Competing Consumers¶
1. Nombre del Patrón¶
- Nombre oficial: Competing Consumers
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Consumidores Competidores
2. Resumen Ejecutivo¶
Competing Consumers es un patrón en el que múltiples consumidores están conectados al mismo canal de mensajes y compiten por procesar cada mensaje. Cuando un mensaje llega al canal, exactamente uno de los consumidores lo recibe y lo procesa. Los demás consumidores no ven ese mensaje. El efecto es la distribución de carga de trabajo entre múltiples instancias de procesamiento para lograr escalabilidad horizontal y paralelismo.
El problema que resuelve es fundamental para cualquier sistema que necesite procesar alto volumen de mensajes: un solo consumidor tiene un límite de throughput determinado por su capacidad de CPU, I/O, red y recursos downstream. Cuando el volumen de mensajes supera esa capacidad, el consumer lag crece indefinidamente y los mensajes se procesan con latencia creciente. Competing Consumers resuelve esto distribuyendo la carga entre N instancias que procesan en paralelo.
Aparece en toda arquitectura que necesite escalabilidad horizontal de procesamiento de mensajes. En Kafka, se materializa como Consumer Groups donde cada instancia del consumidor es un miembro del grupo y Kafka asigna particiones entre los miembros. En SQS, múltiples consumidores (o Lambdas) compiten naturalmente por mensajes de la misma queue. En RabbitMQ, múltiples consumidores registrados en la misma queue reciben mensajes de forma round-robin. Es el mecanismo fundamental de scaling out del procesamiento de mensajes.
3. Definición Detallada¶
Propósito¶
El propósito de Competing Consumers es escalar horizontalmente la capacidad de procesamiento de mensajes añadiendo más instancias de consumidor al mismo canal, de modo que la carga se distribuya automáticamente entre ellas.
Lógica Arquitectónica¶
Competing Consumers implementa el principio de paralelismo a nivel de mensaje (o de partición). En lugar de que un único consumidor procese todos los mensajes secuencialmente, múltiples consumidores procesan subconjuntos de mensajes en paralelo. El throughput total del sistema es aproximadamente N veces el throughput de un consumidor individual (menos overhead de coordinación).
El mecanismo de distribución depende del broker:
- Kafka (Consumer Groups): el broker asigna particiones a los miembros del consumer group. Cada partición la procesa exactamente un miembro. Si hay 12 particiones y 3 consumidores, cada uno procesa 4 particiones.
- RabbitMQ: los mensajes se distribuyen round-robin entre los consumidores registrados en la queue. No hay particiones; cada mensaje va a un solo consumidor.
- SQS: cuando múltiples consumidores invocan
ReceiveMessage, SQS distribuye mensajes entre ellos. Con Lambda, AWS gestiona la concurrencia automáticamente. - Azure Service Bus: múltiples receivers en la misma queue compiten por mensajes. Con Sessions, los mensajes de una misma sesión van al mismo receiver.
Principio de Diseño Subyacente¶
El principio es scale-out por distribución de trabajo. Es el mismo principio que el load balancing en web servers: cuando un servidor no es suficiente, se añaden más servidores detrás de un load balancer. En messaging, el "load balancer" es el broker o el protocolo del consumer group.
Problema Estructural que Resuelve¶
Sin Competing Consumers, el throughput de procesamiento está limitado por la capacidad de un solo consumidor. Si un consumidor procesa 100 mensajes/segundo y la tasa de producción es 500 mensajes/segundo, el consumer lag crece a 400 mensajes/segundo. Después de una hora, hay 1.44 millones de mensajes pendientes. No hay forma de resolver esto con un solo consumidor — se necesitan al menos 5 consumidores procesando en paralelo.
Contexto en el que Emerge¶
Competing Consumers emerge cuando:
- El volumen de mensajes supera la capacidad de un solo consumidor.
- Se necesita resiliencia: si un consumidor falla, los demás continúan procesando.
- Se necesita reducir la latencia de procesamiento distribuyendo la carga.
- El procesamiento de cada mensaje es independiente (no hay dependencia entre mensajes consecutivos para la misma partición).
Por Qué No Es Trivial¶
Las decisiones de diseño de Competing Consumers son complejas:
- Número de consumidores vs. particiones: en Kafka, el número máximo de consumidores útiles es igual al número de particiones. Más consumidores que particiones significa consumidores ociosos.
- Ordering: en Kafka, el orden se garantiza dentro de una partición. Si se necesita orden por clave, los mensajes con la misma clave deben ir a la misma partición y ser procesados por el mismo consumidor.
- Rebalance: cuando un consumidor se une o abandona el grupo, Kafka reasigna particiones. Durante el rebalance, el procesamiento se pausa y los consumidores deben manejar la revocación y asignación de particiones.
- Idempotencia: durante rebalances, un mensaje puede ser entregado a dos consumidores diferentes. Ambos deben manejar duplicados.
- Hot partitions: si una partition key tiene más mensajes que las demás (skewed distribution), el consumidor asignado a esa partición se sobrecarga mientras otros están ociosos.
- State management: si el procesamiento requiere estado local (caché, buffers de aggregación), el rebalance puede invalidar ese estado.
Relación con Sistemas Distribuidos y Mensajería¶
Competing Consumers es la materialización del partitioned parallel processing en messaging. En la teoría de sistemas distribuidos, corresponde al concepto de work stealing o task distribution aplicado al procesamiento de mensajes.
Las implementaciones varían significativamente:
- En Kafka, el Consumer Group Protocol gestiona la asignación de particiones mediante un líder del grupo que ejecuta la estrategia de asignación (Range, RoundRobin, Sticky, CooperativeSticky). El protocolo garantiza que cada partición se asigna a exactamente un miembro del grupo.
- En RabbitMQ, la distribución es round-robin a nivel de mensaje, no de partición. Con
prefetch=1, cada consumidor recibe un mensaje a la vez. No hay "particiones" ni rebalance. - En SQS, la distribución es inherente: cada
ReceiveMessagedevuelve mensajes que no fueron entregados a otros consumidores recientemente (visibility timeout). Con Lambda, la concurrencia se gestiona automáticamente. - En Azure Service Bus, la distribución es por lock: cada mensaje se bloquea para el consumer que lo recibe (PeekLock). Sessions proporcionan affinity para mensajes relacionados.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Competing Consumers, un único consumidor es el cuello de botella del procesamiento. Los síntomas son claros y medibles:
- Consumer lag creciente: la diferencia entre el último mensaje producido y el último mensaje procesado crece con el tiempo.
- Latencia creciente: los mensajes nuevos esperan cada vez más tiempo antes de ser procesados.
- Procesamiento no escalable: añadir más CPU o memoria al consumidor tiene un límite vertical. No hay forma de escalar horizontalmente.
- Single point of failure: si el único consumidor falla, todo el procesamiento se detiene.
Síntomas del Problema¶
- Consumer lag que crece linealmente con el tiempo.
- Alertas de latencia de procesamiento que disparan durante picos de producción.
- Un solo pod/container/server procesando mientras el broker tiene millones de mensajes pendientes.
- Incapacidad de procesar durante campañas de venta (Black Friday, Cyber Monday) porque un solo consumidor no escala.
- Downtime total de procesamiento cuando el único consumidor falla o se reinicia.
Impacto Operativo y Arquitectónico¶
Sin Competing Consumers:
- El sistema no puede escalar horizontalmente para manejar picos de demanda.
- La latencia de procesamiento es inversamente proporcional a la tasa de producción: a más producción, más lag.
