Channel Purger¶
1. Nombre del Patrón¶
- Nombre oficial: Channel Purger
- Categoría: System Management (Gestión del Sistema)
- Traducción contextual: Purgador de Canal
2. Resumen Ejecutivo¶
Channel Purger es un patrón de gestión del sistema que permite eliminar todos los mensajes de un canal de mensajería. Se utiliza principalmente en escenarios operacionales y de testing: limpiar canales contaminados con mensajes de prueba, recuperar un sistema tras un fallo que produjo mensajes corruptos, preparar entornos de test entre ejecuciones, o eliminar un backlog de mensajes obsoletos que no tiene sentido procesar.
Este patrón existe porque los canales de mensajería son buffers persistentes: los mensajes permanecen en el canal hasta que son consumidos. Cuando el contenido del canal se vuelve inválido, obsoleto o perjudicial, se necesita un mecanismo para vaciarlo de forma controlada.
3. Definición Detallada¶
Propósito¶
El propósito de Channel Purger es proporcionar un mecanismo para vaciar un canal de mensajería de forma controlada, eliminando todos los mensajes pendientes sin procesarlos. Es una operación destructiva y deliberada que se ejecuta cuando el contenido del canal no debe ser procesado.
Lógica Arquitectónica¶
En condiciones normales, los mensajes en un canal se procesan por sus consumidores. Pero hay situaciones donde procesar los mensajes pendientes es incorrecto o perjudicial:
- Mensajes corruptos: un productor con un bug generó miles de mensajes con formato inválido que envenenarían a los consumidores.
- Mensajes obsoletos: tras un outage prolongado, los mensajes acumulados son tan antiguos que procesarlos produciría resultados incorrectos (precios desactualizados, estados obsoletos).
- Contaminación de testing: en un entorno compartido, mensajes de prueba de un equipo contaminan el canal que otro equipo necesita limpio.
- Recovery tras disaster: se necesita un estado limpio para reiniciar el sistema desde cero.
Channel Purger proporciona una alternativa controlada a la solución destructiva (eliminar y recrear el canal) y a la solución lenta (consumir y descartar cada mensaje individualmente).
Principio de Diseño Subyacente¶
El principio es operación destructiva controlada con intención explícita: vaciar un canal no debe ser un accidente sino una decisión operacional deliberada, auditada y reversible (en la medida de lo posible).
Por Qué No Es Trivial¶
- Atomicidad: ¿se garantiza que NO llegan mensajes nuevos durante la purga? Si el productor sigue publicando, el canal puede no quedar realmente vacío.
- Selectividad: ¿se purgan TODOS los mensajes o solo los que cumplen un criterio (por ejemplo, mensajes anteriores a cierto timestamp)?
- Auditoría: ¿se registra qué mensajes se eliminaron? En entornos regulados, eliminar mensajes sin registro puede violar compliance.
- Impacto en consumidores: si hay consumidores activos, ¿qué ocurre cuando el canal se vacía? ¿Los consumidores se desconectan? ¿Generan errores?
- Multi-subscription: en un canal pub-sub, ¿se purgan todas las subscripciones o solo una?
4. Problema que Resuelve¶
El Problema Antes del Patrón¶
Sin Channel Purger:
- Un canal con 500,000 mensajes corruptos debe procesarse uno por uno (cada mensaje llega al consumidor, falla, va a DLQ, se descarta). Esto puede tomar horas y saturar la DLQ.
- Un entorno de test acumula mensajes de ejecuciones anteriores que interfieren con la ejecución actual.
- Tras un disaster recovery, no hay forma de empezar desde un estado limpio sin eliminar y recrear la infraestructura de canales (perdiendo configuración, ACLs, subscripciones).
- Un backlog de mensajes obsoletos consume storage y distorsiona métricas de consumer lag.
Ejemplos Reales¶
- E-commerce: un bug en el servicio de pricing publicó 200,000 mensajes con precios incorrectos en el topic de precios. En lugar de que 15 consumidores procesen precios erróneos, se purga el topic y se republica con precios correctos.
