Control Bus¶
1. Nombre del Patrón¶
- Nombre oficial: Control Bus
- Categoría: System Management (Gestión del Sistema de Mensajería)
- Traducción contextual: Bus de Control
2. Resumen Ejecutivo¶
Control Bus es el patrón que establece un canal de gestión separado — un plano de control — para administrar, configurar y monitorear la infraestructura de mensajería en tiempo de ejecución, sin interferir con el flujo de mensajes de negocio. Es la separación arquitectónica entre el data plane (por donde fluyen los mensajes de negocio) y el control plane (por donde fluyen las instrucciones de gestión).
El problema que resuelve es operacionalmente crítico: en un sistema de integración con docenas de canales, routers, transformers y endpoints, ¿cómo se ajusta el comportamiento del sistema en producción sin redesplegar, sin detener el flujo de mensajes y sin conectarse manualmente a cada componente? Control Bus responde proporcionando un mecanismo unificado para enviar comandos de gestión (activar un canal, cambiar una regla de routing, ajustar un throttle, habilitar un wire tap) a cualquier componente del sistema a través de mensajes de control.
La vigencia de este patrón es alta. Kubernetes separa su control plane (API Server, etcd, scheduler) del data plane (pods, services). Los sistemas de feature flags (LaunchDarkly, Unleash) son Control Buses para la lógica de negocio. Las plataformas de service mesh (Istio, Linkerd) implementan control planes que configuran sidecars dinámicamente. El principio es idéntico al del patrón original: gestionar la infraestructura a través de mensajes, no de intervención manual directa.
3. Definición Detallada¶
Propósito¶
Control Bus proporciona un canal dedicado y una interfaz unificada para enviar comandos de gestión a los componentes de la infraestructura de integración. Su propósito es permitir la administración dinámica del sistema de mensajería — activar/desactivar canales, cambiar reglas de routing, ajustar parámetros de rendimiento, habilitar diagnósticos — sin modificar código, sin redesplegar y sin interrumpir el flujo de mensajes de negocio.
Lógica Arquitectónica¶
En un sistema de integración en producción, los componentes (canales, routers, transformers, endpoints) no son estáticos. Las necesidades cambian: un canal debe cerrarse temporalmente durante una migración, una regla de routing debe ajustarse para dirigir tráfico a un nuevo servicio, un wire tap debe activarse para diagnosticar un problema. Sin Control Bus, cada uno de estos cambios requiere intervención manual directa en el componente afectado — modificar configuración, redesplegar, reiniciar.
Control Bus introduce un mecanismo de comunicación para gestión que usa el mismo paradigma que el propio sistema de mensajería: mensajes. Los comandos de gestión se envían como mensajes a un canal de control, y cada componente suscrito ejecuta los comandos relevantes. Esto tiene consecuencias arquitectónicas profundas:
- Gestión centralizada: un punto único desde donde se pueden enviar comandos a cualquier componente.
- Gestión distribuida: cada componente procesa localmente los comandos que le aplican.
- Gestión auditable: los comandos de control son mensajes y, como tales, pueden registrarse, auditarse y reproducirse.
- Gestión programática: los comandos pueden originarse no solo de operadores humanos, sino de sistemas de auto-healing, schedulers o pipelines de CI/CD.
Principio de Diseño Subyacente¶
El principio es separación del plano de control y el plano de datos. Esta separación es uno de los principios más fundamentales de la ingeniería de sistemas distribuidos. En networking, la separación control plane / data plane es la base de SDN (Software-Defined Networking). En Kubernetes, el API Server gestiona el estado deseado (control plane) y los kubelets ejecutan la reconciliación (data plane). Control Bus aplica este mismo principio a la infraestructura de mensajería.
Problema Estructural que Resuelve¶
Sin Control Bus, la gestión del sistema de integración es ad-hoc: scripts SSH que se conectan a cada nodo, consolas de administración propietarias de cada broker, ficheros de configuración que requieren reinicio para aplicarse. Esto produce una gestión frágil, no reproducible, no auditable y propensa a errores humanos. Control Bus estructura la gestión como un flujo de mensajes, aplicando al propio sistema de gestión las mismas virtudes que la mensajería aporta a la integración de negocio.
Contexto en el que Emerge¶
Control Bus emerge en sistemas de integración medianos y grandes donde la gestión manual se vuelve inviable. Cuando hay 10 canales y 5 componentes, un operador puede conectarse a cada uno. Cuando hay 200 canales, 50 routers, 30 transformers y 100 endpoints distribuidos en 15 servidores, la gestión manual es imposible. Control Bus emerge como necesidad operacional.
Relación con Sistemas Distribuidos¶
En teoría de sistemas distribuidos, Control Bus implementa un patrón de difusión de configuración (configuration dissemination). Es análogo a sistemas como etcd, Consul o ZooKeeper, que actúan como fuentes de verdad para configuración distribuida y notifican a los componentes suscritos cuando la configuración cambia.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Control Bus, los operadores deben gestionar cada componente de la infraestructura de integración de forma individual y directa:
- Cambios de configuración: modificar archivos de configuración en cada nodo y reiniciar servicios.
- Activación de diagnósticos: conectarse al componente específico para habilitar logging detallado o wire taps.
- Cambios de routing: modificar código o configuración de routers y redesplegar.
- Feature toggles: hardcodear condiciones en el código y redesplegar para activar/desactivar funcionalidades.
Síntomas del Problema¶
- Cambios operacionales que requieren ventanas de mantenimiento y redespliegues completos.
- Incapacidad de responder rápidamente a incidentes (activar diagnósticos, redirigir tráfico) porque cada cambio requiere un proceso de deploy.
- Inconsistencias entre componentes cuando un cambio de configuración se aplica a algunos nodos pero no a todos.
- Falta de auditoría sobre qué cambios de configuración se aplicaron, cuándo y por quién.
- Operadores que necesitan acceso SSH directo a servidores de producción, lo cual es un riesgo de seguridad.