- No hay resiliencia: un fallo del consumidor detiene todo el procesamiento hasta que se recupera.
- Los SLAs de latencia de procesamiento no pueden cumplirse durante picos.
Riesgos Si No Se Implementa Correctamente¶
- Over-partitioning: crear 1000 particiones "por si acaso" consume recursos del broker sin beneficio si nunca se usan más de 10 consumidores.
- Under-partitioning: crear pocas particiones limita el número máximo de consumidores. Cambiar el número de particiones en Kafka es disruptivo para los consumidores que usan key-based partitioning.
- Rebalance storms: consumidores que se unen y abandonan frecuentemente (deployments, crashes, scaling events) causan rebalances continuos que reducen el throughput efectivo.
- Uneven distribution: partition keys con distribución sesgada producen "hot partitions" que sobrecargan un consumidor mientras otros están ociosos.
Ejemplos Reales¶
- Retail: durante Black Friday, una plataforma de e-commerce procesa 50,000 pedidos/minuto. Un solo consumidor puede procesar 500/minuto. Se necesitan 100 instancias del Order Processor compitiendo por mensajes del topic de pedidos.
- Banca: un sistema de prevención de fraude evalúa cada transacción en tiempo real. Con 10,000 transacciones/segundo y cada evaluación tomando 50ms, se necesitan al menos 500 consumidores para mantener la latencia por debajo de 100ms.
- Telecomunicaciones: un sistema de procesamiento de CDRs (Call Detail Records) recibe 1 millón de CDRs/hora. Múltiples consumidores procesan CDRs en paralelo para billing.
- Logistics: un sistema de tracking procesa eventos de ubicación de 100,000 vehículos. Múltiples consumidores actualizan la posición en la base de datos en paralelo.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el throughput de producción supera la capacidad de un solo consumidor.
- Cuando se necesita resiliencia ante fallos de consumidores individuales.
- Cuando se necesita reducir la latencia de procesamiento distribuyendo la carga.
- Cuando el procesamiento de mensajes es independiente (o ordenado por partición/clave).
- Cuando se necesita escalar horizontalmente el procesamiento de forma elástica (añadir/remover consumidores según demanda).
Cuándo No Usarlo¶
- Cuando se necesita orden estricto global de todos los mensajes (no solo por partición). Competing Consumers no garantiza orden global.
- Cuando el procesamiento de un mensaje depende del resultado del mensaje anterior (secuencial estricto).
- Cuando el volumen es bajo y un solo consumidor es suficiente con margen amplio.
Precondiciones¶
- El broker soporta distribución de mensajes entre múltiples consumidores en el mismo canal (consumer groups en Kafka, multiple consumers en RabbitMQ, multiple receivers en SQS).
- El procesamiento de cada mensaje es independiente o el orden se preserva por partición/clave.
- Los consumidores son stateless o manejan correctamente la transferencia de estado durante rebalances.
Restricciones¶
- En Kafka, el número máximo de consumidores útiles en un consumer group es igual al número de particiones del topic.
- Los rebalances introducen pausas de procesamiento cuando consumidores se unen o abandonan el grupo.
- La distribución de carga depende de la distribución de partition keys. Keys con distribución sesgada producen carga desigual.
Dependencias¶
- Broker que soporte distribución de mensajes (Kafka, RabbitMQ, SQS, Service Bus).
- Mecanismo de coordinación entre consumidores (consumer group protocol en Kafka, queue semantics en RabbitMQ/SQS).
- Infrastructure para escalar consumidores (Kubernetes, ECS, Lambda).
Supuestos Arquitectónicos¶
- Los consumidores son instancias idénticas del mismo servicio (same code, same configuration).
- El procesamiento de cada mensaje no depende del estado dejado por mensajes anteriores procesados por otras instancias.
- Los consumidores son idempotentes (pueden manejar duplicados producidos por rebalances).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Microservicios event-driven con alto volumen de eventos.
- Sistemas de e-commerce durante picos de demanda.
- Procesamiento de transacciones financieras en tiempo real.
- Sistemas de telemetría y IoT con millones de eventos.
- Pipelines de procesamiento de datos (ETL, streaming analytics).
- Cualquier servicio que necesite escalar horizontalmente el procesamiento de mensajes.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Competing Consumers desacopla el número de consumidores de la lógica de procesamiento. El código del consumidor es el mismo independientemente de si hay 1 o 100 instancias. La flexibilidad para escalar es máxima: se añaden o remueven instancias según demanda sin cambios de código.
Simplicidad vs. Robustez¶
Un solo consumidor es simple de operar. Múltiples consumidores requieren gestión de coordinación (rebalances), distribución de carga, y manejo de duplicados. La robustez ante fallos y picos de demanda justifica la complejidad adicional.
Throughput vs. Ordering¶
Más consumidores significan más throughput pero potencialmente menos control sobre el orden de procesamiento. En Kafka, el orden se preserva por partición: mensajes con la misma key se procesan en orden por el mismo consumidor. Pero el orden global entre particiones no está garantizado.
Escalabilidad vs. Coordinación¶
Cada consumidor adicional incrementa el throughput pero también incrementa el overhead de coordinación (rebalances en Kafka, visibility timeout en SQS). Hay un punto donde añadir más consumidores produce rendimientos decrecientes por el overhead de coordinación.
Resiliencia vs. Complejidad¶
Con múltiples consumidores, el fallo de uno no detiene el procesamiento — los demás continúan y las particiones del consumidor fallido se reasignan. Pero esta resiliencia requiere que el sistema maneje correctamente rebalances, duplicados y estado transitorio.
Costo vs. Performance¶
Cada consumidor adicional consume recursos (CPU, memoria, conexiones de red, conexiones de DB). El costo escala linealmente con el número de consumidores. El beneficio (throughput) también escala linealmente hasta el límite del broker o de los recursos downstream.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: publica mensajes al canal.
- Canal de Mensajes: topic, queue o subscription que almacena los mensajes.
- Consumer Group / Consumer Pool: el conjunto de consumidores que compiten por mensajes del mismo canal.
- Consumer Instance: cada instancia individual del servicio consumidor.
- Coordinator: el mecanismo que distribuye mensajes o particiones entre consumidores (Kafka group coordinator, SQS visibility timeout, RabbitMQ round-robin).
- Resources Downstream: bases de datos, APIs, servicios que los consumidores invocan durante el procesamiento.
Flujo Lógico¶
flowchart TD
subgraph Kafka Consumer Group
A1([Consumer Instance]) -->|Subscribe al grupo| B1[Group Coordinator]
B1 -->|Rebalance: asigna particiones| C1[Consumer 1: particiones 0-3]
B1 -->|Rebalance: asigna particiones| D1[Consumer 2: particiones 4-7]
B1 -->|Rebalance: asigna particiones| E1[Consumer 3: particiones 8-11]
C1 --> F1[Poll loop y procesa mensajes]
D1 --> F1
E1 --> F1
F1 --> G1[Commit offsets]
end
subgraph SQS Competing Consumers
H1[(Cola SQS)] -->|ReceiveMessage| I1[Consumer 1: mensaje A]
H1 -->|ReceiveMessage| J1[Consumer 2: mensaje B]
H1 -->|ReceiveMessage| K1[Consumer 3: mensaje C]
I1 -->|Procesa mensaje| L1[DeleteMessage]
J1 -->|Procesa mensaje| L1
K1 -->|Procesa mensaje| L1
endResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Producer | Publicar mensajes al canal con partition key adecuada |
| Canal | Almacenar mensajes, gestionar distribución entre consumidores |
| Consumer Group | Coordinar asignación de particiones/mensajes |
| Consumer Instance | Procesar mensajes, commitear/acknowledge, manejar errores |
| Downstream Resources | Proporcionar capacidad para N consumidores simultáneos |
Interacciones¶
- Producer → Canal: publicación de mensajes con partition key.
