Idempotent Receiver¶
1. Nombre del Patrón¶
- Nombre oficial: Idempotent Receiver
- Categoría: Messaging Endpoints (Endpoints de Mensajería)
- Traducción contextual: Receptor Idempotente
2. Resumen Ejecutivo¶
Idempotent Receiver es un patrón que garantiza que un consumidor de mensajes puede procesar el mismo mensaje múltiples veces sin producir efectos secundarios duplicados. En un sistema de mensajería con semántica de entrega at-least-once — que es la semántica de prácticamente todos los sistemas de messaging en producción — los mensajes duplicados no son una posibilidad remota sino una certeza estadística. El Idempotent Receiver absorbe esta duplicación de forma segura.
Este es uno de los patrones más críticos en arquitecturas modernas. Sin él, cada duplicación de mensaje puede producir pagos dobles, notificaciones repetidas, registros duplicados en bases de datos, contadores incrementados incorrectamente y cualquier otro efecto secundario que la lógica de negocio produzca al procesar un mensaje.
3. Definición Detallada¶
Propósito¶
El propósito de Idempotent Receiver es hacer que el procesamiento de mensajes sea una operación idempotente: aplicar la operación una vez produce exactamente el mismo resultado que aplicarla N veces. Si un consumidor recibe y procesa el mensaje M, y luego recibe M de nuevo (duplicado), el resultado observable del sistema debe ser idéntico a haberlo procesado una sola vez.
Lógica Arquitectónica¶
La idempotencia en messaging se implementa mediante una de estas estrategias:
-
Deduplicación explícita: el consumidor mantiene un registro de los
message_idque ya procesó. Al recibir un mensaje, consulta el registro; si el ID ya existe, descarta el mensaje sin procesarlo. Si no existe, lo procesa y registra el ID. -
Operaciones naturalmente idempotentes: el consumidor usa operaciones que por su naturaleza producen el mismo resultado sin importar cuántas veces se ejecuten. Por ejemplo:
UPDATE account SET balance = 1500es idempotente;UPDATE account SET balance = balance + 100no lo es. -
Idempotency keys de negocio: se usa un identificador de negocio (como
payment_idoorder_id) como clave de idempotencia, de modo que la operación se ejecuta "si y solo si" no se ha ejecutado previamente con ese identificador.
Principio de Diseño Subyacente¶
El principio es absorber la duplicación inherente al sistema de transporte sin contaminar la lógica de negocio. El sistema de messaging no puede garantizar exactly-once delivery en todos los escenarios de fallo (esto es un resultado teórico demostrable en sistemas distribuidos). Por lo tanto, la responsabilidad de manejar duplicados recae en el receptor, no en el broker.
Problema Estructural que Resuelve¶
En un sistema distribuido con messaging, los duplicados ocurren por múltiples razones:
- Redelivery tras timeout de acknowledgment: el consumidor procesa el mensaje pero falla al confirmar (ack). El broker asume que no se procesó y lo reentrega.
- Producer retry: el productor envía un mensaje, el broker lo recibe pero la confirmación al productor se pierde. El productor reintenta y envía el mismo mensaje de nuevo.
- Consumer rebalance: en Kafka, un rebalance de consumer group puede causar que mensajes ya procesados (pero con offset no commiteado) se reprocesen.
- Infrastructure failover: ante failover de un nodo del broker, mensajes que ya fueron entregados pueden reentregarse.
- Network partitions: en una partición de red, tanto el broker como el consumidor pueden asumir que el otro no recibió el mensaje/ack.
Estos escenarios no son teóricos — ocurren en producción con regularidad suficiente para que cualquier sistema sin idempotencia acumule datos corruptos o duplicados con el tiempo.
Contexto en el que Emerge¶
Idempotent Receiver emerge tan pronto como un sistema de messaging se usa en producción para operaciones con efectos secundarios: pagos, cambios de estado, notificaciones, actualizaciones de inventario, registros contables, o cualquier operación que no debe ocurrir dos veces.
Por Qué No Es Trivial¶
La idempotencia parece simple conceptualmente ("si ya procesé este mensaje, lo ignoro"), pero la implementación tiene desafíos significativos:
- Atomicidad: la operación de negocio y el registro de deduplicación deben ser atómicas. Si se procesa el mensaje pero no se registra el ID (por un crash entre ambas operaciones), el siguiente intento procesará de nuevo.
- Tamaño del registro de deduplicación: si se almacena cada
message_idprocesado, el registro crece indefinidamente. Se necesita una estrategia de retención (TTL, ventana temporal). - Distributed deduplication: si hay múltiples instancias del consumidor (Competing Consumers), el registro de deduplicación debe ser compartido y consistente entre todas las instancias.
- Idempotencia de lado effects: si el procesamiento produce side effects externos (llamar a una API, enviar un email), hacer idempotente la operación local no basta — también hay que evitar el side effect duplicado.
- Natural vs. artificial idempotency: algunas operaciones son naturalmente idempotentes (SET), otras requieren transformación para serlo (cambiar INCREMENT por SET-IF-NOT-EXISTS).
Relación con Sistemas Distribuidos y Mensajería¶
En la teoría de sistemas distribuidos, la entrega exactly-once de mensajes es imposible en un sistema asíncrono con posibilidad de fallos (una consecuencia del Two Generals Problem y de la imposibilidad de consenso en sistemas asíncronos con fallos — FLP). Las plataformas que ofrecen "exactly-once" (como Kafka Transactions) lo hacen dentro de boundaries específicos (produce-transform-produce dentro de Kafka), no de forma universal.
Fuera de esos boundaries — especialmente cuando el side effect es externo a Kafka (escribir en una base de datos, llamar a una API) — la responsabilidad de idempotencia recae en el consumidor.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Idempotent Receiver:
- Un pago de $100 se procesa dos veces porque el ack se perdió → el cliente es cobrado $200.
- Una notificación push se envía 3 veces porque el consumer rebalanceó → el usuario recibe spam.
- Un registro se inserta dos veces en la base de datos → datos duplicados que corrompen reports y analytics.