Impacto Operativo y Arquitectónico¶
Sin Control Bus:
- El MTTR (Mean Time to Recovery) se incrementa porque cada ajuste operacional requiere un ciclo de deploy.
- Los cambios de configuración son propensos a errores humanos y difíciles de revertir.
- La gestión no es reproducible: no hay forma de reproducir el estado de configuración de un entorno en otro.
- La automatización de la gestión (auto-scaling, auto-healing, canary deployments) es imposible sin un mecanismo programático de control.
Riesgos Si No Se Implementa Correctamente¶
- Control Bus como single point of failure: si el bus de control falla, se pierde la capacidad de gestionar el sistema.
- Comandos sin autenticación: si cualquiera puede enviar comandos de control, el sistema está expuesto a manipulación maliciosa.
- Efectos secundarios no previstos: un comando de control mal diseñado puede afectar a componentes que no deberían verse afectados.
Ejemplos Reales¶
- Plataforma Enterprise: una plataforma de integración con 200+ flujos de mensajería necesita desactivar temporalmente un flujo que envía notificaciones durante una migración de base de datos, sin afectar los demás flujos.
- E-commerce: durante Black Friday, el equipo de operaciones necesita ajustar dinámicamente los throttle rates de los canales de pedidos sin redesplegar.
- Telecomunicaciones: un router de mensajes debe cambiar sus reglas para dirigir tráfico de un operador a un nuevo endpoint después de una fusión corporativa.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando el sistema de integración tiene múltiples componentes distribuidos que necesitan gestión dinámica.
- Cuando los cambios de configuración deben aplicarse sin downtime ni redespliegues.
- Cuando se necesita auditoría de los cambios operacionales.
- Cuando se desea automatizar la gestión (auto-healing, auto-scaling, feature flags).
- Cuando múltiples operadores o sistemas necesitan coordinar cambios en la infraestructura de integración.
Cuándo No Usarlo¶
- En sistemas pequeños con pocos componentes donde la gestión directa es manejable.
- Cuando los cambios de configuración son extremadamente infrecuentes y un redespliegue es aceptable.
- Cuando los componentes no soportan reconfiguración en caliente.
Precondiciones¶
- Los componentes de la infraestructura de integración deben soportar reconfiguración dinámica (sin reinicio).
- Debe existir una infraestructura de mensajería que pueda transportar comandos de control.
- Debe existir un modelo de seguridad que controle quién puede enviar qué comandos.
Restricciones¶
- El Control Bus introduce dependencia en la infraestructura de mensajería para la gestión — si el broker falla, se pierde tanto el data plane como el control plane a menos que estén en infraestructuras separadas.
- Los comandos de control deben ser idempotentes para tolerar duplicados.
- La latencia del Control Bus determina la rapidez con que los cambios de configuración se propagan.
Dependencias¶
- Infraestructura de mensajería (para el canal de control).
- Componentes con interfaces de gestión (APIs o handlers de comandos de control).
- Sistema de autenticación y autorización para comandos de control.
- Persistencia para el estado actual de configuración (para que nuevos componentes puedan sincronizarse).
6. Fuerzas Arquitectónicas¶
Centralización vs. Distribución¶
Control Bus centraliza el envío de comandos pero distribuye la ejecución. Esto es un equilibrio deliberado: el operador o sistema automatizado tiene un punto único de control, pero cada componente procesa sus comandos localmente. La tensión aparece cuando se necesita coordinación: ¿qué pasa si un comando debe aplicarse a 10 componentes de forma atómica? El bus por sí solo no garantiza atomicidad.
Agilidad vs. Seguridad¶
Control Bus aumenta la agilidad operacional (cambios instantáneos sin deploy) pero introduce riesgo de seguridad: un comando incorrecto o malicioso puede alterar el comportamiento del sistema en producción. La tensión se resuelve con autenticación, autorización, validación de comandos y auditoría.
Acoplamiento al Mecanismo de Control¶
Cada componente que se integra con el Control Bus debe implementar una interfaz de gestión. Esto añade complejidad al desarrollo del componente. La tensión es entre la capacidad de gestión dinámica y la simplicidad del componente.
Consistencia de Configuración¶
Cuando un comando de control se propaga a múltiples componentes, puede haber ventanas donde algunos componentes ya aplicaron el cambio y otros no. Esta inconsistencia temporal puede causar comportamiento impredecible durante la transición.
Resiliencia del Propio Control Bus¶
Si el Control Bus usa la misma infraestructura de messaging que el data plane, un fallo en el broker afecta tanto al negocio como a la gestión. Si usa una infraestructura separada, se duplica el costo y la complejidad. La tensión entre resiliencia y simplicidad es real.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Operador / Sistema Automatizado: origina comandos de gestión (humano a través de una consola, CI/CD pipeline, auto-healer).
- Control Bus (Canal de Control): canal dedicado que transporta comandos de gestión.
- Componente Gestionable: cualquier elemento de la infraestructura de integración que puede recibir y ejecutar comandos de control (router, transformer, endpoint, channel manager).
- Control Store: almacén persistente del estado actual de configuración para que nuevos componentes se sincronicen.
- Audit Log: registro inmutable de todos los comandos de control ejecutados.
Flujo Lógico¶
flowchart TD
A([Operador / Automatización]) -->|Envía comando de control| B[Control Bus]
B -->|Distribuye comando| C[Componente Gestionable]
C -->|Evalúa si aplica| D{Comando es para este componente?}
D -->|No| E([Ignora])
D -->|Sí| F[Valida comando: formato, permisos, coherencia]
F --> G[Ejecuta cambio de configuración]
G -->|Publica resultado| H{Éxito?}
H -->|Sí| I[Confirmación en bus de respuesta]
H -->|No| J[Error en bus de respuesta]
G --> K[(Control Store: persiste nuevo estado)]
G --> L[(Audit Log: comando + resultado + timestamp)]Responsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Operador / Automatización | Formular y enviar comandos de control válidos |
| Control Bus | Transportar comandos con entrega garantizada |
| Componente Gestionable | Interpretar, validar y ejecutar comandos de control |
| Control Store | Persistir el estado de configuración para sincronización |
| Audit Log | Registrar todos los comandos para trazabilidad y compliance |
Decisiones de Diseño Clave¶
- Granularidad de comandos: ¿comandos atómicos (cambiar una propiedad) o compuestos (cambiar un conjunto de propiedades como transacción)?
