Durable Subscriber¶
1. Nombre del Patrón¶
- Nombre oficial: Durable Subscriber
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Suscriptor Durable / Suscriptor Persistente
2. Resumen Ejecutivo¶
Durable Subscriber es un patrón de endpoint que garantiza que un suscriptor no pierda mensajes publicados en un canal publish-subscribe durante los períodos en que está desconectado o no disponible. A diferencia de un suscriptor no durable que solo recibe mensajes mientras está activamente conectado, un suscriptor durable mantiene su suscripción registrada en el broker incluso cuando está offline, y el broker almacena los mensajes pendientes para entregarlos cuando el suscriptor se reconecte.
El problema que resuelve es la fiabilidad del consumo en escenarios pub-sub: en un modelo publish-subscribe estándar, si un suscriptor está caído durante una publicación, pierde ese mensaje para siempre. Esto es inaceptable en escenarios donde la completitud del consumo es crítica. Durable Subscriber responde registrando una suscripción persistente que sobrevive a desconexiones, reinicios y ventanas de mantenimiento.
Este patrón es esencial en banca, donde un suscriptor de auditoría que registra cada transacción para cumplimiento regulatorio no puede permitirse perder ni un solo evento, ni siquiera durante un deploy o un reinicio planificado. La durabilidad de la suscripción garantiza que todos los mensajes publicados durante el downtime estén disponibles cuando el suscriptor vuelva.
3. Definición Detallada¶
Propósito¶
Durable Subscriber establece una suscripción persistente entre un consumidor y un canal publish-subscribe que sobrevive a desconexiones del consumidor. El broker retiene los mensajes publicados durante la ausencia del suscriptor y los entrega cuando este se reconecta, asegurando que no se pierde ningún mensaje.
Lógica Arquitectónica¶
En el modelo publish-subscribe, el broker mantiene una lista de suscriptores para cada canal. Cuando un mensaje se publica, el broker lo entrega a todos los suscriptores activos. El problema surge cuando un suscriptor se desconecta:
- Suscriptor no durable: la suscripción se elimina cuando el suscriptor se desconecta. Los mensajes publicados durante la desconexión no se almacenan para este suscriptor y se pierden irrecuperablemente.
- Suscriptor durable: la suscripción persiste en el broker aunque el suscriptor se desconecte. Los mensajes publicados durante la desconexión se almacenan en la suscripción y se entregan cuando el suscriptor se reconecta.
Esta distinción tiene consecuencias arquitectónicas fundamentales:
- Completitud garantizada: el suscriptor durable procesará eventualmente todos los mensajes publicados, sin gaps temporales.
- Desacoplamiento temporal real: el productor y el consumidor no necesitan estar activos simultáneamente. El messaging asíncrono alcanza su pleno potencial.
- Costo de storage: los mensajes retenidos para suscriptores ausentes consumen storage en el broker. Si un suscriptor está offline por períodos prolongados, la acumulación puede ser significativa.
Principio de Diseño Subyacente¶
El principio es suscripción con estado persistente en el broker. En lugar de que la suscripción sea una relación efímera que existe solo mientras el suscriptor está conectado, la suscripción es un recurso persistente con su propio estado (posición de lectura, mensajes pendientes) que el broker gestiona independientemente del ciclo de vida del suscriptor.
Problema Estructural que Resuelve¶
En un sistema distribuido, los consumidores experimentan interrupciones por múltiples razones:
- Deploys: durante un rolling update, las instancias se reinician.
- Mantenimiento: parches de seguridad, upgrades de runtime, cambios de configuración.
- Fallos: crash de la aplicación, OOM, fallo de hardware.
- Escalado: auto-scaling que reduce instancias durante períodos de bajo tráfico.
Sin durabilidad, cada una de estas interrupciones produce un gap en el procesamiento. En sistemas con alta frecuencia de publicación, incluso un reinicio de 30 segundos puede significar cientos de mensajes perdidos.
Contexto en el que Emerge¶
Durable Subscriber emerge en cualquier escenario donde:
- El canal es publish-subscribe (múltiples consumidores independientes).
- La completitud del consumo es un requisito (audit, compliance, reconciliación).
- Los consumidores experimentan interrupciones (deploys, mantenimiento, fallos).
- La pérdida de un solo mensaje tiene consecuencias de negocio (financieras, regulatorias, operacionales).
Por Qué No Es Trivial¶
La durabilidad introduce complejidades que deben gestionarse:
- Acumulación de backlog: si un suscriptor está offline por mucho tiempo, los mensajes se acumulan. ¿Cuánto storage se asigna? ¿Qué pasa cuando se llena?
- Catch-up performance: cuando el suscriptor se reconecta, debe procesar el backlog acumulado. Si el volumen es alto, el catch-up puede tomar horas y el suscriptor estará procesando mensajes "del pasado" mientras siguen llegando mensajes nuevos.
- Suscripciones huérfanas: si un suscriptor se elimina sin desregistrar su suscripción durable, los mensajes se siguen acumulando indefinidamente sin ser consumidos.
- Ordering durante catch-up: ¿el suscriptor procesa el backlog en orden o puede saltar mensajes antiguos para priorizar mensajes recientes?
- Idempotencia: durante reconexiones, puede haber overlap — mensajes que ya fueron entregados pero no confirmados. El suscriptor debe ser idempotente.
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, Durable Subscriber implementa una forma de reliable delivery en el contexto pub-sub. La suscripción durable actúa como un buffer del consumidor gestionado por el broker, similar al concepto de mailbox en sistemas de actores.
Cada plataforma implementa la durabilidad de forma diferente:
- En Kafka, toda suscripción es inherentemente durable: el consumer group mantiene su offset en el log, y los mensajes se retienen por política de retención independientemente de si fueron consumidos. Kafka no tiene el concepto de suscriptor "no durable" — el log persiste.
- En Azure Service Bus, una subscription en un Topic es durable por defecto: los mensajes se almacenan en la subscription queue hasta que se consumen o expiran.
- En JMS (ActiveMQ, etc.), existe la distinción explícita entre
createConsumer(no durable) ycreateDurableSubscriber(durable). El suscriptor durable tiene un nombre registrado que persiste en el broker. - En RabbitMQ, una queue durable con binding a un exchange persiste los mensajes. Si no hay queue (suscriptor no durable), los mensajes del exchange se descartan.
- En Google Pub/Sub, las subscriptions son durables por defecto con retención configurable (por defecto 7 días, máximo 31 días).
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Durable Subscriber, un sistema publish-subscribe tiene una debilidad fundamental: los mensajes publicados mientras un suscriptor está offline se pierden para ese suscriptor. Esto crea un modelo de entrega "best-effort" que solo funciona cuando todos los suscriptores están siempre disponibles — una suposición imposible en sistemas distribuidos.
Las consecuencias incluyen:
- Gaps en el procesamiento: el suscriptor procesa todos los mensajes excepto los publicados durante sus ventanas de downtime, creando gaps invisibles.
- Inconsistencia: diferentes suscriptores del mismo canal tienen visiones diferentes de la realidad, porque cada uno perdió mensajes en momentos diferentes.