- Coordinator → Consumer Instances: asignación de particiones (Kafka), distribución round-robin (RabbitMQ), o distribución por visibility timeout (SQS).
- Consumer Instance → Canal: poll/receive de mensajes, commit/acknowledge de procesamiento.
- Consumer Instance → Downstream: invocación de base de datos, APIs, servicios.
Contratos Implícitos¶
- Cada mensaje se entrega a exactamente un consumidor del grupo (dentro de la garantía del broker).
- Los consumidores son instancias idénticas que procesan los mismos tipos de mensajes.
- Los consumidores manejan duplicados producidos por rebalances o failures.
- Los downstream resources soportan N conexiones simultáneas.
Decisiones de Diseño Clave¶
- Número de particiones: determina el paralelismo máximo en Kafka. Debe estimarse considerando el throughput futuro, no solo el actual.
- Partition key strategy: determina cómo se distribuyen los mensajes entre particiones. Impacta el balance de carga y el ordering.
- Scaling strategy: manual (ajustar replicas) o automático (HPA en Kubernetes basado en consumer lag).
- Rebalance strategy: en Kafka, Cooperative Sticky reduce el impacto de rebalances al no revocar particiones innecesariamente.
- Connection pool sizing: los downstream resources (DB, APIs) deben dimensionarse para N consumidores × conexiones por consumidor.
8. Ejemplo Arquitectónico Detallado¶
Dominio: Retail — Procesamiento de Pedidos en Alta Temporada¶
Contexto del Negocio¶
Una plataforma de retail online procesa ventas en toda Latinoamérica. Durante temporada normal, procesa 5,000 pedidos/hora. Durante eventos de alta demanda (Black Friday, Cyber Monday, Hot Sale), el volumen alcanza 200,000 pedidos/hora (55 pedidos/segundo). Cada pedido requiere: validación, reserva de inventario, procesamiento de pago, generación de orden de envío, y notificación al cliente.
Necesidad de Integración¶
El Checkout Service publica eventos OrderCreated en Kafka. El Order Processor Service consume estos eventos y ejecuta el flujo de procesamiento. Durante temporada normal, 2 instancias del Order Processor son suficientes. Durante alta demanda, se necesitan 20+ instancias.
Sistemas Involucrados¶
- Checkout Service: publica
OrderCreateden Kafka conorderIdcomo partition key. - Apache Kafka: topic
retail.orders.createdcon 24 particiones, retención de 7 días. - Order Processor Service: microservicio Spring Boot con
@KafkaListeneren consumer grouporder-processors. - Inventory Service: API REST para reserva de stock (rate limit: 200 req/s).
- Payment Gateway: API para procesamiento de pagos (rate limit: 100 req/s).
- Shipping Service: API para generación de órdenes de envío.
- Notification Service: consume eventos de orden procesada para notificar al cliente.
- PostgreSQL: base de datos del Order Processor para estado de pedidos.
Restricciones Técnicas¶
- Latencia máxima de procesamiento por pedido: 5 segundos.
- El topic tiene 24 particiones (máximo 24 consumidores en paralelo).
- Inventory Service soporta 200 requests/segundo. Con 20 consumidores, cada uno puede hacer 10 requests/segundo.
- Payment Gateway soporta 100 requests/segundo. Con 20 consumidores, cada uno puede hacer 5 requests/segundo.
- Los pedidos del mismo cliente deben procesarse en orden (partition key = customerId OR orderId).
- El sistema debe escalar automáticamente durante picos y reducirse después.
Flujos de Datos¶
Checkout Service → Kafka (retail.orders.created, 24 partitions)
→ Order Processor Instance 1 [partitions 0-3]
→ Order Processor Instance 2 [partitions 4-7]
→ Order Processor Instance 3 [partitions 8-11]
→ Order Processor Instance 4 [partitions 12-15]
→ Order Processor Instance 5 [partitions 16-19]
→ Order Processor Instance 6 [partitions 20-23]
Cada instancia:
→ Validate Order
→ Reserve Inventory (API call)
→ Process Payment (API call)
→ Generate Shipping Order (API call)
→ Publish OrderProcessed event
Decisiones Arquitectónicas¶
- 24 particiones: suficientes para escalar hasta 24 instancias en pico. Durante temporada normal, 2-4 instancias con 6-12 particiones cada una.
- Partition key = customerId: garantiza que todos los pedidos del mismo cliente se procesan en orden por el mismo consumidor.
- Cooperative Sticky Rebalance: minimiza el impacto de añadir/remover consumidores.
- HPA (Horizontal Pod Autoscaler): escala automáticamente basado en consumer lag (métrica custom de Prometheus).
- Circuit breaker: cada consumidor tiene circuit breakers para Inventory, Payment y Shipping APIs, para evitar cascading failures.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Hot partition (un cliente con muchos pedidos) | Partition key por orderId para distribución uniforme (trade-off: pierde ordering por cliente) |
| Rebalance durante pico | Cooperative Sticky Rebalance reduce pausas. Scaling gradual (2→4→8→12→20) |
| Inventory API saturada | Circuit breaker + rate limiter per consumer. Escalar Inventory API en paralelo |
| Consumer falla a mitad de procesamiento | Transactional outbox + idempotent processing. El pedido se reprocesa sin duplicar efectos |
| Scaling down causa rebalance | Scheduled scaling: escalar up antes del pico, esperar lag = 0 antes de escalar down |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Configuración del Consumer Group¶
@Configuration
public class OrderProcessorKafkaConfig {
@Bean
public ConcurrentKafkaListenerContainerFactory<String, OrderCreatedEvent>
orderProcessorFactory(ConsumerFactory<String, OrderCreatedEvent> cf) {
ConcurrentKafkaListenerContainerFactory<String, OrderCreatedEvent> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(cf);
factory.setConcurrency(4); // 4 threads por instancia
factory.getContainerProperties().setAckMode(
ContainerProperties.AckMode.MANUAL_IMMEDIATE);
factory.setCommonErrorHandler(new DefaultErrorHandler(
new DeadLetterPublishingRecoverer(kafkaTemplate),
new FixedBackOff(1000L, 3)));
return factory;
}
}
spring:
kafka:
consumer:
group-id: order-processors
auto-offset-reset: latest
enable-auto-commit: false
max-poll-records: 10
properties:
partition.assignment.strategy: org.apache.kafka.clients.consumer.CooperativeStickyAssignor
max.poll.interval.ms: 300000
session.timeout.ms: 30000
Paso 2: Handler del Order Processor¶
@Component
public class OrderProcessorHandler {
private final InventoryClient inventoryClient;
private final PaymentClient paymentClient;
private final ShippingClient shippingClient;
private final OrderRepository orderRepository;
private final OrderEventGateway eventGateway;
@KafkaListener(
topics = "retail.orders.created",
groupId = "order-processors",
containerFactory = "orderProcessorFactory"
)
public void processOrder(
@Payload OrderCreatedEvent event,
Acknowledgment ack) {
String orderId = event.getOrderId();
log.info("Processing order {} on partition {}",
orderId, /* partition from header */);
try {
// 1. Validate
Order order = Order.fromEvent(event);
order.validate();
// 2. Reserve inventory
InventoryReservation reservation =
inventoryClient.reserve(order.getItems());
// 3. Process payment
PaymentResult payment =
paymentClient.process(order.getPaymentDetails());
// 4. Generate shipping order
ShippingOrder shipping =
shippingClient.createOrder(order.getShippingDetails());
// 5. Update order state
order.markAsProcessed(reservation, payment, shipping);
orderRepository.save(order);
// 6. Publish success event
eventGateway.publishOrderProcessed(order);
// 7. Acknowledge
ack.acknowledge();
} catch (InventoryException e) {
handleInventoryFailure(event, e, ack);
} catch (PaymentException e) {
handlePaymentFailure(event, e, ack);
} catch (Exception e) {
log.error("Unexpected error processing order {}", orderId, e);
throw e; // Framework retry + dead-letter
}
}
}
Paso 3: Autoscaling basado en Consumer Lag¶
# Kubernetes HPA con métricas custom de Prometheus
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-processor-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-processor
minReplicas: 2
maxReplicas: 24 # = número de particiones
metrics:
- type: External
external:
metric:
name: kafka_consumer_lag
selector:
matchLabels:
consumer_group: order-processors
topic: retail.orders.created
target:
type: AverageValue
averageValue: "1000" # Escalar si lag > 1000 por pod
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Pods
value: 4
periodSeconds: 60
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Pods
value: 2
periodSeconds: 120
Paso 4: Monitoring de la Distribución¶
@Component
public class ConsumerGroupMetrics {
private final MeterRegistry meterRegistry;
@Scheduled(fixedRate = 10000)
public void reportPartitionAssignment() {
// Reportar particiones asignadas a esta instancia
KafkaListenerEndpointRegistry registry = ...;
for (MessageListenerContainer container : registry.getAllListenerContainers()) {
Collection<TopicPartition> assigned = container.getAssignedPartitions();
meterRegistry.gauge("kafka.consumer.assigned_partitions",
Tags.of("instance", instanceId),
assigned.size());
}
}
}
Paso 5: Scenario de Black Friday¶
Secuencia temporal durante un evento de alta demanda:
T-24h: 2 instancias procesando 5,000 pedidos/hora. Lag = 0.
