Message Store¶
1. Nombre del Patrón¶
- Nombre oficial: Message Store
- Categoría: System Management (Gestión del Sistema de Mensajería)
- Traducción contextual: Almacén de Mensajes
2. Resumen Ejecutivo¶
Message Store es el patrón que persiste los mensajes que fluyen por el sistema de integración en un almacén duradero y consultable, permitiendo su inspección, análisis, replay y auditoría mucho después de que el flujo de procesamiento haya concluido. A diferencia de los canales de mensajería que almacenan mensajes temporalmente para entrega, el Message Store retiene mensajes de forma duradera con propósitos que trascienden el procesamiento inmediato.
El problema que resuelve es la efimeralidad inherente de los mensajes: en un sistema de integración, un mensaje existe solo mientras viaja del productor al consumidor. Una vez consumido y procesado, desaparece del canal. Si posteriormente se necesita inspeccionar ese mensaje para una auditoría regulatoria, para diagnosticar un error en producción, para reprocesarlo con lógica corregida, o para alimentar un modelo analítico, no hay forma de recuperarlo. Message Store responde a esta limitación capturando y persistiendo mensajes en un almacén independiente del flujo de procesamiento.
La vigencia de este patrón es alta. En la arquitectura moderna se materializa como event stores en sistemas event-sourced, como la retención extendida de Kafka que convierte al log en un Message Store de facto, como audit data lakes donde se persisten eventos para compliance, y como data warehouses de eventos para analytics. La regulación financiera que exige retención de mensajes de transacciones por 7 años (MiFID II en Europa, SOX en EE.UU., Basel III global) ha convertido a Message Store en un componente obligatorio en toda arquitectura de integración de servicios financieros.
3. Definición Detallada¶
Propósito¶
Message Store proporciona un mecanismo de persistencia paralelo al flujo de mensajería que captura, almacena, indexa y permite consultar los mensajes que fluyen por el sistema. Su propósito fundamental es convertir mensajes efímeros en registros duraderos accesibles para auditoría, debugging, replay, reconciliación y analytics.
Lógica Arquitectónica¶
En un sistema de mensajería, los mensajes tienen un ciclo de vida acotado al flujo de procesamiento:
Una vez que el consumer confirma el procesamiento (acknowledge), el broker puede eliminar el mensaje del canal. El mensaje cumplió su propósito de transporte y deja de existir. Message Store añade una rama de persistencia en paralelo:
Productor → Canal → Consumer (flujo normal, sin cambios)
↘
Message Store (persistencia duradera e independiente)
La captura puede realizarse mediante diferentes mecanismos:
- Wire Tap: un componente que copia cada mensaje del canal al store sin afectar el flujo principal.
- Consumer dedicado: un consumer group independiente que solo persiste mensajes.
- Interceptor del framework: middleware que persiste el mensaje antes de pasarlo al consumer.
- Log nativo de la plataforma: Kafka con retención extendida actúa como Message Store.
- CDC (Change Data Capture): captura de cambios de la base de datos del broker.
Principio de Diseño Subyacente¶
El principio es observación pasiva sin interferencia con el flujo principal. El Message Store es un sistema de registro que opera en paralelo al flujo de mensajería. No modifica los mensajes, no añade latencia al camino crítico, y no afecta la entrega a los consumers normales. Es un observador que captura una copia fiel de cada mensaje para propósitos que no forman parte del procesamiento transaccional.
Problema Estructural que Resuelve¶
La efimeralidad de los mensajes crea un vacío de información que afecta múltiples dimensiones:
- Auditoría: sin un store, la evidencia de cada transacción procesada depende de logs dispersos en múltiples sistemas con diferentes formatos, retenciones y niveles de detalle.
- Debugging post-mortem: cuando un consumer produce resultados incorrectos, la pregunta "¿qué mensaje causó este resultado?" solo puede responderse si el mensaje original se conserva.
- Replay: cuando se despliega una nueva versión de un consumer con lógica corregida, ¿cómo se reprocesan los mensajes afectados si ya fueron consumidos y eliminados?
- Reconciliación: comparar lo que un sistema envió con lo que otro recibió requiere una fuente de verdad sobre el contenido exacto de cada mensaje.
- Analytics: los mensajes de integración contienen datos de negocio valiosos que se pierden si no se capturan para análisis.
Contexto en el que Emerge¶
Message Store emerge cuando los mensajes tienen valor más allá de su procesamiento inmediato. Esto incluye:
- Industrias reguladas donde la retención de registros de transacciones es un requisito legal.
- Sistemas event-sourced donde los eventos son la fuente de verdad del estado.
- Plataformas que necesitan capacidad de replay para recovery o evolución de consumers.
- Organizaciones que usan datos de integración para analytics y data science.
- Sistemas donde el debugging de problemas de integración es frecuente y costoso.
Relación con Sistemas Distribuidos y Mensajería¶
Message Store es conceptualmente análogo al Write-Ahead Log (WAL) de bases de datos: un registro inmutable de todas las operaciones que permite recovery y auditoría. En el contexto de event sourcing, el event store es un Message Store especializado donde la secuencia completa de eventos constituye la fuente de verdad del estado del sistema.
En Kafka, la configuración de retención transforma al broker en un Message Store:
retention.ms=-1(retención infinita): Kafka se convierte en un store permanente.retention.ms=604800000(7 días): Kafka es un store temporal.- Con Tiered Storage (Confluent, Amazon MSK): los datos se mueven automáticamente a object storage, extendiendo la retención sin impactar el performance del broker.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Message Store, los mensajes son efímeros y esta efimeralidad genera múltiples problemas operacionales:
- Auditoría fragmentada: cuando un regulador solicita evidencia de una transacción procesada hace 6 meses, la organización debe compilar logs de múltiples sistemas, correlacionarlos manualmente y esperar que ningún log se haya purgado. El proceso toma semanas y el resultado es frecuentemente incompleto.
- Debugging sin datos: un consumer produce un resultado incorrecto. El equipo pregunta "¿qué mensaje recibió?". Nadie lo sabe — el mensaje fue consumido y ya no existe.
- Replay imposible: se descubre un bug en un consumer que procesó incorrectamente 50,000 mensajes la semana pasada. La corrección está lista, pero los mensajes ya no existen para reprocesarlos.
- Reconciliación manual: el Sistema A dice que envió 1,000 mensajes. El Sistema B dice que recibió 997. ¿Cuáles son los 3 que faltan? Sin un store, la investigación es una búsqueda manual en logs de ambos sistemas.
- Analytics desconectado: el equipo de data quiere analizar patrones en las transacciones del último año, pero los mensajes solo existen durante su tránsito por el broker.
Síntomas del Problema¶
- Equipos que implementan persistencia ad-hoc de mensajes en tablas auxiliares ("por si acaso").
- Investigaciones de incidentes que se bloquean con la frase "el mensaje original ya no existe".
- Auditorías regulatorias que cuestan meses de esfuerzo manual para compilar evidencia.
- Proyectos de analytics que requieren nueva instrumentación porque los datos de mensajería solo son accesibles en tránsito.
- Requests de replay que se rechazan con "no podemos, los mensajes ya no existen".
