Test Message¶
1. Nombre del Patrón¶
- Nombre oficial: Test Message
- Categoría: System Management (Gestión del Sistema)
- Traducción contextual: Mensaje de Prueba / Mensaje Sintético
2. Resumen Ejecutivo¶
Test Message es un patrón de gestión del sistema que consiste en inyectar mensajes sintéticos en el sistema de mensajería para verificar que los componentes de integración funcionan correctamente de extremo a extremo. A diferencia de los health checks que verifican que un servicio responde, los Test Messages verifican que el flujo completo de integración — desde la producción hasta el consumo, pasando por routing, transformación y entrega — opera correctamente.
El problema que resuelve es la detección proactiva de fallos en la infraestructura de integración antes de que impacten a transacciones reales de negocio.
3. Definición Detallada¶
Propósito¶
El propósito de Test Message es proporcionar un mecanismo de monitoreo sintético (synthetic monitoring) para la infraestructura de messaging. Se inyectan mensajes de prueba en los canales de producción (o en canales paralelos dedicados), y se verifica que esos mensajes son procesados correctamente dentro de un SLA definido.
Lógica Arquitectónica¶
En una arquitectura de integración, hay múltiples puntos de fallo posibles que no son detectables mediante health checks individuales: un canal puede estar accesible pero no entregar mensajes, un router puede estar funcionando pero con reglas incorrectas, un transformer puede estar corriendo pero produciendo resultados erróneos, un consumidor puede estar vivo pero sin procesar su cola.
Test Message proporciona una verificación end-to-end que cruza todos estos componentes. Si el Test Message llega correctamente al destino y con el contenido esperado, todo el pipeline funciona. Si no llega, o llega incorrecto, algo en el pipeline está fallando.
Principio de Diseño Subyacente¶
El principio es verificación proactiva mediante tráfico sintético: no esperar a que una transacción real falle para descubrir un problema, sino inyectar continuamente mensajes de prueba que verifiquen el funcionamiento del sistema.
Problema Estructural que Resuelve¶
Los health checks tradicionales (HTTP liveness/readiness probes) verifican que cada componente individual está vivo, pero no verifican que el flujo de integración entre componentes funciona. Un servicio puede responder al health check pero tener un bug que causa que ignore mensajes. Un broker puede estar accesible pero tener un canal corrupto. Un router puede estar corriendo pero con una configuración obsoleta.
Por Qué No Es Trivial¶
- Identificación de Test Messages: ¿cómo distingue el sistema un mensaje de prueba de un mensaje real? Se necesita un mecanismo claro (header
test: true, canal dedicado, o content marker) que permita a los consumidores filtrar o procesar diferentemente. - Impacto en métricas: si los Test Messages se cuentan como mensajes reales, inflan las métricas de throughput. Deben excluirse de métricas de negocio.
- Side effects: si el Test Message llega a un consumidor que tiene side effects (enviar un email, hacer un pago), el side effect de prueba puede causar problemas reales. Los consumidores deben reconocer y manejar Test Messages.
- Cobertura: ¿qué rutas y transformaciones cubren los Test Messages? Un solo tipo de Test Message puede no cubrir todas las ramas de un Content-Based Router.
- Frecuencia: demasiado frecuente genera ruido y costo; demasiado infrecuente no detecta fallos a tiempo.
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Test Messages:
- Los fallos de integración se descubren cuando un proceso de negocio falla. Un pedido no se procesa, una transferencia no llega, una notificación no se envía — y el equipo descubre el problema cuando el cliente se queja o el proceso batch falla horas después.
- No hay forma de verificar que un pipeline de messaging funciona end-to-end sin enviar una transacción real.
- Los fallos silenciosos (un consumidor que deja de procesar pero no genera errores visibles) pasan desapercibidos durante horas o días.
Ejemplos Reales¶
- Banca: un banco inyecta una "transacción fantasma" de $0.01 entre cuentas internas cada 15 minutos para verificar que el pipeline de pagos funciona end-to-end. Si la transacción no completa en 30 segundos, se genera una alerta P1.
