El modelo declarativo (@KafkaListener) es extraordinariamente simple para el desarrollador: anotar un método y la magia ocurre. Pero la robustez depende de la configuración correcta del framework: error handling, retry policy, dead-letter topic, concurrency, ack mode. Sin esta configuración, el consumer es frágil.
Latencia vs. Eficiencia¶
Event-Driven Consumer minimiza la latencia al procesar mensajes inmediatamente. Pero el procesamiento individual de cada mensaje puede ser menos eficiente que batch processing para operaciones con overhead fijo (queries de DB, transacciones, llamadas a APIs).
Concurrencia vs. Orden¶
Aumentar la concurrencia del listener mejora el throughput pero puede violar el orden de procesamiento. Para preservar el orden, la concurrencia debe limitarse a una instancia por partición (en Kafka) o por session (en Service Bus).
Control vs. Conveniencia¶
El Event-Driven Consumer delega el control del poll loop al framework. Esto es conveniente pero reduce la capacidad de ajuste fino. El Polling Consumer ofrece más control pero más complejidad.
Escalabilidad vs. Predictibilidad¶
La concurrencia configurable permite escalar el procesamiento, pero la carga variable puede hacer impredecible el uso de recursos. En serverless (Lambda), la escalabilidad es automática pero el costo es proporcional a las invocaciones.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Message Handler: el método o función que contiene la lógica de procesamiento de negocio.
- Listener Container: el componente del framework que gestiona el lifecycle del consumer, el poll loop subyacente y la invocación del handler.
- Message Channel: el topic, queue o subscription del que se reciben mensajes.
- Broker: el sistema de mensajería que almacena y entrega los mensajes.
- Error Handler: el componente que gestiona fallos del handler (retry, dead-letter, skip).
Flujo Lógico¶
flowchart TD
A([Application Startup]) -->|Registra handler como listener| B[Listener Container]
B -->|Inicia conexión con broker| C[(Broker)]
C -->|Entrega mensaje push/pull| D[Deserializa el mensaje]
D -->|Mensaje deserializado| E[Invoca handler]
E --> F[Handler ejecuta lógica de negocio]
F --> G{Handler exitoso?}
G -->|Sí| H([Acknowledge mensaje])
G -->|No| I[Error Handler]
I -->|Según configuración| J{Estrategia}
J -->|Retry| E
J -->|Dead-letter| K([Envía a dead-letter queue])
J -->|Skip| L([Descarta mensaje])
H --> CResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Handler | Ejecutar la lógica de negocio para cada mensaje |
| Listener Container | Gestionar lifecycle, deserialización, invocación, acknowledgment, error handling |
| Broker | Entregar mensajes al consumer |
| Error Handler | Gestionar fallos: retry con backoff, dead-letter, logging |
Interacciones¶
- Framework → Handler: invocación del método handler con el mensaje deserializado.
- Framework → Broker: acknowledgment del mensaje tras procesamiento exitoso.
- Framework → Error Handler: invocación cuando el handler lanza excepción.
- Error Handler → Broker: publicación en dead-letter topic/queue si los retries se agotan.
Contratos Implícitos¶
- El handler recibe un objeto deserializado del tipo esperado.
- El framework acknowledges automáticamente si el handler retorna sin excepción.
- Si el handler lanza una excepción, el framework aplica la política de error configurada.
- El handler es thread-safe si la concurrencia está habilitada.
Decisiones de Diseño Clave¶
- Concurrency level: número de threads que procesan mensajes simultáneamente. Impacta throughput vs. ordering vs. resource usage.
- Ack mode: auto-ack (después de entrega), manual (después de procesamiento explícito), transactional (dentro de una transacción). Impacta durabilidad.
- Error handling strategy: retry count, backoff interval, dead-letter destination, skip policy.
- Listener scope: un listener por tipo de mensaje, un listener genérico que routea internamente, o listeners agrupados por dominio.
- Batch vs. individual: algunos frameworks permiten batch listeners que reciben un lote de mensajes a la vez.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Notificaciones en Tiempo Real — Push Notifications para Transacciones Bancarias¶
Contexto del Negocio¶
Un banco digital envía notificaciones push a sus clientes cada vez que ocurre una transacción en su cuenta: cargo, abono, transferencia recibida, pago con tarjeta. El banco tiene 3 millones de clientes activos y procesa 5 millones de transacciones diarias. La latencia entre la transacción y la notificación push debe ser menor a 2 segundos.
Necesidad de Integración¶
El Transaction Service publica eventos de transacción en Kafka. El Notification Service debe consumir estos eventos y enviar notificaciones push inmediatamente a través de Firebase Cloud Messaging (FCM) para Android y Apple Push Notification Service (APNS) para iOS.
Sistemas Involucrados¶
- Transaction Service: publica
TransactionCompletedevents en Kafka. - Apache Kafka: topic
banking.transactions.completedcon 32 particiones. - Notification Service: microservicio Spring Boot con
@KafkaListenerque consume eventos y envía push notifications. - Firebase Cloud Messaging (FCM): servicio de Google para push notifications en Android.
- Apple Push Notification Service (APNS): servicio de Apple para push notifications en iOS.
- PostgreSQL: base de datos de preferencias de notificación del usuario (canales habilitados, device tokens, quiet hours).