- Un decremento de inventario se aplica dos veces → el stock muestra -1 cuando debería ser 0.
- Una transferencia interbancaria se ejecuta dos veces → discrepancia contable que requiere conciliación manual.
Síntomas del Problema¶
- Registros duplicados en bases de datos que aparecen "misteriosamente" y no se explican por la lógica de negocio.
- Discrepancias en contadores, saldos o inventarios que solo se detectan en conciliación.
- Clientes que reportan notificaciones duplicadas o cargos dobles.
- Logs que muestran el mismo mensaje procesado múltiples veces en intervalos cortos.
Impacto Operativo y Arquitectónico¶
- Financiero: pagos duplicados, cargos incorrectos, conciliaciones costosas.
- Reputacional: notificaciones repetidas, experiencia de usuario degradada.
- Datos: corrupción silenciosa de datos que se propaga a downstream systems.
- Operacional: tiempo invertido en diagnosticar y corregir duplicaciones.
Riesgos Si No Se Implementa Correctamente¶
- Race conditions en deduplicación: dos instancias del consumidor procesan el mismo mensaje simultáneamente antes de que ninguna registre el ID → ambas procesan → duplicación.
- Ventana de deduplicación insuficiente: el TTL del registro de deduplicación es menor que el intervalo máximo de redelivery → duplicados tardíos no se detectan.
- Deduplicación sin atomicidad: el proceso crashea entre "procesar" y "registrar ID" → el siguiente intento procesa de nuevo.
Ejemplos Reales¶
- Banca: un banco procesa transferencias SWIFT. Un timeout de ack causa redelivery. Sin idempotencia, la transferencia de €50,000 se ejecuta dos veces. El banco pierde €50,000 y debe iniciar un proceso de reversión con el banco corresponsal.
- E-commerce: un servicio de inventario decrementa stock al recibir un evento
OrderPlaced. Un consumer rebalance causa reprocesamiento. Sin idempotencia, el stock se decrementa dos veces y el producto aparece como agotado cuando aún tiene unidades. - SaaS: un servicio de billing genera facturas al recibir eventos
SubscriptionRenewed. Un duplicate produce una factura doble que se cobra al cliente.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Siempre que un consumidor de mensajes produzca efectos secundarios (escritura en DB, llamada a API, envío de notificación, cambio de estado).
- En todo sistema con semántica de entrega at-least-once (es decir, todos los sistemas de messaging en producción).
- Cuando la duplicación de la operación tiene consecuencias de negocio negativas.
Cuándo No Usarlo¶
- Cuando el procesamiento es inherentemente idempotente sin esfuerzo adicional (por ejemplo, actualizar una cache con el último valor conocido — un SET puro).
- Cuando la duplicación es aceptable (por ejemplo, incrementar un contador de página vistas donde un error de ±1 es irrelevante).
- Cuando se opera dentro de los boundaries de exactly-once de la plataforma (Kafka Transactions produce-consume-produce sin side effects externos).
Precondiciones¶
- Los mensajes tienen un identificador único (
message_id) o la lógica de negocio tiene una clave natural de idempotencia (payment_id,order_id). - Existe un almacén accesible para el registro de deduplicación (database, Redis, en-memory store).
- El almacén de deduplicación es accesible por todas las instancias del consumidor.
Restricciones¶
- La ventana de deduplicación debe ser mayor que el intervalo máximo de redelivery del broker.
- La consulta al registro de deduplicación añade latencia a cada procesamiento.
- El registro de deduplicación consume storage y debe gestionarse (TTL, purga).
6. Fuerzas Arquitectónicas¶
Correctitud vs. Performance¶
La deduplicación explícita añade una consulta (y posiblemente una escritura) al registro de deduplicación por cada mensaje. Esto incrementa la latencia y reduce el throughput. La alternativa — operaciones naturalmente idempotentes — no tiene overhead adicional pero requiere rediseñar la lógica de negocio.
Simplicidad vs. Robustez¶
Una deduplicación simple (hash set en memoria) es rápida pero no sobrevive a reinicios y no se comparte entre instancias. Una deduplicación robusta (base de datos compartida con transacciones) es resiliente pero más compleja y lenta.
Consistencia vs. Disponibilidad¶
Si el registro de deduplicación no está disponible, ¿el consumidor debe rechazar el mensaje (consistencia) o procesarlo con riesgo de duplicación (disponibilidad)? La respuesta depende del costo de la duplicación vs. el costo de la indisponibilidad.
Ventana vs. Storage¶
Una ventana de deduplicación más larga protege contra duplicados tardíos pero consume más storage. Una ventana más corta ahorra storage pero puede no detectar duplicados que llegan fuera de la ventana.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Mensaje entrante: con
message_ido clave de idempotencia. - Consumidor: la lógica que procesa el mensaje.
- Deduplication Store: el registro de IDs ya procesados (Redis, PostgreSQL, DynamoDB, en-memory).
- Lógica de negocio: la operación con side effects que debe ser idempotente.
Flujo Lógico¶
flowchart TD
A([Recibe mensaje: message_id = MSG-123]) --> B{Consulta Deduplication Store: existe MSG-123?}
B -->|Sí existe| C[Descarta mensaje duplicado]
C --> D([Confirma ACK + log duplicate discarded])
B -->|No existe| E[Inicia transacción]
E --> F[Ejecuta lógica de negocio]
F --> G[(Registra MSG-123 en Deduplication Store)]
G --> H[Confirma transacción]
H --> I([Confirma ACK al broker])Punto crítico: los pasos 5 y 6 deben ser atómicos (misma transacción). Si la lógica de negocio escribe en la misma base de datos que el Deduplication Store, esto es una transacción local. Si son bases de datos diferentes, se necesita un mecanismo adicional (como el Outbox Pattern).