- Testing: un pipeline CI/CD ejecuta integration tests que producen mensajes en colas. Entre test runs, las colas deben purgarse para evitar contaminación entre tests.
- Banca: tras un failover de datacenter, se detecta que los mensajes acumulados durante el failover (30 minutos) contienen timestamps inconsistentes. Se decide purgar y reprocesar desde el event store.
5. Contexto de Aplicación¶
Cuándo Usarlo¶
- En entornos de test/staging para limpiar entre ejecuciones.
- Tras un incidente que contaminó un canal con mensajes inválidos o corruptos.
- Cuando un backlog de mensajes obsoletos no tiene valor y consume recursos.
- Como parte de un procedimiento de disaster recovery.
- Cuando se necesita reiniciar un consumidor desde un estado limpio.
Cuándo No Usarlo¶
- Como sustituto de manejo de errores adecuado (DLQ, retry, error handling).
- En producción de forma rutinaria — si se necesita purgar frecuentemente, el diseño tiene un problema.
- Sin autorización explícita — la purga es una operación destructiva.
- Cuando los mensajes tienen valor de auditoría y no se pueden eliminar sin violar compliance.
Precondiciones¶
- Acceso administrativo al sistema de mensajería.
- Confirmación de que los mensajes a purgar no tienen valor y pueden ser destruidos.
- Los consumidores están detenidos o pueden manejar un canal vacío.
- Existe un registro de auditoría de la operación de purga.
6. Fuerzas Arquitectónicas¶
Velocidad de Recovery vs. Pérdida de Datos¶
La purga permite recuperar rápidamente un estado limpio, pero destruye mensajes que podrían tener valor (para auditoría, replay, debugging). La tensión es entre velocidad de recovery y preservación de información.
Simplicidad vs. Selectividad¶
Purgar todo es simple pero puede eliminar mensajes válidos mezclados con inválidos. Purgar selectivamente preserva los mensajes válidos pero requiere criterios de selección y es más complejo.
Automatización vs. Control¶
Una purga automática (por ejemplo, "purgar mensajes con más de 24 horas") es eficiente pero puede producir pérdida no intencionada. Una purga manual requiere intervención humana pero proporciona control.
7. Estructura Conceptual del Patrón¶
Actores o Componentes Involucrados¶
- Operador/Sistema: quien decide y ejecuta la purga.
- Channel: el canal a purgar.
- Broker: el sistema de mensajería que gestiona el canal.
- Audit Log: registro de la operación de purga.
- Consumers: consumidores que deben ser notificados o detenidos durante la purga.
Flujo Lógico¶
flowchart TD
A([Operador identifica necesidad de purga]) --> B[Detiene o pausa consumidores del canal]
B --> C[(Audit Log: registra intención de purga)]
C --> D[Ejecuta purga en el broker]
D --> E[(Broker elimina todos los mensajes del canal)]
E --> F{Canal vacío?}
F -->|Verificado| G[Reanuda consumidores]
G --> H[(Audit Log: registra completación)]
H --> I([Purga completada])8. Ejemplo Arquitectónico Detallado¶
Dominio: Testing — Pipeline CI/CD con Integration Tests¶
Contexto¶
Una organización ejecuta integration tests de su pipeline de pedidos cada hora en un entorno de staging. Cada test run produce ~5,000 mensajes en 8 colas de RabbitMQ. Sin purga entre runs, los mensajes residuales de una ejecución interfieren con la siguiente (un consumidor procesa un mensaje del test anterior y el assertion del test actual falla).
Diseño¶
Se implementa un Channel Purger como step del pipeline CI/CD:
# ci-pipeline.yml
steps:
- name: Purge test queues
run: |
for queue in orders.test inventory.test payments.test shipping.test \
notifications.test returns.test analytics.test dlq.test; do
rabbitmqadmin purge queue name=$queue
echo "Purged: $queue"
done
- name: Run integration tests
run: ./run-integration-tests.sh
- name: Collect test results
run: ./collect-results.sh
Decisiones¶
- Purge before test, not after: se purga antes de cada test run (no después) para garantizar estado limpio aunque el test anterior haya fallado a mitad de ejecución.