- E-commerce: una plataforma inyecta un pedido sintético cada 5 minutos para verificar que el flujo order→inventory→payment→shipping→notification funciona. El pedido sintético se identifica por un
customer_idespecial y es filtrado antes de ejecutar side effects reales. - Salud: un hospital inyecta un mensaje HL7 de prueba (con un patient ID reservado para testing) cada hora para verificar que la interfaz entre el LIS y el EMR funciona.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En todo sistema de messaging en producción donde los fallos silenciosos son inaceptables.
- Cuando los SLAs de integración requieren verificación proactiva, no solo reactiva.
- Cuando el pipeline de integración tiene múltiples etapas y un fallo en cualquiera puede pasar desapercibido.
- En escenarios de alta criticidad: pagos, operaciones financieras, sistemas de salud, infraestructura crítica.
Cuándo No Usarlo¶
- En pipelines simples y bien monitoreados donde el consumer lag y las métricas de error proporcionan suficiente visibilidad.
- Cuando el costo de implementar Test Messages (filtering en consumidores, exclusión de métricas) supera el beneficio.
- En entornos de desarrollo o staging donde las pruebas end-to-end se ejecutan de otra forma.
Precondiciones¶
- Existe un mecanismo para identificar Test Messages (header, canal dedicado, content marker).
- Los consumidores pueden reconocer y manejar Test Messages sin ejecutar side effects reales.
- Existe un sistema de verificación que detecta si el Test Message llegó (o no) al destino esperado.
6. Fuerzas Arquitectónicas¶
Detección Proactiva vs. Costo Operacional¶
Test Messages proporcionan detección proactiva de fallos pero añaden tráfico al sistema, requieren lógica de filtering en consumidores y necesitan exclusión de métricas de negocio.
Cobertura vs. Complejidad¶
Un solo tipo de Test Message verifica una ruta. Verificar todas las rutas de un Content-Based Router requiere múltiples tipos de Test Messages, incrementando la complejidad.
Realismo vs. Seguridad¶
Un Test Message muy realista (que simula una transacción real) tiene mayor cobertura pero mayor riesgo de producir side effects no deseados. Un Test Message claramente sintético es más seguro pero puede no detectar ciertos tipos de fallos.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Test Message Generator: componente que produce Test Messages periódicamente.
- Test Message: el mensaje sintético con un identificador que lo distingue de mensajes reales.
- Pipeline de Integración: los canales, routers, transformadores y consumidores que procesan el mensaje.
- Test Message Verifier: componente que verifica que el Test Message llegó al destino esperado dentro del SLA.
- Alerting: sistema que genera alertas cuando un Test Message no completa a tiempo.
Flujo Lógico¶
flowchart TD
A([Generator]) -->|Cada N minutos: test=true, test_id, generated_at| B[Pipeline procesa Test Message]
B -->|Routing, transformación| C{Consumidores detectan test=true}
C -->|Sin side effects reales o sandbox| D[Consumer final produce ACK]
D -->|test_id + completed_at + result| E[Verifier compara tiempos]
E --> F{completed_at - generated_at > SLA?}
F -->|Sí o sin ACK en timeout| G([ALERT])
F -->|No: dentro de SLA| H([OK])
E --> I[Dashboard: success rate, latency, failures]8. Ejemplo Arquitectónico Detallado¶
Dominio: Banca — Verificación del Pipeline de Pagos¶
Contexto¶
Un banco procesa pagos interbancarios a través de un pipeline: ingesta → validación → sanctions screening → routing → compensación. El SLA es que un pago debe completarse en menos de 60 segundos. Un fallo silencioso en el screening de sanciones (API externa no disponible) detuvo el pipeline durante 4 horas sin que nadie lo detectara hasta que el batch de conciliación nocturno encontró discrepancias.
Diseño del Test Message¶
El banco implementa un Test Message que:
- Se genera cada 10 minutos por un scheduled job.
- Simula un pago de €0.01 entre dos cuentas internas del banco (cuentas de testing).
- Incluye un header
X-Test-Message: truey untest_idúnico. - Recorre todo el pipeline: ingesta → validación → screening (el API de sanciones tiene una lista blanca para los nombres de las cuentas de testing) → routing → compensación (compensación interna, sin salir del banco).
- Al final del pipeline, un "Test Message Sink" registra el
test_idy el timestamp de completación. - Un Verifier job consulta cada minuto si hay Test Messages que no completaron dentro del SLA (60 segundos).