Estrategias de Implementación¶
| Estrategia | Mecanismo | Pros | Contras |
|---|---|---|---|
| Deduplication Store | Tabla/Redis con message_ids procesados | Universal, explícita | Overhead por mensaje, storage |
| Upsert (SET vs INSERT) | INSERT ... ON CONFLICT DO NOTHING | Sin store adicional | Solo para inserts |
| Conditional Update | UPDATE ... WHERE version = N | Optimistic locking natural | Solo para updates |
| Idempotency Key en API | Header Idempotency-Key en llamadas downstream | Protege side effects externos | Requiere soporte del API |
| Event Sourcing | Verificar si el evento ya fue aplicado | Natural en ES | Solo en arquitecturas ES |
8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Procesamiento de Pagos con Tarjeta¶
Contexto del Negocio¶
Un banco emisor de tarjetas procesa 5 millones de transacciones diarias de débito y crédito. Cada transacción llega como un mensaje desde la red de pagos (Visa/Mastercard) al sistema de autorización del banco. El sistema debe:
- Verificar fondos disponibles.
- Aplicar el cargo a la cuenta del tarjetahabiente.
- Registrar la transacción en el ledger.
- Enviar confirmación a la red de pagos.
- Notificar al tarjetahabiente (push notification).
Una transacción duplicada significa un cargo doble al cliente. Esto produce: queja del cliente, proceso de reversa, compensación, costo operativo, daño reputacional y potencial sanción regulatoria.
Diseño del Idempotent Receiver¶
┌─────────────────────────────────────────────────────┐
│ Payment Authorization Service │
│ │
│ 1. Receive message from Kafka │
│ 2. Extract transaction_id (idempotency key) │
│ 3. BEGIN TRANSACTION │
│ 4. SELECT FROM processed_transactions │
│ WHERE txn_id = ? FOR UPDATE │
│ 5. IF EXISTS → ROLLBACK, ACK, return │
│ 6. Check funds (SELECT balance) │
│ 7. Debit account (UPDATE balance) │
│ 8. Insert ledger entry │
│ 9. INSERT INTO processed_transactions(txn_id,...) │
│ 10. COMMIT TRANSACTION │
│ 11. ACK message to Kafka │
│ 12. Async: send push notification │
└─────────────────────────────────────────────────────┘
Sistemas Involucrados¶
- Kafka Cluster: canal
payments.authorizationscon transacciones de la red de pagos. - Payment Authorization Service: microservicio Java/Spring que procesa autorizaciones.
- PostgreSQL: base de datos con tablas
accounts,ledger_entriesyprocessed_transactions. - Redis: cache opcional para fast-path deduplication (antes de consultar PostgreSQL).
- Notification Service: servicio downstream para push notifications.
Decisiones Arquitectónicas¶
-
Idempotency key = transaction_id (no message_id): se usa el ID de negocio de la transacción como clave de idempotencia. Esto protege contra duplicados tanto a nivel de messaging (redelivery) como a nivel de negocio (la red de pagos envía la misma transacción dos veces).
-
Deduplicación en la misma transacción DB: el check de duplicado y la operación de negocio ocurren en la misma transacción PostgreSQL. Esto garantiza atomicidad sin necesidad de 2PC.
-
Two-level deduplication: Redis como fast-path (check rápido antes de ir a PostgreSQL) + PostgreSQL como source of truth (con constraint UNIQUE en
txn_id). Redis puede tener falsos negativos (key expirada) pero PostgreSQL nunca los tiene. -
SELECT FOR UPDATE: el check de duplicado usa
SELECT ... FOR UPDATEpara evitar race conditions entre instancias concurrentes del servicio. -
Notification como side effect asíncrono: la push notification se envía después del commit, no dentro de la transacción. Si se envía duplicada (porque el crash ocurrió después de commit pero antes de ack), es aceptable (una notificación duplicada es molesta pero no costosa; un pago duplicado sí lo es).
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Recepción del Mensaje¶
El Payment Authorization Service (3 instancias en Kafka consumer group cg-payments) recibe un mensaje del topic payments.authorizations:
{
"headers": {
"message_id": "msg-2026-04-07-x8f3a",
"correlation_id": "txn-VISA-2026-8847291",
"timestamp": "2026-04-07T14:32:15Z",
"source": "payment-network-gateway"
},
"body": {
"transaction_id": "TXN-VISA-8847291",
"card_number_hash": "sha256:a1b2c3...",
"account_id": "ACC-44821",
"amount": 125.50,
"currency": "EUR",
"merchant": "Amazon.es",
"merchant_category": "5411",
"authorization_type": "PURCHASE"
}
}
Paso 2: Fast-Path Deduplication (Redis)¶
El servicio consulta Redis: EXISTS dedup:TXN-VISA-8847291.
- Si existe: el mensaje es un duplicado conocido. Se descarta inmediatamente sin consultar PostgreSQL. Se hace ACK al broker. Latencia: <1ms.
- Si no existe: puede ser nuevo o puede ser un duplicado cuyo key expiró en Redis. Se continúa al paso 3.
Paso 3: Transacción Atómica en PostgreSQL¶
BEGIN;
-- Check de duplicado con lock
SELECT txn_id FROM processed_transactions
WHERE txn_id = 'TXN-VISA-8847291'
FOR UPDATE NOWAIT;
-- Si retorna fila → DUPLICADO
-- ROLLBACK, ACK, return
-- Si no retorna fila → NUEVO, continuar
-- Verificar fondos
SELECT balance FROM accounts WHERE account_id = 'ACC-44821' FOR UPDATE;
-- balance = 2340.00 → sufficient
-- Debitar cuenta
UPDATE accounts SET balance = balance - 125.50
WHERE account_id = 'ACC-44821';
-- Registrar en ledger
INSERT INTO ledger_entries (txn_id, account_id, amount, currency, type, timestamp)
VALUES ('TXN-VISA-8847291', 'ACC-44821', -125.50, 'EUR', 'PURCHASE', NOW());
-- Registrar deduplicación
INSERT INTO processed_transactions (txn_id, processed_at, result)
VALUES ('TXN-VISA-8847291', NOW(), 'APPROVED');
COMMIT;
Todo ocurre en una sola transacción PostgreSQL: el check de duplicado, el débito, el ledger y el registro de deduplicación. Si cualquier paso falla, todo se revierte. No hay ventana donde la operación se ejecutó pero no se registró.