- Named queues for testing: las colas de test tienen un sufijo
.testpara evitar accidentalmente purgar colas de producción. - Audit en CI log: el output del pipeline CI/CD actúa como registro de auditoría de la purga.
9. Desarrollo Paso a Paso del Ejemplo¶
Paso 1: Pre-Purge Verification¶
El script de CI verifica que está conectado al entorno de staging (no producción):
VHOST=$(rabbitmqadmin show overview -f raw_json | jq -r '.vhost')
if [ "$VHOST" != "staging" ]; then
echo "ERROR: Not connected to staging! Aborting purge."
exit 1
fi
Paso 2: Consumer Shutdown¶
Los consumidores de staging se detienen antes de la purga para evitar race conditions:
kubectl scale deployment order-processor --replicas=0 -n staging
kubectl scale deployment inventory-service --replicas=0 -n staging
# Wait for graceful shutdown
kubectl wait --for=condition=Available=False deployment/order-processor -n staging --timeout=30s
Paso 3: Purge Execution¶
Se purgan todas las colas de test:
for queue in orders.test inventory.test payments.test shipping.test; do
count=$(rabbitmqadmin get queue=$queue count=1 2>/dev/null | wc -l)
rabbitmqadmin purge queue name=$queue
echo "Purged $queue (had ~$count messages)"
done
Paso 4: Verification¶
Se verifica que las colas están vacías:
for queue in orders.test inventory.test payments.test shipping.test; do
msgs=$(rabbitmqadmin show queue name=$queue -f raw_json | jq '.messages')
if [ "$msgs" != "0" ]; then
echo "ERROR: $queue still has $msgs messages after purge!"
exit 1
fi
done
echo "All queues purged successfully."