- Equipos que mantienen retenciones de Kafka excesivamente largas "por si necesitamos los datos".
Impacto Operativo y Arquitectónico¶
- Compliance en riesgo: sin retención estructurada de mensajes, las auditorías regulatorias son un ejercicio de arqueología con resultado incierto.
- MTTR alto: la incapacidad de inspeccionar mensajes históricos extiende los tiempos de investigación de incidentes.
- Capacidad de recovery limitada: sin replay, la recuperación de errores requiere intervención manual del productor o workarounds manuales.
- Datos de negocio desaprovechados: los mensajes de integración son un activo de datos que se pierde si no se captura.
Riesgos Si No Se Implementa Correctamente¶
- Store como cuello de botella: si la persistencia es síncrona y está en el camino crítico del flujo, el store se convierte en un single point of failure.
- Crecimiento descontrolado: sin políticas de retención, el almacenamiento crece indefinidamente.
- PII sin controles: mensajes con datos personales almacenados sin cifrado, anonimización o políticas de eliminación violan GDPR.
- Store incompleto: si el mecanismo de captura pierde mensajes, el store tiene gaps que reducen su valor para auditoría.
Ejemplos Reales¶
- Banca de inversión: una firma de trading almacena cada mensaje de orden, ejecución, confirmación y liquidación por 7 años para cumplimiento de MiFID II. El store contiene ~3 millones de mensajes diarios y es consultable por reguladores en 72 horas.
- Salud: un hospital almacena todos los mensajes HL7 de resultados de laboratorio por 10 años para compliance regulatorio y posibles litigios por mala praxis.
- E-commerce: una plataforma almacena todos los eventos de pedido en un data lake para analytics de comportamiento de compra, detección de fraude y reconciliación financiera.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- Cuando la regulación exige retención de registros de transacciones por períodos definidos (MiFID II: 7 años, HIPAA: 6 años, SOX: 7 años).
- Cuando se necesita capacidad de replay para reprocesar mensajes con lógica corregida o nueva.
- Cuando los datos de negocio en los mensajes son valiosos para analytics y data science.
- Cuando el debugging de problemas de integración requiere inspección de mensajes históricos.
- Cuando se necesita reconciliación objetiva entre sistemas basada en los mensajes intercambiados.
- Cuando se implementa event sourcing y los eventos deben persistirse como fuente de verdad.
Cuándo No Usarlo¶
- Cuando los mensajes son genuinamente efímeros (heartbeats, métricas operacionales de baja criticidad).
- Cuando Kafka con retención adecuada ya cumple los requisitos de almacenamiento y consultabilidad.
- Cuando el volumen de mensajes hace que la persistencia completa sea económicamente inviable y la regulación no lo exige.
- Cuando todos los mensajes contienen datos cuya retención está prohibida o severamente restringida.
Precondiciones¶
- Existe un mecanismo de captura confiable (Wire Tap, consumer dedicado, interceptor).
- Existe almacenamiento con capacidad para el volumen y período de retención requeridos.
- Existe una política de retención definida que cumple requisitos regulatorios y de privacidad.
Restricciones¶
- La captura no debe impactar la latencia ni la disponibilidad del flujo principal.
- El store debe soportar consultas eficientes por los criterios de búsqueda más frecuentes.
- La retención debe satisfacer simultáneamente requisitos regulatorios (mínimo) y de privacidad (máximo).
Dependencias¶
- Infraestructura de almacenamiento duradero y escalable.
- Mecanismo de captura de mensajes (Wire Tap, consumer group dedicado).
- Políticas de retención y purga automatizadas.
- Índices para consultas eficientes.
- Cifrado en reposo para mensajes con datos sensibles.
Supuestos Arquitectónicos¶
- Los mensajes tienen un identificador único que permite su localización en el store.
- El almacén es confiable (replicado, con backups, con disaster recovery).
- La política de retención es compatible con la regulación aplicable.
- El mecanismo de captura es confiable y no introduce gaps significativos.
Tipo de Sistemas Donde Aparece con Más Frecuencia¶
- Sistemas financieros y bancarios (compliance regulatorio).
- Sistemas de salud (retención de registros clínicos).
- Plataformas de e-commerce (analytics, reconciliación).
- Sistemas event-sourced (event store como fuente de verdad).
- Sistemas de seguros (trazabilidad de claims).
- Cualquier industria regulada con requisitos de retención de datos.
6. Fuerzas Arquitectónicas¶
Durabilidad vs. Performance¶
La persistencia de mensajes en un store externo tiene costo en latencia y recursos. Si la captura es síncrona (el flujo espera al store), la latencia del flujo se incrementa. Si es asíncrona (la captura ocurre en background), hay una ventana donde un fallo podría causar pérdida del mensaje en el store. El balance depende de si la completitud del store es un requisito regulatorio (tolerancia cero a gaps) o una conveniencia operacional (gaps ocasionales son aceptables).
Completitud vs. Costo de Almacenamiento¶
Almacenar todos los mensajes de todos los canales proporciona máxima visibilidad pero el costo acumulado puede ser significativo. En un sistema que procesa 5 millones de mensajes diarios, almacenar 7 años de mensajes con índices y tiering representa terabytes de datos. La alternativa es almacenar selectivamente (solo mensajes de canales críticos, solo mensajes de ciertos tipos), lo que reduce costos pero introduce gaps.
Retención Regulatoria vs. Privacidad¶
La regulación financiera exige retención prolongada: MiFID II (7 años), SOX (7 años), Basel III (5 años). La regulación de privacidad (GDPR) exige minimización de datos y derecho al olvido. Cuando un mensaje contiene simultáneamente datos de transacción (retener 7 años) y datos personales (eliminar bajo solicitud), la tensión es directa. Las soluciones incluyen anonimización, pseudonimización, o separación del PII del contenido transaccional.
Consultabilidad vs. Simplicidad¶
Un store que solo almacena mensajes como blobs binarios es simple pero inútil para consultas sofisticadas. Un store con indexación completa (tipo de mensaje, timestamp, campos de negocio, correlation ID) es consultable pero más costoso y complejo. El nivel de indexación debe alinearse con los patrones de consulta reales.
Centralización vs. Distribución¶
Un Message Store centralizado proporciona una vista unificada pero puede ser un cuello de botella. Stores distribuidos por dominio o por servicio escalan mejor pero dificultan las consultas cross-domain y la correlación de mensajes entre servicios.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Canal de Mensajería: el flujo principal de donde se capturan los mensajes.
- Mecanismo de Captura: Wire Tap, consumer dedicado o interceptor que copia mensajes al store.
- Message Store: el almacén duradero con capacidad de escritura, lectura y consulta.
- Índice: estructura que permite localizar mensajes eficientemente por múltiples criterios.
- Policy Engine: componente que gestiona retención, tiering, purga y archiving.
- Query Interface: API, portal web o herramienta de consulta para acceder a mensajes almacenados.