T-1h: Scaling manual preventivo a 6 instancias. Rebalance: 4 particiones/instancia.
T+0: Black Friday inicia. Producción sube a 50,000/hora.
T+5m: HPA detecta lag > 1000. Escala a 10 instancias. Rebalance.
T+15m: Producción sube a 200,000/hora. HPA escala a 20 instancias.
T+20m: Rebalance completo. 20 instancias, ~1.2 particiones/instancia + 4 ociosos.
(24 particiones / 20 consumers = algunos consumers con 1, otros con 2)
T+12h: Producción baja a 20,000/hora. HPA comienza scale-down gradual.
T+14h: 6 instancias. Lag estable = 0.
T+24h: Volvemos a 2 instancias. Evento terminado.
Manejo de Errores¶
- Consumer instance crash: Kafka detecta heartbeat missing, remueve del grupo, reasigna particiones a las instancias restantes. Los mensajes del consumer fallido se reprocesan desde el último offset commiteado.
- Inventory API down: circuit breaker se abre. Los mensajes fallan, retry policy se aplica. Si persiste, mensajes van a dead-letter topic.
- Rebalance during processing: con Cooperative Sticky, solo las particiones del nuevo/removido consumer se reasignan. Los demás continúan sin interrupción.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.programming.language import Java
from diagrams.onprem.queue import Kafka
from diagrams.onprem.database import PostgreSQL
from diagrams.generic.compute import Rack
from diagrams.k8s.compute import Pod
from diagrams.k8s.compute import Deploy
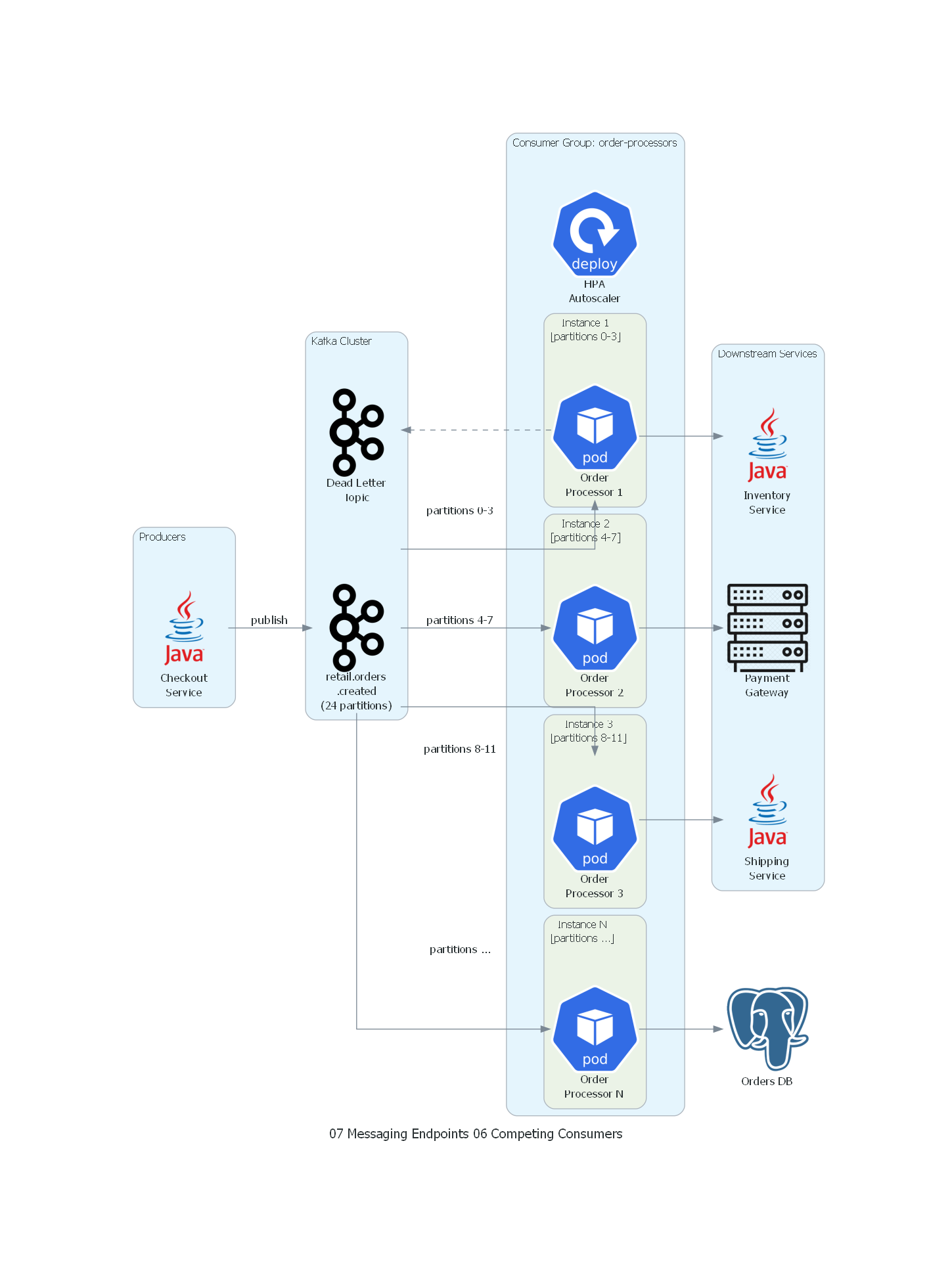
with Diagram("Competing Consumers - Retail Order Processing", show=False, direction="LR"):
with Cluster("Producers"):
checkout = Java("Checkout\nService")
with Cluster("Kafka Cluster"):
topic = Kafka("retail.orders\n.created\n(24 partitions)")
dlt = Kafka("Dead Letter\nTopic")
with Cluster("Consumer Group: order-processors"):
hpa = Deploy("HPA\n(lag-based)")
with Cluster("Instance 1\n[partitions 0-3]"):
consumer1 = Pod("Order\nProcessor 1")
with Cluster("Instance 2\n[partitions 4-7]"):
consumer2 = Pod("Order\nProcessor 2")
with Cluster("Instance 3\n[partitions 8-11]"):
consumer3 = Pod("Order\nProcessor 3")
with Cluster("Instance N\n[partitions ...]"):
consumerN = Pod("Order\nProcessor N")
with Cluster("Downstream Services"):
inventory = Java("Inventory\nService")
payment = Rack("Payment\nGateway")
shipping = Java("Shipping\nService")
db = PostgreSQL("Orders DB")
checkout >> Edge(label="publish") >> topic
topic >> Edge(label="partitions 0-3") >> consumer1
topic >> Edge(label="partitions 4-7") >> consumer2
topic >> Edge(label="partitions 8-11") >> consumer3
topic >> Edge(label="partitions ...") >> consumerN
consumer1 >> inventory
consumer2 >> payment
consumer3 >> shipping
consumerN >> db
consumer1 >> Edge(style="dashed") >> dlt
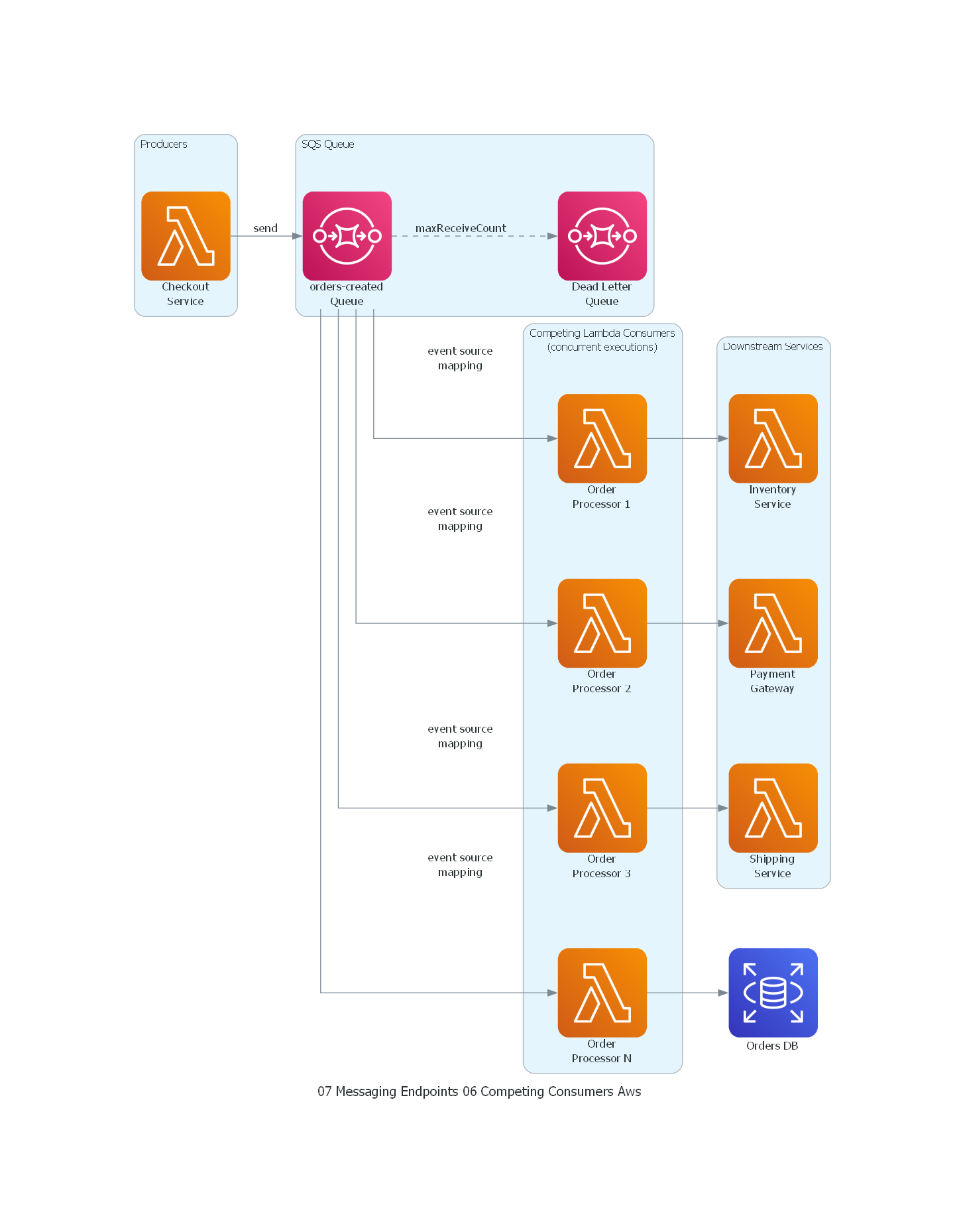