- Modelo de addressing: ¿cada componente tiene una dirección única, o se usan selectores/topics para dirigir comandos a grupos de componentes?
- Confirmación: ¿el componente confirma la ejecución del comando, o es fire-and-forget?
- Rollback: ¿los comandos son reversibles? ¿Se mantiene historial de configuraciones para rollback?
- Separación de infraestructura: ¿el Control Bus comparte la infraestructura de messaging con el data plane o tiene su propia infraestructura?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Plataforma Enterprise — Control Plane para Integración Multi-País¶
Contexto del Negocio¶
Una corporación financiera multinacional opera una plataforma de integración que conecta 45 sistemas internos y 120 socios externos en 12 países. La plataforma procesa 8 millones de mensajes diarios: transacciones interbancarias, reportes regulatorios, notificaciones a clientes, sincronización de datos entre sucursales. Los flujos de integración varían por país según regulación local, horarios de mercado y acuerdos bilaterales con socios.
Necesidad de Integración¶
El equipo de operaciones necesita gestionar dinámicamente:
- Activación/desactivación de flujos por país: durante ventanas de mantenimiento de reguladores locales, ciertos flujos deben pausarse sin afectar otros países.
- Cambio de reglas de routing: cuando un nuevo socio reemplaza a uno existente, el routing debe actualizarse sin redespliegue.
- Ajuste de throttling: durante picos de volumen (cierre de mercados, fin de mes), los rates deben ajustarse dinámicamente.
- Habilitación de diagnósticos: cuando hay un problema con un flujo específico, se necesita activar wire taps y logging detallado sin reiniciar servicios.
- Feature flags: nuevas funcionalidades de integración se despliegan con flags desactivados y se activan gradualmente por país.
Sistemas Involucrados¶
- Control Console: aplicación web para operadores.
- Control Bus: topic Kafka dedicado (
platform.control.commands). - Config Store: base de datos PostgreSQL con el estado de configuración.
- Integration Routers: 24 instancias de routers distribuidos en 4 regiones.
- Channel Managers: componentes que gestionan la activación/desactivación de canales.
- Throttle Controllers: componentes que gestionan rate limiting por flujo.
- Diagnostic Controllers: componentes que activan/desactivan wire taps y logging.
- Audit Service: servicio que persiste todos los comandos de control.
Diseño del Control Bus¶
| Canal Kafka | Función | Particionamiento | Retención |
|---|---|---|---|
platform.control.commands | Comandos de control salientes | Por target_component | 30 días |
platform.control.responses | Confirmaciones/errores | Por command_id | 30 días |
platform.control.audit | Registro inmutable de comandos | Por timestamp | 365 días |
Decisiones Arquitectónicas¶
-
Kafka como infraestructura de control: se usa el mismo cluster Kafka pero con topics dedicados y ACLs estrictas. La retención de 30 días permite que un nuevo nodo que se une al cluster pueda replay los últimos comandos para sincronizarse.
-
Comandos tipados con schema: cada comando es un mensaje con schema Avro registrado, lo que permite validación automática y evolución del formato de comandos.
-
Modelo de addressing por component type + instance: los comandos incluyen
target_type(router, throttle, channel) y opcionalmentetarget_instance(específico) otarget_region(broadcast regional). -
Confirmación obligatoria: cada componente publica una confirmación o error en
platform.control.responses, lo que permite al operador verificar que el comando se aplicó correctamente.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Comando de Desactivación de Flujo¶
El regulador financiero de Brasil notifica que realizará mantenimiento en su sistema de reporting durante 4 horas. El operador debe desactivar el flujo de reportes regulatorios para Brasil sin afectar los demás países.
El operador accede a la Control Console y selecciona: Pausar flujo → Reporting Regulatorio → Brasil. La consola genera el siguiente comando:
{
"command_id": "CMD-2026-0407-001",
"command_type": "pause_flow",
"target_type": "channel_manager",
"target_region": "BR",
"params": {
"flow_id": "regulatory-reporting-br",
"reason": "Regulador BR en mantenimiento programado",
"scheduled_resume": "2026-04-07T22:00:00Z"
},
"issued_by": "ops-user-jgarcia",
"issued_at": "2026-04-07T18:00:00Z"
}
Paso 2: Propagación por el Control Bus¶
El comando se publica en platform.control.commands con partition key channel_manager. Todos los Channel Managers suscritos reciben el comando.
Paso 3: Ejecución por el Channel Manager de Brasil¶
El Channel Manager de la región BR recibe el comando, verifica que target_region coincide con su región, valida que el flujo regulatory-reporting-br existe y está activo, y ejecuta la pausa:
- Detiene el consumo del canal
regulatory.reports.br.outbound. - Los mensajes que lleguen al canal se acumularán (backlog) pero no se perderán.
- Registra el estado "paused" en su configuración local y en el Config Store.
Paso 4: Confirmación¶
El Channel Manager publica una confirmación:
{
"command_id": "CMD-2026-0407-001",
"status": "executed",
"component": "channel-manager-br-01",
"details": {
"flow_id": "regulatory-reporting-br",
"previous_state": "active",
"current_state": "paused",
"pending_messages": 0
},
"executed_at": "2026-04-07T18:00:02Z"
}
Paso 5: Reanudación Automática¶
A las 22:00 UTC, un scheduler lee el campo scheduled_resume del comando original y genera un comando de reanudación:
{
"command_id": "CMD-2026-0407-002",
"command_type": "resume_flow",
"target_type": "channel_manager",
"target_region": "BR",
"params": {
"flow_id": "regulatory-reporting-br",
"reason": "Reanudación automática post-mantenimiento"
},
"issued_by": "system-scheduler",
"issued_at": "2026-04-07T22:00:00Z"
}
El Channel Manager reanuda el consumo, procesando primero los mensajes acumulados durante la pausa.
