Selective Consumer¶
1. Nombre del Patrón¶
- Nombre oficial: Selective Consumer
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Consumidor Selectivo
2. Resumen Ejecutivo¶
Selective Consumer es un patrón de endpoint que permite a un consumidor recibir únicamente los mensajes que cumplen criterios específicos definidos por un filtro o selector aplicado en el punto de consumo. En lugar de recibir todos los mensajes de un canal y descartar los irrelevantes en la aplicación, el consumidor declara una condición de filtrado que el broker o la infraestructura de messaging evalúa antes de entregar el mensaje.
El problema que resuelve es la eficiencia en el consumo selectivo: cuando un canal contiene mensajes de interés variable para diferentes consumidores, ¿cómo evita cada consumidor procesar (e incluso recibir) mensajes que no le incumben? Selective Consumer responde declarando un filtro en el endpoint que actúa como una puerta de admisión — solo los mensajes que pasan el filtro son entregados al consumidor.
Este patrón es especialmente relevante en escenarios donde múltiples consumidores comparten un canal pero cada uno necesita un subconjunto diferente de los mensajes. En logística, por ejemplo, un consumidor que solo procesa envíos de alta prioridad puede usar un selector que filtre por el atributo de prioridad, evitando recibir los miles de envíos de prioridad estándar que no necesita procesar.
3. Definición Detallada¶
Propósito¶
Selective Consumer establece un mecanismo de filtrado en el endpoint de consumo que restringe los mensajes entregados al consumidor a aquellos que satisfacen una expresión de selección. Su propósito es reducir el volumen de mensajes que el consumidor debe procesar, filtrando en la infraestructura de messaging antes de la entrega.
Lógica Arquitectónica¶
En un canal compartido por mensajes heterogéneos, sin filtrado en el endpoint cada consumidor recibe todos los mensajes y debe implementar su propio filtrado en la aplicación. Esto tiene implicaciones:
- Tráfico innecesario: el broker envía mensajes al consumidor que este descartará inmediatamente.
- Procesamiento desperdiciado: el consumidor debe deserializar y evaluar cada mensaje antes de determinar si lo procesa.
- Acknowledge complejo: el consumidor debe hacer acknowledge de mensajes que no procesó, lo cual puede ser confuso semánticamente.
Selective Consumer elimina estas ineficiencias aplicando el filtro antes de la entrega:
- El consumidor se suscribe al canal declarando una expresión de selección (selector).
- El broker evalúa cada mensaje contra el selector del consumidor.
- Solo los mensajes que satisfacen el selector son entregados al consumidor.
- Los mensajes que no satisfacen el selector son ignorados por este consumidor (pero pueden ser entregados a otros consumidores con diferentes selectores).
Principio de Diseño Subyacente¶
El principio es filtrado en el punto de entrega, no en el punto de procesamiento. En lugar de que el consumidor reciba todo y filtre, la infraestructura filtra y el consumidor recibe solo lo relevante. Esto mueve la responsabilidad del filtrado al componente que tiene acceso más eficiente a los metadatos del mensaje.
Problema Estructural que Resuelve¶
Cuando un canal transporta mensajes con diferentes niveles de relevancia para diferentes consumidores, sin selección en el endpoint:
- Cada consumidor es un filter embebido que descarta una proporción de los mensajes recibidos.
- El throughput efectivo del consumidor es una fracción del throughput total porque la mayor parte del procesamiento se gasta en evaluación y descarte.
- El dimensionamiento del consumidor debe considerar el volumen total del canal, no solo el volumen relevante.
Contexto en el que Emerge¶
Selective Consumer emerge en escenarios donde:
- Un canal transporta mensajes con atributos de clasificación (prioridad, región, tipo, cliente).
- Diferentes consumidores necesitan subconjuntos distintos de los mensajes del canal.
- El volumen total del canal es significativamente mayor que el volumen relevante para cada consumidor.
- La plataforma de messaging soporta mecanismos de selección (JMS selectors, Azure Service Bus subscription filters, SNS subscription filter policies).
Por Qué No Es Trivial¶
La decisión de dónde colocar el filtro tiene implicaciones importantes:
- En el broker: eficiente para el consumidor, pero puede sobrecargar el broker si los selectores son complejos.
- En el consumidor: no requiere soporte del broker, pero consume bandwidth y CPU del consumidor.
- En una capa intermedia (subscription/topic filter): balance entre ambos, pero requiere configuración adicional.
- Interacción con Competing Consumers: si múltiples instancias del mismo consumidor compiten, ¿todas tienen el mismo selector?
- Mensajes huérfanos: si ningún consumidor tiene un selector que matchee un mensaje, ¿qué pasa con ese mensaje?
Relación con Sistemas Distribuidos y Mensajería¶
Selective Consumer se implementa de formas muy diferentes según la plataforma:
- En JMS, los selectors son expresiones SQL-like sobre headers y properties del mensaje, evaluadas por el broker.
- En Azure Service Bus, las subscription filters en Topics son expresiones SQL o correlation filters evaluadas por el servicio.
- En AWS SNS, las subscription filter policies filtran por atributos del mensaje antes de fan-out a SQS/Lambda.
- En Kafka, no existe selector nativo; el filtrado se implementa en el consumidor (client-side) o con Kafka Streams/ksqlDB que materializan topics filtrados.
- En Google Pub/Sub, los subscription filters son expresiones evaluadas por el servicio.
La ausencia de selector nativo en Kafka es particularmente significativa: obliga a implementar el filtrado en la aplicación o a materializar topics filtrados, lo que cambia fundamentalmente la arquitectura.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Selective Consumer, un consumidor que necesita solo un subconjunto de los mensajes de un canal debe:
- Recibir todos los mensajes: el broker entrega cada mensaje al consumidor, independientemente de su relevancia.
- Deserializar y evaluar: el consumidor deserializa cada mensaje para inspeccionar los campos de clasificación.
- Descartar la mayoría: si solo el 5% de los mensajes son relevantes, el 95% del trabajo del consumidor es filtrado y descarte.
- Acknowledge lo descartado: el consumidor debe confirmar los mensajes descartados para que no se reentreguen.
Síntomas del Problema¶
- Un consumidor con CPU alta y throughput efectivo bajo (mucho procesamiento, poco trabajo real).
- Métricas de "mensajes recibidos" vs. "mensajes procesados" con un ratio muy bajo (indicador de filtrado ineficiente).
- Consumidores sobre-dimensionados para compensar el overhead de recibir y descartar mensajes irrelevantes.
- Complejidad innecesaria en el consumidor: lógica de filtrado mezclada con lógica de negocio.
- Latencia de procesamiento alta porque el consumidor está ocupado procesando (y descartando) mensajes irrelevantes.
Impacto Operativo y Arquitectónico¶
Sin filtrado en el endpoint:
- El dimensionamiento de los consumidores debe basarse en el volumen total del canal, no en el volumen relevante. Esto puede significar 10x o 20x más recursos de los necesarios.