Paso 4: Post-Commit¶
Después del commit exitoso:
- Se registra el
txn_iden Redis con TTL de 24 horas:SET dedup:TXN-VISA-8847291 1 EX 86400. - Se hace ACK del mensaje al broker (commit del offset en Kafka).
- Se publica un evento
PaymentAuthorizeden el topicpayments.authorizedpara downstream (notification service, analytics).
Paso 5: Escenario de Duplicado¶
5 segundos después, el mismo mensaje llega de nuevo (redelivery por timeout de ack en un intento anterior):
- Redis check:
EXISTS dedup:TXN-VISA-8847291→ TRUE. - Mensaje descartado. ACK inmediato. Latencia: <1ms.
- Log:
WARN: Duplicate message discarded, txn_id=TXN-VISA-8847291.
Sin el Idempotent Receiver, el cliente habría sido cobrado €251.00 en lugar de €125.50.
Paso 6: Escenario de Race Condition¶
Dos instancias del servicio reciben el mismo mensaje simultáneamente (posible durante un rebalance):
- Instancia A:
SELECT ... FOR UPDATE→ no encuentra registro → adquiere lock. - Instancia B:
SELECT ... FOR UPDATE→ bloqueada por el lock de A. - Instancia A: ejecuta operación, INSERT deduplication, COMMIT → libera lock.
- Instancia B:
SELECT ... FOR UPDATE→ AHORA encuentra el registro → ROLLBACK → duplicado detectado.
El FOR UPDATE serializa los accesos concurrentes al mismo txn_id, eliminando la race condition.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.inmemory import Redis
from diagrams.onprem.monitoring import Grafana
with Diagram("Idempotent Receiver - Payment Authorization", show=False, direction="LR"):
with Cluster("Payment Network"):
network_gw = Server("Visa/MC\nGateway")
with Cluster("Kafka"):
auth_topic = Kafka("payments\n.authorizations")
result_topic = Kafka("payments\n.authorized")
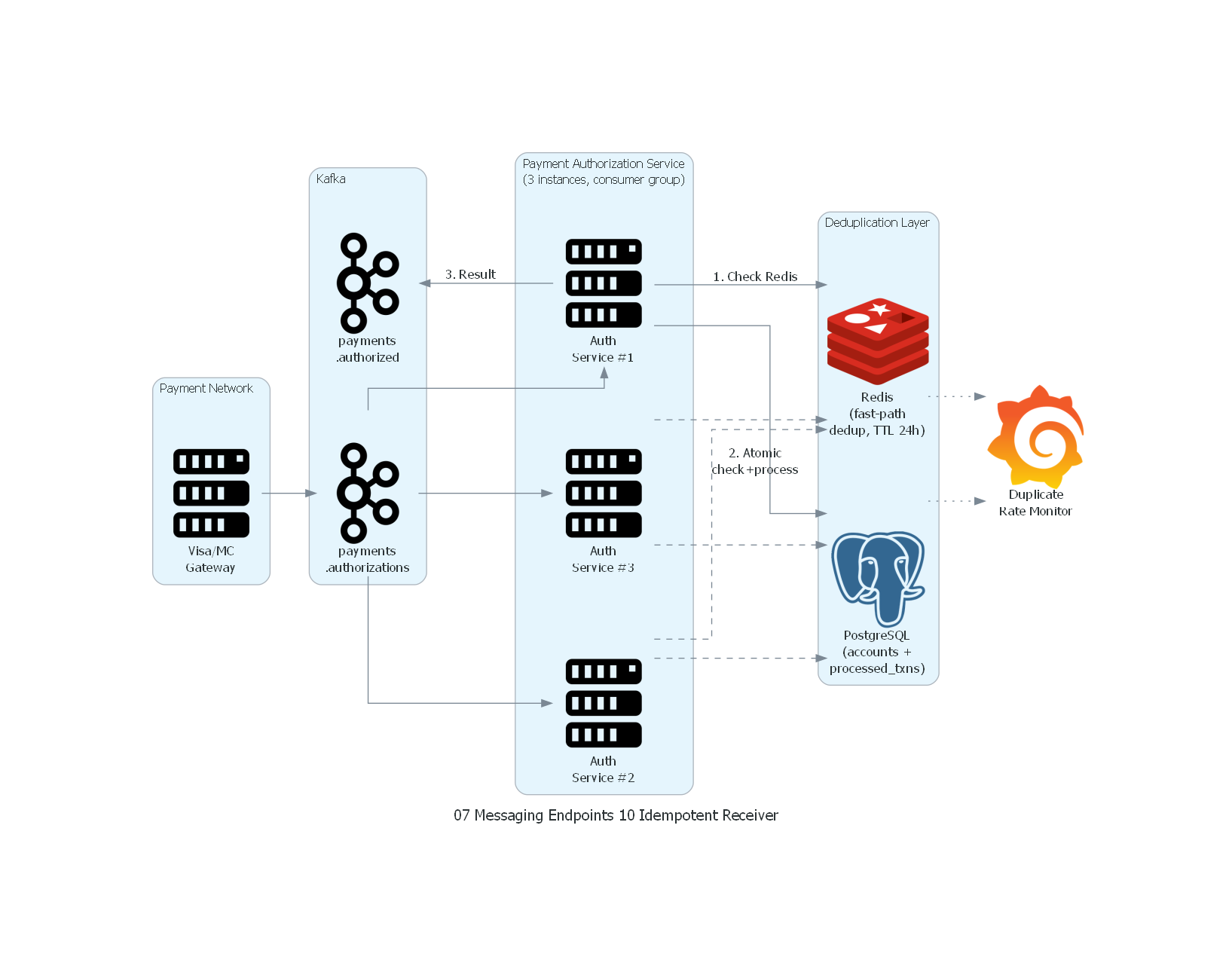
with Cluster("Payment Authorization Service\n(3 instances, consumer group)"):