Resultado¶
Cuando el API de sanciones falla, el Test Message se queda esperando en el filtro de screening. En 70 segundos, el Verifier detecta que el Test Message no completó y genera una alerta P1. El equipo investiga, detecta el fallo del API externo y activa el fallback (caché local de sanciones). Tiempo de detección: 70 segundos en lugar de 4 horas.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Generación¶
Un Cronjob de Kubernetes ejecuta cada 10 minutos un producer que envía al topic payments.inbound:
{
"headers": {
"message_id": "test-msg-2026-04-08-14:30-a8f3",
"test": "true",
"test_id": "TEST-2026-04-08-a8f3c291",
"generated_at": "2026-04-08T14:30:00Z",
"test_route": "SEPA_INTERNAL"
},
"body": {
"payment_id": "TEST-PAY-a8f3c291",
"debtor_account": "TESTACCT001",
"creditor_account": "TESTACCT002",
"amount": 0.01,
"currency": "EUR"
}
}
Paso 2: Procesamiento Normal¶
El mensaje recorre el pipeline como cualquier pago:
- Validator: valida campos → OK (las cuentas TEST existen en el sistema).
- Sanctions Screener: consulta el API → la whitelist devuelve CLEAR inmediatamente.
- Router: determina que es SEPA interno → publica en
payments.sepa.internal. - Compensación interna: registra un movimiento de €0.01 entre las dos cuentas de test.
Paso 3: Verificación¶
Al final del pipeline, el consumidor de compensación detecta test=true y publica un ACK en el topic test.results:
{
"test_id": "TEST-2026-04-08-a8f3c291",
"completed_at": "2026-04-08T14:30:12Z",
"latency_ms": 12000,
"result": "SUCCESS",
"stages_passed": ["validator", "sanctions", "router", "settlement"]
}
Paso 4: Evaluación y Alerta¶
El Verifier consume de test.results y:
- Calcula latencia: 12 segundos < 60 segundos SLA → OK.
- Registra en la time-series database (Prometheus/InfluxDB).
- Si no recibe ACK dentro de 70 segundos del
generated_at, genera alerta PagerDuty.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
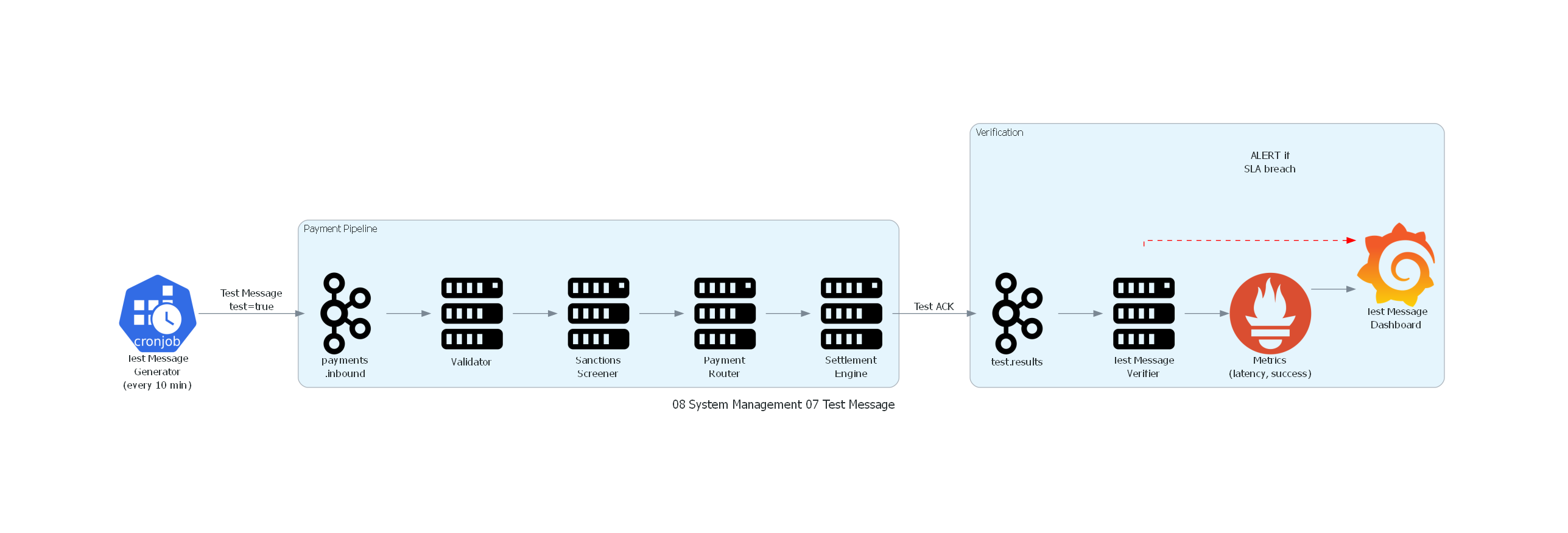
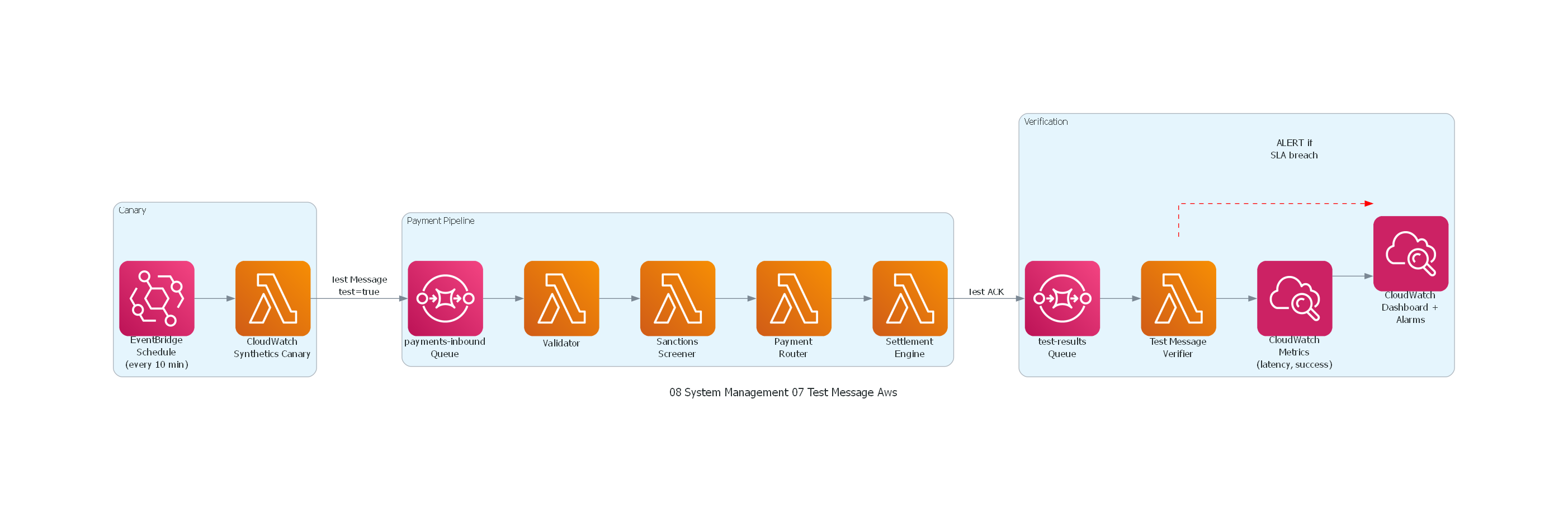
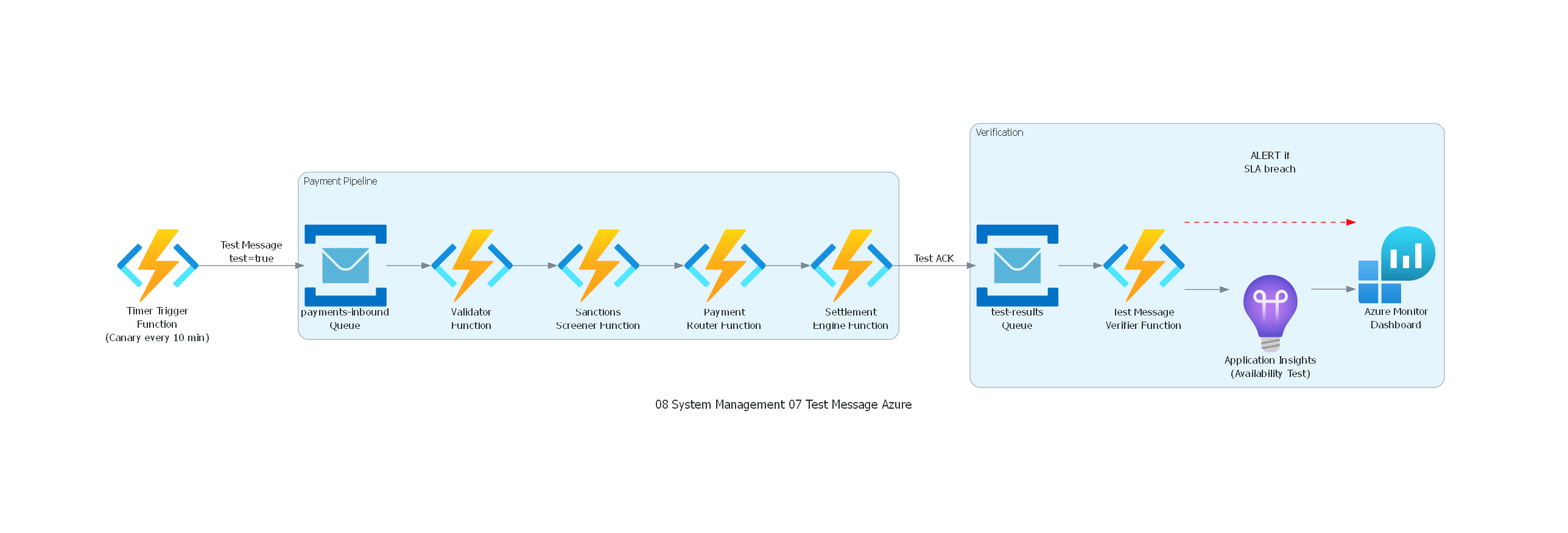
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import Kafka