- El monitoring por tipo de procesamiento es confuso porque las métricas incluyen mensajes descartados.
- La escalabilidad del consumidor está limitada por el volumen total del canal, incluso si solo necesita una pequeña fracción.
Riesgos Si No Se Implementa Correctamente¶
- Selector demasiado restrictivo: un selector que filtra demasiado puede causar que el consumidor no reciba mensajes que debería procesar (falsos negativos).
- Selector demasiado permisivo: un selector que no filtra suficiente anula su beneficio.
- Mensajes huérfanos: mensajes que no matchean ningún selector de ningún consumidor se acumulan en el canal sin ser procesados.
- Overhead del broker: selectores complejos evaluados en el broker pueden degradar su rendimiento.
- Evolución de selectores: cambiar un selector en producción requiere cuidado — los mensajes producidos durante el cambio pueden perderse o duplicarse.
Ejemplos Reales¶
- Logística: un canal
shipments.eventstransporta eventos de 100,000 envíos diarios. Un servicio de escalamiento solo necesita procesar eventos de envíos de alta prioridad (5% del volumen). Sin selector, el servicio recibe 100,000 eventos para procesar 5,000. - Banca: un topic de transacciones contiene todas las transacciones del banco. El equipo de compliance necesita solo las transacciones superiores a 10,000 EUR para anti-lavado. Sin selector, procesa millones de transacciones para detectar las miles relevantes.
- SaaS multi-tenant: un canal de eventos contiene eventos de todos los tenants. El servicio de un tenant enterprise necesita solo sus eventos. Sin selector, recibe los eventos de todos los tenants.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando un canal transporta mensajes con atributos de clasificación y el consumidor solo necesita un subconjunto.
- Cuando el volumen de mensajes irrelevantes es significativamente mayor que el de relevantes.
- Cuando la plataforma de messaging soporta selectors nativos y el overhead del broker es aceptable.
- Cuando múltiples consumidores comparten un canal y cada uno necesita un subconjunto diferente.
Cuándo No Usarlo¶
- Cuando el consumidor necesita todos los mensajes del canal — un selector que matchea todo es overhead sin beneficio.
- Cuando la plataforma no soporta selectors nativos (Kafka) y el client-side filtering es más directo.
- Cuando el criterio de filtrado requiere inspección profunda del payload (no solo headers/properties), lo cual la mayoría de selectores no soporta.
- Cuando el diseño correcto es tener canales separados por tipo en lugar de un canal compartido con selectores. A menudo, un canal dedicado (topic por tipo de evento) es más claro que un canal compartido con selectores.
Precondiciones¶
- Los mensajes tienen atributos de clasificación accesibles al mecanismo de selección (headers, properties, message attributes).
- La plataforma soporta algún mecanismo de selección (JMS selectors, subscription filters, filter policies).
- El criterio de selección es expresable con las primitivas que soporta la plataforma.
Restricciones¶
- Los selectores típicamente operan sobre headers y properties, no sobre el body del mensaje. Esto requiere que la información de clasificación se externalice en headers.
- La complejidad del selector puede estar limitada por la plataforma (longitud máxima de expresión, operadores soportados).
- Cambiar un selector en un consumidor activo puede requerir recrear la suscripción.
Dependencias¶
- Soporte de la plataforma de messaging para mecanismos de selección.
- Convención de que los productores incluyan atributos de clasificación en los headers/properties de los mensajes.
- Acuerdo entre productores y consumidores sobre los nombres y valores de los atributos de clasificación.
Supuestos Arquitectónicos¶
- Los atributos de clasificación están disponibles sin deserializar el payload.
- El broker puede evaluar selectores sin degradación significativa de rendimiento.
- Los mensajes que no matchean ningún selector se gestionan adecuadamente (otro consumidor sin filtro, dead-letter, expiración).
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas JMS legacy con selectores SQL.
- Arquitecturas Azure Service Bus con topic subscriptions filtradas.
- Arquitecturas AWS SNS/SQS con subscription filter policies.
- Sistemas de eventos multi-tenant donde cada tenant filtra sus eventos.
6. Fuerzas Arquitectónicas¶
Acoplamiento vs. Flexibilidad¶
Selective Consumer añade flexibilidad al permitir que diferentes consumidores del mismo canal reciban subconjuntos diferentes sin modificar el productor. Sin embargo, introduce acoplamiento implícito: el consumidor depende de que el productor incluya los atributos de clasificación en los headers. Si el productor cambia la estructura de headers, los selectores se rompen.
Simplicidad vs. Robustez¶
Un canal dedicado por tipo de mensaje es más simple y explícito que un canal compartido con selectores. Pero cuando el número de subconjuntos posibles es grande o dinámico (por ejemplo, un selector por tenant en un sistema multi-tenant), los canales dedicados producen explosión combinatoria y los selectores son más robustos.
Eficiencia del Consumidor vs. Carga del Broker¶
Mover el filtrado al broker reduce la carga del consumidor pero aumenta la del broker. Si el broker evalúa selectores complejos para miles de suscripciones, puede convertirse en cuello de botella. El balance depende de los recursos relativos de broker y consumidores.
Granularidad del Canal vs. Complejidad del Selector¶
- Canales granulares (un topic por tipo): no necesitan selectores, pero producen muchos canales.
- Canal compartido con selectores: menos canales, pero mayor complejidad en la configuración de suscripciones.
- La elección depende de la cardinalidad de los tipos: pocos tipos → canales dedicados; muchos tipos o combinaciones → selectores.
Latencia vs. Precisión¶
Un selector evaluado en el broker añade latencia de evaluación (mínima en la práctica). Un filtrado en el consumidor no añade latencia de broker pero sí latencia de transferencia y procesamiento de mensajes innecesarios. Para volúmenes altos, el selector en el broker gana en latencia efectiva.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: envía mensajes al canal con atributos de clasificación en headers/properties.
- Canal (Message Channel): el canal compartido que transporta mensajes heterogéneos.
- Selector/Filter: la expresión de filtrado asociada a la suscripción del consumidor.
- Broker/Subscription Engine: el componente que evalúa el selector contra cada mensaje.
- Consumidor Selectivo: el consumidor que solo recibe mensajes que satisfacen su selector.
Flujo Lógico¶
flowchart TD
A([Productor]) -->|Envía mensaje con headers de clasificación| B[(Canal / Broker)]
B -->|Para cada suscripción| C{Evalúa selector vs headers}
C -->|Selector matchea| D[Entrega mensaje al consumidor selectivo]
C -->|Selector no matchea| E([No entrega a este consumidor])
D --> F[Consumidor procesa mensaje]
F --> G([Acknowledge mensaje])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Incluir atributos de clasificación en headers/properties del mensaje |
| Canal/Broker | Almacenar mensajes, evaluar selectores, entregar solo mensajes que matchean |
| Selector | Definir la expresión de filtrado |
| Consumidor | Declarar su selector al suscribirse, procesar los mensajes filtrados |
Interacciones¶
- Productor → Canal: envío de mensajes con headers de clasificación.