Paso 6: Auditoría¶
El Audit Service ha registrado ambos comandos (pausa y reanudación), sus confirmaciones, los operadores/sistemas que los emitieron y los timestamps exactos. Este registro es consultable para compliance y post-mortem.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.database import PostgreSQL
from diagrams.onprem.client import User
from diagrams.onprem.monitoring import Grafana
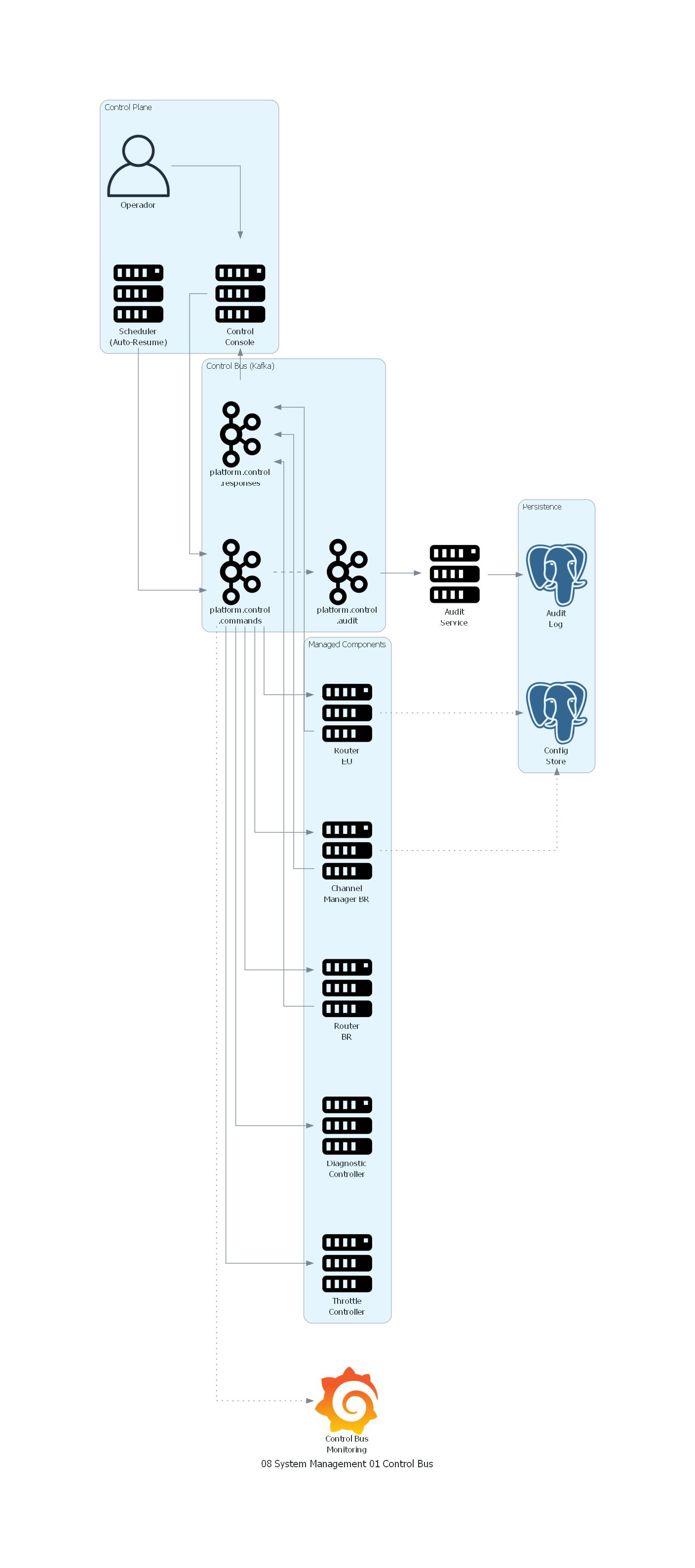
with Diagram("Control Bus - Enterprise Platform", show=False, direction="LR"):
with Cluster("Control Plane"):
operator = User("Operador")
console = Server("Control\nConsole")
scheduler = Server("Scheduler\n(Auto-Resume)")
with Cluster("Control Bus (Kafka)"):
cmd_topic = Kafka("platform.control\n.commands")
resp_topic = Kafka("platform.control\n.responses")
audit_topic = Kafka("platform.control\n.audit")
with Cluster("Managed Components"):
router_eu = Server("Router\nEU")
router_br = Server("Router\nBR")
channel_mgr = Server("Channel\nManager BR")
throttle = Server("Throttle\nController")
diag = Server("Diagnostic\nController")
with Cluster("Persistence"):
config_store = PostgreSQL("Config\nStore")
audit_db = PostgreSQL("Audit\nLog")
monitoring = Grafana("Control Bus\nMonitoring")
# Control flow
operator >> console >> cmd_topic
scheduler >> cmd_topic
cmd_topic >> router_eu
cmd_topic >> router_br
cmd_topic >> channel_mgr
cmd_topic >> throttle
cmd_topic >> diag
channel_mgr >> resp_topic
router_eu >> resp_topic
router_br >> resp_topic
resp_topic >> console
cmd_topic >> Edge(style="dashed") >> audit_topic
audit_topic >> Server("Audit\nService") >> audit_db
channel_mgr >> Edge(style="dotted") >> config_store
router_eu >> Edge(style="dotted") >> config_store
cmd_topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.aws.compute import Lambda
from diagrams.aws.database import Dynamodb
from diagrams.aws.integration import SNS, SQS, Eventbridge
from diagrams.aws.management import Cloudwatch, SystemsManager
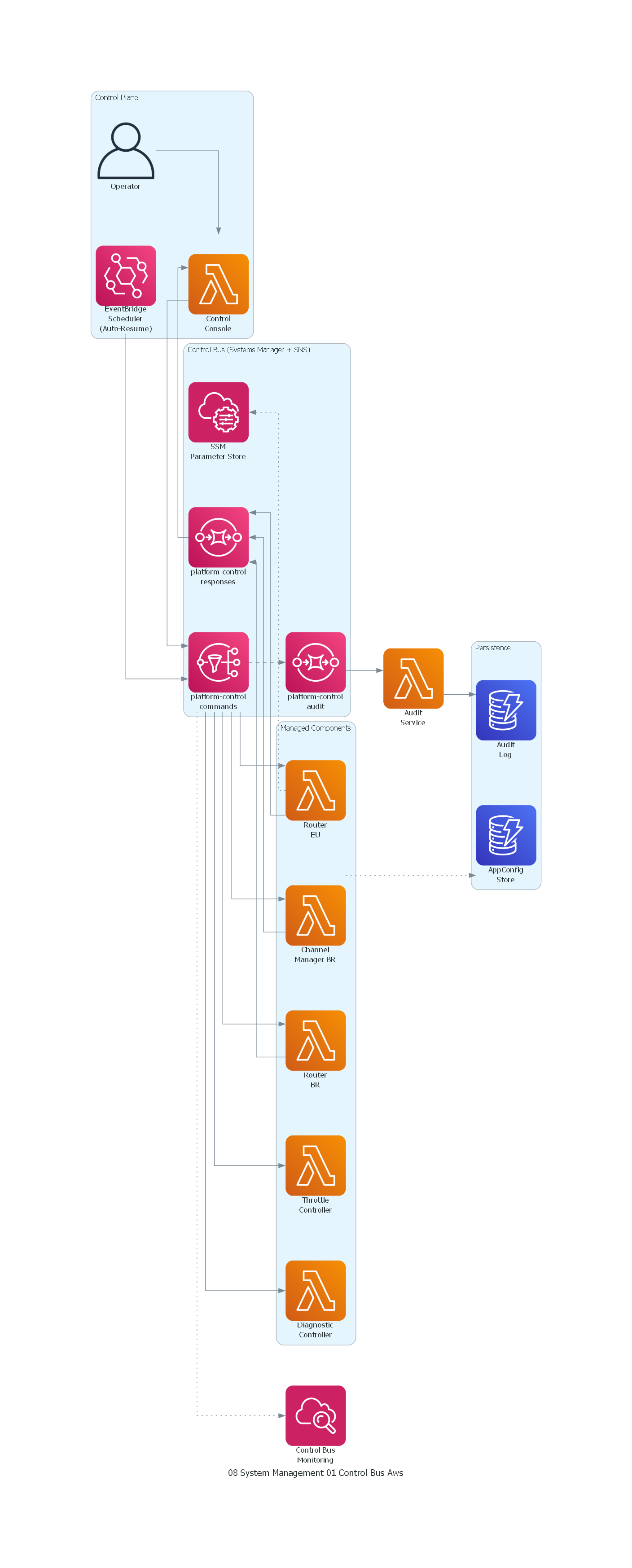
with Diagram("Control Bus - Enterprise Platform (AWS)", show=False, direction="LR"):
with Cluster("Control Plane"):
operator = User("Operator")
console = Lambda("Control\nConsole")
scheduler = Eventbridge("EventBridge\nScheduler\n(Auto-Resume)")
with Cluster("Control Bus (Systems Manager + SNS)"):
ssm = SystemsManager("SSM\nParameter Store")
cmd_topic = SNS("platform-control\ncommands")
resp_queue = SQS("platform-control\nresponses")
audit_queue = SQS("platform-control\naudit")