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import RDS
from diagrams.aws.integration import SQS
with Diagram("Competing Consumers - Retail Order Processing (AWS)", show=False, direction="LR"):
with Cluster("Producers"):
checkout = Lambda("Checkout\nService")
with Cluster("SQS Queue"):
queue = SQS("orders-created\nQueue")
dlq = SQS("Dead Letter\nQueue")
with Cluster("Competing Lambda Consumers\n(concurrent executions)"):
consumer1 = Lambda("Order\nProcessor 1")
consumer2 = Lambda("Order\nProcessor 2")
consumer3 = Lambda("Order\nProcessor 3")
consumerN = Lambda("Order\nProcessor N")
with Cluster("Downstream Services"):
inventory = Lambda("Inventory\nService")
payment = Lambda("Payment\nGateway")
shipping = Lambda("Shipping\nService")
db = RDS("Orders DB")
checkout >> Edge(label="send") >> queue
queue >> Edge(label="event source\nmapping") >> consumer1
queue >> Edge(label="event source\nmapping") >> consumer2
queue >> Edge(label="event source\nmapping") >> consumer3
queue >> Edge(label="event source\nmapping") >> consumerN
consumer1 >> inventory
consumer2 >> payment
consumer3 >> shipping
consumerN >> db
queue >> Edge(style="dashed", label="maxReceiveCount") >> dlq
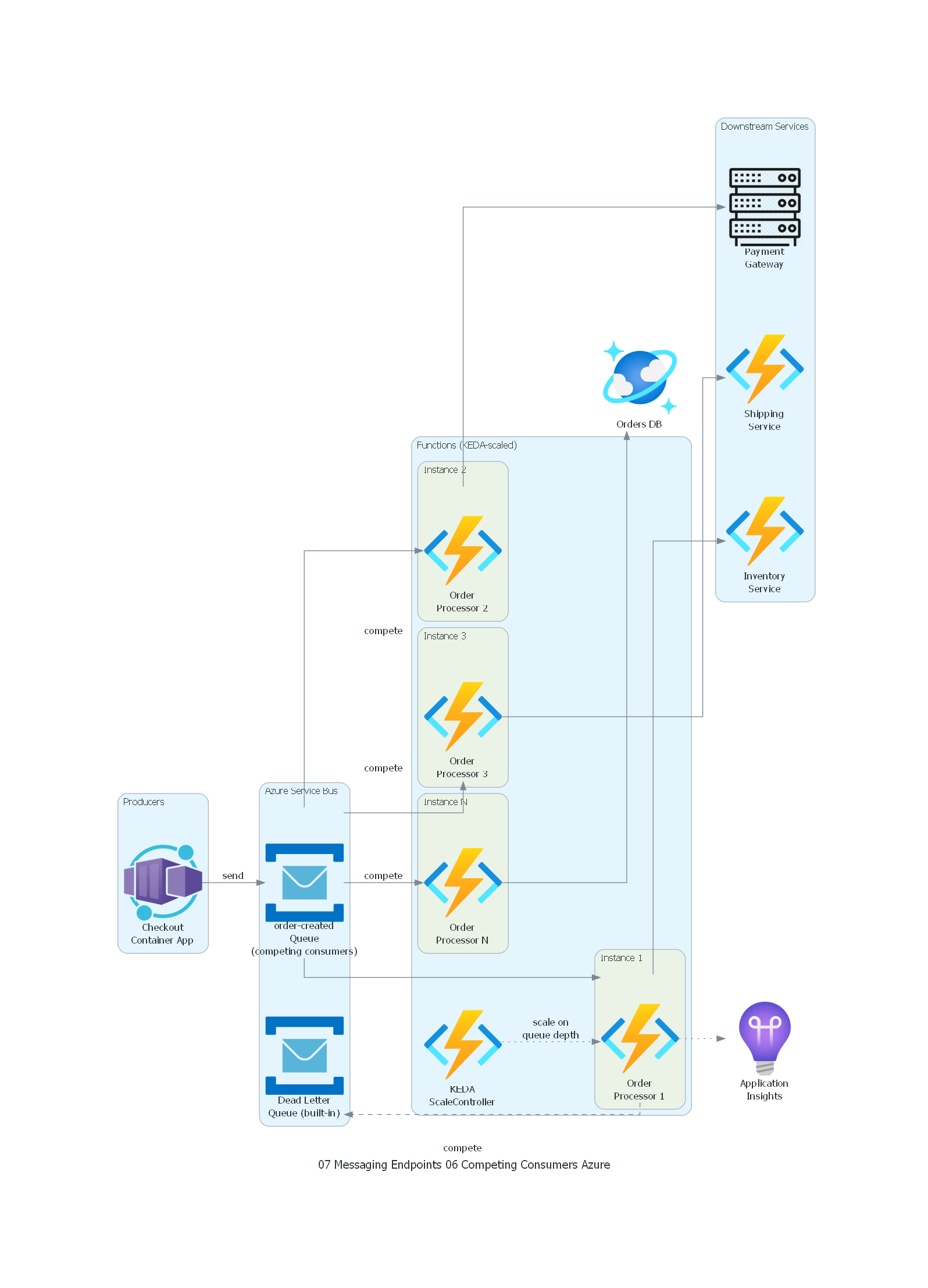
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
from diagrams.azure.devops import ApplicationInsights
from diagrams.generic.compute import Rack
with Diagram("Competing Consumers - Retail Order Processing (Azure)", show=False, direction="LR"):
with Cluster("Producers"):
checkout = ContainerApps("Checkout\nContainer App")
with Cluster("Azure Service Bus"):
queue = ServiceBus("order-created\nQueue\n(competing consumers)")
dlq = ServiceBus("Dead Letter\nQueue (built-in)")
with Cluster("Functions (KEDA-scaled)"):
keda = FunctionApps("KEDA\nScaleController")
with Cluster("Instance 1"):
consumer1 = FunctionApps("Order\nProcessor 1")
with Cluster("Instance 2"):
consumer2 = FunctionApps("Order\nProcessor 2")
with Cluster("Instance 3"):
consumer3 = FunctionApps("Order\nProcessor 3")
with Cluster("Instance N"):
consumerN = FunctionApps("Order\nProcessor N")
with Cluster("Downstream Services"):
inventory = FunctionApps("Inventory\nService")
payment = Rack("Payment\nGateway")
shipping = FunctionApps("Shipping\nService")
db = CosmosDb("Orders DB")
monitoring = ApplicationInsights("Application\nInsights")
checkout >> Edge(label="send") >> queue
queue >> Edge(label="compete") >> consumer1
queue >> Edge(label="compete") >> consumer2
queue >> Edge(label="compete") >> consumer3
queue >> Edge(label="compete") >> consumerN
consumer1 >> inventory
consumer2 >> payment
consumer3 >> shipping
consumerN >> db
consumer1 >> Edge(style="dashed") >> dlq