- Consumidor → Broker: suscripción declarando el selector.
- Broker → Consumidor: entrega solo de mensajes que satisfacen el selector.
Contratos Implícitos¶
- Los headers de clasificación tienen nombres y valores conocidos por productores y consumidores.
- El selector es compatible con la sintaxis de la plataforma.
- Los mensajes que no matchean ningún selector tienen un destino definido (otro consumidor, expiración, dead-letter).
Decisiones de Diseño Clave¶
- Selector en broker vs. filtrado en cliente: ¿la plataforma soporta selectors nativos o se filtra en la aplicación?
- Atributos en headers vs. en payload: ¿la información de clasificación está en headers (accesible al selector) o en el body (requiere deserialización)?
- Selectores estáticos vs. dinámicos: ¿el selector se define al crear la suscripción y no cambia, o puede actualizarse en runtime?
- Cobertura de mensajes: ¿existe un consumidor "catch-all" que recibe mensajes que no matchean ningún otro selector?
- Combinación con Competing Consumers: ¿múltiples instancias del mismo consumidor comparten el mismo selector?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Logística — Procesamiento Prioritario de Eventos de Envío¶
Contexto del Negocio¶
Una empresa de logística global procesa 200,000 envíos diarios con tres niveles de prioridad: CRITICAL (envíos médicos, 1%), HIGH (envíos express, 9%) y STANDARD (envíos regulares, 90%). Los eventos de envío (creación, pickup, transit, delivery, exception) fluyen por un único topic de eventos.
Un equipo de operaciones de escalamiento necesita un servicio que solo procese eventos de envíos CRITICAL y HIGH para intervención proactiva. Este servicio no necesita ni debe procesar los 180,000 eventos diarios de envíos STANDARD.
Necesidad de Integración¶
El servicio de escalamiento necesita consumir selectivamente del topic logistics.shipment.events, filtrando solo los eventos con prioridad CRITICAL o HIGH. El filtrado debe ser eficiente para que el servicio no desperdicie recursos procesando y descartando el 90% del volumen.
Sistemas Involucrados¶
- Kafka Topic / Azure Service Bus Topic:
logistics.shipment.eventscon todos los eventos. - Escalation Service: consumidor selectivo que procesa solo eventos de alta prioridad.
- Standard Processing Service: consumidor que procesa todos los eventos (sin filtro).
- Notification Service: envía alertas al equipo de operaciones cuando hay excepciones en envíos prioritarios.
- Escalation Dashboard: UI que muestra el estado de envíos prioritarios.
Restricciones Técnicas¶
- El productor incluye el header
priority(CRITICAL, HIGH, STANDARD) en cada mensaje. - La latencia de procesamiento para envíos CRITICAL no debe exceder 10 segundos.
- El servicio de escalamiento debe poder escalar independientemente del servicio de procesamiento estándar.
- No se deben perder eventos de prioridad CRITICAL ni HIGH.
Diseño del Selective Consumer¶
Opción A: Azure Service Bus con Subscription Filter
Topic: logistics.shipment.events
Subscription: escalation-sub
Filter: priority IN ('CRITICAL', 'HIGH')
Subscription: standard-processing-sub
Filter: (no filter - recibe todos)
Subscription: audit-sub
Filter: (no filter - recibe todos)
Opción B: Kafka con client-side filtering
Topic: logistics.shipment.events (partitioned by shipment_id)
Consumer Group: cg-escalation
Filter (in application): message.header("priority") in ["CRITICAL", "HIGH"]
Consumer Group: cg-standard-processing
Filter: none (processes all)
Decisiones Arquitectónicas¶
- Prioridad en header, no en body: el atributo
priorityse incluye como header/property del mensaje para que sea accesible a los mecanismos de selección sin deserializar el payload. - Subscription filter (Service Bus) vs. client-side filter (Kafka): en Azure Service Bus, el filtro en la suscripción evita la entrega de mensajes irrelevantes. En Kafka, el filtrado es client-side y el consumidor recibe todos los mensajes pero solo procesa los relevantes.
- Catch-all subscription: la suscripción de procesamiento estándar no tiene filtro y recibe todos los eventos, asegurando que ningún evento quede sin procesar.
- Escalado independiente: el servicio de escalamiento se escala según el volumen de eventos prioritarios (10% del total), no según el volumen total.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Productor omite header priority | Validación en el productor + monitoring de mensajes sin header |
| Selector no matchea por typo en el valor | Enum validado para valores de prioridad + tests de integración |
| Mensajes huérfanos (no matchean ningún selector) | Subscription catch-all sin filtro |
| Kafka sin selector nativo → overhead client-side | Materializar un topic filtrado con Kafka Streams si el volumen lo justifica |
| Cambio de selector en producción pierde mensajes | Blue-green deployment de suscripciones |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Producción del Evento¶
Un envío CRITICAL de suministros médicos (ID: SHP-2026-CRIT-7291) experimenta un retraso en aduana. El sistema de tracking genera un evento:
{
"event_id": "EVT-2026-04-07-38291847",
"shipment_id": "SHP-2026-CRIT-7291",
"event_type": "EXCEPTION",
"exception_code": "CUSTOMS_DELAY",
"priority": "CRITICAL",
"timestamp": "2026-04-07T08:45:12Z",
"origin_country": "DE",
"destination_country": "ES",
"estimated_delay_hours": 4,
"cargo_description": "Medical supplies - temperature sensitive"
}
El mensaje se publica en el topic logistics.shipment.events con headers: - priority: CRITICAL - event-type: EXCEPTION - region: EMEA
Paso 2: Evaluación del Selector (Azure Service Bus)¶
El broker evalúa los filtros de cada suscripción:
- escalation-sub (filter:
priority IN ('CRITICAL', 'HIGH')):priority = 'CRITICAL'→ MATCH → entrega al Escalation Service. - standard-processing-sub (sin filtro): → MATCH → entrega al Standard Processing Service.
- audit-sub (sin filtro): → MATCH → entrega al Audit Service.
El Escalation Service recibe el mensaje; el Standard Processing Service también; ninguno recibe mensajes que no le corresponden.
Paso 3: Procesamiento en el Escalation Service¶
El Escalation Service recibe el evento EXCEPTION para un envío CRITICAL:
- Evalúa la severidad: envío CRITICAL + excepción CUSTOMS_DELAY + delay estimado 4 horas → severidad ALTA.
- Consulta el SLA del envío: entrega comprometida para hoy a las 14:00.
- Calcula impacto: con 4 horas de delay, la entrega estimada sería a las 16:45, incumpliendo el SLA por 2:45.
- Crea un caso de escalamiento en el sistema de gestión de incidentes.