Paso 5: Consumer Restart¶
Se reinician los consumidores:
kubectl scale deployment order-processor --replicas=2 -n staging
kubectl scale deployment inventory-service --replicas=2 -n staging
Paso 6: Test Execution¶
Los integration tests se ejecutan contra un estado limpio.
10. Diagrama Técnico del Patrón¶
Código Python con diagrams¶
Ver / Copiar código de los diagramas
from diagrams import Diagram, Cluster, Edge
from diagrams.onprem.queue import RabbitMQ
from diagrams.onprem.ci import GithubActions
from diagrams.onprem.compute import Server
from diagrams.k8s.compute import Deploy
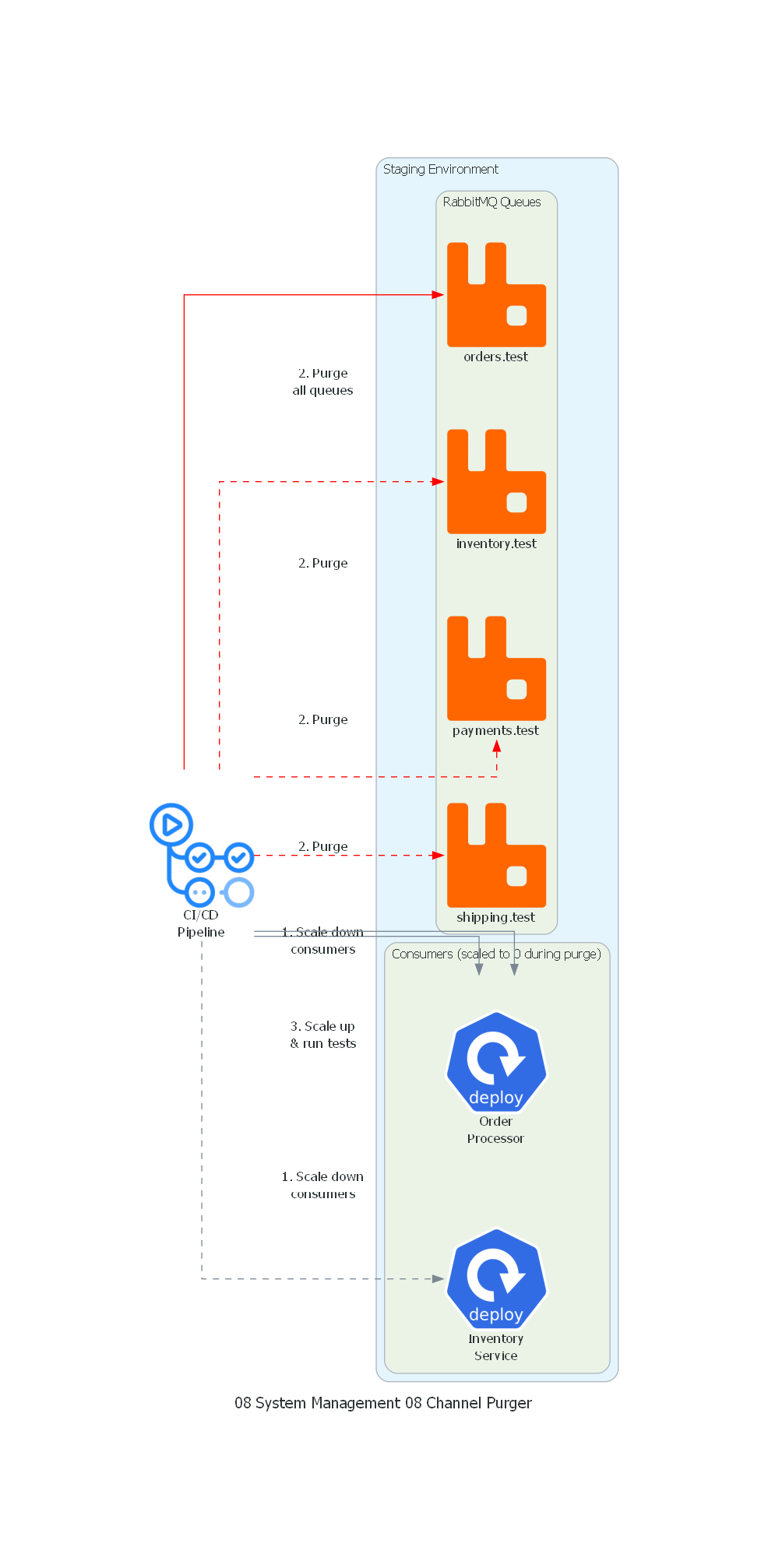
with Diagram("Channel Purger - CI/CD Integration Testing", show=False, direction="TB"):
ci = GithubActions("CI/CD\nPipeline")
with Cluster("Staging Environment"):
with Cluster("RabbitMQ Queues"):
q1 = RabbitMQ("orders.test")
q2 = RabbitMQ("inventory.test")
q3 = RabbitMQ("payments.test")
q4 = RabbitMQ("shipping.test")
with Cluster("Consumers (scaled to 0 during purge)"):
c1 = Deploy("Order\nProcessor")
c2 = Deploy("Inventory\nService")
# Purge flow
ci >> Edge(label="1. Scale down\nconsumers") >> c1
ci >> Edge(label="1. Scale down\nconsumers", style="dashed") >> c2
ci >> Edge(label="2. Purge\nall queues", color="red") >> q1
ci >> Edge(label="2. Purge", color="red", style="dashed") >> q2
ci >> Edge(label="2. Purge", color="red", style="dashed") >> q3
ci >> Edge(label="2. Purge", color="red", style="dashed") >> q4
ci >> Edge(label="3. Scale up\n& run tests") >> c1