Flujo Lógico¶
flowchart TD
subgraph Captura
A([Productor]) -->|Publica mensaje| B[(Canal de Mensajería)]
B -->|Flujo principal| C[Consumer Normal procesa mensaje]
B -->|En paralelo| D[Mecanismo de Captura intercepta/copia]
D -->|Enriquece con metadata| E[(Message Store: persiste mensaje)]
E --> F[(Índice: indexa para búsquedas)]
end
subgraph Consulta posterior
G([Usuario / Sistema]) -->|Consulta por criterios| H[(Índice)]
H -->|Localiza en tier correspondiente| I[(Message Store)]
I -->|Retorna contenido + metadata| G
end
subgraph Gestión de retención
J[Policy Engine evalúa retención] -->|Archiva o elimina| K[(Message Store: cold storage / purga)]
J -->|Actualiza o elimina entradas| L[(Índice)]
endResponsabilidades¶
| Componente | Responsabilidad |
|---|---|
| Mecanismo de Captura | Copiar mensajes al store sin afectar el flujo principal |
| Message Store | Persistir mensajes de forma duradera, confiable e inmutable |
| Índice | Permitir búsquedas eficientes por criterios múltiples |
| Policy Engine | Gestionar retención, tiering y purga automatizada |
| Query Interface | Proporcionar acceso consultable a mensajes históricos |
Interacciones¶
- Canal → Mecanismo de Captura: copia del mensaje (vía Wire Tap, consumer dedicado, interceptor).
- Captura → Store: escritura del mensaje con metadata.
- Store → Índice: indexación para consultas.
- Usuarios/Sistemas → Query Interface → Índice → Store: flujo de consulta.
- Policy Engine → Store/Índice: purga y archiving periódico.
Contratos Implícitos¶
- La captura no modifica el mensaje original ni interfiere con el flujo de procesamiento.
- El store retiene mensajes por al menos el período definido en la política de retención.
- Los mensajes almacenados son inmutables (una vez escritos, no se modifican).
- Las consultas retornan resultados consistentes y completos dentro del período de retención.
Decisiones de Diseño Clave¶
- Mecanismo de captura: ¿Wire Tap asíncrono, consumer group dedicado, CDC, o log nativo del broker?
- Formato de almacenamiento: ¿mensaje original binario, JSON normalizado, formato columnar (Parquet)?
- Estrategia de indexación: ¿qué campos se indexan? ¿Full-text o solo campos clave?
- Tiering de almacenamiento: ¿hot/warm/cold tiers con movimiento automático por antigüedad?
- Estrategia de retención: ¿retención uniforme o por tipo de mensaje y regulación?
8. Ejemplo Arquitectónico Detallado¶
Dominio: Servicios Financieros — Almacenamiento de Mensajes de Trading para Compliance de 7 Años¶
Contexto del Negocio¶
Una firma de banca de inversión ejecuta 500,000 operaciones de trading diarias en múltiples asset classes (equities, fixed income, FX, derivatives). Cada operación genera una secuencia de mensajes: orden, validación de compliance pre-trade, routing al venue de ejecución, confirmación de ejecución, instrucción de liquidación, y confirmación de settlement. La regulación MiFID II exige que todos estos mensajes se retengan por un mínimo de 7 años, estén disponibles para inspección regulatoria en 72 horas y sean inmutables.
Necesidad de Integración¶
La firma necesita un Message Store centralizado que capture todos los mensajes del ciclo de vida de trading, los persista de forma inmutable y consultable por 7 años, y proporcione una interfaz que permita a compliance, legal y reguladores localizar cualquier mensaje en minutos. El volumen es aproximadamente 3 millones de mensajes diarios (promedio de 6 mensajes por operación).
Sistemas Involucrados¶
- Order Management System (OMS): genera órdenes de trading.
- Pre-Trade Compliance Engine: valida cada orden contra reglas regulatorias.
- Smart Order Router (SOR): dirige la orden al venue óptimo.
- Execution Management System (EMS): gestiona ejecución en el venue.
- Settlement System: gestiona la liquidación post-trade.
- Kafka Topics: canales de mensajería para cada etapa.
- Message Store: almacén centralizado con tiering automático.
- Compliance Portal: interfaz de consulta para equipos de compliance.
Restricciones Técnicas¶
- Inmutabilidad: los mensajes no pueden modificarse ni eliminarse antes de su fecha de expiración.
- Disponibilidad: cualquier mensaje debe ser recuperable en menos de 72 horas para reguladores (menos de 1 segundo para hot tier).
- Integridad: cada mensaje se almacena con un hash criptográfico que permite verificar que no fue alterado.
- Volumen: ~3M mensajes/día × 365 × 7 = ~7.6 billones de mensajes en estado estable.
- La captura no debe añadir más de 5ms de latencia al flujo de trading.
Diseño del Message Store¶
Kafka Topics (flujo de trading):
trading.orders
trading.pretrade-compliance
trading.routing-decisions
trading.executions
trading.settlement-instructions
trading.settlement-confirmations
Captura (Kafka Connect S3 Sink + OpenSearch Sink):
Consumer group: cg-message-store
Captura asíncrona (no impacta el flujo principal)
Message Store con tiering:
Hot (0-90 días): OpenSearch (búsqueda full-text, sub-segundo)
Warm (90 días-2 años): S3 Parquet + Athena (SQL, segundos)
Cold (2-7 años): S3 Glacier + restore on-demand (horas)
Índice global:
DynamoDB: trade_id → [message_ids] → tier + ubicación
Decisiones Arquitectónicas¶
- Captura asíncrona vía consumer group dedicado: un consumer group
cg-message-storelee de todos los topics de trading. Es asíncrono — el flujo principal de trading no se ve afectado. El lag típico es < 2 segundos. - Inmutabilidad por diseño: en OpenSearch, los índices se cierran después de 24h (no se pueden modificar). En S3, Object Lock previene eliminación. Cada mensaje se almacena con SHA-256 del contenido original.
- Tiering automático: lifecycle policies mueven datos de hot a warm (90 días) y de warm a cold (2 años). El índice de DynamoDB se actualiza con la nueva ubicación.
- Dual sink: el consumer de captura escribe simultáneamente a OpenSearch (para consultas inmediatas) y a S3 (para archivo de largo plazo). OpenSearch puede reconstruirse desde S3 si es necesario.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación y Captura del Mensaje de Orden¶
El OMS genera una orden de compra de 10,000 acciones de Telefónica (TEF.MC) y la publica en trading.orders:
{
"message_id": "msg-ord-20260407-093015-001",
"trade_id": "TRD-20260407-001",
"type": "order.new",
"timestamp": "2026-04-07T09:30:15.001Z",
"payload": {
"instrument": "TEF.MC", "side": "BUY", "quantity": 10000,
"order_type": "LIMIT", "price": 4.25, "currency": "EUR",
"client_id": "CLT-INST-4521", "trader_id": "TRD-JGARCIA"
}
}
El consumer cg-message-store lee este mensaje 1.2 segundos después y lo persiste:
{
"capture_metadata": {
"captured_at": "2026-04-07T09:30:16.201Z",
"source_topic": "trading.orders",
"source_partition": 7, "source_offset": 1284729,
"capture_lag_ms": 1200,
"content_hash": "sha256:3f2a87b1c4d9e..."