Restricciones Técnicas¶
- Latencia end-to-end (transacción → push notification) menor a 2 segundos.
- Throughput promedio: 58 transacciones/segundo (5M/día). Pico: 500 transacciones/segundo.
- Cada notificación requiere consultar las preferencias del usuario y sus device tokens.
- FCM y APNS tienen rate limits propios que deben respetarse.
- Las notificaciones durante "quiet hours" del usuario deben encolarse, no enviarse.
Flujos de Datos¶
Transaction Service → Kafka (banking.transactions.completed)
→ [Notification Service @KafkaListener]
→ Consulta preferencias de usuario
→ Render notification template
→ FCM (Android) / APNS (iOS)
→ Push notification al dispositivo del cliente
Decisiones Arquitectónicas¶
- Event-Driven Consumer: se usa
@KafkaListenerpara latencia mínima. No hay necesidad de batch processing — cada transacción genera una notificación individual. - Concurrency = 8: 8 threads concurrentes procesan mensajes en paralelo para mantener el throughput durante picos.
- Manual ack mode: el mensaje se acknowledges solo después de que la notificación se envía exitosamente.
- Retry con backoff: si FCM/APNS falla, se reintenta 3 veces con backoff exponencial antes de enviar a dead-letter topic.
- Async push sending: las llamadas a FCM/APNS se hacen de forma asíncrona (non-blocking HTTP) para no bloquear los threads del listener.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Definición del Handler¶
@Component
public class TransactionNotificationHandler {
private final NotificationPreferenceService preferenceService;
private final NotificationTemplateEngine templateEngine;
private final PushNotificationSender pushSender;
private final MeterRegistry metrics;
@KafkaListener(
topics = "banking.transactions.completed",
groupId = "notification-service",
concurrency = "8",
containerFactory = "kafkaListenerContainerFactory"
)
public void handleTransactionCompleted(
@Payload TransactionCompletedEvent event,
@Header(KafkaHeaders.RECEIVED_KEY) String accountId,
Acknowledgment ack) {
Timer.Sample timer = Timer.start(metrics);
try {
// 1. Consultar preferencias del usuario
NotificationPreference prefs =
preferenceService.getByAccountId(accountId);
if (!prefs.isPushEnabled()) {
ack.acknowledge();
return;
}
if (prefs.isQuietHoursActive()) {
// Encolar para envío posterior
queueForLater(event, prefs);
ack.acknowledge();
return;
}
// 2. Render notification
PushNotification notification =
templateEngine.render(event, prefs.getLocale());
// 3. Enviar push notification
pushSender.send(prefs.getDeviceTokens(), notification);
// 4. Acknowledge solo después de envío exitoso
ack.acknowledge();
timer.stop(metrics.timer("notification.processing.duration"));
} catch (Exception e) {
// No acknowledge — el framework aplicará retry policy
throw e;
}
}
}
Paso 2: Configuración del Listener Container¶
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConcurrentKafkaListenerContainerFactory<String, TransactionCompletedEvent>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, TransactionCompletedEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(
ContainerProperties.AckMode.MANUAL_IMMEDIATE);
factory.setCommonErrorHandler(errorHandler());
factory.setConcurrency(8);
return factory;
}
@Bean
public DefaultErrorHandler errorHandler() {
// Retry 3 veces con backoff exponencial, luego dead-letter
BackOff backOff = new ExponentialBackOff(1000L, 2.0);
((ExponentialBackOff) backOff).setMaxElapsedTime(30000L);
DeadLetterPublishingRecoverer recoverer =
new DeadLetterPublishingRecoverer(kafkaTemplate);
return new DefaultErrorHandler(recoverer, backOff);
}
}
Paso 3: Push Notification Sender (Async)¶
@Component
public class PushNotificationSender {
private final FirebaseMessaging fcm;
private final ApnsClient apns;
public CompletableFuture<Void> send(
List<DeviceToken> tokens, PushNotification notification) {
List<CompletableFuture<Void>> futures = tokens.stream()
.map(token -> {
if (token.isAndroid()) {
return sendFcm(token, notification);
} else {
return sendApns(token, notification);
}
})
.toList();
return CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
}
}
Paso 4: Monitoreo de Latencia End-to-End¶
@KafkaListener(topics = "banking.transactions.completed", ...)
public void handleTransactionCompleted(
@Payload TransactionCompletedEvent event,
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long kafkaTimestamp,
Acknowledgment ack) {
long latencyMs = System.currentTimeMillis() - kafkaTimestamp;
metrics.timer("notification.e2e.latency").record(latencyMs, TimeUnit.MILLISECONDS);
if (latencyMs > 2000) {
log.warn("SLA breach: notification latency {}ms for tx {}",
latencyMs, event.getTransactionId());
}
// ... procesamiento
}
Paso 5: Scaling y Performance Tuning¶
Con 8 threads concurrentes y 32 particiones, Kafka asigna 4 particiones por thread. Si el throughput no es suficiente, se puede:
- Aumentar
concurrencya 16 o 32 (hasta el número de particiones). - Desplegar múltiples instancias del Notification Service en el mismo consumer group.
- Optimizar el handler: caché de preferencias de usuario, batching de llamadas a FCM.