- Miedo al deploy: los equipos evitan desplegar sus servicios porque cada deploy implica pérdida de mensajes. Los deploys se acumulan y se convierten en "big bang" releases.
- Reconciliación manual: se necesitan procesos batch periódicos para detectar y reparar los gaps, lo cual es costoso y propenso a errores.
Síntomas del Problema¶
- Discrepancias entre el conteo de mensajes publicados y el conteo de mensajes procesados por cada suscriptor.
- Auditorías que detectan transacciones no registradas en el log de auditoría.
- Procesos de reconciliación de fin de día que encuentran inconsistencias después de cada ventana de mantenimiento.
- Equipos que programan deploys solo durante horas de bajo tráfico para minimizar la pérdida.
- Arquitecturas que duplican la publicación a un segundo canal "de backup" para mitigar la pérdida.
Impacto Operativo y Arquitectónico¶
Sin durabilidad:
- La confiabilidad del sistema pub-sub es proporcional al uptime del suscriptor más débil.
- Los SLAs de completitud de procesamiento no pueden cumplirse si los consumidores tienen downtime.
- Se necesitan mecanismos compensatorios (reconciliación, replay, re-publicación) que añaden complejidad y costo.
- La arquitectura event-driven pierde una de sus promesas fundamentales: el desacoplamiento temporal.
Riesgos Si No Se Implementa Correctamente¶
- Suscripción huérfana: una suscripción durable que nadie consume acumula mensajes indefinidamente, consumiendo storage del broker.
- Backlog inmanejable: un suscriptor que estuvo offline durante horas o días enfrenta un backlog masivo al reconectarse, potencialmente causando presión de memoria o timeout.
- Falsa seguridad: asumir que la suscripción durable garantiza entrega exactamente una vez (solo garantiza al menos una vez; la idempotencia sigue siendo necesaria).
- Retención insuficiente: si la política de retención del broker expira mensajes antes de que el suscriptor se reconecte, la durabilidad es inútil.
Ejemplos Reales¶
- Banca: un suscriptor de auditoría registra cada transacción bancaria para cumplimiento de SOX/Basel. Si pierde transacciones durante un deploy de 2 minutos a las 10:00 AM (hora pico), puede faltar documentación de miles de transacciones, resultando en hallazgos de auditoría externa.
- Salud: un suscriptor que alimenta el historial clínico electrónico con resultados de laboratorio. Si pierde un resultado durante mantenimiento, el médico toma decisiones sin información completa.
- E-commerce: un suscriptor que actualiza el inventario basándose en ventas. Si pierde eventos de venta durante un deploy, el inventario queda desincronizado y se venden productos agotados.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando la completitud del consumo es un requisito de negocio (audit, compliance, reconciliación).
- Cuando el suscriptor experimenta downtime planificado (deploys, mantenimiento) o no planificado (fallos).
- Cuando la pérdida de un solo mensaje tiene consecuencias de negocio inaceptables.
- Cuando el canal es publish-subscribe y múltiples suscriptores independientes consumen de forma desacoplada.
- Cuando el desacoplamiento temporal entre productor y consumidor es un objetivo arquitectónico.
Cuándo No Usarlo¶
- Cuando los mensajes son efímeros y la pérdida es aceptable (por ejemplo, heartbeats, métricas de telemetría de baja criticidad).
- Cuando el suscriptor está siempre disponible y la probabilidad de downtime es negligible (raro en la práctica).
- Cuando la plataforma hace la durabilidad innecesaria como concepto explícito (Kafka, donde el log retiene todo).
- Cuando los mensajes tienen TTL corto y pierden relevancia rápidamente (alertas de tráfico en tiempo real).
Precondiciones¶
- La plataforma de messaging soporta suscripciones durables (JMS durable subscriptions, Azure Service Bus subscriptions, Google Pub/Sub subscriptions, Kafka consumer groups).
- El broker tiene storage suficiente para retener mensajes durante el downtime esperado del suscriptor.
- Existe una política de retención definida que cubre las ventanas de downtime más largas esperadas.
Restricciones¶
- El storage del broker es finito; la retención tiene límites.
- El catch-up después de un downtime prolongado puede impactar el rendimiento del suscriptor y del broker.
- La suscripción durable es un recurso que debe gestionarse (crear, monitorear, eliminar cuando no se necesita).
Dependencias¶
- Infraestructura de messaging con soporte de durabilidad.
- Política de retención configurada adecuadamente.
- Monitoreo de consumer lag para detectar suscriptores atrasados.
- Idempotencia en los handlers (porque la durabilidad implica at-least-once delivery).
Supuestos Arquitectónicos¶
- El broker es confiable y no pierde mensajes retenidos (replicación, persistence).
- La política de retención es suficiente para cubrir las ventanas de downtime más largas.
- El suscriptor puede procesar el backlog acumulado en un tiempo razonable tras la reconexión.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas financieros y bancarios (audit trails, compliance).
- Sistemas de salud (historiales clínicos, resultados de laboratorio).
- E-commerce (inventario, fulfillment, reconciliación).
- Cualquier sistema event-driven con requisitos de completitud.
6. Fuerzas Arquitectónicas¶
Completitud vs. Costo de Storage¶
La durabilidad garantiza que ningún mensaje se pierde durante el downtime, pero requiere que el broker retenga mensajes para suscriptores ausentes. Cuanto más largo sea el downtime potencial, más storage se necesita. El balance está en definir políticas de retención que cubran los escenarios de downtime realistas sin sobre-dimensionar el storage.
Fiabilidad vs. Latencia de Catch-Up¶
Un suscriptor que se reconecta después de un downtime prolongado debe procesar un backlog potencialmente grande. Durante el catch-up, el suscriptor está procesando mensajes "del pasado" mientras siguen llegando mensajes nuevos. La latencia del procesamiento de mensajes recientes se degrada hasta que el backlog se consume.
Desacoplamiento Temporal vs. Complejidad Operacional¶
La durabilidad habilita el verdadero desacoplamiento temporal entre productor y consumidor, que es una promesa fundamental del messaging asíncrono. Pero introduce complejidad operacional: suscripciones que gestionar, storage que monitorear, backlog que alertar, suscripciones huérfanas que limpiar.
Consistencia vs. Rendimiento de Catch-Up¶
Procesar el backlog en orden estricto garantiza consistencia pero puede ser lento. Algunas aplicaciones priorizan mensajes recientes sobre antiguos (por ejemplo, un dashboard de tiempo real). La decisión de procesar en orden o priorizar mensajes recientes depende del caso de uso.
Simplicidad del Modelo vs. Gestión del Ciclo de Vida¶
En JMS, la creación de un durable subscriber requiere un nombre explícito y un client ID. En Kafka, el consumer group es implícitamente durable. La simplicidad del modelo de Kafka (todo es durable) elimina la decisión pero no elimina la necesidad de gestionar el offset y la retención.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Productor: publica mensajes en el canal pub-sub.
- Canal Pub-Sub: el topic o exchange donde se publican los mensajes.
- Suscripción Durable: recurso persistente en el broker que almacena mensajes para un suscriptor específico, incluso cuando está offline.
- Suscriptor (Consumer): la aplicación que consume mensajes de su suscripción durable.
- Broker: gestiona las suscripciones durables, retiene mensajes y los entrega cuando el suscriptor se conecta.