with Cluster("Managed Components"):
router_eu = Lambda("Router\nEU")
router_br = Lambda("Router\nBR")
channel_mgr = Lambda("Channel\nManager BR")
throttle = Lambda("Throttle\nController")
diag = Lambda("Diagnostic\nController")
with Cluster("Persistence"):
config_store = Dynamodb("AppConfig\nStore")
audit_db = Dynamodb("Audit\nLog")
monitoring = Cloudwatch("Control Bus\nMonitoring")
# Control flow
operator >> console >> cmd_topic
scheduler >> cmd_topic
cmd_topic >> router_eu
cmd_topic >> router_br
cmd_topic >> channel_mgr
cmd_topic >> throttle
cmd_topic >> diag
channel_mgr >> resp_queue
router_eu >> resp_queue
router_br >> resp_queue
resp_queue >> console
cmd_topic >> Edge(style="dashed") >> audit_queue
audit_queue >> Lambda("Audit\nService") >> audit_db
channel_mgr >> Edge(style="dotted") >> config_store
router_eu >> Edge(style="dotted") >> ssm
cmd_topic >> Edge(style="dotted") >> monitoring
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.client import User
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.general import Helpsupport
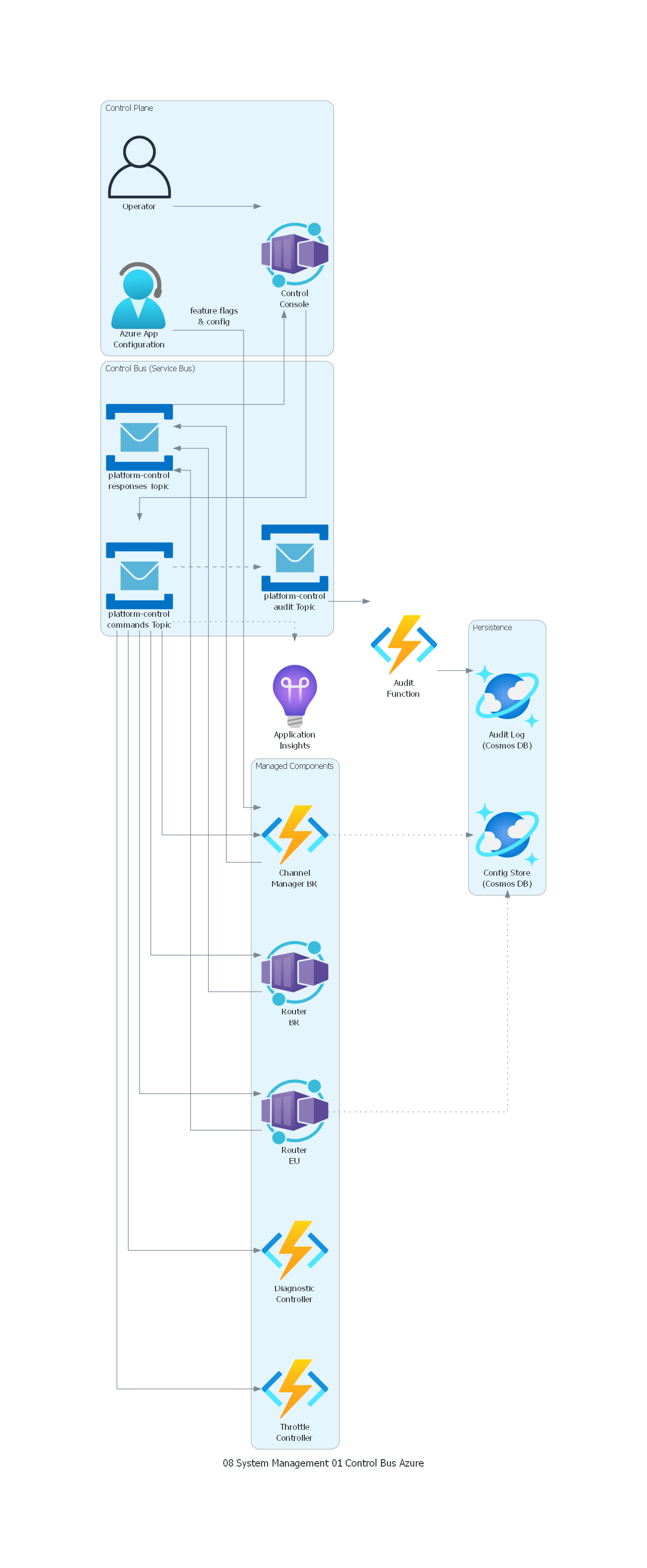
with Diagram("Control Bus - Enterprise Platform (Azure)", show=False, direction="LR"):
with Cluster("Control Plane"):
operator = User("Operator")
console = ContainerApps("Control\nConsole")
app_config = Helpsupport("Azure App\nConfiguration")
with Cluster("Control Bus (Service Bus)"):
cmd_topic = ServiceBus("platform-control\ncommands Topic")
resp_topic = ServiceBus("platform-control\nresponses Topic")
audit_topic = ServiceBus("platform-control\naudit Topic")
with Cluster("Managed Components"):
router_eu = ContainerApps("Router\nEU")
router_br = ContainerApps("Router\nBR")
channel_mgr = FunctionApps("Channel\nManager BR")
throttle = FunctionApps("Throttle\nController")
diag = FunctionApps("Diagnostic\nController")
with Cluster("Persistence"):
config_store = CosmosDb("Config Store\n(Cosmos DB)")
audit_db = CosmosDb("Audit Log\n(Cosmos DB)")
monitoring = ApplicationInsights("Application\nInsights")
# Control flow
operator >> console >> cmd_topic
app_config >> Edge(label="feature flags\n& config") >> channel_mgr
cmd_topic >> router_eu
cmd_topic >> router_br
cmd_topic >> channel_mgr
cmd_topic >> throttle
cmd_topic >> diag
channel_mgr >> resp_topic
router_eu >> resp_topic
router_br >> resp_topic
resp_topic >> console
cmd_topic >> Edge(style="dashed") >> audit_topic
audit_topic >> FunctionApps("Audit\nFunction") >> audit_db
channel_mgr >> Edge(style="dotted") >> config_store