svc1 = Server("Auth\nService #1")
svc2 = Server("Auth\nService #2")
svc3 = Server("Auth\nService #3")
with Cluster("Deduplication Layer"):
redis = Redis("Redis\n(fast-path\ndedup, TTL 24h)")
pg = PostgreSQL("PostgreSQL\n(accounts +\nprocessed_txns)")
monitoring = Grafana("Duplicate\nRate Monitor")
# Flow
network_gw >> auth_topic
auth_topic >> svc1
auth_topic >> svc2
auth_topic >> svc3
svc1 >> Edge(label="1. Check Redis") >> redis
svc1 >> Edge(label="2. Atomic\ncheck+process") >> pg
svc1 >> Edge(label="3. Result") >> result_topic
svc2 >> Edge(style="dashed") >> redis
svc2 >> Edge(style="dashed") >> pg
svc3 >> Edge(style="dashed") >> redis
svc3 >> Edge(style="dashed") >> pg
redis >> Edge(style="dotted") >> monitoring
pg >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb, ElasticacheForRedis
from diagrams.aws.integration import SQS, SNS
from diagrams.aws.management import Cloudwatch
from diagrams.aws.network import APIGateway
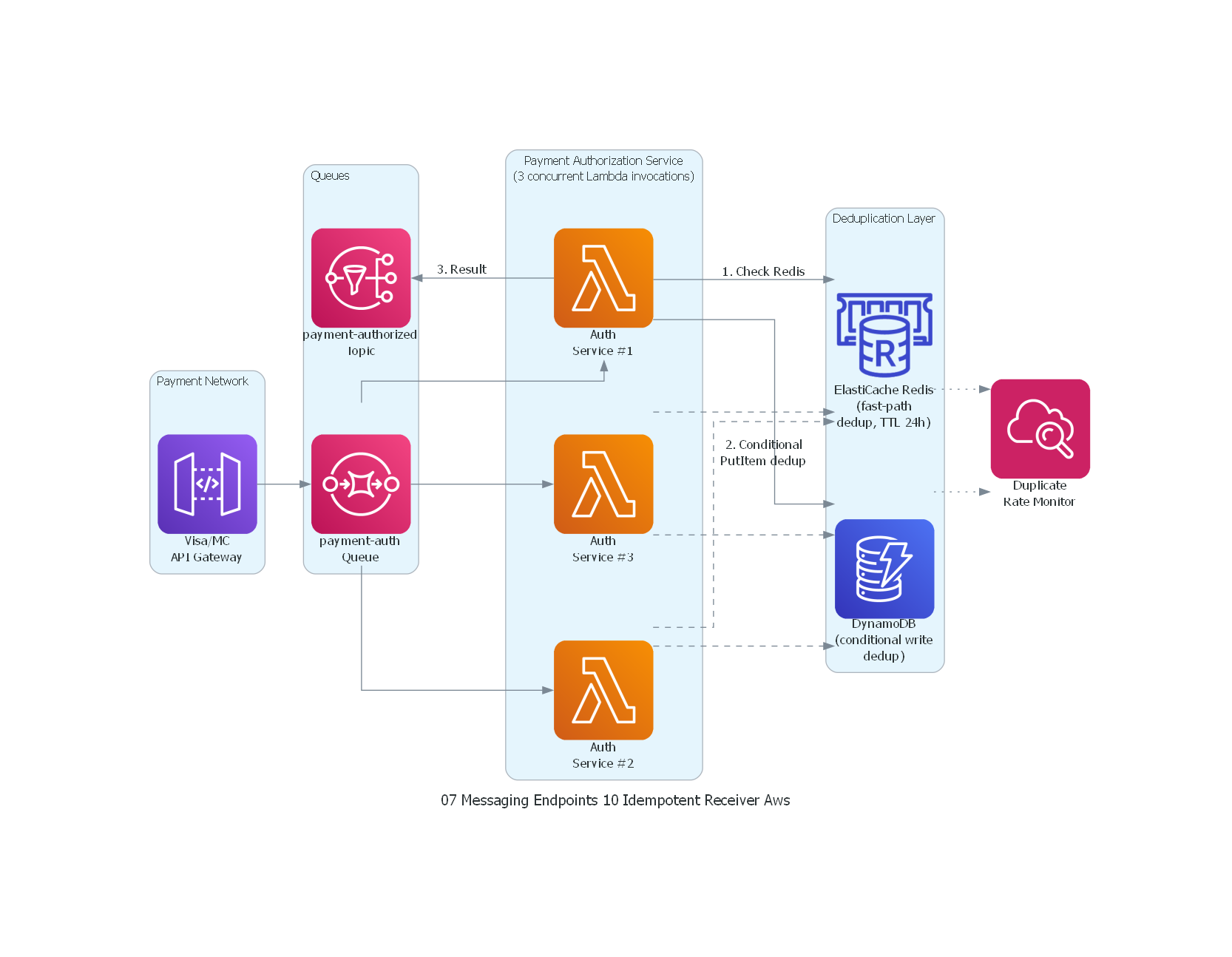
with Diagram("Idempotent Receiver - Payment Authorization (AWS)", show=False, direction="LR"):
with Cluster("Payment Network"):
network_gw = APIGateway("Visa/MC\nAPI Gateway")
with Cluster("Queues"):
auth_queue = SQS("payment-auth\nQueue")
result_topic = SNS("payment-authorized\nTopic")
with Cluster("Payment Authorization Service\n(3 concurrent Lambda invocations)"):
svc1 = Lambda("Auth\nService #1")
svc2 = Lambda("Auth\nService #2")
svc3 = Lambda("Auth\nService #3")
with Cluster("Deduplication Layer"):
redis = ElasticacheForRedis("ElastiCache Redis\n(fast-path\ndedup, TTL 24h)")
dynamo = Dynamodb("DynamoDB\n(conditional write\ndedup)")
monitoring = Cloudwatch("Duplicate\nRate Monitor")
# Flow
network_gw >> auth_queue
auth_queue >> svc1
auth_queue >> svc2
auth_queue >> svc3
svc1 >> Edge(label="1. Check Redis") >> redis