Flujo Lógico¶
flowchart TD
A([Suscriptor]) -->|Registra suscripción durable con ID estable| B[(Broker)]
B -->|Asocia suscripción al canal pub-sub| C[Consume mensajes normalmente]
C -->|Deploy, fallo o mantenimiento| D[Suscriptor se desconecta]
D --> E([Productor sigue publicando])
E -->|Mensajes nuevos| F[(Broker almacena en suscripción durable)]
F -->|Suscriptor se reconecta con mismo ID| G[Broker entrega mensajes acumulados]
G --> H[Procesa backlog + mensajes nuevos]
H --> I([Acknowledge / Commit offset])Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Productor | Publicar mensajes al canal (no necesita saber si los suscriptores son durables) |
| Suscripción Durable | Almacenar mensajes para el suscriptor mientras está offline |
| Broker | Gestionar las suscripciones, retener mensajes, entregar al reconectar |
| Suscriptor | Registrarse con un ID estable, procesar mensajes, confirmar, ser idempotente |
Interacciones¶
- Suscriptor → Broker: registro de suscripción durable con nombre/ID estable.
- Productor → Canal: publicación de mensajes (transparente, no cambia por durabilidad).
- Broker → Suscripción: almacenamiento de mensajes para suscriptores offline.
- Broker → Suscriptor: entrega de mensajes retenidos al reconectar + mensajes nuevos.
Contratos Implícitos¶
- El suscriptor usa un identificador estable (durable subscription name, consumer group ID) que no cambia entre reinicios.
- La política de retención del broker cubre el downtime máximo esperado del suscriptor.
- El suscriptor es idempotente (puede recibir un mensaje más de una vez durante reconexiones).
Decisiones de Diseño Clave¶
- Identificador de suscripción: ¿nombre fijo en código, configuración, o derivado del nombre del servicio?
- Política de retención: ¿cuánto tiempo retener mensajes para suscriptores offline?
- Catch-up strategy: ¿procesar el backlog en orden, priorizar mensajes recientes, o descartar mensajes más antiguos que un umbral?
- Clean-up de suscripciones huérfanas: ¿cómo detectar y eliminar suscripciones que nadie consume?
- Alertas de lag: ¿cuándo alertar que un suscriptor durable está acumulando backlog?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Auditoría de Transacciones¶
Contexto del Negocio¶
Un banco procesa 2 millones de transacciones diarias (transferencias, pagos, compras con tarjeta, retiros ATM). El regulador requiere que cada transacción se registre en un log de auditoría inmutable dentro de los 60 segundos siguientes a su ejecución. El log de auditoría debe ser completo — no puede faltar ni una sola transacción.
Necesidad de Integración¶
El core bancario publica cada transacción en un topic banking.transactions.completed. El servicio de auditoría debe consumir cada transacción y registrarla en un data store inmutable. La suscripción del servicio de auditoría debe ser durable para garantizar que no se pierden transacciones durante deploys, reinicios o fallos del servicio.
Sistemas Involucrados¶
- Core Bancario: publica transacciones completadas al topic.
- Kafka Topic:
banking.transactions.completed— canal pub-sub con todas las transacciones. - Audit Service: suscriptor durable que consume transacciones y las registra.
- Immutable Audit Store: base de datos append-only para el log de auditoría (Amazon QLDB, PostgreSQL con triggers de protección, o Elasticsearch con write-only index).
- Reconciliation Service: proceso batch diario que compara el conteo de transacciones del core con el conteo del audit store.
- Monitoring Dashboard: monitorea el consumer lag del Audit Service.
Restricciones Técnicas¶
- El topic tiene 90 días de retención (requisito regulatorio).
- El Audit Service debe procesar cada transacción exactamente una vez en el audit store (idempotente).
- El SLA de latencia es 60 segundos desde la publicación hasta el registro en el audit store.
- El Audit Service se despliega con rolling updates que causan downtime de ~30 segundos por instancia.
- El regulador exige evidencia de completitud: no puede faltar ninguna transacción en el audit log.
Diseño de la Suscripción Durable¶
Con Kafka:
Topic: banking.transactions.completed
Partitions: 32 (por account_id hash)
Replication Factor: 3
Retention: 90 days
Consumer Group: cg-audit-service
Instances: 3 (cada una consume ~10-11 particiones)
Auto-commit: false (manual commit después de escritura exitosa)
Offset reset: earliest (si no hay offset, empezar desde el inicio)
El consumer group cg-audit-service es la "suscripción durable" en Kafka. Kafka retiene los mensajes en el topic por 90 días independientemente de si se consumen. El consumer group mantiene su offset, y cuando una instancia se reinicia, retoma desde el último offset committed.
Decisiones Arquitectónicas¶
- Consumer group como suscripción durable: en Kafka, el consumer group mantiene offsets persistentes. Si una instancia se cae, otra del mismo grupo toma sus particiones (rebalance). Si todo el grupo se cae, los offsets se retienen y el procesamiento se retoma al reiniciar.
- Manual commit: el offset se commitea solo después de escribir exitosamente en el audit store, asegurando at-least-once delivery.
- Idempotencia en el audit store: cada escritura usa el
transaction_idcomo clave. Si un mensaje se procesa dos veces (por reconexión), la segunda escritura es un upsert que no cambia el resultado. - Retención de 90 días: permite reprocesar transacciones de hasta 3 meses atrás si se detecta un gap. El suscriptor puede retroceder su offset manualmente.
Riesgos y Mitigaciones¶
| Riesgo | Mitigación |
|---|---|
| Pérdida de mensajes durante deploy | Consumer group retiene offsets; rolling update solo reinicia una instancia a la vez |
| Backlog acumulado tras downtime largo | Alertas de consumer lag > 5 minutos; auto-scaling del Audit Service |
| Doble procesamiento tras reconexión | Escritura idempotente en audit store (upsert by transaction_id) |
| Suscripción huérfana | No aplica en Kafka (el topic retiene mensajes por política, no por consumer group) |
| Retención insuficiente | 90 días cubre todas las ventanas de downtime realistas |
| Core bancario produce más rápido de lo que el audit consume | Monitoreo de lag + escalado horizontal del consumer group |
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Operación Normal¶
El Audit Service (3 instancias, consumer group cg-audit-service) consume transacciones del topic normalmente:
- Instancia A consume particiones 0-10.
- Instancia B consume particiones 11-21.
- Instancia C consume particiones 22-31.
Cada instancia procesa ~700 transacciones/minuto, registrándolas en el audit store y commiteando offsets.
Paso 2: Deploy del Audit Service¶
A las 10:00 AM, se inicia un rolling update del Audit Service. El proceso:
- 10:00:00 — Instancia A recibe señal SIGTERM. Cierra el consumer gracefully (commitea el último offset procesado). Las particiones 0-10 quedan sin consumidor.
- 10:00:05 — Kafka detecta que Instancia A dejó el grupo. Ejecuta rebalance. Instancia B asume particiones 0-5; Instancia C asume particiones 6-10.
- 10:00:05 - 10:00:30 — Durante estos 25 segundos, el core bancario sigue publicando (~290 transacciones). Los mensajes se escriben en las particiones del topic (que es durable por definición).