- Envía notificación inmediata al equipo de operaciones EMEA via el Notification Service.
- Actualiza el Escalation Dashboard con el nuevo caso.
Paso 4: Mensajes Estándar No Entregados¶
Simultáneamente, 500 eventos de envíos STANDARD llegan al topic. La suscripción escalation-sub evalúa cada uno:
priority = 'STANDARD'→ NO MATCH → el mensaje NO se entrega al Escalation Service.
El Escalation Service no recibe estos 500 mensajes, no los deserializa, no los evalúa. Su throughput y latencia no se ven afectados por el volumen de mensajes estándar.
Paso 5: Monitoreo¶
El dashboard operacional muestra:
- escalation-sub: 200 mensajes/hora (solo CRITICAL + HIGH).
- standard-processing-sub: 20,000 mensajes/hora (todos).
- Ratio de filtrado: el Escalation Service procesa solo el 1% del volumen total.
- Latencia del Escalation Service: p99 = 3 segundos (dentro del SLA de 10s).
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
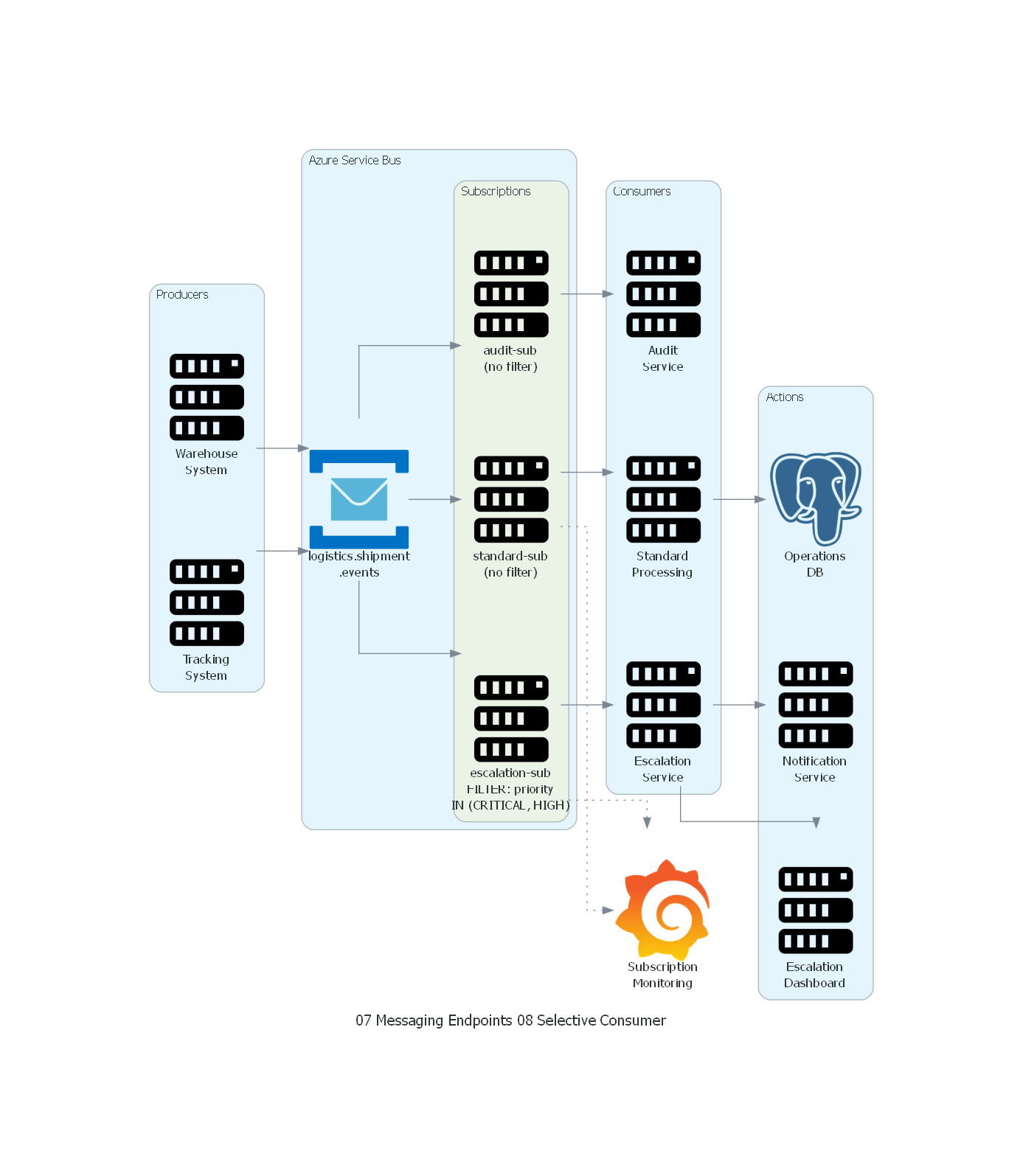
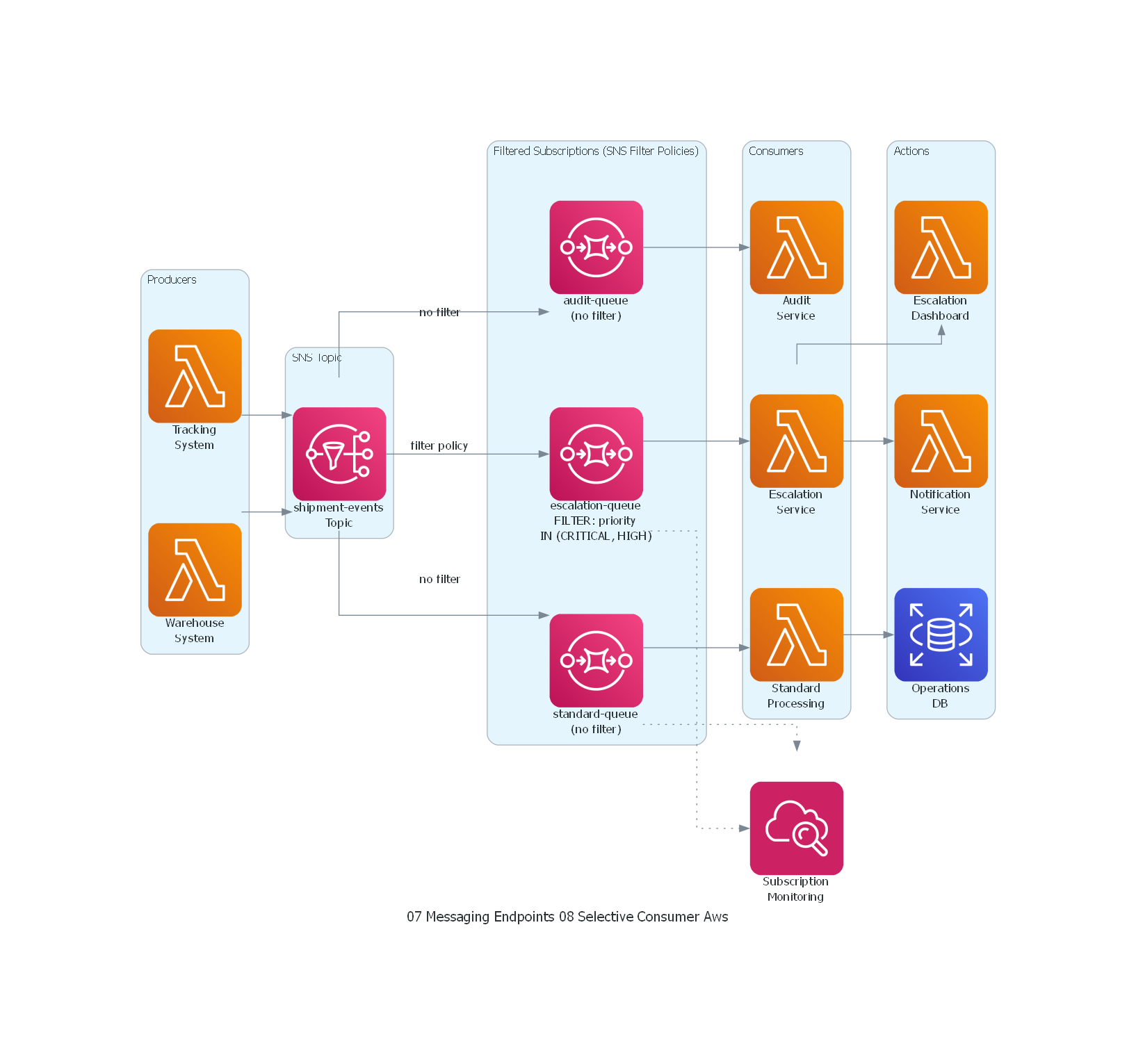
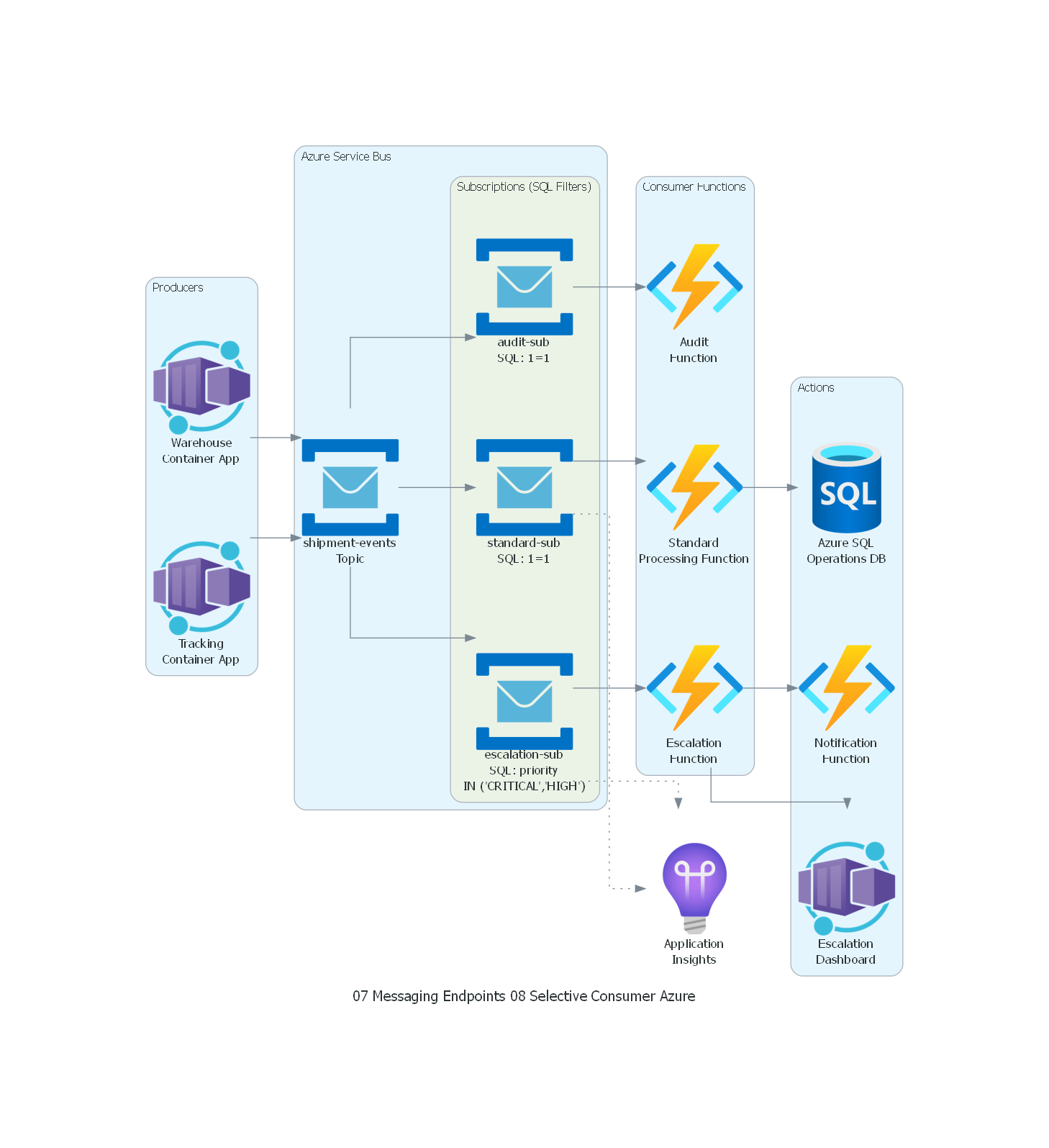
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.azure.integration import ServiceBus
with Diagram("Selective Consumer - Logistics Priority Filtering", show=False, direction="LR"):
with Cluster("Producers"):
tracking = Server("Tracking\nSystem")
warehouse = Server("Warehouse\nSystem")
with Cluster("Azure Service Bus"):
topic = ServiceBus("logistics.shipment\n.events")
with Cluster("Subscriptions"):
esc_sub = Server("escalation-sub\nFILTER: priority\nIN (CRITICAL, HIGH)")
std_sub = Server("standard-sub\n(no filter)")
audit_sub = Server("audit-sub\n(no filter)")
with Cluster("Consumers"):
escalation = Server("Escalation\nService")
standard = Server("Standard\nProcessing")
audit = Server("Audit\nService")
with Cluster("Actions"):
dashboard = Server("Escalation\nDashboard")
notifications = Server("Notification\nService")
db = PostgreSQL("Operations\nDB")
monitoring = Grafana("Subscription\nMonitoring")
# Flow
tracking >> topic
warehouse >> topic
topic >> esc_sub >> escalation
topic >> std_sub >> standard
topic >> audit_sub >> audit
escalation >> dashboard
escalation >> notifications
standard >> db
esc_sub >> Edge(style="dotted") >> monitoring
std_sub >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import RDS
from diagrams.aws.integration import SNS, SQS
from diagrams.aws.management import Cloudwatch
with Diagram("Selective Consumer - Logistics Priority Filtering (AWS)", show=False, direction="LR"):
with Cluster("Producers"):
tracking = Lambda("Tracking\nSystem")
warehouse = Lambda("Warehouse\nSystem")
with Cluster("SNS Topic"):
topic = SNS("shipment-events\nTopic")
with Cluster("Filtered Subscriptions (SNS Filter Policies)"):
esc_q = SQS("escalation-queue\nFILTER: priority\nIN (CRITICAL, HIGH)")
std_q = SQS("standard-queue\n(no filter)")
audit_q = SQS("audit-queue\n(no filter)")
with Cluster("Consumers"):
escalation = Lambda("Escalation\nService")
standard = Lambda("Standard\nProcessing")