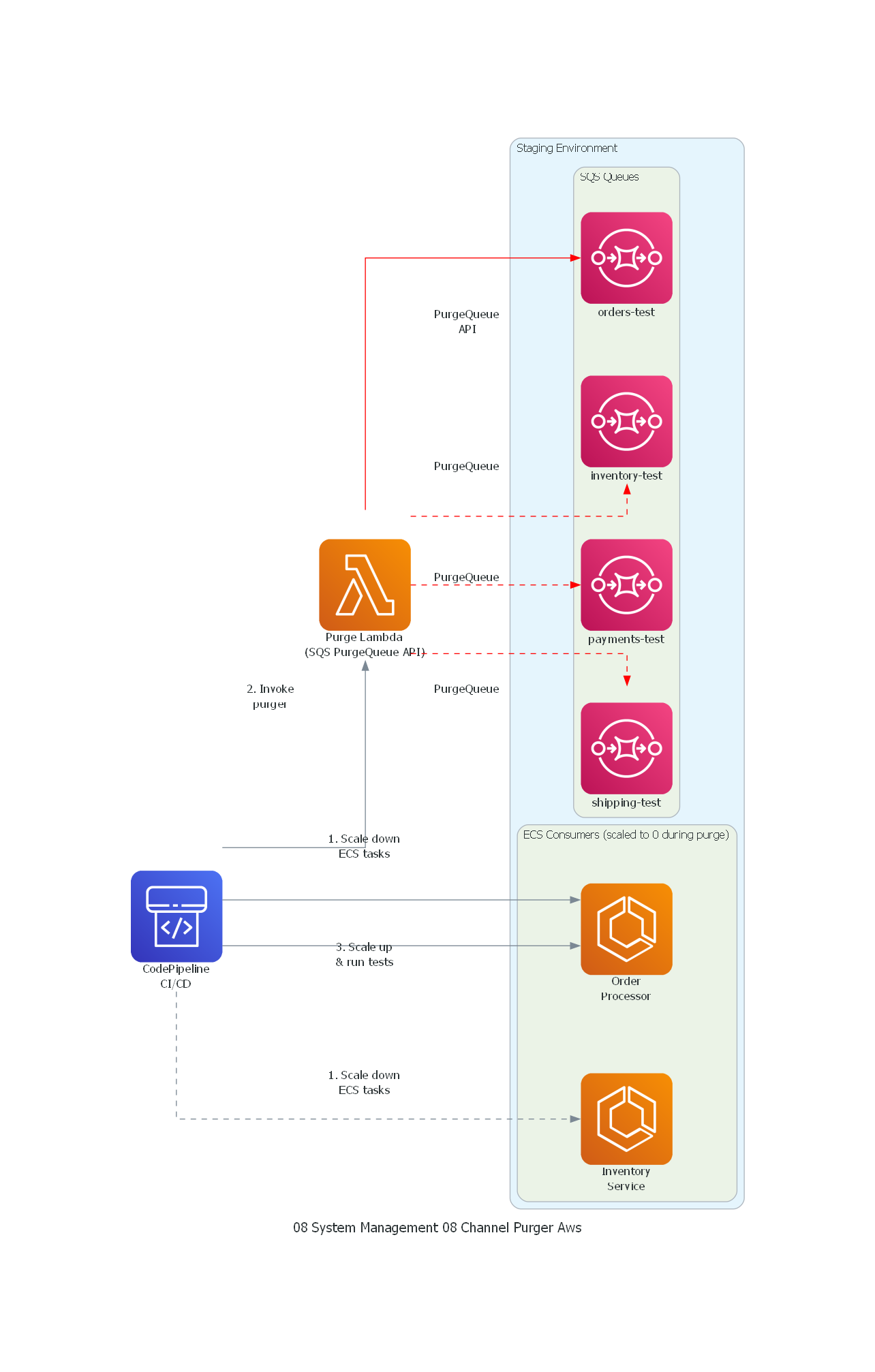
from diagrams import Diagram, Cluster, Edge
from diagrams.aws.compute import ECS, Lambda
from diagrams.aws.devtools import Codepipeline
from diagrams.aws.integration import SQS
with Diagram("Channel Purger - CI/CD Integration Testing (AWS)", show=False, direction="TB"):
ci = Codepipeline("CodePipeline\nCI/CD")
purger = Lambda("Purge Lambda\n(SQS PurgeQueue API)")
with Cluster("Staging Environment"):
with Cluster("SQS Queues"):
q1 = SQS("orders-test")
q2 = SQS("inventory-test")
q3 = SQS("payments-test")
q4 = SQS("shipping-test")
with Cluster("ECS Consumers (scaled to 0 during purge)"):
c1 = ECS("Order\nProcessor")
c2 = ECS("Inventory\nService")
# Purge flow
ci >> Edge(label="1. Scale down\nECS tasks") >> c1
ci >> Edge(label="1. Scale down\nECS tasks", style="dashed") >> c2
ci >> Edge(label="2. Invoke\npurger") >> purger
purger >> Edge(label="PurgeQueue\nAPI", color="red") >> q1
purger >> Edge(label="PurgeQueue", color="red", style="dashed") >> q2
purger >> Edge(label="PurgeQueue", color="red", style="dashed") >> q3
purger >> Edge(label="PurgeQueue", color="red", style="dashed") >> q4
ci >> Edge(label="3. Scale up\n& run tests") >> c1
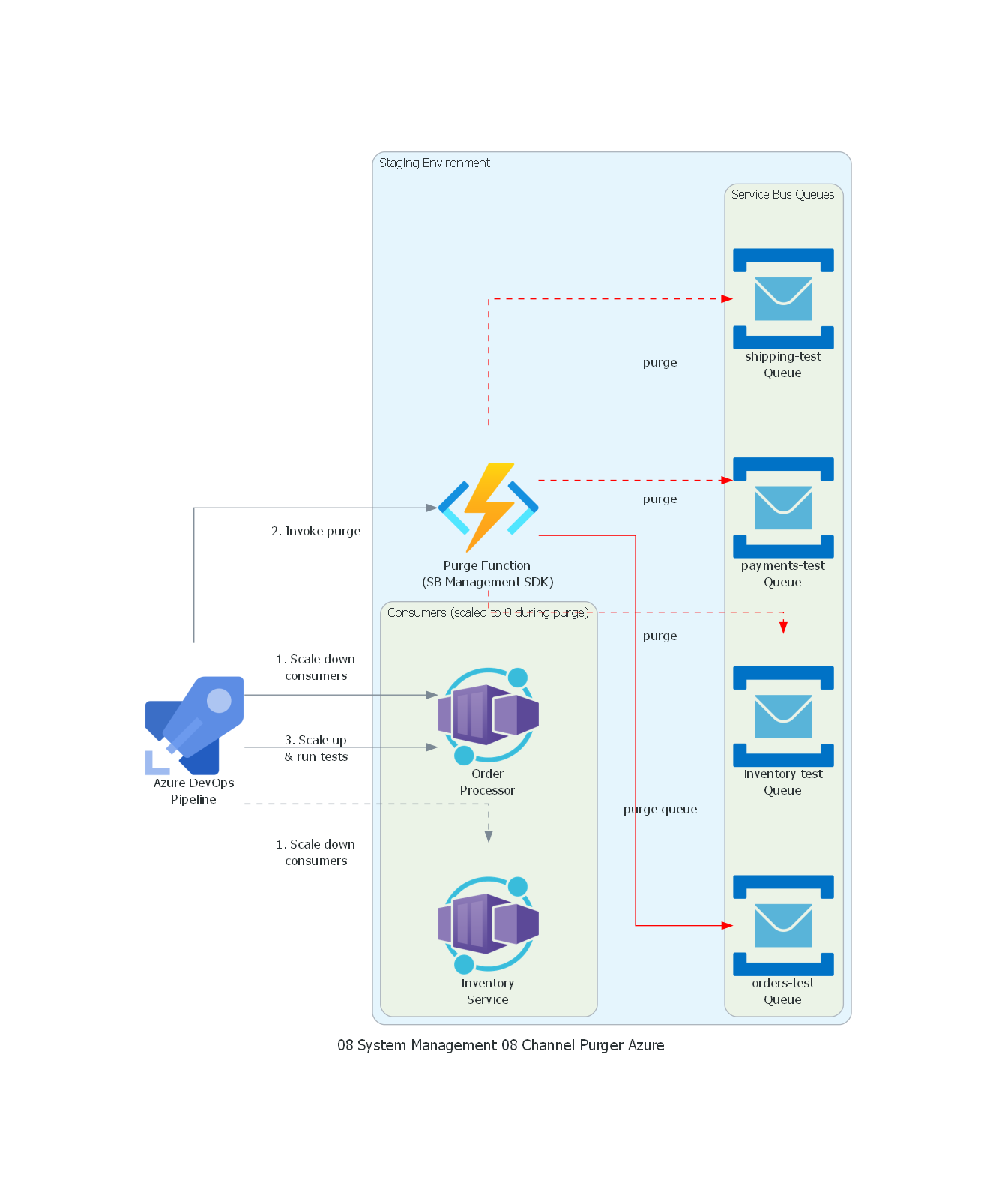
from diagrams import Diagram, Cluster, Edge
from diagrams.azure.compute import FunctionApps, ContainerApps
from diagrams.azure.devops import Pipelines
from diagrams.azure.integration import ServiceBus
with Diagram("Channel Purger - CI/CD Integration Testing (Azure)", show=False, direction="TB"):