- 10:00:30 — La nueva Instancia A arranca, se une al consumer group. Rebalance redistribuye particiones.
- 10:00:35 — Instancia A retoma desde el último offset committed. Procesa las ~290 transacciones acumuladas durante los 30 segundos de downtime.
Resultado: cero transacciones perdidas. La durabilidad del topic (retención de 90 días) y la persistencia de offsets del consumer group aseguraron que ningún mensaje se perdió durante el deploy.
Paso 3: Fallo No Planificado¶
A las 14:30, la Instancia B sufre un OOM y se termina abruptamente sin commit limpio:
- Kafka detecta la ausencia de Instancia B (falta de heartbeat, session timeout 30s).
- Rebalance: Instancias A y C asumen las particiones de B.
- Los últimos mensajes procesados por B pero no commiteados se re-entregan a A y C.
- El audit store usa upsert por
transaction_id→ los mensajes re-entregados se escriben sin duplicar registros. - El auto-healer reinicia Instancia B. Al volver, se une al grupo y recibe particiones.
Resultado: cero transacciones perdidas, cero duplicados en el audit store. La combinación de suscripción durable + idempotencia aseguró completitud y correctitud.
Paso 4: Verificación de Completitud¶
A medianoche, el Reconciliation Service ejecuta su proceso diario:
- Cuenta las transacciones del core bancario del día: 2,147,832.
- Cuenta los registros en el audit store del día: 2,147,832.
- Diferencia: 0.
- Genera reporte de reconciliación: COMPLETO — todas las transacciones auditadas.
Paso 5: Escenario de Downtime Prolongado¶
Hipotéticamente, si todo el Audit Service estuviera down por 2 horas (por ejemplo, un fallo de infraestructura):
- El core bancario publica ~166,000 transacciones durante las 2 horas.
- Kafka retiene todos los mensajes en el topic (retención 90 días).
- Al reiniciar, el consumer group retoma desde el último offset.
- Las 3 instancias procesan el backlog de 166,000 transacciones.
- A throughput normal (~2,100 transacciones/minuto entre las 3 instancias), el backlog se consume en ~79 minutos.
- Se escala temporalmente a 6 instancias para reducir el catch-up a ~40 minutos.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.monitoring import Grafana
from diagrams.aws.database import QLDB
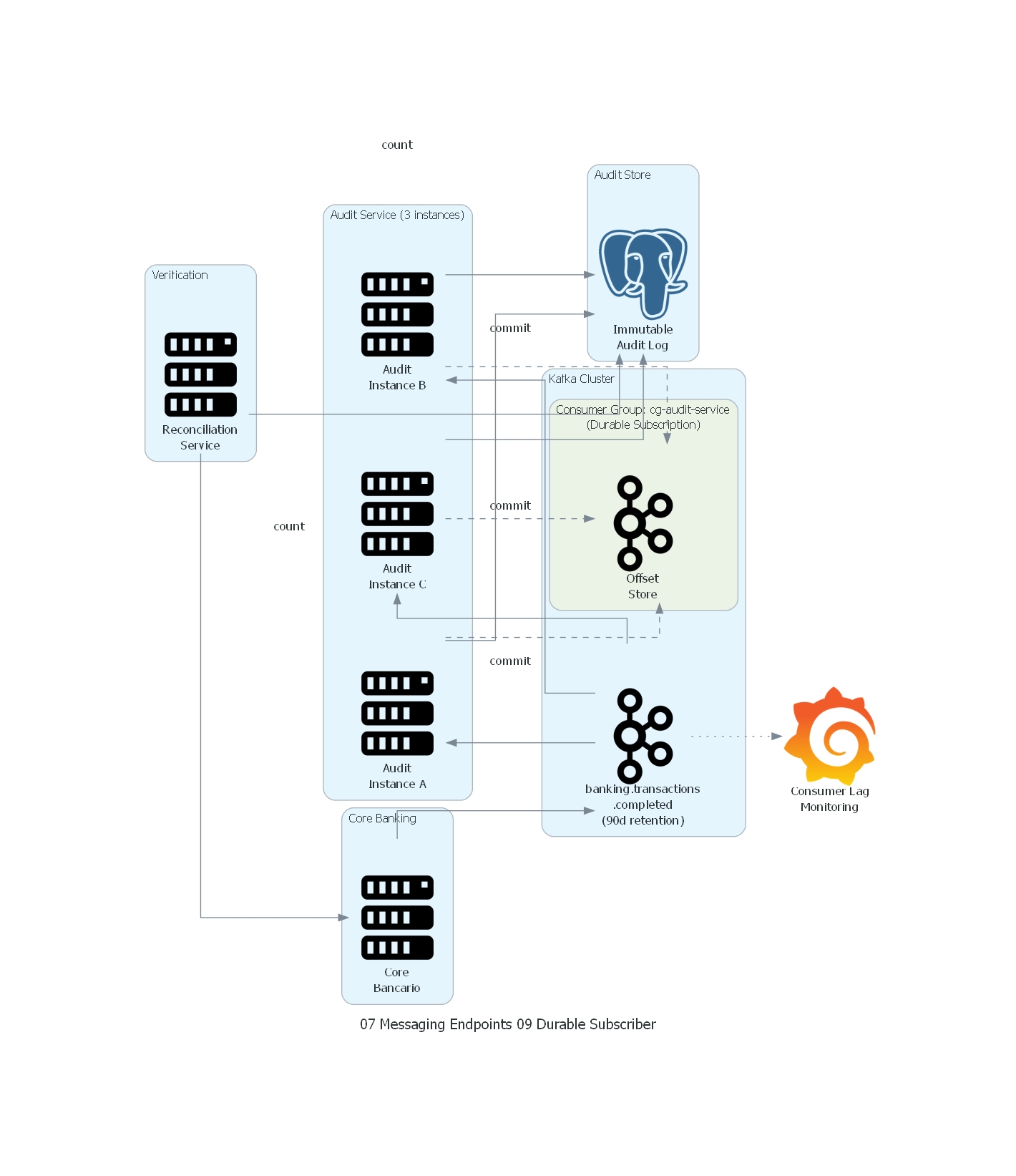
with Diagram("Durable Subscriber - Banking Audit", show=False, direction="LR"):
with Cluster("Core Banking"):
core = Server("Core\nBancario")
with Cluster("Kafka Cluster"):
topic = Kafka("banking.transactions\n.completed\n(90d retention)")
with Cluster("Consumer Group: cg-audit-service\n(Durable Subscription)"):
offset_store = Kafka("Offset\nStore")
with Cluster("Audit Service (3 instances)"):
audit_a = Server("Audit\nInstance A")
audit_b = Server("Audit\nInstance B")
audit_c = Server("Audit\nInstance C")
with Cluster("Audit Store"):
audit_db = PostgreSQL("Immutable\nAudit Log")
with Cluster("Verification"):
reconciliation = Server("Reconciliation\nService")
monitoring = Grafana("Consumer Lag\nMonitoring")
# Flow
core >> topic
topic >> audit_a
topic >> audit_b
topic >> audit_c
audit_a >> audit_db
audit_b >> audit_db
audit_c >> audit_db
audit_a >> Edge(style="dashed", label="commit") >> offset_store
audit_b >> Edge(style="dashed", label="commit") >> offset_store