audit = Lambda("Audit\nService")
with Cluster("Actions"):
dashboard = Lambda("Escalation\nDashboard")
notifications = Lambda("Notification\nService")
db = RDS("Operations\nDB")
monitoring = Cloudwatch("Subscription\nMonitoring")
# Flow
tracking >> topic
warehouse >> topic
topic >> Edge(label="filter policy") >> esc_q >> escalation
topic >> Edge(label="no filter") >> std_q >> standard
topic >> Edge(label="no filter") >> audit_q >> audit
escalation >> dashboard
escalation >> notifications
standard >> db
esc_q >> Edge(style="dotted") >> monitoring
std_q >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import SQLDatabases
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Selective Consumer - Logistics Priority Filtering (Azure)", show=False, direction="LR"):
with Cluster("Producers"):
tracking = ContainerApps("Tracking\nContainer App")
warehouse = ContainerApps("Warehouse\nContainer App")
with Cluster("Azure Service Bus"):
topic = ServiceBus("shipment-events\nTopic")
with Cluster("Subscriptions (SQL Filters)"):
esc_sub = ServiceBus("escalation-sub\nSQL: priority\nIN ('CRITICAL','HIGH')")
std_sub = ServiceBus("standard-sub\nSQL: 1=1")
audit_sub = ServiceBus("audit-sub\nSQL: 1=1")
with Cluster("Consumer Functions"):
escalation = FunctionApps("Escalation\nFunction")
standard = FunctionApps("Standard\nProcessing Function")
audit = FunctionApps("Audit\nFunction")
with Cluster("Actions"):
dashboard = ContainerApps("Escalation\nDashboard")
notifications = FunctionApps("Notification\nFunction")
db = SQLDatabases("Azure SQL\nOperations DB")
monitoring = ApplicationInsights("Application\nInsights")
# Flow
tracking >> topic
warehouse >> topic
topic >> esc_sub >> escalation
topic >> std_sub >> standard
topic >> audit_sub >> audit
escalation >> dashboard
escalation >> notifications
standard >> db
esc_sub >> Edge(style="dotted") >> monitoring
std_sub >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura del Selective Consumer para procesamiento prioritario de eventos logísticos:
- Los sistemas de Tracking y Warehouse producen eventos al topic logistics.shipment.events.
- El topic tiene tres suscripciones, cada una con su propio filtro:
- escalation-sub: filtro
priority IN ('CRITICAL', 'HIGH')— solo entrega eventos prioritarios. - standard-sub: sin filtro — entrega todos los eventos.
- audit-sub: sin filtro — entrega todos los eventos para auditoría.
- El Escalation Service solo recibe el subconjunto filtrado, procesando con baja latencia.
- El Standard Processing y Audit Service reciben todo el volumen.
- Grafana monitorea el throughput y lag de cada suscripción.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Message Channel | Topic logistics.shipment.events |
| Selector/Filter | Filtro en escalation-sub |
| Selective Consumer | Escalation Service (consume solo lo filtrado) |
| Non-selective Consumer | Standard Processing (consume todo) |
| Atributo de clasificación | Header "priority" del mensaje |