ci = Pipelines("Azure DevOps\nPipeline")
with Cluster("Staging Environment"):
with Cluster("Service Bus Queues"):
q1 = ServiceBus("orders-test\nQueue")
q2 = ServiceBus("inventory-test\nQueue")
q3 = ServiceBus("payments-test\nQueue")
q4 = ServiceBus("shipping-test\nQueue")
purge_func = FunctionApps("Purge Function\n(SB Management SDK)")
with Cluster("Consumers (scaled to 0 during purge)"):
c1 = ContainerApps("Order\nProcessor")
c2 = ContainerApps("Inventory\nService")
# Purge flow
ci >> Edge(label="1. Scale down\nconsumers") >> c1
ci >> Edge(label="1. Scale down\nconsumers", style="dashed") >> c2
ci >> Edge(label="2. Invoke purge") >> purge_func
purge_func >> Edge(label="purge queue", color="red") >> q1
purge_func >> Edge(label="purge", color="red", style="dashed") >> q2
purge_func >> Edge(label="purge", color="red", style="dashed") >> q3
purge_func >> Edge(label="purge", color="red", style="dashed") >> q4
ci >> Edge(label="3. Scale up\n& run tests") >> c1
Correspondencia Patrón ↔ Diagrama¶
| Concepto del Patrón | Componente del Diagrama |
|---|---|
| Operador/Sistema | CI/CD Pipeline |
| Canales a purgar | RabbitMQ queues (.test) |
| Consumers pausados | Deployments scaled to 0 |
| Operación de purga | Red edges (destructive operation) |
11. Beneficios¶
- Estado limpio garantizado: elimina contaminación entre test runs, incidentes, o períodos de operación.
- Recovery rápido: permite reiniciar desde cero sin recrear infraestructura.
- Liberación de recursos: elimina backlog que consume storage sin valor.