audit_c >> Edge(style="dashed", label="commit") >> offset_store
reconciliation >> Edge(label="count") >> audit_db
reconciliation >> Edge(label="count") >> core
topic >> Edge(style="dotted") >> monitoring
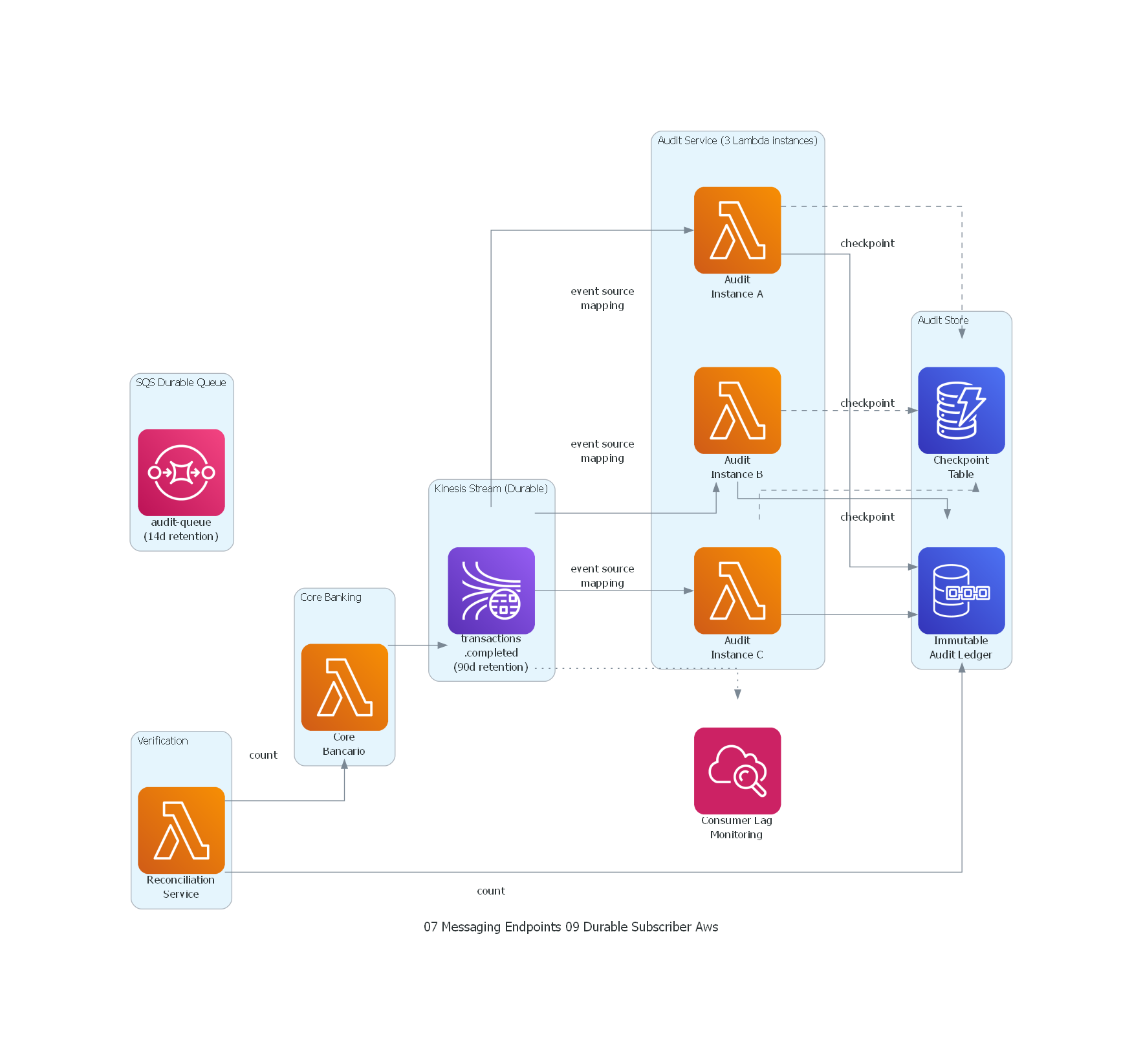
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import QLDB, Dynamodb
from diagrams.aws.integration import SQS
from diagrams.aws.analytics import KinesisDataStreams
from diagrams.aws.management import Cloudwatch
with Diagram("Durable Subscriber - Banking Audit (AWS)", show=False, direction="LR"):
with Cluster("Core Banking"):
core = Lambda("Core\nBancario")
with Cluster("Kinesis Stream (Durable)"):
stream = KinesisDataStreams("transactions\n.completed\n(90d retention)")
with Cluster("SQS Durable Queue"):
queue = SQS("audit-queue\n(14d retention)")
with Cluster("Audit Service (3 Lambda instances)"):
audit_a = Lambda("Audit\nInstance A")
audit_b = Lambda("Audit\nInstance B")
audit_c = Lambda("Audit\nInstance C")
with Cluster("Audit Store"):
audit_db = QLDB("Immutable\nAudit Ledger")
checkpoint = Dynamodb("Checkpoint\nTable")
with Cluster("Verification"):
reconciliation = Lambda("Reconciliation\nService")
monitoring = Cloudwatch("Consumer Lag\nMonitoring")
# Flow
core >> stream
stream >> Edge(label="event source\nmapping") >> audit_a
stream >> Edge(label="event source\nmapping") >> audit_b
stream >> Edge(label="event source\nmapping") >> audit_c
audit_a >> audit_db
audit_b >> audit_db
audit_c >> audit_db
audit_a >> Edge(style="dashed", label="checkpoint") >> checkpoint
audit_b >> Edge(style="dashed", label="checkpoint") >> checkpoint
audit_c >> Edge(style="dashed", label="checkpoint") >> checkpoint
reconciliation >> Edge(label="count") >> audit_db
reconciliation >> Edge(label="count") >> core
stream >> Edge(style="dotted") >> monitoring
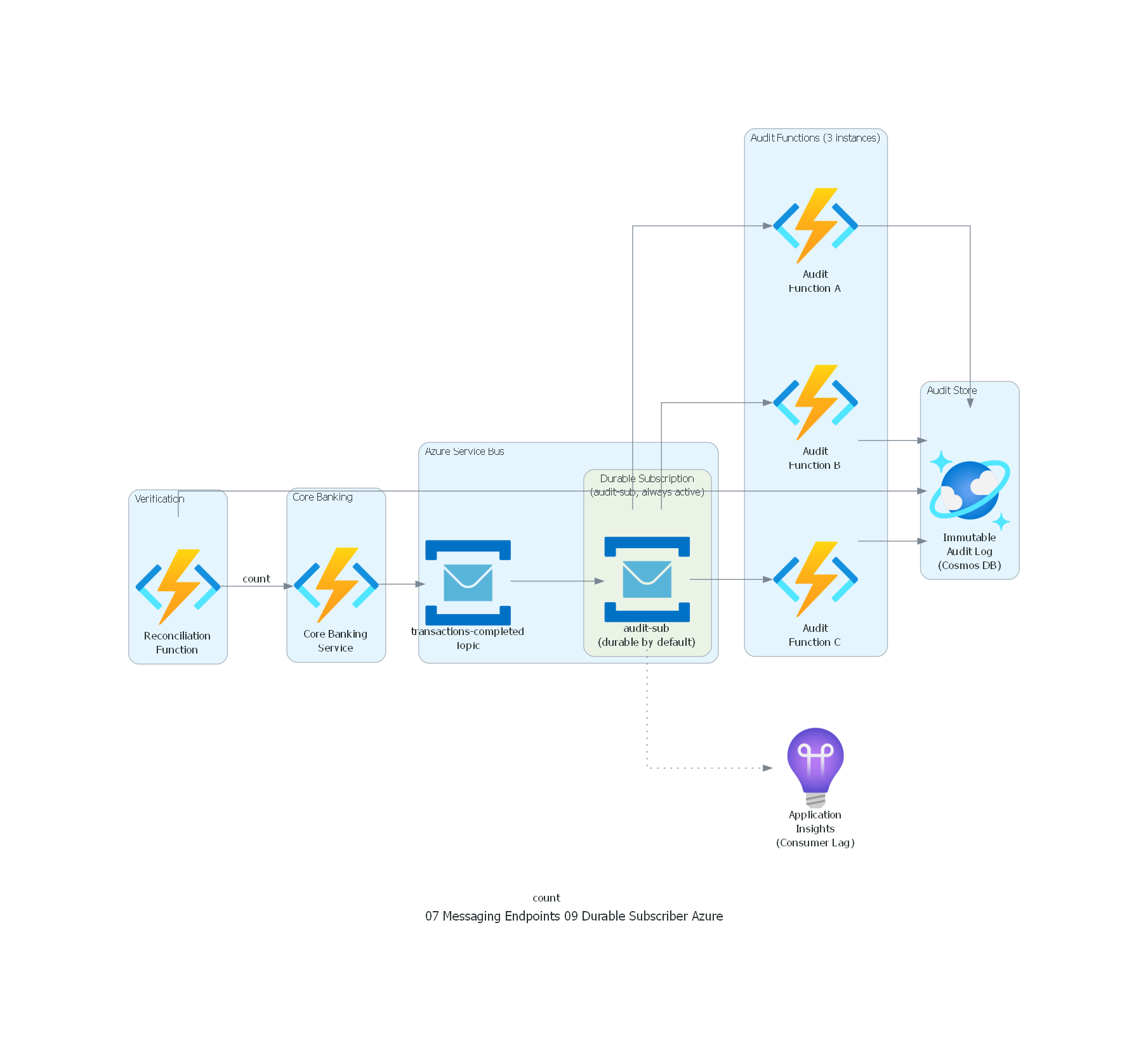
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
with Diagram("Durable Subscriber - Banking Audit (Azure)", show=False, direction="LR"):
with Cluster("Core Banking"):
core = FunctionApps("Core Banking\nService")
with Cluster("Azure Service Bus"):
topic = ServiceBus("transactions-completed\nTopic")
with Cluster("Durable Subscription\n(audit-sub, always active)"):
audit_sub = ServiceBus("audit-sub\n(durable by default)")
with Cluster("Audit Functions (3 instances)"):
audit_a = FunctionApps("Audit\nFunction A")
audit_b = FunctionApps("Audit\nFunction B")
audit_c = FunctionApps("Audit\nFunction C")
with Cluster("Audit Store"):
audit_db = CosmosDb("Immutable\nAudit Log\n(Cosmos DB)")
with Cluster("Verification"):
reconciliation = FunctionApps("Reconciliation\nFunction")
monitoring = ApplicationInsights("Application\nInsights\n(Consumer Lag)")
# Flow
core >> topic
topic >> audit_sub
audit_sub >> audit_a
audit_sub >> audit_b
audit_sub >> audit_c
audit_a >> audit_db
audit_b >> audit_db
audit_c >> audit_db
reconciliation >> Edge(label="count") >> audit_db
reconciliation >> Edge(label="count") >> core
audit_sub >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura del Durable Subscriber para auditoría de transacciones bancarias:
- El Core Bancario publica transacciones completadas al topic Kafka.