Manejo de Errores¶
- FCM/APNS timeout: retry 3 veces con backoff. Si falla después de 3 intentos, el mensaje va a dead-letter topic.
- Device token inválido: FCM/APNS retorna error específico. Se desregistra el token y no se reintenta.
- Base de datos no disponible: si no se pueden consultar las preferencias, el handler falla y el framework reintenta.
- Quiet hours: no es un error. El mensaje se acknowledges y la notificación se encola para envío posterior.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.language import Java
from diagrams.onprem.queue import Kafka
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.compute import Rack
from diagrams.saas.communication import Twilio
from diagrams.programming.framework import Spring
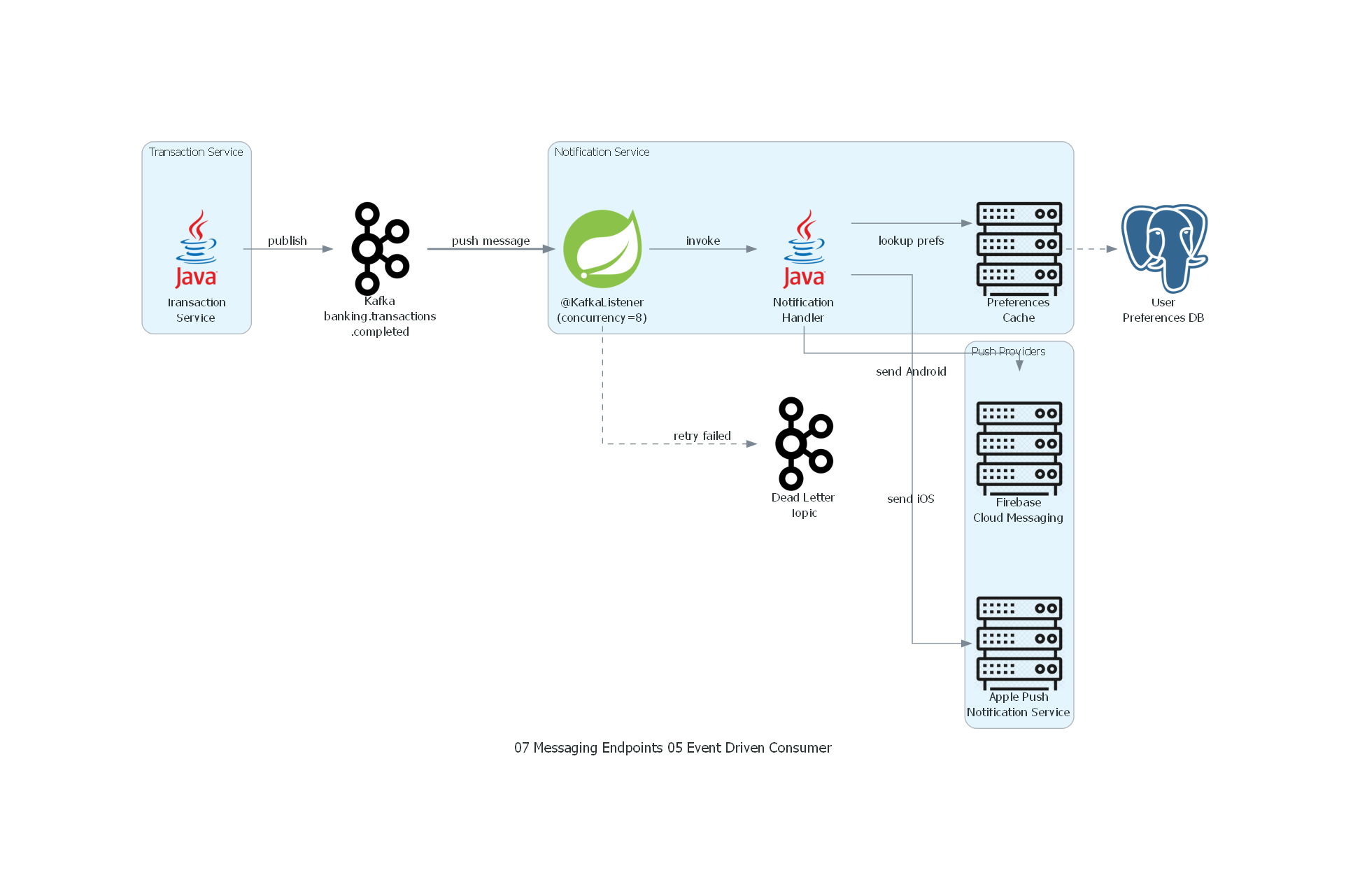
with Diagram("Event-Driven Consumer - Push Notifications", show=False, direction="LR"):
with Cluster("Transaction Service"):
tx_service = Java("Transaction\nService")
kafka = Kafka("Kafka\nbanking.transactions\n.completed")
dlt = Kafka("Dead Letter\nTopic")
with Cluster("Notification Service"):
listener = Spring("@KafkaListener\n(concurrency=8)")
handler = Java("Notification\nHandler")
prefs_cache = Rack("Preferences\nCache")
with Cluster("Push Providers"):
fcm = Rack("Firebase\nCloud Messaging")
apns = Rack("Apple Push\nNotification Service")
db = PostgreSQL("User\nPreferences DB")
tx_service >> Edge(label="publish") >> kafka