| Subscription Engine | Azure Service Bus subscription filters |
11. Beneficios¶
Impacto Técnico¶
- Reducción de volumen: el consumidor selectivo procesa solo los mensajes relevantes, reduciendo el throughput necesario. En el ejemplo, el Escalation Service procesa 1% del volumen total.
- Menor latencia: al procesar menos mensajes, el consumidor tiene menor latencia y mayor capacidad de respuesta para los mensajes que sí importan.
- Dimensionamiento eficiente: el consumidor se dimensiona según el volumen filtrado, no según el volumen total del canal. Esto reduce costos de infraestructura significativamente.
- Separación de concerns: la lógica de filtrado está declarada en la suscripción, no embebida en el código del consumidor.
Impacto Organizacional¶
- Independencia de equipos: el equipo de escalamiento configura su propio selector sin depender del equipo que mantiene el productor o el procesamiento estándar.
- Claridad de responsabilidad: el selector documenta explícitamente qué mensajes procesa cada servicio.
- Evolución independiente: cambiar el criterio de filtrado (por ejemplo, incluir prioridad MEDIUM) solo requiere actualizar el selector, sin cambiar código.
Impacto Operacional¶
- Monitoreo por suscripción: cada suscripción tiene sus propias métricas de lag, throughput y errores, proporcionando visibilidad granular.
- Aislamiento: un problema en el Escalation Service no afecta al Standard Processing ni viceversa.
- Backpressure natural: si el Escalation Service se atrasa, solo los mensajes prioritarios se acumulan, no todo el volumen del canal.
Beneficios de Mantenibilidad y Evolución¶
- Nuevos consumidores selectivos: añadir un nuevo consumidor con un selector diferente (por ejemplo, solo región APAC) solo requiere crear una nueva suscripción.
- Evolución del criterio: cambiar el selector no requiere redespliegue de la aplicación (en plataformas que permiten actualizar suscripciones dinámicamente).
- Migración: si se decide crear un canal dedicado para eventos CRITICAL, se puede migrar gradualmente cambiando el selector antes de crear el canal.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Gestión de suscripciones: cada consumidor selectivo requiere una suscripción con su selector. En sistemas con muchos consumidores, las suscripciones proliferan y se vuelven difíciles de gestionar.
- Dependencia de headers: los selectores requieren que la información de clasificación esté en headers/properties. Si el productor no los incluye o los incluye incorrectamente, el filtrado falla silenciosamente.
- Debugging: cuando un consumidor no recibe un mensaje esperado, diagnosticar si el problema está en el selector, en los headers del mensaje o en el broker requiere investigación en múltiples niveles.
Riesgos de Mal Uso¶
- Selector como sustituto de diseño de canales: usar selectores complejos sobre un canal mega-compartido cuando la solución correcta es tener canales dedicados. Los selectores compensan un mal diseño de canales, no lo resuelven.