- El topic retiene mensajes por 90 días, asegurando durabilidad.
- El consumer group
cg-audit-service(que es la suscripción durable) mantiene offsets persistentes. - Las tres instancias del Audit Service consumen del topic, escriben en el Immutable Audit Log y commitean offsets.
- Los offsets se almacenan en el Offset Store de Kafka (
__consumer_offsets). - El Reconciliation Service verifica completitud comparando conteos del core y del audit log.
- Grafana monitorea el consumer lag para detectar atrasos.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Canal Pub-Sub | Kafka Topic banking.transactions.completed |
| Suscripción Durable | Consumer Group cg-audit-service + Offset Store |
| Suscriptor | Audit Service (3 instancias) |
| Retención de mensajes para offline | Kafka retention 90 días |
| Estado de la suscripción | Consumer group offsets |
| Verificación de completitud | Reconciliation Service |
11. Beneficios¶
Impacto Técnico¶
- Cero pérdida de mensajes durante downtime: la suscripción durable almacena mensajes para el suscriptor ausente, eliminando el gap de procesamiento durante deploys, fallos y mantenimiento.
- Desacoplamiento temporal real: el productor y el consumidor operan de forma verdaderamente independiente. El productor no necesita saber si el consumidor está activo.
- Reprocesamiento: en Kafka, el suscriptor puede retroceder su offset para reprocesar mensajes pasados, lo cual es invaluable para recovery, debugging y migración.
- Escalabilidad del catch-up: el backlog acumulado se puede procesar en paralelo añadiendo más instancias al consumer group.
Impacto Organizacional¶
- Deploys sin miedo: los equipos pueden desplegar sus servicios en cualquier momento sin preocuparse por perder mensajes. Los rolling updates son seguros.
- Mantenimiento sin ventanas especiales: no se necesitan ventanas de mantenimiento coordinadas con los productores.
- Auditoría completa: para requisitos regulatorios (SOX, Basel III, GDPR), la durabilidad asegura que el log de auditoría es completo.
Impacto Operacional¶
- Resiliencia ante fallos: los fallos de consumidores son recuperables sin intervención manual (el suscriptor retoma desde el último offset al reiniciar).
- Observabilidad: el consumer lag de la suscripción durable es una métrica directa de la salud del suscriptor.
- Recovery simplificado: ante un fallo catastrófico, se puede recrear el suscriptor y retomar desde un offset pasado.
Beneficios de Mantenibilidad y Evolución¶
- Migración de servicios: se puede migrar el Audit Service a una nueva tecnología manteniendo el consumer group (y su offset), retomando donde dejó el servicio anterior.
- Replay para testing: en ambientes de test, se puede retroceder el offset para reprocesar mensajes y validar cambios de lógica.
- Evolución gradual: un nuevo servicio de auditoría puede crear su propia suscripción durable y consumir el historial completo desde el inicio del topic.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Gestión de suscripciones: las suscripciones durables son recursos que deben crearse, monitorearse y eventualmente eliminarse. En JMS y Azure Service Bus, la creación es explícita; en Kafka, implícita (el consumer group se crea al primer commit).