kafka >> Edge(label="push message", style="bold") >> listener
listener >> Edge(label="invoke") >> handler
handler >> Edge(label="lookup prefs") >> prefs_cache
prefs_cache >> Edge(style="dashed") >> db
handler >> Edge(label="send Android") >> fcm
handler >> Edge(label="send iOS") >> apns
listener >> Edge(label="retry failed", style="dashed") >> dlt
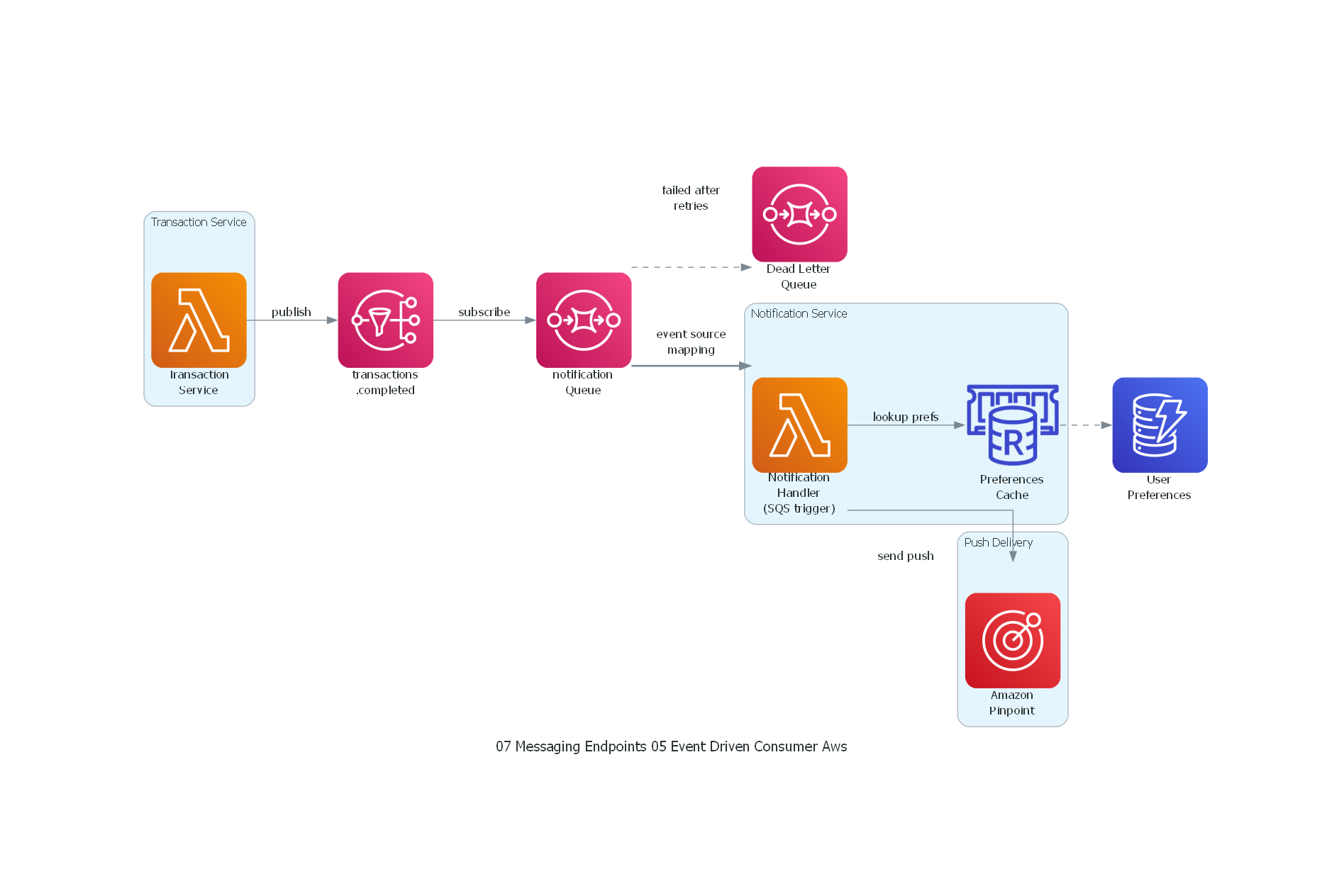
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb, ElasticacheForRedis
from diagrams.aws.integration import SQS, SNS
from diagrams.aws.mobile import Pinpoint
with Diagram("Event-Driven Consumer - Push Notifications (AWS)", show=False, direction="LR"):
with Cluster("Transaction Service"):
tx_service = Lambda("Transaction\nService")
topic = SNS("transactions\n.completed")
queue = SQS("notification\nQueue")
dlq = SQS("Dead Letter\nQueue")
with Cluster("Notification Service"):
handler = Lambda("Notification\nHandler\n(SQS trigger)")
prefs_cache = ElasticacheForRedis("Preferences\nCache")
with Cluster("Push Delivery"):
pinpoint = Pinpoint("Amazon\nPinpoint")
db = Dynamodb("User\nPreferences")
tx_service >> Edge(label="publish") >> topic
topic >> Edge(label="subscribe") >> queue
queue >> Edge(label="event source\nmapping", style="bold") >> handler
handler >> Edge(label="lookup prefs") >> prefs_cache
prefs_cache >> Edge(style="dashed") >> db
handler >> Edge(label="send push") >> pinpoint