keda >> Edge(style="dotted", label="scale on\nqueue depth") >> consumer1
consumer1 >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
- Checkout Service publica pedidos en Kafka con 24 particiones.
- Consumer Group contiene N instancias del Order Processor. Kafka asigna subconjuntos de particiones a cada instancia.
- HPA (Horizontal Pod Autoscaler) escala el número de instancias basándose en el consumer lag.
- Cada instancia procesa mensajes de sus particiones asignadas, invocando servicios downstream (Inventory, Payment, Shipping) y persistiendo en la base de datos.
- Dead Letter Topic recibe mensajes que fallaron después de los retries.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Competing Consumers | Consumer Group: order-processors (N instances) |
| Message Channel | Kafka topic retail.orders.created (24 partitions) |
| Distribution Mechanism | Kafka consumer group protocol (partition assignment) |
| Individual Consumer | Each Order Processor Pod |
| Scaling Mechanism | HPA (lag-based autoscaling) |
| Error Handling | Dead Letter Topic |
11. Beneficios¶
Impacto Técnico¶
- Escalabilidad horizontal: el throughput escala linealmente con el número de consumidores (hasta el límite de particiones o recursos downstream).
- Resiliencia: el fallo de un consumidor no detiene el procesamiento. Las particiones se reasignan a los consumidores restantes.
- Elasticidad: los consumidores se pueden añadir o remover dinámicamente según la demanda, con escalado automático basado en métricas.
- Distribución de carga: la carga se distribuye automáticamente entre consumidores por el mecanismo del broker.
Impacto Organizacional¶
- Independencia de scaling del código de negocio: el código del handler es el mismo para 1 o 100 instancias. El scaling es configuración de infraestructura, no cambio de código.
- Predictibilidad de costos: el costo escala linealmente con la demanda. Durante baja demanda, se usan pocas instancias; durante picos, se escala.
- Confianza en SLAs: la capacidad de escalar horizontalmente permite cumplir SLAs de latencia de procesamiento incluso durante picos extremos.
Impacto Operacional¶
- Autoscaling: con Kubernetes HPA o KEDA, el scaling es automático basado en consumer lag o throughput.
- Rolling deployments: las instancias se pueden actualizar una a una. Kafka reasigna particiones del consumidor que se reinicia a los demás.
- Canary deployments: una instancia con nueva versión puede unirse al consumer group para procesar un subconjunto de particiones como canary.
Beneficios de Mantenibilidad y Evolución¶
- Separación de concerns: la lógica de procesamiento está en el handler; la lógica de scaling está en la infraestructura (HPA, KEDA, Lambda concurrency).