- Catch-up management: decidir cómo manejar un backlog grande (procesar todo, priorizar recientes, escalar) requiere planificación.
- Idempotencia obligatoria: la durabilidad implica at-least-once delivery, lo cual obliga a que todos los handlers sean idempotentes.
Riesgos de Mal Uso¶
- Suscripciones huérfanas: en JMS y Azure Service Bus, una suscripción durable que nadie consume sigue acumulando mensajes. Si no se detecta y limpia, consume storage indefinidamente.
- Retención insuficiente: configurar retención de 1 día cuando el downtime máximo puede ser de 3 días produce pérdida de mensajes — la durabilidad es ilusoria.
- Falsa seguridad: asumir que la suscripción durable provee exactly-once delivery. No es así — provee at-least-once, y la idempotencia es responsabilidad del consumidor.
Sobreingeniería¶
- Durabilidad para mensajes efímeros: usar suscripciones durables para heartbeats, métricas de telemetría o señales de presencia que pierden relevancia en segundos es sobre-ingeniería que consume storage innecesariamente.
- Retención excesiva: retener mensajes 90 días cuando el downtime máximo realista es 1 hora es costoso y no añade valor práctico.
Costos de Operación¶
- Storage del broker: los mensajes retenidos para suscriptores durables consumen storage proporcional al volumen de publicación × tiempo de retención.
- Catch-up load: un suscriptor que procesa un backlog grande consume más recursos del broker (IO, CPU) que un suscriptor en steady-state.
- Monitoreo adicional: cada suscripción durable necesita monitoreo de lag, storage y salud.
Anti-Patterns Relacionados¶
- Zombie Subscription: suscripción durable que nadie consume, acumulando millones de mensajes que nunca se procesarán.
- Infinite Retention: retención configurada sin límite "por seguridad", resultando en storage que crece sin control.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Guaranteed Delivery: mientras Durable Subscriber asegura que el suscriptor no pierde mensajes durante downtime, Guaranteed Delivery asegura que el mensaje llega al broker de forma confiable. Juntos proporcionan entrega extremo a extremo.
- Idempotent Receiver: la durabilidad implica at-least-once delivery, lo cual hace indispensable la idempotencia en el consumidor.
- Competing Consumers: múltiples instancias del suscriptor durable (consumer group) compiten por mensajes, proporcionando escalabilidad y resiliencia.
- Publish-Subscribe Channel: Durable Subscriber opera exclusivamente sobre canales pub-sub.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Publish-Subscribe Channel define el canal. Transactional Client define cómo el productor publica transaccionalmente.
- Después: Idempotent Receiver maneja duplicados. Message Dispatcher distribuye los mensajes recibidos a handlers internos.
Combinaciones Comunes¶
- Durable Subscriber + Idempotent Receiver: combinación obligatoria. La durabilidad produce reentregas; la idempotencia las maneja.
- Durable Subscriber + Competing Consumers: el consumer group es tanto durable (retiene offsets) como competing (múltiples instancias procesan en paralelo).
- Durable Subscriber + Selective Consumer: suscripción durable con filtro, que retiene solo los mensajes que matchean el selector durante el downtime.
Diferencias con Patrones Similares¶
- vs. Guaranteed Delivery: Guaranteed Delivery es sobre la producción (el productor asegura que el mensaje llega al broker). Durable Subscriber es sobre el consumo (el suscriptor asegura que no pierde mensajes).
- vs. Message Store: Message Store almacena mensajes permanentemente para auditoría. Durable Subscriber retiene mensajes temporalmente para entrega al suscriptor.
- vs. Polling Consumer: un Polling Consumer puede ser durable si mantiene su posición de lectura, pero la durabilidad es una propiedad ortogonal al mecanismo de consumo (poll vs. push).
Encaje en un Flujo Mayor de Integración¶
Durable Subscriber garantiza la completitud del consumo en la cadena de integración. Es especialmente crítico en los extremos de la cadena: los suscriptores que materializan datos (audit stores, search indexes, data lakes, caches) deben ser durables para mantener la consistencia eventual con la fuente de verdad.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Durable Subscriber es más relevante que nunca porque las arquitecturas modernas dependen fundamentalmente de él:
- Kafka consumer groups: el modelo de Kafka hace la durabilidad implícita. Todo consumer group es un durable subscriber por diseño. El log retiene mensajes por política de retención, y los offsets se almacenan persistentemente. Esto hace que la durabilidad sea el modo por defecto, no una opción.
- Azure Service Bus subscriptions: las subscriptions son durables por defecto. Los mensajes se retienen en la subscription queue hasta su consumo o expiración.
- Google Pub/Sub subscriptions: durables con retención configurable (default 7 días, max 31 días).
- AWS SQS: inherentemente durable (los mensajes persisten en la queue hasta su consumo o expiración).
El concepto no ha cambiado, pero su ubicuidad ha aumentado. En lugar de ser una opción explícita (como en JMS), la durabilidad es ahora el comportamiento por defecto en la mayoría de las plataformas modernas.
Qué Parte Sigue Siendo Esencial¶
- La gestión de offsets/posición: entender cómo el suscriptor mantiene su posición de lectura y qué significa un offset "committed" vs. "latest".
- La política de retención: configurar la retención del canal para cubrir las ventanas de downtime esperadas.
- El monitoreo de consumer lag: la métrica de lag es la señal más importante de la salud del suscriptor durable.
- La idempotencia como complemento obligatorio: la durabilidad no provee exactly-once; la idempotencia sigue siendo responsabilidad del consumidor.
Cómo Se Implementa Hoy¶
| Plataforma | Mecanismo de Durabilidad | Gestión de Posición |
|---|---|---|
| Kafka | Consumer group + topic retention | Offsets en __consumer_offsets |
| Azure Service Bus | Subscription (durable por defecto) | Lock/Complete por mensaje |
| Google Pub/Sub | Subscription (durable por defecto) | Ack deadline + seek |
| AWS SQS | Queue (durable por defecto) | Visibility timeout + delete |
| JMS | createDurableSubscriber(name) | Broker-managed cursor |
| RabbitMQ | Durable queue + durable exchange | Ack por mensaje |
15. Implementación en Arquitecturas Modernas¶
Apache Kafka¶
# Consumer configuration
group.id=cg-audit-service
enable.auto.commit=false
auto.offset.reset=earliest
// Manual commit after successful processing
consumer.poll(Duration.ofMillis(100)).forEach(record -> {
auditStore.write(record.value()); // idempotent write
consumer.commitSync(Map.of(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1)
));
});
En Kafka, la durabilidad es inherente. El consumer group mantiene offsets persistentes. auto.offset.reset=earliest asegura que un consumer group nuevo empiece desde el inicio del topic. El commit manual asegura que solo se avanza el offset después de procesar exitosamente.
Azure Service Bus¶
// Subscription durable por defecto
var processor = client.CreateProcessor("banking.transactions", "audit-sub",
new ServiceBusProcessorOptions
{
AutoCompleteMessages = false,
MaxConcurrentCalls = 10
});
processor.ProcessMessageAsync += async (args) =>
{
await auditStore.WriteAsync(args.Message.Body);
await args.CompleteMessageAsync(args.Message); // acknowledge
};
En Azure Service Bus, la subscription audit-sub es durable por defecto. Los mensajes se retienen en la subscription hasta que se completan. Si el servicio está offline, los mensajes se acumulan en la subscription.