from diagrams.onprem.compute import Server
from diagrams.onprem.monitoring import Grafana, Prometheus
from diagrams.k8s.compute import Cronjob
with Diagram("Test Message - Payment Pipeline Verification", show=False, direction="LR"):
generator = Cronjob("Test Message\nGenerator\n(every 10 min)")
with Cluster("Payment Pipeline"):
inbound = Kafka("payments\n.inbound")
validator = Server("Validator")
sanctions = Server("Sanctions\nScreener")
router = Server("Payment\nRouter")
settlement = Server("Settlement\nEngine")
with Cluster("Verification"):
test_results = Kafka("test.results")
verifier = Server("Test Message\nVerifier")
prom = Prometheus("Metrics\n(latency, success)")
grafana = Grafana("Test Message\nDashboard")
# Flow
generator >> Edge(label="Test Message\ntest=true") >> inbound
inbound >> validator >> sanctions >> router >> settlement
settlement >> Edge(label="Test ACK") >> test_results
test_results >> verifier
verifier >> prom >> grafana
verifier >> Edge(label="ALERT if\nSLA breach", color="red", style="dashed") >> grafana
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import Lambda
from diagrams.aws.integration import SQS, Eventbridge
from diagrams.aws.management import Cloudwatch
with Diagram("Test Message - Payment Pipeline Verification (AWS)", show=False, direction="LR"):
with Cluster("Canary"):
scheduler = Eventbridge("EventBridge\nSchedule\n(every 10 min)")
generator = Lambda("CloudWatch\nSynthetics Canary")
with Cluster("Payment Pipeline"):
inbound = SQS("payments-inbound\nQueue")
validator = Lambda("Validator")
sanctions = Lambda("Sanctions\nScreener")
router = Lambda("Payment\nRouter")
settlement = Lambda("Settlement\nEngine")
with Cluster("Verification"):
test_results = SQS("test-results\nQueue")
verifier = Lambda("Test Message\nVerifier")
metrics = Cloudwatch("CloudWatch\nMetrics\n(latency, success)")
dashboard = Cloudwatch("CloudWatch\nDashboard +\nAlarms")
# Flow
scheduler >> generator
generator >> Edge(label="Test Message\ntest=true") >> inbound
inbound >> validator >> sanctions >> router >> settlement