queue >> Edge(label="failed after\nretries", style="dashed") >> dlq
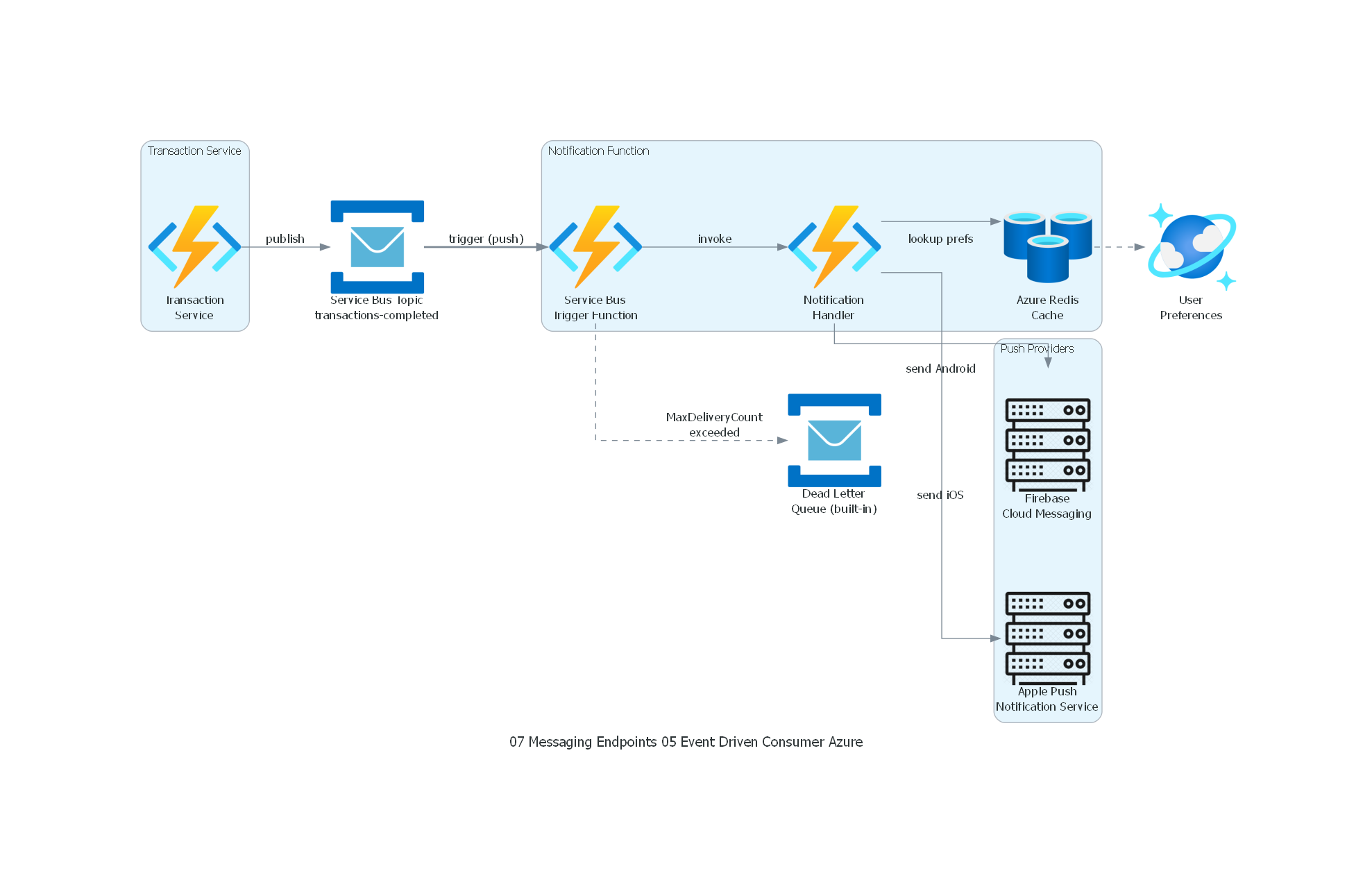
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis, CosmosDb
from diagrams.azure.integration import ServiceBus
from diagrams.generic.compute import Rack
with Diagram("Event-Driven Consumer - Push Notifications (Azure)", show=False, direction="LR"):
with Cluster("Transaction Service"):
tx_service = FunctionApps("Transaction\nService")
topic = ServiceBus("Service Bus Topic\ntransactions-completed")
dlq = ServiceBus("Dead Letter\nQueue (built-in)")
with Cluster("Notification Function"):
listener = FunctionApps("Service Bus\nTrigger Function")
handler = FunctionApps("Notification\nHandler")
prefs_cache = CacheForRedis("Azure Redis\nCache")
with Cluster("Push Providers"):
fcm = Rack("Firebase\nCloud Messaging")
apns = Rack("Apple Push\nNotification Service")
db = CosmosDb("User\nPreferences")
tx_service >> Edge(label="publish") >> topic
topic >> Edge(label="trigger (push)", style="bold") >> listener
listener >> Edge(label="invoke") >> handler
handler >> Edge(label="lookup prefs") >> prefs_cache
prefs_cache >> Edge(style="dashed") >> db
handler >> Edge(label="send Android") >> fcm
handler >> Edge(label="send iOS") >> apns
listener >> Edge(label="MaxDeliveryCount\nexceeded", style="dashed") >> dlq
Explicación del Diagrama¶
- Transaction Service publica eventos de transacciones completadas en Kafka.