Google Pub/Sub¶
from google.cloud import pubsub_v1
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project, "audit-sub")
# La subscription es durable. Mensajes se retienen hasta ack o expiración.
def callback(message):
audit_store.write(message.data)
message.ack()
streaming_pull = subscriber.subscribe(subscription_path, callback=callback)
Spring Kafka con Idempotencia¶
@KafkaListener(
topics = "banking.transactions.completed",
groupId = "cg-audit-service",
containerFactory = "manualAckFactory"
)
public void onTransaction(
@Payload TransactionEvent event,
Acknowledgment ack
) {
// Idempotent write: upsert by transaction_id
auditRepository.upsert(event.getTransactionId(), event);
ack.acknowledge(); // commit offset
}
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Consumer lag: la métrica principal. Mide la diferencia entre el último mensaje publicado y el último mensaje procesado por el suscriptor. Un lag creciente indica que el suscriptor no mantiene el ritmo.
- Mensaje más antiguo sin procesar: el age del mensaje más viejo en la suscripción. Indica cuánto tiempo de datos "atrasados" tiene el suscriptor.
- Throughput de catch-up vs. steady-state: diferenciar entre el throughput normal y el throughput de catch-up (que debería ser mayor para reducir el backlog).
Monitoreo¶
- Alertas de lag: alertar cuando el consumer lag excede un umbral (por ejemplo, 5 minutos para auditoría).
- Alertas de suscripción huérfana: detectar suscripciones durables cuyos consumidores no se han conectado en X días.
- Storage growth: monitorear el crecimiento del storage de suscripciones durables, especialmente para suscriptores con lag alto.
Versionado¶
- Estabilidad del consumer group ID: el ID del consumer group no debe cambiar entre versiones del servicio. Un cambio de ID crea una nueva suscripción que empieza desde el offset configurado (earliest/latest), no desde donde dejó la versión anterior.
- Migración de consumer group: si se necesita cambiar el consumer group ID, se debe crear el nuevo grupo, configurar su offset al mismo punto que el anterior, y desregistrar el anterior.
Seguridad¶
- ACL por consumer group: en Kafka, definir ACLs que restrinjan qué consumer groups pueden consumir de qué topics.
- Protección contra reset de offset: restringir quién puede resetear offsets de consumer groups en producción.
Manejo de Errores¶
- Retry con backoff: mensajes que fallan deben reintentarse con backoff exponencial antes de enviarse a dead-letter.
- Dead-letter por suscripción: cada suscripción durable debe tener un mecanismo de dead-letter para mensajes que no pueden procesarse después de N intentos.
- Poison message isolation: un mensaje que causa crash del consumidor no debe bloquear toda la suscripción.
Performance¶
- Catch-up scaling: durante períodos de catch-up, escalar temporalmente el número de instancias del consumer group para reducir el tiempo de recuperación.
- Prefetch tuning: configurar el prefetch (max.poll.records en Kafka, prefetchCount en Service Bus) para optimizar el throughput de catch-up.
- Batch processing: procesar mensajes en batches durante catch-up para reducir overhead per-message.
Escalabilidad¶
- El número máximo de instancias de un consumer group está limitado por el número de particiones del topic.
- Para escalar más allá de las particiones, se pueden crear topics con más particiones (Kafka) o múltiples suscripciones (Service Bus, Pub/Sub).
17. Errores Comunes¶
Cambiar el Consumer Group ID en un Deploy¶
Cambiar el group.id de un consumer group durante un deploy crea una nueva suscripción que empieza desde el offset configurado (earliest o latest). Si es latest, se pierden todos los mensajes publicados hasta ese momento. Si es earliest, se reprocesan todos los mensajes desde el inicio del topic. Ambas situaciones son problemáticas.
No Monitorear Consumer Lag¶
Un suscriptor durable que acumula lag silenciosamente puede parecer saludable (no hay errores, no hay crashes) pero está procesando datos cada vez más atrasados. Sin monitoreo de lag, el problema se detecta cuando un usuario reporta datos desactualizados o cuando una auditoría encuentra gaps.
Retención Insuficiente¶
Configurar retención de 1 día cuando el downtime máximo realista (fallo de infraestructura + diagnosis + recovery) puede ser de 2 días significa que la durabilidad no cubre el escenario más crítico. La retención debe calcularse como: downtime máximo esperado + margen de seguridad.
Suscripciones Huérfanas No Detectadas¶
En JMS y Azure Service Bus, una suscripción durable creada por un servicio que ya no existe sigue acumulando mensajes. Sin un proceso de detección y limpieza de suscripciones huérfanas, estas consumen storage indefinidamente.
No Implementar Idempotencia¶
Confiar en que la suscripción durable provee exactly-once delivery es un error fundamental. La durabilidad provee at-least-once: durante reconexiones, mensajes procesados pero no confirmados se reentregarán. Sin idempotencia en el consumidor, los mensajes re-entregados producen duplicados.
Auto-Commit de Offsets¶
En Kafka, enable.auto.commit=true commitea offsets periódicamente, independientemente de si el mensaje se procesó exitosamente. Si el consumidor crashea después del auto-commit pero antes de procesar, el mensaje se pierde. El commit manual después del procesamiento exitoso es la práctica correcta para suscriptores durables.
18. Conclusión Técnica¶
Durable Subscriber es un patrón que garantiza la completitud del consumo en escenarios publish-subscribe, asegurando que los mensajes publicados durante el downtime del suscriptor no se pierden sino que se retienen para entrega posterior. Es el patrón que hace posible el verdadero desacoplamiento temporal entre productores y consumidores.
Cuándo aporta valor: siempre que la pérdida de mensajes durante downtime sea inaceptable. En sistemas financieros, de salud, de auditoría, de compliance, o cualquier sistema donde la completitud del procesamiento es un requisito de negocio.
Cuándo evita problemas importantes: durante deploys, reinicios planificados, fallos de hardware y escalado automático — todos eventos que causan downtime temporal del suscriptor. Sin durabilidad, cada uno de estos eventos produce un gap invisible en el procesamiento que puede tener consecuencias regulatorias, financieras u operacionales.
Cuándo no conviene adoptarlo: para mensajes efímeros cuya pérdida es aceptable (heartbeats, métricas de baja criticidad, señales de presencia). En esos casos, la durabilidad añade costo de storage sin beneficio de negocio.
Recomendación para arquitectos: en plataformas modernas (Kafka, Azure Service Bus, Google Pub/Sub), la durabilidad es el comportamiento por defecto. La decisión no es "¿usar durabilidad?" sino "¿cómo configurarla correctamente?": defina políticas de retención que cubran los peores escenarios de downtime, implemente idempotencia en todos los consumidores, monitoree el consumer lag como métrica primaria de salud, y establezca procesos para detectar y limpiar suscripciones huérfanas. La durabilidad sin idempotencia es incompleta; la idempotencia sin durabilidad es insuficiente. Ambos patrones deben implementarse juntos.