svc1 >> Edge(label="2. Conditional\nPutItem dedup") >> dynamo
svc1 >> Edge(label="3. Result") >> result_topic
svc2 >> Edge(style="dashed") >> redis
svc2 >> Edge(style="dashed") >> dynamo
svc3 >> Edge(style="dashed") >> redis
svc3 >> Edge(style="dashed") >> dynamo
redis >> Edge(style="dotted") >> monitoring
dynamo >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CacheForRedis, CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
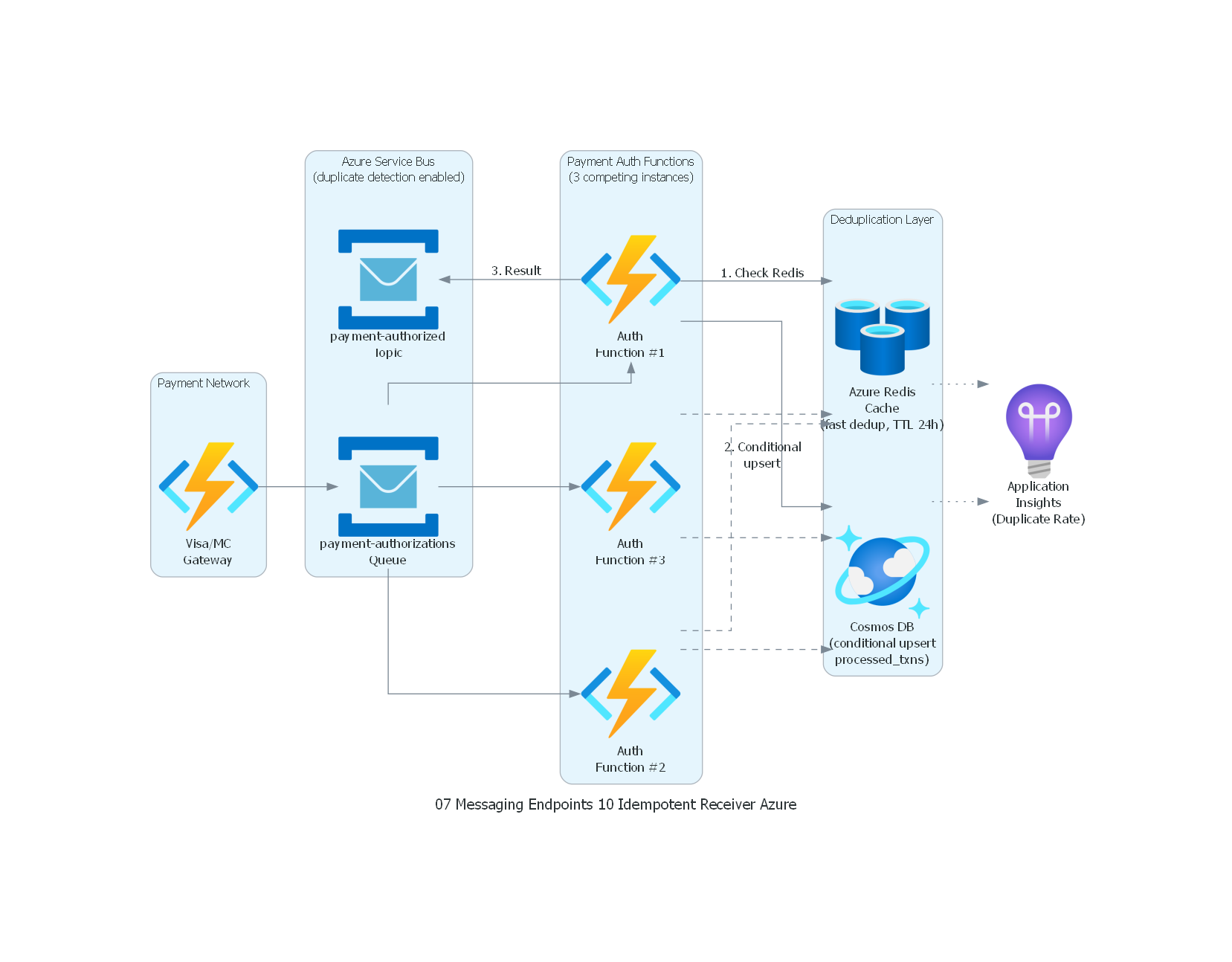
with Diagram("Idempotent Receiver - Payment Authorization (Azure)", show=False, direction="LR"):
with Cluster("Payment Network"):
network_gw = FunctionApps("Visa/MC\nGateway")
with Cluster("Azure Service Bus\n(duplicate detection enabled)"):
auth_queue = ServiceBus("payment-authorizations\nQueue")
result_topic = ServiceBus("payment-authorized\nTopic")
with Cluster("Payment Auth Functions\n(3 competing instances)"):
svc1 = FunctionApps("Auth\nFunction #1")
svc2 = FunctionApps("Auth\nFunction #2")
svc3 = FunctionApps("Auth\nFunction #3")
with Cluster("Deduplication Layer"):
redis = CacheForRedis("Azure Redis\nCache\n(fast dedup, TTL 24h)")
cosmos = CosmosDb("Cosmos DB\n(conditional upsert\nprocessed_txns)")
monitoring = ApplicationInsights("Application\nInsights\n(Duplicate Rate)")
# Flow
network_gw >> auth_queue
auth_queue >> svc1
auth_queue >> svc2
auth_queue >> svc3
svc1 >> Edge(label="1. Check Redis") >> redis
svc1 >> Edge(label="2. Conditional\nupsert") >> cosmos
svc1 >> Edge(label="3. Result") >> result_topic
svc2 >> Edge(style="dashed") >> redis
svc2 >> Edge(style="dashed") >> cosmos
svc3 >> Edge(style="dashed") >> redis
svc3 >> Edge(style="dashed") >> cosmos
redis >> Edge(style="dotted") >> monitoring
cosmos >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
- El Payment Network Gateway publica transacciones en el topic Kafka.