- Kafka entrega mensajes al
@KafkaListenerdel Notification Service (push semántico desde la perspectiva del handler). - Listener Container (8 threads concurrentes) deserializa y distribuye a los handlers.
- Handler consulta preferencias del usuario (con caché), renderiza la notificación, y envía a FCM o APNS.
- Dead Letter Topic recibe mensajes que fallaron después de los retries configurados.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Event-Driven Consumer | @KafkaListener (concurrency=8) |
| Message Handler | Notification Handler |
| Push delivery | Kafka → Listener Container → Handler |
| Error Handler | Retry → Dead Letter Topic |
| Message Channel | Kafka topic banking.transactions.completed |
11. Beneficios¶
Impacto Técnico¶
- Latencia mínima: el mensaje se procesa inmediatamente al ser entregado. No hay delay de poll interval.
- Simplicidad de código: el desarrollador escribe un método anotado, no un poll loop completo. El framework gestiona lifecycle, deserialización, concurrencia, commits y errores.
- Concurrency configurable: la concurrencia se ajusta mediante configuración, sin cambios en el código del handler.
- Error handling declarativo: retry policies, dead-letter destinations y backoff se configuran declarativamente.
Impacto Organizacional¶
- Productividad: los desarrolladores se concentran en la lógica de negocio del handler, no en la mecánica de consumo.
- Estandarización: todos los consumers del equipo siguen el mismo patrón (listener annotation + handler method), facilitando revisión de código y onboarding.
- Consistencia: el framework aplica las mismas políticas de error handling, ack mode y concurrency a todos los consumers.
Impacto Operacional¶
- Observabilidad integrada: los frameworks modernos proporcionan métricas de consumer (latencia, throughput, errores) out-of-the-box.
- Scaling declarativo: aumentar la concurrencia o el número de instancias no requiere cambios de código.
Beneficios de Mantenibilidad y Evolución¶
- Evolución de policies: cambiar la retry policy o el error handling se hace en la configuración del factory, no en el código de cada handler.
- Nuevo consumer: añadir un nuevo consumer es anotar un nuevo método, no escribir un nuevo poll loop.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Framework magic: el comportamiento del consumer depende de la configuración del framework, que puede ser opaca. Debugar por qué un mensaje no se procesa requiere entender internamente cómo funciona el listener container.
- Configuration complexity: la cantidad de propiedades configurables del listener container es significativa: ack mode, concurrency, error handler, retry template, container type, idle event interval, etc.
Riesgos de Mal Uso¶
- Concurrency excesiva: configurar demasiados threads sin considerar los recursos downstream (base de datos, APIs) puede saturar esos recursos.
- Handlers que bloquean: un handler que hace I/O síncrono lento (HTTP calls con timeout largo, DB queries lentos) bloquea el thread del listener y reduce el throughput.
- Auto-ack con processing failure: si el ack mode es "automático tras entrega" y el handler falla, el mensaje se pierde.
- Ignorar ordering: procesar en paralelo mensajes que requieren orden por clave produce inconsistencias.
Sobreingeniería¶
- Implementar un listener container propio cuando Spring Kafka o MassTransit proporcionan uno robusto y probado.
- Crear abstracciones adicionales sobre
@KafkaListenerque ocultan la configuración sin añadir valor.
Costos de Operación¶
- Los rebalances en Kafka afectan a todos los listeners del consumer group, causando pausas de procesamiento.
- El monitoring del listener container requiere entender las métricas específicas del framework.
Anti-Patterns Relacionados¶
- Fire-and-Forget Handler: un handler que no maneja excepciones, permitiendo que mensajes se pierdan silenciosamente.
- Thread-Unsafe Handler: un handler con estado mutable compartido que produce race conditions cuando la concurrencia está habilitada.
- Slow Handler: un handler que bloquea durante segundos (HTTP timeout, DB lock wait) reduciendo drásticamente el throughput.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Competing Consumers: múltiples instancias del event-driven consumer en el mismo consumer group compiten por mensajes. Cada instancia tiene su propio listener container.
- Messaging Gateway: el gateway del lado consumidor puede usar internamente un event-driven consumer para recibir mensajes y entregar objetos de dominio al handler.
- Idempotent Receiver: necesario cuando el framework entrega at-least-once (retries, rebalances). El handler debe ser idempotente.
Patrones que Suelen Aparecer Antes o Después¶
- Service Activator: es la generalización del Event-Driven Consumer. El message handler "activa" un servicio de negocio en respuesta al mensaje.
- Message Dispatcher: si el listener recibe múltiples tipos de mensajes, un dispatcher los dirige al handler correcto.
Combinaciones Comunes¶
- Event-Driven Consumer + Competing Consumers: múltiples instancias con listeners concurrentes para throughput horizontal.
- Event-Driven Consumer + Dead Letter Channel: retry policy con fallback a dead-letter para mensajes problemáticos.