settlement >> Edge(label="Test ACK") >> test_results
test_results >> verifier
verifier >> metrics >> dashboard
verifier >> Edge(label="ALERT if\nSLA breach", color="red", style="dashed") >> dashboard
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps
from diagrams.azure.devops import ApplicationInsights
from diagrams.azure.integration import ServiceBus
from diagrams.azure.analytics import LogAnalyticsWorkspaces
with Diagram("Test Message - Payment Pipeline Verification (Azure)", show=False, direction="LR"):
generator = FunctionApps("Timer Trigger\nFunction\n(Canary every 10 min)")
with Cluster("Payment Pipeline"):
inbound = ServiceBus("payments-inbound\nQueue")
validator = FunctionApps("Validator\nFunction")
sanctions = FunctionApps("Sanctions\nScreener Function")
router = FunctionApps("Payment\nRouter Function")
settlement = FunctionApps("Settlement\nEngine Function")
with Cluster("Verification"):
test_results = ServiceBus("test-results\nQueue")
verifier = FunctionApps("Test Message\nVerifier Function")
app_insights = ApplicationInsights("Application Insights\n(Availability Test)")
dashboard = LogAnalyticsWorkspaces("Azure Monitor\nDashboard")
# Flow
generator >> Edge(label="Test Message\ntest=true") >> inbound
inbound >> validator >> sanctions >> router >> settlement
settlement >> Edge(label="Test ACK") >> test_results
test_results >> verifier
verifier >> app_insights >> dashboard
verifier >> Edge(label="ALERT if\nSLA breach", color="red", style="dashed") >> dashboard
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Test Message Generator | Cronjob que produce cada 10 min |
| Test Message | Mensaje con header test=true |
| Pipeline bajo verificación | Validator → Sanctions → Router → Settlement |
| Test Message Verifier | Servicio que evalúa latencia y completitud |
| Alerting | PagerDuty triggered por Verifier |
| Dashboard | Grafana con métricas de Prometheus |
11. Beneficios¶
- Detección proactiva: fallos se detectan en minutos (frecuencia del Test Message), no en horas (cuando un proceso batch o un usuario reporta).