- Selectores no testeados: cambiar un selector sin tests de integración puede hacer que el consumidor deje de recibir mensajes o reciba mensajes incorrectos.
- Mensajes huérfanos: si todos los consumidores tienen selectores y ninguno matchea un mensaje, ese mensaje queda sin procesar indefinidamente.
Sobreingeniería¶
- Selectores dinámicos por request: construir un sistema que genere selectores dinámicamente por cada request o por cada usuario, creando miles de suscripciones efímeras que sobrecargan el broker.
- Filtrado multicapa: aplicar selectores en el broker Y filtrado adicional en la aplicación, duplicando la lógica de filtrado en dos lugares que pueden desincronizarse.
Costos de Operación¶
- Carga del broker: en plataformas donde el broker evalúa los selectores (JMS, Azure Service Bus), muchas suscripciones con selectores complejos pueden degradar el rendimiento del broker.
- Storage por suscripción: en Azure Service Bus, cada suscripción mantiene su propia cola de mensajes, consumiendo storage proporcional al volumen filtrado.
Anti-Patterns Relacionados¶
- God Channel con mil selectores: un solo canal para toda la organización con cientos de selectores es más complejo y frágil que canales bien diseñados.
- Selector sin catch-all: todas las suscripciones tienen selectores restrictivos y ninguna captura mensajes que no matchean, resultando en mensajes perdidos.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Message Filter: Message Filter es un patrón de routing que filtra mensajes entre canales. Selective Consumer aplica el mismo concepto pero en el endpoint de consumo, no en el routing.
- Content-Based Router: un CBR inspecciona el contenido del mensaje y lo redirige a diferentes canales. Selective Consumer es un CBR invertido: el consumidor declara qué quiere recibir, en lugar de que un router decida a dónde enviar.
- Publish-Subscribe Channel: Selective Consumer opera típicamente sobre canales pub-sub donde múltiples consumidores comparten el canal.
- Competing Consumers: múltiples instancias del mismo consumidor selectivo (mismo selector) compiten por los mensajes filtrados.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Message Channel define el canal compartido. El productor usa Message con headers de clasificación.
- Después: los mensajes filtrados pueden procesarse con Message Dispatcher interno si hay múltiples tipos de evento dentro del subconjunto filtrado.
Combinaciones Comunes¶
- Selective Consumer + Competing Consumers: múltiples instancias del Escalation Service con el mismo selector compiten por los eventos prioritarios.
- Selective Consumer + Durable Subscriber: la suscripción es durable para no perder mensajes filtrados durante downtime.
- Selective Consumer + Idempotent Receiver: los mensajes filtrados pueden reentregarse, por lo que el consumidor debe ser idempotente.
Diferencias con Patrones Similares¶
- vs. Message Filter: Message Filter es un componente explícito en un pipeline de routing. Selective Consumer es una capacidad del endpoint.
- vs. Message Dispatcher: el dispatcher distribuye mensajes ya recibidos a handlers internos. El Selective Consumer filtra antes de recibir.
- vs. Content-Based Router: el router actúa en el productor/medio. El Selective Consumer actúa en el consumidor.
Encaje en un Flujo Mayor de Integración¶
Selective Consumer es el último punto de filtrado antes del procesamiento. En una cadena completa: el productor publica en un canal (Message Channel), opcionalmente un router redistribuye (Content-Based Router), y el consumidor selectivo filtra en el punto de entrega (Selective Consumer). Cada nivel de filtrado reduce el volumen que debe procesar el siguiente nivel.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Argumentación¶
La relevancia del Selective Consumer depende fuertemente de la plataforma de messaging:
- Alta relevancia en Azure Service Bus, AWS SNS, Google Pub/Sub y JMS, donde los subscription filters son nativos y ampliamente utilizados.
- Baja relevancia directa en Kafka, donde no existe selector nativo y el filtrado se implementa client-side o materializando topics filtrados con Kafka Streams.
En las arquitecturas modernas, la tendencia es hacia canales más granulares (un topic por tipo de evento) en lugar de canales compartidos con selectores. Esto reduce la necesidad de filtrado en el endpoint. Sin embargo, en escenarios multi-tenant, multi-region o con filtrado por atributos dinámicos, los selectores siguen siendo la solución más pragmática.
Qué Parte Sigue Siendo Esencial¶
- El concepto de filtrado en el endpoint: independientemente de cómo se implemente, la idea de que el consumidor declare qué mensajes necesita es fundamental.
- La decisión de dónde filtrar: broker-side vs. client-side vs. materialización de topics filtrados es una decisión arquitectónica recurrente.
- La gestión de headers de clasificación: la práctica de incluir atributos de filtrado en headers/properties del mensaje es universal.
Cómo Se Implementa Hoy¶
| Plataforma | Implementación | Tipo de filtrado |
|---|---|---|
| Azure Service Bus | Subscription SQL/Correlation Filter | Broker-side |
| AWS SNS | Subscription Filter Policy | Broker-side |
| Google Pub/Sub | Subscription Filter | Broker-side |
| JMS (ActiveMQ, etc.) | Message Selector (SQL92 subset) | Broker-side |
| Kafka | Consumer-side filter / Kafka Streams | Client-side / Materialización |
| RabbitMQ | Routing Key + Binding | Broker-side (routing, no SQL) |
15. Implementación en Arquitecturas Modernas¶
Azure Service Bus (Subscription Filter)¶
// Crear suscripción con filtro SQL
var options = new CreateSubscriptionOptions("logistics.shipment.events", "escalation-sub");
var rule = new CreateRuleOptions("priority-filter",
new SqlRuleFilter("priority IN ('CRITICAL', 'HIGH')"));
await adminClient.CreateSubscriptionAsync(options);
await adminClient.CreateRuleAsync("logistics.shipment.events", "escalation-sub", rule);
// Consumir de la suscripción filtrada
var processor = client.CreateProcessor(
"logistics.shipment.events", "escalation-sub");
processor.ProcessMessageAsync += async (args) => {
// Solo recibe mensajes CRITICAL y HIGH
var body = args.Message.Body.ToString();
await ProcessEscalation(body);
await args.CompleteMessageAsync(args.Message);
};
AWS SNS (Subscription Filter Policy)¶
Solo los mensajes con MessageAttribute priority igual a CRITICAL o HIGH se entregan a la SQS queue suscrita.