- Event-Driven Consumer + Idempotent Receiver: idempotencia en el handler para manejar redeliveries.
Diferencias con Patrones Similares¶
- vs. Polling Consumer: Event-Driven Consumer es push-based (el framework entrega mensajes al handler); Polling Consumer es pull-based (la aplicación solicita mensajes explícitamente). Event-Driven optimiza latencia; Polling optimiza control.
- vs. Service Activator: Service Activator es el patrón general de activar lógica de negocio en respuesta a un mensaje. Event-Driven Consumer es el mecanismo de recepción que puede alimentar un Service Activator.
Encaje en un Flujo Mayor de Integración¶
Event-Driven Consumer es el mecanismo de recepción estándar en microservicios event-driven modernos. Es el punto de entrada de mensajes en un servicio, donde los eventos del broker se convierten en invocaciones de lógica de negocio. En una cadena de microservicios event-driven, cada servicio tiene event-driven consumers que reciben eventos, procesan lógica de negocio, y publican nuevos eventos (a través de Messaging Gateway).
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Event-Driven Consumer es el modelo predominante de consumo en la mayoría de las aplicaciones modernas, gracias a los frameworks que lo implementan como abstracción de primera clase.
A favor de la vigencia:
@KafkaListenerde Spring Kafka es la forma estándar de consumir mensajes de Kafka en el ecosistema Spring. Es un Event-Driven Consumer por definición.- AWS Lambda triggered by SQS/SNS/EventBridge es un event-driven consumer serverless que ha escalado masivamente.
- Azure Functions con triggers de Service Bus, Event Hubs y Cosmos DB Change Feed son event-driven consumers gestionados.
- MassTransit y NServiceBus en .NET operan con modelo event-driven (consumers registrados que reciben mensajes automáticamente).
- El modelo de webhooks (HTTP POST al consumer cuando ocurre un evento) es event-driven consumer sobre HTTP.
Matiz importante:
- En Kafka, el event-driven consumer (
@KafkaListener) es internamente un polling consumer. El framework ejecuta el poll loop y abstrae la semántica a push-based. Comprender ambos patrones es necesario para configurar y operar correctamente.
Cómo Se Implementa Hoy¶
- Spring Kafka:
@KafkaListenerconConcurrentKafkaListenerContainerFactory. - Spring AMQP:
@RabbitListenerpara RabbitMQ consumers. - MassTransit:
IConsumer<T>que recibe mensajes automáticamente. - AWS Lambda: event source mapping que invoca funciones con batches de mensajes.
- Azure Functions: trigger bindings que invocan funciones cuando llegan mensajes.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka (via Spring Kafka)¶
@KafkaListener con ConcurrentKafkaListenerContainerFactory proporciona consumo event-driven sobre Kafka. Internamente ejecuta un poll loop pero expone semántica push al desarrollador. Configuración clave: concurrency (threads), AckMode (MANUAL, RECORD, BATCH), ErrorHandler (retry + dead-letter), batch (individual vs. batch listener).
RabbitMQ (via Spring AMQP)¶
@RabbitListener proporciona consumo push nativo. RabbitMQ es inherentemente push-based (basicConsume). Configuración de prefetch controla cuántos mensajes no-acked puede tener el consumer simultáneamente, proporcionando backpressure.
AWS Lambda + SQS/SNS¶
Lambda con SQS event source mapping es un event-driven consumer fully managed. AWS gestiona el polling, batching, invocación, retry y dead-letter. Configuración clave: batchSize, maximumBatchingWindowInSeconds, functionResponseTypes (para partial batch failure reporting), maxConcurrency.
Azure Functions + Service Bus¶
Azure Functions con Service Bus trigger reciben mensajes automáticamente. Configuración en host.json: maxConcurrentCalls, maxAutoLockRenewalDuration, autoCompleteMessages. Para scaling: KEDA-based autoscaling en Kubernetes, o consumption plan en Azure.
MassTransit (.NET)¶
IConsumer<TMessage> se registra en el DI container y MassTransit gestiona la recepción, deserialización, invocación, retry y dead-letter. Configuración de ConcurrentMessageLimit, UseMessageRetry, UseInMemoryOutbox.
Apache Camel¶
Las rutas Camel con from("kafka:topic") o from("rabbitmq:queue") son event-driven consumers. Cada mensaje que llega activa la ruta de procesamiento. Camel gestiona conexión, deserialización y error handling.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: mensajes procesados/segundo, latencia de procesamiento (p50, p95, p99), tasa de errores, mensajes en dead-letter, concurrency utilizada, consumer lag.
- Health checks: listener container activo, consumer registrado en el grupo, particiones asignadas.
- Alertas: tasa de errores supera umbral, latencia degrada, consumer removido del grupo (rebalance), dead-letter topic creciendo.
Tracing¶
- El listener container debe extraer el trace ID del header del mensaje y establecerlo como parent span.
- Cada invocación del handler produce un span que se asocia al trace del mensaje.
- Los frameworks modernos (Spring Cloud Sleuth/Micrometer Tracing, OpenTelemetry) proporcionan instrumentación automática.
Monitoreo¶
- Dashboard por consumer: throughput, latencia, errores, concurrency, lag.
- Dashboard por topic: producción vs. consumo, lag por partición, rebalance events.