},
"original_message": { ... }
}
Paso 2: Captura de Todo el Ciclo de Vida¶
En los siguientes 45 segundos, la operación genera 5 mensajes más que se capturan en secuencia:
| # | Tipo | Topic | Contenido clave |
|---|---|---|---|
| 1 | order.new | trading.orders | Orden original |
| 2 | compliance.approved | trading.pretrade-compliance | Pre-trade check passed |
| 3 | routing.decision | trading.routing-decisions | Routed to BME (Bolsas y Mercados Españoles) |
| 4 | execution.fill | trading.executions | Filled 10,000 @ 4.24 EUR |
| 5 | settlement.instruction | trading.settlement-instructions | T+2 settlement via Iberclear |
| 6 | settlement.confirmed | trading.settlement-confirmations | Settled 2026-04-09 |
Cada mensaje se almacena en OpenSearch (hot) y en S3 (archivo). El índice de DynamoDB vincula TRD-20260407-001 con los 6 message_id.
Paso 3: Consulta Inmediata (Hot Tier)¶
Ese mismo día, un compliance officer necesita verificar que la operación TRD-20260407-001 pasó el pre-trade compliance check:
OpenSearch responde en 45ms con el mensaje de compliance approval, incluyendo el contenido completo y el hash de integridad verificado.
Paso 4: Auditoría Regulatoria (Warm Tier)¶
18 meses después, el regulador (CNMV) solicita toda la cadena de mensajes de la operación TRD-20260407-001. Los mensajes ya migraron de OpenSearch a S3 Parquet. El compliance portal consulta DynamoDB para localizar los mensajes:
Athena ejecuta la consulta SQL sobre el Parquet en S3 y retorna los 6 mensajes en 3.2 segundos. El portal verifica el hash de cada mensaje y presenta la cadena completa al regulador.
Paso 5: Recuperación de Archivo (Cold Tier)¶
5 años después, un litigio requiere acceso a la misma operación. Los datos están en S3 Glacier. El portal inicia un restore request:
Al día siguiente, los mensajes están disponibles como S3 estándar, consultables via Athena. Los hashes de integridad verifican que los mensajes no fueron alterados en 5 años de almacenamiento.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
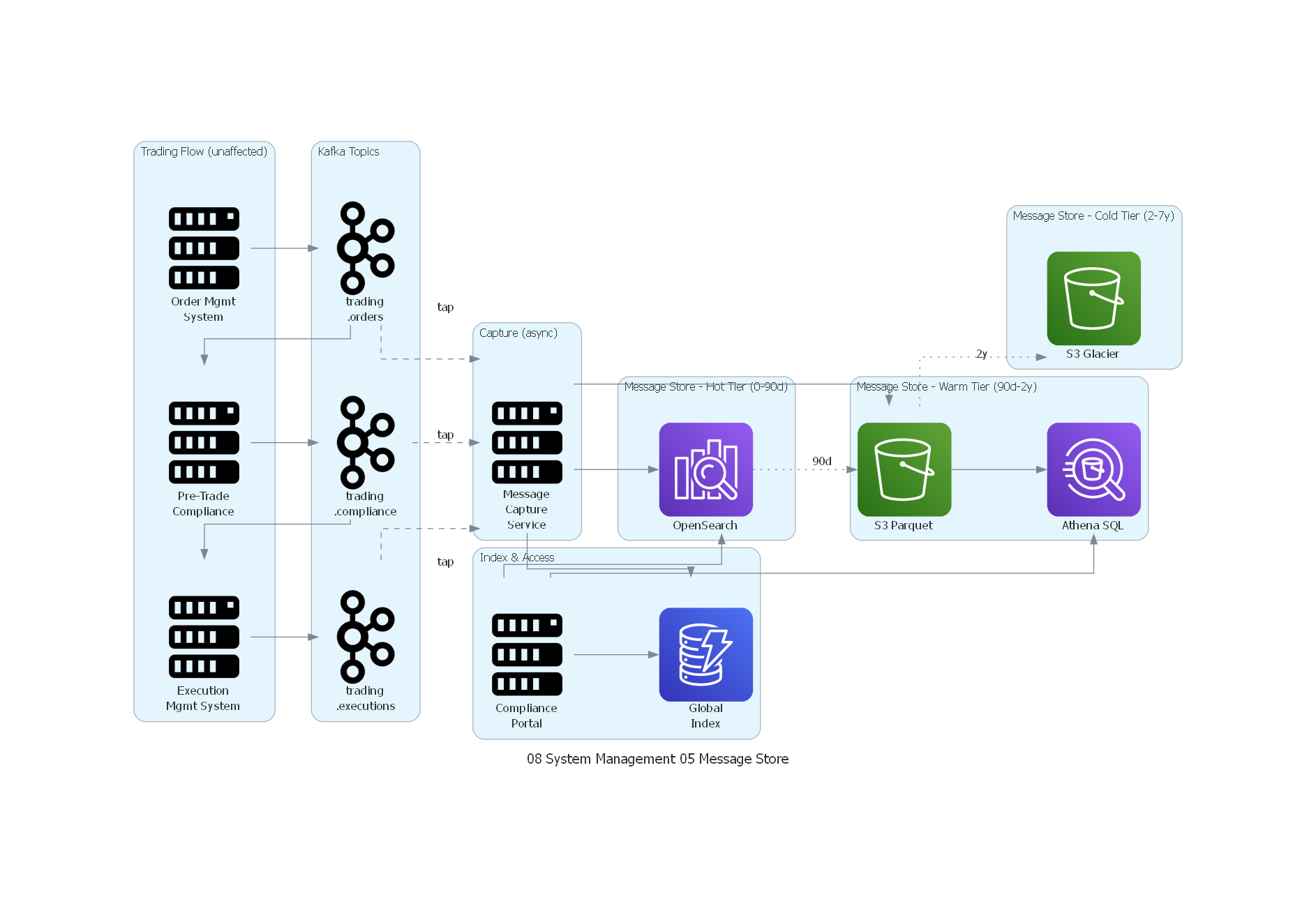
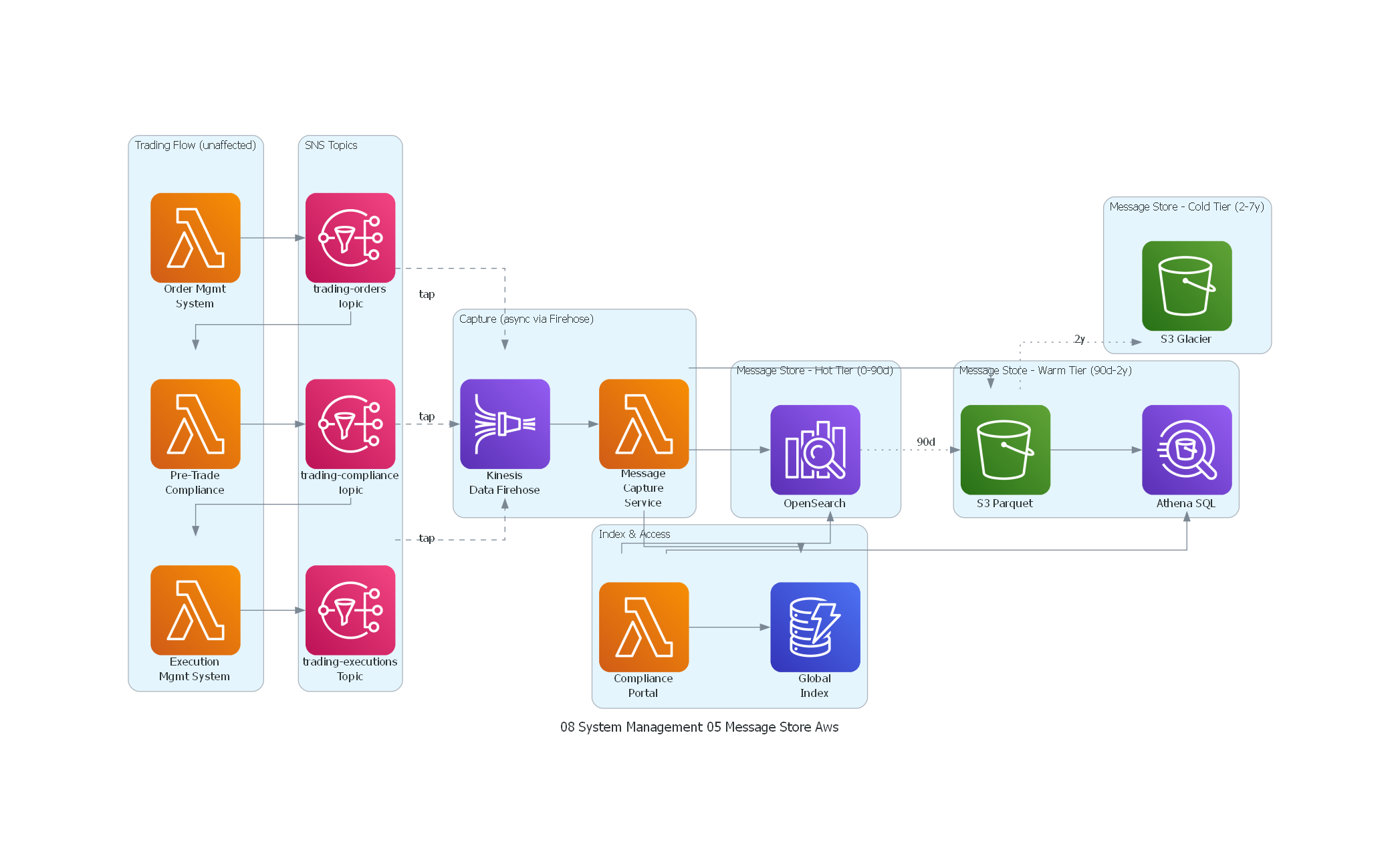
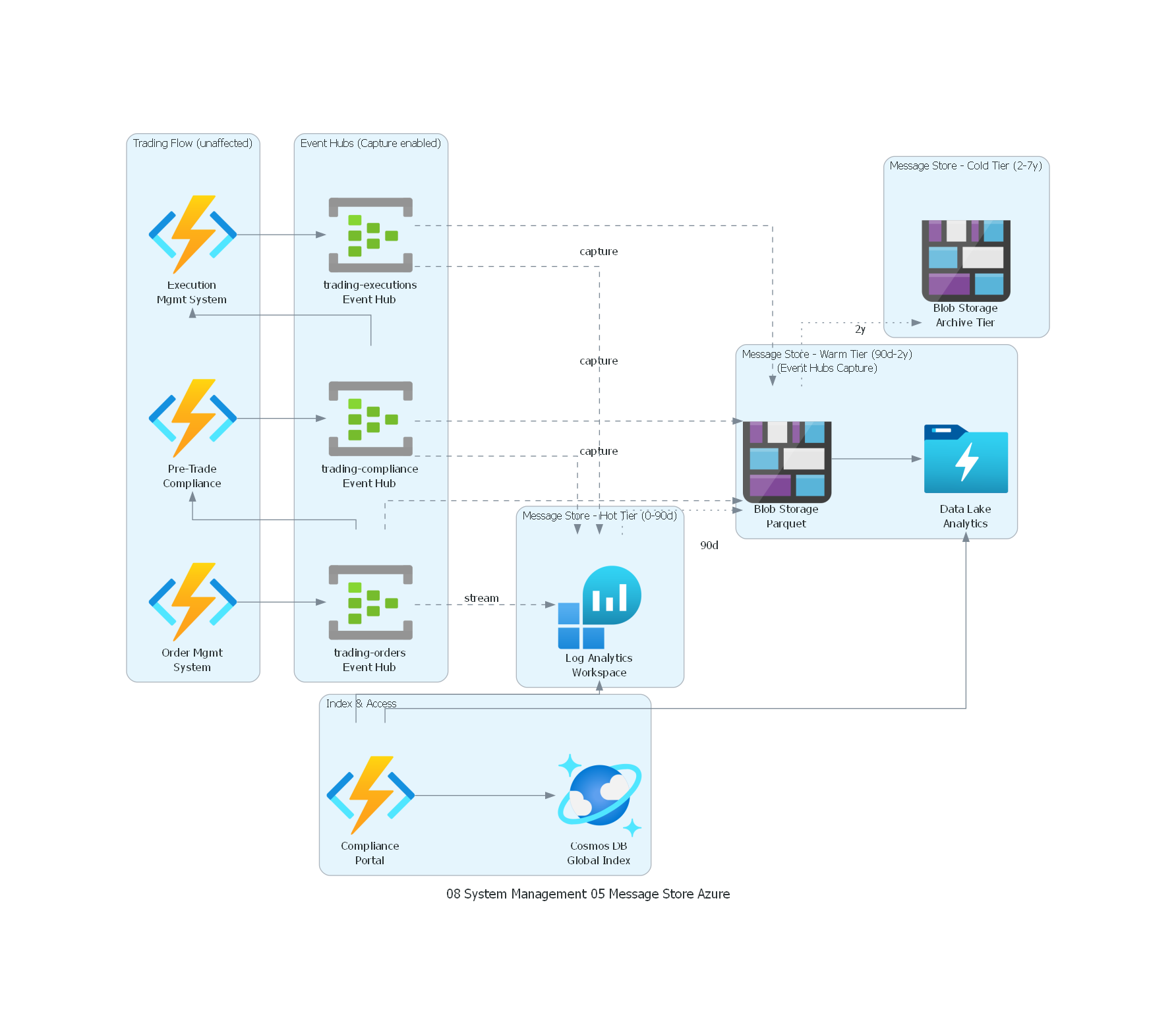
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.aws.storage import S3
from diagrams.aws.analytics import ElasticsearchService, Athena
from diagrams.aws.database import Dynamodb
with Diagram("Message Store - Trading Compliance", show=False, direction="TB"):
with Cluster("Trading Flow (unaffected)"):
oms = Server("Order Mgmt\nSystem")
compliance_eng = Server("Pre-Trade\nCompliance")
ems = Server("Execution\nMgmt System")
with Cluster("Kafka Topics"):
orders = Kafka("trading\n.orders")
compliance_t = Kafka("trading\n.compliance")
exec_t = Kafka("trading\n.executions")
with Cluster("Capture (async)"):
capture = Server("Message\nCapture\nService")
with Cluster("Message Store - Hot Tier (0-90d)"):
opensearch = ElasticsearchService("OpenSearch")
with Cluster("Message Store - Warm Tier (90d-2y)"):
s3_warm = S3("S3 Parquet")
athena = Athena("Athena SQL")
with Cluster("Message Store - Cold Tier (2-7y)"):