- Tres instancias del Authorization Service (consumer group) compiten por mensajes.
- Cada instancia ejecuta deduplicación en dos niveles: Redis (fast-path) y PostgreSQL (source of truth con transacción atómica).
- Los resultados se publican en un topic de salida para downstream consumers.
- Grafana monitorea la tasa de duplicados detectados como indicador de salud.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Mensaje entrante | Transaction message en Kafka topic |
| Consumidor con idempotencia | Auth Service instances (con lógica de dedup) |
| Deduplication Store (fast) | Redis con TTL 24h |
| Deduplication Store (source of truth) | PostgreSQL tabla processed_transactions |
| Lógica de negocio | Dentro del Auth Service (débito + ledger) |
| Competing Consumers | 3 instancias en consumer group |
| Monitoring | Grafana duplicate rate dashboard |
11. Beneficios¶
Impacto Técnico¶
- Correctitud garantizada: la operación de negocio se ejecuta exactamente una vez por clave de idempotencia, independientemente de cuántas veces llegue el mensaje.
- Resiliencia ante fallos de infraestructura: redeliveries, rebalances, network partitions y producer retries no producen duplicación.
- Compatibilidad con at-least-once: permite usar la semántica de entrega más robusta y mejor soportada sin sufrir sus consecuencias negativas.
Impacto Organizacional¶
- Confianza en los datos: los equipos de negocio pueden confiar en que los registros son correctos y no contienen duplicados.
- Reducción de soporte: menos quejas de clientes por duplicaciones, menos procesos de reversión manual.
Impacto Operacional¶
- Métricas de duplicación: la tasa de duplicados detectados es un indicador valioso de salud del sistema de messaging (una tasa creciente indica problemas de infraestructura).
- Simplificación de recovery: ante un fallo, se puede reprocesar un batch de mensajes sin temor a duplicación.
Beneficios de Mantenibilidad y Evolución¶
- Replay seguro: se pueden "rebobinar" offsets de Kafka para reprocesar mensajes históricos (por ejemplo, tras un bug fix) sin riesgo de duplicación.
- Testing simplificado: en tests, se pueden enviar mensajes duplicados deliberadamente para verificar que la idempotencia funciona.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Deduplication store: infraestructura adicional (Redis, tabla de deduplicación) que debe operarse, monitorearse y escalarse.
- Atomicidad: garantizar que la operación de negocio y el registro de deduplicación son atómicos requiere diseño cuidadoso.
- Gestión de ventana temporal: definir y mantener el TTL del registro de deduplicación.
Riesgos de Mal Uso¶
- Deduplicación sin atomicidad: registrar el ID después de la operación (no en la misma transacción) deja una ventana de duplicación ante crashes.
- Usar message_id en lugar de business key: si el productor reenvía el mismo mensaje lógico con un message_id diferente, la deduplicación por message_id no lo detectará. La clave de idempotencia debe ser de negocio (
transaction_id), no de infraestructura. - Ventana insuficiente: un TTL de 5 minutos cuando el redelivery puede ocurrir horas después (por ejemplo, tras un outage prolongado del consumidor).
Anti-Patterns Relacionados¶
- Dedup-and-Pray: consultar Redis, procesar, y luego registrar en Redis — si el crash ocurre entre procesar y registrar, hay duplicación. La deduplicación debe ser atómica con la operación.
- Global In-Memory Dedup: mantener un Set en memoria del proceso como deduplication store. Se pierde ante reinicios. Solo es válido como cache de fast-path, no como store definitivo.
- Ignoring Side Effects: hacer idempotente la escritura en DB pero no las llamadas a APIs externas (payment gateway, notification service). El side effect externo se duplica.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Transactional Client (Outbox): garantiza atomicidad entre cambio de estado y publicación de evento en el productor. Idempotent Receiver garantiza correctitud en el consumidor. Juntos proporcionan exactly-once processing end-to-end.
- Competing Consumers: múltiples instancias del consumidor requieren un Deduplication Store compartido.
- Dead Letter Channel: los mensajes que fallan tras N reintentos van a DLQ. La idempotencia permite reintentar sin riesgo de duplicación antes de enviar a DLQ.
- Correlation Identifier: el correlation_id puede usarse como clave de idempotencia cuando representa una operación de negocio única.
Patrones que Suelen Aparecer Antes o Después¶
- Antes: Guaranteed Delivery (el broker garantiza que el mensaje llega, posiblemente más de una vez).
- Después: Message Store (los mensajes procesados se almacenan para auditoría, y el Deduplication Store puede consultarse como parte del audit trail).
Diferencias con Patrones Similares¶
- vs. Message Filter: un filter descarta mensajes que no cumplen un criterio de negocio. Un Idempotent Receiver descarta mensajes que ya fueron procesados. La semántica es diferente.
- vs. Exactly-Once Delivery: exactly-once es una propiedad del sistema de transporte; Idempotent Receiver es una propiedad del consumidor. En la práctica, exactly-once se implementa mediante at-least-once delivery + Idempotent Receiver.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta (Crítica)¶
Argumentación¶
Idempotent Receiver es posiblemente el patrón más importante para la correctitud de datos en arquitecturas event-driven modernas. La razón es simple: at-least-once es la semántica de entrega por defecto en todas las plataformas de messaging en producción:
- Kafka: at-least-once por defecto. Exactly-once solo dentro de Kafka Transactions (no cubre side effects externos).
- RabbitMQ: at-least-once con manual ack.
- SQS: at-least-once (Standard) o exactly-once (FIFO, con deduplication window de 5 minutos).
- Azure Service Bus: at-least-once con PeekLock. Duplicate detection window opcional (hasta 7 días).
- Google Pub/Sub: at-least-once por defecto. Exactly-once delivery como feature reciente (con overhead).
En todas estas plataformas, la idempotencia del consumidor es el mecanismo que cierra la brecha entre at-least-once delivery y exactly-once processing.