- Verificación end-to-end: a diferencia de health checks por componente, Test Message verifica que todo el flujo funciona integrado.
- SLA measurement: la latencia del Test Message es una medición directa del SLA del pipeline bajo condiciones reales.
- Confidence for changes: antes y después de un deploy, los Test Messages confirman que el pipeline sigue funcionando.
- Historical baseline: el histórico de latencias de Test Messages proporciona un baseline para detectar degradaciones graduales.
12. Desventajas y Riesgos¶
- Side effects no deseados: si un consumidor no detecta correctamente el Test Message y ejecuta side effects reales (enviar un pago real, notificar a un cliente).
- Inflación de métricas: si los Test Messages no se excluyen de métricas de negocio, inflan throughput y distorsionan dashboards.
- Costo: los Test Messages consumen recursos del pipeline (CPU, I/O, bandwidth). En pipelines de alto volumen, el costo es marginal; en pipelines con costo por mensaje (SQS), puede ser relevante.
- Falsa seguridad: un Test Message que solo recorre una ruta no detecta fallos en las demás rutas.
- Complejidad de filtering: cada consumidor debe implementar lógica para detectar y manejar Test Messages.
13. Relación con Otros Patrones¶
- Wire Tap: puede usarse para capturar Test Messages en un canal auxiliar sin alterar el flujo principal.
- Message History: el histórico del Test Message a través del pipeline puede verificarse contra el historial esperado.
- Control Bus: el generador de Test Messages puede controlarse vía Control Bus (activar, desactivar, cambiar frecuencia).
- Channel Purger: en entornos de test, los Test Messages acumulados pueden purgarse.
- Content-Based Router: se necesitan múltiples tipos de Test Messages para verificar cada ruta del router.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Alta¶
Test Message se ha generalizado en la industria bajo el nombre de synthetic monitoring o canary messages. Herramientas como AWS CloudWatch Synthetics, Datadog Synthetic Monitoring y custom canary jobs implementan este patrón.