s3_cold = S3("S3 Glacier")
with Cluster("Index & Access"):
index = Dynamodb("Global\nIndex")
portal = Server("Compliance\nPortal")
# Trading flow
oms >> orders >> compliance_eng
compliance_eng >> compliance_t >> ems
ems >> exec_t
# Async capture (wire tap)
orders >> Edge(style="dashed", label="tap") >> capture
compliance_t >> Edge(style="dashed", label="tap") >> capture
exec_t >> Edge(style="dashed", label="tap") >> capture
# Persistence
capture >> opensearch
capture >> s3_warm
capture >> index
# Tiering
opensearch >> Edge(label="90d", style="dotted") >> s3_warm
s3_warm >> Edge(label="2y", style="dotted") >> s3_cold
s3_warm >> athena
# Access
portal >> index
portal >> opensearch
portal >> athena
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.storage import S3
from diagrams.aws.analytics import ElasticsearchService, Athena, KinesisDataFirehose
from diagrams.aws.database import Dynamodb
from diagrams.aws.compute import Lambda
from diagrams.aws.integration import SNS, SQS
with Diagram("Message Store - Trading Compliance (AWS)", show=False, direction="TB"):
with Cluster("Trading Flow (unaffected)"):
oms = Lambda("Order Mgmt\nSystem")
compliance_eng = Lambda("Pre-Trade\nCompliance")
ems = Lambda("Execution\nMgmt System")
with Cluster("SNS Topics"):
orders = SNS("trading-orders\nTopic")
compliance_t = SNS("trading-compliance\nTopic")
exec_t = SNS("trading-executions\nTopic")
with Cluster("Capture (async via Firehose)"):
firehose = KinesisDataFirehose("Kinesis\nData Firehose")
capture = Lambda("Message\nCapture\nService")
with Cluster("Message Store - Hot Tier (0-90d)"):
opensearch = ElasticsearchService("OpenSearch")
with Cluster("Message Store - Warm Tier (90d-2y)"):
s3_warm = S3("S3 Parquet")
athena = Athena("Athena SQL")
with Cluster("Message Store - Cold Tier (2-7y)"):
s3_cold = S3("S3 Glacier")
with Cluster("Index & Access"):
index = Dynamodb("Global\nIndex")
portal = Lambda("Compliance\nPortal")
# Trading flow
oms >> orders >> compliance_eng
compliance_eng >> compliance_t >> ems
ems >> exec_t
# Async capture (wire tap via SNS subscription)
orders >> Edge(style="dashed", label="tap") >> firehose
compliance_t >> Edge(style="dashed", label="tap") >> firehose
exec_t >> Edge(style="dashed", label="tap") >> firehose
firehose >> capture
# Persistence
capture >> opensearch
capture >> s3_warm
capture >> index
# Tiering
opensearch >> Edge(label="90d", style="dotted") >> s3_warm
s3_warm >> Edge(label="2y", style="dotted") >> s3_cold
s3_warm >> athena
# Access
portal >> index
portal >> opensearch
portal >> athena
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.database import CosmosDb
from diagrams.azure.integration import ServiceBus
from diagrams.azure.analytics import EventHubs, LogAnalyticsWorkspaces, DataLakeStoreGen1
from diagrams.azure.storage import BlobStorage
with Diagram("Message Store - Trading Compliance (Azure)", show=False, direction="TB"):
with Cluster("Trading Flow (unaffected)"):
oms = FunctionApps("Order Mgmt\nSystem")
compliance_eng = FunctionApps("Pre-Trade\nCompliance")