- Evolución independiente: se puede cambiar la estrategia de rebalance, el número de particiones o la política de scaling sin modificar el código de procesamiento.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Rebalance handling: los rebalances son operaciones complejas que causan pausas de procesamiento. En Kafka, un rebalance puede durar segundos a minutos dependiendo del número de particiones y consumidores.
- State management: si los consumidores mantienen estado local (caché, buffers de aggregación), el rebalance puede invalidar ese estado cuando las particiones se reasignan.
- Ordering guarantees: preservar el orden de procesamiento requiere partition key strategy cuidadosa y puede limitar el paralelismo.
Riesgos de Mal Uso¶
- Más consumidores que particiones: en Kafka, las instancias que no tienen particiones asignadas están ociosas, consumiendo recursos sin contribuir al throughput.
- Ignoring downstream limits: escalar consumidores a 50 instancias cuando la base de datos solo soporta 100 conexiones simultáneas causa fallos en cascada.
- Frequent scaling events: escalar up y down muy frecuentemente causa rebalances constantes que reducen el throughput efectivo.
Sobreingeniería¶
- Implementar 100 particiones y autoscaling complejo para un topic que procesa 100 mensajes/día.
- Construir un coordinador custom de consumer group cuando Kafka o RabbitMQ proporcionan uno nativo.
- Implementar state transfer between consumers durante rebalances cuando el procesamiento es stateless.
Costos de Operación¶
- Cada instancia de consumidor consume CPU, memoria, conexiones de red y conexiones de base de datos.
- El monitoreo se multiplica por N instancias: métricas per-instance, per-partition, per-consumer-group.
- Los rebalances requieren monitoreo y alerting dedicados.
Anti-Patterns Relacionados¶
- Thundering Herd: todos los consumidores se reinician simultáneamente (deployment), causando un rebalance masivo seguido de un pico de processing que satura downstream resources.
- Partition Key Hotspot: una partition key con distribución extremadamente sesgada (ej: un cliente genera el 50% del tráfico) produce un hot partition que no se beneficia de competing consumers.
- Scale First, Fix Later: escalar consumidores para compensar handlers lentos en lugar de optimizar el handler. El costo crece linealmente pero la raíz del problema persiste.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Event-Driven Consumer / Polling Consumer: cada instancia de Competing Consumers usa internamente un Polling Consumer (Kafka) o un Event-Driven Consumer (RabbitMQ, Lambda).
- Idempotent Receiver: necesario porque los rebalances pueden causar que un mensaje sea procesado por dos consumidores diferentes.
- Transactional Client: cada consumidor que modifica estado local y publica eventos debe usar Transactional Client (outbox) para garantizar atomicidad.
Patrones que Suelen Aparecer Antes o Después¶
- Content-Based Router: antes de los Competing Consumers, un router puede dirigir mensajes a diferentes topics/queues según su tipo. Cada topic tiene su propio grupo de competing consumers.
- Splitter/Aggregator: un splitter divide un mensaje grande en partes que se procesan por competing consumers, y un aggregator reagrupa los resultados.
Combinaciones Comunes¶
- Competing Consumers + Kafka Consumer Groups + Kubernetes HPA: la combinación estándar para microservicios escalables sobre Kafka.
- Competing Consumers + SQS + Lambda: la combinación serverless donde Lambda escala automáticamente el número de invocaciones concurrentes.
- Competing Consumers + Dead Letter Channel: los mensajes que fallan se envían a dead-letter para inspección, sin bloquear el procesamiento de los demás.
Diferencias con Patrones Similares¶
- vs. Publish-Subscribe: en Competing Consumers, cada mensaje se entrega a exactamente un consumidor del grupo. En Publish-Subscribe, cada mensaje se entrega a todos los suscriptores. Son patrones opuestos en distribución.
- vs. Message Dispatcher: Message Dispatcher distribuye mensajes a handlers dentro de un solo proceso. Competing Consumers distribuye mensajes entre múltiples procesos/instancias.
Encaje en un Flujo Mayor de Integración¶
Competing Consumers es el patrón de escalabilidad horizontal en cualquier flujo de integración basado en mensajería. Se aplica en cada punto donde el throughput de un solo consumidor es insuficiente. En una cadena de microservicios event-driven, cada servicio puede tener su propio grupo de competing consumers, escalando independientemente según su carga específica.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Competing Consumers es uno de los patrones más fundamentales y más utilizados en arquitecturas modernas. Es la forma estándar de escalar el procesamiento de mensajes en toda la industria.
A favor de la vigencia:
- Los Kafka Consumer Groups son Competing Consumers. Toda organización que usa Kafka usa este patrón.
- AWS Lambda con SQS event source mapping es Competing Consumers serverless, usado masivamente en aplicaciones cloud-native.
- Kubernetes HPA y KEDA han hecho que el autoscaling de consumidores basado en métricas sea accesible y automatizado.
- La tendencia hacia arquitecturas event-driven y microservicios refuerza la necesidad de escalabilidad horizontal de procesamiento de mensajes.
- Los picos de demanda (ventas estacionales, eventos de tráfico, batch processing) requieren elasticidad que solo Competing Consumers proporciona.
Evolución moderna:
- Cooperative Sticky Rebalance en Kafka reduce significativamente el impacto de los rebalances.
- KEDA (Kubernetes Event-Driven Autoscaling) permite autoscaling basado en consumer lag, queue depth, y otras métricas de messaging.
- Lambda concurrency controls en AWS proporcionan scaling fino de competing consumers serverless.
- Static group membership en Kafka elimina rebalances para deployments predictibles.
Cómo Se Implementa Hoy¶
- Kafka Consumer Groups: la implementación más común. Cada instancia del microservicio con el mismo
group.ides un competing consumer. - SQS + Lambda: Lambda escala automáticamente las invocaciones concurrentes basándose en la queue depth.
- Azure Service Bus + Functions: Functions escala automáticamente los receivers basándose en la queue length.
- RabbitMQ + Multiple Consumers: múltiples consumidores en la misma queue con prefetch control.
- Kubernetes KEDA: escala pods basándose en métricas de Kafka consumer lag o SQS queue depth.
15. Implementación en Arquitecturas Modernas¶
Apache Kafka Consumer Groups¶
Kafka implementa Competing Consumers nativamente mediante el protocolo de Consumer Groups. Configuración clave: group.id (identifica el grupo), partition.assignment.strategy (CooperativeStickyAssignor recomendado), max.poll.records y max.poll.interval.ms (control del batch y timeout). El número de consumidores útiles está limitado por el número de particiones. El escalado se logra añadiendo instancias al deployment (Kubernetes replicas).
AWS SQS + Lambda¶
SQS con Lambda event source mapping proporciona competing consumers serverless. AWS gestiona el polling, batching y concurrencia. Configuración: BatchSize, MaximumBatchingWindowInSeconds, ScalingConfig.MaximumConcurrency. Lambda escala automáticamente hasta el límite de concurrencia configurado. Para FIFO queues, Lambda respeta el message group ID para ordering.
Azure Service Bus + Azure Functions¶
Functions con Service Bus trigger escalan automáticamente los receivers. Para queues, múltiples instancias de la Function compiten por mensajes. Para topics con subscriptions, cada Function app tiene su subscription. Configuración: maxConcurrentCalls, isSessionsEnabled (para ordering por session).
RabbitMQ¶
Múltiples consumidores registrados en la misma queue reciben mensajes en round-robin. prefetch controla cuántos mensajes no-acked puede tener cada consumidor, proporcionando backpressure. No hay "rebalance" como en Kafka; añadir o remover consumidores es instantáneo.