router_eu >> Edge(style="dotted") >> config_store
cmd_topic >> Edge(style="dotted") >> monitoring
Explicación del Diagrama¶
El diagrama muestra la arquitectura del Control Bus para la plataforma financiera multinacional:
- El Operador interactúa con la Control Console para enviar comandos. El Scheduler también genera comandos automáticos (reanudaciones programadas).
- Los comandos se publican en el topic platform.control.commands del Control Bus.
- Todos los componentes gestionables (routers, channel managers, throttle controllers, diagnostic controllers) están suscritos al topic y procesan los comandos que les corresponden.
- Las confirmaciones se publican en platform.control.responses y la consola las muestra al operador.
- Todos los comandos se copian al topic de auditoría y se persisten en la base de datos de auditoría.
- Los componentes persisten su configuración en el Config Store para sincronización.
- Grafana monitorea el propio Control Bus (latencia de comandos, errores, throughput).
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Originador de comandos | Operador + Console, Scheduler |
| Control Bus (canal de control) | Topics Kafka de commands/responses/audit |
| Componente Gestionable | Routers, Channel Manager, Throttle Controller, Diagnostic Controller |
| Control Store | PostgreSQL Config Store |
| Audit Log | PostgreSQL Audit Log vía Audit Service |
11. Beneficios¶
Impacto Técnico¶
- Reconfiguración sin downtime: los cambios de configuración se aplican en caliente, sin necesidad de redespliegues ni reinicio de servicios.
- Gestión unificada: un punto de entrada para gestionar todos los componentes de la infraestructura de integración, independientemente de su tecnología o ubicación.
- Automatización: los comandos de control pueden originarse de sistemas automatizados (auto-healers, schedulers, CI/CD), habilitando operaciones autónomas.
- Reproducibilidad: la secuencia de comandos de control puede reproducirse para recrear el estado de configuración de un entorno en otro (staging → producción).
Impacto Organizacional¶
- Reducción de privilegios: los operadores gestionan el sistema a través de la consola de control en lugar de requerir acceso SSH directo a los servidores.
- Segregación de responsabilidades: diferentes roles pueden tener permisos para diferentes tipos de comandos (SRE puede ajustar throttling, compliance puede activar wire taps).
- Auditoría completa: cada acción de gestión queda registrada con quién la ejecutó, cuándo y qué efecto tuvo.