- Simplificación operacional: más rápido y seguro que consumir y descartar mensajes uno por uno.
12. Desventajas y Riesgos¶
- Pérdida irreversible: los mensajes purgados se pierden permanentemente. Si alguno tenía valor, no se puede recuperar.
- Riesgo de purga accidental: purgar el canal equivocado (producción en lugar de staging) es un incidente grave.
- Compliance: en entornos regulados, eliminar mensajes puede violar requisitos de retención.
- Race conditions: si productores siguen publicando durante la purga, el canal puede no quedar vacío.
- Consumer impact: consumidores activos pueden experimentar errores o comportamiento inesperado durante la purga.
Anti-Patterns¶
- Purge as Error Handling: usar purga rutinariamente para "solucionar" problemas de procesamiento en lugar de corregir la causa raíz.
- Unprotected Purge: ejecutar purga sin verificar que se está en el entorno correcto, sin auditoría ni aprobación.
13. Relación con Otros Patrones¶
- Dead Letter Channel: antes de purgar un canal, los mensajes que podrían tener valor pueden moverse a DLQ para inspección.
- Message Store: si se necesita preservar los mensajes antes de purgar, se puede copiar al Message Store primero.
- Wire Tap: un Wire Tap puede capturar los mensajes antes de la purga para respaldo.
- Test Message: Channel Purger y Test Message trabajan juntos en pipelines de testing — purge before test, inject test messages, verify results.
- Control Bus: la operación de purga puede ejecutarse a través del Control Bus como una operación de gestión.