Kafka (Client-Side Filtering)¶
@KafkaListener(topics = "logistics.shipment.events", groupId = "cg-escalation")
public void consume(ConsumerRecord<String, ShipmentEvent> record) {
String priority = new String(record.headers()
.lastHeader("priority").value());
if (!"CRITICAL".equals(priority) && !"HIGH".equals(priority)) {
return; // skip - client-side filtering
}
processEscalation(record.value());
}
En Kafka, el filtrado es responsabilidad del consumidor. Para alto volumen, una alternativa más eficiente es materializar un topic filtrado con Kafka Streams:
KStream<String, ShipmentEvent> all = builder.stream("logistics.shipment.events");
KStream<String, ShipmentEvent> priority = all.filter((key, event) ->
"CRITICAL".equals(event.getPriority()) || "HIGH".equals(event.getPriority()));
priority.to("logistics.shipment.events.priority");
Google Pub/Sub (Subscription Filter)¶
from google.cloud import pubsub_v1
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project, "escalation-sub")
# La suscripción se crea con filtro:
# filter = 'attributes.priority = "CRITICAL" OR attributes.priority = "HIGH"'
def callback(message):
# Solo recibe mensajes que pasaron el filtro
process_escalation(message.data)
message.ack()
subscriber.subscribe(subscription_path, callback=callback)
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas por suscripción: cada suscripción filtrada debe tener sus propias métricas de throughput, lag, error rate y message age.
- Ratio de filtrado: monitorear qué porcentaje de los mensajes del canal pasa cada filtro. Un cambio inesperado en el ratio indica un problema en el productor o en el selector.
- Tracing: los mensajes filtrados deben mantener la cadena de tracing para poder correlacionarlos con el evento original.
Monitoreo¶
- Selector coverage: verificar que todos los mensajes del canal son matcheados por al menos un selector. Mensajes sin match son potencialmente huérfanos.
- Selector performance: en plataformas donde el broker evalúa selectores, monitorear el tiempo de evaluación para detectar selectores que degradan rendimiento.
- Subscription health: monitorear el estado de cada suscripción (activa, inactiva, lag creciente).
Versionado¶
- Selector como configuración versionada: tratar los selectores como configuración que se versiona en Git, no como configuración manual del broker.
- Evolución de atributos: si los atributos de clasificación cambian (renaming, nuevos valores), los selectores deben actualizarse coordinadamente.
Seguridad¶
- Authorization por suscripción: cada suscripción filtrada puede tener permisos diferentes, restringiendo quién puede consumir qué subconjunto de mensajes.
- Data isolation: en escenarios multi-tenant, los selectores deben asegurar que un tenant no pueda recibir mensajes de otro.
Manejo de Errores¶
- Selector inválido: un selector con sintaxis incorrecta debe ser rechazado al crear la suscripción, no al intentar consumir.
- Header ausente: definir el comportamiento cuando un mensaje no tiene el header sobre el que opera el selector (¿match o no match?).
- Dead-letter por suscripción: cada suscripción filtrada puede tener su propia dead-letter queue.
Performance¶
- Límite de suscripciones: cada plataforma tiene un límite práctico de suscripciones por topic. Azure Service Bus: 2,000. Google Pub/Sub: 10,000.
- Complejidad del selector: selectores simples (igualdad, IN) se evalúan rápidamente. Selectores con funciones, LIKE o expresiones complejas pueden ser lentos.
- Índice de atributos: algunas plataformas indexan los atributos del mensaje para acelerar la evaluación de selectores.
Escalabilidad¶
- La escalabilidad de cada suscripción filtrada es independiente. El consumidor selectivo se escala según el volumen filtrado.
- Añadir nuevas suscripciones no afecta a las existentes (en plataformas bien diseñadas).
17. Errores Comunes¶
Usar Selectores Como Sustituto de Canales Dedicados¶
Cuando el criterio de filtrado es estable y bien conocido (por ejemplo, tipos de evento), la solución correcta suele ser canales dedicados (un topic por tipo) en lugar de un canal compartido con selectores. Los selectores añaden complejidad y dependencia de headers; los canales dedicados son explícitos y auto-documentados.
No Incluir Atributos de Clasificación en Headers¶
Si la información de filtrado está solo en el body del mensaje, los mecanismos de selección broker-side no pueden acceder a ella. Los productores deben extraer los atributos de clasificación relevantes a headers/properties del mensaje. Este es un contrato que debe documentarse y validarse.
No Tener un Consumidor Catch-All¶
Si todas las suscripciones tienen selectores restrictivos y un mensaje no matchea ninguno, ese mensaje queda huérfano. Siempre debe existir al menos una suscripción sin filtro (o con filtro permisivo) que capture todos los mensajes, aunque solo sea para auditoría o dead-letter.
Selectores Que No Se Testean¶
Un selector con un typo (priortiy en lugar de priority) o un valor incorrecto (CRITICA en lugar de CRITICAL) filtra silenciosamente todos los mensajes, y el consumidor parece estar funcionando correctamente pero sin procesar nada. Los selectores deben testearse con mensajes de prueba como parte del pipeline de CI/CD.
Ignorar el Comportamiento en Kafka¶
Asumir que Kafka soporta selectores nativos y diseñar la arquitectura en consecuencia lleva a implementaciones ineficientes. En Kafka, la alternativa correcta es materializar topics filtrados con Kafka Streams o aceptar el filtrado client-side y dimensionar el consumidor en consecuencia.
Selectores Demasiado Complejos¶
Un selector como priority IN ('CRITICAL', 'HIGH') AND region = 'EMEA' AND event_type != 'HEARTBEAT' AND customer_tier >= 3 es difícil de mantener, testear y debuggear. Si la lógica de filtrado es compleja, es preferible un canal dedicado o un Message Filter explícito antes del consumidor.
18. Conclusión Técnica¶
Selective Consumer es un patrón de endpoint que permite a los consumidores declarar qué mensajes necesitan recibir, filtrando en la infraestructura de messaging antes de la entrega. Es la respuesta a la pregunta: ¿cómo evita un consumidor procesar mensajes irrelevantes cuando comparte un canal con otros consumidores?
Cuándo aporta valor: cuando un canal transporta mensajes con atributos de clasificación y el consumidor solo necesita un subconjunto, especialmente cuando el volumen irrelevante es significativamente mayor que el relevante. El valor está en la reducción de procesamiento, la eficiencia de recursos y la claridad de responsabilidad.
Cuándo evita problemas importantes: en escenarios multi-tenant donde la separación de datos entre tenants es crítica, los selectores aseguran que cada consumidor solo recibe los mensajes de su tenant. En escenarios de priorización, los selectores permiten dimensionar consumidores prioritarios de forma eficiente.
Cuándo no conviene adoptarlo: cuando la solución correcta es tener canales dedicados por tipo, cuando la plataforma no soporta selectores nativos (Kafka) y el filtrado client-side es aceptable, o cuando todos los mensajes del canal son relevantes para el consumidor.
Recomendación para arquitectos: evalúe si los selectores son la solución correcta o si canales dedicados serían más claros. Si usa selectores, trate los atributos de clasificación como un contrato de integración: documéntelos, valídelos en el productor, testeelos en CI/CD, y asegure que existe un consumidor catch-all para mensajes que no matchean ningún selector. En Kafka, considere materializar topics filtrados con Kafka Streams como alternativa arquitectónicamente más limpia que el filtrado client-side.