ems = FunctionApps("Execution\nMgmt System")
with Cluster("Event Hubs (Capture enabled)"):
orders = EventHubs("trading-orders\nEvent Hub")
compliance_t = EventHubs("trading-compliance\nEvent Hub")
exec_t = EventHubs("trading-executions\nEvent Hub")
with Cluster("Message Store - Hot Tier (0-90d)"):
log_analytics = LogAnalyticsWorkspaces("Log Analytics\nWorkspace")
with Cluster("Message Store - Warm Tier (90d-2y)\n(Event Hubs Capture)"):
blob_warm = BlobStorage("Blob Storage\nParquet")
data_lake = DataLakeStoreGen1("Data Lake\nAnalytics")
with Cluster("Message Store - Cold Tier (2-7y)"):
blob_cold = BlobStorage("Blob Storage\nArchive Tier")
with Cluster("Index & Access"):
index = CosmosDb("Cosmos DB\nGlobal Index")
portal = FunctionApps("Compliance\nPortal")
# Trading flow
oms >> orders >> compliance_eng
compliance_eng >> compliance_t >> ems
ems >> exec_t
# Event Hubs Capture (automatic archival)
orders >> Edge(style="dashed", label="capture") >> blob_warm
compliance_t >> Edge(style="dashed", label="capture") >> blob_warm
exec_t >> Edge(style="dashed", label="capture") >> blob_warm
# Hot tier
orders >> Edge(style="dashed", label="stream") >> log_analytics
compliance_t >> Edge(style="dashed") >> log_analytics
exec_t >> Edge(style="dashed") >> log_analytics
# Tiering
log_analytics >> Edge(label="90d", style="dotted") >> blob_warm
blob_warm >> Edge(label="2y", style="dotted") >> blob_cold
blob_warm >> data_lake
# Access
portal >> index
portal >> log_analytics
portal >> data_lake
Explicación del Diagrama¶
El diagrama muestra tres aspectos clave del Message Store:
- El flujo de trading (arriba) opera sin cambios — los traders y el OMS no se ven afectados por el store.
- La captura asíncrona (líneas punteadas) copia mensajes de cada topic al store sin impactar latencia.
- El tiering de almacenamiento mueve datos automáticamente: hot (OpenSearch, 0-90 días), warm (S3 Parquet + Athena, 90 días-2 años), cold (S3 Glacier, 2-7 años).
- El índice global (DynamoDB) permite localizar cualquier mensaje en cualquier tier.
- El Compliance Portal consulta el tier apropiado según la antigüedad del mensaje.
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Canal de Mensajería | Topics de Kafka (orders, compliance, executions) |
| Mecanismo de Captura | Message Capture Service (async consumer) |
| Message Store | OpenSearch + S3 Parquet + S3 Glacier |
| Índice | DynamoDB Global Index |
| Policy Engine | Lifecycle policies (tiering automático) |
| Query Interface | Compliance Portal + Athena |
11. Beneficios¶
Impacto Técnico¶
- Replay capability: los mensajes almacenados pueden re-publicarse al sistema para reprocesamiento. Un consumer con un bug puede corregirse y reprocesar los mensajes afectados sin intervención del productor.
- Debugging con contexto completo: el mensaje original que causó un error está disponible para inspección, eliminando la necesidad de reproducir condiciones o adivinar el input.
- Desacoplamiento temporal ampliado: un nuevo consumer puede unirse al sistema meses o años después y procesar mensajes históricos.