Cómo Se Implementa Hoy¶
| Plataforma/Framework | Mecanismo |
|---|---|
| Spring Kafka | @Transactional + tabla de deduplicación en misma DB |
| Kafka Streams | State store interno para deduplicación |
| AWS Lambda + SQS FIFO | Deduplication ID nativo (5 min window) |
| Azure Service Bus | MessageId duplicate detection (configurable window) |
| Temporal/Cadence | Workflow ID como idempotency key nativo |
| Stripe API | Header Idempotency-Key en requests |
15. Implementación en Arquitecturas Modernas¶
PostgreSQL (Deduplication Table)¶
CREATE TABLE processed_messages (
idempotency_key VARCHAR(255) PRIMARY KEY,
processed_at TIMESTAMP NOT NULL DEFAULT NOW(),
result JSONB
);
-- TTL via pg_cron o partitioned table por fecha
CREATE INDEX idx_processed_at ON processed_messages(processed_at);
Redis (Fast-Path Cache)¶
SET dedup:{idempotency_key} 1 EX 86400 -- TTL 24 hours
GET dedup:{idempotency_key} -- returns 1 if exists, nil if not
Spring Kafka con Transacción Local¶
@KafkaListener(topics = "payments.authorizations")
@Transactional
public void handlePayment(ConsumerRecord<String, PaymentMessage> record) {
String txnId = record.value().getTransactionId();
if (processedRepository.existsById(txnId)) {
log.warn("Duplicate detected: {}", txnId);
return; // ACK implícito por Spring
}
// Business logic
accountService.debit(record.value());
ledgerService.record(record.value());
// Register deduplication (same transaction)
processedRepository.save(new ProcessedMessage(txnId, Instant.now()));
}
DynamoDB (Conditional Write)¶
try:
table.put_item(
Item={'txn_id': txn_id, 'processed_at': now, ...},
ConditionExpression='attribute_not_exists(txn_id)'
)
# First time → process
process_payment(event)
except ConditionalCheckFailedException:
# Duplicate → skip
logger.warn(f"Duplicate: {txn_id}")
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Duplicate rate: porcentaje de mensajes descartados como duplicados. Una tasa creciente indica problemas de infraestructura (rebalances frecuentes, timeouts de ack, producer retries excesivos).
- Deduplication store size: tamaño del registro de deduplicación. Si crece sin control, indica que el TTL es demasiado largo o que la purga no funciona.
- Deduplication latency: tiempo que toma la consulta al Deduplication Store. Si crece, indica que el store necesita optimización.
Monitoreo¶
- Alerta si duplicate rate > umbral (por ejemplo, >5% indica un problema sistémico).
- Alerta si deduplication store latency > umbral.
- Dashboard con: total processed, total duplicates, duplicate rate, store size, store latency.
Seguridad¶
- El Deduplication Store contiene IDs de transacciones que pueden ser sensibles. Aplicar mismos controles de acceso que la base de datos de negocio.
Retención¶
- El TTL del Deduplication Store debe ser mayor que el máximo tiempo de redelivery posible. Para Kafka, esto es
max.poll.interval.ms+ tiempo máximo de outage del consumidor. Un TTL de 24-72 horas es típico. - Usar partitioned tables por fecha en PostgreSQL para purga eficiente.
17. Errores Comunes¶
Usar Message ID en Lugar de Business Key¶
El message_id es único por envío, no por operación de negocio. Si el productor reenvía la misma operación con un nuevo message_id, la deduplicación por message_id no la detectará. Siempre usar un identificador de negocio como clave de idempotencia.
Deduplicación No Atómica¶
Procesar el mensaje y luego registrar el ID en pasos separados deja una ventana de fallo. Si el proceso crashea entre ambos pasos, el mensaje se reprocesará. La solución: misma transacción de base de datos para la operación y el registro de deduplicación.
Ignorar Side Effects Externos¶
Hacer idempotente la escritura en DB pero no proteger las llamadas a APIs externas (payment gateway, notification service, email). Solución: usar Idempotency-Key en las llamadas externas, o diseñar los side effects como operaciones atómicas con el registro de deduplicación.
Ventana de Deduplicación Demasiado Corta¶
Un TTL de 5 minutos cuando el consumidor puede estar caído durante horas. Cuando el consumidor se recupera y reprocesa mensajes, los IDs ya expiraron y los mensajes se procesan como nuevos.
In-Memory Deduplication Como Única Capa¶
Un HashSet en memoria es rápido pero se pierde al reiniciar el proceso. Solo debe usarse como cache/fast-path, con un store persistente como respaldo.
18. Conclusión Técnica¶
Idempotent Receiver no es un patrón "nice-to-have" — es un requisito de correctitud en cualquier sistema de messaging con efectos secundarios. La pregunta no es si implementar idempotencia, sino cómo implementarla de la forma más eficiente y robusta para cada caso.
Cuándo aporta valor: siempre que un consumidor produzca efectos secundarios (escrituras en DB, llamadas a APIs, cambios de estado, notificaciones). Es decir, en prácticamente todos los consumidores de producción.
Cuándo evita problemas importantes: evita duplicación de pagos, registros, notificaciones y cualquier operación de negocio. En sectores regulados (banca, seguros, salud), la ausencia de idempotencia es una vulnerabilidad operativa y regulatoria.
Cuándo no conviene adoptarlo: cuando la operación es naturalmente idempotente (SET puro, cache update) o cuando la duplicación es explícitamente aceptable (métricas aproximadas, logs informativos).
Recomendación para arquitectos: implemente idempotencia en todos los consumidores desde el día uno. Use claves de negocio (no message_id) como idempotency keys. Garantice atomicidad entre la operación de negocio y el registro de deduplicación. Use Redis como fast-path y una base de datos persistente como source of truth. Monitoree la tasa de duplicados como indicador de salud del sistema de messaging. Y recuerde: at-least-once delivery + Idempotent Receiver = exactly-once processing. Esta ecuación es la base de la correctitud en sistemas event-driven.