Impacto Operacional¶
- MTTR reducido: durante un incidente, el operador puede activar diagnósticos, redirigir tráfico o pausar flujos en segundos en lugar de minutos u horas.
- Cambios reversibles: los comandos de control pueden incluir rollback automático o manual, permitiendo revertir cambios rápidamente.
- Visibilidad: el estado de configuración de todos los componentes es consultable desde la consola de control.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Infraestructura adicional: el Control Bus requiere su propio canal, consola, config store y audit log — componentes que deben desarrollarse y mantenerse.
- Interfaz de gestión en cada componente: cada componente gestionable debe implementar un handler de comandos de control, lo cual añade complejidad al desarrollo.
- Consistencia de configuración: gestionar la consistencia entre el estado de configuración persistido y el estado real del componente requiere reconciliación.
Riesgos de Mal Uso¶
- Control Bus como herramienta de despliegue: usar el Control Bus para cambios que deberían ser parte del ciclo de desarrollo y despliegue (cambios de lógica de negocio, no de configuración operacional).
- Comandos sin validación: enviar comandos sin validar que son coherentes con el estado actual del sistema puede dejar componentes en estados inconsistentes.
- Dependencia del operador: si el sistema depende de intervención constante a través del Control Bus, es síntoma de un diseño que debería automatizarse.
Sobreingeniería¶
- Control Bus para sistemas simples: implementar un Control Bus completo para un sistema con 3 componentes es sobreingeniería. Ficheros de configuración con hot-reload son suficientes.
- Granularidad excesiva de comandos: exponer cada parámetro de cada componente como un comando de control produce una API de gestión inmanejable.
Anti-Patterns Relacionados¶
- God Console: una consola que controla absolutamente todo sin segregación de responsabilidades ni permisos granulares.
- Configuration Drift: componentes que acumulan cambios vía Control Bus sin que esos cambios se reflejen en la configuración declarativa (Infrastructure as Code), resultando en configuración que no puede recrearse desde cero.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Wire Tap (este capítulo): el Control Bus frecuentemente se usa para activar/desactivar wire taps dinámicamente.
- Detour (este capítulo): los desvíos temporales de flujo se controlan a través del Control Bus.
- Message Channel (Capítulo 2): el Control Bus es en sí mismo un Message Channel con una función especializada.
- Message Router (Capítulo 2): los routers son componentes gestionables típicos cuyos reglas de routing se actualizan vía Control Bus.
Patrones que Suelen Aparecer Juntos¶
- Control Bus + Wire Tap: activar/desactivar wire taps dinámicamente para diagnóstico.
- Control Bus + Detour: activar/desactivar rutas alternativas de validación.
- Control Bus + Channel Purger: invocar la limpieza de un canal a través de un comando de control.
- Control Bus + Test Message: programar la inyección de mensajes de prueba vía Control Bus.
Diferencias con Patrones Similares¶
- vs. Message Channel: un Message Channel es genérico; el Control Bus es un canal con función específica de gestión.
- vs. Message Store: el Message Store persiste mensajes de negocio; el Config Store del Control Bus persiste estado de configuración.
Encaje en un Flujo Mayor de Integración¶
Control Bus es un patrón transversal que se conecta con todos los demás componentes de la arquitectura de integración. No participa en el flujo de mensajes de negocio, pero controla cómo ese flujo se comporta. Es el "sistema nervioso" de la arquitectura de integración.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Control Bus es más relevante hoy que cuando fue formulado originalmente. Las arquitecturas modernas han llevado la separación control plane / data plane a un nivel de sofisticación que Hohpe y Woolf no podían anticipar en 2003:
- Kubernetes: el control plane (API Server, etcd, scheduler, controller manager) es un Control Bus para la infraestructura de contenedores. Los operadores envían comandos (kubectl apply) que se propagan a los nodos del cluster.
- Service Mesh (Istio, Linkerd): el control plane configura dinámicamente los sidecars (data plane) con reglas de routing, circuit breakers, retry policies y mTLS — exactamente la función del Control Bus.
- Feature Flag Systems (LaunchDarkly, Unleash, Flagsmith): son Control Buses para la lógica de negocio. Permiten activar/desactivar funcionalidades sin redespliegue, con targeting, porcentajes y scheduling.
- GitOps (ArgoCD, Flux): el repositorio Git actúa como Control Bus declarativo. Los cambios en configuración se pushean a Git y se reconcilian automáticamente con el estado del cluster.
- Apache Kafka Control Plane: Kafka utiliza internamente topics de control (
__consumer_offsets,__cluster_metadata) para gestionar su propia infraestructura.
Cómo Se Implementa Hoy¶
| Tecnología | Implementación de Control Bus | Mecanismo |
|---|---|---|
| Kubernetes | API Server + etcd | Declarativo (desired state → reconciliation) |
| Istio | istiod (control plane) | xDS protocol para configuración de Envoy |
| LaunchDarkly | Feature flag service | SSE/Streaming para propagación de flags |
| Consul | KV store + watches | Notificación push a agentes locales |
| Apache Camel | ControlBus component | Comandos JMX/REST para rutas Camel |
| Spring Integration | Control Bus bean | SpEL expressions para gestionar componentes |
Qué Parte Sigue Siendo Esencial¶
- La separación control plane / data plane es un principio de diseño universal.
- La gestión programática a través de mensajes o APIs (en lugar de intervención manual) es requisito en cualquier sistema moderno.
- La auditoría de cambios de configuración es requisito de compliance en industrias reguladas.
15. Implementación en Arquitecturas Modernas¶
Kubernetes como Control Bus¶
# El manifiesto declarativo es el "comando de control"
apiVersion: apps/v1
kind: Deployment
metadata:
name: order-router
labels:
routing-version: "v2"
spec:
replicas: 3
template:
spec:
containers:
- name: router
env:
- name: ROUTING_RULES_VERSION
value: "v2"
- name: EU_ENDPOINT
value: "eu-processor-v2.svc.cluster.local"
El kubectl apply es el envío del comando al Control Bus (API Server). El scheduler y los kubelets reconcilian el estado deseado. etcd persiste la configuración (Config Store).