- Data asset: los mensajes almacenados son un activo de datos que alimenta analytics, machine learning, y business intelligence.
Impacto Organizacional¶
- Compliance automatizado: las solicitudes regulatorias se responden consultando el store en minutos, no compilando evidencia manualmente.
- Reducción de disputas: cuando hay discrepancias entre sistemas, el store provee evidencia objetiva del contenido exacto de cada mensaje.
- Habilitación de data-driven: los equipos de analytics acceden a datos de integración históricos sin instrumentación adicional.
Impacto Operacional¶
- Recovery mejorado: si un consumer pierde su estado, puede reconstruirlo reprocesando mensajes desde el store.
- Investigación acelerada: los incidentes se investigan consultando el store en lugar de buscando en logs dispersos.
- Capacity planning informado: el volumen y patrones de mensajes informan decisiones de dimensionamiento.
12. Desventajas y Riesgos¶
Complejidad Añadida¶
- Infraestructura adicional: el store requiere su propia infraestructura de almacenamiento, indexación, tiering, backup y disaster recovery.
- Costo de almacenamiento: almacenar millones de mensajes diarios por años requiere storage significativo, especialmente en tiers consultables.
- Sincronización de índices: los índices deben mantenerse consistentes con el almacenamiento subyacente a través de tiering y purga.
Riesgos de Mal Uso¶
- Store como sistema de integración: usar el Message Store como fuente de mensajes para consumers (en lugar del canal normal), convirtiendo el store en un cuello de botella y cambiando su semántica.
- Retención sin política: almacenar todo indefinidamente sin políticas de retención, causando crecimiento descontrolado.
- PII sin gobernanza: almacenar mensajes con datos personales sin cifrado, anonimización ni derecho al olvido.
Sobreingeniería¶
- Store para mensajes efímeros: almacenar heartbeats, métricas de health-check o mensajes de coordinación interna sin valor post-procesamiento.
- Indexación total: indexar todos los campos de todos los mensajes cuando las consultas típicas solo usan 3-4 campos. Exceso de indexación incrementa costos y latencia de escritura.
Anti-Patterns Relacionados¶
- Store Without Query: un Message Store que almacena pero no permite consultas eficientes es un sumidero de datos, no un asset.
- Store as Source of Truth (sin intención): usar el store como fuente de verdad del estado del sistema sin las garantías de consistencia que eso requiere.
13. Relación con Otros Patrones¶
Patrones Complementarios¶
- Wire Tap (este capítulo): el mecanismo más común de captura de mensajes hacia el Message Store.
- Message History (este capítulo): los mensajes con historial almacenados en el store proporcionan trazabilidad completa.
- Correlation Identifier (Capítulo 4): permite correlacionar mensajes relacionados en el store por ID de transacción o conversación.
- Channel Adapter (Capítulo 3): adaptador que conecta el canal al store para la captura.
Patrones que Suelen Aparecer Juntos¶
- Message Store + Wire Tap: Wire Tap captura, Message Store almacena. Es la combinación canónica.
- Message Store + Correlation Identifier: permite consultar todos los mensajes de una transacción en el store.
- Message Store + Message History: almacenar mensajes con su ruta completa proporciona máxima trazabilidad.
- Message Store + Dead Letter Channel: los mensajes fallidos se almacenan en el store para análisis post-mortem.
- Message Store + Claim Check: los datos grandes se almacenan en el claim check store; el store de mensajes guarda la referencia.
Diferencias con Patrones Similares¶
- vs. Wire Tap: Wire Tap es el mecanismo de captura; Message Store es el almacenamiento. Wire Tap copia, Message Store persiste.
- vs. Claim Check: Claim Check almacena datos grandes temporalmente para reducir tamaño del mensaje; Message Store almacena mensajes completos permanentemente para auditoría.
- vs. Event Store (Event Sourcing): un Event Store es un Message Store especializado donde los eventos son la fuente de verdad. Message Store es más general — puede ser solo para auditoría o analytics.
Encaje en un Flujo Mayor de Integración¶
Message Store es un componente transversal que opera en paralelo a todos los flujos de integración. No participa en el procesamiento de mensajes — es un observador que captura copias para propósitos que trascienden el flujo inmediato (auditoría, replay, analytics, compliance).
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Argumentación¶
Message Store tiene relevancia creciente, impulsado por tres tendencias convergentes:
- Regulación creciente: MiFID II, DORA, SOX, HIPAA, CCPA y regulaciones sectoriales exigen retención de datos de transacciones. El Message Store es la respuesta arquitectónica natural a estos requisitos.
- Event Sourcing y Event-Driven Architecture: la adopción de event sourcing convierte al event store en el corazón del sistema — la fuente de verdad inmutable del estado. Es Message Store elevado a principio arquitectónico.
- Kafka como Message Store nativo: con retención configurable (incluyendo infinita) y tiered storage, Kafka se ha convertido en un Message Store de facto para muchas organizaciones.
- Data Mesh y Data Products: los mensajes de integración son reconocidos como data products que tienen consumidores más allá del procesamiento operacional — analytics, ML, compliance.
Cómo Se Implementa Hoy¶
| Tecnología | Rol como Message Store | Mecanismo |
|---|---|---|
| Kafka (retención extendida) | Store nativo | Log retention + tiered storage |
| EventStoreDB | Event store para event sourcing | Streams inmutables + proyecciones |
| Amazon S3 + Athena | Cold store consultable | Parquet/Avro + SQL serverless |
| OpenSearch / Elasticsearch | Hot store con full-text search | Indexación en near-real-time |
| Apache Iceberg | Data lakehouse para eventos | Formato tabular con time travel |
| Azure Event Hub Capture | Auto-capture a blob storage | AVRO/Parquet automático |
| Confluent Tiered Storage | Kafka con tiering transparente | Segments movidos a S3 |
| Delta Lake | Data lakehouse con ACID | Tables con schema evolution |
Qué Parte Sigue Siendo Esencial¶
- La persistencia de mensajes para compliance regulatorio es un requisito no negociable.
- La capacidad de replay es esencial para recovery, evolución y corrección de consumers.
- El valor analítico de los datos de mensajería es un activo cada vez más reconocido.