Versionado¶
- El handler debe manejar múltiples versiones de mensajes si el schema evoluciona.
- Los frameworks soportan custom deserializers que manejan versiones diferentes.
Seguridad¶
- Las credenciales del broker se configuran en el consumer factory.
- SSL/TLS y SASL para comunicación con el broker.
- Los handlers no deben exponer datos sensibles en logs.
Manejo de Errores¶
- Retry automático: configurar retry policy con backoff exponencial. Spring Kafka
DefaultErrorHandlersoportaExponentialBackOff. - Dead-letter topic/queue: mensajes que fallan después de N retries se envían a DLT para inspección posterior.
- Poison pill handling: mensajes que no pueden deserializarse se envían a DLT sin pasar por el handler.
Retries¶
- Retries dentro del listener container (framework-managed) vs. retries por redelivery del broker (nack/reject en RabbitMQ).
- Exponential backoff evita saturar recursos durante fallos transitorios.
Idempotencia¶
- Los handlers deben ser idempotentes porque los mensajes pueden reentregarse (retry, rebalance, duplicados del productor).
- Deduplication por message ID o idempotency key en el handler.
Performance¶
- Thread pool sizing: el número de threads del listener debe balancear throughput vs. presión sobre recursos downstream.
- Non-blocking I/O: los handlers que hacen HTTP calls deben usar clients asíncronos para no bloquear threads del listener.
- Caching: datos frecuentemente consultados (preferencias de usuario, configuraciones) deben cachearse para reducir latencia del handler.
Escalabilidad¶
- En Kafka: añadir instancias del servicio al consumer group (hasta el número de particiones).
- En RabbitMQ: añadir consumidores a la queue (scaling horizontal natural).
- En Lambda: la concurrencia se escala automáticamente hasta el límite configurado.
17. Errores Comunes¶
Handler que Bloquea con I/O Síncrono¶
Un handler que ejecuta HTTP calls síncronos con timeout de 30 segundos bloquea el thread del listener. Con 8 threads y 8 requests lentos simultáneos, todo el consumer se detiene. La solución es usar non-blocking I/O o aumentar la concurrencia con awareness del impacto.
Auto-Acknowledge sin Control de Errores¶
Configurar AckMode.RECORD (auto-ack after delivery) sin error handler significa que si el handler falla, el mensaje se acknowledges de todas formas y se pierde. Para procesamiento crítico, siempre usar AckMode.MANUAL o configurar un error handler con retry + dead-letter.
Concurrency que Viola Ordering¶
Configurar concurrency = 16 con 4 particiones en Kafka resulta en que múltiples threads procesan la misma partición, violando el orden. La concurrencia no debe exceder el número de particiones si el orden es importante.
Ignorar Rebalances¶
En Kafka, los rebalances causan que particiones se reasignen entre consumers. Si un handler está procesando un mensaje cuando ocurre un rebalance, el procesamiento puede perderse. Implementar ConsumerRebalanceListener para manejar la revocación de particiones.
Handler con Estado Mutable¶
Un handler que mantiene estado en variables de instancia (contador, buffer, caché local mutable) sin sincronización produce race conditions cuando la concurrencia está habilitada. Los handlers deben ser stateless o usar synchronized/atomic correctamente.
No Configurar Dead-Letter¶
Sin dead-letter topic/queue, los mensajes que fallan permanentemente se reintentan infinitamente (si hay retry) o se pierden silenciosamente (si no hay retry). Siempre configurar dead-letter como fallback final.
18. Conclusión Técnica¶
Event-Driven Consumer es el modelo predominante de consumo de mensajes en aplicaciones modernas, gracias a los frameworks que abstraen la complejidad del poll loop y exponen una interfaz declarativa simple: anotar un método y recibir mensajes automáticamente.
Para un arquitecto de sistemas modernos, las directrices son:
- Usar Event-Driven Consumer como modelo por defecto para consumo de mensajes en microservicios. El modelo declarativo es más productivo y menos propenso a errores que un poll loop manual.
- Configurar error handling explícitamente: retry con backoff exponencial y dead-letter topic como fallback. Nunca dejar el error handling en defaults implícitos.
- Dimensionar la concurrencia según la capacidad de los recursos downstream (DB, APIs, brokers), no según la tasa de producción de mensajes.
- Implementar handlers idempotentes: los mensajes pueden reentregarse por retries, rebalances o duplicados del productor.
- Comprender el mecanismo subyacente: en Kafka,
@KafkaListeneres un poll loop abstraído. Configurar correctamentemax.poll.interval.ms,max.poll.recordsysession.timeout.msrequiere entender el polling subyacente. - Monitorear latencia end-to-end: la latencia desde la producción del evento hasta la finalización del procesamiento es la métrica que el negocio entiende (SLA de 2 segundos para notificaciones).
En el contexto de notificaciones bancarias del ejemplo, el Event-Driven Consumer permite enviar push notifications a 3 millones de clientes con latencia sub-segundo en condiciones normales. El handler es simple (consultar preferencias, renderizar, enviar), la concurrencia es configurable (8 threads para throughput normal, escalable a 32 para picos), y los fallos se manejan declarativamente (retry + dead-letter). El desarrollador se concentra en la lógica de notificación, no en la mecánica de consumo de Kafka.