En el contexto de event-driven architectures con pipelines complejos, la verificación end-to-end mediante Test Messages es frecuentemente la única forma de detectar fallos silenciosos proactivamente.
Implementación Moderna¶
- Kubernetes Cronjob como generador.
- CloudWatch Synthetics / Datadog Synthetic Monitors para verificación automatizada.
- Prometheus + Grafana para métricas y dashboards.
- PagerDuty / OpsGenie para alerting.
- Feature flags para activar/desactivar Test Messages por pipeline.
15. Implementación en Arquitecturas Modernas¶
AWS¶
- Cronjob → Lambda scheduled → SQS → Pipeline → Lambda verifier → CloudWatch alarm.
- CloudWatch Synthetics para verificación HTTP-based de APIs que producen/consumen mensajes.
Azure¶
- Azure Function timer trigger → Service Bus → Pipeline → Function verifier → Application Insights alert.
- Azure Monitor availability tests.
Kafka¶
- Kafka producer scheduled → topic → pipeline → consumer que publica en
test.results→ verifier consumer → Prometheus.
Spring Boot¶
@Scheduled(fixedRate = 600000) // every 10 minutes
public void generateTestMessage() {
var testMsg = PaymentMessage.builder()
.paymentId("TEST-" + UUID.randomUUID())
.amount(BigDecimal.valueOf(0.01))
.test(true)
.build();
kafkaTemplate.send("payments.inbound", testMsg);
testTracker.register(testMsg.getPaymentId(), Instant.now());
}
16. Consideraciones de Gobierno y Operación¶
Observabilidad¶
- Test success rate: porcentaje de Test Messages que completan dentro del SLA. Target: 99.9%+.
- Test latency: p50, p95, p99 de la latencia end-to-end de Test Messages.
- Test failure reason: categorización de fallos (timeout, error de procesamiento, side effect fallo).
Seguridad¶
- Las cuentas, IDs y datos de Test Messages deben ser claramente distinguibles y no deben poder confundirse con datos reales.
- Los Test Messages no deben contener datos sensibles reales.
Mantenimiento¶
- Los Test Messages deben actualizarse cuando el pipeline cambia (nueva ruta, nuevo formato, nuevo consumidor).
- La whitelist de test data (cuentas de testing, IDs reservados) debe mantenerse actualizada.
17. Errores Comunes¶
No Distinguir Test Messages de Mensajes Reales¶
Sin un mecanismo claro de identificación (header, test account, content marker), un Test Message puede procesarse como real y causar side effects.
Un Solo Tipo de Test Message para Pipeline Complejo¶
Si el pipeline tiene 5 rutas y el Test Message solo cubre 1, las otras 4 rutas no están verificadas. Se necesita un Test Message por ruta significativa.
Test Messages Solo en Horario Laboral¶
Los fallos no respetan horarios. Los Test Messages deben ejecutarse 24/7, especialmente fuera de horario laboral cuando hay menos visibilidad humana.
No Excluir de Métricas de Negocio¶
Los Test Messages inflando dashboards de throughput y revenue producen datos incorrectos para el negocio.
18. Conclusión Técnica¶
Test Message es la forma más directa y confiable de verificar que un pipeline de integración funciona end-to-end en producción. Mientras que los health checks verifican componentes individuales, los Test Messages verifican el flujo completo: producción, routing, transformación, consumo y side effects.
Cuándo aporta valor: en pipelines críticos donde un fallo silencioso tiene impacto de negocio significativo. Pagos, transacciones financieras, sistemas de salud, infraestructura crítica.
Cuándo evita problemas importantes: detecta fallos de integración en minutos en lugar de horas, reduciendo dramáticamente el MTTR (Mean Time To Recovery).
Recomendación para arquitectos: implemente Test Messages como parte del "day one" de cada pipeline crítico. Use headers para identificar Test Messages, no contenido. Cubra todas las rutas significativas del pipeline. Monitoree test success rate y latency como SLIs del pipeline. Y asegúrese de que TODOS los consumidores del pipeline reconocen y manejan Test Messages correctamente.