15. Implementación en Arquitecturas Modernas¶
Kafka con Retención Extendida y Tiered Storage¶
# Topic configurado como Message Store nativo
retention.ms=220752000000 # 7 años
retention.bytes=-1 # Sin límite de tamaño
cleanup.policy=delete # Retener todo
# Confluent Tiered Storage
confluent.tier.feature=true
confluent.tier.local.hotset.ms=2592000000 # 30 días en local
confluent.tier.backend=S3
confluent.tier.s3.bucket=trading-message-archive
Kafka Connect S3 Sink (Captura → Archive)¶
{
"name": "trading-message-store",
"config": {
"connector.class": "io.confluent.connect.s3.S3SinkConnector",
"topics.regex": "trading\\..*",
"s3.bucket.name": "trading-message-store",
"s3.region": "eu-west-1",
"format.class": "io.confluent.connect.s3.format.parquet.ParquetFormat",
"partitioner.class": "io.confluent.connect.storage.partitioner.TimeBasedPartitioner",
"path.format": "'year'=YYYY/'month'=MM/'day'=dd/'hour'=HH",
"partition.duration.ms": 3600000,
"flush.size": 10000,
"rotate.interval.ms": 300000,
"storage.class": "io.confluent.connect.s3.storage.S3Storage"
}
}
EventStoreDB para Event Sourcing¶
// Persistir evento en el event store
var eventData = new EventData(
Uuid.NewUuid(),
"OrderPlaced",
JsonSerializer.SerializeToUtf8Bytes(new {
TradeId = "TRD-20260407-001",
Instrument = "TEF.MC",
Side = "BUY",
Quantity = 10000,
Price = 4.25m
})
);
await client.AppendToStreamAsync(
$"trade-TRD-20260407-001",
StreamState.Any,
new[] { eventData }
);
// Consultar todos los eventos de una operación
var events = client.ReadStreamAsync(
Direction.Forwards,
$"trade-TRD-20260407-001",
StreamPosition.Start
);
await foreach (var resolvedEvent in events) {
Console.WriteLine($"{resolvedEvent.Event.EventType}: {
Encoding.UTF8.GetString(resolvedEvent.Event.Data.Span)}");
}
Spring Integration con JDBC Message Store¶
@Configuration
public class MessageStoreConfig {
@Bean
public JdbcMessageStore messageStore(DataSource dataSource) {
JdbcMessageStore store = new JdbcMessageStore(dataSource);
store.setRegion("trading");
return store;
}
@Bean
public IntegrationFlow tradingCaptureFlow(JdbcMessageStore messageStore) {
return IntegrationFlow
.from(Kafka.messageDrivenChannelAdapter(
consumerFactory, "trading.orders"))
.wireTap(sf -> sf.handle(msg ->
messageStore.addMessage(msg)))
.channel("orderProcessingChannel")
.get();
}
}
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Métricas de captura: mensajes capturados/segundo, lag de captura (diferencia entre publicación y almacenamiento), tasa de errores de captura.
- Métricas de storage: volumen total por tier, crecimiento diario, costo por tier, uso de capacidad.
- Métricas de consulta: latencia de consultas, consultas por día, consultas por tipo.
- Alertas de completitud: comparar conteo de mensajes en flujo principal vs. store para detectar gaps.
- Alertas de integridad: verificación periódica de hashes de contenido para detectar corrupción.
Políticas de Retención¶
- Definir por tipo de mensaje y regulación:
- Mensajes de trading (MiFID II): 7 años, inmutables.
- Mensajes con PII (GDPR): máximo 2 años o hasta solicitud de eliminación.
- Mensajes operacionales: 90 días.
- Automatizar purga con lifecycle policies.
- Documentar el fundamento regulatorio de cada política.
Seguridad¶
- Cifrado en reposo: AES-256 con claves gestionadas por KMS.
- Control de acceso: RBAC — compliance puede consultar todo; developers solo su dominio.
- Inmutabilidad: Object Lock en S3, índices cerrados en OpenSearch, write-only permissions.
- Anonimización de PII: redactar datos personales antes de almacenar, o separar PII en un store con retención diferente.
- Audit trail del store: registrar quién consultó qué mensaje y cuándo.
Disaster Recovery¶
- Replicación cross-region para datos regulatorios.
- Backups periódicos de índices.
- Tests de recovery trimestrales: verificar que se pueden restaurar mensajes de cold storage.
Performance¶
- Captura asíncrona — nunca en el camino crítico del flujo principal.
- Hot tier con respuesta sub-segundo para consultas operacionales.
- Warm tier con respuesta de segundos para consultas analíticas (Athena sobre Parquet).
- Cold tier con restore bajo demanda para litigios y auditorías excepcionales.
17. Errores Comunes¶
Captura Síncrona en el Camino Crítico¶
Hacer que el flujo principal de mensajería espere a que el store confirme la persistencia. Esto acopla la latencia y disponibilidad del store al flujo de producción. Si el store tiene degradación, el flujo de trading se degrada. La captura debe ser siempre asíncrona (consumer group dedicado con su propio lag).
Retención Sin Política¶
Almacenar todo indefinidamente sin política de retención definida. El store crece sin control, los costos se disparan, las consultas se degradan y el equipo no sabe qué puede eliminar sin riesgo regulatorio. Las políticas de retención deben definirse antes de la primera escritura.
Store Sin Índice Útil¶
Almacenar millones de mensajes en S3 como archivos JSON sin indexar. Cuando alguien necesita encontrar un mensaje específico, la búsqueda es un full scan de terabytes. Invertir en indexación (DynamoDB, OpenSearch, Athena sobre Parquet) es esencial para que el store sea útil.
PII Sin Controles de Privacidad¶
Almacenar mensajes con nombres, emails, números de cuenta sin cifrado adicional ni mecanismos de anonimización o eliminación selectiva. Esto viola GDPR y regulaciones de privacidad. La solución es anonimizar PII antes de almacenar o separar el PII en un store con políticas de retención más estrictas.
Store Desacoplado sin Monitoreo de Completitud¶
No verificar que el store contiene todos los mensajes del flujo principal. Si el consumer de captura se atrasa, falla o pierde mensajes, el store tiene gaps invisibles que se descubren solo durante una auditoría. Monitorear el lag del consumer de captura y alertar ante discrepancias.
Confundir Archive con Message Store¶
Archivar mensajes en un formato que no permite consulta eficiente (archivos tar.gz en S3 sin particionamiento ni indexación). Un archive no es un Message Store. El store debe ser consultable, no solo almacenable.
18. Conclusión Técnica¶
Message Store es el patrón que transforma mensajes efímeros en un data asset duradero y consultable, habilitando compliance regulatorio, replay, debugging y analytics sobre los datos que fluyen por el sistema de integración.
Cuándo aporta valor: cuando los mensajes tienen valor más allá de su procesamiento inmediato — sea por requisitos regulatorios (retención de 7 años), operacionales (replay para recovery o corrección), o de negocio (analytics sobre datos de transacciones). El valor es máximo en industrias reguladas donde la evidencia de cada transacción es un requisito legal.
Cuándo evita problemas importantes: Message Store evita la pérdida irrecuperable de mensajes procesados, la incapacidad de replay cuando se descubren errores, la dependencia de logs dispersos para auditoría regulatoria, y la pérdida de datos de negocio valiosos para analytics.
Cuándo no conviene adoptarlo: cuando los mensajes son genuinamente efímeros sin valor post-procesamiento, cuando Kafka con retención adecuada ya satisface los requisitos, o cuando el costo de almacenamiento supera el valor de los datos.
Recomendación para arquitectos: diseñe el Message Store como parte integral de la arquitectura de integración, no como un componente que se añade después bajo presión regulatoria. Defina políticas de retención por tipo de mensaje antes de la primera escritura. Implemente tiering automático para optimizar costos. Asegúrese de que la captura es asíncrona y no impacta el flujo principal. Invierta en indexación proporcionada a los patrones de consulta reales. Y resuelva la tensión entre retención regulatoria y privacidad desde el diseño — no son requisitos compatibles por defecto, y la arquitectura del store debe acomodar ambos.