Feature Flags con Unleash¶
Feature: regulatory-reporting-br
Environment: production
Strategy: userWithId
Parameters: countryCode=BR
State: DISABLED
Scheduled Enable: 2026-04-07T22:00:00Z
El sistema de feature flags actúa como Control Bus para la lógica de negocio. Los cambios se propagan a las aplicaciones clientes vía streaming, sin redespliegue.
Apache Camel Control Bus¶
from("direct:control")
.to("controlbus:route?routeId=regulatory-br&action=stop");
from("direct:resume")
.to("controlbus:route?routeId=regulatory-br&action=start");
Apache Camel implementa Control Bus como componente nativo que permite start/stop/suspend/resume de rutas dinámicamente.
Spring Cloud Config + Bus¶
# Cambio en config server
routing.rules.eu.endpoint=eu-processor-v2
# Propagación vía Spring Cloud Bus (RabbitMQ/Kafka)
POST /actuator/busrefresh
Spring Cloud Bus propaga cambios de configuración a todas las instancias de un microservicio simultáneamente.
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas del Control Bus: comandos enviados/segundo, latencia de propagación, tasa de errores de ejecución, comandos pendientes de confirmación.
- Dashboard de estado de configuración: visualización del estado actual de todos los componentes gestionables (activo, pausado, throttled, en diagnóstico).
- Alertas: comando sin confirmación después de N segundos, tasa de errores de comandos > umbral, config drift detectado.
Seguridad¶
- RBAC: definir roles granulares (ops-viewer puede ver configuración, ops-editor puede pausar flujos, ops-admin puede cambiar routing).
- Aprobación dual: para comandos de alto impacto (desactivar canal de producción), requerir aprobación de un segundo operador.
- Encryption: los comandos de control pueden contener información sensible (credenciales de nuevos endpoints) y deben transportarse cifrados.
- Rate limiting: limitar la frecuencia de comandos de control para prevenir abuso.
Auditoría¶
- Cada comando debe registrar: quién lo emitió, cuándo, qué componente fue afectado, cuál fue el resultado, cuál era el estado anterior y cuál es el nuevo estado.
- Los registros de auditoría deben ser inmutables (append-only) y tener retención alineada con requisitos regulatorios.
Versionado de Comandos¶
- Los comandos de control deben tener schema versionado para permitir evolución sin romper componentes existentes.
- Componentes en versiones diferentes deben poder coexistir, interpretando los comandos que entienden e ignorando los que no.
Reconciliación y Config Drift¶
- Periódicamente, un proceso de reconciliación debe verificar que el estado real de cada componente coincide con el estado declarado en el Config Store.
- Los drift detectados deben alertarse y, opcionalmente, corregirse automáticamente.
17. Errores Comunes¶
Usar el Control Bus para Cambios de Lógica de Negocio¶
El Control Bus es para gestión operacional (routing, throttling, diagnósticos, feature flags), no para cambios de lógica de negocio que deberían pasar por el ciclo de desarrollo, testing y despliegue. La frontera entre "configuración operacional" y "lógica de negocio" debe definirse claramente.
No Persistir el Estado de Configuración¶
Si los comandos de control se aplican solo en memoria de los componentes y no se persisten en un Config Store, un reinicio del componente pierde toda la configuración. El componente debe poder reconstruir su configuración desde el Config Store al iniciar.
Falta de Confirmación de Comandos¶
Enviar comandos fire-and-forget sin esperar confirmación deja al operador sin certeza de que el cambio se aplicó. La confirmación es esencial para operación confiable.
Control Bus sin Autenticación¶
Un Control Bus sin autenticación ni autorización permite que cualquier sistema o persona envíe comandos de gestión. Esto es un riesgo de seguridad crítico en producción.
Config Drift Silencioso¶
Cuando los cambios vía Control Bus no se reflejan en el sistema de Infrastructure as Code (Terraform, Helm charts, GitOps), se produce config drift: el estado real del sistema diverge del estado declarativo. Esto hace que los redespliegues desde IaC sobrescriban los cambios hechos vía Control Bus.
No Planificar Rollback¶
Los comandos de control deben ser reversibles. Sin un mecanismo de rollback (manual o automático), un comando erróneo puede dejar el sistema en un estado incorrecto sin forma rápida de volver al estado anterior.
18. Conclusión Técnica¶
Control Bus es el patrón que transforma la infraestructura de integración de un artefacto estático (configurado en tiempo de despliegue) a un sistema dinámico (configurable en tiempo de ejecución). La separación del plano de control y el plano de datos no es una optimización — es un requisito operacional en cualquier sistema de integración no trivial.
Cuándo aporta valor: en toda plataforma de integración con más de un puñado de componentes, donde los cambios operacionales deben aplicarse rápidamente, sin downtime y con auditoría. El valor se multiplica cuando la gestión debe automatizarse (auto-healing, canary deployments, scheduled maintenance).
Cuándo evita problemas importantes: Control Bus evita la intervención manual directa en servidores de producción, que es la fuente más frecuente de errores operacionales y violaciones de seguridad. Evita también el acoplamiento entre cambios de configuración y ciclos de despliegue, que es la causa principal de lentitud operacional.
Cuándo no conviene adoptarlo: en sistemas pequeños donde la gestión directa (ficheros de configuración, variables de entorno, restart) es suficiente. El overhead de implementar un Control Bus completo (canal, consola, config store, audit log, handlers en cada componente) solo se justifica en sistemas con complejidad operacional real.
Recomendación para arquitectos: diseñe el Control Bus como un ciudadano de primera clase de la arquitectura, no como un afterthought. Defina desde el inicio qué aspectos del sistema son gestionables dinámicamente (y cuáles no), qué roles tienen permisos para qué comandos, cómo se persiste y reconcilia la configuración, y cómo se auditan los cambios. Un Control Bus bien diseñado es la diferencia entre un sistema que se opera con confianza y un sistema que se opera con miedo.