14. Relevancia Actual del Patrón¶
Evaluación: Relevancia Media¶
Channel Purger es más una herramienta operacional que un patrón de diseño. En la práctica moderna:
- RabbitMQ:
rabbitmqadmin purge queueorabbitmqctl purge_queue. - Kafka: no hay purge nativo. Las alternativas son: eliminar y recrear el topic, o cambiar la retención a 1ms temporalmente (
kafka-configs --alter --add-config retention.ms=1), o avanzar los offsets de los consumer groups al final. - SQS:
PurgeQueueAPI nativa. - Azure Service Bus:
PurgeMessagesAPI o settingAutoDeleteOnIdle. - Google Pub/Sub:
seeka un timestamp futuro para saltar mensajes, o eliminar y recrear la subscription.
Es una operación estándar que toda plataforma soporta de alguna forma. Su valor como "patrón" reside en la disciplina de ejecutarla de forma controlada, auditada y segura.
15. Implementación en Arquitecturas Modernas¶
RabbitMQ¶
AWS SQS¶
Kafka (reset offsets)¶
kafka-consumer-groups --bootstrap-server localhost:9092 \
--group my-consumer-group \
--topic my-topic \
--reset-offsets --to-latest --execute
Azure Service Bus¶
var receiver = client.CreateReceiver(queueName);
while (true) {
var messages = await receiver.ReceiveMessagesAsync(100, TimeSpan.FromSeconds(5));
if (!messages.Any()) break;
foreach (var msg in messages)
await receiver.CompleteMessageAsync(msg);
}
16. Consideraciones de Gobierno y Operación¶
Auditoría¶
- Toda operación de purga debe registrarse: quién, cuándo, qué canal, cuántos mensajes eliminados, por qué motivo.
- En entornos regulados, obtener aprobación antes de ejecutar.
Seguridad¶
- Restringir acceso a la operación de purga (RBAC: solo operadores senior o CI/CD service accounts).
- Implementar protecciones contra purga accidental de producción (naming conventions, environment checks, confirmation prompts).
Monitoreo¶
- Alerta si se ejecuta una purga en producción (puede ser intencional pero debe ser visible).
- Registrar la reducción de queue depth como evento operacional.
17. Errores Comunes¶
Purgar el Canal Equivocado¶
El error más grave: purgar producción cuando se pretendía purgar staging. Mitigación: naming conventions que incluyan el entorno (orders.prod vs orders.staging), environment checks en scripts, y RBAC que limite purge en producción.
Purgar Sin Detener Consumidores¶
Si los consumidores están activos durante la purga, pueden experimentar comportamiento inesperado (desconexiones, errores de canal vacío). Detener consumidores antes de purgar y reiniciarlos después.
Purgar Sin Verificar Valor¶
Asumir que todos los mensajes pendientes son basura sin verificar. Antes de purgar, inspeccionar una muestra (Wire Tap, peek) para confirmar que no hay mensajes válidos mezclados.
Usar Purge Como Solución Permanente¶
Si se necesita purgar el mismo canal repetidamente porque acumula mensajes inválidos, el problema está en el productor o en el consumidor, no en el canal.
18. Conclusión Técnica¶
Channel Purger es una herramienta operacional esencial que todo equipo que opera infraestructura de messaging debe tener disponible y saber usar de forma segura. No es un patrón de diseño que se "aplique" en la arquitectura — es una capacidad operacional que se usa en escenarios de testing, recovery e incidentes.
Cuándo aporta valor: en CI/CD para limpiar entre test runs, en recovery tras incidentes que contaminaron canales, en eliminación de backlog obsoleto.
Cuándo evita problemas: una purga rápida y controlada evita horas de procesamiento de mensajes inválidos que saturarían DLQs y consumidores.
Cuándo no conviene: como sustituto de error handling adecuado, en producción de forma rutinaria, o sin auditoría y autorización.
Recomendación para arquitectos: incluya la capacidad de purge en sus runbooks operacionales. Implemente naming conventions y protecciones de entorno para prevenir purgas accidentales en producción. Y recuerde: si necesita purgar frecuentemente, el problema real está en otro lugar.