Kubernetes (KEDA / HPA)¶
KEDA (Kubernetes Event-Driven Autoscaling) escala deployments basándose en métricas de messaging:
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: order-processor-scaledobject
spec:
scaleTargetRef:
name: order-processor
minReplicaCount: 2
maxReplicaCount: 24
triggers:
- type: kafka
metadata:
bootstrapServers: kafka:9092
consumerGroup: order-processors
topic: retail.orders.created
lagThreshold: "1000"
Spring Kafka¶
ConcurrentKafkaListenerContainerFactory con setConcurrency(N) crea N threads por instancia, cada uno procesando particiones asignadas. Combinado con Kubernetes replicas, proporciona scaling a dos niveles: threads por pod × pods por deployment.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas clave: consumer lag por partición, throughput por instancia, latencia de procesamiento por instancia, rebalance count, rebalance duration, instancias activas, particiones por instancia.
- Health checks: verificar que cada instancia tiene particiones asignadas (en Kafka), que el lag no crece, que los heartbeats se envían.
- Alertas: lag creciente (scaling insuficiente o handler lento), rebalance frecuentes (instancias inestables), instancias sin particiones (over-provisioned), downstream saturado.
Tracing¶
- Cada instancia propaga el trace ID desde el mensaje al procesamiento.
- Los dashboards de tracing muestran la distribución de procesamiento entre instancias.
- Los rebalances deben rastrearse como eventos de infraestructura que correlacionan con pausas de procesamiento.
Monitoreo¶
- Dashboard de consumer group: lag total, lag por partición, throughput total, instancias activas, distribución de particiones.
- Dashboard por instancia: particiones asignadas, throughput, latencia, errores, uso de recursos.
- Dashboard de downstream: conexiones activas, latencia de API, tasa de errores.
Versionado¶
- Durante rolling deployments, instancias con versiones diferentes pueden coexistir en el mismo consumer group. Los handlers deben ser backward-compatible con mensajes de versiones anteriores del schema.
Seguridad¶
- Todas las instancias usan las mismas credenciales para el broker y los downstream services.
- Las credenciales deben gestionarse vía secrets management (Kubernetes Secrets, AWS Secrets Manager, Azure Key Vault).
- Rotation de credenciales debe ser coordinada entre todas las instancias.
Manejo de Errores¶
- Instance failure: Kafka detecta la ausencia de heartbeats y reasigna particiones. Los mensajes no-commiteados se reprocesan por otra instancia.
- Slow instance: si una instancia tarda más que
max.poll.interval.ms, Kafka la remueve del grupo. Monitorear latencia de procesamiento por instancia. - Downstream failure: si una API downstream falla, todos los consumidores que la invocan fallan. Circuit breaker y retry con backoff en cada instancia.
Retries¶
- Retry dentro de cada instancia para errores transitorios.
- Dead-letter para errores permanentes.
- No reintentar a nivel de consumer group (no hay mecanismo nativo de redistribución por error).
Idempotencia¶
- Los rebalances pueden causar que un mensaje se procese en dos instancias. Ambas deben manejar el duplicado.
- Deduplication store (base de datos, Redis) accesible por todas las instancias para verificar mensajes ya procesados.
Performance¶
- Partition key distribution: verificar que las partition keys se distribuyen uniformemente entre particiones. Keys sesgadas producen hot partitions.
- Downstream connection pooling: cada instancia necesita su pool de conexiones. El total de conexiones = instancias × pool size.
- Batch processing: configurar
max.poll.recordssegún la capacidad de procesamiento y el tiempo demax.poll.interval.ms.
Escalabilidad¶
- Escalar horizontalmente añadiendo instancias hasta el número de particiones.
- Para escalar más allá del número de particiones, se necesita reparticionar el topic (operación disruptiva en Kafka).
- En SQS/Lambda, la escalabilidad no está limitada por particiones.
- Planificar el número de particiones considerando el throughput máximo futuro, no solo el actual.
17. Errores Comunes¶
Más Consumidores que Particiones¶
En Kafka, si hay 12 particiones y 20 consumidores, 8 consumidores estarán ociosos. Consumen recursos (CPU, memoria, conexiones) sin contribuir al throughput. El número máximo de consumidores útiles es igual al número de particiones.
Partition Key Sesgada¶
Usar una partition key con distribución desigual (ej: país, donde un país genera el 80% del tráfico) produce una hot partition que no se beneficia del paralelismo. La solución es usar una key con distribución más uniforme o añadir un componente aleatorio.
No Dimensionar Downstream Resources¶
Escalar consumidores a 20 instancias cuando la base de datos tiene un pool de 50 conexiones y cada consumidor usa 5 conexiones resulta en: 20 × 5 = 100 conexiones, excediendo el pool. Los downstream resources deben dimensionarse para el número máximo de consumidores.
Rebalance Storms por Deployments¶
Un deployment que reinicia todas las instancias simultáneamente causa un rebalance masivo seguido de otro cuando las instancias se reinician. La solución es rolling deployment con maxUnavailable: 1 y maxSurge: 1.
Ignorar el Impacto de Rebalances¶
Cada rebalance pausa el procesamiento en todas las instancias (Eager protocol) o en las afectadas (Cooperative). No monitorear la frecuencia y duración de rebalances oculta una fuente significativa de degradación de throughput.
Scaling Reactivo demasiado Lento¶
Si el HPA reacciona cuando el lag ya es de 100,000 mensajes, el tiempo de recovery puede ser largo. El scaling preventivo (antes de eventos conocidos como Black Friday) y thresholds agresivos de lag reducen el impacto.
18. Conclusión Técnica¶
Competing Consumers es el patrón fundamental de escalabilidad horizontal para procesamiento de mensajes. Sin este patrón, todo sistema de messaging tiene un cuello de botella fijo en la capacidad de un único consumidor. Con este patrón, el throughput escala linealmente con el número de instancias, proporcionando la elasticidad necesaria para manejar desde cargas normales hasta picos extremos.
Para un arquitecto de sistemas modernos, las directrices son:
- Diseñar el número de particiones para el throughput máximo futuro, no para el actual. Cambiar particiones en Kafka es disruptivo. 12 a 24 particiones es un punto de partida razonable para la mayoría de los topics.
- Usar partition key con distribución uniforme para evitar hot partitions. Verificar la distribución con métricas de lag por partición.
- Configurar Cooperative Sticky Rebalance en Kafka para minimizar el impacto de añadir/remover consumidores.
- Implementar autoscaling basado en consumer lag con KEDA o HPA custom. El consumer lag es la métrica más directa de la necesidad de escalar.
- Dimensionar downstream resources para N consumidores: base de datos (connection pool), APIs (rate limits), servicios (throughput). Si los downstream no escalan, los consumidores adicionales no aportan valor.
- Implementar idempotencia en todos los handlers porque los rebalances pueden causar procesamiento duplicado.
- Planificar scaling para eventos conocidos: escalar preventivamente antes de Black Friday, campañas, cierres de mes, o cualquier pico predecible.
En el contexto del retail del ejemplo, Competing Consumers permite que la plataforma escale de 2 instancias procesando 5,000 pedidos/hora durante temporada normal, a 20 instancias procesando 200,000 pedidos/hora durante Black Friday, y vuelva a 2 instancias después. El mismo código del handler procesa pedidos en todas las configuraciones. El escalado es una decisión de infraestructura (replicas del deployment, configuración del HPA), no una decisión de código. Esta separación entre lógica de procesamiento y estrategia de escalado es lo que hace de Competing Consumers un patrón tan poderoso y tan universalmente aplicado.